Новости | Статьи | Образцы документов | Методики | Файлы | Словарь терминов
Реклама
Кратко о том, как совершить основные
действия в программе Statistica
6.0
Подготовка данных к обработке
Все данные должны быть представлены в
виде таблицы.
Каждая строка таблицы – один участник
исследования. То есть, если всего
обследованы, например, 42 человека (и
экспериментальная, и контрольная группа
вместе), то таблица содержит 42 строки
плюс заголовки.
(В примере, о котором пойдет речь дальше,
78 участников исследования)
Каждый столбец таблицы – переменная.
При подготовке данных переменной
будем считать любую информацию об
участнике исследования. Например, первой
переменной – первым столбиком таблицы
– может стать порядковый номер или даже
какое-то уникальное имя испытуемого.
Само по себе имя в исследовании НЕ
требуется. Оно может пригодиться только
для того, чтобы точно и аккуратно внести
всю информацию по этому конкретному
человеку.
Следующей переменной может являться
тип группы – экспериментальная или
контрольная. Можно так и назвать
переменную – «группа». Для всех участников
исследования надо заполнить эту
переменную. Обратите внимание: для всех
участников ОДНОЙ группы следует
использовать ОДНО И ТО ЖЕ обозначение.
Например, эксп.г. – для всех участников
экспериментальной группы, контр.г.
– для всех участников контрольной
группы. Далее можно указать пол участников
исследования.
В файле с примером данных первой
переменной является пол (Pol).
Следующей переменной является возраст
(Age). Здесь просто указан
возраст в годах. Далее следует переменная
Edu – уровень образования.
Эта переменная может принимать только
3 значения – «средне-спец.», «высшее»,
«неполное высшее». Далее указан стаж в
годах. Следующая переменная – семейное
положение, тоже может принимать несколько
значений. В этом примере первые шесть
переменных содержат общую
социально-демографическую информацию;
это еще не методики.
Далее идут методики. Переменная номер
7 – Результат методики «Уровень
профессионального стресса», может
принимать значения от 0 до 60. Переменная
8 – уровни проф.стресса, рассчитанные
по данным методики.
Следующие три переменные – №9, 10, 11 –
соответствуют трем шкалам методики
Маслач (название шкал сейчас нам не
важны). Каждая из них может принимать
значения от 0 до определенного уровня,
сейчас это не важно.
Переменные 12, 13 и 14 – оценки компонентов
социально-психологического климата:
эмоциональный, когнитивный и поведенческий
компоненты. Рассчитываются по методике.
Могут принимать только три значения
-1, 0, 1.
Итого в нашем примере получаем 14
переменных.
Обращаю Ваше внимание на то, что переменные
бывают разные. Нас будет интересовать
в первую очередь разделение переменных
на метрические и номинативные.
Метрические переменные – например,
возраст, показатели по шкале интеллекта,
и др. – могут принимать разные значение
в определенном диапазоне, причем большее
или меньшее значение соответствует
большему или меньшему уровню измеряемого
признака.
Номинативные переменные могут принимать
фиксированное число значений. Например,
переменная «пол». Может принимать два
значение – М или Ж. Переменная «уровень
образования»: может принимать три
значения – средне-спец., высшее, неполное
высшее. Переменная «тип группы» – тоже
номинативная, она задает принадлежность
участника к экспериментальной или к
контрольной группе.
Вопрос: определите, какие переменные
из Вашего исследования являются
метрическими, какие – номинативными.
Это крайне важно для выбора методов
исследования.
Результатом данного этапа работы
является таблица с данными (составленная
на бумаге или – лучше – в программе
Excel), плюс понимание, какие
переменные являются метрические, какие
– номинативными.
Создание нового файла в программе
Statistica 6.0
Откройте программу и выберите в верхнем
меню File – New.
(Рекомендую пользоваться английской
версией программы)
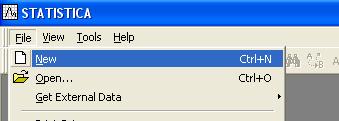
Появится окно, в котором можно выбрать
необходимое количество переменных
(Number of
Variables) и количество
наблюдений (Number of
Cases). В нашем примере будет
14 переменных и 78 наблюдений. Нажмите
ОК.

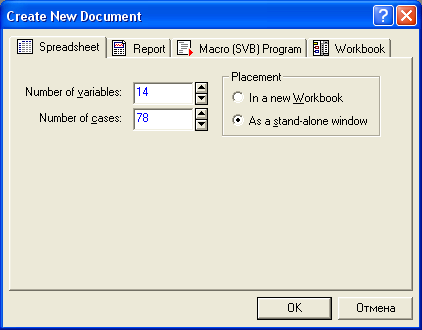
Получим чистый файл, в который можно
вносить результаты исследования.
Возможно, этот лист будет виден не
полностью, поэтому снизу и справа есть
полосы прокрутки.
Результатом данного этапа является
чистый лист, на который можно вносить
результаты исследования.
Пример такого листа ниже.
Ввод данных
Если Вы создавали таблицу данных в
программе Excel, то можно
будет скопировать данные оттуда в
статистику.
(Вообще говоря, программа Statistica
поддерживает импорт данных из Excel,
но для этого нужно очень правильно
организовать данные и очень правильно
выполнять сам импорт. Можно наделать
ошибок. Поэтому предлагаю переносить
данные «вручную».)
Как создать названия переменных
При создании нового файла все переменные
в нем уже подписаны и называются Var1,
Var2, Var3 и
т.д. Чтобы работать было удобнее, нужно
их переименовать. Для этого на заголовках
переменных щелкните дважды левой
кнопкой мышки (обозначение –
2ЛКМ). Откроется окно. В нём щелкните на
кнопку «All Specs…»,
как показано на рисунке.
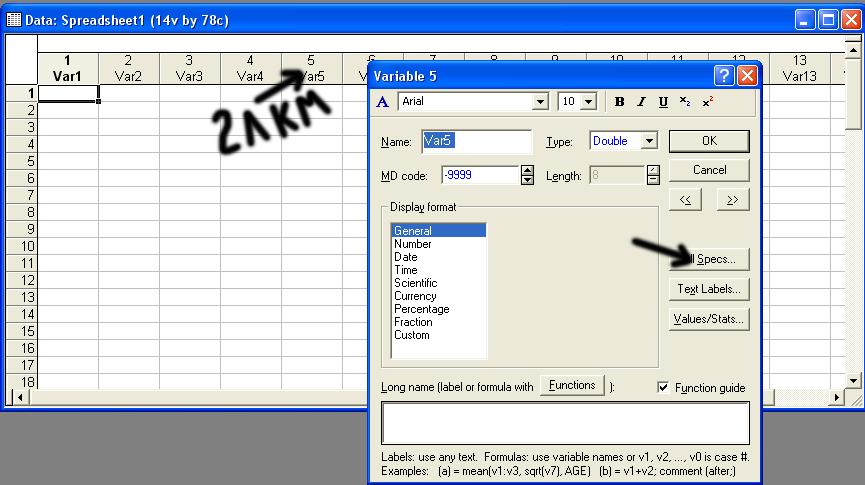
Откроется окно, в котором можно подписать
все переменные.
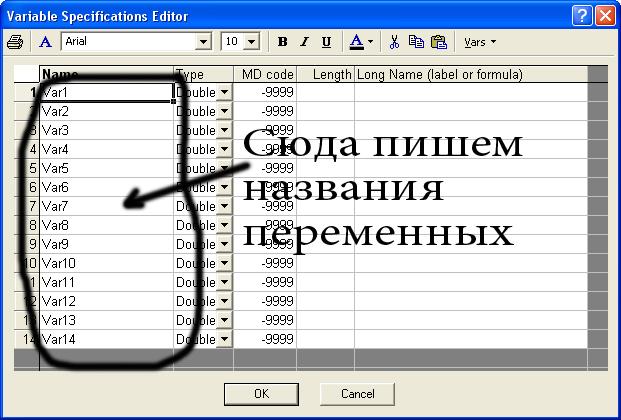
После этого нажмите ОК. Названия
переменных, которые Вы напишете, появятся
вместо Var1 и т.д. Нумерация
переменных останется, и это нормально.
Далее нужно заполнить данными всю
таблицу. Если Вы уже вносили данные в
программу Excel, то можно
там выделить диапазон с данными (без
какой-либо нумерации и без названий
переменных), копировать, и вставить в
программу Statistica.
После этого желательно сохранить файл
с данными: меню File – Save
As…, далее укажите, куда
следует поместить данный файл и как
назвать. Тип файла программа пишет
автоматически. Для сохранения нажмите
кнопку «Сохранить». После сохранения
файла его название появляется на экране,
на синем фоне в строке заголовка. Это
выглядит примерно так:
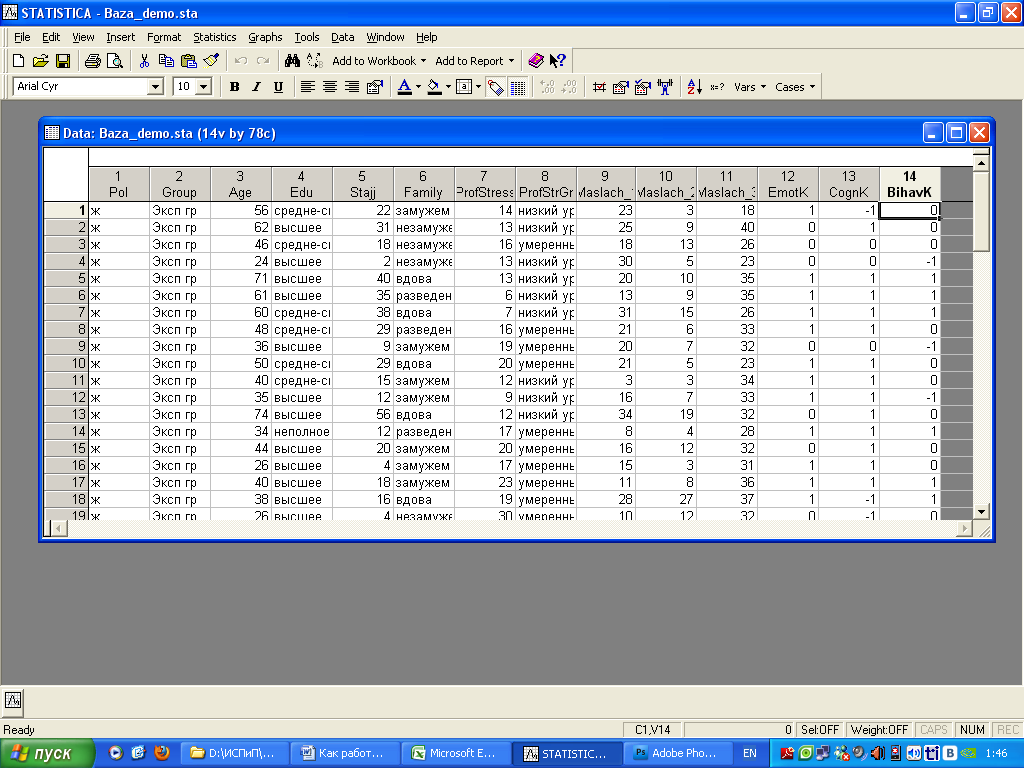
Результатом этого этапа является
заполненный и сохраненный файл с
результатами исследования.
Расчеты в программе
С этого момента самый полезный пункт
верхнего меню – Statistics.
Сравнение средних значений в двух
группах – Т-критерий Стьюдента
Данный критерий можно применять для
сравнения средних значений ТОЛЬКО
метрических переменных и ТОЛЬКО в ДВУХ
группах (не в трех, четырех, …)
В нашем примере метрическими являются
переменные:
-
№3 –Age – возраст
-
№5 – Stajj – стаж работы
-
№7 – ProfStress – показатель профессионального
стресса -
№9 – Maslach_1 – первый показатель методики
Маслач -
№10 – Maslach_2 – второй показатель методики
Маслач -
№11 – Maslach_3 – третий показатель методики
Маслач
Переменная «Пол» делит всех участников
на две группы – мужчины и женщины.
Переменная «Group» делит
всех участников на две группы –
экспериментальная группа и контрольная
группа.
Соответственно, в нашем примере с помощью
Т-критерия Стьюдента можно проверить,
1) отличаются ли средние значения
перечисленных выше переменных у мужчин
и женщин; 2) отличаются ли средние значения
перечисленных выше переменных у
участников экспериментальной и
контрольной группы.
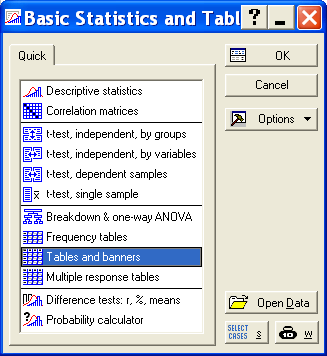
В верхнем меню
выберите пункт
Statistics – в нём
Basic Statistics/Tables.
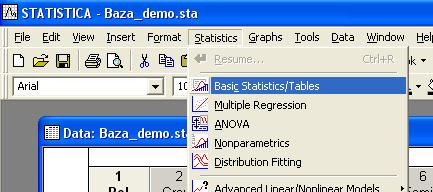
Далее как на
рисунке – t-test, independent, by
groups. Это критерий Стьюдента.
выберите, нажмите ОК.
Появляется окошко с настройками. Прежде
всего, нужно выбрать переменные, для
которых хотим провести расчет. Для этого
щелкните кнопку Variables как
показано на рисунке:
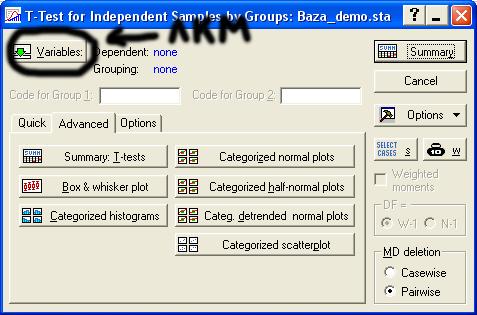
Появляется окно выбора переменных.
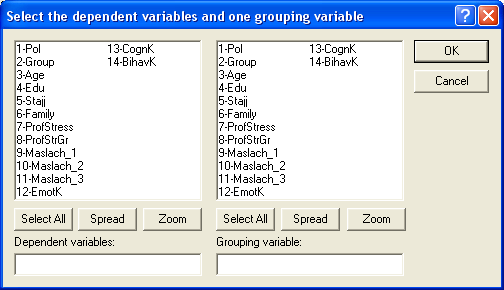
Здесь в левой части – Dependent
variables – нужно указать те
метрические переменные, средние значения
которых хотим сравнить. Например, это
переменные 3, 5, 7, 9-11 (возраст, стаж, стресс,
и т.д.). Можно выбрать переменные из
списка или в пустом окне напечатать
номера.
В правой части – Grouping
variable – указываем ОДНУ
переменную, которая делит нашу выборку
на две группы. Например, можно выбрать
переменную 1-Pol, тогда
будем сравнивать показатели мужчин и
женщин. Либо можно здесь выбрать
переменную 2-Group, тогда
будем сравнивать экспериментальную и
контрольную группы. Если нас интересуют
оба варианта, то придется дважды применять
Т-критерий. Но за один раз выбирается
только одна переменная в правой части
окна.
Сейчас рассмотрим пример с переменной
1-Pol. Это будет выглядеть
так:
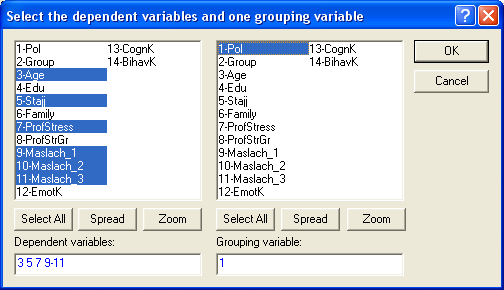
Теперь ОК.
Программа возвращает нас в предыдущее
окно. Для выполнения расчетов нужно
нажать кнопку Summary, одну
из двух, они показаны на картинке.
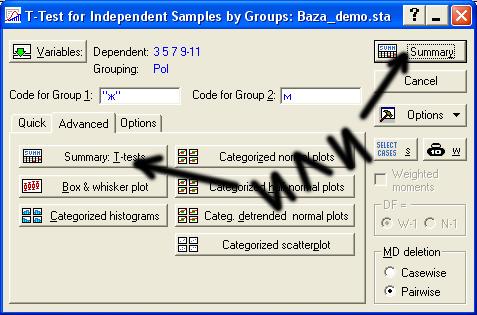
На экране появится еще одно окно –
Workbook1. В этот файл программа
будет записывать все результаты
вычислений.
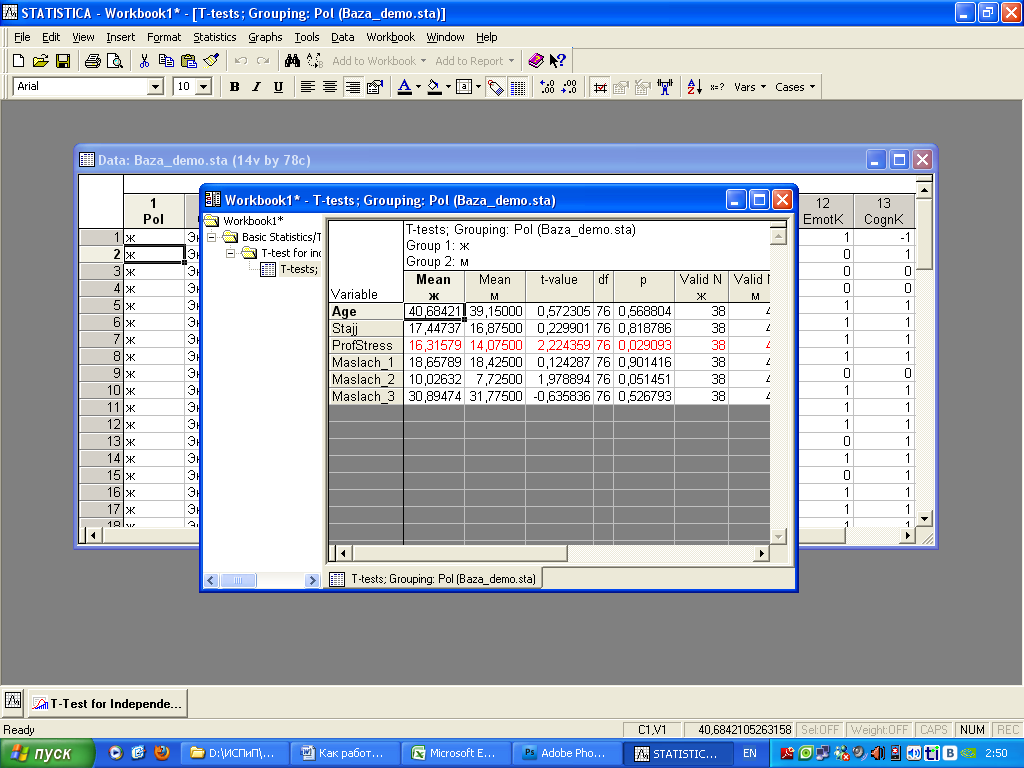
Рассмотрим подробно полученные
результаты.
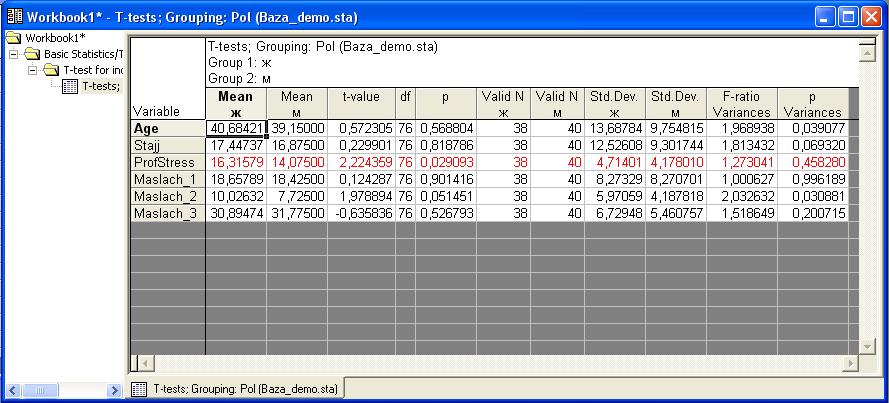
В таблице слева на сером фоне перечислены
переменные, средние значения которых
мы сравнивали. Столбцы «Mean
ж» и «Mean м» содержат
средние значения переменных для женщин
и мужчин соответственно. То есть, средний
возраст женщин составляет 40,68, средний
возраст мужчин – 39,15 лет. Средний стаж
женщин 17,44, мужчин – 16,87 лет. Далее столбец
t-value содержит
значение t-критерия, нам
оно не надо. Столбец df
обозначает количество степеней свободы,
нам тоже это не надо. (То есть, приводя
в работе результаты статистической
обработки данных, неплохо бы эти цифры
указать, но расшифровывать не надо).
Следующий столбец –p –
нужен обязательно. Это то самый уровень
достоверности различий средних значений.
Наверное, самый важный столбик из этой
таблицы.
Теоретическое отступление. Чтобы
проверить, различаются ли средние
значения в двух группах, сначала мы
рассчитываем эти значения. И почти
всегда средние значения в двух группах
будут хоть сколько-нибудь отличаться.
То есть, мы почти всегда получаем НЕ
ОДИНАКОВЫЕ средние значения. В нашем
примере то же самое – средние значения
для женщин и мужчин по всем переменным
разные. Но где-то они отличаются больше,
где-то – меньше. И «на глаз» мы не можем
определить, отличаются ли средние
значения «чуть-чуть» или «сильно».
Определить это можно только с помощью
статистических критериев, например, по
t-критерию Стьюдента.
Не вдаваясь в подробности расчетов,
предлагаю запомнить:
Средние значения в двух группах по
какой-либо переменной достоверно
отличаются, если показатель p<0,05
(в программе эти переменные выделены
красным цветом)
В этом случае говорят также, что различия
средних значений являются достоверными
(или – статистически значимыми) на 5%
уровне.
Иногда, если p больше 0,05,
но меньше, чем 0,1, то говорят, что различия
есть на уровне статистической тенденции.
То есть, это менее выраженные различия.
Но обычно если р>0,05, то говорят, что
достоверных различий не выявлено /не
установлено /не обнаружено. Но ДАЖЕ ЕСЛИ
p>0,1, НЕЛЬЗЯ ГОВОРИТЬ,
ЧТО СРЕДНИЕ ЗНАЧЕНИЯ ОДИНАКОВЫЕ.
Таким образом, в данном случае для мужчин
и женщин достоверно отличаются только
показатели профессионального стресса
(значение р=0,029, это меньше, чем 0,05). На
уровне тенденции есть различия по
показателю Маслач_2 (здесь р=0,051, это
больше, чем 0,05, но меньше, чем 0,1). Для
других переменных достоверных отличий
не выявлено.
Теперь рассмотрим сравнение средних
значений в экспериментальной и контрольной
группе.
Снова в верхнем меню выберите пункт
Statistics – в нём Basic
Statistics/Tables.
Поскольку мы уже запустили этот модуль
программы, то на экране появится окно
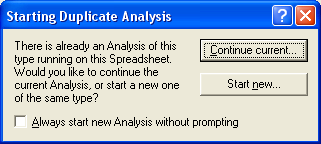
Можно выбрать «Continue
current», чтобы продолжить
расчет.
Чтобы перейти к сравнению экспериментальной
и контрольной группы, щелкните кнопку
Variable. В правой части окна
– Grouping variable
– выберите переменную номер 2. Нажмите
ОК. Нажмите Summary, как на
картинках выше.
Получим такой результат.
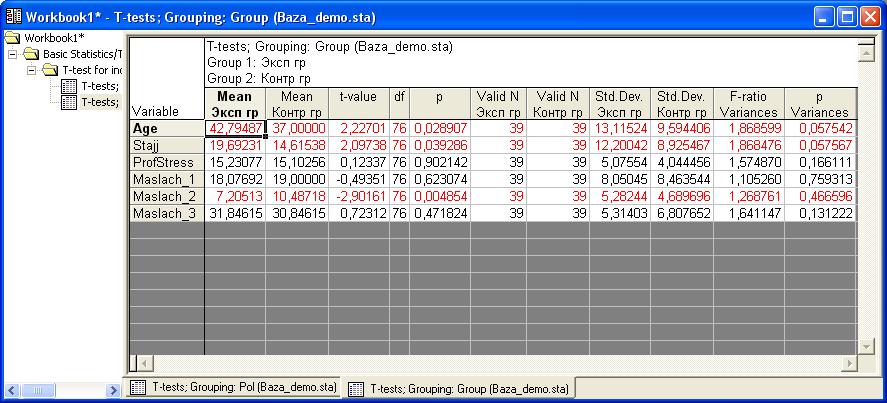
Обратите внимание, что для участников
экспериментальной и контрольной группы
достоверно отличается средний возраст,
средний стаж и средние значения по
показателю Маслач_2. По другим переменным
достоверных отличий не выявлено.
Как закрыть программу.

Сначала надо закрыть все расчеты. Для
этого в нижнем левом углу щелкните на
прямоугольник, откроется окно расчетов,
закрывайте его крестиком или кнопкой
Cancel.
Вторым шагом закрывайте окно Workbook1
– тоже крестиком. Этот файл можно
сохранить, но это не обязательно.
Третий шаг – закрывайте файл с данными.
Четвертое – закрывайте программу.
Позже допишу:
Сравнение средних значений в двух
группах – непараметрический метод.
Сравнение средних значений в трех и
более группах – дисперсионный анализ
Анализ таблиц сопряженности –
Хи-квадрат.
|
Любят |
Не любят |
|
|
М |
10 |
20 |
|
Д |
19 |
11 |
По критерию Хи-квадрат здесь получим,
что достоверно отличается распределение
по признаку «любят/не любят мороженое»
среди мальчиков и девочек. То ест, они
«по-разному» относятся к мороженому.
|
Любят ирать |
Не любят |
|
|
М |
16 |
14 |
|
Д |
15 |
15 |
Здесь по Хи-квадрату получим, что
достоверных различий не обнаружено. То
есть мальчики и девочки «не отличаются»
по любви/не любви к комп играм.
Проверяем, отличатся ли уровень
образования участников экспериментальной
и контрольной группы.

Коэффициенты корреляции.
Перенос результатов в Excel
11
Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5