Начало. Продолжение в
- ggplot2: сопоставления, визуальные средства, статистические преобразования и слои
- Названия элементов графика ggplot2: название графика, осей, легенд
Что такое ggplot2 и ggvis
ggplot2 – это расширение языка R, предназначенное для визуализации данных. Для создания графики ggplot2 использует систему абстрактных понятий: массив данных, визуальные средства, геометрические объекты, сопоставление переменных из массива визуальным средствам, статистическое преобразование переменных, системы координат и пр. Пакет ggplot2 является одним из самых популярных среди R-пользователей: в январе-мае 2013 года его скачали не менее 82 тысяч раз, что ставит его на третье место среди всех R-расширений (если учесть, что второе место занимает пакет digest, который используется для вычисления криптографических хеш-значений объектов в R, т.е. вряд ли он часто применяется пользователями напрямую, а гораздо чаще является зависимостью для других расширений, в т.ч. и для ggplot2, то ggplot2 переезжает на второе место). Функции ggplot2 берут на себя решение многих второстепенных вопросов (нужна ли легенда, где её разместить, какие границы выбрать для осей и пр.) и позволяют пользователю сконцентрироваться на самом важном. Для эффективного использования функционала ggplot2 пользователю необходимо понять принципы, заложенные в этом расширении.
Необходимо добавить несколько слов про ggvis: это совсем свежий R-пакет, реализующий идеи грамматики графики в интерактивном веб-ключе. Если ggplot2 вы будете использовать для создания статичных изображений, то ggvis предназначен для производства визуализаций аналогичного плана, но они будут интерактивными. В качестве бэкэнда визуализации ggvis использует vega, которая, в свою очередь, покоится на плечах D3.js, а для организации взаимодействия с пользователем ggvis использует R-расширение shiny.
ggplot2 начинался с того, что его будущий создатель Хэдли Викхэм прочитал книгу Лэланда Вилкинсона “The Grammar of Graphics“. Среди прочего Вилкинсон – это тот товарищ, который в статистическом пакете SPSS поменял предыдущую систему визуализации на новую, основанную на оригинальном языке программирования графики GPL (не путать с названием лицензионного договора GNU General Public License!).
И в 2005 году Викхэм создаёт своё первое расширение для R – он реализует идеи, представленные в книге Вилкинсона, в R-коде пакета ggplot. Это был его первый пакет для R, и, как позже говорит сам Хэдли, написан он был не самым лучшим образом (с точки зрения позднего Хэдли 🙂 ). Сегодня Хэдли – автор уже не одного десятка разных пакетов, включая лидера из упомянутого выше рейтинга. В 2007 году Хэдли выпустил радикально переделанный ggplot и, чтобы не ломать скрипты и пакеты, написанные другими пользователями под синтаксис первой версии, он меняет название на ggplot2. В 2009 году Хэдли публикует книгу ggplot2: Elegant Graphics for Data Analysis. В 2012 году выходит очередная версия пакета под номером 0.9, одно из значительных улучшений в которой – это переделанная внутренняя структура, которая упрощает сторонним пользователям процесс подключения к разработке ggplot2. В начале 2014 года в git-репозитории ggplot2 насчитывается 21 разработчик. Хэдли – молодец, он смог грамотно перевести ggplot2 из формата личного проекта на рельсы разработки открытым сообществом. А это, я подозреваю, не просто! Нужно было наступить на горло своей песне, сократить время, затрачиваемое на чистую разработку и добавление функций, а сконцентрироваться на такой “скучной ерунде”, как написание документации, комментирование кода и т.д.
25 февраля 2014 года в почтовой группе, посвящённой ggplot2, Хэдли Викхэм официально объявил, что отныне работа над ggplot2 будет вестись в режиме поддержки: сами разработчики больше не будут добавлять в расширение новые функции, будут только вылавливать ошибки. Добавлением новых функций будут заниматься сами пользователи, которые могут дорабатывать ggplot2 и предлагать включать свои наработки в официальную версию. Соответственно, чтобы подчеркнуть переход ggplot2 на новый этап, версия расширения сменится на 1.0.0, а Хэдли ещё напишет популярным языком инструкцию о том, как сообщать об ошибках и предлагать свои наработки (чувствуете, опять работа с сообществом!).
Основы графической грамматики
В ggplot2 график является результатом взаимодействия ряда элементов:
- Массив данных (data)
- Схема соответствия переменных из массива визуальным средствам (aesthetic)
- Геометрический объект (geom)
- Статистическое преобразование (stat)
- Координатная система (coord)
- Ориентиры (guide)
- Панели (facet)
- Художественное оформление (theme)
Например, пользователь сообщает компьютеру, что хочет использовать массив данных про автомобили, переменная “скорость” будет выражена через положение по горизонтали, переменная “тормозной путь” через положение по вертикали, всё это нужно нарисовать с помощью геометрических объектов типа “точка”.
Вы спросите, а почему не заданы статистическое преобразование, координатная система, ориентиры и прочее. Все явно не указанные пользователем элементы графика берутся из значений по умолчанию. Например, если пользователь в качестве графического объекта указал тип “точки”, то по умолчанию статистических преобразований производиться не будет. А если он укажет тип “столбик”, то наблюдения в исходной переменной будут сгруппированы, а результатом применения статистики станет количество наблюдений в каждой группе.
На языке ggplot2 (да-да, я не оговорился: язык ggplot2 – это отдельный язык, а не R, но об этом позже) пример с точками будет выглядеть так:
ggplot(data = cars, aes(x = speed, y = dist)) + geom_point()
Аналогичный результат мы получим, если укажем не геометрию (geom_point), а соответствующую ей по умолчанию статистику (stat_identity).
ggplot(data = cars, aes(x = speed, y = dist)) + stat_identity()
Пример со столбиками:
ggplot(data = cars, aes(x = speed)) + geom_bar()
Умолчания распространяются и на другие элементы графика. Координатная система по умолчанию – декартова (coord_cartesian). Можем заменить на полярные координаты (coord_polar):
ggplot(data = cars, aes(x = speed)) + geom_bar() + coord_polar()
А что за дурацкий серый фон у графиков – часто звучит такой вопрос. Это тоже умолчание, но теперь уже в оформлении (theme_grey). Предполагается, что пользователь поместит график в публикацию, т.е. окружит его текстом. В обычной публикации цвет фона (бумаги) – белый, чернила – чёрные. “Средний” цвет страницы – серый. Если график сделать на белом фоне, то он будет резко выделяться на странице и вносить дисгармонию. А серый фон предназначен для уравновешивания цветового баланса страницы.
# Чёрно-белое оформление ggplot(data = cars, aes(x = speed, y = dist)) + stat_identity() + theme_bw()
Как нарисовать картограмму с помощью ggplot2 и ggmap
Продолжение в
- ggplot2: сопоставления, визуальные средства, статистические преобразования и слои
- Названия элементов графика ggplot2: название графика, осей, легенд
[This article was first published on R on Stats and R, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
- Introduction
- Data
- Basic principles of
{ggplot2} - Create plots with
{ggplot2}- Scatter plot
- Line plot
- Combination of line and points
- Histogram
- Density plot
- Combination of histogram and densities
- Boxplot
- Barplot
- Further personalization
- Labels
- Axis ticks
- Log transformations
- Limits
- Legend
- Shape, color, size and transparency
- Smooth and regression lines
- Facets
- Themes
- Interactive plot with
{plotly} - Combine plots with
{patchwork} - Flip coordinates
- Save plot
- To go further

Introduction
R is known to be a really powerful programming language when it comes to graphics and visualizations (in addition to statistics and data science of course!).
To keep it short, graphics in R can be done in two ways, via the:
{graphics}package (the base graphics in R, loaded by default){ggplot2}package (which needs to be installed and loaded beforehand)
The {graphics} package comes with a large choice of plots (such as plot, hist, barplot, boxplot, pie, mosaicplot, etc.) and additional related features (e.g., abline, lines, legend, mtext, rect, etc.). It is often the preferred way to draw plots for most R users, and in particular for beginners to intermediate users.
Since its creation in 2005 by Hadley Wickham, {ggplot2} has grown in use to become one of the most popular R packages and the most popular package for graphics and data visualizations. The {ggplot2} package is a much more modern approach to creating professional-quality graphics. More information about the package can be found at ggplot2.tidyverse.org.
In this article, we will see how to create common plots such as scatter plots, line plots, histograms, boxplots, barplots, density plots in R with this package. If you are unfamiliar with any of these types of graph, you will find more information about each one (when to use it, its purpose, what does it show, etc.) in my article about descriptive statistics in R.
Data
To illustrate plots with the {ggplot2} package we will use the mpg dataset available in the package. The dataset contains observations collected by the US Environmental Protection Agency on fuel economy from 1999 to 2008 for 38 popular models of cars (run ?mpg for more information about the data):
library(ggplot2) dat <- ggplot2::mpg
Before going further, let’s transform the cyl, drv, fl, year and class variables in factor with the transform() function:
dat <- transform(dat, cyl = factor(cyl), drv = factor(drv), fl = factor(fl), year = factor(year), class = factor(class) )
Basic principles of {ggplot2}
The {ggplot2} package is based on the principles of “The Grammar of Graphics” (hence “gg” in the name of {ggplot2}), that is, a coherent system for describing and building graphs. The main idea is to design a graphic as a succession of layers.
The main layers are:
- The dataset that contains the variables that we want to represent. This is done with the
ggplot()function and comes first. - The variable(s) to represent on the x and/or y-axis, and the aesthetic elements (such as color, size, fill, shape and transparency) of the objects to be represented. This is done with the
aes()function (abbreviation of aesthetic). - The type of graphical representation (scatter plot, line plot, barplot, histogram, boxplot, etc.). This is done with the functions
geom_point(),geom_line(),geom_bar(),geom_histogram(),geom_boxplot(), etc. - If needed, additional layers (such as labels, annotations, scales, axis ticks, legends, themes, facets, etc.) can be added to personalize the plot.
To create a plot, we thus first need to specify the data in the ggplot() function and then add the required layers such as the variables, the aesthetic elements and the type of plot:
ggplot(data) + aes(x = var_x, y = var_y) + geom_x()
datainggplot()is the name of the data frame which contains the variablesvar_xandvar_y.- The
+symbol is used to indicate the different layers that will be added to the plot. Make sure to write the+symbol at the end of the line of code and not at the beginning of the line, otherwise R throws an error. - The layer
aes()indicates what variables will be used in the plot and more generally, the aesthetic elements of the plot. - Finally,
xingeom_x()represents the type of plot. - Other layers are usually not required unless we want to personalize the plot further.
Note that it is a good practice to write one line of code per layer to improve code readability.
Create plots with {ggplot2}
In the following sections we will show how to draw the following plots:
- scatter plot
- line plot
- histogram
- density plot
- boxplot
- barplot
In order to focus on the construction of the different plots and the use of {ggplot2}, we will restrict ourselves to drawing basic (yet beautiful) plots without unnecessary layers. For the sake of completeness, we will briefly discuss and illustrate different layers to further personalize a plot at the end of the article (see this section).
Note that if you still struggle to create plots with {ggplot2} after reading this tutorial, you may find the {esquisse} addin useful. This addin allows you to interactively (that is, by dragging and dropping variables) create plots with the {ggplot2} package. Give it a try!
Scatter plot
We start by creating a scatter plot using geom_point. Remember that a scatter plot is used to visualize the relation between two quantitative variables.
- We start by specifying the data:
ggplot(dat) # data

- Then we add the variables to be represented with the
aes()function:
ggplot(dat) + # data aes(x = displ, y = hwy) # variables

- Finally, we indicate the type of plot:
ggplot(dat) + # data aes(x = displ, y = hwy) + # variables geom_point() # type of plot

You will also sometimes see the aesthetic elements (aes() with the variables) inside the ggplot() function in addition to the dataset:
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point()

This second method gives the exact same plot than the first method. I tend to prefer the first method over the second for better readability, but this is more a matter of taste so the choice is up to you.
Line plot
Line plots, particularly useful in time series or finance, can be created similarly but by using geom_line():
ggplot(dat) + aes(x = displ, y = hwy) + geom_line()

Combination of line and points
An advantage of {ggplot2} is the ability to combine several types of plots and its flexibility in designing it. For instance, we can add a line to a scatter plot by simply adding a layer to the initial scatter plot:
ggplot(dat) + aes(x = displ, y = hwy) + geom_point() + geom_line() # add line

Histogram
A histogram (useful to visualize distributions) can be plotted using geom_histogram():
ggplot(dat) + aes(x = hwy) + geom_histogram()

By default, the number of bins is equal to 30. You can change this value using the bins argument inside the geom_histogram() function:
ggplot(dat) + aes(x = hwy) + geom_histogram(bins = sqrt(nrow(dat)))

Here I specify the number of bins to be equal to the square root of the number of observations (following Sturge’s rule) but you can specify any numeric value.
Density plot
Density plots can be created using geom_density():
ggplot(dat) + aes(x = hwy) + geom_density()

Combination of histogram and densities
We can also superimpose a histogram and a density curve on the same plot:
ggplot(dat) + aes(x = hwy, y = ..density..) + geom_histogram() + geom_density()

Or superimpose several densities:
ggplot(dat) + aes(x = hwy, color = drv, fill = drv) + geom_density(alpha = 0.25) # add transparency

The argument alpha = 0.25 has been added for some transparency. More information about this argument can be found in this section.
Boxplot
A boxplot (also very useful to visualize distributions) can be plotted using geom_boxplot():
# Boxplot for one variable ggplot(dat) + aes(x = "", y = hwy) + geom_boxplot()

# Boxplot by factor ggplot(dat) + aes(x = drv, y = hwy) + geom_boxplot()

It is also possible to plot the points on the boxplot with geom_jitter(), and to vary the width of the boxes according to the size (i.e., the number of observations) of each level with varwidth = TRUE:
ggplot(dat) + aes(x = drv, y = hwy) + geom_boxplot(varwidth = TRUE) + # vary boxes width according to n obs. geom_jitter(alpha = 0.25, width = 0.2) # adds random noise and limit its width

The geom_jitter() layer adds some random variation to each point in order to prevent them from overlapping (an issue known as overplotting).1 Moreover, the alpha argument adds some transparency to the points (see more in this section) to keep the focus on the boxes and not on the points.
Finally, it is also possible to divide boxplots into several panels according to the levels of a qualitative variable:
ggplot(dat) + aes(x = drv, y = hwy) + geom_boxplot(varwidth = TRUE) + # vary boxes width according to n obs. geom_jitter(alpha = 0.25, width = 0.2) + # adds random noise and limit its width facet_wrap(~year) # divide into 2 panels

For a visually more appealing plot, it is also possible to use some colors for the boxes depending on the x variable:
ggplot(dat) + aes(x = drv, y = hwy, fill = drv) + # add color to boxes with fill geom_boxplot(varwidth = TRUE) + # vary boxes width according to n obs. geom_jitter(alpha = 0.25, width = 0.2) + # adds random noise and limit its width facet_wrap(~year) + # divide into 2 panels theme(legend.position = "none") # remove legend

In that case, it best to remove the legend as it becomes redundant. See more information about the legend in this section.
Barplot
A barplot (useful to visualize qualitative variables) can be plotted using geom_bar():
ggplot(dat) + aes(x = drv) + geom_bar()

By default, the heights of the bars correspond to the observed frequencies for each level of the variable of interest (drv in our case).
Again, for a more appealing plot, we can add some colors to the bars with the fill argument:
ggplot(dat) + aes(x = drv, fill = drv) + # add colors to bars geom_bar() + theme(legend.position = "none") # remove legend

We can also create a barplot with two qualitative variables:
ggplot(dat) + aes(x = drv, fill = year) + # fill by years geom_bar()

In order to compare proportions across groups, it is best to make each bar the same height using position = "fill":
ggplot(dat) + geom_bar(aes(x = drv, fill = year), position = "fill")

To draw the bars next to each other for each group, use position = "dodge":
ggplot(dat) + geom_bar(aes(x = drv, fill = year), position = "dodge")

Further personalization
Labels
The first things to personalize in a plot is the labels to make the plot more informative to the audience. We can easily add a title, subtitle, caption and edit axis titles with the labs() function:
p <- ggplot(dat) + aes(x = displ, y = hwy) + geom_point() p + labs( title = "Fuel efficiency for 38 popular models of car", subtitle = "Period 1999-2008", caption = "Data: ggplot2::mpg. See more at www.statsandr.com", x = "Engine displacement (litres)", y = "Highway miles per gallon (mpg)" )

As you can see in the above code, you can save one or more layers of the plot in an object for later use. This way, you can save your “main” plot, and add more layers of personalization until you get the desired output. Here we saved the main scatter plot in an object called p and we will refer to it for the subsequent personalizations.
Axis ticks
Axis ticks can be adjusted using scale_x_continuous() and scale_y_continuous() for the x and y-axis, respectively:
# Adjust ticks p + scale_x_continuous(breaks = seq(from = 1, to = 7, by = 0.5)) + # x-axis scale_y_continuous(breaks = seq(from = 10, to = 45, by = 5)) # y-axis

Log transformations
In some cases, it is useful to plot the log transformation of the variables. This can be done with the scale_x_log10() and scale_y_log10() functions:
p + scale_x_log10() + scale_y_log10()

Limits
The most convenient way to control the limits of the plot is to use again the scale_x_continuous() and scale_y_continuous() functions in addition to the limits argument:
p + scale_x_continuous(limits = c(3, 6)) + scale_y_continuous(limits = c(20, 30))

It is also possible to simply take a subset of the dataset with the subset() or filter() function. See how to subset a dataset if you need a reminder.
Legend
By default, the legend is located to the right side of the plot (when there is a legend to be displayed of course). To control the position of the legend, we need to use the theme() function in addition to the legend.position argument:
p + aes(color = class) + theme(legend.position = "top")

Replace "top" by "left" or "bottom" to change its position and by "none" to remove it.
The title of the legend can be removed with legend.title = element_blank():
p + aes(color = class) +
theme(
legend.title = element_blank(),
legend.position = "bottom"
)

The legend now appears at the bottom of the plot, without the legend title.
Shape, color, size and transparency
There are a very large number of options to improve the quality of the plot or to add additional information. These include:
- shape,
- size,
- color, and
- alpha (transparency).
We can for instance change the shape of all points in a scatter plot by adding shape to geom_point(), or vary the shape according to the values taken by another variable (in that case, the shape argument must be inside aes()):2
# Change shape of all points ggplot(dat) + aes(x = displ, y = hwy) + geom_point(shape = 4)

# Change shape of points based on a categorical variable ggplot(dat) + aes(x = displ, y = hwy, shape = drv) + geom_point()

Following the same principle, we can modify the color, size and transparency of the points based on a qualitative or quantitative variable. Here are some examples:
p <- ggplot(dat) + aes(x = displ, y = hwy) + geom_point() # Change color for all points p + geom_point(color = "steelblue")

# Change color based on a qualitative variable p + aes(color = drv)

# Change color based on a quantitative variable p + aes(color = cty)

# Change color based on a criterion (median of cty variable) p + aes(color = cty > median(cty))

# Change size of all points p + geom_point(size = 4)

# Change size of points based on a quantitative variable p + aes(size = cty)

# Change transparency based on a quantitative variable p + aes(alpha = cty)

We can of course mix several options (shape, color, size, alpha) to build more complex graphics:
p + geom_point(size = 0.5) + aes(color = drv, shape = year, alpha = cty)

Smooth and regression lines
In a scatter plot, it is possible to add a smooth line fitted to the data:
p + geom_smooth()

In the context of simple linear regression, it is often the case that the regression line is displayed on the plot. This can be done by adding method = lm (lm stands for linear model) in the geom_smooth() layer:
p + geom_smooth(method = lm)

It is also possible to draw a regression line for each level of a categorical variable:
p + aes(color = drv, shape = drv) + geom_smooth(method = lm, se = FALSE)

The se = FALSE argument removes the confidence interval around the regression lines.
Facets
facet_grid allows you to divide the same graphic into several panels according to the values of one or two qualitative variables:
# According to one variable p + facet_grid(. ~ drv)

# According to 2 variables p + facet_grid(drv ~ year)

It is then possible to add a regression line to each facet:
p + facet_grid(. ~ drv) + geom_smooth(method = lm)

facet_wrap() can also be used, as illustrated in this section.
Themes
Several functions are available in the {ggplot2} package to change the theme of the plot. The most common themes after the default theme (i.e., theme_gray()) are the black and white (theme_bw()), minimal (theme_minimal()) and classic (theme_classic()) themes:
# Black and white theme p + theme_bw()

# Minimal theme p + theme_minimal()

# Classic theme p + theme_classic()

I tend to use the minimal theme for most of my R Markdown reports as it brings out the patterns and points and not the layout of the plot, but again this is a matter of personal taste. See more themes at ggplot2.tidyverse.org/reference/ggtheme.html and in the {ggthemes} package.
In order to avoid having to change the theme for each plot you create, you can change the theme for the current R session using the theme_set() function as follows:
theme_set(theme_minimal())
Interactive plot with {plotly}
You can easily make your plots created with {ggplot2} interactive with the {plotly} package:
library(plotly) ggplotly(p + aes(color = year))
You can now hover over a point to display more information about that point. There is also the possibility to zoom in and out, to download the plot, to select some observations, etc. More information about {plotly} for R can be found here.
Combine plots with {patchwork}
There are several ways to combine plots made in {ggplot2}. In my opinion, the most convenient way is with the {patchwork} package using symbols such as +, / and parentheses.
We first need to create some plots and save them:
p_a <- ggplot(dat) + aes(x = displ, y = hwy) + geom_point() p_b <- ggplot(dat) + aes(x = hwy) + geom_histogram() p_c <- ggplot(dat) + aes(x = drv, y = hwy) + geom_boxplot()
Now that we have 3 plots saved in our environment, we can combine them. To have plots next to each other simply use the + symbol:
library(patchwork) p_a + p_b + p_c

To display them above each other simply use the / symbol:
p_a / p_b / p_c

And finally, to combine them above and next to each other, mix +, / and parentheses:
p_a + p_b / p_c

(p_a + p_b) / p_c

Flip coordinates
Flipping coordinates of your plot is useful to create horizontal boxplots, or when labels of a variable are so long that they overlap each other on the x-axis. See with and without flipping coordinates below:
# without flipping coordinates p1 <- ggplot(dat) + aes(x = class, y = hwy) + geom_boxplot() # with flipping coordinates p2 <- ggplot(dat) + aes(x = class, y = hwy) + geom_boxplot() + coord_flip() library(patchwork) p1 + p2 # left: without flipping, right: with flipping

This can be done with many types of plot, not only with boxplots. For instance, if a categorical variable has many levels or the labels are long, it is usually best to flip the coordinates for a better visual:
ggplot(dat) + aes(x = class) + geom_bar() + coord_flip()

Save plot
The ggsave() function will save the most recent plot in your current working directory unless you specify a path to another folder:
ggplot(dat) +
aes(x = displ, y = hwy) +
geom_point()
ggsave("plot1.pdf")
To go further
By now you have seen that {ggplot2} is a very powerful and complete package to create plots in R. This article illustrated only the tip of the iceberg, and you will find many tutorials on how to create more advanced plots and visualizations with {ggplot2} online. If you want to learn more than what is described in the present article, I highly recommend starting with:
- the chapters Data visualisation and Graphics for communication from the book R for Data Science from Garrett Grolemund and Hadley Wickham
- the book ggplot2: Elegant Graphics for Data Analysis from Hadley Wickham
- the ggplot2 extensions guide which lists many of the packages that extend
{ggplot2} - the
{ggplot2}cheat sheet
Thanks for reading. I hope this article helped you to create your first plots with the {ggplot2} package. As a reminder, for simple graphs, it is sometimes easier to draw them via the {esquisse} addin. After some time, you will quickly learn how to create them by yourselves and in no time you will be able to build complex and sophisticated data visualizations.
As always, if you have a question or a suggestion related to the topic covered in this article, please add it as a comment so other readers can benefit from the discussion.
Время на прочтение
11 мин
Количество просмотров 16K
R — очень мощный инструмент для работы со статистикой: от предварительной обработки до построения моделей любой сложности и соответствующей графики.
Простой гугл-запрос выдаст большое количество литературы по тому, как «легко и быстро» использовать R. Здесь будут и огромные книги, и многочисленные заметки на Stack Overflow, которые, на первый взгляд, кажутся бесконечной кладезью примеров, из которой каждый в два счета соберет необходимый код для решения конкретной задачи. Однако, на деле это совсем не так. Материалов, которые бы рассказали, например, как построить простой график «с нуля» с готовыми рецептами для решения затруднений, которые возникнут по ходу решения этой задачи, очень мало.
Для решения практических задач нужны конкретные пошаговые инструкции, а не подробное описание всей мощи того или иного пакета. Кроме того, готовые учебные примеры (те же ирисы) зачастую малополезны, поскольку сразу пропускают один из самых важных этапов работы со статистикой — предварительный сбор и обработку самих данных. А ведь именно на эту работу зачастую уходит чуть ли не бóльшая часть всего времени! Отдельной проблемой оказывается создание графиков, которые соответствуют формальным, а чаще — неформальным, — стандартам определенной профессиональной среды.
Мне и моим коллегам регулярно требуется делать всё большее количество визуализаций статистики и основанных на них моделей для публикации научных результатов. Поскольку исследования касаются экономики, многие такие работы похожи и на профессиональную публицистику.
В какой-то момент стало понятно, что для эффективной коллективной работы нужен своего рода полноценный конвейер обработки статистики. Эта статья родилась как вводное руководство для коллег и шпаргалка для самого себя, чтобы запустить этот конвейер. Думается, что этот материал может быть полезен и более широкой аудитории.
Графика в R «без боли»: пошаговое руководство
Базовая настройка R
Для работы нужна стандартная связка: R + RStudio. Они доступны бесплатно для всех распространенных платформ. Сначала устанавливается R, затем RStudio. Здесь проблем обычно не возникает.
Перед работой лучше сразу сохранить новый скрипт где-нибудь в своей файловой системе и сразу установить рабочую директорию R в папку, где хранится скрипт (меню Session — Set Working Directory — To Source File Location). Последнее замечание важно, потому что иначе запуск любого внешнего или собственного скрипта после перезагрузки RStudio не случится. По какой-то причине RStudio по умолчанию не делает этого, что было бы логично.
Даже в базовом пакете R есть стандартные средства визуализации (функция plot), которые позволяют строить многие виды графиков, но всё же для полноценных, гибко настраиваемых иллюстраций этих возможностей явно недостаточно.
Наиболее широкой используемой библиотекой для графики в R является пакет ggplot2, который будем использовать и мы.
Также стоит сразу установить пакеты readxl (для чтения файлов .xls, .xlsx) и dplyr (для работы с массивами), scales (для работы с различными шкалами данных), Cairo (для вывода графики из ggplot в файлы). Всё это можно сделать одной командой:
install.packages("ggplot2", "readxl", "scales", "dplyr", "Cairo")Сбор и подготовка данных
Самое удивительное в том, что этому этапу в любой литературе, будь то серьезная теоретическая книга по прикладной теоретической статистике или руководства конкретных статистических пакетов, посвящено катастрофически мало места и времени. Тем не менее, по опыту самостоятельных исследований и руководства студентами и младшими коллегами известно, что именно на этот этап может приходиться львиная доля времени и сил, поэтому очень важно экономить их хотя бы при решении чисто технических задач.
Вопросов здесь два:
- Как выбрать правильный формат файла?
- Как лучше всего структурировать данные?
С форматом дилемма проста: CSV против Microsoft Excel (не так уж важно, «новый» .xlsx старый» .xls). Многие считают, что CSV выигрывает за счет простоты (по сути, это обычный текстовый файл, в котором значения столбцов отделяются запятой или точкой с запятой) и скорости. Но я выбираю Excel в силу двух причин: во-первых, в таком файле можно хранить несколько таблиц одновременно на разных вкладках, во-вторых, что более важно, не приходится задумываться о выборе правильного разделителя колонок и десятичного знака. Для CSV это часто приходится прописывать вручную в коде R и следить за тем, чтобы файл с данными сохранялся с такими же настройками.
Структурирование данных — вопрос более сложный, требующий базового понимания того, как должны быть устроены базы данных. Если не вдаваться в теорию реляционных баз данных про разные нормальные формы, то таблица данных должна быть избыточной, то есть содержать лишние столбцы. Это нужно для того, чтобы потом уже в скрипте в R иметь возможность гибко отбирать те или иные фрагменты информации для дальнейшей обработки. Например, если мы хотим изобразить примитивный временной ряд, то мы должны сделать колонки, соответствующие всем возможным группировочным признакам. Например, если это ряд ежегодных наблюдений над численностью населения условного города Северовосточинска, то нам понадобятся следующие столбцы: year (год), var (название показателя), value (значение показателя).
К этому стилю представления информации мы будем приводить любые исходные данные.
Пример
Задача: построить сопоставление динамики объемов лесозаготовки в России, Сибирском федеральном округе и Красноярском крае в 2009—2018 гг.
Данные для этой задачи получить довольно просто: достаточно найти соответствующий показатель в Единой межведомственной информационно-статистической системе. Дальше возникает тонкость. Можно сразу скачать данные в формате .xlsx и затем вручную структурировать их так, как показано выше. К счастью, некоторые источники информации (например, ЕМИСС) позволяют делать это возможностями самого сервиса, что сильно упрощает работу и сокращает время, требуемое для ее выполнения.
Итак, для ЕМИСС достаточно перейти в режим «Настройки» (соответствующая кнопка в правом верхнем углу страницы данных) и переместить все признаки, кроме «Период» из графы «Столбцы» в графу «Строки». Получается таблица, практически готовая для нашей дальнейшей работы. Далее уже в Excel (или любом другом подходящем редакторе) есть смысл привести структуру таблицы к виду, похожему на представленный выше и убедиться в том, что первая строка содержит только названия переменных, причем данных латиницей (в принципе, R может работать и с русскоязычными заголовками, но это неудобно при написании кода). Получилась такая таблица (приводится фрагмент в несколько строк).
Теперь можно назвать этот лист logging, сохранить всю книгу в файл graphs.xlsx и переходить в RStudio.
Подключаем нужные библиотеки.
library(ggplot2)
library(readxl)
library(Cairo)
library(scales)
library(dplyr)Если график готовится для русскоязычного издания, нужно обязательно настроить соответствующую локаль. Самый современный вариант, который будет работать в большинстве случаев — это, разумеется, кодировка UTF-8:
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")Если система старая (какой-нибудь древний Windows или Linux), то понадобится сначала понять, какая кодировка используется по умолчанию — это всё уже не такая простая задача, которая далека от цели данной статьи.
Теперь нужно загрузить данные в R.
df_logging <- read_excel("graphs.xlsx", sheet ="logging")Опция sheet здесь задает имя листа внутри книги Excel, из которого будут загружаться данные.
Построим самый простой вариант требуемого графика.
ggplot(data=df_logging, aes(x=year, y=value)) +
geom_line(aes(linetype=location))
В принципе, практически «из коробки» получился весьма достойный график, который вполне пригоден для начального анализа изучаемого процесса, но с точки зрения возможной публикации требует еще значительной доработки.
Сначала приведем сам по себе графический стиль к более академическому. В пакете ggplot2 есть несколько готовых базовых тем оформления. Наиболее подходящей для нашего случая можно признать тему theme_classic. В рамках ее настройки можно сразу задать базовый кегль шрифта и его гарнитуру. Мои личные предпочтения принадлежат современной шрифтовой системе PT Sans, PT Serif, PT Mono. Но, разумеется, можно задать более классический Times или Helvetica. Также, у издания, в котором планируется публикация, на этот счет могут быть особые указания. Базовый кегль опытным путем определен как 12 пт.
ggplot(data=df_logging, aes(x=year, y=value)) +
geom_line(aes(linetype=location)) +
theme_classic(base_family = "PT Sans", base_size = 12)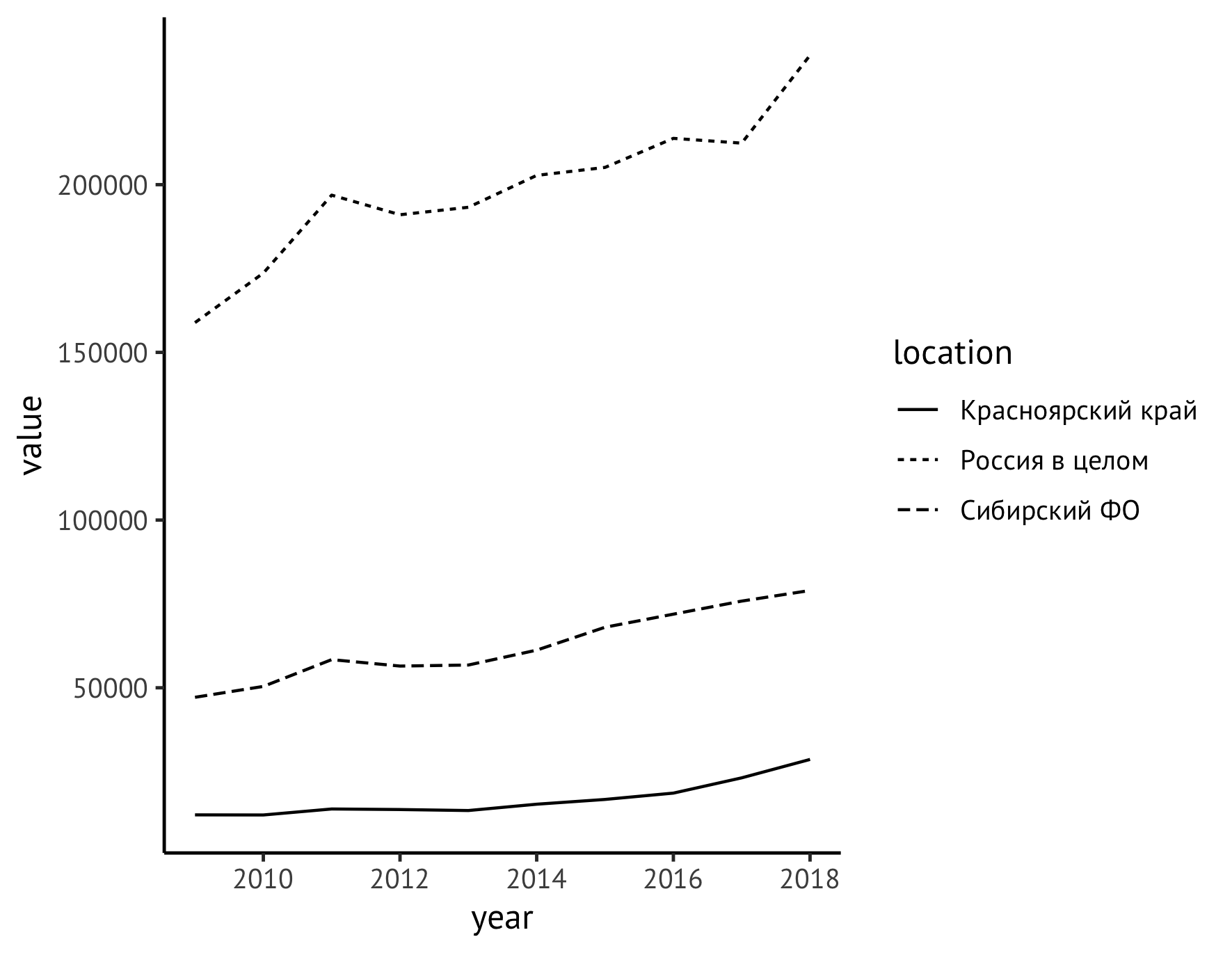
Далее передвинем легенду из правого поля графика вниз (с помощью инструкции theme) и одновременно зададим осмысленные названия осям (инструкция labs). Вдоль оси Y напишем название показателя с единицами измерения («Объемы лесозаготовки, млн куб. м»), а подписи по оси X удалим вовсе, поскольку ясно, что там отмечены годы.
ggplot(data=df_logging, aes(x=year, y=value)) +
geom_line(aes(linetype=location)) +
theme_classic(base_family = "PT Sans", base_size = 12) +
theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) +
labs(x = "", y = "Объемы лесозаготовки, тыс. куб. м", color="")
Чтобы сделать единицы измерения показателя более удобными для восприятия, перейдем от тыс. куб. м к миллионам. Для этого нужно просто разделить значения на 1000, то есть откорректировать первую строку нашего кода следующим образом:
ggplot(data=df_logging, aes(x=year, y=value/1000))Одновременно нужно изменить единицы измерения в надписи:
labs(x = "", y = "Объемы лесозаготовки, млн куб. м", color="")И сразу немного улучшим стиль изображения, добавив точки для обозначения каждого наблюдаемого значения, для чего допишем инструкцию:
geom_point(size=2)Также можно явно задать стиль самих линий. Логично показатель для России сделать сплошной линией, а для СФО и Красноярского края — разными версиями прерывистых:
scale_linetype_manual(values=c("twodash", "solid", "dotted"))Теперь общий код и график выглядят так:
ggplot(data=df_logging, aes(x=year, y=value/1000)) +
geom_line(aes(linetype=location)) +
geom_point(size=1) +
theme_classic(base_family = "PT Sans", base_size = 12) +
theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) +
scale_linetype_manual(values=c("twodash", "solid", "dotted")) +
labs(x = "", y = "Объемы лесозаготовки, млн куб. м", color="")
Остается решить более содержательную задачу — повысить информативность нашего графика. Сейчас по нему видно, что в целом показатель для всех объектов наблюдения рос, причем примерно с 2014 года сильнее, чем прежде. Но было бы куда нагляднее, если бы мы изобразили прямо на графике еще и значения в первый и последние годы и, скажем, в пиковом 2011-м. В этом поможет новая инструкция geom_text:
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")),
data = subset(df_logging, year == 2009 | year == 2018 | year == 2011),
check_overlap = TRUE, vjust=-0.8)На первый взгляд, выглядит довольно сложно, и надо сказать, что действительно собрать ее было не так просто. Постараюсь объяснить, что здесь происходит. Сама по себе geom_text добавляет на график текстовые надписи. Для этого инструкции необходим набор данных data. Если бы мы указали в нем непосредственно df_logging, то получили бы надписи над каждой точкой. Так делают довольно часто, но для достаточно простых динамических рядов, как наши, такой подход только создаст ненужный визуальный шум, не снабдив нас новой информацией о поведении наблюдаемого показателя. Поэтому мы возьмем только те годы, которые существенны для понимания динамики показателя: 2009 (начало наблюдений), 2011 (локальный пик), 2018 (конец наблюдений). В этом поможет стандартный subset.
Для корректного отображения чисел в соответствии с русскоязычной традицией нам нужна запятая как разделитель целой и десятичной частей (decimal.mark), а для отсечения количества знаков после запятой — инструкция digits. Различные эксперименты с ней, в том числе с применением функции round привели к тому, что если нам нужен один знак после запятой, в digits надо передать значение 3.
Опция check_overlap здесь напрямую не нужна, но может пригодиться в других случаях: это автоматический контроль наложения надписей друг на друга. Опция vjust управляет размещением надписей по вертикали. Значение подобрано, исходя из вкусовых соображений.
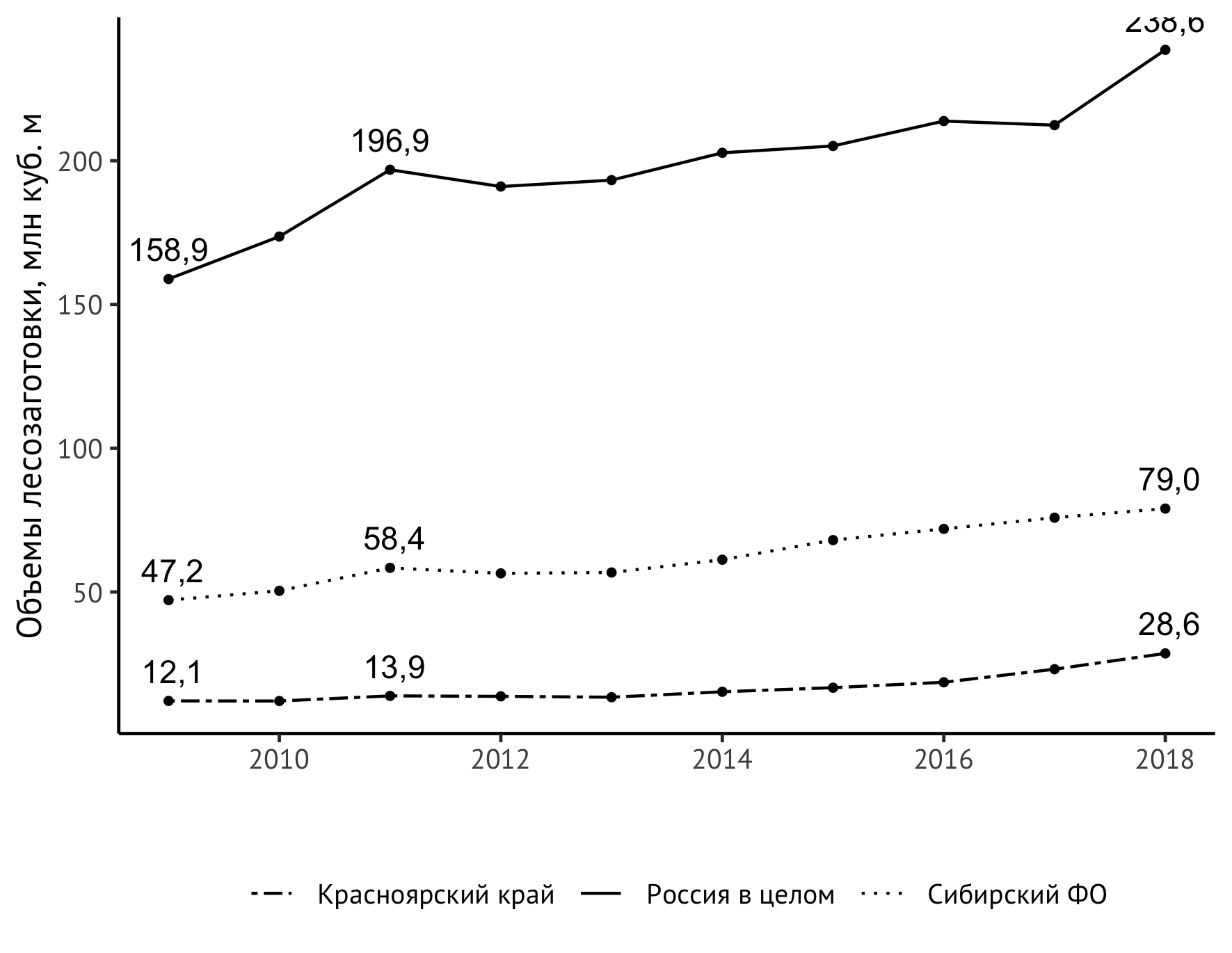
Теперь график действительно интересно рассматривать!
Но обнаружилась неожиданная проблема — верхнее правое значение «срезается» размером изображения по вертикали. Решить эту проблему можно разными способами. Я выкрутился с помощью небольшого растяжения шкалы вертикальной оси с указанием явной верхней границы в 250 млн куб. м:
scale_y_continuous(limits = c(0,250))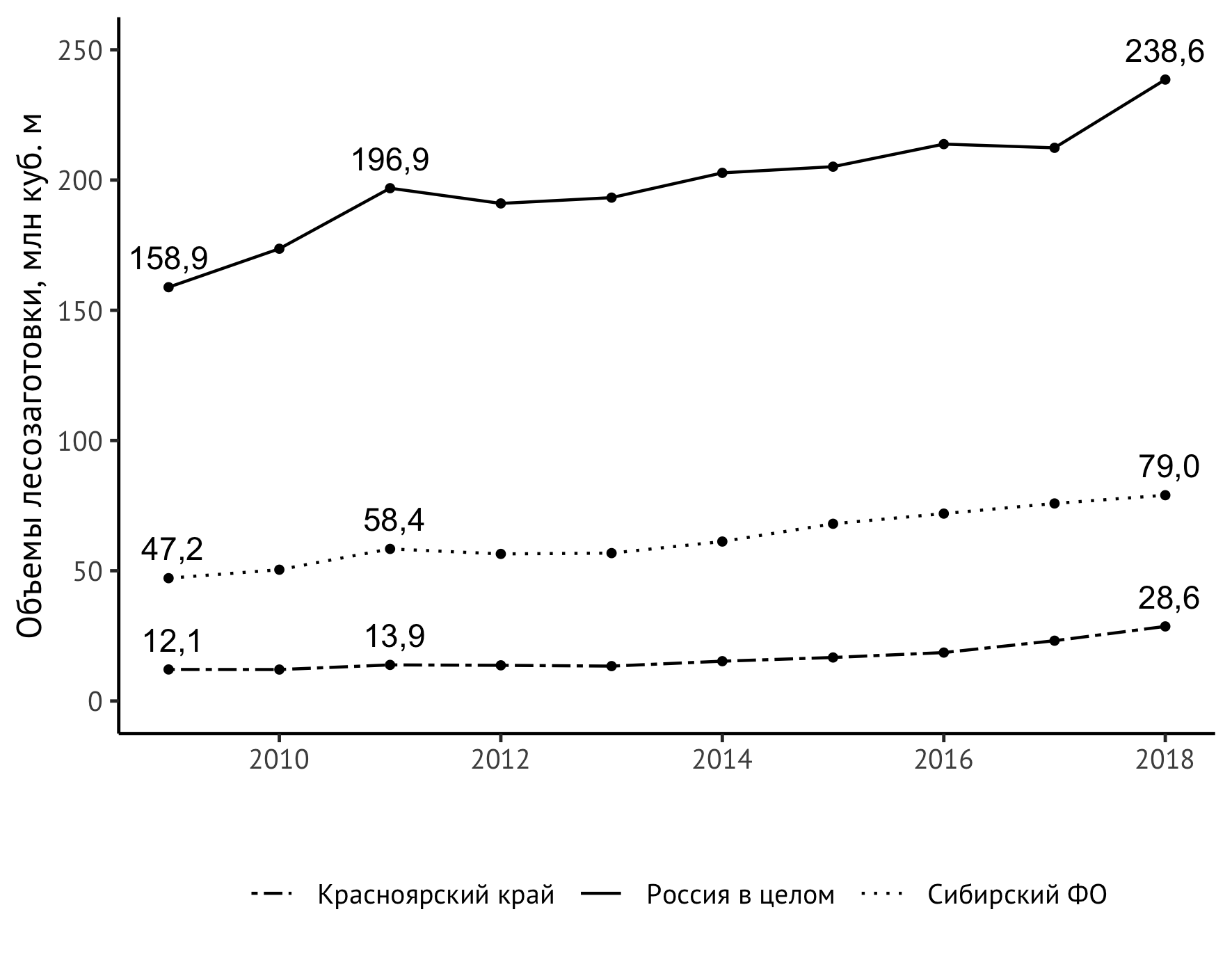
Готово! Итак, итоговый код выглядит так:
ggplot(data=df_logging, aes(x=year, y=value/1000)) +
geom_line(aes(linetype=location)) +
geom_point(size=1) +
theme_classic(base_family = "PT Sans", base_size = 12) +
theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) +
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")),
data = subset(df_logging, year == 2009 | year == 2018 | year == 2011),
check_overlap = TRUE, vjust=-0.8) +
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")),
data = subset(df_logging, year == 2009 | year == 2018 | year == 2011),
check_overlap = TRUE, vjust=-0.8) +
scale_linetype_manual(values=c("twodash", "solid", "dotted")) +
scale_y_continuous(limits = c(0,250)) +
labs(x = "", y = "Объемы лесозаготовки, млн куб. м", color="")Полученное в итоге изображение входит в монографию: Структурная модернизация как фактор повышения конкурентоспособности региона (на примере Красноярского края) / под ред. Шишацкого Н. Г. — Новосибирск: ИЭОПП СО РАН, 2020 (в печати).
Экспорт
Встроенный в RStudio плагин просмотра графиков позволяет экспортировать изображения в несколько форматов без дополнительных команд, буквально в несколько кликов. Проблема в том, что для практических задач этот сервис оказывается практически бесполезным. При сохранении в растровые форматы (.jpg, .png), по умолчанию выставляется очень низкое разрешение, поэтому при импорте изображения, например, в Word, оно будет размытым. С векторными .eps или .pdf ситуация откровенно хуже: сохранение происходит либо с ошибками, не позволяющими затем открыть файл, либо сохраняется без возможности использования русскоязычных надписей.
Решением является использование функции ggsave из пакет ggplot.
Если на выходе требуется обычный растровый файл, например, формата .png, всё достаточно просто:
ggsave("logging.png", width=709, height=549, units="px")Геометрию (опции width и height) и единицы измерения (units) можно и не указывать, но тогда по умолчанию изображение будет экспортировать квадратным, что вряд ли удобно. Поэтому лучше придумать свою пропорцию и необходимый размер и задать эти параметры вручную, как это сделано в вышеприведенной строке кода.
Для последующего использования изображения в бумажных изданиях разумно экспортировать изображение в векторные форматы, чтобы потом при верстке была возможность свободного изменения геометрии изображения. Многие журналы предпочитают формат .eps — его же удобно использовать для экспорта в Word. Нам понадобится уже установленный и подключенный драйвер Cairo:
ggsave(filename = "export.eps", width=15, height=11.6, units="cm", device = cairo_ps)Файлы будут сохраняться в текущую директорию, в которой расположен скрипт R.
Что еще почитать
Литературы по графике в R довольно много. Вот несколько примеров, первым из которых является работа автора пакета ggplot:
- Wickham, Hadley. ggplot2: Elegant Graphics for Data Analysis;
- Chang, Winston. R Graphics Cookbook, 2nd edition;
- Prabhakaran, Selva. Top 50 ggplot2 Visualizations — The Master List (With Full R Code).
Наверное, лучшей и наиболее подробной книгой по графике в R на русском языке назовем книгу Тимофея Самсонова. Визуализация и анализ географических данных на языке R. Это отличный подробный путеводитель по очень многим общим и специфическим задачам, которые можно решить с помощью R.
Также можно посоветовать книгу на русском про R в целом:
Шитиков В. К., Мастицкий С. Э. Классификация, регрессия, алгоритмы Data Mining с использованием R. 2017.
Просто интересный и мотивирующий пример — мощная презентация об использовании ggplot2 при подготовке рисунков для влиятельной газеты Financial Times.
Перевод. Оригинал здесь.
Это введение в ggplot2 — это отличный пакет R для визуализации данных, которое не предполагает, что вы уже знакомы с R.
Для лучшего понимания можно посмотреть хорошо оформленную версию этой статьи в репозитории Github, которая также содержит некоторые примеры наборов данных, используемые мною, в также версию этого поста в виде кода с комментариями.
Давайте сначала посмотрим, что может ggplot2.
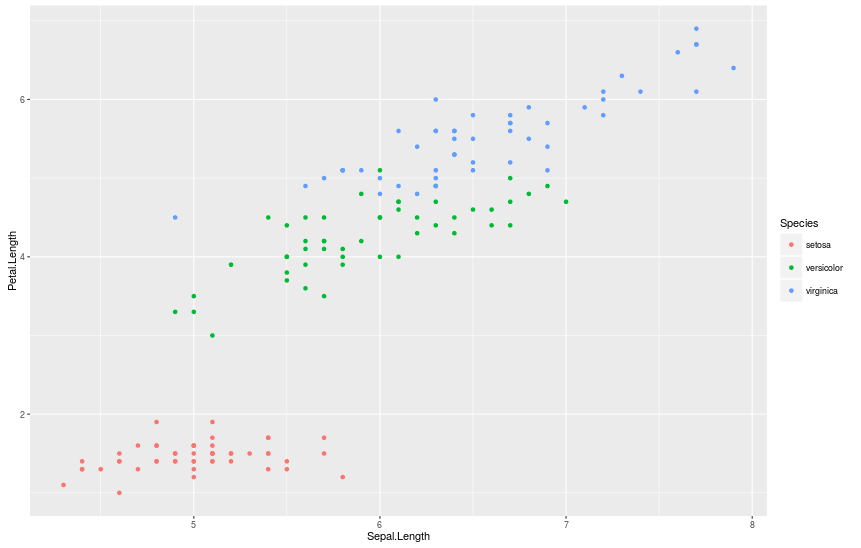
Набор данных «ирисы Фишера» и одна простая команда…
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species)
Установка
Вы можете скачать R здесь. После установки вы можете запустить R в интерактивном режиме, введя R в командной строке, или открыв стандартный GUI.
Основы R
Векторы
Векторы являются базовой структурой данных в R и создаются с помощью команды c(). Элементы вектора должны быть одинакового типа.
> numbers = c(23, 13, 5, 7, 31)
> names = c(«edwin», «alice», «bob»)
Индексы элементов начинаются с 1, доступ к элементам производится с помощью квадратных скобок.
> numbers[1]
[1] 23
> names[1]
[1] «edwin»
Data frame
Data frame — это подобие матрицы, но с именованными столбцами, которые могут быть разных типов (как таблицы баз данных).
> books = data.frame(title = c(«harry potter», «war and peace», «lord of the rings»), author = c(«rowling», «tolstoy», «tolkien»), num_pages = c(«350», «875», «500»))
Вы можете получать доступ к столбцам данных с помощью префикса $.
> books$title
[1] harry potter war and peace lord of the rings
Levels: harry potter lord of the rings war and peace
> books$author[1]
[1] rowling
Levels: rowling tolkien tolstoy
Также с помощью $ вы можете создавать новые столбцы
> books$num_bought_today = c(10, 5, 
> books$num_bought_yesterday = c(18, 13, 20)
> books$total_num_bought = books$num_bought_today + books$num_bought_yesterday
read.table
Предположим, вам необходимо экспортировать в data frame файл TSV.
Файл tsv без заголовка
Для примера возьмем файл students.tsv (со столбцами, описывающими возраст, оценку и имя каждого студента).
13 100 alice
14 95 bob
13 82 eve
Вы можете импортировать этот файл в R с помощью команды read.table().
> students = read.table(«students.tsv»,
+ header = F, # файл не содержит заголовка («F» — это сокращение для «FALSE»), поэтому мы должны вручную задать имена столбцов.
+ sep = «t», # разделители — табуляция
+ col.names = c(«age», «score», «name») # имена столбцов)
Теперь мы можем обращаться к различным столбцам в data frame с помощью students$age, students$score и students$name.
Файл csv с заголовком
В качестве примера файла другого формата посмотрим studentsWithHeader.tsv.
age,score,name
13,100,alice
14,95,bob
13,82,eve
У нас те же данные, но теперь они разделены запятыми и имеют заголовок. Мы можем импортировать этот файл следующим образом:
> students = read.table(«students.tsv», sep = «,»,
+ header = T) # первая строка содержит имена столбцов
Примечание: есть также функция read.csv, в которой по умолчанию sep = «,».
help
У функции read.table очень много опций. Для того, чтобы вывести их все, просто введите (read.table) (или ?read.table).
# Это работает с любыми функциями.
help(read.table)
?read.table
ggplot2
Теперь, зная основы R, можно приступить к изучению пакета ggplot2.
Установка
Одной из сильных сторон R является отличный набор пакетов на все случаи жизни. Для установки пакета используется функция install.packages().
install.packages(«ggplot2»)
Для загрузки пакета в текущей сессии R используется функция library().
library(ggplot2)
Построение диаграмм рассеяния с помощью функции qplot()
Давайте посмотрим, как в ggplot2 строить диаграммы рассеяния. Мы будем использовать набор данных iris, который автоматически загружается в R.
Что содержит data frame? Для того, чтобы посмотреть несколько первых строк данных, используется функция head.
> head(iris) # по умолчанию функция head выводит первые 6 строк
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> head(iris, n = 10) # мы можем явно задать, какое количество строк вывести
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
(data frame на самом деле содержит данные по трем видам ирисов: setosa, versicolor, and virginica.)
Давайте построим график Sepal.Length vs Petal.Length, используя функцию qplot() из ggplot2.
> # строим Sepal.Length vs. Petal.Length, используя данные из набора iris
> # * Первый аргумент «Sepal.Length» соответствует оси x.
> # * Второй аргумент «Petal.Length» соответствует оси y.
> # * «data = iris» означает искать данные в data frame «iris».
> qplot(Sepal.Length, Petal.Length, data = iris)
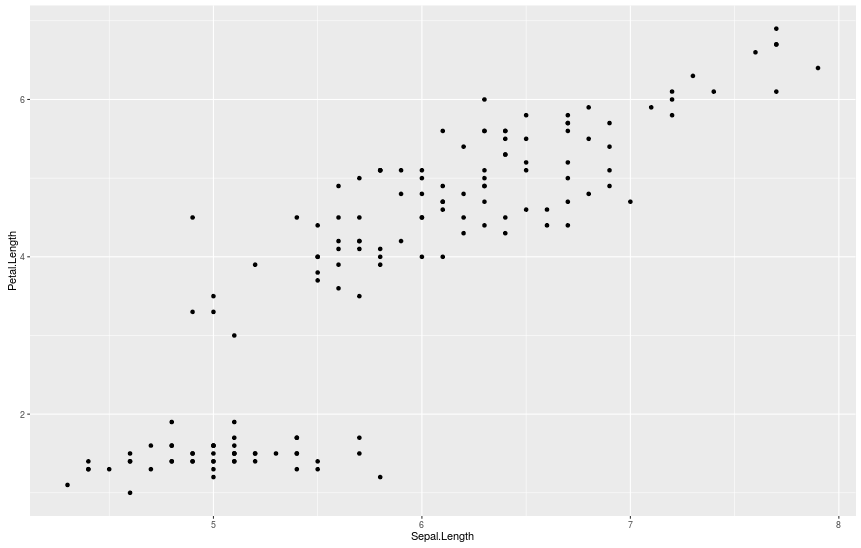
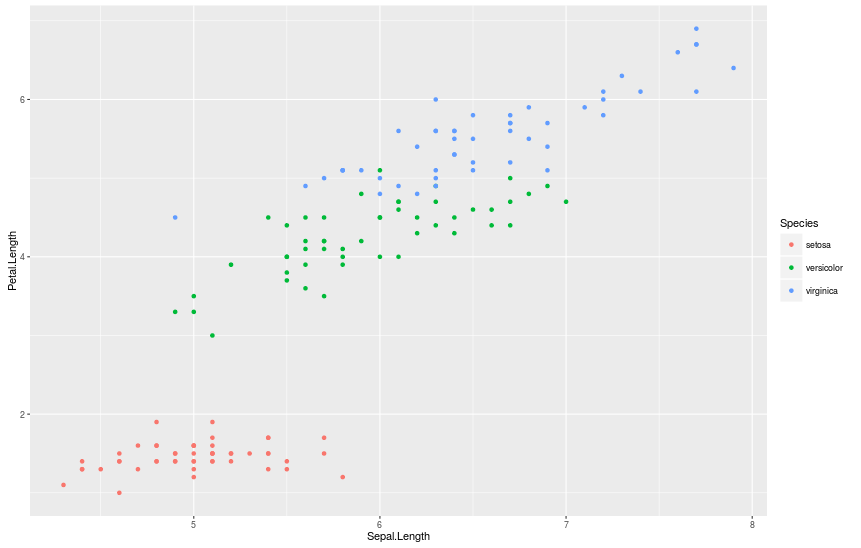
Чтобы увидеть на графике расположение каждого вида, мы можем раскрасить их, добавив аргумент color = Species.
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species)
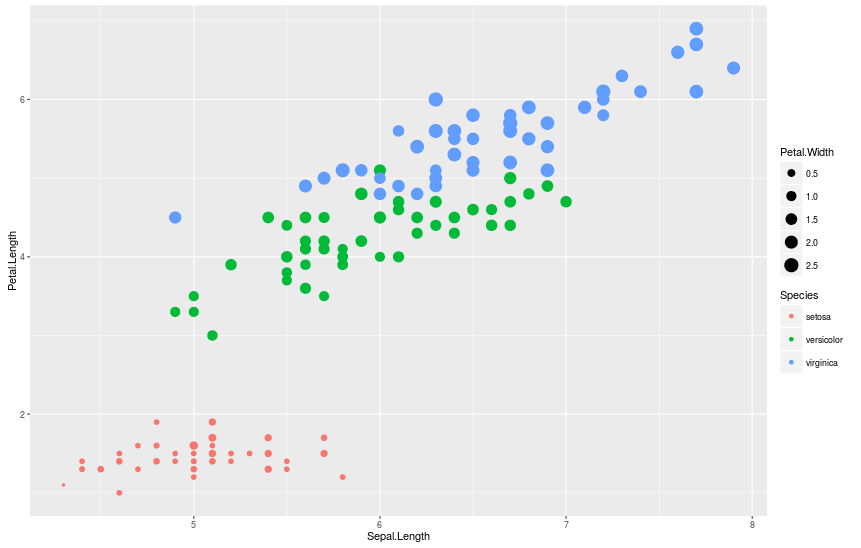
Аналогично, мы можем задать размер каждой точки в соответствии со значением, добавив аргумент size = Sepal.Width.
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species, size = Petal.Width)
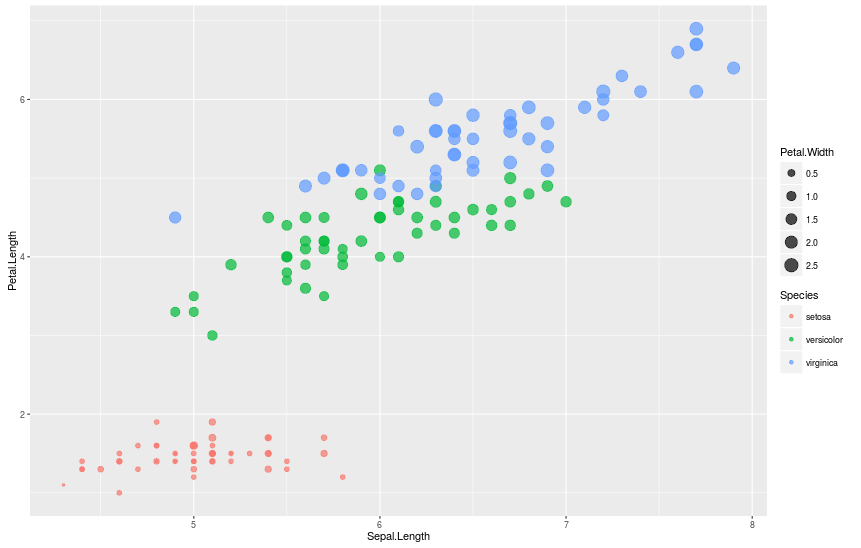
> # Задав значение alpha для каждой точки 0.7, мы уменьшим эффект перекрытия.
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species, size = Petal.Width, alpha = I(0.7))
И наконец, давайте исправим подписи осей и добавим заголовок к графику.
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species, xlab = «Sepal Length», ylab = «Petal Length», main = «Sepal vs. Petal Length in Fisher’s Iris data»)

Другие типы графиков
В приведенном выше примере мы просто задействовали тип графика, используемый по умолчанию при двух аргументах у функции qplot().
> # Эти две функции эквивалентны
> qplot(Sepal.Length, Petal.Length, data = iris, geom = «point»)
> qplot(Sepal.Length, Petal.Length, data = iris)
Но мы также легко можем использовать другие типы графиков.
Гистограммы: geom = “bar”
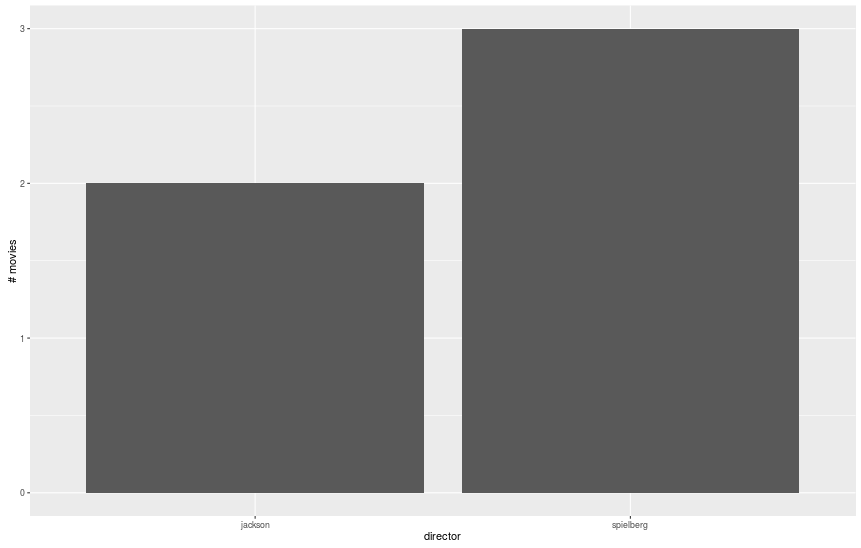
> movies = data.frame(director = c(«spielberg», «spielberg», «spielberg», «jackson», «jackson»), movie = c(«jaws», «avatar», «schindler’s list», «lotr», «king kong»), minutes = c(124, 163, 195, 600, 187))
> # Строим гистограмму количества фильмов каждого режиссера.
> qplot(director, data = movies, geom = «bar», ylab = «# movies»)
> # Здесь высота столбца равна общей продолжительности фильмов каждого режиссера.
> qplot(director, weight = minutes, data = movies, geom = «bar», ylab = «total length (min.)»)

Линейные графики: geom = “line”
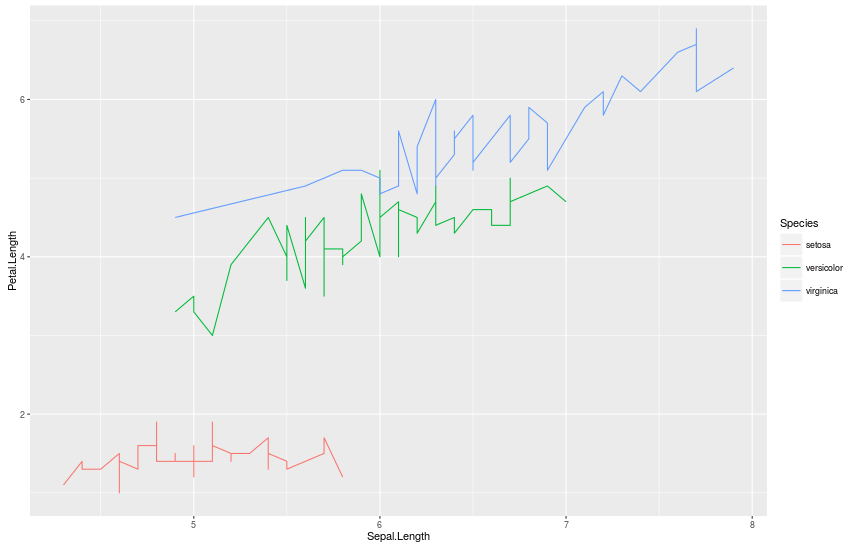
> qplot(Sepal.Length, Petal.Length, data = iris, geom = «line», color = Species)
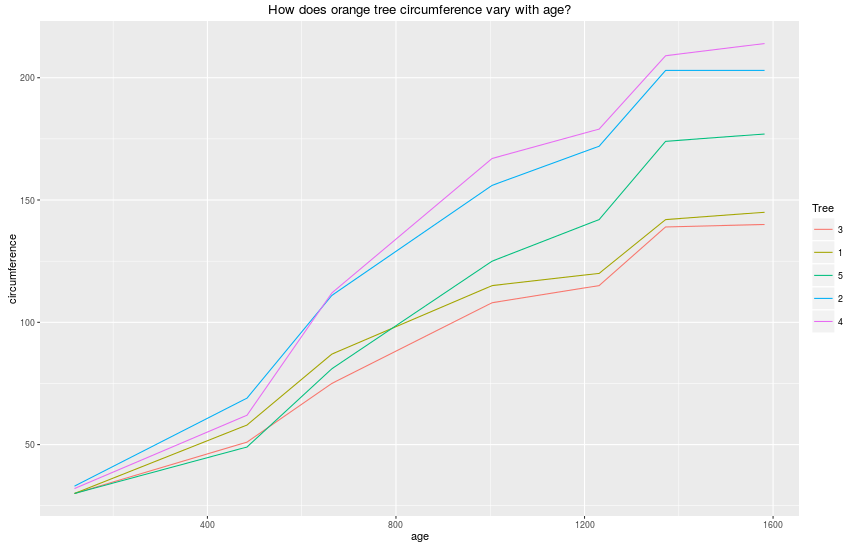
> # «Orange» — это еще один встроенный набор данных, который описывает рост апельсиновых деревьев.
> qplot(age, circumference, data = Orange, geom = «line», colour = Tree, main = «How does orange tree circumference vary with age?»)
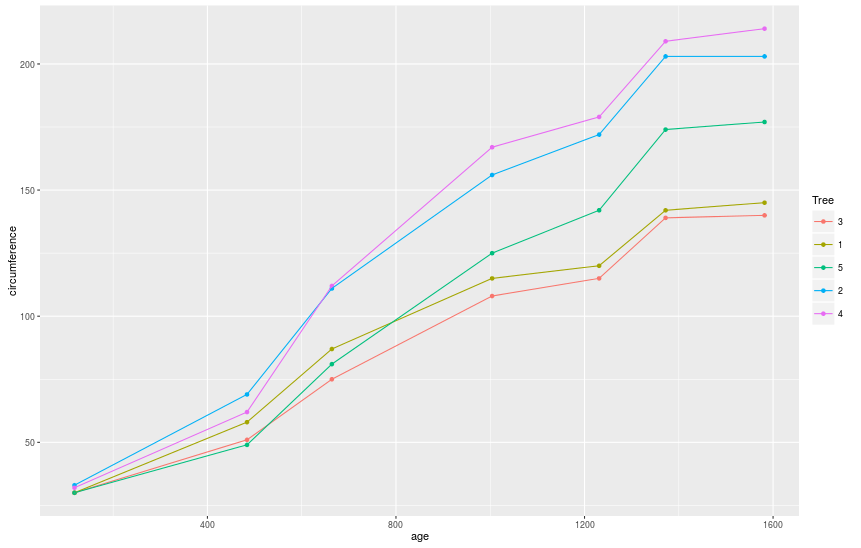
> # Мы также можем строить графики, содержащие как точки, так и линии.
> qplot(age, circumference, data = Orange, geom = c(«point», «line»), colour = Tree)
Краткое руководство по началу работы с методами визуализации данных в пакете ggplot2.

Что такое визуализация данных?
Это практика визуализации данных в виде графиков, значков, презентаций и т. д. Чаще всего он используется для преобразования сложных данных в удобоваримые идеи для нетехнической аудитории.
Это отличная книга, которую можно использовать в качестве отправной точки, если вы новичок в визуализации данных — Рассказывание историй с данными.
Если вам интересно узнать больше о визуализации данных с помощью Python, посмотрите мой другой учебник — Matplotlib в Python.
Что такое R?
R — это язык программирования, который в основном используется для статистического анализа. Это распространенный инструмент для анализа в сфере финансов и здравоохранения.
R предоставляет широкий спектр статистических (линейное и нелинейное моделирование, классические статистические тесты, анализ временных рядов, классификация, кластеризация и т. Д.) И графических методов и обладает высокой расширяемостью.
Отличные ресурсы для начала работы с R,
- Кодекадемия
- Гуру99
- Книга R
Что такое ggplot2?
Ggplot2 — это пакет R из tidyverse. Его популярность объясняется простотой настройки графиков и удаления или изменения компонентов графика на высоком уровне абстракции.
Если вам интересно узнать больше, посмотрите эту книгу — Визуализация данных в R с помощью ggplot2
Синтаксис построения графиков в ggplot основан на простом подходе к построению графиков по слоям.
- данные
- эстетика — переменные
- геометрический стиль — здесь вы определяете стиль графика
- дополнительные слои для настройки — заголовок, метки, ось и т. д.
Структура выглядит примерно так.
ggplot(data = Example_Data) +
aes(x = Variable_1, y = Variable_2) +
geom_bar() #this is an example of a bar plot sysntaxВ этом руководстве я предполагаю, что у вас есть базовые навыки работы с концепциями R.
Давайте начнем!
Готовим нашу окружающую среду
Для начала нам нужно установить пакеты tidyverse и ggplot2.
install.packages(c("ggplot2", "tidyverse")
Далее нам нужно будет загрузить библиотеку ggplot2.
library(ggplot2)
Гистограммы
Что касается данных, мы будем работать с набором данных под названием reviews. Файл уже прочитан в нашу среду. Набор данных reviews представляет собой набор обзоров фильмов с 4 основных сайтов с обзорами, Fandango, Rotten Tomatoes, IMDB и Metacritic.
Нас интересуют следующие входы:
- data = отзывы
- эстетика = (ось x = рейтинг сайта, ось y = средний рейтинг)
- геометрический стиль = гистограмма
Чтобы создать столбчатую диаграмму, которая показывает средние оценки для каждого веб-сайта, мы можем сделать следующее.
ggplot(data=reviews) +
aes(x = Rating_Site, y = avg) +
geom_bar(stat = 'identity')

Гистограммы
Гистограммы показывают нам, насколько часто встречается значение. Ниже представлена гистограмма, показывающая частотное распределение оценок в нашем наборе данных обзоров. Обратите внимание, что добавлены некоторые дополнительные слои.
ggplot(data = reviews) +
aes(x = Rating, fill = "red") +
geom_histogram(bins=30) +
labs(title = "Distribution of Ratings")

Дополнительные шаги:
- fill — мы использовали это в эстетическом слое, чтобы указать желаемый цвет.
- geom_histogram () — здесь мы определяем, что хотим гистограмму.
- labs — чтобы добавить заголовок, мы использовали новый слой для меток.
Здесь мы видим, что мы изменили и добавили 3 новых слоя. ggplot позволяет очень легко настраивать графики в соответствии с нашими личными предпочтениями.
Коробчатые графики
Коробчатые диаграммы — еще один отличный инструмент для визуализации описательной статистики. Если вы хотите узнать больше о коробчатых графиках, ознакомьтесь с этой статьей коллеги по Data Science — Майкла Галарника.
На диаграмме ниже показан разброс для всех рейтинговых сайтов.
ggplot(data=reviews) +
aes(x=Rating_Site, y = Rating, color = Rating_Site) +
geom_boxplot() +
labs(title="Comparison of Movie Ratings") +
theme(panel.background = element_rect(fill = "white"), legend.position="none")

Теперь мы смотрим на эту коробочную диаграмму: мы изменили или добавили несколько новых слоев.
- color — цвет позволяет нам настроить границу строки элемента, здесь мы выбираем передачу переменной rating_site. Благодаря этому каждая коробка отличается по цвету друг от друга.
- geom_boxplot () — указать стиль графика
- panel.background — это позволяет нам удалить серый фон и заполнить его белым. Лично я предпочитаю всегда использовать белый фон, но в зависимости от того, что вы пытаетесь передать, иногда более полезными могут быть разные цвета фона.
- legend.position — здесь я заявляю, что нужно удалить метки легенды. Почему? Если бы я оставил легенду видимой, она просто указала бы, к какому rating_site соответствует цвет каждой коробчатой диаграммы, на которую он ссылается. Это повторяется, поскольку ясно, что xlabels уже показывают нам рейтинг rating_site.
В целом, мы видим, что прямоугольник, представляющий рейтинги Fandango, расположен выше по оси Y, чем рейтинги других сайтов. Для сравнения, поле «Тухлые помидоры» длиннее, что означает, что рейтинги разнесены друг от друга.
Обзор
ggplot — один из самых мощных инструментов для визуализации в R. Как только вы погрузитесь глубже в эту тему, вы увидите, насколько широкими возможностями настройки вы можете пользоваться для создания красочных, подробных и ярких графиков.
В библиотеке ggplot доступно намного больше графиков, а также в других популярных библиотеках, доступных в R. Стоит изучить все различные варианты и найти, какая библиотека соответствует вашему стилю кодирования и анализа.
Следите за обновлениями — я поделюсь дополнительными уроками по созданию других графиков в ggplot.