|
|
ABBYY FineReader: как работать
|
|
Как установить ABBYY FineReader 11
|
|
|
|
Как запустить ABBYY FineReader
|
Как настроить ABBYY FineReader 12 Professional
|
|
|
|
ABBYY FineReader — как переводить
|
<
ABBYY FineReader: как распознать текст
|
|
|
|
|






ABBYY FineReader 12 Professional — лицензия
Обзор ABBYY FineReader 12
PDF-документы давно стали необходимой составляющей офисной работы. В этом формате хранятся цифровые архивы, юристы согласуют договоры, дизайнеры верстают брошюры, издательства публикуют электронные книги. До недавнего времени главным достоинством и одновременно с этим недостатком PDF-документов было отсутствие возможности редактировать текст в них. Благодаря развитию технологий эту и другие задачи научилась решать программа ABBYY FineReader, которая стала многофункциональным редактором любых документов. «Хайтек» вместе с ABBYY рассказывает, как технологически устроено редактирование PDF-документов в новой версии FineReader 15, каким образом программа сравнивает версии документов и как работает распознавание иероглифов с помощью нейросетей.
Читайте «Хайтек» в
Диджитализация документооборота массово началась еще во второй половине ХХ века. Многие предприятия переходили на электронные документы. В офисах устанавливали первые компьютеры со специальным софтом для обработки и хранения важной информации. Тогда и появились популярные текстовые редакторы. Сотрудники набирали вручную документы, а затем, с появлением в 1993 году PDF, стали экспортировать их в этот формат.
На первый взгляд казалось: если весь документооборот станет электронным, то о шкафах с бумажными каталогами и завалах на рабочих столах можно будет забыть. На практике оказалось, что чем больше организация использует компьютеры для цифрового документооборота, тем больше документов она печатает. 64% крупных компаний уверены, что по крайней мере до 2025 года печать будет значимой частью их бизнеса. С другой стороны, если сегодня в офис по традиционной почте приходит бумажный документ, его немедленно отсканируют и переведут в цифру. Как правило, сканы документов хранят в виде PDF-файлов.
Документом в формате PDF удобнее пользоваться — его можно послать по электронной почте с уверенностью, что информация дойдет до адресата без искажений (если, конечно, кто-то не решит внести изменения собственноручно), и, в отличие от DOC, его трудно изменить. Это особенно важно, если речь идет о контрактах или коммерческих предложениях.
Офисные сотрудники отмечают рост объемов использования PDF: каждый второй респондент ответил, что регулярно работает с документами в этом формате и нуждается в специализированной программе. За последние два года количество таких рабочих файлов в мире выросло в три раза — эти данные приводят эксперты IDC в исследовании «Addressing the document disconnect». В России PDF также пользуется популярностью. Также по результатам исследования ABBYY выяснилось, что в наиболее частые сценарии работы с PDF-документами вошли совершенно не типичные для этого формата ранее задачи: 52% респондентов вносят мелкие правки в текст PDF, исправляют ошибки или опечатки; 62% опрошенных часто ищут информацию в тексте PDF и 60% копируют текст из документа. Поэтому от программ, работающих с PDF, требуются новые возможности для редактирования, сравнения и распознавания текстов. Все они есть в новом FineReader 15.
Почему так сложно редактировать текст в PDF?
Изначально PDF не предназначался для того, что его каким-либо образом изменяли. Что было и его преимуществом — это безопасность, одинаковое отображение на любом устройстве и удобный способ обмена информацией, и недостатком — невозможность внесения правок, поиска по тексту и сравнения документов.
Особенности отображения текста в PDF
Несмотря на то, что PDF — это формат текста, в цифровом виде эти буквы, слова и предложения на самом деле не существуют, они «нарисованы». Содержимое хранится в виде потоков — это могут быть текст, изображения и векторная графика. Типичных для формата DOC слов, строчек, абзацев и таблиц в PDF нет. В формате нет и букв как таковых, а есть коды символов. Такие коды с одинаковыми характеристиками объединяются в группы по виду и размеру шрифта. Этот шрифт определяет, как символ должен отображаться в документе, сопоставляя код символа и глиф — набор команд для отрисовки. Еще одно отличие от обычного текстового документа — объекты в PDF существуют в трех измерениях. По координате Z судят о глубине расположения объекта на странице, ведь текст может находиться поверх изображения или наоборот.
Текст в PDF-документе напоминает «мешочек букв», который нужно правильно отобразить в конкретных местах документа с соответствующим форматированием.
С 2008 года PDF стал открытым форматом, что позволило разработчикам без проблем и дополнительных отчислений создавать программы для чтения файлов PDF, конвертеры и другие полезные вещи. Развитие OCR привело к тому, что у ранее неизменного PDF-документа появилась возможность редактирования — сначала построчного, а затем и в пределах абзацев.
Как ABBYY FineReader помогает редактировать PDF
Чтобы редактировать PDF-документ, его необходимо сначала подготовить к этому. Главная задача этого процесса — понять и проанализировать структуру текста. А ключевая сложность — отсутствие как абзацев, так и вообще форматирования в PDF. Поэтому сразу после того, как программа распознала текст, она начинает воссоздавать абзацы.
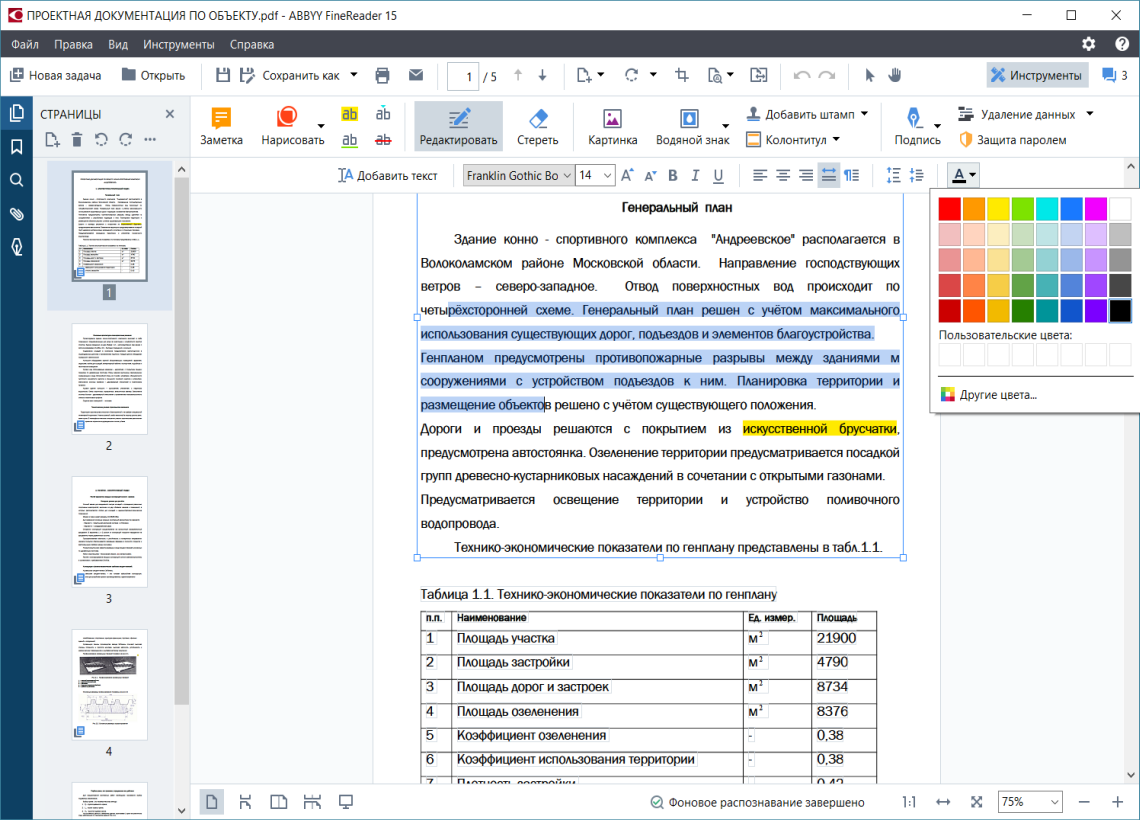
Если речь идет о digital-born-документе (изначально созданный на компьютере, а не отсканированный бумажный документ — «Хайтек»), то в режиме редактирования подключаются фоновые процессы, и программа приступает к анализу структуры документа. Для этого используется технология, которая строит блоки на основе данных, записанных в PDF, а не на основе распознавания. За считанные доли секунды технология должна пройти всю цепочку по определению параметров текста: места, где находятся заголовки, подзаголовки, отдельные абзацы и другие элементы. Потом — распихать «мешочки букв» по этим блокам, сформировать строки.
Следующий этап — синтез. Специальные технологии определяют внешние параметры текста — отступы и межстрочные интервалы. Благодаря этому из хаотичной структуры снова появляется текстовый документ с форматированием. И уже в него можно вносить правки — менять слова и целые абзацы, исправлять форматирование, сохранять изменения и так далее.
Функция построчного редактирования уже была в предыдущей версии FineReader (ABBYY FineReader 14 вышла в январе 2017 года — «Хайтек»). Этого было достаточно, чтобы внести небольшие исправления в текст: заменить несколько букв или цифр. Новый ABBYY FineReader 15 стал универсальным текстовым редактором, в котором вносить изменения можно в целые абзацы.
Как отредактировать текст в отсканированном документе
Отдельная офисная задача — отредактировать скан-копию бумажного документа. Раньше для этого пользователю приходилось конвертировать файл в редактируемый формат или просто искать исходник.
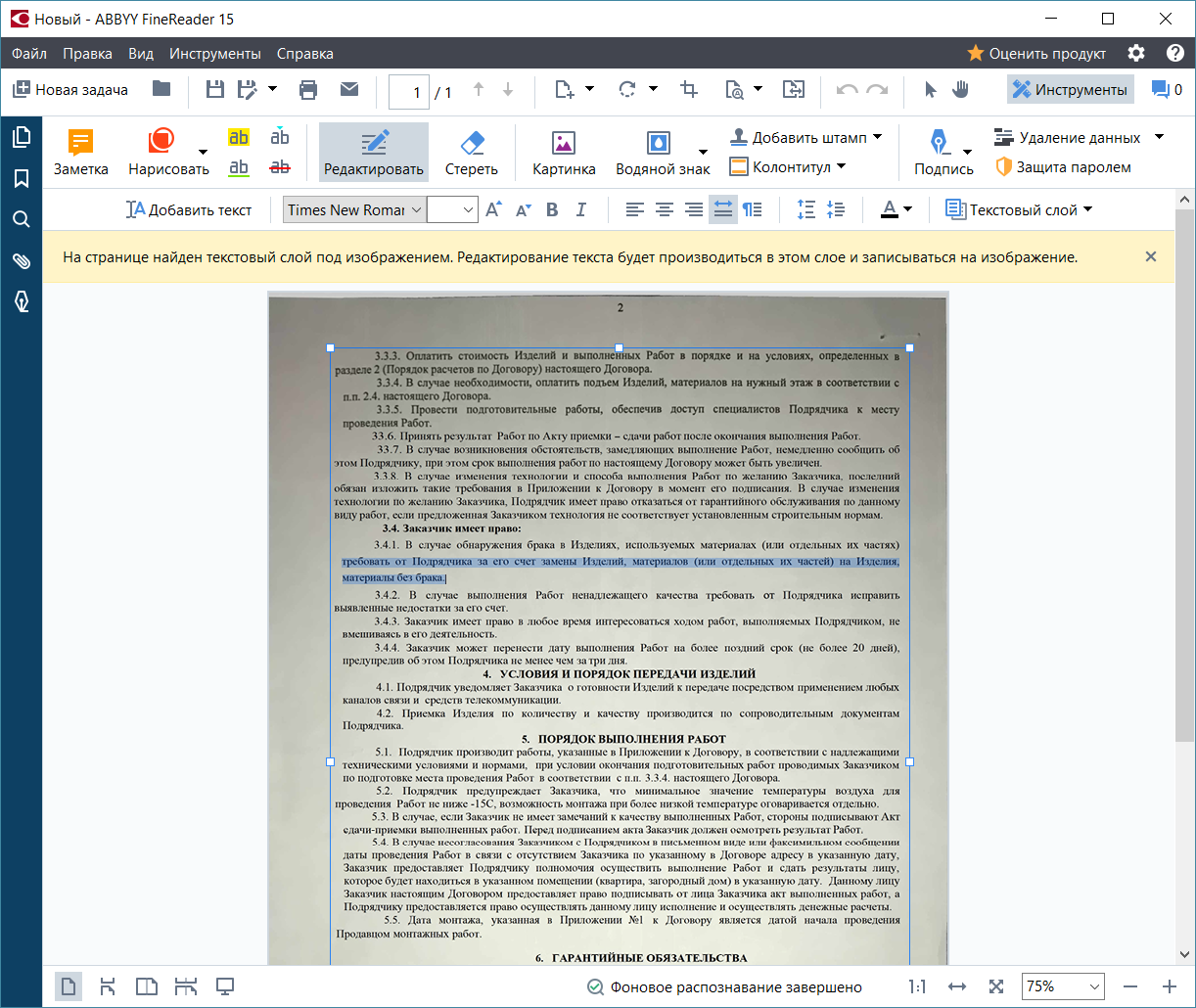
Когда пользователь редактирует скан, ABBYY FineReader 15 в первую очередь распознает документ и создает временный текстовый слой на тех страницах, которые пользователь просматривает. В режиме редактирования создается текстовое представление страницы — именно его редактирует пользователь. Затем эти правки встраиваются в изображение страницы в отсканированном документе.
Как найти в PDF внесенные правки и избежать обмана
Сравнение документов — особо важный для бизнеса сегмент офисных задач. Прежде всего, потому что неожиданные правки могут стоить очень больших денег. Иногда их незаметно пытаются внести в уже подписанный договор и воспользоваться человеческой невнимательностью — такие документы обычно сравнивают юристы, внимательно вычитывая распечатки оригинала, созданного в Word, и ответа контрагента — отсканированный вариант.
Поиск отличий в текстовых документах может быть полезен еще и в том случае, если над ними работают одновременно несколько человек или со временем один и тот же файл периодически изменяют. Это позволяет быстро найти последние правки, которые внесли в файл коллеги. В файлах DOCX для этого есть режим Track Changes, создающий на основе двух версий документа третью — с подсвеченными отличиями в тексте. В новом ABBYY FineReader 15 можно сохранить результаты сравнения любых документов в таком DOCX c Track Changes и в привычном режиме увидеть все различия.
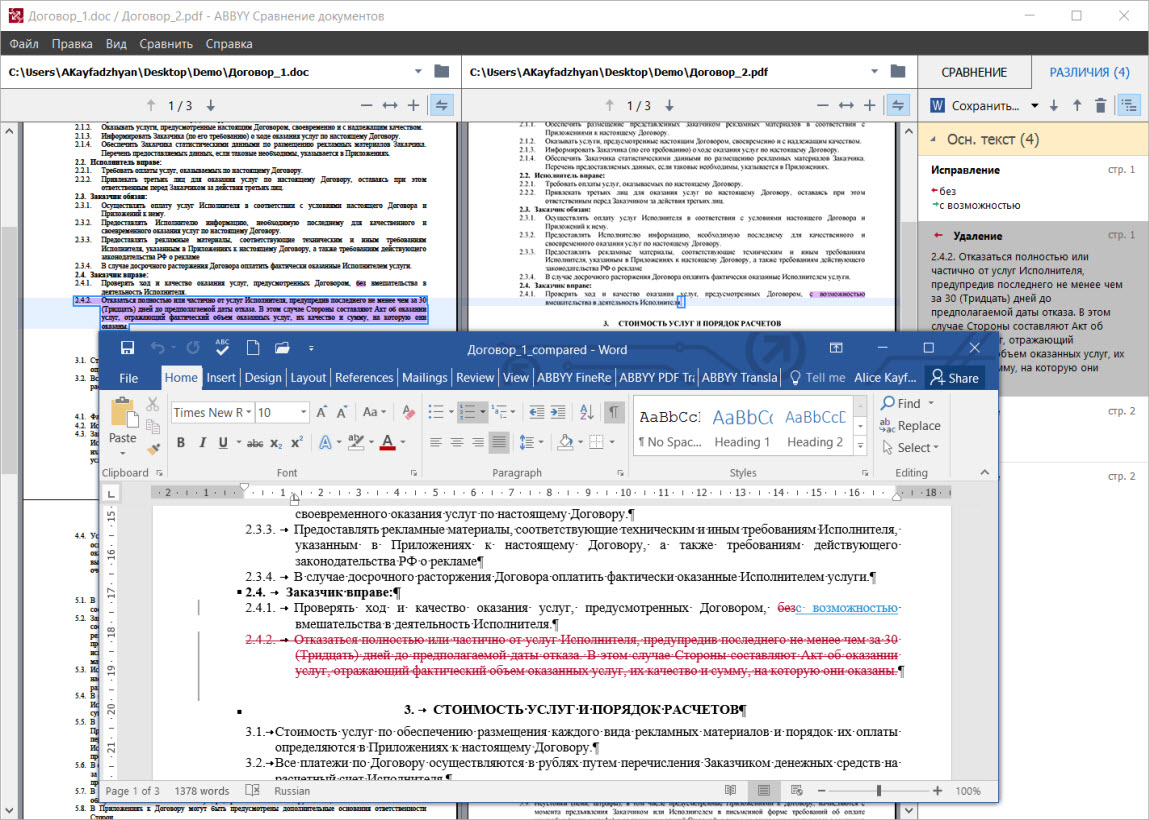
Сравнивать в ABBYY FineReader 15 можно практически что угодно — PDF, сканы или изображения, файлы DOC, DOCX и даже таблицы из Excel. В программу загружаются оба документа, которые при необходимости распознаются с помощью OCR. На основе извлеченного текста в документе определяются дополнительные элементы форматирования — например, колонтитулы, нумерация списков. В программе используется специальный алгоритм, который позволяет быстро выявлять отличия в версиях документов.
Разностный алгоритм принимает два файла на вход. Первый, обычно более ранний — файл А, второй — файл B. Алгоритм определяет количество вставок или удалений, необходимых для превращения одного файла в другой, находя для этого кратчайший путь.
Сравнение проходит в три этапа. Сначала текст, полученный в результате распознавания, разбивается на параграфы. Алгоритм считает, что один параграф — это один объект для сравнения. Все несовпадающие фрагменты обрабатываются во время второго прохода алгоритма — уже по строчкам. Программа определяет, какие строки внутри параграфа совпадают не полностью.
Остается последний проход, уже в рамках несовпадающих строк, который сравнивает отдельные буквы. Этот процесс чуть сложнее: дополнительно используются различные эвристики — варианты распознавания. Если буквы совпадают по вариантам распознавания и процент уверенности распознавания этого элемента превышает 50%, то считается, что они эквивалентны. Не учитываются в качестве различий разные виды кавычек, скобок и маркеры списка.
Для каждого символа существует несколько вариантов распознавания: иногда их число доходит до 20. У каждого из этих вариантов есть процент уверенности, на сколько, по оценке технологии, буква соответствует отсканированному изображению. Затем в ходе анализа документа часть вариантов исключается, так как они не соответствуют эталону или не подходят по морфологии.
На этапе сравнения в программе запускается проверка: совпадает ли эта буква с той, что в документе? Если буква получена в результате распознавания, то проверяется похожесть символов в версиях и рассматриваются варианты распознавания. Возможно, «А» в бумажном документе распозналась ошибочно, и из-за этого при сравнении могут возникнуть разночтения. Тогда в вариантах распознавания ищется другая буква, у которой тоже высокий процент вероятности. Если вероятность больше 50%, в распознанном документе происходит замена. Это помогает избежать ошибок из-за плохого качества сканов.
Но поиск отличий в тексте — лишь один из этапов сравнения документов. Необходимо представить найденные отличия в том виде, в котором пользователю будет комфортно с ними работать. Например, слово «мама» заменили на «папа». По факту изменились только две буквы. Но более наглядно для пользователя будет выглядеть полная замена одного слова на другое, а не замененные на «п» буквы «м». Поэтому программа дорабатывает различия: растягивает и объединяет их до конца слова, строки или параграфа. Программа пытается восстановить логику, по которой действовал человек, вносивший исправления. И сделать так, чтобы различие выглядело более естественно и читалось понятно.
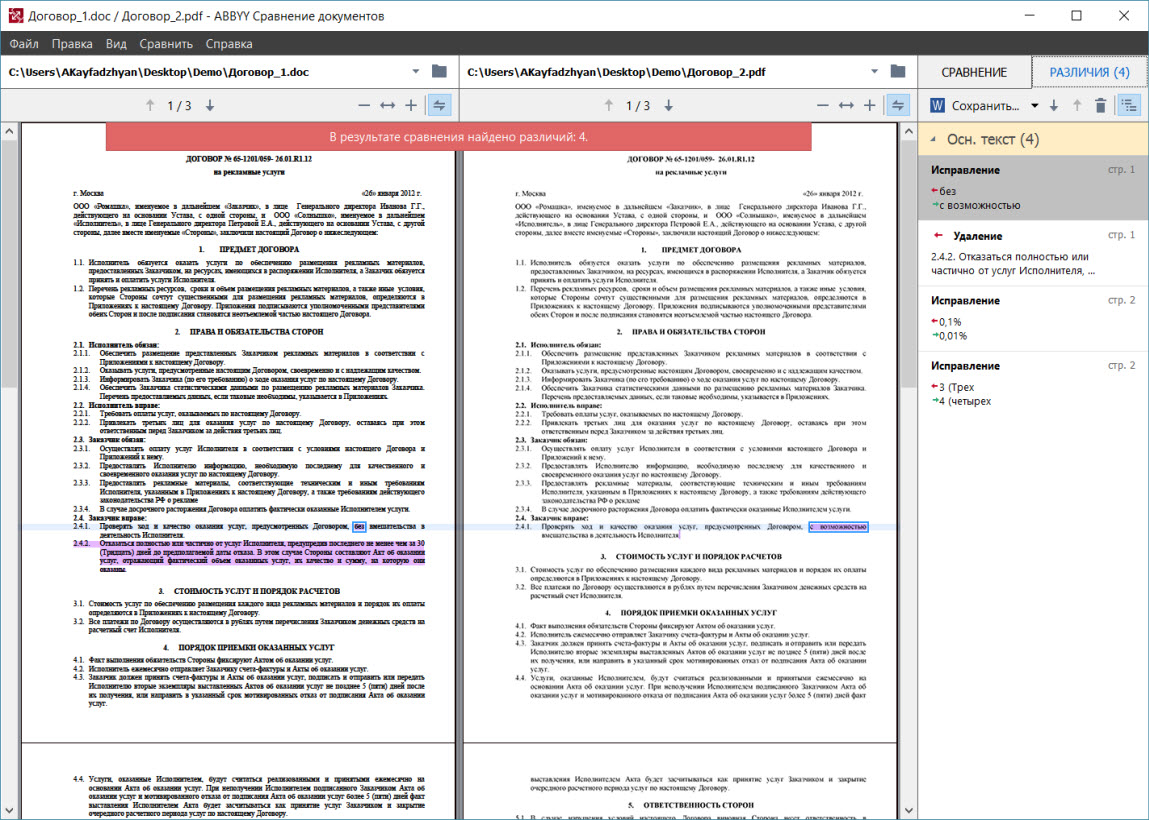
В завершении работы с документами программа объединяет обнаруженные различия в группы. Это необходимо, например, чтобы отделить внесенные исправления в основном тексте от колонтитулов и нумерации списка. В большинстве случаев колонтитулы не интересуют пользователя с точки зрения сравнения, за исключением вставок. Например, если у вас есть список на 100 позиций, в середине которого добавили или изменили один из пунктов. Чтобы работать с документом было удобнее, различия в нумерации попадают в отдельную группу.
В финале пользователь может посмотреть все исправления в документе так, как ему удобно. На выбор есть несколько способов: сохранить новую версию документа в формате DOCX, где все изменения уже подсвечиваются в режиме Track Changes, получить PDF с комментариями в местах изменений или создать таблицу с перечнем правок в Word.
Среди поддерживаемых ABBYY FineReader 15 функций:
- просмотр PDF-документов;
- редактирование текста в PDF-документе в пределах абзаца;
- удаление конфиденциальных данных;
- сравнение документов разного формата и написанных на разных языках;
- автоматизация задач по оцифровке и конвертации;
- распознавание и конвертирование документов;
- комментирование и согласование;
- защита и цифровая подпись.
Как работают нейросети для распознавания иероглифов и арабской вязи
Распознавание иероглифов осложняется тем, что в отличие от европейских языков, они состоят из большого количества черточек, палочек, наклонов. Но размер иероглифов вполне сопоставим с размером европейских букв. В низком разрешении сканов иероглифы могут и вовсе выглядеть как кляксы. Носитель языка поймет символ, исходя из контекста. Программа же работает поэтапно: сначала анализирует изображение всего документа, определяет абзацы, разбивает распознанные строки на слова, а слова — на отдельные символы. На этом этапе алгоритмы опираются не на контекст, как человек, а на внешний вид иероглифа, и здесь многое зависит от качества изображения. Для распознавания японского, китайского и корейского языков компания ABBYY внедрила нейросети. Они решают две главные задачи при работе с иероглифами — улучшение качества распознавания и «модернизацию» языков.
Качество и скорость в быстром и нормальном режиме
Внедрение нейросетей значительно повысило качество распознавания японского и китайского в быстром режиме, но скорость работы на начальном этапе разработки снизилась. Для клиентов, работающих с большим потоком документов, даже небольшая просадка по скорости может привести к сильному замедлению в обработке данных. Оказалось, что скорость проседает в документах с большим количеством символов с простой структурой — таких, как японская буквенная азбука (в современном японском языке используется три основных системы письма: кандзи — иероглифы китайского происхождения и две слоговые азбуки, созданные в Японии — хирагана и катакана — «Хайтек»).


Эту проблему решили с помощью кэша. Когда программа распознает страницу, одна и та же буква может попадаться на ней несколько раз. Встретив букву «А», написанную одним и тем же шрифтом, ABBYY FineReader анализирует и запоминает ее особенности. Этот принцип оптимизации позволяет не тратить время на распознавание одинаковых символов. Для японского и китайского ранее не использовался кэш, потому что встретить один и тот же иероглиф на странице, написанной естественным языком, можно очень редко. Но для символов с простой структурой это оказалось полезным. Включение кэша позволило ускорить и нормальный, и быстрый режим распознавания.
Почему важно следить за развитием языка
В предыдущих версиях FineReader в японском языке присутствовали иероглифы, которые уже не используются в современных документах. Это заметили сотрудники японского офиса ABBYY: время от времени программа вставляла при распознавании один-два устаревших символа. Для рядового носителя языка это воспринимается как буквы из русского дореволюционного алфавита для нас. Чтобы исправить эту ошибку, потребовалось создать в программе «новый язык» — Japanese Modern. Легко заставить программу не отображать те или иные устаревшие символы. Но необходимо было не просто выбросить ненужное, но и оставить всё необходимое, найти множество иероглифов, которые отображают всё богатство современного японского языка.

Новое множество символов формировалось в несколько этапов. Для тестирования создавали подходящие наборы изображений документов. Если в пакет попадала хотя бы одна страница с устаревшими формами, весь комплект оказывался непригодным. Приходилось вынимать эту страничку и формировать новый комплект материалов. Наконец удалось добиться того, чтобы в результатах распознавания почти не было устаревших символов и при этом правильно отображались все современные иероглифы.
Для китайского в FineReader всегда поддерживали традиционный и упрощенный языки. При этом по составу символов они не отличались. Получить разный результат распознавания всё равно было возможно, потому что в программе было заложено разное распределение вероятностей. В новой версии в результате экспериментов удалось выделить символы, необходимые для распознавания упрощенного китайского. В FineReader заложена возможность создавать пользовательский язык. Используя этот инструмент и внося изменения в состав, специалисты сравнивали результаты распознавания на разных образцах документов, и в результате в упрощенном китайском остался только необходимый набор иероглифов.
Корейская письменность, хангыль — нечто среднее между китайским и европейским письмом. Внешне это квадратные символы, напоминающие иероглифы, и на одной странице текста можно насчитать больше сотни уникальных. С другой стороны, это фонетическая письменность, то есть основанная на записывании звуков. Имеется алфавит, содержащий 24 буквы (плюс можно дополнительно посчитать диграфы и дифтонги). Но, в отличие от латиницы или кириллицы, звуки пишутся не в линию, а объединяются в блоки. Каждый блок может состоять из двух, трех или четырех букв. Первой всегда идет согласная, затем одна или две гласных, и в конце может стоять еще одна согласная. Для корейского обучили отдельную нейросеть, которая, помимо корейских слогов, распознает и некоторые иероглифы. Вместо распознавания символов целиком технология определяет отдельные буквы в них.
Как резать арабскую вязь на фрагменты
Арабский язык отличается от других тем, что найти линии порезки между символами в арабской вязи очень сложно. Даже гистограмма при распознавании арабского отличается: выглядит как бесконечный набор горбиков и ямочек.
Варианты разделения текста на символы создаются всегда, даже для европейских языков. В процессе работы программа выбирает наиболее вероятный путь распознавания. В случае с арабским языком таких вариантов очень много, и это приводило к ошибкам. Поэтому для повышения точности программу научили видеть не отдельную букву, а всё слово целиком. Для этого была разработана сеть end-to-end (e2e). Она полезна не только для арабского, но и для европейских языков — например, в дизайнерских шрифтах, когда на изображениях сложно построить путь для распознавания.

При e2e-подходе на вход в нейросеть поступает набор изображений — фрагментов, состоящих из отдельных слов. На выходе такая нейросеть выдает последовательность графем, которые затем проходят дополнительную обработку: проводится словарный анализ, корректируются пробелы.
Для обучения использовался набор из нескольких сотен тысяч фрагментов — отдельные слова из отсканированных газет, журналов, официальных документов. Они были выбраны в несколько итераций: сначала собирали базу из слов, которые удачно распознали, и обучали нейросеть на этом датасете. Потом еще раз обучали, корректировали, выявляли ошибки. Часть, которую не смогли распознать, отдельно отдавали на доразметку и корректировку фрагментов. В результате всё больше очищали датасет для обучения, улучшая общее качество распознавания.
Кроме того, часть данных для обучения была создана искусственно. Это было необходимо для распознавания шрифтов, для которых было собрано мало образцов. В таких случаях использовался корпус текста, в который добавлялись различные искажения, типичные для этапа сканирования документа: шум, размытие символа. Это делала в автоматическом режиме специальная программа — генератор синтетики, или «портилка».
Сначала в ходе обучения такой подход привел к тому, что потерялась информация об охватывающих прямоугольниках символов, которые необходимо отображать для пользователя на этапе верификации. Отказавшись от посимвольного распознавания, пришлось внедрить альтернативный механизм, который дополнял результаты распознавания информацией об охватывающих прямоугольниках и резал слова на отдельные символы.
Сочетание новых алгоритмов машинного обучения сделало возможным создание многофункционального текстового редактора для работы с PDF, сканами и digital-born-документами. Внесение правок, сравнение файлов и распознавание сложных языков дает пользователю возможность полноценно работать с файлами вне зависимости от их формата. По сути, это позволяет охватить все спектры офисных задач по работе с электронными и даже бумажными документами, максимально упрощая работу сотрудникам и снижая вероятность ошибок из-за человеческого фактора.
Работа по распознаванию изображений состоит из следующих этапов:
- Получить отсканированные изображения (сканы).
- Открыть их в OCR-программе (FineReader).
- Сделать разметку страниц на блоки. То есть, разбить страницу на области, в каждой из которых будет находиться или текст, или рисунки, или таблицы, или другое однородное содержимое.
- Собственно распознавание.
- Вычитка распознанного, сверка полученного текста и исходных сканов.
- Сохранение полученных результатов в одном из документальных форматов (DOC, RTF, PDF, HTML и т. д.).
При распознавании текстов возможны два варианта: или вы сканируете материал сами, или работаете с уже отсканированным текстом.
В первом случае этапы «Получить изображения» и «Открыть изображения» объединяются в одно — FineReader полученные сканы сразу же открывает в своем пакете. Во втором случае этап «Получить изображения» уже пройден, надо только открыть их в программе.
Рассмотрим оба варианта по очереди.
Отсканировать текст в FineReader
Сканирование запускается через «Файл → Сканировать страницы» или кнопкой меню «Сканировать», или Ctrl-K.
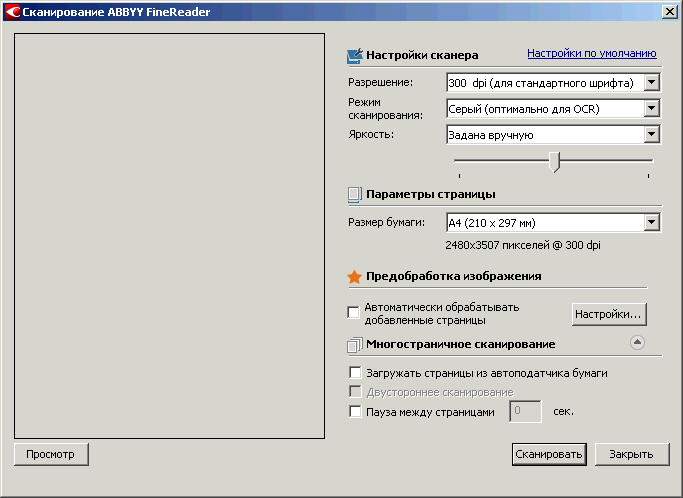
Рис. 1 Интерфейс сканирования
Однако, прежде чем начинать сканировать, неплохо бы разобраться, как получить сканы, наиболее оптимальные для распознавания. А для этого понять, чем «хороший» (с точки зрения FineReader) скан отличается от «не очень хорошего».
Для качественного распознавания программе требуется три вещи. Во-первых, возможность надежно отличить текст и иллюстрации от фона страницы. Во-вторых, чтобы буквы, цифры и прочее содержимое были четкими и разборчивыми, чтобы не возникало ситуаций «здесь и человеческий глаз не всегда поймет, что именно напечатано». В-третьих, строки текста на скане должны идти так же ровно, как они напечатаны на странице книги, без перекосов и искажений. Есть еще и другие требования к качественному скану, но эти можно считать ключевыми.
1. Для надежного различения «здесь текст, а здесь фон страницы» требуется, чтобы переход между тем и другим был резким, не размытым. Вот образцы страниц с плохой и с хорошей четкостью. Во первом случае, естественно, будет распознаваться хуже, с большим количеством ошибок.

Рис. 2. Размытые границы литер

Рис. 3. Четкие границы литер
Обычная причина размытых границ «текст-фон» — сканирование с нарушенной фокусировкой, то, что обычно называют «не в фокусе». Поэтому перед началом работы желательно проверить ваш сканер на этот момент.
Другая причина, которая может помешать различению текста и фона — слишком «плотный» фон страницы. В норме он должен быть или чисто белым, или белым с небольшой примесью какого-нибудь цвета. Если сканируются книги старых изданий, где бумага часто бывает пожелтевшей, то фон тоже может быть желтоватый (но умеренно).
Если же фон выглядит заметно перетемненным, то такие страницы опять же будут распознаваться хуже.
То, какой вид будет у фона, зависит от выставленной яркости сканирования. Ее можно регулировать через движок «Яркость». Для начала имеет смысл поставить 50%, проверить, что при этом будет, при необходимости поправить.
2. Разборчивость литер текста в основном зависит от яркости и от разрешения сканирования.
Если яркость слишком велика, линии букв будут будут рваными, они станут как бы рассыпаться на отдельные кусочки. Если яркость мала, то детали букв начинают сливаться между собой, возникают бесформенные пятна. И то, и другое для программ распознавания не очень-то съедобная «пища».
Яркость здесь настраивается так же, как и в предыдущем случае — ставим для начала в интерфейсе сканирования 50%, а дальше по ситуации.
Рис. 4. Страница со слишком большой яркостью

Рис. 5. Страница со слишком маленькой яркостью (перетемненный фон страницы)

Рис. 6. А вот эта же страница, но в нормальном виде
Разрешение сканирования определяет сколько пикселей в скане будет приходиться на каждую букву. Если этих пикселей достаточно для отрисовки контура буквы, то проблем при распознавании не будет. Если же недостаточно, то буквы могут стать плохо различимыми даже для человеческого глаза, не говоря уже о программах распознавания.

Рис. 7. Здесь отсканировано на 100 точек
Рисунки 7-9 также можно считать примерами несколько перетемненного фона.

Рис. 8. То же самое, но на 200 точек

Рис. 9. То же самое, но на 400 точек
При выборе разрешения обычно руководствуются следующими правилами:
- 300 точек выбирается для книг массовых изданий (страницы заполненные текстом обычного размера, почти без рисунков);
- 400 точек выбирается для книг и журналов с заметным объемом текста небольшими кеглями (примечания, подписи под рисунками, таблицы, врезки мелким текстом);
- 600 точек выбирается для книг, напечатанных совсем мелкими кеглями (многие справочники и энциклопедии, книги-миниатюры). Или же с мелкодеталированными рисунками, например, гравюрами. Сюда же надо отнести многие книги издания 1990-х годов — тогда издатели экономили на бумаге и часто печатали совсем крохотульными буквами.
Интерфейс сканирования в FineReader позволяет выбирать только 300 точек или 600 (строка «Разрешение»). Поэтому если у вас много материала, который желательно делать на 400 точек, то лучше сканировать не из-под FineReader, а из программы, идущей вместе со сканером.
Или же в настройках FineReader переключиться с собственного интерфейса программы на TWAIN-интерфейс вашего сканера («Сервис → Настройки → закладка «Сканировать/Открыть» → щелкнуть внизу по «Использовать интерфейс сканера»). Тогда вы сможете сканировать из FineReader, но работать будете в интерфейсе сканера (обычно там больший объем настроек и функций).
3. Ровные, аккуратно выглядящие строчки текста в основном обеспечиваются предобработкой изображения («пред-» в данном случае означает «выполняемое после сканирования, но перед распознаванием»). После правильно сделанной предобработки содержимое страниц будет распознаваться с более высоким качеством.
FineReader для этого имеет достаточно богатый набор функций, который можно увидеть в настройках программы, на закладке «Сканировать/Открыть». Также это окошко можно вызвать через кнопку «Настройки» в окошке интерфейса сканирования.
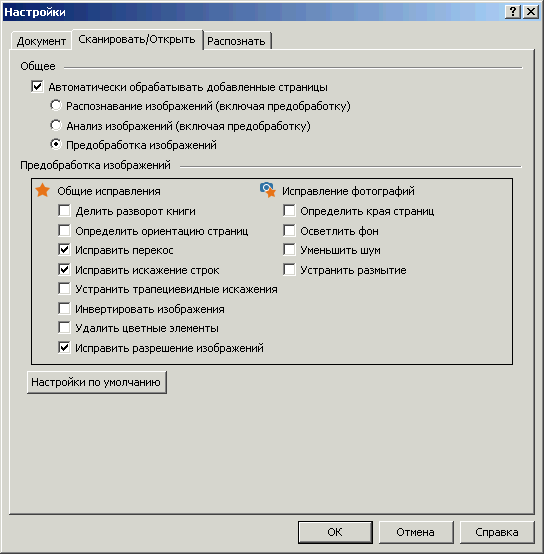
Рис. 10. Настройки предобработки
«Делить разворот книги» надо выбирать, когда книга сканировалась не постранично, а разворотами. Тогда для распознавания они будут нарезаны постранично.
«Определять ориентацию страниц» используется в том случае, если книга сканировалась повернутой набок. Тогда она будет развернута в свое нормальное положение. Но если в книге есть страницы, которые напечатаны повернутыми на 90 градусов относительно основной массы, то галочку здесь лучше снять. Иначе при выводе распознанного в PDF вы можете получить часть страниц в «книжной» ориентации, а часть — в «альбомной». Повернуть нужные страницы в этом случае лучше вручную, во встроенном редакторе изображений
«Исправить перекосы» устраняет перекосы страниц. Настройка однозначно необходимая, но надо иметь в виду, что PDF «Текст под изображением страницы», полученный из таких сканов, будет иметь не совсем аккуратный вид — сероватые клинья по краям страницы (там где делался поворот).
«Исправить искажения строк» выравнивает изгибы строк, которые при сканировании часто образуются около переплета (их еще называют «усы»).

Рис. 11. Пример страницы с изгибами строк
«Устранить трапециевидные искажения» исправляет деформации страниц, появляющиеся если книга не очень плотно прижата к стеклу сканера.
«Инвертировать изображения» необходима, если в сканируемом материале много текста «светлые буквы на темном фоне» и вы хотите преобразовать их в обычное «темные буквы на светлом фоне».
«Удалить цветные элементы» полезно, если на странице вида «черные буквы на белом фоне» надо убрать разные ненужности, вроде пометок ручкой на полях, подписей и печатей (офисная документация), а то и просто пятен. Но если на этой же странице есть какие-то сделанные в цвете «нужности» — графики, диаграммы или фотографии, то галочку ставить нельзя. Иначе будут удалены и они.
«Исправить разрешение изображений» — пункт, требующий более развернутого пояснения, чем предыдущие. Дело в том, что процесс распознавания в FineReader очень чувствителен к тому, какое разрешение выставлено в свойствах данного изображения. От этого существенно зависит то, насколько точно будут определены кегли букв текста, межбуквенные и межстрочные расстояния и прочее подобное. Поэтому галочка здесь необходима. Кроме того, не стоит удивляться, если по ходу распознавания вы будете постоянно получать сообщения FineReader «на странице такой-то неправильно выставлено разрешение и хорошо бы его исправить».
Кроме настроек предобработки на закладке «Сканировать/Открыть» есть блок настроек «Общее». Здесь задается набор основных действий, которые будут выполнены над открываемыми страницами. Варианты таких действий могут быть следующие:
- просто открыть отсканированные изображения, ничего с ними при этом не делая. Для этого надо снять галочку «Автоматически обрабатывать добавленные страницы».
Подобное имеет смысл только в том случае, если у вас сканы настолько высокого качества, что их уже ничем особенно не улучшишь. Можно сразу отправлять на распознавание. Бывает конечно и такое, но гораздо реже, чем хотелось бы :-), поэтому галочку лучше оставить. - открыть изображения, выполнить предобработку, но до вашей команды пока больше ничего не делать. Для этого надо выбрать пункт «Предобработка изображений».
Так обычно делают если надо не запускать сразу распознавание, а сначала посмотреть, что получилось в результате предобработки, насколько она хорошо отработала по данному набору изображений. - открыть изображения, выполнить предобработку, выполнить разметку на блоки, распознавание пока не запускать. Для этого надо выбрать пункт «Анализ изображений (включая предобработку)».
Наиболее часто выбираемый вариант. Сканы у вас вполне приличного качества, то, что с ними сделает предобработка вы хорошо представляете, проверять после нее нет необходимости. Значит соединяем в одно три описанных выше этапа работы с изображениями и начинаем смотреть насколько хорошо сделана разметка. - все этапы распознавания проходят автоматически, без какого-либо промежуточного контроля. Вы сразу получаете готовый результат и начинаете его вычитывать. Для этого надо выбрать пункт «Распознавание изображений (включая предобработку)». Так имеет смысл делать только если у вас сканы хорошего качества и с очень простым внешним видом — например сплошной текст на одном языке и ничего более. Во всех остальных случаях лучше выбирать вариант 2 или 3. Особенно если у вас страницы со сложным форматированием, таблицами, диаграммами, рисунками и т. д.

Рис. 12. Пример страницы со сложной версткой

Рис. 13. Пример страницы со сложной версткой
Открыть изображения в FineReader
Это второй вариант работы с изображениями: не сканировать их самому, а получить в уже готовом виде и открыть в FineReader. Делается через кнопку «Открыть» в меню основного окна или через «Файл → Открыть PDF или изображение», или через Ctrl-O.
Рис. 14. Окно «Открыть изображение»
В открывшемся окошке Проводника выбираете изображения, задаёте необходимые настройки (кнопка «Настройки») и нажимаете «Открыть». Настройки здесь используются те же самые, что описаны для сканирования, работать с ними надо так же.
Когда страницы открыты в FineReader, то пакет по умолчанию создается безымянным («Документ без имени») и хранится в TMP-папке, только в пределах текущего сеанса работы. Чтобы случайно не потерять результаты работы, рекомендуется сразу же после создания сохранить пакет под каким-нибудь постоянным именем («Файл → Сохранить документ FineReader»).
Разметка страниц на блоки
После того, как вы открыли сканы, надо выполнить разметку страниц на блоки. Это делается через «Документ → Анализ документа» или через Ctrl-Shift-E.
Основных рабочих целей у разметки две.
Во-первых, отделить то, что на странице есть текст, от того, что текстом не является. «Текстом» в данном случае считается все, что FineReader в состоянии распознать. «Не-текстом» соответственно считается все, что он распознать не в состоянии. В основном это иллюстративная часть страницы — рисунки, чертежи, графики, диаграммы и прочее подобное. Формулы, рукописные записи и ноты с этой точки зрения тоже считаются не-текстом — распознавать их FineReader пока не умеет. А значит при разметке их надо пометить, как «картинка».
Во-вторых, еще надо то, что есть текст, разметить по категориям — просто текст, таблицы, примечания (сноски), колонтитулы, оглавления и тому подобное. Чтобы потом, когда вы будете читать распознанное в текстовом редакторе, все эти элементы выглядели бы именно так, как вы и привыкли (были бы отформатированы соответствующим образом).
Размеченная страница может иметь примерно следующий вид:

Рис. 15. Окно «Изображение» с размеченной страницей
Теперь надо просмотреть разметку, сделанную программой на каждой из страниц и при необходимости поправить ее.
Погрешности разметки обычно бывают следующих видов.
1. Какая-то часть содержимого страницы (текст, рисунок и т. д.) выделена правильно в смысле границ области, но ей присвоено не то содержимое. Например, фрагмент текста размечен, как рисунок или наоборот.
В этом случае надо щелкнуть мышью по такой области, открыть контекстное меню, выбрать в нем «Изменить тип области», в открывшейся подменюшке выбрать требуемый тип («Текст», «Таблица», «Картинка», «Фоновая картинка», «Штрих-код»).

Рис. 16. Контекстное меню «Изменить тип области»
Быстро посмотреть где какая область можно по цвету рамок. «Текст» выделяется рамками темно-зеленого цвета, «Таблица» — синего, «Картинка» — светло-красного, «Фоновая картинка» — темно-красного, «Штрих-код» — светло-зеленого.
2. В смысле содержимого область выделена правильно, но в смысле размеров (границ) выделено не все, что в данном случае требовалось. Или же наоборот — попал кусок от соседней области с другим содержимым.

Рис. 17. Страница с некорректно сделанной разметкой
К верхней области «картинка» прихвачены окружающие ее подписи (должны быть размечены, как «текст»).
В нижнюю область «картинка» при разметке не попала часть изображения.
Чтобы это поправить, надо сначала щелкнуть в окошке «Изображение» по кнопке «Стрелка».
![]()
А затем щелкать по каждой неправильно размеченной области и перемещать ее границы. Примерно таким же образом, как обычно перемещают границы окошек открытых программ.
3. Какая-то часть содержимого страницы разметкой вообще пропущена, не попала ни в одну из созданных областей.
Рис. 18. Из разметки выпала формула (не попала ни в один из блоков)
Здесь надо будет создать на странице новую область (выделить пропущенную часть страницы рамкой), а затем присвоить созданной области нужный тип.
Для этого надо сначала щелкнуть в окошке «Изображение» по значку «Выделить зону распознавания»
![]()
После этого обвести нужный участок рамкой (как обычно в графическом редакторе выделяют часть рисунка) и наконец задать тип области. Последняя операция уже описана в пункте 1.
Если текстовая часть страницы вам нужна просто, как сплошной текст (что чаще всего и бывает), то этого вполне достаточно. Если же вы хотите, чтобы в Word различные элементы оформления распознанных страниц (примечания, колонтитулы) выглядели бы именно, как примечания и колонтитулы, то надо проверить и этот момент.
Регулируется он через контекстное меню. Щелкаете по нужной области «Текст» на проверяемой странице, в контекстном меню выбираете пункт «Назначение текста», внутри его подменюшки смотрите против какого пункта стоит галочка (обычно это «Автоопределение»). Если стоит не там, где надо, переключаетесь на нужный элемент.

Рис. 19. Контекстное меню «Назначение текста»
Распознавание
После того, как исправлены ошибки в разметке, можно запускать распознавание. Это делается через «Документ → Распознать документ» или через Ctrl-Shift-R. Перед этим не забудьте выставить язык распознавания и задать необходимые настройки.
Язык выставляется через окошко «Язык документа» в панели кнопок основного окна программы.
Рис. 20. Выбор языка через основное меню
Или в настройках («Сервис → Настройки → закладка «Документ»).
Рис. 21. Выбор языка через настройки FineReader
Если в открывшемся списке нет нужного вам языка, то нажмите «Выбор языков» в нижней части списка и в открывшемся окошке поставьте галочку против необходимого вам языка (набора языков). После этого он будет добавлен в список.
В настройках распознавания («Сервис → Настройки → закладка «Распознать») режим распознавания лучше оставить в умолчательном значении («Тщательное распознавание»). «Быстрое распознавание» имеет смысл ставить только если у вас что-то несложное по виду и с очень хорошим качеством сканирования. Например, отсканированная в черно-белом распечатка текстового документа без иллюстраций.
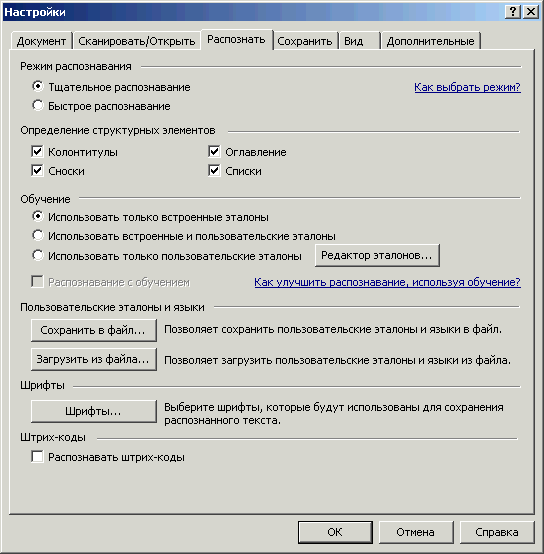
Рис. 22. Настройки, закладка «Распознать»
Из остальных настроек основное значение имеет группа «Определение структурных элементов». Здесь перечислены детали оформления страниц: сноски (примечания), колонтитулы, списки, оглавления. Когда против элемента поставлена галочка, он будет распознан и сохранен в DOC/RTF/DOCX не просто как часть текста на странице, а именно, как сноска, колонтитул, список или оглавление.
Только не забудьте при этом важный момент. Если вам приходится распознавать области с подобным содержимым, то одной галочки в настройках закладки «Распознать» может оказаться мало. Кроме этого еще требуется на этапе разметки правильно пометить эти области маркером «Назначение текста» из контекстного меню.
Вычитка
Вычитку распознанного текста в FineReader можно делать двумя способами. Или с помощью функции «Проверка», или обычным образом, просматривая страницы во встроенном редакторе FineReader. Через окно «Крупный план» сверяем со сканом, где есть ошибки — исправляем.
Функция «Проверка» запускается кнопкой в правом верхнем углу меню или через Ctrl-F7. Ее работа построена на том, что во время распознавания FineReader помечает символы и слова, которые были распознаны с недостаточно высоким уровнем достоверности. То есть, у программы по их поводу есть некоторое сомнение «может это действительно тот символ, который вам предъявлен, но может быть и что-то другое». Во время проверки такие сомнительные места по очереди показываются пользователю, чтобы он при необходимости их поправил.
Окно проверки устроено достаточно просто. В верхней его части показывается фрагмент страницы, в котором находится проверяемый символ. В нижней части выводится строка распознанного текста с этим символом, а также расположены несколько кнопок для несложного редактирования.
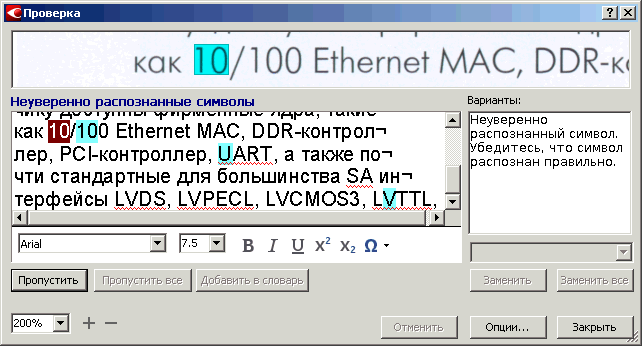
Рис. 23. Окно «Проверка»
Если все порядке, символ определен правильно, то нажимаем на «Пропустить». Если он определен неверно, то вводим правильное значение или с помощью клавиатуры, или если на клавиатуре такого нет, то с помощью кнопки «Вставить символ» (греческая буква «омега»). После чего нажимаем на «Подтвердить».
Аналогичным образом действуем если символ распознан верно, а вот его форматирование — неверно. Например в тексте книги в каком-то месте идет курсив, а распознался он, как обычный шрифт. Для переформатирования используем кнопки в нижней части окна.
Но возможности окна проверки все-таки достаточно ограничены. И по тому, какого размера кусочек страницы может быть показан в верхней части окна, и по возможностям редактирования, которые здесь имеются. Поэтому все перемещения по тексту, от одной точки проверки до другой, отслеживаются еще и в окнах «Текст» и «Крупный план». Все время, пока идет работа, курсоры в «Тексте» и «Крупном плане» перемещаются синхронно их положению в «Проверке».
Если в проверяемом фрагменте страницы (в его скане) вдруг потребовалось увидеть больше, чем несколько слов, показанных в «Проверке», то можно это сделать в «Крупном плане». Если для правки текущей ошибки требуются возможности редактора из «Текста», то можно на время переключиться в него (просто щелкнув по его окошку), сделать необходимую работу и вернуться обратно в «Проверку» (щелкнув по ее окошку). После возвращения в «Проверку», там будут отображены все изменения, которые вы сделали в «Тексте».

Рис. 24. Пример работы в одновременно открытых окнах «Проверка», «Текст» и «Крупный план»
Если вам окошко «Проверка» с его ограниченными возможностями не очень-то удобно (привыкли работать со всеми удобствами текстовых редакторов и привычки менять не собираетесь), то можно с самого начала делать эту работу в окне «Текст».
Места, требующие проверки, там отображаются в полном объеме — это символы и слова, выделенные светло-голубым. Возможность перемещаться от ошибки к ошибке, не просматривая всю страницу целиком, тоже имеется — кнопки «Следующая ошибка» и «Предыдущая ошибка» на панели кнопок с левой стороны окна.
Теоретически, по замыслу создателей FineReader, окна «Проверка» должно быть вполне достаточно для полноценной вычитки распознанного текста. Все сомнительные места отмечены, движемся вдоль них, правим ошибки, на выходе получаем полностью вычищенный текст.
Но, как это часто бывает, теория здесь расходится с повседневной практикой работы. В распознанных текстах систематически встречаются ошибочные места, которые, как ошибки, не помечены. То есть FineReader распознает какой-то символ/слово неверно, но при этом с полной уверенностью, что распознал правильно.
Поэтому для полноценной вычитки одного только окна «Проверка» обычно бывает недостаточно — в особенности если в тексте много научных или технических терминов, профессионального жаргона и тому подобной «несловарности». Надо еще пройтись по распознанному вручную — внимательно просмотреть его в окне «Текст» и проверить все мало-мальски сомнительные места.
Вычитка текста в окне «Текст» мало чем отличается от обычной корректорской работы. Настраиваете окна «Текст» и «Крупный план» так, чтобы они занимали большую часть рабочего окна программы, переходите к очередной проверяемой странице, просматриваете ее текст. Если обнаруживаете сомнительное или явно ошибочное место, то щелкаете по нему — при этом курсор в «Крупном плане» устанавливается точно в том же самом месте оригинала (скана). Сравниваете оригинал и распознанное, при необходимости правите, двигаетесь дальше.
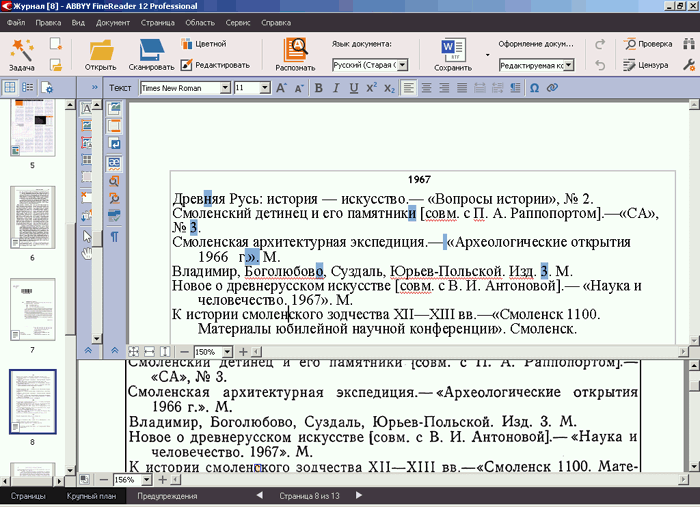
Рис. 25. Вычитка с помощью окон «Текст» и «Крупный план»
Функциональность редактора окна «Текст» ничем особо не отличается от функциональности любого текстового редактора средней степени сложности. Вид у кнопок в меню достаточно типовой, каких-либо проблем при работе с ними возникать не должно. Если надо поправить какой-то символ, который на клавиатуре отсутствует, то, как и в окошке «Проверка», надо нажать на кнопку с греческой «омегой» и в открывшейся таблице выбрать необходимое.
Сохранение результатов
Когда отсканированный материал распознан и вычитан, его надо сохранить в одном из документальных форматов — DOC, DOCX, RTF, PDF, HTML и т. д. Это делается через «Файл → Сохранить документ как → выбрать нужный формат» или через кнопку «Сохранить» в основном меню FineReader.
В открывшемся окошке Проводника выбираете формат, через кнопку «Настройки» задаете параметры сохранения, нажимаете «ОК». Если хотите сразу же посмотреть нет ли заметных ошибок во внешнем виде сохраненного текста, то кроме этого поставьте галочку в «Открыть документ после сохранения». Тогда он сразу же будет открыт в редакторе (браузере, программе просмотра).
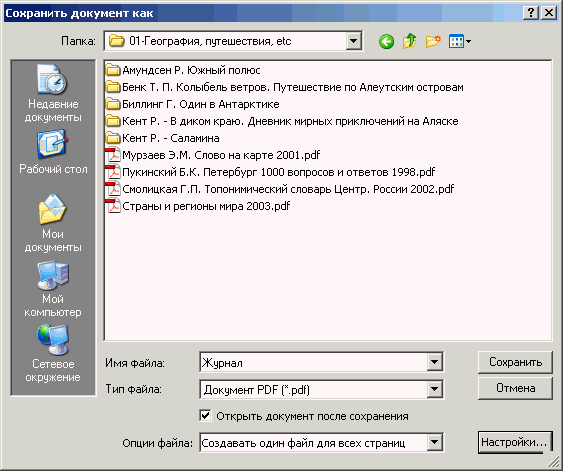
Рис. 26. Окно сохранения распознанного текста
Обычная практика распознавания — на вход поступает отсканированный текст книги или журнала, на выходе все его страницы сохраняются в файл с названием этой книги. Именно такая настройка «Создавать один файл для всех страниц» стоит по умолчанию в строке «Опции файла». Если же у вас распознается не какой-то цельный текст, а просто россыпь страниц (например офисная документация), то здесь надо будет выставить «Сохранять отдельный файл для каждой страницы».
Настройки сохранения в форматах DOC, DOCX, RTF
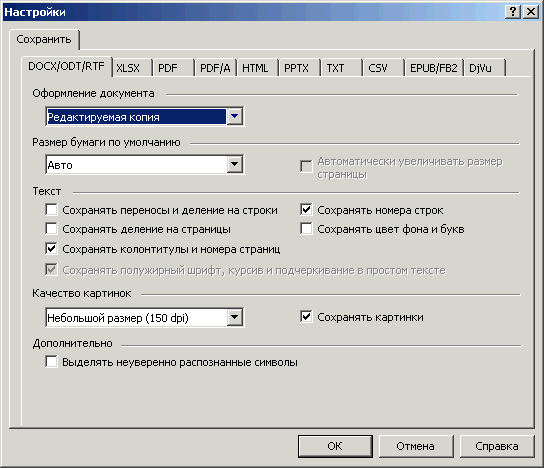
Рис. 27. Настройки сохранения в DOC/DOCX/RTF
Ключевое и основное, что здесь надо выбрать — это с какой степенью точности в сохраняемом документе будет отображен внешний вид оригинала (один из режимов сохранения в окошке «Оформление документа»). Все остальные настройки — не более, чем уточнение и деталировка этого пункта.
Вариантов выбора здесь четыре: «Точная копия», «Редактируемая копия», «Форматированный текст» и «Простой текст».
1. «Точная копия».
По замыслу разработчиков здесь должно было быть практически зеркальное подобие распознаваемой страницы. Именно потому так и названо. С точным воспроизведением шрифтов, размеров букв (кеглей), расстояний между буквами в словах, расстояний между словами, строками и абзацами и других деталей верстки. Идея, в общем-то, неплохая, но возможности реализовать ее в задуманном объеме у FineReader обычно не хватает.
Шрифты и их начертание (Normal, Italic, Bold) часто воспроизводятся по принципу «как выйдет, так и получится». Могут быть переданы точно. Может случиться так, что шрифт, использованный на распознаваемой странице, будет замещен другим шрифтом (сходным по виду, но другим). Может случиться так, что начертание Normal будет распознано как Bold или же наоборот. И так далее, и тому подобное.
С воспроизведение кеглей, расстояний и прочего форматирования ситуация не намного лучше — более или менее точно воспроизвести внешний вид (верстку) распознаваемой страницы обычно удается лишь в случаях чего-нибудь не очень сложного.
В результате получается не очень понятно что — Word-документ, который можно только читать (ну и копировать оттуда текст). Редактировать его за пределами «пару букв убрать, пару букв вставить» малореально. А редактировать таки требуется — он ведь дальше пойдет в какую-то работу, а значит надо будет переделывать форматирование под потребности будущего использования.
С одной стороны весь текст здесь раскидан по многочисленным фреймам, что изрядно осложняет работу с ним. С другой стороны во время распознавания программа генерирует кучу Word’овских стилей — все форматирование в тексте делается исключительно через стили. Вполне обычно, когда на текст книги среднего размера (300-400 страниц) генерируется несколько сотен различных стилей. Что еще больше усложняет редактирование.
Резюме — выбирать этот режим сохранения особого смысла не имеет, работать с сохраненным текстом здесь достаточно неудобно.
Если же вам требуется полное воспроизведение внешнего вида оригинала, то это и проще, и практичнее сделать в виде PDF «Текст под изображением страницы» или же PDF «Только текст и картинки» (об этих способах вывода немного ниже).
2. «Редактируемая копия».
По смыслу это облегченная версия «Точной копии». Внешний вид оригинала воспроизводится не с такой степенью дотошности, как в предыдущем случае, фреймов с текстом заметно поменьше (хотя периодически попадаются). Однако, хоть этот вариант и называется «редактируемым», работать с ним тоже, не сказать чтобы удобно.
Если Word-документ нужен, как есть, только для просмотреть его его содержимое и скопировать нужный фрагмент текста, то вполне можно использовать и этот вариант. Если же требуется много переделывать, переформатировывать и так далее, то лучше выбирать что-то другое.
Причина та же самая — слишком много возни по преобразованию текста из того вида, который выдаст «Редактируемая копия», в тот вид, который может потребоваться вам. Все еще осталось какое-то количество текста во фреймах, в форматировании все еще сохраняется тенденция точно воспроизводить внешний вид (верстку) оригинала. Да и привычка генерировать кучу стилей никуда не делась.
Резюме — работать с текстом здесь не так хлопотно, как в «Точной копии», но по прежнему оставляет желать лучшего.
3. «Форматированный текст».
Степень соответствия оригиналу здесь сведена к минимуму — воспроизведение шрифтов и кеглей, примерного расположения материала на страницах оригинала, общего вида текста и таблиц.
Работать с этим вариантом заметно проще, чем с предыдущими, однако все еще затруднительно из-за большого количества стилей. Впрочем это достаточно просто лечится — можно быстро пройтись по тексту и наложить на него ваш собственный комплект стилей.
4. «Простой текст».
Хотя он называется «Простой текст», но здесь можно сохранять как сам текст, так и текст с картинками. Форматирование в этом варианте сведено к минимуму — обычные Word’овские абзацы от одного края страницы до другого, плюс воткнутые между ними картинки. Привычная по предыдущим вариантам куча стилей тоже не генерируется.
Но при желании даже здесь можно оставить исходную разбивку на строки и на страницы. Плюс сохранять начертания шрифта — обычный, курсив, полужирный.
Обычно для сохранения выбирается или «Форматированный текст», или «Простой текст» — в зависимости от того, что вы собираетесь делать дальше и как использовать распознанное.
Теперь об остальных настройках этого окна.
- «Размер бумаги по умолчанию».
Здесь задается Word’овская настройка «Параметры страницы → Размер бумаги», то есть на бумаге какого формата вы будете делать распечатку. Обычно выставляется А4. Но надо иметь в виду, что в режимах «Точная копия» и «Редактируемая копия» один к одному сохраняется не только содержимое распознанной страницы, но и ее исходный размер. В результате если поставить здесь формат бумаги, больший, чем размер страницы, то при печати вокруг текста будут пустые поля. Если же поставить меньший формат, то часть материала страницы может быть потеряна (окажется за границами листа бумаги). - «Сохранять переносы и деление на строки».
Если галочка поставлена, то будет сохранена та разбивка на строки, которая имеется в оригинале. Переносы строк в этом случае делаются мягкими. Если галочки не ставить, то текст пойдет обычными Word-овскими абзацами, со строками от одного края страницы до другого. - «Сохранять деление на страницы».
Если галочка поставлена, то будет сохранена та разбивка на страницы, которая имеется в оригинале. Если галочки не ставить, то текст на страницы будет разбивать сам Word. - «Сохранять колонтитулы и номера страниц».
Если галочка поставлена, то текст, размеченный и распознанный, как колонтитулы и номера страниц, будет сохранен и размещен в соответствующих Word-овских полях. Если галочку не ставить, то эта часть текста вообще не выводится. - «Сохранять номера строк».
Если галочка поставлена, то в списках с пронумерованными строками будет сохранена нумерация этих строк. - «Сохранять цвет фона и букв».
Если галочка поставлена, то текст, напечатанный в цвете (или на цветном фоне), будет выведен, как в оригинале. Если галочки не ставить, то весь текст будет выводиться обычным образом — черным на белом фоне (или на белым на черном фоне). - «Сохранять полужирный шрифт, курсив и подчеркивание в простом тексте».
Вывод в «Простой текст» можно делать по принципу «все одним и тем же начертанием, Normal», а можно с сохранением начертания, которое было в оригинале. Здесь как раз этот момент и регулируется. - «Выделять неуверенно распознанные символы».
Эту галочку надо ставить если вы предпочитаете вычитывать распознанный текст не в FineReader, а в каком-нибудь текстовом редакторе. Тогда все пометки символов и слов, которые у вас были в окне «Текст», будут воспроизведены в сохраненном документе. - «Сохранять картинки».
Определяется будут ли кроме текста сохраняться еще и изображения. - «Качество картинок».
Здесь определяется степень сжатия изображений из оригинала. Оно может регулироваться по трем направлениям — через различные алгоритмы сжатия, через разрешение сохраняемого изображения и через глубину цвета в нем. Подробности можно посмотреть, если в строке «Качество картинок» выбрать вариант «Пользовательское». Наиболее практично пользоваться именно им, а не пресетами «Небольшой размер (150 dpi)» и «Высокое качество (разрешение исходного изображения)».
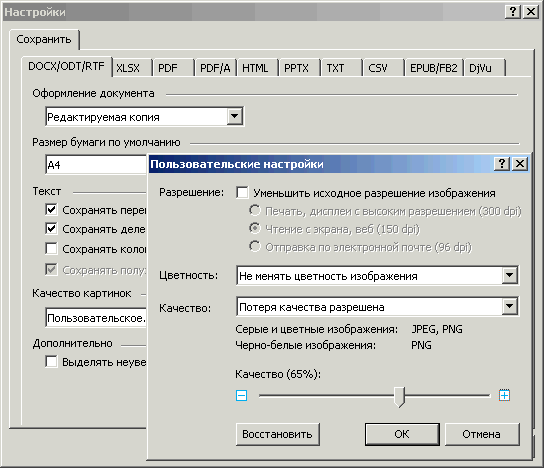
Рис. 28. Окно настройки качества изображения
Поскольку при уменьшении исходного разрешения и последующем сжатии возможны плохо предсказуемые искажения, то галочку «Уменьшать исходное разрешение изображения» лучше убрать.
Глубину цвета ставите по ситуации. Если изображения нужны, как есть, то выбираете «Не менять цветность изображения». Если достаточно просто общего вида, точное воспроизведение цветов не обязательно, то выбираете «Конвертировать цветные изображения в серые». Преобразование цветных и серых изображений в черно-белые лучше не выбирать, потому что бинаризация может давать много искажений (причем плохо предсказуемых). Пункт «Автоматически» тоже лучше не выбирать — не очень понятно какая логика работы там заложена и что вы при этом будете получать на выходе.
Движок «Качество» (цифры в нем) можно считать аналогом настройки «Quality» в JPEG-сжатии и регулировать здесь по опыту работы с JPEG-изображениями.
Настройки сохранения в форматах PDF и PDF/A

Рис. 29. Настройки сохранения в PDF
Режимов сохранения здесь тоже четыре: «Только текст и картинки», «Текст поверх изображения страницы», «Текст под изображением страницы», «Только изображение».
- «Только текст и картинки».
Здесь вы фактически получите PDF-вариант того, что выдается в «Точной копии» — распознанный текст и иллюстрации из окна «Текст» в виде, максимально приближенном к оригиналу. Качество воспроизведения оригинала здесь выше, чем в DOC/DOCX/RTF, поскольку PDF-формат имеет для этого заметно больше возможностей. - «Текст поверх изображения страницы».
Это PDF, состоящий из двух слоев — исходное изображение (нижний слой), на которое наложен распознанный текст (верхний слой). Такой вариант достаточно удобен, если PDF потом будет редактироваться - «Текст под изображением страницы».
Это PDF составленный из тех же двух слоев — исходное изображение и распознанный текст. Только они идут в обратном порядке — изображение верхним слоем, текст нижним (невидимым) слоем. Такой способ вывода еще называется «PDF с текстовой подложкой» и используется, когда надо получить с одной стороны точную копию внешнего вида оригинала, а с другой стороны возможность копировать текст этого оригинала. - «Только изображение».
Это PDF, собранный из исходных изображений. Кроме самих изображений там больше ничего нет.
Теперь об остальных настройках этого окошка.
1. «Размер бумаги по умолчанию».
В PDF-выводе смысл этой настройки такой же, как и в предыдущем случае — формат листа, на котором будет печататься страница.
В предыдущем случае говорилось о правиле «если страница меньше, чем заданный формат, то вокруг текста будут пустые поля, если больше — часть текста будет обрезана». В PDF оно соблюдается еще более жестко, поскольку здесь исходная страница в любом варианте воспроизводится один к одному. Поэтому наиболее разумно ставить здесь «Использовать размер оригинала».
2. «Сохранять цвет фона и букв».
3. «Сохранять колонтитулы».
Смысл этих двух настроек такой же, как и в предыдущем случае.
4. «Создать оглавление».
Если в настройках распознавания была поставлена галочка «Определение структурных элементов → Оглавление», то распознанное таким образом оглавление книги может быть использовано для автоматического создания оглавления в PDF-файле.
5. «Разрешить теги PDF».
В PDF теги — это функциональный аналог Word-вских стилей, способ структурной разметки содержимого PDF-файла. С их помощью сохраняется информация о разбивке текста на главы, о заголовках, оглавлении, иллюстрациях, таблицах, примечаниях, гиперссылках, математических формулах и прочем подобном.
Если вам надо будет часто копировать из PDF куски текста, то галочку здесь стоит поставить. Тогда скопированный текст будет гораздо больше соответствовать тому, как он выглядит на странице PDF.
Также теги полезны если PDF приходится просматривать на экранах различных размеров — от десктопов до смартфонов. В таких случаях PDF-читалкам приходится переформатировывать содержимое страниц под текущий размер экрана и с теговой разметкой это проходит значительно более аккуратно, без заметных искажений первоначального вида.
6. «Использовать смешанное растровое содержимое (MRC)».
MRC (Mixed Raster Content) — это название технологии сжатия, способной давать заметно большие кратности сжатия, чем известные всем JPEG и JPEG 2000. Многие знакомы с ней по формату DjVu — он построен именно на базе MRC. Выбор «надо ставить галочку или нет» здесь неоднозначный и определяется исходя из вашего расклада дел.
Основной плюс — размер получаемого PDF. Может быть в несколько раз меньше PDF, полученного с теми же настройками сжатия, но без MRC.
Какие могут быть минусы:
— MRC-сжатие так устроено, что при работе всегда дает плохо предсказуемое количество искажений. По причине того, что искажения здесь только частью зависят от настроек сжатия, а в изрядной мере от содержимого страницы. Текст, рисунки, графики, фотографии — при MRC-сжатии все они ведут себя заметно по разному и дают разное количество искажений.
— заметно большая ресурсоемкость при сжатии и просмотре таких PDF. Даже на сегодняшних компьютерах MRC-PDF может открываться и пролистываться не привычно-плавно, а скачками, когда очередная страница выводится на экран не вся сразу, а по частям.
7. «Сохранять картинки».
8. «Качество изображения».
Смысл этих настроек такой же, как и в предыдущем случае — надо или не надо при создании PDF сохранять изображения и с каким уровнем сжатия их сохранять. Рекомендации тоже аналогичные — убрать галочку из «Уменьшить исходное разрешение», цветность лучше не менять, движок «Качество» выставлять по аналогии со сжатием в JPEG 2000.
9. «Шрифты».
Если поставить «Использовать шрифты Windows», то для распознавания и последующего вывода будет использоваться тот набор шрифтов, который установлен у вас на компьютере. Если поставить «Использовать предопределенные шрифты», то только тот комплект шрифтов, который устанавливается при инсталляции FineReader.
Предпочтительнее выставлять первый вариант, поскольку при этом будет использоваться гораздо большее разнообразие шрифтов и программе будет легче подбирать соответствие шрифтам распознаваемых книг.
10. «Встраивать шрифты».
Если вам требуется, чтобы при просмотре PDF-файла на другом компьютере он был виден именно так, как вы его получили (именно в этих шрифтах), то надо поставить здесь галочку.
11. «Параметры защиты PDF».
Здесь можно выставить парольную защиту на просмотр PDF, печать, копирование из него текста и рисунков, редактирование.
Если у вас возникнут вопросы по работе FineReader, на которые вы не нашли ответа в тексте статьи, то их можно задать на форуме разработчиков программы.