Содержание:
- Что такое файл robots.txt?
- Для чего нужен файл robots.txt?
- Нюансы при использовании файла robots.txt
- Терминология файла robots.txt
- Директивы в robots.txt
- Директива User-agent
- Директива Disallow
- Директива Allow
- Алгоритм интерпретации директив Allow и Disallow
- Пустые Allow и Disallow
- Директива Sitemap
- Директива Clean-param
- Директива Host
- Директива Crawl-delay
- Комментарии в файле robots.txt
- Маски в robots.txt: для чего нужны и как правильно использовать
- Директивы в robots.txt
- Общие правила составления robots.txt
- Создание robots.txt
- Ручное создание robots.txt
- Онлайн создание файла robots.txt
- Как проверить robots.txt
- Проверки в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
- Проверки в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- Проверка с помощью Google Robots.txt Parser и Matcher Library
- Другие особенности работы с robots.txt
- Создание robots.txt
- Файл robots.txt по типам сайтов
- Файл robots.txt для Landing Page
- Файл robots.txt для интернет-магазина
- Готовые шаблоны файла robots.txt для популярных CMS
- Файл robots.txt для WordPress
- Файл robots.txt для 1С-Битрикс
- Файл robots.txt для OpenCart
- Файл robots.txt для MODx
- Файл robots.txt для Diafan
- Файл robots.txt для Drupal
- Файл robots.txt для NetCat
- Файл robots.txt для Joomla
- Популярные файлы robots.txt под задачи
- Закрыть от индексации полностью сайт в robots.txt
- Закрыть от индексации все страницы кроме главной в robots.txt
- Закрыть одну страницу в robots.txt
- Пример robots.txt для Яндекса
- Пример robots.txt для Google
- Пример robots.txt для всех поисковиков
- Популярные вопросы про файл robots.txt
- В заключение
Любой владелец многостраничного сайта заинтересован в получении трафика из поисковых систем, как рекламного, так и органического. Чтобы сайт по запросу пользователей выходил в выдаче Google и Яндекс (не важно топ 3, топ 10 или топ 100) необходимо, чтобы сайт прошел индексацию поисковыми системами. Индексация сайта — это процесс «сканирования» сайта поисковыми «роботами» в результате чего они получают информацию о всех его страниц и имеющемся на нем контенте.
На любом сайте есть не только контент для пользователей, но и различные системные файлы, которые не должны попадать в индексацию и соответственно в выдачу. Когда поисковый робот начинает сканировать сайт, для него нет разницы, системный перед ним файл или нет — он просканирует все. При этом на посещение сайта у поискового робота отведено ограниченное количество времени, поэтому важно, чтобы он проиндексировал именно нужные нам страницы. Иначе робот посчитает сайт бесполезным и позиции сайта могут в итоге снизиться в поисковой выдаче.
Со стороны владельца сайта можно повлиять на процесс сканирования сайта, прописывая определенные правила для поисковых роботов. Для того, чтобы поисковые роботы проиндексировали только необходимые для нас страницы, обязательно нужно создавать файл robots.txt с набором правил и фильтров.
Что такое файл robots.txt?
Файл robots.txt – это текстовый файл в формате .txt, который размещается в корневой папке сайта и содержит инструкции по обходу страниц, которые необходимо исключить из индексации поисковых систем.
Для сайта https://discript.ru/ путь размещения следующий: https://discript.ru/robots.txt
В нем есть своя структура, правила, и в целом он в некотором роде выполняет функцию «фильтра». Говоря проще, именно при помощи robots.txt мы указываем, какие страницы сайта робот должен сканировать, а какие – нет.
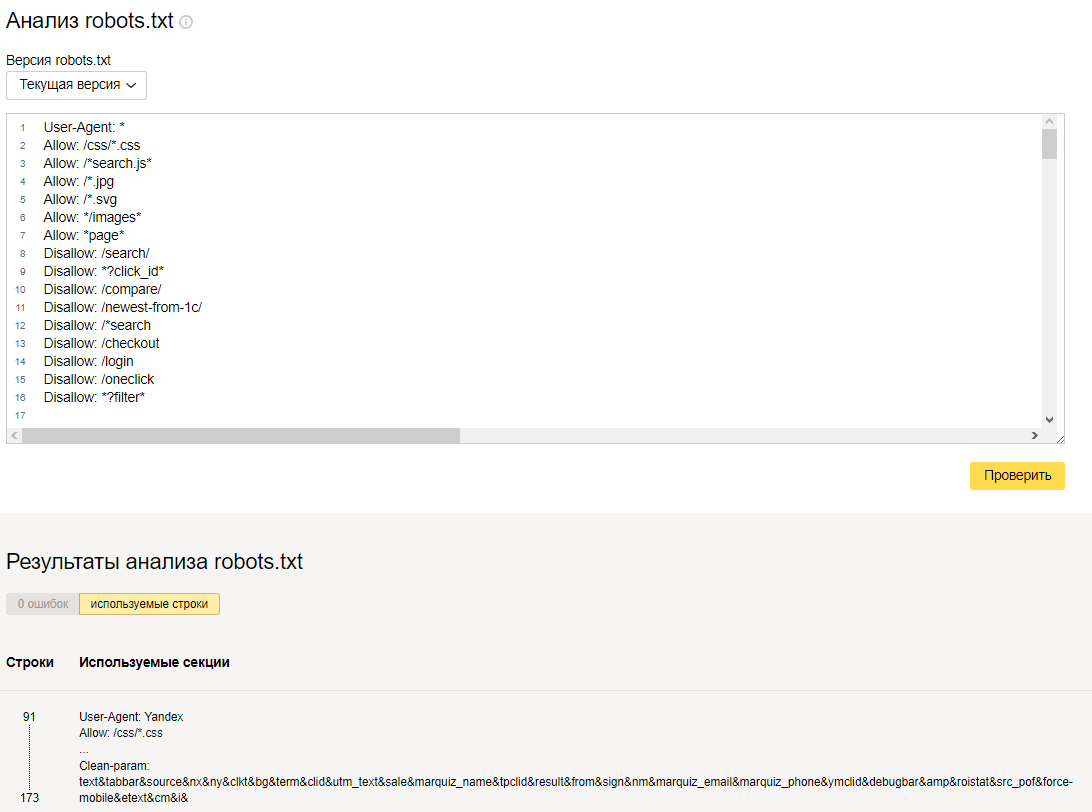
Пример файла robots.txt в панели Яндекс Вебмастер
Google: файл robots.txt носит рекомендательный характер и не служит для 100% ограничением для поисковых роботов. 
Источник справка Google: https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=ru
Для чего нужен файл robots.txt?
Когда поисковый робот (краулер / паук) заходит на сайт, то в первую очередь он ищет именно этот файл.
При этом пауки в любом случае могут обойти страницы сайта — независимо от того, есть ли на нем robots.txt или нет. Просто если файл robots.txt есть, то роботы с высокой вероятностью будут следовать правилам, прописанным в файле.
А если он есть, но при этом неправильно настроен, то сайт и вовсе может выпасть из поиска или просто не будет проиндексирован.
Файл robots позволяет исключить из индекса:
- Мусорные страницы.
- Дубли страниц.
- Служебные страницы.
Правильная настройка файла robots.txt позволяет сохранить крауленговый бюджет и повысить частоту сканирования нужных разделов.
К тому же вы можете запретить сканирование дополнительных файлов, таких как:
- Дубли изображений в сжатом формате.
- Дополнительные стили сайта.
- Скрипты.
Но данные элементы следует запрещать к сканированию аккуратно, т.к. данное действие не должно мешать поисковым системам интерпретировать контент.
Нюансы при использовании файла robots.txt
Обратите внимание, что при работе с файлом robots.txt есть свои нюансы:
- Правила используемые в robots.txt не всегда интерпретируются всеми поисковыми системами одинаково.
Например, директива «Clean-param» считается ошибкой при интерпретации Google. - Для поисковых роботов правила являются рекомендациями и не всегда роботы следуют им.
- Если страница закрыта в файле robots.txt, но при этом на данную страницу есть ссылки, то Google может добавить такую страницу в индекс. И для удаления подобной страницы из поисковой выдачи требуются другие инструменты.
Терминология файла robots.txt
В файле robots.txt основная работа происходит с Директивами и Директориями, важно не запутаться и понимать отличия между терминами:
Директория — это папка, в которой находятся файлы вашей системы управления.
Директива — это список команд, инструкции в robots.txt для одного или нескольких поисковых роботов при помощи которых производится управление индексацией сайта. В файле robots.txt используются 5 директив.
Директивы в robots.txt
5 директив используемых в robots.txt:
- User-agent
- Disallow
- Аllow
- Sitemap
- Clean-param
А так же:
- Маски
- Комментарии
Существует 2 устаревших директивы:
- Host
- Crawl-delay
Директива User-agent
User-agent — это директива для определения, какому поисковому боту необходимо выполнять указанные инструкции.
Все поисковые роботы начинают обработку robots.txt с проверки записи User-agent и определения подходящих инструкций работы с сайтом.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно
User-agent: *
# Указывает директивы для всех роботов Яндекса
User-agent: Yandex
# Указывает директивы для всех роботов Google
User-agent: Googlebot
Через robots.txt можно обратиться не только к главному роботу поисковой системы, но и к вспомогательным роботам, например, в Яндексе есть робот, который индексирует изображения: YandexImages или робот, который индексирует видео: YandexVideo.
Существует мнение, что роботы лучше индексируют сайт, если к ним обращаться напрямую, а не через общую инструкцию, но с точки зрения синтаксиса разницы нет никакой.
Если в директиве User-agent указать конкретного робота, то учитывать правила общего назначения (User-agent: *) указанный робот не будет.
Кроме того, в robots.txt не имеет значения регистр символов. То есть одинаково правильно будет записать: User-agent: Googlebot или User-agent: googlebot.
Таким образом, директива User-agent указывает только на робота (или на всех сразу), а уже после нее должна идти команда или команды с непосредственным указанием команд для выбранного робота.
Директива Disallow
Disallow — запрещающая директива. Она запрещает поисковому роботу обход каталогов, адресов или файлов сайта. Данная директива является наиболее используемой. Путь к тем файлам, каталогам или адресам, которые не нужно индексировать, прописываются после слеша «/».
Рассмотрим несколько примеров
Как в robots.txt запретить индексацию сайта:
User-agent: * # — Инструкции для всех роботов.
Disallow: / # — Закрыты от индексации все страницы сайта.
Данный пример закрывает от индексации весь сайт для всех роботов.
Как robots.txt запретить индексацию папки wp-includes для всех роботов:
User-agent: * # — Инструкции для всех роботов.
Disallow: /wp-includes # — Закрыт от индексации раздел wp-includes.
Данный пример закрывает для индексации все файлы, которые находятся в этом каталоге.
А вот если вам, например, нужно запретить индексирование всех страниц с результатами поиска только от робота Яндекс, то в файле robots.txt прописывается следующее правило:
User-agent: Yandex # — Инструкции для бота Yandex.
Disallow: /search # — Закрыт от индексации раздел search.
Запрет на индексацию в этом случае распространяется именно на страницы, у которых в URL есть «/search».
Директива Disallow допускает работу с масками, которые позволяют производить операции с группой файлов и папок.
Директива Allow
Allow — разрешающая директива, логически противоположная директиве Disallow. То есть она принудительно открывает для индексирования указанные каталоги, файлы, адреса. Директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * # — Инструкции для всех роботов.
Disallow: / # — Закрыты от индексации все страницы сайта.
Allow: /blog # — Открыт для индексирования раздел blog.
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /blog.
Если же необходимо разрешить индексировать все страницы, в адресе которых присутствует вхождение blog, то следует использовать конструкцию:
User-agent: * # — Инструкции для всех роботов.
Disallow: / # — Закрыт от индексации все страницы сайта.
Allow: /*blog # — Открыт для индексирования любые страницы с вхождением blog в URL.
Иногда директивы Allow и Disallow используются в паре. Это может понадобиться для того, чтобы открыть роботу доступ к подкаталогу, который расположен в каталоге с запрещенным доступом.
Алгоритм интерпретации директив Allow и Disallow
Когда бот определяет свои инструкции по User-agent, то встает вопрос, по какому алгоритму интерпретировать правила. Ведь одно правило, может противоречить другому. Или например, нужно открыть для индексирования вложенный раздел, но корневой закрыть от индексации.
Роботы интерпретируют robots.txt последовательно сортируя инструкции по длине URL от короткого к длинному. При этом если длина правила совпадает для Allow и Disallow, то более приоритетное правилом является Allow.
Рассмотрим механизм на примере:
Вам необходимо, чтобы раздел /catalog/mebel/divan/ индексировался роботом, а раздел /catalog/mebel/ был закрыть от роботов.
При этом Вы имеете следующий файл robots.txt
User-agent: *
Disallow: /catalog/avto/
Allow: /catalog/mebel/divan/
Disallow: /catalog/test/
Allow: /
Disallow: /catalog/mebel/
То робот информацию прочитает так:
User-agent: * # — Инструкции для всех роботов.
Allow: / # — Сайт доступен для индексации
Disallow: /catalog/avto/ # — Раздел /catalog/avto/ закрыт для индексирования.
Disallow: /catalog/test/ # — Раздел /catalog/test/ закрыт для индексирования.
Disallow: /catalog/mebel/ # — Раздел /catalog/mebel/ закрыт для индексирования.
Allow: /catalog/mebel/divan/ # — Раздел /catalog/mebel/divan/ доступен для индексирования, при этом раздел /catalog/mebel/ и другие подразделы данного каталога закрыты от индексирования.
Зная, как боты интерпретируют правила из robots.txt дает больше возможностей по составлению правил для индексирования сайта.
Пустые Allow и Disallow
Если в файле robots.txt присутствуют пустые Allow и Disallow, то роботы интерпретируют их так:
Пустой Disallow — соответствует директиве Allow: /, т.е. разрешает индексировать весь сайт.
Пустой Allow — не интерпретируется роботом.
Директива Sitemap
Sitemap — директива указывающая ссылку на карту сайта: sitemap.xml. Данная директива позволяет боту быстрее найти файл sitemap.xml.
Robots.txt с указанием адреса карты сайта:
User-agent: * # — Инструкции для всех роботов.
Disallow: /page # — Закрыт от индексации раздел page.
Sitemap: http://www.site.ru/sitemap.xml
В файле robots.txt допускается использование нескольких директив Sitemap
Директиву Sitemap можно размещать с отступом в строку от других директив. Что в свою очередь значит, что данная директива не привязывается к определенному User-agent и достаточно указать 1 раз в файле robots.
Примеры допустимого использования директивы:
Второй вариант:
Директива Clean-param
Clean-param — директива позволяет исключить из индексации страницы с динамическими get-параметрами. Такие страницы могут отдавать одинаковое содержимое, имея различные URL (например, UTM). Данная директива позволяет сэкономить крауленговый бюджет за счёт исключения из индексирования страниц дублей. Clean-param интерпретирует только Яндекс, роботы Google на данную директиву выдадут ошибку.
Директива Clean-param применима только для Яндекса (Google выдаст ошибку), поэтому без особой надобности её использовать не рекомендуется.
Примечания:
- Иногда для закрытия таких страниц используется директива Disallow. В некоторых случаях рекомендуем использовать Clean-param, так как эта директива позволяет передавать основному URL или сайту некоторые накопленные показатели, например ссылочные.
- Директива Clean-Param может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
- Директива имеет ограничение на 500 символов. Если требуется больше символов, то необходимо использовать несколько директив Clean-Param.
Рекомендации к применению:
- При использовании UTM-меток
- Дубли генерируемые get-параметрами
- При использовании идентификаторов в get-параметрах.
Синтаксис директивы Clean-param:
Clean-param: parm1&parm2&parm3 [Путь]

Через & указаны параметры, которые необходимо не учитывать,
[Путь] — адрес, для которого применяется инструкция. Если данного параметра нет, то применяется ко всем страницам на сайте.
В директиве Clean-param допускается использовать регулярные выражения, но с ограничениями.
При использовании регулярных выражений необходимо использовать следующие символы: a-z0-9.-/*_.
Рассмотрим на примере страницы со следующим URL:
- www.site.ru/page.htm
- www.site.ru/page.html?&parm1=1&parm2=2&parm3=3
- www.site.ru/page.html?&parm1=1&parm4=4
Данные страницы являются дублями и имеют одинаковый контент. Поэтому нам необходимо с помощью директивы Clean-param удалить из индексирования страницы с параметрами:
- parm1
- parm2
- parm3
- parm4
Ограничение учета параметров только для раздела /page
User-agent: *
Disallow: /catalog
Clean-param: parm1&parm2&parm3&parm4 /page # Исключить параметры parm1, parm2, parm3, parm4 и только для page.html
Ограничение учета параметров только для всего сайта
User-agent: *
Disallow: /catalog
Clean-param: parm1&parm2&parm3&parm4 # Исключить параметры parm1, parm2, parm3, parm4 на всех страницах сайта.
Пример использования регулярных выражений. Ограничение учета параметров для страниц в URL, у которых есть вхождение page.
User-agent: *
Disallow: /catalog
Clean-param: parm1&parm2&parm3&parm4 /*page # Исключить параметры parm1, parm2, parm3, parm4 для всех страниц содержащих вхождение в URL page.
Директива Host
Host — директива указывающая поисковым роботам Яндекса главное зеркало ресурса.
Директива Host перестала учитываться поисковой системой Яндекс в марте 2018 года. (В Google никогда не учитывалась). Данную директиву можно удалить из файла, но на зеркалах необходимо настроить 301-редирект. Подробнее по ссылке: https://yandex.ru/blog/platon/pereezd-sayta-posle-otkaza-ot-direktivy-host
Данная директива применялась для проектов, где доступ к сайту осуществляется по нескольким адресам.
Например, сайт мог быть доступен по следующим адресам:
- site.ru
- www.site.ru
- old.site.ru
- site.com
Но контент на данных страницах полностью дублировался.
Пример файла robots с директивой Host:
User-agent: Yandex
Disallow: /page
Host: site.ru # Указание основного зеркала сайта
Директива Crawl-delay
Crawl-delay — директива позволяющая задать скорость обхода страниц поисковым ботам для вашего ресурса. Данная директива учитывались только Яндексом. На текущий момент не поддерживается совсем.
Директиву Crawl-delay с 22 февраля 2018 года Яндекс перестал учитывать. Подробнее по ссылке https://yandex.ru/support/webmaster/robot-workings/crawl-delay.html
Если необходимо указать скорость обхода для поискового бота используйте панель вебмастера https://yandex.ru/support/webmaster/service/crawl-rate.html#crawl-rate
Комментарии в файле robots.txt
Комментарии в robots.txt — поясняющие заметки, которые не интерпретируются роботами и позволяют пользователю получить уточнения по работе директив.
Комментарии пишутся после символа решетки «#» и действуют до конца строки.
Комментарии упрощают работу и помогают быстрее сориентироваться в файле. В комментарии добавляют актуальную и полезную информацию, например, ссылку на партнерку:

Некоторые вебмастера добавляют в комментариях к robots.txt рекламные тексты.
В комментариях robots.txt можно прописать все, что угодно, однако идеальный комментарий— это тот, в котором мало строк, но много смысла.
Маски в robots.txt: для чего нужны и как правильно использовать
Маска в robots.txt — это условная запись, в которую входят названия целой группы папок или файлов. Маски используются для того, чтобы одновременно совершать операции над несколькими файлами (или папками) и обозначаются спецсимволом-звездочкой — «*».
На самом деле, использование масок не только упрощает работу, оно зачастую просто необходимо. Предположим, у вас на сайте есть список файлов в папке /documents/. Среди этих файлов есть презентации в формате .pdf, и вы не хотите, чтобы их сканировал робот. Значит эти файлы нужно исключить из поиска.
Как это сделать? Можно перечислить все файлы формата .pdf вручную:
- Disallow: /documents/admin.pdf
- Disallow: /documents/town.pdf
- Disallow: /documents/leto.pdf
- Disallow: /documents/sity.pdf
- Disallow: /documents/europe.pdf
- Disallow: /documents/s-112.pdf
Но если таких файлов сотни, то указывать их придется очень долго, поэтому куда быстрее просто указать маску *.pdf, которая скроет все файлы в формате pdf в рамках одной директивы:
- Disallow: /documents/*.pdf
Специальный символ «*», который используется при создании масок, обозначает любую последовательность символов, в том числе и пробел.
Пример использования маски.
User-agent: *
Disallow: /
Disallow: *.pdf # — Закрыты от сканирования все файлы pdf.
Disallow: admin*.pdf # — Закрыты от сканирования файлы pdf из раздела admin.
Disallow: a*m.pdf # — Закрыты от сканирования файлы pdf из разделов начинающихся на a и m перед расширением файла .pdf.
Disallow: /img/*.* # — Закрыты от сканирования все элементы в папке img.
Allow: /*blog # — Открыты для индексирования любые страницы с вхождением blog в URL.
Общие правила составления robots.txt
Очень важно грамотно работать с файлом robots.txt, иначе можно собственноручно отправить на индексацию документы, которые индексировать не планировалось.
- наличие файла robots.txt на сайте;
- в правильном ли месте он расположен;
- грамотно ли он составлен;
- насколько он работоспособен, т.е. доступны ли указанные в нем документы для индексации.
Файл robots.txt должен располагаться исключительно в корневой папке сайта, т.е. он должен быть доступен по адресу site.ru/robots.txt.
Не допускается наличие вложений, например, site.ru/page/robots.txt. Если файл robots.txt располагается не в корне сайта (и у него другой URL), то роботы поисковых систем его не увидят и будут индексировать все страницы сайта.
При этом важно помнить, что файл robots.txt привязан к адресу домена вплоть до протокола. То есть для http и https требуется 2 разных robots.txt, даже если затем адреса совпадают. Также один и тот же файл нельзя использовать для субдоменов (хостов) и других портов.
Один robots.txt действителен для всех файлов во всех подкаталогах, которые относятся к одному хосту, протоколу и номеру порта.
Корректность файла robots.txt можно оценить, проверив его по следующим пунктам:
- Один файл robots.txt.Файл должен быть один для каждого сайта и называться он должен robots.txt.
- robots.txt отсутствует или он закрыт от индексирования (Disallow: /);
- Размещение robots.txt в корне сайта. Файл robots.txt должен располагаться в корневой папке сайта. Если он расположен в другом месте, то роботы его не увидят и будут индексировать весь сайт (включая файлы, которые индексировать не нужно).
- Заглавные буквы в названии не используются.
Неверно:
site.ru/RoBoTs.txt
Верно:
site.ru/robots.txt
-
Запрещено использовать кириллицу в директориях robots.txt. Чтобы указывать названия кириллических доменов, нужно использовать Punycode для их преображения. Адреса сайтов также указывают в кодировке UTF-8, включающей коды символов ASCII.
Для перевода кирилического URL используйте инструмент: https://www.punycoder.com
Неверно:
User-agent: Yandex
Disallow: /корзина
Sitemap: сайт123.рф/sitemap.xmlВерно:
-
Инструкции пишутся отдельно для каждого робота, т.е. в директиве User Agent не допускается никаких перечислений. Если хотите назначить правила для всех роботов, то необходимо использовать User-agent: *. В файле robots.txt знак «*» — это любое число любых символов;
Неверно:
User-agent: Yandex, Google, Mail
Disallow: /Верно:
User-agent: Yandex
Disallow: /User-agent: Google
Disallow: /User-agent: Mail
Disallow: / -
Есть несколько правил для одного агента, например, несколько правил «User-agent: Yandex». В правильно составленном файле такое правило может быть только одно.
Неверно:
User-agent: Yandex
Disallow: /User-agent: Yandex
Disallow: /catalogUser-agent: Yandex
Disallow: /testВерно:
User-agent: Yandex
Disallow: /
Disallow: /catalog
Disallow: /test -
Каждая директива должна начинаться с новой строки;
Неверно:
User-agent: *
Disallow: /catalog Disallow: /new Allow: /testВерно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /test -
1 директива = 1 параметр, т.е. например, Disallow: /admin, и никаких Disallow: /admin /manage и т.д. в одной строчке;
Неверно:
User-agent: *
Disallow: /catalog /new /testВерно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /test -
В начало строки не ставится пробел;
Неверно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /testВерно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /test -
Параметр директивы должен быть прописан в одну строку;
Неверно:
User-agent: *
Disallow: /catalog_
new_cat
Disallow: /new
Allow: /testВерно:
User-agent: *
Disallow: /catalog_new_cat
Disallow: /new
Allow: /test -
Параметры директивы не нужно добавлять в кавычки, также они не требуют закрывающих точки с запятой;
Неверно:
User-agent: *
Disallow: «/catalog_new_cat»
Disallow: /new;
Allow: /testВерно:
User-agent: *
Disallow: /catalog_new_cat
Disallow: /new
Allow: /test -
Комментарии допускаются после знака #;
Неверно:
User-agent: *
# Этот комментарий заставит игнорировать строчку Disallow: /catalog_new_cat
Disallow: /new
Allow: /testВерно:
User-agent: *
Disallow: /catalog_new_cat # Этот комментарий заставит учитывать строку
Disallow: /new
Allow: /test -
Перед правилом отсутствует директива User-agent. Любое правило в robots.txt всегда начинается с User-agent.
Неверно:
Disallow: /catalog
Disallow: /new
Allow: /testВерно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /test -
Пустые строки между директивами. Правильная настройка robots.txt запрещает наличие пустых строк между директивами «User-agent», «Disallow» и директивами, следующими за «Disallow» в рамках текущего «User-agent».
Неверно:
User-agent: Yandex
Disallow: /
User-agent: Google
Disallow: /catalog
User-agent: Mail
Disallow: /testUser-agent: Yandex
Disallow: /
User-agent: Yandex
Disallow: /
Disallow: /catalogDisallow: /test
Верно:
User-agent: Yandex
Disallow: /User-agent: Google
Disallow: /catalogUser-agent: Mail
Disallow: /testUser-agent: Yandex
Disallow: /
Disallow: /catalog
Disallow: /test -
Некорректные адреса. Например, путь к файлу Sitemap должен указываться полностью, включая протокол.
Неверно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /testsitemap: /sitemap
Верно:
- Слишком большой (более 32Кб), недоступный по каким-либо причинам или пустой robots.txt будет трактоваться как полностью разрешающий;
- В robots.txt допускается использовать более 2048 директивы (команд).
- Максимальная длина одного правила — 1024 символа. Но такая ошибка встречается довольно редко.
- Некорректный тип контента. Должен быть: text/plain.
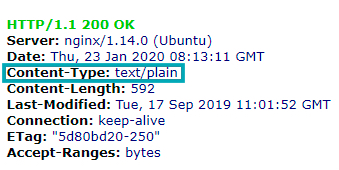
Ошибка, когда на уровне хостинга robots.txt имеет кодировку HTML:
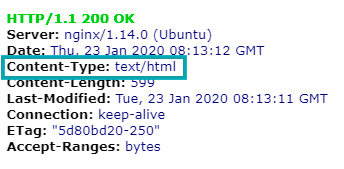
Проверить тип контента можно на сайте https://bertal.ru/
Четкое соблюдение вышеописанных правил при создании и настройке файла robots.txt имеет огромное значение. Незамеченный или пропущенный слэш, звездочка или запятая могут привести к тому, что сайт закроется от индексации полностью. То есть даже незначительная разница в синтаксисе приводит к существенным отличиям в функционале.
Создание robots.txt
Файл robots.txt нужно разместить в корневой папке, то есть в той, которая называется так же, как и ваш движок и содержит в себе индексный файл index.html и файлы системы управления, на базе которой и сделан сайт.
Чтобы загрузить в эту папку файл robots.txt можно использовать панель управления сервером, админку в CMS, Total Commander или другие способы.
Ручное создание robots.txt
Чтобы самостоятельно создать файл robots.txt не потребуется никаких дополнительных программ. Достаточно будет любого текстового редактора, например, стандартного блокнота, notepade++, Microsoft Word и другие текстовые редакторы.
Чтобы создать robots.txt просто сохраните файл под таким именем и с расширением .txt., и уже после этого вносите в него все необходимые инструкции в зависимости от стоящих перед вами задач.
На некоторых движках уже есть встроенная функция, которая позволяет создать robots.txt. Если у вас ее нет, то можно использовать специальные модули или плагины. Но в целом, нет никакой разницы, каким именно способом вы создадите robots.txt.
Онлайн создание файла robots.txt
В случае, когда у вас не один, а несколько сайтов, и создание файлов robots.txt будет занимать долгое время, можно воспользоваться онлайн-сервисами, которые генерируют robots.txt. автоматически. Но учтите, что такие файлы могут требовать ручной корректировки, поэтому все равно нужно понимать правила их составления и знать особенности синтаксиса.
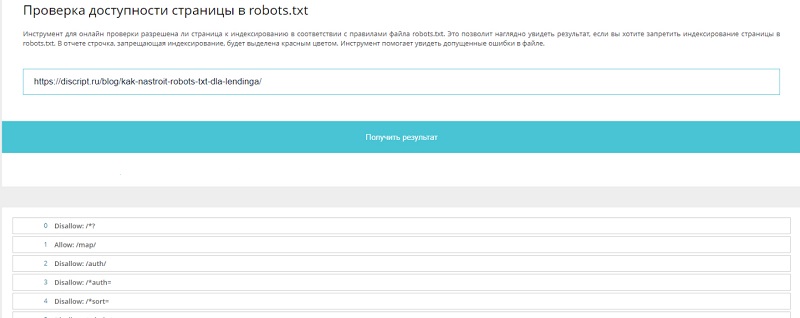
Для составления robots.txt можете воспользоваться нашим инструментом: http://tools.discript.ru/robots-check/. Он позволяет выгрузить robots.txt, как с вашего сайта, так и загрузить готовый шаблон для CMS и скорректировать уже под Ваши задачи.
Далее в статье также можно найти готовые шаблоны robots.txt.
Как проверить robots.txt
Проверить, насколько правильно составлен robots.txt, можно при помощи:
Инструмента http://tools.discript.ru/robots-check/.
С его помощью вы можете проверить свой файл и внести в него корректировки в режиме онлайн. Для этого укажите URL страницы в соответствующем поле. Инструмент покажет, допущены ли ошибки в обновленной версии. Также вы можете использовать подготовленные шаблоны файлов robots.txt для наиболее популярных CMS, в которых уже указаны все основные условия.
Инструмент позволяет скачать итоговый файл и сразу разместить его на сайте.
Проверки в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Здесь анализируется каждая строка содержимого поля «текст robots.txt» и директивы, которые он содержит. Здесь также можно увидеть, какие страницы открыты для индексации, а какие — закрыты.
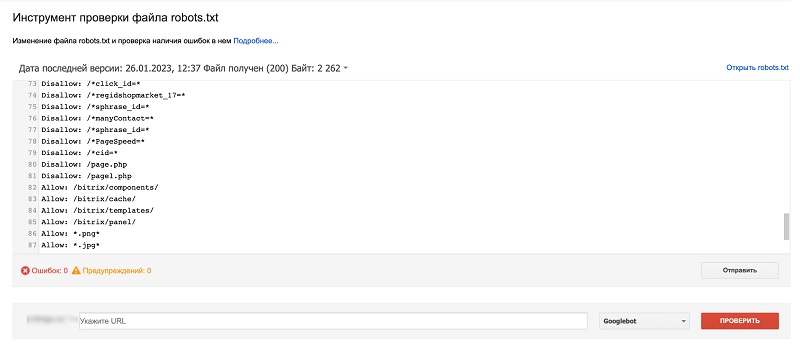
Проверки в Google: https://www.google.com/webmasters/tools/robots-testing-tool
Здесь можно проверить, содержится ли в файле запрет на сканирование роботом Googlebot определенных адресов на ресурсе:
Проверка с помощью Google Robots.txt Parser и Matcher Library
В 2019 году Google представил доступ к своему парсеру. Скачать его можно с GitHab по ссылке https://github.com/google/robotstxt
Данная библиотека используется Google для парсинга файла robots.txt. Если Вы хотите получать файл, способом, как это делает Google, то можете воспользоваться библиотекой запустив её у себя.
Другие особенности работы с robots.txt
-
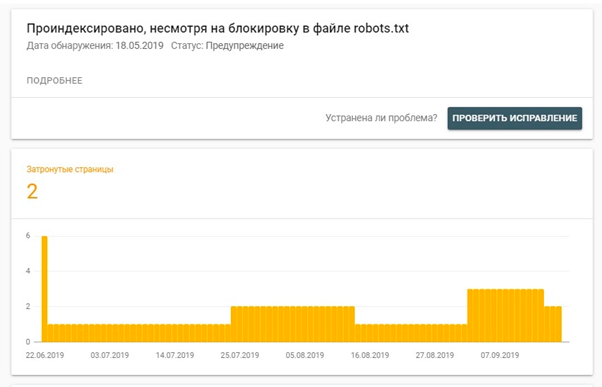
Страницы, закрытые с помощью файла robots.txt, могут быть проиндексированы в Google. Например, когда на них ведет много внутренних и внешних ссылок.
В таком случае в панели Google Search Console можно видеть такой отчет:
По этому вопросу в Google справочнике указано:
Файл robots.txt не предназначен для блокировки показа веб-страниц в результатах поиска. Если на других сайтах есть ссылки на вашу страницу, содержащие ее описание, то она все равно может быть проиндексирована, даже если роботу Googlebot запрещено ее посещать. Если файл robots.txt запрещает роботу Googlebot обрабатывать веб-страницу, она все равно может показываться в Google, но связанный с ней результат поиска может не содержать описания и выглядеть следующим образом:
Источник: https://support.google.com/webmasters/answer/6062608?hl=ru
Поэтому, чтобы закрыть от индексирования страницы, которые содержат конфиденциальную информацию, нужно использовать более надежные методы: не только robots.txt, но и html-теги.
Если нужно закрыть внутри зоны документ, то устанавливается следующий код:
— запрещено индексировать содержимое и переходить по ссылкам на странице;
Или (полная альтернатива):
Такие теги показывают роботам, что страницу не нужно показывать в результатах поиска, а также не нужно переходить по ссылкам на ней.
Однако при использовании только мета-тега краулинговый бюджет будет расходоваться намного быстрее, поэтому лучше всего применять комбинированный способ. Он, к тому же, с большим приоритетом выполняется поисковыми роботами.
-
Для изображений настройка robots.txt выглядит следующим образом:
Чтобы скрыть определенное изображение от робота Google Картинок
User-agent: Googlebot-Image
Disallow: /images/dogs.jpg
Чтобы скрыть все изображения с вашего сайта от робота Картинок
User-agent: Googlebot-Image
Disallow: /
Чтобы запретить сканирование всех файлов определенного типа (в данном случае GIF)
User-agent: Googlebot
Disallow: /*.gif$
Файл robots.txt важен для продвижения, потому что дает поисковикам указания, которые напрямую влияют на результативность работы сайта. Например, в нем можно установить запрет на индексацию «мусорных» или некачественных страниц, закрыть страницу с доступом в административную панель, страницы с приватными данными, дублирующие документы и т.д.
-
Рекомендуется закрывать от индексации следующие страницы:
- страницы входа в CMS-систему вида «/bitrix», «/login», «/admin», «/administrator», «/wp-admin».
- служебные папки вида «cgi-bin», «wp-icnludes», «cache», «backup»
- страницы авторизации, смены пароля, оформления заказа: «basket&step=», «register=», «change_password=», «logout=».
- результаты поиска «search», «poisk».
- версию для печати вида: «_print», «version=print» и аналогичные.
- страницы совершения действия вида «?action=ADD2BASKET», «?action=BUY».
- разделы с дублированным и неуникальным контентом, скажем, RSS-фиды: «feed», «rss», «wp-feed».
Если на сайте есть ссылки на страницы, которые закрыты в файле robots.txt, то рекомендуется убрать эти ссылки, чтобы не передавать на них статический вес.
Наиболее часто дублями страниц, попавшими в индекс, являются документы с неопределенными в БД GET-параметрами. Примерами таких параметров являются UTM-метки (и прочие метки рекламных кампаний). Если на сайте не настроен rel=»canonical», то потенциальные данные дубли лучше закрывать от индексации.
Список наиболее частых параметров:
- openstat
- from
- gclid
- utm_source
- utm_medium
- utm_campaign
- utm_прочие
- yclid
Следует помнить, что GET параметры могут идти после знака «?», либо после знака «&» (если их более одного). Поэтому для закрытия GET параметров необходимо для каждого знака указывать отдельное правило:
- Disallow: *?register=*
- Disallow: *®ister=*
Либо не указывать ни один из данных знаков (не самый лучший вариант для коротких GET параметров т.к. они могут быть частью более длинных вариантов. Например, GET параметр id входит в GET параметр page_id):
- Disallow: *register=*
Пример закрытия таких страниц:
- Disallow: *openstat=*
- Disallow: *from=*
- Disallow: *gclid=*
- Disallow: *?utm_*
- Disallow: *&utm_*
- Disallow: *yclid=*
Пример закрытия всех GET параметров главной страницы:
- Disallow: /?*
Также для закрытия страниц с неопределенными GET параметрами можно сделать следующее: закрыть на сайте все GET параметры, принудительно открыв при этом нужные GET параметры.
Но нужно осторожно использовать данный метод, чтобы случайно не закрыть важные страницы на сайте.
Пример использования:
Disallow: /*?* # закрываем все страницы с GET параметрами
Allow: /*?page=* # открываем для сканирования страницы пагинации
# дополнительно можно закрыть страницы пагинации, которые содержат два GET параметра
Disallow: /*?*&page=*
Disallow: /*?page=*&*Используя сервис Screaming Frog Seo Spider можно также определить, какие еще страницы необходимо закрыть от индексации. Часто такие страницы можно найти с помощью дублей тегов и мета-тегов. Найти их помогут фильтры по дублям title/h1/description.
Также можно выгрузить проиндексированные страницы в Яндекс.Вебмастер и проверить, какие еще из них стоит исключить из индекса:
- Одним из требований поисковиков Google и Yandex является открытие для индексации файлов JavaScript и CSS, так как они используются ими для анализа удобства сайта и его ранжирования.


Определить весь список ресурсов, которые нужно открыть для индексации, можно при помощи Google Search Console.
Для этого указываем URL для сканирования:
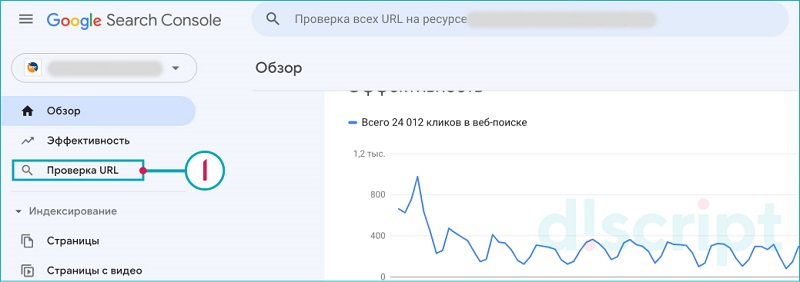
Далее нажимаем на ссылку «Изучить просканированную страницу»
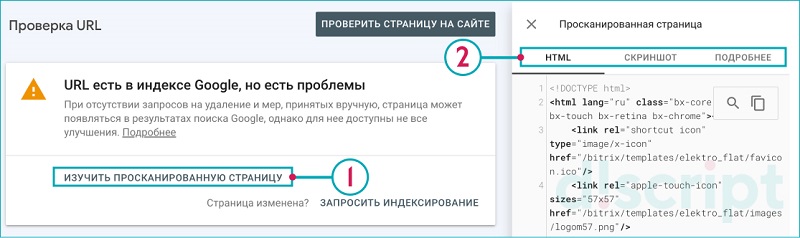
Переходим на вкладку «Скриншот» и нажимаем на «Проверить страницу на сайте»:
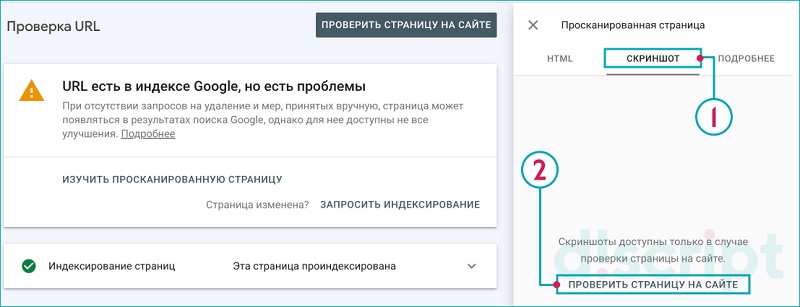
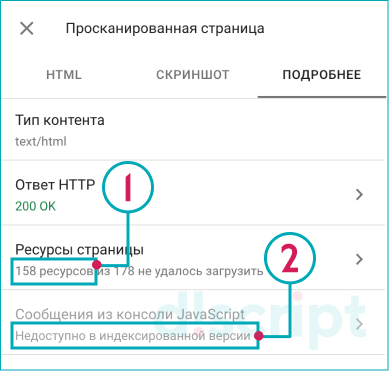
Получаем результаты:
- Как видит страницу Google.
- Какие элементы JS/CSS и др. не подгрузились

И ресурсы, требующие внимания
Файл robots.txt по типам сайтов
Рассмотрим различные файлы robots.txt по типам сайтов от Landing Page до интернет-магазинов.
Файл robots.txt для Landing Page
Файл robots.txt для Landing Page рассмотрели в рамках отдельной статьи: https://discript.ru/blog/kak-nastroit-robots-txt-dla-lendinga/
Оптимизация файла для Landing Page отличается от любого другой сайта, тем что он запрещает индексирование любых разделов, кроме главной страницы. При этом файлы CSS-стилей и JS-кода остаются доступными для роботов.
User-agent: *
Allow: /images/
Disallow: /js/
Disallow: /css/
User-agent: Googlebot
Allow: /
User-agent: Yandex
Allow: /images/
Disallow: /js/
Disallow: /css/
Файл robots.txt для интернет-магазина
При составлении файла robots.txt необходимо понимать, что у интернет-магазина встречается функционал, который не встречается у других типов сайтов (информационные, сайты услуг).
К такому функционалу интернет-магазина можно отнести:
- Страницы с результатами поиска (чтобы избежать дубли страниц);
- Страницы меток и тегов;
- Страницы сортировок товаров;
- Страницы фильтров товаров;
- Страницы корзины;
- Страницы оформления заказов;
- Страницы личных кабинетов;
- Страницы входа;
- Страницы регистрации.
Часто такие разделы могут формировать мусорные страницы и страницы дубли. По этому такие страницы у интернет-магазина рекомендуется закрывать в файле robots.txt. Напомним, что в индексе необходимо оставить страницы полезные для пользователей.
Для составления файла robots.txt для интернет-магазина необходимо учитывать структуру вашего проекта и сделать анализ на ошибки и мусорные страницы.
Но мы подготовили для Вас шаблоны на основе популярных CMS. Обычно интернет-магазины создаются на Bitrix, OpenCart, WordPress, MODx. Вы можете использовать подходящий шаблон под вашу CMS и доработать файл под нюансы вашего проекта.
Готовые шаблоны файла robots.txt для популярных CMS
Предлагаем готовые файлы robots.txt для различных CMS
Файл robots.txt для WordPress
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /cgi-bin
Disallow: /*?
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: *?attachment_id=
Disallow: */page/
Allow: */uploads
Allow: /wp-*.js
Allow: /wp-*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.svg
Allow: /wp-*.pdf
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для 1С-Битрикс
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /*index.php$
Disallow: /admin/
Disallow: /bitrix/
Disallow: /cgi-bin/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?
Disallow: /*&print=
Disallow: /*?print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*action=*
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*back_url=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*course_id=
Disallow: /*pagen_*
Disallow: /*page_*
Disallow: /*showall
Disallow: /*show_all=
Disallow: /*clear_cache=
Disallow: /*order_by
Disallow: /*sort=
Allow: /map/
Allow: /bitrix/components/
Allow: /bitrix/cache/
Allow: /bitrix/*.js
Allow: /bitrix/templates/
Allow: /bitrix/panel/
Allow: /bitrix/*.css
Allow: /bitrix/images/
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для OpenCart
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=vDisallow: /*?page=
Disallow: /*&page=
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
Disallow: /*compare-productsvDisallow: /*search
Disallow: /*cart
Disallow: /*checkout
Disallow: /*login
Disallow: /*logout
Disallow: /*vouchersvDisallow: /*wishlist
Disallow: /*my-account
Disallow: /*order-history
Disallow: /*newsletter
Disallow: /*return-add
Disallow: /*forgot-password
Disallow: /*downloads
Disallow: /*returns
Disallow: /*transactions
Disallow: /*create-account
Disallow: /*recurring
Disallow: /*address-book
Disallow: /*reward-points
Disallow: /*affiliate-forgot-password
Disallow: /*create-affiliate-account
Disallow: /*affiliate-loginvDisallow: /*affiliates
Allow: /catalog/view/javascript/
Allow: /catalog/view/theme/*/
Allow: /image/
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для MODx
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /manager/
Disallow: /assets/components/
Disallow: /core/
Disallow: /connectors/
Disallow: /mgr/
Disallow: /index.php
Disallow: /*?
Allow: /*.js
Allow: /*.css
Allow: /images/
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для Diafan
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /m/
Disallow: *?
Disallow: /news/rss/
Disallow: /cart/
Disallow: /search/
Allow: /image/
Allow: /*.js
Allow: /*.css
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для Drupal
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /profiles/
Disallow: /scripts/
Disallow: /themes/
Disallow: /database/
Disallow: /sites/
Disallow: /updates/
Disallow: /profile
Disallow: /profile/*
Disallow: /index.php
Disallow: /changelog.txt
Disallow: /cron.php
Disallow: /install.mysql.txt
Disallow: /install.pgsql.txt
Disallow: /install.php
Disallow: /install.txt
Disallow: /license.txt
Disallow: /maintainers.txt
Disallow: /update.php
Disallow: /upgrade.txt
Disallow: /xmlrpc.php
Disallow: /admin/
Disallow: /comment/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /filter/tips/
Disallow: /node/add/
Disallow: /search/
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /user/register/
Disallow: /user/password/
Disallow: /user/login/
Disallow: /user/logout/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /?q=admin/
Disallow: /?q=comment/
Disallow: /?q=filter/tips/
Disallow: /?q=node/add/
Disallow: /?q=search/
Disallow: /?q=user/password/
Disallow: /?q=user/register/
Disallow: /?q=user/login/
Disallow: /?q=user/logout/
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: *register*
Disallow: *login*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index.php
Disallow: /*?
Allow: /*?page=
Allow: /images/
Allow: /*.js
Allow: /*.css
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для NetCat
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=vDisallow: /*?page=
Disallow: /*&page=
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
Disallow: /*compare-productsvDisallow: /*search
Disallow: /*cart
Disallow: /*checkout
Disallow: /*login
Disallow: /*logout
Disallow: /*vouchersvDisallow: /*wishlist
Disallow: /*my-account
Disallow: /*order-history
Disallow: /*newsletter
Disallow: /*return-add
Disallow: /*forgot-password
Disallow: /*downloads
Disallow: /*returns
Disallow: /*transactions
Disallow: /*create-account
Disallow: /*recurring
Disallow: /*address-book
Disallow: /*reward-points
Disallow: /*affiliate-forgot-password
Disallow: /*create-affiliate-account
Disallow: /*affiliate-loginvDisallow: /*affiliates
Allow: /catalog/view/javascript/
Allow: /catalog/view/theme/*/
Allow: /image/
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для Joomla
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /modules/
Disallow: /plugins/
Disallow: /tmp/
Disallow: /templates
Disallow: *catid
Disallow: *0&idvDisallow: *id
Disallow: /finvil/
Disallow: /index.php*
Disallow: /index2.php*
Disallow: /index.html
Disallow: /application.php
Disallow: /component/
Disallow: /*mailto/
Disallow: /*.pdf
Disallow: /*print=
Disallow: /*tag
Disallow: /*%
Disallow: /search*
Disallow: /*start
Disallow: /*=atom
Disallow: /*=rss
Disallow: /*print=1
Disallow: /*?
Disallow: /*&
Allow: /index.php?option=com_xmap&sitemap=1&view=xml
Allow: /index.php?option=com_xmap&view=xml&id=1
Allow: /images/
Allow: /templates/*.css
Allow: /templates/*.jsvAllow: /media/*.pngAllow: /media/*.js
Allow: /modules/*.css
Allow: /modules/*.js
Sitemap: http://site.ru/sitemap.xml
Популярные файлы robots.txt под задачи
Закрыть от индексации полностью сайт в robots.txt
User-agent: *
Disallow: /
Закрыть от индексации все страницы кроме главной в robots.txt
User-agent: *
Disallow: /
Allow: /$
Закрыть одну страницу в robots.txt
User-agent: *
Disallow: /URL # где URL ваша страница
Пример robots.txt для Яндекса
User-agent: Yandex
Disallow: /URL # где URL ваша страница
Пример robots.txt для Google
User-agent: Google
Disallow: /URL # где URL ваша страница
Пример robots.txt для всех поисковиков
User-agent: *
Disallow: /URL # где URL ваша страница
Популярные вопросы про файл robots.txt
Как создать файл robots txt для сайта в онлайн?
Для быстрого создания файла воспользуйтесь инструментом https://tools.discript.ru/robots-check/ он позволит быстро сгенерировать подходящий файл для вашего сайта.
Как проверить robots.txt онлайн?
Для быстрой проверки сайта Вы можете воспользоваться следующими инструментами:
- https://www.google.com/webmasters/tools/siteoverview?hl=ru
- http://webmaster.yandex.ru/robots.xml
Если Вам необходимо изучить файл robots конкурентов, то можете воспользоваться инструментом https://tools.discript.ru/robots-check/ или перейти по адресу site.ru/robots.txt, где site.ru сайт файл, которого ходите изучить.
Как проверить закрыт ли сайт от индексации?
Для быстрой проверки, закрыта ли страницы от индексации Вы можете воспользоваться инструментом https://tools.discript.ru/robots/, для этого достаточно указал URL, который хотите проверить.
Что делать если «Нет используемых роботом файлов sitemap»?
Данная ошибка появляется в панели Яндекс Вебмастера. Чтобы помочь Яндексу найти файл sitemap, вы можете его указать в панели Вебмастера.
Или добавить в файле директиву sitemap, как это сделать читайте тут
Как проверить есть ли robots.txt на сайте?
Чтобы проверить есть ли на сайте файл robots.txt достаточно перейти по адресу site.ru/robots.txt, где site.ru сайт файл, которого ходите изучить. Если открылся файл robots.txt, то он присутствует на проверяемом сайте.
Как удалить цифры по маске в robots.txt?
User-agent: *
Disallow: *0
Disallow: *1
Disallow: *2
Disallow: *3
Disallow: *0
Disallow: *5
Disallow: *6
Disallow: *7
Disallow: *8
Disallow: *9
Как производить экранирование символов в robots.txt?
Спецификация robots.txt не допускает использования регулярных выражений. В url допустимы только * и &.
В заключение
Таким образом при работе с robots.txt необходимо знать:
- Правила составления и расположения файла;
- Функции отдельных директив и способы их применения;
- Рекомендации по закрытию определенных страниц;
- Инструменты для проверки robots.txt: http://tools.discript.ru/robots-check/, а также инструменты Яндекс и Google.
Важно помнить, что проверка robots.txt — один из первых этапов создания любого проекта, и от того, насколько точно она будет проведена, может зависеть конечный результат работы.
В следующей статье мы поговорим о терминологии, применяемой при работе над скоростью загрузки.
обновлено: 13.01.2020 1567520449
Александр Коваленко, CEO/founder агентства Advermedia.ua, опыт в SEO более 10 лет.
Канал автора в телеграм: @seomnenie
Информация о статье

Заголовок
Robots.txt: полное руководство по настройке
Описание
В данной статьей мы подготовили максимальной развернутое руководство по предназначению, созданию и настройке файла robots.txt для управления индексацией вашего сайта. Данный FAQ будет полезен собственникам сайтов, вебмастерам для своих проектов, а также SEO-специалистам, как начинающим (вникнуть и разобраться), так и опытным (освежить знания и все актуальные обновления).
Автор
Организация
advermedia.ua
Логотип
![]()
![]() Loading…
Loading…

CEO/founder агентства Advermedia.ua, опыт в SEO более 10 лет.
Канал автора в телеграм: @seomnenie
Новые материалы
Подписаться на телеграм канал СEO Advermedia Мнение SEO
Публикуем интересные материалы из блога и разбираем вопросы по SEO от подписчиков!

https://t.me/seomnenie
Подписаться
Оптимизируйте свои подборки
Сохраняйте и классифицируйте контент в соответствии со своими настройками.
В файле robots.txt содержатся инструкции, которые говорят поисковым роботам, какие URL на вашем сайте им разрешено обрабатывать.
С его помощью можно ограничить количество запросов на сканирование и тем самым снизить нагрузку на сайт. Файл robots.txt не предназначен для того, чтобы запрещать показ ваших материалов в результатах поиска Google. Если вы не хотите, чтобы какие-либо страницы с вашего сайта были представлены в Google, добавьте на них директиву noindex или сделайте их доступными только по паролю.
Для чего служит файл robots.txt
Файл robots.txt используется прежде всего для управления трафиком поисковых роботов на вашем сайте. Как правило, с его помощью также можно исключить контент из результатов поиска Google (это зависит от типа контента).
| Как директивы из файла robots.txt обрабатываются при сканировании файлов разного типа | |
|---|---|
| Веб-страница |
Файл robots.txt позволяет управлять сканированием веб-страниц в форматах, которые робот Googlebot может обработать (он поддерживает, например, HTML или PDF, но не мультимедийные файлы). С его помощью вы можете уменьшить количество запросов, которые Google отправляет вашему серверу, или запретить сканировать разделы сайта, в которых содержится неважная или повторяющаяся информация.
Страницы, сканирование которых запрещено в файле robots.txt, все равно могут показываться в результатах поиска, но без описания. |
| Медиафайл |
Файл robots.txt может использоваться как для управления трафиком поисковых роботов, так и для блокировки показа изображений, видеороликов и аудиофайлов в результатах поиска Google. Такая блокировка не помешает другим владельцам сайтов и пользователям размещать ссылки на ваш медиаконтент. Советуем ознакомиться со следующими статьями:
|
| Ресурсный файл | При помощи файла robots.txt вы можете запретить сканирование таких файлов, как вспомогательные изображения, скрипты и файлы стилей, если считаете, что они лишь в незначительной степени влияют на оформление страниц. Однако не следует блокировать доступ к ним, если это может затруднить поисковому роботу интерпретацию контента. В противном случае страницы могут быть проанализированы неправильно. |
Каковы ограничения при использовании файла robots.txt
Прежде чем создавать или изменять файл robots.txt, проанализируйте риски, связанные с этим методом. Иногда для запрета индексирования URL лучше выбирать другие средства.
-
Правила robots.txt поддерживаются не всеми поисковыми системами.
Правила в файлах robots.txt необязательны для исполнения. Googlebot и большинство других поисковых роботов следуют этим инструкциям, однако некоторые системы могут игнорировать их. Чтобы надежно скрыть информацию от поисковых роботов, воспользуйтесь другими способами. Например, вы можете защитить конфиденциальные файлы на сервере паролем. -
Разные поисковые роботы интерпретируют синтаксис файлов robots.txt по-разному.
Хотя роботы основных поисковых систем следуют правилам в файле robots.txt, каждый из них может интерпретировать их по-своему. Поэтому ознакомьтесь с синтаксисом для других систем. -
Если доступ к странице запрещен в файле robots.txt, она все равно может быть проиндексирована по ссылкам с других сайтов.
Google не будет напрямую сканировать и индексировать контент, который заблокирован в файле robots.txt. Однако если на такой URL ссылаются другие сайты, то он все равно может быть найден и добавлен в индекс. После этого страница может появиться в результатах поиска (во многих случаях вместе с текстом ссылки, которая на нее ведет). Если вас это не устраивает, рекомендуем защитить файлы на сервере паролем или использовать директивуnoindexв тегеmetaили HTTP-заголовке ответа. Альтернативное решение – полностью удалить страницу.
Как создать или изменить файл robots.txt
Ознакомьтесь с инструкциями по созданию файла robots.txt. Если у вас уже есть такой файл, узнайте, как изменить его.
Если вам нужна дополнительная информация, воспользуйтесь следующими ресурсами:
- Как создать и отправить файл robots.txt
- Как обновить файл robots.txt
- Как Google интерпретирует спецификацию robots.txt
Если не указано иное, контент на этой странице предоставляется по лицензии Creative Commons «С указанием авторства 4.0», а примеры кода – по лицензии Apache 2.0. Подробнее об этом написано в правилах сайта. Java – это зарегистрированный товарный знак корпорации Oracle и ее аффилированных лиц.
Последнее обновление: 2023-02-14 UTC.


Содержание

Постараемся в этой статье ответить на вопрос о том, что такое правильный robots.txt и как провести настройку этого файла. В общих чертах, его назначение в том, чтобы оптимизировать процесс краулинга.
Поисковые системы регулярно считывают содержимое каждого сайта для того, чтобы индексировать актуальные страницы и материалы. Robots.txt указывает краулерам, какие разделы сайта нужно просматривать, а какие — нет. С его помощью повышается эффективность процесса — поисковая система обрабатывает сайт быстрее и запоминает релевантную информацию. Не стоит путать это с ускорением загрузки сайта. Впоследствии, когда пользователи будут делать запросы, они увидят ваш сайт в выдаче, в частности, благодаря правильной настройке Robots.txt.
Чтобы анализировать конверсии при изменениях в robots.txt, рекомендуем установить аналитику:

Оптимизируйте маркетинг и увеличивайте продажи вместе с Calltouch
Узнать подробнее
Что такое robots.txt
Robots.txt для сайта — это служебный файл-рекомендация. Он формирует исключения и запреты для поисковых алгоритмов, взаимодействующих с сайтом. Эти запреты не допускают индексации определенных разделов или содержимого сайта, позволяют увидеть алгоритмам только нужные элементы.
Для чего используется Robots.txt
Данный файл говорит краулерам и роботам, какие страницы сайта они должны просматривать, а к каким доступ запрещён. Это важно в связи с тем, что случайно могут быть проанализированы страницы с нерелевантным контентом. В некоторых случаях есть риск запустить бесконечный цикл считывания — например, с календарём, который генерирует новый URL для каждой даты.
Как говорится в спецификации robots.txt для Google, правильный robots.txt должен являться текстовым файлом в кодировке ASCII или UTF-8. Строки или иначе — директивы — должны отделяться типами прерывания CR, CR/LF или LF.
Обращайте внимание на размер файла, так как у каждой поисковой системы свой лимит. Google читает robots.txt не более 500 Кб, а Яндекс посчитает всё содержимое открытым, если файл весит больше 32 Кб.
Где должен располагаться Robots.txt
Файл располагается в корневом каталоге сайта, например, https://www.calltouch.ru/robots.txt.
Внимание: файл строго привязан к адресу домена вплоть до протокола. То есть, для http и https требуется предусмотреть 2 разных robots.txt, даже если затем адреса совпадают. Также один и тот же файл не применим для субдоменов.
Когда используются правила robots.txt
На самом деле веб-сайтам не стоит полагаться на robots.txt в целях контроля краулинга. В первую очередь стоит позаботиться об архитектуре сайта и о том, чтобы сделать его более доступным для поисковых роботов, очистив от всего лишнего. Тем не менее, если на сайте работают плохо оптимизированные разделы, которые лучше скрыть от глаз пользователей, и эти проблемы не устранимы в обозримой перспективе, robots.txt будет правильным решением.
Google рекомендует использовать данный файл только в целях оптимизации работы поискового робота. Иногда чтение плохо индексируемых разделов затягивается.
Вот некоторые примеры страниц и разделов, индексация которых нежелательна:
- Страницы категорий с нестандартной сортировкой могут повлечь создание дублей основной страницы;
- Пользовательский контент, не подлежащий модерации;
- Страницы с конфиденциальной информацией;
- Внутренние поисковые страницы, которых может насчитываться бесконечное множество.
Когда не стоит прибегать к robots.txt
При грамотном использовании данный файл несёт пользу, но есть ситуации, в которых его применение в целях блокировки краулинга только мешает.
Блокировка Javascript/CSS
Поисковым системам необходим доступ ко всем ресурсам, чтобы корректно рендерить страницы — это необходимая часть ранжирования. Если же, к примеру, Javascript, оказывающий подчас определяющее влияние на функционал страницы и пользовательский опыт отключен, это может привести к плохим результатам вплоть до понижения в выдаче.
Например, если ваша страница содержит редиректы с помощью Javascript, а тот, в свою очередь, закрыт от индексации, робот распознает в таком перенаправлении клоакинг — подмену страницы.
Блокировка по URL
Robots.txt можно использовать для блокировки URL со специфическими параметрами, но это далеко не всегда верное решение. Правильная настройка robots,txt предполагает использование Google Search Console — такой способ будет приемлем с точки зрения поисковых систем.
Можно разместить информацию в самом URL — /items#filter=date, так как краулеры не считывают это. Если URL-параметр должен быть использован обязательно, ссылка может содержать rel=nofollow во избежание индексации.
Блокировка URL с обратными ссылками
Если обратные ссылки запрещены robots.txt, поисковый робот не сможет перейти по ссылкам с других сайтов на ваш ресурс. Из-за этого ваш сайт не получит баллов ранжирования и опустится в выдаче.
Установка правил против краулеров соцсетей
Даже если вы не хотите, чтобы поисковые системы читали ваши страницы, возможно, доступ роботов соцсетей не помешает. Ведь они формируют сниппеты в случае репоста ваших страниц в соцсети. Например, Facebook* (*продукт компании Meta, которая признана экстремистской организацией в России) будет пытаться зайти на каждую страницу, которую постят в нём, чтобы отображать релевантный сниппет.
Блокировка доступа к сайтам в процессе разработки
Использование robots.txt для блокировки всего сайта в процессе разработки хорошо работает. В то же время, Google рекомендует убирать из индексации страницы, но давать возможность роботу их читать. В целом же, следует делать такие сайты недоступными для посещения вообще.
Когда нечего блокировать
Некоторые сайты с весьма чистой архитектурой не испытывают потребности в блокировке каких-либо разделов. В такой ситуации вообще можно не создавать robots.txt, а возвращать страницу 404.
Эффективный маркетинг с Calltouch
- Анализируйте весь маркетинг и продажи в одном окне
- Удобные дашборды и воронки от показов рекламы до ROI
Узнать подробнее

Как создать robots.txt
Создать файл можно тремя способами, выбор зависит от целей и навыков. Сервисы облегчают работу с robots.txt, но ручная коррекция все-таки потребуется. Поэтому для каждого варианта, хоть и в разной степени, придется самостоятельно разобраться с темой или обратиться к специалисту.
Ручное создание
Файл robots.txt можно создать в любом текстовом редакторе, например, в Блокноте и Microsoft Word. В документе прописывают специальный код-инструкцию, в нем указывают, какие элементы не подлежат индексации. После этого его сохраняют в формате.txt под названием «robots».
Готовый текстовый документ загружается в корневую папку с названием сайта, где находится файл index.html и файлы базового движка. Чтобы загрузить robots.txt на сервер, используют:
- панель управления сервером;
- консоль или пульт управления в CMS;
- любой FTP-клиент.
Система каждый раз будет обращаться к роботу, чтобы понять, что можно индексировать на сайте, а что нет.
Онлайн-генераторы
Специальные сервисы помогут автоматически сгенерировать нужный файл, например, такой инструмент есть на сайте CY-PR. Генераторы облегчают работу тем, кто владеет сразу несколькими сайтами, так как прописывать характеристики для каждого достаточно долго. Автоматизация упростит процесс, но корректировать автоматически сгенерированные файлы придется вручную. Чтобы устранять возможные ошибки, нужно изучить базовый синтаксис robots.txt.
Готовые шаблоны
В интернете представлено много шаблонов файла robots.txt, которые подходят для всех популярных движков (WordPress, Drupal). В шаблоне прописаны стандартные директивы, поэтому файл не нужно создавать полностью вручную.
Если учесть индивидуальные особенности проекта, на его основе можно сделать качественный robots.txt. Но для этого тоже необходимы хотя бы минимальные знания синтаксиса, потому что шаблон не может предоставить корректно настроенный, готовый к работе, файл.
Синтаксис robots.txt
Как настроить robots.txt? Примерно так может выглядеть блок robots.txt, ориентированный на Google.

Комментарии
Комментарии — это строки, которые полностью игнорируются поисковыми системами. Они начинаются со знака #. Они нужны для заметок о том, какие действия выполняют строки файла. Рекомендуется документировать каждую директиву в robots.txt, чтобы она могла быть удалена за ненадобностью или отредактирована.
Указания User-agent
Это блок, который даёт указания поисковым системам и роботам, используя директиву User-agent. Например, если вы хотите установить правила отдельно для Яндекса и Google. Тем не менее, он не применим для Facebook* (*продукт компании Meta, которая признана экстремистской организацией в России) и рекламный сетей — на них можно повлиять только через специальный токен с применением особых правил.
Каждый робот предусматривает собственный user-agent токен.
Краулеры сперва учитывают наиболее точные директивы, разделённые дефисом, а затем переходят к объемлющим. Так, Googlebot News сначала выполнит указания для User-agent «googlebot-news», а потом уже «googlebot» и впоследствии «*».
Наиболее распространённые роботы в российском сегменте — это:
- Googlebot
- Mediapartners-Google
- Yandex
- Facebook* (*продукт компании Meta, которая признана экстремистской организацией в России)
Конечно, этот список далеко не исчерпывающий. Чтобы ознакомиться с полным перечнем используемых поисковиками и другими системами роботов, лучше прочитайте их документацию.
Наименования роботов в robots.txt нечувствительны к регистру. «Googlebot» и «googlebot» вполне взаимозаменяемы.
Шаблоны адресов
Вместо того, чтобы прописывать большой перечень конечных URL для блокировки, достаточно указать только шаблоны адресов.
Для эффективного использования такой функции понадобится два знака:
- * — данный символ группировки обозначает любое количество символов. Его лучше располагать в начале или внутри адреса, но не в конце. Можно использовать сразу несколько групповых символов — например, «Disallow: */notebooks?*filter=». Правила с полными адресами не должны начинаться с данного символа.
- $ — знак доллара означает конец адреса. Так, «Disallow: */item$» будет соответствовать URL, заканчивающемуся на «/item», но не «/item?filter» или подобным.
Обратите внимание, что эти правила уже чувствительны к регистру. Если вы запрещаете адреса с параметром «search», роботы всё ещё будут просматривать адреса, содержащие «Search».
Директивы работают только с телом адреса и не включают протокол или сам домен. Слэш в начале адреса означает, что данная директория располагается сразу после основного каталога. Например, «Disallow: /start» будет соответствовать «www.site.ru/start».
Пока вы не добавите * или / в начало директивы, она не будет ничему соответствовать. «Disallow: start» не будет иметь смысла — роботы её не поймут.
Чтобы наглядно продемонстрировать правило, приведём таблицу примеров:

Sitemap.xml
Директива Sitemap в robots.txt говорит поисковикам, где найти карту сайта в формате XML. Это поможет им лучше ориентироваться в структуре страниц.
Для Sitemap вы должны указать полный путь, как это сделано у нас: «Sitemap: https://www.calltouch.ru/sitemap.xml». Также следует отметить, что Sitemap не всегда располагается на том же домене, что и весь сайт.
Поисковые роботы прочитают указанные в robots.txt карты сайтов, но они не появятся в том же Google Search Console, пока вы не дадите на это разрешение.
Host
Этот элемент раньше работал исключительно как инструкция для Яндекса, другим поисковым системам она была непонятна. Он указывал роботу Яндекса на главное зеркало сайта, и система рассматривала его в приоритетном порядке.
Директива Host уже не поддерживается Яндексом, решение об этом было принято еще в 2018 году. Теперь вместо нее схожий функционал выполняет раздел «Переезд сайта», доступный в Яндекс.Вебмастере.
Блоки в robots.txt
Директива Disallow в robots.txt может использоваться по-разному для многих агентов. Покажем, каким образом могут быть представлены разные комбинации блоков.
Важно помнить, что robots.txt — это всего-навсего набор рекомендаций. Вредоносные краулеры проигнорируют этот файл, прочитав то, что захотят, поэтому бессмысленно использовать robots.txt в качестве меры защиты.
Несколько блоков User-Agent
Вы можете назначить правило сразу нескольким роботам, указав их в начале. Например, следующая директива Disallow будет работать как для Яндекса, так и для Google.

Пустые строки между блоками
Поисковые системы игнорируют пустые строки между директивами. Даже если одна директива будет отделена таким образом от предыдущей, робот всё равно её прочитает.

В следующем примере сразу два робота будут руководствоваться одним правилом.

Комбинация отдельных блоков
Разные блоки, в которых указан один и тот же агент, будут учитываться. Таким образом, Google не станет читать оба раздела, указанных в файле.

Директива Allow
Эта директива даёт доступ к указанному разделу. Вообще она действует по умолчанию, но может применяться для отмены ранее поставленного правила Disallow для вложенного раздела. Если вы запретили доступ к «/notebooks», а затем указали директиву «Allow: /notebooks/gamers», то директория /notebooks/gamers окажется читаема для краулеров, даже с учётом того, что вышестоящая запрещена к просмотру.
Приоритеты в robots.txt
Если указано несколько правил Allow и Disallow, роботы обращают внимание на те, у которых больше длина в знаках. Рассмотрим пример пути «/home/search/shirts»:

В этом случае весь путём разрешён к чтению, так как директива Allow содержит 9 знаков, а Disallow — максимум 7. Если вам нужно обойти это правило, то для увеличения длины строки можно добавлять *.
![]()
Если длина Allow и Disallow совпадает, то приоритет отдаётся Disallow.
Директивы robots.txt
Директивы robots.txt помогают снизить затраты ресурсов на краулинг. Вы упредительно добавляете правила в robots.txt вместо того, чтобы ждать, пока поисковые системы считают все страницы, а затем предпринимать меры. Такой подход гораздо быстрее и проще.
Следующие директивы работают аналогично Allow и Disallow, используя символы * и /.
Noindex
Директива Noindex полезна для повышения точности индексирования. Disallow никак не избавляет от необходимости индексации указанную страницу, в то время как Noindex позволяет убрать страницу из индекса.
Но тот же Google официально не поддерживает директиву Noindex — ситуация может измениться со дня на день. В подобной неопределённости лучше использовать данный инструмент для решения краткосрочных задач, как дополнительную меру, но не основное решение.

Помимо Noindex Google негласно поддерживает и ряд других директив, размещаемых в robots.txt. Важно помнить, что не все краулеры поддерживают эти директивы, и однажды они могут перестать работать. Не стоит на них полагаться.
Что нужно исключать из индекса
Правильный robots.txt не должен содержать:
- Дубли страниц. Страница должна быть доступна по одному URL. Поисковые системы при обращении должны получать индивидуальные страницы с уникальным содержимым. Для скрытия дублей нужно использовать маски.
- Страницы с неуникальным контентом. Их стоит скрывать от поисковых систем до момента, когда они окажутся в индексе.
- Страницы с индикаторами сессий.
- Файлы, связанные с движком и управлением сайтом. К таким относят шаблоны, темы, панель администратора.
- Нерелевантные пользователям страницы. Это разделы, не имеющие уникального контента или содержания.
Кириллица в файле Robots
Символы кириллицей в файлах robots.txt или HTTP-заголовка недопустимы. Для работы с доменами, прописанными на кириллице, существует Punycode — метод преобразования, работающий в многоязычной системе доменов. Он позволяет преобразовать кириллицу и безошибочно прописать символы в нужных местах.
Советы по использованию операторов
Есть несколько операторов, наиболее распространенными из которых считаются: * и $. Они позволяют:
- Блокировать нужные типы файлов. Например, при необходимости заблокировать файлы, имеющие расширение .json, это будет выглядеть следующим образом: Disallow: /*.json$.
- Блокировать URL, имеющий параметр ?, после которого располагаются GET-запросы. Такой способ применяется в случаях, когда у сайта настроен человекопонятный url для всех страниц, а документы, характеризующиеся GET-параметрами, оказываются дублями.
Особенности robots.txt
Существует ряд ключевых рекомендаций и наблюдений касаемо влияния, оказываемого robots.txt на сайт.
- Пропишите запасной блок или правило сразу для всех роботов. Если все ваши директивы прописаны для ограниченного количества роботов, те, которых нет в списке, окажутся в состоянии неопределённости, так как для них не предусмотрено правил.
- Важно поддерживать актуальность robots.txt. Проблемы часто возникают в ситуации, когда robots.txt создавался на первоначальных этапах разработки сайта. По мере развития ресурса многие страницы могли стать актуальными, но всё ещё скрыты от роботов, и не только.
- Избегайте путей, внутри которых содержится отключенная директория.
- Чувствительность к регистру может стать причиной проблем.
- Не отключайте обратные ссылки с внешних ресурсов.
- Crawl-delay может иметь последствия. Данная директива заставляет поисковых роботов работать с вашим сайтом медленнее обычного. Из-за этого важные страницы могут обрабатываться реже оптимального графика. Директива не поддерживает Гуглом, зато работает в случае с Яндексом.
- Убедитесь, что robots.txt возвращает только коды 5**, если сайт отключен. Так роботы поймут, что сайт отключен на обслуживание и вернутся к нему позже.
- Robots.txt имеет приоритет над другими параметрами индексации, задаваемыми вне файла.
- Отключение мигрирующего домена повлияет на успех миграции. В данном случае роботы могут не найти редиректы со старого сайта на новый.
![]()
Сквозная аналитика Calltouch
- Анализируйте воронку продаж от показов до денег в кассе
- Автоматический сбор данных, удобные отчеты и бесплатные интеграции
Узнать подробнее
Тестирование и аудит robots.txt
Учитывая то, какие негативные последствия может повлечь некорректная настройка файла robots.txt, следует ознакомиться с тем, как их избежать и проверить корректность настройки.
Правильная настройка robots.txt для Яндекса и Гугла для новичков и даже мастеров бывает затруднительна без использования специальных инструментов. К примеру, с помощью GSC robots.txt tester tool в Google Search Console вы можете увидеть последние кешированные копии страниц, а также просмотреть рендеры googlebot. Обратите внимание, что инструмент работает только с Google.
Отслеживание изменений в robots.txt
Когда над сайтом работает множество специалистов, изменение даже одного знака в robots.txt способно повлечь серьёзные последствия. Поэтому регулярный мониторинг файла крайне важен.
- Используйте Google Search Console, чтобы узнать, какую версию robots.txt в данный момент использует Google. Для Яндекса необходимо использовать Яндекс.Вебмастер.
- Проверяйте размер файла, чтобы он соответствовал лимитам.
Заключение
Файл robots.txt — ключевой инструмент для организации работы с поисковыми системами, который способен повлиять на параметры выдачи и SEO-продвижение. Он регулирует индексацию, определяет, какие страницы и разделы увидит поисковой робот и как он оценит ресурс. Это влияет на позиции сайта в выдаче и, соответственно, на его трафик. Поэтому правильная настройка robots.txt обеспечит экономию бюджета и времени на продвижение ресурса.
Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
- дубли страниц;
- служебные файлы;
- файлы, которые бесполезны для посетителей;
- страницы с неуникальным контентом.
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Главное правило называется User-agent. В нем мы создаем кодовое слово для роботов. Если робот видит такое слово, он понимает, что это правило для него.
Пример:
User-agent: Yandex
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
User-agent: *
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Allow: /category/
Даем рекомендацию, чтобы индексировались категории.
Disallow: /
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
- * – звездочка означает любую последовательность символов (либо отсутствие символов).
- $ – знак доллара является своеобразной точкой, которая прерывает последовательность символов.
Disallow: /category/$ # закрываем только страницу категорий Disallow: /category/* # закрываем все страницы в папке категории
Sitemap
Данная директива нужна для того, чтобы сориентировать робота, если он заплутает. Мы показываем роботу дорогу к Sitemap.
Пример:
Sitemap: http://site.ru/sitemap.xml
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Crawl-delay: 10
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
User-agent: * Disallow: /
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Есть потрясающий инструмент, который позволит вам включиться в творческую работу с директивами и прописать правильный robots.txt – инструмент от Яндекс.Вебмастера.
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем «Проверить» и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
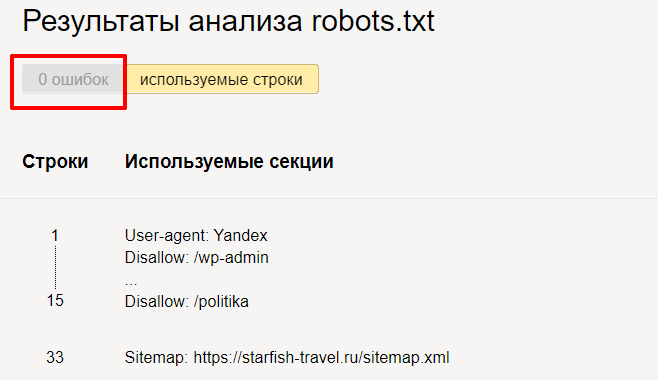
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
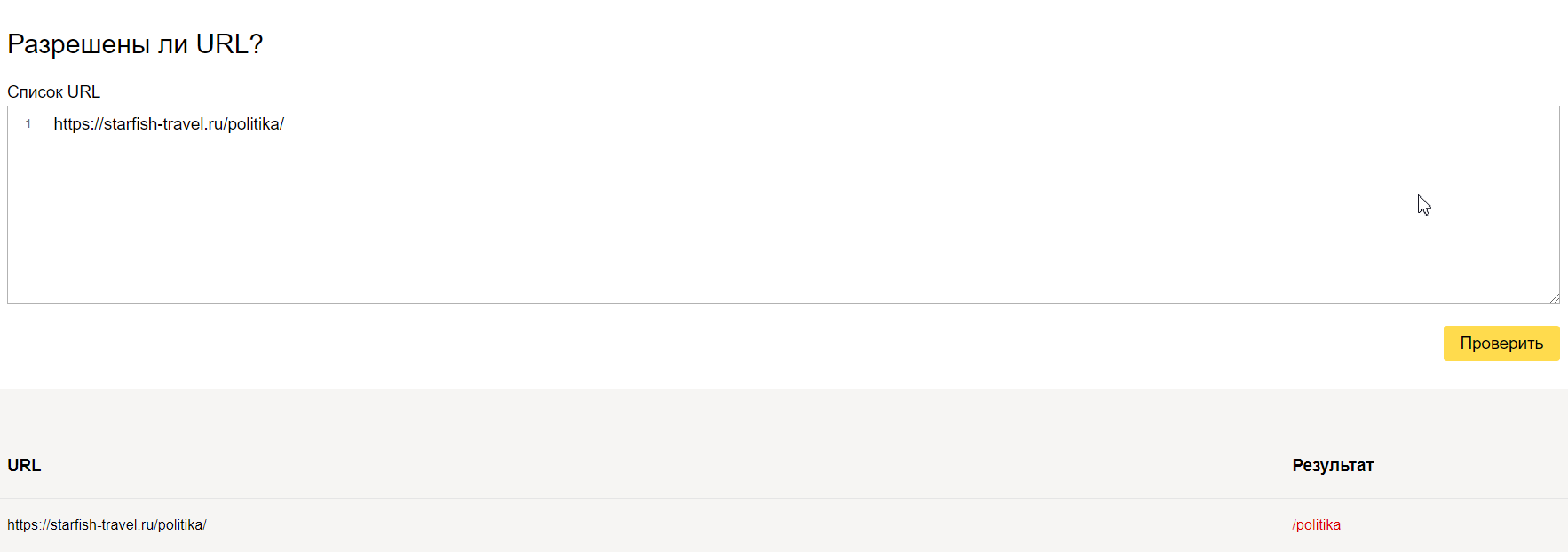
Вводим список адресов, которые нас интересуют, и нажимаем «Проверить». Инструмент сообщит нам, разрешены ли для индексации данные адреса страниц, а в столбце «Результат» будет видно, почему страница индексируется или не индексируется.
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
User-agent: * Disallow: /cgi-bin # папка на хостинге Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ # Все служебные файлы можно закрыть другим образом: Disallow: /wp- Disallow: /xmlrpc.php # файл WordPress API Disallow: /*? # поиск Disallow: /?s= # поиск Allow: /*.css # стили Allow: /*.js # скрипты Sitemap: https://site.ru/sitemap.xml # путь к карте сайта (надо прописать свой сайт)
Правильный robots.txt для Joomla
User-agent: * Disallow: /administrator/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Sitemap: https://site.ru/sitemap.xml
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Правильно настроенный файл robots.txt способен оказать позитивное влияние на продвижение сайта. Если вы хотите избавиться от мусора и навести порядок на сайте, файл robots.txt готов прийти на помощь.