Мануал по команде grep на человеческом языке.
Команда grep, одна из самых известных и употребительных команд Юниксовидных ОС, ведет свое начало от первого текстового редактора Юникс — ed.
Команда grep служит для поиска строк, содержащих заданный пользователем образец.
Наткнулся на замечательный проект Human — человеческий мануал. Те кто частенько обращаются с мануалам замечали, что многие из них написаны, чтобы только они были. Разработчику все понятно — и пользователь разберется. Вот и автор проекта решил перевести мануалы наиболее используемых программ на человеческий язык и надо сказать ему это удалось.
Команда grep, одна из самых известных и употребительных команд Юниксовидных ОС, служит для поиска строк, содержащих заданный пользователем образец.
взято с: http://rus-linux.net/lib.php?name=MyLDP/consol/HuMan/grep-ru.html
HuMan: grep
Оригинал:
Автор: Алексей Дмитриев
Дата: 3 января 2009
Введение
Команда grep, одна из самых известных и употребительных команд Юниксовидных ОС, ведет свое начало от первого текстового редактора Юникс — ed. В этом редакторе была команда g/re/p (global/regular expression/print), которая и дала свое название новой программе.
Команда grep служит для поиска строк, содержащих заданный пользователем образец.
grep ОБРАЗЕЦ имя_файла
Причем обязательным для ввода является только ОБРАЗЕЦ, можно обойтись даже без имени файла (аргумента).
Если не указано имени файла, то команда обрабатывает стандартный ввод, например строки, набранные на клавиатуре:
$ grep коту меня есть кошка,(Enter)
вернее это кот,(Enter)
вернее это кот,
который умеет(Enter)
который умеет
ловить мышей.(Enter)
(Ctrl+c)
В скобках показано, когда я нажимал клавишу Enter, чтобы перейти на новую строку. Одновременно, при нажатии Enter, программа выводила строки, содержащие ОБРАЗЕЦ (кот), отсюда и удвоение этих строк. Видно, что команда реагировала просто на сочетание букв, а не на слово «кот», иначе строка со словом «который» не попала бы в вывод.
Тут мы подошли к очень важному определению строки. Строкой команда grep (как и все остальные команды Юникс) считает все символы, находящиеся между двумя символами новой строки. Эти невидимые на экране символы возникают в тексте каждый раз, когда пользователь нажимает клавишу Enter. В Юниксовидных системах символ новой строки обозначается обратным слэшем с буквой n (n). Таким образом, строка может быть любого размера, начиная с одного символа и до многомегабайтного текста. И команда grep честно выведет эту строку, при условии, что она содержит ОБРАЗЕЦ.
Работа с файлами
Команда grep может обрабатывать любое количество файлов одновременно. Создадим три файла:
123.txt: alice.txt: ast.txt:1234 Алиса очень Символ астериска
5678 красивая девочка, обозначается (*)
89*0 у нее такая ****** звездочкой.
длинная коса!
И дадим команду:
$ grep '*' 123.txt ast.txt alice.txt123.txt:89*0
ast.txt:обозначается (*).
alice.txt:у нее такая ******
В выводе перечислены файлы, и указано, в каком из них какая строка содержит символ астериска. ОБРАЗЕЦ (*) пришлось взять в кавычки, чтобы командный интерпретатор понял, что имеется в виду символ, а не условный знак. Попробуйте без кавычек, увидите — ничего не получится.
Команда grep вовсе не ограничена одним выражением в качестве ОБРАЗЦА, можно задавать хоть целые фразы. Только их нужно заключать в кавычки (одинарные или двойные):
$ grep 'ная ко' 123.txt ast.txt alice.txtalice.txt:длинная коса!
Возможности поиска при помощи команды grep могут быть значительно расширены применением групповых символов. Например, уже упоминавшийся астериск (звездочка) используется для представления любого символа или группы символов, если речь идет о тексте, и любого файла или группы файлов, если речь идет о директории.
Создадим директорию /example, в которую поместим файлы наших примеров: 123.txt, ast.txt, alice.txt и дадим команду:
$ grep '*' example/*example/123.txt:89*0
example/alice.txt:у нее такая ******
example/ast.txt:обозначается (*)
То есть мы приказали просмотреть все файлы директории /example. Таким способом можно обследовать такие огромные директории как /usr, /dev, и любые другие.
Опция -r
—recursive
Еще больше увеличит зону поисков опция -r, которая заставит команду grep рекурсивно обследовать все дерево указанной директории, то есть субдиректории, субдиректории субдиректорий, и так далее вплоть до файлов. Например:
$ grep -r menu /boot
/boot/grub/grub.txt:Highlight the menu entry you want to edit and press 'e', then
/boot/grub/grub.txt:Press the [Esc] key to return to the GRUB menu.
/boot/grub/menu.lst:# GRUB configuration file '/boot/grub/menu.lst'.
/boot/grub/menu.lst:gfxmenu (hd0,3)/boot/message
Опция -i
—ignore-case
Приказывает команде игнорировать регистр символов, таким образом, поиск будет производиться как среди заглавных, так и среди строчных букв.
Опция -c
—count
Эта опция не выводит строки, а подсчитывает количество строк, в которых обнаружен ОБРАЗЕЦ. Например:
$ grep -c root /etc/group
8
То есть в восьми строках файла /etc/group встречается сочетание символов root.
Опция -n
—line-number
При использовании этой опции вывод команды grep будет указывать номера строк, содержащих ОБРАЗЕЦ:
$ grep -n print /etc/printcap1:# /etc/printcap
3:# See "man printcap" for information on editing this file.
5:# In most cases it is better to use a tool to write the printcap
9:# cupsd print daemon at this URL: http://localhost:631
Опция -v
—invert-match
Выполняет работу, обратную обычной — выводит строки, в которых ОБРАЗЕЦ не встречается:
$ grep -v print /etc/printcap#
#
# for you (at least initially), such as apsfilter
# (/usr/share/apsfilter/SETUP, used in conjunction with the
# LPRng lpd daemon), or with the web interface provided by the
# (if you use CUPS).
Опция -w
—word-regexp
Заставит команду grep искать только строки, содержащие все слово или фразу, составляющую ОБРАЗЕЦ. Например:
$ grep -w "длинная ко" example/*
Не дает вывода, то есть не находит строк, содержащих выражение «длинная ко». А вот команда:
$ grep -w "длинная коса" example/*example/alice.txt:длинная коса!
находит точное соответствие в файле alice.txt.
Опция -x
—line-regexp
Еще более строгая. Она отберет только те строки исследуемого файла или файлов, которые полностью совпадают с ОБРАЗЦОМ.
$ grep -x "1234" example/*example/123.txt:1234
Внимание: Мне попадались (на собственном компьютере) версии grep (например, GNU 2.5), в которых опция -x работала неадекватно. В то же время, другие версии (GNU 2.5.1) работали прекрасно. Если что-то не ладится с этой опцией, попробуйте другую версию, или обновите свою.
Опция -l
—files-with-matches
Команда grep с этой опцией не возвращает строки, содержащие ОБРАЗЕЦ, но сообщает лишь имена файлов, в которых данный образец найден:
$ grep -l 'Алиса' example/*example/alice.txt
Замечу, что сканирование каждого из заданных файлов продолжается только до первого совпадения с ОБРАЗЦОМ.
Опция -L
—files-without-match
Наоборот, сообщает имена тех файлов, где не встретился ОБРАЗЕЦ:
$ grep -L 'Алиса' example/*example/123.txt
example/ast.txt
Как мы имели случай заметить, команда grep, в поисках соответствия ОБРАЗЦУ, просматривает только содержимое файлов, но не их имена. А так часто нужно найти файл по его имени или другим параметрам, например времени модификации! Тут нам придет на помощь простейший программный канал (pipe). При помощи знака программного канала — вертикальной черты (|) мы можем направить вывод команды ls, то есть список файлов в текущей директории, на ввод команды grep, не забыв указать, что мы, собственно, ищем (ОБРАЗЕЦ). Например:
Desktop$ ls | grep grepgrep/
grep-ru.txt
Находясь в директории Desktop, мы «попросили» найти на Рабочем столе все файлы, в названии которых есть выражение «grep». И нашли одну директорию grep/ и текстовой файл grep-ru.txt, который я в данный момент и пишу.
Если мы хотим искать по другим параметрам файла, а не по его имени, то следует применить команду ls -l, которая выводит файлы со всеми параметрами:
Desktop$ ls -l | grep 2008-12-30-rw-r--r-- 1 ya users 27 2008-12-30 08:06 123.txt
drwxr-xr-x 2 ya users 4096 2008-12-30 08:49 example/
-rw-r--r-- 1 ya users 11931 2008-12-30 14:59 grep-ru.txt
И вот мы получили список всех файлов, модифицированных 30 декабря 2008 года.
Команда grep незаменима при просмотре логов и конфигурационных файлов. Классически примером использования команды grep стал программный канал с командой dmesg. Команда dmesg выводит те самые сообщения ядра, которые мы не успеваем прочесть во время загрузки компьютера. Допустим, мы подключили через USB порт новый принтер, и теперь хотим узнать, как ядро «окрестило» его. Дадим такую команду:
$ dmesg | grep -i usb
Опция -i необходима, так как usb часто пишется заглавными буквами. Проделайте этот пример самостоятельно — у него длинный вывод, который не укладывается в рамки данной статьи.
Немного хитростей
Если продолжить описание множества опций команды grep, то статья станет утомительной и нечитаемой. Поэтому, рассмотрев необходимый минимум опций, можно развлечься всякими хитростями при применении этой замечательной команды.
Хитрость первая
Как заставить grep указать в выводе имя файла, где найдено соответствие ОБРАЗЦУ? Например, мы хотим найти строку, содержащую выражение «красивая девочка» в файле alice.txt, да так, чтобы в выводе фигурировало имя файла (для отчета). Если просто дать команду:
$ grep -w 'красивая девочка' alice.txtкрасивая девочка,
То никакого имени файла там не будет. Но стоит добавить в аргументы еще один файл, как все заработает. Обычно, чтобы избежать неожиданностей, указывают файл /dev/null:
$ grep -w 'красивая девочка' alice.txt /dev/nullalice.txt:красивая девочка,
Хитрость вторая
Используя «чистые» опции команды grep, мы можем получить все строки, содержащие ОБРАЗЕЦ либо в составе других слов (без опций), либо в виде заданного слова (опция -w). А как найти слова, которые заканчиваются на -ОБРАЗЕЦ или начинаются с ОБРАЗЕЦ-? Для этого существуют специальные значки: , означающий, что ОБРАЗЕЦ будет концом слова.
$ grep 'kot' kot.txtkot
kotoroe
antrekot
kotovasiya
okot
skotobaza
nekotoroe
Это был файл kot.txt целиком.
$ grep 'kot>' kot.txtkot
antrekot
okot
А это были слова, оканчивающиеся на -kot.
$ grep 'kot
kotoroe
kotovasiya
Эти начинаются на kot-.
$ grep '' kot.txtkot
А вот был «чистый» кот.
Прошу простить за транслитерацию, но с нашими буквами эта хитрость как-то не срабатывает, а с английскими словами не все поймут.
Хитрость третья.
Как быть, если ОБРАЗЕЦ начинается с дефиса, ведь команда примет его за опцию?
Попробуем:
$ grep '--анонимность' anonim.txtgrep: unrecognized option `--анонимность'
Так и есть — принимает за опцию. Ну так дадим ей опцию -e, которая означает: «Воспринимать ОБРАЗЕЦ только как образец».
$ grep -e '--анонимность' anonim.txt--анонимность
Совсем другое дело.
Хитрость четвертая.
Как посмотреть соседние строчки?
$ grep -C 2 -e '--анонимность' anonim.txtТребуется соблюсти следующие условия:
--анонимность
--секретность
--неразглашение.
Просмотр вверх и вниз на две строки.
$ grep -A 1 -e '--анонимность' anonim.txt--анонимность
--секретность
Просмотр вниз на одну строку.
$ grep -B 1 -e '--анонимность' anonim.txtТребуется соблюсти следующие условия:
--анонимность
Просмотр вверх на одну строку.
Хитрость пятая.
$ grep -r menu /bootБинарный файл /boot/grub/stage2 совпадает
Бинарный файл /boot/grub/stage2_eltorito совпадает
/boot/grub/grub.txt:Highlight the menu entry you want to edit and press 'e', then
/boot/grub/grub.txt:Press the [Esc] key to return to the GRUB menu.
/boot/grub/menu.lst:# GRUB configuration file '/boot/grub/menu.lst'.
/boot/grub/menu.lst:gfxmenu (hd0,3)/boot/message
Что означают сообщения в первых двух строках вывода?
Сообщение «Бинарный файл совпадает» («Binary file matches») появляется, когда совпадение с образцом встречается в бинарных файлах. Если бы grep вывел строки из таких файлов на дисплей, толку было бы немного, а на дисплее могла возникнуть неразбериха (а может быть, и чего похуже, если драйвер терминала воспримет какие-либо фрагменты бинарного файла как команды). Если вы хотите все-таки увидеть эти строки, то применяйте опцию -a или —binary-files=text. Если хотите подавить вывод сообщений «Бинарный файл совпадает», то применяйте опцию -I или —binary-files=without-match.
Хитрость шестая.
Как искать строки, содержащие несколько ОБРАЗЦОВ?
Применить программный канал, канализируя вывод одной команды grep с вводом следующей команды grep.
$ grep 'у' example/* | grep '*'example/alice.txt:у нее такая ******
Первый grep ищет у нас «у», а второй — «*» и оба находят искомое в одной строке: «у нее такая ******». Можно сделать эту цепочку команд grep любой длины, было бы чего искать, да строчки достаточно длинные 🙂
Хитрость седьмая, и пока последняя.
Можно ли искать одновременно в стандартном вводе и в файле?. Можно, если перед именем файла поставить дефис:
$ echo многие употребляют астериск неправильно | grep 'астериск' - example/*(стандартный ввод):многие употребляют астериск неправильно
example/ast.txt:Символ астериска
Внимание: Если перед дефисом и после него не будет пробелов, то команда не сработает.
Но настало время вернуться к опциям команды grep.
Пока я занимался хитростями, успел позабыть, какие из опций уже описал, а какие нет. Поэтому я дал команду:
$ grep 'Опция' grep-ru.txt > option.txt
и получил файл option.txt, в котором перечислены все фигурирующие в файле grep-ru.txt опции.
Общее количество опций программы подавляет, поэтому пойдем по алфавиту, пропуская те, что я уже описал.
Опция -f имя_файла
—file=имя_файла
Весьма полезная опция, когда нужно искать несколько ОБРАЗЦОВ, причем не в одной строке, как мы делали в шестой Хитрости, а в разных. Для того чтобы воспользоваться этой опцией, нужно составить файл, в котором поместить искомые ОБРАЗЦЫ по одному на строчке:
pattern.txt:nobody
root
ya
А затем дать команду:
# grep -f pattern.txt /etc/passwdnobody:x:65534:65533:nobody:/var/lib/nobody:/bin/bash
root:x:0:0:root:/root:/bin/bash
ya:x:1000:100:alex dmitriev:/home/ya:/bin/bash
Предупреждение: Эта полезная опция, к сожалению, работает не на всех версиях grep. На версии GNU grep 2.5 работает неадекватно, а на GNU grep 2.5.1 — прекрасно. Так что обновляйтесь, господа. Текущая стабильная версия GNU grep — 2.5.3.
Опция -o
—only-matching
Возвращает не всю строку, где найдено соответствие ОБРАЗЦУ, а только совпадающую с ОБРАЗЦОМ часть строки.
Без опции -o:
$ grep 'английскими' grep-ru.txtПрошу простить за транслитерацию, но с нашими буквами как-то эта хитрость не срабатывает,
а с английскими словами не все поймут.
А вот с опцией -o:
$ grep -o 'английскими' grep-ru.txtанглийскими
Опция -q
—quiet —silent
Ничего не выдает на стандартный вывод. В случае нахождения соответствия с ОБРАЗЦОМ немедленно отключается с нулевым статусом. Отключается также при обнаружении ошибки. Для чего это — не знаю. У меня получалось, что программа мгновенно прекращает работу, есть ли совпадения, нет ли, без всяких сообщений, в том числе и о нулевом статусе. Опробовал обе доступные версии grep.
Опция -s
—no-messages
Подавляет сообщения о несуществующих или нечитаемых файлах.
Предупреждение: традиционные версии последних двух опции (-q и -s) не соответствуют стандарту POSIX.2 и не совпадают с GNU версиями. Поэтому их нельзя применять в скриптах для командной оболочки. Просто перенаправляйте вывод на /dev/null.
Опции — расширения GNU
Опции
-A —after-context=ЧИСЛО_СТРОК
-B —before-context=ЧИСЛО_СТРОК
-C —context=ЧИСЛО_СТРОК
С этими тремя опциями мы уже познакомились в четвертой Хитрости, они позволяют посмотреть соседние строки. -A: количество строк после совпадения с ОБРАЗЦОМ, -B: количество строк перед совпадением, и -C: количество строк вокруг совпадения.
Опция —colour[=КОГДА]
Выделяет найденные строки цветом. Значения КОГДА могут быть: never (никогда), always (всегда), или auto. Пример:
$ grep -o 'английскими' --color grep-ru.txtанглийскими
Опция -D ДЕЙСТВИЕ
—devices=ДЕЙСТВИЕ
Если исследуемый файл является файлом устройства, FIFO (именованным каналом) или сокетом, то следует применять эту опцию. ДЕЙСТВИЙ всего два: read (прочесть), и skip (пропустить). Если вы указываете ДЕЙСТВИЕ read (используется по умолчанию), то программа попытается прочесть специальный файл, как если бы он был обычным файлом; если указываете ДЕЙСТВИЕ skip, то файлы устройств, FIFO и сокеты будут молча проигнорированы.
Опция -d ДЕЙСТВИЕ
—directories=ДЕЙСТВИЕ
Если входной файл является директорией, то используйте эту опцию. ДЕЙСТВИЕ read (прочесть) попытается прочесть директорию как обычный файл (некоторые ОС и файловые системы запрещают это; тогда появятся соответствующие сообщения, либо директории молча пропустят). Если ДЕЙСТВИЕ skip (пропустить), то директории будут молча проигнорированы. Если ДЕЙСТВИЕ recurse (рекурсивно), то grep будет просматривать все файлы и субдиректории внутри заданного каталога рекурсивно. Это эквивалент опции -r, с которой мы уже познакомились.
Опция -H
—with-filename
Выдает имя файла для каждого совпадения с ОБРАЗЦОМ. Мы успешно делали это без всяких опций в Хитрости второй.
Опция -h
—no-filename
Подавляет вывод имен файлов, когда задано несколько файлов для исследования.
Опция -I
Обрабатывает бинарные файлы как не содержащие совпадений с ОБРАЗЦОМ; эквивалент опции —binary-files=without-match.
Опция —include=ОБРАЗЕЦ_имени_файла
При рекурсивном исследовании директорий обследовать только файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
Опция —exclude=ОБРАЗЕЦ_имени_файла
При рекурсивном исследовании директорий пропускать файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
Опция -m ЧИСЛО_СТРОК
—max-count=ЧИСЛО_СТРОК
Прекратить обработку файла после того, как количество совпадений с ОБРАЗЦОМ достигнет ЧИСЛА_СТРОК:
$ grep -m 2 'kot' kot.txtkot
kotoroe
Опция -y
Синоним опции -i (не различать верхний и нижний регистр символов).
Опции -U и -u применяются только под MS-DOS и MS-Windows, тут нечего о них говорить.
Опция —mmap
Использует системный вызов mmap вместо системного вызова read. Может дать лучшую производительность, а может привести к ошибкам. Это для продвинутых пользователей.
Опция -Z
—null
Если в выводе программы имена файлов (например при опции -l), то опция -Z после каждого имени файла выводит нулевой байт вместо символа новой строки (как обычно происходит). Это делает вывод однозначным, даже если имена файлов содержат символы новой строки. Эта опция может быть использована совместно с такими командами как: find -print0, perl -0, sort -z, xargs -0 для обработки файловых имен, составленных необычно, даже содержащих символы новой строки. (Хотел бы я знать, как можно включить символ новой строки в имя файла. Если кто знает, не поленитесь — сообщите мне.)
Опция -z
—null-data
Рассматривает ввод как набор строк, каждая из которых заканчивается не символом новой строки, а нулевым байтом. Как и предыдущая опция, используется совместно с вышеперечисленными командами для обработки экзотических имен файлов.
Команда grep и регулярные выражения
Регулярные выражения (Regular Expressions) это система синтаксического разбора текстовых фрагментов по формализованному шаблону, основанная на системе записи ОБРАЗЦОВ для поиска. Проще говоря, регулярное выражение — тот же, уже привычный нам ОБРАЗЕЦ для поиска, только составленный по определенным правилам. Как математические формулы составляются при помощи набора операторов (плюс, минус, степень, корень и прочее), так и регулярные выражения конструируются при помощи различных операторов (?, *, +, {n} и прочие).
Тема регулярных выражений настолько обширна, что требует для своего освещения отдельной статьи; в данной статье мы не будем ее подробно разбирать. Скажу лишь, что существует несколько версий синтаксиса регулярных выражений: Базовый (basic) BRE, Расширенный (extended) ERE и регулярные выражения языка Perl.
Опция -G
—basic-regexp
Рассматривает ОБРАЗЕЦ как базовое регулярное выражение. Эта опция используется по умолчанию.
Опция -E
—extended-regexp
Рассматривает ОБРАЗЕЦ как расширенное регулярное выражение.
Опция -P
—perl-regexp
Рассматривает ОБРАЗЕЦ как регулярное выражение языка Perl.
Опция -F
—fixed-strings
Рассматривает ОБРАЗЕЦ как список «фиксированных выражений» (fixed strings — термин из области регулярных выражений), разделенных символами новой строки. Будет искать соответствия любому из них.
Кроме того, существуют две альтернативные команды EGREP и FGREP. Обе они соответствуют опциям -E и -F соответственно.
Опции —help и —version (-V) общеизвестны, и я не буду на них останавливаться.
Команда grep и символы кириллицы.
Читая эту статью, вы не могли не заметить, что большинство примеров составлено на русском языке. Я еще не встречал консольных команд, столь хорошо «владеющих русским». Теперь, когда я разобрался с этой командой, то уже не понимаю, как мог обходиться без нее при написании статей (по-русски, разумеется). Лишь некоторые опции «дают прокол» при обработке символов кириллицы.
Резюме команды grep
Команда grep настолько полезна, многофункциональна и проста в употреблении, что, однажды познакомившись с ней, невозможно представить себе работу без нее. Особенно полезна эта команда в качестве фильтра в составе программных каналов (pipes).
������������� ������� ��������� ��������� ���������� (man-��)
grep (1)
���������������� ������� |
��������
grep — ����� ������� � �����
���������
-
/usr/bin/grep [ -bchilnsvw ] ������������_����������_���������
[ ���_����� … ] -
/usr/xpg4/bin/grep [ -E | -F ] [ -c | -l | -q ] [ -bhinsvwx ]
-e ������_�������� … [ -f ����_�������� ] …
[ ���_����� … ] -
/usr/xpg4/bin/grep [ -E | -F ] [ -c | -l | -q ] [ -bhinsvwx ]
[ -e ������_�������� … ] -f ����_�������� …
[ ���_����� … ] -
/usr/xpg4/bin/grep [ -E | -F ] [ -c | -l | -q ] [ -bhinsvwx ]
������� [ ���_����� … ]
��������
������ grep ��������� ����� ������� � ��������� ������ � ������
��� ������, ���������� ���� �������. ��� ���������� ���������� �������������������
�������� �������������.
������ ����������� ��� ������������� � ������_�������� ��������
$, *, [, ^, |, (, ) � ,
��������� ��� �������� ������������� ���������� ��������������. ����� ����� ����
������_�������� � ��������� ������� ‘… ‘.
���� ���_����� �� �������, grep ������������ ����� � �����������
������� ������. ������ ������ ��������� ������ ���������� �
����������� �������� �����. ���� ����� ������������� � ���������� ������,
����� ������ ��������� ������� �������� ��� �����.
/usr/bin/grep
������� /usr/bin/grep ���������� ��� ������� �������� ������������ ���������� ���������,
��������� �� �������� ����������� ����������� regexp(5).
/usr/xpg4/bin/grep
����� -E � -F ������ �� ������ �������������
������_�������� ���������� /usr/xpg4/bin/grep.
���� ������� ����� -E, ���������
/usr/xpg4/bin/grep �������������� ������� � ������ ��� ������
���������� ��������� (��. �������� ����� -E). ���� �� ������� ����� -F,
grep �������������� ������_�������� ��� ������������� ������. ���� �� ����
�� ���� ����� �� �������, grep �������������� �������� ������_�������� ��� �������
���������� ���������, ��������� �� �������� ����������� �����������
regex(5).
�����
��������� ����� �������������� ������ �����������, /usr/bin/grep
� /usr/xpg4/bin/grep:
-
-b ���������� ������ ������ ������� �����, � ������� ��� ���� �������.
��� ����� ����������� ��� ������ ������ �� ��������� (����� ���������� � 0).-c ������ ������ ���������� �����, ���������� �������. -h ������������� ������ ����� �����, ����������� ��������������� ������,
����� ���������� �������. ������������ ��� ������ �� ���������� ������.-i ���������� ������� �������� ��� ����������. -l ������ ������ ����� ������, ���������� ��������������� ������,
�� ������ � ������. ���� ������� ������ � ���������� ������� �����,
��� ����� �� �����������.-n ������ ����� ������ ������� �� ����� � ����� (������ ���������� � 1). -s ��������� ������ ��������� � �� ������������ ��� ����������� ��� ������ ������. -v ������ ��� ������, �� ����������� ���������� �������. -w ���� ��������� ��� �����, ��� ���� �� ��� ���� �������� �������������
< � >.
/usr/xpg4/bin/grep
��������� ����� �������������� ������ �������� /usr/xpg4/bin/grep:
-
-e ������_�������� ������ ���� ��� ��������� �������� ��� ������. ������� �
������_�������� ������ ����������� ��������� ����� ������.
������ ������� ����� ������, ����� ��� ������� ����� ������ ������.
���� ������������ � ���� ������ �� ������� ����� -E ��� -F,
������ ������� ����� ��������������� ��� ������� ���������� ���������.
������� grep ������������ ��������� ����� -e � -f. ��� ������ �����,
��������������� �������, ������������ ��� �������� �������, �� �������
������������� �� ���������.-E ������������ � �������� ����������� �����������. ������������� ������
�������� ������� ��� ������ ���������� ���������. ���� ����� ��
������ ���������� ���������-�������� �������������� � ������� �������, ������
��������� ���������������. ������ ������ ���������� ��������� �������������
����� ������. ������ ������� ����� ������������������ ��� ������ ����������
��������� � ������������ � ��������� �� �������� �����������
����������� regex(5), �� �����������
������������ ( � ), ������:-
������ ���������� ���������, �� ������� ���� +, �������������
������ ��� ����� ���������� ������� ����������� ���������. -
������ ���������� ���������, �� ������� ���� ?, �������������
0 ��� ������ ��������� ������� ����������� ���������. -
������ ���������� ����������, ����������� ��������� | ���
��������� ����� ������, ������������� ������, ����������������
� ����� �� ��������� ���������. -
������ ���������� ��������� ����� ����� � ������� ������
() ��� �����������.
������������ ��������� ����� ��������� [], ����� *?+,
������������, �, �������, �������� | � ������ ����� ������.-f ����_�������� ������ ���� ��� ��������� �������� �� ����� � ��������� ������
������ ����_��������. ������� � �����_�������� ����������� ��������
����� ������. ������ ������� ����� ������ � ������� ������ ������ �
�����_��������. ���� ������ ������ � ���� ������ �� �������
����� -E ��� -F, ������ ������� �������� ������� ���������� ����������.-F ������ ������������� � �������������� ��������. ������ ������� ������
��� ������, � �� ��� ���������� ���������. ���� ������� ������
�������� ����� �� �������� � �������� ������ ������ ������, ����� ������
��������� ��������������� �������. ������ ������-������� ������������� �����
������. ��������� ��. �� �������� fgrep(1).-q �������������� �����. � ����������� �������� ����� �� �������� ������,
����� ��������������� �����. ���� ���� �� ������� ����� �������������
�������, ������������ ������ ������ 0.-x ������� ���������������� ������ ������, ��� ������� ������� ������������
��� ������������� � ������������� ������� ��� ���������� ����������. -
������ ���������� ���������, �� ������� ���� +, �������������
��������
�������������� ��������� ��������:
-
���_����� ��� �����, � ������� ������ ����������� ����� �� �������.
���� ����� �� �������, ����� ������� � ����������� ������� ������.
/usr/bin/grep
-
������� ������ ������� ��� ������ �� ������� �������.
/usr/xpg4/bin/grep
-
������� ������ ���� ��� ��������� �������� ��� ������ �� ������� �������.
���� ������� ������������ ��� ��, ��� ���� �� �� ��� ����� � ����
-e������_��������.
�������������
����� -epattern_list ����� ��� �� ������, ��� � ������� ������_��������, ��
��������� �������� ������_�������� � ������. ��� ����� ���������� � �������,
����� ������� �������� ��������� �������� � ���� ��������� ����������.
����� �������� ��������� ����� -e � -f. ��� ���� ������� grep
���������� ��� �������� ������� ��� ������������� � �������� ��������.
(������, ��� ������� �������� �� ��������. ���� ���������� ������� �����
�������� ������ ������, ��� ����� ������ ������� ������ ��, ��� �����,
������������� ����� ������� ��� ������ ������, � ��������� �������, �� ����, —
���������������.)
����� -q ���� �������� �������� �����������, ��������� �� �������
(��� ������) � ������ ������. ��� ������ � ���������� ������ ��� ������������
����� ������� ������������������ (��������� ��������� ��������� ������, ���
������ ����� ������� ������ ������������) � �� ������� �������������� ������
������������ ��� ������������ ������ ������-���������� (��������� grep ������
������� ������ ������ ��� ����������� ������������ ���� ���� ��� ������
� ����������� ����������-������� ��������� ������ ������� ��� ������.)
������ � �������� �������
�������� ��������� ������ ��� ������ � ������� �������� ��
2 ������� (2**31 ������) ��. �� �������� ����������� �����������
largefile(5).
�������
������ 1: ����� ���� ��������� �����
����� ����� ��� ��������� ����� «Posix» (���������� �� ��������) � �����
text.mm � ������ ������ ��������������� �����:
example% /usr/bin/grep -i -n posix text.mm
������ 2: ����� ������ �����
����� ����� ��� ������ ������ � ����������� ������� ������:
example% /usr/bin/grep ^$
���
example% /usr/bin/grep -v .
������ 3: ����� �����, ���������� ������������� ���������
��� ��������� ������� ������ ��� ������, ���������� ���������
abc, def ��� � ��, � ������:
example% /usr/xpg4/bin/grep -E ‘abc def’
example% /usr/xpg4/bin/grep -F ‘abc def’
������ 4: ����� �����, ��������������� �������
��� ��������� ������� ������ ��� ������ abc ��� def:
example% /usr/xpg4/bin/grep -E ‘^abc$ ^def$’
example% /usr/xpg4/bin/grep -F -x ‘abc def’
���������� �����
�������� ��������� ���������� ����� LC_COLLATE,
LC_CTYPE, LC_MESSAGES � NLSPATH,
�������� �� ������ ������� grep,
��. �� �������� ����������� ����������� environ(5).
������ ������
������� ����������� �� ���������� ��������� ������:
| 0 | ������� ���� ��� ��������� ��������������� �����. |
| 1 | ��������������� ������ �� �������. |
| 2 |
�������� �������������� ������ ��� ����������� ����� (���� ���� ���� ������� ��������������� ������). |
��������
�������� ��������� ��������� ��. �� �������� ����������� �����������
attributes(5):
/usr/bin/grep
| ��� �������� | �������� �������� |
| �������� � ������ | SUNWcsu |
| CSI | �������� |
/usr/xpg4/bin/grep
| ��� �������� | �������� �������� |
| �������� � ������ | SUNWxcu4 |
| CSI | �������� |
������
-
egrep(1),
fgrep(1),
sed(1),
sh(1),
attributes(5),
environ(5),
largefile(5),
regex(5),
regexp(5),
XPG4(5)
����������
/usr/bin/grep
������ ���������� ������ �������� ��������� ����������� ������. ����
�������������� ������ �� ����������� �������� ���������, grep ����� �����
����� ������ �� ������� ������ �������; ���� ��� ����� ������ �������������
�������, ����� ������ ��� ������.
/usr/xpg4/bin/grep
���� ���� �������� ������ ������� LINE_MAX ������ ��� �������� ������,
���������� ������ �������������. �������� LINE_MAX ���������� � �����
/usr/include/limits.h.
Copyright 2002 �. �������,
OpenXS Initiative, ������� �� ������� ����
������������� ������� ��������� ��������� ���������� (man-��)
grep (1)
NAME
grep - search a file for a pattern
SYNOPSIS
grep [-E| -F][-c| -l| -q][-insvx]
-e
pattern_list…
[-f
pattern_file]…[file…]
grep [-E| -F][-c| -l| -q][-insvx][-e
pattern_list]…
-f
pattern_file…[file…]
grep [-E| -F][-c| -l| -q][-insvx]
pattern_list[file…]
DESCRIPTION
The grep utility shall search the input files, selecting lines
matching one or more patterns; the types of patterns are
controlled by the options specified. The patterns are specified by
the -e option, -f option, or the
pattern_list operand. The pattern_list‘s value shall consist
of one or more patterns separated by <newline>s;
the pattern_file‘s contents shall consist of one or more patterns
terminated by <newline>. By default, an input line
shall be selected if any pattern, treated as an entire basic regular
expression (BRE) as described in the Base Definitions volume
of IEEE Std 1003.1-2001, Section 9.3, Basic Regular Expressions,
matches any part of the line excluding the terminating <newline>;
a null BRE shall match every line. By default, each
selected input line shall be written to the standard output.
Regular expression matching shall be based on text lines. Since a
<newline> separates or terminates patterns (see the
-e and -f options below), regular expressions cannot contain
a <newline>. Similarly, since patterns are matched
against individual lines (excluding the terminating <newline>s) of
the input, there is no way for a pattern to match a
<newline> found in the input.
OPTIONS
The grep utility shall conform to the Base Definitions volume
of IEEE Std 1003.1-2001, Section 12.2, Utility Syntax Guidelines.
The following options shall be supported:
- -E
-
Match using extended regular expressions. Treat each pattern specified
as an ERE, as described in the Base Definitions volume
of IEEE Std 1003.1-2001, Section 9.4, Extended Regular Expressions.
If any entire ERE pattern matches some part of an input line excluding
the terminating <newline>, the line shall be matched.
A null ERE shall match every line. - -F
-
Match using fixed strings. Treat each pattern specified as a string
instead of a regular expression. If an input line contains
any of the patterns as a contiguous sequence of bytes, the line shall
be matched. A null string shall match every line. - -c
- Write only a count of selected lines to standard output.
- -e pattern_list
-
Specify one or more patterns to be used during the search for input.
The application shall ensure that patterns in
pattern_list are separated by a <newline>. A null pattern can
be specified by two adjacent <newline>s in
pattern_list. Unless the -E or -F option is also
specified, each pattern shall be treated as a BRE, as
described in the Base Definitions volume of IEEE Std 1003.1-2001,
Section
9.3, Basic Regular Expressions. Multiple -e and -f options
shall be accepted by the grep utility. All of
the specified patterns shall be used when matching lines, but the
order of evaluation is unspecified. - -f pattern_file
-
Read one or more patterns from the file named by the pathname pattern_file.
Patterns in pattern_file shall be
terminated by a <newline>. A null pattern can be specified by an empty
line in pattern_file. Unless the -E or
-F option is also specified, each pattern shall be treated as
a BRE, as described in the Base Definitions volume of
IEEE Std 1003.1-2001, Section 9.3, Basic Regular Expressions. - -i
-
Perform pattern matching in searches without regard to case; see the
Base Definitions volume of IEEE Std 1003.1-2001,
Section 9.2, Regular Expression General Requirements. - -l
-
(The letter ell.) Write only the names of files containing selected
lines to standard output. Pathnames shall be written once
per file searched. If the standard input is searched, a pathname of
«(standard input)» shall be written, in the POSIX
locale. In other locales, «standard input» may be replaced by
something more appropriate in those locales. - -n
-
Precede each output line by its relative line number in the file,
each file starting at line 1. The line number counter shall
be reset for each file processed. - -q
-
Quiet. Nothing shall be written to the standard output, regardless
of matching lines. Exit with zero status if an input line is
selected. - -s
-
Suppress the error messages ordinarily written for nonexistent or
unreadable files. Other error messages shall not be
suppressed. - -v
-
Select lines not matching any of the specified patterns. If the -v
option is not specified, selected lines shall be
those that match any of the specified patterns. - -x
-
Consider only input lines that use all characters in the line excluding
the terminating <newline> to match an entire
fixed string or regular expression to be matching lines.
OPERANDS
The following operands shall be supported:
- pattern_list
-
Specify one or more patterns to be used during the search for input.
This operand shall be treated as if it were specified as
-e pattern_list. - file
-
A pathname of a file to be searched for the patterns. If no file
operands are specified, the standard input shall be
used.
STDIN
The standard input shall be used only if no file operands are
specified. See the INPUT FILES section.
INPUT FILES
The input files shall be text files.
ENVIRONMENT VARIABLES
The following environment variables shall affect the execution of
grep:
- LANG
-
Provide a default value for the internationalization variables that
are unset or null. (See the Base Definitions volume of
IEEE Std 1003.1-2001, Section 8.2, Internationalization Variables
for
the precedence of internationalization variables used to determine
the values of locale categories.) - LC_ALL
-
If set to a non-empty string value, override the values of all the
other internationalization variables. - LC_COLLATE
-
Determine the locale for the behavior of ranges, equivalence classes,
and multi-character collating elements within regular
expressions. - LC_CTYPE
-
Determine the locale for the interpretation of sequences of bytes
of text data as characters (for example, single-byte as
opposed to multi-byte characters in arguments and input files) and
the behavior of character classes within regular
expressions. - LC_MESSAGES
-
Determine the locale that should be used to affect the format and
contents of diagnostic messages written to standard
error. - NLSPATH
-
Determine the location of message catalogs for the processing of LC_MESSAGES
.
ASYNCHRONOUS EVENTS
Default.
STDOUT
If the -l option is in effect, and the -q option is not,
the following shall be written for each file containing
at least one selected input line:
-
"%sn", <file>
Otherwise, if more than one file argument appears, and -q
is not specified, the grep utility shall prefix
each output line by:
-
"%s:", <file>
The remainder of each output line shall depend on the other options
specified:
-
If the -c option is in effect, the remainder of each output
line shall contain:-
"%dn", <count>
Otherwise, if -c is not in effect and the -n option is
in effect, the following shall be written to standard
output:-
"%d:", <line number>
Finally, the following shall be written to standard output:
-
"%s", <selected-line contents>
-
STDERR
The standard error shall be used only for diagnostic messages.
OUTPUT FILES
None.
EXTENDED DESCRIPTION
None.
EXIT STATUS
The following exit values shall be returned:
- 0
- One or more lines were selected.
- 1
- No lines were selected.
- >1
- An error occurred.
CONSEQUENCES OF ERRORS
If the -q option is specified, the exit status shall be zero
if an input line is selected, even if an error was detected.
Otherwise, default actions shall be performed.
The following sections are informative.
APPLICATION USAGE
Care should be taken when using characters in pattern_list that
may also be meaningful to the command interpreter. It is
safest to enclose the entire pattern_list argument in single
quotes:
-
'...'
The -e pattern_list option has the same effect as the
pattern_list operand, but is useful when
pattern_list begins with the hyphen delimiter. It is also useful
when it is more convenient to provide multiple patterns as
separate arguments.
Multiple -e and -f options are accepted and grep
uses all of the patterns it is given while matching input
text lines. (Note that the order of evaluation is not specified. If
an implementation finds a null string as a pattern, it is
allowed to use that pattern first, matching every line, and effectively
ignore any other patterns.)
The -q option provides a means of easily determining whether
or not a pattern (or string) exists in a group of files.
When searching several files, it provides a performance improvement
(because it can quit as soon as it finds the first match) and
requires less care by the user in choosing the set of files to supply
as arguments (because it exits zero if it finds a match even
if grep detected an access or read error on earlier file
operands).
EXAMPLES
To find all uses of the word «Posix» (in any case) in file text.mm
and write with line numbers:
-
grep -i -n posix text.mm
To find all empty lines in the standard input:
-
grep ^$
or:
-
grep -v .
Both of the following commands print all lines containing strings
«abc» or «def» or both:
-
grep -E 'abc|def' grep -F 'abc def'
Both of the following commands print all lines matching exactly «abc»
or «def» :
-
grep -E '^abc$|^def$' grep -F -x 'abc def'
RATIONALE
This grep has been enhanced in an upwards-compatible way to
provide the exact functionality of the historical
egrep and fgrep commands as well. It was the clear intention
of the standard developers to consolidate the three
greps into a single command.
The old egrep and fgrep commands are likely to be supported
for many years to come as implementation extensions,
allowing historical applications to operate unmodified.
Historical implementations usually silently ignored all but one of
multiply-specified -e and -f options, but were
not consistent as to which specification was actually used.
The -b option was omitted from the OPTIONS section because block
numbers are implementation-defined.
The System V restriction on using — to mean standard input was
omitted.
A definition of action taken when given a null BRE or ERE is specified.
This is an error condition in some historical
implementations.
The -l option previously indicated that its use was undefined
when no files were explicitly named. This behavior was
historical and placed an unnecessary restriction on future implementations.
It has been removed.
The historical BSD grep -s option practice is easily duplicated
by redirecting standard output to
/dev/null. The -s option required here is from System
V.
The -x option, historically available only with fgrep,
is available here for all of the non-obsolescent
versions.
FUTURE DIRECTIONS
None.
SEE ALSO
sed
COPYRIGHT
Portions of this text are reprinted and reproduced in electronic form
from IEEE Std 1003.1, 2003 Edition, Standard for Information Technology
— Portable Operating System Interface (POSIX), The Open Group Base
Specifications Issue 6, Copyright (C) 2001-2003 by the Institute of
Electrical and Electronics Engineers, Inc and The Open Group. In the
event of any discrepancy between this version and the original IEEE and
The Open Group Standard, the original IEEE and The Open Group Standard
is the referee document. The original Standard can be obtained online at
http://www.opengroup.org/unix/online.html .
Index
- NAME
- SYNOPSIS
- DESCRIPTION
- OPTIONS
- OPERANDS
- STDIN
- INPUT FILES
- ENVIRONMENT VARIABLES
- ASYNCHRONOUS EVENTS
- STDOUT
- STDERR
- OUTPUT FILES
- EXTENDED DESCRIPTION
- EXIT STATUS
- CONSEQUENCES OF ERRORS
- APPLICATION USAGE
- EXAMPLES
- RATIONALE
- FUTURE DIRECTIONS
- SEE ALSO
- COPYRIGHT
Джон Бамбенек и Агнешка Клус
2009
перевод В.Айсин
Вступление
Скорее всего, если вы какое-то время работали в системе Linux в качестве системного администратора или разработчика, вы использовали команду grep. Инструмент устанавливается по умолчанию почти на каждую установку Linux, BSD и Unix, независимо от дистрибутива, и даже доступен для Windows (с wingrep или через Cygwin).
GNU и Free Software Foundation распространяют grep как часть своего набора инструментов с открытым исходным кодом. Другие версии grep распространяются для других операционных систем, но в этой книге основное внимание уделяется версии GNU, поскольку на данный момент она является наиболее распространенной.
Команда grep позволяет пользователю быстро и легко находить текст в заданном файле или выводить его. Предоставляя строку для поиска, grep распечатает только строки, содержащие эту строку, и может распечатать соответствующие номера строк для этого текста. «Простое» использование команды хорошо известно, но существует множество более сложных применений, которые делают grep мощным инструментом поиска.
Цель этой книги — собрать всю информацию, которая может понадобиться администратору или разработчику, в небольшое руководство, которое можно носить с собой. Хотя «простое» использование grep не требует особого образования, продвинутые приложения и использование регулярных выражений могут стать довольно сложными. Название инструмента фактически является аббревиатурой от «Global RegularExpression Print», что указывает на его назначение.
GNU grep на самом деле представляет собой комбинацию четырех различных инструментов, каждый со своим уникальным стилем поиска текста: основные регулярные выражения, расширенные регулярные выражения, фиксированные строки и регулярные выражения в стиле Perl. Существуют и другие реализации программ, подобных grep, например, agrep, zipgrep и grep-подобные функции в .NET, PHP и SQL. В этом руководстве будут описаны особенности и сильные стороны каждого стиля.
Официальный сайт grep: http://www.gnu.org/software/grep/. Он содержит информацию о проекте и некоторую краткую документацию. Исходный код grep составляет всего 712 КБ, а текущая версия на момент написания — 2.5.3. Этот карманный справочник актуален для этой версии, но информация в целом будет действительна для более ранних и более поздних версий.
Важно отметить, что текущая версия grep, поставляемая с Mac OS X 10.5.5 — 2.5.1; тем не менее, большинство параметров в этой книге по-прежнему будут работать в этой версии. Помимо программы GNU, существуют и другие программы «grep», которые обычно устанавливаются по умолчанию в HP-UX, AIX и более старых версиях Solaris. По большей части синтаксис регулярных выражений в этих версиях очень похож, но параметры различаются. Эта книга имеет дело исключительно с версией GNU, потому что она более надежна и мощна, чем другие версии.
Условные обозначения, используемые в этой книге
В этой книге используются следующие типографские условные обозначения:
Курсив
Обозначает команды, новые термины, URL-адреса, адреса электронной почты, имена файлов, расширения файлов, пути, каталоги и служебные программы Unix.
Моноширинный шрифт
Указывает параметры, переключатели, переменные, атрибуты, ключи, функции, типы, классы, пространства имен, методы, модули, свойства, параметры, значения, объекты, события, обработчики событий, теги XML, теги HTML, макросы, содержимое файлов или вывод команд.
Моноширинный курсивный шрифт
Показывает текст, который следует заменить значениями, введенными пользователем.
Использование примеров кода
Эта книга предназначена для того, чтобы помочь вам выполнить свою работу. Как правило, вы можете использовать код из этой книги в своих программах и документации. Вам не нужно связываться с нами для получения разрешения, если вы не воспроизводите значительную часть кода. Например, для написания программы, использующей несколько фрагментов кода из этой книги, не требуется разрешения. Для продажи или распространения компакт-дисков с примерами из книг О’Рейли требуется разрешение. Чтобы ответить на вопрос, цитируя эту книгу и цитируя пример кода, не требуется разрешения. Для включения значительного количества примеров кода из этой книги в документацию по вашему продукту требуется разрешение.
Мы ценим, но не требуем указания авторства. Атрибуция обычно включает название, автора, издателя и ISBN. Например: «grep Pocket Reference — Джон Бамбенек и Агнешка Клус. Copyright 2009, Джон Бамбенек и Агнешка Клус, 978-0-596-15360-1».
Если вы считаете, что использование примеров кода выходит за рамки добросовестного использования или разрешения, предоставленного здесь, не стесняйтесь обращаться к нам по адресу permissions@oreilly.com.
Комментарии и вопросы
Комментарии и вопросы, касающиеся этой книги, просьба направлять издателю:
O’Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, CA 95472
800-998-9938 (в США или Канаде)
707-829-0515 (международный или местный)
707-829-0104 (факс)
У нас есть веб-страница для этой книги, где мы перечисляем исправления, примеры и любую дополнительную информацию. Вы можете получить доступ к этой странице по адресу:
http://www.oreilly.com/catalog/9780596153601
Чтобы оставить комментарий или задать технические вопросы по этой книге, отправьте электронное письмо по адресу:
bookquestions@oreilly.com
Для получения дополнительной информации о наших книгах, конференциях, ресурсных центрах и сети O’Reilly посетите наш веб-сайт:
http://www.oreilly.com
Благодарности
От Джона Бамбенека
Я хотел бы поблагодарить Изабель Канкл и остальную команду О’Рейли, стоящую за редактированием и выпуском этой книги. Моя жена и сын заслуживают благодарности за поддержку и любовь, когда я завершил этот проект. Мой соавтор, Агнешка, сыграла неоценимую роль в облегчении выполнения обременительной задачи по написанию книги; она внесла большой вклад в этот проект. Брайан Кребс из The Washington Post заслуживает похвалы за идею написания этой книги. Время, проведенное в Internet Storm Center, позволило мне поработать с некоторыми из лучших специалистов в области информационной безопасности, и их отзывы оказались чрезвычайно полезными в процессе технической проверки. Особая благодарность адресована Чарльзу Хэмби, Марку Хофману и Дональду Смиту. И, наконец, закусочная Merry Anne’s Diner в центре Шампейна, штат Иллинойс, заслуживает благодарности за то, что позволила мне часами появляться среди ночи, чтобы занять один из их столиков, пока я это писал.
От Агнешки Клус
Во-первых, я хочу поблагодарить своего соавтора Джона Бамбенека за возможность поработать над этой книгой. Для меня это определенно было литературным приключением. Это открыло окна возможностей и дало мне возможность заглянуть в мир, который иначе я бы попасть не смогла. Я также хотел бы поблагодарить мою семью и друзей за их поддержку и терпение.
Концептуальный обзор
Команда grep предоставляет множество способов поиска строк текста в файле или потоке вывода. Например, можно найти все экземпляры указанного слова или строки в файле. Это может быть полезно, например, для извлечения определенных записей журнала из объемных системных журналов. В файлах можно искать определенные шаблоны, например типичный образец номера кредитной карты. Такая гибкость делает grep мощным инструментом для обнаружения наличия (или отсутствия) информации в файлах. Есть два способа ввода данных в grep, каждый из которых имеет свои особенности.
Во-первых, grep можно использовать для поиска заданного файла или файлов в системе. Например, файлы на диске можно искать на предмет наличия (или отсутствия) определенного содержимого. grep также можно использовать для отправки вывода другой команды, которая затем будет искать желаемый контент. Например, grep можно использовать для извлечения важной информации из команды, которая в противном случае выдает чрезмерный объем вывода.
При поиске в текстовых файлах grep можно использовать для поиска определенной строки во всех файлах во всей файловой системе. Например, номера социального страхования следуют известному шаблону, поэтому можно выполнить поиск в каждом текстовом файле в системе, чтобы найти вхождения этих номеров в его файлы (например, для академической среды, чтобы соответствовать федеральным законам о конфиденциальности). По умолчанию возвращается имя файла и строка текста, содержащая эту строку, но также можно включить номера строк.
Кроме того, grep может проверять вывод команды, чтобы найти вхождения строки. Например, системный администратор может запустить сценарий для обновления программного обеспечения в системе, которая имеет большой объем «отладочной» информации и может заботиться только о том, чтобы видеть сообщения об ошибках. В этом случае команда grep может искать строку (например, «ERROR»), которая указывает на ошибки, отфильтровывая информацию, которую администратор не хочет видеть.
Как правило, команда grep предназначена для поиска только текстового вывода или текстовых файлов. Команда позволит вам искать двоичные (или другие нетекстовые) файлы, но в этом отношении утилита ограничена. Уловки для поиска информации в двоичных файлах с помощью grep (т.е., с помощью команды strings) описаны в последнем разделе («Дополнительные советы и приемы с grep»).
Хотя обычно можно интегрировать grep в управление текстом или выполнение операций «поиск и замена», это не самый эффективный способ выполнить работу. Программы sed и awk более удобны для выполнения таких функций.
Есть два основных способа поиска с помощью grep: поиск фиксированных строк и поиск шаблонов текста. Поиск фиксированных строк довольно прост. Однако поиск шаблона может очень быстро усложниться, в зависимости от того, насколько изменчив этот желаемый шаблон. Для поиска текста с переменным содержанием используйте регулярные выражения.
Введение в регулярные выражения
Регулярные выражения, источник букв «re» в «grep», являются основой для создания мощного и гибкого инструмента обработки текста. Выражения могут добавлять, удалять, разделять и вообще управлять всеми видами текста и данных. Это простые инструкции, которые расширяют возможности пользователя по обработке файлов, особенно в сочетании с другими командами. При правильном применении регулярные выражения могут значительно упростить сложную задачу.
Многие различные команды в мире Unix/Linux используют некоторые формы регулярных выражений в дополнение к некоторым языкам программирования. Например, команды sed и awk используют регулярные выражения не только для поиска информации, но и для управления ею.
На самом деле существует множество различных разновидностей регулярных выражений. Например, и Java, и Perl имеют собственный синтаксис для регулярных выражений. Некоторые приложения имеют свои собственные версии регулярных выражений, например Sendmail и Oracle. GNU grep использует версию регулярных выражений GNU, которая очень похожа (но не идентична) регулярным выражениям POSIX.
На самом деле, большинство разновидностей регулярных выражений очень похожи, но у них есть ключевые различия. Например, некоторые экранированные символы, метасимволы или специальные операторы будут вести себя по-разному в зависимости от того, какой тип регулярных выражений вы используете. Незначительные различия между разновидностями могут привести к совершенно разным результатам при использовании одного и того же выражения с разными типами регулярных выражений. В этой книге будут затронуты только регулярные выражения, используемые grep и Perlstyle grep (grep -P).
Обычно регулярные выражения включаются в команду grep в следующем формате:
grep [options] [regexp] [filename]Регулярные выражения состоят из двух типов символов: обычных текстовых символов, называемых литералами, и специальных символов, таких как звездочка (*), называемых метасимволами. Метапоследовательность позволяет использовать метасимволы в качестве литералов или определять специальные символы или условия (например, границы слов или «символы табуляции»). Строка, которую мы надеемся найти, является целевой строкой (target string). Регулярное выражение (regular expression) — это особый шаблон поиска, который вводится для поиска определенной целевой строки. Это может быть то же самое, что и целевая строка, или может включать некоторые функции регулярных выражений, обсуждаемые далее.
Кавычки и регулярные выражения
Обычно регулярное выражение (или regxp) помещается в одинарные кавычки (символ на клавиатуре под двойной кавычкой, а не под клавишей тильды [~]). Для этого есть несколько причин. Во-первых, обычно оболочки Unix интерпретируют пробел как конец аргумента и начало нового. В только что показанном формате вы видите синтаксис команды grep, в котором регулярное выражение отделяется от имени файла пробелом. Что делать, если в строке, которую вы хотите найти, есть символ «пробел»? Кавычки сообщают grep (или другой команде Unix), где аргумент начинается и останавливается, когда задействованы пробелы или другие специальные символы.
Другая причина заключается в том, что различные типы кавычек могут означать разные вещи с помощью команд оболочки, таких как grep. Например, использование одинарной кавычки под клавишей тильды (также называемой обратным апострофом) указывает оболочке выполнить все внутри этих кавычек как команду, а затем использовать это как строку. Например:
grep `whoami` filenameбудет запускать команду whoami (которая возвращает имя пользователя, запускающего оболочку в системах Unix), а затем использовать эту строку для поиска. Например, если бы я вошел в систему с именем пользователя «bambenek», grep будет искать filename с использованием «bambenek».
Однако двойные кавычки работают так же, как одинарные, но с одним важным отличием. С двойными кавычками становится возможным использовать переменные среды как часть шаблона поиска:
grep "$HOME" filenameПеременная среды HOME обычно является абсолютным путем к домашнему каталогу вошедшего в систему пользователя. Только что показанная команда grep определит значение переменной HOME, а затем выполнит поиск по этой строке. Если вы поместите $HOME в одинарные кавычки, он не распознает его как переменную среды.
Важно создать регулярное выражение с правильным типом кавычек, потому что разные типы могут давать совершенно разные результаты. Начальные и конечные кавычки должны быть одинаковыми, иначе будет сгенерирована ошибка, сообщающая вам, что ваш синтаксис неверен. Обратите внимание, что можно комбинировать использование разных кавычек для объединения функций. Это будет обсуждаться позже в разделе «Дополнительные советы и приемы с grep».
Метасимволы
Помимо кавычек, положение и комбинация других специальных символов по-разному влияют на регулярное выражение. Например, следующая команда ищет в файле name.list букву «e», за которой следует «a»:
grep -e 'e[a]' name.listНо просто добавив символ каретки ^, вы меняете все значение выражения. Теперь вы ищете букву «е», за которой следует все, что не является буквой «а»:
grep -e 'e[^a]' name.listПоскольку метасимволы помогают определить манипуляцию, важно с ними ознакомиться. В таблице 1 приведен список регулярно используемых специальных символов и их значений.
Таблица 1. Метасимволы регулярного выражения
(Из книги Джеффри Э. Фридла «Освоение регулярных выражений» (О’Рейли) с некоторыми дополнениями).
| Метасимвол | Имя | Совпадения |
|---|---|---|
| Элементы, соответствующие одному символу | ||
| . | Точка | Один любой символ |
| […] | Класс символов | Любой символ, указанный в скобках |
| [^…] | Отрицательный класс символов | Любой символ, не указанный в скобках |
| char | Escape-символ | Символ после косой черты; используется, когда вы хотите найти «специальный» символ, такой как «$» (т.е. используете «$»). |
| Элементы, соответствующие позиции | ||
| ^ | Каретка | Начало строки |
| $ | Знак доллара | Конец строки |
| < | Обратная косая черта и символ меньше | Начало слова |
| > | Обратная косая черта и символ больше | Конец слова |
| Квантификаторы | ||
| ? | Знак вопроса | Ноль или одно предыдущее выражение |
| * | Звездочка | Любое число (включая ноль); иногда используется как общий подстановочный знак |
| + | Плюс | Одно или несколько из предыдущих выражений |
| {N} | Точное совпадение | Точное совпадение N раз |
| {N,} | По крайней мере | По крайней мере N раз |
| {min,max} | Указанный диапазон | Соответствие диапазону от min до max раз |
| Другое | ||
| | | Чередование | Соответствует любому заданному выражению |
| — | Дефис | Обозначает диапазон |
| (…) | Круглые скобки | Используются для ограничения диапазона изменения |
| 1, 2, … | Обратная ссылка | Соответствует тексту, ранее указанному в круглых скобках (например, первый набор, второй набор и т.д.) |
| b | Граница слова | Пакетные символы, которые обычно обозначают конец слова (например, пробел, точка и т.д.) |
| B | Обратная косая черта | Это альтернатива использованию «\» для сопоставления обратной косой черты, используемой для удобства чтения |
| w | Символ слова | Используется для сопоставления любого символа «слова» (т.е. любой буквы, числа, и символа подчеркивания) |
| W | Не символ слова | Соответствует любому символу, который не используется в словах (т.е. не букве, не цифре и не знаку подчеркивания) |
| ` | Начало буфера | Соответствует началу буфера, отправляемому в grep |
| ‘ | Конец буфера | Соответствует концу буфера, отправляемому в grep |
Таблица ссылается на что-то, известное как метасимвол. Бывают случаи, когда вам потребуется искать буквальный символ, который обычно используется в качестве метасимвола. Например, предположим, что вы ищете суммы, содержащие знак доллара в файле price.list:
grep '[1-9]$' price.listВ результате поиск будет пытаться сопоставить числа в конце строки. Это определенно не то, чего вы хотите. Используя метасимвол, экранированный обратной косой чертой (), вы избегаете такой путаницы:
grep '[1-9]$' price.listМетасимвол $ становится литералом и поэтому ищется в price.list как строка.
Например, возьмем текстовый файл (price.list) со следующим содержимым:
123
123$
Использование двух только что показанных команд дает следующие результаты:
$ grep '[1-9]$' price.list
123$
$ grep '[1-9]$' price.list
123
В первом примере команда искала настоящий символ доллара. Во втором примере знак доллара имел значение своего особого метасимвола и соответствовал концу строки, а значит, соответствовал бы только тем строкам, которые заканчивались числом. Следует помнить о значении этих специальных символов, поскольку они могут существенно повлиять на то, как обрабатывается поиск.
Вот краткое изложение метасимволов регулярных выражений, а также несколько примеров, чтобы прояснить, как они используются:
. (любой одиночный символ)
Символ «точка» — один из немногих типов подстановочных знаков, доступных в регулярных выражениях. Этот конкретный подстановочный знак будет соответствовать любому одиночному символу. Это полезно, если пользователь желает создать шаблон поиска с некоторыми неизвестными ему символами в середине. Например, следующий шаблон grep будет соответствовать «red», «rod», «rad», «rzd» и так далее:
'r.d'Этот символ «точка» можно использовать повторно с любым интервалом, необходимым для поиска нужного содержания.
[...] (класс символов)
«Класс символов» — один из наиболее гибких инструментов, и он появляется снова и снова при использовании регулярных выражений. Есть два основных способа использования классов символов: указать диапазон и указать список символов. Важным моментом является то, что класс символов будет соответствовать только одному символу:
'[a-f]'
'[aeiou]'
Первый шаблон будет искать любую букву между «a» и «f». Диапазоны могут быть прописными, строчными буквами или цифрами. Также может использоваться комбинация диапазонов, например [a-fA-F0-5]. Второй пример будет искать любой из заданных символов, в данном случае гласные. Класс символов также может включать в себя список специальных символов, но их нельзя использовать в качестве диапазона.
[^...] (отрицание)
Класс символов «отрицание» позволяет пользователю искать что угодно, кроме определенного символа или набора символов. Например, пользователь, которому не нравятся четные числа, может использовать следующий шаблон поиска:
'..[^24680]'Это будет искать любой трехсимвольный шаблон, который не заканчивается четным числом. Любой список или диапазон символов может быть помещен в инвертируемый символьный класс.
(escape)
«escape» — это один из метасимволов, который может иметь несколько значений в зависимости от того, как он используется. Когда он помещается перед другим метасимволом, он означает, что этот символ следует рассматривать как буквальный символ, а не как его особое значение. (Его также можно использовать в сочетании с другими символами, такими как b или ', чтобы передать особое значение. Эти конкретные комбинации будут рассмотрены позже.) Рассмотрим следующие два примера:
'.'
'.'
Первый пример будет соответствовать любому одиночному символу и вернет каждый фрагмент текста в файле. Во втором примере будет соответствовать только фактический символ «точки». Escape указывает регулярному выражению игнорировать особое значение метасимвола и обрабатывать его в обычном режиме.
^ (начало строки)
Когда символ каретки используется вне класса символов, это больше не означает отрицание; вместо этого это означает начало строки. Если он используется сам по себе, он будет соответствовать каждой строке на экране, потому что каждая строка имеет начало. Более полезно, когда пользователь хочет сопоставить строки текста, начинающиеся с определенного шаблона:
'^red'Этот шаблон будет соответствовать только строкам, начинающимся с «red», а не всем, которые содержат слово «red». Это полезно для структурированной коммуникации или языков программирования, например, где строки могут начинаться с определенных строк, содержащих важную информацию (например, #DEFINE в Си). Однако смысл теряется, если он не находится в начале строки.
$ (конец строки)
Как обсуждалось ранее, знак доллара соответствует концу строки. Используемый отдельно, он будет соответствовать каждой строке в потоке, кроме последней строки, которая заканчивается символом «конца файла» вместо символа «конца строки». Это полезно для поиска строк, которые имеют желаемое значение в конце строки. Например:
'-$'найдет все строки, последним символом которых является тире, что типично для слов с переносом, когда они слишком длинные, чтобы поместиться в одной строке. Это выражение найдет только те строки, в которых слова через дефис разделены между строками.
< (начало слова)
Если пользователь хотел создать шаблон поиска, который соответствует началу слова, и шаблон, вероятно, повторяется внутри слова (но не в начале), можно использовать этот конкретный escape-код. Например, возьмем следующий пример:
'<un'Этот шаблон будет соответствовать словам, начинающимся с префикса «un», таким как «unimaginable», «undetected» или «undervalued». Он не будет соответствовать таким словам, как «funding», «blunder» или «sun». Он определяет начало слова, ища пробел или другое «разделение», которое указывает на начало нового слова (точка, запятая и т.д.).
> (конец слова)
Подобно предыдущему экранированию, этот шаблон будет соответствовать концу слова. После символов ищется символ «разделения», обозначающий конец слова (пробел, табуляция, точка, запятая и т.д.). Например:
'ing>'будет соответствовать словам, оканчивающимся на «ing» (например, «spring»), а не словам, которые просто содержат «ing» (например, «kingdom»).
* (общий подстановочный знак)
Звездочка, вероятно, является наиболее часто используемым метасимволом. Это общий подстановочный знак, классифицируемый как квантификатор, который специально используется для повторяющихся шаблонов. Для некоторых метасимволов вы можете назначить минимальные и максимальные границы, которые управляют количеством, выводимым из шаблона, но звездочка не устанавливает никаких ограничений или границ. Нет ограничений на количество пробелов до или после символа. Предположим, пользователь хочет знать, описаны ли различные форматы конкретного установщика в файле. Результаты этой простой команды:
'install.*file'результаты должны вывести все строки, содержащие «install» (с любым количеством текста между ними), а затем «file». Необходимо использовать символ точки; в противном случае он будет соответствовать только «installfile», а не итерациям «install» и «file» с символами между ними.
- (диапазон)
При использовании внутри класса символов в квадратных скобках символ тире указывает диапазон значений вместо необработанного списка значений. Когда тире используется вне класса символов в квадратных скобках, оно интерпретируется как буквальный символ тире без его специального значения.
'[0-5]'# (обратные ссылки)
Обратные ссылки позволяют повторно использовать ранее сопоставленный шаблон для определения будущих совпадений. Формат обратной ссылки: , за которым следует номер шаблона в последовательности (слева направо), на которую ссылаются. Обратные ссылки более подробно описаны в разделе «Дополнительные советы и приемы с grep».
b (граница слова)
Последовательность b относится к любому символу, который указывает, что слово началось или закончилось (аналогично > и <, обсуждавшимся ранее). В этом случае не имеет значения, начало или конец слова; он просто ищет знаки препинания или пробелы. Это особенно полезно, когда вы ищете строку, которая может быть отдельным словом или набором символов в другом, несвязанном слове:
'bheartb'Это совпадало бы с точным словом «heart» и не более того (не «disheartening», не «hearts» и т.д.). Если вы ищете определенное слово, числовое значение или строку и не хотите получать совпадения, когда эти слова или значения являются частью другого значения, необходимо использовать b, > или <.
B (обратная косая черта)
Последовательность B — это особенный случай, потому что он не сам по себе escape, а скорее псевдоним для другого. В этом случае B идентичен \, а именно, чтобы интерпретировать символ косой черты буквально в шаблоне поиска, а не с его особым значением. Цель этого псевдонима — сделать шаблон поиска более читабельным и избежать двойных косых черт, которые могут иметь неоднозначное значение в сложных выражениях.
'c:Bwindows'В этом примере выполняется поиск строки «c:windows».
w и W (словесные или несловесные символы)
Последовательности w и W идут рука об руку, потому что их значения противоположны. w будет соответствовать любому символу «слово» и эквивалентно '[a-zA-Z0-9_]'. W будет соответствовать любому другому символу (включая непечатаемые), который не попадает в категорию «словесный символ». Это может быть полезно при анализе структурированных файлов, в которых текст вставлен со специальными символами (например, :, $, % и т.д.).
` (начало буфера)
Эта метапоследовательность, как и «начало строки», будет соответствовать началу буфера, поскольку он передается тому, что обрабатывает регулярное выражение. Поскольку grep работает со строками, буфер и строка обычно синонимичны (но не всегда). Этот переход используется так же, как и метапоследовательность «начало строки», о которой говорилось ранее.
' (конец буфера)
Этот переход похож на метапоследовательность «конец строки», за исключением того, что он ищет конец буфера, который передается тому, что обрабатывает регулярное выражение. В обоих случаях экранирования буфера в начале и в конце они используются крайне редко, и вместо них проще использовать начало и конец строки.
Ниже приводится список метасимволов, используемых в расширенных регулярных выражениях:
? (необязательное совпадение)
Использование вопросительного знака имеет иное значение, чем при обычном использовании подстановочных знаков имени файла (GLOB). В GLOB символ ? означает любой одиночный символ. В регулярных выражениях это означает, что предыдущий символ (или строка, если помещается после подшаблона) является «необязательным» шаблоном соответствия. Это позволяет использовать несколько условий соответствия с одним шаблоном регулярного выражения. Например:
'colors?'будет соответствовать как «color», так и «colors». Символ «s» является необязательным совпадением, поэтому, если он отсутствует, он не вызывает сбоя в шаблоне.
+ (повторяющееся совпадение)
Знак плюс указывает, что регулярное выражение ищет совпадение с одним или несколькими предыдущими символами (или подшаблоном). Например:
'150+'соответствует 150 с любым количеством дополнительных нулей (например, 1500, 15000, 1500000 и т.д.).
{N} (совпадение ровно N раз)
Скобки, помещенные после символа, указывают на конкретное количество повторений для поиска. Например:
'150{3}b'соответствует 15, за которым следуют 3 нуля. Значит, 1500 не будет совпадать, а 15000 подойдет. Обратите внимание на использование метапоследовательности b «граница слова». В этом случае, если желаемое совпадение — именно «15000» и нет проверки границы слова, «150000», «150002345» или «15000asdf» будут соответствовать также потому, что все они содержат желаемую строку поиска «15000».
{N,} (совпадение не менее N раз)
Как и в предыдущем примере, добавление числа и запятой после него означает, что регулярное выражение будет искать не менее N повторений. Например:
'150{3,}b'будет соответствовать «15», за которым следует по крайней мере три нуля, и поэтому «15», «150» и «1500» не будут совпадать. Используйте экранирование границы слова, чтобы избежать случаев, когда требуется точное совпадение определенного числа. (например, «1500003456», «15000asdf» и т. д.). Использование b проясняет смысл.
{N,M} (совпадение от N до M раз)
Если вы хотите сопоставить несколько чисел между двумя значениями повторений, можно указать оба значения между фигурными скобками, разделенными запятой. Например:
'150{2,3}b'совпадут «1500» и «15000» и больше ничего.
| (чередование (или))
Символ «вертикальная черта» указывает на чередование внутри регулярного выражения. Подумайте об этом как о способе дать регулярному выражению возможность выбора условий совпадения с одним выражением. Например:
'apple|orange|banana|peach'будет соответствовать любой из указанных строк, независимо от того, попадают ли другие в область поиска. В этом случае, если в тексте есть «apple», «orange», «banana» или «peach», он будет соответствовать этому содержанию.
() (подшаблон)
Последняя важная особенность расширенных регулярных выражений — это возможность создавать подшаблоны. Это позволяет регулярным выражениям, которые повторяют целые строки, использовать чередование для целых строк, иметь обратные ссылки и делать регулярные выражения более читаемыми:
'(red|blue) plate'
'(150){3}'
Первый пример будет соответствовать либо «red plate», либо «blue plate». Без круглых скобок регулярное выражение 'red|blue plate' соответствовало бы «red» (обратите внимание на отсутствие слова «plate») или «blue plate». Подшаблоны в скобках помогают ограничить диапазон чередования. Во втором примере регулярное выражение будет соответствовать «150150150». Без круглых скобок будет соответствовать «15000». Скобки позволяют сопоставить при повторении целых строк вместо отдельных символов. Метасимволы обычно универсальны для различных команд grep, таких как egrep, fgrep и grep -P. Однако бывают случаи, когда символ имеет другой смысл. Любые различия будут обсуждаться в разделе, относящемся к этой команде.
Классы символов POSIX
Кроме того, регулярные выражения поставляются с набором определений символов POSIX, которые создают сокращения для поиска определенных классов символов. В таблице 2 показан список этих сокращений и их значение. POSIX — это в основном набор стандартов, созданных Институтом инженеров по электротехнике и радиоэлектронике (IEEE) для описания поведения операционных систем в стиле Unix. Он очень старый, но большая часть его содержимого все еще используется. Среди прочего, в POSIX есть определения того, как регулярные выражения должны работать с такими утилитами оболочки, как grep.
Таблица 2. Определения символов POSIX
| Определение POSIX | Содержание определения символа |
|---|---|
| [:alpha:] | Любой алфавитный символ, независимо от регистра |
| [:digit:] | Любой числовой символ |
| [:alnum:] | Любой алфавитный или цифровой символ |
| [:blank:] | Пробелы или символы табуляции |
| [:xdigit:] | Шестнадцатеричные символы; любое число или символы A-F или a-f |
| [:punct:] | Любой знак препинания |
| [:print:] | Любой печатный символ (не управляющие символы) |
| [:space:] | Любой пробельный символ |
| [:graph:] | Исключить символы пробела |
| [:upper:] | Любая заглавная буква |
| [:lower:] | Любая строчная буква |
| [:cntrl:] | Управляющие символы |
Многие из этих определений POSIX являются более удобочитаемыми эквивалентами классов символов. Например, [:upper:] можно также записать как [A-Z], и для этого используется меньше символов. Для некоторых других классов, таких как [:cntrl:], нет хороших эквивалентов классов символов. Чтобы использовать их в регулярном выражении, просто разместите их так же, как и класс символов. Важно отметить, что одно размещение этих определений символов POSIX будет соответствовать только одному одиночному символу. Чтобы сопоставить повторения классов символов, вам придется повторить определение. Например:
'[:digit:]'
'[:digit:][:digit:][:digit:]'
'[:digit:]{3}'
В первом примере будет сопоставлен любой единственный числовой символ. Во втором примере будут сопоставлены только трехзначные числа (или более длинные). Третий пример — это более чистый и короткий способ написания второго примера. Многие энтузиасты регулярных выражений стараются достичь как можно большего с помощью как можно меньшего количества нажатий клавиш. Покажите им второй пример, и они могут блевануть от отвращения. Третий пример — более эффективный способ сделать то же самое.
Создание регулярного выражения
Как и в алгебре, у grep есть правила приоритета обработки. Повторение обрабатывается перед объединением. Конкатенация обрабатывается перед чередованием. Строки объединяются, просто находясь рядом друг с другом внутри регулярного выражения — специального символа для обозначения объединения не существует.
Например, возьмите следующее регулярное выражение:
'pat{2}ern|red'В этом примере повторение обрабатывается первым, что дает два «t». Затем строки соединяются, образуя «pattern» на одной стороне пайпа и «red» — на другой. Затем чередование обрабатывается, создавая регулярное выражение, которое будет искать «pattern» или «red». Однако что, если вы захотите выполнить поиск по словам «patpatern», «red», «pattern» или «pattred»? В этом случае, как и в алгебре, круглые скобки «отменяют» правила старшинства. Например:
2 + 3 / 5
(2 + 3) / 5
Эти два математических уравнения дают разные результаты из-за скобок. Здесь концепция та же:
'(pat){2}ern|red'
'pat{2}(ern|red)'
В первом примере сначала будет объединено слово «pat», а затем оно будет повторяться дважды, в результате чего будут получены строки поиска «patpatern» и «red». Во втором примере сначала обрабатывается подшаблон чередования, поэтому регулярное выражение будет искать «pattern» и «pattred». Использование круглых скобок может помочь вам настроить регулярное выражение для соответствия определенному содержимому в зависимости от того, как вы его создаете. Даже если нет необходимости отменять правила приоритета для конкретного регулярного выражения, иногда имеет смысл использовать круглые скобки для улучшения читаемости.
Регулярное выражение может продолжаться, пока одинарная кавычка не закрыта. Например:
$ grep 'patt
> ern' filename
Здесь одинарная кавычка не заканчивалась до того, как пользователь нажал клавишу Return сразу после второго «t» (пробел не был нажат). В следующей строке отображается приглашение командной строки >, которое указывает, что он все еще ожидает завершения строки, прежде чем обработать команду. Пока вы продолжаете нажимать Return, он будет выдавать вам подсказку, пока вы не нажмете Ctrl-C, чтобы разорвать или закрыть цитату, после чего он обработает команду. Это позволяет вводить длинные регулярные выражения в командной строке (или в сценарии оболочки), не забивая их все в одну строку, что потенциально делает их менее удобочитаемыми.
В этом случае регулярное выражение ищет слово «pattern». Команда игнорирует переносы и не вводит их в само регулярное выражение, поэтому можно нажать Enter в середине слова и продолжить с того места, где вы остановились. Забота об удобочитаемости важна, потому что «пробельные» клавиши не так легко увидеть, что делает этот пример отличным претендентом на подшаблоны, помогающие сделать регулярное выражение более понятным.
Также можно использовать несколько разных групп строк с собственными кавычками. Например:
'patt''ern'будет искать слово «pattern», как если бы оно было набрано с ожидаемым регулярным выражением 'pattern'. Этот пример не очень практичен, и нет веских причин делать это с помощью простого текста. Однако при объединении разных типов цитат этот метод позволяет использовать преимущества каждого типа цитат для создания регулярного выражения с использованием переменных среды и/или вывода команд. Например:
$ echo $HOME/home/bambenek$ whoamibambenek
показывает, что переменная окружения $HOME установлена в /home/bambenek и что вывод команды whoami — «bambenek». Итак, следующее регулярное выражение:
'username:'`whoami`' and home directory
is '"$HOME"
будет соответствовать строке «username:bambenek and home directory is /home/bambenek» путем вставки в вывод команды whoami и настройки переменной окружения $HOME. Это краткий обзор регулярных выражений и способов их использования. Сложности регулярных выражений посвящены целые книги, но этого учебника достаточно, чтобы вы начали понимать, что вам нужно знать, чтобы использовать команду grep.
Основы grep
Есть два способа использовать grep. Первый проверяет файлы следующим образом:
grep regexp filenamegrep ищет указанное регулярное выражение в данном файле (filename). Второй метод использования grep — это проверка «стандартного ввода». Например:
cat filename | grep regexpВ этом случае команда cat отобразит содержимое файла. Вывод этой команды передается в команду grep, которая затем отображает только те строки, которые содержат данное регулярное выражение. Две только что показанные команды дают одинаковые результаты, потому что команда cat просто передает файл без изменений, но вторая форма полезна для «греппинга» других команд, которые изменяют их ввод.
Когда grep вызывается без аргумента имени файла и без передачи какого-либо ввода, он позволяет вам вводить текст и повторяет его, как только получит строку, содержащую регулярное выражение. Для выхода нажмите Ctrl-D.
Иногда вывод бывает очень большим, и его трудно прокрутить в терминале. Обычно это происходит с большими файлами, которые часто содержат повторяющиеся фразы, например, журнал ошибок. В этих случаях передача вывода по конвейеру в команду more или less будет «разбивать на страницы» его так, чтобы одновременно отображался только один экран текста:
grep regexp filename | moreДругой способ упростить просмотр вывода — перенаправить результаты в новый файл, а затем открыть выходной файл в текстовом редакторе позже:
grep regexp filename > newfilenameКроме того, может быть полезно искать строки, содержащие несколько шаблонов, а не только один. В следующем примере текстовый файл editinginfo содержит дату, имя пользователя и файл, который был отредактирован этим пользователем в указанную дату. Если администратора интересуют только файлы, редактируемые «Смитом», он набирает следующее:
cat editinginfo | grep SmithРезультат будет выглядеть так:
May 20, 2008
June 21, 2008
.
.
Администратор может пожелать сопоставить несколько шаблонов, что может быть выполнено путем «сцепления» команд grep вместе. Теперь мы знакомы с командой cat filename | grep regexp и знаем, что она делает. Отправляя второй grep по конвейеру вместе с любым количеством конвейерных команд grep, вы создаете очень точный поиск:
cat filename | grep regexp | grep regexp2В этом случае команда ищет строки в filename, которые содержат как regexp, так и regexp2. В частности, grep будет искать regexp2 в результатах поиска grep для regexp. Используя предыдущий пример, если администратор хотел видеть каждую дату, когда Смит редактировал какой-либо файл, кроме hi.txt, он мог бы выполнить следующую команду:
cat editinginfo | grep Smith | grep -v hi.txtРезультатом будет следующий вывод:
June 21, 2008 Smith world.txt
Важно отметить, что «объединение» команд grep в большинстве случаев неэффективно. Часто регулярное выражение может быть создано для объединения нескольких условий в один поиск.
Например, вместо предыдущего примера, который объединяет три разные команды, то же самое можно сделать с помощью:
grep Smith | grep -v hi.txtИспользование символа вертикальной черты приведет к запуску одной команды и предоставит результаты этой команды следующей команде в последовательности. В этом случае grep ищет строки, в которых есть «Smith», и отправляет эти результаты следующей команде grep, которая исключает строки, содержащие «hi.txt». Если поиск может быть выполнен с использованием меньшего количества команд или с меньшим количеством решений, которые необходимо принимать, тем более эффективно он будет. Для небольших файлов производительность не является проблемой, но при поиске в файлах журнала размером в гигабайты производительность может быть важным фактором.
Если вы хотите выполнять поиск по контенту, который непрерывно передается в потоковом режиме, следует использовать команды конвейерной передачи. Например, если вы хотите в реальном времени отслеживать указанный контент в файле журнала, она может использовать следующую команду:
tail -f /var/log/messages | grep WARNINGЭта команда откроет последние 10 строк файлов /var/log/messages (обычно это главный файл системного журнала в системе Linux), но оставит файл открытым и распечатает все содержимое, помещенное в файл, пока он работает ( параметр -f для tail часто называется «follow»). Таким образом, только что показанная команда будет искать любую запись, содержащую строку «WARNING», отображать ее на консоли и игнорировать все другие сообщения.
Важно отметить, что grep будет искать строку и, как только увидит новую строку, перезапустит весь поиск со следующей строки. Это означает, что если вы ищете предложение с помощью grep, существует вполне реальная вероятность того, что символ новой строки в середине предложения в файле помешает вам найти это предложение напрямую. Даже указание символа новой строки в шаблоне поиска не решит эту проблему. Некоторые текстовые редакторы и приложения для повышения производительности просто переносят слова в строки, не помещая символ новой строки, поэтому поиск в этих случаях не лишен смысла, но это важное ограничение, о котором следует помнить.
Чтобы получить подробную информацию о реализации регулярных выражений на вашем конкретном компьютере, просмотрите справочные страницы regex и re_format. Однако важно отметить, что не все функции и возможности регулярных выражений встроены в grep. Например, поиск и замена недоступны. Что еще более важно, есть некоторые полезные метапоследовательности, которые по умолчанию отсутствуют.
Например, d — это метапоследовательность, которая соответствует любому числовому символу (от 0 до 9) в некоторых регулярных выражениях. Однако, похоже, это недоступно с помощью grep при стандартном распространении и параметрах компиляции (за исключением Perlstyle grep, который будет рассмотрен позже). В этом руководстве делается попытка охватить то, что доступно по умолчанию в стандартной установке, и попытаться стать авторитетным источником информации о возможностях и ограничениях grep.
Программа grep на самом деле представляет собой пакет из четырех различных программ сопоставления с образцом, которые используют разные модели регулярного выражения. Каждая система сопоставления с образцом имеет свои сильные и слабые стороны, и каждая из них будет подробно рассмотрена в следующих разделах. Мы начнем с исходной модели, которую мы назовем базовой grep.
Основные регулярные выражения (grep или grep -G)
В этом разделе основное внимание уделяется базовым функциям grep. Большинство флагов для базового grep одинаково применимы и к другим версиям, которые мы обсудим позже.
Базовый grep или grep -G — это тип сопоставления с шаблоном по умолчанию, который используется при вызове grep. grep интерпретирует данный набор шаблонов как базовое регулярное выражение при выполнении команды. Это вызываемая программа grep по умолчанию, поэтому параметр -G почти всегда избыточен.
Как и любая команда, grep имеет несколько параметров, которые контролируют как найденные совпадения, так и способ отображения результатов grep. Версия GNU grep предлагает большинство параметров, перечисленных в следующих подразделах.
Контроль соответствия
-e pattern, --regexp=pattern
grep -e -style doc.txtГарантирует, что grep распознает шаблон как аргумент регулярного выражения. Полезно, если регулярное выражение начинается с дефиса, что делает его похожим на параметр команды. В этом случае grep будет искать строки, соответствующие «-style».
-f file, --file=file
grep -f pattern.txt searchhere.txtБерет шаблоны из file. Эта опция позволяет вам вводить все шаблоны, которые вы хотите сопоставить, в файл, называемый здесь pattern.txt. Затем grep ищет все шаблоны из pattern.txt в указанном файле searchhere.txt. Шаблоны аддитивны; то есть grep возвращает каждую строку, соответствующую любому шаблону. В файле шаблонов должен быть указан один шаблон в каждой строке. Если файл pattern.txt пуст, ничего не будет найдено.
-i, --ignore-case
grep -i 'help' me.txtИгнорирует использование заглавных букв в заданных регулярных выражениях либо через командную строку, либо в файле регулярных выражений, заданных параметром -f. В приведенном здесь примере выполняется поиск в файле me.txt строки «help» с любой итерацией строчных и прописных букв в слове («HELP», «HelP» и т.д.). Похожий, но устаревший синоним этой опции — -y.
-v, --invert-match
grep -v oranges filenameВозвращает несоответствующие строки вместо совпадающих. В этом случае выводом будет каждая строка в filename, не содержащая шаблона «oranges».
-w, --word-regexp
grep -w 'xyz' filenameСоответствует только в том случае, если вводимый текст совпадает со словами полностью. В этом примере недостаточно, чтобы строка содержала три буквы «xyz» подряд; вокруг них должны быть пробелы или знаки препинания. Буквы, цифры и символ подчеркивания считаются частью слова; любой другой символ считается границей слова, как и начало и конец строки. Это эквивалент помещения b в начало и конец регулярного выражения.
-x, --line-regexp
grep -x 'Hello, world!' filenameПодобно -w, но должно соответствовать всей строке. Этот пример соответствует только строкам, полностью состоящим из «Hello, world!». Строки с дополнительным содержанием не будут сопоставлены. Это может быть полезно для анализа файлов журнала на предмет определенного содержимого, которое может включать случаи, которые вам неинтересны.
Общий контроль вывода
-c, --count
grep -c contact.html access.logВместо обычного вывода вы получаете только количество строк, совпадающих в каждом входном файле. В приведенном здесь примере grep просто вернет количество обращений к файлу contact.html через журнал доступа веб-сервера.
grep -c -v contact.html access.logВ этом примере возвращается количество всех строк, не соответствующих данной строке. Это будет каждый раз, когда кто-то будет обращаться к файлу, не совпадающему с contact.html на веб-сервере.
--color[=WHEN], --colour[=WHEN]
grep -color[=auto] regexp filenameПредполагая, что терминал может поддерживать цвет, grep раскрасит шаблон на выходе. Это делается путем окружения совпадающей (непустой) строки, совпадающих строк, контекстных строк, имен файлов, номеров строк, смещения байтов и разделителей метапоследовательностей, которые терминал распознает как цветные маркеры. Цвет определяется переменной окружения GREP_COLORS (обсуждается позже). WHEN имеет три варианта: never, always и auto.
-l, --files-with-match
grep -l "ERROR:" *.logВместо обычного вывода печатает только имена входных файлов, содержащих шаблон. Как и в случае с -L, поиск останавливается на первом совпадении. Если администратора просто интересуют имена файлов, которые содержат шаблон, но не хочет выводить все совпадающие строки, эта опция выполняет эту функцию. Это может сделать grep более эффективным, остановив поиск, как только он найдет соответствующий шаблон, вместо продолжения поиска по всему файлу. Это часто называют «ленивым сопоставлением».
-L , --files-without-match
grep -L 'ERROR:' *.logВместо обычного вывода печатает только имена входных файлов, которые не содержат совпадений. Например, в примере печатаются все файлы журнала, не содержащие отчетов об ошибках. Это эффективное использование grep, потому что он прекращает поиск каждого файла, когда находит какое-либо совпадение, вместо того, чтобы продолжать поиск во всем файле для нескольких совпадений.
-m NUM, --max-count=NUM
grep -m 10 'ERROR:' *.logЭтот параметр указывает grep прекратить чтение файла после совпадения NUM строк (в этом примере только 10 строк содержат «ERROR:»). Это полезно для чтения больших файлов, где вероятно повторение, например файлов журналов. Если вы просто хотите увидеть, присутствуют ли строки, не переполняя терминал, используйте эту опцию. Это помогает различать распространенные и периодические ошибки, как в примере здесь.
-o, --only-matching
grep -o pattern filenameПечатает только соответствующий текст, а не всю строку ввода. Это особенно полезно при реализации grep для проверки раздела диска или двоичного файла на наличие нескольких шаблонов. Это выведет шаблон, который был сопоставлен, без содержимого, которое могло бы вызвать проблемы для терминала.
-q, --quiet, --silent
grep -q pattern filenameПодавляет вывод. Команда по-прежнему передает полезную информацию, потому что можно проверить статус выхода команды grep (0 — успех, если совпадение найдено, 1, если совпадение не найдено, 2, если программа не может быть запущена из-за ошибки). Этот параметр используется в сценариях для определения наличия шаблона в файле без отображения ненужного вывода.
-s, --no-messages
grep -s pattern filenameНезаметно отбрасывает все сообщения об ошибках, возникающие из-за несуществующих файлов или ошибок разрешений. Это полезно для сценариев, которые ищут всю файловую систему без прав root, и, таким образом, скорее всего, столкнутся с ошибками разрешений, которые могут быть нежелательными. С другой стороны, это также будет скрывать полезную диагностическую информацию, что может означать, что проблемы могут быть не обнаружены.
Управление префиксом выходной строки
-b, --byte-offset
grep -b pattern filenameОтображает байтовое смещение каждого совпадающего текста вместо номера строки. Первый байт в файле — это байт 0, и подсчитываются невидимые символы завершения строки (новая строка в Unix). Поскольку по умолчанию печатаются целые строки, отображаемое число является байтовым смещением начала строки. Это особенно полезно для анализа двоичных файлов, создания (или обратного проектирования) исправлений или других задач, где номера строк не имеют смысла.
grep -b -o pattern filenameПараметр -o печатает смещение вместе с самим совпадающим шаблоном, а не со всей совпадающей строкой, содержащей шаблон. Это заставляет grep печатать байтовое смещение начала совпадающей строки вместо совпадающей строки.
-H, --with-filename
grep -H pattern filenameВключает имя файла перед каждой печатаемой строкой и используется по умолчанию, когда для поиска вводится более одного файла. Это полезно при поиске только одного файла, и вы хотите, чтобы имя файла содержалось в выводе. Обратите внимание, что здесь используются относительные (не абсолютные) пути и имена файлов.
-h, --no-filename
grep -h pattern *Противоположность -H. Когда задействовано более одного файла, подавляется печать имени файла перед каждым выводом. Это значение по умолчанию, когда задействован только один файл или стандартный ввод. Это полезно для подавления имен файлов при поиске целых каталогов.
--label=LABEL
gzip -cd file.gz | grep --label=LABEL patternКогда ввод берется из стандартного ввода (например, когда вывод другого файла перенаправляется в grep), опция --label добавит к строке префикс LABEL. В этом примере команда gzip отображает содержимое несжатого файла внутри file.gz, а затем передает его в grep.
-n, --line-number
grep -n pattern filenameВключает номер для каждой отображаемой строки, где первая строка файла — 1. Это может быть полезно при отладке кода, позволяя вам войти в файл и указать конкретный номер строки для начала редактирования.
-T, --initial-tab
grep -T pattern filenameВставляет табуляцию перед каждой совпадающей строкой, помещая табуляцию между информацией, сгенерированной grep, и совпадающими строками. Эта опция полезна для уточнения макета. Например, он может отделить номера строк, байтовые смещения, метки и т.д., от совпадающего текста.
-u, --unix-byte-offsets
grep -u -b pattern filenameЭтот параметр работает только на платформах MS-DOS и Microsoft Windows, и его нужно вызывать с помощью -b. Эта опция вычислит байтовое смещение, как если бы он работал в системе Unix, и удалит символы возврата каретки.
-Z, --null
grep -Z pattern filenameПечатает ASCII NUL (нулевой байт) после каждого имени файла. Это полезно при обработке имен файлов, которые могут содержать специальные символы (например, возврат каретки).
Управление контекстной строкой
-A NUM, --after-context=NUM
grep -A 3 Copyright filenameПредлагает контекст для совпадающих строк путем печати NUM строк, следующих за каждым совпадением. Разделитель групп (--) помещается между каждым набором совпадений. В этом случае он напечатает следующие три строки после соответствующей строки. Это полезно, например, при поиске в исходном коде. В приведенном здесь примере будут напечатаны три строки после любой строки, содержащей «Copyright», которая обычно находится в верхней части файлов исходного кода.
-B NUM, --before-context=NUM
grep -B 3 Copyright filenameТа же концепция, что и опция -A NUM, за исключением того, что она печатает строки перед совпадением, а не после него. В этом случае он напечатает три строки перед соответствующей строкой. Это полезно, например, при поиске в исходном коде. В приведенном здесь примере будут напечатаны три строки перед любой строкой, содержащей «Copyright», которая обычно находится в верхней части файлов исходного кода.
-C NUM, -NUM, --context=NUM
grep -C 3 Copyright filenameПараметр -C NUM работает так, как если бы пользователь ввел оба параметра -A NUM и -B NUM. Он отобразит NUM строк до и после совпадения. Разделитель групп (--) помещается между каждым набором совпадений. В этом случае будут напечатаны три строки выше и ниже совпадающей строки. Опять же, это полезно, например, при поиске в исходном коде. В приведенном здесь примере будут напечатаны три строки до и после любой строки, содержащей «Copyright», которая обычно находится в верхней части файлов исходного кода.
Выбор файла и каталога
-a , --text
grep -a pattern filenameЭквивалент опции --binary-files=text, позволяющий обрабатывать двоичный файл, как если бы это был текстовый файл.
--binary-files=TYPE
grep --binary-files=TYPE pattern filenameTYPE может быть binary, without-match или text. Когда grep впервые исследует файл, он определяет, является ли файл «двоичным» файлом (файлом, в основном состоящим из нечитаемого человеком текста), и соответствующим образом изменяет свой вывод. По умолчанию, совпадение в двоичном файле приводит к тому, что grep просто отображает сообщение «Binary file somefile.bin matches». Поведение по умолчанию также можно указать с помощью параметра --binary-files=binary.
Когда TYPE не совпадает (without-match), grep не выполняет поиск в двоичном файле и продолжает работу, как если бы в нем не было совпадений (эквивалент опции -l). Когда TYPE является текстом, двоичный файл обрабатывается как текст (эквивалент опции -a). Когда TYPE не совпадает, grep просто пропускает эти файлы и не выполняет поиск по ним. Иногда --binary-files=text выводит двоичный мусор, и терминал может интерпретировать часть этого мусора как команды, которые, в свою очередь, могут сделать терминал нечитаемым до сброса. Чтобы исправить это, используйте команды tput init и tput reset.
-D ACTION, --devices=ACTION
grep -D read 123-45-6789 /dev/hda1Если входным файлом является специальный файл, такой как FIFO или сокет, этот флаг сообщает grep, как действовать дальше. По умолчанию grep обрабатывает эти файлы, как если бы они были обычными файлами в системе. Если ACTION установлено в skip, grep будет игнорировать их. В этом примере выполняется поиск показанного фальшивого номера социального страхования по всему разделу диска. Когда ACTION установлено в read, grep будет читать через устройство, как если бы это был обычный файл.
-d ACTION, --directories=ACTION
grep -d ACTION pattern filenameЭтот флаг сообщает grep, как обрабатывать каталоги, представленные как входные файлы. Когда ACTION read, он читает каталог, как если бы это был файл. recurse ищет файлы в этом каталоге (так же, как опция -R), а skip пропускает каталог без поиска в нем.
--exclude=GLOB
grep --exclude=PATTERN pathУточняет список входных файлов, указывая grep игнорировать файлы, имена которых соответствуют указанному шаблону. PATTERN может быть полным именем файла или может содержать типичные подстановочные знаки «file-globbing», которые оболочка использует при сопоставлении файлов (*,? И []). Например, --exclude=*.exe пропустит все файлы с расширением .exe.
--exclude-from=FILE
grep --exclude-from=FILE pathПодобно опции --exclude, за исключением того, что она берет список шаблонов из указанного имени файла, в котором каждый шаблон перечисляется в отдельной строке. grep проигнорирует все файлы, соответствующие любым строкам в списке заданных шаблонов.
--exclude-dir=DIR
grep --exclude-dir=DIR pattern pathЛюбые каталоги в пути, соответствующем шаблону DIR, будут исключены из рекурсивного поиска. В этом случае необходимо указать фактическое имя каталога (относительное имя или абсолютный путь), чтобы его можно было игнорировать. Этот параметр также должен использоваться с параметром -r или параметром -d recurse, чтобы быть актуальным.
-l
grep -l pattern filenameТо же, что и параметр --binary-files=without-match. Когда grep находит двоичный файл, он предполагает, что в этом файле нет совпадений.
--include=GLOB
grep --include=*.log pattern filenameОграничивает поиск входными файлами, имена которых соответствуют заданному шаблону (в данном случае файлы, заканчивающиеся на .log). Этот параметр особенно полезен при поиске в каталогах с помощью параметра -R. Файлы, не соответствующие заданному шаблону, игнорируются. Имя файла может быть указано целиком или может содержать типичные подстановочные знаки «file-globbing», которые оболочка использует при сопоставлении файлов (*, ? и []).
-R, -r, --recursive
grep -R pattern path
grep -r pattern path
Ищет все файлы в каждом каталоге, отправленном в grep как входной файл.
Другие параметры
--line-buffered
grep --line-buffered pattern filenameИспользует буферизацию строки для вывода. Вывод буферизации строки обычно приводит к снижению производительности. По умолчанию grep использует небуферизованный вывод. Обычно это вопрос предпочтений.
--mmap
grep --mmap pattern filenameИспользует функцию mmap() вместо функции read() для обработки данных. Это может привести к повышению производительности, но может вызвать ошибки, если есть проблема ввода-вывода или файл сжимается во время поиска.
-U, --binary
grep -U pattern filenameПараметр, специфичный для MS-DOS/Windows, заставляющий grep обрабатывать все файлы как двоичные. Обычно grep удаляет символы возврата каретки перед сопоставлением с образцом; эта опция отменяет такое поведение. Однако это требует от вас более внимательного отношения к написанию шаблонов. Например, если содержимое файла содержит шаблон, но имеет символ новой строки посередине, поиск этого шаблона не найдет содержимого.
-V, --version
Просто выводит информацию о версии grep и завершает работу.
-z, --null-data
grep -z patternСтроки ввода обрабатываются так, как если бы каждая из них оканчивалась нулевым байтом или символом ASCII NUL вместо новой строки. Аналогично параметрам -Z или --null, за исключением того, что этот параметр работает с вводом, а не выводом.
Последнее ограничение базового grep: метасимволы «расширенных» регулярных выражений — ?, +, {, }, |, ( и ) — не работают с базовым grep. Функции, предоставляемые этими символами, существуют, если вы поставите перед ними метапоследовательность. Подробнее об этом в следующем разделе.
Расширенные регулярные выражения (egrep или grep -E)
grep -E и egrep — это одна и та же команда. Команды ищут в файлах шаблоны, которые были интерпретированы как расширенные регулярные выражения. Расширенное регулярное выражение выходит за рамки простого использования ранее упомянутых параметров; он использует дополнительные метасимволы для создания более сложных и мощных поисковых строк. Что касается параметров командной строки, grep -E и grep используют одни и те же параметры — единственная разница заключается в том, как они обрабатывают шаблон поиска:
?
? в выражении несет значение необязательного. Любой символ, предшествующий вопросительному знаку, может появляться или не появляться в целевой строке. Например, вы ищете слово «behavior», которое также можно записать как «behaviour». Вместо использования параметра или (|) вы можете использовать команду:
egrep 'behaviou?r' filenameВ результате поиск будет успешным как для «behavior», так и для «behaviour», поскольку он будет одинаково относиться к присутствию или отсутствию буквы «u».
+
Знак плюс будет смотреть на предыдущий символ и допускать неограниченное количество повторений при поиске совпадающих строк. Например, следующая команда будет соответствовать как «pattern1», так и «pattern11111», но не будет соответствовать «pattern»:
egrep 'pattern1 +' filename{n,m}
Фигурные скобки используются для определения того, сколько раз шаблон должен быть повторен, прежде чем совпадение произойдет. Например, вместо поиска «patternnnn» вы можете ввести следующую команду:
egrep 'pattern{4}' filenameЭто будет соответствовать любой строке, содержащей «patternnnn», без необходимости набирать повторяющиеся строки. Чтобы сопоставить хотя бы четыре повторения, вы должны использовать следующую команду:
egrep 'pattern{4,}' filenameС другой стороны, посмотрите на следующий пример:
egrep 'pattern{,4}' filenameНесмотря на то, что это соответствовало бы уже используемым соглашениям, это неверно. Только что показанная команда не приведет к совпадениям, потому что возможность иметь «не более чем X» совпадений недоступна.
Чтобы сопоставить от четырех до шести повторений, используйте следующее:
egrep 'pattern{4,6}' filename|
Этот символ, используемый в регулярном выражении, означает «или». В результате вертикальная черта (|) позволяет объединить несколько шаблонов в одно выражение. Например, предположим, что вам нужно найти одно из двух имен в файле. Вы можете ввести следующую команду:
egrep ‘name1|name2’ filename
Он будет соответствовать строкам, содержащим «name1» или «name2».
()
Скобки могут использоваться для «группировки» определенных строк текста с целью обратных ссылок, чередования или просто для удобства чтения. Кроме того, использование круглых скобок может помочь разрешить любую двусмысленность в том, что именно пользователь хочет от шаблона поиска. Паттерны, помещенные в круглые скобки, часто называют подшаблонами.
Также круглые скобки ограничивают вертикальную черту (|). Это позволяет пользователю более точно определить, какие строки являются частью операции «или» или входят в ее объем. Например, для поиска строк, содержащих «pattern» или «pattarn», вы должны использовать следующую команду:
egrep 'patt(a|e)rn' filenameБез круглых скобок шаблон поиска был бы patta|ern, который будет соответствовать, если будет найдена строка «patta» или «ern», и результат сильно отличается от намерения.
В основных регулярных выражениях обратная косая черта () отменяет поведение метасимвола и заставляет поиск соответствовать символу в буквальном смысле. То же самое происходит в egrep, но есть исключение. Метасимвол { не поддерживается традиционным egrep. Хотя некоторые версии интерпретируют { буквально, его следует избегать в шаблонах egrep. Вместо этого следует использовать [{] для сопоставления символа без использования специального значения.
Не совсем верно, что базовый grep также не имеет этих метасимволов. Они есть, но их нельзя использовать напрямую. Каждому из специальных метасимволов в расширенных регулярных выражениях должен предшествовать метасимвол, чтобы прояснить его особое значение. Обратите внимание, что это противоположность нормальному экранированию, которое обычно лишает особого смысла.
В таблице 3 показано, как использовать метасимволы расширенных регулярных выражений с базовой командой grep.
Таблица 3. Сравнение базовых и расширенных регулярных выражений
| Базовые регулярные выражения | Расширенные регулярные выражения |
|---|---|
| ‘(red)’ | ‘(red)’ |
| ‘а{1,3}’ | ‘а{1,3}’ |
| ‘behavioriou?r’ | ‘behavioriou?r’ |
| ‘pattern+’ | ‘pattern+’ |
Из таблицы 3 вы понимаете, почему люди предпочитают просто использовать расширенный grep, когда они хотят использовать расширенные регулярные выражения. Помимо удобства, также легко забыть поместить необходимый escape-код в базовые регулярные выражения, что приведет к тому, что шаблон не будет возвращать никаких совпадений. Идеальное регулярное выражение должно быть четким и содержать как можно меньше символов.
Фиксированные строки (fgrep или grep -F)
В следующем разделе мы обсудим grep -F или fgrep. fgrep известен как фиксированная строка или быстрый grep. Он известен как «быстрый grep» из-за отличной производительности по сравнению с grep и egrep. Это достигается за счет полного отказа от регулярных выражений и поиска определенного строкового шаблона. Это полезно для точного поиска определенного статического контента, аналогично тому, как работает Google.
Команда для вызова fgrep:
fgrep string_pattern filenameПо замыслу, fgrep должен работать быстро и без интенсивных функций; в результате может потребоваться более ограниченный набор параметров командной строки. Самые распространенные из них:
-b
fgrep -b string_pattern filenameПоказывает номер блока, в котором был найден string_pattern. Поскольку по умолчанию печатаются целые строки, отображаемый номер байта является байтовым смещением начала строки.
-c
fgrep -c string_pattern filenameПодсчитывается количество строк, содержащих один или несколько экземпляров string_pattern.
-e, -string
fgrep -e string_pattern filenameИспользуется для поиска более чем одного шаблона или когда string_pattern начинается с дефиса. Хотя вы можете использовать символ новой строки, чтобы указать более одной строки, вместо этого вы можете использовать несколько параметров -e, что полезно при написании сценариев:
fgrep -e string_pattern1
-e string_pattern2 filename
-f file
fgrep -f string_pattern filenameВыводит результаты поиска в новый файл вместо печати непосредственно в терминал. Это не похоже на поведение опции -f в grep; там он указывает входной файл шаблона поиска.
-h
fgrep -h string_pattern filenameКогда поиск выполняется более чем в одном файле, использование -h останавливает отображение filenames в fgrep до совпадающего вывода.
-i
fgrep -i string_pattern filenameПараметр -i указывает fgrep игнорировать заглавные буквы, содержащиеся в string_pattern, при сопоставлении с шаблоном.
-l
fgrep -l string_pattern filenameОтображает файлы, содержащие string_pattern, но не сами совпадающие строки.
-n
fgrep -n строковый_шаблон имя_файла
fgrep -n string_pattern filenameРаспечатывает номер строки перед строкой, которая соответствует заданному string_pattern.
-v
fgrep -v string_pattern filenameСоответствует любым строкам, которые не содержат заданный string_pattern.
-x
fgrep -x string_pattern filenameРаспечатывает строки, которые полностью соответствуют string_pattern. Это поведение fgrep по умолчанию, поэтому обычно его не нужно указывать.
Регулярные выражения в стиле Perl (grep -P)
Регулярные выражения в стиле Perl используют библиотеку Perl-совместимых регулярных выражений (PCRE) для интерпретации шаблона и выполнения поиска. Как следует из названия, этот стиль использует реализацию регулярных выражений Perl. У Perl есть преимущество, потому что язык был оптимизирован для поиска текста и манипуляций с ним. В результате PCRE может быть более эффективным и более функциональным для поиска контента. Как следствие, это может быть ужасно запутанным и сложным. Другими словами, использование PCRE для поиска информации похоже на использование на себе травки для операции на головном мозге: он выполняет свою работу с минимальными усилиями, но это ужасный беспорядок.
Конкретные функции и параметры поиска с помощью PCRE не зависят от самого grep, а используют библиотеку libpcre и базовую версию Perl. Это означает, что он может сильно различаться между машинами и операционными системами. Обычно справочные страницы pcrepattern или pcre предоставляют машинно-зависимую информацию о параметрах, доступных на вашем компьютере. Ниже приводится общий набор функций поиска PCRE, которые должны быть доступны на большинстве машин.
Также обратите внимание, что регулярные выражения в стиле Perl могут присутствовать или не присутствовать по умолчанию в вашей операционной системе. Системы на основе Fedora и Red Hat, как правило, включают их (при условии, что вы устанавливаете библиотеку PCRE), но Debian, например, не включает регулярные выражения в стиле Perl по умолчанию в своем пакете grep. Вместо этого они поставляют программу pcregrep, которая предоставляет очень похожие функции на grep -P. Разумеется, отдельные лица могут скомпилировать свой собственный двоичный файл grep, который включает поддержку PCRE, если они того пожелают.
Чтобы проверить, встроена ли поддержка регулярных выражений в стиле Perl в вашу версию grep, выполните следующую команду (или что-то подобное):
$ grep -P test /bin/ls
grep: The -P option is not supported
Обычно это означает, что при сборке grep не удалось найти библиотеку libpcre или что она была намеренно отключена с помощью параметра конфигурации --disable-perl-regexp при компиляции. Решение состоит в том, чтобы либо установить libpcre и перекомпилировать grep, либо найти подходящий пакет для вашей операционной системы.
Общая форма использования grep в стиле Perl:
grep -P options pattern fileВажно отметить, что, в отличие от grep -F и grep -E, здесь нет команды «pgrep». Команда pgrep используется для поиска запущенных процессов на машине. Все те же параметры командной строки, которые присутствуют для grep, будут работать с grep -P; Единственная разница в том, как обрабатывается шаблон. PCRE предоставляет дополнительные метасимволы и классы символов, которые можно использовать для расширения возможностей поиска. За исключением дополнительных метасимволов и классов, шаблон строится так же, как и типичное регулярное выражение.
В этом разделе рассматриваются только четыре аспекта параметров PCRE: типы символов, восьмеричный поиск, свойства символов и параметры PCRE.
Типы символов
Хотя здесь есть некоторое совпадение со стандартным grep, PCRE поставляется со своим собственным набором метасимволов, которые обеспечивают более надежный набор сопоставлений. Таблица 4 содержит список экранирований, доступных в PCRE.
Таблица 4. Особые побеги PCRE
| a | Соответствует символу «alarm» (HEX 07). |
| cX | Соответствует Ctrl-X, где X — любая буква |
| e | Соответствует escape-символу (HEX 1B) |
| f | Соответствует символу подачи формы (HEX 0C) |
| n | Соответствует символу новой строки (HEX 0A) |
| r | Соответствует возврату каретки (HEX 0D) |
| t | Соответствует символу табуляции (HEX 09) |
| d | Любая десятичная цифра |
| D | Любой недесятичный символ |
| s | Любой пробельный символ |
| S | Любой непробельный символ |
| w | Любой символ «слова» |
| W | Любой «несловесный» символ. |
| b | Соответствует границе слова |
| B | Соответствует любому символу не на границе слова |
| A | Соответствует началу текста |
| Z | Соответствует концу текста или перед новой строкой |
| z | Соответствует концу текста |
| G | Соответствует первой подходящей позиции |
Восьмеричный поиск
Для поиска восьмеричных знаков используйте метасимвол /, за которым следует восьмеричное число метасимвола. Например, чтобы найти «пробел», используйте /40 или /040. Однако это одна из областей, где PCRE может быть неоднозначным, если вы не будете осторожны. Метасимвол / также может использоваться для обратной ссылки (ссылка на предыдущий шаблон, данный PCRE).
Например, /1 — это обратная ссылка на первый образец в списке, а не на восьмеричный символ 1. Чтобы избежать двусмысленности, самый простой способ — указать восьмеричный символ как трехзначное число. В режиме UTF-8 разрешено до 777. Все однозначные числа, указанные после косой черты, интерпретируются как обратная ссылка, а если шаблонов больше XX, то XX также интерпретируется как обратная ссылка.
Кроме того, PCRE может выполнять поиск по символу в шестнадцатеричном формате или по строке символов, представленных в шестнадцатеричном формате. Например, x0b будет искать шестнадцатеричный символ 0b. Для поиска шестнадцатеричной строки просто используйте x{0b0b....}, где строка заключена в фигурные скобки.
Свойства символа
Кроме того, PCRE поставляется с набором функций, которые будут искать символы на основе их свойств. Он бывает двух видов: язык и тип символов. Для этого используется последовательность p или P. p ищет, присутствует ли данное свойство, тогда как P соответствует любому символу, где его нет.
Например, для поиска наличия (или отсутствия) символов, принадлежащих определенному языку, вы должны использовать p{Greek} для поиска греческих символов. С другой стороны, P{Greek} будет соответствовать любому символу, не входящему в набор символов греческого языка. Для получения полного списка доступных языков обратитесь к странице руководства для конкретной реализации pcrepattern в вашей системе.
Другой набор свойств относится к атрибутам данного символа (прописные буквы, пунктуация и т.д.). Заглавная буква обозначает основную группу символов, а строчная буква относится к подгруппе. Если указана только заглавная буква (например, /p{L}), сопоставляются все подгруппы. В таблице 5 приведен полный список кодов свойств.
Таблица 5. Свойства символа PCRE
| C | Другое | No | Другой номер |
| Cc | Control | P | Пунктуация |
| Cf | Format | Pc | Пунктуация соединителя |
| Cn | Без назначения | Pd | Пунктуация тире |
| Co | Частное использование | Pe | Закрытие знаков препинания |
| Cs | Заменитель | Pf | Конечная пунктуация |
| L | Буква | Пи | Начальная пунктуация |
| Ll | Строчные буквы | Po | Другая пунктуация |
| Lm | Модификатор | Ps | Открытая пунктуация |
| Lo | Другая буква | S | Символ |
| Lt | Заглавный регистр | Sc | Символ валюты |
| Lu | Прописные буквы | Sk | Символ модификатора |
| M | Отметка | Sm | Математический символ |
| Mc | Отметка расстояния | Так | Другой символ |
| Me | Заключительная метка | Z | Разделитель |
| Mn | Метка без интервала | Zl | Разделитель строк |
| N | Число | Zp | Разделитель абзаца |
| Nd | Десятичное число | Zs | Разделитель пробелов |
| Nl | Буквенный номер |
Эти свойства позволяют создавать более надежные шаблоны с меньшим количеством символов на основе большого количества свойств. Однако одно важное замечание: если pcre компилируется вручную, для поддержки этих параметров необходимо использовать параметр конфигурации --enable-unicode-properties. Некоторые пакеты libpcre (например, пакеты Fedora или Debian) имеют это встроенное средство (особенно международно ориентированные), а другие нет. Чтобы проверить, встроена ли поддержка в pcre, выполните следующее (или что-то в этом роде):
$ grep -P 'p{Cc}' /bin/ls
grep: support for P, p, and X has not been compiled
Это сообщение об ошибке о компиляции поддержки связано с pcre, а не с grep, что не совсем интуитивно понятно. Решение состоит в том, чтобы либо найти лучший пакет, либо скомпилировать свой собственный с правильными параметрами.
Опции PCRE
Наконец, есть четыре различных параметра, которые могут изменить способ поиска текста PCRE: PCRE_CASELESS (i), PCRE_MULTILINE (m), PCRE_DOTALL (s) и PCRE_EXTENDED (x). PCRE_CASELESS будет соответствовать шаблонам независимо от различий в заглавных буквах. По умолчанию PCRE обрабатывает строку текста как одну строку, даже если присутствует несколько символов n. PCRE_MULTILINE позволит обрабатывать эти символы n как строки, поэтому, если используется $ или ^, он будет искать строки на основе наличия n и фактических жестких строк в строке поиска.
PCRE_DOTALL заставляет PCRE интерпретировать метасимвол . (точка) для включения новой строки при сопоставлении с «подстановочными знаками». PCRE_EXTENDED полезен для включения комментариев (помещенных в неэкранированные символы #) в сложные строки поиска.
Чтобы включить эти параметры, поместите указанную букву параметра в круглые скобки со знаком вопроса в начале. Например, чтобы создать шаблон, который будет искать слово «copyright» в регистронезависимом формате, вы должны использовать следующий шаблон:
'(?i)copyright'В скобках можно использовать любую комбинацию букв. Эти параметры можно разместить так, чтобы они работали только с частью строки поиска: просто поместите их в начало той части строки, где параметр должен вступить в силу. Чтобы отменить вариант, поставьте перед буквой - (дефис). Например:
'Copy(?i)righ(?-i)t'Это будет соответствовать «CopyRIGHt», «CopyrIgHt» и «Copyright», но не будет соответствовать «COPYright» или «CopyrighT».
'(?imsx)copy(?-sx)right'Это установит все параметры PCRE, которые мы обсуждали, но как только он достигнет символа «r», PCRE_DOTALL и PCRE_EXTENDED будут отключены.
Если использование регулярных выражений на основе Perl кажется сложным, это потому, что это так. Это гораздо больше, чем можно здесь обсудить, но главное преимущество PCRE — это его гибкость и мощность, которые выходят далеко за рамки того, что могут делать регулярные выражения. Обратной стороной является большая сложность и двусмысленность, которые могут возникнуть.
Введение в grep-релевантные переменные среды
В предыдущих примерах мы познакомились с концепцией переменных среды и их влиянием на grep. Переменные среды позволяют настраивать параметры и поведение grep по умолчанию, определяя параметры среды оболочки, тем самым облегчая вашу жизнь. Выполните команду env в терминале, чтобы вывести все текущие параметры. Ниже приводится пример того, что вы можете увидеть:
$ env
USER=user
LOGNAME=user
HOME=/home/user
PATH=/usr/local/sbin:/usr/local/bin:/usr
/sbin:/usr/bin:/sbin:/bin:/usr/X11R6/bin:.
SHELL=/usr/local/bin/tcsh
OSTYPE=linux
LS_COLORS=no=0:fi=0:di=36:ln=33:ex=32
:bd=0:cd=0:pi=0:so=0:do=0:or=31
VISUAL=vi
EDITOR=vi
MANPATH=/usr/local/man:/usr/man:/usr
/share/man:/usr/X11R6/man
...
Управляя файлом .profile в вашем домашнем каталоге, вы можете вносить постоянные изменения в переменные. Например, используя только что показанный результат, предположим, что вы решили сменить EDITOR с vi на vim. В .profile введите:
setenv EDITOR vimПосле записи изменений это гарантирует, что vim будет редактором по умолчанию для каждого сеанса, использующего этот .profile. В предыдущих примерах используются некоторые встроенные переменные, но если вы разбираетесь в коде, нет никаких ограничений (за исключением вашего воображения) на переменные, которые вы создаете и устанавливаете.
Повторюсь, grep — мощный инструмент поиска благодаря множеству доступных пользователю опций. Переменные ничем не отличаются. Есть несколько конкретных вариантов, о которых мы подробно расскажем позже. Однако следует отметить, что grep возвращается к языку C, когда переменные LC_foo, LC_ALL или LANG не установлены, когда локальный каталог не установлен или когда не соблюдается поддержка национального языка (NLS).
Начнем с того, что «locale» — это соглашение, используемое для общения на определенном языке. Например, когда вы устанавливаете для переменной LANG или language значение English, вы используете соглашения, связанные с английским языком, для взаимодействия с системой. Когда компьютер запускается, по умолчанию используются соглашения, установленные в ядре, но эти настройки можно изменить.
LC_ALL на самом деле не переменная, а скорее макрос, который позволяет вам выполнить «set locale» для всех целей. Хотя LC_foo — это параметр, зависящий от локали для множества наборов символов, foo можно заменить на ALL, COLLATE, CTYPE, MONETARY или TIME, и это лишь некоторые из них. Затем они устанавливаются для создания общих языковых соглашений для среды, но становится возможным использовать соглашения одного языка для установки формата для представления денег, а другие — для временных соглашений.
Как это связано с grep? Например, многие классы символов POSIX зависят от того, какая конкретная локаль используется. PCRE также активно заимствует из настроек локали, особенно для классов символов, которые он использует. Поскольку grep предназначен для поиска текста в текстовых файлах, то, как язык обрабатывается на компьютере, имеет значение, и это определяется локалью.
Для большинства пользователей можно оставить настройки локали по умолчанию. Пользователи, которые хотят выполнять поиск на других языках или хотят работать на языке, отличном от языка системной среды, могут захотеть изменить их.
Теперь, когда мы ознакомились с концепцией локали, переменные среды, специфичные для grep, следующие:
GREP_OPTIONSЭта переменная переопределяет «скомпилированные» параметры по умолчанию для grep. Это как если бы они были помещены в командную строку как сами параметры. Например, предположим, что вы хотите создать переменную для параметра --binary-files и установить для нее текст. Следовательно, --binary-files автоматически подразумевает --binary-files=text, без необходимости записывать его. Однако --binary-files можно переопределить определенными и разными переменными (например, --binary-files=without-match).
Этот параметр особенно полезен для сценариев, где набор «default options» можно указать один раз в переменных среды, и на него больше не нужно ссылаться. Однако есть одна проблема: любые параметры, установленные с помощью GREP_OPTIONS, будут интерпретироваться, как если бы они были помещены в командную строку. Это означает, что параметры командной строки не переопределяют переменную среды, и если они конфликтуют, grep выдаст ошибку. Например:
$ export GREP_OPTIONS=-E
$ grep -G '(red)' test
grep: conflicting matchers specified
При установке параметров в эту переменную среды необходимо проявлять некоторую осторожность и внимание, и почти всегда лучше устанавливать только те параметры, которые имеют общий характер (например, как обрабатывать двоичные файлы или устройства, использовать ли цвет, так далее.).
GREP_COLORS (или GREP_COLOR для более старых версий)Эта переменная определяет цвет, который будет использоваться для выделения совпадающего шаблона. Это вызывается с параметром —color[=WHEN], где WHEN — never, auto или always. Параметр должен быть двузначным числом из списка в Таблице 6, которое соответствует определенному цвету.
Таблица 6. Список вариантов цвета
| Цвет | Цветовой код |
|---|---|
| Черный (Black) | 0;30 |
| Темно-серый (Dark gray) | 1;30 |
| Синий (Blue) | 0;34 |
| Голубой (Light blue) | 1;34 |
| Зеленый (Green) | 0;32 |
| Светло-зеленый (Light green) | 1;32 |
| Голубой (Cyan) | 0;36 |
| Светло-голубой (Light cyan) | 1;36 |
| Красный (Red) | 0;31 |
| Светло-красный (Light red) | 1;31 |
| Фиолетовый (Purple) | 0;35 |
| Светло-фиолетовый (Light purple) | 1;35 |
| Коричневый (Brown) | 0;33 |
| Желтый (Yellow) | 1;33 |
| Светло-серый (Light gray) | 0;37 |
| Белый (White) | 1;37 |
Цвета необходимо указывать в определенном синтаксисе, потому что выделение также охватывает дополнительные поля, а не только совпадающие слова. По умолчанию установлено следующее:
GREP_COLORS='ms=01;31:mc=01;31:sl=:cx=:fn=35:ln=32:bn=32:se=36'Если желаемый цвет начинается с 0 (например, с 0;30, который является черным), 0 можно отбросить, чтобы сократить настройку. Если настройки оставлены пустыми, используется обычный текст цвета терминала по умолчанию. ms обозначает совпадающую строку (т.е. введенный вами шаблон), mc соответствует контексту (т.е. строки, показанные с параметром -C), sl обозначает цвет выбранных строк, cx — цвет для выбранного контекста, fn — цвет имени файла (если показан), ln — цвет номеров строк (если показан), bn — номеров байтов (если показан), а se — цвет разделителя.
LC_ALL, LC_COLLATE, LANGЭти переменные должны быть указаны в таком порядке, но в конечном итоге они определяют подборку или расположение в правильной последовательности выраженных диапазонов. Например, это может быть последовательность букв для алфавита.
LC_ALL, LC_CTYPE, LANGЭти переменные определяют LC_CTYPE или тип символов, которые будет использовать grep. Например, какие символы являются пробелами, какие будут фидом формы и т.д.
LC_ALL, LC_MESSAGES, LANGЭти переменные определяют локаль MESSAGES и язык, на котором grep будет выводить сообщения. Это яркий пример того, как grep возвращается к языку Си по умолчанию, то есть к американскому английскому языку.
POSIXLY_CORRECTЕсли установлено, grep следует требованиям POSIX.2, согласно которым любые параметры, следующие за именами файлов, рассматриваются также как имена файлов. В противном случае эти параметры обрабатываются так, как если бы они перемещались перед именами файлов и рассматривались как параметры. Например, grep -E string filename -C 3 интерпретирует «-C 3» как имена файлов, а не как параметр. Кроме того, в POSIX.2 указано, что любые нераспознанные параметры помечаются как «illegal» — по умолчанию в GNU grep они рассматриваются как «invalid».
Выбор между типами grep и соображениями производительности
Теперь, когда мы рассмотрели все четыре программы grep, вопрос в том, как определить, какие из них использовать для данной задачи. Для большинства рутинных задач люди склонны использовать стандартную команду grep (grep -G), потому что производительность не является проблемой при поиске небольших файлов и когда нет необходимости в сложных шаблонах поиска. Как правило, основной grep — это выбор по умолчанию для большинства людей, и поэтому возникает вопрос, когда имеет смысл использовать что-то еще.
Когда использовать grep -E
Хотя с помощью grep -G можно сделать почти все, что можно сделать с помощью grep -E, последний имеет то преимущество, что позволяет выполнить задачу с меньшим количеством символов без противоречащего здравому смыслу экранирования, описанного ранее. Все дополнительные функции в расширенных регулярных выражениях связаны с квантификаторами или подшаблонами. Кроме того, если требуется значительное использование обратных ссылок, идеально подходят расширенные регулярные выражения.
Когда использовать grep -F
Есть одно предварительное условие для использования grep -F, и если пользователь не может удовлетворить это требование, grep -F просто не подходит. А именно, любой шаблон поиска для grep -F не может содержать никаких метасимволов, escape-символов, подстановочных знаков или альтернатив. Его производительность выше, но за счет утраты части функциональности.
Тем не менее, grep -F чрезвычайно полезен для быстрого поиска в больших объемах данных строго определенных строк, что делает его идеальным инструментом для быстрого поиска в огромных файлах журнала. Фактически, довольно легко разработать надежный сценарий «log watching» с помощью команды grep -F и хорошего текстового файла, в котором перечислены важные слова или фразы, которые следует извлечь из файлов журнала для анализа.
Еще одно хорошее применение grep -F — это поиск в почтовых журналах и почтовых папках для обеспечения доставки электронной почты пользователям, особенно в системах с большим количеством почтовых учетных записей. Это стало возможным благодаря присвоению каждому сообщению электронной почты уникального идентификатора сообщения. Например:
grep -FHr MESSAGE-ID /var/mailЭта команда будет искать фиксированную строку MESSAGE-ID для всех файлов внутри /var/mail (и рекурсивно просматривать все подкаталоги), а затем отображать совпадение, а также имя файла. Это быстрый и понятный способ узнать, у каких пользователей есть конкретное сообщение в почтовом ящике. Настоящим преимуществом является то, что эту информацию можно проверить без необходимости заглядывать в почтовый ящик пользователя и решать проблемы конфиденциальности при чтении почты других людей. На самом деле вы можете захотеть выполнить поиск в каталогах почтовых ящиков и папках для спама, которые обычно не хранятся в /var/mail, но вы понимаете, как это работает.
Когда использовать grep -P
Регулярные выражения в стиле Perl, несомненно, являются наиболее мощными из всех стилей, представленных в этой книге. Они также являются наиболее сложными, подвержены ошибкам пользователя и потенциально способны снизить производительность системы, если они будут выполнены неправильно. Однако это явно лучший стиль из всех форматов регулярных выражений, используемых в этой книге.
По этой причине многие приложения предпочитают использовать PCRE вместо регулярных выражений GNU. Например, популярная система обнаружения вторжений snort использует PCRE для сопоставления плохих пакетов в сети. Шаблоны написаны грамотно, так что потери пакетов могут быть очень незначительными, даже если одна машина может искать все пакеты, проходящие через полностью загруженный 100-мегабитный или гигабитный интерфейс. Как было сказано ранее, правильное написание регулярного выражения имеет тенденцию быть более важным, чем конкретный формат регулярного выражения, который вы используете.
Некоторые люди просто предпочитают использовать grep -P по умолчанию (например, указав -P внутри своей переменной среды GREP_OPTIONS). Если поиск будет осуществляться «международным» способом, классы символов языка PCRE значительно упростят это. PCRE поставляется с гораздо большим количеством классов символов для точной настройки регулярного выражения, помимо того, что возможно, например, с определениями POSIX. Наиболее важно то, что возможность использовать различные параметры PCRE (например, PCRE_MULTILINE) позволяет выполнять поиск более мощными способами, чем регулярные выражения GNU.
Для простых и умеренно сложных регулярных выражений достаточно grep -E. Однако есть ограничения, которые могут подтолкнуть пользователя к PCRE. Это компромисс между сложностью и функциональностью. PCRE также помогает пользователям создавать регулярные выражения, которые можно почти сразу же перенести непосредственно в сценарии Perl (или перенести из сценариев Perl) без необходимости выполнять большой перевод.
Последствия для производительности
В большинстве случаев производительность grep не является проблемой. Даже файлы размером в мегабайты можно быстро найти с помощью любой из специальных программ grep без какой-либо заметной разницы в производительности. Очевидно, что чем больше файл, тем больше времени занимает поиск. Для поиска в гигабайтах или терабайтах данных, когда важна производительность, grep -F, вероятно, является хорошим решением, но только если можно создать шаблон поиска без использования каких-либо метасимволов, чередований или обратных ссылок. Это не всегда так.
Чем больше «вариантов» дано grep, тем больше времени занимает конкретный поиск. Например, использование множества чередований заставляет grep искать строки несколько раз, а не только один раз. Это может быть необходимо для данного шаблона поиска, но иногда чередование может быть переписано как класс символов. Например:
grep -E '(0|2|4|6|8)' filename
grep -E '[02468]' filename
При сравнении двух примеров, очевидно, что второй работает лучше, потому что не используется чередование, и строки не нужно искать несколько раз. Избегайте чередования, когда существуют другие альтернативы, выполняющие то же самое.
Безусловно, самая большая причина снижения производительности при использовании grep — это использование обратных ссылок. Время, необходимое grep для выполнения команды, увеличивается почти экспоненциально с использованием дополнительных обратных ссылок. По сути, обратные ссылки могут стать удобными псевдонимами для предыдущих подшаблонов; однако производительность пострадает. Обратные ссылки не следует использовать, если производительность вызывает беспокойство и по этой причине подшаблоны не используют чередование. См. следующий раздел для более подробного обсуждения обратных ссылок.
В заключение, среди grep -G, grep -E и grep -P нет большого влияния на производительность; это в основном зависит от того, как построено само регулярное выражение. Тем не менее, grep -P предоставляет больше возможностей для снижения производительности, но также и максимальную гибкость для соответствия большому разнообразию контента.
Дополнительные советы и хитрости с grep
Как упоминалось ранее, grep можно очень эффективно использовать для поиска содержимого в файлах или в файловой системе. Можно использовать предыдущие совпадения для поиска более поздних строк (так называемые обратные ссылки). Есть также множество уловок для поиска закрытой личной информации и даже для поиска двоичных строк в двоичных файлах. В следующих разделах обсуждаются некоторые дополнительные советы и приемы.
Обратные ссылки
Программа grep может выполнять поиск на основе нескольких предыдущих условий. Например, если вы хотите найти все строки, в которых многократно используется определенный набор слов, один шаблон grep не будет работать; однако это можно сделать с помощью обратных ссылок.
Предположим, вы хотите найти любую строку, в которой есть несколько экземпляров слов «red», «blue» или «green». Представьте себе следующий текстовый файл:
The red dog fetches the green ball.
The green dog fetches the blue ball.
The blue dog fetches the blue ball.
Только третья строка повторяет использование того же цвета. Шаблон регулярного выражения '(red|green|blue)*(red|green|blue)' вернет все три строки. Чтобы решить эту проблему, вы можете использовать обратные ссылки:
grep -E '(red|green|blue).*1' filenameЭта команда соответствует только третьей строке, как и предполагалось. Для расширенных регулярных выражений для указания обратной ссылки можно использовать только одну цифру (т.е. Вы можете ссылаться только на девятую обратную ссылку). Используя регулярные выражения в стиле Perl, теоретически вы можете иметь намного больше (как минимум две цифры).
Это может быть использовано для проверки синтаксиса XML (т.е. «открывающие» и «закрывающие» теги одинаковы), синтаксиса HTML (сопоставление всех строк с различными открывающими и закрывающими «заголовочными» тегами, такими как <h1>, <h2> и т.д.), или даже проанализировать написание на предмет бессмысленного повторения модных словечек.
Важно отметить, что обратные ссылки требуют использования скобок для определения номеров ссылок. grep будет читать шаблон поиска слева направо, и, начиная с первого найденного подшаблона в скобках, он начнет нумерацию с 1.
Обычно обратные ссылки используются, когда подшаблон содержит чередование, как в предыдущем примере. Однако не требуется, чтобы подшаблон действительно содержал чередование. Например, предполагая, что существует большой подшаблон, на который вы хотите позже сослаться в регулярном выражении, вы можете использовать обратную ссылку в качестве искусственного «псевдонима» для этого подшаблона без необходимости набирать весь шаблон несколько раз. Например:
grep -E '(I am the very model of a
modern major general.).*1' filename
будет искать повторы предложения «I am the very model of a modern major general», разделенные любым количеством необязательного содержимого. Это, безусловно, уменьшает количество нажатий клавиш и делает регулярное выражение более управляемым, но также вызывает некоторые проблемы с производительностью, как обсуждалось ранее. Пользователь должен взвесить преимущества удобства и производительности, в зависимости от того, чего он пытается достичь.
Поиск двоичных файлов
До этого момента казалось, что grep можно было использовать только для поиска текстовых строк в текстовых файлах. Это то, для чего он чаще всего используется, но grep также может искать строки в двоичных файлах.
Важно отметить, что «текстовые» файлы существуют на компьютерах в основном для удобства чтения человеком. Компьютеры говорят исключительно в двоичном и машинном коде. Полный набор символов ASCII состоит из 255 символов, из которых только около 60 являются «удобочитаемыми». Однако многие компьютерные программы также содержат текстовые строки. Например, экраны «help», имена файлов, сообщения об ошибках и ожидаемый ввод пользователя могут отображаться в виде текста внутри двоичных файлов.
Команда grep практически не делает различий между поиском в текстовых или двоичных файлах. Пока вы скармливаете ему шаблоны (даже двоичные шаблоны), он с радостью будет искать в любом файле шаблоны, которые вы ему предписываете для поиска. Он выполняет начальную проверку, чтобы увидеть, является ли файл двоичным, и соответствующим образом изменяет способ отображения результатов (если вы вручную не укажете другое поведение):
bash$ grep help /bin/ls
Binary file /bin/ls matches
Эта команда ищет строку «help» в двоичном файле ls. Вместо того, чтобы показывать строку, в которой появляется текст, он просто указывает на то, что совпадение было найдено. Причина снова связана с тем фактом, что компьютерные программы являются двоичными и поэтому не читаются человеком. Например, в программах нет «строк». В двоичных файлах не добавляются разрывы строк, потому что они могут изменить код — это просто функция, позволяющая сделать текстовые файлы более удобочитаемыми, поэтому grep сообщает вам только о том, есть ли совпадение. Чтобы получить представление о типе текста в двоичном файле, вы можете использовать команду strings. Например, strings /bin/ls перечислит все текстовые строки в команде ls.
Есть еще один способ поиска двоичных файлов, который также специфичен для двоичных данных. В этом случае вам нужно полагаться на некоторые уловки, потому что вы не можете вводить двоичные данные напрямую с обычной клавиатуры. Вместо этого вам нужно использовать специальную форму регулярного выражения для ввода шестнадцатеричного эквивалента данных, которые вы хотите найти. Например, если вы хотите найти двоичный файл с шестнадцатеричной строкой ABAA, вы должны ввести следующую команду:
bash$ grep '[xabaa]' test.hex
Binary file test.hex matches
Общий формат — ввести /x, а затем шестнадцатеричную строку, которую вы хотите сопоставить. Нет никаких реальных ограничений на размер строки, которую вы можете ввести. Этот тип поиска может быть полезен при анализе вредоносных программ. Например, платформа metasploit (http://www.metasploit.org) может генерировать двоичные полезные данные для использования удаленных машин. Эта полезная нагрузка может использоваться для создания удаленной оболочки, добавления учетных записей или выполнения других вредоносных действий.
Используя шестнадцатеричный поиск, можно было бы определить по двоичным строкам, какие полезные данные metasploit использовались в реальной атаке. Кроме того, если вы можете определить уникальную шестнадцатеричную строку, которая использовалась в вирусе, вы можете создать базовый антивирусный сканер с помощью grep. Фактически, многие старые антивирусные сканеры делали более или менее именно это, ища уникальные двоичные строки в файлах по списку известных плохих шестнадцатеричных сигнатур.
Многие сообщения о переполнении буфера или эксплойте написаны на Си, и обычно каждую шестнадцатеричную цифру в Си записывают с помощью метасимвола x. Например, возьмите следующую полезную нагрузку эксплойта переполнения буфера:
"xebx17x5ex89x76x08x31xc0x88x46
x07x89x46x0cxb0x0bx89xf3x8dx4e
x08x31xd2xcdx80xe8xe4xffxffxff
x2fx62x69x6ex2fx73x68x58";Может быть более выгодно написать регулярное выражение таким же образом вместо того, чтобы печатать всю шестнадцатеричную строку, если только по той или иной причине, кроме как разрешить копирование и вставку из кода эксплойта. Любой способ может сработать — это ваше предпочтение. Только что показанный эксплойт работает против машин Red Hat 5 и 6 (не Enterprise Red Hat), поэтому этот конкретный код бесполезен, но нетрудно найти код эксплойта в дикой природе.
Интересно отметить, что этот метод не работает для поиска файлов, которые распознаются как текстовые. Например, если вы попытаетесь найти текст в текстовом файле, используя шестнадцатеричный эквивалент кодов ASCII, grep не найдет содержимое. Поиск шестнадцатеричных строк работает только для файлов, которые grep распознает как «двоичные».
Полезные рецепты
Ниже приводится краткий список полезных рецептов grep для поиска определенных классов контента. Поскольку доступность регулярных выражений на основе Perl варьируется, в списке будут использоваться расширенные рецепты в стиле grep, хотя Perl во многих случаях будет работать быстрее.
Ввод этих команд в командную строку и возврат вывода по умолчанию на экран может не иметь особого смысла, если вы хотите найти конфиденциальную информацию в разделе. Было бы разумнее использовать параметры -l и -r для рекурсии по всей файловой системе и отображения совпадающих имен файлов вместо целых строк.
Для многих рецептов имеет смысл ставить b до и после строки. Это гарантирует, что в контенте есть какие-то пробелы до и после него, что предотвращает случай, когда вы ищете 9-значное число, которое выглядит как номер социального страхования, но дает ложноположительные совпадения для 29-значных чисел.
Наконец, эти шаблоны (и, возможно, другие, которые могут иметь смысл) могут быть помещены в файл и использованы в качестве списка входных шаблонов, переданных в grep, так что все они ищутся одновременно.
IP-адреса
$ grep -E 'b[0-9]{1,3}(.[0-9]{1,3}){3}
b' patterns
123.24.45.67
312.543.121.1
Этот шаблон поможет указать IP-адреса в файле. Важно отметить, что [0–9] можно было бы так же легко заменить на [:digit:] для лучшей читаемости. Однако большинство пользователей предпочитают использовать меньше нажатий клавиш по сравнению с удобочитаемостью, когда им предоставляется выбор. Второе примечание: это также найдет строки, которые не являются действительными IP-адресами, например, второй из перечисленных в примере. Регулярные выражения работают с отдельными символами, и нет хорошего способа указать grep искать диапазон значений от 1 до 255. В этом случае могут быть ложные срабатывания. Более сложная формула, гарантирующая, что ложные срабатывания не регистрируются, выглядит так:
$ grep -E 'b((25[0-5]|2[0-4][0-9]|[01]?
[0-9][0-9]?).){3}(25[0-5]|2[0-4][0-9]|
[01]?[0-9][0-9]?)b' patterns
В этом случае он гарантирует, что найдет IP-адреса с октетом от 0 до 255, установив комбинацию шаблонов, которые будут работать. Это гарантирует совпадение исключительно IP-адресов, но это более сложно и имеет более низкую производительность.
MAC-адреса
$ grep -Ei 'b[0-9a-f]{2}
(:[0-9a-f]{2}){5}b' patterns
ab:14:ed:41:aa:00
В этом случае добавляется дополнительная опция -i, поэтому использование заглавных букв не учитывается. Как и в случае с IP-рецептом, [:xdigit:] можно использовать вместо [0-9a-f], если требуется лучшая читаемость.
Email-адреса
$ grep -Ei 'b[a-z0-9]{1,}@*.
(com|net|org|uk|mil|gov|edu)b' patterns
test@some.com
test@some.edu
test@some.co.uk
Список, показанный здесь, представляет собой лишь частичное подмножество доменов верхнего уровня, которые в настоящее время одобрены для использования. Например, можно искать только адреса в США, поэтому результат .uk может не иметь особого смысла. Возможно, целью является выявление явных спамеров в почтовых журналах, и в этом случае можно посоветовать поиск домена верхнего уровня .info (мы никогда не встречали никого, кто получал бы легитимную электронную почту из этого домена верхнего уровня). Показанный узор в основном является отправной точкой для настройки.
Номера телефонов США
$ grep -E 'b((|)[0-9]{3}
()|-|)-|)[0-9]{3}(-|)[0-9]{4}b'
patterns
(312)-555-1212
(312) 555-1212
312-555-1212
3125551212
В этом случае схема немного сложнее из-за большого разнообразия телефонных номеров в США. Могут быть пробелы, дефисы, круглые скобки или вообще ничего. Обратите внимание на то, как круглые скобки указывают на присутствие различных символов, включая отсутствие символа вообще.
Номера социального страхования
$ grep -E 'b[0-9]{3}( |-|)
[0-9]{2}( |-|)[0-9]{4}b' patterns
333333333
333 33 3333
333-33-3333
Номера социального страхования являются ключом к идентификации личности в Соединенных Штатах, поэтому использование этого идентификатора становится все более ограниченным. Многие организации в настоящее время активно ищут все файлы в системе для номеров социального страхования с помощью таких инструментов, как Spider. Этот инструмент не намного сложнее, чем список этих рецептов grep. Однако в этом случае схема намного проще, чем для телефонных номеров.
Номера кредитных карт
Для большинства номеров кредитных карт это выражение работает:
$ grep -E 'b[0-9]{4}(( |-|)
[0-9]{4}){3}b' patterns
1234 5678 9012 3456
1234567890123456
1234-5678-9012-3456
Номера карт American Express будут улавливаться этим выражением:
$ grep -E 'b[0-9]{4}( |-|)
[0-9]{6}( |-|)[0-9]{5}b' patterns
1234-567890-12345
123456789012345
1234 567890 12345
Эти две версии существуют, потому что American Express использует другой шаблон, чем остальные кредитные карты. Однако основная идея остается той же: поиск групп чисел, которые соответствуют общему шаблону номера кредитной карты.
Защищенный авторским правом или конфиденциальный материал
Наконец, во многих организациях есть внутренние классификации данных, которые упрощают идентификацию конфиденциальной информации внутри организации. Будем надеяться, что эти классификации данных содержат необходимый текст, который должен отображаться в документе. Эти строки можно просто ввести в качестве шаблонов поиска в grep (или fgrep), чтобы быстро определить, где на диске может находиться защищенная информация, особенно на тех машинах, которым эта информация не принадлежит.
Большинство форматов файлов с текстом не являются настоящими файлами ASCII, но обычно текстовое содержимое можно найти и идентифицировать внутри файла. Например, вы можете использовать команду grep для поиска определенных строк в файлах Word, даже если эти файлы нельзя просмотреть в терминале.
Например, если ваша корпорация использует тег «ACME Corp. — Proprietary and Confidential», вы можете использовать следующую команду для поиска файлов с таким содержимым:
fgrep -l 'ACME Corp. -
Proprietary and Confidential' patterns
Поиск в большом количестве файлов
Как и многие команды оболочки, команда grep обрабатывает большое количество файлов в данной команде. Например, grep sometext * проверяет каждое имя файла в текущем каталоге на предмет «sometext». Однако существует ограничение на количество файлов, которые можно обработать одной командой. Если вы попросите grep обработать слишком много файлов, появится сообщение об ошибке «Too Many Files» или что-то подобное (в зависимости от вашей оболочки).
Инструмент под названием xargs может обойти это ограничение. Однако, чтобы вызвать его, требуется некоторая осмотрительность. Например, для поиска «ABCDEFGH» в каждом файле в системе можно использовать следующую команду:
find / -print | xargs grep 'ABCDEFGH'Она будет искать в каждом файле на машине строку «ABCDEFGH», но не будет встречаться с типичными ошибками, которые возникают, когда открыто слишком много файлов. Обычно это ограничение является функцией ядра, которая позволяет выделить только определенное количество страниц памяти для аргументов командной строки. За исключением перекомпиляции ядра для большего значения, лучше всего использовать xargs.
Совпадение шаблонов в нескольких строках
В начале этой книги мы говорили, что grep не может сопоставлять строки, если они занимают несколько строк, но это не совсем так. Хотя большинство версий grep не могут легко обрабатывать несколько строк, grep -P может решить эту проблему в многострочном режиме. Например, возьмите следующий файл:
red
dog
Обычные уловки grep, даже указание символа новой строки, не будут соответствовать, если вы хотите найти строку с «red» и следующую строку «dog».
$ grep -E 'redndog' test
$ grep -G 'redndog' test
$ grep -F 'redndog' test
Однако это возможно, если вы используете PCRE_MULTILINE с grep -P:
$ grep -P '(?m)redndog' test
red
dog
Это позволяет пользователю преодолеть ограничение в grep, когда он будет проверять только отдельные строки. Это также одна из многих причин, по которым grep -P обычно используется для более мощных поисковых приложений.
Наконец, существует множество веб-сайтов и форумов, где вы можете найти полезные шаблоны регулярных выражений для конкретных приложений. Скорее всего, другие использовали регулярные выражения и grep для извлечения содержимого из того же приложения. Возможности безграничны.
Рекомендации
- Справочная страница re_format(7)
- Справочная страница regex(3)
- Справочная страница grep(1)
- Справочная страница pcre(3)
- Справочная страница pcrepattern(3)
- Friedl, Jeffery E.F. (2006). Mastering Regular Expressions. O’Reilly Media, Inc.
Updated: 05/04/2019 by
On Unix-like operating systems, the grep command processes text line by line, and prints any lines which match a specified pattern.
This page covers the GNU/Linux version of grep.
Syntax
grep [OPTIONS] PATTERN [FILE...]
Overview
Grep, which stands for «global regular expression print,» is a powerful tool for matching a regular expression against text in a file, multiple files, or a stream of input. It searches for the PATTERN of text you specified on the command line, and outputs the results for you.
Example usage
Let’s say want to quickly locate the phrase «our products» in HTML files on your machine. Let’s start by searching a single file. Here, our PATTERN is «our products» and our FILE is product-listing.html.
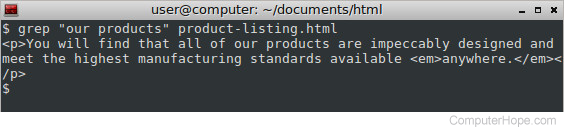
A single line was found containing our pattern, and grep outputs the entire matching line to the terminal. The line is longer than our terminal width so the text wraps around to the following lines, but this output corresponds to exactly one line in our FILE.
Note
The PATTERN is interpreted by grep as a regular expression. In the above example, all the characters we used (letters and a space) are interpreted literally in regular expressions, so only the exact phrase will be matched. Other characters have special meanings, however — some punctuation marks, for example. For more information, see: Regular expression quick reference.
Viewing grep output in color
If we use the —color option, our successful matches will be highlighted for us:

Viewing line numbers of successful matches
It will be even more useful if we know where the matching line appears in our file. If we specify the -n option, grep will prefix each matching line with the line number:

Our matching line is prefixed with «18:» which tells us this corresponds to line 18 in our file.
Performing case-insensitive grep searches
What if «our products» appears at the beginning of a sentence, or appears in all uppercase? We can specify the -i option to perform a case-insensitive match:
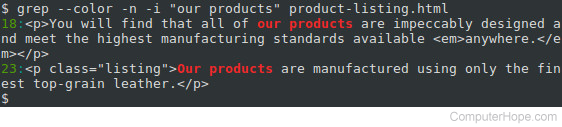
Using the -i option, grep finds a match on line 23 as well.
Searching multiple files using a wildcard
If we have multiple files to search, we can search them all using a wildcard in our FILE name. Instead of specifying product-listing.html, we can use an asterisk («*«) and the .html extension. When the command is executed, the shell expands the asterisk to the name of any file it finds (in the current directory) which ends in «.html«.
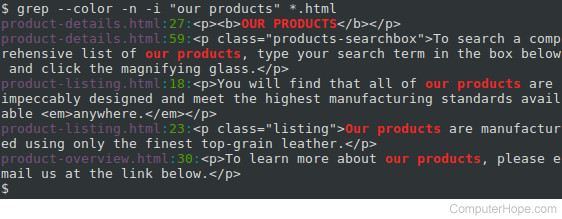
Notice that each line starts with the specific file where that match occurs.
Recursively searching subdirectories
We can extend our search to subdirectories and any files they contain using the -r option, which tells grep to perform its search recursively. Let’s change our FILE name to an asterisk («*«), so that it matches any file or directory name, and not only HTML files:
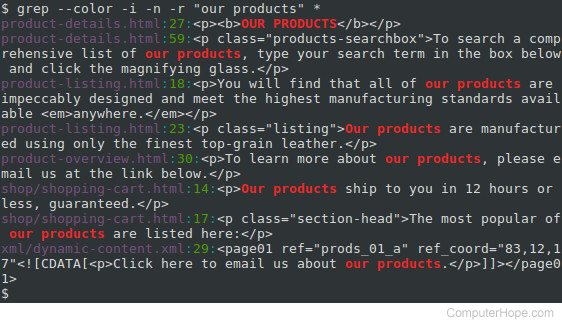
This gives us three additional matches. Notice that the directory name is included for any matching files that are not in the current directory.
Using regular expressions to perform more powerful searches
The true power of grep is that it can match regular expressions. (That’s what the «re» in «grep» stands for). Regular expressions use special characters in the PATTERN string to match a wider array of strings. Let’s look at a simple example.
Let’s say you want to find every occurrence of a phrase similar to «our products» in your HTML files, but the phrase should always start with «our» and end with «products». We can specify this PATTERN instead: «our.*products».
In regular expressions, the period («.«) is interpreted as a single-character wildcard. It means «any character that appears in this place will match.» The asterisk («*«) means «the preceding character, appearing zero or more times, will match.» So the combination «.*» will match any number of any character. For instance, «our amazing products«, «ours, the best-ever products«, and «ourproducts» will match. And because we’re specifying the -i option, «OUR PRODUCTS» and «OuRpRoDuCtS will match as well. Let’s run the command with this regular expression, and see what additional matches we can get:
Here, we also got a match from the phrase «our fine products«.
Grep is a powerful tool to help you work with text files, and it gets even more powerful when you become comfortable using regular expressions.
Technical description
grep searches the named input FILEs (or standard input if no files are named, or if a single dash («—«) is given as the file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.
Also, three variant programs egrep, fgrep and rgrep are available:
- egrep is the same as running grep -E. In this mode, grep evaluates your PATTERN string as an extended regular expression (ERE). Nowadays, ERE does not «extend» very far beyond basic regular expressions, but they can still be very useful. For more information about extended regular expressions, see: Basic vs. extended regular expressions, below.
- fgrep is the same as running grep -F. In this mode, grep evaluates your PATTERN string as a «fixed string» — every character in your string is treated literally. For example, if your string contains an asterisk («*«), grep will try to match it with an actual asterisk rather than interpreting this as a wildcard. If your string contains multiple lines (if it contains newlines), each line will be considered a fixed string, and any of them can trigger a match.
- rgrep is the same as running grep -r. In this mode, grep performs its search recursively. If it encounters a directory, it traverses into that directory and continue searching. (Symbolic links are ignored; if you want to search directories that are symbolically linked, use the -R option instead).
In older operating systems, egrep, fgrep and rgrep were distinct programs with their own executables. In modern systems, these special command names are shortcuts to grep with the appropriate flags enabled. They are functionally equivalent.
General options
| —help | Print a help message briefly summarizing command-line options, and exit. |
| -V, —version | Print the version number of grep, and exit. |
Match selection options
| -E, —extended-regexp |
Interpret PATTERN as an extended regular expression (see: Basic vs. extended regular expressions). |
| -F, —fixed-strings | Interpret PATTERN as a list of fixed strings, separated by newlines, that is to be matched. |
| -G, —basic-regexp | Interpret PATTERN as a basic regular expression (see: Basic vs. extended regular expressions). This is the default option when running grep. |
| -P, —perl-regexp | Interpret PATTERN as a Perl regular expression. This functionality is still experimental, and may produce warning messages. |
Matching control options
| -e PATTERN, —regexp=PATTERN |
Use PATTERN as the pattern to match. This can specify multiple search patterns, or to protect a pattern beginning with a dash (—). |
| -f FILE, —file=FILE | Obtain patterns from FILE, one per line. |
| -i, —ignore-case | Ignore case distinctions in both the PATTERN and the input files. |
| -v, —invert-match | Invert the sense of matching, to select non-matching lines. |
| -w, —word-regexp | Select only those lines containing matches that form whole words. The test is that the matching substring must either be at the beginning of the line, or preceded by a non-word constituent character. Or, it must be either at the end of the line or followed by a non-word constituent character. Word-constituent characters are letters, digits, and underscores. |
| -x, —line-regexp | Select only matches that exactly match the whole line. |
| -y | The same as -i. |
General output control
| -c, —count | Instead of the normal output, print a count of matching lines for each input file. With the -v, —invert-match option (see below), count non-matching lines. |
| —color[=WHEN], —colour[=WHEN] |
Surround the matched (non-empty) strings, matching lines, context lines, file names, line numbers, byte offsets, and separators (for fields and groups of context lines) with escape sequences to display them in color on the terminal. The colors are defined by the environment variable GREP_COLORS. The older environment variable GREP_COLOR is still supported, but its setting does not have priority. WHEN is never, always, or auto. |
| -L, —files-without-match |
Instead of the normal output, print the name of each input file from which no output would normally be printed. The scanning stops on the first match. |
| -l, —files-with-matches |
Instead of the normal output, print the name of each input file from which output would normally be printed. The scanning stops on the first match. |
| -m NUM, —max-count=NUM |
Stop reading a file after NUM matching lines. If the input is standard input from a regular file, and NUM matching lines are output, grep ensures that the standard input is positioned after the last matching line before exiting, regardless of the presence of trailing context lines. This enables a calling process to resume a search. When grep stops after NUM matching lines, it outputs any trailing context lines. When the -c or —count option is also used, grep does not output a count greater than NUM. When the -v or —invert-match option is also used, grep stops after outputting NUM non-matching lines. |
| -o, —only-matching | Print only the matched (non-empty) parts of a matching line, with each such part on a separate output line. |
| -q, —quiet, —silent | Quiet; do not write anything to standard output. Exit immediately with zero status if any match is found, even if an error was detected. Also see the -s or —no-messages option. |
| -s, —no-messages | Suppress error messages about nonexistent or unreadable files. |
Output line prefix control
| -b, —byte-offset | Print the 0-based byte offset in the input file before each line of output. If -o (—only-matching) is specified, print the offset of the matching part itself. |
| -H, —with-filename | Print the file name for each match. This is the default when there is more than one file to search. |
| -h, —no-filename | Suppress the prefixing of file names on output. This is the default when there is only one file (or only standard input) to search. |
| —label=LABEL | Display input actually coming from standard input as input coming from file LABEL. This is especially useful when implementing tools like zgrep, e.g., gzip -cd foo.gz | grep —label=foo -H something. See also the -H option. |
| -n, —line-number | Prefix each line of output with the 1-based line number within its input file. |
| -T, —initial-tab | Make sure that the first character of actual line content lies on a tab stop, so that the alignment of tabs looks normal. This is useful with options that prefix their output to the actual content: -H, -n, and -b. To improve the probability that lines from a single file will all start at the same column, this also causes the line number and byte offset (if present) to be printed in a minimum size field width. |
| -u, —unix-byte-offsets |
Report Unix-style byte offsets. This switch causes grep to report byte offsets as if the file were a Unix-style text file, i.e., with CR characters stripped off. This produces results identical to running grep on a Unix machine. This option has no effect unless -b option is also used; it has no effect on platforms other than MS-DOS and MS-Windows. |
| -Z, —null | Output a zero byte (the ASCII NUL character) instead of the character that normally follows a file name. For example, grep -lZ outputs a zero byte after each file name instead of the usual newline. This option makes the output unambiguous, even in the presence of file names containing unusual characters like newlines. This option can be used with commands like find -print0, perl -0, sort -z, and xargs -0 to process arbitrary file names, even those that contain newline characters. |
Context line control
| -A NUM, —after-context=NUM |
Print NUM lines of trailing context after matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -B NUM, —before-context=NUM |
Print NUM lines of leading context before matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -C NUM, —NUM, —context=NUM |
Print NUM lines of output context. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
File and directory selection
| -a, —text | Process a binary file as if it were text; this is equivalent to the —binary-files=text option. |
| —binary-files=TYPE | If the first few bytes of a file indicate that the file contains binary data, assume that the file is of type TYPE. By default, TYPE is binary, and grep normally outputs either a one-line message saying that a binary file matches, or no message if there is no match. If TYPE is without-match, grep assumes that a binary file does not match; this is equivalent to the -I option. If TYPE is text, grep processes a binary file as if it were text; this is equivalent to the -a option. Warning: grep —binary-files=text might output binary garbage, which can have nasty side effects if the output is a terminal and if the terminal driver interprets some of it as commands. |
| -D ACTION, —devices=ACTION |
If an input file is a device, FIFO or socket, use ACTION to process it. By default, ACTION is read, which means that devices are read as if they were ordinary files. If ACTION is skip, devices are silently skipped. |
| -d ACTION, —directories=ACTION |
If an input file is a directory, use ACTION to process it. By default, ACTION is read, i.e., read directories as if they were ordinary files. If ACTION is skip, silently skip directories. If ACTION is recurse, read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -r option. |
| —exclude=GLOB | Skip files whose base name matches GLOB (using wildcard matching). A file-name glob can use *, ?, and […] as wildcards, and to quote a wildcard or backslash character literally. |
| —exclude-from=FILE | Skip files whose base name matches any of the file-name globs read from FILE (using wildcard matching as described under —exclude). |
| —exclude-dir=DIR | Exclude directories matching the pattern DIR from recursive searches. |
| -I | Process a binary file as if it did not contain matching data; this is equivalent to the —binary-files=without-match option. |
| —include=GLOB | Search only files whose base name matches GLOB (using wildcard matching as described under —exclude). |
| -r, —recursive | Read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -d recurse option. |
| -R, —dereference-recursive |
Read all files under each directory, recursively. Follow all symbolic links, unlike -r. |
Other options
| —line-buffered | Use line buffering on output. This can cause a performance penalty. |
| —mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, —mmap yields better performance. However, —mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, —binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this causes some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, —null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or —null option, this option can be used with commands like sort -z to process arbitrary file names. |
Regular expressions
A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, using various operators to combine smaller expressions.
grep understands three different versions of regular expression syntax: «basic» (BRE), «extended» (ERE) and «perl» (PRCE). In GNU grep, there is no difference in available functionality between basic and extended syntaxes. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are summarized afterwards. Perl regular expressions give additional functionality.
The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any metacharacter with special meaning may be quoted by preceding it with a backslash.
The period (.) matches any single character.
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by [ and ]. It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression [0123456789] matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, [a-d] is equivalent to [abcd]. Many locales sort characters in dictionary order, and in these locales [a-d] is often not equivalent to [abcd]; it might be equivalent to [aBbCcDd], for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are [:alnum:], [:alpha:], [:cntrl:], [:digit:], [:graph:], [:lower:], [:print:], [:punct:], [:space:], [:upper:], and [:xdigit:]. For example, [[:alnum:]] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as [0-9A-Za-z]. (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal ] place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
Anchoring
The caret ^ and the dollar sign $ are metacharacters that respectively match the empty string at the beginning and end of a line.
The backslash character and special expressions
The symbols < and > respectively match the empty string at the beginning and end of a word. The symbol b matches the empty string at the edge of a word, and B matches the empty string provided it’s not at the edge of a word. The symbol w is a synonym for [_[:alnum:]] and W is a synonym for [^_[:alnum:]].
Repetition
A regular expression may be followed by one of several repetition operators:
| ? | The preceding item is optional and matched at most once. |
| * | The preceding item will be matched zero or more times. |
| + | The preceding item will be matched one or more times. |
| {n} | The preceding item is matched exactly n times. |
| {n,} | The preceding item is matched n or more times. |
| {n,m} | The preceding item is matched at least n times, but not more than m times. |
Concatenation
Two regular expressions may be concatenated; the resulting regular expression matches any string formed by concatenating two substrings that respectively match the concatenated expressions.
Alternation
Two regular expressions may be joined by the infix operator |; the resulting regular expression matches any string matching either alternate expression.
Precedence
Repetition takes precedence over concatenation, which in turn takes precedence over alternation. A whole expression may be enclosed in parentheses to override these precedence rules and form a subexpression.
Back references and subexpressions
The back-reference n, where n is a single digit, matches the substring previously matched by the nth parenthesized subexpression of the regular expression.
Basic vs. extended regular expressions
In basic regular expressions the metacharacters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions ?, +, {, |, (, and ).
Traditional versions of egrep did not support the { metacharacter, and some egrep implementations support { instead, so portable scripts should avoid { in grep -E patterns and should use [{] to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification. For example, the command grep -E ‘{1’ searches for the two-character string {1 instead of reporting a syntax error in the regular expression. POSIX allows this behavior as an extension, but portable scripts should avoid it.
Environment variables
The behavior of grep is affected by the following environment variables.
The locale for category LC_foo is specified by examining the three environment variables LC_ALL, LC_foo, and LANG, in that order. The first of these variables that is set specifies the locale. For example, if LC_ALL is not set, but LC_MESSAGES is set to pt_BR, then the Brazilian Portuguese locale is used for the LC_MESSAGES category. The C locale is used if none of these environment variables are set, if the locale catalog is not installed, or if grep was not compiled with national language support (NLS).
Other variables of note:
| GREP_OPTIONS | This variable specifies default options to be placed in front of any explicit options. For example, if GREP_OPTIONS is ‘—binary- files=without-match —directories=skip‘, grep behaves as if the two options —binary-files=without-match and —directories=skip had been specified before any explicit options. Option specifications are separated by whitespace. A backslash escapes the next character, so it can specify an option containing whitespace or a backslash. | ||||||||||||||||||||||
| GREP_COLOR | This variable specifies the color used to highlight matched (non-empty) text. It is deprecated in favor of GREP_COLORS, but still supported. The mt, ms, and mc capabilities of GREP_COLORS have priority over it. It can only specify the color used to highlight the matching non-empty text in any matching line (a selected line when the -v command-line option is omitted, or a context line when -v is specified). The default is 01;31, which means a bold red foreground text on the terminal’s default background. | ||||||||||||||||||||||
| GREP_COLORS | Specifies the colors and other attributes used to highlight various parts of the output. Its value is a colon-separated list of capabilities that defaults to ms=01;31:mc=01;31:sl=:cx=:fn=35:ln=32:bn=32:se=36 with the rv and ne boolean capabilities omitted (i.e., false). Supported capabilities are as follows:
Note that boolean capabilities have no =… part. They are omitted (i.e., false) by default and become true when specified. See the Select Graphic Rendition (SGR) section in the documentation of the text terminal that is used for permitted values and their meaning as character attributes. These substring values are integers in decimal representation and can be concatenated with semicolons. grep takes care of assembling the result into a complete SGR sequence (33[…m). Common values to concatenate include 1 for bold, 4 for underline, 5 for blink, 7 for inverse, 39 for default foreground color, 30 to 37 for foreground colors, 90 to 97 for 16-color mode foreground colors, 38;5;0 to 38;5;255 for 88-color and 256-color modes foreground colors, 49 for default background color, 40 to 47 for background colors, 100 to 107 for 16-color mode background colors, and 48;5;0 to 48;5;255 for 88-color and 256-color modes background colors. |
||||||||||||||||||||||
| LC_ALL, LC_COLLATE, LANG | These variables specify the locale for the LC_COLLATE category, which determines the collating sequence used to interpret range expressions like [a-z]. | ||||||||||||||||||||||
| LC_ALL, LC_CTYPE, LANG | These variables specify the locale for the LC_CTYPE category, which determines the type of characters, e.g., which characters are whitespace. | ||||||||||||||||||||||
| LC_ALL, LC_MESSAGES, LANG | These variables specify the locale for the LC_MESSAGES category, which determines the language that grep uses for messages. The default C locale uses American English messages. | ||||||||||||||||||||||
| POSIXLY_CORRECT | If set, grep behaves as POSIX requires; otherwise, grep behaves more like other GNU programs. POSIX requires that options that follow file names must be treated as file names; by default, such options are permuted to the front of the operand list and are treated as options. Also, POSIX requires that unrecognized options be diagnosed as «illegal», but since they are not really against the law the default is to diagnose them as «invalid». POSIXLY_CORRECT also disables _N_GNU_nonoption_argv_flags_, described below. | ||||||||||||||||||||||
| _N_GNU_nonoption_argv_flags_ | (Here N is grep‘s numeric process ID). If the ith character of this environment variable’s value is 1, do not consider the ith operand of grep to be an option, even if it appears to be one. A shell can put this variable in the environment for each command it runs, specifying which operands are the results of file name wildcard expansion and therefore should not be treated as options. This behavior is available only with the GNU C library, and only when POSIXLY_CORRECT is not set. |
Exit status
The exit status is 0 if selected lines are found, and 1 if not found. If an error occurred the exit status is 2.
Examples
Tip
If you haven’t already seen our example usage section, we suggest reviewing that section first.
grep chope /etc/passwd
Search /etc/passwd for user chope.
grep "May 31 03" /etc/httpd/logs/error_log
Search the Apache error_log file for any error entries that happened on May 31st at 3 A.M. By adding quotes around the string, this lets you place spaces in the grep search.
grep -r "computerhope" /www/
Recursively search the directory /www/, and all subdirectories, for any lines of any files which contain the string «computerhope«.
grep -w "hope" myfile.txt
Search the file myfile.txt for lines containing the word «hope«. Only lines containing the distinct word «hope» are matched. Lines where «hope» is part of a word (e.g., «hopes») are not be matched.
grep -cw "hope" myfile.txt
Same as previous command, but displays a count of how many lines were matched, rather than the matching lines themselves.
grep -cvw "hope" myfile.txt
Inverse of previous command: displays a count of the lines in myfile.txt which do not contain the word «hope».
grep -l "hope" /www/*
Display the file names (but not the matching lines themselves) of any files in /www/ (but not its subdirectories) whose contents include the string «hope«.
ed — A simple text editor.
egrep — Filter text which matches an extended regular expression.
sed — A utility for filtering and transforming text.
sh — The Bourne shell command interpreter.