Принципы построения компьютера
Основным принципом построения всех современных компьютеров является программное управление. В его основе лежит представление алгоритма решения любой задачи в виде программы вычислений.
Все вычисления, предписанные алгоритмом решения задачи, должны быть представлены в виде программы, состоящей из последовательности управляющих слов _ команд. Каждая команда содержит указания на конкретную выполняемую операцию, места нахождения (адреса) операндов и ряд служебных признаков. Операнды _ переменные, значения которых участвуют в операциях преобразования данных. Программы и обрабатываемые ими данные должны совместно храниться в памяти компьютера.
Для доступа к программам, командам и операндам используются их адреса. В качестве адресов выступают номера ячеек памяти компьютера, предназначенных для хранения объектов. Информация (командная и данные: числовая, текстовая, графическая и другая информация) кодируется двоичным кодом (цифрами 0 и 1). Поэтому различные типы информации, размещенные в памяти, практически неразличимы, идентификация их возможна лишь при выполнении программы, согласно ее логике, по контексту.
Выполнение каждой команды программы предполагает многократное обращение к памяти (выборка команд, выборка операндов, отсылка результатов и т.п.). В первых структурах ЭВМ использовалось централизованное управление, при котором одна и та же аппаратура выполняла и основные, и вспомогательные действия. Это было оправдано для первых дорогих машин, но не позволяло выполнять параллельные работы. Эволюция вычислительной техники потребовала децентрализации.
Децентрализация построения и управления вызвала к жизни такие элементы, которые являются общим стандартом структур современных компьютеров:
- модульность построения;
- магистральность;
- иерархия управления.
Модульность построения предполагает выделение в структуре компьютера автономных, функционально, логически и конструктивно законченных устройств: процессор, модуль памяти, накопитель на магнитном диске, дисплей и т.п.
Модульная конструкция компьютера делает его открытой системой, способной к адаптации и совершенствованию. К нему можно подключать дополнительные устройства, улучшая его технические и экономические показатели. Появляется возможность наращивания вычислительной мощи, улучшения структуры путем замены отдельных устройств на более совершенные, изменения и управления конфигурацией системы, приспособления ее к конкретным условиям применения в соответствии с требованиями пользователей.
В качестве основных средств подключения и объединения модулей в систему используются магистрали, или шины. Стандартная система сопряжения (интерфейс) обеспечивает возможность формирования требуемой конфигурации, гибкость структуры и адаптацию к изменяющимся условиям функционирования.
В современных вычислителях принцип децентрализации и параллельной работы распространен как на периферийные устройства, так и на сами компьютеры, их процессоры. Появились вычислительные системы, которые содержат несколько вычислителей, работающих согласованно и параллельно. Внутри самого компьютера произошло еще более резкое разделение функций между средствами обработки. Появились отдельные специализированные процессоры, например, сопроцессоры, выполняющие обработку чисел с плавающей точкой, матричные процессоры и др.
Модульность структуры потребовала стандартизации и унификации оборудования, номенклатуры технических и программных средств, средств сопряжения — интерфейсов, конструктивных решений, унификации типовых элементов замены, элементной базы и нормативно-технической документации. Все это способствовало улучшению технических и эксплуатационных характеристик компьютеров, росту технологичности их производства.
Децентрализация управления предполагает иерархическую организацию структуры компьютера. Главный или центральный модуль системы определяет последовательность работ подчиненных модулей и их инициализацию, после чего они продолжают работу по собственным программам управления. Результаты выполнения требуемых операций представляются ими «вверх по иерархии» для правильной координации всех работ. Подключаемые модули могут, в свою очередь, использовать специальные шины, или магистрали, для обмена управляющими сигналами, адресами и данными.
Иерархический принцип построения и управления характерен не только для структуры компьютера в целом, но и для отдельных его подсистем. Например, по этому же принципу строится система памяти.
Децентрализация управления и структуры компьютера позволила перейти к более сложным многопрограммным (мультипрограммным) режимам. При этом в компьютере одновременно могут обрабатываться несколько программ пользователей.
Структурные схемы и взаимодействие устройств компьютера
Классическая схема компьютера, отвечающая программному принципу управления, логично вытекает из последовательного характера преобразований, выполняемых человеком по некоторому алгоритму (программе). Обобщенная структурная схема ЭВМ первых поколений представлена на рис.13.2.
В любом компьютере имеются устройства ввода информации (УВв), с помощью которых пользователи вводят программы решаемых задач и данные. Введенная информация сначала полностью или частично запоминается в оперативном запоминающем устройстве (ОЗУ), а затем переносится во внешнее запоминающее устройство (ВЗУ), предназначенное для длительного хранения информации, где преобразуется в специальный информационный объект — файл.
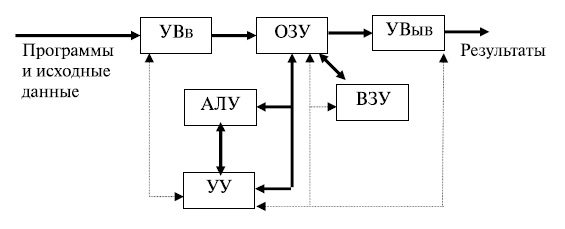
Рис.
13.2.
Структурная схема первых компьютеров
При использовании файла в вычислительном процессе его содержимое переносится в ОЗУ. Затем программная информация команда за командой считывается в устройство управления.
Устройство управления (УУ) предназначается для автоматического выполнения программ путем принудительной координации всех остальных устройств. Цепи сигналов управления показаны на рис.13.2 штриховыми линиями. Вызываемые из ОЗУ команды дешифрируются устройством управления: определяют код операции, которую необходимо выполнить следующей, и адреса операндов, принимающих участие в данной операции.
Арифметико-логическое устройство (АЛУ) выполняет арифметические и логические операции над данными. Основной частью АЛУ является операционный автомат, в состав которого входят сумматоры, счетчики, регистры, логические преобразователи и др. Он каждый раз перестраивается на выполнение очередной операции. Результаты выполнения отдельных операций сохраняются для последующего использования на одном из регистров АЛУ или записываются в память. Отдельные признаки результатов r (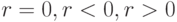 и др.) устройство управления использует для изменения порядка выполнения команд программы. Результаты, полученные после выполнения всей программы вычислений, передаются на устройство вывода информации (УВыв). В качестве УВыв могут использоваться экран дисплея, принтер, графопостроитель и др.
и др.) устройство управления использует для изменения порядка выполнения команд программы. Результаты, полученные после выполнения всей программы вычислений, передаются на устройство вывода информации (УВыв). В качестве УВыв могут использоваться экран дисплея, принтер, графопостроитель и др.
Классическая структура компьютера представляла собой «удивительно изящное инженерное решение», хорошо отвечающее тогдашнему уровню развития промышленных технологий. Она стала фактическим стандартом (de facto), которому стали следовать производители вычислительной техники.
В персональных компьютерах, относящихся к компьютерам четвертого поколения, произошло дальнейшее изменение структуры (рис.13.3). Соединение всех устройств в единую машину обеспечивается с помощью общей шины, представляющей собой линии передачи данных, адресов, сигналов управления и питания. Единая система аппаратурных соединений значительно упростила структуру, сделав ее децентрализованной. Все передачи данных по шине осуществляются под управлением сервисных программ.
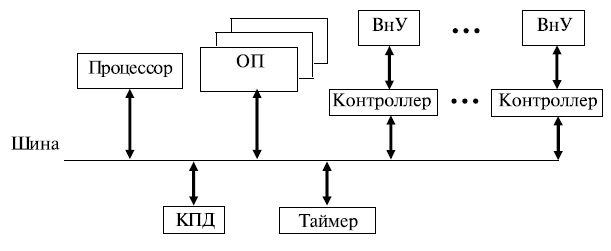
Рис.
13.3.
Структура ПК
Ядро ПК образуют процессор, основная память (ОП), состоящая из оперативной памяти и постоянного запоминающего устройства (ПЗУ), и видеопамять. ПЗУ предназначается для записи и постоянного хранения наиболее часто используемых программ управления.
Подключение всех внешних устройств (ВнУ), дисплея, клавиатуры, внешних ЗУ и др. обеспечивается через соответствующие адаптеры — согласователи скоростей работы сопрягаемых устройств, или контроллеры — специальные устройства управления периферийной аппаратурой. Контроллеры в ПК играют роль каналов ввода-вывода. В качестве особых устройств следует выделить таймер — устройство измерения времени, и контроллер прямого доступа к памяти (КПД) — устройство, обеспечивающее доступ к ОП, минуя процессор.
Организацию согласованной работы шин и устройств выполняют микросхемы системной логики, называемые чипсетом (Chipset). Большинство наборов микросхем системной логики имеют ярко выраженную иерархическую структуру построения, отвечающую уровням высокоскоростных и ввода-вывода данных. Уровень высокоскоростных устройств образуют процессоры, видеопамять, оперативная память; уровень низко-скоростных устройств образуют любые внешние устройства.
Компьютерные системы
Полувековая история развития вычислительной техники была связана с совершенствованием классической структуры компьютера, имеющей следующие отличительные признаки:
- ядро компьютера — процессор — единственный вычислитель в структуре, дополненный каналами обмена информацией и памятью;
- линейная организация ячеек всех видов памяти фиксированного размера;
- одноуровневая адресация ячеек памяти, стирающая различия между всеми типами информации;
- внутренний машинный язык низкого уровня, при котором команды содержат элементарные операции преобразования простых операндов;
- последовательное централизованное управление вычислениями;
- достаточно примитивные возможности устройства ввода-вывода.
Классическая структура компьютера уже сослужила добрую службу человечеству. В ходе эволюции она была дополнена целым рядом частных доработок, позволяющих ликвидировать наиболее «узкие места» и обеспечить максимальную производительность в рамках достигнутых технологий. Однако, несмотря на все успехи, классическая структура уже не обеспечивает возможностей дальнейшего наращивания производительности. Теория и практика построения компьютеров подошли к рубежам микроэлектроники, за которыми стоят множество практически неразре-шимых проблем в областях системотехники, дальнейшего наращивания частоты работы микросхем, программирования, компиляции и т.д.
Дальнейшее поступательное развитие вычислительной техники напрямую связано с переходом к параллельным вычислениям, с идеями построения многопроцессорных систем и сетей, объединяющих большое количество отдельных процессоров и (или) ЭВМ. Здесь появляются огромные возможности совершенствования средств вычислительной техники. Но следует отметить, что при несомненных практических достижениях в области параллельных вычислений до настоящего времени отсутствует их единая теоретическая база.
С появлением в начале нового тысячелетия многоядерных микропроцессоров эра компьютеров классической структуры и связанных с ними последовательных вычислений заканчивается. На смену идут новые параллельные структуры с новыми принципами их построения. Они становятся экономически более выгодными. Будущее вычислительной техники — именно за этими системами.
Под вычислительной (компьютерной) системой (ВС) понимают совокупность взаимосвязанных и взаимодействующих процессоров или ЭВМ, периферийного оборудования и программного обеспечения, предназначенную для сбора, хранения, обработки и распределения информации. Отличительной особенностью ВС по отношению к ЭВМ является наличие в них нескольких вычислителей, реализующих параллельную обработку. Создание ВС преследует следующие основные цели: повышение производительности системы за счет ускорения процессов обработки данных, повышение надежности и достоверности вычислений, предоставление пользователям дополнительных сервисных услуг и т.д.
Основные принципы построения, закладываемые при создании ВС:
- возможность работы в разных режимах;
- модульность структуры технических и программных средств, которая позволяет совершенствовать и модернизировать вычислительные системы без коренных их переделок;
- унификация и стандартизация технических и программных решений;
- иерархия в организации управления процессами;
- способность систем к адаптации, самонастройке и самоорганизации;
- обеспечение необходимым сервисом пользователей при выполнении вычислений.
Существует большое количество признаков, по которым классифицируют вычислительные системы: по целевому назначению и выполняемым функциям, по типам и числу ЭВМ или процессоров, по архитектуре системы, режимам работы, методам управления элементами системы, степени разобщенности элементов вычислительной системы и др. Однако основными из них являются признаки структурной и функциональной организации вычислительной системы.
Большое разнообразие структур ВС затрудняет их изучение. Поэтому их классифицируют с учетом их обобщенных характеристик. С этой целью вводится понятие «архитектура системы».
Архитектура ВС — совокупность характеристик и параметров, определяющих функционально-логическую и структурную организацию системы и затрагивающих в основном уровень параллельно работающих вычислителей. Понятие архитектуры охватывает общие принципы построения и функционирования, наиболее существенные для пользователей, которых больше интересуют возможности систем, а не детали их технического исполнения. Поскольку ВС появились как системы параллельной обработки, рассмотрим классификацию архитектур именно c этой точки зрения.
Классификация архитектур была предложена М. Флинном (M. Flynn) в начале 60-хгг. В ее основу заложено два возможных вида параллелизма: независимость потоков заданий (команд), существующих в системе, и независимость (несвязанность) данных, обрабатываемых в каждом потоке. Классификация до настоящего времени еще не потеряла своего значения. Однако подчеркнем, что, как и любая классификация, она носит временный и условный характер. Своим долголетием она обязана тому, что оказалась справедливой для ВС, в которых вычислительные модули построены на принципах классической структуры ЭВМ. С появлением систем, ориентированных на потоки данных и использование ассоциативной обработки, эта классификация может быть некорректной.
Согласно данной классификации существует четыре основных архитектуры ВС, представленных на рис.13.4:
- одиночный поток команд — одиночный поток данных (ОКОД), в английском варианте Single Instruction Single Data (SISD) — одиночный поток инструкций — одиночный поток данных (рис.13.4a);
- одиночный поток команд — множественный поток данных (ОКМД), или Single Instruction Multiple Data (SIMD) — одиночный поток инструкций — одиночный поток данных (рис.13.4б);
- множественный поток команд — одиночный поток данных (МКОД), или Multiple Instruction Single Data (MISD) — множественный поток инструкций — одиночный поток данных (рис.13.4в);
- множественный поток команд — множественный поток данных (МКМД), или Multiple Instruction Multiple Data (MIMD) — множественный поток инструкций — множественный поток данных (рис.13.4г).
Коротко рассмотрим отличительные особенности каждой из архитектур.
Архитектура ОКОД охватывает все однопроцессорные и одномашинные варианты систем, то есть варианты с одним вычислителем. Все ЭВМ классической структуры попадают в этот класс. Здесь параллелизм вычислений обеспечивается путем совмещения выполнения операций отдельными блоками АЛУ, а также параллельной работой устройств ввода-вывода информации и процессора. Закономерности организации вы-числительного процесса в этих структурах достаточно хорошо изучены.
Архитектура ОКМД предполагает создание структур векторной или матричной обработки. Системы этого типа обычно строятся как однородные, т.е. процессорные элементы, входящие в систему, идентичны и все они управляются одной и той же последовательностью команд. Однако каждый процессор обрабатывает свой поток данных. Под эту схему хорошо подходят задачи обработки матриц или векторов (массивов), задачи решения систем линейных и нелинейных, алгебраических и дифференциальных уравнений, задачи теории поля и др. В структурах данной архитектуры желательно обеспечивать соединения между процессорами, соответствующие реализуемым математическим зависимостям. Как правило, эти связи напоминают матрицу, в которой каждый процессорный элемент связан с соседними.
Рис.
13.4.
Архитектуры вычислительных систем: а) ОКОД (SISD) — архитектура; б) ОКМД (SIMD) — архитектура; в) МКОД (MISD) — архитектура; г) МКМД (MIMD) — архитектура
Эту схему использовали и используют все суперЭВМ без исключения, начиная с таких известных систем, как Cyber-205 и Gray различных модификаций. Узким местом подобных систем является необходимость изменения коммутации между процессорами, когда связь между ними отличается от матричной. Кроме того, задачи, допускающие широкий матричный параллелизм, составляют достаточно узкий класс задач. Структуры ВС этого типа по существу являются структурами специализированных суперЭВМ.
Архитектура МКОД предполагает построение своеобразного процессорного конвейера, в котором результаты обработки передаются от одного процессора к другому по цепочке. Выгоды такого вида обработки понятны. Прототипом таких вычислений может служить схема любого производственного конвейера. В современных ЭВМ по этому принципу реализована схема совмещения операций, в которой различные функциональные блоки работают параллельно, и каждый из них делает свою часть в общем цикле обработки команды.
В ВС этого типа конвейер должны образовывать группы процессоров. Однако при переходе на системный уровень очень трудно выявить подобный регулярный характер в универсальных вычислениях. Кроме того, на практике нельзя обеспечить и «большую длину» такого конвейера, при которой достигается наивысший эффект. Вместе с тем конвейерная схема нашла применение в так называемых скалярных процессорах суперЭВМ — они применяются как специальные процессоры для поддержки векторной обработки.
Архитектура МКМД предполагает, что все процессоры системы работают с различными программами и с индивидуальным набором данных. В простейшем случае они могут быть автономны и независимы. Такая схема использования ВС часто применяется во многих крупных вычислительных центрах для увеличения пропускной способности центра.
Наибольший интерес представляет организация согласованной работы процессоров системы, когда каждый элемент делает часть общей программы. Общая теоретическая база такого вида работ пока только создается. Но можно привести примеры большой эффективности этой модели вычислений. Подобные системы могут быть многомашинными и многопроцессорными. Переход на многоядерные микропроцессоры позволяет создавать мощные центры параллельной обработки, имеющие в своем составе тысячи процессоров. Проектировщики компьютерных систем сосредотачивают свои усилия на разработках разноплановых структур ВС (сосредоточенных и распределенных систем) именно в архитектуре МКМД.
Контрольные вопросы
- Каково содержание понятия «структура компьютера»?
- По каким техническим характеристикам осуществляется оценка и выбор компьютера?
- Что представляет собой класс карманных персональных компьютеров?
- Каковы основные тенденции развития компьютеров?
- Объясните суть принципа иерархии построения ЭВМ.
- Перечислите отличительные особенности классической структуры ЭВМ.
- Каковы отличительные особенности структуры ПК?
- Объясните многообразие шин, используемых в структуре ПК.
- Каковы основные предпосылки появления и развития компьютерных систем?
- Какие принципы положены в основу классификации архитектур компьютерных систем?
МКОД-структуры предполагают
построение своеобразного процессорного
конвейера, в котором результаты обработки
данных передаются от одного процессора
к другому по цепочке. Выгоды такой
обработки заключены в конвейерной схеме
совмещения операций, где параллельно
работают различные функциональные
блоки, каждый из которых делает свою
часть в цикле обработки команд. Однако
указанная структура не получила большой
практической реализации, так как задачи,
в которых несколько процессоров могли
бы эффективно обрабатывать один поток
данных,:в науке и технике неизвестны. К
этому классу можно отнести фрагменты
многофункциональной обработки данных
или команд с фиксированной и плавающей
точкой.
Множественный поток команд
— множественный поток данных (МКМД) —
Multiple Instruction Multiple Data (MIND) — множественный
поток инструкций — множественный поток
данных.
МКМД-структуры предполагают,
что все процессоры системы работают по
своим программам с собственным потоком
команд. В простейшем случае они могут
быть автономны и независимы. Такая схема
использования ВС часто применяется на
многих крупных вычислительных центрах
для увеличения пропускной способности.
2. Показатели целевой эффективности
ТВС.
Выбор показателей целевой
эффективности сети определяется ее
назначением, в связи с чем имеет место
большое многообразие показателей группы
W4. С помощью этих показателей оценивается
эффект (целевой результат), получаемый
за счет решения тех или иных прикладных
задач на ЭВМ сети (с использованием
общесетевых ресурсов — аппаратных,
программных, информационных), а не с
использованием других, малоэффективных
средств. Для количественной оценки
этого эффекта могут применяться самые
различные единицы измерения. Примеры
показателей целевой эффективности:
точностные WTH, надежностные WH и временные
WBp показатели, применяемые в системах
специального назначения для оценки
эффективности использования в них
сетевых структур. Например, вероятность
вычисления некоторого задания и оценка
времени на выполнение некоторого задания
и оценка времени на выполнение этого
задания.
Билет 23.
1. Для построения вычислительных
систем необходимо, чтобы элементы или
модули, комплектующие систему, были
совместимы. Понятие совместимости имеет
три аспекта:
аппаратный или технический;
программный;
информационный.
Техническая совместимость
(Hard Ware) предполагает, что еще в процессе
разработки аппаратуры обеспечиваются
следующие условия: подключаемая друг
к другу аппаратура должна иметь единые
стандартные, унифицированные средства
соединения: кабели, число проводов в
них, единое назначение проводов, разъемы,
заглушки, адаптеры, платы и т.д.;
параметры электрических
сигналов, которыми обмениваются
технические устройства, тоже должны
соответствовать друг другу: амплитуды
импульсов, полярность сигналов,
длительность их, скважность и т.д.;
алгоритмы взаимодействия (последовательности
сигналов по отдельным проводам) не
должны вступать в противоречие друг с
другом.
Последний пункт тесно связан
с программной совместимостью. Программная
совместимость (Soft Ware) требует, чтобы
программы, передаваемые из одного
технического средства в другое (между
ЭВМ, процессорами, между процессами и
внешними устройствами), были правильно
поняты и выполнены другим устройством.
2. Перспективы развития
информационных технологий зависит
прежде всего от их общего состояния в
мире на сегодняшний день и в России.
Состояние информационных
технологий в России можно охарактеризовать
следующим образом.
Телефонная плотность (с учетом
всех операторов) составляет 22 телефона
на 100 человек. Число абонентов подвижных
средств связи составило 2 млн. человек.
Услуги сотовой связи предоставляются
в 79 регионах, а пейджинга — в 74 регионах
страны.
Основную часть от общего числа
абонентов сотовой подвижной связи (СПС)
составляют пользователи сетей стандарта
GSM — Global System for Mobile telecommunication — глобальная
система для локальной связи или Мобильная
система (около 60%). СПС этого стандарта
предоставляют услуги в 226 городах на
территории 60 субъектов РФ. Развитие
сетей стандарта NMT — 450 — Nordie Mobile Telephone —
северный мобильный телефон или Мобильная
система проходит более медленно, чем
GSM из-за меньшего набора предоставляемых
услуг. Общее число абонентов сетейММТ-450
составляет более 225 тыс. человек, услуги
предоставляются в 470 городах РФ.
Билет 24.
1. Следует подчеркнуть, что
эталонная модель не определяет средства
реализации протоколов, а только
специфирует их. Таким образом, функции
каждого уровня могут быть реализованы
различными программными и аппаратными
средствами. Основным условием при этом
является то , что взаимодействие между
любыми смежными уровнями должно быть
четко определено, то есть должно
осуществляется через точку доступа
посредством стандартного межуровневого
интерфейса.
При разработке эталонной модели
число ее уровней определялось из
следующих соображений:
разбивка на уровне должна
максимально отражать логическую
структуру компьютерной сети;
межуровневые границы должны
быть определены таким образом, чтобы
обеспечивались минимальное число и
прирост межуровневых связей;
большое количество уровней, с
одной стороны, упрощает внесение
изменений в систему, с другой стороны,
увеличивает количество межуровневых
протоколов и затрудняет описание модели
в целом.
С учетом вышеизложенного МОС
была предложена 7-уровневая модель ВОС
(рис. 37).
Основным с точки зрения
пользователя является (седьмой) прикладной
уровень, который обеспечивает поддержку
прикладных процессов конечных
пользователей и определяет семантику
данных, то есть смысловое содержание
информации, которой обмениваются
открытые системы в процессе их
взаимодействия. С этой целью данный
уровень, кроме протоколов взаимодействия,
прикладных процессов, поддерживает
протоколы передачи файлов, виртуального
терминала, электронной почты и им
подобные.
2. Семейство протоколов TCP/IP
широко применяется во всем мире для
объединения компьютеров в сеть Internet.
Единая сеть Internet состоит из множества
сетей различной физической природы, от
локальных сетей типа Ethernet и Token Ring, до
глобальных сетей типа NSFNET. Основное
внима- ние в книге уделяется принципам
организации межсетевого взаимодействия.
Многие технические детали, исторические
вопросы опущены. Более подробную
информацию о протоколах TCP/IP можно найти
в RFC (Requests For Comments) — специальных документах,
выпускаемых Сетевым Информационным
Центром (Network Information Center — NIC). Приложение
1 содержит путеводитель по RFC, а приложение
2 отражает положение дел в области
стандартизации протоколов семейства
TCP/IP на начало 1991 года.
В книге приводятся примеры,
основанные на реализации TCP/IP в ОС UNIX.
Однако основные положения применимы
ко всем реализациям TCP/IP.
Надеюсь, что эта книга будет
полезна тем, кто профессионально работает
или собирается начать работать в среде
TCP/IP: системным администраторам, системным
программистам и менеджерам сети.
Основы TCP/IP
Термин «TCP/IP» обычно
обозначает все, что связано с протоколами
TCP и IP. Он охватывает целое семейство
протоколов, прикладные программы и даже
саму сеть. В состав семейства входят
протоколы UDP, ARP, ICMP, TEL- NET, FTP и многие
другие. TCP/IP — это технология межсетевого
взаимо- действия, технология internet. Сеть,
которая использует технологию internet,
называется «internet». Если речь идет
о глобальной сети, объе- диняющей
множество сетей с технологией internet, то
ее называют Internet.
Модуль IP создает единую
логическую сеть
Архитектура протоколов TCP/IP
предназначена для объединенной сети,
состоящей из соединенных друг с другом
шлюзами отдельных разнородных пакетных
подсетей, к которым подключаются
разнородные машины. Каждая из подсетей
работает в соответствии со своими
специфическими требованиями и имеет
свою природу средств связи. Однако
предполагается, что каждая под- сеть
может принять пакет информации (данные
с соответствующим сетевым заголовком)
и доставить его по указанному адресу в
этой конкретной под- сети. Не требуется,
чтобы подсеть гарантировала обязательную
доставку пакетов и имела надежный
сквозной протокол. Таким образом, две
машины, подключенные к одной подсети
могут обмениваться пакетами.
Когда необходимо передать
пакет между машинами, подключенными к
раз- ным подсетям, то машина-отправитель
посылает пакет в соответствующий шлюз
(шлюз подключен к подсети также как
обычный узел). Оттуда пакет направ-
ляется по определенному маршруту через
систему шлюзов и подсетей, пока не
достигнет шлюза, подключенного к той
же подсети, что и машина-получатель; там
пакет направляется к получателю.
Объединенная сеть обеспечивает
датаграммный сервис.
Проблема доставки пакетов в
такой системе решается путем реализации
во всех узлах и шлюзах межсетевого
протокола IP. Межсетевой уровень является
по существу базовым элементом во всей
архитектуре протоколов, обеспечивая
возможность стандартизации протоколов
верхних уровней.
Билет 25.
1. С момента появления первых
вычислительных систем было опробовано
большое количество разнообразных
структур систем, отличающихся друг от
друга различными техническими решениями.
Практика показала, что каждая структура
ВС эффективно обрабатывает лишь задачи
определенного класса. При этом необходимо,
чтобы структура ВС максимально
соответствовала структуре решаемых
задач. Только в этом случае система
обеспечивает максимальную производительность.
Поскольку универсальной
структуры ВС не существует (для обработки
задач любого типа), то интересны результаты
по сопоставлению различных видов
программного параллелизма и соответствующих
им структур ВС.
Классификация уровней
программного параллелизма включает
шесть позиций:
независимые задания;отдельные
части заданий; программы и подпрограммы;
циклы и итерации (повторение); операторы
и команды; фазы отдельных команд.
Структуры ВС, которые обеспечивают
перечисленные виды программного
параллелизма, рассматривались ранее.
В структуре МКМД можно найти все
перечисленные выше виды программного
параллелизма (рис. 36). Этот класс дает
большое разнообразие структур, сильно
отличающихся друг от друга своими
характеристиками. Успехи микроинтегральной
технологии и появление БИС и СБИС
позволяют расширить границы оперативного
взаимодействия и быстродействиями
между комплексами системы. Возможно
построение систем с сотнями и даже
тысячами процессорных элементов, с
расширением их в непосредственной
близости друг от друга. Если каждый
процессор системы имеет собственную
память, то он также будет сохранять
известную автономию в вычислениях.
Считается, что именно такие системы
займут доминирующее положение в мире
компьютеров в ближайшие десять –
пятнадцать лет нового тысячелетия.
Подобные ВС получили название
систем с массовым параллелизмом
(Mass-Parallel Processing, MPP). Все процессорные
элементы в таких системах должны быть
связаны единой коммутационной средой.
Передача данных в МРР-системах
предполагает обмен не отдельными данными
под централизованным управлением, а
подготовленными процессами (программами
вместе с данными). Этот принцип построения
вычислений уже не соответствует принципам
программного управления классической
ЭВМ. Передача данных процесса по его
готовности больше соответствует
принципам построения «потоковых машин»
(машин, управляющих потоками данных).
Подобный подход позволяет строить
системы с громадной производительностью
и реализовывать проекты с любыми видами
параллелизма, например, перейти к
«систолическим (сокращенным) вычислениям»
с произвольным параллелизмом. Однако
для этого необходимо решить целый ряд
проблем, связанных с описанием и
программированием коммутаций процессов
и управления ими.
Управления вычислительными
процессами в ВС осуществляется с помощью
операционных систем, которые являются
частью общего программного обеспечения.
Программное обеспечение –
software – комплекс программ, обеспечивающий
обработку или передачу данных в ВС.
Программное обеспечение вместе с
техническим обеспечением являются
важнейшими характеристиками систем и
сетей. Они определяются функциональностью,
качеством, размерами и формами
использования.
Функциональность представляется
целями, которые должны быть достигнуты,
типами используемых данных и результатами,
которые необходимо получить.
Качество программного обеспечения
характеризуется скоростью обработки
данных, отсутствием тупиковых ситуаций,
поведением при возникающих отказах.
Размеры программного обеспечения
определяют сложность используемой
системы, объем и типы ее запоминающих
устройств, затраты на обслуживание.
2.
ТВС принадлежит к классу
человеко-машинных систем (СЧМ). Это
относится и к отдельным функциональным
частям сети (подсистемам): абонентским
системам, сетям передачи данных и их
звеньям и узлам, центрам обработки
информации и т.д. Следовательно, при
оценке эффективности сети независимо
от ее принадлежности к этому или иному
типу СЧМ необходимо учитывать параметры
и характеристики всех трех компонентов:
человека (обслуживающего персонала
сети и пользователей), машины
(программно-аппаратных средств сети) и
производственной среды.
Деление по признакам:
по виду эксплуатации
(использования) системы, а именно: СЧМ
регулярного (постоянного) применения
в течение более или менее длительного
времени; СЧМ многоразового применения,
используемые периодически, причем
периодичность использования определяется
назначением системы; СЧМ одноразового
применения, используемые однократно,
причем длительность использования
определяется назначением системы и
зависит от сложившихся условий ее
функционирования;
по роли и месту человека-оператора
в системе. Здесь выделяются три вида
СЧМ: целеустремленные системы, в которых
процесс функционирования полностью
определяется человеком; целенаправленные
системы, в которых человек и технические
средства рассматриваются как равнозначные
элементы системы; целесообразные
системы, в которых человек не управляет
процессом функционирования, а лишь
обеспечивает его. При оценке этих систем
необходимо учитывать соответственно
человеко-системный, равноэлементный и
системотехнический подход;
по степени влияния трудовой
деятельности человека-оператора на
эффективность функционирования СЧМ.
Здесь выделяют три типа СЧМ: системы
типа «А», в которых работа оператора
выполняется по жесткому технологическому
графику; система типа «В», в которых
такой график отсутствует, поэтому
оператор может изменять темп и ритм
своей работы;
системы типа «С», для которых
характерным является задание конечного
результата.
Например, корпоративные
вычислительные сети (КВС) можно отнести
к таким видам СЧМ:
по виду использования это СЧМ
регулярного применения (в них
профилактические работы проводятся
без выключения сети, в оперативном
режиме). Однако отдельные подсистемы и
звенья КВС могут относится к СЧМ
многоразового применения: это отдельные
абонентские системы или ЛВС, которые
могут периодически отключаться ввиду
отсутствия необходимости в их использовании
или переключаться на проведение
профилактических работ;
по роли и месту человека-оператора
в сети они являются целенаправленными
СЧМ, в которых человек и материальные
(неэргатические) объекты рассматриваются
как равнозначные элементы. Соотношение
значимости этих элементов могут быть
различными, но не такими, чтобы сеть
следовало относить уже к другому типу
— целеустремленным (когда человек-оператор
полностью определяет процесс
функционирования КВС) или целесообразным,
когда человек оператор лишь обеспечивает
процесс функционирования сети);
по степени влияния трудовой
деятельности человека-оператора на
эффективность функционирования СЧМ
относятся главным образом к типу «В»,
в которых жесткий технологический
график работы человека-оператора
отсутствует. Он может изменять свои
темп и ритм работы, и здесь особенно
явно ощущается зависимость эффективности
функционирования сети от человека-оператора.
Однако могут быть и также случаи, когда
сеть, рассматриваемая в обычном режиме
как СЧМ типа «В», работает как система
типа «С», для которой характерным
является задание конечного результата
(заданный объем работы в любом случае
должен быть выполнен, например – передача
фиксированного объема новостей всем
адресатам за приемлемое или заданное
время). Следовательно, одна и та же сеть
для обдих пользователей рассматривается
как система типа «В», а для других — как
система типа «С».
Степень детализации при учете
характеристик трудовой деятельности
человека-оператора в ходе оценки
эффективности функционирования сети
определяется типом КВС и наличием
достоверных данных по этим характеристикам.
Однако практически, принимая во внимание
непостоянство состава обслуживающего
персонала сети, тем более пользователей,
и, как следствие, отсутствие достоверных
сведений об индивидуальных характеристиках
и трудовой деятельности, приходится
пользоваться ожидаемыми усредненными
характеристиками этой деятельности.
Билет 26.
1. Вычислительные сети,
построенные на модели ВОС д. удовлетворять
требованиям открытости, гибкости,
эффективности. Открытость – возможность
включения дополнительных ЭВМ, терминалов,
узлов и линий связи без изменения
технических и программных средств сети.
Гибкость – сохранение работоспособности
при изменении структуры сети в результате
выхода из строя ЭВМ, линий, узлов связей.
Допустимость изменения типов ЭВМ, а
также возможность работы любых главных
ЭВМ с терминалами различных типов.
Эффективность – обеспечение требуемого
качества обслуживания пользователя
при минимальных затратах.
Архитектура эталонной модели
ВОС является семиуровневой. Под уровнем
понимается иерархическое подмножество
функций ВОС, определяющих услуги смежному
верхнему уровню по обмену данными и
использующие для этого услуги смежного
нижнего уровня. Услуга – это функциональная
возможность, представляемая одному или
нескольким вышерасположенным уровням.
7 – пользовательские службы;
6– преобразование (представление)
данных; 5 – организация и проведение
диалога; 4 – представление сквозных
соединений; 3 – прокладка соединений
между системами; 2 – передача данных
между смежными системами; 1 –сопряжение
систем с физическими функциями системы.
Физический уровень 1: предоставляет
механические, электрические, функциональные
и процедурные средства для установления,
поддержания и разъединения логических
соединений между логическими объектами
канального уровня; реализует функции
передачи битов данных через физические
среды.
Спецификации физического
уровня определяют такие характеристики,
как уровни напряжений, синхронизацию
изменения напряжений, скорость передачи
физической информации, максимальные
расстояния передачи информации,
физические соединители и другие
аналогичные характеристики. На этом
уровне работают электрические схемы
передающих/принимающих звеньев сетевых
устройств (адаптеров, напр.), репитеры,
хабы. Единицы информации – простые биты
данных.
Канальный уровень 2: предоставляет
услуги по обмену данными между логическими
объектами сетевого уровня и выполняет
функции, связанные формированием и
передачей кадров, обнаружением и
исправлением ошибок, возникающих на
физическом уровне посредством вычисления
контрольной суммы, проверяет доступность
среды передачи. Кадром называется пакет
канального уровня; поскольку пакет на
предыдущих уровнях может состоять из
одного или многих кадров. Канальный
уровень обеспечивает надежный транзит
данных через физический канал. На этом
уровне работают сетевые адаптеры,
коммутаторы. Протоколы – Ethernet, Token Ring,
FDDI
Сетевой уровень 3: Этот уровень
служит для образования единой транспортной
системы, объединяющей несколько сетей
с различными принципами передачи
информации между конечными узлами. На
этом уровне вводится понятие «сеть».
В данном случае под сетью понимается
совокупность компьютеров, соединенных
между собой в соответствии с одной из
стандартных типовых топологий и
использующих для передачи данных один
из протоколов канального уровня,
определенный для этой топологии. Таким
образом, внутри сети доставка данных
регулируется канальным уровнем, а вот
доставкой данных между сетями занимается
сетевой уровень. Сообщения сетевого
уровня принято называть пакетами
(packets). При организации доставки пакетов
на сетевом уровне используется понятие
«номер сети». В этом случае адрес
получателя состоит из номера сети и
номера компьютера в этой сети. На этом
уровне происходит формирование пакетов
по правилам тех промежуточных сетей,
через которые проходит исходный пакет
и маршрутизация пакетов, т.е. определение
и реализация маршрутов, по которым
передаются пакеты. Маршрутизация
сводится к образованию логических
каналов. Еще одной важной функцией
сетевого уровня является контроль
нагрузки на сеть с целью предотвращения
перегрузок. Примерами протоколов
сетевого уровня являются протокол
межсетевого взаимодействия IP стека
TCP/IP и протокол межсетевого обмена
пакетами IPX стека Novell. На этом уровне
работают маршрутизаторы (аппаратные и
программные).
Транспортный уровень 4: Работа
транспортного уровня заключается в
том, чтобы обеспечить приложениям или
верхним уровням стека — прикладному и
сеансовому — передачу данных с той
степенью надежности, которая им требуется.
Модель OSI определяет пять классов
сервиса, предоставляемых транспортным
уровнем. Эти виды сервиса отличаются
качеством предоставляемых услуг:
срочностью, возможностью восстановления
прерванной связи, наличием средств
мультиплексирования нескольких
соединений между различными прикладными
протоколами через общий транспортный
протокол, а главное — способностью к
обнаружению и исправлению ошибок
передачи, таких как искажение, потеря
и дублирование пакетов. Как правило,
все протоколы, начиная с транспортного
уровня и выше, реализуются программными
средствами конечных узлов сети —
компонентами их сетевых операционных
систем. В качестве примера транспортных
протоколов можно привести протоколы
TCP и UDP стека TCP/IP и протокол SPX стека
Novell.
Сеансовый уровень 5 обеспечивает
управление диалогом для того, чтобы
фиксировать, какая из сторон является
активной в настоящий момент, а также
предоставляет средства синхронизации.
Последние позволяют вставлять контрольные
точки в длинные передачи, чтобы в случае
отказа можно было вернуться назад к
последней контрольной точке, вместо
того, чтобы начинать все с начала. На
этом уровне определяется тип связи
(дуплекс или полудуплекс), начало и
окончание сообщения. На практике немногие
приложения используют сеансовый уровень,
и он редко реализуется. (Предназначен
для организации синхронизации диалога,
ведущегося станциями сети. Последовательность
и режим обменов запросами и ответами)
Представительный уровень 6:
реализуются функции представления
данных (кодирование, форматирование,
структурирование). Например, на этом
уровне выделенные для передачи данные
преобразуются в кода EBCAIC в ASCII и т.п.
Представительный уровень отвечает за
то, чтобы информация, посылаемая из
прикладного уровня одной системы, была
читаемой для прикладного уровня другой
системы. На этом уровне может выполняться
шифрование и дешифрование данных,
благодаря которому секретность обмена
данными обеспечивается сразу для всех
прикладных сервисов. Примером протокола,
работающего на уровне представления,
является протокол Secure Socket Layer (SSL).
Прикладной уровень 7 включает
средства управления прикладными
процессами. На этом уровне определяются
и оформляются в блоки те данные, которые
подлежат передачи по сети. Уровень
включает, например, такие средства
взаимодействия прикладных программ,
как прием и хранение пакетов в «почтовых
ящиках”. Примерами таких прикладных
процессов могут служить программы
обработки крупномасштабных таблиц,
программы обработки слов, программы
банковских терминалов и т.д. Прикладной
уровень идентифицирует и устанавливает
наличие предполагаемых партнеров для
связи, синхронизирует совместно
работающие прикладные программы, а
также устанавливает соглашение по
процедурам устранения ошибок и управления
целостностью информации. Прикладной
уровень также определяет, имеется ли в
наличии достаточно ресурсов для
предполагаемой связи. Единица данных,
которой оперирует прикладной уровень,
обычно называется сообщением (message).
2. хз
Билет 27.
1.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #


Классификация архитектур вычислительных систем по Флинну. Какие существуют типы параллелизма? Организация памяти при параллельной обработки данных.
Классификация архитектур вычислительных систем по Флинну
Как известно, из классификаций архитектур вычислительных систем самой первой и наиболее известной является представленная в 1966 [1] году М.Флинном. Данная классификация основывается на понятии потока – последовательность команд, элементов или данных, обрабатываемая процессором. Флинн выделяет четыре класса архитектур на основе числа потоков команд и потоков данных: SISD,MISD,SIMD,MIMD.
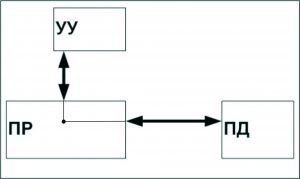
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К данному классу принадлежат классические последовательные машины, или их ещё называют, машины фон-неймановского типа. Данные машины имеют только один поток команд, обрабатывающиеся последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Все однопоточные программы используют вычислительную систему в этом режиме.
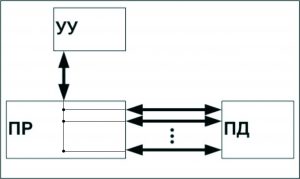
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Подобного рода архитектуры сохраняют один поток команд, включающий, векторные команды, в отличие от предыдущего класса. Это позволяет выполнять одну арифметическую операцию сразу над многими данными – элементами вектора. Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры.
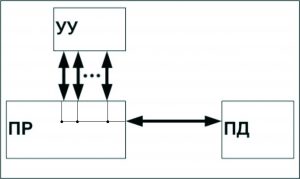
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Данный класс предполагает, что в архитектуре имеется множество процессоров, которые обрабатывают один и тот же поток данных. Однако до сих пор нет реального примера существования вычислительной системы, построенной на данном принципе. Как аналог работы такой системы, можно представить работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Так как база данных одна, а команд много, то это и будет множественный поток команд и одиночный поток данных.
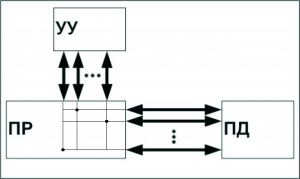
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. В данном классе, обрабатывается несколько данных, для которых выполняется несколько команд. К данному классу можно отнести многоядерные системы, а также все суперскалярные процессоры в общем виде.
В книге К.Ванга и Ф.Бриггса [2] сделаны некоторые дополнения к классификации Флина. Оставляя четыре ранее введенных базовых класса (SISD, SIMD, MISD, MIMD), авторы внесли следующие изменения.
Класс SISD разбивается на два подкласса:
- архитектуры с единственным функциональным устройством, например, PDP-11;
- архитектуры, имеющие в своем составе несколько функциональных устройств — CDC 6600, CRAY-1, FPS AP-120B, CDC Cyber 205, FACOM VP-200.
В класс SIMD также вводится два подкласса:
- архитектуры с пословно-последовательной обработкой информации — ILLIAC IV, PEPE, BSP;
- архитектуры с разрядно-последовательной обработкой — STARAN, ICL DAP.
В классе MIMD авторы различают:
- вычислительные системы со слабой связью между процессорами, к которым они относят все системы с распределенной памятью, например, Cosmic Cube,
- и вычислительные системы с сильной связью (системы с общей памятью), куда попадают такие компьютеры, как C.mmp, BBN Butterfly, CRAY Y-MP, Denelcor HEP.
Типы параллелизма
В источнике [3] выделяют четыре типа параллелизма: параллелизм на уровне битов, команд, данных, а также задач.
Параллелизм на уровне битов
При реализации операций обеспечивается максимальное распараллеливание, так, например, при осуществление сложения битов числа все биты машинного слова одновременно складываются, а так же используются специальный механизм учета переносов [4]. Чтобы увеличить диапазон чисел, обрабатываемых одной командой, следует увеличить размер машинного слова. Так, выполнен переход от 8-ми до 16-ти и далее к 32 разрядному машинному слову. На данный момент процессоры имеют 64-разрядное машинное слово, некоторые команды могут работать с 128-разрядными данными (процессор Larrabee работает с данными размером 512 битов). При использование машинного слова с большей разрядностью быстрее обрабатываются большие числа. Чтобы обработать 32-битное число для 16-битной машины требуется как минимум 2 команды, а для 32-битной – только одна. Но это верно не для всех 64-битных процессоров, ведь в них реализованы не все операции над 64-битными числами. так же ограничено использование команд, которые в результате дают 128-битные числа и числа большей разрядности.
Для определения диапазона адресного пространства также используется машинное слово. Вычислительная система работает с диапазоном адресного пространства, так как оно используется для задания адреса. Для 32-битных вычислительных систем максимальный адрес -1, адресное пространство составляет 4 ГБ. Для 64-битного машинного слова адресное пространство составляет или 16 ГБ. В табл. 1 представлены названия единиц измерения памяти.
таблица 1
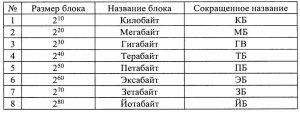
У первых вычислительных систем все числа занимали как минимум одно машинное слово, это приводило к неэффективному распределению памяти при задании небольших чисел. Для обеспечения эффективного распределения памяти в нынешних вычислительных системах, следует использовать данные разной длинны. Необходимость увеличения адресного пространства также является следствием усложнения решаемых задач. Для того, чтобы эффективно использовать 64-битные процессоры следует использовать операционную систему для работы с процессорами в 64-х битном режиме, а не использовать возможности этих процессоров работать в 32-битном режиме. Система Linux была первой операционной системой, которая полностью поддерживала работу процессора в этом режиме, далее появилась версия Microsoft Windows XP и Vista. На сегодняшний момент уже используются системы с оперативной памятью 16 ГБ, серверы с оперативной памятью 256ГБ, 8ГБ модули с оперативной памятью в серийном производстве.
Далее следует рассмотреть собственно параллелизм. Его можно реализовать как с помощью конвейера, так и суперескалярности, т.е. наличия нескольких независимых блоков для выполнения команд.
Параллелизм на уровне команд. Конвейер
Давно уже известна идея использования конвейера для увеличения производительности выполнения сложных операций. Происходит деление команды на независимые микрокоманды, время выполнения которых примерно одинаково. Количество микрокоманд равно числу блоков конвейера. Блоки конвейера последовательно обрабатывают очередную команду, выполняя ее микрокоманды. Полностью выполненной команда считается только после завершения обработки последним блоком конвейера.
Конвейерный принцип выполнения команд впервые был использован в машине ATLAS, 1962 г. [5], разработанной в Манчестерском университете. Выделяют 4 стадии выполнения команд: выборка команды, вычисление адреса операнда, выборка операнда и выполнение операции. Для Pentium в конвейер добавлен еще один блок записи результата. С помощью конвейеризации получилось уменьшить время выполнения команд с 6 до 1,6 микросекунд.
Время выполнения одной команды при ее последовательном выполнении от начала до конца примем за 1. Если конвейер состоит из m устройств (ступеней), то длина конвейер равна m. Если не брать в расчет накладные расходы, связанные с «перемещением» результатов выполнения предыдущих операций, то чтобы выполнить одну микрооперацию потребуется 1/m единиц времени. Далее выясним время выполнения программы, которая состоит из n последовательных команд без конвейера и с конвейером. Без конвейера потребуется n единиц времени (при том что время выполнения одной команды принято за 1).
Если использовать конвейер, то первая команда будет выполняться 1 единицу, а каждая очередная команда будет заканчиваться с интервалом 1/m единиц времени. Общее время выполнения такой программы равно 1+(n–1)/m.
Сравним полученные значения для n=100 команд и m=5 блоков конвейера. Без конвейера потребуется T1=100 (единиц времени), с конвейером T2=1+99/5=21 (единиц времени), т.е. почти в 5 раз быстрее. Конвейер позволяет увеличить производительность процессора, что интересно коэффициент ускорения почти прямо пропорционален длине конвейера. Именно поэтому длина конвейера для современных процессоров значительно больше 5. Конвейер Pentium 4 состоит из 35 блоков. Фактически увеличение числа блоков конвейера эквивалентно увеличению тактовой частоты, так как приводит к уменьшению времени выполнения одной команды.
Возникает тогда такой вопрос: можно ли бесконечно увеличивать число блоков конвейера? Нет, так как увеличение числа блоков способствует усложнению архитектуры процессора, увеличивает его тепловыделение. Время выполнения микрокоманды становится соизмеримым с накладными расходами, это уменьшает эффективность использования конвейера. Незнание свойств конвейера может поспособствовать потери производительности. Доказательством этого можно представить данный пример. Пусть в программе используется команда перехода. Для конвейера длиной 5 блоков адрес перехода определяется блоком 3, команду выполняет блок № 4 т.е. блоки второй половины конвейера. К моменту выполнения команды очередные 3 команды уже будут обработаны, несмотря на необходимость обрабатывать совсем другие команды. Такую ситуацию называют остановом конвейера. После того как определились адреса перехода, результаты обработки очередных команд должны быть аннулированы, а следующая команда, находящаяся по адресу перехода, начинает выполняться сначала. Если увеличить длину конвейера соответственно произойдет увеличение потерь, связанных с использованием команд перехода. Современные процессоры имеют блоки прогнозирования переходов, которые уменьшают потери, связанные с наличием команд перехода. Знание алгоритмов предсказания позволит снизить потери, связанные с командами перехода. Далее будут рассмотрены некоторые из них.
Команды сериализации
Конвейер считается одним из способов параллельного выполнения команды. Команды процессора имеют особые команды, которые чтобы начать выполнение ждут завершения всех начатых команд. При их выполнении другие команды не выполняются, данные команды имеют название команды сериализации. Приведем пример команды сериализации – команда cupid, использующаяся для определения особенностей процессора. Чтобы увеличить точность измерения времени, данную команду следует использовать перед началом и в конце замеров.
Предсказание переходов
Имеет свое начало с процессора типа Pentium. Дает возможность уменьшить потери производительности конвейера из-за наличия переходов.
Существует статистическое и динамическое предсказание. Для команд перехода, выполняющиеся в первый раз, используется статистическое предсказание. Для процессора типа Pentium – должна выполняться следующая команда, т.е. фактически нет предсказания.
Для процессоров имеющих более совершенный вид считалось, что ссылка вперед – перехода не будет, а ссылка назад – что переход будет. Это потому что, ссылка назад соответствует циклу, а пишутся циклы чтобы многократно выполнять один и тот же участок кода. Поэтому, статистическое предсказание верно, когда оператор условного перехода при первом его выполнении перехода не существует, т.е. имеет место естественный порядок выполнения команд. Исключением являются только циклы.
В процесс статистического предсказания команда заноситься в буфер предсказания перехода вместе с адресом, куда фактически выполняется переход. Так же устанавливается флаг в 1, если переход был.
Динамическое предсказание для Pentium. Данное предсказание применяется для команд перехода, выполняющихся повторно и которые уже имеют информацию. Каждая команда перехода имеет свой адрес (Адрес1), адрес, куда необходимо перейти (Адрес2) и битовые флаги (два флага). Если хотя бы один флаг из двух установлен в 1, то прогнозируется наличие перехода. Прогнозируется отсутствие перехода, при обоих флагах равны 0.
В дальнейшем в зависимости от того имеется переход или нет, значения флагов корректируются. Если переход есть и есть флаг, равный 0, то он устанавливается в 1. Если перехода нет и есть флаг равный 1, то он сбрасывается в 0. Данный алгоритм способствует минимизации числа ошибок, если очень маленькая вероятность наличия или отсутствия переходов. Если наличие переходов и их отсутствие равновероятны, то вероятность ошибок максимальна.
Динамическое предсказание для Pentium 2 и выше. Данное предсказание применяется для команд перехода, выполняющихся повторно и которые уже имеют информацию. Каждая команда перехода имеет свой адрес (Адрес1), адрес, куда необходимо перейти (Адрес2), битовые флаги (4 флага) и счетчик исполнения команды по модулю 4, наращивающийся при каждом выполнении команды. Когда происходит первое выполнение, команды перехода записываются в свободную строку буфера (все поля нулевые) Адрес1, Адрес2 и один флаг, номер которого соответствует счетчику исполнения команд, устанавливается в 1, если переход был. Далее, если соответствующий флаг равен 1, то имеется наличие перехода, если флаг равен 0, то отсутствие перехода. При варианте, что предсказание о переходе оказалось ошибочным, соответствующий флаг инвертируется. Данный алгоритм сокращает количество ошибок при периодическом характере наличия и отсутствия ошибок. К ошибкам приводят все нарушения периода, в том числе и при вычислении периода.
Рассмотренные выше алгоритмы предсказания все время усовершенствуются для минимизации потерь, но свести на данный момент их к нулю не могут. По этой причине рекомендуется уменьшать число команд перехода в программе, причем чем мощнее, а следовательно, с более длинным конвейером используется процессор, тем более требуется.
Параллелизм на уровне команд. Суперскалярность
Все команды программы делятся на независимые и зависимые команды.
Команды называются зависимыми, если их операнды определяются предшествующими командами. Независимыми командами называют те, которые используют константы, введенные данные или данные, для которых команды уже гарантированно выполнены. Команды, готовые для выполнения – это независимые команды. Их можно выполнять одновременно, если имеются свободные устройства для выполнения этих команд.
Суперскалярные процессоры используются для истинного распараллеливания вычислений. Которые имеют не одно, а несколько однотипных устройств для выполнения операций.
CDC 6600 (1964) [5] был первым компьютером, который имел несколько функциональных блоков. Данный компьютер выпустила фирма Control Data Corporation (CDC) при участии одного из ее основателей Суймура Р.Крэя (Seymour R. Cray)
Компьютер CDC 7600 (1969) включал в себя 8 независимых конвейерных устройств, поэтому в нем соединились преимущества конвейерных и суперскалярных ЭВМ.
ILLIAC IV (1974): матричные процессоры. Проект включал в себя сделать 256 процессорных элементов (ПЭ) и разбить их на 4 квадранта по 64 ПЭ, и предусмотреть возможность перестройки в 2 квадранта по 128 ПЭ или 1 квадрант из 256 ПЭ, ткт 40 нс, производительность 1 Гфлоп. Начались работы в 1967 году, к концу 1971 изготовлена система из 1-го квадранта, в 1974 г. она введена в эксплуатацию, доводка велась до 1975 года. Из-за того, что стоимость проекта была в 4 раза выше, сделан лишь 1 квадрант, такт 80нс, реальная производительность до 50 Мфлоп. Но даже при неудачном завершение проекта, данная разработка использовалась при построении серии других суперкомпьютеров.
CRAI 1 (1976): векторно-конвейерные процессоры, создателем которых является компания Cray Research. Время такта 12.5 нс, 12 ковейерных функциональных устройств, пиковая производительность 160 миллионов операций в секунду, оперативная память до 1 Мслова (слово – 64 разряда), цикл памяти 50нс. Самым главным нововведением является включение векторных команд, работающих с целыми массивами независимых данных, которые позволяют эффективно использовать конвейерные функциональные устройства.
Самые первые суперскалярные процессоры фирмы Intel включали в себя два параллельных блока для выполнения операций, первый блок для выполнения произвольных операций, второй – для выполнения только простых операций. Одновременное использование обоих блоков в этом случае было осуществимо только при «правильной» последовательности команд в программе, что при решении конкретных задач практически невозможно. Именно поэтому по возможности компиляторы упорядочивали команды программы таким образом, чтобы максимально использовать оба блока. Тогда и появился режим оптимизации программ, который зависит от используемого процессора.
На сегодняшний момент процессоры суперскалярные и содержат разное число специализированых блоков, к примеру, блоки для выполнения арифметических операций, операций с плавающей точкой.
Параллелизм на уровне данных. SIMD команды
Очень часто, при решении практических задач приходится для множества данных выполнять одну и ту же операцию. В данном случае можно использовать суперскалярность процессоров, но именно для этого случая современные процессоры имеют специальные команды. В соответствии с их назначением они относятся к группе Single Instruction Multiple Data – одна команда для множества данных (SIMD). Векторно-конвейерными называются компьютеры, которые вместе с конвейером обеспечивают возможность одновременной обработки сразу целого массива. Обычно SIMD команды реализуются с помощью специального конвейера, из-за этого могут выполняться одновременно с основным потоком команд. Представителем данного направления является семейство векторно-конвейерных компьютеров CRAY. Для персональных компьютеров ограничен размер блока 128 битами. Блок может интерпретироваться как массив байтов, 2-байтовых и 4-байтовых слов, а также двух данных длинной 8 байтов, и, наконец, одного блока длинной 16 байтов. Набор команд, а также интерпретация данных (целые, с плавающей точкой) все время расширяется. На сегодня для персональных компьютеров используется несколько классов команд этой группы (MMX – Multi Media Extensions., 3DNow, SSE – Streaming SIMD Extension) разных версий. SIMD команды позволяют распараллелить обработку множества данных без накладных расходов. На сегодняшний момент применение этих команд упрощено в связи с возможностью их использования в С программе.
Пример применения операции сложения для массивов целых чисел, состоящих из четырех чисел:
//Выделение памяти и инициализация массивов
__declspec (align(16))
int x[]={1,2,3,4},
y[]={5,6,7,8},
z=[4];
//Сложение элементов массивов
*(__m128i*)z=_mm_add_epi32(*(__m128i*)x,*(__m128i*)y);
printf(«%d%d%d%dn»,z[0],z[1],z[2],z[3]);
Для сложения чисел фактически выполняется следующие команды:
- загрузка первого массива в 128-битный регистр (т.е. сразу 4-х слагаемых);
- загрузка второго массива в 128-битный регистр (т.е. сразу 4-х слагаемых);
- сложение всех элементов массива (одна команда);
- запись результата в массив.
Параллелизм на уровне задач
Понятие «задача» имеет разный смысл. Если рассматривать процессоров, задачей является программа во время выполнения, а переключение между задачами, это переключение между этими программами, которое инициируется операционной системой и может быть: при истечении кванта времени, если задача ждет выполнения запроса, если требуется выполнения более привилегированных задач. Рассматривая операционные системы, вместо термина задача можно использовать термин процесс, в который фактически вкладывается тот же смысл. Именно поэтому параллелизм на уровне задач предполагает возможность параллельного выполнения отдельных программ. Также наряду с обычными процессами, которым соответствует программа, операционные системы для параллельного выполнения могут использовать отдельных функции процесса (потоки). Рассмотрим параллелизм на уровне процессов и потоков. В этом случае при использовании одного одноядерного процессора может выполняться одновременно только одна функция одного процесса. При режиме разделения времени и высокой скорости выполнения команд может показаться одновременное выполнение, но это не так. Фактически при переключении между потоками старый поток блокируется.
В системах с одни ядром и без Hyper-Threading (HT) технологии в исполнении команд участвует исполнительный блок и внутренний Кеш. Эти элементы вычислительной системы можно назвать вычислительным блоком. Для многопроцессорных систем, вычислительная система имеет несколько вычислительных блоков. Для систем с НТ технологией фактически входит один исполнительный блок, который имеет вид двух логических блоков за счет того, что дублируются некоторые его части (регистры). В многоядерной системе используется несколько вычислительных систем, расположенных физически внутри одной схемы. Многоядерные системы могут использовать как общий внутренний Кеш, так и каждое ядро свой Кеш. Возможна комбинация многоядерности и НТ.
В НТ технологии все ресурсы вычислительного блока (одного) делятся между исполняемыми потоками операционной системой. К примеру, если один поток ждет ввода – вывода данных, то второй поток выполняется с помощью вычислительного блока. Все логические блоки имеют свою копию регистров, поэтому переключения состояния фактически не потребуется, как это в обычных однопроцессорных системах. Общий эффект существенно зависит от потоков, которые работают в паре. При том что все потоки используют одни и те же ресурсы, эффекта фактически не будет, так как устройство одно.
Чтобы достичь истинно параллельного выполнения функций следует иметь несколько процессоров или несколько ядер процессора.
Появление многоядерных процессоров фактически сделало доступными высокопроизводительные вычисления (High Performance Computing – HPC) на домашних компьютерах.
То есть в одной микросхеме располагаются теперь несколько полноценных и равноправных процессорных устройств. Данная технология применяется как в недорогих процессорах (Intel Core 2, AMD Athlon), так и в процессорах для мощных рабочих станций и серверов (AMD Opteron, Intel Xeon). Количество ядер все время растет. На сегодняшний день используются процессоры с 2, 4 и 8 ядрами, в стадии исследования и разработки находятся процессоры с десятками и сотнями ядер, поэтому распараллеливание и масштабирование (т.е. распределение между всеми ядрами процессора) приложений является сложной как теоретической, так и практической задачей, которая на данный момент пока не решена в полной мере.
Память и параллелизм
Как известно, выполнение команд происходит гораздо значительно быстрее, чем доступ к памяти. Чтобы уменьшить потери, связанные с разной скоростью доступа, используется многоуровневая память. Существуют несколько уровней памяти, которые задаются в порядке увеличения времени доступа: регистры, Кеш-память (несколько уровней), оперативная память, внешняя память. Обеспечение параллелизма осуществляется за счет того, что во время выполнения команд и обработки данных используется регистровая и Кеш-память первого уровня, заполняющиеся данными до того, пока они будут использоваться, и до момента, когда они будут нужны, они, как правило, уже находятся в нужной памяти (если конечно, число команд перехода минимизировано!)
Следует рассмотреть классические архитектуры систем с параллельной обработкой данных и команд с точки зрения использования памяти.
Массивно-параллельные компьютеры (MPP)
Данная система включает в себя несколько компьютеров со своей локальной памятью соединяются в одну вычислительную систему с помощью коммутационных устройств [6].
Система состоит из однородных вычислительных узлов, включающих:
- один или несколько центральных процессоров (обычно RISC);
- локальную память (прямой доступ к памяти других узлов невозможен);
- коммуникационный процессор или сетевой адаптер;
- иногда – жесткие диски (как в SP) и/или другие устройства I/O.
Примеры: IBM RS/6000 SP2, Intel PARAGON/ASCI Red, CRAY T3E, Hitachi SR 8000, транспьютерные системы Parsytec.
Достоинством данной архитектуры можно считать возможность ее расширения. Недостаток является медленная передача данных между компьютерами. На сегодняшний момент коммуникационные устройства уменьшают потери, которые связаны с передачей данных, но в любом случае эта операция значительно медленнее, чем при использовании своей памяти.
Симметричные мультипроцессорные системы (SMP – Symmetrical Multi Processor systems)
Одинаковые процессоры подключаются к общей памяти, при этом скорость обращения к общей памяти для всех процессоров одинакова. Процессоры подключаются к памяти либо с помощью общей шины (базовые 2-4-х процессорные SMP-серверы), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность Кешей (гарантия использования актуального значения, данного независимо от того, в каком Кеше изменено его значение). Хоть и проблема передачи данных между памятью решается автоматически, остается ещё одна, это подключение процессоров к общей памяти. Количество процессоров, которые можно подключить, обычно невелико, около 2-4 устройства. Использование 32-х устройств очень дорого, стоимость такой вычислительной системы сотни тысяч долларов.
В связи с использованием общей памяти необходима синхронизация и блокировка в случае попытки доступа к занятому ресурсу с эксклюзивным доступом.
Примеры: HP 9000 V-class, N-class; SMP-сервер и рабочие станции на базе процессоров Intel(IBM, HP,Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.).
Системы с неоднородным доступом к памяти (NUMA – Non-Uniform Memory Access systems)
Состоит система из однородных базовых модулей (плат), которые имеют в своём составе небольшое число процессоров и блок памяти. Объединены модули с помощью высокоскоростного коммутатора. Обеспечивается поддержка единого адресного пространства, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. Доступ к локальной памяти в несколько раз быстрее, чем к удаленной, а скорость доступа к удаленной памяти будет больше, чем дальше будет удалена память от процессора.
В случае если аппаратно поддерживается когерентность Кешей во всей системе (обычно это так), говорят об архитектуре cc-NUMA (cache-coherent NUMA).
В случае попытки доступа к занятому ресурсу с эксклюзивным доступом, при использование общей памяти, необходима синхронизация и блокировка. Также при разработке алгоритма желательно обеспечить доступ к «своей» памяти везде, где есть возможно.
Примеры: Примеры: HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600.
Параллельные векторные системы (PVP)
Главным признаком PVP-систем можно считать наличие специальных векторно-конвейерных процессоров, которые имеют команды однотипной обработки векторов независимых данных, которые эффективно выполняются на конвейерных функциональных устройствах.
В основном, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в многопроцессорных конфигурациях. Объединение несколько узлов происходит с помощью коммутатора (аналогично MPP).
Примеры: NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY SV1, CRAY X1, серия Fujitsu VPP.
Кластерные системы
В качестве дешевого варианта массивно-параллельного компьютера используется набор рабочих станций (или даже ПК) общего назначения. Что узлы имели связь используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора.
Когда происходит объединении в кластер компьютеров разной мощности или разной архитектуры говорят о гетерогенных (неоднородных) кластерах.
Узлы кластера можно одновременно использовать в качестве пользовательских рабочих станций. Если это не нужно, узлы можно существенно облегчить и/или установить в стойку.
Актуальной проблемой является доступа к «чужой» памяти, из-за этого часто такая система используется для одновременного решения нескольких независимых задач.
Примеры: NT-кластер в NCSA, Beowulf-кластеры.
Многоядерные процессоры
С точки зрения программиста, многоядерным процессором является несколько процессоров, имеющие раздельный Кеш 0 уровня (Кеш 2-го и более высоких уровней чаще общий, но может быть и раздельным) и общую оперативную память. По этой причине желательно при разработке алгоритмов обеспечивать максимальную независимость данных, которые используются в разных ядрах. Синхронизация и блокировка являются на данный момент актуальной проблемой.
Используемая литература:
- Flynn M. Very high-speed computing system // Proc. IEEE. 1966. N 54. P.1901-1909.
- Hwang K., Briggs F.A. Computer Architecture and Parallel Processing. 1984. P.32-40.
- http://ru.wikipedia.org/wiki/Параллельные_вычисления; http://ru.wikipedia.org/wiki/Нейрокомпьютер ;
- Гергелъ В.П., Стронгин Р.Г Основы параллельных вычислений для многопроцессорных вычислительных систем. Нижний Новгород: -Издательство Нижегородского госуниверситета, 2003
- Воеводин В.В., Воеводин Вл.в. Параллельные вычисления. СПб: БХВ – Петербург, 2004 – 608с.

Большое разнообразие структур ВС затрудняет их изучение. Поэтому вычислительные системы классифицируют с учетом их обобщенных характеристик. С этой целью вводится понятие «архитектура системы».
Архитектура ВС — совокупность характеристик и параметров, определяющих функционально-логическую и структурную организацию системы. Понятие архитектуры охватывает общие принципы построения и функционирования, наиболее существенные для пользователей, которых больше интересуют возможности систем, а не детали их технического исполнения. Поскольку ВС появились как параллельные системы, то и рассмотрим классификацию архитектур под этой точкой зрения.
Эта классификация архитектур была предложена М. Флинном (М. Flynn) в начале 60-х гг. В ее основу заложено два возможных вида параллелизма: независимость потоков заданий (команд), существующих в системе, и независимость (несвязанность) данных, обрабатываемых в каждом потоке. Классификация до настоящего времени еще не потеряла своего значения. Однако подчеркнем, что, как и любая классификация, она носит временный и условный характер. Своим долголетием она обязана тому, что оказалась справедливой для ВС, в которых ЭВМ и процессоры реализуют программные последовательные методы вычислений. С появлением систем, ориентированных на потоки данных и использование ассоциативной обработки, данная классификация может быть некорректной.
Согласно этой классификации существует четыре основных архитектуры ВС, представленных на рисунке:




Рис.Архитектура ВС: а — ОКОД (SISD)-архитектура; 6— ОКМД (SIMD)- архитектура; в — МКОД (MISD)-архитектура; г — МКМД (МШО)-архитектура
· одиночный поток команд — одиночный поток данных (ОКОД), в английском варианте — Single Instruction Single Data (SISD) — одиночный поток инструкций — одиночный поток данных;
· одиночный поток команд — множественный поток данных (ОКМД), или Single Instruction Multiple Data (SIMD) — одиночный поток инструкций — одиночный поток данных;
· множественный поток команд — одиночный поток данных (МКОД), или Multiple Instruction Single Data (MISD) — множественный поток инструкций — одиночный поток данных;
· множественный поток команд — множественный поток данных (МКМД), или Multiple Instruction Multiple Data (MIMD) — множественный поток инструкций — множественный поток данных (MIMD).
Коротко рассмотрим отличительные особенности каждой из архитектур.
Архитектура ОКОД охватывает все однопроцессорные и одномашинные варианты систем, т.е. с одним вычислителем. Все ЭВМ классической структуры попадают в этот класс. Здесь параллелизм вычислений обеспечивается путем совмещения выполнения операций отдельными блоками АЛУ, а также параллельной работы устройств ввода-вывода информации и процессора. Закономерности организации вычислительного процесса в этих структурах достаточно хорошо изучены.
Архитектура ОКМД предполагает создание структур векторной или матричной обработки. Системы этого типа обычно строятся как однородные, т.е. процессорные, элементы, входящие в систему, идентичны, и все они управляются одной и той же последовательностью команд. Однако каждый процессор обрабатывает свой поток данных. Под эту схему хорошо подходят задачи обработки матриц или векторов (массивов), задачи решения систем линейных и нелинейных, алгебраических и дифференциальных уравнений, задачи теории поля и др. В структурах данной архитектуры желательно обеспечивать соединения между процессорами, соответствующие реализуемым математическим зависимостям. Как правило, эти связи напоминают матрицу, в которой каждый процессорный элемент связан с соседними.
По этой схеме строились системы: первая суперЭВМ — ILLIAC-IV, отечественные параллельные системы — ПС-2000, ПС-3000. Идея векторной обработки широко использовалась в таких известных суперЭВМ, как Cyber-205 и Gray-I, II, III. Узким местом подобных систем является необходимость изменения коммутации между процессорами, когда связь между ними отличается от матричной. Кроме того, задачи, допускающие широкий матричный параллелизм, составляют достаточно узкий класс задач. Структуры ВС этого типа, по существу, являются структурами специализированных суперЭВМ.
Третий тип архитектуры МКОД предполагает построение своеобразного процессорного конвейера, в котором результаты обработки передаются от одного процессора к другому по цепочке. Выгоды такого вида обработки понятны. Прототипом таких вычислений может служить схема любого производственного конвейера. В современных ЭВМ по этому принципу реализована схема совмещения операций, в которой параллельно работают различные функциональные блоки, и каждый из них делает свою часть в общем цикле обработки команды.
В ВС этого типа конвейер должны образовывать группы процессоров. Однако при переходе на системный уровень очень трудно выявить подобный регулярный характер в универсальных вычислениях. Кроме того, на практике нельзя обеспечить и «большую длину» такого конвейера, при которой достигается наивысший эффект. Вместе с тем конвейерная схема нашла применение в так называемых скалярных процессорах суперЭВМ, в которых они применяются как специальные процессоры для поддержки векторной обработки.
Архитектура МКМД предполагает, что все процессоры системы работают по своим программам с собственным потоком команд. В простейшем случае они могут быть автономны и независимы. Такая схема использования ВС часто применяется на многих крупных вычислительных центрах для увеличения пропускной способности центра. Больший интерес представляет возможность согласованной работы ЭВМ (процессоров), когда каждый элемент делает часть общей задачи. Общая теоретическая база такого вида работ практически отсутствует.
Классификация параллельных вычислительных систем
Даже краткое перечисление типов современных параллельных вычислительных систем (ВС) дает понять, что для ориентирования в этом многообразии необходима четкая система классификации. От ответа на главный вопрос — что заложить в основу классификации — зависит, насколько конкретная система классификации помогает разобраться с тем, что представляет собой архитектура ВС и насколько успешно данная архитектура позволяет решать определенный круг задач. Попытки систематизировать все множество архитектур параллельных вычислительных систем предпринимались достаточно давно и длятся по сей день, но к однозначным выводам пока не привели. Исчерпывающий обзор существующих систем классификации ВС приведен в [5].
Классификация Флинна
Среди всех рассматриваемых систем классификации ВС наибольшее признание получила классификация, предложенная в 1966 году М. Флинном [99, 100]. В ее основу положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. В зависимости от количества потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD, MIMD.




Рис. 10.5.Архитектура вычислительных систем по Флинну: а — SISD; б — MISD;
в —SIMD; г -MIMD
MIMD
SIMD
MISD
SISD
SISD (Single Instruction Stream/Single Data Stream) — одиночный поток команд и одиночный поток данных (а). Представителями этого класса являются, прежде всего, классические фон-неймановские ВМ, где имеется только один поток команд, команды обрабатываются последовательно и каждая команда инициирует одну операцию с одним потоком данных. То, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка, не имеет значения, поэтому в класс SISD одновременно попадают как ВМ CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными. Некоторые специалисты считают, что к SISD-системам можно причислить и векторно-конвейерные ВС, если рассматривать вектор как неделимый элемент данных для соответствующей команды.
MISD (Multiple Instruction Stream/Single Data Stream) — множественный поток команд и одиночный поток данных (б). Из определения следует, что в архитектуре ВС присутствует множество процессоров, обрабатывающих один и тот же поток данных. Примером могла бы служить ВС, на процессоры которой подается искаженный сигнал, а каждый из процессоров обрабатывает этот сигнал с помощью своего алгоритма фильтрации. Тем не менее, ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не сумели представить (убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей относят к данному классу конвейерные системы, однако это не нашло окончательного признания. Отсюда принято считать, что пока данный класс пуст. Наличие пустого класса не (следует считать недостатком классификации Флинна. Такие классы, по мнению I некоторых исследователей, могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
SIMD (Single Instruction Stream/Multiple Data Stream) — одиночный поток команд и множественный поток данных (в). ВМ данной архитектуры позволяют выполнять одну арифметическую операцию сразу над многими данными — элементами вектора. Бесспорными представителями класса SIMD считаются матрицы процессоров, где единое управляющее устройство контролирует множество процессорных элементов. Все процессорные элементы получают от устройства управления одинаковую команду и выполняют ее над своими локальными данными. В принципе в этот класс можно включить и векторно-конвейерные ВС, если каждый элемент вектора рассматривать как отдельный элемент потока данных.
MIMD (Multiple Instruction Stream/Multiple Data Stream) — множественный поток команд и множественный поток данных (г). Класс предполагает наличие в вычислительной системе множества устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы. Кроме того, приобщение к классу MIMD зависит от трактовки. Так, ранее упоминавшиеся векторно-конвейерные ВС можно вполне отнести и к классу MIMD, если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) над множественным скалярным потоком.

- Классификация архитектуры ВС Базу
- Виды литературных произведений (публикаций), в которых отражаются результаты научного исследования и научной работы
- Корпоративная социальная ответственность
- Сбербанк и Яндекс
- Цифровизация мониторинга данных в медицине
- Библиографический поиск литературных источников для научного исследования
- Этические нормы в поведении руководителя
- Was Julia happy in marriage? How did her relationships with Michael change in course of time?
- Построение базы данных на рынке офисных центров
- Угрозы информационной и имущественной безопасности современной организации со стороны ее нелояльных сотрудников
- Актуальные направления научных исследований по теме «Проблемы развития небанковских кредитных организаций
- Кража как наиболее распространенная форма хищения
5.1. Классификация архитектур вычислительных систем с параллельной обработкой данных
5.2. Симметричная многопроцессорная архитектура SMP
5.3. Массивно-параллельная архитектура MPP
5.4. Гибридная архитектура NUMA
5.5. Параллельная архитектура PVP с векторными процессорами
5.6. Кластерная архитектура
5.7. Основные тенденции развития вычислительной техники
5.7.1. Повышение тактовой частоты
5.7.2. Увеличение объема и пропускной способности подсистемы памяти
5.7.3. Увеличение количества параллельно работающих вычислительных устройств
5.7.4. Системы на одном кристалле и новые технологии
5.7.5. Нанотехнологии
5.1. Классификация архитектур вычислительных систем с параллельной обработкой данных
Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего, это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Понятие архитектуры высокопроизводительной системы является достаточно широким, поскольку под архитектурой можно понимать и способ параллельной обработки данных, используемый в системе, и организацию памяти, и топологию связи между процессорами, и способ исполнения системой арифметических операций. Попытки систематизировать все множество архитектур впервые были предприняты в конце 60-х годов и продолжаются по сей день.
В 1966 г. М. Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В его основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором.
Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
- SISD (Single Instruction Single Data) – 1 поток команд и 1 поток данных.
- MISD (Multiple Instruction Single Data) – несколько потоков команд и 1 поток данных.
- SIMD (Single Instruction Multiple Data) – 1 поток команд и несколько потоков данных.
- MIMD (Multiple Instruction Multiple Data) – несколько потоков команд и несколько потоков данных.
|
|
|
|
Рисунок 5.1 – Архитектура SISD, 1 поток команд и 1 поток данных |
Рисунок 5.2 – Архитектура MISD, несколько потоков команд и 1 поток данных |
|
|
|
|
Рисунок 5.3 – Архитектура SIMD, 1 поток команд и несколько потоков данных |
Рисунок 5.4 – MIMD, несколько потоков команд и несколько потоков данных |
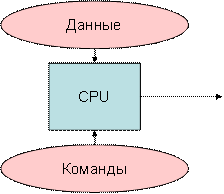
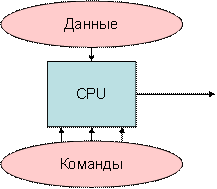
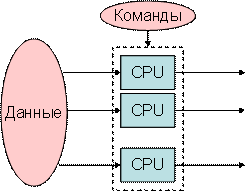
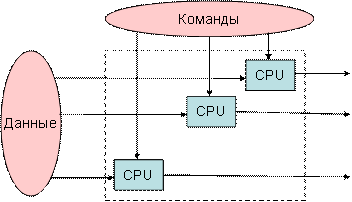
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций.
В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций, что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных.
Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем векторный поток данных следует рассматривать как поток из одиночных неделимых векторов.
Примерами компьютеров с архитектурой SISD могут служить большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, создано не было. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, мы имеем дело с множественным потоком команд и одиночным потоком данных.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров (от 1024 до 16384), которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных.
Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille.
Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта частотогенератора (такт частотогенератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа являются, например, компьютеры Hitachi S3600.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от упомянутых выше многопроцессорных SISD-машин, команды и данные связаны, потому что они представляют различные части одной и той же задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач с целью сокращения времени выполнения основной задачи.
Большое разнообразие попадающих в MIMD класс вычислительных систем делает классификацию Флинна не полностью адекватной. Действительно, и четырехпроцессорный SX-5 компании NEC, и тысячепроцессорный Cray T3E попадают в этот класс. Это заставляет использовать другой подход к классификации, иначе описывающий классы компьютерных систем.
Другой подход к классификации состоит в разделении вычислительных систем по способам обработки множественного потока команд.
Одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков. Такая возможность используется в MIMD-компьютерах, которые обычно называют конвейерными или векторными. В основе векторных компьютеров лежит концепция конвейеризации, т.е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов.
Каждый поток обрабатывается своим собственным устройством. Такая возможность используется в параллельных компьютерах. В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными.
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
5.2. Симметричная многопроцессорная архитектура SMP
SMP (symmetric multiprocessing) – симметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP (рис.5.5) является наличие общей физической памяти, разделяемой всеми процессорами.
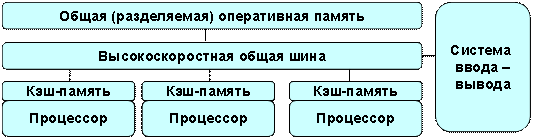 Рисунок 5.5 – Схематический вид SMP-архитектуры
Рисунок 5.5 – Схематический вид SMP-архитектуры
Память служит, в частности, для передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют равные права и одну и ту же адресацию для всех ячеек памяти. Поэтому SMP-архитектура называется симметричной. Последнее обстоятельство позволяет очень эффективно обмениваться данными с другими вычислительными устройствами.
SMP-система строится на основе высокоскоростной системной шины (SGI PowerPath, Sun Gigaplane, DEC TurboLaser), к слотам которой подключаются функциональные блоки типов: процессоры (ЦП), подсистема ввода/вывода (I/O) и т. п. Для подсоединения к модулям I/O используются уже более медленные шины (PCI, VME64).
Наиболее известными SMP-системами являются SMP-cерверы и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.) Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы по процессорам, но иногда возможна и явная привязка.
Основные преимущества SMP-систем:
— простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают независимо друг от друга. Однако можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти. Для SMP-систем существуют довольно эффективные средства автоматического распараллеливания;
— простота эксплуатации. Как правило, SMP-системы используют систему кондиционирования, основанную на воздушном охлаждении, что облегчает их техническое обслуживание;
— относительно невысокая цена.
Недостатки:
— системы с общей памятью плохо масштабируются.
Этот существенный недостаток SMP-систем не позволяет считать их по-настоящему перспективными. Причиной плохой масштабируемости является то, что в данный момент шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти.
В настоящее время конфликты могут происходить при наличии 8-24 процессоров. Все это очевидно препятствует увеличению производительности при увеличении числа процессоров и числа подключаемых пользователей. В реальных системах можно задействовать не более 32 процессоров. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. При работе с SMP-системами используют так называемую парадигму программирования с разделяемой памятью (shared memory paradigm).
5.3. Массивно-параллельная архитектура MPP
MPP (massive parallel processing) – массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), коммуникационные процессоры(роутеры) или сетевые адаптеры, иногда – жесткие диски и/или другие устройства ввода/вывода. По сути, такие модули представляют собой полнофункциональные компьютеры (см. рис. 5.6).
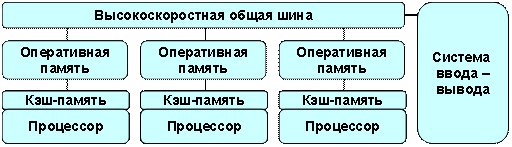 Рисунок 5.6 – Схематический вид архитектуры с раздельной памятью
Рисунок 5.6 – Схематический вид архитектуры с раздельной памятью
Доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами.
Используются два варианта работы операционной системы на машинах MPP-архитектуры:
— полноценная операционная система (ОС) работает только на управляющей машине (front-end), на каждом отдельном модуле функционирует сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения.
— на каждом модуле работает полноценная UNIX-подобная ОС, устанавливаемая отдельно.
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (ASCI Red, ASCI Blue Pacific).
Недостатки:
— отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
— каждый процессор может использовать только ограниченный объем локального банка памяти;
— вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
Системами с раздельной памятью являются суперкомпьютеры МВС-1000, IBM RS/6000 SP, SGI/CRAY T3E, системы ASCI, Hitachi SR8000, системы Parsytec. Машины последней серии CRAY T3E от SGI, основанные на базе процессоров Dec Alpha 21164 с пиковой производительностью 1200 Мфлопс/с (CRAY T3E-1200), способны масштабироваться до 2048 процессоров.
При работе с MPP-системами используют так называемую Massive Passing Programming Paradigm – парадигму программирования с передачей данных (MPI, PVM, BSPlib).
5.4. Гибридная архитектура NUMA
Главная особенность гибридной архитектуры NUMA (nonuniform memory access) – неоднородный доступ к памяти.
Суть этой архитектуры – в особой организации памяти, а именно: память физически распределена по различным частям системы, но логически она является общей, так что пользователь видит единое адресное пространство. Система построена из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной. По существу, архитектура NUMA является MPP (массивно-параллельной) архитектурой, где в качестве отдельных вычислительных элементов берутся SMP (симметричная многопроцессорная архитектура) узлы. Доступ к памяти и обмен данными внутри одного SMP-узла осуществляется через локальную память узла и происходит очень быстро, а к процессорам другого SMP-узла тоже есть доступ, но более медленный и через более сложную систему адресации.
Гибридная архитектура совмещает достоинства систем с общей памятью и относительную дешевизну систем с раздельной памятью.
В структурной схеме компьютера с гибридной сетью (рис. 5.7) три процессора связываются между собой при помощи общей оперативной памяти в рамках одного SMP-узла. Узлы связаны сетью типа «бабочка» (Butterfly).
Впервые идею гибридной архитектуры предложил Стив Воллох, он воплотил ее в системах серии Exemplar. Вариант Воллоха – система, состоящая из восьми SMP-узлов. Фирма HP купила идею и реализовала на суперкомпьютерах серии SPP. Идею подхватил Сеймур Крей (Seymour R. Cray) и добавил новый элемент – когерентный кэш, создав так называемую архитектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), которая расшифровывается как «неоднородный доступ к памяти с обеспечением когерентности кэшей». Он ее реализовал на системах типа Origin.
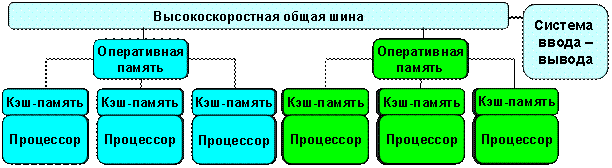 Рисунок 5.7 – Структурная схема компьютера с гибридной сетью
Рисунок 5.7 – Структурная схема компьютера с гибридной сетью
Организация когерентности многоуровневой иерархической памяти
Понятие когерентности кэшей описывает тот факт, что все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы этого избежать, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров.
Для обеспечения когерентности кэшей существует несколько возможностей:
— использовать механизм отслеживания шинных запросов (snoopy bus protocol), в котором кэши отслеживают переменные, передаваемые к любому из центральных процессоров и при необходимости модифицируют собственные копии таких переменных;
— выделять специальную часть памяти, отвечающую за отслеживание достоверности всех используемых копий переменных.
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях, SGI Origin3000, Sun HPC 15000, IBM/Sequent NUMA-Q 2000. На сегодня максимальное число процессоров в cc-NUMA-системах может превышать 1000 (серия Origin3000). Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического «подразделения» системы, когда отдельные «разделы» системы работают под управлением разных ОС. При работе с NUMA-системами, так же, как с SMP, используют так называемую парадигму программирования с общей памятью (shared memory paradigm).
5.5. Параллельная архитектура PVP с векторными процессорами
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гбайт/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP-архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дорого стоят, эти машины не могут быть общедоступными.
Наиболее популярны три машины PVP-архитектуры:
1. CRAY X1, SMP-архитектура (рис. 5.8). Пиковая производительность системы в стандартной конфигурации может составлять десятки терафлопс.
2. NEC SX-6, NUMA-архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность одного процессора составляет 9,6 Гфлопс. Система масштабируется с единым образом операционной системы до 512 процессоров.
3. Fujitsu-VPP5000 (vector parallel processing), MPP-архитектура (рис. 5.9). Производительность одного процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти – 8 Тбайт. Система масштабируется до 512 процессоров.
Парадигма программирования на PVP-системах предусматривает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
За счет большой физической памяти (доли терабайта) даже плохо векторизуемые задачи на PVP-системах решаются быстрее на машинах со скалярными процессорами.
|
|
|
|
Рисунок 5.8 – CRAY SV-2 |
Рисунок 5.9 – Fujitsu-VPP5000 |


5.6. Кластерная архитектура
Кластер представляет собой два или более компьютеров (часто называемых узлами), объединяемые при помощи сетевых технологий на базе шинной архитектуры или коммутатора и предстающие перед пользователями в качестве единого информационно-вычислительного ресурса.
Кластерная архитектура представлена на рис. 5.10.

Рисунок 5.10 – Кластерная архитектура
В качестве узлов кластера могут быть выбраны серверы, рабочие станции и даже обычные персональные компьютеры. Узел характеризуется тем, что на нем работает единственная копия операционной системы.
Элементами кластера являются – один управляющий узел и остальные вычислительные, связанные в локальную сеть.
Управляющий узел – подготовка параллельных программ и данных, взаимодействие с вычислительными узлами через управляющую сеть.
Вычислительные узлы – выполнение параллельной программы, обмен данными через коммуникационную сеть.
Возможности масштабируемости кластеров позволяют многократно увеличивать производительность приложений для большего числа пользователей технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. Такие суперкомпьютерные системы являются самыми дешевыми, поскольку собираются на базе стандартных комплектующих элементов («off the shelf»), процессоров, коммутаторов, дисков и внешних устройств.
Кластеры условно можно разделить на классы.
Класс I. Класс машин строится целиком из стандартных деталей, которые продают многие поставщики компьютерных компонентов (низкие цены, простое обслуживание, аппаратные компоненты доступны из различных источников).
Класс II. Система имеет эксклюзивные или не слишком широко распространенные детали. Таким образом, можно достичь очень хорошей производительности, но при более высокой стоимости.
Кластеры могут существовать в различных конфигурациях. Наиболее распространенными типами кластеров являются:
— системы высокой надежности – в случае сбоя какого-либо узла другой узел кластера может взять на себя нагрузку неисправного узла, и пользователи не заметят прерывания в доступе;
— системы для высокопроизводительных вычислений – предназначены для параллельных расчетов. Эти кластеры обычно собраны из большого числа компьютеров. Разработка таких кластеров является сложным процессом, требующим на каждом шаге согласования таких вопросов как инсталляция, эксплуатация и одновременное управление большим числом компьютеров, технические требования параллельного и высокопроизводительного доступа к одному и тому же системному файлу (или файлам) и межпроцессорная связь между узлами, и координация работы в параллельном режиме. Эти проблемы проще всего решаются при обеспечении единого образа операционной системы для всего кластера;
— многопоточные системы – используются для обеспечения единого интерфейса к ряду ресурсов, которые могут со временем произвольно наращиваться (или сокращаться). Типичным примером может служить группа web-серверов.
Отметим, что границы между этими типами кластеров до некоторой степени размыты, и кластер может иметь такие свойства или функции, которые выходят за рамки перечисленных типов. Более того, при конфигурировании большого кластера, используемого как система общего назначения, приходится выделять блоки, выполняющие все перечисленные функции.
В 1994 году Томас Стерлинг (Sterling) и Дон Беккер (Becker) создали 16-узловой кластер из процессоров Intel DX4, соединенных сетью 10 Мбит/с Ethernet с дублированием каналов. Они назвали его «Beowulf» (рис. 5.7 – 5.9) по названию старинной эпической поэмы. Кластер возник в центре NASA Goddard Space Flight Center для поддержки необходимыми вычислительными ресурсами проекта Earth and Space Sciences. Проектно-конструкторские работы быстро превратились в то, что известно сейчас как проект Beowulf.
|
|
|
|
Рисунок 5.11 – Лезвие (Blade) – вычислительный узел |
Рисунок 5.12 – Blade – модуль |
|
|
|
|
Рисунок 5.13 – Кластер Beowulf (на лезвиях) |
Рисунок 5.14 – Коммутационный узел |




Проект стал основой общего подхода к построению параллельных кластерных компьютеров, он описывает многопроцессорную архитектуру, которая может с успехом использоваться для параллельных вычислений. Beowulf-кластер, как правило, является системой, состоящей из одного серверного узла (который обычно называется головным), а также одного или нескольких подчиненных (вычислительных) узлов, соединенных посредством стандартной компьютерной сети. Система строится с использованием стандартных аппаратных компонентов, таких как ПК, запускаемые под Linux, стандартные сетевые адаптеры (например, Ethernet) и коммутаторы. Нет особого программного пакета, называемого «Beowulf». Вместо этого имеется несколько кусков программного обеспечения, которые многие пользователи нашли пригодными для построения кластеров Beowulf. Beowulf использует такие программные продукты как операционная система Linux, системы передачи сообщений PVM, MPI, системы управления очередями заданий и другие стандартные продукты. Серверный узел контролирует весь кластер и обслуживает файлы, направляемые к клиентским узлам.
5.7. Основные тенденции развития вычислительной техники
Сердцем вычислительной системы является один или несколько процессоров. Поэтому именно с модернизаций процессоров, как основной вычислительной части, связывается прогресс вычислительной техники.
Рассмотрим основные направления развитие микропроцессоров.
5.7.1. Повышение тактовой частоты
Для повышения тактовой частоты при выбранных материалах используются:
— более совершенный технологический процесс с меньшими проектными нормами;
— увеличение числа слоев металлизации;
— более совершенная схемотехника меньшей каскадности и с более совершенными транзисторами,
— более плотная компоновка функциональных блоков кристалла.
Уменьшение размеров транзисторов, сопровождаемое снижением напряжения питания с 5 В до 2,5-3 В и ниже, увеличивает быстродействие и уменьшает выделяемую тепловую энергию. Все производители микропроцессоров перешли с проектных норм 0,35-0,25 мкм на 0,18 мкм и 0,12 мкм и стремятся использовать уникальную 0,07 мкм технологию.
Уменьшение длины межсоединений актуально для повышения тактовой частоты работы, так как существенную долю длительности такта занимает время прохождения сигналов по проводникам внутри кристалла. Например, в Alpha 21264 предприняты специальные меры по кластеризации обработки, призванные локализовать взаимодействующие элементы микропроцессора. Проблема уменьшения длины межсоединений на кристалле при использовании традиционных технологий решается путем увеличения числа слоев металлизации.
5.7.2. Увеличение объема и пропускной способности подсистемы памяти
Возможные решения по увеличению пропускной способности подсистемы памяти включают:
— создание кэш-памяти одного или нескольких уровней,
— увеличение пропускной способности интерфейсов между процессором и кэш-памятью и конфликтующей с этим увеличением пропускной способности между процессором и основной памятью.
Совершенствование интерфейсов реализуется как увеличением пропускной способности шин (путем увеличения частоты работы шины и/или ее ширины), так и введением дополнительных шин, расшивающих конфликты между процессором, кэш-памятью и основной памятью. В последнем случае одна шина работает на частоте процессора с кэш-памятью, а вторая – на частоте работы основной памяти.
Общая тенденция увеличения размеров кэш-памяти реализуется по-разному:
— внешние кэш-памяти данных и команд с двух тактовым временем доступа объемом от 256 Кбайт до 2 Мбайт со временем доступа 2 такта в HP PA-8000;
— отдельный кристалл кэш-памяти второго уровня, размещенный в одном корпусе в Pentium Pro;
— размещение отдельных кэш-памяти команд и кэш-памяти данных первого уровня объемом по 8 Кбайт и общей для команд и данных кэш-памяти второго уровня объемом 96 Кбайт в Alpha 21164.
Наиболее используемое решение состоит в размещении на кристалле отдельных кэш-памятей первого уровня для данных и команд с возможным созданием внекристальной кэш-памяти второго уровня.
5.7.3. Увеличение количества параллельно работающих вычислительных устройств
Каждое семейство микропроцессоров демонстрирует в следующем поколении увеличение числа функциональных исполнительных устройств и улучшение их характеристик, как временных (сокращение числа ступеней конвейера и уменьшение длительности каждой ступени), так и функциональных (введение ММХ-расширений системы команд и т.д.).
В настоящее время процессоры могут выполнять до 6 операций за такт. Однако число операций с плавающей точкой в такте ограничено двумя для R10000 и Alpha 21164, а 4 операции за такт делает HP PA-8500. Для того чтобы загрузить функциональные исполнительные устройства, используются переименование регистров и предсказание переходов, устраняющие зависимости между командами по данным и управлению, буферы динамической переадресации.
Широко используются архитектуры с длинным командным словом – VLIW. Так, архитектура IA-64, развиваемая Intel и HP, использует объединение нескольких инструкций в одной команде (EPIC). Это позволяет упростить процессор и ускорить выполнение команд. Процессоры с архитектурой IA-64 могут адресоваться к 4 Гбайтам памяти и работать с 64-разрядными данными. Архитектура IA-64 используется в микропроцессоре Merced, обеспечивая производительность до 6 Гфлоп при операциях с одинарной точностью и до 3 Гфлоп – с повышенной точностью на частоте 1 ГГц.
5.7.4. Системы на одном кристалле и новые технологии
В настоящее время получили широкое развитие системы, выполненные на одном кристалле – SOC (System On Chip). Сфера применения SOC – от игровых приставок до телекоммуникаций.
Основной технологический прорыв в области SOC удалось сделать корпорации IBM, которая в 1999 году смогла реализовать процесс объединения на одном кристалле логической части микропроцессора и оперативной памяти. Использование новой технологии открывает перспективу для создания более мощных и миниатюрных микропроцессоров и помогает создавать компактные, быстродействующие и недорогие электронные устройства.
Для создания SOC IBM использует самые современные технологические решения, одним из которых являются медные межсоединения (copper interconnect). Первым микропроцессором IBM с медными межсоединениями в 1998 г. стал PowerPC 750. По сравнению с технологией, где межсоединения выполнены на основе алюминия, медь позволяет сделать кристалл меньшим по размеру и более быстродействующим. Медная металлизация уменьшает общее сопротивление, что позволяет увеличить скорость работы кристалла на 15-20 %. Обычно эта технология дополняется еще одной новинкой: технологией кремний на изоляторе – КНИ (SOI, Silicon On Insulator). Она уменьшает паразитные емкости, возникающие между элементами микросхемы и подложкой. Благодаря этому тактовую частоту работы транзисторов также можно увеличить. Возрастание скорости от использования КНИ приближается к 20-30%. Таким образом, общий рост производительности в идеальном случае может достигнуть 50%.
5.7.5. Нанотехнологии
Нанотехнологии – это технологии, оперирующие величинами порядка нанометра. Это технологии манипуляции отдельными атомами и молекулами, в результате которых создаются структуры сложных спецификаций. Слово «нано» (в древнегреческом языке «nano» – «карлик») означает миллиардную часть единицы измерения и является синонимом бесконечно малой величины, в сотни раз меньшей длины волны видимого света и сопоставимой с размерами атомов. Поэтому переход от «микро» к «нано» – это уже не количественный, а качественный переход: скачок от манипуляции веществом к манипуляции отдельными атомами. Мир таких бесконечно малых величин намного меньше, чем мир сегодняшних микрокристаллов и микротранзисторов.
По мнению аналитиков, предел миниатюризации для традиционной кремниевой электроники наступит через 10-15 лет, а число транзисторов в более сложных устройствах вроде электрических схем неуклонно растет.
Ученые из лаборатории Lucent Technologies Bell Labs сообщили о создании транзистора, который в миллион раз меньше крупицы песка. Это событие может стать ключевым моментом в создании миниатюрных компьютерных микросхем с малым потреблением энергии. Транзисторы являются «мозгом» компьютеров и любых других электронных устройств. Используя органическую молекулу и химические внутренние процессы, исследователи уменьшили размер транзистора до 1-2 нм (миллиардной части метра), чего еще никому не удавалось.
При создании транзисторов использовалась техника «самосборки», когда молекулы фактически сами присоединяются одна к другой с помощью электродов, сделанных из золота. Это позволило уменьшить размер канала до 1-2 нм, причем использованная методика относительно недорога и позволяет увеличить плотность транзисторов на единицу площади. Хотя пока получен только экспериментальный образец, исследователи настроены весьма оптимистично и считают, что вскоре станет возможным строить микропроцессоры и микросхемы памяти из транзисторов размером с молекулу.