| title | description | author | ms.author | ms.reviewer | ms.date | ms.service | ms.subservice | ms.topic | f1_keywords | helpviewer_keywords | dev_langs | monikerRange | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
FROM clause plus JOIN, APPLY, PIVOT (T-SQL) |
FROM clause plus JOIN, APPLY, PIVOT (Transact-SQL) |
VanMSFT |
vanto |
randolphwest |
03/13/2023 |
sql |
t-sql |
reference |
|
|
TSQL |
>=aps-pdw-2016||=azuresqldb-current||=azure-sqldw-latest||>=sql-server-2016||>=sql-server-linux-2017||=azuresqldb-mi-current |
FROM clause plus JOIN, APPLY, PIVOT (Transact-SQL)
[!INCLUDE sqlserver2016-asdb-asdbmi-asa-pdw]
In Transact-SQL, the FROM clause is available on the following statements:
- DELETE
- UPDATE
- SELECT
The FROM clause is usually required on the SELECT statement. The exception is when no table columns are listed, and the only items listed are literals or variables or arithmetic expressions.
This article also discusses the following keywords that can be used on the FROM clause:
- JOIN
- APPLY
- PIVOT
:::image type=»icon» source=»../../includes/media/topic-link-icon.svg» border=»false»::: Transact-SQL syntax conventions
Syntax
Syntax for SQL Server and Azure SQL Database:
[ FROM { <table_source> } [ , ...n ] ]
<table_source> ::=
{
table_or_view_name [ FOR SYSTEM_TIME <system_time> ] [ [ AS ] table_alias ]
[ <tablesample_clause> ]
[ WITH ( < table_hint > [ [ , ] ...n ] ) ]
| rowset_function [ [ AS ] table_alias ]
[ ( bulk_column_alias [ , ...n ] ) ]
| user_defined_function [ [ AS ] table_alias ]
| OPENXML <openxml_clause>
| derived_table [ [ AS ] table_alias ] [ ( column_alias [ , ...n ] ) ]
| <joined_table>
| <pivoted_table>
| <unpivoted_table>
| @variable [ [ AS ] table_alias ]
| @variable.function_call ( expression [ , ...n ] )
[ [ AS ] table_alias ] [ (column_alias [ , ...n ] ) ]
}
<tablesample_clause> ::=
TABLESAMPLE [ SYSTEM ] ( sample_number [ PERCENT | ROWS ] )
[ REPEATABLE ( repeat_seed ) ]
<joined_table> ::=
{
<table_source> <join_type> <table_source> ON <search_condition>
| <table_source> CROSS JOIN <table_source>
| left_table_source { CROSS | OUTER } APPLY right_table_source
| [ ( ] <joined_table> [ ) ]
}
<join_type> ::=
[ { INNER | { { LEFT | RIGHT | FULL } [ OUTER ] } } [ <join_hint> ] ]
JOIN
<pivoted_table> ::=
table_source PIVOT <pivot_clause> [ [ AS ] table_alias ]
<pivot_clause> ::=
( aggregate_function ( value_column [ [ , ] ...n ] )
FOR pivot_column
IN ( <column_list> )
)
<unpivoted_table> ::=
table_source UNPIVOT <unpivot_clause> [ [ AS ] table_alias ]
<unpivot_clause> ::=
( value_column FOR pivot_column IN ( <column_list> ) )
<column_list> ::=
column_name [ , ...n ]
<system_time> ::=
{
AS OF <date_time>
| FROM <start_date_time> TO <end_date_time>
| BETWEEN <start_date_time> AND <end_date_time>
| CONTAINED IN (<start_date_time> , <end_date_time>)
| ALL
}
<date_time>::=
<date_time_literal> | @date_time_variable
<start_date_time>::=
<date_time_literal> | @date_time_variable
<end_date_time>::=
<date_time_literal> | @date_time_variable
Syntax for Azure Synapse Analytics and Parallel Data Warehouse:
FROM { <table_source> [ , ...n ] }
<table_source> ::=
{
[ database_name . [ schema_name ] . | schema_name . ] table_or_view_name [ AS ] table_or_view_alias
[ <tablesample_clause> ]
| derived_table [ AS ] table_alias [ ( column_alias [ , ...n ] ) ]
| <joined_table>
}
<tablesample_clause> ::=
TABLESAMPLE ( sample_number [ PERCENT ] ) -- Azure Synapse Analytics Dedicated SQL pool only
<joined_table> ::=
{
<table_source> <join_type> <table_source> ON search_condition
| <table_source> CROSS JOIN <table_source>
| left_table_source { CROSS | OUTER } APPLY right_table_source
| [ ( ] <joined_table> [ ) ]
}
<join_type> ::=
[ INNER ] [ <join hint> ] JOIN
| LEFT [ OUTER ] JOIN
| RIGHT [ OUTER ] JOIN
| FULL [ OUTER ] JOIN
<join_hint> ::=
REDUCE
| REPLICATE
| REDISTRIBUTE
[!INCLUDEsql-server-tsql-previous-offline-documentation]
Arguments
<table_source>
Specifies a table, view, table variable, or derived table source, with or without an alias, to use in the [!INCLUDEtsql] statement. Up to 256 table sources can be used in a statement, although the limit varies depending on available memory and the complexity of other expressions in the query. Individual queries may not support up to 256 table sources.
[!NOTE]
Query performance may suffer with lots of tables referenced in a query. Compilation and optimization time is also affected by additional factors. These include the presence of indexes and indexed views on each <table_source> and the size of the <select_list> in the SELECT statement.
The order of table sources after the FROM keyword doesn’t affect the result set that is returned. [!INCLUDEssNoVersion] returns errors when duplicate names appear in the FROM clause.
table_or_view_name
The name of a table or view.
If the table or view exists in another database on the same instance of [!INCLUDEssNoVersion], use a fully qualified name in the form database.schema.object_name.
If the table or view exists outside the instance of [!INCLUDEssNoVersion]l, use a four-part name in the form linked_server.catalog.schema.object. For more information, see sp_addlinkedserver (Transact-SQL). A four-part name that is constructed by using the OPENDATASOURCE function as the server part of the name can also be used to specify the remote table source. When OPENDATASOURCE is specified, database_name and schema_name may not apply to all data sources and is subject to the capabilities of the OLE DB provider that accesses the remote object.
[AS] table_alias
An alias for table_source that can be used either for convenience or to distinguish a table or view in a self-join or subquery. An alias is frequently a shortened table name used to refer to specific columns of the tables in a join. If the same column name exists in more than one table in the join, [!INCLUDEssNoVersion] may require that the column name is qualified by a table name, view name, or alias to distinguish these columns. The table name can’t be used if an alias is defined.
When a derived table, rowset or table-valued function, or operator clause (such as PIVOT or UNPIVOT) is used, the required table_alias at the end of the clause is the associated table name for all columns, including grouping columns, returned.
WITH (<table_hint> )
Specifies that the query optimizer uses an optimization or locking strategy with this table and for this statement. For more information, see Table Hints (Transact-SQL).
rowset_function
Applies to: [!INCLUDE ssnoversion-md] and [!INCLUDEsqldbesa].
Specifies one of the rowset functions, such as OPENROWSET, which returns an object that can be used instead of a table reference. For more information about a list of rowset functions, see Rowset Functions (Transact-SQL).
Using the OPENROWSET and OPENQUERY functions to specify a remote object depends on the capabilities of the OLE DB provider that accesses the object.
bulk_column_alias
Applies to: [!INCLUDE ssnoversion-md] and [!INCLUDEsqldbesa].
An optional alias to replace a column name in the result set. Column aliases are allowed only in SELECT statements that use the OPENROWSET function with the BULK option. When you use bulk_column_alias, specify an alias for every table column in the same order as the columns in the file.
[!NOTE]
This alias overrides the NAME attribute in the COLUMN elements of an XML format file, if present.
user_defined_function
Specifies a table-valued function.
OPENXML <openxml_clause>
Applies to: [!INCLUDE ssnoversion-md] and [!INCLUDEsqldbesa].
Provides a rowset view over an XML document. For more information, see OPENXML (Transact-SQL).
derived_table
A subquery that retrieves rows from the database. derived_table is used as input to the outer query.
derived_table can use the [!INCLUDEtsql] table value constructor feature to specify multiple rows. For example, SELECT * FROM (VALUES (1, 2), (3, 4), (5, 6), (7, 8), (9, 10) ) AS MyTable(a, b);. For more information, see Table Value Constructor (Transact-SQL).
column_alias
An optional alias to replace a column name in the result set of the derived table. Include one column alias for each column in the select list, and enclose the complete list of column aliases in parentheses.
table_or_view_name FOR SYSTEM_TIME <system_time>
Applies to: [!INCLUDEsssql16-md] and later versions, and [!INCLUDEsqldbesa].
Specifies that a specific version of data is returned from the specified temporal table and its linked system-versioned history table
TABLESAMPLE clause
Applies to: [!INCLUDE ssnoversion-md], [!INCLUDEsqldbesa], and [!INCLUDEssazuresynapse-md].
Specifies that a sample of data from the table is returned. The sample may be approximate. This clause can be used on any primary or joined table in a SELECT or UPDATE statement. TABLESAMPLE can’t be specified with views.
[!NOTE]
When you use TABLESAMPLE against databases that are upgraded to [!INCLUDEssNoVersion], the compatibility level of the database is set to 110 or higher, PIVOT is not allowed in a recursive common table expression (CTE) query. For more information, see ALTER DATABASE Compatibility Level (Transact-SQL).
SYSTEM
An implementation-dependent sampling method specified by ISO standards. In [!INCLUDEssNoVersion], this is the only sampling method available and is applied by default. SYSTEM applies a page-based sampling method in which a random set of pages from the table is chosen for the sample, and all the rows on those pages are returned as the sample subset.
sample_number
An exact or approximate constant numeric expression that represents the percent or number of rows. When specified with PERCENT, sample_number is implicitly converted to a float value; otherwise, it is converted to bigint. PERCENT is the default.
PERCENT
Specifies that a sample_number percent of the rows of the table should be retrieved from the table. When PERCENT is specified, [!INCLUDEssNoVersion] returns an approximate of the percent specified. When PERCENT is specified the sample_number expression must evaluate to a value from 0 to 100.
ROWS
Specifies that approximately sample_number of rows are retrieved. When ROWS is specified, [!INCLUDEssNoVersion] returns an approximation of the number of rows specified. When ROWS is specified, the sample_number expression must evaluate to an integer value greater than zero.
REPEATABLE
Indicates that the selected sample can be returned again. When specified with the same repeat_seed value, [!INCLUDEssNoVersion] returns the same subset of rows as long as no changes have been made to any rows in the table. When specified with a different repeat_seed value, [!INCLUDEssNoVersion] will likely return some different sample of the rows in the table. The following actions to the table are considered changes: insert, update, delete, index rebuild or defragmentation, and database restore or attach.
repeat_seed
A constant integer expression used by [!INCLUDEssNoVersion] to generate a random number. repeat_seed is bigint. If repeat_seed isn’t specified, [!INCLUDEssNoVersion] assigns a value at random. For a specific repeat_seed value, the sampling result is always the same if no changes have been applied to the table. The repeat_seed expression must evaluate to an integer greater than zero.
Joined table
A joined table is a result set that is the product of two or more tables. For multiple joins, use parentheses to change the natural order of the joins.
Join type
Specifies the type of join operation.
INNER
Specifies all matching pairs of rows are returned. Discards unmatched rows from both tables. When no join type is specified, this is the default.
FULL [ OUTER ]
Specifies that a row from either the left or right table that doesn’t meet the join condition is included in the result set, and output columns that correspond to the other table are set to NULL. This is in addition to all rows typically returned by the INNER JOIN.
LEFT [ OUTER ]
Specifies that all rows from the left table not meeting the join condition are included in the result set, and output columns from the other table are set to NULL in addition to all rows returned by the inner join.
RIGHT [ OUTER ]
Specifies all rows from the right table not meeting the join condition are included in the result set, and output columns that correspond to the other table are set to NULL, in addition to all rows returned by the inner join.
Join hint
For [!INCLUDEssNoVersion] and [!INCLUDEssSDS], specifies that the [!INCLUDEssNoVersion] query optimizer uses one join hint, or execution algorithm, per join specified in the query FROM clause. For more information, see Join Hints (Transact-SQL).
For [!INCLUDEssazuresynapse-md] and [!INCLUDEssPDW], these join hints apply to INNER joins on two distribution incompatible columns. They can improve query performance by restricting the amount of data movement that occurs during query processing. The allowable join hints for [!INCLUDEssazuresynapse-md] and [!INCLUDEssPDW] are as follows:
REDUCE
Reduces the number of rows to be moved for the table on the right side of the join in order to make two distribution incompatible tables compatible. The REDUCE hint is also called a semi-join hint.
REPLICATE
Causes the values in the joining column from the table on the left side of the join to be replicated to all nodes. The table on the right is joined to the replicated version of those columns.
REDISTRIBUTE
Forces two data sources to be distributed on columns specified in the JOIN clause. For a distributed table, [!INCLUDEssPDW] performs a shuffle move. For a replicated table, [!INCLUDEssPDW] performs a trim move. To understand these move types, see the «DMS Query Plan Operations» section in the «Understanding Query Plans» article in the [!INCLUDEpdw-product-documentation]. This hint can improve performance when the query plan is using a broadcast move to resolve a distribution incompatible join.
JOIN
Indicates that the specified join operation should occur between the specified table sources or views.
ON <search_condition>
Specifies the condition on which the join is based. The condition can specify any predicate, although columns and comparison operators are frequently used, for example:
SELECT p.ProductID, v.BusinessEntityID FROM Production.Product AS p INNER JOIN Purchasing.ProductVendor AS v ON (p.ProductID = v.ProductID);
When the condition specifies columns, the columns don’t have to have the same name or same data type; however, if the data types aren’t the same, they must be either compatible or types that [!INCLUDEssNoVersion] can implicitly convert. If the data types can’t be implicitly converted, the condition must explicitly convert the data type by using the CONVERT function.
There can be predicates that involve only one of the joined tables in the ON clause. Such predicates also can be in the WHERE clause in the query. Although the placement of such predicates doesn’t make a difference for INNER joins, they might cause a different result when OUTER joins are involved. This is because the predicates in the ON clause are applied to the table before the join, whereas the WHERE clause is semantically applied to the result of the join.
For more information about search conditions and predicates, see Search Condition (Transact-SQL).
CROSS JOIN
Specifies the cross-product of two tables. Returns the same rows as if no WHERE clause was specified in an old-style, non-SQL-92-style join.
left_table_source { CROSS | OUTER } APPLY right_table_source
Specifies that the right_table_source of the APPLY operator is evaluated against every row of the left_table_source. This functionality is useful when the right_table_source contains a table-valued function that takes column values from the left_table_source as one of its arguments.
Either CROSS or OUTER must be specified with APPLY. When CROSS is specified, no rows are produced when the right_table_source is evaluated against a specified row of the left_table_source and returns an empty result set.
When OUTER is specified, one row is produced for each row of the left_table_source even when the right_table_source evaluates against that row and returns an empty result set.
For more information, see the Remarks section.
left_table_source
A table source as defined in the previous argument. For more information, see the Remarks section.
right_table_source
A table source as defined in the previous argument. For more information, see the Remarks section.
PIVOT clause
table_source PIVOT <pivot_clause>
Specifies that the table_source is pivoted based on the pivot_column. table_source is a table or table expression. The output is a table that contains all columns of the table_source except the pivot_column and value_column. The columns of the table_source, except the pivot_column and value_column, are called the grouping columns of the pivot operator. For more information about PIVOT and UNPIVOT, see Using PIVOT and UNPIVOT.
PIVOT performs a grouping operation on the input table with regard to the grouping columns and returns one row for each group. Additionally, the output contains one column for each value specified in the column_list that appears in the pivot_column of the input_table.
For more information, see the Remarks section that follows.
aggregate_function
A system or user-defined aggregate function that accepts one or more inputs. The aggregate function should be invariant to null values. An aggregate function invariant to null values doesn’t consider null values in the group while it is evaluating the aggregate value.
The COUNT(*) system aggregate function isn’t allowed.
value_column
The value column of the PIVOT operator. When used with UNPIVOT, value_column can’t be the name of an existing column in the input table_source.
FOR pivot_column
The pivot column of the PIVOT operator. pivot_column must be of a type implicitly or explicitly convertible to nvarchar(). This column can’t be image or rowversion.
When UNPIVOT is used, pivot_column is the name of the output column that becomes narrowed from the table_source. There can’t be an existing column in table_source with that name.
IN ( column_list )
In the PIVOT clause, lists the values in the pivot_column that becomes the column names of the output table. The list can’t specify any column names that already exist in the input table_source that is being pivoted.
In the UNPIVOT clause, lists the columns in table_source that is narrowed into a single pivot_column.
table_alias
The alias name of the output table. pivot_table_alias must be specified.
UNPIVOT <unpivot_clause>
Specifies that the input table is narrowed from multiple columns in column_list into a single column called pivot_column. For more information about PIVOT and UNPIVOT, see Using PIVOT and UNPIVOT.
AS OF <date_time>
Applies to: [!INCLUDEsssql16-md] and later versions, and [!INCLUDEsqldbesa].
Returns a table with single record for each row containing the values that were actual (current) at the specified point in time in the past. Internally, a union is performed between the temporal table and its history table and the results are filtered to return the values in the row that was valid at the point in time specified by the <date_time> parameter. The value for a row is deemed valid if the system_start_time_column_name value is less than or equal to the <date_time> parameter value and the system_end_time_column_name value is greater than the <date_time> parameter value.
FROM <start_date_time> TO <end_date_time>
Applies to: [!INCLUDEsssql16-md] and later versions, and [!INCLUDEsqldbesa].
Returns a table with the values for all record versions that were active within the specified time range, regardless of whether they started being active before the <start_date_time> parameter value for the FROM argument or ceased being active after the <end_date_time> parameter value for the TO argument. Internally, a union is performed between the temporal table and its history table and the results are filtered to return the values for all row versions that were active at any time during the time range specified. Rows that became active exactly on the lower boundary defined by the FROM endpoint are included and rows that became active exactly on the upper boundary defined by the TO endpoint aren’t included.
BETWEEN <start_date_time> AND <end_date_time>
Applies to: [!INCLUDEsssql16-md] and later versions, and [!INCLUDEsqldbesa].
Same as above in the FROM <start_date_time> TO <end_date_time> description, except it includes rows that became active on the upper boundary defined by the <end_date_time> endpoint.
CONTAINED IN (<start_date_time> , <end_date_time>)
Applies to: [!INCLUDEsssql16-md] and later versions, and [!INCLUDEsqldbesa].
Returns a table with the values for all record versions that were opened and closed within the specified time range defined by the two datetime values for the CONTAINED IN argument. Rows that became active exactly on the lower boundary or ceased being active exactly on the upper boundary are included.
ALL
Returns a table with the values from all rows from both the current table and the history table.
Remarks
The FROM clause supports the SQL-92 syntax for joined tables and derived tables. SQL-92 syntax provides the INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER, and CROSS join operators.
UNION and JOIN within a FROM clause are supported within views and in derived tables and subqueries.
A self-join is a table that is joined to itself. Insert or update operations that are based on a self-join follow the order in the FROM clause.
Because [!INCLUDEssNoVersion] considers distribution and cardinality statistics from linked servers that provide column distribution statistics, the REMOTE join hint isn’t required to force evaluating a join remotely. The [!INCLUDEssNoVersion] query processor considers remote statistics and determines whether a remote-join strategy is appropriate. REMOTE join hint is useful for providers that don’t provide column distribution statistics.
Use APPLY
Both the left and right operands of the APPLY operator are table expressions. The main difference between these operands is that the right_table_source can use a table-valued function that takes a column from the left_table_source as one of the arguments of the function. The left_table_source can include table-valued functions, but it can’t contain arguments that are columns from the right_table_source.
The APPLY operator works in the following way to produce the table source for the FROM clause:
-
Evaluates right_table_source against each row of the left_table_source to produce rowsets.
The values in the right_table_source depend on left_table_source. right_table_source can be represented approximately this way:
TVF(left_table_source.row), whereTVFis a table-valued function. -
Combines the result sets that are produced for each row in the evaluation of right_table_source with the left_table_source by performing a UNION ALL operation.
The list of columns produced by the result of the APPLY operator is the set of columns from the left_table_source that is combined with the list of columns from the right_table_source.
Use PIVOT and UNPIVOT
The pivot_column and value_column are grouping columns that are used by the PIVOT operator. PIVOT follows the following process to obtain the output result set:
-
Performs a GROUP BY on its input_table against the grouping columns and produces one output row for each group.
The grouping columns in the output row obtain the corresponding column values for that group in the input_table.
-
Generates values for the columns in the column list for each output row by performing the following:
-
Grouping additionally the rows generated in the GROUP BY in the previous step against the pivot_column.
For each output column in the column_list, selecting a subgroup that satisfies the condition:
pivot_column = CONVERT(<data type of pivot_column>, 'output_column') -
aggregate_function is evaluated against the value_column on this subgroup and its result is returned as the value of the corresponding output_column. If the subgroup is empty, [!INCLUDEssNoVersion] generates a null value for that output_column. If the aggregate function is COUNT and the subgroup is empty, zero (0) is returned.
-
[!NOTE]
The column identifiers in theUNPIVOTclause follow the catalog collation. For [!INCLUDEssSDS_md], the collation is alwaysSQL_Latin1_General_CP1_CI_AS. For [!INCLUDEssNoVersion_md] partially contained databases, the collation is alwaysLatin1_General_100_CI_AS_KS_WS_SC. If the column is combined with other columns, then a collate clause (COLLATE DATABASE_DEFAULT) is required to avoid conflicts.
For more information about PIVOT and UNPIVOT including examples, see Using PIVOT and UNPIVOT.
Permissions
Requires the permissions for the DELETE, SELECT, or UPDATE statement.
Examples
A. Use a FROM clause
The following example retrieves the TerritoryID and Name columns from the SalesTerritory table in the [!INCLUDEssSampleDBnormal] sample database.
SELECT TerritoryID, Name FROM Sales.SalesTerritory ORDER BY TerritoryID;
[!INCLUDEssResult]
TerritoryID Name
----------- ------------------------------
1 Northwest
2 Northeast
3 Central
4 Southwest
5 Southeast
6 Canada
7 France
8 Germany
9 Australia
10 United Kingdom
(10 row(s) affected)
B. Use the TABLOCK and HOLDLOCK optimizer hints
The following partial transaction shows how to place an explicit shared table lock on Employee and how to read the index. The lock is held throughout the whole transaction.
BEGIN TRANSACTION SELECT COUNT(*) FROM HumanResources.Employee WITH (TABLOCK, HOLDLOCK);
C. Use the SQL-92 CROSS JOIN syntax
The following example returns the cross product of the two tables Employee and Department in the [!INCLUDEssSampleDBnormal] database. A list of all possible combinations of BusinessEntityID rows and all Department name rows are returned.
SELECT e.BusinessEntityID, d.Name AS Department FROM HumanResources.Employee AS e CROSS JOIN HumanResources.Department AS d ORDER BY e.BusinessEntityID, d.Name;
D. Use the SQL-92 FULL OUTER JOIN syntax
The following example returns the product name and any corresponding sales orders in the SalesOrderDetail table in the [!INCLUDEssSampleDBnormal] database. It also returns any sales orders that have no product listed in the Product table, and any products with a sales order other than the one listed in the Product table.
-- The OUTER keyword following the FULL keyword is optional. SELECT p.Name, sod.SalesOrderID FROM Production.Product AS p FULL JOIN Sales.SalesOrderDetail AS sod ON p.ProductID = sod.ProductID ORDER BY p.Name;
E. Use the SQL-92 LEFT OUTER JOIN syntax
The following example joins two tables on ProductID and preserves the unmatched rows from the left table. The Product table is matched with the SalesOrderDetail table on the ProductID columns in each table. All products, ordered and not ordered, appear in the result set.
SELECT p.Name, sod.SalesOrderID FROM Production.Product AS p LEFT OUTER JOIN Sales.SalesOrderDetail AS sod ON p.ProductID = sod.ProductID ORDER BY p.Name;
F. Use the SQL-92 INNER JOIN syntax
The following example returns all product names and sales order IDs.
-- By default, SQL Server performs an INNER JOIN if only the JOIN -- keyword is specified. SELECT p.Name, sod.SalesOrderID FROM Production.Product AS p INNER JOIN Sales.SalesOrderDetail AS sod ON p.ProductID = sod.ProductID ORDER BY p.Name;
G. Use the SQL-92 RIGHT OUTER JOIN syntax
The following example joins two tables on TerritoryID and preserves the unmatched rows from the right table. The SalesTerritory table is matched with the SalesPerson table on the TerritoryID column in each table. All salespersons appear in the result set, whether or not they are assigned a territory.
SELECT st.Name AS Territory, sp.BusinessEntityID FROM Sales.SalesTerritory AS st RIGHT OUTER JOIN Sales.SalesPerson AS sp ON st.TerritoryID = sp.TerritoryID;
H. Use HASH and MERGE join hints
The following example performs a three-table join among the Product, ProductVendor, and Vendor tables to produce a list of products and their vendors. The query optimizer joins Product and ProductVendor (p and pv) by using a MERGE join. Next, the results of the Product and ProductVendor MERGE join (p and pv) are HASH joined to the Vendor table to produce (p and pv) and v.
[!IMPORTANT]
After a join hint is specified, the INNER keyword is no longer optional and must be explicitly stated for an INNER JOIN to be performed.
SELECT p.Name AS ProductName, v.Name AS VendorName FROM Production.Product AS p INNER MERGE JOIN Purchasing.ProductVendor AS pv ON p.ProductID = pv.ProductID INNER HASH JOIN Purchasing.Vendor AS v ON pv.BusinessEntityID = v.BusinessEntityID ORDER BY p.Name, v.Name;
I. Use a derived table
The following example uses a derived table, a SELECT statement after the FROM clause, to return the first and last names of all employees and the cities in which they live.
SELECT RTRIM(p.FirstName) + ' ' + LTRIM(p.LastName) AS Name, d.City FROM Person.Person AS p INNER JOIN HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID INNER JOIN ( SELECT bea.BusinessEntityID, a.City FROM Person.Address AS a INNER JOIN Person.BusinessEntityAddress AS bea ON a.AddressID = bea.AddressID ) AS d ON p.BusinessEntityID = d.BusinessEntityID ORDER BY p.LastName, p.FirstName;
J. Use TABLESAMPLE to read data from a sample of rows in a table
The following example uses TABLESAMPLE in the FROM clause to return approximately 10 percent of all the rows in the Customer table.
SELECT * FROM Sales.Customer TABLESAMPLE SYSTEM(10 PERCENT);
K. Use APPLY
The following example assumes that the following tables and table-valued function exist in the database:
| Object Name | Column Names |
|---|---|
| Departments | DeptID, DivisionID, DeptName, DeptMgrID |
| EmpMgr | MgrID, EmpID |
| Employees | EmpID, EmpLastName, EmpFirstName, EmpSalary |
| GetReports(MgrID) | EmpID, EmpLastName, EmpSalary |
The GetReports table-valued function, returns the list of all employees that report directly or indirectly to the specified MgrID.
The example uses APPLY to return all departments and all employees in that department. If a particular department doesn’t have any employees, there won’t be any rows returned for that department.
SELECT DeptID, DeptName, DeptMgrID, EmpID, EmpLastName, EmpSalary FROM Departments d CROSS APPLY dbo.GetReports(d.DeptMgrID);
If you want the query to produce rows for those departments without employees, which will produce null values for the EmpID, EmpLastName and EmpSalary columns, use OUTER APPLY instead.
SELECT DeptID, DeptName, DeptMgrID, EmpID, EmpLastName, EmpSalary FROM Departments d OUTER APPLY dbo.GetReports(d.DeptMgrID);
L. Use CROSS APPLY
The following example retrieves a snapshot of all query plans residing in the plan cache, by querying the sys.dm_exec_cached_plans dynamic management view to retrieve the plan handles of all query plans in the cache. Then the CROSS APPLY operator is specified to pass the plan handles to sys.dm_exec_query_plan. The XML Showplan output for each plan currently in the plan cache is in the query_plan column of the table that is returned.
USE master; GO SELECT dbid, object_id, query_plan FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle); GO
M. Use FOR SYSTEM_TIME
Applies to: [!INCLUDEsssql16-md] and later versions, and [!INCLUDEsqldbesa].
The following example uses the FOR SYSTEM_TIME AS OF date_time_literal_or_variable argument to return table rows that were actual (current) as of January 1, 2014.
SELECT DepartmentNumber, DepartmentName, ManagerID, ParentDepartmentNumber FROM DEPARTMENT FOR SYSTEM_TIME AS OF '2014-01-01' WHERE ManagerID = 5;
The following example uses the FOR SYSTEM_TIME FROM date_time_literal_or_variable TO date_time_literal_or_variable argument to return all rows that were active during the period defined as starting with January 1, 2013 and ending with January 1, 2014, exclusive of the upper boundary.
SELECT DepartmentNumber, DepartmentName, ManagerID, ParentDepartmentNumber FROM DEPARTMENT FOR SYSTEM_TIME FROM '2013-01-01' TO '2014-01-01' WHERE ManagerID = 5;
The following example uses the FOR SYSTEM_TIME BETWEEN date_time_literal_or_variable AND date_time_literal_or_variable argument to return all rows that were active during the period defined as starting with January 1, 2013 and ending with January 1, 2014, inclusive of the upper boundary.
SELECT DepartmentNumber, DepartmentName, ManagerID, ParentDepartmentNumber FROM DEPARTMENT FOR SYSTEM_TIME BETWEEN '2013-01-01' AND '2014-01-01' WHERE ManagerID = 5;
The following example uses the FOR SYSTEM_TIME CONTAINED IN (date_time_literal_or_variable, date_time_literal_or_variable) argument to return all rows that were opened and closed during the period defined as starting with January 1, 2013 and ending with January 1, 2014.
SELECT DepartmentNumber, DepartmentName, ManagerID, ParentDepartmentNumber FROM DEPARTMENT FOR SYSTEM_TIME CONTAINED IN ('2013-01-01', '2014-01-01') WHERE ManagerID = 5;
The following example uses a variable rather than a literal to provide the date boundary values for the query.
DECLARE @AsOfFrom DATETIME2 = DATEADD(month, -12, SYSUTCDATETIME()); DECLARE @AsOfTo DATETIME2 = DATEADD(month, -6, SYSUTCDATETIME()); SELECT DepartmentNumber, DepartmentName, ManagerID, ParentDepartmentNumber FROM DEPARTMENT FOR SYSTEM_TIME FROM @AsOfFrom TO @AsOfTo WHERE ManagerID = 5;
Examples: [!INCLUDEssazuresynapse-md] and [!INCLUDEssPDW]
N. Use the INNER JOIN syntax
The following example returns the SalesOrderNumber, ProductKey, and EnglishProductName columns from the FactInternetSales and DimProduct tables where the join key, ProductKey, matches in both tables. The SalesOrderNumber and EnglishProductName columns each exist in one of the tables only, so it isn’t necessary to specify the table alias with these columns, as is shown; these aliases are included for readability. The word AS before an alias name isn’t required but is recommended for readability and to conform to the ANSI standard.
-- Uses AdventureWorks SELECT fis.SalesOrderNumber, dp.ProductKey, dp.EnglishProductName FROM FactInternetSales AS fis INNER JOIN DimProduct AS dp ON dp.ProductKey = fis.ProductKey;
Since the INNER keyword isn’t required for inner joins, this same query could be written as:
-- Uses AdventureWorks SELECT fis.SalesOrderNumber, dp.ProductKey, dp.EnglishProductName FROM FactInternetSales AS fis INNER JOIN DimProduct AS dp ON dp.ProductKey = fis.ProductKey;
A WHERE clause could also be used with this query to limit results. This example limits results to SalesOrderNumber values higher than ‘SO5000’:
-- Uses AdventureWorks SELECT fis.SalesOrderNumber, dp.ProductKey, dp.EnglishProductName FROM FactInternetSales AS fis INNER JOIN DimProduct AS dp ON dp.ProductKey = fis.ProductKey WHERE fis.SalesOrderNumber > 'SO50000' ORDER BY fis.SalesOrderNumber;
O. Use the LEFT OUTER JOIN and RIGHT OUTER JOIN syntax
The following example joins the FactInternetSales and DimProduct tables on the ProductKey columns. The left outer join syntax preserves the unmatched rows from the left (FactInternetSales) table. Since the FactInternetSales table doesn’t contain any ProductKey values that don’t match the DimProduct table, this query returns the same rows as the first inner join example earlier in this article.
-- Uses AdventureWorks SELECT fis.SalesOrderNumber, dp.ProductKey, dp.EnglishProductName FROM FactInternetSales AS fis LEFT OUTER JOIN DimProduct AS dp ON dp.ProductKey = fis.ProductKey;
This query could also be written without the OUTER keyword.
In right outer joins, the unmatched rows from the right table are preserved. The following example returns the same rows as the left outer join example above.
-- Uses AdventureWorks SELECT fis.SalesOrderNumber, dp.ProductKey, dp.EnglishProductName FROM DimProduct AS dp RIGHT OUTER JOIN FactInternetSales AS fis ON dp.ProductKey = fis.ProductKey;
The following query uses the DimSalesTerritory table as the left table in a left outer join. It retrieves the SalesOrderNumber values from the FactInternetSales table. If there are no orders for a particular SalesTerritoryKey, the query returns a NULL for the SalesOrderNumber for that row. This query is ordered by the SalesOrderNumber column, so that any NULLs in this column appear at the top of the results.
-- Uses AdventureWorks SELECT dst.SalesTerritoryKey, dst.SalesTerritoryRegion, fis.SalesOrderNumber FROM DimSalesTerritory AS dst LEFT OUTER JOIN FactInternetSales AS fis ON dst.SalesTerritoryKey = fis.SalesTerritoryKey ORDER BY fis.SalesOrderNumber;
This query could be rewritten with a right outer join to retrieve the same results:
-- Uses AdventureWorks SELECT dst.SalesTerritoryKey, dst.SalesTerritoryRegion, fis.SalesOrderNumber FROM FactInternetSales AS fis RIGHT OUTER JOIN DimSalesTerritory AS dst ON fis.SalesTerritoryKey = dst.SalesTerritoryKey ORDER BY fis.SalesOrderNumber;
P. Use the FULL OUTER JOIN syntax
The following example demonstrates a full outer join, which returns all rows from both joined tables but returns NULL for values that don’t match from the other table.
-- Uses AdventureWorks SELECT dst.SalesTerritoryKey, dst.SalesTerritoryRegion, fis.SalesOrderNumber FROM DimSalesTerritory AS dst FULL JOIN FactInternetSales AS fis ON dst.SalesTerritoryKey = fis.SalesTerritoryKey ORDER BY fis.SalesOrderNumber;
This query could also be written without the OUTER keyword.
-- Uses AdventureWorks SELECT dst.SalesTerritoryKey, dst.SalesTerritoryRegion, fis.SalesOrderNumber FROM DimSalesTerritory AS dst FULL JOIN FactInternetSales AS fis ON dst.SalesTerritoryKey = fis.SalesTerritoryKey ORDER BY fis.SalesOrderNumber;
Q. Use the CROSS JOIN syntax
The following example returns the cross-product of the FactInternetSales and DimSalesTerritory tables. A list of all possible combinations of SalesOrderNumber and SalesTerritoryKey are returned. Notice the absence of the ON clause in the cross join query.
-- Uses AdventureWorks SELECT dst.SalesTerritoryKey, fis.SalesOrderNumber FROM DimSalesTerritory AS dst CROSS JOIN FactInternetSales AS fis ORDER BY fis.SalesOrderNumber;
R. Use a derived table
The following example uses a derived table (a SELECT statement after the FROM clause) to return the CustomerKey and LastName columns of all customers in the DimCustomer table with BirthDate values later than January 1, 1970 and the last name ‘Smith’.
-- Uses AdventureWorks SELECT CustomerKey, LastName FROM ( SELECT * FROM DimCustomer WHERE BirthDate > '01/01/1970' ) AS DimCustomerDerivedTable WHERE LastName = 'Smith' ORDER BY LastName;
S. REDUCE join hint example
The following example uses the REDUCE join hint to alter the processing of the derived table within the query. When using the REDUCE join hint in this query, the fis.ProductKey is projected, replicated and made distinct, and then joined to DimProduct during the shuffle of DimProduct on ProductKey. The resulting derived table is distributed on fis.ProductKey.
-- Uses AdventureWorks SELECT SalesOrderNumber FROM ( SELECT fis.SalesOrderNumber, dp.ProductKey, dp.EnglishProductName FROM DimProduct AS dp INNER REDUCE JOIN FactInternetSales AS fis ON dp.ProductKey = fis.ProductKey ) AS dTable ORDER BY SalesOrderNumber;
T. REPLICATE join hint example
This next example shows the same query as the previous example, except that a REPLICATE join hint is used instead of the REDUCE join hint. Use of the REPLICATE hint causes the values in the ProductKey (joining) column from the FactInternetSales table to be replicated to all nodes. The DimProduct table is joined to the replicated version of those values.
-- Uses AdventureWorks SELECT SalesOrderNumber FROM ( SELECT fis.SalesOrderNumber, dp.ProductKey, dp.EnglishProductName FROM DimProduct AS dp INNER REPLICATE JOIN FactInternetSales AS fis ON dp.ProductKey = fis.ProductKey ) AS dTable ORDER BY SalesOrderNumber;
U. Use the REDISTRIBUTE hint to guarantee a Shuffle move for a distribution incompatible join
The following query uses the REDISTRIBUTE query hint on a distribution incompatible join. This guarantees the query optimizer uses a Shuffle move in the query plan. This also guarantees the query plan won’t use a Broadcast move, which moves a distributed table to a replicated table.
In the following example, the REDISTRIBUTE hint forces a Shuffle move on the FactInternetSales table because ProductKey is the distribution column for DimProduct, and isn’t the distribution column for FactInternetSales.
-- Uses AdventureWorks SELECT dp.ProductKey, fis.SalesOrderNumber, fis.TotalProductCost FROM DimProduct AS dp INNER REDISTRIBUTE JOIN FactInternetSales AS fis ON dp.ProductKey = fis.ProductKey;
V. Use TABLESAMPLE to read data from a sample of rows in a table
The following example uses TABLESAMPLE in the FROM clause to return approximately 10 percent of all the rows in the Customer table.
SELECT * FROM Sales.Customer TABLESAMPLE SYSTEM(10 PERCENT);
See also
- CONTAINSTABLE (Transact-SQL)
- FREETEXTTABLE (Transact-SQL)
- INSERT (Transact-SQL)
- OPENQUERY (Transact-SQL)
- OPENROWSET (Transact-SQL)
- Operators (Transact-SQL)
- WHERE (Transact-SQL)
В этом учебном пособии вы узнаете, как использовать FROM в SQL Server (Transact-SQL) с синтаксисом и примерами.
Описание
Оператор FROM SQL Server (Transact-SQL) FROM используется для отображения таблиц и любых объединений, необходимых для запроса в SQL Server.
Синтаксис
Синтаксис FROM в SQL Server (Transact-SQL):
FROM table1
[ { INNER JOIN
| LEFT OUTER JOIN
| RIGHT OUTER JOIN
| FULL OUTER JOIN } table2
ON table1.column1 = table2.column1 ]
Параметры или аргументы
table1 и table2 — таблицы, используемые в SQL предложении. Эти две таблицы объединены на основе table1.column1 = table2.column1.
Примечание
- Должна быть хотя бы одна таблица, указанная в FROM в SQL Server (Transact-SQL).
- Если в FROM есть две или более таблиц, эти таблицы обычно объединяются в FROM с использованием соединений INNER join или OUTER join. Хотя таблицы также могут быть объединены с использованием старого синтаксиса в предложении WHERE, мы рекомендуем использовать новые стандарты и включить вашу информацию о соединении в предложение FROM. Дополнительную информацию см. в разделе joins SQL Server.
Пример с одной таблицей
Трудно объяснить синтаксис предложения SQL Server FROM, поэтому давайте рассмотрим некоторые примеры.
Мы начнем с рассмотрения того, как использовать FROM только с одной таблицей.
Например:
|
SELECT * FROM employees WHERE first_name = ‘Юлия’; |
В этом примере SQL-запроса мы использовали предложение FROM, чтобы отобразить таблицу, называемую employees. Никаких объединений не выполняется, поскольку мы используем только одну таблицу.
Пример двух таблиц с INNER JOIN
Рассмотрим, как использовать FROM с двумя таблицами и INNER JOIN.
Например:
|
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
В этом примере SQL-запроса используется предложение FROM для отображения двух таблиц — suppliers и orders. И мы используем предложение FROM, чтобы в INNER JOIN указать соединение между таблицами suppliers и orders на основе столбца supplier_id в обеих таблицах.
Пример двух таблиц с OUTER JOIN
Рассмотрим, как использовать предложение FROM, когда мы объединяем вместе две таблицы с помощью OUTER JOIN. В этом случае мы рассмотрим LEFT OUTER JOIN.
Например:
|
SELECT employees.employee_id, contacts.last_name FROM employees LEFT OUTER JOIN contacts ON employees.employee_id = contacts.contact_id WHERE employees.first_name = ‘Юлия’; |
В этом примере SQL-запроса используется предложение FROM для отображения двух таблиц — employees и contacts. И мы используем предложение FROM, чтобы указать LEFT OUTER JOIN между таблицами employees и contacts на основе столбца employee_id в обеих таблицах.
❮ SQL Справочник Ключевых слов
FROM
Команда FROM используется для указания того, из какой таблицы следует выбрать или удалить данные.
Следующая инструкция SQL выбирает столбцы «CustomerName» и «City» из таблицы «Customers»:
Следующая инструкция SQL выбирает все столбцы из таблицы «Customers»:
Следующая инструкция SQL удаляет клиента «Alfreds Futterkiste» из таблицы «Customers»:
Пример
DELETE FROM Customers
WHERE CustomerName=’Alfreds Futterkiste’;
Попробуйте сами »
❮ SQL Справочник Ключевых слов
From Wikipedia, the free encyclopedia
The SQL From clause is the source of a rowset to be operated upon in a Data Manipulation Language (DML) statement. From clauses are very common, and will provide the rowset to be exposed through a Select statement, the source of values in an Update statement, and the target rows to be deleted in a Delete statement.
[1]
FROM is an SQL reserved word in the SQL standard. [2]
The FROM clause is used in conjunction with SQL statements, and takes the following general form:
SQL-DML-Statement FROM table_name WHERE predicate
The From clause can generally be anything that returns a rowset, a table, view, function, or system-provided information like the Information Schema, which is typically running proprietary commands and returning the information in a table form.[3]
Examples[edit]
The following query returns only those rows from table mytable where the value in column mycol is greater than 100.
SELECT * FROM mytable WHERE mycol > 100
Requirement[edit]
The From clause is technically required in relational algebra and in most scenarios to be useful. However many relational DBMS implementations may not require it for selecting a single value, or single row — known as DUAL table in Oracle database.[4]
Other systems will require a From statement with a keyword, even to select system data.[5]
select to_char(sysdate, 'Dy DD-Mon-YYYY HH24:MI:SS') as "Current Time" from dual;
References[edit]
- ^ «From clause in Transact SQL».
- ^ «Reserved Words in SQL».
- ^ «System Information Schema Views (Transact-SQL)».
- ^ «Selecting from the DUAL Table».
- ^ «Oracle Dates and Times».
Вступление и DDL – Data Definition Language (язык описания данных)
Часть первая — habrahabr.ru/post/255361
DML – Data Manipulation Language (язык манипулирования данными)
В первой части мы уже немного затронули язык DML, применяя почти весь набор его команд, за исключением команды MERGE.
Рассказывать про DML я буду по своей последовательности выработанной на личном опыте. По ходу, так же постараюсь рассказать про «скользкие» места, на которые стоит акцентировать внимание, эти «скользкие» места, схожи во многих диалектах языка SQL.
Т.к. учебник посвящается широкому кругу читателей (не только программистам), то и объяснение, порой будет соответствующее, т.е. долгое и нудное. Это мое видение материала, которое в основном получено на практике в результате профессиональной деятельности.
Основная цель данного учебника, шаг за шагом, выработать полное понимание сути языка SQL и научить правильно применять его конструкции. Профессионалам в этой области, может тоже будет интересно пролистать данный материал, может и они смогут вынести для себя что-то новое, а может просто, будет полезно почитать в целях освежить память. Надеюсь, что всем будет интересно.
Т.к. DML в диалекте БД MS SQL очень сильно связан с синтаксисом конструкции SELECT, то я начну рассказывать о DML именно с нее. На мой взгляд конструкция SELECT является самой главной конструкцией языка DML, т.к. за счет нее или ее частей осуществляется выборка необходимых данных из БД.
Язык DML содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
В данной части, мы рассмотрим, только базовый синтаксис команды SELECT, который выглядит следующим образом:
SELECT [DISTINCT] список_столбцов или *
FROM источник
WHERE фильтр
ORDER BY выражение_сортировки
Тема оператора SELECT очень обширная, поэтому в данной части я и остановлюсь только на его базовых конструкциях. Я считаю, что, не зная хорошо базы, нельзя приступать к изучению более сложных конструкций, т.к. дальше все будет крутиться вокруг этой базовой конструкции (подзапросы, объединения и т.д.).
Также в рамках этой части, я еще расскажу о предложении TOP. Это предложение я намерено не указал в базовом синтаксисе, т.к. оно реализуется по-разному в разных диалектах языка SQL.
Если язык DDL больше статичен, т.е. при помощи него создаются жесткие структуры (таблицы, связи и т.п.), то язык DML носит динамический характер, здесь правильные результаты вы можете получить разными путями.
Обучение так же будет продолжаться в режиме Step by Step, т.е. при чтении нужно сразу же своими руками пытаться выполнить пример. После делаете анализ полученного результата и пытаетесь понять его интуитивно. Если что-то остается непонятным, например, значение какой-нибудь функции, то обращайтесь за помощью в интернет.
Примеры будут показываться на БД Test, которая была создана при помощи DDL+DML в первой части.
Для тех, кто не создавал БД в первой части (т.к. не всех может интересовать язык DDL), может воспользоваться следующим скриптом:
Скрипт создания БД Test
-- создание БД
CREATE DATABASE Test
GO
-- сделать БД Test текущей
USE Test
GO
-- создаем таблицы справочники
CREATE TABLE Positions(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
CREATE TABLE Departments(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
GO
-- заполняем таблицы справочники данными
SET IDENTITY_INSERT Positions ON
INSERT Positions(ID,Name)VALUES
(1,N'Бухгалтер'),
(2,N'Директор'),
(3,N'Программист'),
(4,N'Старший программист')
SET IDENTITY_INSERT Positions OFF
GO
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name)VALUES
(1,N'Администрация'),
(2,N'Бухгалтерия'),
(3,N'ИТ')
SET IDENTITY_INSERT Departments OFF
GO
-- создаем таблицу с сотрудниками
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name)
)
GO
-- заполняем ее данными
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1,NULL),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3,1003),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2,1000),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3,1000)
Все, теперь мы готовы приступить к изучению языка DML.
SELECT – оператор выборки данных
Первым делом, для активного редактора запроса, сделаем текущей БД Test, выбрав ее в выпадающем списке или же командой «USE Test».
Начнем с самой элементарной формы SELECT:
SELECT *
FROM Employees
В данном запросе мы просим вернуть все столбцы (на это указывает «*») из таблицы Employees – можно прочесть это как «ВЫБЕРИ все_поля ИЗ таблицы_сотрудники». В случае наличия кластерного индекса, возвращенные данные, скорее всего будут отсортированы по нему, в данном случае по колонке ID (но это не суть важно, т.к. в большинстве случаев сортировку мы будем указывать в явном виде сами при помощи ORDER BY …):
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | ManagerID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 | NULL |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 | 1003 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 | 1000 |
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 | 1000 |
Вообще стоит сказать, что в диалекте MS SQL самая простая форма запроса SELECT может не содержать блока FROM, в этом случае вы можете использовать ее, для получения каких-то значений:
SELECT
5550/100*15,
SYSDATETIME(), -- получение системной даты БД
SIN(0)+COS(0)
| (No column name) | (No column name) | (No column name) |
|---|---|---|
| 825 | 2015-04-11 12:12:36.0406743 | 1 |
Обратите внимание, что выражение (5550/100*15) дало результат 825, хотя если мы посчитаем на калькуляторе получится значение (832.5). Результат 825 получился по той причине, что в нашем выражении все числа целые, поэтому и результат целое число, т.е. (5550/100) дает нам 55, а не (55.5).
Запомните следующее, что в MS SQL работает следующая логика:
- Целое / Целое = Целое (т.е. в данном случае происходит целочисленное деление)
- Вещественное / Целое = Вещественное
- Целое / Вещественное = Вещественное
Т.е. результат преобразуется к большему типу, поэтому в 2-х последних случаях мы получаем вещественное число (рассуждайте как в математике – диапазон вещественных чисел больше диапазона целых, поэтому и результат преобразуется к нему):
SELECT
123/10, -- 12
123./10, -- 12.3
123/10. -- 12.3
Здесь (123.) = (123.0), просто в данном случае 0 можно отбросить и оставить только точку.
При других арифметических операциях действует та же самая логика, просто в случае деления этот нюанс более актуален.
Поэтому обращайте внимание на тип данных числовых столбцов. В том случае если он целый, а результат вам нужно получить вещественный, то используйте преобразование, либо просто ставьте точку после числа указанного в виде константы (123.).
Для преобразования полей можно использовать функцию CAST или CONVERT. Для примера воспользуемся полем ID, оно у нас типа int:
SELECT
ID,
ID/100, -- здесь произойдет целочисленное деление
CAST(ID AS float)/100, -- используем функцию CAST для преобразования в тип float
CONVERT(float,ID)/100, -- используем функцию CONVERT для преобразования в тип float
ID/100. -- используем преобразование за счет указания что знаменатель вещественное число
FROM Employees
| ID | (No column name) | (No column name) | (No column name) | (No column name) |
|---|---|---|---|---|
| 1000 | 10 | 10 | 10 | 10.000000 |
| 1001 | 10 | 10.01 | 10.01 | 10.010000 |
| 1002 | 10 | 10.02 | 10.02 | 10.020000 |
| 1003 | 10 | 10.03 | 10.03 | 10.030000 |
На заметку. В БД ORACLE синтаксис без блока FROM недопустим, там для этой цели используется системная таблица DUAL, которая содержит одну строку:
SELECT 5550/100*15, -- а в ORACLE результат будет равен 832.5 sysdate, sin(0)+cos(0) FROM DUAL
Примечание. Имя таблицы во многих РБД может предваряться именем схемы:
SELECT * FROM dbo.Employees -- dbo – имя схемыСхема – это логическая единица БД, которая имеет свое наименование и позволяет сгруппировать внутри себя объекты БД такие как таблицы, представления и т.д.
Определение схемы в разных БД может отличатся, где-то схема непосредственно связанна с пользователем БД, т.е. в данном случае можно сказать, что схема и пользователь – это синонимы и все создаваемые в схеме объекты по сути являются объектами данного пользователя. В MS SQL схема – это независимая логическая единица, которая может быть создана сама по себе (см. CREATE SCHEMA).
По умолчанию в базе MS SQL создается одна схема с именем dbo (Database Owner) и все создаваемые объекты по умолчанию создаются именно в данной схеме. Соответственно, если мы в запросе указываем просто имя таблицы, то она будет искаться в схеме dbo текущей БД. Если мы хотим создать объект в конкретной схеме, мы должны будем так же предварить имя объекта именем схемы, например, «CREATE TABLE имя_схемы.имя_таблицы(…)».
В случае MS SQL имя схемы может еще предваряться именем БД, в которой находится данная схема:
SELECT * FROM Test.dbo.Employees -- имя_базы.имя_схемы.таблицаТакое уточнение бывает полезным, например, если:
- в одном запросе мы обращаемся к объектам расположенных в разных схемах или базах данных
- требуется сделать перенос данных из одной схемы или БД в другую
- находясь в одной БД, требуется запросить данные из другой БД
- и т.п.
Схема – очень удобное средство, которое полезно использовать при разработке архитектуры БД, а особенно крупных БД.
Так же не забываем, что в тексте запроса мы можем использовать как однострочные «— …», так и многострочные «/* … */» комментарии. Если запрос большой и сложный, то комментарии могут очень помочь, вам или кому-то другому, через некоторое время, вспомнить или разобраться в его структуре.
Если столбцов в таблице очень много, а особенно, если в таблице еще очень много строк, плюс к тому если мы делаем запросы к БД по сети, то предпочтительней будет выборка с непосредственным перечислением необходимых вам полей через запятую:
SELECT ID,Name
FROM Employees
Т.е. здесь мы говорим, что нам из таблицы нужно вернуть только поля ID и Name. Результат будет следующим (кстати оптимизатор здесь решил воспользоваться индексом, созданным по полю Name):
| ID | Name |
|---|---|
| 1003 | Андреев А.А. |
| 1000 | Иванов И.И. |
| 1001 | Петров П.П. |
| 1002 | Сидоров С.С. |
На заметку. Порой бывает полезным посмотреть на то как осуществляется выборка данных, например, чтобы выяснить какие индексы используются. Это можно сделать если нажать кнопку «Display Estimated Execution Plan – Показать расчетный план» или установить «Include Actual Execution Plan – Включить в результат актуальный план выполнения запроса» (в данном случае мы сможем увидеть уже реальный план, соответственно, только после выполнения запроса):
Анализ плана выполнения очень полезен при оптимизации запроса, он позволяет выяснить каких индексов не хватает или же какие индексы вообще не используются и их можно удалить.
Если вы только начали осваивать DML, то сейчас для вас это не так важно, просто возьмите на заметку и можете спокойно забыть об этом (может это вам никогда и не пригодится) – наша первоначальная цель изучить основы языка DML и научится правильно применять их, а оптимизация это уже отдельное искусство. Порой важнее, чтобы на руках просто был правильно написанный запрос, который возвращает правильные результат с предметной точки зрения, а его оптимизацией уже занимаются отдельные люди. Для начала вам нужно научиться просто правильно писать запросы, используя любые средства для достижения цели. Главная цель которую вы сейчас должны достичь – чтобы ваш запрос возвращал правильные результаты.

Задание псевдонимов для таблиц
При перечислении колонок их можно предварять именем таблицы, находящейся в блоке FROM:
SELECT Employees.ID,Employees.Name
FROM Employees
Но такой синтаксис обычно использовать неудобно, т.к. имя таблицы может быть длинным. Для этих целей обычно задаются и применяются более короткие имена – псевдонимы (alias):
SELECT emp.ID,emp.Name
FROM Employees AS emp
или
SELECT emp.ID,emp.Name
FROM Employees emp -- ключевое слово AS можно отпустить (я предпочитаю такой вариант)
Здесь emp – псевдоним для таблицы Employees, который можно будет использоваться в контексте данного оператора SELECT. Т.е. можно сказать, что в контексте этого оператора SELECT мы задаем таблице новое имя.
Конечно, в данном случае результаты запросов будут точно такими же как и для «SELECT ID,Name FROM Employees». Для чего это нужно будет понятно дальше (даже не в этой части), пока просто запоминаем, что имя колонки можно предварять (уточнять) либо непосредственно именем таблицы, либо при помощи псевдонима. Здесь можно использовать одно из двух, т.е. если вы задали псевдоним, то и пользоваться нужно будет им, а использовать имя таблицы уже нельзя.
На заметку. В ORACLE допустим только вариант задания псевдонима таблицы без ключевого слова AS.
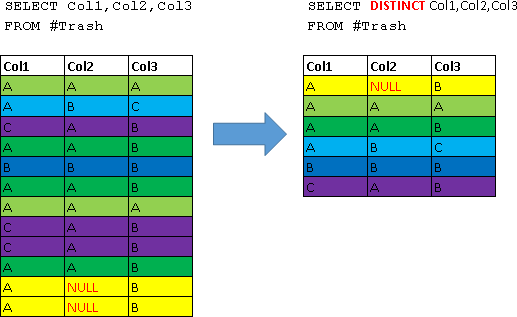
DISTINCT – отброс строк дубликатов
Ключевое слово DISTINCT используется для того чтобы отбросить из результата запроса строки дубликаты. Грубо говоря представьте, что сначала выполняется запрос без опции DISTINCT, а затем из результата выбрасываются все дубликаты. Продемонстрируем это для большей наглядности на примере:
-- создадим для демонстрации временную таблицу
CREATE TABLE #Trash(
ID int NOT NULL PRIMARY KEY,
Col1 varchar(10),
Col2 varchar(10),
Col3 varchar(10)
)
-- наполним данную таблицу всяким мусором
INSERT #Trash(ID,Col1,Col2,Col3)VALUES
(1,'A','A','A'), (2,'A','B','C'), (3,'C','A','B'), (4,'A','A','B'),
(5,'B','B','B'), (6,'A','A','B'), (7,'A','A','A'), (8,'C','A','B'),
(9,'C','A','B'), (10,'A','A','B'), (11,'A',NULL,'B'), (12,'A',NULL,'B')
-- посмотрим что возвращает запрос без опции DISTINCT
SELECT Col1,Col2,Col3
FROM #Trash
-- посмотрим что возвращает запрос с опцией DISTINCT
SELECT DISTINCT Col1,Col2,Col3
FROM #Trash
-- удалим временную таблицу
DROP TABLE #Trash
Наглядно это будет выглядеть следующим образом (все дубликаты помечены одним цветом):
Теперь давайте рассмотрим где это можно применить, на более практичном примере – вернем из таблицы Employees только уникальные идентификаторы отделов (т.е. узнаем ID отделов в которых числятся сотрудники):
SELECT DISTINCT DepartmentID
FROM Employees
| DepartmentID |
|---|
| 1 |
| 2 |
| 3 |
Здесь мы получили три строки, т.к. 2 сотрудника у нас числятся в одном отделе (ИТ).
Теперь узнаем в каких отделах, какие должности фигурируют:
SELECT DISTINCT DepartmentID,PositionID
FROM Employees
| DepartmentID | PositionID |
|---|---|
| 1 | 2 |
| 2 | 1 |
| 3 | 3 |
| 3 | 4 |
Здесь мы получили 4 строчки, т.к. повторяющихся комбинаций (DepartmentID, PositionID) в нашей таблице нет.
Ненадолго вернемся к DDL
Так как данных для демонстрационных примеров начинает не хватать, а рассказать хочется более обширно и понятно, то давайте чуть расширим нашу таблицу Employess. К тому же немного вспомним DDL, как говорится «повторение – мать учения», и плюс снова немного забежим вперед и применим оператор UPDATE:
-- создаем новые колонки
ALTER TABLE Employees ADD
LastName nvarchar(30), -- фамилия
FirstName nvarchar(30), -- имя
MiddleName nvarchar(30), -- отчество
Salary float, -- и конечно же ЗП в каких-то УЕ
BonusPercent float -- процент для вычисления бонуса от оклада
GO
-- наполняем их данными (некоторые данные намерено пропущены)
UPDATE Employees
SET
LastName=N'Иванов',FirstName=N'Иван',MiddleName=N'Иванович',
Salary=5000,BonusPercent= 50
WHERE ID=1000 -- Иванов И.И.
UPDATE Employees
SET
LastName=N'Петров',FirstName=N'Петр',MiddleName=N'Петрович',
Salary=1500,BonusPercent= 15
WHERE ID=1001 -- Петров П.П.
UPDATE Employees
SET
LastName=N'Сидоров',FirstName=N'Сидор',MiddleName=NULL,
Salary=2500,BonusPercent=NULL
WHERE ID=1002 -- Сидоров С.С.
UPDATE Employees
SET
LastName=N'Андреев',FirstName=N'Андрей',MiddleName=NULL,
Salary=2000,BonusPercent= 30
WHERE ID=1003 -- Андреев А.А.
Убедимся, что данные обновились успешно:
SELECT *
FROM Employees
| ID | Name | … | LastName | FirstName | MiddleName | Salary | BonusPercent |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | Иванов | Иван | Иванович | 5000 | 50 | |
| 1001 | Петров П.П. | Петров | Петр | Петрович | 1500 | 15 | |
| 1002 | Сидоров С.С. | Сидоров | Сидор | NULL | 2500 | NULL | |
| 1003 | Андреев А.А. | Андреев | Андрей | NULL | 2000 | 30 |
Задание псевдонимов для столбцов запроса
Думаю, здесь будет проще показать, чем написать:
SELECT
-- даем имя вычисляемому столбцу
LastName+' '+FirstName+' '+MiddleName AS ФИО,
-- использование двойных кавычек, т.к. используется пробел
HireDate AS "Дата приема",
-- использование квадратных скобок, т.к. используется пробел
Birthday AS [Дата рождения],
-- слово AS не обязательно
Salary ZP
FROM Employees
| ФИО | Дата приема | Дата рождения | ZP |
|---|---|---|---|
| Иванов Иван Иванович | 2015-04-08 | 1955-02-19 | 5000 |
| Петров Петр Петрович | 2015-04-08 | 1983-12-03 | 1500 |
| NULL | 2015-04-08 | 1976-06-07 | 2500 |
| NULL | 2015-04-08 | 1982-04-17 | 2000 |
Как видим заданные нами псевдонимы столбцов, отразились в заголовке результирующей таблицы. Собственно, это и есть основное предназначение псевдонимов столбцов.
Обратите внимание, т.к. у последних 2-х сотрудников не указано отчество (NULL значение), то результат выражения «LastName+’ ‘+FirstName+’ ‘+MiddleName» так же вернул нам NULL.
Для соединения (сложения, конкатенации) строк в MS SQL используется символ «+».
Запомним, что все выражения в которых участвует NULL (например, деление на NULL, сложение с NULL) будут возвращать NULL.
На заметку.
В случае ORACLE для объединения строк используется оператор «||» и конкатенация будет выглядеть как «LastName||’ ‘||FirstName||’ ‘||MiddleName». Для ORACLE стоит отметить, что у него для строковых типов есть исключение, для них NULL и пустая строка » это одно и тоже, поэтому в ORACLE такое выражение вернет для последних 2-х сотрудников «Сидоров Сидор » и «Андреев Андрей ». На момент версии ORACLE 12c, насколько я знаю, опции которая изменяет такое поведение нет (если не прав, прошу поправить меня). Здесь мне сложно судить хорошо это или плохо, т.к. в одних случаях удобнее поведение NULL-строки как в MS SQL, а в других как в ORACLE.В ORACLE тоже допустимы все перечисленные выше псевдонимы столбцов, кроме […].
Для того чтобы не городить конструкцию с использованием функции ISNULL, в MS SQL мы можем применить функцию CONCAT. Рассмотрим и сравним 3 варианта:
SELECT
LastName+' '+FirstName+' '+MiddleName FullName1,
-- 2 варианта для замены NULL пустыми строками '' (получаем поведение как и в ORACLE)
ISNULL(LastName,'')+' '+ISNULL(FirstName,'')+' '+ISNULL(MiddleName,'') FullName2,
CONCAT(LastName,' ',FirstName,' ',MiddleName) FullName3
FROM Employees
| FullName1 | FullName2 | FullName3 |
|---|---|---|
| Иванов Иван Иванович | Иванов Иван Иванович | Иванов Иван Иванович |
| Петров Петр Петрович | Петров Петр Петрович | Петров Петр Петрович |
| NULL | Сидоров Сидор | Сидоров Сидор |
| NULL | Андреев Андрей | Андреев Андрей |
В MS SQL псевдонимы еще можно задавать при помощи знака равенства:
SELECT
'Дата приема'=HireDate, -- помимо "…" и […] можно использовать '…'
[Дата рождения]=Birthday,
ZP=Salary
FROM Employees
Использовать для задания псевдонима ключевое слово AS или же знак равенства, наверное, больше дело вкуса. Но при разборе чужих запросов, данные знания могут пригодиться.
Напоследок скажу, что для псевдонимов имена лучше задавать, используя только символы латиницы и цифры, избегая применения ‘…’, «…» и […], то есть использовать те же правила, что мы использовали при наименовании таблиц. Дальше, в примерах я буду использовать только такие наименования и никаких ‘…’, «…» и […].
Основные арифметические операторы SQL
| Оператор | Действие |
|---|---|
| + | Сложение (x+y) или унарный плюс (+x) |
| — | Вычитание (x-y) или унарный минус (-x) |
| * | Умножение (x*y) |
| / | Деление (x/y) |
| % | Остаток от деления (x%y). Для примера 15%10 даст 5 |
Приоритет выполнения арифметических операторов такой же, как и в математике. Если необходимо, то порядок применения операторов можно изменить используя круглые скобки — (a+b)*(x/(y-z)).
И еще раз повторюсь, что любая операция с NULL дает NULL, например: 10+NULL, NULL*15/3, 100/NULL – все это даст в результате NULL. Т.е. говоря просто неопределенное значение не может дать определенный результат. Учитывайте это при составлении запроса и при необходимости делайте обработку NULL значений функциями ISNULL, COALESCE:
SELECT
ID,Name,
Salary/100*BonusPercent AS Result1, -- без обработки NULL значений
Salary/100*ISNULL(BonusPercent,0) AS Result2, -- используем функцию ISNULL
Salary/100*COALESCE(BonusPercent,0) AS Result3 -- используем функцию COALESCE
FROM Employees
| ID | Name | Result1 | Result2 | Result3 |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 2500 | 2500 | 2500 |
| 1001 | Петров П.П. | 225 | 225 | 225 |
| 1002 | Сидоров С.С. | NULL | 0 | 0 |
| 1003 | Андреев А.А. | 600 | 600 | 600 |
| 1004 | Николаев Н.Н. | NULL | 0 | 0 |
| 1005 | Александров А.А. | NULL | 0 | 0 |
Немного расскажу о функции COALESCE:
COALESCE (expr1, expr2, ..., exprn) - Возвращает первое не NULL значение из списка значений.
Пример:
SELECT COALESCE(f1, f1*f2, f2*f3) val -- в данном случае вернется третье значение
FROM (SELECT null f1, 2 f2, 3 f3) q
В основном, я сосредоточусь на рассказе конструкций языка DML и по большей части не буду рассказывать о функциях, которые будут встречаться в примерах. Если вам непонятно, что делает та или иная функция поищите ее описание в интернет, можете даже поискать информацию сразу по группе функций, например, задав в поиске Google «MS SQL строковые функции», «MS SQL математические функции» или же «MS SQL функции обработки NULL». Информации по функциям очень много, и вы ее сможете без труда найти. Для примера, в библиотеке MSDN, можно узнать больше о функции COALESCE:
Вырезка из MSDN Сравнение COALESCE и CASE
Выражение COALESCE — синтаксический ярлык для выражения CASE. Это означает, что код COALESCE(expression1,…n) переписывается оптимизатором запросов как следующее выражение CASE:
CASE WHEN (expression1 IS NOT NULL) THEN expression1 WHEN (expression2 IS NOT NULL) THEN expression2 ... ELSE expressionN END
Для примера рассмотрим, как можно воспользоваться остатком от деления (%). Данный оператор очень полезен, когда требуется разбить записи на группы. Например, вытащим всех сотрудников, у которых четные табельные номера (ID), т.е. те ID, которые делятся на 2:
SELECT ID,Name
FROM Employees
WHERE ID%2=0 -- остаток от деления на 2 равен 0
| ID | Name |
|---|---|
| 1000 | Иванов И.И. |
| 1004 | Николаев Н.Н. |
| 1002 | Сидоров С.С. |
ORDER BY – сортировка результата запроса
Предложение ORDER BY используется для сортировки результата запроса.
SELECT
LastName,
FirstName,
Salary
FROM Employees
ORDER BY LastName,FirstName -- упорядочить результат по 2-м столбцам – по Фамилии, и после по Имени
| LastName | FirstName | Salary |
|---|---|---|
| Андреев | Андрей | 2000 |
| Иванов | Иван | 5000 |
| Петров | Петр | 1500 |
| Сидоров | Сидор | 2500 |
После имя поля в предложении ORDER BY можно задать опцию DESC, которая служит для сортировки этого поля в порядке убывания:
SELECT LastName,FirstName,Salary
FROM Employees
ORDER BY -- упорядочить в порядке
Salary DESC, -- 1. убывания Заработной Платы
LastName, -- 2. по Фамилии
FirstName -- 3. по Имени
| LastName | FirstName | Salary |
|---|---|---|
| Иванов | Иван | 5000 |
| Сидоров | Сидор | 2500 |
| Андреев | Андрей | 2000 |
| Петров | Петр | 1500 |
Для заметки. Для сортировки по возрастанию есть ключевое слово ASC, но так как сортировка по возрастанию применяется по умолчанию, то про эту опцию можно забыть (я не помню случая, чтобы я когда-то использовал эту опцию).
Стоит отметить, что в предложении ORDER BY можно использовать и поля, которые не перечислены в предложении SELECT (кроме случая, когда используется DISTINCT, об этом случае я расскажу ниже). Для примера забегу немного вперед используя опцию TOP и покажу, как например, можно отобрать 3-х сотрудников у которых самая высокая ЗП, с учетом что саму ЗП в целях конфиденциальности я показывать не должен:
SELECT TOP 3 -- вернуть только 3 первые записи из всего результата
ID,LastName,FirstName
FROM Employees
ORDER BY Salary DESC -- сортируем результат по убыванию Заработной Платы
| ID | LastName | FirstName |
|---|---|---|
| 1000 | Иванов | Иван |
| 1002 | Сидоров | Сидор |
Конечно здесь есть случай, что у нескольких сотрудников может быть одинаковая ЗП и тут сложно сказать каких именно трех сотрудников вернет данный запрос, это уже нужно решать с постановщиком задачи. Допустим, после обсуждения с постановщиком данной задачи, вы согласовали и решили использовать следующий вариант – сделать дополнительную сортировку по полю даты рождения (т.е. молодым у нас дорога), а если и дата рождения у нескольких сотрудников может совпасть (ведь такое тоже не исключено), то можно сделать третью сортировку по убыванию значений ID (в последнюю очередь под выборку попадут те, у кого ID окажется максимальным – например, те кто был принят последним, допустим табельные номера у нас выдаются последовательно):
SELECT TOP 3 -- вернуть только 3 первые записи из всего результата
ID,LastName,FirstName
FROM Employees
ORDER BY
Salary DESC, -- 1. сортируем результат по убыванию Заработной Платы
Birthday, -- 2. потом по Дате рождения
ID DESC -- 3. и для полной однозначности результата добавляем сортировку по ID
Т.е. вы должны стараться чтобы результат запроса был предсказуемым, чтобы вы могли в случае разбора полетов объяснить почему в «черный список» попали именно эти люди, т.е. все было выбрано честно, по утверждённым правилам.
Сортировать можно так же используя разные выражения в предложении ORDER BY:
SELECT LastName,FirstName
FROM Employees
ORDER BY CONCAT(LastName,' ',FirstName) -- используем выражение
Так же в ORDER BY можно использовать псевдонимы заданные для колонок:
SELECT CONCAT(LastName,' ',FirstName) fi
FROM Employees
ORDER BY fi -- используем псевдоним
Стоит отметить что в случае использования предложения DISTINCT, в предложении ORDER BY могут использоваться только колонки, перечисленные в блоке SELECT. Т.е. после применения операции DISTINCT мы получаем новый набор данных, с новым набором колонок. По этой причине, следующий пример не отработает:
SELECT DISTINCT
LastName,FirstName,Salary
FROM Employees
ORDER BY ID -- ID отсутствует в итоговом наборе, который мы получили при помощи DISTINCT
Т.е. предложение ORDER BY применяется уже к итоговому набору, перед выдачей результата пользователю.
Примечание 1. Так же в предложении ORDER BY можно использовать номера столбцов, перечисленных в SELECT:
SELECT LastName,FirstName,Salary FROM Employees ORDER BY -- упорядочить в порядке 3 DESC, -- 1. убывания Заработной Платы 1, -- 2. по Фамилии 2 -- 3. по ИмениДля начинающих выглядит удобно и заманчиво, но лучше забыть и никогда не использовать такой вариант сортировки.
Если в данном случае (когда поля явно перечислены), такой вариант еще допустим, то для случая с использованием «*» такой вариант лучше никогда не применять. Почему – потому что, если кто-то, например, поменяет в таблице порядок столбцов, или удалит столбцы (и это нормальная ситуация), ваш запрос может так же работать, но уже неправильно, т.к. сортировка уже может идти по другим столбцам, и это коварно тем что данная ошибка может обнаружиться очень нескоро.
В случае, если бы столбы были явно перечислены, то в вышеуказанной ситуации, запрос либо бы продолжал работать, но также правильно (т.к. все явно определено), либо бы он просто выдал ошибку, что данного столбца не существует.
Так что можете смело забыть, о сортировке по номерам столбцов.
Примечание 2.
В MS SQL при сортировке по возрастанию NULL значения будут отображаться первыми.SELECT BonusPercent FROM Employees ORDER BY BonusPercentСоответственно при использовании DESC они будут в конце
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESCЕсли необходимо поменять логику сортировки NULL значений, то используйте выражения, например:
SELECT BonusPercent FROM Employees ORDER BY ISNULL(BonusPercent,100)В ORACLE для этой цели предусмотрены 2 опции NULLS FIRST и NULLS LAST (применяется по умолчанию). Например:
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC NULLS LASTОбращайте на это внимание при переходе на ту или иную БД.
TOP – возврат указанного числа записей
Вырезка из MSDN. TOP – ограничивает число строк, возвращаемых в результирующем наборе запроса до заданного числа или процентного значения. Если предложение TOP используется совместно с предложением ORDER BY, то результирующий набор ограничен первыми N строками отсортированного результата. В противном случае возвращаются первые N строк в неопределенном порядке.
Обычно данное выражение используется с предложением ORDER BY и мы уже смотрели примеры, когда нужно было вернуть N-первых строк из результирующего набора.
Без ORDER BY обычно данное предложение применяется, когда нужно просто посмотреть на неизвестную нам таблицу, в которой может быть очень много записей, в этом случае мы можем, для примера, попросить вернуть нам только первые 10 строк, но для наглядности мы скажем только 2:
SELECT TOP 2
*
FROM Employees
Так же можно указать слово PERCENT, для того чтобы вернулось соответствуй процент строк из результирующего набора:
SELECT TOP 25 PERCENT
*
FROM Employees
На моей практике чаше применяется именно выборка по количеству строк.
Так же с TOP можно использовать опцию WITH TIES, которая поможет вернуть все строки в случае неоднозначной сортировки, т.е. это предложение вернет все строки, которые равны по составу строкам, которые попадают в выборку TOP N, в итоге строк может быть выбрано больше чем N. Давайте для демонстрации добавим еще одного «Программиста» с окладом 1500:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary)
VALUES(1004,N'Николаев Н.Н.','n.nikolayev@test.tt',3,3,1003,1500)
и введем еще одного сотрудника без указания должности и отдела с окладом 2000:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary)
VALUES(1005,N'Александров А.А.','a.alexandrov@test.tt',NULL,NULL,1000,2000)
Теперь давайте выберем при помощи опции WITH TIES всех сотрудников, у которых оклад совпадает с окладами 3-х сотрудников, с самым маленьким окладом (надеюсь дальше будет понятно, к чему я клоню):
SELECT TOP 3 WITH TIES
ID,Name,Salary
FROM Employees
ORDER BY Salary
Здесь хоть и указано TOP 3, но запрос вернул 4 записи, т.к. значение Salary которое вернуло TOP 3 (1500 и 2000) оказалось у 4-х сотрудников. Наглядно это работает примерно следующим образом:
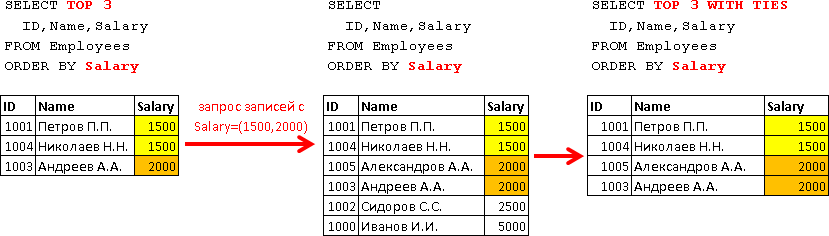
На заметку.
В разных БД TOP реализуется разными способами, в MySQL для этого есть предложение LIMIT, в котором дополнительно можно задать начальное смещение.В ORACLE 12c, тоже ввели свой аналог совмещающий функциональность TOP и LIMIT – ищите по словам «ORACLE OFFSET FETCH». До версии 12c для этой цели обычно использовался псевдостолбец ROWNUM.
А что же будет если применить одновременно предложения DISTINCT и TOP? На такие вопросы легко ответить, проводя эксперименты. В общем, не бойтесь и не ленитесь экспериментировать, т.к. большая часть познается именно на практике. Порядок слов в операторе SELECT следующий, первым идет DISTINCT, а после него идет TOP, т.е. если рассуждать логически и читать слева-направо, то первым применится отброс дубликатов, а потом уже по этому набору будет сделан TOP. Что-ж проверим и убедимся, что так и есть:
SELECT DISTINCT TOP 2
Salary
FROM Employees
ORDER BY Salary
| Salary |
|---|
| 1500 |
| 2000 |
Т.е. в результате мы получили 2 самые маленькие зарплаты из всех. Конечно может быть случай что ЗП для каких-то сотрудников может быть не указанной (NULL), т.к. схема нам это позволяет. Поэтому в зависимости от задачи принимаем решение либо обработать NULL значения в предложении ORDER BY, либо просто отбросить все записи, у которых Salary равна NULL, а для этого переходим к изучению предложения WHERE.
WHERE – условие выборки строк
Данное предложение служит для фильтрации записей по заданному условию. Например, выберем всех сотрудников работающих в «ИТ» отделе (его ID=3):
SELECT ID,LastName,FirstName,Salary
FROM Employees
WHERE DepartmentID=3 -- ИТ
ORDER BY LastName,FirstName
| ID | LastName | FirstName | Salary |
|---|---|---|---|
| 1004 | NULL | NULL | 1500 |
| 1003 | Андреев | Андрей | 2000 |
| 1001 | Петров | Петр | 1500 |
Предложение WHERE пишется до команды ORDER BY.
Порядок применения команд к исходному набору Employees следующий:
- WHERE – если указано, то первым делом из всего набора Employees идет отбор только удовлетворяющих условию записей
- DISTINCT – если указано, то отбрасываются все дубликаты
- ORDER BY – если указано, то делается сортировка результата
- TOP – если указано, то из отсортированного результата возвращается только указанное число записей
Рассмотрим для наглядности пример:
SELECT DISTINCT TOP 1
Salary
FROM Employees
WHERE DepartmentID=3
ORDER BY Salary
Наглядно это будет выглядеть следующим образом:

Стоит отметить, что проверка на NULL делается не знаком равенства, а при помощи операторов IS NULL и IS NOT NULL. Просто запомните, что на NULL при помощи оператора «=» (знак равенства) сравнивать нельзя, т.к. результат выражения будет так же равен NULL.
Например, выберем всех сотрудников, у которых не указан отдел (т.е. DepartmentID IS NULL):
SELECT ID,Name
FROM Employees
WHERE DepartmentID IS NULL
| ID | Name |
|---|---|
| 1005 | Александров А.А. |
Теперь для примера посчитаем бонус для всех сотрудников у которых указано значение BonusPercent (т.е. BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus
FROM Employees
WHERE BonusPercent IS NOT NULL
Да, кстати, если подумать, то значение BonusPercent может равняться нулю (0), а так же значение может быть внесено со знаком минус, ведь мы не накладывали на данное поле никаких ограничений.
Хорошо, рассказав о проблеме, нам пока сказали считать, что если (BonusPercent<=0 или BonusPercent IS NULL), то это означает что у сотрудника так же нет бонуса. Для начала, как нам сказали, так и сделаем, реализуем это при помощи логического оператора OR и NOT:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus
FROM Employees
WHERE NOT(BonusPercent<=0 OR BonusPercent IS NULL)
Т.е. здесь мы начали изучать булевы операторы. Выражение в скобках «(BonusPercent<=0 OR BonusPercent IS NULL)» проверяет на то что у сотрудника нет бонуса, а NOT инвертирует это значение, т.е. говорит «верни всех сотрудников которые не сотрудники у которых нет бонуса».
Так же данное выражение можно переписать и сразу сказав сразу «верни всех сотрудников, у которых есть бонус» выразив это выражением (BonusPercent>0 и BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus
FROM Employees
WHERE BonusPercent>0 AND BonusPercent IS NOT NULL
Также в блоке WHERE можно делать проверку разного рода выражений с применением арифметических операторов и функций. Например, аналогичную проверку можно сделать, использовав выражение с функцией ISNULL:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus
FROM Employees
WHERE ISNULL(BonusPercent,0)>0
Булевы операторы и простые операторы сравнения
Да, без математики здесь не обойтись, поэтому сделаем небольшой экскурс по булевым и простым операторам сравнения.
Булевых операторов в языке SQL всего 3 – AND, OR и NOT:
| AND | логическое И. Ставится между двумя условиями (условие1 AND условие2). Чтобы выражение вернуло True, нужно, чтобы истинными были оба условия |
|---|---|
| OR | логическое ИЛИ. Ставится между двумя условиями (условие1 OR условие2). Чтобы выражение вернуло True, достаточно, чтобы истинным было только одно условие |
| NOT | инвертирует условие/логическое_выражение. Накладывается на другое выражение (NOT логическое_выражение) и возвращает True, если логическое_выражение = False и возвращает False, если логическое_выражение = True |
Для каждого булева оператора можно привести таблицы истинности где дополнительно показано какой будет результат, когда условия могут быть равны NULL:
Есть следующие простые операторы сравнения, которые используются для формирования условий:
| Условие | Значение |
|---|---|
| = | Равно |
| < | Меньше |
| > | Больше |
| <= | Меньше или равно |
| >= | Больше или равно |
| <> != |
Не равно |
Плюс имеются 2 оператора для проверки значения/выражения на NULL:
| IS NULL | Проверка на равенство NULL |
|---|---|
| IS NOT NULL | Проверка на неравенство NULL |
Приоритет: 1) Все операторы сравнения; 2) NOT; 3) AND; 4) OR.
При построении сложных логических выражений используются круглые скобки:
((условие1 AND условие2) OR NOT(условие3 AND условие4 AND условие5)) OR (…)
Так же при помощи использования круглых скобок, можно изменить стандартную последовательность вычислений.
Здесь я постарался дать представление о булевой алгебре в достаточном для работы объеме. Как видите, чтобы писать условия посложнее без логики уже не обойтись, но ее здесь немного (AND, OR и NOT) и придумывали ее люди, так что все достаточно логично.
Идем к завершению второй части
Как видите даже про базовый синтаксис оператора SELECT можно говорить очень долго, но, чтобы остаться в рамках статьи, напоследок я покажу дополнительные логических операторы – BETWEEN, IN и LIKE.
BETWEEN – проверка на вхождение в диапазон
Этот оператор имеет следующий вид:
проверяемое_значение [NOT] BETWEEN начальное_ значение AND конечное_ значение
В роли значений могут выступать выражения.
Разберем на примере:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary BETWEEN 2000 AND 3000 -- у кого ЗП в диапазоне 2000-3000
| ID | Name | Salary |
|---|---|---|
| 1002 | Сидоров С.С. | 2500 |
| 1003 | Андреев А.А. | 2000 |
| 1005 | Александров А.А. | 2000 |
Собственно, BETWEEN это упрощенная запись вида:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary>=2000 AND Salary<=3000 -- все у кого ЗП в диапозоне 2000-3000
Перед словом BETWEEN может использоваться слово NOT, которое будет осуществлять проверку значения на не вхождение в указанный диапазон:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary NOT BETWEEN 2000 AND 3000 -- аналогично выражению NOT(Salary>=2000 AND Salary<=3000)
Соответственно, в случае использования BETWEEN, IN, LIKE вы можете так же объединять их с другими условиями при помощи AND и OR:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary BETWEEN 2000 AND 3000 -- у кого ЗП в диапазоне 2000-3000
AND DepartmentID=3 -- учитывать сотрудников только отдела 3
IN – проверка на вхождение в перечень значений
Этот оператор имеет следующий вид:
проверяемое_значение [NOT] IN (значение1, значение2, …)
Думаю, проще показать на примере:
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID IN(3,4) -- у кого должность равна 3 или 4
| ID | Name | Salary |
|---|---|---|
| 1001 | Петров П.П. | 1500 |
| 1003 | Андреев А.А. | 2000 |
| 1004 | Николаев Н.Н. | 1500 |
Т.е. по сути это аналогично следующему выражению:
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID=3 OR PositionID=4 -- у кого должность равна 3 или 4
В случае NOT это будет аналогично (получим всех кроме тех, кто из отдела 3 и 4):
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID NOT IN(3,4) -- аналогично выражению NOT(PositionID=3 OR PositionID=4)
Так же запрос с NOT IN можно выразить и через AND:
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID<>3 AND PositionID<>4 -- равносильно PositionID NOT IN(3,4)
Учтите, что искать NULL значения при помощи конструкции IN не получится, т.к. проверка NULL=NULL вернет так же NULL, а не True:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID IN(1,2,NULL) -- NULL записи не войдут в результат
В этом случае разбивайте проверку на несколько условий:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID IN(1,2) -- 1 или 2
OR DepartmentID IS NULL -- или NULL
Или же можно написать что-то вроде:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE ISNULL(DepartmentID,-1) IN(1,2,-1) -- если вы уверены, что в нет и не будет департамента с ID=-1
Думаю, первый вариант, в данном случае будет более правильным и надежным. Ну ладно, это всего лишь пример, для демонстрации того какие еще конструкции можно строить.
Так же стоит упомянуть еще более коварную ошибку, связанную с NULL, которую можно допустить при использовании конструкции NOT IN. Для примера, давайте попробуем выбрать всех сотрудников, кроме тех, у которых отдел равен 1 или у которых отдел вообще не указан, т.е. равен NULL. В качестве решения напрашивается вариант:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID NOT IN(1,NULL)
Но выполнив запрос, мы не получим ни одной строки, хотя мы ожидали увидеть следующее:
| ID | Name | DepartmentID |
|---|---|---|
| 1001 | Петров П.П. | 3 |
| 1002 | Сидоров С.С. | 2 |
| 1003 | Андреев А.А. | 3 |
| 1004 | Николаев Н.Н. | 3 |
Опять же шутку здесь сыграло NULL указанное в списке значений.
Разберем почему в данном случае возникла логическая ошибка. Разложим запрос при помощи AND:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID<>1
AND DepartmentID<>NULL -- проблема из-за этой проверки на NULL - это условие всегда вернет NULL
Правое условие (DepartmentID<>NULL) нам всегда здесь даст неопределенность, т.е. NULL. Теперь вспомним таблицу истинности для оператора AND, где (TRUE AND NULL) дает NULL. Т.е. при выполнении левого условия (DepartmentID<>1) из-за неопределенного правого условия в результате мы получим неопределенное значение всего выражения (DepartmentID<>1 AND DepartmentID<>NULL), поэтому строка не войдет в результат.
Переписать условие правильно можно следующим образом:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID NOT IN(1) -- или в данном случае просто DepartmentID<>1
AND DepartmentID IS NOT NULL -- и отдельно проверяем на NOT NULL
IN еще можно использовать с подзапросами, но к такой форме мы вернемся, уже в последующих частях данного учебника.
LIKE – проверка строки по шаблону
Про данный оператор я расскажу только в самом простом виде, который является стандартом и поддерживается большинством диалектов языка SQL. Даже в таком виде при помощи него можно решить много задач, которые требуют выполнить проверку по содержимому строки.
Этот оператор имеет следующий вид:
проверяемая_строка [NOT] LIKE строка_шаблон [ESCAPE отменяющий_символ]
В «строке_шаблон» могут применятся следующие специальные символы:
- Знак подчеркивания «_» — говорит, что на его месте может стоять любой единичный символ
- Знак процента «%» — говорит, что на его месте может стоять сколько угодно символов, в том числе и ни одного
Рассмотрим примеры с символом «%» (на практике, кстати он чаще применяется):
SELECT ID,Name
FROM Employees
WHERE Name LIKE 'Пет%' -- у кого имя начинается с букв "Пет"
SELECT ID,LastName
FROM Employees
WHERE LastName LIKE '%ов' -- у кого фамилия оканчивается на "ов"
SELECT ID,LastName
FROM Employees
WHERE LastName LIKE '%ре%' -- у кого фамилия содержит сочетание "ре"
Рассмотрим примеры с символом «_»:
SELECT ID,LastName
FROM Employees
WHERE LastName LIKE '_етров' -- у кого фамилия состоит из любого первого символа и последующих букв "етров"
SELECT ID,LastName
FROM Employees
WHERE LastName LIKE '____ов' -- у кого фамилия состоит из четырех любых символов и последующих букв "ов"
При помощи ESCAPE можно задать отменяющий символ, который отменяет проверяющее действие специальных символов «_» и «%». Данное предложение используется, когда в строке нужно непосредственно проверить наличие знака процента или знака подчеркивания.
Для демонстрации ESCAPE давайте занесем в одну запись мусор:
UPDATE Employees
SET
FirstName='Это_мусор, содержащий %'
WHERE ID=1005
И посмотрим, что вернут следующие запросы:
SELECT *
FROM Employees
WHERE FirstName LIKE '%!%%' ESCAPE '!' -- строка содержит знак "%"
SELECT *
FROM Employees
WHERE FirstName LIKE '%!_%' ESCAPE '!' -- строка содержит знак "_"
В случае, если требуется проверить строку на полное совпадение, то вместо LIKE лучше использовать просто знак «=»:
SELECT *
FROM Employees
WHERE FirstName='Петр'
На заметку.
В MS SQL в шаблоне оператора LIKE так же можно задать поиск по регулярным выражениям, почитайте о нем в интернете, в том случае, если вам станет недостаточно стандартных возможностей данного оператора.В ORACLE для поиска по регулярным выражениям применяется функция REGEXP_LIKE.
Немного о строках
В случае проверки строки на наличие Unicode символов, нужно будет ставить перед кавычками символ N, т.е. N’…’. Но так как у нас в таблице все символьные поля в формате Unicode (тип nvarchar), то для этих полей можно всегда использовать такой формат. Пример:
SELECT ID,Name
FROM Employees
WHERE Name LIKE N'Пет%'
SELECT ID,LastName
FROM Employees
WHERE LastName=N'Петров'
Если делать правильно, при сравнении с полем типа varchar (ASCII) нужно стараться использовать проверки с использованием ‘…’, а при сравнении поля с типом nvarchar (Unicode) нужно стараться использовать проверки с использованием N’…’. Это делается для того, чтобы избежать в процессе выполнения запроса неявных преобразований типов. То же самое правило используем при вставке (INSERT) значений в поле или их обновлении (UPDATE).
При сравнении строк стоит учесть момент, что в зависимости от настройки БД (collation), сравнение строк может быть, как регистро-независимым (когда ‘Петров’=’ПЕТРОВ’), так и регистро-зависимым (когда ‘Петров'<>’ПЕТРОВ’).
В случае регистро-зависимой настройки, если требуется сделать поиск без учета регистра, то можно, например, сделать предварительное преобразование правого и левого выражения в один регистр – верхний или нижний:
SELECT ID,Name
FROM Employees
WHERE UPPER(Name) LIKE UPPER(N'Пет%') -- или LOWER(Name) LIKE LOWER(N'Пет%')
SELECT ID,LastName
FROM Employees
WHERE UPPER(LastName)=UPPER(N'Петров') -- или LOWER(LastName)=LOWER(N'Петров')
Немного о датах
При проверке на дату, вы можете использовать, как и со строками одинарные кавычки ‘…’.
Вне зависимости от региональных настроек в MS SQL можно использовать следующий синтаксис дат ‘YYYYMMDD’ (год, месяц, день слитно без пробелов). Такой формат даты MS SQL поймет всегда:
SELECT ID,Name,Birthday
FROM Employees
WHERE Birthday BETWEEN '19800101' AND '19891231' -- сотрудники 80-х годов
ORDER BY Birthday
В некоторых случаях, дату удобнее задавать при помощи функции DATEFROMPARTS:
SELECT ID,Name,Birthday
FROM Employees
WHERE Birthday BETWEEN DATEFROMPARTS(1980,1,1) AND DATEFROMPARTS(1989,12,31)
ORDER BY Birthday
Так же есть аналогичная функция DATETIMEFROMPARTS, которая служит для задания Даты и Времени (для типа datetime).
Еще вы можете использовать функцию CONVERT, если требуется преобразовать строку в значение типа date или datetime:
SELECT
CONVERT(date,'12.03.2015',104),
CONVERT(datetime,'2014-11-30 17:20:15',120)
Значения 104 и 120, указывают какой формат даты используется в строке. Описание всех допустимых форматов вы можете найти в библиотеке MSDN задав в поиске «MS SQL CONVERT».
Функций для работы с датами в MS SQL очень много, ищите «ms sql функции для работы с датами».
Примечание. Во всех диалектах языка SQL свой набор функций по работе с датами и применяется свой подход по работе с ними.
Немного о числах и их преобразованиях
Информация этого раздела наверно больше будет полезна ИТ-специалистам. Если вы таковым не являетесь, а ваша цель просто научится писать запросы для получения из БД необходимой вам информации, то такие тонкости вам возможно и не понадобятся, но в любом случае можете бегло пройтись по тексту и взять что-то на заметку, т.к. если вы взялись за изучение SQL, то вы уже приобщаетесь к ИТ.
В отличие от функции преобразования CAST, в функции CONVERT можно задать третий параметр, который отвечает за стиль преобразования (формат). Для разных типов данных может использоваться свой набор стилей, которые могут повлиять на возвращаемый результат. Использование стилей мы уже затрагивали при рассмотрении преобразования строки функцией CONVERT в типы date и datetime.
Подробней про функции CAST, CONVERT и стили можно почитать в MSDN – «Функции CAST и CONVERT (Transact-SQL)»: msdn.microsoft.com/ru-ru/library/ms187928.aspx
Для упрощения примеров здесь будут использованы инструкции языка Transact-SQL – DECLARE и SET.
Конечно, в случае преобразования целого числа в вещественное (которое я привел вначале данного урока, в целях демонстрации разницы между целочисленным и вещественным делением), знание нюансов преобразования не так критично, т.к. там мы делали преобразование целого числа в вещественное (диапазон которого намного больше диапазона целых):
DECLARE @min_int int SET @min_int=-2147483648
DECLARE @max_int int SET @max_int=2147483647
SELECT
-- (-2147483648)
@min_int,CAST(@min_int AS float),CONVERT(float,@min_int),
-- 2147483647
@max_int,CAST(@max_int AS float),CONVERT(float,@max_int),
-- numeric(16,6)
@min_int/1., -- (-2147483648.000000)
@max_int/1. -- 2147483647.000000
Возможно не стоило указывать способ неявного преобразования, получаемого делением на (1.), т.к. желательно стараться делать явные преобразования, для большего контроля типа получаемого результата. Хотя, в случае, если мы хотим получить результат типа numeric, с указанным количеством цифр после запятой, то мы можем в MS SQL применить трюк с умножением целого значения на (1., 1.0, 1.00 и т.д):
DECLARE @int int SET @int=123
SELECT
@int*1., -- numeric(12, 0) - 0 знаков после запятой
@int*1.0, -- numeric(13, 1) - 1 знак
@int*1.00, -- numeric(14, 2) - 2 знака
-- хотя порой лучше сделать явное преобразование
CAST(@int AS numeric(20, 0)), -- 123
CAST(@int AS numeric(20, 1)), -- 123.0
CAST(@int AS numeric(20, 2)) -- 123.00
В некоторых случаях детали преобразования могут быть действительно важны, т.к. они влияют на правильность полученного результата, например, в случае, когда делается преобразование числового значения в строку (varchar). Рассмотрим примеры по преобразованию значений типа money и float в varchar:
-- поведение при преобразовании money в varchar
DECLARE @money money
SET @money = 1025.123456789 -- произойдет неявное преобразование в 1025.1235, т.к. тип money хранит только 4 цифры после запятой
SELECT
@money, -- 1025.1235
-- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0)
CAST(@money as varchar(20)), -- 1025.12
CONVERT(varchar(20), @money), -- 1025.12
CONVERT(varchar(20), @money, 0), -- 1025.12 (стиль 0 - без разделителя тысячных и 2 цифры после запятой (формат по умолчанию))
CONVERT(varchar(20), @money, 1), -- 1,025.12 (стиль 1 - используется разделитель тысячных и 2 цифры после запятой)
CONVERT(varchar(20), @money, 2) -- 1025.1235 (стиль 2 - без разделителя и 4 цифры после запятой)
-- поведение при преобразовании float в varchar
DECLARE @float1 float SET @float1 = 1025.123456789
DECLARE @float2 float SET @float2 = 1231025.123456789
SELECT
@float1, -- 1025.123456789
@float2, -- 1231025.12345679
-- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0)
-- стиль 0 - Не более 6 разрядов. По необходимости используется экспоненциальное представление чисел
-- при преобразовании в varchar здесь творятся действительно страшные вещи
CAST(@float1 as varchar(20)), -- 1025.12
CONVERT(varchar(20), @float1), -- 1025.12
CONVERT(varchar(20), @float1, 0), -- 1025.12
CAST(@float2 as varchar(20)), -- 1.23103e+006
CONVERT(varchar(20), @float2), -- 1.23103e+006
CONVERT(varchar(20), @float2, 0), -- 1.23103e+006
-- стиль 1 - Всегда 8 разрядов. Всегда используется экспоненциальное представление чисел.
-- этот стиль для float тоже не очень точен
CONVERT(varchar(20), @float1, 1), -- 1.0251235e+003
CONVERT(varchar(20), @float2, 1), -- 1.2310251e+006
-- стиль 2 - Всегда 16 разрядов. Всегда используется экспоненциальное представление чисел.
-- здесь с точностью уже получше
CONVERT(varchar(30), @float1, 2), -- 1.025123456789000e+003 - OK
CONVERT(varchar(30), @float2, 2) -- 1.231025123456789e+006 - OK
Как видно из примера, плавающие типы float, real в некоторых случаях действительно могут создать большую погрешность, особенно при перегонке в строку и обратно (такое может быть при разного рода интеграциях, когда данные, например, передаются в текстовых файлах из одной системы в другую).
Если нужно явно контролировать точность до определенного знака, более 4-х, то для хранения данных, порой лучше использовать тип decimal/numeric. Если хватает 4-х знаков, то можно использовать и тип money – он примерно соотвествует numeric(20,4).
-- decimal и numeric
DECLARE @money money SET @money = 1025.123456789 -- 1025.1235
DECLARE @float1 float SET @float1 = 1025.123456789
DECLARE @float2 float SET @float2 = 1231025.123456789
DECLARE @numeric numeric(28,9) SET @numeric = 1025.123456789
SELECT
CAST(@numeric as varchar(20)), -- 1025.12345679
CONVERT(varchar(20), @numeric), -- 1025.12345679
CAST(@money as numeric(28,9)), -- 1025.123500000
CAST(@float1 as numeric(28,9)), -- 1025.123456789
CAST(@float2 as numeric(28,9)) -- 1231025.123456789
Примечание.
С версии MS SQL 2008, можно использовать вместо конструкции:DECLARE @money money SET @money = 1025.123456789Более короткий синтаксис инициализации переменных:
DECLARE @money money = 1025.123456789
Заключение второй части
В этой части, я постарался вспомнить и отразить наиболее важные моменты, касающиеся базового синтаксиса. Базовая конструкция – это костяк, без которого нельзя приступать к изучению более сложных конструкций языка SQL.
Надеюсь, данный материал поможет людям, делающим первые шаги в изучении языка SQL.
Удачи в изучении и применении на практике данного языка.
Часть третья — habrahabr.ru/post/255825