Время на прочтение
11 мин
Количество просмотров 180K
Данная статья будет полезной тем, кто только начал знакомиться с микросервисной архитектурой и с сервисом Apache Kafka. Материал не претендует на подробный туториал, но поможет быстро начать работу с данной технологией. Я расскажу о том, как установить и настроить Kafka на Windows 10. Также мы создадим проект, используя Intellij IDEA и Spring Boot.
Зачем?
Трудности в понимании тех или иных инструментов часто связаны с тем, что разработчик никогда не сталкивался с ситуациями, в которых эти инструменты могут понадобиться. С Kafka всё обстоит точно также. Опишем ситуацию, в которой данная технология будет полезной. Если у вас монолитная архитектура приложения, то разумеется, никакая Kafka вам не нужна. Всё меняется с переходом на микросервисы. По сути, каждый микросервис – это отдельная программа, выполняющая ту или иную функцию, и которая может быть запущена независимо от других микросервисов. Микросервисы можно сравнить с сотрудниками в офисе, которые сидят за отдельными столами и независимо от коллег решают свою задачу. Работа такого распределённого коллектива немыслима без централизованной координации. Сотрудники должны иметь возможность обмениваться сообщениями и результатами своей работы между собой. Именно эту проблему и призвана решить Apache Kafka для микросервисов.
Apache Kafka является брокером сообщений. С его помощью микросервисы могут взаимодействовать друг с другом, посылая и получая важную информацию. Возникает вопрос, почему не использовать для этих целей обычный POST – reqest, в теле которого можно передать нужные данные и таким же образом получить ответ? У такого подхода есть ряд очевидных минусов. Например, продюсер (сервис, отправляющий сообщение) может отправить данные только в виде response’а в ответ на запрос консьюмера (сервиса, получающего данные). Допустим, консьюмер отправляет POST – запрос, и продюсер отвечает на него. В это время консьюмер по каким-то причинам не может принять полученный ответ. Что будет с данными? Они будут потеряны. Консьюмеру снова придётся отправлять запрос и надеяться, что данные, которые он хотел получить, за это время не изменились, и продюсер всё ещё готов принять request.
Apache Kafka решает эту и многие другие проблемы, возникающие при обмене сообщениями между микросервисами. Не лишним будет напомнить, что бесперебойный и удобный обмен данными – одна из ключевых проблем, которую необходимо решить для обеспечения устойчивой работы микросервисной архитектуры.
Установка и настройка ZooKeeper и Apache Kafka на Windows 10
Первое, что надо знать для начала работы — это то, что Apache Kafka работает поверх сервиса ZooKeeper. ZooKeeper — это распределенный сервис конфигурирования и синхронизации, и это всё, что нам нужно знать о нём в данном контексте. Мы должны скачать, настроить и запустить его перед тем, как начать работу с Kafka. Прежде чем начать работу с ZooKeeper, убедитесь, что у вас установлен и настроен JRE.
Скачать свежею версию ZooKeeper можно с официального сайта.
Извлекаем из скаченного архива ZooKeeper`а файлы в какую-нибудь папку на диске.
В папке zookeeper с номером версии, находим папку conf и в ней файл “zoo_sample.cfg”.

Копируем его и меняем название копии на “zoo.cfg”. Открываем файл-копию и находим в нём строчку dataDir=/tmp/zookeeper. Прописываем в данной строчке полный путь к нашей папке zookeeper-х.х.х. У меня это выглядит так: dataDir=C:\ZooKeeper\zookeeper-3.6.0

Теперь добавим системную переменную среды: ZOOKEEPER_HOME = C: ZooKeeper zookeeper-3.4.9 и в конце системной переменной Path добавим запись: ;%ZOOKEEPER_HOME%bin;
Запускаем командную строку и пишем команду:
zkserverЕсли всё сделано правильно, вы увидите примерно следующее.
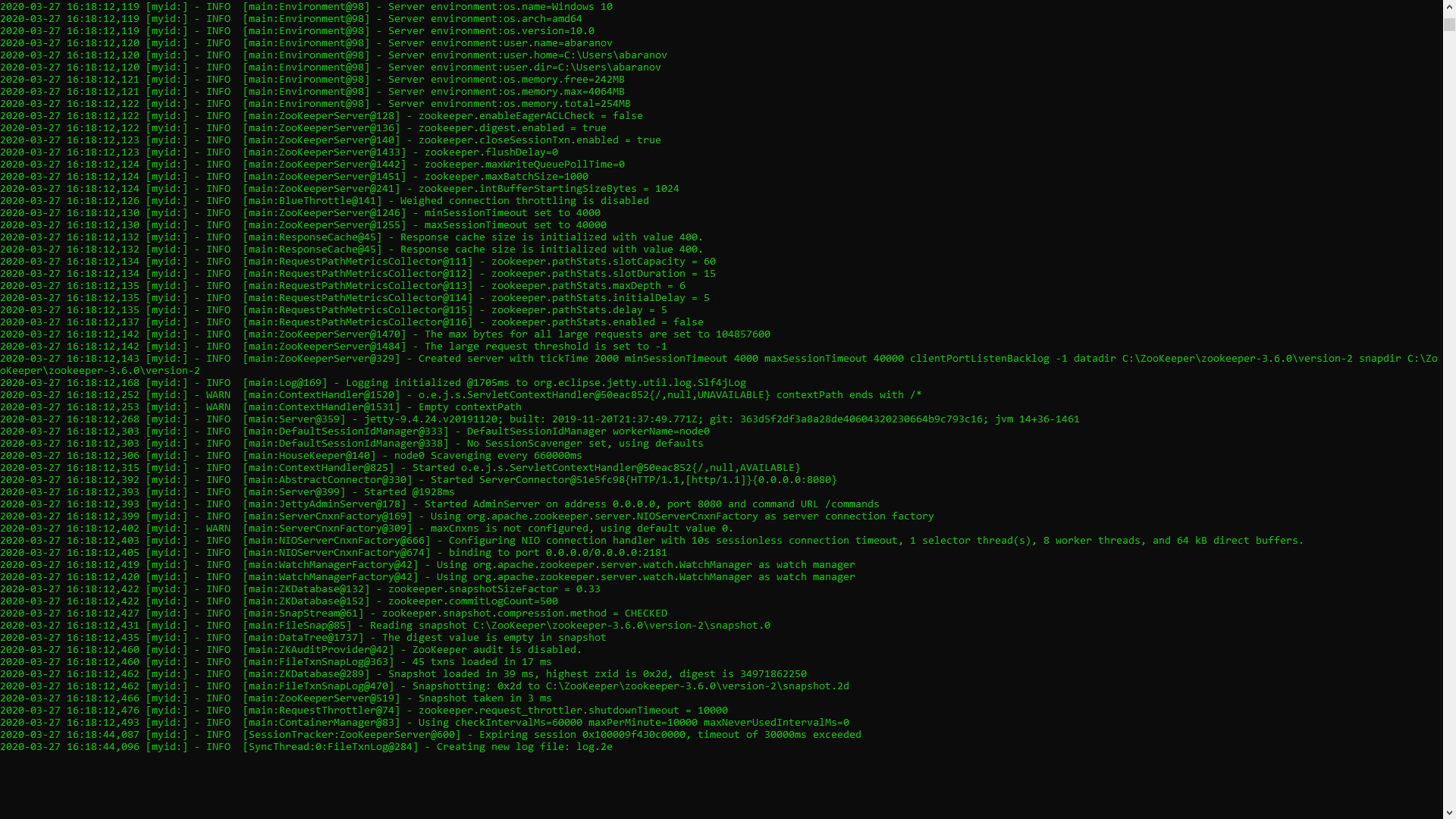
Это означает, что ZooKeeper стартанул нормально. Переходим непосредственно к установке и настройке сервера Apache Kafka. Скачиваем свежую версию с официального сайта и извлекаем содержимое архива: kafka.apache.org/downloads
В папке с Kafka находим папку config, в ней находим файл server.properties и открываем его.

Находим строку log.dirs= /tmp/kafka-logs и указываем в ней путь, куда Kafka будет сохранять логи: log.dirs=c:/kafka/kafka-logs.
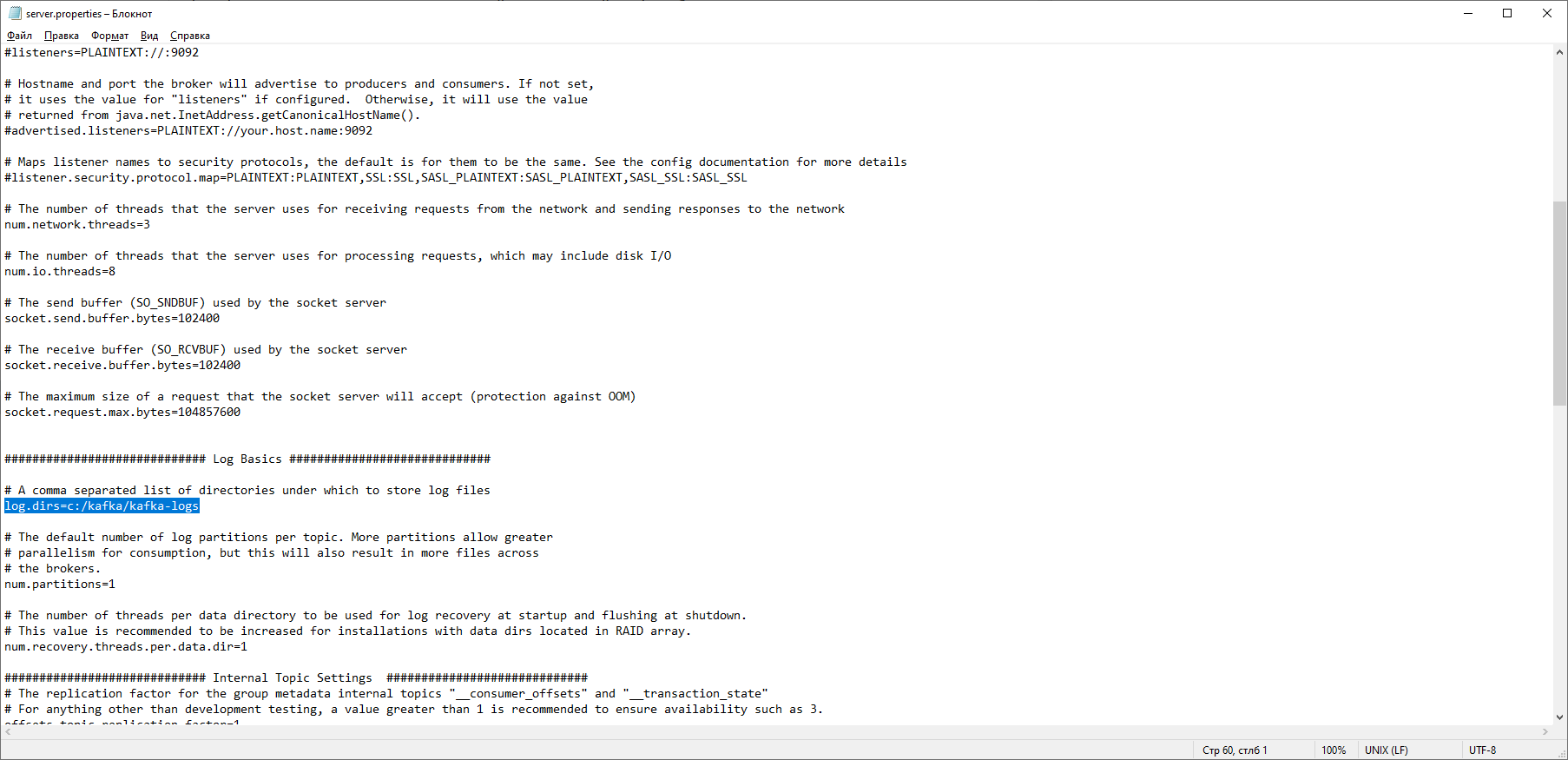
В этой же папке редактируем файл zookeeper.properties. Строчку dataDir=/tmp/zookeeper меняем на dataDir=c:/kafka/zookeeper-data, не забывая при этом, после имени диска указывать путь к своей папке с Kafka. Если вы всё сделали правильно, можно запускать ZooKeeper и Kafka.

Для кого-то может оказаться неприятной неожиданностью, что никакого GUI для управления Kafka нет. Возможно, это потому, что сервис рассчитан на суровых нёрдов, работающих исключительно с консолью. Так или иначе, для запуска кафки нам потребуется командная строка.
Сначала надо запустить ZooKeeper. В папке с кафкой находим папку bin/windows, в ней находим файл для запуска сервиса zookeeper-server-start.bat, кликаем по нему. Ничего не происходит? Так и должно быть. Открываем в этой папке консоль и пишем:
start zookeeper-server-start.batОпять не работает? Это норма. Всё потому что zookeeper-server-start.bat для своей работы требует параметры, прописанные в файле zookeeper.properties, который, как мы помним, лежит в папке config. Пишем в консоль:
start zookeeper-server-start.bat c:kafkaconfigzookeeper.properties Теперь всё должно стартануть нормально.

Ещё раз открываем консоль в этой папке (ZooKeeper не закрывать!) и запускаем kafka:
start kafka-server-start.bat c:kafkaconfigserver.propertiesДля того, чтобы не писать каждый раз команды в командной строке, можно воспользоваться старым проверенным способом и создать батник со следующим содержимым:
start C:kafkabinwindowszookeeper-server-start.bat C:kafkaconfigzookeeper.properties
timeout 10
start C:kafkabinwindowskafka-server-start.bat C:kafkaconfigserver.propertiesСтрока timeout 10 нужна для того, чтобы задать паузу между запуском zookeeper и kafka. Если вы всё сделали правильно, при клике на батник должны открыться две консоли с запущенным zookeeper и kafka.Теперь мы можем прямо из командной строки создать продюсера сообщений и консьюмера с нужными параметрами. Но, на практике это может понадобиться разве что для тестирования сервиса. Гораздо больше нас будет интересовать, как работать с kafka из IDEA.
Работа с kafka из IDEA
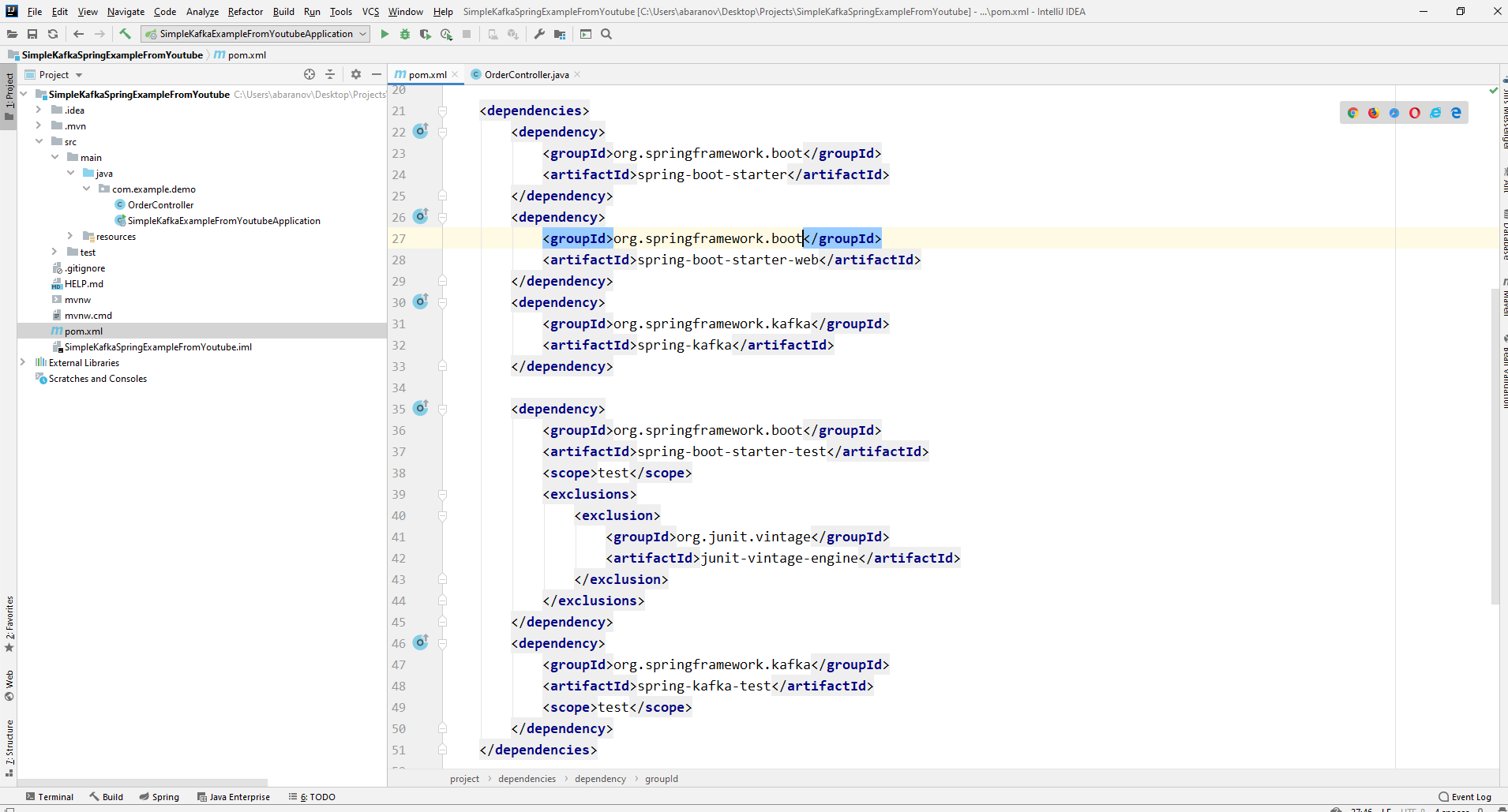
Мы напишем максимально простое приложение, которое одновременно будет и продюсером и консьюмером сообщения, а затем добавим в него полезные фичи. Создадим новый спринг-проект. Удобнее всего делать это с помощью спринг-инициалайзера. Добавляем зависимости org.springframework.kafka и spring-boot-starter-web


В итоге файл pom.xml должен выглядеть так:
Для того, чтобы отправлять сообщения, нам потребуется объект KafkaTemplate<K, V>. Как мы видим объект является типизированным. Первый параметр – это тип ключа, второй – самого сообщения. Пока оба параметра мы укажем как String. Объект будем создавать в классе-рестконтроллере. Объявим KafkaTemplate и попросим Spring инициализировать его, поставив аннотацию Autowired.
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;В принципе, наш продюсер готов. Всё что осталось сделать – это вызвать у него метод send(). Имеется несколько перегруженных вариантов данного метода. Мы используем в нашем проекте вариант с 3 параметрами — send(String topic, K key, V data). Так как KafkaTemplate типизирован String-ом, то ключ и данные в методе send будут являться строкой. Первым параметром указывается топик, то есть тема, в которую будут отправляться сообщения, и на которую могут подписываться консьюмеры, чтобы их получать. Если топик, указанный в методе send не существует, он будет создан автоматически. Полный текст класса выглядит так.
@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
Контроллер мапится на localhost:8080/msg, в теле запроса передаётся ключ и само сообщений.
Отправитель сообщений готов, теперь создадим слушателя. Spring так же позволяет cделать это без особых усилий. Достаточно создать метод и пометить его аннотацией @KafkaListener, в параметрах которой можно указать только топик, который будет слушаться. В нашем случае это выглядит так.
@KafkaListener(topics="msg")У самого метода, помеченного аннотацией, можно указать один принимаемый параметр, имеющий тип сообщения, передаваемого продюсером.
Класс, в котором будет создаваться консьюмер необходимо пометить аннотацией @EnableKafka.
@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}Так же в файле настроек application.property необходимо указать параметр консьюмера groupe-id. Если этого не сделать, приложение не запустится. Параметр имеет тип String и может быть любым.
spring.kafka.consumer.group-id=app.1
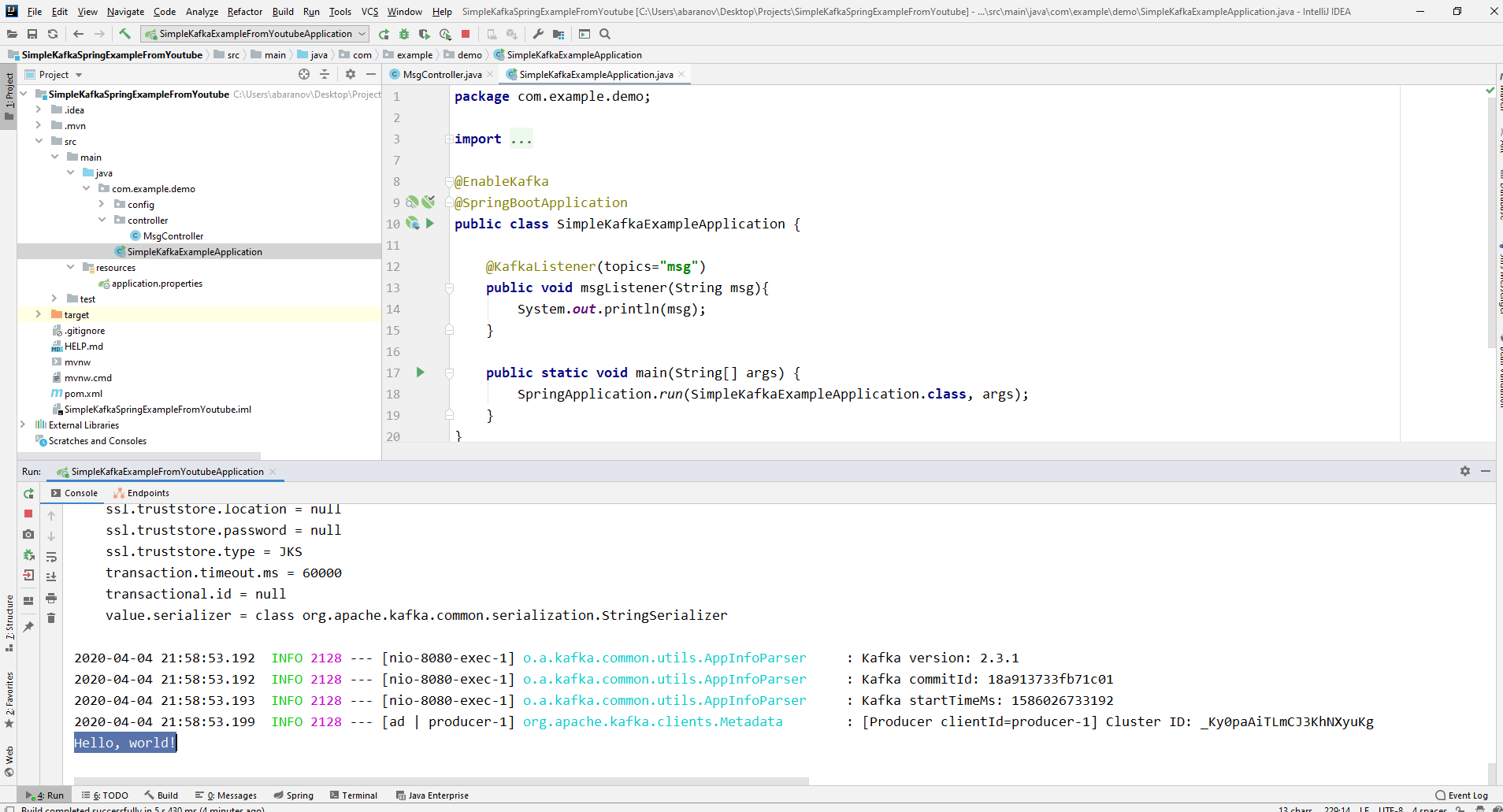
Наш простейший кафка-проект готов. У нас есть отправитель и получатель сообщений. Осталось только запустить. Для начала запускаем ZooKeeper и Kafka с помощью батника, который мы написали ранее, затем запускаем наше приложение. Отправлять запрос удобнее всего с помощью Postman. В теле запроса не забываем указывать параметры msgId и msg.

Если мы видим в IDEA такую картину, значит всё работает: продюсер отправил сообщение, консьюмер получил его и вывел в консоль.
Усложняем проект
Реальные проекты с использованием Kafka конечно же сложнее, чем тот, который мы создали. Теперь, когда мы разобрались с базовыми функциями сервиса, рассмотрим, какие дополнительные возможности он предоставляет. Для начала усовершенствуем продюсера.
Если вы открывали метод send(), то могли заметить, что у всех его вариантов есть возвращаемое значение ListenableFuture<SendResult<K, V>>. Сейчас мы не будем подробно рассматривать возможности данного интерфейса. Здесь будет достаточно сказать, что он нужен для просмотра результата отправки сообщения.
@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}Метод addCallback() принимает два параметра – SuccessCallback и FailureCallback. Оба они являются функциональными интерфейсами. Из названия можно понять, что метод первого будет вызван в результате успешной отправки сообщения, второго – в результате ошибки.Теперь, если мы запустим проект, то увидим на консоли примерно следующее:
SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]Посмотрим ещё раз внимательно на нашего продюсера. Интересно, что будет если в качестве ключа будет не String, а, допустим, Long, а в качестве передаваемого сообщения и того хуже – какая-нибудь сложная DTO? Попробуем для начала изменить ключ на числовое значение…

Если мы укажем в продюсере в качестве ключа Long, то приложение нормально запуститься, но при попытке отправить сообщение будет выброшен ClassCastException и будет сообщено, что класс Long не может быть приведён к классу String.

Если мы попробуем вручную создать объект KafkaTemplate, то увидим, что в конструктор в качестве параметра передаётся объект интерфейса ProducerFactory<K, V>, например DefaultKafkaProducerFactory<>. Для того, чтобы создать DefaultKafkaProducerFactory, нам нужно в его конструктор передать Map, содержащий настройки продюсера. Весь код по конфигурации и созданию продюсера вынесем в отдельный класс. Для этого создадим пакет config и в нём класс KafkaProducerConfig.
@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
В методе producerConfigs() создаём мапу с конфигурациями и в качестве сериализатора для ключа указываем LongSerializer.class. Запускаем, отправляем запрос из Postman и видим, что теперь всё работает, как надо: продюсер отправляет сообщение, а консьюмер принимает его.
Теперь изменим тип передаваемого значения. Что если у нас не стандартный класс из библиотеки Java, а какой-нибудь кастомный DTO. Допустим такой.
@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}Для отправки DTO в качестве сообщения, нужно внести некоторые изменения в конфигурацию продюсера. В качестве сериализатора значения сообщения укажем JsonSerializer.class и не забудем везде изменить тип String на UserDto.
@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}Отправим сообщение. В консоль будет выведена следующая строка:

Теперь займёмся усложнением консьюмера. До этого наш метод public void msgListener(String msg), помеченный аннотацией @KafkaListener(topics=«msg») в качестве параметра принимал String и выводил его на консоль. Как быть, если мы хотим получить другие параметры передаваемого сообщения, например, ключ или партицию? В этом случае тип передаваемого значения необходимо изменить.
@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}Из объекта ConsumerRecord мы можем получить все интересующие нас параметры.
Мы видим, что вместо ключа на консоль выводятся какие-то кракозябры. Это потому, что для десериализации ключа по умолчанию используется StringDeserializer, и если мы хотим, чтобы ключ в целочисленном формате корректно отображался, мы должны изменить его на LongDeserializer. Для настройки консьюмера в пакете config создадим класс KafkaConsumerConfig.
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}Класс KafkaConsumerConfig очень похож на KafkaProducerConfig, который мы создавали ранее. Здесь так же присутствует Map, содержащий необходимые конфигурации, например, такие как десериализатор для ключа и значения. Созданная мапа используется при создании ConsumerFactory<>, которая в свою очередь, нужна для создания KafkaListenerContainerFactory<?>. Важная деталь: метод возвращающий KafkaListenerContainerFactory<?> должен называться kafkaListenerContainerFactory(), иначе Spring не сможет найти нужного бина и проект не скомпилируется. Запускаем.

Видим, что теперь ключ отображается как надо, а это значит, что всё работает. Конечно, возможности Apache Kafka далеко выходят за пределы тех, что описаны в данной статье, однако, надеюсь, прочитав её, вы составите представление о данном сервисе и, самое главное, сможете начать работу с ним.
Мойте руки чаще, носите маски, не выходите без необходимости на улицу, и будьте здоровы.

Apache Kafka is an open-source event streaming platform that can transport huge volumes of data at very low latency.
Companies like LinkedIn, Uber, and Netflix use Kafka to process trillions of events and petabtyes of data each day.
Kafka was originally developed at LinkedIn, to help handle their real-time data feeds. It’s now maintained by the Apache Software Foundation, and is widely adopted in industry (being used by 80% of Fortune 100 companies).
Why Should You Learn Apache Kafka?
Kafka lets you:
- Publish and subscribe to streams of events
- Store streams of events in the same order they happened
- Process streams of events in real time
The main thing Kafka does is help you efficiently connect diverse data sources with the many different systems that might need to use that data.
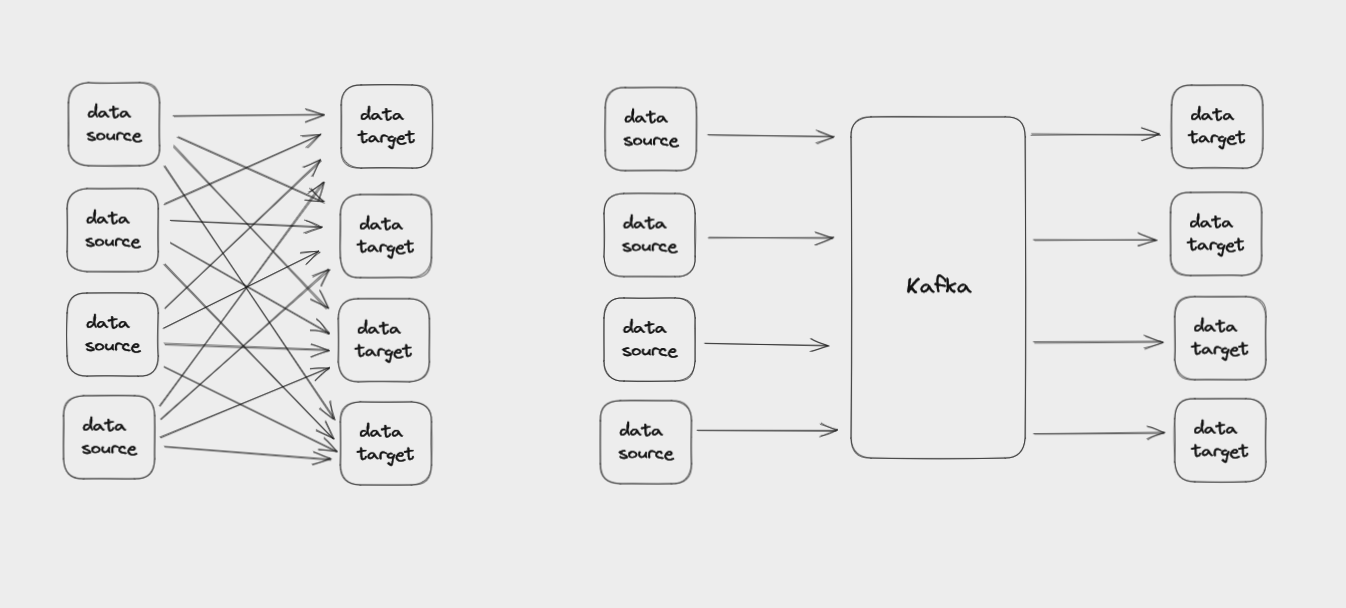
Some of the things you can use Kafka for include:
- Personalizing recommendations for customers
- Notifying passengers of flight delays
- Payment processing in banking
- Online fraud detection
- Managing inventory and supply chains
- Tracking order shipments
- Collecting telemetry data from Internet of Things (IoT) devices
What all these uses have in common is that they need to take in and process data in real time, often at huge scales. This is something Kafka excels at. To give one example, Pinterest uses Kafka to handle up to 40 million events per second.
Kafka is distributed, which means it runs as a cluster of nodes spread across multiple servers. It’s also replicated, meaning that data is copied in multiple locations to protect it from a single point of failure. This makes Kafka both scalable and fault-tolerant.
Kafka is also fast. It’s optimized for high throughput, making effective use of disk storage and batched network requests.
This article will:
- Introduce you to the core concepts behind Kafka
- Show you how to install Kafka on your own computer
- Get you started with the Kafka Command Line Interface (CLI)
- Help you build a simple Java application that produces and consumes events via Kafka
Things the article won’t cover:
- More advanced Kafka topics, such as security, performance, and monitoring
- Deploying a Kafka cluster to a server
- Using managed Kafka services like Amazon MSK or Confluent Cloud
Table of Contents
- Event Streaming and Event-Driven Architectures
- Core Kafka Concepts
a. Event Messages in Kafka
b. Topics in Kafka
c. Partitions in Kafka
d. Offsets in Kafka
e. Brokers in Kafka
f. Replication in Kafka
g. Producers in Kafka
h. Consumers in Kafka
i. Consumer Groups in Kafka
j. Kafka Zookeeper - How to Install Kafka on Your Computer
- How to Start Zookeeper and Kafka
- The Kafka CLI
a. How to List Topics
b. How to Create a Topic
c. How to Describe Topics
d. How to Partition a Topic
e. How to Set a Replication Factor
f. How to Delete a Topic
g. How to usekafka-console-producer
h. How to usekafka-console-consumer
i. How to usekafka-consumer-groups - How to Build a Kafka Client App with Java
a. How to Set Up the Project
b. How to Install the Dependencies
c. How to Create a Kafka Producer
d. How to Send Multiple Messages and Use Callbacks
e. How to Create a Kafka Consumer
f. How to Shut Down the Consumer - Where to Take it From Here
Before we dive into Kafka, we need some context on event streaming and event-driven architectures.
Event Streaming and Event-Driven Architectures
An event is a record that something happened, as well as information about what happened. For example: a customer placed an order, a bank approved a transaction, inventory management updated stock levels.
Events can triggers one or more processes to respond to them. For example: sending an email receipt, transmitting funds to an account, updating a real-time dashboard.
Event streaming is the process of capturing events in real-time from sources (such as web applications, databases, or sensors) to create streams of events. These streams are potentially unending sequences of records.
The event stream can be stored, processed, and sent to different destinations, also called sinks. The destinations that consume the streams could be other applications, databases, or data pipelines for further processing.
As applications have become more complex, often being broken up into different microservices distributed across multiple data centers, many organizations have adopted an event-driven architecture for their applications.
This means that instead of parts of your application directly asking each other for updates about what happened, they each publish events to event streams. Other parts of the application continuously subscribe to these streams and only act when they receive an event that they are interested in.
This architecture helps ensure that if part of your application goes down, other parts won’t also fail. Additionally, you can add new features by adding new subscribers to the event stream, without having to rewrite the existing codebase.
Core Kafka Concepts
Kafka has become one of the most popular ways to implement event streaming and event-driven architectures. But it does have a bit of a learning curve and you need to understand a couple of concepts before you can make effective use of it.
These core concepts are:
- event messages
- topics
- partitions
- offsets
- brokers
- producers
- consumers
- consumer groups
- Zookeeper
Event Messages in Kafka
When you write data to Kafka, or read data from it, you do this in the form of messages. You’ll also see them called events or records.
A message consists of:
- a key
- a value
- a timestamp
- a compression type
- headers for metadata (optional)
- partition and offset id (once the message is written to a topic)
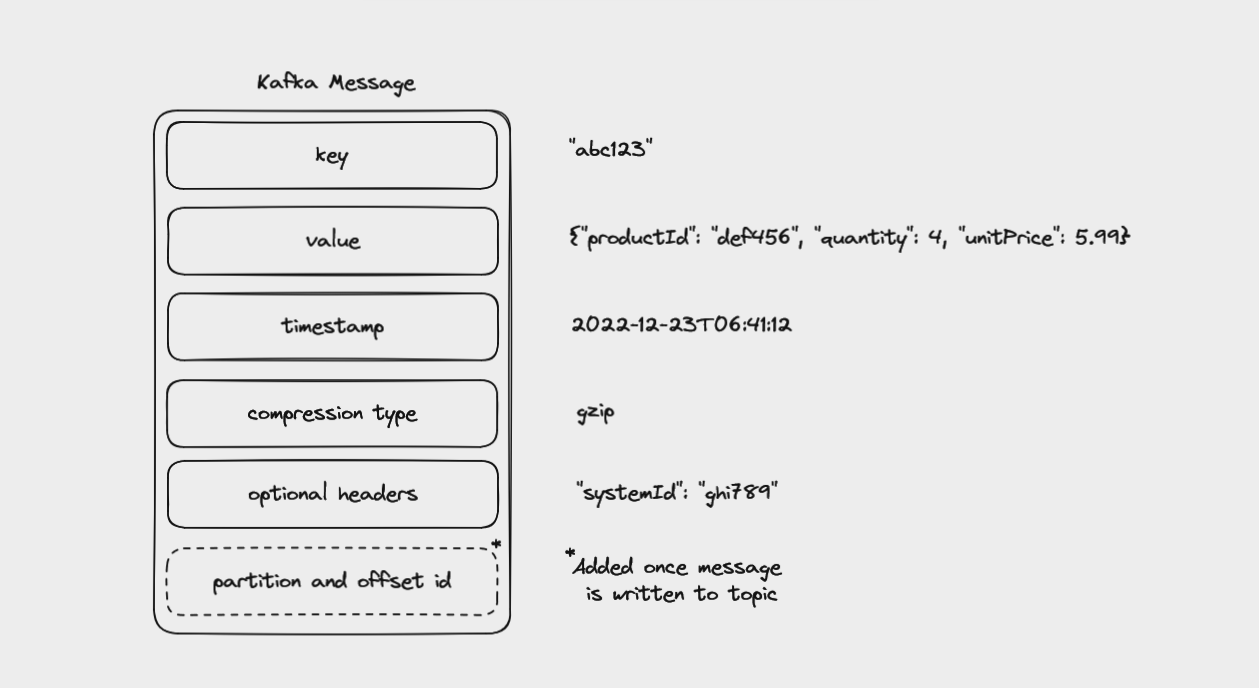
Every event in Kafka is, at its simplest, a key-value pair. These are serialized into binary, since Kafka itself handles arrays of bytes rather than complex language-specific objects.
Keys are usually strings or integers and aren’t unique for every message. Instead, they point to a particular entity in the system, such as a specific user, order, or device. Keys can be null, but when they are included they are used for dividing topics into partitions (more on partitions below).
The message value contains details about the event that happened. This could be as simple as a string or as complex as an object with many nested properties. Values can be null, but usually aren’t.
By default, the timestamp records when the message was created. You can overwrite this if your event actually occurred earlier and you want to record that time instead.
Messages are usually small (less than 1 MB) and sent in a standard data format, such as JSON, Avro, or Protobuf. Even so, they can be compressed to save on data. The compression type can be set to gzip, lz4, snappy, zstd, or none.
Events can also optionally have headers, which are key-value pairs of strings containing metadata, such as where the event originated from or where you want it routed to.
Once a message is sent into a Kafka topic, it also receives a partition number and offset id (more about these later).
Topics in Kafka
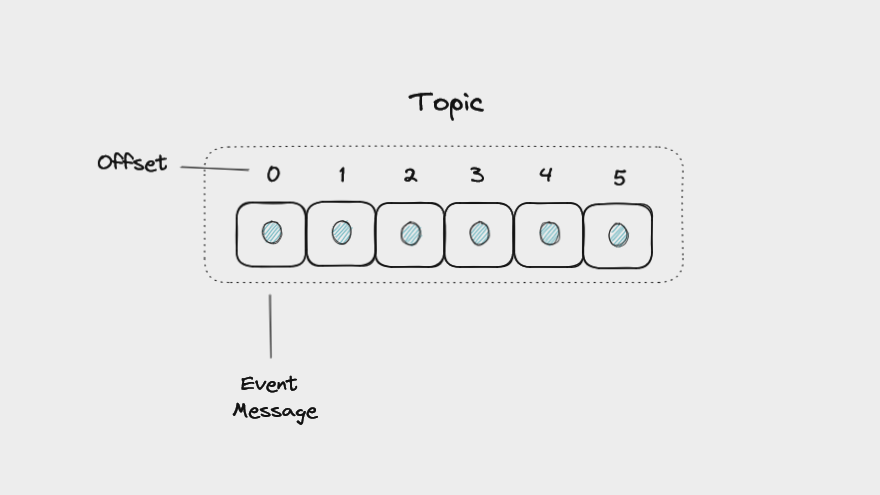
Kafka stores messages in a topic, an ordered sequence of events, also called an event log.
Different topics are identified by their names and will store different kinds of events. For example a social media application might have posts, likes, and comments topics to record every time a user creates a post, likes a post, or leaves a comment.
Multiple applications can write to and read from the same topic. An application might also read messages from one topic, filter or transform the data, and then write the result to another topic.
One important feature of topics is that they are append-only. When you write a message to a topic, it’s added to the end of the log. Events in a topic are immutable. Once they’re written to a topic, you can’t change them.
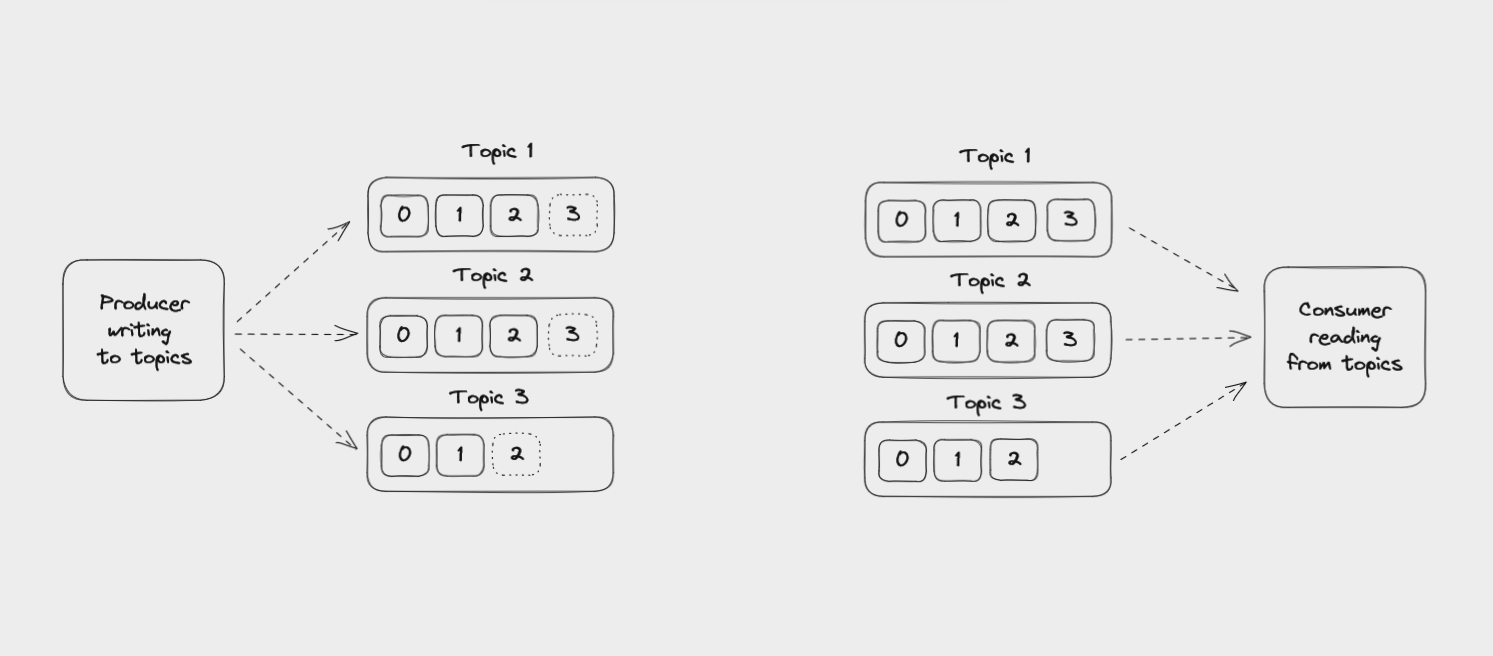
Unlike with messaging queues, reading an event from a topic doesn’t delete it. Events can be read as often as needed, perhaps several times by multiple different applications.
Topics are also durable, holding onto messages for a specific period (by default 7 days) by saving them to physical storage on disk.
You can configure topics so that messages expire after a certain amount of time, or when a certain amount of storage is exceeded. You can even store messages indefinitely as long as you can pay for the storage costs.
Partitions in Kafka
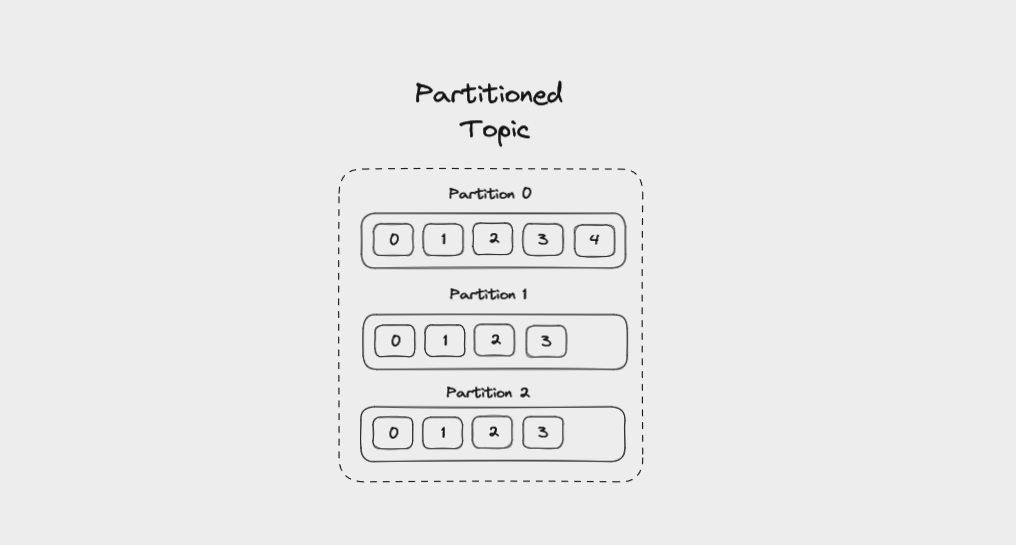
In order to help Kafka to scale, topics can be divided into partitions. This breaks up the event log into multiple logs, each of which lives on a separate node in the Kafka cluster. This means that the work of writing and storing messages can be spread across multiple machines.
When you create a topic, you specify the amount of partitions it has. The partitions are themselves numbered, starting at 0. When a new event is written to a topic, it’s appended to one of the topic’s partitions.
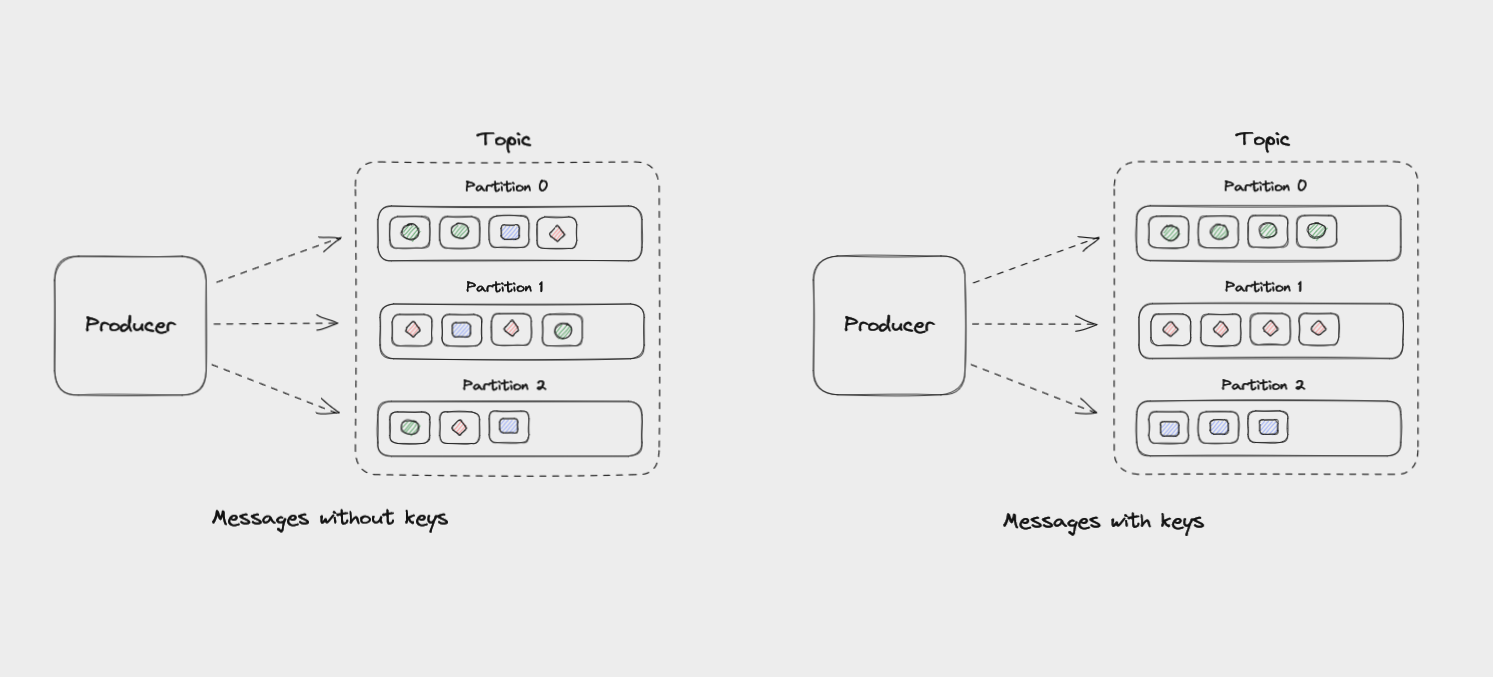
If messages have no key, they will be evenly distributed among partitions in a round robin manner: partition 0, then partition 1, then partition 2, and so on. This way, all partitions get an even share of the data but there’s no guarantee about the ordering of messages.
Messages that have the same key will always be sent to the same partition, and in the same order. The key is run through a hashing function which turns it into an integer. This output is then used to select a partition.
Messages within each partition are guaranteed to be ordered. For example, all messages with the same customer_id as their key will be sent to the same partition in the order in which Kafka received them.
Offsets in Kafka
Each message in a partition gets an id that is an incrementing integer, called an offset. Offsets start at 0 and are incremented every time Kafka writes a message to a partition. This means that each message in a given partition has a unique offset.
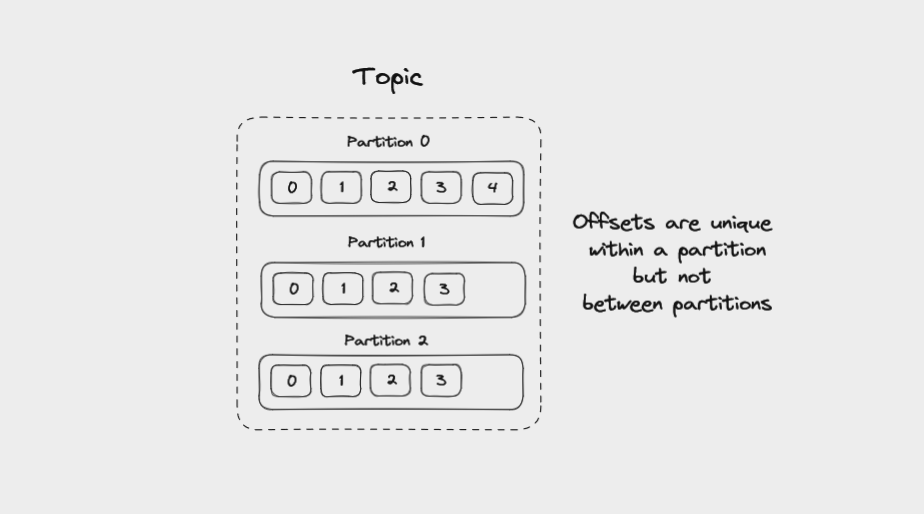
Offsets are not reused, even when older messages get deleted. They continue to increment, giving each new message in the partition a unique id.
When data is read from a partition, it is read in order from the lowest existing offset upwards. We’ll see more about offsets when we cover Kafka consumers.
Brokers in Kafka
A single «server» running Kafka is called a broker. In reality, this might be a Docker container running in a virtual machine. But it can be a helpful mental image to think of brokers as individual servers.
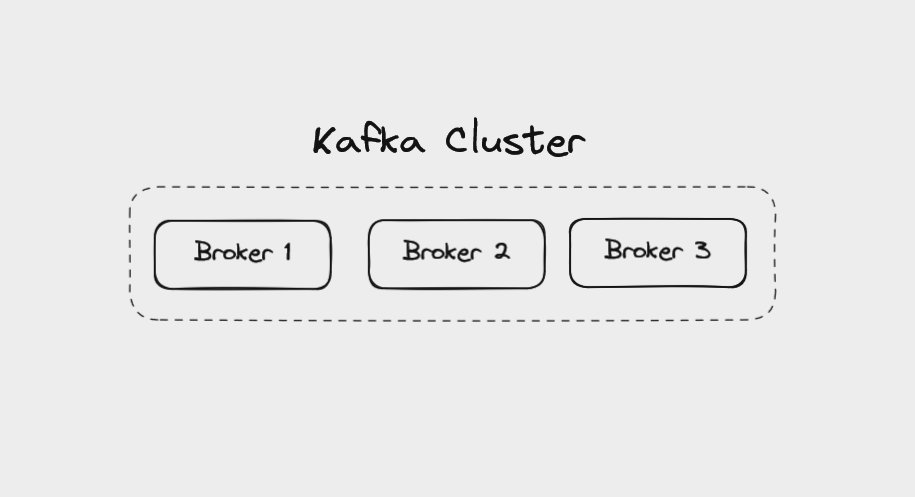
Multiple brokers working together make up a Kafka cluster. There might be a handful of brokers in a cluster, or more than 100. When a client application connects to one broker, Kafka automatically connects it to every broker in the cluster.
By running as a cluster, Kafka becomes more scalable and fault-tolerant. If one broker fails, the others will take over its work to ensure there is no downtime or data loss.
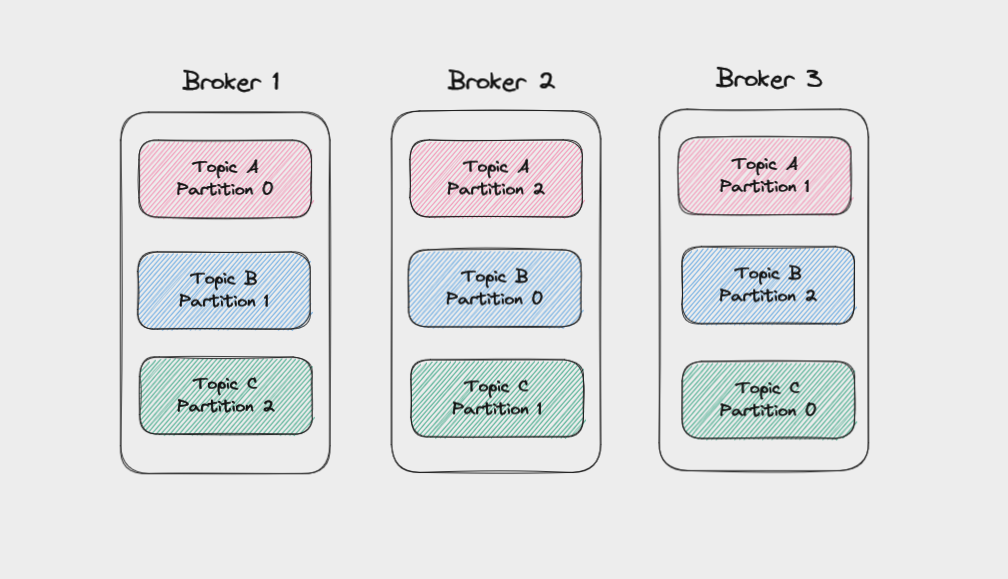
Each broker manages a set of partitions and handles requests to write data to or read data from these partitions. Partitions for a given topic will be spread evenly across the brokers in a cluster to help with load balancing. Brokers also manage replicating partitions to keep their data backed up.
Replication in Kafka
To protect against data loss if a broker fails, Kafka writes the same data to copies of a partition on multiple brokers. This is called replication.
The main copy of a partition is called the leader, while the replicas are called followers.
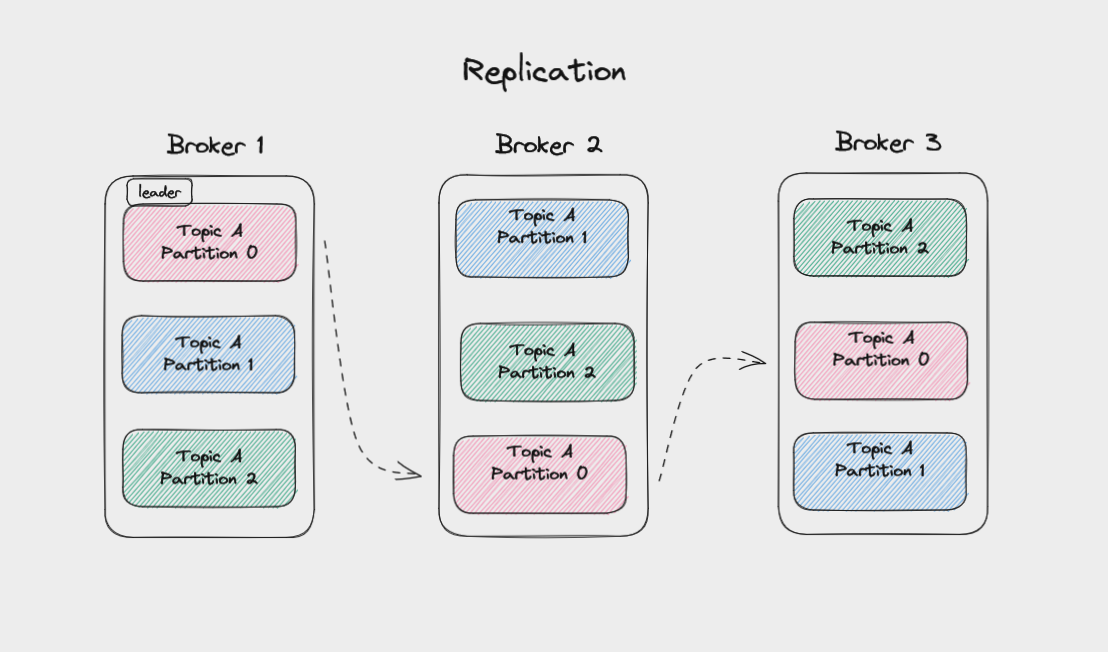
When a topic is created, you set a replication factor for it. This controls how many replicas get written to. A replication factor of three is common, meaning data gets written to one leader and replicated to two followers. So even if two brokers failed, your data would still be safe.
Whenever you write messages to a partition, you’re writing to the leader partition. Kafka then automatically copies these messages to the followers. As such, the logs on the followers will have the same messages and offsets as on the leader.
Followers that are up to date with the leader are called In-Sync Replicas (ISRs). Kafka considers a message to be committed once a minimum number of replicas have saved it to their logs. You can configure this to get higher throughput at the expense of less certainty that a message has been backed up.
Producers in Kafka
Producers are client applications that write events to Kafka topics. These apps aren’t themselves part of Kafka – you write them.
Usually you will use a library to help manage writing events to Kafka. There is an official client library for Java as well as dozens of community-supported libraries for languages such as Scala, JavaScript, Go, Rust, Python, C#, and C++.
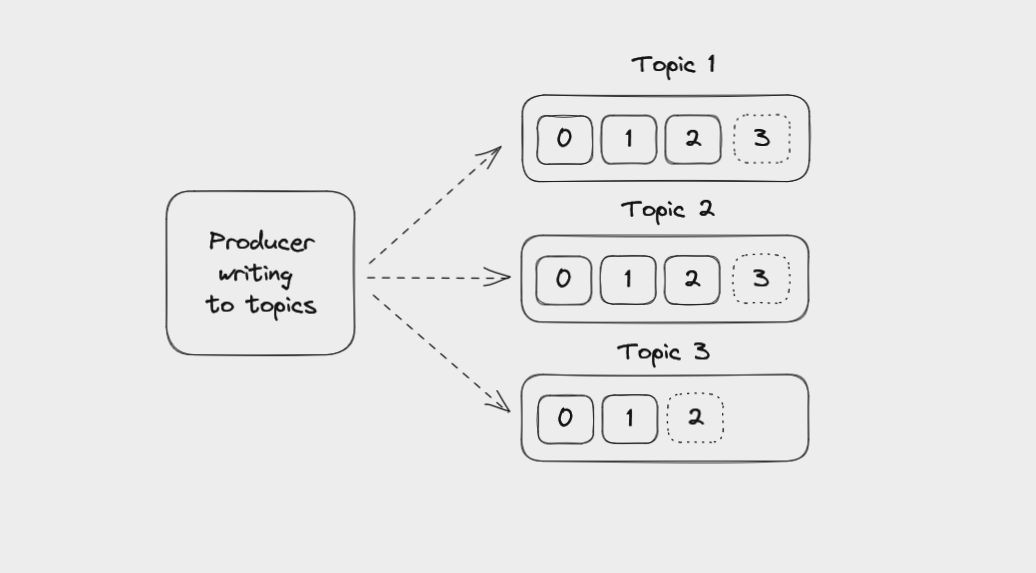
Producers are totally decoupled from consumers, which read from Kafka. They don’t know about each other and their speed doesn’t affect each other. Producers aren’t affected if consumers fail, and the same is true for consumers.
If you need to, you could write an application that writes certain events to Kafka and reads other events from Kafka, making it both a producer and a consumer.
Producers take a key-value pair, generate a Kafka message, and then serialize it into binary for transmission across the network. You can adjust the configuration of producers to batch messages together based on their size or some fixed time limit to optimize writing messages to the Kafka brokers.
It’s the producer that decides which partition of a topic to send each message to. Again, messages without keys will be distributed evenly among partitions, while messages with keys are all sent to the same partition.
Consumers in Kafka
Consumers are client applications that read messages from topics in a Kafka cluster. Like with producers, you write these applications yourself and can make use of client libraries to support the programming language your application is built with.
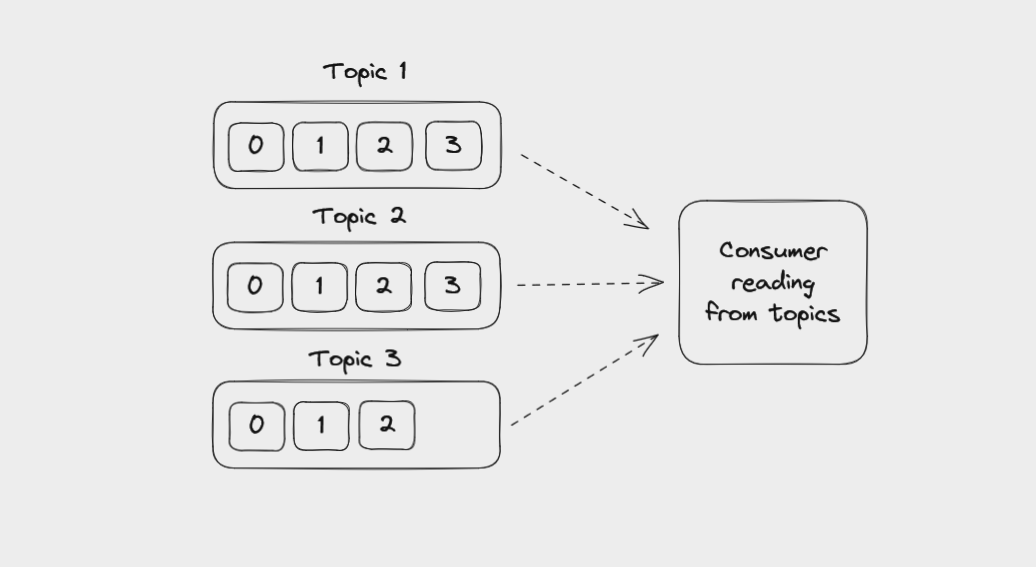
Consumers can read from one or more partitions within a topic, and from one or more topics. Messages are read in order within a partition, from the lowest available offset to the highest. But if a consumer reads data from several partitions in the same topic, the message order between these partitions is not guaranteed.
For example, a consumer might read messages from partition 0, then partition 2, then partition 1, then back to partition 0. The messages from partition 0 will be read in order, but there might be messages from the other partitions mixed among them.
It’s important to remember that reading a message does not delete it. The message is still available to be read by any other consumer that needs to access it. It’s normal for multiple consumers to read from the same topic if they each have uses for the data in it.
By default, when a consumer starts up it will read from the current offset in a partition. But consumers can also be configured to go back and read from the oldest existing offset.
Consumers deserialize messages, converting them from binary into a collection of key-value pairs that your application can then work with. The format of a message should not change during a topic’s lifetime or your producers and consumers won’t be able to serialize and deserialize it correctly.
One thing to be aware of is that consumers request messages from Kafka, it doesn’t push messages to them. This protects consumers from becoming overwhelmed if Kafka is handling a high volume of messages. If you want to scale consumers, you can run multiple instances of a consumer together in a consumer group.
Consumer Groups in Kafka
An application that reads from Kafka can create multiple instances of the same consumer to split up the work of reading from different partitions in a topic. These consumers work together as a consumer group.
When you create a consumer, you can assign it a group id. All consumers in a group will have the same group id.
You can create consumer instances in a group up to the number of partitions in a topic. So if you have a topic with 5 partitions, you can create up to 5 instances of the same consumer in a consumer group. If you ever have more consumers in a group than partitions, the extra consumer will remain idle.
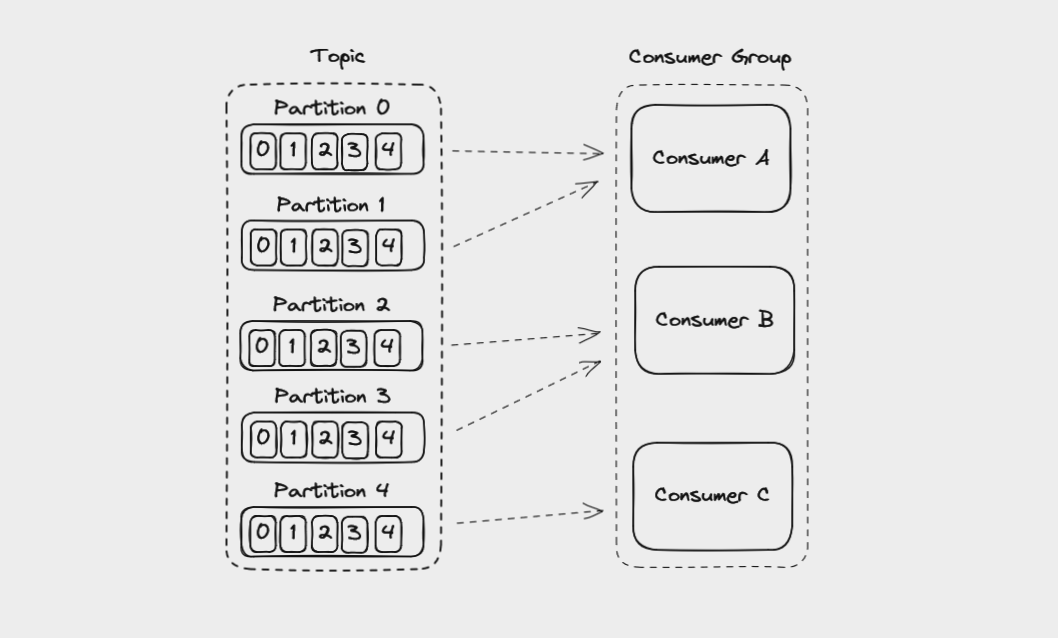
If you add another consumer instance to a consumer group, Kafka will automatically redistribute the partitions among the consumers in a process called rebalancing.
Each partition is only assigned to one consumer in a group, but a consumer can read from multiple partitions. Also, multiple different consumer groups (meaning different applications) can read from the same topic at the same time.
Kafka brokers use an internal topic called __consumer_offsets to keep track of which messages a specific consumer group has successfully processed.
As a consumer reads from a partition, it regularly saves the offset it has read up to and sends this data to the broker it is reading from. This is called the consumer offset and is handled automatically by most client libraries.
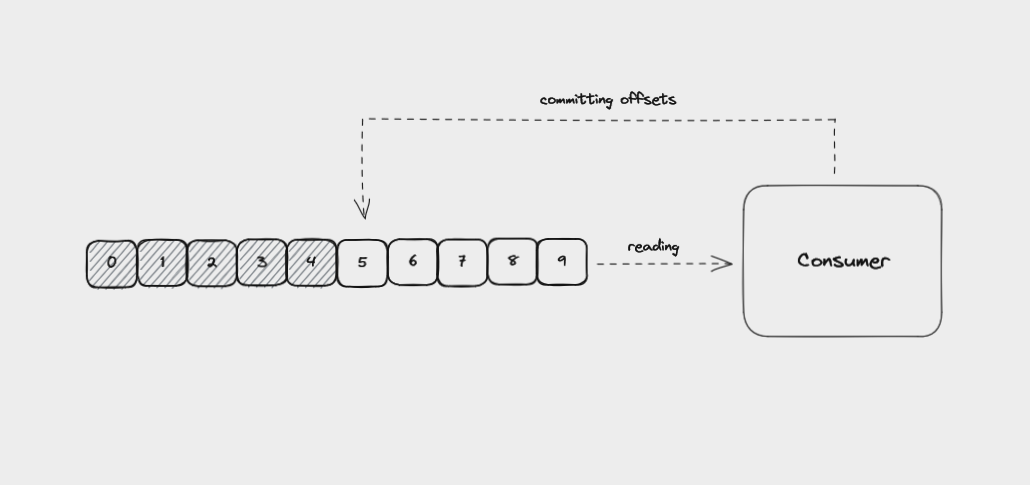
If a consumer crashes, the consumer offset helps the remaining consumers to know where to start from when they take over reading from the partition.
The same thing happens if a new consumer is added to the group. The consumer group rebalances, the new consumer is assigned a partition, and it picks up reading from the consumer offset of that partition.
Kafka Zookeeper
One other topic that we briefly need to cover here is how Kafka clusters are managed. Currently this is usually done using Zookeeper, a service for managing and synchronizing distributed systems. Like Kafka, it’s maintained by the Apache Foundation.
Kafka uses Zookeeper to manage the brokers in a cluster, and requires Zookeeper even if you’re running a Kafka cluster with only one broker.
Recently, a proposal has been accepted to remove Zookeeper and have Kafka manage itself (KIP-500), but this is not yet widely used in production.
Zookeeper keeps track of things like:
- Which brokers are part of a Kafka cluster
- Which broker is the leader for a given partition
- How topics are configured, such as the number of partitions and the location of replicas
- Consumer groups and their members
- Access Control Lists – who is allowed to write to and read from each topic
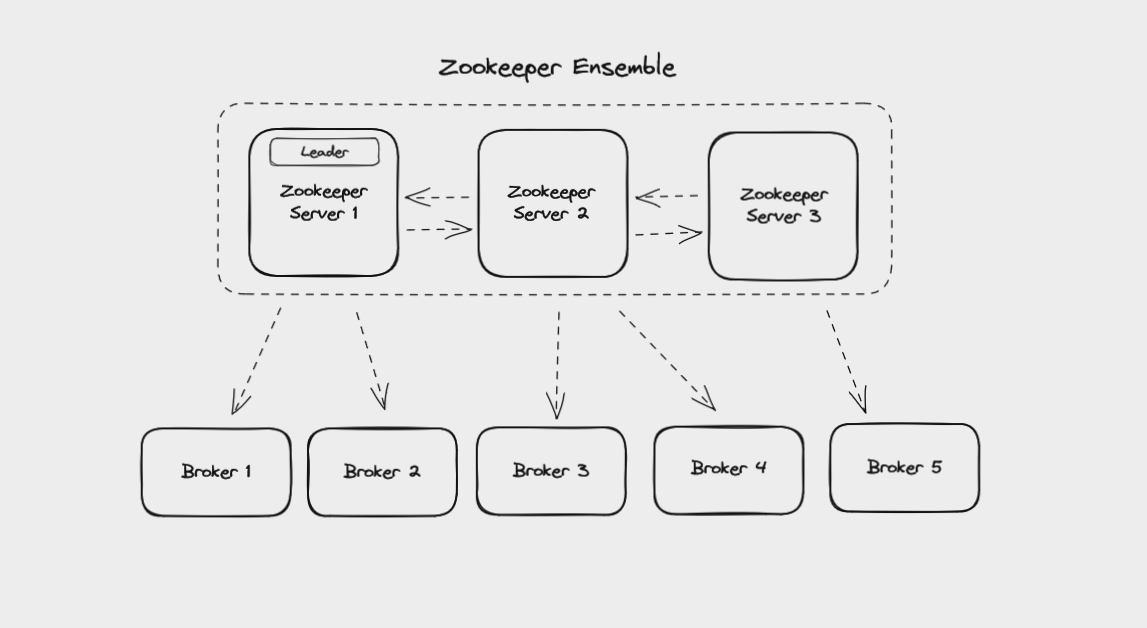
Zookeeper itself runs as a cluster called an ensemble. This means that Zookeeper can keep working even if one node in the cluster fails. New data gets written to the ensemble’s leader and replicated to the followers. Your Kafka brokers can read this data from any of the Zookeeper nodes in the ensemble.
Now that you understand the main concepts behind Kafka, let’s get some hands-on practice working with Kafka.
You’re going to install Kafka on your own computer, practice interacting with Kafka brokers from the command line, and then build a simple producer and consumer application with Java.
How to Install Kafka on Your Computer
At the time of writing this guide, the latest stable version of Kafka is 3.3.1. Check kafka.apache.org/downloads to see if there is a more recent stable version. If there is, you can replace «3.3.1» with the latest stable version in all of the following instructions.
Install Kafka on macOS
If you’re using macOS, I recommend using Homebrew to install Kafka. It will make sure you have Java installed before it installs Kafka.
If you don’t already have Homebrew installed, install it by following the instructions at brew.sh.
Next, run brew install kafka in a terminal. This will install Kafka’s binaries at usr/local/bin.
Finally, run kafka-topics --version in a terminal and you should see 3.3.1. If you do, you’re all set.
To make it easier to work with Kafka, you can add Kafka to the PATH environment variable. Open your ~/.bashrc (if using Bash) or ~/.zshrc (if using Zsh) and add the following line, replacing USERNAME with your username:
PATH="$PATH:/Users/USERNAME/kafka_2.13-3.3.1/bin"You’ll need to close your terminal for this change to take effect.
Now, if you run echo $PATH you should see that the Kafka bin directory has been added to your path.
Install Kafka on Windows (WSL2) and Linux
Kafka isn’t natively supported on Windows, so you will need to use either WSL2 or Docker. I’m going to show you WSL2 since it’s the same steps as Linux.
To set up WSL2 on Widows, follow the instructions in the official docs.
From here on, the instructions are the same for both WSL2 and Linux.
First, install Java 11 by running the following commands:
wget -O- https://apt.corretto.aws/corretto.key | sudo apt-key add -
sudo add-apt-repository 'deb https://apt.corretto.aws stable main'
sudo apt-get update; sudo apt-get install -y java-11-amazon-corretto-jdk
Once this has finished, run java -version and you should see something like:
openjdk version "11.0.17" 2022-10-18 LTS
OpenJDK Runtime Environment Corretto-11.0.17.8.1 (build 11.0.17+8-LTS)
OpenJDK 64-Bit Server VM Corretto-11.0.17.8.1 (build 11.0.17+8-LTS, mixed mode)From your root directory, download Kafka with the following command:
wget https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz
The 2.13 means it is using version 2.13 of Scala, while 3.3.1 refers to the Kafka version.
Extract the contents of the download with:
tar xzf kafka_2.13-3.3.1.tgz
If you run ls, you’ll now see kafka_2.13-3.3.1 in your root directory.
To make it easier to work with Kafka, you can add Kafka to the PATH environment variable. Open your ~/.bashrc (if using Bash) or ~/.zshrc (if using Zsh) and add the following line, replacing USERNAME with your username:
PATH="$PATH:home/USERNAME/kafka_2.13-3.3.1/bin"
You’ll need to close your terminal for this change to take effect.
Now, if you run echo $PATH you should see that the Kafka bin directory has been added to your path.
Run kafka-topics.sh --version in a terminal and you should see 3.3.1. If you do, you’re all set.
How to Start Zookeeper and Kafka
Since Kafka uses Zookeeper to manage clusters, you need to start Zookeeper before you start Kafka.
How to Start Kafka on macOS
In one terminal window, start Zookeeper with:
/usr/local/bin/zookeeper-server-start /usr/local/etc/zookeeper/zoo.cfg
In another terminal window, start Kafka with:
/usr/local/bin/kafka-server-start /usr/local/etc/kafka/server.properties
While using Kafka, you need to keep both these terminal windows open. Closing them will shut down Kafka.
How to Start Kafka on Windows (WSL2) and Linux
In one terminal window, start Zookeeper with:
~/kafka_2.13-3.3.1/bin/zookeeper-server-start.sh ~/kafka_2.13-3.3.1/config/zookeeper.properties
In another terminal window, start Kafka with:
~/kafka_2.13-3.3.1/bin/kafka-server-start.sh ~/kafka_2.13-3.3.1/config/server.properties
While using Kafka, you need to keep both these terminal windows open. Closing them will shut down Kafka.
Now that you have Kafka installed and running on your machine, it’s time to get some hands-on practice.
When you install Kafka, it comes with a Command Line Interface (CLI) that lets you create and manage topics, as well as produce and consume events.
First, make sure Zookeeper and Kafka are running in two terminal windows.
In a third terminal window, run kafka-topics.sh (on WSL2 or Linux) or kafka-topics (on macOS) to make sure the CLI is working. You’ll see a list of all the options you can pass to the CLI.
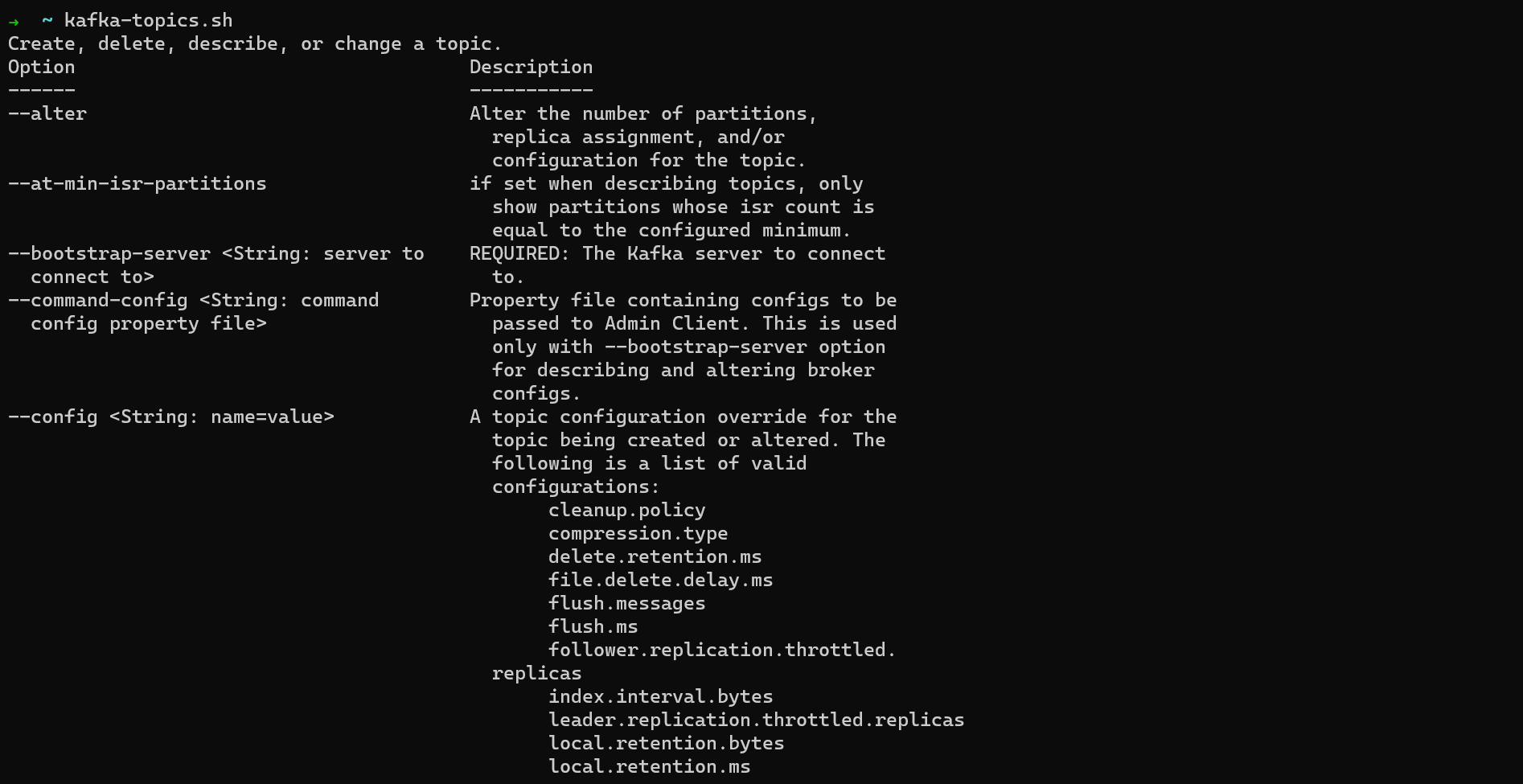
Note: When working with the Kafka CLI, the command will be kafka-topics.sh on WSL2 and Linux. It will be kafka-topics.sh on macOS if you directly installed the Kafka binaries and kafka-topics if you used Homebrew. So if you’re using Homebrew, remove the .sh extension from the example commands in this section.
How to List Topics
To see the topics available on the Kafka broker on your local machine, use:
kafka-topics.sh --bootstrap-server localhost:9092 --list
This means «Connect to the Kafka broker running on localhost:9092 and list all topics there». --bootstrap-server refers to the Kafka broker you are trying to connect to and localhost:9092 is the IP address it’s running at. You won’t see any output since you haven’t created any topics yet.
How to Create a Topic
To create a topic (with the default replication factor and number of partitions), use the --create and --topic options and pass them a topic name:
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my_first_topic
If you use an _ or . in your topic name, you will see the following warning:
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Since Kafka could confuse my.first.topic with my_first_topic, it’s best to only use either underscores or periods when naming topics.
How to Describe Topics
To describe the topics on a broker, use the --describe option:
kafka-topics.sh --bootstrap-server localhost:9092 --describe
This will print the details of all the topics on this broker, including the number of partitions and their replication factor. By default, these will both be set to 1.
If you add the --topic option and the name of a topic, it will describe only that topic:
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic my_first_topic
How to Partition a Topic
To create a topic with multiple partitions, use the --partitions option and pass it a number:
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my_second_topic --partitions 3
How to Set a Replication Factor
To create a topic with a replication factor higher than the default, use the --replication-factor option and pass it a number:
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my_third_topic --partitions 3 --replication-factor 3
You should get the following error:
ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1.
Since you’re only running one Kafka broker on your machine, you can’t set a replication factor higher than one. If you were running a cluster with multiple brokers, you could set a replication factor as high as the total number of brokers.
How to Delete a Topic
To delete a topic, use the --delete option and specify a topic with the --topic option:
kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic my_first_topic
You won’t get any output to say the topic was deleted but you can check using --list or --describe.
How to Use kafka-console-producer
You can produce messages to a topic from the command line using kafka-console-producer.
Run kafka-console-producer.sh to see the options you can pass to it.
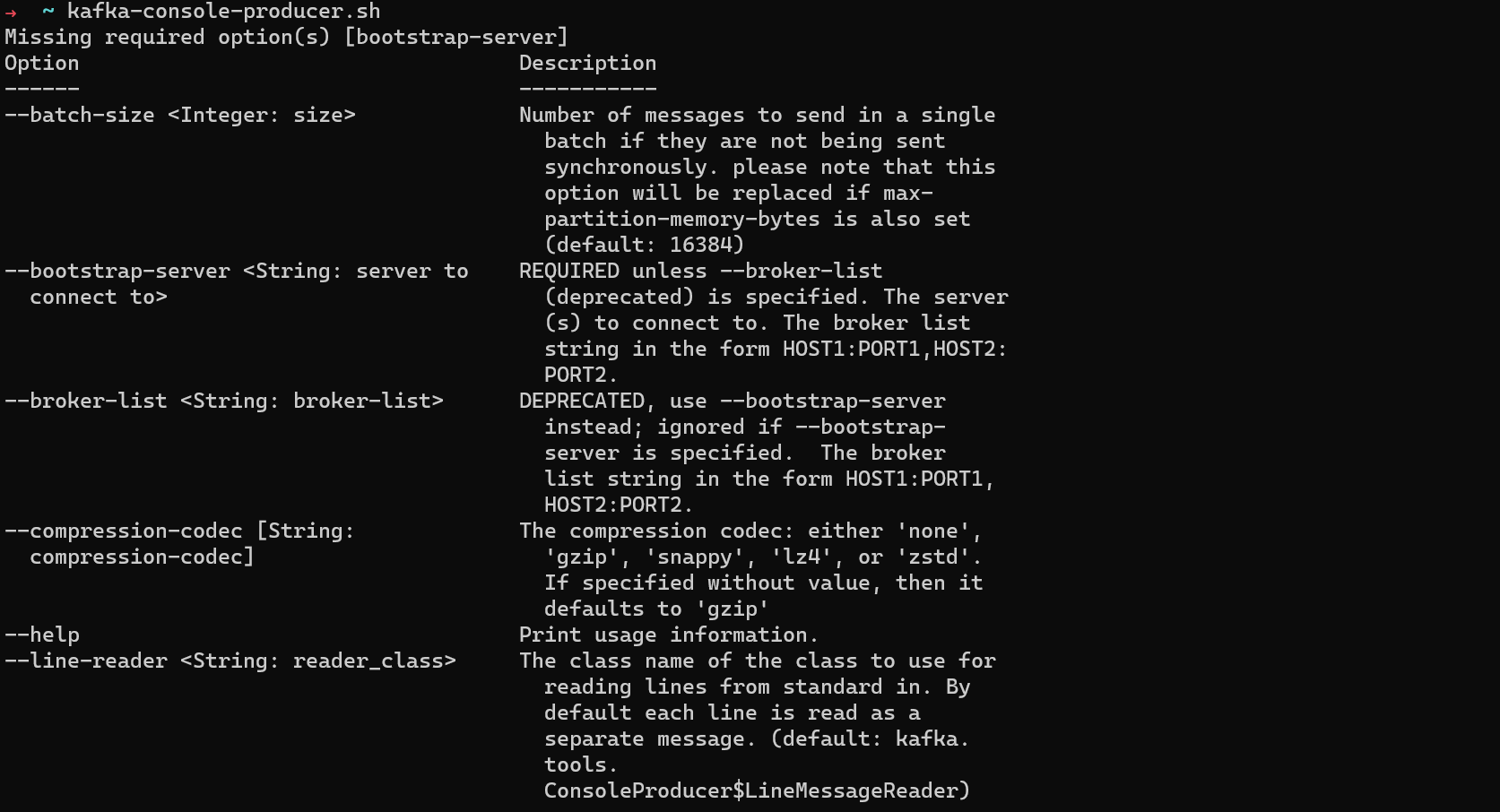
To create a producer connected to a specific topic, run:
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic TOPIC_NAME
Let’s produce messages to the my_first_topic topic.
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my_first_topic
Your prompt will change and you will be able to type text. Press enter to send that message. You can keep sending messages until you press ctrl + c.
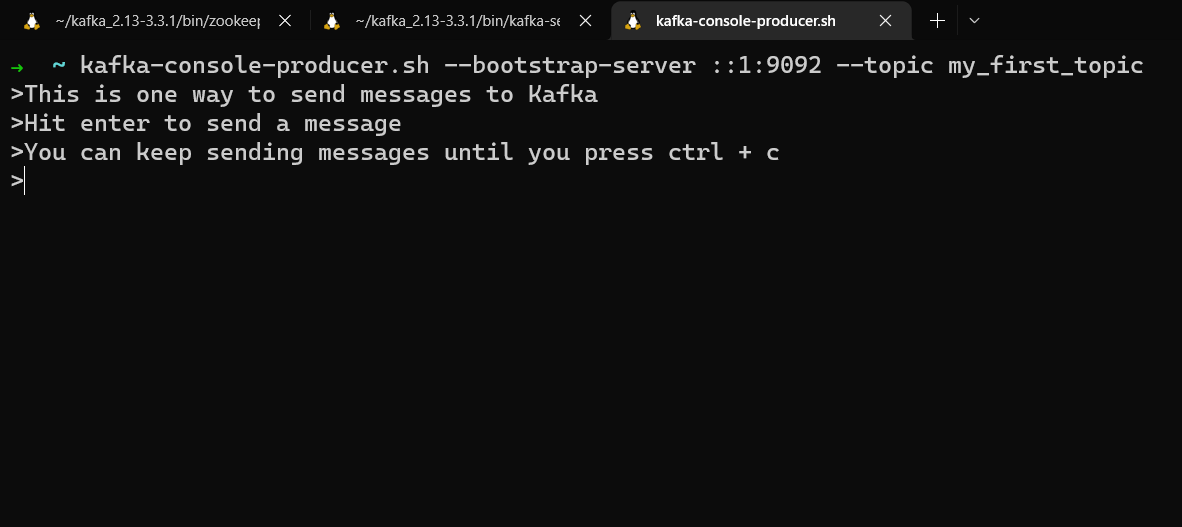
If you produce messages to a topic that doesn’t exist, you’ll get a warning, but the topic will be created and the messages will still get sent. It’s better to create a topic in advance, however, so you can specify partitions and replication.
By default, the messages sent from kafka-console-producer have their keys set to null, and so they will be evenly distributed to all partitions.
You can set a key by using the --property option to set parse.key to be true and providing a key separator, such as :
For example, we can create a books topic and use the books’ genre as a key.
kafka-topics.sh --bootstrap-server localhost:9092 --topic books --create
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic books --property parse.key=true --property key.separator=:
Now you can enter keys and values in the format key:value. Anything to the left of the key separator will be interpreted as a message key, anything to the right as a message value.
science_fiction:All Systems Red
fantasy:Uprooted
horror:Mexican Gothic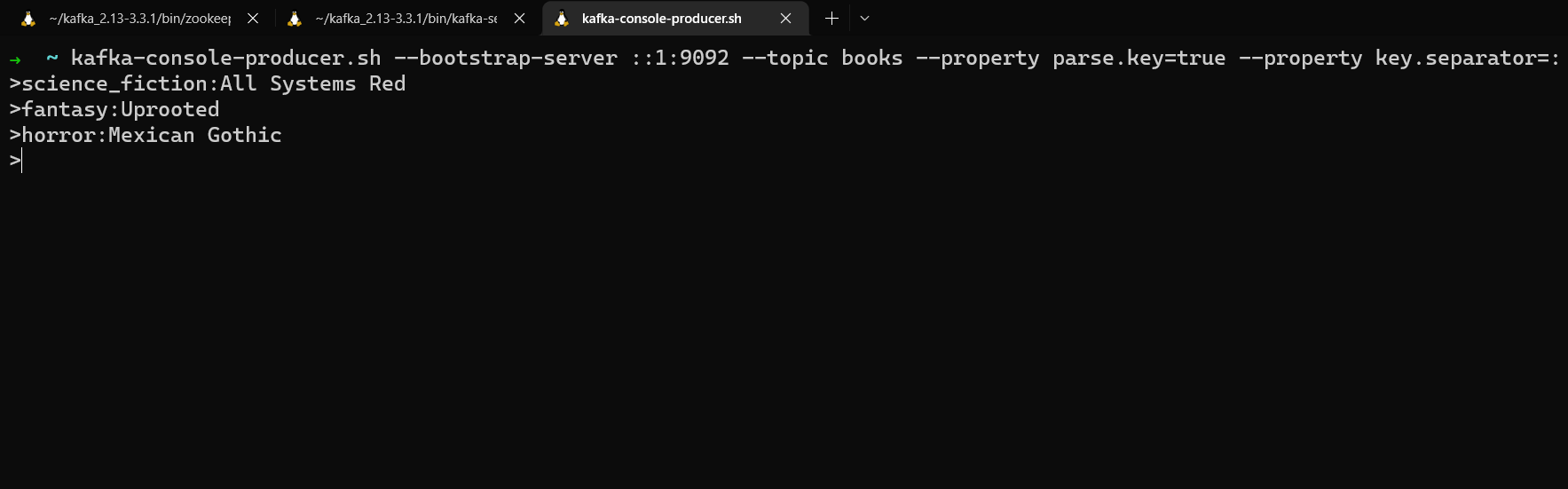
Now that you’ve produced messages to a topic from the command line, it’s time to consume those messages from the command line.
How to Use kafka-console-consumer
You can consumer messages from a topic from the command line using kafka-console-consumer.
Run kafka-console-consumer.sh to see the options you can pass to it.
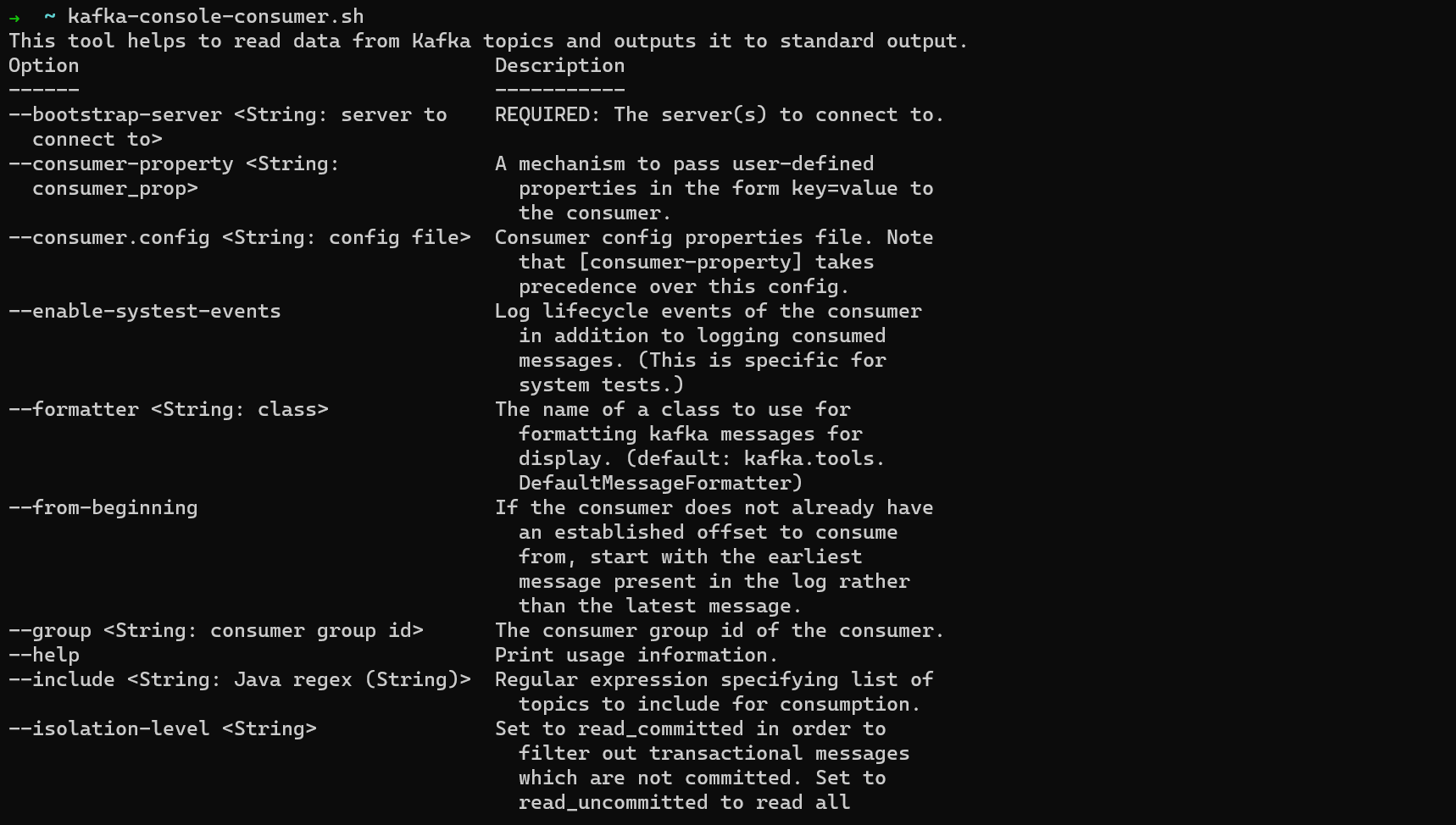
To create a consumer, run:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TOPIC_NAME
When you start a consumer, by default it will read messages as they are written to the end of the topic. It won’t read messages that were previously sent to the topic.
If you want to read the messages you already sent to a topic, use the --from-beginning option to read from the beginning of the topic:
kafka-console-consumer --bootstrap-server localhost:9092 --topic my_first_topic --from-beginning
The messages might appear «out of order». Remember, messages are ordered within a partition but ordering can’t be guaranteed between partitions. If you don’t set a key, they will be sent round robin between partitions and ordering isn’t guaranteed.
You can display additional information about messages, such as their key and timestamp, by using the --property option and setting the print property to true.
Use the --formatter option to set the message formatter and the --property option to select which message properties to print.
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_first_topic --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.timestamp=true --property print.key=true --property print.value=true
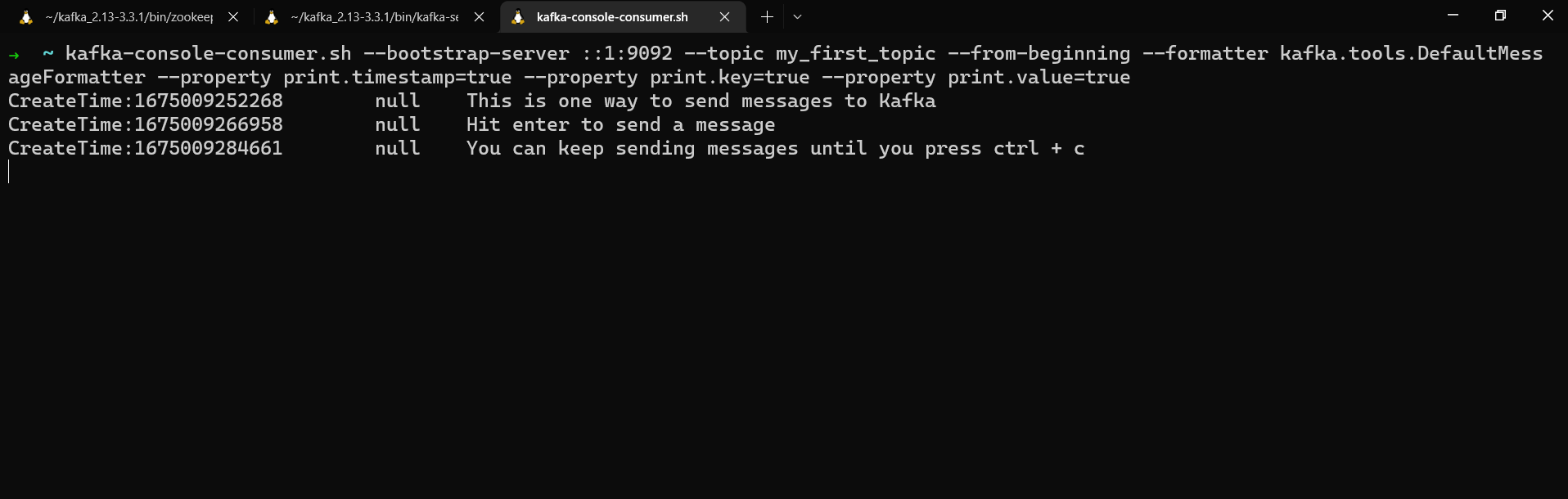
We get the messages’ timestamp, key, and value. Since we didn’t assign any keys when we sent these messages to my_first_topic, their key is null.
How to Use kafka-consumer-groups
You can run consumers in a consumer group using the Kafka CLI. To view the documentation for this, run:
kafka-consumer-groups.sh
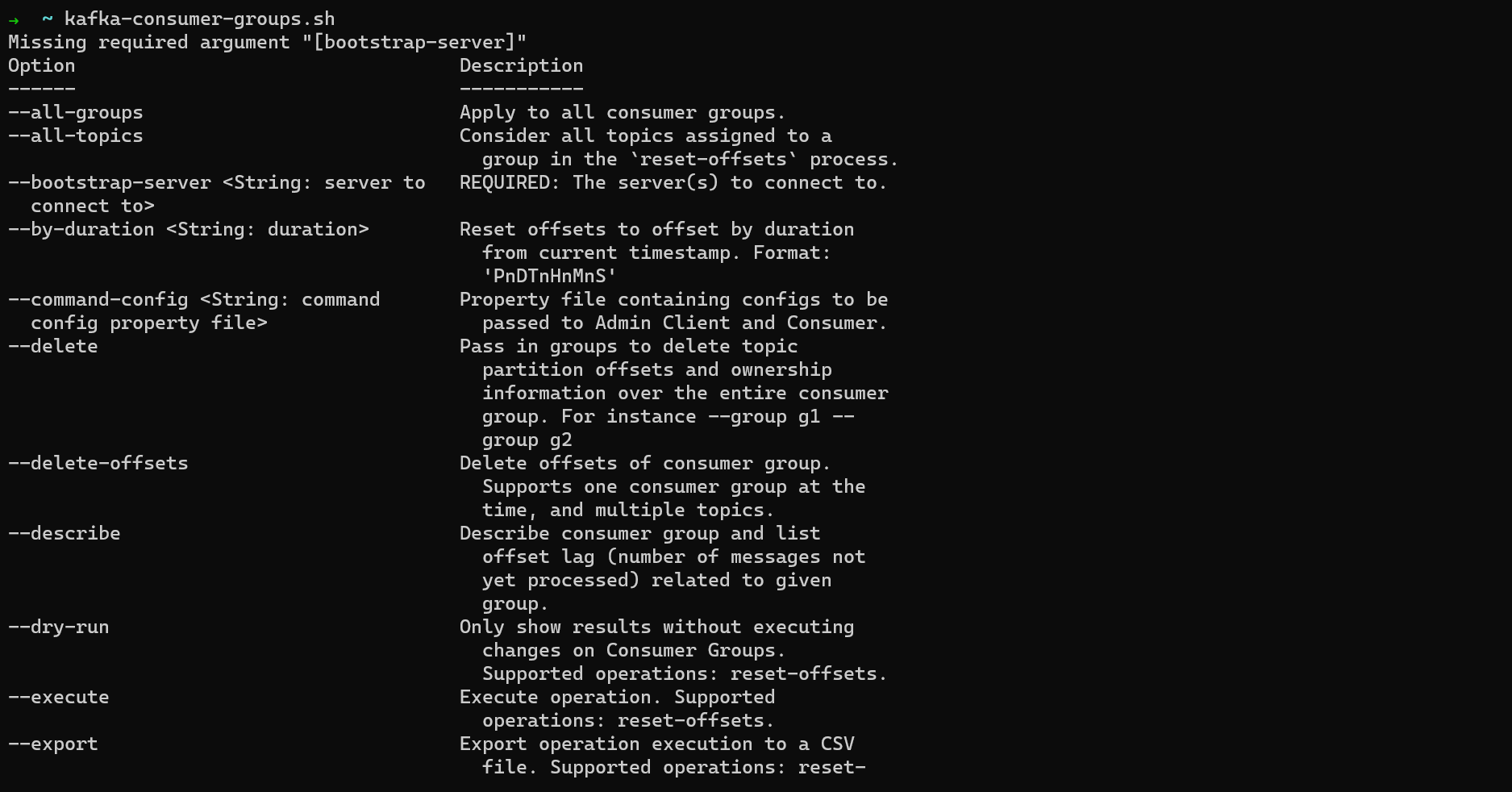
First, create a topic with three partitions. Each consumer in a group will consume from one partition. If there are more consumers than partitions, any extra consumers will be idle.
kafka-topics.sh --bootstrap-server localhost:9092 --topic fantasy_novels --create --partitions 3
You add a consumer to a group when you create it using the --group option. If you run the same command multiple times with the same group name, each new consumer will be added to the group.
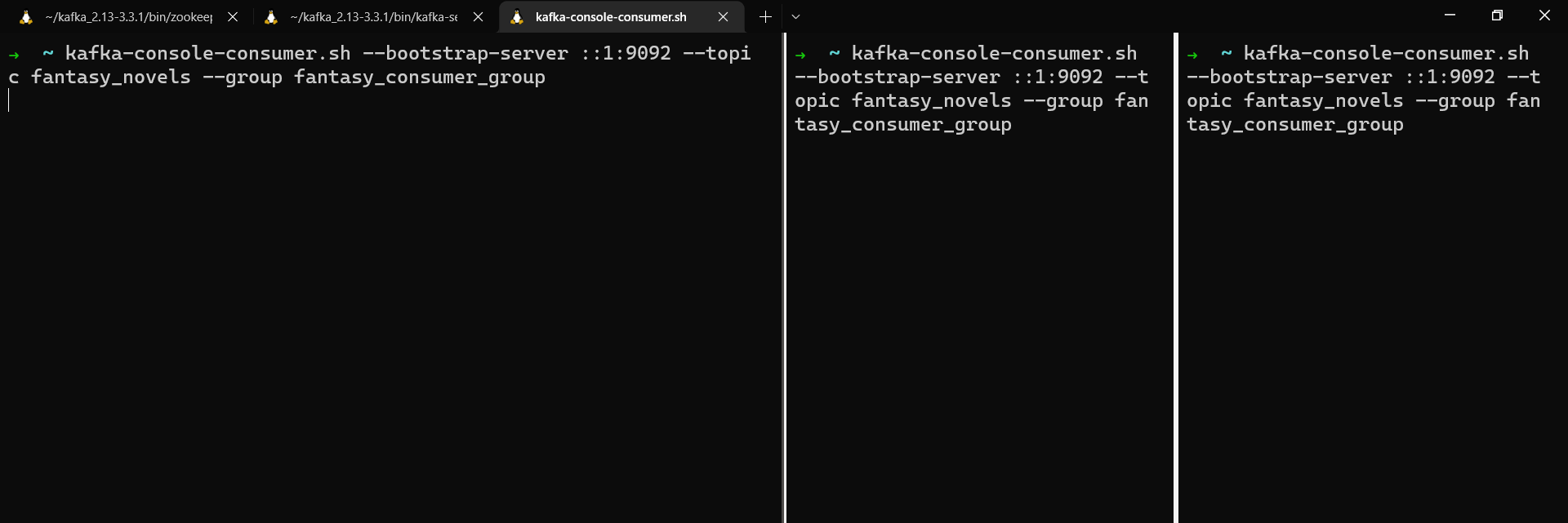
To create the first consumer in your consumer group, run:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic fantasy_novels --group fantasy_consumer_group
Next, open two new terminal windows and run the same command again to add a second and third consumer to the consumer group.
In a different terminal window, create a producer and send a few messages with keys to the topic.
Note: Since Kafka 2.4, Kafka will send messages in batches to one «sticky» partition for better performance. In order to demonstrate messages being sent round robin between partitions (without sending a large volume of messages), we can set the partitioner to RoundRobinPartitioner.
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic fantasy_novels --property parse.key=true --property key.separator=: --property partitioner.class=org.apache.kafka.clients.producer.RoundRobinPartitioner
tolkien:The Lord of the Rings
le_guin:A Wizard of Earthsea
leckie:The Raven Tower
de_bodard:The House of Shattered Wings
okorafor:Who Fears Death
liu:The Grace of Kings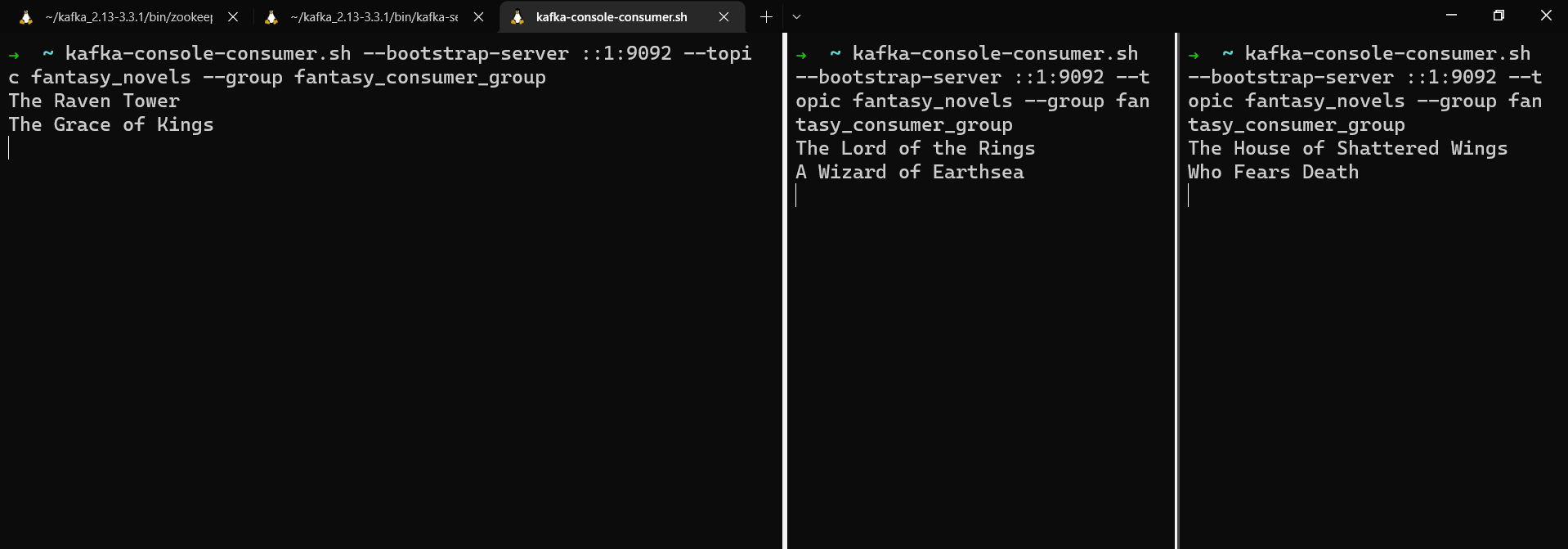
If you stop one of the consumers, the consumer group will rebalance and future messages will be sent to the remaining consumers.
Now that you have some experience working with Kafka from the command line, the next step is to build a small application that connects to Kafka.
How to Build a Kafka Client App with Java
We’re going to build a simple Java app that both produces messages to and consumes messages from Kafka. For this we’ll use the official Kafka Java client.
If at any point you get stuck, the full code for this project is available on GitHub.
Preliminaries
First of all, make sure you have Java (at least JDK 11) and Kafka installed.
We’re going to send messages about characters from The Lord of the Rings. So let’s create a topic for these messages with three partitions.
From the command line, run:
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic lotr_characters --partitions 3
How to Set Up the Project
I recommend using IntelliJ for Java projects, so go ahead and install the Community Edition if you don’t already have it. You can download it from jetbrains.com/idea
In Intellij, select File, New, and Project.
Give your project a name and select a location for it on your computer. Make sure you have selected Java as the language, Maven as the build system, and that the JDK is at least Java 11. Then click Create.
Note: If you’re on Windows, IntelliJ can’t use a JDK installed on WSL. To install Java on the Windows side of things, go to docs.aws.amazon.com/corretto/latest/corretto-11-ug/downloads-list and download the Windows installer. Follow the installation steps, open a command prompt, and run java -version. You should see something like:
openjdk version "11.0.18" 2023-01-17 LTS
OpenJDK Runtime Environment Corretto-11.0.18.10.1 (build 11.0.18+10-LTS)
OpenJDK 64-Bit Server VM Corretto-11.0.18.10.1 (build 11.0.18+10-LTS, mixed mode)
Once your Maven project finishes setting up, run the Main class to see «Hello world!» and make sure everything worked.
How to Install the Dependencies
Next, we’re going to install our dependencies. Open up pom.xml and inside the <project> element, create a <dependencies> element.
We’re going to use the Java Kafka client for interacting with Kafka and SLF4J for logging, so add the following inside your <dependencies> element:
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-simple -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.6</version>
</dependency>
The package names and version numbers might be red, meaning you haven’t downloaded them yet. If this happens, click on View, Tool Windows, and Maven to open the Maven menu. Click on the Reload All Maven Projects icon and Maven will install these dependencies.
Create a HelloKafka class in the same directory as your Main class and give it the following contents:
package org.example;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HelloKafka {
private static final Logger log = LoggerFactory.getLogger(HelloKafka.class);
public static void main(String[] args) {
log.info("Hello Kafka");
}
}
To make sure your dependencies are installed, run this class and you should see [main] INFO org.example.HelloKafka - Hello Kafka printed to the IntelliJ console.
How to Create a Kafka Producer
Next, we’re going to create a Producer class. You can call this whatever you want as long as it doesn’t clash with another class. So don’t use KafkaProducer as you’ll need that class in a minute.
package org.example;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Producer {
private static final Logger log = LoggerFactory.getLogger(KafkaProducer.class);
public static void main(String[] args) {
log.info("This class will produce messages to Kafka");
}
}
All of our Kafka-specific code is going to go inside this class’s main() method.
The first thing we need to do is configure a few properties for the producer. Add the following inside the main() method:
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Properties stores a set of properties as pairs of strings. The ones we’re using are:
ProducerConfig.BOOTSTRAP_SERVERS_CONFIGwhich specifies the IP address to use to access the Kafka clusterProducerConfig.KEY_SERIALIZER_CLASS_CONFIGwhich specifies the serializer to use for message keysProducerConfig.VALUE_SERIALIZER_CLASS_CONFIGwhich specifies the serializer to use for message values
We’re going to connect to our local Kafka cluster running on localhost:9092, and use the StringSerializer since both our keys and values will be strings.
Now we can create our producer and pass it the configuration properties.
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
To send a message, we need to create a ProducerRecord and pass it to our producer. ProducerRecord contains a topic name, and optionally a key, value, and partition number.
We’re going to create the ProducerRecord with the topic to use, the message’s key, and the message’s value.
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("lotr_characters", "hobbits", "Bilbo");
We can now use the producer’s send() method to send the message to Kafka.
producer.send(producerRecord);
Finally, we need to call the close() method to stop the producer. This method handles any messages currently being processed by send() and then closes the producer.
producer.close();
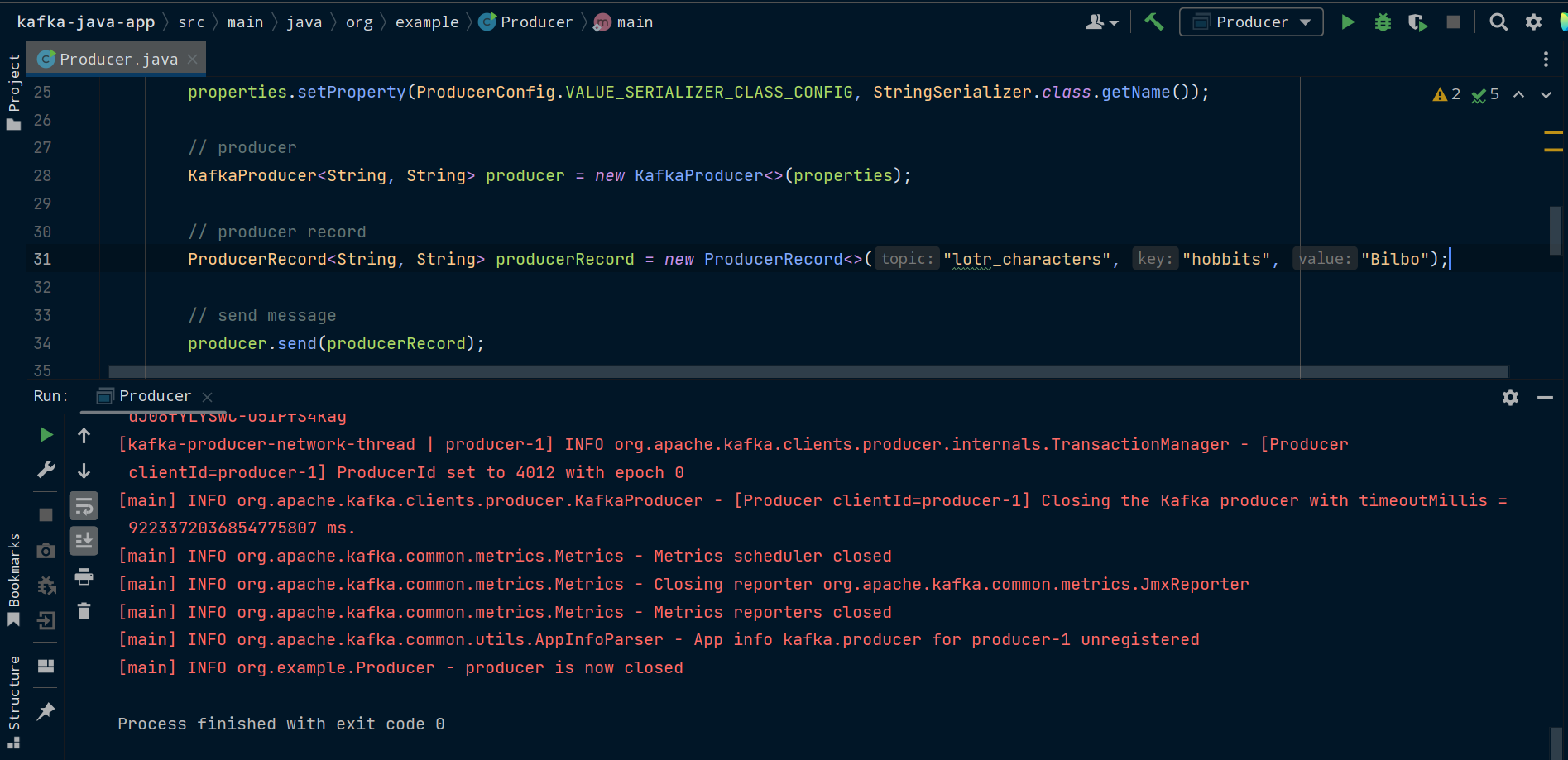
Now it’s time to run our producer. Make sure you have Zookeeper and Kafka running. Then run the main() method of the Producer class.
Note: On Windows, your producer might not be able to connect to a Kafka broker running on WSL. To fix this, you’re going to need to do the following:
- In a WSL terminal, navigate to Kafka’s config folder:
cd ~/kafka_2.13-3.3.1/config/ - Open
server.properties, for example with Nano:nano server.properties - Uncomment
#listeners=PLAINTEXT//:9092 - Replace it with
listeners=PLAINTEXT//[::1]:9092 - In your
Producerclass, replace"localhost:9092"with"[::1]:9092"
[::1], or 0:0:0:0:0:0:0:1, refers to the loopback address (or localhost) in IPv6. This is equivalent to 127.0.0.1 in IPv4.
If you change listeners, when you try to access the Kafka broker from the command line you’ll also have to use the new IP address, so use --bootstrap-server ::1:9092 instead of --bootstrap-server localhost:9092 and it should work.
We can now check that Producer worked by using kafka-console-consumer in another terminal window to read from the lotr_characters topic and see the message printed to the console.
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic lotr_characters --from-beginning
How to Send Multiple Messages and Use Callbacks
So far we’re only sending one message. If we update Producer to send multiple messages, we’ll be able to see how keys are used to divide messages between partitions. We can also take this opportunity to use a callback to view the sent message’s metadata.
To do this, we’re going to loop over a collection of characters to generate our messages.
So replace this:
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("lotr_characters", "hobbits", "Bilbo");
producer.send(producerRecord);
with this:
HashMap<String, String> characters = new HashMap<String, String>();
characters.put("hobbits", "Frodo");
characters.put("hobbits", "Sam");
characters.put("elves", "Galadriel");
characters.put("elves", "Arwen");
characters.put("humans", "Éowyn");
characters.put("humans", "Faramir");
for (HashMap.Entry<String, String> character : characters.entrySet()) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("lotr_characters", character.getKey(), character.getValue());
producer.send(producerRecord, (RecordMetadata recordMetadata, Exception err) -> {
if (err == null) {
log.info("Message received. n" +
"topic [" + recordMetadata.topic() + "]n" +
"partition [" + recordMetadata.partition() + "]n" +
"offset [" + recordMetadata.offset() + "]n" +
"timestamp [" + recordMetadata.timestamp() + "]");
} else {
log.error("An error occurred while producing messages", err);
}
});
}
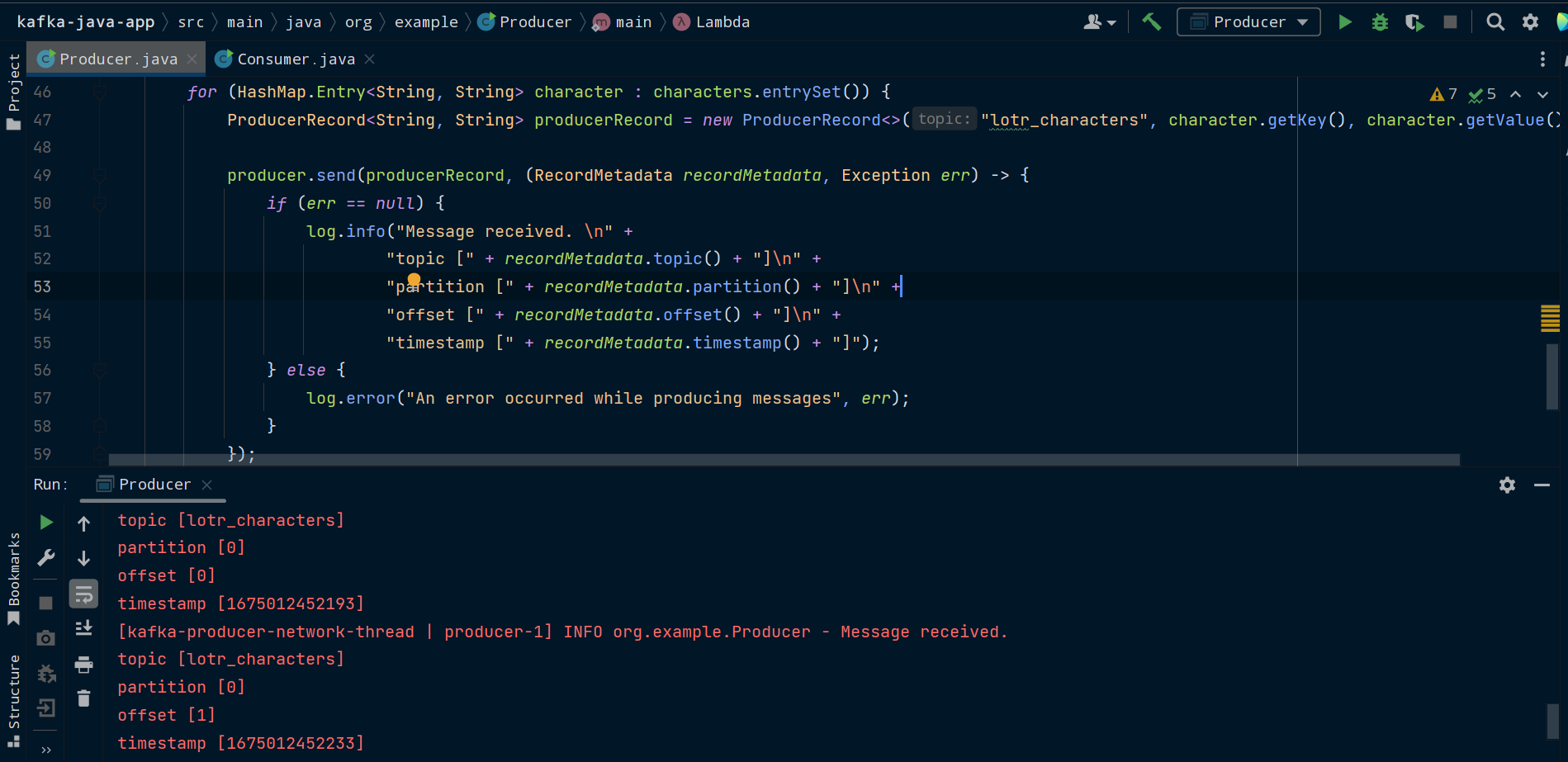
Here, we’re iterating over the collection, creating a ProducerRecord for each entry, and passing the record to send(). Behind the scenes, Kafka will batch these messages together to make fewer network requests. send() can also take a callback as a second argument. We’re going to pass it a lambda which will run code when the send() request completes.
If the request completed successfully, we get back a RecordMetadata object with metadata about the message, which we can use to see things such as the partition and offset the message ended up in.
If we get back an exception, we could handle it by retrying to send the message, or alerting our application. In this case, we’re just going to log the exception.
Run the main() method of the Producer class and you should see the message metadata get logged.
The full code for the Producer class should now be:
package org.example;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashMap;
import java.util.Properties;
public class Producer {
private static final Logger log = LoggerFactory.getLogger(Producer.class);
public static void main(String[] args) {
log.info("This class produces messages to Kafka");
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
HashMap<String, String> characters = new HashMap<String, String>();
characters.put("hobbits", "Frodo");
characters.put("hobbits", "Sam");
characters.put("elves", "Galadriel");
characters.put("elves", "Arwen");
characters.put("humans", "Éowyn");
characters.put("humans", "Faramir");
for (HashMap.Entry<String, String> character : characters.entrySet()) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("lotr_characters", character.getKey(), character.getValue());
producer.send(producerRecord, (RecordMetadata recordMetadata, Exception err) -> {
if (err == null) {
log.info("Message received. n" +
"topic [" + recordMetadata.topic() + "]n" +
"partition [" + recordMetadata.partition() + "]n" +
"offset [" + recordMetadata.offset() + "]n" +
"timestamp [" + recordMetadata.timestamp() + "]");
} else {
log.error("An error occurred while producing messages", err);
}
});
}
producer.close();
}
}
Next, we’re going to create a consumer to read these messages from Kafka.
How to Create a Kafka Consumer
First, create a Consumer class. Again, you can call it whatever you want, but don’t call it KafkaConsumer as you will need that class in a moment.
All the Kafka-specific code will go in Consumer‘s main() method.
package org.example;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Consumer {
private static final Logger log = LoggerFactory.getLogger(Consumer.class);
public static void main(String[] args) {
log.info("This class consumes messages from Kafka");
}
}
Next, configure the consumer properties.
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "lotr_consumer_group");
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
Just like with Producer, these properties are a set of string pairs. The ones we’re using are:
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIGwhich specifies the IP address to use to access the Kafka clusterConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIGwhich specifies the deserializer to use for message keysConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIGwhich specifies the deserializer to use for message valuesConsumerConfig.GROUP_ID_CONFIGwhich specifies the consumer group this consumer belongs toConsumerConfig.AUTO_OFFSET_RESET_CONFIGwhich specifies the offset to start reading from
We’re connecting to the Kafka cluster on localhost:9092, using string deserializers since our keys and values are strings, setting a group id for our consumer, and telling the consumer to read from the start of the topic.
Note: If you’re running the consumer on Windows and accessing a Kafka broker running on WSL, you’ll need to change "localhost:9091" to "[::1]:9092" or "0:0:0:0:0:0:0:1:9092", like you did in Producer.
Next, we create a KafkaConsumer and pass it the configuration properties.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
We need to tell the consumer which topic, or topics, to subscribe to. The subscribe() method takes in a collection of one or more strings, naming the topics you want to read from. Remember, consumers can subscribe to more than one topic at the same time. For this example, we’ll use one topic, the lotr_characters topic.
String topic = "lotr_characters";
consumer.subscribe(Arrays.asList(topic));
The consumer is now ready to start reading messages from the topic. It does this by regularly polling for new messages.
We’ll use a while loop to repeatedly call the poll() method to check for new messages.
poll() takes in a duration for how long it should read for at a time. It then batches these messages into an iterable called ConsumerRecords. We can then iterate over ConsumerRecords and do something with each individual ConsumerRecord.
In a real-world application, we would process this data or send it to some further destination, like a database or data pipeline. Here, we’re just going to log the key, value, partition, and offset for each message we receive.
while(true){
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> message : messages){
log.info("key [" + message.key() + "] value [" + message.value() +"]");
log.info("partition [" + message.partition() + "] offset [" + message.offset() + "]");
}
}
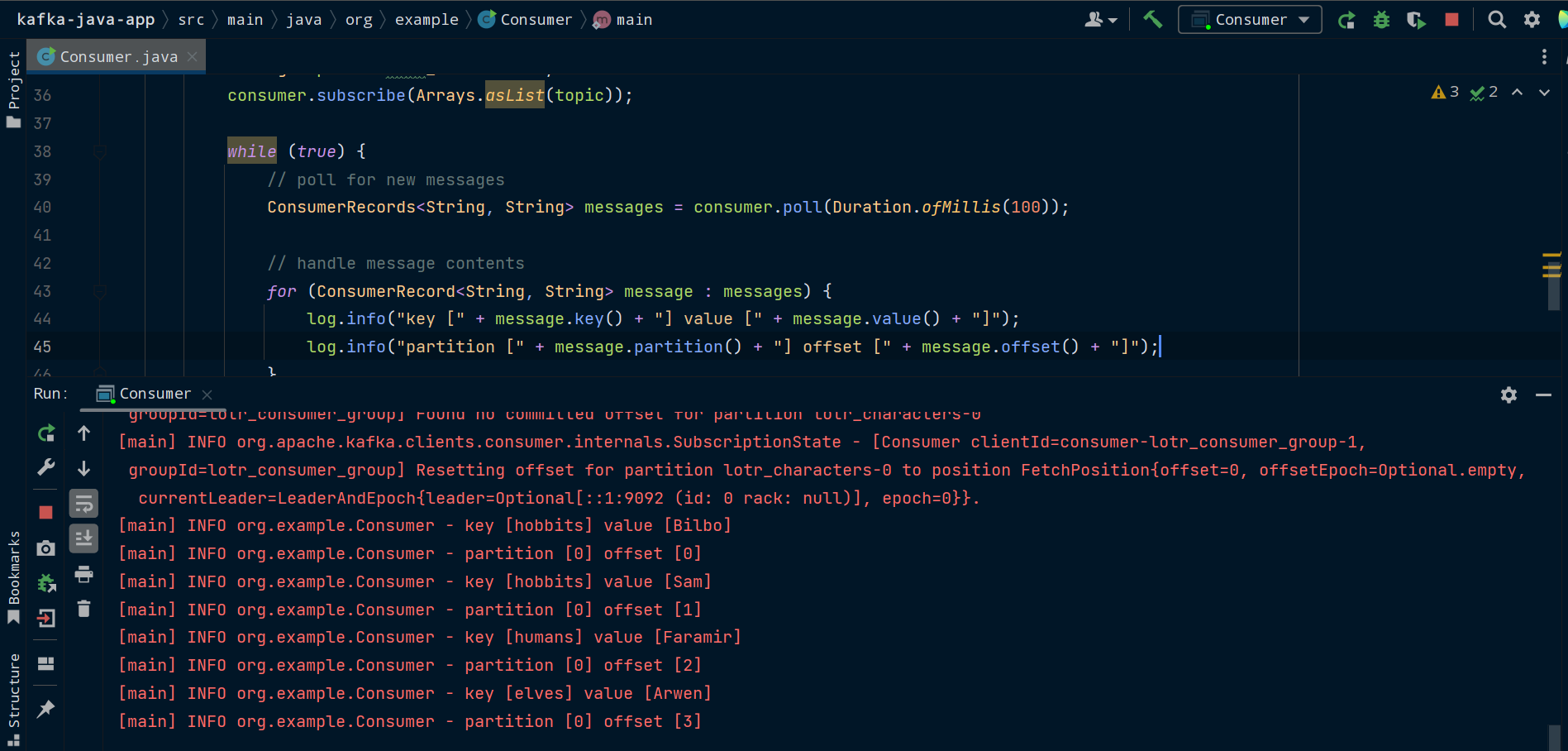
Now it’s time to run our consumer. Make sure you have Zookeeper and Kafka running. Run the Consumer class and you’ll see the messages that Producer previously sent to the lotr_characters topic in Kafka.
How to Shut Down the Consumer
Right now, our consumer is running in an infinite loop and polling for new messages every 100 ms. This isn’t a problem, but we should add safeguards to handle shutting down the consumer if an exception occurs.
We’re going to wrap our code in a try-catch-finally block. If an exception occurs, we can handle it in the catch block.
The finally block will then call the consumer’s close() method. This will close the socket the consumer is using, commit the offsets it has processed, and trigger a consumer group rebalance so any other consumers in the group can take over reading the partitions this consumer was handling.
try {
// subscribe to topic(s)
String topic = "lotr_characters";
consumer.subscribe(Arrays.asList(topic));
while (true) {
// poll for new messages
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(100));
// handle message contents
for (ConsumerRecord<String, String> message : messages) {
log.info("key [" + message.key() + "] value [" + message.value() + "]");
log.info("partition [" + message.partition() + "] offset [" + message.offset() + "]");
}
}
} catch (Exception err) {
// catch and handle exceptions
log.error("Error: ", err);
} finally {
// close consumer and commit offsets
consumer.close();
log.info("consumer is now closed");
}Consumer will continuously poll its assigned topics for new messages and shut down safely if it experiences an exception.
The full code for the Consumer class should now be:
package org.example;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class Consumer {
private static final Logger log = LoggerFactory.getLogger(Consumer.class);
public static void main(String[] args) {
log.info("This class consumes messages from Kafka");
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "lotr_consumer_group");
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
try {
String topic = "lotr_characters";
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> message : messages) {
log.info("key [" + message.key() + "] value [" + message.value() + "]");
log.info("partition [" + message.partition() + "] offset [" + message.offset() + "]");
}
}
} catch (Exception err) {
log.error("Error: ", err);
} finally {
consumer.close();
log.info("The consumer is now closed");
}
}
}You now have a basic Java application that can send messages to and read messages from Kafka. If you got stuck at any point, the full code is available on GitHub.
Where to Take it from Here
Congratulations on making it this far. You’ve learned:
- the main concepts behind Kafka
- how to communicate with Kafka from the command line
- how to build a Java app that produces to and consumes from Kafka
There’s plenty more to learn about Kafka, whether that’s Kafka Connect for connecting Kafka to common data systems or the Kafka Streams API for processing and transforming your data.
Some resources you might find useful as you continue your journey with Kafka are:
- the official Kafka docs
- courses from Confluent
- Conduktor’s kafkademy
I hope this guide has been helpful and made you excited to learn more about Kafka, event streaming, and real-time data processing.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Apache Kafka – Введение
В больших данных используется огромный объем данных. Что касается данных, у нас есть две основные проблемы. Первая задача состоит в том, как собрать большой объем данных, а вторая задача – проанализировать собранные данные. Чтобы преодолеть эти трудности, вам нужна система обмена сообщениями.
Кафка предназначена для распределенных высокопроизводительных систем. Кафка имеет тенденцию работать очень хорошо как замена более традиционному брокеру сообщений. По сравнению с другими системами обмена сообщениями, Kafka имеет лучшую пропускную способность, встроенное разбиение, репликацию и собственную отказоустойчивость, что делает его подходящим для крупномасштабных приложений обработки сообщений.
Что такое система обмена сообщениями?
Система обмена сообщениями отвечает за передачу данных из одного приложения в другое, поэтому приложения могут сосредоточиться на данных, но не беспокоиться о том, как их обмениваться. Распределенный обмен сообщениями основан на концепции надежной очереди сообщений. Сообщения помещаются в очередь асинхронно между клиентскими приложениями и системой обмена сообщениями. Доступны два типа шаблонов обмена сообщениями: один – «точка-точка», а другой – система обмена сообщениями «публикация-подписка». Большинство шаблонов сообщений следуют pub-sub .
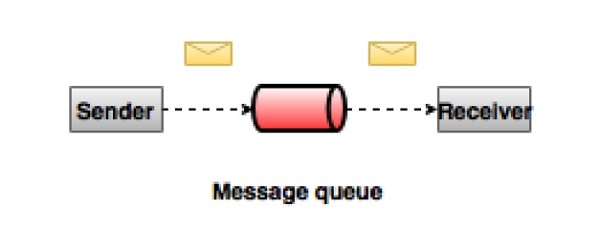
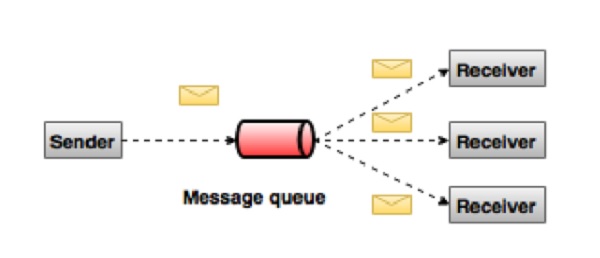
Система обмена сообщениями точка-точка
В системе точка-точка сообщения сохраняются в очереди. Один или несколько потребителей могут потреблять сообщения в очереди, но конкретное сообщение может потреблять максимум один потребитель. Как только потребитель прочитает сообщение в очереди, оно исчезнет из этой очереди. Типичным примером этой системы является система обработки заказов, где каждый заказ обрабатывается одним обработчиком заказов, но несколько процессоров заказов могут работать одновременно. Следующая диаграмма изображает структуру.
Публикация-подписка Система сообщений
В системе публикации-подписки сообщения сохраняются в теме. В отличие от двухточечной системы, потребители могут подписаться на одну или несколько тем и использовать все сообщения в этой теме. В системе «Публикация-подписка» производители сообщений называются издателями, а потребители сообщений – подписчиками. Примером из реальной жизни является Dish TV, который публикует различные каналы, такие как спортивные состязания, фильмы, музыка и т. Д., И любой может подписаться на свой собственный набор каналов и получать их, когда доступны их подписанные каналы.
Что такое Кафка?
Apache Kafka – это распределенная система обмена сообщениями «публикация-подписка» и надежная очередь, которая может обрабатывать большой объем данных и позволяет передавать сообщения из одной конечной точки в другую. Кафка подходит как для автономного, так и для онлайн-рассылки сообщений. Сообщения Kafka сохраняются на диске и реплицируются в кластере для предотвращения потери данных. Kafka построен поверх службы синхронизации ZooKeeper. Он очень хорошо интегрируется с Apache Storm и Spark для анализа потоковых данных в реальном времени.
Выгоды
Ниже приведены некоторые преимущества Кафки –
-
Надежность – Кафка распределяется, разбивается, тиражируется и отказоустойчива.
-
Масштабируемость – система обмена сообщениями Kafka легко масштабируется без простоев.
-
Долговечность – Kafka использует
распределенный журнал фиксации,
который означает, что сообщения сохраняются на диске настолько быстро, насколько это возможно, а значит, и долговечны -
Производительность – Кафка обладает высокой пропускной способностью для публикации и подписки сообщений. Он поддерживает стабильную производительность даже при хранении многих ТБ сообщений.
Надежность – Кафка распределяется, разбивается, тиражируется и отказоустойчива.
Масштабируемость – система обмена сообщениями Kafka легко масштабируется без простоев.
Долговечность – Kafka использует распределенный журнал фиксации,
который означает, что сообщения сохраняются на диске настолько быстро, насколько это возможно, а значит, и долговечны
Производительность – Кафка обладает высокой пропускной способностью для публикации и подписки сообщений. Он поддерживает стабильную производительность даже при хранении многих ТБ сообщений.
Kafka очень быстр и гарантирует нулевое время простоя и нулевую потерю данных.
Случаи применения
Кафку можно использовать во многих случаях использования. Некоторые из них перечислены ниже –
-
Метрики – Кафка часто используется для оперативного мониторинга данных. Это включает в себя агрегирование статистики из распределенных приложений для получения централизованных потоков оперативных данных.
-
Решение для агрегации журналов – Kafka может использоваться в рамках всей организации для сбора журналов от нескольких служб и предоставления их в стандартном формате нескольким потребителям.
-
Потоковая обработка – популярные платформы, такие как Storm и Spark Streaming, считывают данные из темы, обрабатывают их и записывают обработанные данные в новую тему, где они становятся доступными для пользователей и приложений. Высокая прочность Kafka также очень полезна в контексте потоковой обработки.
Метрики – Кафка часто используется для оперативного мониторинга данных. Это включает в себя агрегирование статистики из распределенных приложений для получения централизованных потоков оперативных данных.
Решение для агрегации журналов – Kafka может использоваться в рамках всей организации для сбора журналов от нескольких служб и предоставления их в стандартном формате нескольким потребителям.
Потоковая обработка – популярные платформы, такие как Storm и Spark Streaming, считывают данные из темы, обрабатывают их и записывают обработанные данные в новую тему, где они становятся доступными для пользователей и приложений. Высокая прочность Kafka также очень полезна в контексте потоковой обработки.
Нужно для кафки
Kafka – это унифицированная платформа для обработки всех потоков данных в реальном времени. Kafka поддерживает доставку сообщений с низкой задержкой и дает гарантию отказоустойчивости при наличии отказов машины. Он способен обрабатывать большое количество разнообразных потребителей. Кафка очень быстрая, выполняет 2 миллиона операций записи в секунду. Кафка сохраняет все данные на диск, что, по сути, означает, что все записи идут в кеш страниц ОС (ОЗУ). Это позволяет очень эффективно передавать данные из кэша страниц в сетевой сокет.
Апач Кафка – Основы
Прежде чем углубляться в Kafka, вы должны знать основные термины, такие как темы, брокеры, производители и потребители. Следующая диаграмма иллюстрирует основные термины, а таблица подробно описывает компоненты диаграммы.
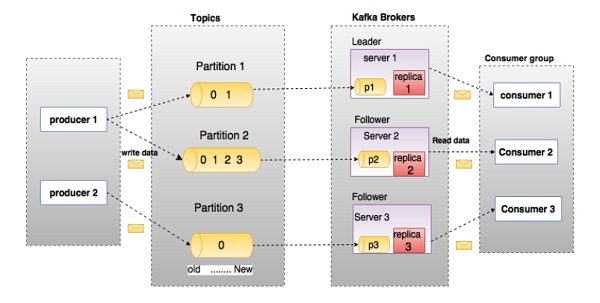
На приведенной выше диаграмме тема настроена на три раздела. Раздел 1 имеет два коэффициента смещения 0 и 1. Раздел 2 имеет четыре коэффициента смещения 0, 1, 2 и 3. Раздел 3 имеет один коэффициент смещения 0. Идентификатор реплики совпадает с идентификатором сервера, на котором она размещена.
Предположим, если коэффициент репликации для темы установлен на 3, то Kafka создаст 3 одинаковые реплики каждого раздела и поместит их в кластер, чтобы сделать доступными для всех своих операций. Чтобы сбалансировать нагрузку в кластере, каждый брокер хранит один или несколько таких разделов. Несколько производителей и потребителей могут публиковать и получать сообщения одновременно.
| S.No | Компоненты и описание |
|---|---|
| 1 |
темы Поток сообщений, относящихся к определенной категории, называется темой. Данные хранятся в темах. Темы разбиты на разделы. Для каждой темы Кафка хранит минимум один раздел. Каждый такой раздел содержит сообщения в неизменной упорядоченной последовательности. Раздел реализован как набор файлов сегментов одинакового размера. |
| 2 |
раздел Темы могут иметь много разделов, поэтому он может обрабатывать произвольный объем данных. |
| 3 |
Смещение раздела Каждое секционированное сообщение имеет уникальный идентификатор последовательности, называемый |
| 4 |
Реплики раздела Реплики – это не что иное, как |
| 5 |
Брокеры
|
| 6 |
Кафка кластер Kafka с несколькими брокерами называется кластером Kafka. Кластер Kafka может быть расширен без простоев. Эти кластеры используются для управления сохранением и репликацией данных сообщений. |
| 7 |
Производители Производители – это издатели сообщений на одну или несколько тем Кафки. Производители отправляют данные брокерам Kafka. Каждый раз, когда производитель публикует сообщение для брокера, он просто добавляет сообщение в последний файл сегмента. На самом деле, сообщение будет добавлено в раздел. Производитель также может отправлять сообщения в раздел по своему выбору. |
| 8 |
Потребители Потребители читают данные от брокеров. Потребители подписываются на одну или несколько тем и используют опубликованные сообщения, извлекая данные у брокеров. |
| 9 |
лидер |
| 10 |
толкатель Узел, который следует инструкциям лидера, называется последователем. Если лидер терпит неудачу, один из последователей автоматически становится новым лидером. Последователь действует как обычный потребитель, извлекает сообщения и обновляет свое собственное хранилище данных. |
темы
Поток сообщений, относящихся к определенной категории, называется темой. Данные хранятся в темах.
Темы разбиты на разделы. Для каждой темы Кафка хранит минимум один раздел. Каждый такой раздел содержит сообщения в неизменной упорядоченной последовательности. Раздел реализован как набор файлов сегментов одинакового размера.
раздел
Темы могут иметь много разделов, поэтому он может обрабатывать произвольный объем данных.
Смещение раздела
Каждое секционированное сообщение имеет уникальный идентификатор последовательности, называемый смещением
.
Реплики раздела
Реплики – это не что иное, как резервные копии
раздела. Реплики никогда не читают и не записывают данные. Они используются для предотвращения потери данных.
Брокеры
Брокеры – это простая система, отвечающая за поддержание опубликованных данных. Каждый брокер может иметь ноль или более разделов на тему. Предположим, если в теме N разделов и N брокеров, у каждого брокера будет один раздел.
Предположим, что если в теме N разделов и более N брокеров (n + m), у первого N брокера будет один раздел, а у следующего M-брокера не будет никакого раздела для этой конкретной темы.
Предположим, что если в теме есть N разделов и меньше, чем N брокеров (нм), каждый брокер будет иметь один или несколько разделов, разделяющих их. Этот сценарий не рекомендуется из-за неравного распределения нагрузки среди брокера.
Кафка кластер
Kafka с несколькими брокерами называется кластером Kafka. Кластер Kafka может быть расширен без простоев. Эти кластеры используются для управления сохранением и репликацией данных сообщений.
Производители
Производители – это издатели сообщений на одну или несколько тем Кафки. Производители отправляют данные брокерам Kafka. Каждый раз, когда производитель публикует сообщение для брокера, он просто добавляет сообщение в последний файл сегмента. На самом деле, сообщение будет добавлено в раздел. Производитель также может отправлять сообщения в раздел по своему выбору.
Потребители
Потребители читают данные от брокеров. Потребители подписываются на одну или несколько тем и используют опубликованные сообщения, извлекая данные у брокеров.
лидер
Лидер
– это узел, отвечающий за все операции чтения и записи для данного раздела. Каждый раздел имеет один сервер, выступающий в качестве лидера.
толкатель
Узел, который следует инструкциям лидера, называется последователем. Если лидер терпит неудачу, один из последователей автоматически становится новым лидером. Последователь действует как обычный потребитель, извлекает сообщения и обновляет свое собственное хранилище данных.
Apache Kafka – кластерная архитектура
Посмотрите на следующую иллюстрацию. На ней показана кластерная диаграмма Кафки.
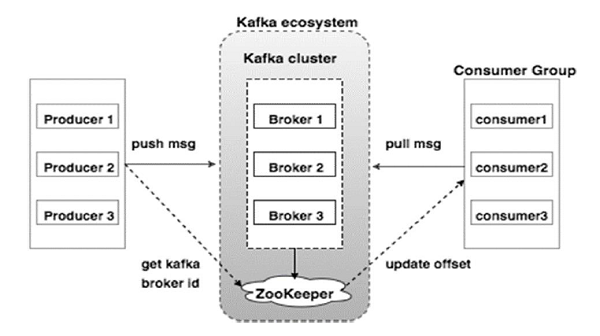
В следующей таблице описан каждый из компонентов, показанных на приведенной выше схеме.
| S.No | Компоненты и описание |
|---|---|
| 1 |
Маклер Кластер Kafka обычно состоит из нескольких брокеров для поддержания баланса нагрузки. Брокеры Kafka не имеют статуса, поэтому они используют ZooKeeper для поддержания своего кластерного состояния. Один экземпляр брокера Kafka может обрабатывать сотни тысяч операций чтения и записи в секунду, а каждый брокер может обрабатывать ТБ сообщений без влияния на производительность. Выбор лидера брокера Kafka может быть сделан ZooKeeper. |
| 2 |
Работник зоопарка ZooKeeper используется для управления и координации брокера Kafka. Сервис ZooKeeper в основном используется для уведомления производителя и потребителя о наличии любого нового брокера в системе Kafka или сбое брокера в системе Kafka. В соответствии с уведомлением, полученным Zookeeper относительно присутствия или отказа брокера, производитель и потребитель принимают решение и начинают согласовывать свою задачу с каким-либо другим брокером. |
| 3 |
Производители Производители передают данные брокерам. Когда запускается новый брокер, все производители ищут его и автоматически отправляют сообщение этому новому брокеру. Производитель Kafka не ждет подтверждений от брокера и отправляет сообщения так быстро, как может обработать брокер. |
| 4 |
Потребители Поскольку брокеры Kafka не имеют состояния, это означает, что потребитель должен поддерживать количество сообщений, использованных с помощью смещения раздела. Если потребитель подтверждает конкретное смещение сообщения, это означает, что потребитель использовал все предыдущие сообщения. Потребитель отправляет брокеру асинхронный запрос на получение, чтобы подготовить буфер байтов к использованию. Потребители могут перемотать или перейти к любой точке раздела, просто указав значение смещения. Значение смещения потребителя сообщается ZooKeeper. |
Маклер
Кластер Kafka обычно состоит из нескольких брокеров для поддержания баланса нагрузки. Брокеры Kafka не имеют статуса, поэтому они используют ZooKeeper для поддержания своего кластерного состояния. Один экземпляр брокера Kafka может обрабатывать сотни тысяч операций чтения и записи в секунду, а каждый брокер может обрабатывать ТБ сообщений без влияния на производительность. Выбор лидера брокера Kafka может быть сделан ZooKeeper.
Работник зоопарка
ZooKeeper используется для управления и координации брокера Kafka. Сервис ZooKeeper в основном используется для уведомления производителя и потребителя о наличии любого нового брокера в системе Kafka или сбое брокера в системе Kafka. В соответствии с уведомлением, полученным Zookeeper относительно присутствия или отказа брокера, производитель и потребитель принимают решение и начинают согласовывать свою задачу с каким-либо другим брокером.
Производители
Производители передают данные брокерам. Когда запускается новый брокер, все производители ищут его и автоматически отправляют сообщение этому новому брокеру. Производитель Kafka не ждет подтверждений от брокера и отправляет сообщения так быстро, как может обработать брокер.
Потребители
Поскольку брокеры Kafka не имеют состояния, это означает, что потребитель должен поддерживать количество сообщений, использованных с помощью смещения раздела. Если потребитель подтверждает конкретное смещение сообщения, это означает, что потребитель использовал все предыдущие сообщения. Потребитель отправляет брокеру асинхронный запрос на получение, чтобы подготовить буфер байтов к использованию. Потребители могут перемотать или перейти к любой точке раздела, просто указав значение смещения. Значение смещения потребителя сообщается ZooKeeper.
Apache Kafka – WorkFlow
На данный момент мы обсудили основные понятия Кафки. Давайте теперь пролить свет на рабочий процесс Кафки.
Kafka – это просто набор тем, разделенных на один или несколько разделов. Раздел Кафки – это линейно упорядоченная последовательность сообщений, где каждое сообщение идентифицируется по их индексу (называемому смещением). Все данные в кластере Кафки являются несвязным объединением разделов. Входящие сообщения записываются в конце раздела, а сообщения последовательно читаются потребителями. Долговечность обеспечивается репликацией сообщений различным брокерам.
Kafka обеспечивает быструю, надежную, устойчивую, отказоустойчивую и безотказную работу системы обмена сообщениями на основе pub-sub и очереди. В обоих случаях производители просто отправляют сообщение в тему, а потребитель может выбрать любой тип системы обмена сообщениями в зависимости от своих потребностей. Давайте рассмотрим шаги в следующем разделе, чтобы понять, как потребитель может выбрать систему обмена сообщениями по своему выбору.
Рабочий процесс обмена сообщениями Pub-Sub
Ниже приведен пошаговый рабочий процесс сообщений Pub-Sub.
-
Производители отправляют сообщения в тему на регулярной основе.
-
Брокер Kafka хранит все сообщения в разделах, настроенных для этой конкретной темы. Это гарантирует, что сообщения в равной степени разделены между разделами. Если производитель отправляет два сообщения и имеется два раздела, Kafka сохранит одно сообщение в первом разделе и второе сообщение во втором разделе.
-
Потребитель подписывается на определенную тему.
-
Как только потребитель подписывается на тему, Kafka предоставит потребителю текущее смещение темы, а также сохранит смещение в ансамбле Zookeeper.
-
Потребитель будет регулярно запрашивать у Кафки новые сообщения (например, 100 мс).
-
Как только Кафка получает сообщения от производителей, она отправляет эти сообщения потребителям.
-
Потребитель получит сообщение и обработает его.
-
Как только сообщения обработаны, потребитель отправит подтверждение брокеру Kafka.
-
Как только Кафка получает подтверждение, он меняет смещение на новое значение и обновляет его в Zookeeper. Поскольку в Zookeeper поддерживаются смещения, потребитель может правильно прочитать следующее сообщение даже во время нарушения правил работы сервера.
-
Этот вышеописанный поток будет повторяться до тех пор, пока потребитель не остановит запрос.
-
Потребитель имеет возможность в любое время перемотать / перейти к нужному смещению темы и прочитать все последующие сообщения.
Производители отправляют сообщения в тему на регулярной основе.
Брокер Kafka хранит все сообщения в разделах, настроенных для этой конкретной темы. Это гарантирует, что сообщения в равной степени разделены между разделами. Если производитель отправляет два сообщения и имеется два раздела, Kafka сохранит одно сообщение в первом разделе и второе сообщение во втором разделе.
Потребитель подписывается на определенную тему.
Как только потребитель подписывается на тему, Kafka предоставит потребителю текущее смещение темы, а также сохранит смещение в ансамбле Zookeeper.
Потребитель будет регулярно запрашивать у Кафки новые сообщения (например, 100 мс).
Как только Кафка получает сообщения от производителей, она отправляет эти сообщения потребителям.
Потребитель получит сообщение и обработает его.
Как только сообщения обработаны, потребитель отправит подтверждение брокеру Kafka.
Как только Кафка получает подтверждение, он меняет смещение на новое значение и обновляет его в Zookeeper. Поскольку в Zookeeper поддерживаются смещения, потребитель может правильно прочитать следующее сообщение даже во время нарушения правил работы сервера.
Этот вышеописанный поток будет повторяться до тех пор, пока потребитель не остановит запрос.
Потребитель имеет возможность в любое время перемотать / перейти к нужному смещению темы и прочитать все последующие сообщения.
Рабочий процесс очереди сообщений / группы потребителей
В системе обмена сообщениями в очереди вместо одного потребителя группа потребителей с одинаковым идентификатором группы
будет подписываться на тему. Проще говоря, потребители, подписывающиеся на тему с одинаковым идентификатором группы
, рассматриваются как единая группа, и сообщения распределяются между ними. Давайте проверим фактический рабочий процесс этой системы.
-
Производители регулярно отправляют сообщения в тему.
-
Kafka хранит все сообщения в разделах, настроенных для этой конкретной темы, аналогично предыдущему сценарию.
-
Отдельный потребитель подписывается на конкретную тему, предположим, что
Тема-01
сидентификатором
группы в
качествеГруппы-1
. -
Kafka взаимодействует с потребителем так же, как и Pub-Sub Messaging, пока новый потребитель не подпишется на ту же тему,
Topic-01
с тем жеидентификатором
группы,
что иGroup-1
. -
По прибытии нового потребителя Kafka переключает свою работу в режим совместного использования и обменивается данными между двумя потребителями. Это совместное использование будет продолжаться до тех пор, пока число потребителей не достигнет количества разделов, настроенных для этой конкретной темы.
-
Как только число потребителей превысит количество разделов, новый потребитель не получит никаких дальнейших сообщений, пока один из существующих потребителей не откажется от подписки. Этот сценарий возникает потому, что каждому потребителю в Kafka будет назначен как минимум один раздел, и как только все разделы будут назначены существующим потребителям, новым потребителям придется ждать.
-
Эта функция также называется
Consumer Group
. Таким же образом, Kafka предоставит лучшее из обеих систем очень простым и эффективным способом.
Производители регулярно отправляют сообщения в тему.
Kafka хранит все сообщения в разделах, настроенных для этой конкретной темы, аналогично предыдущему сценарию.
Отдельный потребитель подписывается на конкретную тему, предположим, что Тема-01
с идентификатором
группы в
качестве Группы-1
.
Kafka взаимодействует с потребителем так же, как и Pub-Sub Messaging, пока новый потребитель не подпишется на ту же тему, Topic-01
с тем же идентификатором
группы,
что и Group-1
.
По прибытии нового потребителя Kafka переключает свою работу в режим совместного использования и обменивается данными между двумя потребителями. Это совместное использование будет продолжаться до тех пор, пока число потребителей не достигнет количества разделов, настроенных для этой конкретной темы.
Как только число потребителей превысит количество разделов, новый потребитель не получит никаких дальнейших сообщений, пока один из существующих потребителей не откажется от подписки. Этот сценарий возникает потому, что каждому потребителю в Kafka будет назначен как минимум один раздел, и как только все разделы будут назначены существующим потребителям, новым потребителям придется ждать.
Эта функция также называется Consumer Group
. Таким же образом, Kafka предоставит лучшее из обеих систем очень простым и эффективным способом.
Роль ZooKeeper
Важнейшей зависимостью Apache Kafka является Apache Zookeeper, который является сервисом распределенной конфигурации и синхронизации. Zookeeper служит координационным интерфейсом между брокерами Kafka и потребителями. Серверы Kafka обмениваются информацией через кластер Zookeeper. Kafka хранит основные метаданные в Zookeeper, такие как информация о темах, брокерах, смещениях потребителей (средства чтения очереди) и так далее.
Поскольку вся критическая информация хранится в Zookeeper, и он обычно реплицирует эти данные по всему ансамблю, сбой Kafka broker / Zookeeper не влияет на состояние кластера Kafka. Кафка восстановит состояние, как только Zookeeper перезапустится. Это дает нулевое время простоя для Кафки. Выбор лидера между брокером Kafka также осуществляется с помощью Zookeeper в случае отказа лидера.
Чтобы узнать больше о Zookeeper, пожалуйста, обратитесь к Zookeeper
Давайте продолжим, как установить Java, ZooKeeper и Kafka на вашем компьютере в следующей главе.
Apache Kafka – этапы установки
Ниже приведены шаги для установки Java на вашем компьютере.
Шаг 1 – Проверка установки Java
Надеемся, что вы уже установили Java на своем компьютере прямо сейчас, поэтому вы просто подтвердите это с помощью следующей команды.
$ java -version
Если Java успешно установлен на вашем компьютере, вы можете увидеть версию установленной Java.
Шаг 1.1 – Скачать JDK
Если Java не загружена, загрузите последнюю версию JDK, перейдя по следующей ссылке и загрузите последнюю версию.
http://www.oracle.com/technetwork/java/javase/downloads/index.html
Теперь последняя версия – JDK 8u 60, а файл – «jdk-8u60-linux-x64.tar.gz». Пожалуйста, загрузите файл на свой компьютер.
Шаг 1.2 – Извлечение файлов
Обычно загружаемые файлы хранятся в папке загрузок, проверяют ее и извлекают настройку tar, используя следующие команды.
$ cd /go/to/download/path $ tar -zxf jdk-8u60-linux-x64.gz
Шаг 1.3 – Перейдите в опционный каталог
Чтобы сделать Java доступным для всех пользователей, переместите извлеченный контент Java в
папку usr / local / java
/.
$ su password: (type password of root user) $ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/
Шаг 1.4 – Установить путь
Чтобы установить переменные path и JAVA_HOME, добавьте следующие команды в файл ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60 export PATH=$PATH:$JAVA_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 1.5 – Альтернативы Java
Используйте следующую команду для изменения Альтернативы Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
Шаг 1.6. Теперь проверьте Java с помощью команды проверки (java -version), описанной в шаге 1.
Шаг 2 – Установка ZooKeeper Framework
Шаг 2.1 – Скачать ZooKeeper
Чтобы установить ZooKeeper Framework на свой компьютер, перейдите по следующей ссылке и загрузите последнюю версию ZooKeeper.
http://zookeeper.apache.org/releases.html
На данный момент последняя версия ZooKeeper – 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Шаг 2.2 – Извлечение файла tar
Извлеките файл tar, используя следующую команду
$ cd opt/ $ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6 $ mkdir data
Шаг 2.3 – Создание файла конфигурации
Откройте файл конфигурации с именем conf / zoo.cfg
с помощью команды vi «conf / zoo.cfg» и всех следующих параметров, чтобы установить в качестве отправной точки.
$ vi conf/zoo.cfg tickTime=2000 dataDir=/path/to/zookeeper/data clientPort=2181 initLimit=5 syncLimit=2
После того, как файл конфигурации был успешно сохранен и снова возвращен в терминал, вы можете запустить сервер zookeeper.
Шаг 2.4 – Запустите ZooKeeper Server
$ bin/zkServer.sh start
После выполнения этой команды вы получите ответ, как показано ниже –
$ JMX enabled by default $ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED
Шаг 2.5 – Запустите CLI
$ bin/zkCli.sh
После ввода вышеуказанной команды вы будете подключены к серверу zookeeper и получите ответ ниже.
Connecting to localhost:2181 ................ ................ ................ Welcome to ZooKeeper! ................ ................ WATCHER:: WatchedEvent state:SyncConnected type: None path:null [zk: localhost:2181(CONNECTED) 0]
Шаг 2.6 – остановка сервера Zookeeper
После подключения сервера и выполнения всех операций вы можете остановить сервер zookeeper с помощью следующей команды –
$ bin/zkServer.sh stop
Теперь вы успешно установили Java и ZooKeeper на свой компьютер. Давайте посмотрим шаги для установки Apache Kafka.
Шаг 3 – Установка Apache Kafka
Давайте продолжим со следующих шагов, чтобы установить Kafka на ваш компьютер.
Шаг 3.1 – Скачать Кафку
Чтобы установить Kafka на свой компьютер, нажмите на ссылку ниже –
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz
Теперь последняя версия, т.е. – kafka_2.11_0.9.0.0.tgz, будет загружена на ваш компьютер.
Шаг 3.2 – Извлечение файла tar
Извлеките файл tar, используя следующую команду –
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz $ cd kafka_2.11.0.9.0.0
Теперь вы загрузили последнюю версию Kafka на свой компьютер.
Шаг 3.3 – Запустить сервер
Вы можете запустить сервер, дав следующую команду –
$ bin/kafka-server-start.sh config/server.properties
После запуска сервера вы увидите ответ ниже на вашем экране –
$ bin/kafka-server-start.sh config/server.properties [2016-01-02 15:37:30,410] INFO KafkaConfig values: request.timeout.ms = 30000 log.roll.hours = 168 inter.broker.protocol.version = 0.9.0.X log.preallocate = false security.inter.broker.protocol = PLAINTEXT ……………………………………………. …………………………………………….
Шаг 4 – остановите сервер
После выполнения всех операций вы можете остановить сервер, используя следующую команду –
$ bin/kafka-server-stop.sh config/server.properties
Теперь, когда мы уже обсудили установку Kafka, мы можем узнать, как выполнять основные операции с Kafka, в следующей главе.
Apache Kafka – Основные операции
Сначала давайте приступим к реализации конфигурации с одним узлом и одним посредником,
а затем перенесем нашу настройку на конфигурацию с одним узлом и несколькими посредниками.
Надеюсь, вы уже установили Java, ZooKeeper и Kafka на свою машину. Прежде чем перейти к настройке Kafka Cluster, сначала вам нужно запустить ZooKeeper, потому что Kafka Cluster использует ZooKeeper.
Запустить ZooKeeper
Откройте новый терминал и введите следующую команду –
bin/zookeeper-server-start.sh config/zookeeper.properties
Чтобы запустить Kafka Broker, введите следующую команду –
bin/kafka-server-start.sh config/server.properties
После запуска Kafka Broker введите команду jps
на терминале ZooKeeper, и вы увидите следующий ответ:
821 QuorumPeerMain 928 Kafka 931 Jps
Теперь вы можете увидеть два демона, запущенных на терминале, где QuorumPeerMain – это демон ZooKeeper, а другой – демон Kafka.
Конфигурация с одним узлом и одним брокером
В этой конфигурации у вас есть один экземпляр ZooKeeper и идентификатор брокера. Ниже приведены шаги для его настройки.
Создание раздела Kafka – Kafka предоставляет утилиту командной строки с именем kafka-topics.sh
для создания разделов на сервере. Откройте новый терминал и введите приведенный ниже пример.
Синтаксис
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic-name
пример
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Hello-Kafka
Мы только что создали тему под названием Hello-Kafka
с одним разделом и одним фактором реплики. Созданный выше вывод будет похож на следующий вывод –
Вывод – Создана тема Hello-Kafka
После создания темы вы можете получить уведомление в окне терминала брокера Kafka и журнал для созданной темы, указанный в «/ tmp / kafka-logs /» в файле config / server.properties.
Список тем
Чтобы получить список тем на сервере Kafka, вы можете использовать следующую команду –
Синтаксис
bin/kafka-topics.sh --list --zookeeper localhost:2181
Выход
Hello-Kafka
Так как мы создали тему, она перечислит только Hello-Kafka
. Предположим, если вы создадите более одной темы, вы получите названия тем в выводе.
Начать продюсер для отправки сообщений
Синтаксис
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-name
Из приведенного выше синтаксиса для клиента командной строки производителя требуются два основных параметра:
Broker-list – список брокеров, которым мы хотим отправлять сообщения. В этом случае у нас есть только один брокер. Файл Config / server.properties содержит идентификатор порта посредника, поскольку мы знаем, что наш посредник прослушивает порт 9092, поэтому вы можете указать его напрямую.
Название темы. Вот пример названия темы.
пример
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka
Производитель будет ждать ввода от stdin и публикует данные в кластере Kafka. По умолчанию каждая новая строка публикуется как новое сообщение, а свойства производителя по умолчанию указываются в файле config /
provider.properties. Теперь вы можете набрать несколько строк сообщений в терминале, как показано ниже.
Выход
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka[2016-01-16 13:50:45,931] WARN property topic is not valid (kafka.utils.Verifia-bleProperties) Hello My first message
My second message
Начать приемник для получения сообщений
Как и для производителя, свойства потребителя по умолчанию указаны в файле config / consumer.proper-ties
. Откройте новый терминал и введите приведенный ниже синтаксис для использования сообщений.
Синтаксис
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name --from-beginning
пример
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka --from-beginning
Выход
Hello My first message My second message
Наконец, вы можете вводить сообщения из терминала производителя и видеть, что они появляются в терминале потребителя. На данный момент у вас есть очень хорошее понимание кластера с одним узлом с одним брокером. Давайте теперь перейдем к конфигурации с несколькими брокерами.
Конфигурация с одним узлом и несколькими брокерами
Прежде чем перейти к настройке кластера с несколькими брокерами, сначала запустите сервер ZooKeeper.
Создайте несколько брокеров Kafka – у нас есть один экземпляр брокера Kafka уже в con-fig / server.properties. Теперь нам нужно несколько экземпляров брокера, поэтому скопируйте существующий файл server.prop-erties в два новых файла конфигурации и переименуйте его в server-one.properties и server-two.prop -ties. Затем отредактируйте оба новых файла и назначьте следующие изменения:
конфиг / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=1 # The port the socket server listens on port=9093 # A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs-1
конфиг / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=2 # The port the socket server listens on port=9094 # A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs-2
Запуск нескольких брокеров. После внесения всех изменений на трех серверах откройте три новых терминала, чтобы запустить каждого брокера по одному.
Broker1 bin/kafka-server-start.sh config/server.properties Broker2 bin/kafka-server-start.sh config/server-one.properties Broker3 bin/kafka-server-start.sh config/server-two.properties
Теперь у нас работают три разных брокера. Попробуйте сами проверить все демоны, набрав jps на терминале ZooKeeper, и вы увидите ответ.
Создание темы
Давайте назначим значение коэффициента репликации как три для этой темы, потому что у нас работают три разных брокера. Если у вас есть два брокера, то назначенное значение реплики будет равно двум.
Синтаксис
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 -partitions 1 --topic topic-name
пример
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 -partitions 1 --topic Multibrokerapplication
Выход
created topic “Multibrokerapplication”
Команда Describe
используется для проверки, какой посредник прослушивает текущую созданную тему, как показано ниже –
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic Multibrokerappli-cation
Выход
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic Multibrokerappli-cation Topic:Multibrokerapplication PartitionCount:1 ReplicationFactor:3 Configs: Topic:Multibrokerapplication Partition:0 Leader:0 Replicas:0,2,1 Isr:0,2,1
Исходя из вышеприведенного вывода, мы можем заключить, что в первой строке дается сводка по всем разделам, показывая название темы, количество разделов и коэффициент репликации, который мы уже выбрали. Во второй строке каждый узел будет лидером для случайно выбранной части разделов.
В нашем случае мы видим, что наш первый брокер (с broker.id 0) является лидером. Тогда Реплики: 0,2,1 означает, что все брокеры копируют тему, наконец, Isr
– это набор синхронных
реплик. Ну, это подмножество реплик, которые в настоящее время живы и захвачены лидером.
Начать продюсер для отправки сообщений
Эта процедура остается такой же, как в настройке одного брокера.
пример
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
Выход
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication [2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties) This is single node-multi broker demo This is the second message
Начать приемник для получения сообщений
Эта процедура остается такой же, как показано в настройке одного брокера.
пример
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Multibrokerapplica-tion --from-beginning
Выход
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Multibrokerapplica-tion —from-beginning This is single node-multi broker demo This is the second message
Основные тематические операции
В этой главе мы обсудим различные основные темы операций.
Изменение темы
Как вы уже поняли, как создать тему в Kafka Cluster. Теперь давайте изменим созданную тему, используя следующую команду
Синтаксис
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name --parti-tions count
пример
We have already created a topic “Hello-Kafka” with single partition count and one replica factor. Now using “alter” command we have changed the partition count. bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic Hello-kafka --parti-tions 2
Выход
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected Adding partitions succeeded!
Удаление темы
Чтобы удалить тему, вы можете использовать следующий синтаксис.
Синтаксис
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_name
пример
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafka
Выход
> Topic Hello-kafka marked for deletion
Примечание. Это не окажет влияния, если для delete.topic.enable не задано значение true.
Apache Kafka – простой пример для продюсера
Давайте создадим приложение для публикации и использования сообщений с помощью клиента Java. Клиент производителя Kafka состоит из следующих API.
KafkaProducer API
Давайте разберемся с наиболее важным набором API производителей Kafka в этом разделе. Центральная часть API KafkaProducer –
класс KafkaProducer
. Класс KafkaProducer предоставляет возможность подключить брокер Kafka в своем конструкторе с помощью следующих методов.
-
Класс KafkaProducer предоставляет метод send для асинхронной отправки сообщений в тему. Подпись send () выглядит следующим образом
Класс KafkaProducer предоставляет метод send для асинхронной отправки сообщений в тему. Подпись send () выглядит следующим образом
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1) , callback);
-
ProducerRecord – производитель управляет буфером записей, ожидающих отправки.
-
Обратный вызов – предоставленный пользователем обратный вызов для выполнения, когда запись была подтверждена сервером (ноль означает отсутствие обратного вызова).
ProducerRecord – производитель управляет буфером записей, ожидающих отправки.
Обратный вызов – предоставленный пользователем обратный вызов для выполнения, когда запись была подтверждена сервером (ноль означает отсутствие обратного вызова).
-
Класс KafkaProducer предоставляет метод сброса, обеспечивающий фактическое завершение всех ранее отправленных сообщений. Синтаксис метода очистки следующий:
Класс KafkaProducer предоставляет метод сброса, обеспечивающий фактическое завершение всех ранее отправленных сообщений. Синтаксис метода очистки следующий:
public void flush()
-
Класс KafkaProducer предоставляет метод partitionFor, который помогает в получении метаданных раздела для данной темы. Это может быть использовано для пользовательского разбиения. Суть этого метода заключается в следующем –
Класс KafkaProducer предоставляет метод partitionFor, который помогает в получении метаданных раздела для данной темы. Это может быть использовано для пользовательского разбиения. Суть этого метода заключается в следующем –
public Map metrics()
Возвращает карту внутренних метрик, поддерживаемых производителем.
-
public void close () – класс KafkaProducer предоставляет блоки методов close, пока все ранее отправленные запросы не будут выполнены.
public void close () – класс KafkaProducer предоставляет блоки методов close, пока все ранее отправленные запросы не будут выполнены.
API продюсера
Центральной частью API производителя является класс Producer
. Класс Producer предоставляет возможность подключить брокер Kafka в своем конструкторе следующими методами.
Класс продюсера
Класс продюсера предоставляет метод send для отправки сообщений в одну или несколько тем с использованием следующих подписей.
public void send(KeyedMessaget<k,v> message) - sends the data to a single topic,par-titioned by key using either sync or async producer. public void send(List<KeyedMessage<k,v>>messages) - sends data to multiple topics. Properties prop = new Properties(); prop.put(producer.type,”async”) ProducerConfig config = new ProducerConfig(prop);
Существует два типа производителей – Sync и Async .
Та же конфигурация API применима и к производителю Sync
. Разница между ними заключается в том, что производитель синхронизации отправляет сообщения напрямую, но отправляет сообщения в фоновом режиме. Асинхронный производитель предпочтителен, когда вы хотите более высокую пропускную способность. В предыдущих выпусках, таких как 0.8, у асинхронного производителя нет обратного вызова для send () для регистрации обработчиков ошибок. Это доступно только в текущей версии 0.9.
public void close ()
Класс Producer предоставляет метод close для закрытия соединений пула производителей со всеми брокерами Kafka.
Настройки конфигурации
Основные параметры конфигурации API производителя приведены в следующей таблице для лучшего понимания –
| S.No | Настройки конфигурации и описание |
|---|---|
| 1 |
ID клиента определяет приложение производителя |
| 2 |
producer.type синхронизация или асинхронность |
| 3 |
ACKs Конфигурация acks контролирует критерии по запросам производителя. |
| 4 |
повторы Если запрос производителя не удался, автоматически повторите попытку с указанным значением. |
| 5 |
bootstrap.servers загрузочный список брокеров. |
| 6 |
linger.ms если вы хотите уменьшить количество запросов, вы можете установить для linger.ms нечто большее, чем какое-либо значение. |
| 7 |
key.serializer Ключ для интерфейса сериализатора. |
| 8 |
value.serializer значение для интерфейса сериализатора. |
| 9 |
размер партии Размер буфера. |
| 10 |
buffer.memory контролирует общий объем памяти, доступной производителю для буферизации. |
ID клиента
определяет приложение производителя
producer.type
синхронизация или асинхронность
ACKs
Конфигурация acks контролирует критерии по запросам производителя.
повторы
Если запрос производителя не удался, автоматически повторите попытку с указанным значением.
bootstrap.servers
загрузочный список брокеров.
linger.ms
если вы хотите уменьшить количество запросов, вы можете установить для linger.ms нечто большее, чем какое-либо значение.
key.serializer
Ключ для интерфейса сериализатора.
value.serializer
значение для интерфейса сериализатора.
размер партии
Размер буфера.
buffer.memory
контролирует общий объем памяти, доступной производителю для буферизации.
ProducerRecord API
ProducerRecord – это пара ключ / значение, отправляемая в кластер Kafka. Конструктор классаProducerRecord для создания записи с парами разделов, ключей и значений с использованием следующей подписи.
public ProducerRecord (string topic, int partition, k key, v value)
-
Тема – определенное пользователем название темы, которое будет добавлено в запись.
-
Раздел – количество разделов
-
Ключ – ключ, который будет включен в запись.
- Значение – запись содержимого
Тема – определенное пользователем название темы, которое будет добавлено в запись.
Раздел – количество разделов
Ключ – ключ, который будет включен в запись.
public ProducerRecord (string topic, k key, v value)
Конструктор класса ProducerRecord используется для создания записи с ключом, парами значений и без разделения.
-
Тема – Создать тему для назначения записи.
-
Ключ – ключ для записи.
-
Значение – запись содержимого.
Тема – Создать тему для назначения записи.
Ключ – ключ для записи.
Значение – запись содержимого.
public ProducerRecord (string topic, v value)
Класс ProducerRecord создает запись без раздела и ключа.
-
Тема – создать тему.
-
Значение – запись содержимого.
Тема – создать тему.
Значение – запись содержимого.
Методы класса ProducerRecord перечислены в следующей таблице:
| S.No | Методы класса и описание |
|---|---|
| 1 |
публичная строковая тема () Тема будет добавлена в запись. |
| 2 |
открытый ключ K () Ключ, который будет включен в запись. Если такой клавиши нет, значение null будет возвращено здесь. |
| 3 |
общедоступное значение V () Записать содержимое. |
| 4 |
раздел () Количество разделов для записи |
публичная строковая тема ()
Тема будет добавлена в запись.
открытый ключ K ()
Ключ, который будет включен в запись. Если такой клавиши нет, значение null будет возвращено здесь.
общедоступное значение V ()
Записать содержимое.
раздел ()
Количество разделов для записи
Приложение SimpleProducer
Перед созданием приложения сначала запустите ZooKeeper и Kafka broker, затем создайте свою собственную тему в Kafka broker, используя команду create topic. После этого создайте класс Java с именем Sim-pleProducer.java
и введите следующую кодировку.
//import util.properties packages import java.util.Properties; //import simple producer packages import org.apache.kafka.clients.producer.Producer; //import KafkaProducer packages import org.apache.kafka.clients.producer.KafkaProducer; //import ProducerRecord packages import org.apache.kafka.clients.producer.ProducerRecord; //Create java class named “SimpleProducer” public class SimpleProducer { public static void main(String[] args) throws Exception{ // Check arguments length value if(args.length == 0){ System.out.println("Enter topic name”); return; } //Assign topicName to string variable String topicName = args[0].toString(); // create instance for properties to access producer configs Properties props = new Properties(); //Assign localhost id props.put("bootstrap.servers", “localhost:9092"); //Set acknowledgements for producer requests. props.put("acks", “all"); //If the request fails, the producer can automatically retry, props.put("retries", 0); //Specify buffer size in config props.put("batch.size", 16384); //Reduce the no of requests less than 0 props.put("linger.ms", 1); //The buffer.memory controls the total amount of memory available to the producer for buffering. props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer"); Producer<String, String> producer = new KafkaProducer <String, String>(props); for(int i = 0; i < 10; i++) producer.send(new ProducerRecord<String, String>(topicName, Integer.toString(i), Integer.toString(i))); System.out.println(“Message sent successfully”); producer.close(); } }
Компиляция – приложение может быть скомпилировано с помощью следующей команды.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
Выполнение – приложение может быть выполнено с помощью следующей команды.
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>
Выход
Message sent successfully To check the above output open new terminal and type Consumer CLI command to receive messages. >> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning 1 2 3 4 5 6 7 8 9 10
Простой потребительский пример
На данный момент мы создали производителя для отправки сообщений в кластер Kafka. Теперь давайте создадим потребителя для потребления сообщений из кластера Kafka. API KafkaConsumer используется для приема сообщений из кластера Kafka. Конструктор класса KafkaConsumer определен ниже.
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)
configs – вернуть карту пользовательских конфигов.
Класс KafkaConsumer имеет следующие важные методы, которые перечислены в таблице ниже.
| S.No | Метод и описание |
|---|---|
| 1 |
public java.util.Set назначение <TopicPar-tition> () Получить набор разделов, назначенных в настоящее время потребителем. |
| 2 |
подписка на открытую строку () Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы. |
| 3 |
public void sub-scribe (темы java.util.List <java.lang.String>, слушатель ConsumerRe-balanceListener) Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы. |
| 4 |
публичный аннулировать подписку () Отписаться на темы из данного списка разделов. |
| 5 |
публичный подпункт void (темы java.util.List <java.lang.String>) Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы. Если данный список тем пуст, он обрабатывается так же, как и отмена подписки (). |
| 6 |
открытый подписок void (шаблон java.util.regex.Pattern, слушатель ConsumerRebalanceLis-tener) Шаблон аргумента относится к шаблону подписки в формате регулярного выражения, а аргумент слушателя получает уведомления от шаблона подписки. |
| 7 |
public void as-sign (разделы java.util.List <TopicPartition>) Вручную назначьте список разделов клиенту. |
| 8 |
опрос() Получить данные для тем или разделов, указанных с помощью одного из API подписки / назначения. Это вернет ошибку, если темы не подписаны перед опросом данных. |
| 9 |
public void commitSync () Смещение коммитов, возвращаемое при последнем опросе () для всех подписанных списков тем и разделов. Та же операция применяется к commitAsyn (). |
| 10 |
public void seek (раздел TopicPartition, длинное смещение) Получить текущее значение смещения, которое потребитель будет использовать в следующем методе poll (). |
| 11 |
общедоступное резюме () Возобновить приостановленные разделы. |
| 12 |
public void wakeup () Пробуждение потребителя. |
public java.util.Set назначение <TopicPar-tition> ()
Получить набор разделов, назначенных в настоящее время потребителем.
подписка на открытую строку ()
Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы.
public void sub-scribe (темы java.util.List <java.lang.String>, слушатель ConsumerRe-balanceListener)
Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы.
публичный аннулировать подписку ()
Отписаться на темы из данного списка разделов.
публичный подпункт void (темы java.util.List <java.lang.String>)
Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы. Если данный список тем пуст, он обрабатывается так же, как и отмена подписки ().
открытый подписок void (шаблон java.util.regex.Pattern, слушатель ConsumerRebalanceLis-tener)
Шаблон аргумента относится к шаблону подписки в формате регулярного выражения, а аргумент слушателя получает уведомления от шаблона подписки.
public void as-sign (разделы java.util.List <TopicPartition>)
Вручную назначьте список разделов клиенту.
опрос()
Получить данные для тем или разделов, указанных с помощью одного из API подписки / назначения. Это вернет ошибку, если темы не подписаны перед опросом данных.
public void commitSync ()
Смещение коммитов, возвращаемое при последнем опросе () для всех подписанных списков тем и разделов. Та же операция применяется к commitAsyn ().
public void seek (раздел TopicPartition, длинное смещение)
Получить текущее значение смещения, которое потребитель будет использовать в следующем методе poll ().
общедоступное резюме ()
Возобновить приостановленные разделы.
public void wakeup ()
Пробуждение потребителя.
ConsumerRecord API
API ConsumerRecord используется для получения записей из кластера Kafka. Этот API состоит из имени темы, номера раздела, из которого принимается запись, и смещения, которое указывает на запись в разделе Kafka. Класс ConsumerRecord используется для создания записи потребителя с определенным именем темы, количеством разделов и парами <ключ, значение>. Имеет следующую подпись.
public ConsumerRecord(string topic,int partition, long offset,K key, V value)
-
Тема – Название темы для записи потребителя, полученной из кластера Kafka.
-
Раздел – Раздел по теме.
-
Ключ – ключ записи, если ключа не существует, возвращается ноль.
-
Значение – запись содержимого.
Тема – Название темы для записи потребителя, полученной из кластера Kafka.
Раздел – Раздел по теме.
Ключ – ключ записи, если ключа не существует, возвращается ноль.
Значение – запись содержимого.
ConsumerRecords API
ConsumerRecords API действует как контейнер для ConsumerRecord. Этот API используется для хранения списка ConsumerRecord для каждого раздела для определенной темы. Его конструктор определен ниже.
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List <Consumer-Record>K,V>>> records)
-
TopicPartition – возвращает карту разделов для определенной темы.
-
Записи – возврат списка ConsumerRecord.
TopicPartition – возвращает карту разделов для определенной темы.
Записи – возврат списка ConsumerRecord.
В классе ConsumerRecords определены следующие методы.
| S.No | Методы и описание |
|---|---|
| 1 |
public int count () Количество записей по всем темам. |
| 2 |
публичный набор разделов () Набор разделов с данными в этом наборе записей (если данные не были возвращены, то набор пуст). |
| 3 |
публичный итератор итератор () Итератор позволяет циклически проходить через коллекцию, получать или перемещать элементы. |
| 4 |
Публичный список записей () Получить список записей для данного раздела. |
public int count ()
Количество записей по всем темам.
публичный набор разделов ()
Набор разделов с данными в этом наборе записей (если данные не были возвращены, то набор пуст).
публичный итератор итератор ()
Итератор позволяет циклически проходить через коллекцию, получать или перемещать элементы.
Публичный список записей ()
Получить список записей для данного раздела.
Настройки конфигурации
Параметры конфигурации основных параметров конфигурации API клиента-клиента перечислены ниже:
| S.No | Настройки и описание |
|---|---|
| 1 |
bootstrap.servers Начальный список брокеров. |
| 2 |
group.id Назначает отдельного потребителя в группу. |
| 3 |
enable.auto.commit Включите автоматическую фиксацию для смещений, если значение истинно, иначе не зафиксировано. |
| 4 |
auto.commit.interval.ms Верните, как часто обновленные смещения записываются в ZooKeeper. |
| 5 |
session.timeout.ms Указывает, сколько миллисекунд Кафка будет ждать, пока ZooKeeper ответит на запрос (чтение или запись), прежде чем отказаться от и продолжать потреблять сообщения. |
bootstrap.servers
Начальный список брокеров.
group.id
Назначает отдельного потребителя в группу.
enable.auto.commit
Включите автоматическую фиксацию для смещений, если значение истинно, иначе не зафиксировано.
auto.commit.interval.ms
Верните, как часто обновленные смещения записываются в ZooKeeper.
session.timeout.ms
Указывает, сколько миллисекунд Кафка будет ждать, пока ZooKeeper ответит на запрос (чтение или запись), прежде чем отказаться от и продолжать потреблять сообщения.
Приложение SimpleConsumer
Шаги приложения производителя остаются неизменными. Сначала запустите брокера ZooKeeper и Kafka. Затем создайте приложение SimpleConsumer
с помощью класса Java с именем SimpleCon-sumer.java
и введите следующий код.
import java.util.Properties; import java.util.Arrays; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.ConsumerRecord; public class SimpleConsumer { public static void main(String[] args) throws Exception { if(args.length == 0){ System.out.println("Enter topic name"); return; } //Kafka consumer configuration settings String topicName = args[0].toString(); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer <String, String>(props); //Kafka Consumer subscribes list of topics here. consumer.subscribe(Arrays.asList(topicName)) //print the topic name System.out.println("Subscribed to topic " + topicName); int i = 0; while (true) { ConsumerRecords<String, String> records = con-sumer.poll(100); for (ConsumerRecord<String, String> record : records) // print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %sn", record.offset(), record.key(), record.value()); } } }
Компиляция – приложение может быть скомпилировано с помощью следующей команды.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
Выполнение – приложение может быть выполнено с помощью следующей команды
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>
Вход – откройте CLI производителя и отправьте несколько сообщений в тему. Вы можете указать smple input как «Hello Consumer».
Вывод – следующим будет вывод.
Subscribed to topic Hello-Kafka offset = 3, key = null, value = Hello Consumer
Apache Kafka – пример группы потребителей
Потребительская группа – это многопоточное или многопользовательское потребление по темам Kafka.
Потребительская группа
-
Потребители могут присоединиться к группе, используя тот же
group.id.
-
Максимальный параллелизм группы заключается в том, что количество потребителей в группе ← нет разделов.
-
Kafka назначает разделы темы потребителю в группе, так что каждый раздел потребляется ровно одним потребителем в группе.
-
Кафка гарантирует, что сообщение будет прочитано только одним потребителем в группе.
-
Потребители могут видеть сообщение в том порядке, в котором они были сохранены в журнале.
Потребители могут присоединиться к группе, используя тот же group.id.
Максимальный параллелизм группы заключается в том, что количество потребителей в группе ← нет разделов.
Kafka назначает разделы темы потребителю в группе, так что каждый раздел потребляется ровно одним потребителем в группе.
Кафка гарантирует, что сообщение будет прочитано только одним потребителем в группе.
Потребители могут видеть сообщение в том порядке, в котором они были сохранены в журнале.
Перебалансировка потребителя
Добавление большего количества процессов / потоков приведет к перебалансировке Kafka. Если какой-либо потребитель или брокер не может отправить пульс ZooKeeper, его можно перенастроить через кластер Kafka. Во время этого перебалансирования Kafka назначит доступные разделы доступным потокам, возможно, переместив раздел в другой процесс.
import java.util.Properties; import java.util.Arrays; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.ConsumerRecord; public class ConsumerGroup { public static void main(String[] args) throws Exception { if(args.length < 2){ System.out.println("Usage: consumer <topic> <groupname>"); return; } String topic = args[0].toString(); String group = args[1].toString(); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", group); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.ByteArraySerializer"); props.put("value.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList(topic)); System.out.println("Subscribed to topic " + topic); int i = 0; while (true) { ConsumerRecords<String, String> records = con-sumer.poll(100); for (ConsumerRecord<String, String> record : records) System.out.printf("offset = %d, key = %s, value = %sn", record.offset(), record.key(), record.value()); } } }
компиляция
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.java
выполнение
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":. ConsumerGroup <topic-name> my-group >>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":. ConsumerGroup <topic-name> my-group
Здесь мы создали пример группы названий my-group
с двумя потребителями. Точно так же вы можете создать свою группу и количество потребителей в группе.
вход
Откройте CLI производителя и отправьте несколько сообщений вроде –
Test consumer group 01 Test consumer group 02
Вывод первого процесса
Subscribed to topic Hello-kafka offset = 3, key = null, value = Test consumer group 01
Вывод второго процесса
Subscribed to topic Hello-kafka offset = 3, key = null, value = Test consumer group 02
Теперь, надеюсь, вы бы поняли SimpleConsumer и ConsumeGroup, используя демонстрационную версию клиента Java. Теперь у вас есть представление о том, как отправлять и получать сообщения с помощью клиента Java. Давайте продолжим интеграцию Kafka с технологиями больших данных в следующей главе.
Apache Kafka – интеграция со штормом
В этой главе мы узнаем, как интегрировать Kafka с Apache Storm.
О Шторме
Первоначально Storm был создан Натаном Марцем и командой BackType. За короткое время Apache Storm стал стандартом для распределенной системы обработки в реальном времени, которая позволяет обрабатывать огромный объем данных. Storm работает очень быстро, и тест показал, что он обрабатывает более миллиона кортежей в секунду на узел. Apache Storm работает непрерывно, потребляя данные из настроенных источников (Spouts) и передает данные по конвейеру обработки (Bolts). Комбинированные, носики и болты составляют топологию.
Интеграция со Storm
Kafka и Storm естественным образом дополняют друг друга, а их мощное сотрудничество позволяет осуществлять потоковую аналитику в реальном времени для быстро перемещающихся больших данных. Интеграция Kafka и Storm облегчает разработчикам прием и публикацию потоков данных из топологий Storm.
Концептуальный поток
Носик является источником потоков. Например, носик может читать кортежи из темы Кафки и выдавать их в виде потока. Болт потребляет входные потоки, обрабатывает и, возможно, испускает новые потоки. Болты могут делать что угодно, от запуска функций, фильтрации кортежей, выполнения потоковых агрегаций, потоковых объединений, общения с базами данных и многого другого. Каждый узел в топологии Storm выполняется параллельно. Топология работает бесконечно, пока вы не прекратите ее. Storm автоматически переназначит все неудачные задачи. Кроме того, Storm гарантирует, что не произойдет потери данных, даже если машины выйдут из строя и сообщения будут отброшены.
Давайте подробно рассмотрим API интеграции Kafka-Storm. Существует три основных класса для интеграции Kafka с Storm. Они заключаются в следующем –
BrokerHosts – ZkHosts & StaticHosts
BrokerHosts – это интерфейс, а ZkHosts и StaticHosts – две его основные реализации. ZkHosts используется для динамического отслеживания брокеров Kafka, сохраняя детали в ZooKeeper, в то время как StaticHosts используется для ручной / статической настройки брокеров Kafka и его данных. ZkHosts – это простой и быстрый способ доступа к брокеру Kafka.
Подпись ZkHosts выглядит следующим образом –
public ZkHosts(String brokerZkStr, String brokerZkPath) public ZkHosts(String brokerZkStr)
Где brokerZkStr – это хост ZooKeeper, а brokerZkPath – путь ZooKeeper для поддержки сведений о брокере Kafka.
KafkaConfig API
Этот API используется для определения параметров конфигурации для кластера Kafka. Подпись Кафки Кон-Фига определяется следующим образом
public KafkaConfig(BrokerHosts hosts, string topic)
Хосты – BrokerHosts могут быть ZkHosts / StaticHosts.
Тема – название темы.
Хосты – BrokerHosts могут быть ZkHosts / StaticHosts.
Тема – название темы.
SpoutConfig API
Spoutconfig – это расширение KafkaConfig, которое поддерживает дополнительную информацию ZooKeeper.
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)
-
Hosts – BrokerHosts может быть любой реализацией интерфейса BrokerHosts.
-
Тема – название темы.
-
zkRoot – корневой путь ZooKeeper.
-
id – носик хранит состояние смещений, которые он потребляет в Zookeeper. Идентификатор должен однозначно идентифицировать ваш носик.
Hosts – BrokerHosts может быть любой реализацией интерфейса BrokerHosts.
Тема – название темы.
zkRoot – корневой путь ZooKeeper.
id – носик хранит состояние смещений, которые он потребляет в Zookeeper. Идентификатор должен однозначно идентифицировать ваш носик.
SchemeAsMultiScheme
SchemeAsMultiScheme – это интерфейс, который определяет, как преобразованный ByteBuffer из Kafka превращается в штормовый кортеж. Он является производным от MultiScheme и принимает реализацию класса Scheme. Существует множество реализаций класса Scheme, и одной из таких реализаций является StringScheme, которая анализирует байт как простую строку. Он также контролирует наименование вашего поля вывода. Подпись определяется следующим образом.
public SchemeAsMultiScheme(Scheme scheme)
-
Схема – байтовый буфер, потребляемый от кафки.
Схема – байтовый буфер, потребляемый от кафки.
KafkaSpout API
KafkaSpout – это наша реализация spout, которая будет интегрироваться с Storm. Он извлекает сообщения из темы kafka и отправляет их в экосистему Storm в виде кортежей. KafkaSpout получает информацию о конфигурации от SpoutConfig.
Ниже приведен пример кода для создания простого носика Кафки.
// ZooKeeper connection string BrokerHosts hosts = new ZkHosts(zkConnString); //Creating SpoutConfig Object SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, "/" + topicName UUID.randomUUID().toString()); //convert the ByteBuffer to String. spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); //Assign SpoutConfig to KafkaSpout. KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
Создание болта
Bolt – это компонент, который принимает кортежи в качестве входных данных, обрабатывает кортежи и создает новые кортежи в качестве выходных данных. Болты будут реализовывать интерфейс IRichBolt. В этой программе для выполнения операций используются два класса болтов WordSplitter-Bolt и WordCounterBolt.
Интерфейс IRichBolt имеет следующие методы –
-
Подготовить – Предоставляет болту среду для выполнения. Исполнители запустят этот метод для инициализации носика.
-
Выполнить – обработать один кортеж ввода.
-
Очистка – вызывается, когда затвор собирается отключиться.
-
DeclareOutputFields – Объявляет схему вывода кортежа.
Подготовить – Предоставляет болту среду для выполнения. Исполнители запустят этот метод для инициализации носика.
Выполнить – обработать один кортеж ввода.
Очистка – вызывается, когда затвор собирается отключиться.
DeclareOutputFields – Объявляет схему вывода кортежа.
Давайте создадим SplitBolt.java, который реализует логику для разделения предложения на слова, и CountBolt.java, который реализует логику для разделения уникальных слов и подсчета его появления.
SplitBolt.java
import java.util.Map; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.task.OutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.IRichBolt; import backtype.storm.task.TopologyContext; public class SplitBolt implements IRichBolt { private OutputCollector collector; @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } @Override public void execute(Tuple input) { String sentence = input.getString(0); String[] words = sentence.split(" "); for(String word: words) { word = word.trim(); if(!word.isEmpty()) { word = word.toLowerCase(); collector.emit(new Values(word)); } } collector.ack(input); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } @Override public void cleanup() {} @Override public Map<String, Object> getComponentConfiguration() { return null; } }
CountBolt.java
import java.util.Map; import java.util.HashMap; import backtype.storm.tuple.Tuple; import backtype.storm.task.OutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.IRichBolt; import backtype.storm.task.TopologyContext; public class CountBolt implements IRichBolt{ Map<String, Integer> counters; private OutputCollector collector; @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.counters = new HashMap<String, Integer>(); this.collector = collector; } @Override public void execute(Tuple input) { String str = input.getString(0); if(!counters.containsKey(str)){ counters.put(str, 1); }else { Integer c = counters.get(str) +1; counters.put(str, c); } collector.ack(input); } @Override public void cleanup() { for(Map.Entry<String, Integer> entry:counters.entrySet()){ System.out.println(entry.getKey()+" : " + entry.getValue()); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } @Override public Map<String, Object> getComponentConfiguration() { return null; } }
Отправка в топологию
Топология Storm – это в основном структура Thrift. Класс TopologyBuilder предоставляет простые и легкие методы для создания сложных топологий. Класс TopologyBuilder имеет методы для установки spout (setSpout) и для установки болта (setBolt). Наконец, TopologyBuilder имеет createTopology для создания топологии. Методы shuffleGrouping и fieldsGrouping помогают установить группировку потока для носика и болтов.
Локальный кластер. В целях разработки мы можем создать локальный кластер, используя объект LocalCluster,
а затем передать топологию, используя метод submitTopology
класса LocalCluster
.
KafkaStormSample.java
import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; import java.util.ArrayList; import java.util.List; import java.util.UUID; import backtype.storm.spout.SchemeAsMultiScheme; import storm.kafka.trident.GlobalPartitionInformation; import storm.kafka.ZkHosts; import storm.kafka.Broker; import storm.kafka.StaticHosts; import storm.kafka.BrokerHosts; import storm.kafka.SpoutConfig; import storm.kafka.KafkaConfig; import storm.kafka.KafkaSpout; import storm.kafka.StringScheme; public class KafkaStormSample { public static void main(String[] args) throws Exception{ Config config = new Config(); config.setDebug(true); config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1); String zkConnString = "localhost:2181"; String topic = "my-first-topic"; BrokerHosts hosts = new ZkHosts(zkConnString); SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic, UUID.randomUUID().toString()); kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4; kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4; kafkaSpoutConfig.forceFromStart = true; kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig)); builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout"); builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter"); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("KafkaStormSample", config, builder.create-Topology()); Thread.sleep(10000); cluster.shutdown(); } }
Перед тем как приступить к компиляции, для интеграции Kakfa-Storm требуется куратор клиентской библиотеки ZooKeeper. Куратор версии 2.9.1 поддерживает Apache Storm версии 0.9.5 (которую мы используем в этом руководстве). Загрузите указанные ниже jar-файлы и поместите их в путь к классу java.
- Куратор-клиент-2.9.1.jar
- Куратор-каркасного 2.9.1.jar
После включения файлов зависимостей, скомпилируйте программу с помощью следующей команды:
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.java
выполнение
Запустите Kafka Producer CLI (объяснено в предыдущей главе), создайте новую тему под названием my-first-topic
и предоставьте несколько примеров сообщений, как показано ниже –
hello kafka storm spark test message another test message
Теперь запустите приложение, используя следующую команду –
java -cp «/path/to/Kafka/apache-storm-0.9.5/lib/*» :. KafkaStormSample
Пример вывода этого приложения указан ниже –
storm : 1 test : 2 spark : 1 another : 1 kafka : 1 hello : 1 message : 2
Apache Kafka – интеграция с искрой
В этой главе мы поговорим о том, как интегрировать Apache Kafka с Spark Streaming API.
О Спарк
Spark Streaming API обеспечивает масштабируемую высокопроизводительную отказоустойчивую обработку потоков потоков данных. Данные могут поступать из многих источников, таких как Kafka, Flume, Twitter и т. Д., И могут обрабатываться с использованием сложных алгоритмов, таких как высокоуровневые функции, такие как map, Reduce, Join и Window. Наконец, обработанные данные можно отправить в файловые системы, базы данных и живые панели мониторинга. Эластичные распределенные наборы данных (RDD) – это фундаментальная структура данных Spark. Это неизменяемая распределенная коллекция объектов. Каждый набор данных в RDD разделен на логические разделы, которые могут быть вычислены на разных узлах кластера.
Интеграция с Spark
Kafka – это потенциальная платформа обмена сообщениями и интеграции для потоковой передачи Spark. Kafka выступает в качестве центрального узла для потоков данных в реальном времени и обрабатывается с использованием сложных алгоритмов в Spark Streaming. После обработки данных Spark Streaming может публиковать результаты в еще одной теме Kafka или хранить в HDFS, базах данных или информационных панелях. Следующая диаграмма изображает концептуальный поток.
Теперь давайте подробно рассмотрим API Kafka-Spark.
SparkConf API
Он представляет конфигурацию для приложения Spark. Используется для установки различных параметров Spark в виде пар ключ-значение.
Класс SparkConf
имеет следующие методы –
-
set (строковый ключ, строковое значение) – установить переменную конфигурации.
-
удалить (строковый ключ) – удалить ключ из конфигурации.
-
setAppName (string name) – установить имя приложения для вашего приложения.
-
get (string key) – получить ключ
set (строковый ключ, строковое значение) – установить переменную конфигурации.
удалить (строковый ключ) – удалить ключ из конфигурации.
setAppName (string name) – установить имя приложения для вашего приложения.
get (string key) – получить ключ
StreamingContext API
Это основная точка входа для функциональности Spark. SparkContext представляет соединение с кластером Spark и может использоваться для создания RDD, аккумуляторов и широковещательных переменных в кластере. Подпись определяется так, как показано ниже.
public StreamingContext(String master, String appName, Duration batchDuration, String sparkHome, scala.collection.Seq<String> jars, scala.collection.Map<String,String> environment)
-
master – кластерный URL для подключения (например, mesos: // host: port, spark: // host: port, local [4]).
-
appName – имя вашей работы, отображаемое в веб-интерфейсе кластера.
-
batchDuration – интервал времени, в течение которого потоковые данные будут разделены на пакеты
master – кластерный URL для подключения (например, mesos: // host: port, spark: // host: port, local [4]).
appName – имя вашей работы, отображаемое в веб-интерфейсе кластера.
batchDuration – интервал времени, в течение которого потоковые данные будут разделены на пакеты
public StreamingContext(SparkConf conf, Duration batchDuration)
Создайте StreamingContext, предоставив конфигурацию, необходимую для нового SparkContext.
-
conf – параметры искры
-
batchDuration – интервал времени, в течение которого потоковые данные будут разделены на пакеты
conf – параметры искры
batchDuration – интервал времени, в течение которого потоковые данные будут разделены на пакеты
API KafkaUtils
API KafkaUtils используется для подключения кластера Kafka к потоковой передаче Spark. Этот API имеет подпись createStream
существенного метода, определенную как ниже.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream( StreamingContext ssc, String zkQuorum, String groupId, scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)
Показанный выше метод используется для создания входного потока, который извлекает сообщения от Kafka Brokers.
-
ssc – объект StreamingContext.
-
zkQuorum – Кворум Зоопарка .
-
groupId – идентификатор группы для этого потребителя.
-
themes – вернуть карту тем для потребления.
-
storageLevel – уровень хранилища, используемый для хранения полученных объектов.
ssc – объект StreamingContext.
zkQuorum – Кворум Зоопарка .
groupId – идентификатор группы для этого потребителя.
themes – вернуть карту тем для потребления.
storageLevel – уровень хранилища, используемый для хранения полученных объектов.
В API KafkaUtils есть еще один метод createDirectStream, который используется для создания входного потока, который напрямую извлекает сообщения из брокеров Kafka без использования какого-либо получателя. Этот поток может гарантировать, что каждое сообщение от Kafka будет включено в преобразования ровно один раз.
Пример приложения сделан в Scala. Чтобы скомпилировать приложение, пожалуйста, скачайте и установите sbt
, инструмент сборки scala (похож на maven). Основной код приложения представлен ниже.
import java.util.HashMap import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord} import org.apache.spark.SparkConf import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka._ object KafkaWordCount { def main(args: Array[String]) { if (args.length < 4) { System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>") System.exit(1) } val Array(zkQuorum, group, topics, numThreads) = args val sparkConf = new SparkConf().setAppName("KafkaWordCount") val ssc = new StreamingContext(sparkConf, Seconds(2)) ssc.checkpoint("checkpoint") val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2) val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1L)) .reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2) wordCounts.print() ssc.start() ssc.awaitTermination() } }
Сценарий сборки
Интеграция искра-кафка зависит от банки с искрой, потоковой искрой и искрой Kafka. Создайте новый файл build.sbt
и укажите детали приложения и его зависимость. Sbt
загрузит необходимый jar при компиляции и упаковке приложения.
name := "Spark Kafka Project" version := "1.0" scalaVersion := "2.10.5" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"
Компиляция / Упаковка
Выполните следующую команду, чтобы скомпилировать и упаковать файл jar приложения. Нам нужно отправить файл jar в консоль spark для запуска приложения.
sbt package
Отправка в Spark
Запустите интерфейс командной строки Kafka Producer (описанный в предыдущей главе), создайте новую тему под названием my-first-topic
и предоставьте несколько примеров сообщений, как показано ниже.
Another spark test message
Выполните следующую команду, чтобы отправить приложение в консоль spark.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming -kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark -kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>
Пример вывода этого приложения показан ниже.
spark console messages .. (Test,1) (spark,1) (another,1) (message,1) spark console message ..
Приложение в реальном времени (Twitter)
Давайте проанализируем приложение в реальном времени, чтобы получить последние твиттеры и их хэштеги. Ранее мы видели интеграцию Storm и Spark с Kafka. В обоих сценариях мы создали Kafka Producer (используя cli) для отправки сообщения в экосистему Kafka. Затем интеграция шторма и искры считывает сообщения с помощью потребителя Kafka и вводит их в экосистему шторма и искры соответственно. Итак, практически нам нужно создать Kafka Producer, который должен –
- Прочитайте каналы Twitter, используя «Twitter Streaming API»,
- Обрабатывать каналы,
- Извлеките хэштеги и
- Отправь это Кафке.
Как только Кафка
получает хеш-теги
, интеграция Storm / Spark получает информацию и отправляет ее в экосистему Storm / Spark.
API потоковой передачи Twitter
«Twitter Streaming API» доступен на любом языке программирования. «Twitter4j» – это неофициальная библиотека Java с открытым исходным кодом, которая предоставляет модуль на основе Java для быстрого доступа к «API потоковой передачи Twitter». «Twitter4j» предоставляет основанную на слушателе структуру для доступа к твитам. Чтобы получить доступ к «API потоковой передачи Twitter», нам нужно войти в учетную запись разработчика Twitter и получить следующие данные аутентификации OAuth .
- Customerkey
- CustomerSecret
- маркер доступа
- AccessTookenSecret
После создания учетной записи разработчика загрузите файлы jar «twitter4j» и поместите их в путь к классу java.
Полный код производителя Твиттера Kafka (KafkaTwitterProducer.java) приведен ниже –
import java.util.Arrays; import java.util.Properties; import java.util.concurrent.LinkedBlockingQueue; import twitter4j.*; import twitter4j.conf.*; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; public class KafkaTwitterProducer { public static void main(String[] args) throws Exception { LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000); if(args.length < 5){ System.out.println( "Usage: KafkaTwitterProducer <twitter-consumer-key> <twitter-consumer-secret> <twitter-access-token> <twitter-access-token-secret> <topic-name> <twitter-search-keywords>"); return; } String consumerKey = args[0].toString(); String consumerSecret = args[1].toString(); String accessToken = args[2].toString(); String accessTokenSecret = args[3].toString(); String topicName = args[4].toString(); String[] arguments = args.clone(); String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length); ConfigurationBuilder cb = new ConfigurationBuilder(); cb.setDebugEnabled(true) .setOAuthConsumerKey(consumerKey) .setOAuthConsumerSecret(consumerSecret) .setOAuthAccessToken(accessToken) .setOAuthAccessTokenSecret(accessTokenSecret); TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance(); StatusListener listener = new StatusListener() { @Override public void onStatus(Status status) { queue.offer(status); // System.out.println("@" + status.getUser().getScreenName() + " - " + status.getText()); // System.out.println("@" + status.getUser().getScreen-Name()); /*for(URLEntity urle : status.getURLEntities()) { System.out.println(urle.getDisplayURL()); }*/ /*for(HashtagEntity hashtage : status.getHashtagEntities()) { System.out.println(hashtage.getText()); }*/ } @Override public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) { // System.out.println("Got a status deletion notice id:" + statusDeletionNotice.getStatusId()); } @Override public void onTrackLimitationNotice(int numberOfLimitedStatuses) { // System.out.println("Got track limitation notice:" + num-berOfLimitedStatuses); } @Override public void onScrubGeo(long userId, long upToStatusId) { // System.out.println("Got scrub_geo event userId:" + userId + "upToStatusId:" + upToStatusId); } @Override public void onStallWarning(StallWarning warning) { // System.out.println("Got stall warning:" + warning); } @Override public void onException(Exception ex) { ex.printStackTrace(); } }; twitterStream.addListener(listener); FilterQuery query = new FilterQuery().track(keyWords); twitterStream.filter(query); Thread.sleep(5000); //Add Kafka producer config settings Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer"); Producer<String, String> producer = new KafkaProducer<String, String>(props); int i = 0; int j = 0; while(i < 10) { Status ret = queue.poll(); if (ret == null) { Thread.sleep(100); i++; }else { for(HashtagEntity hashtage : ret.getHashtagEntities()) { System.out.println("Hashtag: " + hashtage.getText()); producer.send(new ProducerRecord<String, String>( top-icName, Integer.toString(j++), hashtage.getText())); } } } producer.close(); Thread.sleep(5000); twitterStream.shutdown(); } }
компиляция
Скомпилируйте приложение с помощью следующей команды –
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.java
выполнение
Откройте две консоли. Запустите выше скомпилированное приложение, как показано ниже, в одной консоли.
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”: . KafkaTwitterProducer <twitter-consumer-key> <twitter-consumer-secret> <twitter-access-token> <twitter-ac-cess-token-secret> my-first-topic food
Запустите любое из приложений Spark / Storm, описанных в предыдущей главе, в другом окне. Главное, на что следует обратить внимание, это то, что используемая тема должна быть одинаковой в обоих случаях. Здесь мы использовали «my-first-topic» в качестве названия темы.
Выход
Выходные данные этого приложения будут зависеть от ключевых слов и текущего канала Twitter. Пример выходных данных указан ниже (штормовая интеграция).
. . . food : 1 foodie : 2 burger : 1 . . .
Apache Kafka – Инструменты
Kafka Tool упакован в «org.apache.kafka.tools. *. Инструменты подразделяются на системные инструменты и инструменты репликации.
Системные инструменты
Системные инструменты могут быть запущены из командной строки с помощью скрипта класса run. Синтаксис выглядит следующим образом –
bin/kafka-run-class.sh package.class - - options
Некоторые из системных инструментов упомянуты ниже –
-
Kafka Migration Tool – этот инструмент используется для миграции брокера с одной версии на другую.
-
Mirror Maker – этот инструмент используется для обеспечения зеркалирования одного кластера Kafka другому.
-
Consumer Offset Checker – Этот инструмент отображает Consumer Group, Topic, Partition, Off-set, logSize, Owner для указанного набора тем и Consumer Group.
Kafka Migration Tool – этот инструмент используется для миграции брокера с одной версии на другую.
Mirror Maker – этот инструмент используется для обеспечения зеркалирования одного кластера Kafka другому.
Consumer Offset Checker – Этот инструмент отображает Consumer Group, Topic, Partition, Off-set, logSize, Owner для указанного набора тем и Consumer Group.
Инструмент репликации
Репликация Kafka – это инструмент проектирования высокого уровня. Целью добавления инструмента репликации является повышение надежности и доступности. Некоторые из инструментов репликации упомянуты ниже –
-
Инструмент создания тем – создает тему с количеством разделов по умолчанию, коэффициентом репликации и использует схему по умолчанию Kafka для назначения реплики.
-
Инструмент для создания списка тем – этот инструмент выводит информацию для заданного списка тем. Если в командной строке не указано ни одной темы, инструмент запрашивает у Zookeeper все темы и выводит информацию о них. Поля, которые отображает инструмент, – это название темы, раздел, лидер, реплики, isr.
-
Add Partition Tool – Создание темы, необходимо указать количество разделов для темы. Позже для темы может понадобиться больше разделов, когда объем темы увеличится. Этот инструмент помогает добавить больше разделов для определенной темы, а также позволяет вручную назначать реплики добавленным разделам.
Инструмент создания тем – создает тему с количеством разделов по умолчанию, коэффициентом репликации и использует схему по умолчанию Kafka для назначения реплики.
Инструмент для создания списка тем – этот инструмент выводит информацию для заданного списка тем. Если в командной строке не указано ни одной темы, инструмент запрашивает у Zookeeper все темы и выводит информацию о них. Поля, которые отображает инструмент, – это название темы, раздел, лидер, реплики, isr.
Add Partition Tool – Создание темы, необходимо указать количество разделов для темы. Позже для темы может понадобиться больше разделов, когда объем темы увеличится. Этот инструмент помогает добавить больше разделов для определенной темы, а также позволяет вручную назначать реплики добавленным разделам.
Apache Kafka – Приложения
Kafka поддерживает многие из лучших на сегодняшний день промышленных приложений. В этой главе мы дадим очень краткий обзор некоторых наиболее заметных применений Kafka.
щебет
Twitter – это онлайн-сервис социальных сетей, который предоставляет платформу для отправки и получения пользовательских твитов. Зарегистрированные пользователи могут читать и публиковать твиты, но незарегистрированные пользователи могут читать только твиты. Twitter использует Storm-Kafka как часть своей инфраструктуры потоковой обработки.
Apache Kafka используется в LinkedIn для данных потока операций и рабочих показателей. Система обмена сообщениями Kafka помогает LinkedIn в различных продуктах, таких как LinkedIn Newsfeed, LinkedIn Today, для потребления онлайн-сообщений и в дополнение к автономным аналитическим системам, таким как Hadoop. Высокая прочность Kafka также является одним из ключевых факторов, связанных с LinkedIn.
Netflix
Netflix – американский многонациональный поставщик потокового мультимедиа по запросу. Netflix использует Kafka для мониторинга в реальном времени и обработки событий.
Mozilla
Mozilla – это сообщество свободного программного обеспечения, созданное в 1998 году членами Netscape. Кафка вскоре заменит часть текущей производственной системы Mozilla для сбора данных о производительности и использовании из браузера конечного пользователя для таких проектов, как телеметрия, тестовый пилот и т. Д.
оракул
Oracle обеспечивает собственное подключение к Kafka из своего продукта Enterprise Service Bus под названием OSB (Oracle Service Bus), который позволяет разработчикам использовать встроенные посреднические возможности OSB для реализации поэтапных конвейеров данных.
Статья подготовлена на основе открытого занятия из видеокурса по Apache Kafka. Авторы — Анатолий Солдатов, Lead Engineer в Авито, и Александр Миронов, Infrastructure Engineer в Stripe. Базовые темы курса доступны на Youtube.
Слёрм подготовил видеокурс Apache Kafka База, где мы научим вас грамотно применять эту технологию и совершать меньше ошибок.
Kafka и классические сервисы очередей
Для первого погружения в технологию сравним Kafka и классические сервисы очередей, такие как RabbitMQ и Amazon SQS.
Системы очередей обычно состоят из трёх базовых компонентов:
1) сервер,
2) продюсеры, которые отправляют сообщения в некую именованную очередь, заранее сконфигурированную администратором на сервере,
3) консьюмеры, которые считывают те же самые сообщения по мере их появления.
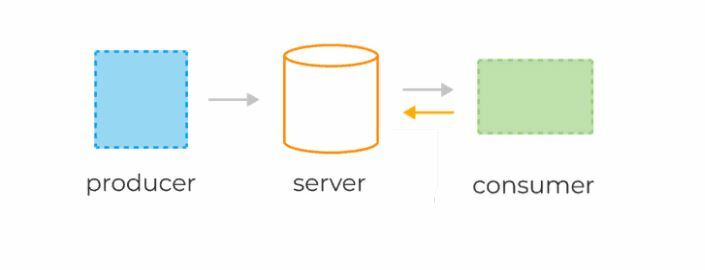
Базовые компоненты классической системы очередей
В веб-приложениях очереди часто используются для отложенной обработки событий или в качестве временного буфера между другими сервисами, тем самым защищая их от всплесков нагрузки.
Консьюмеры получают данные с сервера, используя две разные модели запросов: pull или push.
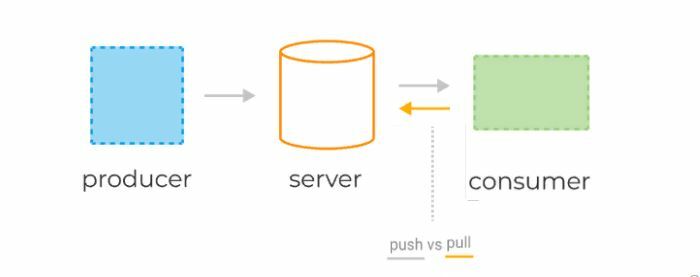
pull-модель — консьюмеры сами отправляют запрос раз в n секунд на сервер для получения новой порции сообщений. При таком подходе клиенты могут эффективно контролировать собственную нагрузку. Кроме того, pull-модель позволяет группировать сообщения в батчи, таким образом достигая лучшей пропускной способности. К минусам модели можно отнести потенциальную разбалансированность нагрузки между разными консьюмерами, а также более высокую задержку обработки данных.
push-модель — сервер делает запрос к клиенту, посылая ему новую порцию данных. По такой модели, например, работает RabbitMQ. Она снижает задержку обработки сообщений и позволяет эффективно балансировать распределение сообщений по консьюмерам. Но для предотвращения перегрузки консьюмеров в случае с RabbitMQ клиентам приходится использовать функционал QS, выставляя лимиты.
Как правило, приложение пишет и читает из очереди с помощью нескольких инстансов продюсеров и консьюмеров. Это позволяет эффективно распределить нагрузку.
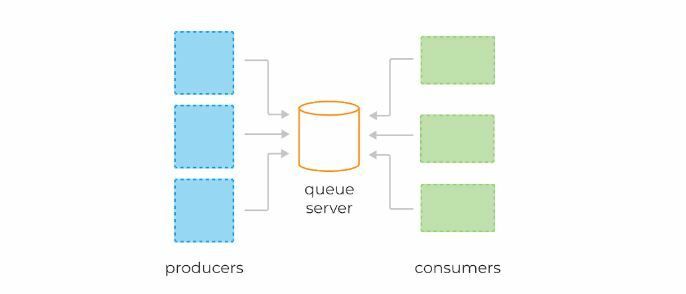
Типичный жизненный цикл сообщений в системах очередей:
- Продюсер отправляет сообщение на сервер.
- Консьюмер фетчит (от англ. fetch — принести) сообщение и его уникальный идентификатор сервера.
- Сервер помечает сообщение как in-flight. Сообщения в таком состоянии всё ещё хранятся на сервере, но временно не доставляются другим консьюмерам. Таймаут этого состояния контролируется специальной настройкой.
- Консьюмер обрабатывает сообщение, следуя бизнес-логике. Затем отправляет ack или nack-запрос обратно на сервер, используя уникальный идентификатор, полученный ранее — тем самым либо подтверждая успешную обработку сообщения, либо сигнализируя об ошибке.
- В случае успеха сообщение удаляется с сервера навсегда. В случае ошибки или таймаута состояния in-flight сообщение доставляется консьюмеру для повторной обработки.
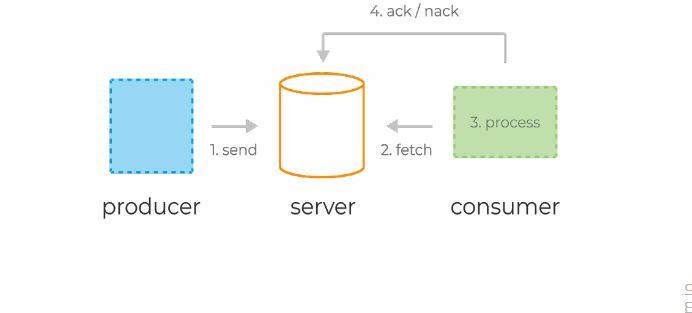
Типичный жизненный цикл сообщений в системах очередей
С базовыми принципами работы очередей разобрались, теперь перейдём к Kafka. Рассмотрим её фундаментальные отличия.
Как и сервисы обработки очередей, Kafka условно состоит из трёх компонентов:
1) сервер (по-другому ещё называется брокер),
2) продюсеры — они отправляют сообщения брокеру,
3) консьюмеры — считывают эти сообщения, используя модель pull.
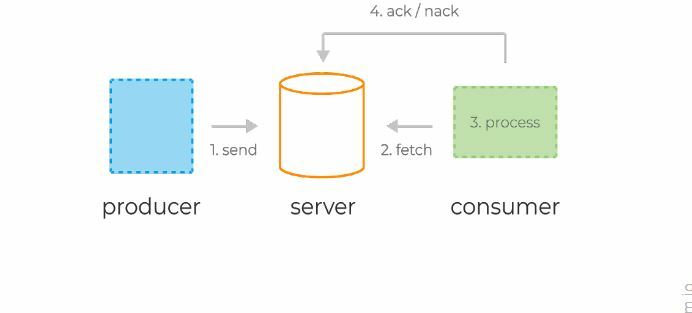
Базовые компоненты Kafka
Пожалуй, фундаментальное отличие Kafka от очередей состоит в том, как сообщения хранятся на брокере и как потребляются консьюмерами.
- Сообщения в Kafka не удаляются брокерами по мере их обработки консьюмерами — данные в Kafka могут храниться днями, неделями, годами.
- Благодаря этому одно и то же сообщение может быть обработано сколько угодно раз разными консьюмерами и в разных контекстах.
В этом кроется главная мощь и главное отличие Kafka от традиционных систем обмена сообщениями.
Теперь давайте посмотрим, как Kafka и системы очередей решают одну и ту же задачу. Начнём с системы очередей.
Представим, что есть некий сайт, на котором происходит регистрация пользователя. Для каждой регистрации мы должны:
1) отправить письмо пользователю,
2) пересчитать дневную статистику регистраций.
В случае с RabbitMQ или Amazon SQS функционал может помочь нам доставить сообщения всем сервисам одновременно. Но при необходимости подключения нового сервиса придётся конфигурировать новую очередь.
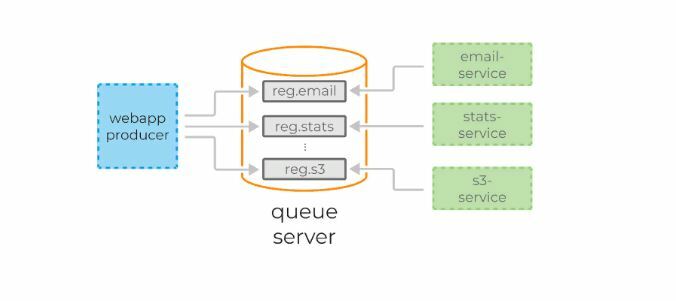
Kafka упрощает задачу. Достаточно послать сообщения всего один раз, а консьюмеры сервиса отправки сообщений и консьюмеры статистики сами считают его по мере необходимости.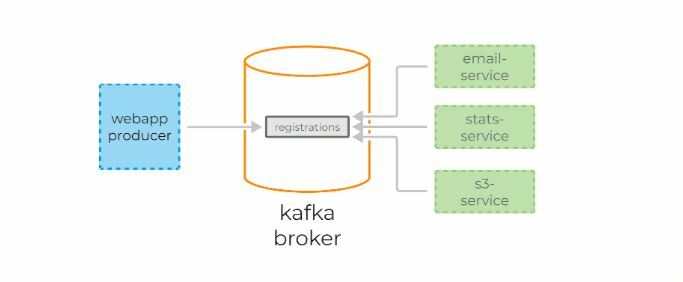
Kafka также позволяет тривиально подключать новые сервисы к стриму регистрации. Например, сервис архивирования всех регистраций в S3 для последующей обработки с помощью Spark или Redshift можно добавить без дополнительного конфигурирования сервера или создания дополнительных очередей.
Кроме того, раз Kafka не удаляет данные после обработки консьюмерами, эти данные могут обрабатываться заново, как бы отматывая время назад сколько угодно раз. Это оказывается невероятно полезно для восстановления после сбоев и, например, верификации кода новых консьюмеров. В случае с RabbitMQ пришлось бы записывать все данные заново, при этом, скорее всего, в отдельную очередь, чтобы не сломать уже имеющихся клиентов.
Структура данных
Наверняка возникает вопрос: «Раз сообщения не удаляются, то как тогда гарантировать, что консьюмер не будет читать одни и те же сообщения (например, при перезапуске)?».
Для ответа на этот вопрос разберёмся, какова внутренняя структура Kafka и как в ней хранятся сообщения.
Каждое сообщение (event или message) в Kafka состоит из ключа, значения, таймстампа и опционального набора метаданных (так называемых хедеров).
Например:

Сообщения в Kafka организованы и хранятся в именованных топиках (Topics), каждый топик состоит из одной и более партиций (Partition), распределённых между брокерами внутри одного кластера. Подобная распределённость важна для горизонтального масштабирования кластера, так как она позволяет клиентам писать и читать сообщения с нескольких брокеров одновременно.
Когда новое сообщение добавляется в топик, на самом деле оно записывается в одну из партиций этого топика. Сообщения с одинаковыми ключами всегда записываются в одну и ту же партицию, тем самым гарантируя очередность или порядок записи и чтения.
Для гарантии сохранности данных каждая партиция в Kafka может быть реплицирована n раз, где n — replication factor. Таким образом гарантируется наличие нескольких копий сообщения, хранящихся на разных брокерах.
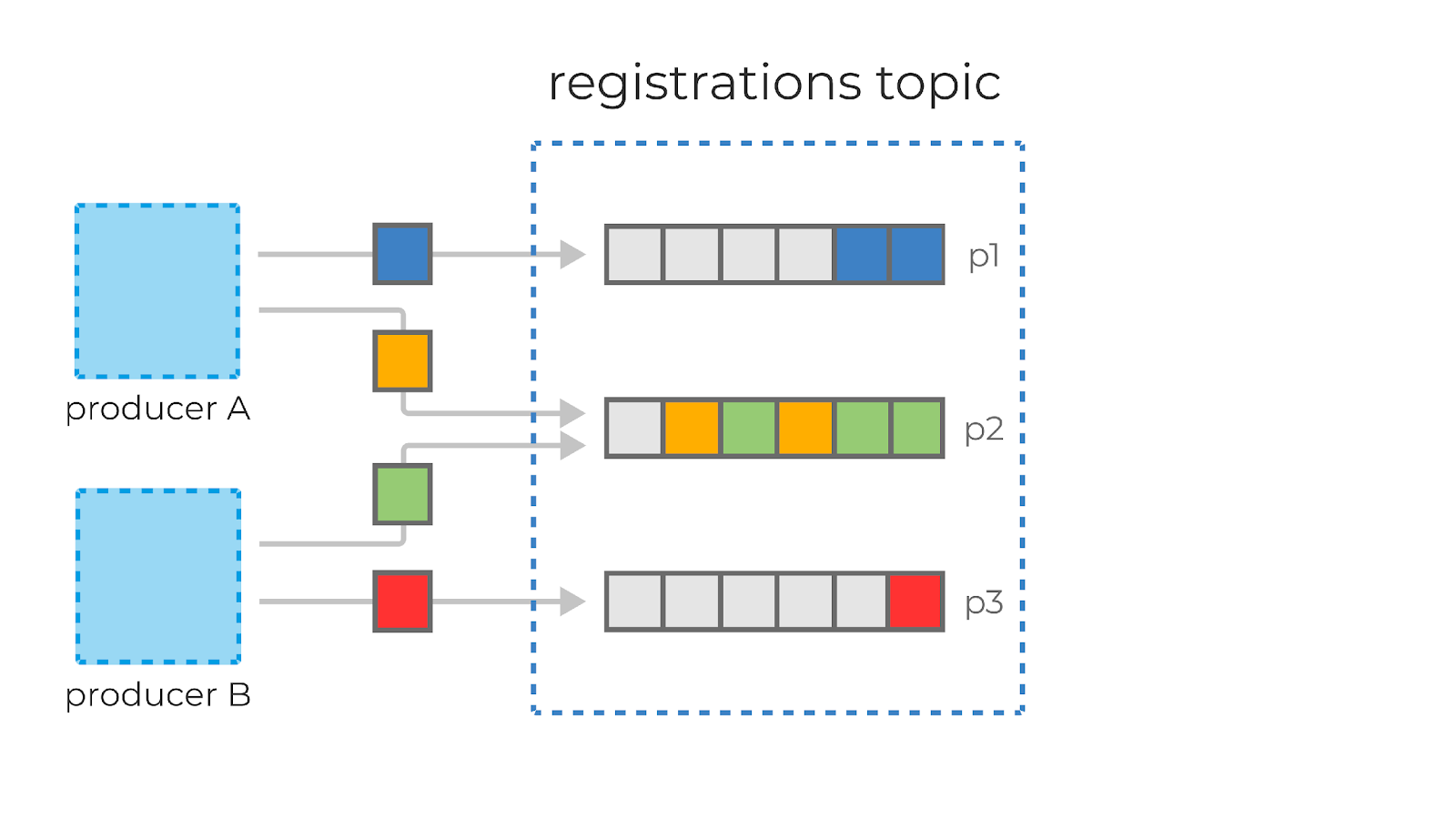
У каждой партиции есть «лидер» (Leader) — брокер, который работает с клиентами. Именно лидер работает с продюсерами и в общем случае отдаёт сообщения консьюмерам. К лидеру осуществляют запросы фолловеры (Follower) — брокеры, которые хранят реплику всех данных партиций. Сообщения всегда отправляются лидеру и, в общем случае, читаются с лидера.
Чтобы понять, кто является лидером партиции, перед записью и чтением клиенты делают запрос метаданных от брокера. Причём они могут подключаться к любому брокеру в кластере.
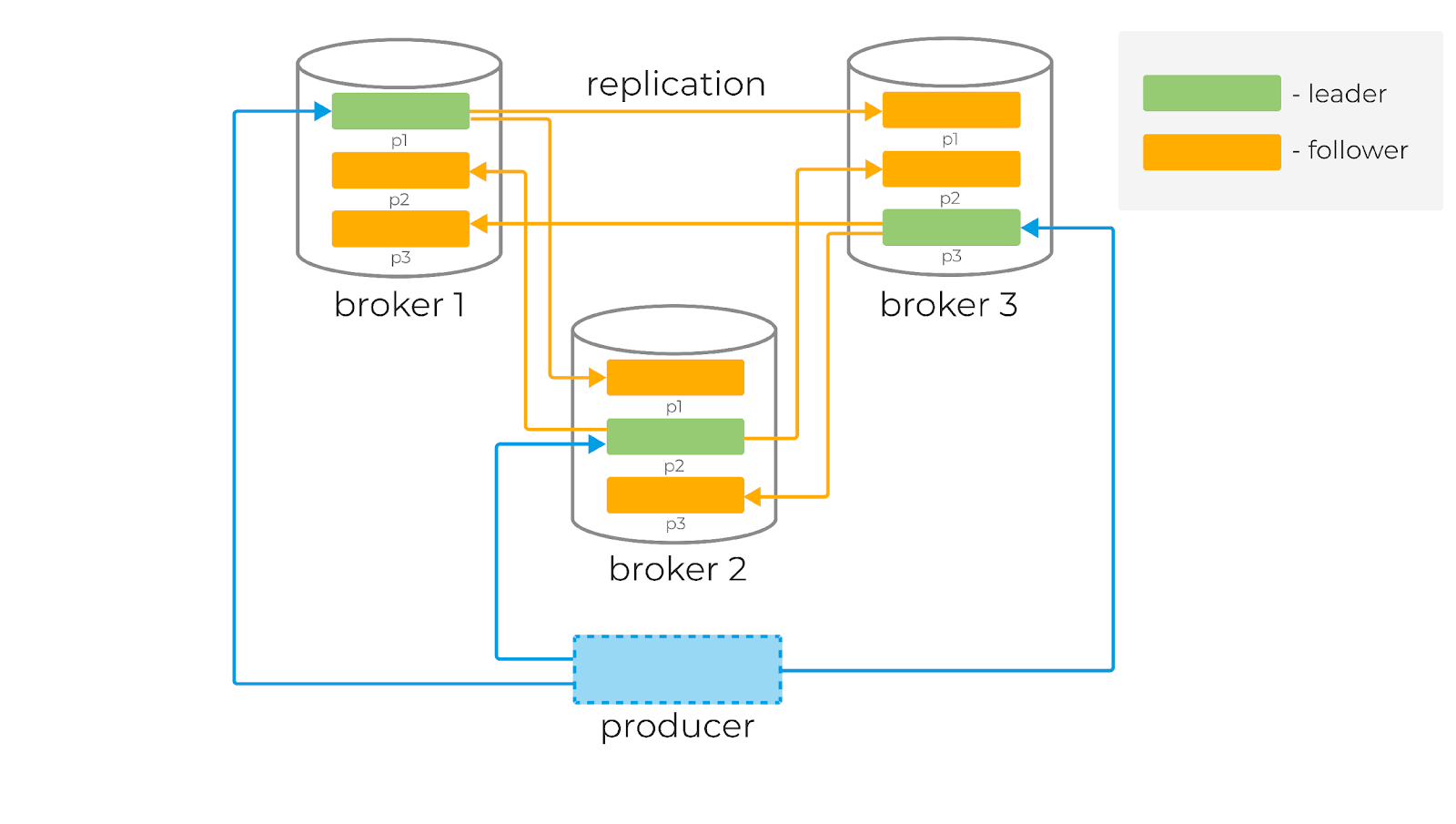
Основная структура данных в Kafka — это распределённый, реплицируемый лог. Каждая партиция — это и есть тот самый реплицируемый лог, который хранится на диске. Каждое новое сообщение, отправленное продюсером в партицию, сохраняется в «голову» этого лога и получает свой уникальный, монотонно возрастающий offset (64-битное число, которое назначается самим брокером).
Как мы уже выяснили, сообщения не удаляются из лога после передачи консьюмерам и могут быть вычитаны сколько угодно раз.
Время гарантированного хранения данных на брокере можно контролировать с помощью специальных настроек. Длительность хранения сообщений при этом не влияет на общую производительность системы. Поэтому совершенно нормально хранить сообщения в Kafka днями, неделями, месяцами или даже годами.
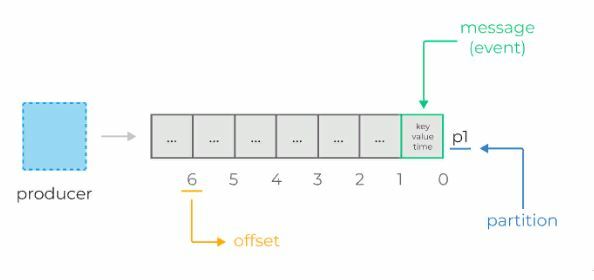
Consumer Groups
Теперь давайте перейдём к консьюмерам и рассмотрим их принципы работы в Kafka. Каждый консьюмер Kafka обычно является частью какой-нибудь консьюмер-группы.
Каждая группа имеет уникальное название и регистрируется брокерами в кластере Kafka. Данные из одного и того же топика могут считываться множеством консьюмер-групп одновременно. Когда несколько консьюмеров читают данные из Kafka и являются членами одной и той же группы, то каждый из них получает сообщения из разных партиций топика, таким образом распределяя нагрузку.
Вернёмся к нашему примеру с топиком сервиса регистрации и представим, что у сервиса отправки писем есть своя собственная консьюмер-группа с одним консьюмером
c1
внутри. Значит, этот консьюмер будет получать сообщения из всех партиций топика.
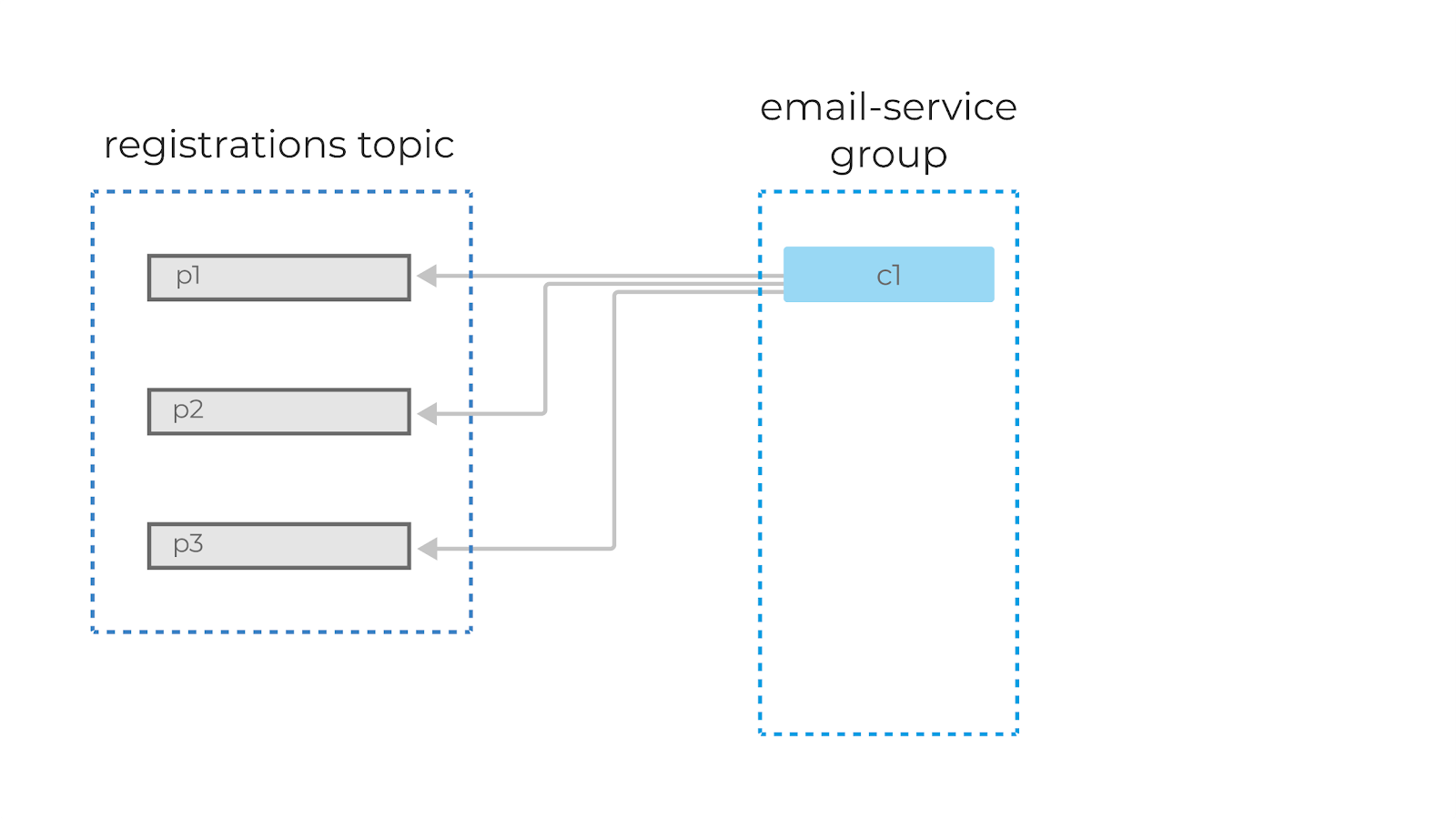
Если мы добавим ещё одного консьюмера в группу, то партиции автоматически распределятся между ними, и
c1
теперь будет читать сообщения из первой и второй партиции, а
c2
— из третьей. Добавив ещё одного консьюмера (c3), мы добьёмся идеального распределения нагрузки, и каждый из консьюмеров в этой группе будет читать данные из одной партиции.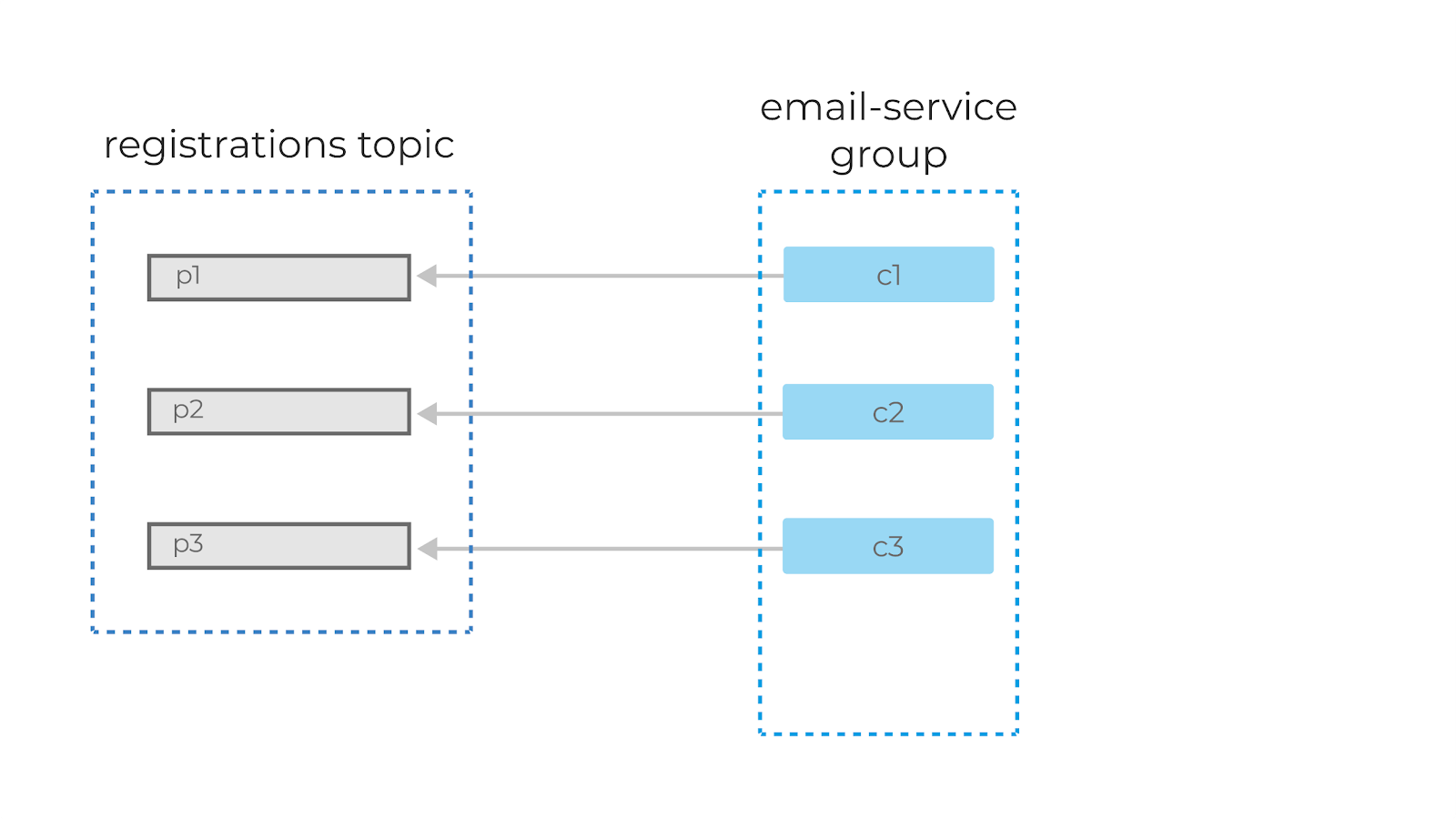
А вот если мы добавим в группу ещё одного консьюмера (c4), то он не будет задействован в обработке сообщений вообще.
Важно понять: внутри одной консьюмер-группы партиции назначаются консьюмерам уникально, чтобы избежать повторной обработки.
Если консьюмеры не справляются с текущим объёмом данных, то следует добавить новую партицию в топик. Только после этого консьюмер c4 начнёт свою работу.
Механизм партиционирования является нашим основным инструментом масштабирования Kafka. Группы являются инструментом отказоустойчивости.
Кстати, как вы думаете, что будет, если один из консьюмеров в группе упадёт? Совершенно верно: партиции автоматически распределятся между оставшимися консьюмерами в этой группе.
Добавлять партиции в Kafka можно на лету, без перезапуска клиентов или брокеров. Клиенты автоматически обнаружат новую партицию благодаря встроенному механизму обновления метаданных. Однако, нужно помнить две важные вещи:
- Гарантия очерёдности данных — если вы пишете сообщения с ключами и хешируете номер партиции для сообщений, исходя из общего числа, то при добавлении новой партиции вы можете просто сломать порядок этой записи.
- Партиции невозможно удалить после их создания, можно удалить только весь топик целиком.
И ещё неочевидный момент: если вы добавляете новую партицию на проде, то есть в тот момент, когда в топик пишут сообщения продюсеры, то важно помнить про настройку auto.offset.reset=earliest в консьюмере, иначе у вас есть шанс потерять или просто не обработать кусок данных, записавшихся в новую партицию до того, как консьюмеры обновили метаданные по топику и начали читать данные из этой партиции.
Помимо этого, механизм групп позволяет иметь несколько несвязанных между собой приложений, обрабатывающих сообщения.
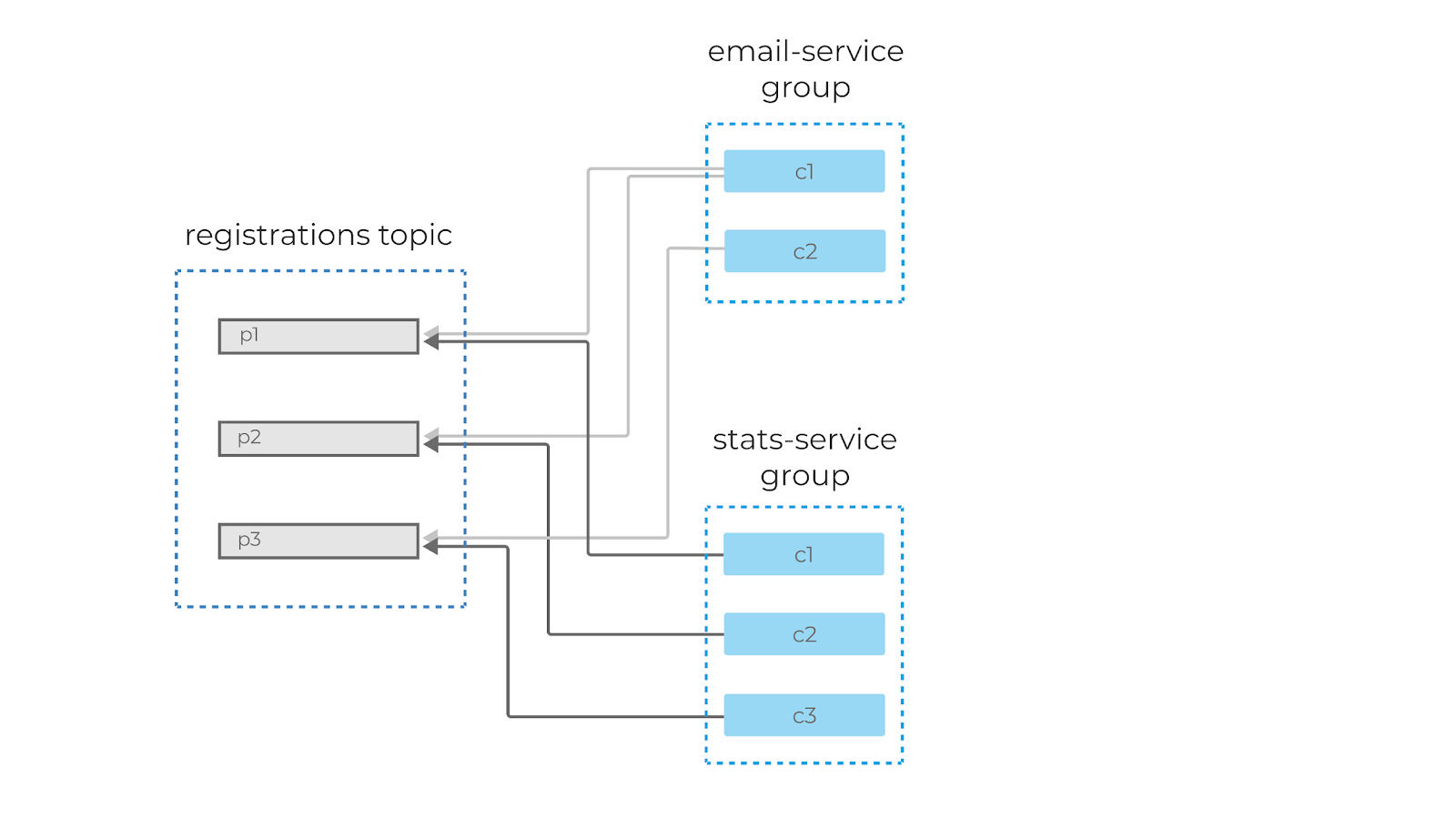
Как мы обсуждали ранее, можно добавить новую группу консьюмеров к тому же самому топику, например, для обработки и статистики регистраций. Эти две группы будут читать одни и те же сообщения из топика тех самых ивентов регистраций — в своём темпе, со своей внутренней логикой.
А теперь, зная внутреннее устройство консьюмеров в Kafka, давайте вернёмся к изначальному вопросу: «Каким образом мы можем обозначить сообщения в партиции, как обработанные?».
Для этого Kafka предоставляет механизм консьюмер-офсетов. Как мы помним, каждое сообщение партиции имеет свой собственный, уникальный, монотонно возрастающий офсет. Именно этот офсет и используется консьюмерами для сохранения партиций.
Консьюмер делает специальный запрос к брокеру, так называемый offset-commit с указанием своей группы, идентификатора топик-партиции и, собственно, офсета, который должен быть отмечен как обработанный. Брокер сохраняет эту информацию в своём собственном специальном топике. При рестарте консьюмер запрашивает у сервера последний закоммиченный офсет для нужной топик-партиции, и просто продолжает чтение сообщений с этой позиции.
В примере консьюмер в группе email-service-group, читающий партицию p1 в топике registrations, успешно обработал три сообщения с офсетами 0, 1 и 2. Для сохранения позиций консьюмер делает запрос к брокеру, коммитя офсет 3. В случае рестарта консьюмер запросит свою последнюю закоммиченную позицию у брокера и получит в ответе 3. После чего начнёт читать данные с этого офсета.
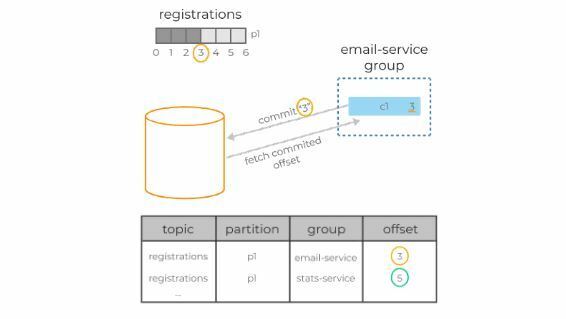
Консьюмеры вольны коммитить совершенно любой офсет (валидный, который действительно существует в этой топик-партиции) и могут начинать читать данные с любого офсета, двигаясь вперёд и назад во времени, пропуская участки лога или обрабатывая их заново.
Ключевой для понимания факт: в момент времени может быть только один закоммиченный офсет для топик-партиции в консьюмер-группе. Иными словами, мы не можем закоммитить несколько офсетов для одной и той же топик-партиции, эмулируя каким-то образом выборочный acknowledgment (как это делалось в системах очередей).
Представим, что обработка сообщения с офсетом 1 завершилась с ошибкой. Однако мы продолжили выполнение нашей программы в консьюмере и запроцессили сообщение с офсетом 2 успешно. В таком случае перед нами будет стоять выбор: какой офсет закоммитить — 1 или 3. В настоящей системе мы бы рекомендовали закоммитить офсет 3, добавив при этом функционал, отправляющий ошибочное сообщение в отдельный топик для повторной обработки (ручной или автоматической). Подобные алгоритмы называются Dead letter queue.
Разумеется, консьюмеры, находящиеся в разных группах, могут иметь совершенно разные закоммиченные офсеты для одной и той же топик-партиции.
Apache ZooKeeper
В заключение нужно упомянуть об ещё одном важном компоненте кластера Kafka — Apache ZooKeeper.
ZooKeeper выполняет роль консистентного хранилища метаданных и распределённого сервиса логов. Именно он способен сказать, живы ли ваши брокеры, какой из брокеров является контроллером (то есть брокером, отвечающим за выбор лидеров партиций), и в каком состоянии находятся лидеры партиций и их реплики.
В случае падения брокера именно в ZooKeeper контроллером будет записана информация о новых лидерах партиций. Причём с версии 1.1.0 это будет сделано асинхронно, и это важно с точки зрения скорости восстановления кластера. Самый простой способ превратить данные в тыкву — потеря информации в ZooKeeper. Тогда понять, что и откуда нужно читать, будет очень сложно.
В настоящее время ведутся активные работы по избавлению Kafka от зависимости в виде ZooKeeper, но пока он всё ещё с нами (если интересно, посмотрите на Kafka improvement proposal 500, там подробно расписан план избавления от ZooKeeper).
Важно помнить, что ZooKeeper по факту является ещё одной распределённой системой хранения данных, за которой необходимо следить, поддерживать и обновлять по мере необходимости.
Традиционно ZooKeeper раскатывается отдельно от брокеров Kafka, чтобы разделить границы возможных отказов. Помните, что падение ZooKeeper — это практически падение всего кластера Kafka. К счастью, нагрузка на ZooKeeper при нормальной работе кластера минимальна. Клиенты Kafka никогда не коннектятся к ZooKeeper напрямую.
→ Дополнительные материалы к уроку
→ Курс Apache Kafka База
The Apache Kafka open source software is one of the best solutions for storing and processing data streams. This messaging and streaming platform, which is licensed under Apache 2.0, features fault tolerance, excellent scalability, and a high read and write speed. These factors, which are highly appealing for Big Data applications, are based on a cluster which allows distributed data storage and replication. There are four different interfaces for communicating with the cluster with a simple TCP protocol serving as the basis for communication.
This Kafka tutorial explains how to get started with the Scala-based application, beginning with installing Kafka and the Apache ZooKeeper software required to use it.
Contents
- Requirements for using Apache Kafka
- Apache Kafka tutorial: how to install Kafka, ZooKeeper, and Java
- Kafka: how to set up the streaming and messaging system
- Enable deleting topics
- Creating .service files for ZooKeeper and Kafka
- How to create the appropriate ZooKeeper file for the Ubuntu systemd session manager
- How creating a Kafka file for the Ubuntu systemd session manager works
- Kafka: launching for the first time and creating an autostart entry
- Apache Kafka tutorial: getting started with Apache Kafka
Requirements for using Apache Kafka
To run a powerful Kafka cluster, you will need the right hardware. The development team recommends using quad-core Intel Xeon machines with 24 gigabytes of memory. It is essential that you have enough memory to always cache the read and write accesses for all applications that actively access the cluster. Since Apache Kafka’s high data throughput is one of its draws, it is crucial to choose a suitable hard drive. The Apache Software Foundation recommends a SATA hard drive (8 x 7200 RPM). When it comes to avoiding performance bottlenecks, the following principle applies: the more hard drives, the better.
In terms of software, there are also some requirements that must be met in order to use Apache Kafka for managing incoming and outgoing data streams. When choosing your operating system, you should opt for a Unix operating system, such as Solaris, or a Linux distribution. This is because Windows platforms receive limited support. Apache Kafka is written in Scala, which compiles to Java bytecode, so you will need the latest version of the Java SE Development Kits (JDK) installed on your system. This also includes the Java Runtime Environment, which is required for running Java applications. You will also need the Apache ZooKeeper service, which synchronizes distributed processes.
To display this video, third-party cookies are required. You can access and change your cookie settings here.
Apache Kafka tutorial: how to install Kafka, ZooKeeper, and Java
For an explanation of what software is required, see the previous part of this Kafka tutorial. If it is not already installed on your system, we recommend installing the Java Runtime Environment first. Many newer versions of Linux distributions, such as Ubuntu, which is used as an example operating system in this Apache Kafka tutorial (Version 17.10), already have OpenJDK, a free implementation of JDK, in their official package repository. This means that you can easily install the Java Development Kit via this repository by typing the following command into the terminal:
sudo apt-get install openjdk-8-jdkImmediately after installing Java, install the Apache ZooKeeper process synchronization service. The Ubuntu package repository also provides a ready-to-use package for this service, which can be executed using the following command line:
sudo apt-get install zookeeperdYou can then use an additional command to check whether the ZooKeeper service is active:
sudo systemctl status zookeeperIf Apache ZooKeeper is running, the output will look like this:

If the synchronization service is not running, you can start it at any time using this command:
sudo systemctl start zookeeperTo ensure that ZooKeeper will always launch automatically at startup, add an autostart entry at the end:
sudo systemctl enable zookeeperFinally, create a user profile for Kafka, which you will need to use the server later. To do so, open the terminal again and enter the following command:
Using the passwd password manager, you can then add a password to the user by typing the following command followed by the desired password:
Next, grant the user “kafka” sudo rights:
You can now log in at any time with the newly-created user profile:
We have arrived at the point in this tutorial where it is time to download and install Kafka. There are a number of trusted sources where you can download both older and current versions of the data stream processing software. For example, you can obtain the installation files directly from the Apache Software Foundation’s download directory. It is highly recommended that you work with a current version of Kafka, so you may need to adjust the following download command before entering it into the terminal:
wget http://www.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgzSince the downloaded file will be compressed, you will then need to unpack it:
sudo tar xvzf kafka_2.12-2.1.0.tgz --strip 1Use the —strip 1 flag to ensure that the extracted files are saved directly to the ~/kafka directory. Otherwise, based on the version used in this Kafka tutorial, Ubuntu would store all files in the ~/kafka/kafka_2.12-2.1.0 directory. To do this, you must have previously created a directory named “kafka” using mkdir and switched to it (via “cd kafka”).
Kafka: how to set up the streaming and messaging system
Now that you have installed Apache Kafka, the Java Runtime Environment and ZooKeeper, you can run the Kafka service at any time. Before you do this, however, you should make a few small adjustments to its configurations so that the software is optimally configured for its upcoming tasks.
Enable deleting topics
Kafka does not allow you to delete topics (i.e. the storage and categorization components in a Kafka cluster) in its default set-up. However, you can easily change this by using the server.properties Kafka configuration file. To open this file, which is located in the config directory, use the following terminal command in the default text editor nano:
sudo nano ~/kafka/config/server.propertiesAt the end of this configuration file, add a new entry, which enables you to delete topics:

Tip
Remember to save the new entry in the Kafka configuration file before closing the nano text editor again
Creating .service files for ZooKeeper and Kafka
The next step in the Kafka tutorial is to create unit files for ZooKeeper and Kafka that allow you to perform common actions such as starting, stopping and restarting the two services in a manner consistent with other Linux services. To do so, you need to create and set up .service files for the systemd session manager for both applications.
How to create the appropriate ZooKeeper file for the Ubuntu systemd session manager
First, create the file for the ZooKeeper synchronization service by entering the following command in the terminal:
sudo nano /etc/systemd/system/zookeeper.serviceThis will not only create the file but also open it in the nano text editor. Now, enter the following lines and then save the file.
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetAs a result, systemd will understand that ZooKeeper requires the network and the file system to be ready before it can start. This is defined in the [Unit] section. The [Service] section specifies that the session manager should use the files zookeeper-server-start.sh and zookeeper-server-stop.sh to start and stop ZooKeeper. It also specifies that ZooKeeper should be restarted automatically if it stops unexpectedly. The [Install] entry controls when the file is started using «.multi-user.target” as the default value for a multi-user system (e.g. a server).
How creating a Kafka file for the Ubuntu systemd session manager works
To create the .service file for Apache Kafka, use the following terminal command:
sudo nano /etc/systemd/system/kafka.serviceThen, copy the following content into the new file that has already been opened in the nano text editor:
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetThe [Unit] section in this file specifies that the Kafka service depends on ZooKeeper. This ensures that the synchronization service is automatically started whenever the kafka.service file is run. The [Service] section specifies that the kafka-server-start.sh and kafka-server-stop.sh shell files should be used for starting and stopping the Kafka server. You can also find the specification for an automatic restart after an unexpected disconnection as well as the multi-user entry in this file.

Kafka: launching for the first time and creating an autostart entry
Once you have successfully created the session manager entries for Kafka and ZooKeeper, you can start Kafka with the following command:
sudo systemctl start kafkaBy default, the systemd program uses a central protocol or journal in which all log messages are automatically written. As a result, you can easily check whether the Kafka server has been started as desired:
The output should look something like this:

If you have successfully started Apache Kafka manually, enable finish by activating automatic start during system boot:
sudo systemctl enable kafkaApache Kafka tutorial: getting started with Apache Kafka
This part of the Kafka tutorial involves testing Apache Kafka by processing an initial message using the messaging platform. To do so, you need a producer and a consumer (i.e. an instance which enables you to write and publish data to topics and an instance which can read data from a topic). First of all, you need to create a topic, which in this case should be called TutorialTopic. Since this is a simple test topic, it should only contain a single partition and a single replica:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TutorialTopicNext, you need to create a producer that adds the first example message «Hello, World!» to the newly created topic. To do so, use the kafka-console-producer.sh shell script, which needs the Kafka server’s host name and port (in this example, Kafka’s default path) as well as the topic name as arguments:
echo "Hello, World!" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic > /dev/nullNext, using the kafka-console-consumer.sh script, create a Kafka consumer that processes and displays messages from TutorialTopic. You will need the Kafka server’s host name and port as well as the topic name as arguments. In addition, the “—from-beginning” argument is attached so that the consumer can actually process the “Hello, World!” message, which was published before the consumer was created:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TutorialTopic --from-beginningAs a result, the terminal presents the “Hello, World!» message with the script running continuously and waiting for more messages to be published to the test topic. So, if the producer is used in another terminal window for additional data input, you should also see this reflected in the window in which the consumer script is running.

На чтение 7 мин Просмотров 2.6к. Опубликовано 31.07.2021
Распределенные системы — это совокупность компьютеров, которые работают вместе, образуя единый компьютер для конечных пользователей. Они позволяют нам масштабироваться с экспоненциальной скоростью и могут обрабатывать миллиарды запросов и обновлений без простоев. Apache Kafka сегодня стала одной из наиболее широко используемых распределенных систем на рынке.
Согласно официальному сайту Kafka, Apache Kafka — это «платформа распределенной потоковой передачи событий с открытым исходным кодом, используемая тысячами компаний для высокопроизводительных конвейеров данных, потоковой аналитики, интеграции данных и критически важных приложений». Kafka используется большинством компаний из списка Fortune 100, включая такие крупные технологические компании, как LinkedIn, Netflix и Microsoft.
В этом руководстве по Apache Kafka мы обсудим использование, ключевые функции и архитектурные компоненты платформы распределенной потоковой передачи. Давайте начнем!
Содержание
- Что такое Kafka?
- Примеры использования Kafka
- Ключевые особенности Кафки
- Компоненты архитектуры Кафки
- Группы потребителей Kafka
- Кафка Перегородки
- Фактор репликации темы
- Кафка Темы
- API Kafka
- Kafka Producer API
- Потребительский API Kafka
- Kafka Connector API
- Kafka Streams API
- Kafka Brokers
- Kafka Consumers
- Продвинутые концепции для дальнейшего изучения
Что такое Kafka?
Apache Kafka — это программная платформа с открытым исходным кодом, написанная на языках программирования Scala и Java. Kafka началась в 2011 году как система обмена сообщениями для LinkedIn, но с тех пор превратилась в популярную платформу распределенной потоковой передачи событий. Платформа способна обрабатывать триллионы записей в день.
Kafka — это распределенная система, состоящая из серверов и клиентов, которые обмениваются данными через сетевой протокол TCP. Система позволяет нам читать, записывать, сохранять и обрабатывать события. Мы можем рассматривать событие как независимую часть информации, которую необходимо передать от производителя к потребителю. Некоторые соответствующие примеры включают платежные транзакции Amazon, обновления местоположения iPhone, заказы на доставку FedEx и многое другое. Kafka в основном используется для построения конвейеров данных и реализации потоковых решений.
Kafka позволяет нам создавать приложения, которые могут постоянно и точно использовать и обрабатывать несколько потоков с очень высокой скоростью. Он работает с потоковой передачей данных из тысяч различных источников данных. С Kafka мы можем:
- обрабатывать записи по мере их появления
- хранить записи точно и последовательно
- публиковать или подписываться на потоки данных или событий
Система обмена сообщениями Kafka с публикацией и подпиской чрезвычайно популярна в сфере больших данных и хорошо интегрируется с Apache Spark и Apache Storm.
Примеры использования Kafka
Вы можете использовать Kafka по-разному, но вот несколько примеров различных вариантов использования, опубликованных на официальном сайте Kafka:
- Обработка финансовых транзакций в режиме реального времени
- Отслеживание и мониторинг транспортных средств в режиме реального времени
- Сбор и анализ данных датчиков
- Сбор и реагирование на взаимодействия с клиентами
- Наблюдение за больными пациентами
- Обеспечение основы для платформ данных, событийно-ориентированных архитектур и микросервисов.
- Выполнение крупномасштабного обмена сообщениями
- Служит журналом фиксации для распределенных систем
- И многое другое
Ключевые особенности Кафки
Давайте посмотрим на некоторые ключевые особенности, которые сделали Kafka настолько популярным:
- Масштабируемость: Kafka управляет масштабируемостью соединителей событий, потребителей, производителей и процессоров.
- Отказоустойчивость: Kafka отказоустойчив и легко справляется с отказами с помощью мастеров и баз данных.
- Последовательность: Kafka может масштабироваться на многих разных серверах, сохраняя при этом порядок ваших данных.
- Высокая производительность: Kafka имеет высокую пропускную способность и низкую задержку. Он остается стабильным даже при работе с большим количеством данных.
- Расширяемость: многие приложения интегрируются с Kafka.
- Возможности репликации: Kafka использует конвейеры приема и может легко реплицировать события.
- Доступность: Kafka может растягивать кластеры по зонам доступности или подключать разные кластеры в разных регионах. Kafka использует ZooKeeper для управления кластерами.
- Возможности подключения: Интерфейс Кафка Connect позволяет интегрировать с различными источниками событий, таких как JMS и AWS S3.
- Сообщество: Kafka — один из самых активных проектов Apache Software Foundation. Сообщество проводит такие мероприятия, как Kafka Summit by Confluent.
Компоненты архитектуры Кафки
Прежде чем мы углубимся в некоторые компоненты архитектуры Kafka, давайте взглянем на некоторые ключевые концепции, которые помогут нам понять это:
Группы потребителей Kafka
Группы потребителей состоят из кластера связанных потребителей, которые выполняют определенные задачи, такие как отправка сообщений в службу. Они могут запускать несколько процессов одновременно. Kafka отправляет сообщения из разделов темы потребителям в группе. Когда сообщения отправляются в группу, каждый раздел читается одним потребителем в большей группе.
Кафка Перегородки
Кафка темы разбиты на разделы. Эти разделы воспроизводятся у разных брокеров. В каждом разделе несколько потребителей могут читать из темы одновременно.
Фактор репликации темы
Фактор репликации темы гарантирует, что данные остаются доступными, а развертывание проходит гладко и эффективно. Если брокер выходит из строя, реплики тем на разных брокерах остаются внутри этих брокеров, чтобы мы могли получить доступ к нашим данным.
Кафка Темы
Темы помогают нам организовать наши сообщения. Мы можем думать о них как о каналах, по которым проходят наши данные. Производители Kafka могут публиковать сообщения в темах, а потребители Kafka могут читать сообщения из тем, на которые они подписаны.
Теперь, когда мы рассмотрели некоторые основополагающие концепции, мы готовы перейти к архитектурным компонентам!
API Kafka
В архитектуре Kafka есть четыре основных API. Давайте посмотрим на них!
Kafka Producer API
API-интерфейс Producer позволяет приложениям публиковать потоки записей в темах Kafka.
Потребительский API Kafka
Consumer API позволяет приложениям подписываться на темы Kafka. Этот API также позволяет приложению обрабатывать потоки записей.
Kafka Connector API
Connector API связывает приложения или системы данных с темами. Этот API помогает нам создавать и управлять производителями и потребителями. Это также позволяет нам повторно использовать соединения в различных решениях.
Kafka Streams API
Streams API позволяет приложениям обрабатывать данные с помощью потоковой обработки. Этот API позволяет приложениям принимать входные потоки из разных тем и обрабатывать их с помощью потокового процессора. Затем приложение может создавать выходные потоки и отправлять их по разным темам.
Kafka Brokers
Один сервер Kafka называется брокером. Обычно несколько брокеров работают как один кластер Kafka. Кластер управляется одним из брокеров, называемым контроллером. Контроллер отвечает за административные действия, такие как назначение разделов другим брокерам и мониторинг сбоев и простоев.
Разделы могут быть назначены нескольким брокерам. Если это произойдет, раздел будет реплицирован. Это создает избыточность на случай отказа одного из брокеров. Брокер отвечает за получение сообщений от производителей и их фиксацию на диске. Брокеры также получают запросы от потребителей и отвечают сообщениями, взятыми из разделов.
Вот визуализация брокера, размещающего несколько тематических разделов:
Kafka Consumers
Потребители получают сообщения из тем Kafka. Они подписываются на темы, а затем получают сообщения, которые продюсеры пишут в тему. Обычно каждый потребитель принадлежит к группе потребителей. В группе потребителей несколько потребителей работают вместе, чтобы читать сообщения из темы.
Давайте посмотрим на некоторые из различных конфигураций потребителей и разделов в теме:
Количество потребителей и разделов в теме равны
В этом сценарии каждый потребитель читает из одного раздела.
Количество разделов в теме больше, чем количество потребителей в группе
В этом сценарии некоторые или все потребители читают более чем из одного раздела.
Один потребитель с несколькими разделами
В этом сценарии все разделы используются одним потребителем.
Количество разделов в теме меньше количества потребителей в группе
В этом сценарии некоторые потребители будут бездействовать.
Kafka Producers
Производители пишут в Kafka сообщения, которые потребители могут прочитать.
Продвинутые концепции для дальнейшего изучения
Поздравляем, вы сделали первые шаги с Apache Kafka! Kafka — эффективная и мощная распределенная система. Возможности масштабирования Kafka позволяют справляться с большими рабочими нагрузками. Часто это предпочтительный выбор по сравнению с другими очередями сообщений для конвейеров данных в реальном времени. В целом, это универсальная платформа, способная поддерживать множество вариантов использования. Теперь вы готовы перейти к более сложным темам Kafka, таким как:
- Сериализация производителя
- Потребительские конфигурации
- Размещение раздела