Для
обеспечения надежной работы с базой
данных следует:
-
убедиться
в наличии свободного пространства на
диске, где будет установлена БД; -
убедиться
в наличии полного доступа к диску, где
будет установлена БД (чтение и запись); -
закрыть
или дождаться завершения выполнения
всех программ, потребляющих большую
часть ресурсов системы – программы
проверки дисков, дефрагментаторы,
полноэкранные игры и другие
высокоприоритетные процессы. -
убедиться
в отсутствии вирусов;
Желательно:
-
установить
разрешение экрана 800×600, так как интерфейс
пользователя оптимизирован для работы
именно в этом разрешении; -
наличие
в системе принтера для печати отчетов
и другой информации;
3 Инструкция пользователя
3.1 Назначение базы данных
База
данных предназначена для работников
гостиницы. В БД должны храниться сведения
о проживающих клиентах и служащих
гостиницы, убирающих в номерах. Имеются
номера трех типов: одноместный, двухместный
и трехместный, отличающиеся стоимостью
проживания в сутки. Количество номеров
в гостинице известно.
О
каждом проживающем должна храниться
следующая информация: номер паспорта,
ФИО, город, из которого он прибыл, дата
поселения в гостинице, выделенный
гостиничный номер, на сколько дней
выделен номер. Каждый номер характеризуется
типом, стоимостью проживания, номером
телефона. Номера упорядочены по этажам.
О служащих гостиницы должна храниться
следующая информация: ФИО, № этажа, где
он убирает, день недели когда он убирает
данный этаж. Служащий гостиницы убирает
все № на одном этаже в определенные дни
недели.
Работа
с БД предполагает обслуживание следующих
запросов:
– получение
списка фамилий, проживающих в заданном
номере,
– вычисление
счета за проживание в гостинице,
– определение
количества свободных мест и свободных
номеров,
– получить
список прибывших из заданного города,
– определить
ФИО убирающего номер в заданный день
недели у некоторого проживающего.
Администратор
БД может вносить следующие изменения:
– освобождение
номера проживающим,
– изменение
расписания уборки для служащего в
указанный день недели,
– увольнение
служащего гостиницы.
Необходимо
предусмотреть возможность выдачи
справки о счете за проживание в гостинице
определенного клиента и отчета о
работе гостиницы за указанный срок
(число клиентов, сколько дней был занят
номер, сумма дохода гостиницы), о кол-ве
свободных номеров гостиницы.
Обозначение
используемых кнопок и их назначение
приведено в таблице 1.
Таблица
1
|
Обозначение |
Назначение |
|
|
Переход |
|
|
Переход |
|
|
Выход; |
|
|
Удалить |
|
|
Найти |
|
|
Добавить |
|
|
Закрыть |
|
|
Распечатать |
3.2 Начало и завершение работы с базой данных
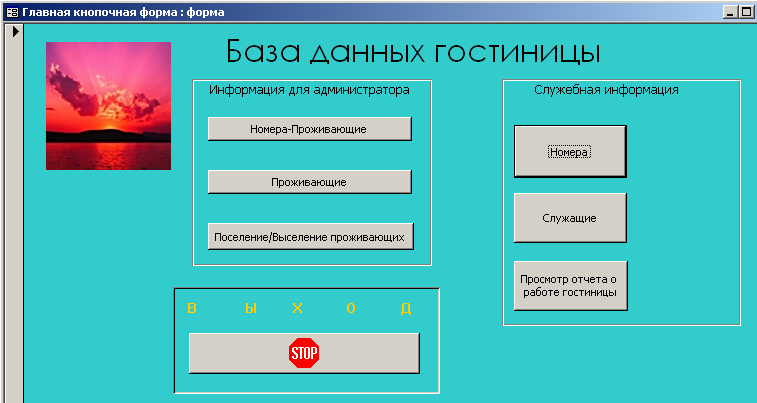
Работа
начинается с того, что Вам будет
представлена информация, приведенная
на рисунке 5.
Рисунок
5
Для
получения различной справочной информации
(п. 3.3) нажмите одну из трех кнопок
раздела «Информация для администратора».
Для
внесения изменений и добавления новых
данных (подраздел 3.4) нажмите одну из
трех кнопок раздела «Служебная информация»
Для
выхода из базы данных нажмите кнопку
«Выход».
Соседние файлы в папке Гостиница
- #
01.05.20143.32 Mб278Гостиница.mdb
- #
В этой статье описана обычная процедура запуска Access и создания базы данных, которая будет использоваться на компьютере, а не в Интернете. В ней рассказано о том, как создать классическую базу данных на основе шаблона или с нуля с собственными таблицами, формами, отчетами и другими объектами. Кроме того, в статье рассмотрены способы импорта существующих данных в новую базу данных.
В этой статье
-
Обзор
-
Создание базы данных с помощью шаблона
-
Создание базы данных без использования шаблона
-
Копирование данных из другого источника в таблицу Access
-
Импорт, добавление или связывание данных из другого источника
-
Добавление части приложения
-
Открытие существующей базы данных Access
Обзор
При первом запуске Access, а также при закрытии базы данных без завершения работы Access отображается представление Microsoft Office Backstage.
Представление Backstage является отправным пунктом для создания новых и открытия существующих баз данных, просмотра релевантных статей на сайте Office.com и т. д., то есть для выполнения любых операций с файлом базы данных или вне базы данных, но не в ней.
Создание базы данных
Когда вы открываете Access, в представлении Backstage отображается вкладка «Новое». Создать базу данных можно несколькими способами:
-
Пустая база данных При этом вы можете начать с нуля. Это хороший вариант, если у вас есть очень конкретные требования к проектированию или есть данные, которые необходимо учитывать или включить.
-
Шаблон, установленный в Access Если вы хотите начать новый проект и начать его, рассмотрите возможность использования шаблона. В Access по умолчанию установлено несколько шаблонов.
-
Шаблон из Office.com В дополнение к шаблонам, поставляемым с Access, много других шаблонов доступно на сайте Office.com. Для их использования даже не нужно открывать браузер, потому что эти шаблоны доступны на вкладке Создать.
Добавление объектов в базу данных
При работе с базой данных в нее можно добавлять поля, таблицы и части приложения.
Части приложения — это функция, позволяющая использовать несколько связанных объектов базы данных как один объект. Например, часть приложения может состоять из таблицы и формы, основанной на ней. С помощью части приложения можно одновременно добавить в базу данных таблицу и форму.
Также можно создавать запросы, формы, отчеты, макросы — любые объекты базы данных, необходимые для работы.
Создание базы данных с помощью шаблона
В Access есть разнообразные шаблоны, которые можно использовать как есть или в качестве отправной точки. Шаблон — это готовая к использованию база данных, содержащая все таблицы, запросы, формы, макросы и отчеты, необходимые для выполнения определенной задачи. Например, существуют шаблоны, которые можно использовать для отслеживания вопросов, управления контактами или учета расходов. Некоторые шаблоны содержат примеры записей, демонстрирующие их использование.
Если один из этих шаблонов вам подходит, с его помощью обычно проще и быстрее всего создать необходимую базу данных. Однако если необходимо импортировать в Access данные из другой программы, возможно, будет проще создать базу данных без использования шаблона. Так как в шаблонах уже определена структура данных, на изменение существующих данных в соответствии с этой структурой может потребоваться много времени.
-
Если база данных открыта, нажмите на вкладке Файл кнопку Закрыть. В представлении Backstage откроется вкладка Создать.
-
На вкладке Создать доступно несколько наборов шаблонов. Некоторые из них встроены в Access, а другие шаблоны можно скачать с сайта Office.com. Дополнительные сведения см. в следующем разделе.
-
Выберите шаблон, который вы хотите использовать.
-
Access предложит имя файла для базы данных в поле «Имя файла». При этом имя файла можно изменить. Чтобы сохранить базу данных в другой папке, отличной от папки, которая отображается под полем «Имя файла», нажмите кнопку
 , перейдите к папке, в которой ее нужно сохранить, и нажмите кнопку «ОК». При желании вы можете создать базу данных и связать ее с сайтом SharePoint.
, перейдите к папке, в которой ее нужно сохранить, и нажмите кнопку «ОК». При желании вы можете создать базу данных и связать ее с сайтом SharePoint. -
Нажмите кнопку Создать.
Access создаст базу данных на основе выбранного шаблона, а затем откроет ее. Для многих шаблонов при этом отображается форма, в которую можно начать вводить данные. Если шаблон содержит примеры данных, вы можете удалить каждую из этих записей, щелкнув область маркировки (затененное поле или полосу слева от записи) и выполнив действия, указанные ниже.
На вкладке Главная в группе Записи нажмите кнопку Удалить.
-
Щелкните первую пустую ячейку в форме и приступайте к вводу данных. Для открытия других необходимых форм или отчетов используйте область навигации. Некоторые шаблоны содержат форму навигации, которая позволяет перемещаться между разными объектами базы данных.
 , перейдите к папке, в которой ее нужно сохранить, и нажмите кнопку «ОК». При желании вы можете создать базу данных и связать ее с сайтом SharePoint.
, перейдите к папке, в которой ее нужно сохранить, и нажмите кнопку «ОК». При желании вы можете создать базу данных и связать ее с сайтом SharePoint.
Дополнительные сведения о работе с шаблонами см. в статье Создание базы данных Access на компьютере с помощью шаблона.
К началу страницы
Создание базы данных без использования шаблона
Если использовать шаблон не имеет ничего интересного, вы можете создать базу данных, создав собственные таблицы, формы, отчеты и другие объекты базы данных. В большинстве случаев это может быть связано с одним или обоими из следующих случаев:
-
Ввести, вставить или импортировать данные в таблицу, которая создается вместе с базой данных, и повторить эту процедуру для новых таблиц, которые создаются с помощью команды Таблица на вкладке Создание.
-
Импортировать данные из других источников, при этом создав таблицы.
Создание пустой базы данных
-
На вкладке Файл щелкните Создать и выберите вариант Пустая база данных.
-
В поле Имя файла введите имя файла. Чтобы сохранить файл в другой папке, отличной от используемой по умолчанию, нажмите кнопку Поиск расположения для размещения базы данных
(рядом с полем Имя файла), откройте нужную папку и нажмите кнопку ОК. -
Нажмите кнопку Создать.
Access создаст базу данных с пустой таблицей «Таблица1» и откроет ее в режиме таблицы. Курсор будет помещен в первую пустую ячейку столбца Щелкните для добавления.
-
Чтобы добавить данные, начните вводить их или вставьте из другого источника (см. раздел Копирование данных из другого источника в таблицу Access).
Ввод данных в представлении таблицы аналогиен вводу данных на листах Excel. Структура таблицы создается при вводе данных. При добавлении нового столбца в таблицу в таблице определяется новое поле. Access автоматически задает тип данных каждого поля на основе введите данные.
Если на этом этапе вводить данные в таблицу «Таблица1» не нужно, нажмите кнопку Закрыть  . Если вы внесли изменения в таблицу, будет предложено сохранить их. Нажмите кнопку Да, чтобы сохранить изменения, кнопку Нет, чтобы не сохранять их, или кнопку Отмена, чтобы оставить таблицу открытой.
. Если вы внесли изменения в таблицу, будет предложено сохранить их. Нажмите кнопку Да, чтобы сохранить изменения, кнопку Нет, чтобы не сохранять их, или кнопку Отмена, чтобы оставить таблицу открытой.
Совет: Access ищет файл с именем Blank.accdb в папке [диск установки]:Program FilesMicrosoft OfficeTemplates1049Access. Если он существует, blank.accdb является шаблоном для всех новых пустых баз данных. Все новые базы данных наследуют содержимое этого файла. Это отличный способ распространения содержимого по умолчанию, например номеров компонентов или заявлений об отказе от ответственности и политик компании.
Важно: Если хотя бы один раз закрыть таблицу «Таблица1» без сохранения, она будет удалена полностью, даже если в нее введены данные.
Добавление таблицы
Добавление таблиц к существующей базе данных осуществляется командами группы Таблицы на вкладке Создать.
Создание таблицы в режиме таблицы. В режиме таблицы можно начать ввод данных сразу, структура таблицы при этом будет создаваться автоматически. Полям присваиваются имена с последовательными номерами («Поле1», «Поле2» и т. д.), а тип данных автоматически задается с учетом вводимых данных.
-
на вкладке Создание в группе Таблицы нажмите кнопку Таблица.
Access создаст таблицу и выделит первую пустую ячейку в столбце Щелкните для добавления.
-
На вкладке Поля в группе Добавление и удаление выберите нужный тип поля. Если нужный тип поля не отображается, нажмите кнопку Другие поля
. -
Откроется список часто используемых типов полей. Выберите необходимый тип поля, и Access добавит в таблицу новое поле в точке вставки.
Поле можно переместить путем перетаскивания. При этом в таблице появляется вертикальная полоса вставки, указывающая место, где будет расположено поле.
-
Чтобы добавить данные, начните вводить их в первую пустую ячейку или вставьте из другого источника (см. раздел Копирование данных из другого источника в таблицу Access).
-
Для переименования столбца (поля) дважды щелкните его заголовок и введите новое название.
Присвойте полям значимые имена, чтобы при просмотре области Список полей было понятно, что содержится в каждом поле.
-
Чтобы переместить столбец, щелкните его заголовок для выделения столбца и перетащите столбец в нужное место. Можно выделить несколько смежных столбцов и перетащить их одновременно. Чтобы выделить несколько смежных столбцов, щелкните заголовок первого столбца, а затем, удерживая нажатой клавишу SHIFT, щелкните заголовок последнего столбца.

 .
.Создание таблицы в режиме конструктора. В режиме конструктора сначала следует создать структуру таблицы. Затем можно переключиться в режим таблицы для ввода данных или ввести данные, используя другой способ, например вставить данные из буфера обмена или импортировать их.
-
На вкладке Создание в группе Таблицы нажмите кнопку Конструктор таблиц.
-
Для каждого поля в таблице введите имя в столбце Имя поля, а затем в списке Тип данных выберите тип данных.
-
При желании можно ввести описание для каждого поля в столбце Описание. Это описание будет отображаться в строке состояния, когда в режиме таблицы курсор будет находиться в данном поле. Описание также отображается в строке состояния для любых элементов управления в форме или отчете, которые создаются путем перетаскивания этого поля из области списка полей, и любых элементов управления, которые создаются для этого поля при использовании мастера отчетов или мастера форм.
-
Когда все необходимые поля будут добавлены, сохраните таблицу:
-
На вкладке Файл щелкните Сохранить.
-
-
Вы можете начать вводить данные в таблицу в любое время, переключившись в таблицу и щелкнув первую пустую ячейку. Вы также можете вкопировать данные из другого источника, как описано в разделе «Копирование данных из другого источника в таблицу Access».

Задание свойств полей в режиме конструктора. Независимо от способа создания таблицы рекомендуется проверить и задать свойства полей. Хотя некоторые свойства доступны в режиме таблицы, другие можно настроить только в режиме конструктора. Чтобы перейти в режим конструктора, в области навигации щелкните таблицу правой кнопкой мыши и выберите пункт Конструктор. Чтобы отобразить свойства поля, щелкните его в сетке конструктора. Свойства отображаются под сеткой конструктора в области Свойства поля.
Щелкните свойство поля, чтобы просмотреть его описание рядом со списком Свойства поля. Более подробные сведения можно получить, нажав кнопку справки.
В следующей таблице описаны некоторые наиболее часто изменяемые свойства полей.
|
Свойство |
Описание |
|
Размер поля |
Для текстовых полей это свойство указывает максимально допустимое количество знаков, сохраняемых в поле. Максимальное значение: 255. Для числовых полей это свойство определяет тип сохраняемых чисел («Длинное целое», «Двойное с плавающей точкой» и т. д.). Для более рационального хранения данных рекомендуется выделять для хранения данных наименьший необходимый размер памяти. Если потребуется, это значение позже можно изменить. |
|
Формат поля |
Это свойство определяет формат отображения данных. Оно не влияет на фактические данные, сохраняемые в этом поле. Вы можете выбрать встроенный формат или задать собственный. |
|
Маска ввода |
Это свойство используется для определения общего шаблона для ввода любых данных в поле. Это позволяет обеспечить правильный ввод и нужное количество знаков для всех данных. Для получения справки по созданию маски ввода нажмите кнопку |
|
Значение по умолчанию |
Это свойство позволяет задать стандартное значение, которое будет отображаться в этом поле при добавлении новой записи. Например, для поля «Дата/время», в котором необходимо записывать дату добавления записи, в качестве значения по умолчанию можно ввести «Date()» (без кавычек). |
|
Обязательное поле |
Это свойство указывает, обязательно ли вводить значение в поле. Если для него задано значение Да, невозможно будет добавить запись, если в это поле не введено значение. |
 справа от поля свойства.
справа от поля свойства.К началу страницы
Копирование данных из другого источника в таблицу Access
Если ваши данные хранятся в другой программе, например Excel, их можно скопировать и вставить в таблицу Access. Как правило, этот метод работает лучше всего, если данные уже разделены на столбцы, как в таблице Excel. Если данные находятся в текстовом редакторе, перед копированием рекомендуется разделить столбцы данных с помощью табуляции или преобразовать данные в таблицу. Если необходимо изменить данные или выполнить с ними другие операции (например, разделить полное имя на имя и фамилию), рекомендуется сделать это перед копированием данных, особенно если вы не знакомы с Access.
При вставке данных в пустую таблицу приложение Access задает тип данных для каждого поля в зависимости от того, какие данные в нем находятся. Например, если во вставляемом поле содержатся только значения даты, для этого поля используется тип данных «Дата/время». Если же вставляемое поле содержит только слова «Да» и «Нет», для этого поля выбирается тип данных «Логический».
Access называет имена полей в зависимости от того, что находится в первой строке в полученных данных. Если первая строка с данными похожа на последующие, Access определяет, что первая строка является частью данных, и присваивает полям общие имена (F1, F2 и т. д.). Если первая строка с данными не похожа на последующие строки, Access определяет, что первая строка состоит из имен полей. Access применит имена полей соответствующим образом и не включит первую строку в данные.
В Access имена присваиваются полям автоматически, поэтому во избежание путаницы поля следует переименовать. Это можно сделать следующим образом:
-
Нажмите клавиши CTRL+S, чтобы сохранить таблицу.
-
В режиме таблицы дважды щелкните заголовок каждого столбца и введите описательное имя поля для каждого столбца.
-
Еще раз сохраните таблицу.
Примечание: Кроме того, для изменения имен полей можно переключиться в режим конструктора. Для этого в области навигации щелкните таблицу правой кнопкой мыши и выберите пункт Конструктор. Чтобы вернуться в режим таблицы, дважды щелкните таблицу в области навигации.
К началу страницы
Импорт, добавление или связывание данных из другого источника
Возможно, у вас есть данные, хранящиеся в другой программе, которые вы хотите импортировать в новую таблицу Access или добавить в существующую. Кроме того, если ваши коллеги хранят данные в других программах, может потребоваться создать связь с такими данными. В обоих случаях работа с данными из других источников не представляет сложности. Вы можете импортировать данные из листа Excel, таблицы в другой базе данных Access, списка SharePoint и других источников. Процесс импорта для разных источников немного различается, однако всегда начинается так, как описано ниже.
-
В Access на вкладке Внешние данные в группе Импорт и связи выберите команду для типа файла, который необходимо импортировать.
Например, чтобы импортировать данные с листа Excel, нажмите кнопку Excel. Если вы не видите нужный тип программы, нажмите кнопку Дополнительно.
Примечание: Если не удается найти нужный тип формата в группе Импорт и связи, может потребоваться запустить программу, в которой созданы эти данные, а затем сохранить в ней данные в файле общего формата (например, как текстовый файл с разделителями) перед импортом данных в Access.
-
В диалоговом окне Внешние данные нажмите кнопку Обзор, чтобы найти исходный файл данных, или введите в поле Имя файла полный путь к нему.
-
Выберите нужный параметр (все программы разрешают импорт, а некоторые — для их связываия) в области «Укажите, как и где нужно хранить данные в текущей базе данных». Вы можете создать новую таблицу, использующую импортируемые данные, или (в некоторых программах) данные в существующую таблицу или связанную таблицу, которая поддерживает связь с данными в программе-источнике.
-
Если будет запущен мастер, следуйте инструкциям на экране. На последней странице мастера нажмите кнопку Готово.
При импорте объектов или связывании таблиц из базы данных Access открывается диалоговое окно Импорт объектов или Связь с таблицами. Выберите нужные элементы и нажмите кнопку ОК.
Точная последовательность действий зависит от выбранного способа обработки данных: импорт, добавление или связывание.
-
Access предложит сохранить сведения о только что завершенной операции импорта. Если вы планируете повторить ее, нажмите кнопку Сохранить шаги импорта и введите нужные сведения. Позже для повторения этой операции достаточно будет нажать кнопку Сохраненные операции импорта
на вкладке Внешние данные в группе Импорт и связи. Если вы не хотите сохранять сведения об операции, нажмите кнопку Закрыть.

 на вкладке Внешние данные в группе Импорт и связи. Если вы не хотите сохранять сведения об операции, нажмите кнопку Закрыть.
на вкладке Внешние данные в группе Импорт и связи. Если вы не хотите сохранять сведения об операции, нажмите кнопку Закрыть.Если вы решили импортировать таблицу, Access импортирует данные в новую таблицу и отображает ее в группе Таблицы в области навигации. Если выбрано добавление данных к существующей таблице, данные добавляются к ней. Если вы связываете данные, в группе Таблицы в области навигации создается связанная таблица.
К началу страницы
Добавление части приложения
Части приложения можно использовать для расширения функциональности баз данных. Часть приложения может быть просто отдельной таблицей, а может включать несколько объектов, таких как таблицы и связанные формы.
Например, часть приложения «Примечания» состоит из таблицы с полем идентификатора, имеющим тип «Счетчик», поля даты и поля MEMO. Ее можно добавить в базу данных и использовать как есть или с минимальными изменениями.
-
Откройте базу данных, в которую вы хотите добавить часть приложения.
-
Откройте вкладку Создание.
-
В группе Шаблоны нажмите кнопку Части приложения. Появится список доступных частей.
-
Щелкните часть приложения, которую вы хотите добавить.
К началу страницы
Открытие существующей базы данных Access
-
На вкладке Файл нажмите кнопку Открыть.
-
В диалоговом окне Открытие файла базы данных найдите базу данных, которую нужно открыть.
-
Выполните одно из следующих действий.
-
Чтобы открыть базу данных в режиме по умолчанию, дважды щелкните ее (режим по умолчанию может быть указан в диалоговом окне Параметры Access или установлен административной политикой).
-
Нажмите кнопку Открыть, чтобы открыть базу данных для общего доступа в многопользовательской среде и предоставить другим пользователям возможность выполнять в ней чтение и запись.
-
Щелкните стрелку рядом с кнопкой Открыть и выберите вариант Открыть для чтения, чтобы открыть базу данных только для чтения, то есть для просмотра без возможности внесения изменений. При этом другие пользователи смогут выполнять запись в базу данных.
-
Щелкните стрелку рядом с кнопкой Открыть и выберите вариант Монопольно, чтобы открыть базу данных в монопольном режиме. Если ее затем попытается открыть другой пользователь, он получит сообщение «Файл уже используется».
-
Щелкните стрелку рядом с кнопкой Открыть и выберите вариант Монопольно для чтения, чтобы открыть базу данных только для чтения. Другие пользователи при этом смогут открывать базу данных только для чтения.
-
Примечание: Вы можете напрямую открывать файлы данных внешних форматов, например dBASE, Microsoft Exchange или Excel. Кроме того, можно открыть напрямую любой источник данных ODBC, например Microsoft SQL Server. Access автоматически создаст базу данных Access в одной папке с файлом данных и добавит ссылки на все таблицы внешней базы данных.
Советы
-
Чтобы открыть одну из недавно использовавшихся баз данных, щелкните Последние на вкладке Файл и выберите имя файла базы данных. Access откроет базу данных, используя параметры, которые применялись при ее открытии в прошлый раз. Если список последних использовавшихся файлов не отображается, щелкните Параметры на вкладке Файл. В диалоговом окне Параметры Access нажмите кнопку Параметры клиента. В разделе Вывод на экран укажите количество документов, которые необходимо отобразить в списке «Последние документы» (не больше 50).
Кроме того, на панели навигации представления Backstage можно отдемонстрировать последние базы данных (1) вкладка «Файл», часть 2) базу данных, которую вы хотите открыть. В нижней части вкладки «Последние» выберите поле «Число последних баз данных», а затем укажите нужное количество.
-
При открытии базы данных с помощью команды Открыть на вкладке Файл можно просмотреть список ярлыков недавно открывавшихся баз данных, нажав в диалоговом окне Открыть кнопку Последние.
К началу страницы
Установка
Когда вы изучаете новый язык, самым важным аспектом является практика. Одно дело – прочитать статью и совсем другое – применить полученную информацию. Давайте начнем с установки базы данных на компьютер.
Первый шаг – установить SQL
Мы будем использовать PostgreSQL (Postgres) – достаточно распространенный SQL диалект. Для этого откроем страницу загрузки, выберем операционную систему (в моем случае Windows), и запустим установку. Если вы установите пароль для вашей базы данных, постарайтесь сразу не забыть его, он нам дальше понадобится. Поскольку наша база будет локальной, можете использовать простой пароль, например: admin.
Следующий шаг – установка pgAdmin
pgAdmin – это графический интерфейс пользователя (GUI – graphical user interface), который упрощает взаимодействие с базой данных PostgreSQL. Перейдите на страницу загрузки, выберите вашу операционную систему и следуйте указаниям (в статье используется Postgres 14 и pgAdmin 4 v6.3.).
После установки обоих компонентов открываем pgAdmin и нажимаем Add new server. На этом шаге установится соединение с существующим сервером, именно поэтому необходимо сначала установить Postgres. Я назвал свой сервер home и использовал пароль, указанный при установке.
Теперь всё готово к созданию таблиц. Давайте создадим набор таблиц, которые моделируют школу. Нам необходимы таблицы: ученики, классы, оценки. При создании модели данных необходимо учитывать, что в одном классе может быть много учеников, а у ученика может быть много оценок (такое отношение называется «один ко многим»).
Мы можем создать таблицы напрямую в pgAdmin, но вместо этого мы напишем код, который можно будет использовать в дальнейшем, например, для пересоздания таблиц. Для создания запроса, который создаст наши таблицы, нажимаем правой кнопкой мыши на postgres (пункт расположен в меню слева home → Databases (1) → postgres и далее выбираем Query Tool.
Начнем с создания таблицы классов (classrooms). Таблица будет простой: она будет содержать идентификатор id и имя учителя – teacher. Напишите следующий код в окне запроса (query tool) и запустите (run или F5).
DROP TABLE IF EXISTS classrooms CASCADE;
CREATE TABLE classrooms (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
teacher VARCHAR(100)
);
В первой строке фрагмент DROP TABLE IF EXISTS classrooms удалит таблицу classrooms, если она уже существует. Важно учитывать, что Postgres, не позволит нам удалить таблицу, если она имеет связи с другими таблицами, поэтому, чтобы обойти это ограничение (constraint) в конце строки добавлен оператор CASCADE. CASCADE – автоматически удалит или изменит строки из зависимой таблицы, при внесении изменений в главную. В нашем случае нет ничего страшного в удалении таблицы, поскольку, если мы на это пошли, значит мы будем пересоздавать всё с нуля, и остальные таблицы тоже удалятся.
Добавление DROP TABLE IF EXISTS перед CREATE TABLE позволит нам систематизировать схему нашей базы данных и создать скрипты, которые будут очень удобны, если мы захотим внести изменения – например, добавить таблицу, изменить тип данных поля и т. д. Для этого нам просто нужно будет внести изменения в уже готовый скрипт и перезапустить его.
Ничего нам не мешает добавить наш код в систему контроля версий. Весь код для создания базы данных из этой статьи вы можете посмотреть по ссылке.
Также вы могли обратить внимание на четвертую строчку. Здесь мы определили, что колонка id является первичным ключом (primary key), что означает следующее: в каждой записи в таблице это поле должно быть заполнено и каждое значение должно быть уникальным. Чтобы не пришлось постоянно держать в голове, какое значение id уже было использовано, а какое – нет, мы написали GENERATED ALWAYS AS IDENTITY, этот приём является альтернативой синтаксису последовательности (CREATE SEQUENCE). В результате при добавлении записей в эту таблицу нам нужно будет просто добавить имя учителя.
И в пятой строке мы определили, что поле teacher имеет тип данных VARCHAR (строка) с максимальной длиной 100 символов. Если в будущем нам понадобится добавить в таблицу учителя с более длинным именем, нам придется либо использовать инициалы, либо изменять таблицу (alter table).
Теперь давайте создадим таблицу учеников (students). Новая таблица будет содержать: уникальный идентификатор (id), имя ученика (name), и внешний ключ (foreign key), который будет указывать (references) на таблицу классов.
DROP TABLE IF EXISTS students CASCADE;
CREATE TABLE students (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
name VARCHAR(100),
classroom_id INT,
CONSTRAINT fk_classrooms
FOREIGN KEY(classroom_id)
REFERENCES classrooms(id)
);
И снова мы перед созданием новой таблицы удаляем старую, если она существует, добавляем поле id, которое автоматически увеличивает своё значение и имя с типом данных VARCHAR (строка) и максимальной длиной 100 символов. Также в эту таблицу мы добавили колонку с идентификатором класса (classroom_id), и с седьмой по девятую строку установили, что ее значение указывает на колонку id в таблице классов (classrooms).
Мы определили, что classroom_id является внешним ключом. Это означает, что мы задали правила, по которым данные будут записываться в таблицу учеников (students). То есть Postgres на данном этапе не позволит нам вставить строку с данными в таблицу учеников (students), в которой указан идентификатор класса (classroom_id), не существующий в таблице classrooms. Например: у нас в таблице классов 10 записей (id с 1 до 10), система не даст нам вставить данные в таблицу учеников, у которых указан идентификатор класса 11 и больше.
INSERT INTO students
(name, classroom_id)
VALUES
('Matt', 1);
/*
ERROR: insert or update on table "students" violates foreign
key constraint "fk_classrooms"
DETAIL: Key (classroom_id)=(1) is not present in table
"classrooms".
SQL state: 23503
*/
Теперь давайте добавим немного данных в таблицу классов (classrooms). Так как мы определили, что значение в поле id будет увеличиваться автоматически, нам нужно только добавить имена учителей.
INSERT INTO classrooms
(teacher)
VALUES
('Mary'),
('Jonah');
SELECT * FROM classrooms;
/*
id | teacher
-- | -------
1 | Mary
2 | Jonah
*/
Прекрасно! Теперь у нас есть записи в таблице классов, и мы можем добавить данные в таблицу учеников, а также установить нужные связи (с таблицей классов).
INSERT INTO students
(name, classroom_id)
VALUES
('Adam', 1),
('Betty', 1),
('Caroline', 2);
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
*/
Но что же случится, если у нас появится новый ученик, которому ещё не назначили класс? Неужели нам придется ждать, пока станет известно в каком он классе, и только после этого добавить его запись в базу данных?
Конечно же, нет. Мы установили внешний ключ, и он будет блокировать запись, поскольку ссылка на несуществующий id класса невозможна, но мы можем в качестве идентификатора класса (classroom_id) передать null. Это можно сделать двумя способами: указанием null при записи значений, либо просто передачей только имени.
-- явно определим значение NULL
INSERT INTO students
(name, classroom_id)
VALUES
('Dina', NULL);
-- неявно определим значение NULL
INSERT INTO students
(name)
VALUES
('Evan');
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
4 | Dina | [null]
5 | Evan | [null]
*/
И наконец, давайте заполним таблицу успеваемости. Этот параметр, как правило, формируется из нескольких составляющих – домашние задания, участие в проектах, посещаемость и экзамены. Мы будем использовать две таблицы. Таблица заданий (assignments), как понятно из названия, будет содержать данные о самих заданиях, и таблица оценок (grades), в которой мы будем хранить данные о том, как ученик выполнил эти задания.
DROP TABLE IF EXISTS assignments CASCADE;
DROP TABLE IF EXISTS grades CASCADE;
CREATE TABLE assignments (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
category VARCHAR(20),
name VARCHAR(200),
due_date DATE,
weight FLOAT
);
CREATE TABLE grades (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
assignment_id INT,
score INT,
student_id INT,
CONSTRAINT fk_assignments
FOREIGN KEY(assignment_id)
REFERENCES assignments(id),
CONSTRAINT fk_students
FOREIGN KEY(student_id)
REFERENCES students(id)
);
Вместо того чтобы вставлять данные вручную, давайте загрузим их с помощью CSV-файла. Вы можете скачать файл из этого репозитория или создать его самостоятельно. Имейте в виду, чтобы разрешить pgAdmin доступ к данным, вам может понадобиться расширить права доступа к папке (в моем случае – это папка db_data).
COPY assignments(category, name, due_date, weight)
FROM 'C:/Users/mgsosna/Desktop/db_data/assignments.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 5
Query returned successfully in 118 msec.
*/
COPY grades(assignment_id, score, student_id)
FROM 'C:/Users/mgsosna/Desktop/db_data/grades.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 25
Query returned successfully in 64 msec.
*/
Теперь давайте проверим, что мы всё сделали верно. Напишем запрос, который покажет среднюю оценку, по каждому виду заданий с группировкой по учителям.
SELECT
c.teacher,
a.category,
ROUND(AVG(g.score), 1) AS avg_score
FROM
students AS s
INNER JOIN classrooms AS c
ON c.id = s.classroom_id
INNER JOIN grades AS g
ON s.id = g.student_id
INNER JOIN assignments AS a
ON a.id = g.assignment_id
GROUP BY
1,
2
ORDER BY
3 DESC;
/*
teacher | category | avg_score
------- | --------- | ---------
Jonah | project | 100.0
Jonah | homework | 94.0
Jonah | exam | 92.5
Mary | homework | 78.3
Mary | exam | 76.0
Mary | project | 69.5
*/
Отлично! Мы установили, настроили и наполнили базу данных.
***
Итак, в этой статье мы научились:
- создавать базу данных;
- создавать таблицы;
- наполнять таблицы данными;
- устанавливать связи между таблицами;
Теперь у нас всё готово, чтобы пробовать более сложные возможности SQL. Мы начнем с возможностей синтаксиса, которые, вероятно, вам еще не знакомы и которые откроют перед вами новые границы в написании SQL-запросов. Также мы разберем некоторый виды соединений таблиц (JOIN) и способы организации запросов в тех случаях, когда они занимают десятки или даже сотни строк.
В следующей части мы разберем:
- виды фильтраций в запросах;
- запросы с условиями типа if-else;
- новые виды соединений таблиц;
- функции для работы с массивами;
Материалы по теме
- 🐘 8 лучших GUI клиентов PostgreSQL в 2021 году
- 🐍🐬 Python и MySQL: практическое введение
- 🐍🗄️ Управление данными с помощью Python, SQLite и SQLAlchemy
База данных – это хранилище, в которое можно сохранять данные, а позже делать по ним поиск и загружать их. Ну например, на форуме в базе данных может храниться информация о пользователях сайта и написанных ими сообщениях. При просмотре страницы скрипт на сервере ищет в БД сообщения на определенную тему и выводит их на странице. Почти любой интерактивный сайт использует БД.
Конечно, можно попробовать сделать свое хранилище (к примеру, на файлах), но вряд ли оно будет работать так же быстро и надежно, как профессиональная база данных. Хорошая база данных гарантирует отсутствие потерь сохраненных данных, даже если неожиданно отключится питание, отсутствие проблем при одновременной работе нескольких пользователей, позволяет искать информацию по произвольным критериям.
@sqlhub – разборы задач sql с нуля до профи.
Есть разные виды баз данных, но этот урок посвящен базам данных, поддерживающим язык SQL. В них любые операции над данными – добавление, удаление, поиск – делаются с помощью отправки SQL-запросов. Сам язык достаточно простой и запросы на нем напоминают обычные предложения на английском языке. Ну к примеру, запрос на удаление из БД пользователя с email ivan@example.com выглядит так: DELETE FROM users WHERE email = 'ivan@example.com'. Если знать английский (“удалить из пользователей где email равен ‘ivan@example.com‘”), то смысл запроса легко понять, даже не зная SQL. Запросы может отправлять как сам разработчик вручную, так и написанная им программа.
SQL – это что-то вроде стандарта в мире баз данных. Зная этот язык, можно работать с разными БД от разных производителей.
Программы, управляющие базой данных
Есть разные программы, которые позволяют создавать и управлять базой данных. Они называются СУБД (системы управления БД). Из бесплатных самые известные – это MySQL и PostgreSQL. MySQL (в 2016 году) более распространена, а в PostgreSQL больше интересных нестандартных возможностей (а также, считается что она более полно поддерживает стандарт).
Есть и коммерческие СУБД – например, MSSQL, Oracle DB.
Наконец, есть еще встраиваемые СУБД, которые используются не отдельно, а встраиваются в другую программу и используются только ей. Ну например, (в 2016 году) встроенную бесплатную СУБД SQLite использовали браузер Chrome, который хранил с ее помощью историю и закладки, Skype для хранения сообщений и множество мобильных приложений под Android и iOS.
Со всеми этими БД можно работать, зная язык SQL.
Устройство базы данных
База данных хранит данные в таблицах. Таблицы создает разработчик, и обычно каждая из них предназначается для своей сущности – например, таблица со списком пользователей, таблица тем на форуме, таблица сообщений на форуме. Таблица состоит из колонок, каждая из которых имеет определенных тип (число, строка). Ну к примеру, таблица для хранения информации о пользователях форума может выглядеть так:
| id | name | password_hash | salt | registered | |
|---|---|---|---|---|---|
| 1 | Администратор | admin@example.com | abbs09s7s6s6 | gt9xbxvx4x30 | 2014-08-02 |
| 2 | Иван | ivan@example.com | hd6bc00c8c7c665ce | gs65s4s4sb0x | 2015-01-01 |
При регистрации скрипт добавляет в нее информацию о новом пользователе, а при логине – проверяет введенные email и пароль. Мы, конечно, в целях безопасности не храним в базе сами пароли в открытом виде, а получаем из них хеш с солью и сохраняем их в колонках password_hash и salt (по которым можно проверить правильность введенного при логине пароля, но нельзя восстановить его). Также, мы присваиваем каждому пользователю уникальный числовой идентификатор (id), который еще называют первичный ключ – это позволяет потом в других таблицах ссылаться на него (например, в таблице сообщений мы можем хранить id автора сообщения, по которому можно достать информацию о нем).
А вот, как может выглядеть таблица сообщений, которые оставили пользователи на форуме. Для простоты представим, что у нас нет отдельных тем, а есть один большой общий поток сообщений:
| id | author_id | posted | text |
|---|---|---|---|
| 1 | 1 | 2014-08-03 | Добро пожаловать на наш форум! Жду ваших сообщений. |
| 2 | 1 | 2014-08-04 | Что-то никого нету… |
| 3 | 1 | 2014-08-05 | Ни души… |
| 4 | 2 | 2015-01-01 | Всем привет. Я новый тут. |
Здесь колонка id хранит идентификатор сообщения, author_id – идентификатор автора сообщения (по которому можно найти его имя, email в первой таблице), posted – дату отправки и text – тело сообщения. Первые 3 сообщения оставил Администратор, а четвертое – Иван.
Все операции с таблицами, включая их создание и заполнение делаются с помощью запросов на языке SQL. Подробнее о том, как это делать, написано ниже по ссылкам.
Работа с базой данных
Как правило сам сервер базы данных (программа, которая обеспечивает ее работу) не имеет своего интерфейса и каких-то окошек, кнопочек, чтобы с ним взаимодействовать. Управление базой данных делается с помощью запуска программы-клиента, который подсоединяется к серверу, пересылает ему SQL запросы и выводит полученные ответы. Одновременно к БД может подсоединиться несколько клиентов.
Как правило, у каждой базы данных есть клиент для командной строки. Это программа с минималистичным интерфейсом, в которой можно писать SQL запросы и видеть полученные ответы. Это то, что стоит использовать начинающему.
Те, кто освоил основы, могут использовать и более сложные программы-клиенты с графическим интерфейсом. Они могут отображать информацию из базы данных в виде таблиц, перемещаться по ним, менять значения в них. При этом можно запускать и вручную написанные SQL запросы. Я не буду тут писать названия конкретных программ, но их легко найти по словам вроде “MySQL GUI”, “MySQL admin”, “PostgreSQL GUI” и так далее. Я бы советовал сначала научиться работать исключительно в клиенте командной строки, а только потом переходить к этим программам.
Наконец, подсоединяться и отправлять запросы к БД можно из программы. Например, скрипт на языке PHP может таким образом выбирать данные из базы и отображать на веб-странице. Для этого нужна библиотека или расширение-клиент для базы данных. В PHP есть даже 2 расширения для этого (PDO и MySQLi), я рекомендую использовать расширение PDO, так как оно поддерживает исключения, за счет чего при какой-то ошибке проще получить информацию о ней.
Изучаем базы данных – ссылки
Теория и туториалы для начинающих:
- основы и туториал по MySQL (немного старый, но еще актуальный): http://phpclub.ru/mysql/doc/tutorial.html
- руководство на русском по PostgreSQL: https://postgrespro.ru/docs/postgresql
- большой учебник по SQL: http://www.pyramidin.narod.ru/rusql/index.htm
Если ты хранишь данные в нескольких таблицах, то необходимо уметь создавать связи между ними. Всего есть 3 вида связей – “один-к-одному”, “один-ко-многим”, “многие-ко-многим”. Вот уроки по этой теме:
- отношения между таблицами в БД: http://jtest.ru/bazyi-dannyix/sql-dlya-nachinayushhix-chast-3.html
- внешние ключи: http://denis.in.ua/foreign-keys-in-mysql.htm
После этого надо научиться правильно проектировать таблицы и связи между ними. Для этого надо изучить нормализацию БД. По этой теме есть разные статьи – некоторые написаны простым языком, а некоторые нет. Это важная тема, если не соблюдать принципы нормализации, то потом с такой базой будет неудобно работать.
- https://habrahabr.ru/post/129195/
- https://habrahabr.ru/post/254773/
- http://club.shelek.ru/viewart.php?id=177
- http://alexvolkov.ru/database-normalizatio.html
Поскольку это очень важная тема, я написал отдельный урок про нормализацию.
Советую изучить style guide – рекомендации по выбору названий для таблиц и колонок: http://www.sqlstyle.guide/ru/
А пока еще несколько полезных ссылок:
- сборник запросов на все случаи жизни (англ): http://www.artfulsoftware.com/infotree/queries.php
- таблицы отличий в диалектах SQL в разных СУБД (англ): http://en.wikibooks.org/wiki/SQL_dialects_reference
- манга-учебник про SQL в картинках: http://www.nostarch.com/mg_databases.htm
Под Windows в командной строке не работают русские буквы
Надо выполнить команду SET NAMES cp866; после соединения: http://gahcep.github.io/blog/2013/01/05/mysql-utf8/
Еще ссылки на тему кодировок при соединении с MySQL из PHP:
- http://fstrange.ru/coder/mysql/kodirovka-krakozyably.html
- http://phpfaq.ru/charset
Что должен знать разработчик?
Вот список понятий, которые стоит знать, если ты хочешь очень хорошо разбираться в MySQL:
- управление базами данных: CREATE DATABASE, DROP DATABASE, SHOW DATABASES
- управление таблицами: CREATE TABLE, ALTER TABLE, DROP TABLE, SHOW TABLES, SHOW CREATE TABLE, DESC table, TRUNCATE table
- управление правами доступа: GRANT, SHOW GRANTS
- типы колонок: ENUM, SET, CHAR, VARCHAR, TEXT, DATE, TIME, DATETIME, TIMESTAMP, INT, FLOAT, TINYINT, DECIMAL, MEDIUMTEXT, LONGTEXT. В чем разница между TIMESTAMP и DATETIME? Между FLOAT и DECIMAL? CHAR и VARCHAR?
- DECIMAL — тип с фиксированной точностью. В отличие от FLOAT/DOUBLE, которые приближенные и могут терять знаки после запятой, DECIMAL хранит заданное число знаков. Используется например, для хранения суммы денег.
- NULL и троичная логика (в БД NULL значит «неизвестно». Например, возраст пользователя неизвестен. Соответственно, все операции с NULL это учитывают: NULL + 5 тоже дает в итоге NULL (5 + неизвестное число дает неизвестное число), сравнение (NULL = NULL) возвращает ложь, чтобы проверить равно ли поле NULL надо использовать IS NULL/IS NOT NULL. http://ru.wikipedia.org/wiki/NULL_(SQL))
- можно ли искать пустые поля условием WHERE x = NULL?
- при создании таблицы можно сделать поля обязательными для заполнения, указав NOT NULL
- SELECT/INSERT/DELETE/UPDATE
- порядок выполнения запроса выборки: FROM+JOIN, WHERE, GROUP, HAVING, ORDER, LIMIT, SELECT (его надо знать наизусть)
- REPLACE, INSERT IGNORE, INSERT .. ON DUPLICATE KEY UPDATE
- выборка данных: DISTINCT, JOIN, ORDER BY, GROUP BY, HAVING, LIMIT
- группировка и агрегатные функции: GROUP BY, COUNT, MAX, MIN, AVG, SUM
- транзакции: BEGIN, ROLLBACK, COMMIT
- внешние ключи: FOREIGN KEY. Внешний ключ — это поле, которое хранит id записи в другой таблице
- первичный ключ: естественный и искусственный
- обычные и уникальные индексы (ключи)
- оптимизация запросов, команда EXPLAIN
- отличие InnoDB от MyISAM
Теория по проектированию БД
Чтобы уметь проектировать базы данных и новые таблицы, нужно знать следующее:
- виды отношений между таблицами: один-к-одному, один-ко-многим, многие-ко-многим
- принципы нормализации БД. В интернете можно найти статьи где “нормальные формы” объясняют простыми словами, например http://club.shelek.ru/viewart.php?id=311 или https://habrahabr.ru/post/193756/ а также, можно почитать мой урок про нормализацию
- способы хранения древовидных (иерархических) данных в БД. Ну например, это нужно для реализации дерева комментариев к статье или дерева категорий товаров в интернет-магазине. Есть такие паттерны: Adjacency List, Closure Path, Nested Sets, Materialized Path. Вот мой урок про них: https://github.com/codedokode/pasta/blob/master/db/trees.md
- способы реализации наследования таблиц (когда есть похожие, но не одинаковые сущности с общим набором свойств: например Пользователи и Администраторы, или несколько видов приложений к сообщению: Видеозапись, Аудиозапись, Файл, Ссылка на сайт). Для таких случаев есть паттерны Single Table Inheritance, Concrete table Inheritance, Class Table Inheritance
- паттерн EAV (Entity-Attribute-Value), описание на англ., на русском. Этот паттерн можно использовать в тех случаях, когда есть сущности с разным набором свойств, и свойства могут добавляться (например объявление: объявления о сдаче квартиры и продаже машины имеют разный набор свойств). Также, в интернете можно найти много обсуждений по поводу того, зло это или нет. Есть также альтернативные подходы, например в PostgreSQL можно использовать индексируемые hstore (англ.) или json (англ.) колонки
Вот цикл статей на Хабре, который подойдет в качестве вступления: 1-3, 4-6, 7-9, 10-13, 14-15, бонус
Самое главное, что надо изучить – это нормализация. Если не знать ее или не следовать ее правилам, то с базой будет неудобно работать.
Чем отличаются движки для таблиц MyISAM и InnoDB?
- http://rtfm.co.ua/mysql-otlichiya-mezhdu-myisam-i-innodb/
- http://itif.ru/otlichiya-myisam-innodb/
Если кратко: MyISAM более простой и не поддерживает внешние ключи и транзакции. А они нужны почти всегда. Потому в 99% случаев тебе нужен InnoDB.
Индексы
Индексы позволяют ускорить поиск по условиям вроде x = ?, x < ?, x BETWEEN ? AND ?, x LIKE 'xxx%', x IN (?, ?, ?), а также сортировку (поля по которым идет сортировка должны идти в конце индекса). Разница на большой таблице может быть огромная — порядка 1 тысячной секунды против нескольких секунд. Ну например, если у нас есть таблица размером в миллион записей и мы делаем запрос
SELECT a, b FROM table ORDER BY y LIMIT 10
то без индекса MySQL вынуждена будет прочитать с диска в память миллион значений, отсортировать их только ради того, чтобы взять первые 10. Если же есть индекс по полю y (который хранит отсортированные по возрастанию значения этого поля) то MySQL просто возьмет из него первые 10 записей. Разница в скорости работы будет огромная.
Вот статьи для начинающих про индексы:
- http://ruhighload.com/post/%D0%A0%D0%B0%D0%B1%D0%BE%D1%82%D0%B0+%D1%81+%D0%B8%D0%BD%D0%B4%D0%B5%D0%BA%D1%81%D0%B0%D0%BC%D0%B8+%D0%B2+MySQL
- http://www.mysql.ru/docs/man/MySQL_indexes.html
- http://habrahabr.ru/post/211022/
Если ты все прочел внимательно, ответь на вопрос, может ли индекс (если да, то какой) ускорить такие запросы:
SELECT * FROM table WHERE x <> 1SELECT * FROM table WHERE x + y < 100SELECT MAX(a) FROM table WHERE b = 2SELECT * FROM table WHERE name LIKE '%Иван%'SELECT * FROM table WHERE b = 1 AND a < 10
Задачка про лайки
С полученными знаниями ты легко сможешь решить эту задачу: есть пользователи (id, имя) и они могут ставить друг другу лайки. Сделай таблицы для хранения всей этой информации и напиши запрос, который выведет такую таблицу:
- id пользователя
- имя
- лайков получено
- лайков поставлено
- взаимных лайков
Сложно? Ну хорошо, давай начнем с более простой задачи: просто выведи 5 самых популярных пользователей.
Далее, выведи список всех пользователей, которые лайкнули пользователей A и B, но при этом не лайкнули пользователя C. Тут есть несколько вариантов решения.
- Если ты используешь несколько связанных друг с другом таблиц, связи необходимо пометить с помощью внешних ключей
- Желательно на уровне БД запретить возможность ставить пользователю лайк другому пользователю дважды (подсказка: можно использовать уникальный или первичный составной ключ)
- Подсказка: эта задача решается без подзапросов
- Подсказка: достаточно использовать всего 2 джойна и группировку
- Подсказка: изучи агрегатные функции, которые можно применять к сгруппированным данным: http://www.mysql.ru/docs/man/Group_by_functions.html
- Подсказка: для подсчета числа взаимных лайков внутри группы можно написать выражение, которое для каждой строчки вернет 0/1 в зависимости от того, обозначает она взаимный лайк или нет, а потом остается только просуммировать эти значения
- Подсказка: задача про пользователей, “которые лайкнули пользователей A и B, но при этом не лайкнули пользователя C”, решается без подзапросов и джойнов, в один проход по таблице с группировкой. Достаточно сгруппировать строки, после чего посчитать число лайков к A, B, С в каждой группе и отобрать те группы, которые соответствуют условию (HAVING).
- Подсказка: изучи функции из этого списка: http://www.mysql.ru/docs/man/Control_flow_functions.html – они тут пригодятся. С их помощью можно найти число записей, соответствующих определенному условию
Усложненная (но более жизненная) задача про лайки
В воображаемой социальной сети есть Пользователи (id, имя), Фото (id, название, автор) и Комментарии К Фото (id, текст, автор, к какому Фото относится). Необходимо добавить возможность для Пользователей ставить лайки другим Пользователям, Фото или Комментариям К Фото. Нужно реализовать такие возможности:
- пользователь не может поставить 2 лайка одной и той же сущности (например одному и тому же Фото)
- пользователь может отозвать лайк
- необходимо иметь возможность посчитать число полученных сущностью лайков и вывести список Пользователей, поставивших лайки
- в будущем могут появиться новые виды сущностей которые можно лайкать
Для начала, нужно решить задачу без оглядки на производительность. Очень желательно следовать принципам нормализации и помечать связи внешними ключами (а также на уровне БД предотвратить возможность повторной отправки лайка). Далее, можно дополнить решение комментариями по поводу оптимизаций производительности.
Тут есть несколько вариантов решения.
Задачка про кинотеатр
Вот дополнительная, более сложная задачка. Есть кинотеатр, в нем идут фильмы. У фильма есть название, длительность (пусть для простоты будет 60, 90 или 120 минут), цена билета (в разное время и дни может быть разная), время начала сеанса (один фильм может быть показан несколько раз в разное время за разную цену). Также, есть информация о купленных билетах (номер билета, на какой сеанс).
Задания:
- составь грамотную нормализованную схему хранения этих данных в БД. Внеси в нее 4-5 фильмов, расписание на один день и несколько проданных билетов.
Сделай запросы, считающие и выводящие в понятном виде:
- ошибки в расписании (фильмы накладываются друг на друга), отсортированные по возрастанию времени. Выводить надо колонки «фильм 1», «время начала», «длительность», «фильм 2», «время начала», «длительность».
- перерывы больше или равные 30 минут между фильмами, выводятся по уменьшению длительности перерыва. Выводить надо колонки «фильм 1», «время начала», «длительность», «время начала второго фильма», «длительность перерыва».
- список фильмов, для каждого указано общее число посетителей за все время, среднее число зрителей за сеанс и общая сумма сбора по каждому, отсортированные по убыванию прибыли. Внизу таблицы должна быть строчка «итого», содержащая данные по всем фильмам сразу.
- число посетителей и кассовые сборы, сгруппированные по времени начала фильма: с 9 до 15, с 15 до 18, с 18 до 21, с 21 до 00:00. (то есть сколько посетителей пришло с 9 до 15 часов, сколько с 15 до 18 и т.д.).
Сложная задача про календарь
Решил предыдущие задачи и они слишком простые? Ок, давай возьмемся за действительно сложную задачу. Напиши SQL-код, выводящий календарь на текущий месяц в виде:
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Подсказка: ты можешь делать запросы без таблиц, например
SELECT 2 + 3, 'Hello' - Подсказка: здесь не надо использовать циклы или процедуры
- Подсказка: функции работы с датой и временем ты можешь найти тут http://dev.mysql.com/doc/refman/5.0/en/date-and-time-functions.html (англ.)
- Подсказка: для сокращения объема кода ты можешь использовать переменные (создаются командой
SET)
select
distinct first_name, last_name
from
actor as a ;
select
last_name, count(last_name) as lnc
from
actor as a
group by
last_name
having count(last_name) > 1;
-- приоритеты логических операторов
SELECT * FROM payment p ;
SELECT
p.amount, p.payment_date
FROM
payment AS p
WHERE
p.amount > 7 AND p.payment_date > '2007-05-01'
OR
p.amount < 3 AND p.payment_date > '2007-05-05'
ORDER BY
p.amount, p.payment_date;
-- приоритеты логических операторов
SELECT DISTINCT
amount
FROM
payment AS p
WHERE
(amount = 1.99 OR amount = 4.99)
OR
(amount = 8.99 OR amount = 10.99)
ORDER BY
amount;
SELECT NOW();
SELECT EXTRACT(YEAR FROM NOW());
SELECT EXTRACT(MONTH FROM NOW());
SELECT EXTRACT(DAY FROM NOW());
SELECT EXTRACT (DOW FROM NOW());
SELECT AGE(NOW(), '2000-12-12');
SELECT EXTRACT(YEAR FROM AGE(NOW(), '2000-12-12'));
SELECT EXTRACT(EPOCH FROM '2020-12-12' - '2000-12-12');
select age('2020-08-01', '2012-03-05');
select '2015-01-11'::date - '2015-01-01'::date;
SELECT
(EXTRACT(epoch from age('2017-6-15', now())) / 86400)::int
SELECT
*
FROM
film AS f
WHERE
--title LIKE('D% C%e');
title ilike('d_i%');
-- LIKE - чувствителен к регистру
-- ilike - не чувствителен к регистру
-- % сколько угодно символов
-- _ один любой символ
SELECT
*
FROM
film f
WHERE
f.title NOT LIKE 'D%'
AND f.description LIKE '%Shark%'
AND f.rental_duration IN(3, 5);
-- функция IN(3, 5) проверяет на наличие одного из указ-х элементов
-- Работа с датами
SELECT
c.create_date
,c.last_update
FROM
customer AS c
;
SELECT
'2022-01-15 15:15:15'::DATE AS " Дата из строки"
,'2022-01-15 15:15:15' AS "Строка"
,timestamp'2022-01-15 15:15:15' AS "Дата+Время 1"
,'2022-01-15 15:15:15'::TIMESTAMP AS "Дата+Время 2"
;
SELECT
-- Использование ::DATE
'2022-01-15 15:15:15'::DATE - '2006-02-13 10:10:10' AS "::DATE 1"
,'2022-01-15'::DATE - '2022-02-13'::DATE AS "::DATE 2"
-- Использование date
,date'2022-01-15' - date'2022-02-13' AS "date 1"
,date'2022-01-15' - '2022-02-13' AS "date 2"
-- timestamp дата
,timestamp'2022-04-13' - '2022-02-13' AS "ts 1"
,timestamp'2022-04-13' - timestamp'2022-02-13' AS "ts 2"
-- timestamp дата+время
,timestamp'2022-04-13 ' - '2022-02-13' AS "ts time 1"
,timestamp'2022-04-13 15:15:15' - timestamp'2022-02-13 10:10:10' AS "ts time 2"
,'2022-04-13 15:15:15'::TIMESTAMP - '2022-02-13 10:10:10'::TIMESTAMP AS "ts time 3"
;
SELECT
'2022-04-13'::TIMESTAMP AS tm
, timestamp'2006-04-13 10:10:10' - date'2006-05-13'
;
SELECT date('2022-04-13 10:10:10') AS "date 1";
SELECT
last_update
,text(last_update )
,last_update ::TEXT
FROM
customer c;
SELECT
create_date AS "Создание"
,last_update AS "Обнова"
,concat(create_date - last_update) AS "Вычет"
,create_date - '2006-02-13' AS "Нов.вычет"
FROM
customer;
Домашнее задание №1
SELECT * FROM film f;
SELECT TEXT(f.last_update) FROM film f;
SELECT f.rental_rate FROM film f;
SELECT
f.title AS "Имя"
,f.release_year AS "Релиз"
,f.rental_rate AS "Ставка"
,round(f.rental_rate / f.rental_duration, 2) AS "Ставка в час"
FROM
film AS f
WHERE
f.rental_rate > 3
AND
f.release_year = 2006
ORDER BY
f.title;
--TEXT(f.release_year) LIKE '2006%'
--EXTRACT(YEAR FROM f.last_update) = '2006'
Домашнее задание №2
SELECT * FROM payment p;
SELECT
*
FROM
payment AS p
WHERE
p.payment_date > '2007-05-01' AND p.amount > 3
OR
p.amount > 10
ORDER BY
p.payment_date;
Домашнее задание №3
SELECT
--a.first_name || ' ' || a.last_name
CONCAT(a.first_name, ' ', a.last_name)
FROM
actor AS a
WHERE
a.first_name LIKE 'F%'
AND
a.last_name NOT LIKE '%s'
ORDER BY
a.last_update;Просмотры: 591
Время на прочтение
9 мин
Количество просмотров 22K
Данные — это один из наиболее важных компонентов геопространственных технологий и, пожалуй, любой другой отрасли. К управлению данными сейчас относятся серьезно во всех отраслях, поэтому знания по этой дисциплине имеют важное значение для карьеры ИТ-специалистов. Этот цикл статей задуман как универсальное руководство, в котором мы рассмотрим тему от и до, начиная с вопроса «Что такое данные?» и заканчивая изучением и применением геопространственных запросов.

Основные понятия баз данных
Что такое данные?
Данные могут представлять собой любую информацию, которая сохраняется с целью обращения к ней в будущем. Эта информация может включать числа, текст, аудио- и видеоматериалы, местонахождение, даты и т. д. Она может быть записана на бумаге либо сохранена на жестком диске компьютера или даже в облаке.
Что такое база данных?
Множество записей данных, собранных вместе, образуют базу данных. Базы данных обычно создаются для того, чтобы пользователи могли обращаться к большому количеству данных и массово выполнять с ними определенные операции.База данных может хранить что угодно: представьте себе, например, блокнот вашей бабушки со всеми ее вкусными рецептами, учетную книгу ваших родителей, куда они записывают все доходы и расходы, или свою страницу в Facebook со списком всех ваших друзей. Из этих примеров видно, что все данные в базе данных относятся более-менее к одному типу.
Зачем нужна база данных?
Создание базы данных упрощает разным пользователям доступ к наборам информации. Приведенные выше примеры показывают, что в базе данных мы можем хранить записи с информацией похожего типа, но это правда лишь отчасти, поскольку с появлением баз данных NoSQL это определение меняется (подробнее читайте далее в статье).Так как размер веб-сайтов становится все больше и степень их интерактивности все выше, данные о пользователях, клиентах, заказах и т. д. становятся важными активами компаний, которые испытывают потребность в надежной и масштабируемой базе данных и инженерах, способных в ней разобраться.
Система управления базами данных (СУБД)
Итак, мы уже знаем, что данные и базы данных важны, но как осуществляется работа с базами данных в компьютерных системах? Вот тут на сцену и выходит СУБД. СУБД — это программное обеспечение, предоставляющее нам способ взаимодействия с базами данных на компьютере для выполнения различных операций, таких как создание, редактирование, вставка данных и т. д. Для этого СУБД предоставляет нам соответствующие API. Редко какие программы не используют СУБД для работы с данными, хранящимися на диске.Помимо операций с данными СУБД также берет на себя резервное копирование, проверку допуска, проверку состояния базы данных и т. д. Поэтому рекомендуется всегда использовать СУБД при работе с базами данных.
Пространственные данные и база данных
Особое внимание мы уделим обработке пространственных данных, поэтому я хотел бы обсудить здесь этот тип данных. Пространственные данные несколько отличаются от остальных. Координаты необходимо сохранять в особом формате, который обычно указан в документации на веб-сайте о базе данных. Этот формат позволяет базе считывать и правильно воспринимать координаты. Если обычно для поиска данных мы используем запросы типа Получить все результаты, где возраст > 15, то пространственный запрос выглядит как-то так: Получить все результаты в радиусе 10 км от определенной точки. Поэтому пространственные данные необходимо хранить в надлежащем формате.
Типы баз данных
Базы данных обычно делятся на два типа: реляционные и нереляционные. Оба типа имеют свои плюсы и минусы. Было бы глупо утверждать, что один лучше другого, поскольку это будет зависеть от варианта использования. Конкретно для пространственных данных я в 99 % случаев использую реляционные базы данных, и вы скоро поймете почему.
Реляционные базы данных и РСУБД
Допустим, ваш начальник просит вас создать электронную таблицу с важной информацией, включающей имена, местонахождения, адреса электронной почты, номера телефонов и должности всех сотрудников. Вы сразу же откроете таблицу Excel или Google Spreadsheets, напишете все эти названия столбцов и начнете собирать информацию.

Закономерность здесь заключается в том, что каждая запись содержит ограниченный и фиксированный набор полей, которые нам нужно заполнить. Таким образом мы создали таблицу со всей информацией, где у каждой записи имеется уникальный первичный ключ, который определяет ее однозначным образом и делает ее доступной для всех операций. В реляционных базах данных любая таблица содержит фиксированное количество столбцов, и можно устанавливать связи между разными столбцами.

Взаимосвязи в реляционных базах данных мы подробно рассмотрим позже.
По сравнению с базами данных NoSQL, недостатком реляционных баз данных является относительно медленное получение результатов, когда количество данных стремительно увеличивается (по мнению автора статьи — прим. пер.). Еще один недостаток заключается в том, что при добавлении каждой записи нужно следовать определенным правилам (типы столбцов, количество столбцов и т. д.), — мы не можем просто добавить отдельный столбец только для одной записи.В реляционных базах данных используется SQL (Structured Query Language — язык структурированных запросов), с помощью которого пользователи могут взаимодействовать с данными, хранящимися в таблицах. SQL стал одним из наиболее широко используемых языков для этой цели. Мы подробнее поговорим об SQL чуть позже.Вот примеры некоторых известных и часто используемых реляционных баз данных: PostgreSQL, MySQL, MS SQL и т. д. У каждой крупной компании, занимающейся реляционными базами данных, есть собственная версия SQL. В большинстве аспектов они выглядят одинаково, но иногда требуется немного изменить какой-нибудь запрос, чтобы получить те же результаты в другой базе данных (например, при переходе из PostgreSQL в MySQL).
Нереляционные базы данных (NoSQL)
Все базы данных, не являющиеся реляционными, относятся к категории нереляционных баз данных. Обычно данные хранятся в нетабличном формате, например:
-
Пара «ключ-значение»
-
Формат JSON, XML
-
Графовый формат
Основное преимущество баз данных NoSQL состоит в том, что все строки независимы и могут иметь разные столбцы. Как показано на изображении ниже, оба пользователя относятся к одной и той же таблице Core_user, но их записи содержат разную информацию.

База данных NoSQL реального времени в Google Firebase
При использовании баз данных NoSQL пользователям иногда приходится прописывать собственную логику, чтобы добавить уникальный ключ к каждой записи и тем самым обеспечить доступ к записям. В большинстве стандартных баз данных NoSQL, таких как Firebase и MongoDB, для хранения данных используется формат JSON. Благодаря этому очень легко и удобно выполнять операции с данными из веб-приложений, используя JavaScript, Python, Ruby и т. д.
Рекомендации по выбору типа базы для хранения пространственных данных
Очевидно, что нам хотелось бы сохранить точку, линию, многоугольник, растры и т. д. так, чтобы это имело смысл, вместо того чтобы сохранять просто координаты. Нам нужна СУБД, которая позволяет не только сохранять данные, но и запрашивать их пространственными методами (буфер, пересечение, вычисление расстояния и т. д.). На сегодняшний день для этого лучше всего подходят реляционные базы данных, поскольку в SQL есть функции, помогающие выполнять подобные операции. Использование таких дополнительных средств, как PostGIS для PostgreSQL, открывает разработчикам возможности для написания сложных пространственных запросов. С другой стороны, NoSQL тоже работает в области геопространственных технологий: например, MongoDB предоставляет кое-какие функции для выполнения геопространственных операций. Однако реляционные базы данных все же лидируют на рынке с большим отрывом.
Работа с РСУБД
Основное внимание мы уделим РСУБД, так как именно эти системы в большинстве случаев мы будем использовать для хранения пространственных данных и работы с ними. В качестве примера мы будем использовать PostgreSQL, поскольку это самая перспективная реляционная база данных с открытым исходным кодом, а ее расширение PostGIS позволяет работать и с пространственными данными. Вы можете установить PostgreSQL, следуя инструкциям из документации. Помимо PostgreSQL рекомендуется также загрузить и установить pgAdmin. Платформа pgAdmin предоставляет веб-интерфейс для взаимодействия с базой данных. Также для этого можно загрузить и установить какое-либо другое совместимое ПО или использовать командную строку.

Пользователи могут изменять множество настроек для баз данных, включая порт, имя пользователя, пароль, доступность извне, выделение памяти и т. д., но это уже другая тема. В этой статье мы сосредоточимся на работе с данными, находящимися в базе.
Создание базы данных. Нам нужно создать базу данных (в идеале должно быть по одной базе данных для каждого проекта).

В инструменте запросов (Query Tool) база данных создается следующим образом:
CREATE DATABASE <database_name>Создание таблиц. Создание таблицы требует некоторых дополнительных соображений, поскольку именно здесь нам нужно определить все столбцы и типы данных в них. Все типы данных, которые можно использовать в PostgreSQL, вы найдете здесь.
pgAdmin позволяет нам выбрать в таблице различные ключи и ограничения, например Not Null (запрет на отсутствующие значения), Primary Key (первичный ключ) и т. д. Обсудим это подробнее чуть позже.

Заметьте, что мы не добавляли столбец первичного идентификатора в список столбцов, поскольку PostgreSQL делает это автоматически. Мы можем создать сколько угодно таблиц в одной базе данных. После того как таблицы созданы, мы можем установить связи между разными таблицами, используя определенные столбцы (обычно столбцы с идентификаторами).В инструменте запросов таблица создается следующим образом:
CREATE TABLE <table_name> (
<column_1> <datatype>,
<column_2> <datatype>,
..
.
..
<column_n> <datatype>
PRIMARY KEY (<column>)
);CRUD-операции с данными в таблицах
CRUD-операции (создание, чтение, обновление и удаление — Create, Retrieve, Update, Delete) — это своего рода hello world в мире СУБД. Поскольку эти операции используются наиболее часто, команды для их выполнения одинаковы во всех РСУБД. Мы будем писать и выполнять запросы в инструменте запросов в pgAdmin, который вызывается следующим образом:
 в pgAdmin")
1. Создание новой записи
Для добавления новой записи в таблицу используйте следующую команду:
INSERT INTO <tablename> (column1, column2, column3,...) VALUES (value1, value2, value3,...);INSERT, INTO, VALUE являются ключевыми словами в SQL, поэтому их нельзя использовать в качестве переменных, значений и т. д. Чтобы добавить новую запись в нашу таблицу пользователей, мы напишем в инструменте запросов следующий запрос:
INSERT INTO users(name, employed, address) VALUES ('Sheldon Cooper', true, 'Pasadena');
Обратите внимание: строки всегда следует заключать в ‘ ‘ (одинарные кавычки), а не в » » (двойные кавычки).
2. Получение записей (всех или нескольких)
Данные, хранящиеся в базе данных, можно извлечь и отобразить на экране. При этом мы можем получить все данные или ограниченное количество записей. Код для получения данных:
select <column1, column2 ,...> from <tablename> Этот код извлекает весь набор данных. Если вы хотите получить только 20 записей, напишите:
select <column1, column2 ,...> from <tablename> limit 20Если вы хотите получить данные из всех столбцов, то вместо перечисления названий всех столбцов можно написать:
select * from <tablename>Если вы хотите получить результат с определенным условием, используйте ключевое слово WHERE, как показано ниже:
select * from <tablename> where <key> = <value>Вы можете создавать даже сложные запросы, о которых мы поговорим позже.В нашем примере мы можем получить нужные нам данные:
--Retrieving Specific columns for all users
select name,employed from users
--Retrieving all columns for all users
select * from users
--Retrieving all columns for first 3 users
select * from users limit 3
--Retrieving all columns for all users where employed = true
select * from users where employed = true
3. Обновление записей (всех или нескольких)РСУБД позволяет нам обновить все или только некоторые записи данных, указав новые значения для столбцов.
UPDATE <tablename>
SET <column1> = <value1>, <column2> = <value2> Если вы хотите обновить определенные строки, добавьте условия с использованием ключевого слова WHERE:
UPDATE <tablename>
SET <column1> = <value1>, <column2> = <value2>
WHERE <column> = <value> В нашем случае мы обновим таблицы с помощью следующих запросов:
-- Make all rows as employed = true
update users set employed = true
-- change employed = false for entries with address = 'nebraska'
update users set employed = false where address = 'nebraska'
4. Удаление записей (всех или нескольких)Удалять записи в SQL легко. Пользователь может удалить либо все строки, либо только определенные строки, добавив условие WHERE.
-- Deleting all entries
Delete from <tablename>
-- Deleting entries based on conditions
Delete from <tablename> where <column> = <value> -- Deleting all entries
Delete from users
-- Deleting entries based on conditions
Delete from users where employed = false
CRUD-операции используются очень часто, поскольку выполняют основные функции в базе данных.
Перевод подготовлен в рамках курса «Базы данных». Все желающих приглашаем на бесплатный двухдневный онлайн-интенсив «Бэкапы и репликация PostgreSQL. Практика применения». Цели занятия: настроить бэкапы; восстановить информацию после сбоя. Регистрация здесь.