Время на прочтение
13 мин
Количество просмотров 66K
Туториал
Recovery mode
Перевод
Узнайте о антипаттернах, планах выполнения, time complexity, настройке запросов и оптимизации в SQL
 Язык структурированных запросов (SQL) является незаменимым навыком в индустрии информатики, и вообще говоря, изучение этого навыка относительно просто. Однако большинство забывают, что SQL — это не только написание запросов, это всего лишь первый шаг дальше по дороге. Обеспечение производительности запросов или их соответствия контексту, в котором вы работаете, — это совсем другая вещь.
Язык структурированных запросов (SQL) является незаменимым навыком в индустрии информатики, и вообще говоря, изучение этого навыка относительно просто. Однако большинство забывают, что SQL — это не только написание запросов, это всего лишь первый шаг дальше по дороге. Обеспечение производительности запросов или их соответствия контексту, в котором вы работаете, — это совсем другая вещь.
Вот почему это руководство по SQL предоставит вам небольшой обзор некоторых шагов, которые вы можете пройти, чтобы оценить ваш запрос:
- Во-первых, вы начнете с краткого обзора важности обучения SQL для работы в области науки о данных;
- Далее вы сначала узнаете о том, как выполняется обработка и выполнение запросов SQL, чтобы понять важность создания качественных запросов. Конкретнее, вы увидите, что запрос анализируется, переписывается, оптимизируется и окончательно оценивается.
- С учетом этого, вы не только перейдете к некоторым антипаттернам запросов, которые начинающие делают при написании запросов, но и узнаете больше об альтернативах и решениях этих возможных ошибок; Кроме того, вы узнаете больше о методическом подходе к запросам на основе набора.
- Вы также увидите, что эти антипаттерны вытекают из проблем производительности и что, помимо «ручного» подхода к улучшению SQL-запросов, вы можете анализировать свои запросы также более структурированным, углубленным способом, используя некоторые другие инструменты, которые помогают увидеть план запроса; И,
- Вы вкратце узнаете о time complexity и big O notation, для получения представления о сложности плана выполнения во времени перед выполнением запроса;
- Вы кратко узнаете о том, как оптимизировать запрос.
Почему следует изучать SQL для работы с данными?
SQL далеко не мертв: это один из самых востребованных навыков, который вы находите в описаниях должностей из индустрии обработки и анализа данных, независимо от того, претендуете ли вы на аналитику данных, инженера данных, специалиста по данным или на любые другие роли. Это подтверждают 70% респондентов опроса О ‘Рейли (O’ Reilly Data Science Salary Survey) за 2016 год, которые указывают, что используют SQL в своем профессиональном контексте. Более того, в этом опросе SQL выделяется выше языков программирования R (57%) и Python (54%).
Вы получаете картину: SQL — это необходимый навык, когда вы работаете над получением работы в индустрии информатики.
Неплохо для языка, который был разработан в начале 1970-х, верно?
Но почему именно так часто используется? И почему он не умер, несмотря на то, что он существует так долго?
Есть несколько причин: одной из первых причин могло бы стать то, что компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в реляционных системах управления потоками данных (RDSMS), и для доступа к этим данным нужен SQL. SQL — это lingua franca данных: он дает возможность взаимодействовать практически с любой базой данных или даже строить свою собственную локально!
Если этого еще недостаточно, имейте в виду, что существует довольно много реализаций SQL, которые несовместимы между вендорами и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является для вас требованием найти свой путь в индустрии (информатики).
Кроме того, можно с уверенностью сказать, что к SQL также присоединились более новые технологии, такие как Hive, интерфейс языка запросов, похожий на SQL, для запросов и управления большими наборами данных, или Spark SQL, который можно использовать для выполнения запросов SQL. Опять же, SQL, который вы там найдете, будет отличаться от стандарта, который вы могли бы узнать, но кривая обучения будет значительно проще.
Если вы хотите провести сравнение, рассматривайте его как обучение линейной алгебре: приложив все эти усилия в этот один предмет, вы знаете, что вы сможете использовать его, чтобы также освоить машинное обучение!
Короче говоря, вот почему вы должны изучить этот язык запросов:
- Его довольно легко освоить, даже для новичков. Кривая обучения довольно проста и постепенна, поэтому вы будете писать запросы в кратчайшие сроки.
- Он следует принципу «учись один раз, используй везде», так что это отличное вложение твоего времени!
- Это отличное дополнение к языкам программирования; В некоторых случаях написание запроса даже предпочтительнее написания кода, потому что он более производительный!
- …
Чего вы все еще ждете? 
Обработка SQL и выполнение запросов
Чтобы повысить производительность вашего SQL-запроса, вы сначала должны знать, что происходит внутри, когда вы нажимаете ярлык для выполнения запроса.
Сначала запрос разбирается в «дерево разбора» (parse tree); Запрос анализируется на предмет соответствия синтаксическим и семантическим требованиям. Синтаксический анализатор создает внутреннее представление входного запроса. Затем эти выходные данные передаются в механизм перезаписи.
Затем оптимизатор должен найти оптимальное выполнение или план запроса для данного запроса. План выполнения точно определяет, какой алгоритм используется для каждой операции, и как координируется выполнение операций.
Чтобы найти наиболее оптимальный план выполнения, оптимизатор перечисляет все возможные планы выполнения, определяет качество или стоимость каждого плана, принимает информацию о текущем состоянии базы данных, а затем выбирает наилучший из них в качестве окончательного плана выполнения. Поскольку оптимизаторы запросов могут быть несовершенными, пользователям и администраторам баз данных иногда приходится вручную изучать и настраивать планы, созданные оптимизатором, чтобы повысить производительность.
Теперь вы, вероятно, задаетесь вопросом, что считается «хорошим планом запроса».
Как вы уже читали, качество стоимости плана играет немаловажную роль. Более конкретно, такие вещи, как количество дисковых операций ввода-вывода (disk I/Os), которые требуются для оценки плана, стоимость CPU плана и общее время отклика, которое может наблюдать клиент базы данных, и общее время выполнения, имеют важное значение. Вот тут-то и возникнет понятие сложности времени (time complexity). Подробнее об этом вы узнаете позже.
Затем выбранный план запроса выполняется, оценивается механизмом выполнения системы и возвращаются результаты запроса.

Написание SQL-запросов
Из предыдущего раздела, возможно, не стало ясно, что принцип Garbage In, Garbage Out (GIGO) естественным образом проявляется в процессе обработки и выполнения запроса: тот, кто формулирует запрос, также имеет ключи к производительности ваших запросов SQL. Если оптимизатор получит плохо сформулированный запрос, он сможет сделать только столько же…
Это означает, что есть некоторые вещи, которые вы можете сделать, когда пишете запрос. Как вы уже видели во введении, ответственность тут двоякая: речь идет не только о написании запросов, которые соответствуют определенному стандарту, но и о сборе идей о том, где проблемы производительности могут скрыться в вашем запросе.
Идеальная отправная точка — подумать о «местах» в ваших запросах, где могут возникнуть проблемы. И, в общем, есть четыре ключевых слова, в которых новички могут ожидать возникновения проблем с производительностью:
- Условие
WHERE; - Любые ключевые слова
INNER JOINилиLEFT JOIN; А также, - Условие
HAVING;
Конечно, этот подход прост и наивен, но, для новичка, эти пункты являются отличными указателями, и можно с уверенностью сказать, что когда вы только начинаете, именно в этих местах происходят ошибки и, как ни странно, где их также трудно заметить.
Тем не менее, вы также должны понимать, что производительность — это нечто, что должно стать значимым. Однако просто сказать, что эти предложения и ключевые слова плохи — это не то, что нужно, когда вы думаете о производительности SQL. Наличие предложения WHERE или HAVING в запросе не обязательно означает, что это плохой запрос…
Ознакомьтесь со следующим разделом, чтобы узнать больше об антипаттернах и альтернативных подходах к построению вашего запроса. Эти советы и рекомендации предназначены в качестве руководства. То, как и если вам действительно нужно переписать ваш запрос, зависит, помимо прочего, от количества данных, базы данных и количества раз, которое вам нужно для выполнения запроса. Это полностью зависит от цели вашего запроса и иметь некоторые предварительные знания о базе данных, с которой вы будете работать, имеет решающее значение!
1. Извлекайте только необходимые данные
Умозаключение «чем больше данных, тем лучше» — не обязательно должна соблюдаться при написании SQL: вы рискуете не только запутаться, получив больше данных, чем вам действительно нужно, но и производительность может пострадать от того, что ваш запрос получает слишком много данных.
Вот почему, как правило, стоит обратить внимание на оператор SELECT, предложение DISTINCT и оператор LIKE.
Оператор SELECT
Первое, что уже можно проверить, когда вы написали запрос, является ли инструкция SELECT максимально компактной. Целью здесь должно быть удаление ненужных столбцов из SELECT. Таким образом вы заставляете себя только извлекать данные, которые служат вашей цели запроса.
Если у вас есть коррелированные подзапросы с EXISTS, вы должны попытаться использовать константу в операторе SELECT этого подзапроса вместо выбора значения фактического столбца. Это особенно удобно, когда вы проверяете только существование.
Помните, что коррелированный подзапрос является подзапросом, использующим значения из внешнего запроса. И обратите внимание, что, несмотря на то, что NULL может работать в этом контексте как «константа», это очень запутанно!
Рассмотрим следующий пример, чтобы понять, что подразумевается под использованием константы:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS
(SELECT '1'
FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr); Совет: полезно знать, что наличие коррелированного подзапроса не всегда является хорошей идеей. Вы всегда можете рассмотреть возможность избавиться от них, например, переписав их с помощью INNER JOIN:
SELECT driverslicensenr, name
FROM drivers
INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr; Операция DISTINCT
Инструкция SELECT DISTINCT используется для возврата только различных значений. DISTINCT — это пункт, которого, безусловно, следует стараться избегать, если можно. Как и в других примерах, время выполнения увеличивается только при добавлении этого предложения в запрос. Поэтому всегда полезно рассмотреть, действительно ли вам нужна эта операция DISTINCT, чтобы получить результаты, которые вы хотите достичь.
Оператор LIKE
При использовании оператора LIKE в запросе индекс не используется, если шаблон начинается с % или _. Это не позволит базе данных использовать индекс (если он существует). Конечно, с другой точки зрения, можно также утверждать, что этот тип запроса потенциально оставляет возможность для получения слишком большого количества записей, которые не обязательно удовлетворяют цели запроса.
Опять же, знание данных, хранящихся в базе данных, может помочь вам сформулировать шаблон, который будет правильно фильтровать все данные, чтобы найти только строки, которые действительно важны для вашего запроса.
2. Ограничьте свои результаты
Если вы не можете избежать фильтрации вашего оператора SELECT, вы можете ограничить свои результаты другими способами. Вот здесь и подходят такие подходы, как предложение LIMIT и преобразования типов данных.
Операторы TOP, LIMIT и ROWNUM
Можно добавить операторы LIMIT или TOP в запросы, чтобы задать максимальное число строк для результирующего набора. Вот несколько примеров:
SELECT TOP 3 *
FROM Drivers;
Обратите внимание, что вы можете дополнительно указать PERCENT, например, если вы измените первую строку запроса с помощью SELECT TOP 50 PERCENT *.
SELECT driverslicensenr, name
FROM Drivers
LIMIT 2;
Кроме того, можно добавить предложение ROWNUM, эквивалентное использованию LIMIT в запросе:
SELECT *
FROM Drivers
WHERE driverslicensenr = 123456 AND ROWNUM <= 3;Преобразования типов данных
Всегда следует использовать наиболее эффективные, т.е. наименьшие, типы данных. Всегда есть риск, когда вы предоставляете огромный тип данных, когда меньший будет более достаточным.
Однако при добавлении преобразования типа данных в запрос увеличивается только время выполнения.
Альтернатива заключается в том, чтобы максимально избежать преобразования типов данных. Обратите внимание также на то, что не всегда возможно удалить или пропустить преобразование типа данных из запросов, но при этом следует обязательно стремиться к их включению и что при этом необходимо проверить эффект добавления перед выполнением запроса.
3. Не делайте запросы более сложными, чем они должны быть
Преобразования типов данных приводят вас к следующему пункту: вам не следует чрезмерно проектировать ваши запросы. Постарайтесь сделать их простыми и эффективными. Это может показаться слишком простым или глупым даже для того, чтобы быть подсказкой, главным образом потому, что запросы могут быть сложными.
Однако в примерах, упомянутых в следующих разделах, вы увидите, что вы можете легко начать делать простые запросы более сложными, чем они должны быть.
Оператор OR
Когда вы используете оператор OR в своем запросе, скорее всего, вы не используете индекс.
Помните, что индекс — это структура данных, которая повышает скорость поиска данных в таблице базы данных, но это обходится дорого: потребуются дополнительные записи и потребуется дополнительное место для хранения, чтобы поддерживать структуру данных индекса. Индексы используются для быстрого поиска или поиска данных без необходимости искать каждую строку в базе данных при каждом обращении к таблице базы данных. Индексы могут быть созданы с использованием одного или нескольких столбцов в таблице базы данных.
Если вы не используете индексы, включенные в базу данных, выполнение вашего запроса неизбежно займет больше времени. Вот почему лучше всего искать альтернативы использованию оператора OR в вашем запросе;
Рассмотрим следующий запрос:
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr = 123456
OR driverslicensenr = 678910
OR driverslicensenr = 345678;Оператор можно заменить на:
Условие с IN; или
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr IN (123456, 678910, 345678);
Две инструкции SELECT с UNION.
Совет: здесь вы должны быть осторожны, чтобы не использовать ненужную операцию UNION, потому что вы просматриваете одну и ту же таблицу несколько раз. В то же время вы должны понимать, что когда вы используете UNIONв своем запросе, время выполнения увеличивается. Альтернативы операции UNION: переформулировка запроса таким образом, чтобы все условия были помещены в одну инструкцию SELECT, или использование OUTER JOIN вместо UNION.
Совет: имейте также в виду, что, хотя OR — и другие операторы, которые будут упомянуты в следующих разделах — скорее всего, не используют индекс, поиск по индексу не всегда предпочтителен!
Оператор NOT
Когда ваш запрос содержит оператор NOT, вполне вероятно, что индекс не используется, как и с оператором OR. Это неизбежно замедлит ваш запрос. Если вы не знаете, что здесь подразумевается, рассмотрите следующий запрос:
SELECT driverslicensenr, name
FROM Drivers
WHERE NOT (year > 1980);
Этот запрос, безусловно, будет выполняться медленнее, чем вы, возможно, ожидаете, в основном потому, что он сформулирован гораздо сложнее, чем может быть: в таких случаях, как этот, лучше всего искать альтернативу. Рассмотрите возможность замены NOT операторами сравнения, такими как >, <> или !>; Приведенный выше пример действительно может быть переписан и выглядеть примерно так:
SELECT driverslicensenr, name
FROM Drivers
WHERE year <= 1980;Это уже выглядит лучше, не так ли?
Оператор AND
Оператор AND — это другой оператор, который не использует индекс и который может замедлить запрос, если он используется чрезмерно сложным и неэффективным образом, как в следующем примере:
SELECT driverslicensenr, name
FROM Drivers
WHERE year >= 1960 AND year <= 1980;
Лучше переписать этот запрос, используя оператор BETWEEN:
SELECT driverslicensenr, name
FROM Drivers
WHERE year BETWEEN 1960 AND 1980;Операторы ANY и ALL
Кроме того, операторы ANY и ALL — это те операторы, с которыми вам следует быть осторожным, поскольку, если включить их в свои запросы, индекс не будет использоваться. Здесь пригодятся альтернативные функции агрегирования, такие как MIN или MAX.
Совет: в тех случаях, когда вы используете предлагаемые альтернативы, вы должны знать о том, что все функции агрегации, такие как SUM, AVG, MIN, MAX над многими строками, могут привести к длительному запросу. В таких случаях можно попытаться минимизировать количество строк для обработки или предварительно вычислить эти значения. Вы еще раз видите, что важно знать о своей среде, своей цели запроса,… Когда вы принимаете решение о том, какой запрос использовать!
Изолируйте столбцы в условиях
Также в случаях, когда столбец используется в вычислении или в скалярной функции, индекс не используется. Возможным решением было бы просто выделить конкретный столбец, чтобы он больше не был частью вычисления или функции. Рассмотрим следующий пример:
SELECT driverslicensenr, name
FROM Drivers
WHERE year + 10 = 1980;Это выглядит забавно, а? Вместо этого попробуйте пересмотреть расчет и переписать запрос примерно так:
SELECT driverslicensenr, name
FROM Drivers
WHERE year = 1970;4. Отсутствие грубой силы
Этот последний совет означает, что не следует пытаться ограничить запрос слишком сильно, так как это может повлиять на его производительность. Это особенно справедливо для соединений и для предложения HAVING.
Порядок таблиц в соединениях
При соединении двух таблиц может быть важно учитывать порядок таблиц в соединении. Если видно, что одна таблица значительно больше другой, может потребоваться переписать запрос так, чтобы самая большая таблица помещалась последней в соединении.
Избыточные условия при соединениях
При добавлении слишком большого количества условий к соединениям SQL обязан выбрать определенный путь. Однако может быть, что этот путь не всегда является более эффективным.
Условие HAVING
Условие HAVING было первоначально добавлено в SQL, так как ключевое слово WHERE не могло использоваться с агрегатными функциями. HAVING обычно используется с операцией GROUP BY, чтобы ограничить группы возвращаемых строк только теми, которые удовлетворяют определенным условиям. Однако, если это условие используется в запросе, индекс не используется, что, как вы уже знаете, может привести к тому, что запрос на самом деле не так хорошо работает.
Если вы ищете альтернативу, попробуйте использовать условие WHERE.
Рассмотрим следующие запросы:
SELECT state, COUNT(*)
FROM Drivers
WHERE state IN ('GA', 'TX')
GROUP BY state
ORDER BY stateSELECT state, COUNT(*)
FROM Drivers
GROUP BY state
HAVING state IN ('GA', 'TX')
ORDER BY state
Первый запрос использует предложение WHERE, чтобы ограничить количество строк, которые необходимо суммировать, тогда как второй запрос суммирует все строки в таблице, а затем использует HAVING, чтобы отбросить вычисленные суммы. В таких случаях вариант с предложением WHERE явно лучше, так как вы не тратите ресурсы.
Видно, что речь идет не об ограничении результирующего набора, а об ограничении промежуточного числа записей в запросе.
Следует отметить, что различие между этими двумя условиями заключается в том, что предложение WHERE вводит условие для отдельных строк, в то время как предложение HAVING вводит условие для агрегаций или результатов выбора, где один результат, такой как MIN, MAX, SUM,… был создан из нескольких строк.
Вы видите, оценка качества, написание и переписывание запросов не является простой задачей, если учесть, что они должны быть максимально производительными; Предотвращение антипаттернов и рассмотрение альтернативных вариантов также будут частью ответственности при написании запросов, которые необходимо выполнять на базах данных в профессиональной среде.
Этот список был лишь небольшим обзором некоторых антипаттернов и советов, которые, надеюсь, помогут начинающим; Если вы хотите получить представление о том, что более старшие разработчики считают наиболее частыми антиобразцами, ознакомьтесь с этим обсуждением.
Set-based против процедурных подходов к написанию запросов
В вышеприведенных антипаттернах подразумевалось то, что они фактически сводятся к разнице в основанных на наборах и процедурных подходах к построению ваших запросов.
Процедурный подход к запросам — это подход, очень похожий на программирование: вы говорите системе, что делать и как это делать.
Примером этого являются избыточные условия в соединениях или случаи, когда вы злоупотребляете условями HAVING, как в приведенных выше примерах, в которых вы запрашиваете базу данных, выполняя функцию и затем вызывая другую функцию, или вы используете логику, содержащую условия, циклы, пользовательские функции (UDF), курсоры,… чтобы получить конечный результат. При таком подходе вы часто будете запрашивать подмножество данных, затем запрашивать другое подмножество данных и так далее.
Неудивительно, что этот подход часто называют «пошаговым» или «построчным» запросом.
Другой подход — подход, основанный на наборе, где вы просто указываете, что делать. Ваша роль состоит в указании условий или требований для результирующего набора, который вы хотите получить из запроса. То, как ваши данные извлекаются, вы оставляете внутренним механизмам, которые определяют реализацию запроса: вы позволяете ядру базы данных определять лучшие алгоритмы или логику обработки для выполнения вашего запроса.
Поскольку SQL основан на наборах, неудивительно, что этот подход будет более эффективным, чем процедурный, и он также объясняет, почему в некоторых случаях SQL может работать быстрее, чем код.
Совет основанный на наборах подход к запросам — также тот, который большинство ведущих работодателей в отрасли информационных технологий попросит вас освоить! Часто необходимо переключаться между этими двумя типами подходов.
Обратите внимание, что если вам когда либо понадобится процедурный запрос, вы должны рассмотреть возможность его переписывания или рефакторинга.
В следующей части будут рассмотрены план и оптимизация запросов

Язык структурированных запросов – SQL, является незаменимым навыком в области науки о данных и, вообще говоря, приобрести этот навык довольно просто. Однако большинство забывают, что в написание запросов SQL – это только первый шаг. Обеспечение выполнения запросов в соответствии с требуемым контекстом – это уже совсем другое.

Вот почему в этом руководстве по SQL предоставлен пошаговый обзор, которые позволит вам оценить качество вашего запроса:
- Во-первых, мы начнем с краткого обзора важности изучения SQL для работы в области науки о данных.
- Затем вы сначала узнаете о том, как обрабатывать и выполнять SQL-запросы, чтобы вы правильно поняли важность написания качественных запросов: в частности, вы увидите, как происходит грамматический разбор запроса, как он переписывается, оптимизируется и, наконец, оценивается.
- В связи с этим, вы не только рассмотрите некоторые антишаблоны запросов, которые новички обычно применяют при написании запросов, но и больше узнаете об альтернативных решениях, позволяющих избегать подобных ошибок. Вы узнаете больше о запросах, основанных на записях и процедурных подходах.
- Вы также увидите, как эти анти-шаблоны связаны с проблемами производительности и что, помимо «ручного» подхода к улучшению SQL-запросов, вы можете анализировать свои запросы также более структурированным, углубленным методом с помощью некоторых инструментов, которые помогут вам рассмотреть план запроса, а также,
- Мы рассмотрим вопросы времени выполнения запросов и нотации O-большое, чтобы получить более подробное представление об оценке временной сложности плана выполнения запроса, и, наконец,
- Вы получите несколько указаний на то, как можно организовать очередь запросов.
Вам требуется пройти курс по SQL? Рассмотрите в качестве варианты курс на DataCamp под названием «Введение в SQL и науку о данных»!
SQL весьма далек от забвения – напротив, это один из самых востребованных навыков, который вы можете найти в описаниях вакансий в области обработки больших данных, независимо от того, хотите ли вы устроиться на должность аналитика данных, инженера по данным, научного сотрудника в области данных или в качестве еще кого-либо. Этот факт подтверждается результатами исследования рынка труда, проведенным O’Reilly в 2016 году: 70% респондентов, участвовавших в опросе, подтвердили, что в своей профессиональной деятельности они используют SQL. Более того, в обзоре результатов этого исследования язык SQL занимает более высокую позицию, по сравнению с другими языками программирования, такими как R (57%) и Python (54%).
Теперь вы понимаете в чем тут дело: SQL является обязательным навыком, если вы хотите получить работу в сфере обработки больших данных.
Неплохо для языка, который был разработан еще в начале 1970-х годов прошлого века, не правда ли?
Но почему так часто используется именно этот язык? И почему он до сих пор не мертв, как многие другие языки того же поколения?
Для объяснения этого факта можно найти несколько причин: во-первых, компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в системах управления реляционными потоками данных (RDSMS), и SQL требуется для доступа к таким хранимым данным. SQL – это универсальный язык данных: он дает вам возможность взаимодействовать практически с любой базой данных или даже создавать свои локальные базы данных!
Только имейте в виду, что существует немало реализаций SQL, которые несовместимы между собой и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является обязательным для каждого, желающего найти свой путь в это наукоемкой отрасли.
Кроме того, можно с уверенностью сказать, что SQL также включается в новые технологии, такие как Hive, SQL-подобный язык запросов, ориентированный на запросы и управление большими наборами данных, или Spark SQL, которые вы можете использовать для выполнения SQL запросов. Но еще раз напоминаем, SQL, который вы найдете в этих технологиях, будет отличаться от стандартного, который вы, возможно, уже знаете, но разобраться в особенностях конкретной реализации, зная стандартный SQL, вам будет значительно проще.
Если хотите, можем привести такую аналогию с линейной алгеброй: сосредоточив все усилия только на этой одной области математики, вы сможете использовать полученные знания и как хорошую основу для овладения машинным обучением!
Короче говоря, вот причины, по которым вам следует изучить язык структурированных запросов:
- Он довольно прост в изучении, даже для новичков. Рост знаний и навыков происходит довольно быстро, и вы в кратчайшие сроки научитесь писать запросы.
- Изучение SQL подчиняется принципу «однажды изученное может применяться повсюду», поэтому это отличное вложение вашего времени и сил!
- Это отличное дополнение к языкам программирования. В некоторых случаях писать запрос даже предпочтительнее, чем писать код, потому что он более эффективен!
- …
И чего же ты все еще ждешь? 🙂
Обработка и выполнение SQL-запросов
Чтобы повысить производительность вашего SQL-запроса, вам сначала нужно знать, что происходит, когда вы запускаете запрос на выполнение.
Во-первых, производится грамматический разбор и строится синтаксическое дерево запроса. Запрос анализируется с целью выявления того, насколько он удовлетворяет синтаксическим и семантическим требованиям. Парсер создает внутреннее представление входящего запроса. Затем это внутреннее представление передается обработчику кода.
Затем в дело вступает оптимизатор – его задача найти оптимальное выполнение или построить оптимальный план данного запроса. План выполнения точно определяет, какой алгоритм используется для каждой операции, и как координируется выполнение операций.
Чтобы действительно найти наиболее оптимальный план выполнения, оптимизатор рассчитывает все возможные планы выполнения, определяет качество или стоимость каждого плана, берет информацию о текущем состоянии базы данных и затем выбирает наилучший план как окончательный и пригодный для выполнения. Оптимизаторы запросов могут быть неидеальными, поэтому пользователям баз данных и администраторам иногда приходится вручную проверять и настраивать планы выполнения запросов, предложенные оптимизатором, чтобы повысить производительность выполнения запроса.
Теперь вы, вероятно, задаетесь вопросом, что считается «хорошим планом запроса».
Как вы уже прочитали выше, критерий стоимости плана играет огромную роль. А именно, для оценки плана необходимы такие вещи, как количество дисковых операций ввода-вывода, стоимость процессора и общее время отклика, которое может наблюдаться для клиента базы данных, а также общее время выполнения. Именно здесь появляется понятие временной сложности. Но об этом вы узнаете чуть позже.
Затем выполняется выбранный план запроса, они оцениваются механизмом выполнения системы и после этого возвращаются результаты вашего запроса.
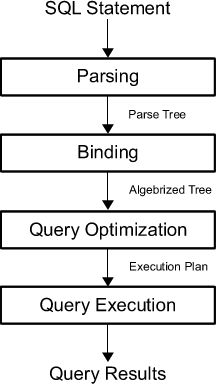
Таким образом эту последовательность можно записать в виде следующего списка шагов (см. картинку с английской терминологией ниже):
- SQL-выражение
- Синтаксической разбор
- Компоновка
- Оптимизация запроса
- Выполнение запроса
- Результаты запроса

Из предыдущего раздела может быть уже понятно, что принцип обработки «что на входе, то и на выходе» (Garbage In, Garbage Out (GIGO)) естественным образом распространяется на обработку и выполнение запроса: тот, кто формулирует запрос, также держит в руках и ключи от производительности SQL-запроса. Если оптимизатор получает плохо сформулированный запрос, он может только сделать так …
Это означает, что есть некоторые вещи, которые вы можете сделать, когда пишете запрос. Как мы уже во введении, ваша ответственность за качество написания запроса складывается из двух составляющих: в написании запросов, соответствующих определенному стандарту, и понимании того, где могут возникать проблемы при исполнении вашего запроса.
Идеальной отправной точкой является анализ узких мест в ваших запросах, то есть тех мест, в которых могут возникнуть проблемы. И, в общем, есть четыре причины и ключевых слова, где новичков могут ожидать проблемы с производительностью:
- Оператор
WHERE; - Ключевые слова
INNER JOINилиLEFT JOIN, - Оператор
HAVING.
Конечно, такой подход слишком прост и наивен, но для новичка эти утверждения являются хорошими указателями, и можно с уверенностью сказать, что, когда вы только начинаете, эти точки – как раз те места, где происходят неправильные действия и, как это ни парадоксально, где их также трудно обнаружить.
Тем не менее, вы также должны понимать, что производительность – это то, что понимается в определенном контексте: просто так сказать, что эти причины и ключевые слова плохи, не есть способ понимания производительности SQL запроса. То есть наличие предложения WHERE или HAVING в вашем запросе не обязательно означает, что это плохой запрос …
Прочитайте наш на следующий раздел, чтобы познакомиться подробнее с анти-шаблонами и альтернативными подходами к написанию запросов. Эти советы и трюки послужат для вас неким ориентиром. Нужно ли вам переписать свой запрос и как это сделать, если его действительно нужно переписать, зависит от количества данных, базы данных и количества раз, которое вам потребуется выполнять запрос. А здесь решающее значение имеет уже только цель вашего запроса и наличие некоторых предварительных знаний о структуре базе данных, к которой вы хотите обратиться!
1. Получайте только нужные данные
Идеология «чем больше данных, тем лучше» ‑ это не то, что вам нужно для написания SQL-запросов: вы рискуете не только затуманить свои идеи, получая данных на много больше, чем вам нужно, но также производительность вашего запроса может пострадать от того, что он будет выбираться слишком много данных.
Вот почему обычно рекомендуется заботиться об инструкции SELECT, операторах DISTINCT и LIKE.
Первое, что вы уже можете проверить, когда вы написали свой запрос, является ли оператор SELECT максимально возможно компактным. При этом ваша цель – удалить ненужные столбцы из оператора SELECT. Таким образом вы будете запрашивать только те данные, которые служат цели вашего запроса.
Помните, что коррелированный подзапрос – это подзапрос, который использует значения из внешнего запроса. И обратите внимание, что, хотя NULL и может здесь использоваться в качестве «константы», это выглядит очень запутанно для понимания вашего запроса другими разработчиками!
Рассмотрим следующий пример, чтобы понять, что мы подразумеваем под использованием константы:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS (SELECT '1' FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr);
Совет: полезно знать, что наличие коррелированного подзапроса не является хорошей идеей. Вы всегда можете отказаться от него, например, переписав запрос через INNER JOIN:
SELECT driverslicensenr, name FROM drivers INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr;
Оператор SELECT DISTINCT используется для возврата только различных значений. DISTINCT – это условие, которого, при возможности, лучше всего избегать. Как вы можете видеть и на других примерах, время выполнения увеличивается только в том случае, если вы добавили это предложение в свой запрос. Поэтому всегда стоит подумать над тем, действительно ли вам нужна операция DISTINCT, чтобы получить нужный вам результат.
Когда вы используете оператор LIKE в запросе, индекс не используется, если шаблон начинается с % или _. Эти шаблоны запрещают использование индексов базы данных (если он имеются). Ну и конечно, с другой стороны, этот тип запроса потенциально оставляет открытой возможность для извлечения слишком большого количества записей, которые не обязательно могут удовлетворять цели вашего запроса.
Отметим еще раз – знания структуры хранимых данных могут помочь вам сформулировать шаблон, который будет правильно фильтровать все данные, чтобы выбрать из базы только те строки, которые действительно важны для вашего запроса.
2. Ограничьте свои результаты
В тех случаях, когда вам не удается избежать фильтрации в инструкции SELECT, вы можете ограничить свои результаты другими способами. Ниже приведены другие подходы, такие как оператор LIMIT и преобразования типов данных.
Вы можете добавить оператор LIMIT или TOP к своим запросам, чтобы установить максимальное число выбираемых в результате строк. Вот некоторые примеры:
SELECT TOP 3 * FROM Drivers;
Обратите внимание, что вы можете дополнительно указать PERCENT, например, если вы измените первую строку запроса с помощью SELECT TOP 50 PERCENT *.
SELECT driverslicensenr, name FROM Drivers LIMIT 2;
Кроме того, вы также можете добавить оператор ROWNUM, что эквивалентно использованию LIMIT в запросе:
SELECT * FROM Drivers WHERE driverslicensenr = 123456 AND ROWNUM <= 3;
Вы всегда должны использовать самые эффективные, то есть самые маленькие, типы данных. Всегда существует риск, когда вы предоставляете огромный тип данных, когда меньший будет более достаточным.
Однако, когда вы добавляете преобразование типа данных в свой запрос, вы увеличиваете время выполнения.
Альтернатива заключается лишь в том, чтобы стараться избегать преобразования типа данных, насколько это возможно. Обратите также внимание, что не всегда возможно удалить или опустить преобразование типа данных из запросов, но вы должны определенно стремиться быть осторожным в их использовании, а в случае использования, советуем проверять эффект применения преобразования типа перед запуском запроса.
3. Пишите запросы как можно проще
Преобразования типов данных приводят вас к следующему: вы не должны чрезмерно усложнять свои запросы. Старайтесь сохранять их простыми и эффективными. Этот совет может показаться слишком простым или глупым, особенно потому, что запросы могут быть и сложными.
Тем не менее, вы увидите на наших примерах в следующих разделах, действительно можно легко начать делать простые запросы более сложными, гораздо сложнее, чем это необходимо на самом деле.
Когда вы используете оператор OR в запросе, вероятно, вы не можете воспользоваться индексом.
Помните, что индекс — это структура данных, которая повышает скорость поиска данных в таблице базы данных, но она имеет свою стоимость: для поддержания индексной структуры данных необходимы дополнительные записи и дополнительное пространство для хранения. Индексы используются для быстрого поиска или поиска данных без необходимости поиска к каждой строке базы данных каждый раз, когда обращается к таблице баз данных. Индексы могут быть созданы на основе одного или нескольких столбцов в таблице базы данных.
Если вы не используете индексы, имеющиеся в базе данных, выполнение вашего запроса неизбежно займет больше времени. Вот почему лучше всего искать альтернативы использованию оператора OR в запросе.
Рассмотрим следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr = 123456 OR driverslicensenr = 678910 OR driverslicensenr = 345678;
Вы можете заменить оператор на:
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr IN (123456, 678910, 345678);
Два оператора SELECTс UNION.
Совет. Здесь вам нужно быть осторожным, и излишне не прибегать к использованию операции объединения UNION, потому что в этом случае вы проходите одну и ту же таблицу несколько раз. С другой стороны, вы должны понимать, что при использовании UNION в запросе время выполнения увеличивается. Альтернативой операции UNION является переформулировка запроса таким образом, чтобы все условия были помещены в одну инструкцию SELECT или с использованием OUTER JOIN вместо UNION.
Совет. Помните также, что, хотя OR и другие операторы, которые будут упомянуты в следующих разделах, вероятно, не используют индекс, индексные запросы не всегда предпочтительны!
Когда ваш запрос содержит оператор NOT, вероятно, индекс не используется, как и для оператора OR. А это неизбежно замедлит выполнение вашего запроса. Если вы не понимаете, что мы подразумеваем, рассмотрите следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE NOT (year > 1980);
Этот запрос определенно будет работать медленнее, чем вы могли бы ожидать, главным образом потому, что он сформулирован намного сложнее, чем это могло бы быть: в таких случаях, как этот, лучше искать альтернативу. Рассмотрите возможность замены NOT операторами сравнения, такими как >, <> или !>. Этот пример запроса действительно может быть переписан примерно в таком виде:
SELECT driverslicensenr, name FROM Drivers WHERE year <= 1980;
Это уже выглядит аккуратно, не так ли?
Оператор AND – это другой оператор, который не использует индекс и тоже может замедлить выполнение вашего запроса, особенно если он используется слишком сложным и неэффективным способом, как в примере ниже:
SELECT driverslicensenr, name FROM Drivers WHERE year >= 1960 AND year <= 1980;
Лучше переписать этот запрос и использовать оператор BETWEEN:
SELECT driverslicensenr, name FROM Drivers WHERE year BETWEEN 1960 AND 1980;
Кроме того, операторы ALL и ALL ‑ это такие операторы, с которыми нужно обращаться очень осторожно, потому что, включение их приводит к отказу от использования индекса. Альтернативными вариантами, которые могут здесь пригодится, являются функции агрегации, такие как MIN или MAX.
Совет. В тех случаях, когда вы используете предлагаемые альтернативы, вы должны знать, что все функции агрегации, такие как SUM, AVG, MIN, MAX во многих строках, могут привести к повышению времени выполнения запроса. В этих случаях вы можете попытаться либо свести к минимуму количество строк для обработки или предварительного расчета этих значений. Здесь вы снова убеждаетесь в том, как важно знать, как можно больше о структуре своих данных, о цели запроса … когда вы принимаете решения о том, какой запрос использовать!
Также в тех случаях, когда столбец используется в вычислениях или в скалярной функции, индекс не используется. Возможное решение проблемы состоит в том, чтобы просто изолировать конкретный столбец, чтобы он больше не являлся частью операции вычисления или функции. Рассмотрим следующий пример:
SELECT driverslicensenr, name FROM Drivers WHERE year + 10 = 1980;
Это выглядит причудливо, да? Попробуйте вместо этого пересмотреть расчет и переписать запрос примерно так:
SELECT driverslicensenr, name FROM Drivers WHERE year = 1970;
4. Скажите нет грубой силе
Этот последний совет на самом деле означает, что вы не должны слишком сильно ограничивать запрос, потому что это может повлиять на его производительность. Это особенно верно для объединений и для предложения HAVING.
Когда вы объединяете две таблицы, может быть важно рассмотреть порядок объединения таблиц. Если вы заметили, что одна таблица значительно больше другой, вы можете переписать свой запрос так, чтобы самая большая таблица была помещена последней в объединении.
- Избыточные условия для объединений
Когда вы добавляете слишком много условий для объединений, вы, по сути, предписываете SQL выбрать определенный путь. Может быть, однако, что этот путь не всегда более эффективен.
Предложение HAVING было первоначально добавлено в SQL, потому что ключевое слово WHERE не могло использоваться с агрегатными функциями. HAVING обычно используется с предложением GROUP BY , чтобы ограничить группы возвращаемых строк только теми, которые соответствуют определенным условиям. Однако, если вы используете это предложение в своем запросе, индекс не используется, который, как вы уже знаете, что может привести к запросу, который будет не реально выполнить.
Если вы ищете альтернативу, подумайте об использовании предложения WHERE. Рассмотрим следующие запросы:
SELECT state, COUNT(*) FROM Drivers WHERE state IN ('GA', 'TX') GROUP BY state ORDER BY state
SELECT state, COUNT(*) FROM Drivers GROUP BY state HAVING state IN ('GA', 'TX') ORDER BY state
В первом запросе используется предложение WHERE, чтобы ограничить количество строк, которые нужно суммировать, тогда как второй запрос суммирует все строки в таблице, а затем использует HAVING для отбрасывания вычисленных сумм. В таких случаях альтернатива с предложением WHERE, очевидно, лучше, поскольку вы не тратите никаких ресурсов.
Вы видите, что здесь речь идет не о ограничении результатов запроса, а об ограничении промежуточного количества записей в запросе.
Обратите внимание, что разница между этими двумя предложениями заключается в том, что оператор WHERE вводит условие для отдельных строк, тогда как оператор HAVING вводит условие агрегирования или повторных выборов, в которых один результат, такой как MIN, MAX, SUM, … был создан из нескольких строк.
Как видите, оценка качества, запись и переписывание запросов –непростая задача, если учесть, что они должны быть максимально эффективными. Избегание анти-шаблонов и использование альтернативных вариантов в написании запросов также являются частью вашей заботы при написании очередей, которые можно запускать в базах данных в профессиональной среде.
Этот список был всего лишь небольшим обзором некоторых анти-шаблонов и советов, которые, надеюсь, помогут новичкам. Если вы хотите получить представление о том, что более старшие разработчики считают наиболее частыми антишаблонами, ознакомьтесь с этим обсуждением.
Методы, основанные на процедурах и процедурных подходах к запросам
Что мы хотели сказать вышеупомянутыми анти-шаблонами, так это указать тот факт, что они сводятся к различию в методах подхода, основанного на наборе данных и процедурномподходе к созданию запросов.
Процедурный подход к созданию запросов – это подход, который очень похож на обычное процедурное программирование: вы сообщаете системе, что делать и как это делать.
Примером такого подхода является избыточные условия в соединениях или случаях, когда вы злоупотребляете предложением HAVING, как в приведенных выше примерах, когда вы запрашиваете базу данных, выполняя функцию, а затем вызываете другую функцию или используете логику, содержащую цикл, условия, пользовательские функции (UDF), курсоры, … для получения окончательного результата. При таком подходе вы часто будете спрашивать подмножество данных, затем запрашивать другое подмножество из данных и так далее.
Неудивительно, что этот подход часто называют «поэтапным» или запросом «по очереди».
Другой подход — это подход, основанный на наборе данных, когда вы просто указываете, что делать. Ваша роль состоит в том, чтобы указать условия или повторные запросы для набора результатов, который вы хотите получить. То, как именно будут извлекаться ваши данные, остается на совести внутренних механизмов, которые определяют реализацию запроса: то есть вы позволяете механизму базы данных определять наилучшие алгоритмы или логику обработки для выполнения вашего запроса.
Поскольку SQL настроен на подход, основанный на наборе данных, вряд ли вас удивит, что этот подход будет более эффективным, чем процедурный, и это также объясняет, почему в некоторых случаях SQL может работать быстрее, чем код.
Совет. Подход, основанный на наборе данных, требуется большинству ведущих работодателей! Поэтому вам потребуется часто переключаться между этими двумя подходами.
Обратите внимание: если вы будете разрабатывать процедурный запрос, вам следует рассмотреть возможность его перезаписи или рефакторинга.
От запроса к планам выполнения
Тот факт, что анти-шаблоны не являются неизменными, а постоянно развиваются по мере роста профессионализма разработчика на SQL, и что для написания альтернативных запросов необходимо рассматривать множество различных вариантов, также означает, что избежать создания анти-шаблоных запросов крайне трудно, последующая их корректировка может быть довольно трудной задаче. И здесь может пригодиться любая помощь, поэтому мы рассмотрим оптимизацию запросов для подхода, основанного на наборе данных с помощью некоторых специальных инструментов.
Обратите также внимание на то, что некоторые из анти-шаблонов, упомянутых в последнем разделе, связаны с проблемами производительности выполнения запроса, например, наличие оператора AND, OR и NOT приводит к невозможности воспользоваться индексом. Понимание производительности требует не только более структурированного, но и более глубокого подхода.
Однако, возможно, такой структурированный и глубокий подход в основном основывается на анализе планов запросов, который, как вы помните, получается при синтаксическом разборе запроса, представляется в виде «дереве разбора» и позволяет определить, какой алгоритм используется для каждой операции, а также метод улучшения производительности выполнения запроса.
Как вы уже прочитали во введении, возможно, вам понадобится перенастраивать планы выполнения, созданные оптимизатором, вручную. В таких случаях вам нужно будет снова проанализировать структуру запроса, просмотрев его план.
Чтобы получить этот план, вам нужно будет использовать инструменты, которые вам предоставляет система управления базами данных. Вот некоторые инструменты, которые уже могут иметься в вашем распоряжении:
- В некоторых пакетах есть инструменты, которые генерируют графическое представление плана запроса. Взгляните на этот пример:
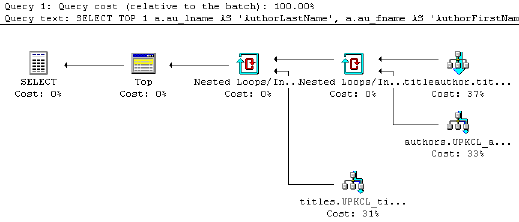
- Другие могут предоставить вам текстовое описание плана запроса. Одним из примеров является оператор
EXPLAIN PLANв Oracle, но конкретный синтаксис команды зависит от той СУБД, с которой вы работаете. В других СУБД это может бытьEXPLAIN(MySQL, PostgreSQL) илиEXPLAIN QUERY PLAN(SQLite).
Заметьте: если вы работаете с PostgreSQL, вы различаете EXPLAIN, по которой вы просто получаете описание того как планировщик намеревается выполнить запрос без его запуска, тогда как EXPLAIN ANALYZE фактически выполняет запрос и возвращает вам сопоставительный анализ ожидаемых и фактических планов запросов. Вообще говоря, фактический план выполнения – это тот, который получается при фактическом выполнении запрос, тогда как оценочный план выполнения оценивает, как может выполняться запрос, при этом не выполняя его фактически. Конечно реальный план выполнения намного полезнее, поскольку он содержит дополнительные сведения и статистику того, что на самом деле произошло при выполнении запроса.
В оставшейся части этого раздела вы узнаете об EXPLAIN и ANALYZE и о том, как вы можете их использовать, чтобы узнать о планах выполнения запросов и вероятной производительности выполнения вашего запроса.
Совет. Если вы хотите больше узнать об EXPLAIN или более подробно ознакомиться с примерами, советуем вам прочитать книгу «Разумные объяснения», написанную Гийомом Леларжем.
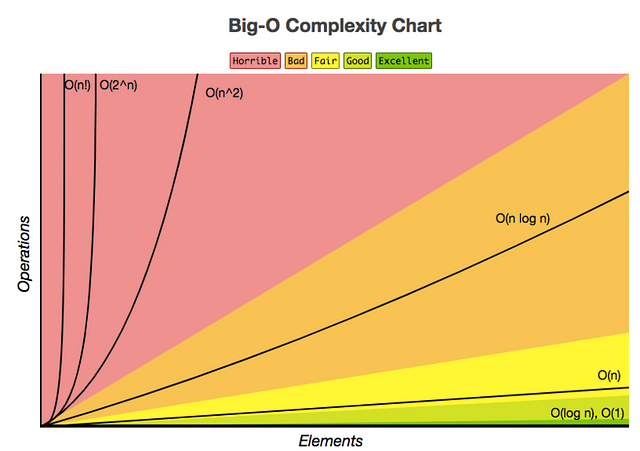
Временная сложность и O-большое
Теперь, когда вы кратко рассмотрели план запроса, вы можете начать разбираться глубже и понимать производительность выполнения запроса в более формальных терминах с помощью теории сложности вычислений. Эта область теоретической информатики, которая, среди прочего, занимается классификацией вычислительных задач в зависимости от их сложности. Этими вычислительными задачами могут быть как алгоритмы так и запросы.
Однако запросы, как правило, классифицироваться не по сложности, а по времени, которое требуется для их выполнения и получения некоторых результатов. Это называется временной сложностью, и для измерения такой тип сложности вы можете использовать формальную нотацию O-большое.
Записью O-большое вы выражаете время выполнения – насколько быстро он будет расти, в зависимости от подаваемой на вход величины при условии, что входная величина становится сколь угодно большой. Нотация O-большого исключает коэффициенты и термины более низкого порядка, поэтому вы можете сосредоточиться на важной части времени выполнения вашего запроса: скорости роста. Таким образом можно отбросить постоянные коэффициенты члены младшего порядка, а временная сложность будет описываться асимптотически. Это означает, что размер входных данных стремится в бесконечность.
На языке баз данных сложность определяет, сколько времени потребуется для выполнения запроса, поскольку размер таблиц баз данных и, следовательно, сами базы данных, постоянно увеличиваются.
Обратите внимание, на то, что размер базы данных не только увеличивается по мере наполнения таблиц, но и благодаря тому факту, что индексы базы данных также вырастают в размере.
Как вы уже видели, план выполнения определяет, среди прочего, какой алгоритм используется для каждой операции, что позволяет время выполнения запроса выражать как функцию размера таблицы, участвующей в плане запроса и называемой функция сложности. Другими словами, вы можете использовать нотацию O-большое и свой план выполнения для оценки сложности запросов и производительности.
В следующих подразделах вы получите общее представление о четырех типах временных сложностей и рассмотрите примеры того, как сложность запросов может варьироваться в зависимости от контекста, в котором вы его выполняете.
Подсказка: индексы являются частью излагаемого здесь материала!
Обратите внимание, однако, что существуют разные типы индексов, различные планы выполнения и различные реализации для различных баз данных, которые необходимо учитывать, так что приведенные ниже оценки временной сложности являются весьма обобщенными и могут варьироваться в зависимости от конкретных реализаций и настроек.
Подробнее см. здесь.
Резюмируя заметим, что вы также можете посмотреть следующий список подсказок для оценки производительности запросов в соответствии с их сложностью по времени выполнения и того, насколько хорошо они будут выполнять:
Тонкая настройка SQL
С учетом плана и временной сложности выполнения запроса, вы можете выполнить более тонкую настройку своего SQL-запроса. Вы можете начать с того, что уделите особе внимание следующим моментам:
- Заменить ненужное полное сканирование больших таблиц на сканирование индексовэ
- Убедиться, что применяется оптимальный порядок соединения таблиц.
- Убедиться, что индексы используются оптимально, а также в том, что
- Небольшие таблицы кэшированы и используются полностью индексированные таблицы.
Поздравляем! Вы дошли до конца этого сообщения в нашем блоге, получив небольшой обзор по теме производительности SQL-запросов. Надеюсь, вы получили больше информации о об анти-шаблонах, оптимизаторе запросов и инструментах, которые можно использовать для просмотра, оценки и интерпретации сложности плана ваших запросов. Однако это только малая часть знаний! Если вы хотите узнать больше, рекомендуем вам прочитать книгу «Системы управления базами данных», написанную Р. Рамакришнаном и Дж. Герке.
Наконец, приведу цитату от пользователя StackOver-flow
«Мой любимый анти-паттерн служит не для проверки запросов. он применяется тогда, когда:Ваш запрос включает несколько таблиц.
Вы считаете, что у вас есть оптимальная структура запроса и не утруждаетесь проверкой своих предположений.
Вы используете первый вариант правильно работающего запроса, не анализируя даже насколько он близок к оптимальному».
Начать работу с SQL вам может помочь вводный курс Data-Camp по SQL для науки о данных!
Перевод статьи Karlijn Willems: SQL Tutorial: How To Write Better Queries
Канал Nuances of programming опубликовал перевод статьи Karlijn Willems «SQL Tutorial: How To Write Better Queries».

Язык структурированных запросов – SQL, является незаменимым навыком в области науки о данных и, вообще говоря, приобрести этот навык довольно просто. Однако большинство забывают, что в написание запросов SQL – это только первый шаг. Обеспечение выполнения запросов в соответствии с требуемым контекстом – это уже совсем другое.
Вот почему в этом руководстве по SQL предоставлен пошаговый обзор, которые позволит вам оценить качество вашего запроса:
- Во-первых, мы начнем с краткого обзора важности изучения SQL для работы в области науки о данных.
- Затем вы сначала узнаете о том, как обрабатывать и выполнять SQL-запросы, чтобы вы правильно поняли важность написания качественных запросов: в частности, вы увидите, как происходит грамматический разбор запроса, как он переписывается, оптимизируется и, наконец, оценивается.
- В связи с этим, вы не только рассмотрите некоторые антишаблоны запросов, которые новички обычно применяют при написании запросов, но и больше узнаете об альтернативных решениях, позволяющих избегать подобных ошибок. Вы узнаете больше о запросах, основанных на записях и процедурных подходах.
- Вы также увидите, как эти анти-шаблоны связаны с проблемами производительности и что, помимо «ручного» подхода к улучшению SQL-запросов, вы можете анализировать свои запросы также более структурированным, углубленным методом с помощью некоторых инструментов, которые помогут вам рассмотреть план запроса, а также,
- Мы рассмотрим вопросы времени выполнения запросов и нотации O-большое, чтобы получить более подробное представление об оценке временной сложности плана выполнения запроса, и, наконец,
- Вы получите несколько указаний на то, как можно организовать очередь запросов.
Вам требуется пройти курс по SQL? Рассмотрите в качестве варианты курс на DataCamp под названием «Введение в SQL и науку о данных»!
Зачем мне изучать SQL, если я занимаюсь данными?
SQL весьма далек от забвения – напротив, это один из самых востребованных навыков, который вы можете найти в описаниях вакансий в области обработки больших данных, независимо от того, хотите ли вы устроиться на должность аналитика данных, инженера по данным, научного сотрудника в области данных или в качестве еще кого-либо. Этот факт подтверждается результатами исследования рынка труда, проведенным O’Reilly в 2016 году: 70% респондентов, участвовавших в опросе, подтвердили, что в своей профессиональной деятельности они используют SQL. Более того, в обзоре результатов этого исследования язык SQL занимает более высокую позицию, по сравнению с другими языками программирования, такими как R (57%) и Python (54%).
Теперь вы понимаете в чем тут дело: SQL является обязательным навыком, если вы хотите получить работу в сфере обработки больших данных.
Неплохо для языка, который был разработан еще в начале 1970-х годов прошлого века, не правда ли?
Но почему так часто используется именно этот язык? И почему он до сих пор не мертв, как многие другие языки того же поколения?
Для объяснения этого факта можно найти несколько причин: во-первых, компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в системах управления реляционными потоками данных (RDSMS), и SQL требуется для доступа к таким хранимым данным. SQL – это универсальный язык данных: он дает вам возможность взаимодействовать практически с любой базой данных или даже создавать свои локальные базы данных!
Только имейте в виду, что существует немало реализаций SQL, которые несовместимы между собой и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является обязательным для каждого, желающего найти свой путь в это наукоемкой отрасли.
Кроме того, можно с уверенностью сказать, что SQL также включается в новые технологии, такие как Hive, SQL-подобный язык запросов, ориентированный на запросы и управление большими наборами данных, или Spark SQL, которые вы можете использовать для выполнения SQL запросов. Но еще раз напоминаем, SQL, который вы найдете в этих технологиях, будет отличаться от стандартного, который вы, возможно, уже знаете, но разобраться в особенностях конкретной реализации, зная стандартный SQL, вам будет значительно проще.
Если хотите, можем привести такую аналогию с линейной алгеброй: сосредоточив все усилия только на этой одной области математики, вы сможете использовать полученные знания и как хорошую основу для овладения машинным обучением!
Короче говоря, вот причины, по которым вам следует изучить язык структурированных запросов:
- Он довольно прост в изучении, даже для новичков. Рост знаний и навыков происходит довольно быстро, и вы в кратчайшие сроки научитесь писать запросы.
- Изучение SQL подчиняется принципу «однажды изученное может применяться повсюду», поэтому это отличное вложение вашего времени и сил!
- Это отличное дополнение к языкам программирования. В некоторых случаях писать запрос даже предпочтительнее, чем писать код, потому что он более эффективен!
- …
И чего же ты все еще ждешь? 🙂
Обработка и выполнение SQL-запросов
Чтобы повысить производительность вашего SQL-запроса, вам сначала нужно знать, что происходит, когда вы запускаете запрос на выполнение.
Во-первых, производится грамматический разбор и строится синтаксическое дерево запроса. Запрос анализируется с целью выявления того, насколько он удовлетворяет синтаксическим и семантическим требованиям. Парсер создает внутреннее представление входящего запроса. Затем это внутреннее представление передается обработчику кода.
Затем в дело вступает оптимизатор – его задача найти оптимальное выполнение или построить оптимальный план данного запроса. План выполнения точно определяет, какой алгоритм используется для каждой операции, и как координируется выполнение операций.
Чтобы действительно найти наиболее оптимальный план выполнения, оптимизатор рассчитывает все возможные планы выполнения, определяет качество или стоимость каждого плана, берет информацию о текущем состоянии базы данных и затем выбирает наилучший план как окончательный и пригодный для выполнения. Оптимизаторы запросов могут быть неидеальными, поэтому пользователям баз данных и администраторам иногда приходится вручную проверять и настраивать планы выполнения запросов, предложенные оптимизатором, чтобы повысить производительность выполнения запроса.
Теперь вы, вероятно, задаетесь вопросом, что считается «хорошим планом запроса».
Как вы уже прочитали выше, критерий стоимости плана играет огромную роль. А именно, для оценки плана необходимы такие вещи, как количество дисковых операций ввода-вывода, стоимость процессора и общее время отклика, которое может наблюдаться для клиента базы данных, а также общее время выполнения. Именно здесь появляется понятие временной сложности. Но об этом вы узнаете чуть позже.
Затем выполняется выбранный план запроса, они оцениваются механизмом выполнения системы и после этого возвращаются результаты вашего запроса.
Таким образом эту последовательность можно записать в виде следующего списка шагов (см. картинку с английской терминологией ниже):
- SQL-выражение
- Синтаксической разбор
- Компоновка
- Оптимизация запроса
- Выполнение запроса
- Результаты запроса

Из предыдущего раздела может быть уже понятно, что принцип обработки «что на входе, то и на выходе» (Garbage In, Garbage Out (GIGO)) естественным образом распространяется на обработку и выполнение запроса: тот, кто формулирует запрос, также держит в руках и ключи от производительности SQL-запроса. Если оптимизатор получает плохо сформулированный запрос, он может только сделать так …
Это означает, что есть некоторые вещи, которые вы можете сделать, когда пишете запрос. Как мы уже во введении, ваша ответственность за качество написания запроса складывается из двух составляющих: в написании запросов, соответствующих определенному стандарту, и понимании того, где могут возникать проблемы при исполнении вашего запроса.
Идеальной отправной точкой является анализ узких мест в ваших запросах, то есть тех мест, в которых могут возникнуть проблемы. И, в общем, есть четыре причины и ключевых слова, где новичков могут ожидать проблемы с производительностью:
- Оператор
WHERE; - Ключевые слова
INNER JOINилиLEFT JOIN, - Оператор
HAVING.
Конечно, такой подход слишком прост и наивен, но для новичка эти утверждения являются хорошими указателями, и можно с уверенностью сказать, что, когда вы только начинаете, эти точки – как раз те места, где происходят неправильные действия и, как это ни парадоксально, где их также трудно обнаружить.
Тем не менее, вы также должны понимать, что производительность – это то, что понимается в определенном контексте: просто так сказать, что эти причины и ключевые слова плохи, не есть способ понимания производительности SQL запроса. То есть наличие предложения WHERE или HAVING в вашем запросе не обязательно означает, что это плохой запрос …
Прочитайте наш на следующий раздел, чтобы познакомиться подробнее с анти-шаблонами и альтернативными подходами к написанию запросов. Эти советы и трюки послужат для вас неким ориентиром. Нужно ли вам переписать свой запрос и как это сделать, если его действительно нужно переписать, зависит от количества данных, базы данных и количества раз, которое вам потребуется выполнять запрос. А здесь решающее значение имеет уже только цель вашего запроса и наличие некоторых предварительных знаний о структуре базе данных, к которой вы хотите обратиться!
1. Получайте только нужные данные
Идеология «чем больше данных, тем лучше» ‑ это не то, что вам нужно для написания SQL-запросов: вы рискуете не только затуманить свои идеи, получая данных на много больше, чем вам нужно, но также производительность вашего запроса может пострадать от того, что он будет выбираться слишком много данных.
Вот почему обычно рекомендуется заботиться об инструкции SELECT, операторах DISTINCT и LIKE.
Первое, что вы уже можете проверить, когда вы написали свой запрос, является ли оператор SELECT максимально возможно компактным. При этом ваша цель – удалить ненужные столбцы из оператора SELECT. Таким образом вы будете запрашивать только те данные, которые служат цели вашего запроса.
Если у вас есть коррелированные подзапросы с оператором EXISTS, вы должны попытаться использовать константу в инструкции SELECT для этого подзапроса вместо того, чтобы выбирать фактическое значение столбца. Это особенно удобно, когда вы проверяете только наличие определенного столбца в таблице.
Помните, что коррелированный подзапрос – это подзапрос, который использует значения из внешнего запроса. И обратите внимание, что, хотя NULL и может здесь использоваться в качестве «константы», это выглядит очень запутанно для понимания вашего запроса другими разработчиками!Рассмотрим следующий пример, чтобы понять, что мы подразумеваем под использованием константы:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS (SELECT '1' FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr);
Совет: полезно знать, что наличие коррелированного подзапроса не является хорошей идеей. Вы всегда можете отказаться от него, например, переписав запрос через INNER JOIN:
SELECT driverslicensenr, name FROM drivers INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr;
Оператор SELECT DISTINCT используется для возврата только различных значений. DISTINCT – это условие, которого, при возможности, лучше всего избегать. Как вы можете видеть и на других примерах, время выполнения увеличивается только в том случае, если вы добавили это предложение в свой запрос. Поэтому всегда стоит подумать над тем, действительно ли вам нужна операция DISTINCT, чтобы получить нужный вам результат.
Когда вы используете оператор LIKE в запросе, индекс не используется, если шаблон начинается с % или _. Эти шаблоны запрещают использование индексов базы данных (если он имеются). Ну и конечно, с другой стороны, этот тип запроса потенциально оставляет открытой возможность для извлечения слишком большого количества записей, которые не обязательно могут удовлетворять цели вашего запроса.
Отметим еще раз – знания структуры хранимых данных могут помочь вам сформулировать шаблон, который будет правильно фильтровать все данные, чтобы выбрать из базы только те строки, которые действительно важны для вашего запроса.
2. Ограничьте свои результаты
В тех случаях, когда вам не удается избежать фильтрации в инструкции SELECT, вы можете ограничить свои результаты другими способами. Ниже приведены другие подходы, такие как оператор LIMIT и преобразования типов данных.
Вы можете добавить оператор LIMIT или TOP к своим запросам, чтобы установить максимальное число выбираемых в результате строк. Вот некоторые примеры:
SELECT TOP 3 * FROM Drivers;
Обратите внимание, что вы можете дополнительно указать PERCENT, например, если вы измените первую строку запроса с помощью SELECT TOP 50 PERCENT *.
SELECT driverslicensenr, name FROM Drivers LIMIT 2;
Кроме того, вы также можете добавить оператор ROWNUM, что эквивалентно использованию LIMIT в запросе:
SELECT * FROM Drivers WHERE driverslicensenr = 123456 AND ROWNUM <= 3;
Вы всегда должны использовать самые эффективные, то есть самые маленькие, типы данных. Всегда существует риск, когда вы предоставляете огромный тип данных, когда меньший будет более достаточным.
Однако, когда вы добавляете преобразование типа данных в свой запрос, вы увеличиваете время выполнения.
Альтернатива заключается лишь в том, чтобы стараться избегать преобразования типа данных, насколько это возможно. Обратите также внимание, что не всегда возможно удалить или опустить преобразование типа данных из запросов, но вы должны определенно стремиться быть осторожным в их использовании, а в случае использования, советуем проверять эффект применения преобразования типа перед запуском запроса.
3. Пишите запросы как можно проще
Преобразования типов данных приводят вас к следующему: вы не должны чрезмерно усложнять свои запросы. Старайтесь сохранять их простыми и эффективными. Этот совет может показаться слишком простым или глупым, особенно потому, что запросы могут быть и сложными.
Тем не менее, вы увидите на наших примерах в следующих разделах, действительно можно легко начать делать простые запросы более сложными, гораздо сложнее, чем это необходимо на самом деле.
Когда вы используете оператор OR в запросе, вероятно, вы не можете воспользоваться индексом.
Помните, что индекс — это структура данных, которая повышает скорость поиска данных в таблице базы данных, но она имеет свою стоимость: для поддержания индексной структуры данных необходимы дополнительные записи и дополнительное пространство для хранения. Индексы используются для быстрого поиска или поиска данных без необходимости поиска к каждой строке базы данных каждый раз, когда обращается к таблице баз данных. Индексы могут быть созданы на основе одного или нескольких столбцов в таблице базы данных.
Если вы не используете индексы, имеющиеся в базе данных, выполнение вашего запроса неизбежно займет больше времени. Вот почему лучше всего искать альтернативы использованию оператора OR в запросе.
Рассмотрим следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr = 123456 OR driverslicensenr = 678910 OR driverslicensenr = 345678;
Вы можете заменить оператор на:
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr IN (123456, 678910, 345678);
Два оператора SELECT с UNION.
Совет. Здесь вам нужно быть осторожным, и излишне не прибегать к использованию операции объединения UNION, потому что в этом случае вы проходите одну и ту же таблицу несколько раз. С другой стороны, вы должны понимать, что при использовании UNION в запросе время выполнения увеличивается. Альтернативой операции UNION является переформулировка запроса таким образом, чтобы все условия были помещены в одну инструкцию SELECT или с использованием OUTER JOIN вместо UNION.
Совет. Помните также, что, хотя OR и другие операторы, которые будут упомянуты в следующих разделах, вероятно, не используют индекс, индексные запросы не всегда предпочтительны!
Когда ваш запрос содержит оператор NOT, вероятно, индекс не используется, как и для оператора OR. А это неизбежно замедлит выполнение вашего запроса. Если вы не понимаете, что мы подразумеваем, рассмотрите следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE NOT (year > 1980);
Этот запрос определенно будет работать медленнее, чем вы могли бы ожидать, главным образом потому, что он сформулирован намного сложнее, чем это могло бы быть: в таких случаях, как этот, лучше искать альтернативу. Рассмотрите возможность замены NOT операторами сравнения, такими как >, <> или !>. Этот пример запроса действительно может быть переписан примерно в таком виде:
SELECT driverslicensenr, name FROM Drivers WHERE year <= 1980;
Это уже выглядит аккуратно, не так ли?
Оператор AND – это другой оператор, который не использует индекс и тоже может замедлить выполнение вашего запроса, особенно если он используется слишком сложным и неэффективным способом, как в примере ниже:
SELECT driverslicensenr, name FROM Drivers WHERE year >= 1960 AND year <= 1980;
Лучше переписать этот запрос и использовать оператор BETWEEN:
SELECT driverslicensenr, name FROM Drivers WHERE year BETWEEN 1960 AND 1980;
Кроме того, операторы ALL и ALL ‑ это такие операторы, с которыми нужно обращаться очень осторожно, потому что, включение их приводит к отказу от использования индекса. Альтернативными вариантами, которые могут здесь пригодится, являются функции агрегации, такие как MIN или MAX.
Совет. В тех случаях, когда вы используете предлагаемые альтернативы, вы должны знать, что все функции агрегации, такие как SUM, AVG, MIN, MAX во многих строках, могут привести к повышению времени выполнения запроса. В этих случаях вы можете попытаться либо свести к минимуму количество строк для обработки или предварительного расчета этих значений. Здесь вы снова убеждаетесь в том, как важно знать, как можно больше о структуре своих данных, о цели запроса … когда вы принимаете решения о том, какой запрос использовать!
Также в тех случаях, когда столбец используется в вычислениях или в скалярной функции, индекс не используется. Возможное решение проблемы состоит в том, чтобы просто изолировать конкретный столбец, чтобы он больше не являлся частью операции вычисления или функции. Рассмотрим следующий пример:
SELECT driverslicensenr, name FROM Drivers WHERE year + 10 = 1980;
Это выглядит причудливо, да? Попробуйте вместо этого пересмотреть расчет и переписать запрос примерно так:
SELECT driverslicensenr, name FROM Drivers WHERE year = 1970;

Команда SELECT позволяет получить данные из базы. Существует возможность задать различные фильтры и лимиты на выборку. Попробуем привести несколько примеров SQL запросов с ограничением выборки в таблице USERS, в которой содержатся данные пользователей.
Условие WHERE в SQL запросе
Получение всех записей в таблице в одном запросе — это очень редкий случай в реальных проектах. Зачастую нужна либо одна запись, либо диапазон, к примеру из 10 или 100 записей либо отвечающее определённому условию. Такую выборку можно сделать с помощью команды условия WHERE в SQL запросе (слово WHERE переводится с английского как «ГДЕ»).
Сравнение (=, !=, <, >, <=, >=)
Продемонстрируем это условие на ограничении выборки по ID пользователя. Приведём сразу несколько примеров запросов:
SELECT * FROM `USERS` WHERE `ID` = 2;
SELECT * FROM `USERS` WHERE `ID` != 2;
SELECT * FROM `USERS` WHERE `ID` < 2;
SELECT * FROM `USERS` WHERE `ID` <= 2;
SELECT * FROM `USERS` WHERE `ID` > 2;
SELECT * FROM `USERS` WHERE `ID` >= 2;Как можно догадаться по математическим символам в этих запросах, выборка ограничена по ID пользователя (по целому числу). При каждом условии может возвращаться разное количество строк из таблицы. К примеру, если указано «WHERE `ID` = 2», то вернётся только одна строка, потому что поле «ID» зачастую уникально (то есть у столбца установлено свойство «PRIMARY KEY»). Если в запросе есть символ неравенства «!=» или сравнения «<, >, <=, >=», то в результатах выборки может присутствовать сразу несколько строк из таблицы.
Поиск подстроки (LIKE) и полное соответствие (=)
Знак равенства «=» можно использовать в SQL запросах не только для чисел, но и для строк. Представим что нам нужно получить выборку из базы, в которой будут содержаться данные о пользователе с именем «Мышь». Запрос получится такой:
SELECT * FROM `USERS` WHERE `NAME` = 'Мышь';В результате мы получим все строки, в которых в столбце имени пользователя «NAME» содержится строка «Мышь». Обратите внимание, что совпадение должно быть полным. То есть в выборку не попадут пользователи, имена которых «Мышь серая», «Мышь белая», «Мышь чёрная». Чтобы выбрать и этих пользователей, необходимо сделать текстовый поиск по значению столбца. Для этого используется команда «LIKE» (в переводе с английского этот предлог звучит как «ПОДОБНО», «ВРОДЕ» или «СЛОВНО»).
С помощью команды «LIKE» можно искать подстроку в столбце. Чтобы сделать это поставьте знак процента «%» с той стороны подстроки, с которой могут находиться другие символы. К примеру:
SELECT * FROM `USERS` WHERE `NAME` LIKE 'Мышь%';В результаты выборки попадёт не только пользователь с именем «Мышь», но и «Мышь серая», «Мышь белая», «Мышь чёрная». Если поставить знак процента ещё и до подстроки:
SELECT * FROM `USERS` WHERE `NAME` LIKE '%Мышь%';то в выборку попадут не только все предыдущие результаты, но и пользователь с именем «Большая мышь».
LIKE делает поиск независимо от регистра. То есть результаты от ‘%мышь%’ и ‘%МЫШЬ%’ будут одинаковыми.
Логика «и» (AND) и «или» (OR)
Бывают случаи, когда необходимо задать несколько ограничений, связанных логикой. К примеру, если надо выбрать пользователей с ID от 2 до 5, то можно использовать условие с «AND»:
SELECT * FROM `USERS` WHERE `ID` >= 2 AND `ID` < 5;Количество условий и «AND» неограниченно:
SELECT * FROM `USERS` WHERE `ID` >= 2 AND `ID` < 5 AND `NAME` LIKE 'Мышь%';Существует возможность использовать логику «ИЛИ» благодаря условию «OR». Продемонстрируем это:
SELECT * FROM `USERS` WHERE `ID` < 2 OR `ID` > 5;С помощью круглых скобок ( ) можно группировать условия OR и AND:
SELECT * FROM `USERS` WHERE (`ID` >= 2 AND `ID` < 5) OR (`ID` > 10 AND `NAME` LIKE 'Мышь%');Выбор определённых столбцов в SELECT
В этой статье во всех SELECT запросах к базе запрашивались все поля. Потому что после слова SELECT стояла звёздочка *. Но чем больше объём данных вы выборке, тем медленнее база данных возвращает ответ. Поэтому старайтесь запрашивать у базы только то, что будете использовать. К примеру, если нужно получить только ID пользователя и имя ‘NAME’, то перечислите эти поля через запятую после слова SELECT:
SELECT `ID`, `NAME` FROM `USERS` WHERE `ID` <= 5;Базы данных сайтов не приспособлены к получению больших выборок. Быстрее всего они работают на объёмах до 100 строк. Если попробовать запросить 100 000 строк из базы и указать вместо конкретных полей *, то можно будет увидеть значительное падение производительности. А чем медленнее загружается ваш сайт, тем меньше посетителей на него будут заходить. Поэтому всегда старайтесь оптимизировать свои запросы к базе.
Результатом выполнения оператора SELECT является таблица. К этой таблице может быть снова применен оператор SELECT и т.д., то есть такие операторы могут быть вложены друг в друга. Вложенные операторы SELECT называют подзапросами.
Синтаксис оператора SELECT использует следующие основные предложения:
SELECT <список столбцов>
FROM <список таблиц>
[WHERE <условие выбора строк>]
[GROUP BY <условие группировки>]
[HAVING <условие выбора групп>]
[ORDER BY <условие сортировки>]Кратко пояснить смысл предложений оператора SELECT можно следующим образом:
SELECT— выбрать данные из указанных столбцов и (если необходимо) выполнить перед выводом их преобразование в соответствии с указанными выражениями и (или) функциямиFROM— из перечисленных таблиц, в которых расположены эти столбцыWHERE— где строки из указанных таблиц должны удовлетворять указанному перечню условий отбора строкGROUP BY— группируя по указанному перечню столбцов с тем, чтобы получить для каждой группы единственное значениеHAVING— имея в результате лишь те группы, которые удовлетворяют указанному перечню условий отбора группORDER BY— сортируя по указанному перечню столбцов
Как видно из синтаксиса рассматриваемого оператора, обязательными являются только два первых предложения: SELECT и FROM.
Рассмотрим каждое предложение оператора SELECT.
Спонсор поста
База данных для примеров
Дальше будет много примеров и логично постоянно использовать одну и ту же БД. Так что на основании базы данных ниже будут продемонстрированы все примеры, не только в этой статье, но и в других.
Постановка задачи: пусть требуется разработать БД для предметной области «Поставка деталей»!
Требуется хранить следующую информацию:
- О поставщиках (P) pnum, pname
- О деталях (D) pnum, dname, dprice
- О поставках (PD) volume
Значения таблицы P
| pnum | pname |
|---|---|
| 1 | Иванов |
| 2 | Петров |
| 3 | Сидоров |
| 4 | Кузнецов |
Значения таблицы D
| pnum | dname | dprice |
|---|---|---|
| 1 | Болт | 10 |
| 2 | Гайка | 20 |
| 3 | Винт | 30 |
Значения таблицы PD
| pnum | dnum | volume |
|---|---|---|
| 1 | 1 | 100 |
| 1 | 2 | 100 |
| 1 | 3 | 300 |
| 2 | 1 | 150 |
| 1 | 2 | 250 |
| 3 | 1 | 1000 |
После служебного слова SELECT перечисляются имена столбцов, значения которых будут входить в результат выполнения запроса.
Столбцы в результирующей таблице размещаются в том порядке, в котором они были указаны в предложении SELECT. Имена столбцов указываются через запятую.
Если имя столбца содержит пробелы или разделители, то его необходимо заключить в квадратные скобки.
При обработке данных из разных таблиц может возникнуть ситуация, когда столбцы разных таблиц имеют одинаковые имена. В этом случае имя столбца необходимо записывать как составное, указывая перед ним имя соответствующей таблицы: <Имя таблицы>.<Имя столбца>
Предложение FROM
В предложении FROM перечисляются имена таблиц, которые содержат столбцы, указанные после слова SELECT.
Пример 1.
Вывести список наименований деталей из таблицы D (“Детали”).
SELECT dname
FROM DПример 2.
Получить всю информацию из таблицы D (“Детали”).
Получить результат можно двумя способами:
-
Явным указанием всех столбцов таблицы.
SELECT dnum, dname, dprice FROM D -
Полный список столбцов таблицы заменяет символ
*.SELECT * FROM D
В результате и первого и второго запроса получаем новую таблицу, представляющую собой полную копию таблицы D (“Детали”).
Можно осуществить выбор отдельных столбцов и их перестановку.
Пример 3.
Получить информацию о наименовании и номере поставщика.
SELECT pname, pnum
FROM PПример 4.
Определить номера поставщиков, которые поставляют детали в настоящее время (то есть номера тех поставщиков, которые присутствуют в таблице PD (“Поставки”)).
SELECT pnum
FROM PDРезультат:
| pnum |
|---|
| 1 |
| 1 |
| 1 |
| 2 |
| 2 |
| 3 |
Дополнительно о SELECT
Теперь, когда мы научились делать простые запросы с SELECT и FROM, можно ненадолго снова вернуться к SELECT.
Агрегатные функции
В операторе SELECT можно использовать агрегатные функции, которые дают единственное значение для целой группы строк в таблице.
Агрегатная функция записывается в следующем виде: <имя функции>(<имя столбца>)
Пользователю доступны следующие агрегатные функции:
SUM‑ вычисляет сумму множества значений указанного столбца;COUNT‑ вычисляет количество значений указанного столбца;MIN/MAX‑ определяет минимальное/максимальное значение в указанном столбце;AVG‑ вычисляет среднее арифметическое значение множества значений столбца;FIRST/LAST‑ определяет первое/последнее значение в указанном столбце.
Пример 5.
Определить общий объем поставляемых деталей.
SELECT SUM(volume)
FROM PD| Expr1000 |
|---|
| 2000 |
Вычисляемые столбцы
Столбцы результирующей таблицы, которых не существовало в исходных таблицах, называются вычисляемыми. Таким столбцам СУБД присваивает системные имена, что не всегда является удобным.
При вычислении результатов любой агрегатной функции СУБД сначала исключает все NULL-значения, после чего требуемая операция применяется к оставшимся значениям.
Для функции COUNT возможен особый вариант использования — COUNT(*). Его назначение состоит в подсчете всех строк в результирующей таблице, включая NULL-значения.
Следует запомнить, что агрегатные функции нельзя вкладывать друг в друга. Такая конструкция работать не будет: MAX(SUM(VOLUME))
Переименование столбца
Язык SQL позволяет задавать новые имена столбцам результирующей таблицы, для чего используется операция AS. Переименование также используют для изменения сложных имен столбцов таблицы.
Например, присвоить новое имя вычисляемому столбцу в предыдущем примере позволит выполнение следующего запроса.
SELECT SUM(volume) AS SUM
FROM PD| Sum |
|---|
| 2000 |
Пример 6.
Определить количество поставщиков, которые поставляют детали в настоящее время.
SELECT COUNT(pnum) AS COUNT
FROM PD| Count |
|---|
| 6 |
Несмотря на то, что реальное число поставщиков деталей в таблице PD равно 3, СУБД возвращает число 6. Такой результат объясняется тем, что СУБД подсчитывает все строки в таблице PD, не обращая внимание на то, что в строках есть одинаковые значения.
Операция DISTINCT
Если до применения агрегатной функции необходимо исключить дублирующиеся значения, следует перед именем столбца указать ключевое слово DISTINCT.
SELECT COUNT(DISTINCT pnum) AS COUNT
FROM PD| Count |
|---|
| 3 |
DISTINCT можно задать только один раз для одного предложения SELECT.
Противоположностью DISTINCT является операция ALL. Она имеет противоположное действие «показать все строки таблицы» и предполагается по умолчанию.
Операция TOP
Итоговый набор записей, получаемых после выполнения запроса можно ограничить первыми N строками или первыми N процентами от общего количества строк результата.
Для этого используется операция TOP, которая записывается в предложении SELECT следующим образом: SELECT TOP N [PERCENT] <список столбцов>
Пример 7.
Определить номера первых двух деталей таблицы D.
SELECT TOP 2 dnum
FROM DСтандарт SQL требует, чтобы при сортировке NULL-значения трактовались либо как превосходящие, либо как уступающие по сравнению со всеми остальными значениями. Так как конкретный вариант стандартом не оговаривается, то в зависимости от используемой СУБД при сортировке NULL-значения следуют до или после остальных значений. В MS SQL Server NULL-значения считаются уступающими по сравнению с остальными значениями.
Предложение WHERE
После служебного слова WHERE указываются условия выбора строк, помещаемых в результирующую таблицу. Существуют различные типы условий выбора:
Типы условий выбора:
- Сравнение значений атрибутов со скалярными выражениями, другими атрибутами или результатами вычисления выражений.
- Проверка значения на принадлежность множеству.
- Проверка значения на принадлежность диапазону.
- Проверка строкового значения на соответствие шаблону.
- Проверка на наличие
null-значения.
Сравнение
В языке SQL используются традиционные операции сравнения =,<>,<,<=,>,>=.
В качестве условия в предложении WHERE можно использовать сложные логические выражения, использующие атрибуты таблиц, константы, скобки, операции AND, OR, отрицание NOT.
Пример 8.
Определить номера деталей, поставляемых поставщиком с номером 2.
SELECT dnum
FROM PD
WHERE pnum = 2Пример 9.
Получить информацию о поставщиках Иванов и Петров.
SELECT *
FROM P
WHERE pname='Иванов' OR pname='Петров'Строковые значения атрибутов заключаются в апострофы.
Проверка на принадлежность множеству
Операция IN проверяет, принадлежит ли значение атрибута заданному множеству.
Пример 10.
Получить информацию о поставщиках ‘Иванов’ и ‘Петров’.
SELECT *
FROM P
WHERE pname IN ('Иванов','Петров')Пример 11.
Получить информацию о деталях с номерами 1 и 2.
SELECT *
FROM D
WHERE dnum IN (1, 2)Проверка на принадлежность диапазону
Операция BETWEEN определяет минимальную и максимальную границу диапазона, в которое должно попадать значение атрибута. Обе границы считаются принадлежащими диапазону.
Пример 12.
Определить номера деталей, с ценой от 10 до 20 рублей.
SELECT dnum
FROM D
WHERE dprice BETWEEN 10 AND 20Пример 13.
Вывести наименования поставщиков, начинающихся с букв от ‘К’ по ‘П’.
SELECT pname
FROM P
WHERE pname BETWEEN 'К' AND 'Р'Сравнение символов
Буква Р в условии запроса объясняется тем, что строки сравниваются посимвольно. Для каждого символа при этом определяется код. Для нашего случая справедливо условие: П < Петров < Р
Проверка строкового значения на соответствие шаблону
Операция LIKE используется для поиска подстрок. Значения столбца, указываемого перед служебным словом LIKE сравниваются с задаваемым после него шаблоном. Форматы шаблонов различаются в конкретных СУБД.
Для СУБД MS SQL Server:
- Символ
%заменяет любое количество любых символов. - Символ
_заменяет один любой символ. [<множество символов>]‑ вместо символа строки может быть подставлен один любой символ из множества возможных, указанных в ограничителях.[^<множество символов>]‑ вместо символа строки может быть подставлен любой из символов кроме символов из множества, указанного в ограничителях.
Множество символов в квадратных скобках можно указывать через запятую, либо в виде диапазона.
Пример 14.
Вывести фамилии поставщиков, начинающихся с буквы И.
SELECT pname
FROM P
WHERE pname LIKE 'И%'Пример 15.
Вывести фамилии поставщиков, начинающихся с букв от К по П.
SELECT pname
FROM P
WHERE dname LIKE '[К-П]%'Проверка на наличие null-значения
Операции IS NULL и IS NOT NULL используются для сравнения значения атрибута со значением NULL.
Пример 16.
Определить наименования деталей, для которых не указана цена.
SELECT dname
FROM D
WHERE dprice IS NULLПример 17.
Определить номера поставщиков, для которых указано наименование.
SELECT pnum
FROM P
WHERE pname IS NOT NULLПредложение GROUP BY
Использование GROUP BY позволяет разбивать таблицу на логические группы и применять агрегатные функции к каждой из этих групп. В результате получим единственное значение для каждой группы.
Обычно предложение GROUP BY применяют, если формулировка задачи содержит фразу «для каждого…», «каждому..» и т.п.
Пример 18.
Определить суммарный объем деталей, поставляемых каждым поставщиком.
SELECT pnum, SUM(VOLUME) AS SUM
FROM PD
GROUP BY pnum| pnum | sum |
|---|---|
| 1 | 600 |
| 2 | 400 |
| 3 | 1000 |
Выполнение запроса можно описать следующим образом: СУБД разбивает таблицу PD на три группы, в каждую из групп помещаются строки с одинаковым значением номера поставщика. Затем к каждой из полученных групп применяется агрегатная функция SUM, что дает единственное итоговое значение для каждой группы.
Рассмотрим два похожих примера. В примере 19 определяется минимальный объем поставки каждого поставщика. В примере 20 определяется объем минимальной поставки среди всех поставщиков.
Пример 19:
SELECT pnum, MIN(VOLUME) AS MIN
FROM PD
GROUP BY pnumПример 20:
SELECT MIN(VOLUME) AS MIN
FROM PРезультаты запросов представлены в следующей таблице:
| pnum | min | max |
|---|---|---|
| 1 | 100 | 100 |
| 2 | 150 | |
| 3 | 1000 |
Следует обратить внимание, что в первом примере мы можем вывести номера поставщиков, соответствующие объемам поставок, а во втором примере – не можем.
Все имена столбцов, перечисленные после ключевого слова SELECT должны присутствовать и в предложении GROUP BY, за исключением случая, когда имя столбца является аргументом агрегатной функции.
Однако в предложении GROUP BY могут быть указаны имена столбцов, не перечисленные в списке вывода после ключевого слова SELECT.
Если предложение GROUP BY расположено после предложения WHERE, то группы создаются из строк, выбранных после применения WHERE.
Пример 21.
Для каждой из деталей с номерами 1 и 2 определить количество поставщиков, которые их поставляют, а также суммарный объем поставок деталей.
SELECT dnum, COUNT(pnum) AS COUNT, SUM(volume) AS SUM
FROM PD
WHERE dnum=1 OR dnum=2
GROUP BY dnumРезультат запроса:
| dnum | COUNT | SUM |
|---|---|---|
| 1 | 3 | 1250 |
| 2 | 2 | 450 |
Чтобы организовать вложенные группировки, после GROUP BY следует указать несколько группирующих столбцов через запятую. В этом случае реальный подсчет данных будет происходить по той группе, которая указана последней.
Предложение HAVING
Предложение HAVING определяет критерий, согласно которому, определенные группы, сформированные с помощью предложения GROUP BY, исключаются из результирующей таблицы.
Выполнение предложения HAVING сходно с выполнением предложения WHERE. Но предложение WHERE исключает строки до того, как выполняется группировка, а предложение HAVING — после. Поэтому предложение HAVING может содержать агрегатные функции, а предложение WHERE — не может.
Пример 22.
Определить номера поставщиков, поставляющих в сумме более 500 деталей.
SELECT pnum, SUM(volume) AS SUM
FROM PD
GROUP BY pnum
HAVING SUM(volume) > 500| pnum | SUM |
|---|---|
| 1 | 600 |
| 3 | 1000 |
Пример 23.
Определить номера поставщиков, которые поставляют только одну деталь.
SELECT pnum, COUNT(dnum) AS COUNT
FROM PD
GROUP BY pnum
HAVING COUNT(dnum) = 1| pnum | SUM |
|---|---|
| 3 | 1 |
Предложение ORDER BY
При выполнении запроса СУБД возвращает строки в случайном порядке. Предложение ORDER BY позволяет упорядочить выходные данные запроса в соответствии со значениями одного или нескольких выбранных столбцов.
Можно задать возрастающий — ASC (от слова Ascend) или убывающий — DESC (от слова Descend) порядок сортировки. По умолчанию принят возрастающий порядок сортировки.
Пример 24.
Отсортировать таблицу PD в порядке возрастания номеров поставщиков, а строки с одинаковыми значениями pnum отсортировать в порядке убывания объема поставок.
SELECT pnum, volume, dnum
FROM PD
ORDER BY pnum ASC, volume DESC| pnum | volume | dnum |
|---|---|---|
| 1 | 300 | 3 |
| 1 | 200 | 2 |
| 1 | 100 | 1 |
| 2 | 250 | 2 |
| 2 | 150 | 1 |
| 3 | 1000 | 1 |
Операцию TOP удобно применять после сортировки результирующего набора с помощью предложения ORDER BY.
Пример 25.
Определить номера первых двух деталей с наименьшей стоимостью.
SELECT TOP 2 dnum
FROM D
ORDER BY dprice ASCСледует отметить, что если в таблице D будут две детали без указания цены, то именно их и отобразит предыдущий запрос. Поэтому при наличии NULL-значений их необходимо исключать с помощью предложения WHERE.
SELECT TOP 2 dnum
FROM D
WHERE dprice IS NOT NULL
ORDER BY dprice ASCЗаключение
В статье было рассмотрен оператор выборки SELECT. Знание оператора SELECT является ключевым при написании любых SQL-запросов. Он позволяет производить выборку данных из таблиц и преобразовывать результаты в соответствии с нужными выражениями и функциями.
Результатом выполнения оператора SELECT является таблица, которую можно вложить в другой оператор SELECT в качестве подзапроса.
Синтаксис оператора SELECT содержит несколько предложений, из которых обязательными являются только SELECT и FROM. Остальные предложения, такие как WHERE, GROUP BY, HAVING и ORDER BY, могут использоваться по желанию для уточнения выборки данных.