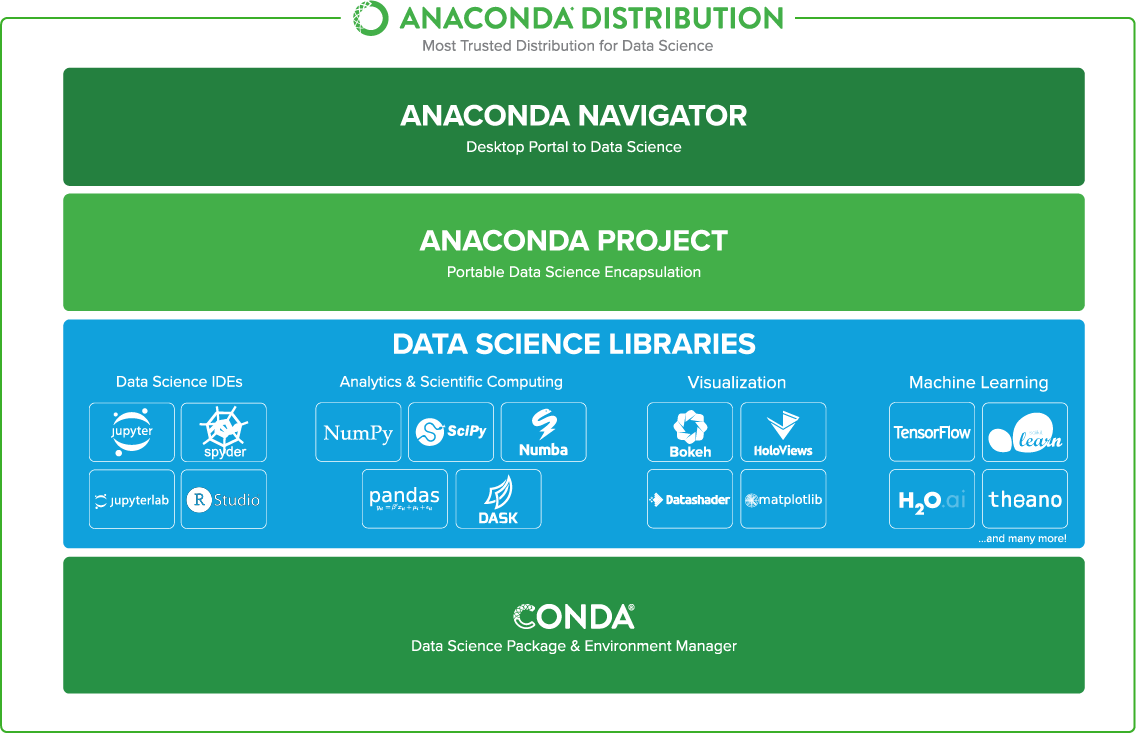
Welcome to Anaconda! This document is here to help you get started with Anaconda Distribution, the free installation that includes conda, Anaconda Navigator, and over 250 scientific and machine learning packages.
Should I use Anaconda Navigator or conda?¶
Anaconda Navigator is a desktop application that is included with every installation of Anaconda Distribution. It is built on top of conda, the open-source package and environment manager, and allows you to manage your packages and environments from a graphical user interface (GUI). This is especially helpful when you’re not comfortable with the command line.
A command line interface (or CLI) is a program on your computer that processes text commands to do various tasks. Conda is a CLI program, which means it can only be used via the command line. On Windows computers, Anaconda recommends that you use the Anaconda Prompt CLI to work with conda. MacOS and Linux users can use their built-in command line applications.
Note
If you installed Miniconda instead of Anaconda Distribution (see Should I use Anaconda Distribution or Miniconda?), Anaconda Navigator is not included. Use the command conda install anaconda-navigator to manually install Navigator onto your computer.
Free Anaconda Learning course — Get Started with Anaconda¶
Learn to use Anaconda Navigator to launch an application. Then, create and run a simple Python program with Spyder and Jupyter Notebook. Watch our short training videos on Anaconda Learning to get up and running with Jupyter Notebook and JupyterLab, along with several other popular integrated development environments (IDEs):

An introduction to Navigator and the command line¶
Navigator and the CLI interact with conda in similar but distinct ways, and each have their benefits and drawbacks. Anaconda recommends that you learn the basics of both to determine what is preferable for your programming workflow. See My first Python program: Hello, Anaconda! to go through a short programming exercise and get a better idea for what you prefer.
What’s next?¶
Spyder external resources¶
Spyder is a free development environment that you can launch from Navigator. The resources below provide more information about using notebooks for your education, research, and work:
- Spyder Project Homepage
- Spyder Documentation
Среды Conda помогает управлять зависимостями и изолировать проекты. Также среды conda не зависят от языка, т.е. они поддерживают языки, отличные от Python.
В этом руководстве мы рассмотрим основы создания и управления средами
Condaдля Python
Conda vs. Pip vs. Venv — в чем разница?
- pip — это менеджер пакетов для Python.
- venv — является менеджером среды для Python.
- conda — является одновременно менеджером пакетов и среды и не зависит от языка.
venv создает изолированные среды только для разработки на Python, а conda может создавать изолированные среды для любого поддерживаемого языка программирования.
Примите во внимание, что pip устанавливает только пакеты Python из PyPI, с помощью conda можно
- Установить пакеты (написанные на любом языке) из репозиториев, таких как Anaconda Repository и Anaconda Cloud.
- Установить пакеты из PyPI, используя pip в активной среде Conda.
Anaconda — это дистрибутивы Python и R. Он предоставляет все необходимое для решения задач по анализу и обработке данных (с применимостью к Python).
Anaconda — это набор бинарных систем, включающий в себя Scipy, Numpy, Pandas и их зависимости.
- Scipy — это пакет статистического анализа.
- Numpy — это пакет числовых вычислений.
- Pandas — уровень абстракции данных для объединения и преобразования данных.
Что такое Анаконда Навигатор?
Anaconda Navigator — это графический интерфейс пользователя на рабочем столе (GUI), включенный в дистрибутив Anaconda, который позволяет запускать приложения и легко управлять пакетами, средами и каналами conda без использования команд командной строки. Навигатор может искать пакеты в Anaconda Cloud или в локальном репозитории Anaconda. Он доступен для Windows, MacOS и Linux.

- JupyterLab — это интерактивная среда разработки для работы с блокнотами, кодом и данными.
- Jupyter Notebok — удобный инструмент для создания красивых аналитических отчетов, позволяет хранить вместе код, изображения, комментарии, формулы и графики. Работа ведется в браузере.
- Spyder — интерактивной IDE для научных расчетов на языке Python. Данная IDE позволяет писать, редактировать и тестировать код. Spyder предлагает просмотр и редактирование переменных с помощью GUI, динамическую интроспекцию кода, нахождение ошибок на лету и многое другое. Также, по необходимости, можно интегрировать Anaconda с другими Python IDE, включая PyCharm и Atom.
- VS Code — это оптимизированный редактор кода с поддержкой таких операций разработки, как отладка, запуск задач и контроль версий.
- Glueviz — используется для визуализации многомерных данных в файлах. Он исследует отношения внутри и между связанными наборами данных.
- Orange 3 — это основанная на компонентах структура интеллектуального анализа данных. Это может быть использовано для визуализации данных и анализа данных. Рабочие процессы в Orange 3 очень интерактивны и предоставляют большой набор инструментов.
- RStudio — это набор интегрированных инструментов, предназначенных для повышения продуктивности работы с R. Он включает в себя основы R и Notebooks.
Зачем использовать Навигатор?
Для запуска многие научные пакеты зависят от конкретных версий других пакетов. Исследователи данных часто используют несколько версий множества пакетов и используют несколько сред для разделения этих разных версий.
Программа командной строки conda является одновременно менеджером пакетов и менеджером среды. Это помогает специалистам по данным гарантировать, что каждая версия каждого пакета имеет все необходимые зависимости и работает правильно.
Navigator — это простой и удобный способ работы с пакетами и средами без необходимости вводить команды conda в окне терминала. Вы можете использовать его, чтобы найти нужные вам пакеты, установить их в среде, запустить пакеты и обновить их — все в Navigator.
Почему Вам могут потребоваться несколько сред Python?
Когда Вы начинаете изучать Python, Вы устанавливаете самую новую версию Python с последними версиями библиотек (пакетов), которые Вам нужны или с которыми Вы хотите поэкспериментировать.
Когда Вы постигните азы Python и загрузите приложения Python из GitHub, Kaggle или других источников. Этим приложениям могут потребоваться другие версии библиотек (пакетов) Python, чем те, которые Вы в настоящее время используете (прошлые версии пакетов или прошлые версии Python).
В этом случае Вам необходимо настроить различные среды.
Помимо этой ситуации, есть и другие варианты использования, когда могут оказаться полезными дополнительные среды:
- У вас есть приложение (разработанное Вами или кем-то еще), которое когда-то работало прекрасно. Но теперь Вы пытались запустить его, и оно не работает. Возможно, один из пакетов больше не совместим с другими частями вашей программы (из-за так называемых критических изменений). Возможное решение состоит в том, чтобы настроить новую среду для вашего приложения, которая содержит версию Python и пакеты, полностью совместимые с вашим приложением.
- Вы сотрудничаете с кем-то еще и хотите убедиться, что ваше приложение работает на компьютере члена вашей команды, или наоборот.
- Вы доставляете приложение своему клиенту и снова хотите убедиться, что оно работает на компьютере вашего клиента.
- Среда состоит из определенной версии Python и некоторых пакетов. Следовательно, если Вы хотите разрабатывать или использовать приложения с разными требованиями к Python или версиями пакетов, Вам необходимо настроить разные среды.
Каналы — это места хранилищ, где Conda ищет пакеты. Каналы существуют в иерархическом порядке. Канал с наивысшим приоритетом является первым, который проверяет Conda в поисках пакета, который вы просили. Вы можете изменить этот порядок, а также добавить к нему каналы (и установить их приоритет).
Рекомендуется добавлять канал в список каналов как элемент с самым низким приоритетом. Таким образом, вы можете включить «специальные» пакеты, которые не являются частью тех, которые установлены по умолчанию (каналы ~ Continuum). В результате вы получите все пакеты по умолчанию — без риска перезаписи их по каналу с более низким приоритетом — И тот «специальный», который вам нужен.

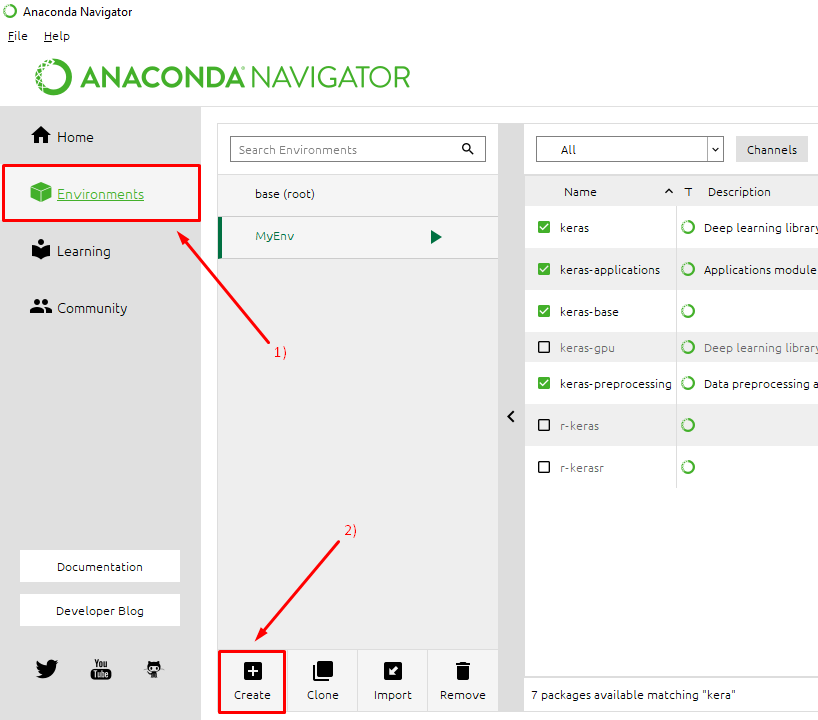
Создание новой среды в Anaconda Navigator
Для создания новой среды, нажимаем пункт Environments, а затем Create:
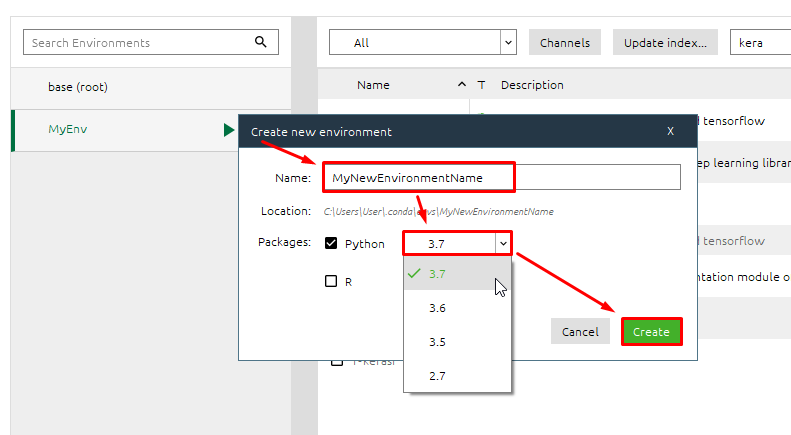
Далее указываем наименование среды и выбираем версию Python:
Добавление нового канала в Anaconda Навигаторе
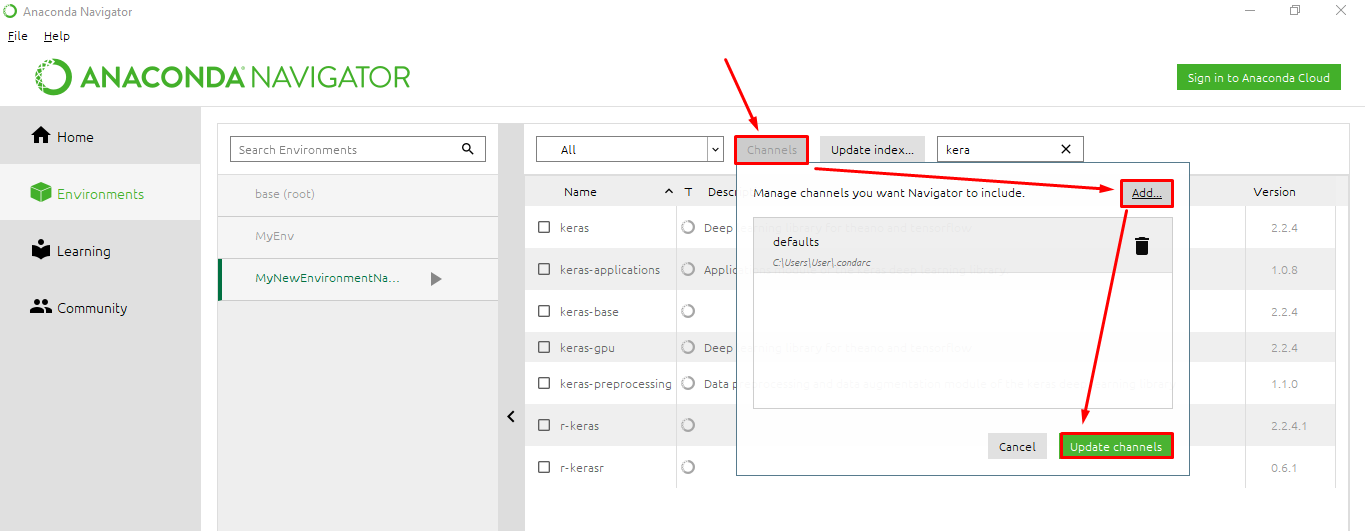
Как начать работу в новой среде Conda?
Итак, Вы создали среду, указали дополнительные каналы, установили необходимые пакеты (библиотеки). Теперь необходимо в Анаконда Навигаторе перейти на вкладку Home и инсталлировать в определенную среду те компоненты, которые Вы хотите использовать.
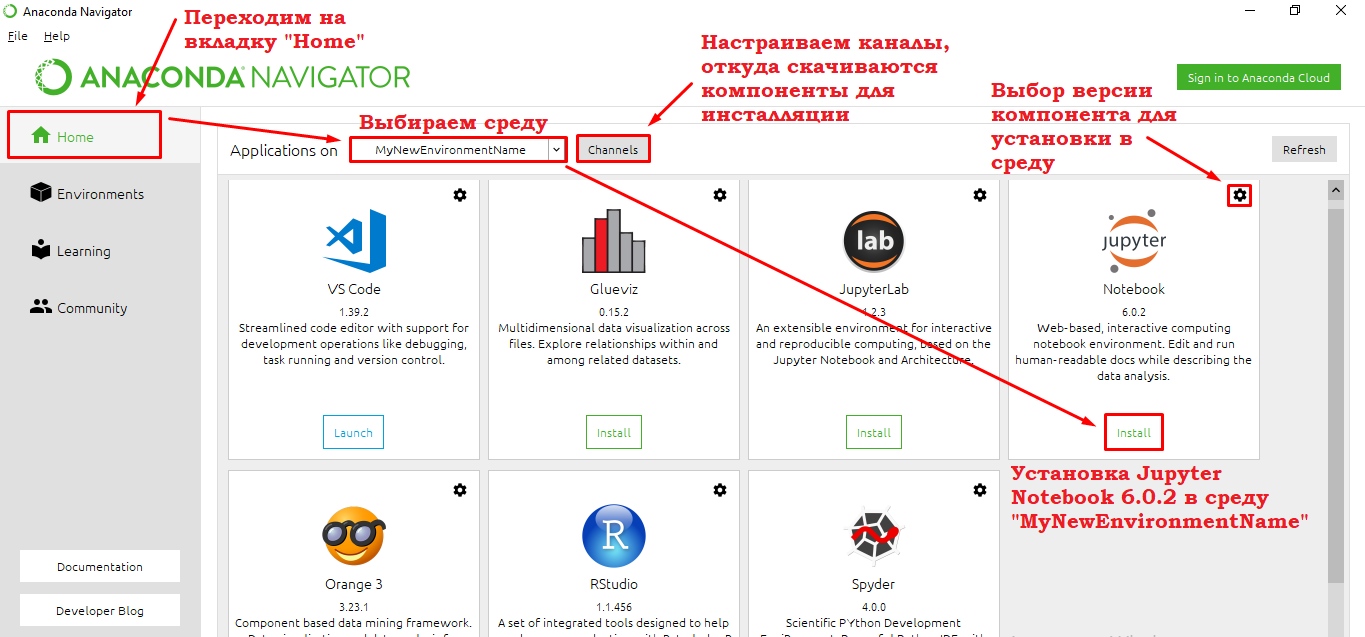
Например, последовательно установим 2 компонента Jupyter Notepad и Spyder. Для компонентов также имеются каналы, откуда скачиваются для инсталляции ПО.
После инсталляции станут доступны кнопки Launch — Запустить компонент для работы в среде.
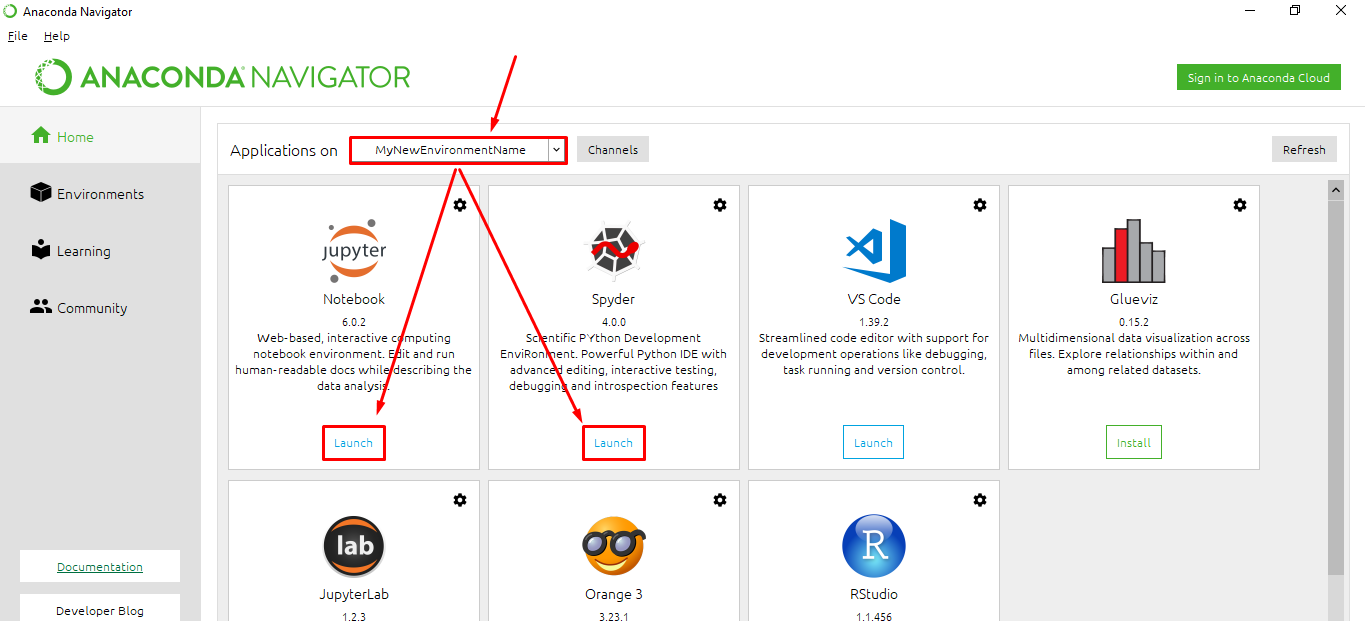
Запустим для примера Spyder:

Настройка среды для Spyder
1. Настройка интерпретатора
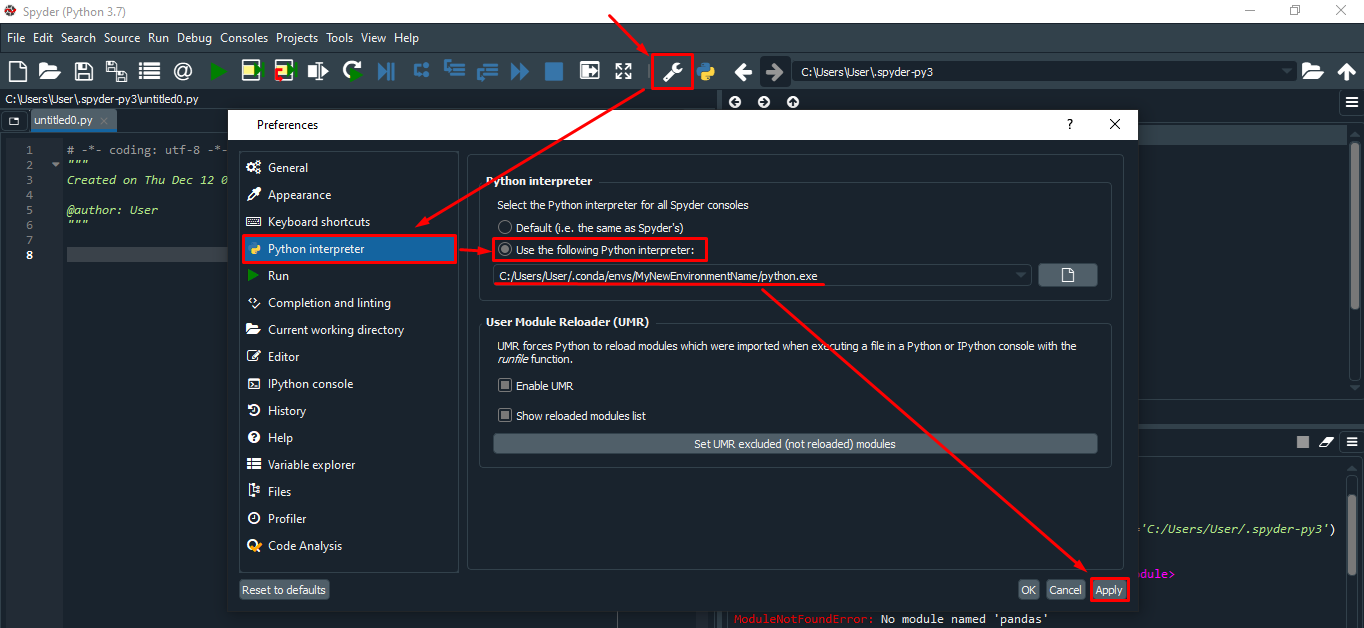
Настройка директории
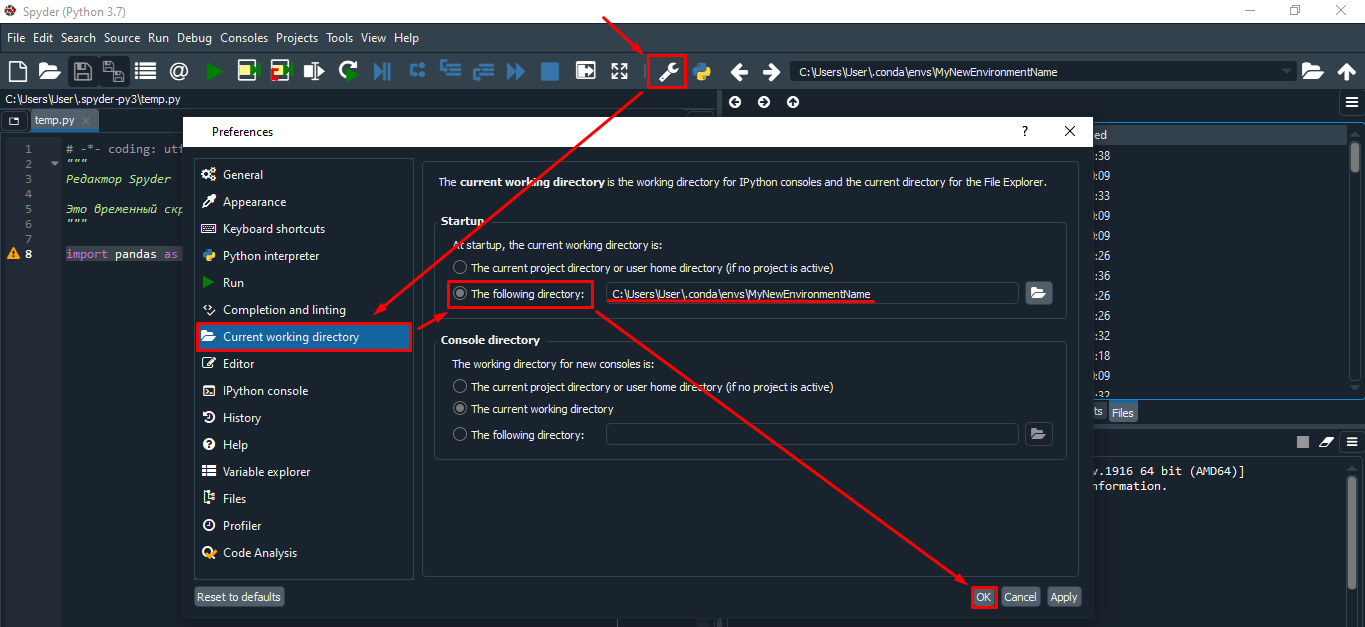
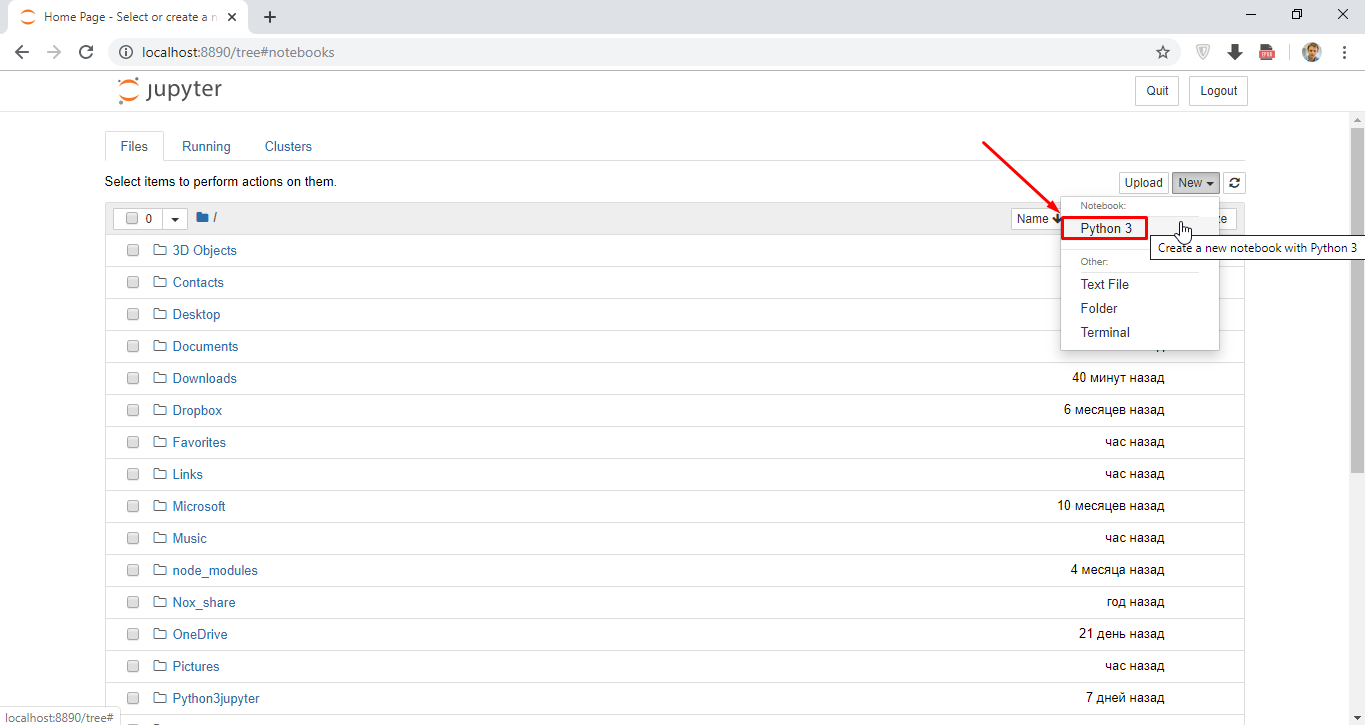
Как открыть Jupyter Notebook в новой среде MyNewEnvironmentName
Для того, чтобы запустить Jupyter Notebook в созданной среде MyNewEnvironmentName, в пуске находим Anaconda3 и запускаем блокнот с названием среды:

Появится консольное окошко — это движок Jupyter Notebook, который работает в фоновом режиме:

В Jupyter запускаем Python 3:
Для того, чтобы убедиться в какой среде мы работаем, можно вбить ряд команд (ниже приведен текст этих команд для Python 3):

Узнать среду, в которой работает Jupyter Notebook:
import sys print(sys.version) print(sys.base_prefix)
Получить список модулей, доступных в Env:
print('n'.join(sys.modules.keys()))
Anaconda3 Prompt cmd Conda Command — Запуск команд через консоль
Для того, чтобы использовать команды conda через командную строку (cmd), необходимо запустить программу Anaconda Prompt (Anaconda3)
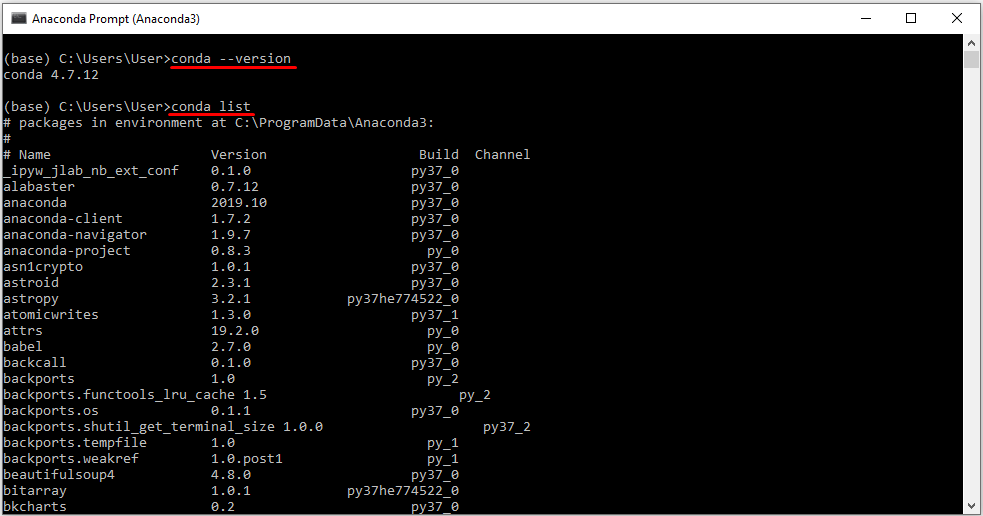
Можете набрать две команды (в качестве проверки работы conda):
Установка новой библиотеки (пакета) в среду
Пакеты управляются отдельно для каждой среды. Изменения, которые вы вносите в пакеты, применяются только к активной среде.
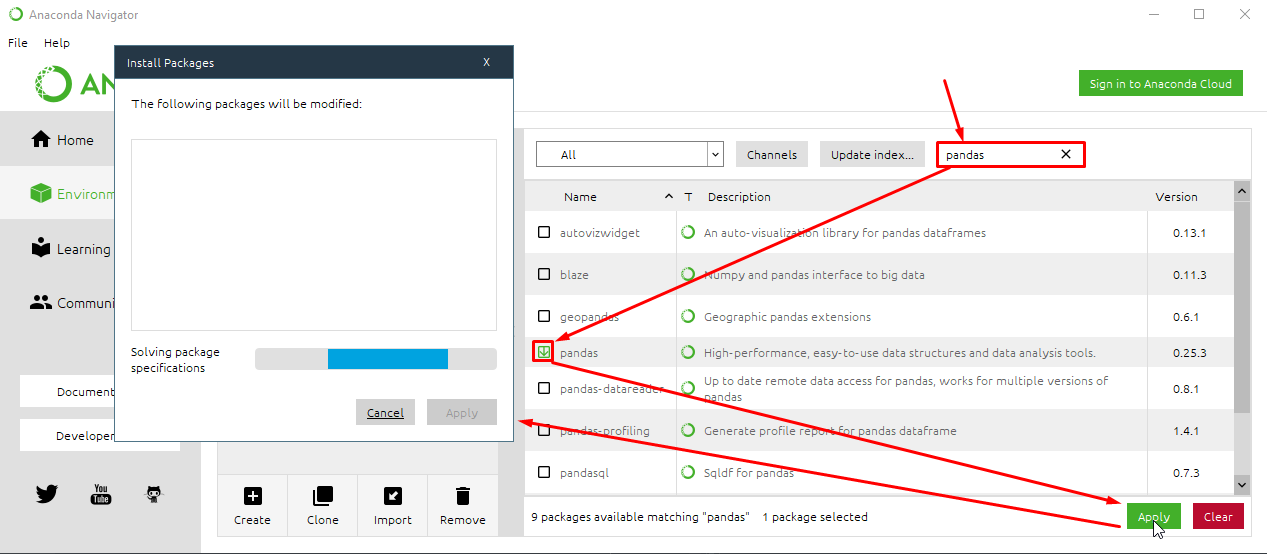

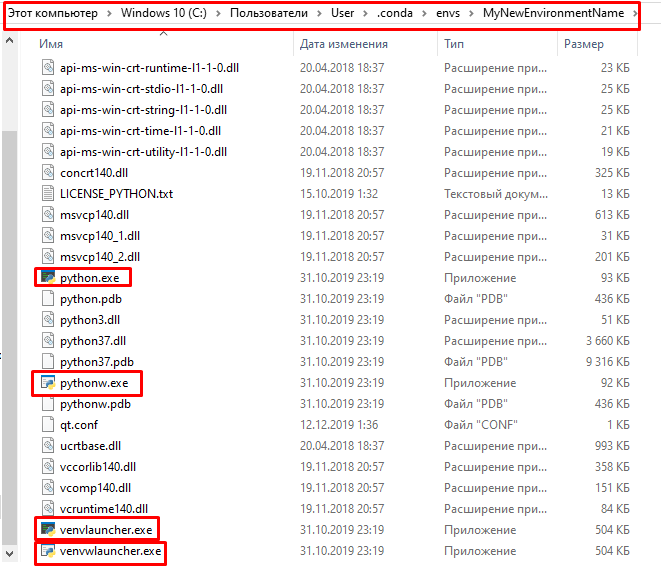
Исполняемые файлы в среде Conda
- python.exe — исполняемый файл Python для приложений командной строки. Так, например, если вы находитесь в каталоге
Example App, вы можете выполнить его:python.exe exampleapp.py - pythonw.exe — исполняемый файл Python для приложений с графическим интерфейсом или приложений без интерфейса пользователя
- venvlauncher.exe —
- venvwlauncher.exe —
Scripts— исполняемые файлы, являющиеся частью установленных пакетов. После активации среды этот каталог добавляется в системный путь, поэтому исполняемые файлы становятся доступными без их полного пути.Scriptsactivate.exe- активирует окружающую среду
Видео по Anaconda Youtube
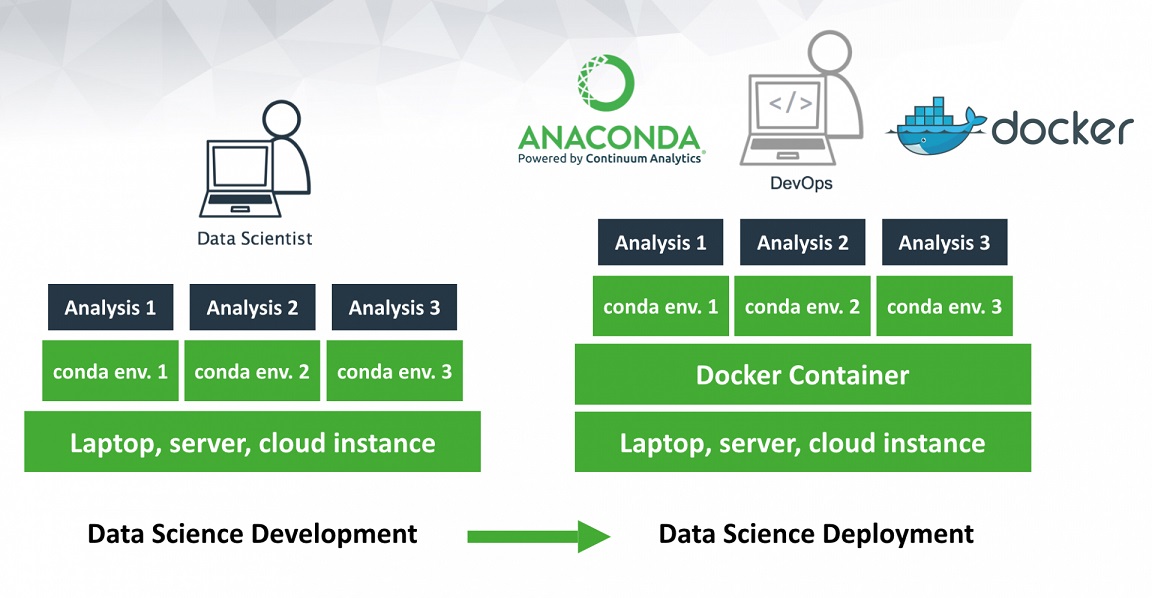
Использование Anaconda с Doker
Anaconda со своей изолированной средой для пакетов Data Science Python и технологией контейнеров Docker создает отличную комбинацию для масштабируемых, воспроизводимых и переносимых развертываний данных.
Вы можете использовать Anaconda с Docker для создания контейнеров и обмена вашими приложениями для обработки данных внутри вашей команды. Совместные рабочие процессы по обработке данных с Anaconda и Docker максимально упрощают переход от разработки к развертыванию.
Jupyter Notebook: цифровая лабораторная тетрадь
Для обеспечения воспроизводимости исследований необходимо регистрировать все, что вы делаете. Это достаточно обременительно, особенно если вы просто хотите просто поэкспериментировать и выполнить специальный анализ.
Отличный инструмент для экспериментов — Jupyter Notebook. Интерактивный интерфейс программирования позволяет мгновенно проверять действия, выполняемые кодом, благодаря чему можно создавать алгоритмы шаг за шагом. Более того, вы можете использовать ячейки Markdown для записи своих идей и выводов одновременно с кодом.
Conda
Управление пакетами, зависимостями и средой для любого языка — Python, R, Ruby, Lua, Scala, Java, JavaScript, C / C ++, FORTRAN и других.
Conda — это система управления пакетами с открытым исходным кодом и система управления средой, работающая в Windows, macOS и Linux. Conda быстро устанавливает, запускает и обновляет пакеты и их зависимости. Conda легко создает, сохраняет, загружает и переключается между средами на вашем локальном компьютере. Он был создан для программ Python, но он может упаковывать и распространять программное обеспечение для любого языка.
Conda как менеджер пакетов поможет вам найти и установить пакеты. Если вам нужен пакет, для которого требуется другая версия Python, вам не нужно переключаться на другой менеджер среды, потому что conda также является менеджером среды. С помощью всего лишь нескольких команд вы можете настроить совершенно отдельную среду для запуска этой другой версии Python, продолжая при этом запускать вашу обычную версию Python в обычной среде.
В конфигурации по умолчанию conda может устанавливать и управлять тысячами пакетов на repo.anaconda.com, которые создаются, проверяются и поддерживаются Anaconda.
Conda может быть объединена с системами непрерывной интеграции, такими как Travis CI и AppVeyor, чтобы обеспечить частое автоматическое тестирование вашего кода.
Пакет conda и менеджер среды включены во все версии Anaconda и Miniconda.
Conda также включена в Anaconda Enterprise , которая обеспечивает управление корпоративными пакетами и средами для Python, R, Node.js, Java и других стеков приложений. Conda также доступна на conda-forge , канале сообщества. Вы также можете получить conda на PyPI , но этот подход может быть не таким современным.
Команды Conda
- conda search package_name — поиск пакета через conda
- conda install package_name — установка пакета через conda
- conda install — установка всего стандартного набора пакетов — более 150, около 3 Гб
- conda list — список установленных пакетов
- conda update conda — обновление conda
- conda clean -t — удаление кеша — архивов .tar.bz2, которые могут занимать много места и не нужны
Управление Conda и Anaconda
Убедитесь, что conda установлена, проверьте версию #
conda info
Обновление пакета conda и менеджера среды
conda update conda
Обновите метапакет анаконды (anaconda)
conda update anaconda
Управление средами — Managing Environments
Получить список всех моих окружений. Активная среда показана с *
conda info --envs
conda info -e
Создать среду и установить программу (ы)
conda create --name snowflakes biopython
conda create -n snowflakes biopython
Активируйте новую среду, чтобы использовать ее
conda activate snowflakes
Дезактивировать окружающую среду
conda deactivate
Создайте новую среду, укажите версию Python
conda create -n bunnies python=3.4 astroid
Сделать точную копию окружения
conda create -n flowers --clone snowflakes
Удалить среду
conda remove -n flowers --all
Сохранить текущую среду в файл
conda env export > puppies.yml
Загрузить среду из файла
conda env create -f puppies.yml
Управление Python
Проверьте версии Python, доступные для установки
conda search --full-name python
conda search -f python
Установите другую версию Python в новой среде
conda create -n snakes python=3.4
Управление конфигурацией .condarc
Получить все ключи и значения из моего файла .condarc
conda config --get
Получить значение ключевых каналов из файла .condarc
conda config --get channels
Добавьте новое значение в каналы, чтобы conda искала пакеты в этом месте
conda config --add channels pandas
Управление пакетами (Packages), включая Python
Просмотр списка пакетов и версий, установленных в активной среде
conda list
Найдите пакет, чтобы узнать, доступен ли он для установки conda.
conda search beautiful-soup
Установите новый пакет. ПРИМЕЧАНИЕ. Если вы не укажете имя среды, оно будет установлено в текущей активной среде.
conda install -n bunnies beautiful-soup
Обновить пакет в текущей среде
conda update beautiful-soup
Поиск пакета в определенном месте (канал pandas на Anaconda.org)
conda search --override-channels -c pandas bottleneck
Установить пакет из определенного канала
conda install -c pandas bottleneck
Найдите пакет, чтобы узнать, доступен ли он в репозитории Anaconda.
conda search --override-channels -c defaults beautiful-soup
Установить коммерческие пакеты Continuum
conda install iopro accelerate
Создайте пакет Conda из пакета Python Index Index (PyPi)
conda skeleton pypi pyinstrument
conda build pyinstrument
Удаление Пакетов (Packages) или Сред (Environments)
Удалить один пакет из любой именованной среды
conda remove --name bunnies beautiful-soup
Удалить один пакет из активной среды
conda remove beautiful-soup
Удалить несколько пакетов из любой среды
conda remove --name bunnies beautiful-soup astroid
Удалить среду
conda remove --name snakes --all
Источники, использованные при создании статьи
- https://protostar.space/why-you-need-python-environments-and-how-to-manage-them-with-conda
- https://kapeli.com/cheat_sheets/Conda.docset/Contents/Resources/Documents/index
4.8
17
голоса
Рейтинг статьи
Conda is a powerful package manager and environment manager that
you use with command line commands at the Anaconda Prompt for Windows,
or in a terminal window for macOS or Linux.
This 20-minute guide to getting started with conda lets you try out
the major features of conda. You should understand how conda works
when you finish this guide.
SEE ALSO: Getting started with Anaconda Navigator, a
graphical user interface that lets you use conda in a web-like interface
without having to enter manual commands. Compare the Getting started
guides for each to see which program you prefer.
Before you start
You should have already installed
Anaconda.
Contents
Starting conda on Windows, macOS, or Linux. 2 MINUTES
Managing conda. Verify that Anaconda is installed and check that conda is updated to the current version. 3 MINUTES
Managing environments. Create environments and move easily between them. 5 MINUTES
Managing Python. Create an environment that has a different version of Python. 5 MINUTES
Managing packages. Find packages available for you to install. Install packages. 5 MINUTES
TOTAL TIME: 20 MINUTES
Starting conda
Windows
-
From the Start menu, search for and open «Anaconda Prompt.»

On Windows, all commands below are typed into the Anaconda Prompt window.
MacOS
-
Open Launchpad, then click the terminal icon.
On macOS, all commands below are typed into the terminal window.
Linux
-
Open a terminal window.
On Linux, all commands below are typed into the terminal window.
Managing conda
Verify that conda is installed and running on your system by typing:
Conda displays the number of the version that you have installed. You do not
need to navigate to the Anaconda directory.
EXAMPLE: conda 4.7.12
Note
If you get an error message, make sure you closed and re-opened the
terminal window after installing, or do it now. Then verify that you are logged
into the same user account that you used to install Anaconda or Miniconda.
Update conda to the current version. Type the following:
Conda compares versions and then displays what is available to install.
If a newer version of conda is available, type y to update:
Tip
We recommend that you always keep conda updated to the latest version.
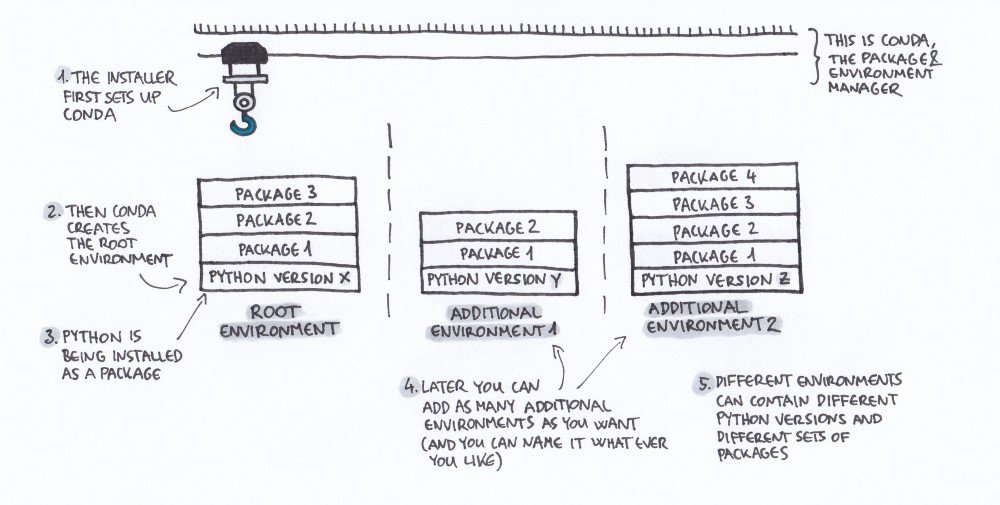
Managing environments
Conda allows you to create separate environments containing files, packages,
and their dependencies that will not interact with other environments.
When you begin using conda, you already have a default environment named
base. You don’t want to put programs into your base environment, though.
Create separate environments to keep your programs isolated from each other.
-
Create a new environment and install a package in it.
We will name the environment
snowflakesand install the package
BioPython. At the Anaconda Prompt or in your terminal window, type
the following:conda create --name snowflakes biopython
Conda checks to see what additional packages («dependencies»)
BioPython will need, and asks if you want to proceed:Type «y» and press Enter to proceed.
-
To use, or «activate» the new environment, type the following:
-
Windows:
conda activate snowflakes -
macOS and Linux:
conda activate snowflakes
Note
conda activateonly works on conda 4.6 and later versions.For conda versions prior to 4.6, type:
-
Windows:
activate snowflakes -
macOS and Linux:
source activate snowflakes
Now that you are in your
snowflakesenvironment, any conda
commands you type will go to that environment until
you deactivate it. -
-
To see a list of all your environments, type:
A list of environments appears, similar to the following:
conda environments: base /home/username/Anaconda3 snowflakes * /home/username/Anaconda3/envs/snowflakes
Tip
The active environment is the one with an asterisk (*).
-
Change your current environment back to the default (base):
conda activateNote
For versions prior to conda 4.6, use:
-
Windows:
activate -
macOS, Linux:
source activate
Tip
When the environment is deactivated, its name is no
longer shown in your prompt, and the asterisk (*) returns to base.
To verify, you can repeat theconda info --envscommand. -
Managing Python
When you create a new environment, conda installs the same Python version you
used when you downloaded and installed Anaconda. If you want to use a different
version of Python, for example Python 3.5, simply create a new environment and
specify the version of Python that you want.
-
Create a new environment named «snakes» that contains Python 3.9:
conda create --name snakes python=3.9
When conda asks if you want to proceed, type «y» and press Enter.
-
Activate the new environment:
-
Windows:
conda activate snakes -
macOS and Linux:
conda activate snakes
Note
conda activateonly works on conda 4.6 and later versions.For conda versions prior to 4.6, type:
-
Windows:
activate snakes -
macOS and Linux:
source activate snakes
-
-
Verify that the snakes environment has been added and is active:
Conda displays the list of all environments with an asterisk (*)
after the name of the active environment:# conda environments: # base /home/username/anaconda3 snakes * /home/username/anaconda3/envs/snakes snowflakes /home/username/anaconda3/envs/snowflakes
The active environment is also displayed in front of your prompt in
(parentheses) or [brackets] like this: -
Verify which version of Python is in your current
environment: -
Deactivate the snakes environment and return to base environment:
conda activateNote
For versions prior to conda 4.6, use:
-
Windows:
activate -
macOS, Linux:
source activate
-
Managing packages
In this section, you check which packages you have installed,
check which are available and look for a specific package and
install it.
-
To find a package you have already installed, first activate the environment
you want to search. Look above for the commands to
activate your snakes environment. -
Check to see if a package you have not installed named
«beautifulsoup4» is available from the Anaconda repository
(must be connected to the Internet):conda search beautifulsoup4
Conda displays a list of all packages with that name on the Anaconda
repository, so we know it is available. -
Install this package into the current environment:
conda install beautifulsoup4
-
Check to see if the newly installed program is in this environment:
More information
-
Conda cheat sheet
-
Full documentation— https://conda.io/docs/
-
Free community support— https://groups.google.com/a/anaconda.com/forum/#!forum/anaconda
-
Paid support options— https://www.anaconda.com/support/
В этой статье я оставляю Руководство по установке Anaconda и использование диспетчера пакетов Conda. Благодаря этому мы можем создавать среды разработки для Python и R с нужными нам библиотеками. Очень интересно начать возиться с машинным обучением, анализом данных и программированием на Python.
Anaconda — это бесплатный дистрибутив с открытым исходным кодом языков программирования Python и R, широко используемых в научные вычисления (Data Science, Data Science, Machine Learning, Science, Engineering, предиктивная аналитика, Big Data и т. д.).
Он устанавливает сразу большое количество приложений, широко используемых в этих дисциплинах, вместо того, чтобы устанавливать их по одному. . Более 1400, и это наиболее часто используемые в этих дисциплинах. Некоторые примеры
- Numpy
- Панды
- Tensorflow
- H20.ai.
- Сципи
- Юпитер
- Даск
- OpenCV
- matplotLib
Некоторое время назад я установил Керас и TensorFlow без седла, но решение Anaconda кажется намного проще и полезнее
Это также великолепный вариант для установки Python в нашей операционной системе с нужными нам библиотеками и изолировали проекты в разных виртуальных средах.
Я специально тестирую его для некоторых скриптов для управления большими CSV для работы, и для которых мне нужны NumPy и Pandas. А сейчас попробую Tensorflow и еще кое-что 
Что я вижу по количеству наблюдаемых пакетов, так это то, что они не ограничиваются анализом данных, потому что мы можем установить сотни плагинов (библиотек), предназначенных для веб-разработки или утилизации, таких как Scrappy. Итак, мы переходим к общему руководству по установке и созданию сред, и мы исследуем приложения, которые мы можем установить.
Анаконда против Конды
Подраздел. Не путайте Anaconda — это пакет, который позволяет нам использовать множество библиотек и программное обеспечение для анализа данных, научных данных и машинного обучения с Conda, которая является менеджером пакетов Anaconda. и виртуальные среды.
Как установить Anaconda на Ubuntu
Anaconda можно установить на Microsoft, MacOs и Linux.. Я расскажу вам о своем опыте работы в Ubuntu.
Есть разные способы установить Anaconda в Ubuntu, но мне больше всего нравится зайти на официальный сайт и скачать файл .sh. Найдите свою операционную систему и интересующую вас версию
Если вы начнете, я рекомендую вам выбрать версию 3.7, которая через несколько лет устареет.
Если вы загружаете .sh для Linux, как я, вам нужно открыть консоль или терминал и перейти в каталог, где он находится, в моем случае загрузок
Помните, что самая распространенная ошибка, с которой возникают проблемы, — это неправильная папка или каталог.
cd Descargas
ls
sh nombre_del_archivo_que_has_descargado.shВ первой строке мы переходим в каталог Downloads, во второй «ls» он перечисляет файлы, которые есть, и поэтому мы можем видеть имя .sh, а в третьей мы выполняем .sh, который, как мы говорим, похож на Windows .exe.
И он запустится. Примите условия лицензии на программное обеспечение, и затем вас спросят, хотите ли вы установить Visual Code Studio. Я сказал да.
Вам нужно отказаться от продажи терминала, чтобы изменения заработали. Итак, мы закрываем терминал, снова открываем и вводим
anaconda-navigatorЭто откроет графический интерфейс с форматом браузера, который позволит нам устанавливать и активировать различные пакеты, хотя мы также можем делать все с консоли.
После установки мы проверим, что все правильно. для этого мы увидим, какую версию мы установили
conda --versionЕсли все будет хорошо, он вернет нас высоко как conda 4.6.4 Если появится ошибка, нам нужно будет посмотреть, что она говорит нам, чтобы решить ее, переустановить и т. Д.
Если вы только что установили, вы должны увидеть, есть ли какие-либо обновления в conda
conda update conda
conda update anacondaЭто сравнивает версию, которая у нас есть, с доступной, и, если есть что-то новое, он спросит нас
Proceed ([y]/n)? yСтавим «и» на «да» и вводим
Создавайте виртуальные рабочие среды с Conda
Каждый проект, который мы делаем, мы можем разместить в отдельной среде, таким образом мы избегаем проблем с зависимостями пакетов и т. Д.
Чтобы создать виртуальную среду, мы будем называть ее компаратор пишем в терминале:
conda create --name comparador python=3.7где компаратор — это имя виртуальной среды, а python = 3.7 — это пакет, который мы хотим установить.
Активируем его с помощью
conda activate comparadorИ мы деактивируем с
conda deactivateПроверяем виртуальные среды на
conda info --envsЭто покажет нам окружение, которое у нас есть, и вернет что-то вроде
# conda environments:
#
base * /home/nacho/anaconda3
comparador /home/nacho/anaconda3/envs/comparadorbase — это root, а звездочка показывает нам активированный.
Также следует отметить одну вещь. При активации среды в консоли имя добавляется в скобки перед приглашением, чтобы мы всегда знали, где мы находимся.
Более интересные команды:
мы можем искать приложения для установки. Представьте, что я хочу установить Keras, потому что сначала смотрю, доступно ли приложение и какие есть версии
conda search kerasКак я вижу, это уже шаг к установке
conda install kerasИ чтобы увидеть все, что мы установили в нашей среде разработки, мы будем использовать
conda listОбработка пакетов pkgs с помощью conda
Вот несколько интересных вариантов. Это поможет нам настроить нашу виртуальную среду с приложениями, которые нам нужны для работы.
Установить пакеты
Есть очень специфические команды. Чтобы установить пакет в определенной среде. Например, Керас в моей недавно созданной среде компаратор
conda install --name comparador kerasЕсли мы не добавим компаратор –name, он установит его в среде, которая у нас активна в данный момент.
Мы можем установить несколько пакетов одновременно (keras и scrappy) с
conda install keras scrappyНо не рекомендуется избегать проблем с зависимостями.
Наконец, мы можем выбрать конкретную версию, которую хотим установить, если нам это интересно по какой-либо причине.
conda install keras=2.2.4Установите пакеты, отличные от Conda
В этом случае мы будем использовать pip
pip installПакеты обновлений
Есть разные варианты. Обновите конкретный пакет с помощью
conda update kerasОбновить питон
conda update pythonОбновить conda
conda update condaИ чтобы обновить весь мета-пакет Anaconda
conda update conda
conda update anacondaУдалить пакеты
Удалить пакеты в данной среде. Например Керас из окружения компаратор
conda remove -n comparador kerasЕсли мы хотим стереть среду, в которой мы находимся
conda remove kerasОдновременно можно удалить несколько пакетов
conda remove keras scrappyИ рекомендуется проверить пакеты, чтобы убедиться, что они были правильно удалены с помощью
conda listДля меня это основы, если вы хотите углубиться здесь, у вас есть официальный справочник conda (на английском языке)
Мы оставили шпаргалка по Конде официальный, с основными командами для быстрого использования раздачи.
Прогулка по графической среде Anaconda
Все это мы делаем с помощью терминала, и мы можем делать это графически с помощью интерфейса Anaconda.
Чтобы начать распространение, нам сначала нужно активировать conda для базовой среды (root).
conda activate baseИ с этим мы можем вызвать Анаконду. Если нет, не запустится
anaconda-navigatorВидите ли, здесь мы находим базовый проект, который является корневым, а затем среды, которые вы создаете и которые в моем случае были компаратор.
Лучше всего это посмотреть на видео
А со знаниями, полученными в статье, мы можем начать возиться со многими библиотеками и приложениями.
Если есть вопросы, оставьте комментарий и я постараюсь вам помочь
Цель этой статьи — предоставить легкое введение в анализ данных с использованием Anaconda. Мы пройдем через написание простого скрипта Python для извлечения, анализа и визуализации данных по различным криптовалютам.
Шаг 1 — Настройка рабочей среды.
Единственные навыки, которые вам понадобятся, это базовое понимание Python.
Шаг 1.1 — Установка Anaconda
Дистрибутив Anaconda можно скачать на официальном сайте.
Установка проходит в стандартном Step-by-Step режиме.
Шаг 1.2 — Настройка рабочей среды проекта
После того, как Anaconda будет установлена, нужно создать и активировать новую среду для организации наших зависимостей.
Зачем использовать среды? Если вы планируете разрабатывать несколько проектов Python на своем компьютере, полезно хранить зависимости (программные библиотеки и пакеты) отдельно, чтобы избежать конфликтов. Anaconda создаст специальный каталог среды для зависимостей каждого проекта, чтобы все было организовано и разделено.
Сделать это можно либо через командную строку
conda create --name cryptocurrency-analysis python=3.6source activate cryptocurrency-analysis(Linux/macOS)
или
activate cryptocurrency-analysis(Windows)
либо через Anaconda Navigator

В данном случае среда активируется автоматически
Затем необходимо установить необходимые зависимости NumPy, Pandas, nb_conda, Jupiter, Plotly, Quandl.
conda install numpy pandas nb_conda jupyter plotly quandlлибо через Anaconda Navigator, поочередно каждый пакет

Это может занять несколько минут.
Шаг 1.3 — Запуск Jupyter Notebook
Так же существует вариант через командную строку jupyter notebook и откройте браузер на http://localhost:8888/
и через Anaconda Navigator
Шаг 1.4 — Импорт зависимостей
После того, как вы откроете пустой Jupyter Notebook, первое, что нужно сделать — это импорт необходимых зависимостей.
import os
import numpy as np
import pandas as pd
import pickle
import quandl
from datetime import datetimeЗатем импорт и активация автономного режима Plotly.
import plotly.offline as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
py.init_notebook_mode(connected=True)
Шаг 2 — Получение данных о ценах на биткоин
Теперь, когда все настроено, мы готовы начать извлечение данных для анализа. Начнем с того, что получим данные о ценах используя бесплатный API от Quandl.
Шаг 2.1 — Определение функции Quandl
Начнем с того, что определим функцию для загрузки и кэширования наборов данных из Quandl.
def get_quandl_data(quandl_id):
'''Download and cache Quandl dataseries'''
cache_path = '{}.pkl'.format(quandl_id).replace('/','-')
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(quandl_id))
except (OSError, IOError) as e:
print('Downloading {} from Quandl'.format(quandl_id))
df = quandl.get(quandl_id, returns="pandas")
df.to_pickle(cache_path)
print('Cached {} at {}'.format(quandl_id, cache_path))
return dfМы используем pickle для сериализации и сохранения загруженных данных в виде файла, что позволит нашему сценарию повторно не загружать одни и те же данные при каждом запуске скрипта.
Функция вернет данные в виде набора данных pandas.
Шаг 2.2 — Получение курса биткоина на бирже Kraken
Реализуем это следующим образом:
btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')Для проверки корректности отрабатывания скрипта мы можем посмотреть первые 5 строк полученного ответа используя метод head().
btc_usd_price_kraken.head()Результат:
| Date | Open | High | Low | Close | Volume (BTC) | Volume (Currency) | Weighted Price |
|---|---|---|---|---|---|---|---|
| 2014-01-07 | 874.67040 | 892.06753 | 810.00000 | 810.00000 | 15.622378 | 13151.472844 | 841.835522 |
| 2014-01-08 | 810.00000 | 899.84281 | 788.00000 | 824.98287 | 19.182756 | 16097.329584 | 839.156269 |
| 2014-01-09 | 825.56345 | 870.00000 | 807.42084 | 841.86934 | 8.158335 | 6784.249982 | 831.572913 |
| 2014-01-10 | 839.99000 | 857.34056 | 817.00000 | 857.33056 | 8.024510 | 6780.220188 | 844.938794 |
| 2014-01-11 | 858.20000 | 918.05471 | 857.16554 | 899.84105 | 18.748285 | 16698.566929 | 890.671709 |
И построить график для визуализации полученного массива
btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price'])
py.iplot([btc_trace])
Здесь мы используем Plotly для генерации наших визуализаций. Это менее традиционный выбор, чем некоторые из более известных библиотек, таких как Matplotlib, но я думаю, что Plotly — отличный выбор, поскольку он создает полностью интерактивные диаграммы с использованием D3.js.
Шаг 2.3 — Получение курса биткоина на нескольких биржах
Характер обмена заключается в том, что ценообразование определяется предложением и спросом, поэтому ни одна биржа не содержит «истинной цены» Биткойна. Чтобы решить эту проблему мы будем извлекать дополнительно данные из трех более крупных бирж для расчета совокупного индекса цены.
Мы будем загружать данные каждой биржи в словарь.
exchanges = ['COINBASE','BITSTAMP','ITBIT']
exchange_data = {}
exchange_data['KRAKEN'] = btc_usd_price_kraken
for exchange in exchanges:
exchange_code = 'BCHARTS/{}USD'.format(exchange)
btc_exchange_df = get_quandl_data(exchange_code)
exchange_data[exchange] = btc_exchange_dfШаг 2.4 — Объединение всех цен в единый набор данных
Определим простую функцию для объединения данных.
def merge_dfs_on_column(dataframes, labels, col):
series_dict = {}
for index in range(len(dataframes)):
series_dict[labels[index]] = dataframes[index][col]
return pd.DataFrame(series_dict)
Затем объединим все данные по столбцу «Weighted Price».
btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')Теперь посмотрим последние пять строк, используя метод tail (), чтобы убедиться, что все выглядит нормально и так как мы хотели.
btc_usd_datasets.tail()Результат:
| Date | BITSTAMP | COINBASE | ITBIT | KRAKEN | avg_btc_price_usd |
|---|---|---|---|---|---|
| 2018-02-28 | 10624.382893 | 10643.053573 | 10621.099426 | 10615.587987 | 10626.030970 |
| 2018-03-01 | 10727.272600 | 10710.946064 | 10678.156872 | 10671.653953 | 10697.007372 |
| 2018-03-02 | 10980.298658 | 10982.181881 | 10973.434045 | 10977.067909 | 10978.245623 |
| 2018-03-03 | 11332.934468 | 11317.108262 | 11294.620763 | 11357.539095 | 11325.550647 |
| 2018-03-04 | 11260.751253 | 11250.771211 | 11285.690725 | 11244.836468 | 11260.512414 |
Шаг 2.5 — Сравнение наборов данных о ценах.
Следующим логическим шагом является визуализация сравнения полученных цен. Для этого мы определим вспомогательную функцию, которая построит график для каждой из бирж при помощи Plotly.
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False):
label_arr = list(df)
series_arr = list(map(lambda col: df[col], label_arr))
layout = go.Layout(
title=title,
legend=dict(orientation="h"),
xaxis=dict(type='date'),
yaxis=dict(
title=y_axis_label,
showticklabels= not seperate_y_axis,
type=scale
)
)
y_axis_config = dict(
overlaying='y',
showticklabels=False,
type=scale )
visibility = 'visible'
if initial_hide:
visibility = 'legendonly'
trace_arr = []
for index, series in enumerate(series_arr):
trace = go.Scatter(
x=series.index,
y=series,
name=label_arr[index],
visible=visibility
)
if seperate_y_axis:
trace['yaxis'] = 'y{}'.format(index + 1)
layout['yaxis{}'.format(index + 1)] = y_axis_config
trace_arr.append(trace)
fig = go.Figure(data=trace_arr, layout=layout)
py.iplot(fig)
И вызовем ее
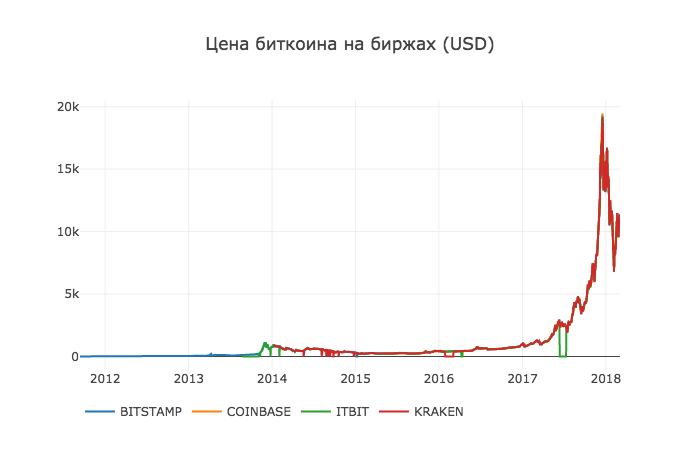
df_scatter(btc_usd_datasets, 'Цена биткоина на биржах (USD) ')
Результат:
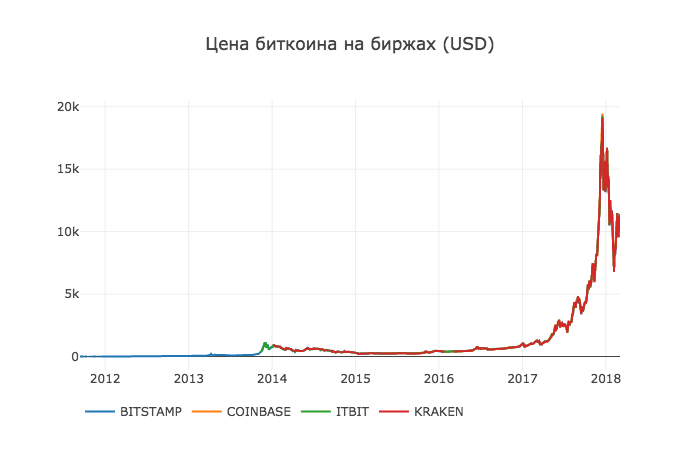
Теперь удалим все нулевые значения, так как мы знаем, что цена никогда не была равна нулю в периоде, который мы рассматриваем.
btc_usd_datasets.replace(0, np.nan, inplace=True)
И пересоздадим график
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')Результат:
Шаг 2.6 — Расчет средней цены
Теперь мы можем вычислить новый столбец, содержащий среднесуточную цену биткоина на всех биржах.
btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)Этот новый столбец является нашим индексом цены биткоина. Построим его график, чтобы убедиться, что он выглядит нормально.
btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])
py.iplot([btc_trace])Результат:

Мы будем использовать эти данные позже, чтобы конвертировать обменные курсы других криптовалют в USD.
Шаг 3 — Получение данных по альтернативным криптовалютам
Теперь, когда у нас есть массив данных с ценами биткойна, давайте возьмем некоторые данные об альтернативных криптовалютах.
Шаг 3.1 — Определение функций для работы с Poloniex API.
Для получения данных мы будем использовать API Poloniex. Определим две вспомогательные функции для загрузки и кэширования JSON данных из этого API.
Сначала мы определим функцию get_json_data, которая будет загружать и кэшировать данные JSON из предоставленного URL.
def get_json_data(json_url, cache_path):
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(json_url))
except (OSError, IOError) as e:
print('Downloading {}'.format(json_url))
df = pd.read_json(json_url)
df.to_pickle(cache_path)
print('Cached response at {}'.format(json_url, cache_path))
return df
Затем мы определим функцию для форматирования HTTP-запросов Poloniex API и вызова нашей новой функции get_json_data для сохранения полученных данных.
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'
start_date = datetime.strptime('2015-01-01', '%Y-%m-%d')
end_date = datetime.now()
pediod = 86400
def get_crypto_data(poloniex_pair):
json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod)
data_df = get_json_data(json_url, poloniex_pair)
data_df = data_df.set_index('date')
return data_dfЭта функция на входе получает пару криптовалют например, «BTC_ETH» и вернет исторические данные по обменному курсу двух валют.
Шаг 3.2 — Загрузка данных из Poloniex
Некоторые из рассматриваемых альтернативных криптовалют нельзя купить на биржах напрямую за USD. По этой причине мы будем загружать обменный курс на биткоин для каждой из них, а затем будем использовать существующие данные о ценах биткоина для преобразования этого значения в USD.
Мы загрузим данные об обмене для девяти популярных криптовалют — Ethereum, Litecoin, Ripple, Ethereum Classic, Stellar, Dash, Siacoin, Monero, and NEM.
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']
altcoin_data = {}
for altcoin in altcoins:
coinpair = 'BTC_{}'.format(altcoin)
crypto_price_df = get_crypto_data(coinpair)
altcoin_data[altcoin] = crypto_price_dfТеперь у нас есть 9 наборов данных, каждый из которых содержит исторические среднедневные биржевые соотношения биткона к альтернативной криптовалюте.
Мы можем просмотреть последние несколько строк таблицы цен на Ethereum, чтобы убедиться, что она выглядит нормально.
altcoin_data['ETH'].tail()| date | close | high | low | open | quoteVolume | volume | weightedAverage |
|---|---|---|---|---|---|---|---|
| 2018-03-01 | 0.079735 | 0.082911 | 0.079232 | 0.082729 | 17981.733693 | 1454.206133 | 0.080871 |
| 2018-03-02 | 0.077572 | 0.079719 | 0.077014 | 0.079719 | 18482.985554 | 1448.732706 | 0.078382 |
| 2018-03-03 | 0.074500 | 0.077623 | 0.074356 | 0.077562 | 15058.825646 | 1139.640375 | 0.075679 |
| 2018-03-04 | 0.075111 | 0.077630 | 0.074389 | 0.074500 | 12258.662182 | 933.480951 | 0.076149 |
| 2018-03-05 | 0.075373 | 0.075700 | 0.074723 | 0.075277 | 10993.285936 | 826.576693 | 0.075189 |
Шаг 3.3 — Конвертирование цен в USD.
Так как теперь у нас есть обменный курс на биткоин для каждой криптовалюты и у нас есть индекс исторических цен биткоина в USD, мы можем напрямую рассчитать цену в USD для каждой альтернативной криптовалюты.
for altcoin in altcoin_data.keys():
altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']Этим мы создали новый столбец в каждом наборе данных альтернативных криптовалют с ценами в USD.
Затем мы можем повторно использовать нашу функцию merge_dfs_on_column, чтобы создать комбинированный набор данных о цене в USD для каждой из криптовалют.
combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
Теперь добавим в набор данных цены биткоина в качестве конечного столбца.
combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
В результате мы имеем набор данных, содержащий ежедневные цены в USD для десяти криптовалют, которые мы рассматриваем.
Используем нашу функцию df_scatter, чтобы отобразить все цены криптовалют на графике.
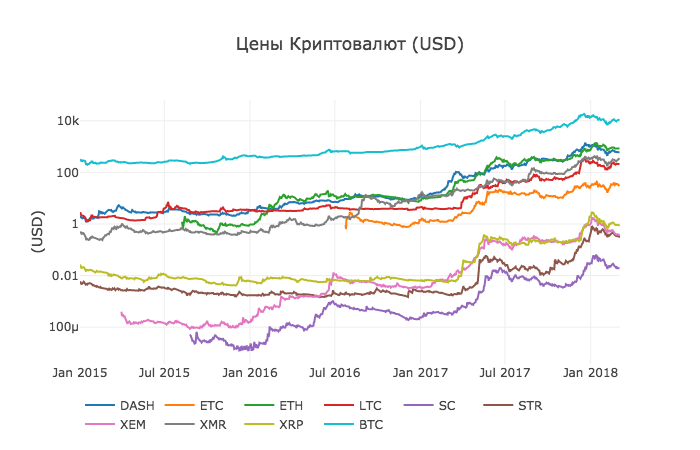
df_scatter(combined_df, 'Цены Криптовалют (USD)', seperate_y_axis=False, y_axis_label='(USD)', scale='log')Этот график дает довольно солидную «общую картину» того, как обменные курсы каждой валюты менялись в течение последних нескольких лет.
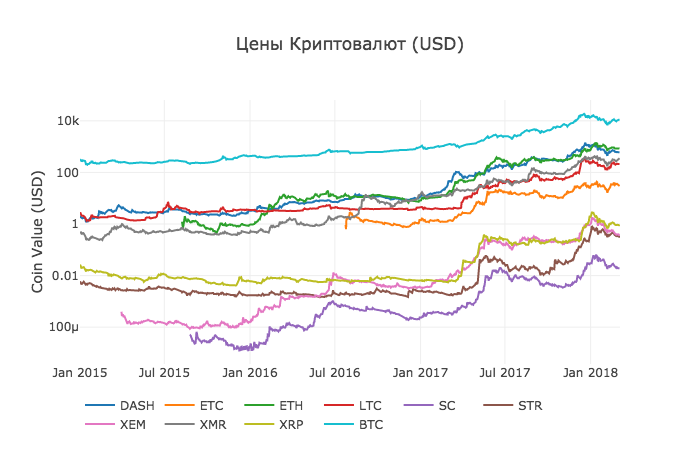
В данном примере мы используем логарифмическую шкалу оси Y, чтобы сравнить все валюты на одном и том же участке. Вы можете попробовать различные значения параметров (например, scale = ‘linear’), чтобы получить разные точки зрения на данные.
Шаг 3.4 — Вычисление корреляции криптовалют.
Вы можете заметить, что обменные курсы криптовалюты, несмотря на их совершенно разные ценности и волатильность, кажутся слегка коррелированными. И как видно по всплеску в апреле 2017 года, даже небольшие колебания, похоже, происходят синхронно на всем рынке.
Мы можем проверить нашу корреляционную гипотезу, используя метод Pandas corr (), который вычисляет коэффициент корреляции Пирсона для каждого столбца в наборе данных по отношению друг к другу. При вычислении также используем метод pct_change (), который преобразует каждую ячейку в наборе данных из абсолютного значения цены в процентное изменение.
Сначала мы вычислим корреляции для 2016 года.
combined_df_2016 = combined_df[combined_df.index.year == 2016]
combined_df_2016.pct_change().corr(method='pearson')Результат:
| DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC | |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.003992 | 0.122695 | -0.012194 | 0.026602 | 0.058083 | 0.014571 | 0.121537 | 0.088657 | -0.014040 |
| ETC | 0.003992 | 1.000000 | -0.181991 | -0.131079 | -0.008066 | -0.102654 | -0.080938 | -0.105898 | -0.054095 | -0.170538 |
| ETH | 0.122695 | -0.181991 | 1.000000 | -0.064652 | 0.169642 | 0.035093 | 0.043205 | 0.087216 | 0.085630 | -0.006502 |
| LTC | -0.012194 | -0.131079 | -0.064652 | 1.000000 | 0.012253 | 0.113523 | 0.160667 | 0.129475 | 0.053712 | 0.750174 |
| SC | 0.026602 | -0.008066 | 0.169642 | 0.012253 | 1.000000 | 0.143252 | 0.106153 | 0.047910 | 0.021098 | 0.035116 |
| STR | 0.058083 | -0.102654 | 0.035093 | 0.113523 | 0.143252 | 1.000000 | 0.225132 | 0.027998 | 0.320116 | 0.079075 |
| XEM | 0.014571 | -0.080938 | 0.043205 | 0.160667 | 0.106153 | 0.225132 | 1.000000 | 0.016438 | 0.101326 | 0.227674 |
| XMR | 0.121537 | -0.105898 | 0.087216 | 0.129475 | 0.047910 | 0.027998 | 0.016438 | 1.000000 | 0.027649 | 0.127520 |
| XRP | 0.088657 | -0.054095 | 0.085630 | 0.053712 | 0.021098 | 0.320116 | 0.101326 | 0.027649 | 1.000000 | 0.044161 |
| BTC | -0.014040 | -0.170538 | -0.006502 | 0.750174 | 0.035116 | 0.079075 | 0.227674 | 0.127520 | 0.044161 | 1.000000 |
Коэффициенты, близкие к 1 или -1, означают, что данные сильно коррелируют или обратно коррелируют соответственно, а коэффициенты, близкие к нулю, означают, что значения имеют тенденцию колебаться независимо друг от друга.
Чтобы визуализировать эти результаты, мы создадим еще одну вспомогательную функцию.
def correlation_heatmap(df, title, absolute_bounds=True):
heatmap = go.Heatmap(
z=df.corr(method='pearson').as_matrix(),
x=df.columns,
y=df.columns,
colorbar=dict(title='Pearson Coefficient'),
)
layout = go.Layout(title=title)
if absolute_bounds:
heatmap['zmax'] = 1.0
heatmap['zmin'] = -1.0
fig = go.Figure(data=[heatmap], layout=layout)
py.iplot(fig)correlation_heatmap(combined_df_2016.pct_change(), "Корреляция криптовалют (2016)")
Здесь темно-красные значения представляют собой сильные корреляции, а синие значения представляют собой сильные обратные корреляции. Все остальные цвета представляют собой разную степень слабых/несуществующих корреляций.
Что говорит нам этот график? По сути, это показывает, что было очень мало статистически значимой связи между тем, как цены разных криптовалют колебались в течение 2016 года.
Теперь, чтобы проверить нашу гипотезу о том, что криптотермины стали более коррелированными в последние месяцы, повторим те же тесты, используя данные за 2017 и 2018 года.
combined_df_2017 = combined_df[combined_df.index.year == 2017]
combined_df_2017.pct_change().corr(method='pearson')Результат:
| DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC | |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.387555 | 0.506911 | 0.340153 | 0.291424 | 0.183038 | 0.325968 | 0.498418 | 0.091146 | 0.307095 |
| ETC | 0.387555 | 1.000000 | 0.601437 | 0.482062 | 0.298406 | 0.210387 | 0.321852 | 0.447398 | 0.114780 | 0.416562 |
| ETH | 0.506911 | 0.601437 | 1.000000 | 0.437609 | 0.373078 | 0.259399 | 0.399200 | 0.554632 | 0.212350 | 0.410771 |
| LTC | 0.340153 | 0.482062 | 0.437609 | 1.000000 | 0.339144 | 0.307589 | 0.379088 | 0.437204 | 0.323905 | 0.420645 |
| SC | 0.291424 | 0.298406 | 0.373078 | 0.339144 | 1.000000 | 0.402966 | 0.331350 | 0.378644 | 0.243872 | 0.325318 |
| STR | 0.183038 | 0.210387 | 0.259399 | 0.307589 | 0.402966 | 1.000000 | 0.339502 | 0.327488 | 0.509828 | 0.230957 |
| XEM | 0.325968 | 0.321852 | 0.399200 | 0.379088 | 0.331350 | 0.339502 | 1.000000 | 0.336076 | 0.268168 | 0.329431 |
| XMR | 0.498418 | 0.447398 | 0.554632 | 0.437204 | 0.378644 | 0.327488 | 0.336076 | 1.000000 | 0.226636 | 0.409183 |
| XRP | 0.091146 | 0.114780 | 0.212350 | 0.323905 | 0.243872 | 0.509828 | 0.268168 | 0.226636 | 1.000000 | 0.131469 |
| BTC | 0.307095 | 0.416562 | 0.410771 | 0.420645 | 0.325318 | 0.230957 | 0.329431 | 0.409183 | 0.131469 | 1.000000 |
correlation_heatmap(combined_df_2017.pct_change(), "Корреляция криптовалют (2017)")
combined_df_2018 = combined_df[combined_df.index.year == 2018]
combined_df_2018.pct_change().corr(method='pearson')| DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC | |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.775561 | 0.856549 | 0.847947 | 0.733168 | 0.717240 | 0.769135 | 0.913044 | 0.779651 | 0.901523 |
| ETC | 0.775561 | 1.000000 | 0.808820 | 0.667434 | 0.530840 | 0.551207 | 0.641747 | 0.696060 | 0.637674 | 0.694228 |
| ETH | 0.856549 | 0.808820 | 1.000000 | 0.700708 | 0.624853 | 0.630380 | 0.752303 | 0.816879 | 0.652138 | 0.787141 |
| LTC | 0.847947 | 0.667434 | 0.700708 | 1.000000 | 0.683706 | 0.596614 | 0.593616 | 0.765904 | 0.644155 | 0.831780 |
| SC | 0.733168 | 0.530840 | 0.624853 | 0.683706 | 1.000000 | 0.615265 | 0.695136 | 0.626091 | 0.719462 | 0.723976 |
| STR | 0.717240 | 0.551207 | 0.630380 | 0.596614 | 0.615265 | 1.000000 | 0.790420 | 0.642810 | 0.854057 | 0.669746 |
| XEM | 0.769135 | 0.641747 | 0.752303 | 0.593616 | 0.695136 | 0.790420 | 1.000000 | 0.744325 | 0.829737 | 0.734044 |
| XMR | 0.913044 | 0.696060 | 0.816879 | 0.765904 | 0.626091 | 0.642810 | 0.744325 | 1.000000 | 0.668016 | 0.888284 |
| XRP | 0.779651 | 0.637674 | 0.652138 | 0.644155 | 0.719462 | 0.854057 | 0.829737 | 0.668016 | 1.000000 | 0.712146 |
| BTC | 0.901523 | 0.694228 | 0.787141 | 0.831780 | 0.723976 | 0.669746 | 0.734044 | 0.888284 | 0.712146 | 1.000000 |
correlation_heatmap(combined_df_2018.pct_change(), "Корреляция криптовалют (2018)")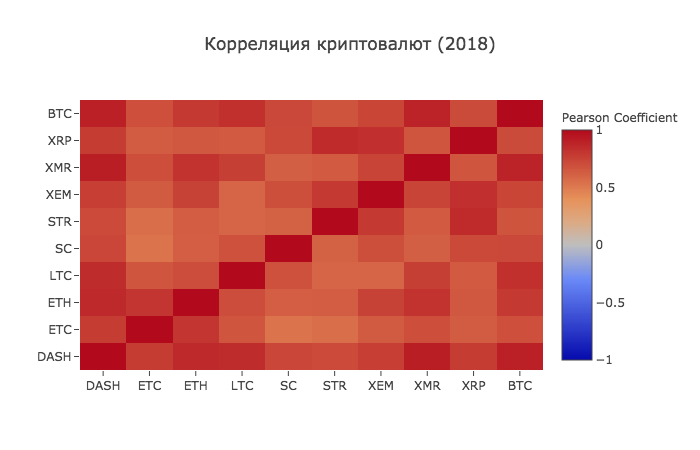
И вот мы видим то, о чем и предполагали — почти все криптовалюты стали более взаимосвязанными друг с другом по всем направлениям.
На этом будем считать, что введение в работу с данными в Anaconda успешно пройдено.