Welcome to ManualMachine
You have been successfully registered
We have sent a verification link to to complete your registration.
If you can’t find the email, check your Junk/Spam folder.


- Buy Points
- How it Works
- FAQ
- Contact Us
- Questions and Suggestions
- Users
 Loading…
Loading…
You can only view or download manuals with
Sign Up and get 5 for free
Upload your files to the site. You get 1 for each file you add
Get 1 for every time someone downloads your manual
Buy as many as you need
View and download manuals available only for
Register and get 5 for free
Upload manuals that we do not have and get 1 for each file
Get 1 for every download of your manual
Buy as much as you need
Время прочтения: 4 мин.
Знакомство с задачей классификации можно начать с Википедии, перейдя по ссылке.
Классификация применяется тогда, когда необходимо выделить схожие объекты из множества различных объектов, для выполнения в дальнейшем каких-либо действий над данными объектами. Например, .pdf документы в составе пакетов документов необходимо сначала классифицировать, что позволит в дальнейшем распознать их и извлечь данные из них.
Компанией ABBYY разработано программное обеспечение ABBYY FlexiCapture 12, которое позволяет достаточно легко справится с задачей классификации .pdf документов.
Более полную информацию о данном продукте можно получить по ссылке.
По другой ссылке выложены различные описания и инструкции. Применим их на практике для создания классификатора.
Итак, для начала работы необходимо запустить Пуск 🡪 Станция Настройки Проектов и создать новый проект Файл 🡪 Создать

Назовем проект Классификация с типом Проект FlexiCapture

Далее необходимо перейти в область Пакеты обучения классификатора

В области Пакеты обучения классификатора создадим новый пакет Файл 🡪 Новый пакет

Назовем пакет Классификатор и загрузим в него изображения Файл 🡪 Загрузить изображения…

Далее каждому загруженному для обучения изображению необходимо установить эталонный класс

В качестве эталонных классов будем использовать определения документов и для этого их потребуется создать Проект 🡪 Определения документов…

Так выглядит окно определений документов после их создания и опубликования

В нашем случае потребуется только два неструктурированных определения График и Анкета. Именно данные изображения были загружены для обучения.
Теперь можно приступать к установлению эталонных классов.

На этапе установки эталонных классов пользоваться предпросмотром обязательно!!
Все что остается сделать далее — выделить изображения с установленными эталонными классами и последовательно сначала запустить обучение, по завершении обучения — запустить классификацию, как показано на картинках ниже.

В результате обучения и классификации должны получиться уверенно классифицированные классы.

Можно подгрузить изображения, не участвующие ранее в обучении, установить для них состояние для тестирования и проверить качество работы классификатора.

Для тестовых изображений эталонный класс тоже установить необходимо, так как оценка об уверенно классифицированных изображениях складывается из сравнения эталонных и результирующих классов

В результате тестирования изображения, не участвующие в обучении, были уверенно классифицированы, что позволяет судить о хорошем качестве созданного классификатора.
Вывод. На практике создали с помощью ABBYY FlexiCapture 12 классификатор, применение которого будет рассмотрено в следующей статье про распознавание и извлечение данных из .pdf документов с помощью ABBYY FlexiCapture 12.
Время на прочтение
8 мин
Количество просмотров 21K
 О продукте FlexiCapture, как показывает опыт, обычные пользователи за пределами компании знают совсем мало («Уж не этим ли ЕГЭ распознают?»), несмотря на то, что он используется во многих крупных организациях. Можно с этим мириться, считая, что продукт не для конечного пользователя, а корпоративный. А можно периодически рассказывать про него всякое, что будет не только полезно тем, кто с ним уже знаком, но и намекнёт далёким от продукта людям, что Flex — это не просто 4 буквы в названии.
О продукте FlexiCapture, как показывает опыт, обычные пользователи за пределами компании знают совсем мало («Уж не этим ли ЕГЭ распознают?»), несмотря на то, что он используется во многих крупных организациях. Можно с этим мириться, считая, что продукт не для конечного пользователя, а корпоративный. А можно периодически рассказывать про него всякое, что будет не только полезно тем, кто с ним уже знаком, но и намекнёт далёким от продукта людям, что Flex — это не просто 4 буквы в названии.
Наши партнеры из новосибирской компании АТАПИ Софтвер поделились своим приемами обработки разных сложных случаев. Это набор конкретных практических советов, которые, мы надеемся, будут вам полезны. Кроме того, каждая из этих историй подобна дзенскому коану — помогает раскрыть истинную природу FlexiCapture во всем ее многообразии.
При обработке нестандартных таблиц будь безмятежен, как цветок лотоса
Основное предназначение ABBYY FlexiCapture – извлекать из документов определенные данные и заносить их в информационную систему. В России большинство документов унифицировано, поэтому обычно это не вызывает трудностей. К несчастью, такого не скажешь о зарубежных документах – скажем, о европейских счетах-фактурах – да и некоторые российские формы «отжигают» не хуже своих зарубежных собратьев. Часто встречаются случаи, когда необходимая информация в таблицах разграничена недостаточно четко, например, вот так:

Здесь в таблице есть две строки с описанием товарных позиций. Если для распознавания такого документа использовать автоматический способ, номенклатурный номер товара (крайнее левое поле) попадет в отдельную колонку и будет распознан верно, а вот поля количество и артикул (третья колонка) попадут в одну и ту же колонку, хотя в нашей таблице это разные поля. Кроме того, в колонки может попасть много лишней текстовой информации – это создаст проблемы при верификации.
Разделить искомые данные на отдельные поля можно с помощью функциональности повторяющейся группы. В Flexilayout Studio создаем элемент типа «повторяющаяся группа» (Repeating Group). Каждый экземпляр группы будет соответствовать строке таблицы, внутри области которой уже организовывается поиск с использованием простых элементов (типа Static Text, Character String, Region и т.д.). В свою очередь, область каждой строки может быть так же выделена с помощью повторяющейся группы, предваряющей поиск непосредственно информации.
Это, пожалуй, лучшее решение для подобных случаев. Однако, надо не забывать, что кроме собственно распознавания, нам нужно привести данные из такой не совсем стандартной таблицы к обычному табличному виду:

Зачем это нужно? Операторам верификации проще обрабатывать данные, когда они представлены в виде таблицы. Кроме того, очень часто бывает, что стандартные и нестандартные таблицы поступают на верификацию друг за другом, и если делать для каждого случая отдельный шаблон, оператору будет трудно переключаться с одного способа представления данных на другой – поэтому он неминуемо начнет делать ошибки.
И еще один момент. На следующем примере видно, что представлять сложные нестандартные таблицы в виде повторяющейся группы в интерфейсе не совсем удобно – такое представление занимает много места.
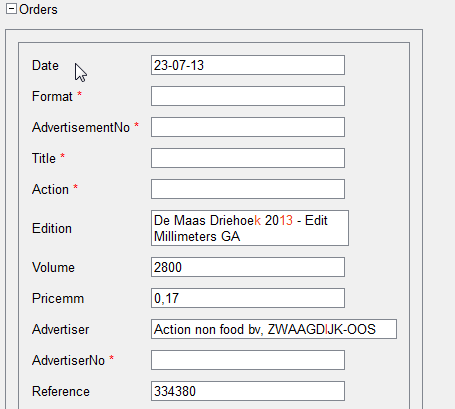
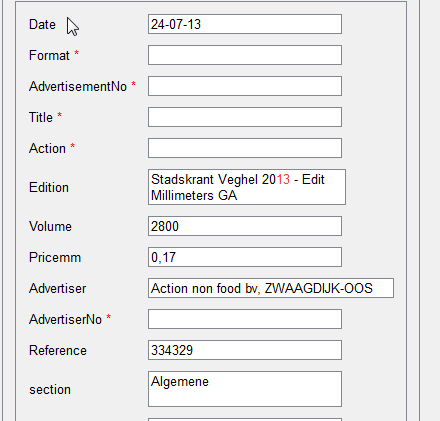
Сравним это с представлением аналогичных данных в виде таблицы:

Как мы видим, в таком виде (как таблица) данные занимают намного меньше места, и у оператора появляется возможность проверять документы быстрее – не тратя время на скроллинг.
Чтобы ускорить процесс верификации и сделать его единообразным, мы используем следующий подход:
- На уровне гибкого описания ищем нужные данные с помощью повторяющейся группы, находим таким образом регионы отдельных строк. Затем в пределах региона каждой строки извлекаем необходимые поля.
- Далее создаем фиктивную таблицу с таким же количеством строк, как в повторяющейся группе. Фиктивная таблица – это таблица, которая наложена в произвольном регионе, то есть она присутствует на форме данных, но не привязана к конкретному изображению документа.
- В проекте FlexiCapture, в настройках определения документа, пишем простое скриптовое правило – оно будет копировать значения из полей, которые система находит в повторяющейся группе, в соответствующие колонки таблицы.
- Сами поля на форме данных можно скрыть, так как вся информация теперь будет храниться и показываться в таблице.
Избегай пасти тигра, улучшая распознавание табличных данных
При работе с таблицами карма разработчика – большое количество различного текстового «мусора» в ячейках с данными. Например, нам надо извлечь цифровое значение Код по ОКВЭД и Дата внесения сведений в ЕГРЮЛ из следующей таблицы:

Если сделать простую таблицу, то в ячейку с кодом будет попадать текстовое описание вида деятельности («Сдача внаем собственного недвижимого имущества»), которое нужно будет удалять либо разработчику с помощью скрипта, либо каждый раз вручную – оператору. Кроме того, в регион таблицы также могут попадать помарки, пометки, штампы, подписи и т.д.
Чтобы подобная лишняя информация не мешала распознаванию, мы можем на уровне гибкого описания отфильтровать эти объекты – задать правила, при помощи которых система будет автоматически находить их и игнорировать при распознавании. В случае с нашим примером достаточно будет настроить «игнор» всех текстовых объектов с русскими буквами и скобками.
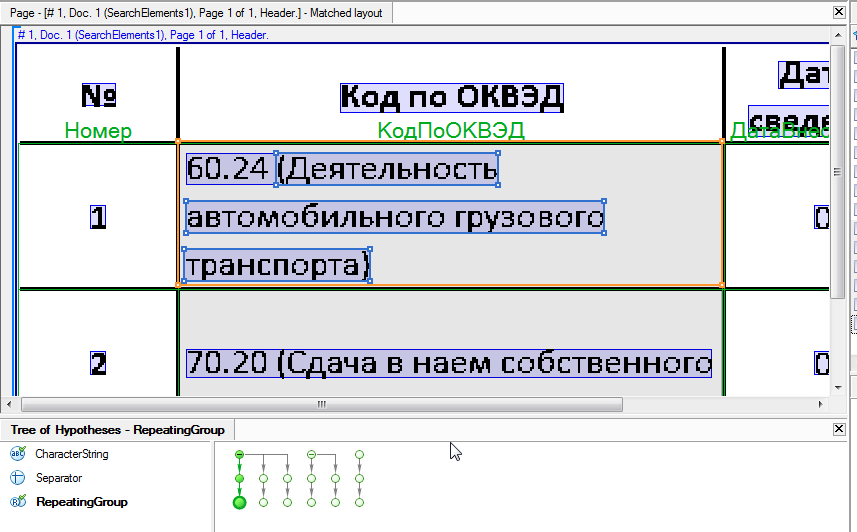
Как видно на рисунке ниже, во FlexiCapture 10 данное поле будет исключено из области распознавания (прямоугольники с серой штриховкой).

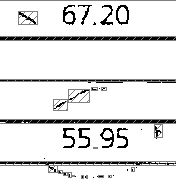
Или же можно пойти от обратного — сначала с помощью повторяющейся группы найти только нужные нам данные (цифровые коды), а затем исключить из распознавания все текстовые или иные объекты изображения из колонки «Код по ОКВЭД», отличные от непосредственно кода.
Примеры таких подходов представлены на картинке ниже: слева мы исключили фиксированный текст MACHINE REAMER 600 первым способом, а на правой – все, кроме цифр, вторым способом:

Настрой вариационное распознавание поля – позволь зеркалу ума отделить красивое от не очень
Бывает так, что формат одного и того же поля сильно различается в однотипных документах. Например, в зарубежных счетах-фактурах может встречаться как обычный черный текст на белом фоне, так и белый текст на черном фоне. Подобную ситуацию мы можем видеть в бланках разнообразных анкет, опросников и т.д.


А бывает и так, что шаблон один, а в реальности на распознавание документы приходят вперемешку – в одних данные впечатаны на принтере, а в другие вписаны человеком так называемым рукопечатным способом.


Не меньше казусов порождает различный формат данных в одних и тех же полях. Если в одном документе будет указана дата в формате 23-февраля-2006, а в другом – 24/11/08, человек поймет, а программе желательно при этом указать разные настройки для этого поля.


Все эти случаи могут вызвать затруднения с распознаванием. ABBYY FlexiCapture позволяет создать два отдельных поля и задавать им разные настройки распознавания: инвертированный или обычный текст, печатный или рукопечатный, распознавание в общей рамке или рисование отдельной рамки на каждый символ. Затем при обработке каждого документа оператор вручную выбирает верный вариант для поля.
Но можно еще немного усовершенствовать процесс распознавания. Первый вариант – обрабатывать документы в разных типах пакетов. Но это тоже довольно неудобно, так как нужно разделять документы на этапе сканирования, да и операторы в конечном итоге могут просто запутаться, куда какой документ отправлять. Зачем грузить оператора лишней работой, когда с этой задачей может справиться программа?
Мы использовали следующий алгоритм. В том месте, где у нас должен находиться искомый текст, создаем три поля:
- первое – скрытое от пользователя поле, которое распознает обычный текст,
- второе – тоже скрытое поле, которое распознает текст как инвертированный,
- третье – видимое пользователю поле, в котором оператору подается на проверку тот из результатов распознавания, который система оценивает как лучший.
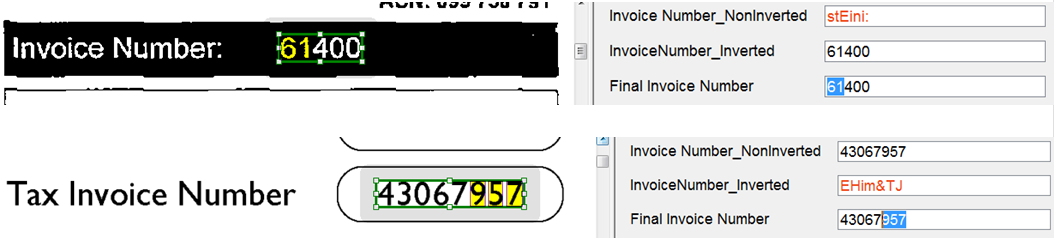
Лучший результат система может выбрать, например, исходя из количества так называемых «подозрительных символов» (Suspicious Symbols) – для этого нужно создать скриптовое правило, которое передает как результат распознавания значение поля с наименьшим количеством «подозрительных символов».
Аналогичный подход с тремя полями и выбором наилучшего варианта распознавания можно использовать для случаев разной разметки или печатного/рукопечатного текста в одном поле.
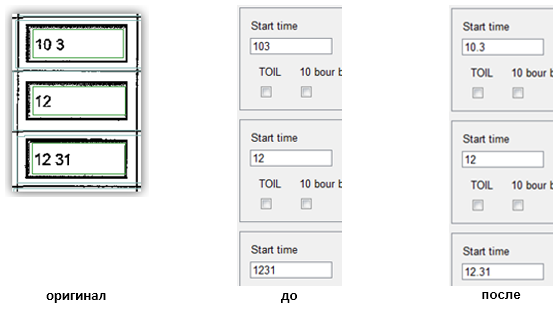
Как вернуть все сущее к единому: выделение дробной части чисел
Казалось бы, какая проблема может быть с дробями? Те же цифры и точки-запятые. Но иногда разделительные знаки дроби не распознаются или исчезают при сканировании, что может привести к неприятным последствиям. Например, итоговая сумма в бумажном счете-фактуре одна, а в электронном – другая (в ней появляется пара лишних нулей). Такое случается, например, при обработке документов, переданных по факсу, распознавании старых документов или с документов с плохим качеством печати.

В FlexiCapture решить такую задачу не очень сложно.
Обычно число знаков в дробной части варьируется от 0 до 2. Чтобы понять, есть ли в распознанном тексте разделитель, нам нужно:
- Вычислить расстояние между последним и предпоследним символами в строке. Для этого от х координаты правой границы предпоследнего символа отнимаем х координату левой границы последнего символа. Это будет S1

- Если число символов в строке равно двум: сравниваем S1 с некоторым коэффициентом, если S1 больше этого значения, то нужно добавить разделитель.
- Если число символов в строке больше двух, то необходимо вычислить расстояние S2 между 2 и 3 символами с конца строки.
- Посчитать отношения S1/S2 и S2/S1

Если какое-то из отношений больше коэффициента, например, 1.5, то вставляем разделитель между соответствующими символами.
Это решение применялось в одном из наших проектов в Австралии. Ниже приведен пример исходного изображения и результаты распознавания – с нашим «улучшайзингом» и без него.
В счете-фактуре, кстати, результат распознавания довольно легко проверить по контрольной сумме. Если в распознанном документе значение поля «Итого» сойдется с суммой по таблице – значит, можно верифицировать результат распознавания без участия оператора. Также может помочь сравнение суммы цифрами с суммой прописью, если такая есть в документе.
Чтобы автоматизировать подбор коэффициентов, можно анализировать среднее расстояние между символами в строке, отношение между высотой и шириной символов и т.д., но, как правило, проще подобрать коэффициенты экспериментальным путем, или методом научного «тыка». Время, которые вы потратите на подбор этих коэффициентов, исчисляется минутами – в то время как оператору верификации такой подход может сэкономить часы работы.
Под взглядом Будды и на железном дереве распустятся цветы. Что делать, если вам нужен полный текстовый слой документа
Мы уже писали, ABBYY FlexiCapture нужна, чтобы извлекать и сохранять конкретные данные из полей: цифры, имена контрагентов и прочее, полный текст документа, как правило, никого не интересует. Но случается и так, что нужно в одном потоке извлекать данные из полей для одних документов и распознавать текст целиком для других.
Возможность извлекать весь текст документа в виде текстового файла может понадобиться, например, для индексации содержимого документа в различных поисковых системах – как широкого пользования, так и внутрикорпоративных.
Такая необходимость возникла у мэрии Новосибирска, которая обрабатывала документы органов власти – приказы, постановления и распоряжения. Им нужны были не только поля из «шапки» документа, по которым документ индексировался в архиве, но и результаты полнотекстового распознавания, чтобы была возможность потом найти документ по ключевому слову из основной части.
Во FlexiCapture уже давно есть возможность настроить экспорт распознанных документов в PDF с текстовым слоем. Но реальность такова, что многие внешние информационные системы не умеют искать по PDF-документам. Более того, что касается именно новосибирского архива, который хранит данные с начала 1920-х годов – многие бумажные первоисточники, которые мы видели, представляли собой довольно ветхие, выцветшие страницы, отпечатанные на печатной машинке. Можно ожидать, что результаты автоматического распознавания для таких файлов могут быть не очень качественными. В то же время именно текстовое содержимое такого архивного документа, а не его шапка, может быть очень важно. Поэтому хорошо бы иметь возможность во FlexiCapture на этапе проверки важных данных (в нашем случае это были номер приказа, дата и т.д.) проверить еще и результаты полнотекстового распознавания.
Решение нашлось. Во FlexiLayout Studio (об этом инструменте для создания гибких описаний мы уже писали) можно создать гибкое описание документа, которое позволит, помимо значимых структурированных данных, извлекать еще и весь текстовый слой документа. Делается это очень просто – например, с помощью повторяющейся группы, которая содержит все строки документа.
Если необходимо, этот текстовый слой можно даже проверить на станции верификации FlexiCapture. Также текст можно будет копировать, индексировать и экспортировать в текстовые форматы. В итоговом PDF-документе мы получим более качественный результат распознавания текстового слоя, так как этот результат будет проверен оператором.
Ниже приведен скриншот со страницы верификации ABBYY FlexiCapture. Как мы видим, теперь можно работать не только с полями, но и со всем текстом в документе.

Спасибо за терпение внимание, осталось всего 3 предложения
Мы привели несколько инженерных лайфхаков, которые, надеемся, помогут вам в работе с нашим продуктом.
Если есть, что добавить – вы решили какую-то еще нестандартную проблему при помощи FlexiCapture – мы будем рады почитать об этом в комментариях.
Татьяна Ганьжина, ABBYY Россия
при активной поддержке специалистов «АТАПИ Софтвер».

© Copyright 2013 ABBYY
РЕШЕНИЯ ABBYY ДЛЯОПТИМИЗАЦИИ ВАШЕГО БИЗНЕСА
Андрей ЗеленскийABBYY Россия

О КОМПАНИИ ABBYY

ABBYY за 30 секундДатаоснования 1989 российская компания с мировым именем
один из крупнейших мировых научных центров поразработке технологий искусственного интеллекта
% оборотав НИОКР 27% ~ в 1,5 раза больше, чем в среднем по рынку
Более 40 миллионов пользователей в 200 странах
известныебрендыкомпании
ABBYY FineReader, ABBYY Lingvo, ABBYY FlexiCapture
Более 60 крупных проектов в России было реализовано на базерешений ABBYY для потокового ввода документов иданных за последние 2 года
Каждый год 9,3 млрд. страниц документов и форм обрабатываютдесятки тысяч организаций во всем мире с помощьютехнологий ABBYY

Группа компаний ABBYY
Сегодня в группу ABBYY входят 14 офисов в 10 странах, гдеработают свыше 1 250 сотрудников и 900 аутсорсеров.
ABBYY Канада
ABBYY США
ABBYY Великобритания
ABBYY Европа
ABBYY Кипр
ABBYY HQ, ABBYY Россия, ABBYY 3A,ABBYY Language Services, ABBYY Press
ABBYY Украина
ABBYY Австралия
ABBYY Тайвань
ABBYY Япония

Миссия ABBYYМы помогаем людям понимать друг друга
Создавая решения в области искусственного интеллекта,ввода документов, обработки данных и перевода,мы превращаем информацию в полезные знания.
5

За последние 10 летABBYY получила более
250НАГРАДот ведущих мировыхизданий и тестовыхлабораторий заинновационность,качество и удобствопродуктов
Награды ABBYY

Решения ABBYY
Для дома и офиса
• Программы дляраспознавания документов иработы с PDF
• Электронные и печатныесловари
• Программы распознавания исловари для смартфонови планшетов
• Онлайн- сервисы ABBYY
Для организаций
• Автоматизация вводадокументов и данных
• Распознавание документов иработа с PDF
• Словари и лингвистическиерешения
• Лингвистические услуги

ПРОДУКТЫ ABBYY ДЛЯРАСПОЗНАВАНИЯ ИРАБОТЫ С PDF

офисных сотрудников отмечают, что работа с бумажными или
электронными документами занимает более 50% ихрабочего времени.
Зачем Вам и Вашим коллегам программыдля распознавания текста и работы с PDF?
78%
60% отметилистремительный ростPDF-документов средирабочих файлов
68% отметилирост бумажныхдокументов впоследние 1-2 года
Здесь и далее: по результатам внешнего исследования ABBYY Россия среди офисных сотрудников, июнь 2014 г.

О формате PDF
PDF – Portable Document Format – кроссплатформенный формат для удобного ибезопасного обмена документами, утвержденный в качестве международногостандарта ISO.
Преимущества:
• Кроссплатформенность• Компактность• Интерактивность• Безопасность• Индексируемость
Особенности:• Сложность
редактирования

Основные типы PDF-файлов
Только изображениестраницы:• Отсканированный
документ или фото,пропущенное черезPDF-принтер
• Поиск и копированиенедоступно
«Нормальный»PDF, или PDF,созданный издругихприложений
PDF с возможностьюпоиска
PDF (толькоизображение)
Только текстовыйслой:• Создан из MS
Office или др.приложений
• Доступен поиски копирование
Текстовый слой подизображением• Является результатом
применения OCR к PDF(только изображение)
• Доступен для поиска икопирования, норезультат зависит откачества текстового слоя
Текст в «кривых»:
• Создан издизайнерскихприложений суказаниемспециальных настроек
• Поиск и копированиенедоступно
Векторный PDF

12
· Копирование
• Не всегда получается скопироватьтекст из PDF
• При перепечатывании бумажногодокумента тратится много времени ивозникают ошибки
• Для внесения изменений требуетсяисходник в редактируемом формате
Редактирование
· Поиск
• Поиск информации затруднен• Нет оперативного доступа к
информации• Неоптимизированные PDF занимают
много места на диске• Затраты на хранение в бумажном виде
Безопасность
• Иногда требуется ограничить правана просмотр или редактирование PDF
• Существует рискнесанкционированного доступа кбумажному документу
Сложности при работе с бумажнымии PDF-документами

Кто сталкивается со сложностями?
Бухгалтеры, финансисты Счета, акты, отчеты и финансовыедокументы
Инженеры, проектировщики,дизайнеры Проектная документация, макеты
Секретари и офис-менеджеры
Входящая корреспонденция, письма,договоры
Специалисты по маркетингу,рекламе, PR
Маркетинговые материалы, прайс-листы, аналитические отчеты
Юристы Договоры, акты, судебные материалыи др. юридические документы
Лингвисты, переводчики,научные сотрудники
Книги, научные статьи, отчеты,документы на перевод
ИТ-специалисты Техническая документация,руководства пользователя
Маркетинговые материалы, прайс-листы, аналитические отчеты
Менеджеры по продажам /работе с клиентами

Как скопироватьтекст из скана?
Как исправить опечатку в PDF?
Как оптимально хранитьдокументы на компьютере?
Как быстро найтинужную информациюв документе?
Как оптимизировать процесссогласования документов?
Как переиспользовать текстиз бумажного документа?
Как создать новый документна основе информации изразных источников?
Как защитить документ от изменений?
Как быстро вбить визитку вконтакты?
Как уменьшить размердокумента?
Сотрудников72%

Топ 5 популярных задачБолее половины офисных сотрудников регулярно сталкиваются со следующимисценариями работы с PDF-документами*:
По результатам внешнего исследования ABBYY Россия среди офисных сотрудников, июнь 2014 г.
*Аналогичные сценарии характерны и для работы с бумажными документами.
62% 60% 54% 52% 48%
1. Поиск по тексту 2. Копирование текста 3. Операции со страницами(добавление, удаление,изменение порядка ит.п.)
4. Внесение правок(исправление опечаток,добавление илиудаление текста илиизображений)
5. Объединение файловразличных форматов вединый PDF-документ
Частично доступны в бесплатном ПО
Требуется специализированное платное ПО

поиск документа вбумажном архиве***
5мин поиск документа в
электронном архиве
15 р.док.
Несколько цифр в рублях
*По результатам внутреннего теста ABBYY**Зависит от скорости сканера. Распознавание 1 стр. — ~ 5 сек.*** — здесь и далее — Исследование Национальной ассоциации инноваций и развития информационныхтехнологий, 2012 г.**** данные Росстат
среднее времяперепечатывания 1 стр*
14мин Средняя зарплата СЗФО
30 тыс. руб.****
41р.Стр.
Экономия на 1сотрудника при среднейзарплате СЗФО 30 тыс.руб.****
11,3тыс.
р./год.
= 7,75 рабочих дней.Экономия времени в2014 году *
~ 62часа

Продукты ABBYY для работы сбумажными и PDF-документами
Для создания, просмотра иэффективной работы с PDF-документами и их содержимым
Для перевода бумажных иPDF-документов в другие форматыс возможностью поиска иредактирования

Если Вам необходима…
универсальная программа для эффективной работы с PDF:универсальная программа для эффективной работы с PDF:
Создание PDF из различныхформатов
Извлечение информации
Просмотр
Поиск
Внесение правок в текст иизображения
Быстрое конвертирование вдругие форматы
Сбор информации из разных файловв PDF для публикации в интернете
Обмен с коллегами
Согласование и добавление пометок
Защита
Сканирование в PDF свозможностью поиска
Оптимизация размера файлов

Ваш выбор…
Коробочная версия:3 110 руб.
Версия для скачивания:2 800 руб.
Дополнительные лицензии:см. прайс-лист
С актуальными ценами вы можете ознакомиться на сайте www.ABBYY.ru.

Интерфейс программы
Единая панель инструментовЕдиная панель инструментов
Панель«Страницы»Панель«Страницы»
Панель«Комментарии»Панель«Комментарии»
СредстванавигацииСредстванавигации
Поиск подокументуПоиск подокументу
Интерфейс главного окна программы

Ключевые преимущества
Простой и понятный интерфейс, объединяющий полезныеинструменты для просмотра и работы с PDF
Внесение незначительных изменений во все типы PDF-файлов
Поиск по тексту и копирование информации из любых типовPDF-файлов, включая отсканированные
Непревзойденная точность при преобразовании PDF вразличные форматы
Соответствие международным стандартам ISO PDF и PDF/A

Работа с PDF/A
PDF/A – оптимальный формат дляэлектронного документооборота.PDF/A – оптимальный формат дляэлектронного документооборота.
Рекомендован Минкомсвязьюдля использования вмежведомственном СЭД
Внедрен в документоoбороте между аппаратом Правительства РФ,Минэкономразвития, Минкомсвязи, Минюстом, Минфином, Минпромторгом,Минспортом, Минкультуры, Минсельхозом и правительствами крупнейшихрегионов.
ABBYY PDF Transformer+ позволяет:
• Создавать PDF/A-документы согласно стандартам ISO,• Открывать и просматривать PDF/A-документы,• Оставлять в них пометки и комментарии совместно с
коллегами,• Устанавливать на них защиту и подписывать их
цифровой подписью,• И многое другое…

Сравнение

Сравнение
ИТОГ: Лучше качество, Больше функций, Есть OCR — возможность вноситьизменения прямо в PDF, включая сканированные PDF. При этом полностьюсохраняется исходное форматирование документа. Изменения, внесенные в PDF спомощью PDF Transformer+, корректно отображаются и обрабатываются другимипопулярными PDF ридерами.

Схема лицензирования

Типы лицензий для корп. клиентов
• Лицензия на рабочееместо
• Для компьютеров,отключенных отлокальной сети,например, ноутбуков
• Автоматическаяактивация
• Лицензия длятерминального сервера
• Кол-во одновременныхподключений ктерминалу не можетпревышать кол-вокупленных лицензий
• НО! Продукт в режимеViеwer доступен всем
Per Seat АА Terminal
Неименные (пакеты)
Именные Именные
• Лицензия на рабочееместо
• Уникальныйдистрибутив дляклиента
• Не требуетсяподключения кинтернету
Site License
Именные
1 2 3

Если Вам необходимо…
• рисовать различные области распознавания и редактировать их свойства,
• проверять результат с помощью встроенной словарной поддержки и вносить изменения враспознанный текст.
Имеют сложную структуру – содержат комбинациюиз текста, таблиц, диаграмм и изображений,
Отсканированы или сфотографированы с дефектами,
• предобрабатывать изображение перед распознаванием,а значит Вам необходимо иметь возможность:
Распознавать бумажные и PDF-документыРаспознавать бумажные и PDF-документы , которые
и Вам важна точность распознавания и сохранения структуры,

Ваш выбор…
Коробочная версия:4 990 руб.
Версия для скачивания:4 490 руб.
Дополнительные лицензии:См. прайс-лист
С актуальными ценами вы можете ознакомиться на сайте www.ABBYY.ru.
Профессиональная программа для оптического распознавания текста (OCR)

Интерфейс программы
Панель«Страницы»Панель«Страницы»
Окно «Текст»содержит результатраспознавания
Окно «Текст»содержит результатраспознавания
Окно «Изображение»показывает исходноеизображение документа
Окно «Изображение»показывает исходноеизображение документа
НастройкиэкспортаНастройкиэкспорта
НастройкираспознаванияНастройкираспознавания
Открытие и предобработкаисходного изображенияОткрытие и предобработкаисходного изображения
Проверка и коррекциярезультатаПроверка и коррекциярезультата

Ключевые преимущества
Непревзойденная точность распознавания благодарятехнологии ABBYY OCR.
Экономия времени и усилий на форматировании: программаточно воссоздает исходную структуру документа: текст,изображения, графики, колонтитулы, сноски и т.п.Удобный пользовательский интерфейс и стартовое окно«Задачи» обеспечивают быстрый доступ к наиболее частымсценариям.
Исходное изображение можно сравнить с распознанным иотредактированным текстом прямо в интерфейсе программы.
190 языков распознавания, включая арабский, китайский идругие азиатские, а также любые их комбинации. Программаавтоматически определяет язык документа.

Версии ABBYY FineReader 12
ABBYY FineReader 12Professional
ABBYY FineReader 12Corporate
Дополнительно:• Гибкая система
лицензирования• Настраиваемые сценарии
работы• Автоматическая обработка
документов по расписанию спомощью Hot Folder
• Приложение дляраспознавания визиток
От 4 490 руб. См. прайс-лист
Для индивидуальных пользователей инебольших компаний:
Для средних и крупных организаций:

Схема лицензирования

Типы лицензийFineReader 12 Corporate
• Лицензия на рабочееместо
• Для компьютеров,отключенных отлокальной сети,например, ноутбуков
• Требуется интернет дляактивации
• Лицензия наодновременный доступ
• Для компьютеров,постоянноподключенных клокальной сети
Per Seat Concurrent
Неименные (пакеты)
Именные Именные
• Лицензия на рабочееместо
• Уникальныйдистрибутив дляклиента
• Не требуетсяподключения кинтернету
Site License
Именные
1 2 3

НОВАЯ ABBYY LINGVO X6

ABBYY LINGVO X6 –НЕЗАМЕНИМЫЙ ПОМОЩНИКПРИ ПЕРЕВОДЕИ ИЗУЧЕНИИ ЯЗЫКА
КАК ДЛЯ ЧАСТНЫХПОЛЬЗОВАТЕЛЕЙ,ТАК И ДЛЯ ОРГАНИЗАЦИЙ.
Программа дает быстрый доступ к современным подробным словаряминостранных языков и предоставляет широкие возможности дляизучения лексики и грамматики.
О продукте

РУКОВОДСТВОБазовые потребности и мотивация:обеспечить сотрудника за разумные деньги ПО, необходимымдля работы и повышающим его производительность.
IT-СПЕЦИАЛИСТЫБазовые потребности и мотивация:получить ПО, отвечающее требованиям руководства, удобное вустановке и поддержке.
СПЕЦИАЛИСТЫ,которые сталкиваются с необходимостью перевода отраслевыхи служебных текстов, либо ведут коммуникации наиностранном языке.Базовые потребности и мотивация: эффективно выполнятьдолжностные обязанности.
Сегмент: корпоративные пользователи

Преимущества для корпоративныхпользователей
• ЭКОНОМИЯ ВРЕМЕНИ ПРИ ПОИСКЕ ПЕРЕВОДА благодаря моментальномупереводу, возникающему при наведении курсора на любое слово в тексте илина изображении.
• ТОЧНЫЙ ПЕРЕВОД ОТРАСЛЕВЫХ ТЕРМИНОВ c помощью более чем 130тематических словарей для 40 тематик.
• ПОДБОР КОРРЕКТНОГО ПЕРЕВОДА В ЗАВИСИМОСТИ ОТ КОНТЕКСТА благодарядоступу к примерам употребления слов.
• 5 минут в день, потраченных на поиск перевода 50сотрудниками – это 4 часа непродуктивной траты рабочеговремени в день, более 80 часов в месяц = ½ рабочего временисотрудника в месяц ->
• Сотрудник для компании стоит в среднем 120 000 в месяц.Lingvo на 50 лицензий стоит 60 000 рублей ->
• Lingvo окупит себя за месяц!
Цените времясвоих
сотрудников?Возьмите Lingvo
на ставку!

ABBYY Lingvo Intranet Server
• Словарь для организаций, разработанный компанией ABBYY — это свыше280 общелексических и тематических словарей от самых авторитетныхиздательств и авторов, включая «HarperCollins Publishers»,
• более 17 миллионов переводов из различных областей экономики,маркетинга, банковского дела, политики, медицины, юриспруденции,машиностроения и других отраслей.

ИНФОРМАЦИЯ ДЛЯIT-СПЕЦИАЛИСТОВ

Академическая скидка
Академическая скидка 40% распространяется на:
l государственные учебные заведения.
l государственные больницы
l учебные центры, имеющие лицензии на ведение образовательнойдеятельности
l государственные библиотеки.
Внимание! Скидка предоставляется только при предоставлении официальногописьма от учебного/медицинского заведения.

Преимущества продуктов ABBYYдля ИТ-специалистов
● Гибкая система лицензирования● Бесплатная техническая поддержка● Возможности сетевой установки и администрирования● Поддержка самых современных операционных систем
●Скидка 40% на обновления с двухпредыдущих версий.

Уровень скидокдля именных лицензий
Для определения уровня скидки суммируются все лицензии на одинпродукт в одном (первом или самом крупном) заказе.
Уровень скидки закрепляется за клиентом в рамках одной версиипродукта.В течение этого срока он сможет приобретать дополнительные лицензиис учётом этого уровня скидки в любом количестве. При этом количествозаказанных в разное время лицензий не суммируется для увеличенияуровня скидки, учитывается только размер самого крупного заказа.
Несколько филиалов одной организации могут объединить свои заказыдля достижения более высокого уровня скидки.

43
Интернет-ресурсы
www.ABBYY.ru — сайт компании
www.lingvo.ru — сайт ABBYY Lingvo
43

© Copyright 2013 ABBYY
ПОТОКОВЫЙ ВВОД ДАННЫХ:ПРОДУКТЫ И ТЕХНОЛОГИИПРЕИМУЩЕСТВАСЦЕНАРИИ ИСПОЛЬЗОВАНИЯ

● ICR – оптическое распознаваниесимволов, написанных от руки
● OMR – распознавание меток● OBR – распознавание одномерных
и двумерных штрих-кодов● Классификация документов● Интеллектуальный анализ
страницы● Извлечение данных из любых
типов документов
ABBYY: компетенции и технологии
ПОТОКОВЫЙ ВВОД ДАННЫХ
Распознаваниедокументов
Потоковый вводданных
Перевод ианализ текста
Услугив области
лингвистики

Вашей компании точно необходимпотоковый ввод данных, если…
Поток документации 5000 и более документов в месяц
Не менее 3 сотрудников вводят вручную данные винформационные системы
Количество контрагентов 50 и более
В компании планируетсясоздание – Общего центра обслуживания
Системы электронного документооборота
Можно выделить неменее 20 типов различных документов

Преимущества решений ABBYY длявашего бизнеса

Корпоративные продукты и решенияABBYY в сфере потокового ввода данных
На базе корпоративных продуктов ABBYY создаются специализированные решениядля обработки документов в любой отрасли.

Варианты распознавания
Полнотекстовое Атрибутивное

Мобильный ввод данныхимпорт изображений в корпоративную систему потокового вводаданных может осуществляться с помощью мобильных устройств

ABBYY как часть ИТ-решений


Схема работы ABBYY FlexiCapture

Ключевые сценарии использованияABBYY FlexiCapture

Выбор архитектуры решения
Зависит от:● Бизнес-процесса
● Объемов обрабатываемых документов
● Каналов связи и технических характеристик
● Требований по интеграции с другими информационными системами
● и т. д.

Успешные проектыABBYY FlexiCapture
Банк ВТБЗадачи
• Передачанепрофильныхзадачи из фронт-офисов в ОЦО
• Автоматическаяобработкаюридических делклиентов, клиентскихисторий, а такжеплатежныхдокументов
• Общий объем -свыше 7000документовежедневно
Решение
•Система вводаданных идокументовABBYY FlexiCapture
•В настоящее времяиспользуется вовсех трех ОЦО ВТБ
Результат
•Автоматическаяобработка более600 различныхтипов документов
•Освобождениевременисотрудниковфронт-офиса отрутинной задачиввода данных
•Повышениескорости икачестваобработкидокументов

Успешные проектыABBYY FlexiCaptureАдминистрация Краснодарского края
Задачи
•Автоматизацияпроцесса обработкиданных обращенийграждан всоответствии стребованиямиФедеральногозакона
•Повышение уровняконтроля надисполнительскойдисциплиной прирассмотренииобращений граждан
Решение
•ПрограммныйкомплексABBYY FlexiCapture
Результат
•Автоматическоеизвлечение информациии ее сохранение в базеданных администрации
•Сотрудникиосвободились отвыполнения рядатрудоемкихмеханических процессов
•В несколько разсократилось времяобработки документов
•Автоматизированаобработка анкетобратной связи

Успешные проектыABBYY FlexiCaptureКомпания ФБ-Лизинг
Задачи
• Автоматизация вводаданных с уведомленийо штрафах ГИБДД
• Внедрение системыавтоматическойпереадресацииинформации оштрафах клиентам
Решение
• ПрограммныйкомплексABBYY FlexiCapture
Результат
• Повышенапроизводительностьтруда сотрудников
• Стандартизирована иускорена обработкауведомлений оштрафах ГИБДД
• Ежемесячно вкомпанииобрабатываетсядо 5 000 документово штрафах

Успешные проектыABBYY FlexiCaptureКЭС-Холдинг
Задачи
•Стандартизация иускорение обработкипервичных учетныхдокументов
•Централизацияфункции обработкидокументовбухгалтерского икадрового учета врамках ОЦО
Решение
•Создание ОЦО
•Внедрение СЭД
•ИспользованиепрограммногокомплексABBYY FlexiCapture
Результат
•Централизованафункцияобработкидокументовбухгалтерского икадрового учета
•Ежемесячно спомощьюсистемы ABBYYобрабатываетсядо 50 000документов


Схема работы ABBYY Recognition Server

Ключевые сценарии использованияABBYY Recognition Server

Успешные проектыABBYY Recognition ServerГруппа Сибур
Задачи
• Создание единогоэлектронногоархива финансовыхдокументов дляорганизациипроцессаобработкиинформации в«СИБУР-Центробслуживаниябизнеса»
• Организацияпотокового вводадокументов вэлектронный архив
Решение
• Решение для потоковоговвода документовABBYY Recognition Server
Результат
• Стало возможнымудаленное ведениебухгалтерского иналогового учета
• Внедренная схемадокументооборотапозволила заметноускорить обменданными междупредприятиями ицентромобслуживания

ABBYY FineReader Банк уже используется в 70% российских банков.
Основные возможностиABBYY FineReader Банк

ABBYY Intelligent Search
● ABBYY Intelligent Search – система интеллектуального поиска по корпоративнымресурсам. Основываясь на понимании смысла текста, ABBYY Intelligent Searchзначительно улучшает качество поиска по различным корпоративным хранилищамкомпании, позволяя сотрудникам своевременно находить всю необходимуюинформацию.
● Система ABBYY Intelligent Search основана на уникальной технологиилингвистического анализа текста ABBYY Compreno. Благодаря технологии, ABBYYIntelligent Search учитывает не только все формы слов, но и их значения, выявляетсмысловые связи между словами, определяет смысл и контекст всего текста. Такойподход позволяет значительно повысить эффективность поиска по сравнению страдиционными системами полнотекстового поиска.

ABBYY COMPARATER
Новая технология сравнения

О программе
ABBYY Comparator – универсальная программа для сравнениядвух версий документа в различных форматах. Программабыстро выявляет несоответствия в тексте и помогаетпредотвратить подписание или публикацию некорректнойверсии документа.
Базовый сценарий использования

Периодически нуждаются всравнении документов
Регулярно нуждаются всравнении документов
Кто пользуется сравнением документов?
Юристы, договорные отделы
Менеджеры по продажамАдминистраторы, секретариHR-менеджеры
Потребность среди офисных сотрудников: 59%
19%
40%
По результатам внешнего исследования ABBYY Россия среди офисных сотрудников, июнь 2014.
Какие документы сравнивают:
Фотографию документа с электроннойкопией (в PDF, MS Office)
Бумажную копию с электронной
Разные версии в формате MS Word
Копию в формате PDF с документом MS Office
37%
55%
61%
78%
W
Бухгалтеры, финансисты

Интерфейс программы
Документ 1 Документ 2
Список различий
Настройки

Ключевые преимущества
Сравнение документов как в текстовых форматах,так и в графических (отсканированные документыили их фотографии, PDF без текстового слоя и т.п.).
Показ действительно важных различий (несущественныеразличия в форматировании, начертании, пробелах итабуляциях игнорируются; есть возможность отключитьпоиск различий в знаках препинания, в одной букве).
Параллельный просмотр найденных несоответствий наобоих документах.
Сохранение результатов сравнения в виде PDF-документа скомментариями – для удобства обмена информацией междусогласующими сторонами.

Технические характеристики
71
Входные форматы файлов для сравнения:
Сохранение результатов сравнения:
• PDF (1-ый документ) с комментариями в местах изменений• PDF (2-ой документ) с комментариями в местах изменений
Форматы Microsoft Office:Word, Excel, PowerPoint
Файлы изображений:GIF, TIFF, BMP, JBIG2, JPEG,JPEG2000, PNG, PDF
Текстовые форматы:OpenDocument (ODT,ODS), RTF, TXT
Другие форматы:HTML, XPS и PDF

ВОПРОСЫАндрей Зеленский
Региональный представитель СЗФО
ABBYY Россия
[email protected]
www.ABBYY.ru

© Copyright 2013 ABBYY
РЕШЕНИЯ ABBYY ДЛЯОПТИМИЗАЦИИ ВАШЕГО БИЗНЕСА
Андрей ЗеленскийABBYY Россия

О КОМПАНИИ ABBYY

ABBYY за 30 секундДатаоснования 1989 российская компания с мировым именем
один из крупнейших мировых научных центров поразработке технологий искусственного интеллекта
% оборотав НИОКР 27% ~ в 1,5 раза больше, чем в среднем по рынку
Более 40 миллионов пользователей в 200 странах
известныебрендыкомпании
ABBYY FineReader, ABBYY Lingvo, ABBYY FlexiCapture
Более 60 крупных проектов в России было реализовано на базерешений ABBYY для потокового ввода документов иданных за последние 2 года
Каждый год 9,3 млрд. страниц документов и форм обрабатываютдесятки тысяч организаций во всем мире с помощьютехнологий ABBYY

Группа компаний ABBYY
Сегодня в группу ABBYY входят 14 офисов в 10 странах, гдеработают свыше 1 250 сотрудников и 900 аутсорсеров.
ABBYY Канада
ABBYY США
ABBYY Великобритания
ABBYY Европа
ABBYY Кипр
ABBYY HQ, ABBYY Россия, ABBYY 3A,ABBYY Language Services, ABBYY Press
ABBYY Украина
ABBYY Австралия
ABBYY Тайвань
ABBYY Япония

Миссия ABBYYМы помогаем людям понимать друг друга
Создавая решения в области искусственного интеллекта,ввода документов, обработки данных и перевода,мы превращаем информацию в полезные знания.
5

За последние 10 летABBYY получила более
250НАГРАДот ведущих мировыхизданий и тестовыхлабораторий заинновационность,качество и удобствопродуктов
Награды ABBYY

Решения ABBYY
Для дома и офиса
• Программы дляраспознавания документов иработы с PDF
• Электронные и печатныесловари
• Программы распознавания исловари для смартфонови планшетов
• Онлайн- сервисы ABBYY
Для организаций
• Автоматизация вводадокументов и данных
• Распознавание документов иработа с PDF
• Словари и лингвистическиерешения
• Лингвистические услуги

ПРОДУКТЫ ABBYY ДЛЯРАСПОЗНАВАНИЯ ИРАБОТЫ С PDF

офисных сотрудников отмечают, что работа с бумажными или
электронными документами занимает более 50% ихрабочего времени.
Зачем Вам и Вашим коллегам программыдля распознавания текста и работы с PDF?
78%
60% отметилистремительный ростPDF-документов средирабочих файлов
68% отметилирост бумажныхдокументов впоследние 1-2 года
Здесь и далее: по результатам внешнего исследования ABBYY Россия среди офисных сотрудников, июнь 2014 г.

О формате PDF
PDF – Portable Document Format – кроссплатформенный формат для удобного ибезопасного обмена документами, утвержденный в качестве международногостандарта ISO.
Преимущества:
• Кроссплатформенность• Компактность• Интерактивность• Безопасность• Индексируемость
Особенности:• Сложность
редактирования

Основные типы PDF-файлов
Только изображениестраницы:• Отсканированный
документ или фото,пропущенное черезPDF-принтер
• Поиск и копированиенедоступно
«Нормальный»PDF, или PDF,созданный издругихприложений
PDF с возможностьюпоиска
PDF (толькоизображение)
Только текстовыйслой:• Создан из MS
Office или др.приложений
• Доступен поиски копирование
Текстовый слой подизображением• Является результатом
применения OCR к PDF(только изображение)
• Доступен для поиска икопирования, норезультат зависит откачества текстового слоя
Текст в «кривых»:
• Создан издизайнерскихприложений суказаниемспециальных настроек
• Поиск и копированиенедоступно
Векторный PDF

12
· Копирование
• Не всегда получается скопироватьтекст из PDF
• При перепечатывании бумажногодокумента тратится много времени ивозникают ошибки
• Для внесения изменений требуетсяисходник в редактируемом формате
Редактирование
· Поиск
• Поиск информации затруднен• Нет оперативного доступа к
информации• Неоптимизированные PDF занимают
много места на диске• Затраты на хранение в бумажном виде
Безопасность
• Иногда требуется ограничить правана просмотр или редактирование PDF
• Существует рискнесанкционированного доступа кбумажному документу
Сложности при работе с бумажнымии PDF-документами

Кто сталкивается со сложностями?
Бухгалтеры, финансисты Счета, акты, отчеты и финансовыедокументы
Инженеры, проектировщики,дизайнеры Проектная документация, макеты
Секретари и офис-менеджеры
Входящая корреспонденция, письма,договоры
Специалисты по маркетингу,рекламе, PR
Маркетинговые материалы, прайс-листы, аналитические отчеты
Юристы Договоры, акты, судебные материалыи др. юридические документы
Лингвисты, переводчики,научные сотрудники
Книги, научные статьи, отчеты,документы на перевод
ИТ-специалисты Техническая документация,руководства пользователя
Маркетинговые материалы, прайс-листы, аналитические отчеты
Менеджеры по продажам /работе с клиентами

Как скопироватьтекст из скана?
Как исправить опечатку в PDF?
Как оптимально хранитьдокументы на компьютере?
Как быстро найтинужную информациюв документе?
Как оптимизировать процесссогласования документов?
Как переиспользовать текстиз бумажного документа?
Как создать новый документна основе информации изразных источников?
Как защитить документ от изменений?
Как быстро вбить визитку вконтакты?
Как уменьшить размердокумента?
Сотрудников72%

Топ 5 популярных задачБолее половины офисных сотрудников регулярно сталкиваются со следующимисценариями работы с PDF-документами*:
По результатам внешнего исследования ABBYY Россия среди офисных сотрудников, июнь 2014 г.
*Аналогичные сценарии характерны и для работы с бумажными документами.
62% 60% 54% 52% 48%
1. Поиск по тексту 2. Копирование текста 3. Операции со страницами(добавление, удаление,изменение порядка ит.п.)
4. Внесение правок(исправление опечаток,добавление илиудаление текста илиизображений)
5. Объединение файловразличных форматов вединый PDF-документ
Частично доступны в бесплатном ПО
Требуется специализированное платное ПО

поиск документа вбумажном архиве***
5мин поиск документа в
электронном архиве
15 р.док.
Несколько цифр в рублях
*По результатам внутреннего теста ABBYY**Зависит от скорости сканера. Распознавание 1 стр. — ~ 5 сек.*** — здесь и далее — Исследование Национальной ассоциации инноваций и развития информационныхтехнологий, 2012 г.**** данные Росстат
среднее времяперепечатывания 1 стр*
14мин Средняя зарплата СЗФО
30 тыс. руб.****
41р.Стр.
Экономия на 1сотрудника при среднейзарплате СЗФО 30 тыс.руб.****
11,3тыс.
р./год.
= 7,75 рабочих дней.Экономия времени в2014 году *
~ 62часа

Продукты ABBYY для работы сбумажными и PDF-документами
Для создания, просмотра иэффективной работы с PDF-документами и их содержимым
Для перевода бумажных иPDF-документов в другие форматыс возможностью поиска иредактирования

Если Вам необходима…
универсальная программа для эффективной работы с PDF:универсальная программа для эффективной работы с PDF:
Создание PDF из различныхформатов
Извлечение информации
Просмотр
Поиск
Внесение правок в текст иизображения
Быстрое конвертирование вдругие форматы
Сбор информации из разных файловв PDF для публикации в интернете
Обмен с коллегами
Согласование и добавление пометок
Защита
Сканирование в PDF свозможностью поиска
Оптимизация размера файлов

Ваш выбор…
Коробочная версия:3 110 руб.
Версия для скачивания:2 800 руб.
Дополнительные лицензии:см. прайс-лист
С актуальными ценами вы можете ознакомиться на сайте www.ABBYY.ru.

Интерфейс программы
Единая панель инструментовЕдиная панель инструментов
Панель«Страницы»Панель«Страницы»
Панель«Комментарии»Панель«Комментарии»
СредстванавигацииСредстванавигации
Поиск подокументуПоиск подокументу
Интерфейс главного окна программы

Ключевые преимущества
Простой и понятный интерфейс, объединяющий полезныеинструменты для просмотра и работы с PDF
Внесение незначительных изменений во все типы PDF-файлов
Поиск по тексту и копирование информации из любых типовPDF-файлов, включая отсканированные
Непревзойденная точность при преобразовании PDF вразличные форматы
Соответствие международным стандартам ISO PDF и PDF/A

Работа с PDF/A
PDF/A – оптимальный формат дляэлектронного документооборота.PDF/A – оптимальный формат дляэлектронного документооборота.
Рекомендован Минкомсвязьюдля использования вмежведомственном СЭД
Внедрен в документоoбороте между аппаратом Правительства РФ,Минэкономразвития, Минкомсвязи, Минюстом, Минфином, Минпромторгом,Минспортом, Минкультуры, Минсельхозом и правительствами крупнейшихрегионов.
ABBYY PDF Transformer+ позволяет:
• Создавать PDF/A-документы согласно стандартам ISO,• Открывать и просматривать PDF/A-документы,• Оставлять в них пометки и комментарии совместно с
коллегами,• Устанавливать на них защиту и подписывать их
цифровой подписью,• И многое другое…

Сравнение

Сравнение
ИТОГ: Лучше качество, Больше функций, Есть OCR — возможность вноситьизменения прямо в PDF, включая сканированные PDF. При этом полностьюсохраняется исходное форматирование документа. Изменения, внесенные в PDF спомощью PDF Transformer+, корректно отображаются и обрабатываются другимипопулярными PDF ридерами.

Схема лицензирования

Типы лицензий для корп. клиентов
• Лицензия на рабочееместо
• Для компьютеров,отключенных отлокальной сети,например, ноутбуков
• Автоматическаяактивация
• Лицензия длятерминального сервера
• Кол-во одновременныхподключений ктерминалу не можетпревышать кол-вокупленных лицензий
• НО! Продукт в режимеViеwer доступен всем
Per Seat АА Terminal
Неименные (пакеты)
Именные Именные
• Лицензия на рабочееместо
• Уникальныйдистрибутив дляклиента
• Не требуетсяподключения кинтернету
Site License
Именные
1 2 3

Если Вам необходимо…
• рисовать различные области распознавания и редактировать их свойства,
• проверять результат с помощью встроенной словарной поддержки и вносить изменения враспознанный текст.
Имеют сложную структуру – содержат комбинациюиз текста, таблиц, диаграмм и изображений,
Отсканированы или сфотографированы с дефектами,
• предобрабатывать изображение перед распознаванием,а значит Вам необходимо иметь возможность:
Распознавать бумажные и PDF-документыРаспознавать бумажные и PDF-документы , которые
и Вам важна точность распознавания и сохранения структуры,

Ваш выбор…
Коробочная версия:4 990 руб.
Версия для скачивания:4 490 руб.
Дополнительные лицензии:См. прайс-лист
С актуальными ценами вы можете ознакомиться на сайте www.ABBYY.ru.
Профессиональная программа для оптического распознавания текста (OCR)

Интерфейс программы
Панель«Страницы»Панель«Страницы»
Окно «Текст»содержит результатраспознавания
Окно «Текст»содержит результатраспознавания
Окно «Изображение»показывает исходноеизображение документа
Окно «Изображение»показывает исходноеизображение документа
НастройкиэкспортаНастройкиэкспорта
НастройкираспознаванияНастройкираспознавания
Открытие и предобработкаисходного изображенияОткрытие и предобработкаисходного изображения
Проверка и коррекциярезультатаПроверка и коррекциярезультата

Ключевые преимущества
Непревзойденная точность распознавания благодарятехнологии ABBYY OCR.
Экономия времени и усилий на форматировании: программаточно воссоздает исходную структуру документа: текст,изображения, графики, колонтитулы, сноски и т.п.Удобный пользовательский интерфейс и стартовое окно«Задачи» обеспечивают быстрый доступ к наиболее частымсценариям.
Исходное изображение можно сравнить с распознанным иотредактированным текстом прямо в интерфейсе программы.
190 языков распознавания, включая арабский, китайский идругие азиатские, а также любые их комбинации. Программаавтоматически определяет язык документа.

Версии ABBYY FineReader 12
ABBYY FineReader 12Professional
ABBYY FineReader 12Corporate
Дополнительно:• Гибкая система
лицензирования• Настраиваемые сценарии
работы• Автоматическая обработка
документов по расписанию спомощью Hot Folder
• Приложение дляраспознавания визиток
От 4 490 руб. См. прайс-лист
Для индивидуальных пользователей инебольших компаний:
Для средних и крупных организаций:

Схема лицензирования

Типы лицензийFineReader 12 Corporate
• Лицензия на рабочееместо
• Для компьютеров,отключенных отлокальной сети,например, ноутбуков
• Требуется интернет дляактивации
• Лицензия наодновременный доступ
• Для компьютеров,постоянноподключенных клокальной сети
Per Seat Concurrent
Неименные (пакеты)
Именные Именные
• Лицензия на рабочееместо
• Уникальныйдистрибутив дляклиента
• Не требуетсяподключения кинтернету
Site License
Именные
1 2 3

НОВАЯ ABBYY LINGVO X6

ABBYY LINGVO X6 –НЕЗАМЕНИМЫЙ ПОМОЩНИКПРИ ПЕРЕВОДЕИ ИЗУЧЕНИИ ЯЗЫКА
КАК ДЛЯ ЧАСТНЫХПОЛЬЗОВАТЕЛЕЙ,ТАК И ДЛЯ ОРГАНИЗАЦИЙ.
Программа дает быстрый доступ к современным подробным словаряминостранных языков и предоставляет широкие возможности дляизучения лексики и грамматики.
О продукте

РУКОВОДСТВОБазовые потребности и мотивация:обеспечить сотрудника за разумные деньги ПО, необходимымдля работы и повышающим его производительность.
IT-СПЕЦИАЛИСТЫБазовые потребности и мотивация:получить ПО, отвечающее требованиям руководства, удобное вустановке и поддержке.
СПЕЦИАЛИСТЫ,которые сталкиваются с необходимостью перевода отраслевыхи служебных текстов, либо ведут коммуникации наиностранном языке.Базовые потребности и мотивация: эффективно выполнятьдолжностные обязанности.
Сегмент: корпоративные пользователи

Преимущества для корпоративныхпользователей
• ЭКОНОМИЯ ВРЕМЕНИ ПРИ ПОИСКЕ ПЕРЕВОДА благодаря моментальномупереводу, возникающему при наведении курсора на любое слово в тексте илина изображении.
• ТОЧНЫЙ ПЕРЕВОД ОТРАСЛЕВЫХ ТЕРМИНОВ c помощью более чем 130тематических словарей для 40 тематик.
• ПОДБОР КОРРЕКТНОГО ПЕРЕВОДА В ЗАВИСИМОСТИ ОТ КОНТЕКСТА благодарядоступу к примерам употребления слов.
• 5 минут в день, потраченных на поиск перевода 50сотрудниками – это 4 часа непродуктивной траты рабочеговремени в день, более 80 часов в месяц = ½ рабочего временисотрудника в месяц ->
• Сотрудник для компании стоит в среднем 120 000 в месяц.Lingvo на 50 лицензий стоит 60 000 рублей ->
• Lingvo окупит себя за месяц!
Цените времясвоих
сотрудников?Возьмите Lingvo
на ставку!

ABBYY Lingvo Intranet Server
• Словарь для организаций, разработанный компанией ABBYY — это свыше280 общелексических и тематических словарей от самых авторитетныхиздательств и авторов, включая «HarperCollins Publishers»,
• более 17 миллионов переводов из различных областей экономики,маркетинга, банковского дела, политики, медицины, юриспруденции,машиностроения и других отраслей.

ИНФОРМАЦИЯ ДЛЯIT-СПЕЦИАЛИСТОВ

Академическая скидка
Академическая скидка 40% распространяется на:
l государственные учебные заведения.
l государственные больницы
l учебные центры, имеющие лицензии на ведение образовательнойдеятельности
l государственные библиотеки.
Внимание! Скидка предоставляется только при предоставлении официальногописьма от учебного/медицинского заведения.

Преимущества продуктов ABBYYдля ИТ-специалистов
● Гибкая система лицензирования● Бесплатная техническая поддержка● Возможности сетевой установки и администрирования● Поддержка самых современных операционных систем
●Скидка 40% на обновления с двухпредыдущих версий.

Уровень скидокдля именных лицензий
Для определения уровня скидки суммируются все лицензии на одинпродукт в одном (первом или самом крупном) заказе.
Уровень скидки закрепляется за клиентом в рамках одной версиипродукта.В течение этого срока он сможет приобретать дополнительные лицензиис учётом этого уровня скидки в любом количестве. При этом количествозаказанных в разное время лицензий не суммируется для увеличенияуровня скидки, учитывается только размер самого крупного заказа.
Несколько филиалов одной организации могут объединить свои заказыдля достижения более высокого уровня скидки.

43
Интернет-ресурсы
www.ABBYY.ru — сайт компании
www.lingvo.ru — сайт ABBYY Lingvo
43

© Copyright 2013 ABBYY
ПОТОКОВЫЙ ВВОД ДАННЫХ:ПРОДУКТЫ И ТЕХНОЛОГИИПРЕИМУЩЕСТВАСЦЕНАРИИ ИСПОЛЬЗОВАНИЯ

● ICR – оптическое распознаваниесимволов, написанных от руки
● OMR – распознавание меток● OBR – распознавание одномерных
и двумерных штрих-кодов● Классификация документов● Интеллектуальный анализ
страницы● Извлечение данных из любых
типов документов
ABBYY: компетенции и технологии
ПОТОКОВЫЙ ВВОД ДАННЫХ
Распознаваниедокументов
Потоковый вводданных
Перевод ианализ текста
Услугив области
лингвистики

Вашей компании точно необходимпотоковый ввод данных, если…
Поток документации 5000 и более документов в месяц
Не менее 3 сотрудников вводят вручную данные винформационные системы
Количество контрагентов 50 и более
В компании планируетсясоздание – Общего центра обслуживания
Системы электронного документооборота
Можно выделить неменее 20 типов различных документов

Преимущества решений ABBYY длявашего бизнеса

Корпоративные продукты и решенияABBYY в сфере потокового ввода данных
На базе корпоративных продуктов ABBYY создаются специализированные решениядля обработки документов в любой отрасли.

Варианты распознавания
Полнотекстовое Атрибутивное

Мобильный ввод данныхимпорт изображений в корпоративную систему потокового вводаданных может осуществляться с помощью мобильных устройств

ABBYY как часть ИТ-решений


Схема работы ABBYY FlexiCapture

Ключевые сценарии использованияABBYY FlexiCapture

Выбор архитектуры решения
Зависит от:● Бизнес-процесса
● Объемов обрабатываемых документов
● Каналов связи и технических характеристик
● Требований по интеграции с другими информационными системами
● и т. д.

Успешные проектыABBYY FlexiCapture
Банк ВТБЗадачи
• Передачанепрофильныхзадачи из фронт-офисов в ОЦО
• Автоматическаяобработкаюридических делклиентов, клиентскихисторий, а такжеплатежныхдокументов
• Общий объем -свыше 7000документовежедневно
Решение
•Система вводаданных идокументовABBYY FlexiCapture
•В настоящее времяиспользуется вовсех трех ОЦО ВТБ
Результат
•Автоматическаяобработка более600 различныхтипов документов
•Освобождениевременисотрудниковфронт-офиса отрутинной задачиввода данных
•Повышениескорости икачестваобработкидокументов

Успешные проектыABBYY FlexiCaptureАдминистрация Краснодарского края
Задачи
•Автоматизацияпроцесса обработкиданных обращенийграждан всоответствии стребованиямиФедеральногозакона
•Повышение уровняконтроля надисполнительскойдисциплиной прирассмотренииобращений граждан
Решение
•ПрограммныйкомплексABBYY FlexiCapture
Результат
•Автоматическоеизвлечение информациии ее сохранение в базеданных администрации
•Сотрудникиосвободились отвыполнения рядатрудоемкихмеханических процессов
•В несколько разсократилось времяобработки документов
•Автоматизированаобработка анкетобратной связи

Успешные проектыABBYY FlexiCaptureКомпания ФБ-Лизинг
Задачи
• Автоматизация вводаданных с уведомленийо штрафах ГИБДД
• Внедрение системыавтоматическойпереадресацииинформации оштрафах клиентам
Решение
• ПрограммныйкомплексABBYY FlexiCapture
Результат
• Повышенапроизводительностьтруда сотрудников
• Стандартизирована иускорена обработкауведомлений оштрафах ГИБДД
• Ежемесячно вкомпанииобрабатываетсядо 5 000 документово штрафах

Успешные проектыABBYY FlexiCaptureКЭС-Холдинг
Задачи
•Стандартизация иускорение обработкипервичных учетныхдокументов
•Централизацияфункции обработкидокументовбухгалтерского икадрового учета врамках ОЦО
Решение
•Создание ОЦО
•Внедрение СЭД
•ИспользованиепрограммногокомплексABBYY FlexiCapture
Результат
•Централизованафункцияобработкидокументовбухгалтерского икадрового учета
•Ежемесячно спомощьюсистемы ABBYYобрабатываетсядо 50 000документов


Схема работы ABBYY Recognition Server

Ключевые сценарии использованияABBYY Recognition Server

Успешные проектыABBYY Recognition ServerГруппа Сибур
Задачи
• Создание единогоэлектронногоархива финансовыхдокументов дляорганизациипроцессаобработкиинформации в«СИБУР-Центробслуживаниябизнеса»
• Организацияпотокового вводадокументов вэлектронный архив
Решение
• Решение для потоковоговвода документовABBYY Recognition Server
Результат
• Стало возможнымудаленное ведениебухгалтерского иналогового учета
• Внедренная схемадокументооборотапозволила заметноускорить обменданными междупредприятиями ицентромобслуживания

ABBYY FineReader Банк уже используется в 70% российских банков.
Основные возможностиABBYY FineReader Банк

ABBYY Intelligent Search
● ABBYY Intelligent Search – система интеллектуального поиска по корпоративнымресурсам. Основываясь на понимании смысла текста, ABBYY Intelligent Searchзначительно улучшает качество поиска по различным корпоративным хранилищамкомпании, позволяя сотрудникам своевременно находить всю необходимуюинформацию.
● Система ABBYY Intelligent Search основана на уникальной технологиилингвистического анализа текста ABBYY Compreno. Благодаря технологии, ABBYYIntelligent Search учитывает не только все формы слов, но и их значения, выявляетсмысловые связи между словами, определяет смысл и контекст всего текста. Такойподход позволяет значительно повысить эффективность поиска по сравнению страдиционными системами полнотекстового поиска.

ABBYY COMPARATER
Новая технология сравнения

О программе
ABBYY Comparator – универсальная программа для сравнениядвух версий документа в различных форматах. Программабыстро выявляет несоответствия в тексте и помогаетпредотвратить подписание или публикацию некорректнойверсии документа.
Базовый сценарий использования

Периодически нуждаются всравнении документов
Регулярно нуждаются всравнении документов
Кто пользуется сравнением документов?
Юристы, договорные отделы
Менеджеры по продажамАдминистраторы, секретариHR-менеджеры
Потребность среди офисных сотрудников: 59%
19%
40%
По результатам внешнего исследования ABBYY Россия среди офисных сотрудников, июнь 2014.
Какие документы сравнивают:
Фотографию документа с электроннойкопией (в PDF, MS Office)
Бумажную копию с электронной
Разные версии в формате MS Word
Копию в формате PDF с документом MS Office
37%
55%
61%
78%
W
Бухгалтеры, финансисты

Интерфейс программы
Документ 1 Документ 2
Список различий
Настройки

Ключевые преимущества
Сравнение документов как в текстовых форматах,так и в графических (отсканированные документыили их фотографии, PDF без текстового слоя и т.п.).
Показ действительно важных различий (несущественныеразличия в форматировании, начертании, пробелах итабуляциях игнорируются; есть возможность отключитьпоиск различий в знаках препинания, в одной букве).
Параллельный просмотр найденных несоответствий наобоих документах.
Сохранение результатов сравнения в виде PDF-документа скомментариями – для удобства обмена информацией междусогласующими сторонами.

Технические характеристики
71
Входные форматы файлов для сравнения:
Сохранение результатов сравнения:
• PDF (1-ый документ) с комментариями в местах изменений• PDF (2-ой документ) с комментариями в местах изменений
Форматы Microsoft Office:Word, Excel, PowerPoint
Файлы изображений:GIF, TIFF, BMP, JBIG2, JPEG,JPEG2000, PNG, PDF
Текстовые форматы:OpenDocument (ODT,ODS), RTF, TXT
Другие форматы:HTML, XPS и PDF

ВОПРОСЫАндрей Зеленский
Региональный представитель СЗФО
ABBYY Россия
[email protected]
www.ABBYY.ru