Зачем нам нужны нейронные процессоры?
Время на прочтение
4 мин
Количество просмотров 13K
Нейросети сейчас называют новым электричеством. Мы их не замечаем, но пользуемся каждый день. Face ID в iPhone, умные ассистенты, сервисы перевода, и даже рекомендации в YouTube — всё это нейросети. Они развиваются настолько стремительно, что даже самые потрясающие открытия выглядят как обыденность.
Например, недавно в одном из самых престижных научных журналов Nature опубликовали исследование группы американских ученых. Они создали нейросеть, которая может считывать активность коры головного мозга и преобразовывать полученные сигналы в речь. С точностью 97 процентов. В будущем, это позволит глухонемым людям «заговорить».
И это только начало. Сейчас мы стоим на пороге новой технической революции сравнимой с открытием электричества. И сегодня мы объясним вам почему.
Как работают нейросети?
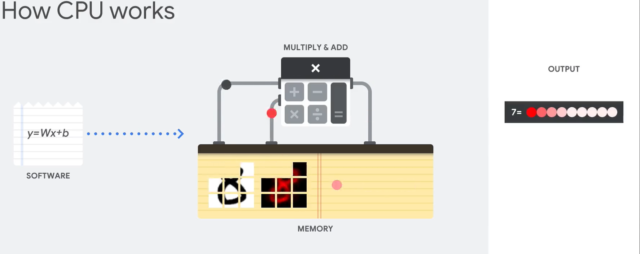
Центральный процессор — это очень сложный микрочип. Он умеет выполнять кучу разных инструкций и поэтому справляется с любыми задачами. Но для работы с нейросетями он не подходит. Почему так?
Сами по себе нейросетевые операции очень простые: они состоят всего из двух арифметических действий: умножения и сложения.
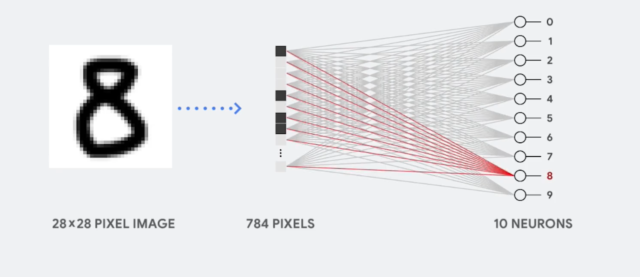
Например, чтобы распознать какое-либо изображение в нейронную сеть нужно загрузить два набора данных: само изображение и некие коэффициенты, которые будут указывать на признаки, которые мы ищем. Эти коэффициенты называются весами.
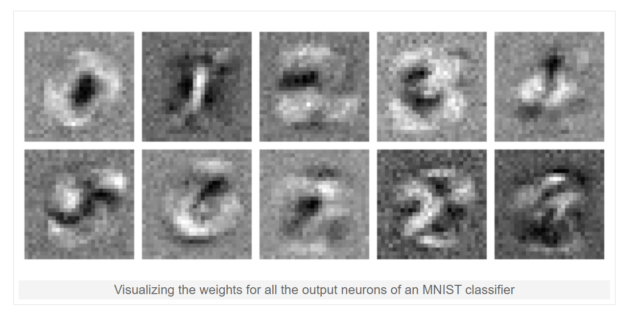
Вот например так выглядят веса для рукописных цифр. Похоже как будто очень много фоток цифр наложили друг на друга.

А вот так для нейросети выглядит кошка или собака. У искусственного интеллекта явно свои представления о мире.
Но вернёмся к арифметике. Перемножив эти веса на исходное изображение, мы получим какое-то значение. Если значение большое, нейросеть понимает:
— Ага! Совпало. Узнаю, это кошка.
А если цифра получилась маленькой значит в областях с высоким весом не было необходимых данных.
Вот как это работает. Видно как от слоя к слою сокращается количество нейронов. В начале их столько же сколько пикселей в изображении, а в конце всего десять — количество ответов. С каждым слоем изображение упрощается до верного ответа. Кстати, если запустить алгоритм в обратном порядке, можно что-нибудь сгенерировать.
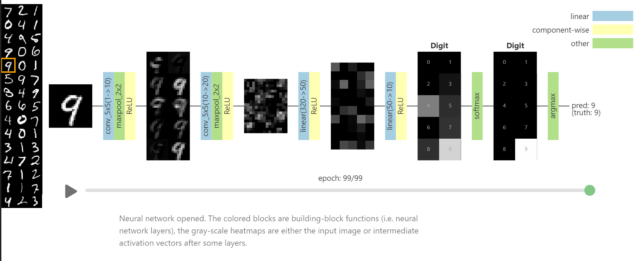
Всё вроде бы просто, да не совсем. В нейросетях очень много нейронов и весов. Даже в простой однослойной нейросети, которая распознает цифры на картинках 28 x 28 пикселей для каждого из 10 нейронов используется 784 коэффициента, т.е. веса, итого 7840 значений. А в глубоких нейросетях таких коэффициентов миллионы.
CPU
И вот проблема: классические процессоры не заточены под такие массовые операции. Они просто вечность будут перемножать и складывать и входящие данные с коэффициентами. Всё потому, что процессоры не предназначены для выполнения массовых параллельных операций.
Ну сколько ядер в современных процессорах? Если у вас восьмиядерный процессор дома, считайте вы счастливчик. На мощных серверных камнях бывает по 64 ядра, ну может немного больше. Но это вообще не меняет дела. Нам нужны хотя бы тысячи ядер.
Где же взять такой процессор? В офисе IBM? В секретных лабораториях Пентагона?
GPU
На самом деле такой процессор есть у многих из вас дома. Это ваша видеокарта.
Видеокарты как раз заточены на простые параллельные вычисления — отрисовку пикселей! Чтобы вывести на 4K-монитор изображение, нужно отрисовать 8 294 400 пикселей (3840×2160) и так 60 раз в секунду (или 120/144, в зависимости от возможностей монитора и пожеланий игрока, прим.ред.). Итого почти 500 миллионов пикселей в секунду!
Видеокарты отличаются по своей структуре от CPU. Почти всё место в видеочипе занимают вычислительные блоки, то есть маленькие простенькие ядра. В современных видюхах их тысячи. Например в GeForce RTX2080 Ti, ядер больше пяти тысяч.

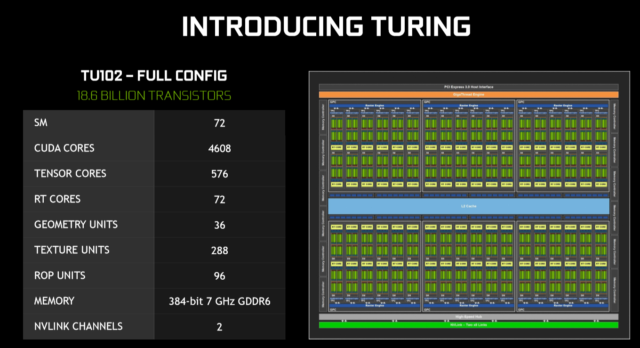
Всё это позволяет нейросетям существенно быстрее крутиться GPU.

Производительность RTX2080 Ti где-то 13 TFLOPS (FLOPS — FLoating-point Operations Per Second), что значит 13 триллионов операций с плавающей запятой в секунду. Для сравнения, мощнейший 64-ядерный Ryzen Threadripper 3990X, выдаёт только 3 TFLOPS, а это заточенный под многозадачность процессор.
Триллионы операций в секунду звучит внушительно, но для действительно продвинутых нейронных вычислений — это как запустить FarCry на калькуляторе.
Недавно мы игрались с алгоритмом интерполяции кадров DAIN, основанном на машинном обучении. Алгоритм очень крутой, но с видеокартой Geforce 1080 уходило 2-3 минуты на обработку одного кадра. А нам нужно чтобы подобные алгоритмы работали в риалтайме, да и желательно на телефонах.
TPU
Именно поэтому существуют специализированные нейронные процессоры. Например, тензорный процессор от Google. Первый такой чип в Google сделали еще в 2015 году, а в 2018 вышла уже третья версия.


Производительность второй версии 180 TFLOPS, а третьей — целых 420 TFLOPS! 420 Триллионов операций в секунду. Как они этого добились?
Каждый такой процессор содержит 10-ки тысяч крохотных вычислительных ядер, заточенных под единственную задачу складывать и перемножать веса. Пока, что он выглядит огромным, но через 15 лет он существенно уменьшится в размерах. Но это еще фигня. Такие процессоры объединяться в кластеры по 1024 штуки, без каких либо просадок в производительности. GPU так не могут.

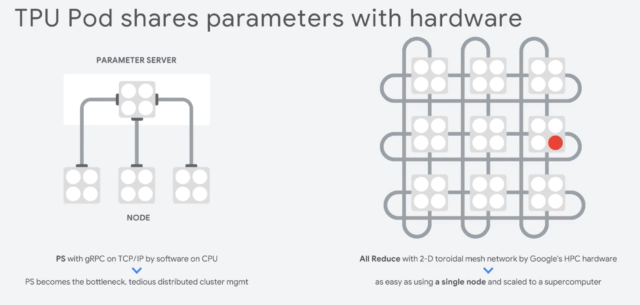
Такой кластер из тензорных процессоров третьей версии могут выдать 430 PFLOPS (пета флопс) производительности. Если что, это 430 миллионов миллиардов операций в секунду.
Где мы и что нас ждёт?
Но как мы уже говорили, это только начало. Текущие нейронные суперкомпьютеры — это как первые классические мейнфреймы занимавшие, целые этажи в зданиях.

В 2000 году первый суперкомпьютер с производительностью 1 терафлопс занимал 150 квадратных метров и стоил 46 миллионов долларов.

Спустя 15 лет NVIDIA мощностью 2,3 терафлопса, которая помещается в руке стоит 59$.

Так что в следующие 15-20 лет суперкомпьютер Google тоже поместится в руке. Ну или где мы там будем носить процессоры?
 Кадр из режиссерской версии фильма «Терминатор-2»
Кадр из режиссерской версии фильма «Терминатор-2»
А мы пока ждём момента, довольствуемся нейромодулями в наших смартфонах — в тех же Qualcomm Snapdragon’ах, Kirin’ах от Huawei и в Apple Bionic — они уже тихо делают свою работу.
И уже через несколько презентаций они начнут меряться не гигагерцами, ядрами и терафлопсами, а чем-то понятным для всех — например, распознанных котиках в секунду. Всё лучше, чем попугаи!
Справочник по нейросетевым процессорам
| Справочник по нейросетевым процессорам | |
|---|---|
 |
|
| Тип | Книга навыков |
| Эффекты | Всезнайка : + 1 |
| Стоимость | 500 $ |
Справочник по нейросетевым процессорам — книга навыков в игре Wasteland 3.
Описание
Руководство по работе, обслуживанию и ремонту.
Местонахождение
В локации «Министерство энергетики» такую книгу можно взять из шкафчика в Гараже, справа от входа.
Материалы сообщества доступны в соответствии с условиями лицензии CC-BY-SA, если не указано иное.
Недавно мы рассказывали, что такое нейросети и как они учатся. Сегодня посмотрим, как нейронки работают в вашем телефоне.
Если пропустили первую статью — вот основное оттуда:
- Нейросеть — это большая куча формул, связанных между собой.
- Обучение нейросетей — это корректировка чисел внутри этих формул.
- Использование нейросети сводится к тому, что мы подаём нужным формулам на вход какие-то числа, а на выходе получаем какие-то другие числа. И мы, люди, это как-то интерпретируем.
- Нейросети — это просто огромный массив математики.
Все формулы нейросети можно разложить на «слои», их может быть сколько угодно. Между слоями будут связи, каждый со своим «весом». «Вес» показывает, как данные меняются при передаче из одного нейрона в другой.
Сколько нейронов (и весов) в нейросети
Теоретически можно сделать очень простую нейросеть, в которой будет только один слой нейронов и одно итоговое значение:
 в нейросети")
Но в реальности толку от такой нейронки мало: проще написать линейный алгоритм и решить всё перебором, чем городить огород с нейросетями.
В современных нейросетях используются десятки миллионов нейронов, разбитые на множество слоёв.
 в нейросети")
Обучение нейронки — это работа с матрицами
Чаще всего нейроны в нейросети не связаны друг с другом поодиночке — вместо этого один нейрон может влиять на несколько других в соседнем слое. Точно так же происходит и с ним — на один нейрон влияют сразу несколько предыдущих.
Чтобы найти значение веса данного нейрона, нам нужно вычесть, сложить или перемножить несколько однородных коэффициентов. В математике проще всего это делать с помощью матриц — специальных конструкций из чисел, которые считаются по простым правилам.
Мы уже рассказывали про матрицы и работу с ними и сделали про них 6 статей. Если интересно, как всё это работает с точки зрения математики, — вот, держите:
Нейросети и процессоры
Одну матрицу процессору посчитать несложно, и даже тысячу матриц одновременно — несложно. Но что, если нам нужно считать миллионы матриц в секунду?
Например, у вас картинка размером 1000 на 1000 пикселей — это миллион пикселей. Вам нужно обработать её в нейросети.
Цветная картинка — это три цветовых слоя. То есть относительно небольшая картинка 1000 × 1000 — это три миллиона чисел.
3 миллиона чисел — это только первый слой нейросети. Дальше можно предположить, что будет ещё 3 слоя. Предположим, что в сумме наша нейронка будет считать 10 миллионов матриц.
Если мы хотим обрабатывать видео, то нам нужно обрабатывать всё это богатство хотя бы 25 раз в секунду. Поэтому в итоге нам нужно считать 250 миллионов матриц в секунду.
Расчёт одной матрицы может требовать сотен и тысяч операций процессора. То есть это уже 250 млрд операций в секунду. Это значит, что мощный процессор, у которого 24 ядра, 48 потоков и частота 4 гигагерца будет работать на пределе своих возможностей. А ему ещё нужно заниматься работой операционной системы и обслуживать другие программы. В одиночку процессору вытягивать такое очень сложно, да и перегреется он в таком режиме слишком быстро.
Современные процессоры состоят из ядер, которые умеют считать что-то параллельно. Но ни у кого нет ста ядер. В обычном процессоре (CPU) от 2 до 16 ядер, и даже если они все будут работать параллельно с максимальной эффективностью, этой скорости всё равно не хватит на работу нейросети в реальном времени. Или хватит, но это будет очень простая нейронка, по сложности сравнимая с обычными алгоритмами.
Помимо обычных процессоров есть видеокарты со специальными графическими процессорами (GPU). Там уже всё гораздо веселее: от тысячи до десятков тысяч ядер. Они маленькие, простые, но могут работать параллельно и быстро — как раз то, что нужно для нейросети. Если нет специального железа, используют их, но есть один нюанс — GPU подходят для неспешного обучения или для несложных нейронок. Если будет что-то сложное, то они начнут сильно греться, потреблять много электричества и могут всё равно не справиться с задачей.
Нейропроцессоры и ускорители
Чтобы разгрузить графический процессор и сделать вычисления более быстрыми, придумали нейронный процессор — он же нейропроцессор или NPU. Он заточен только под одну задачу — складывать и перемножать веса нейронки. Но он делает это супербыстро. Для сравнения:
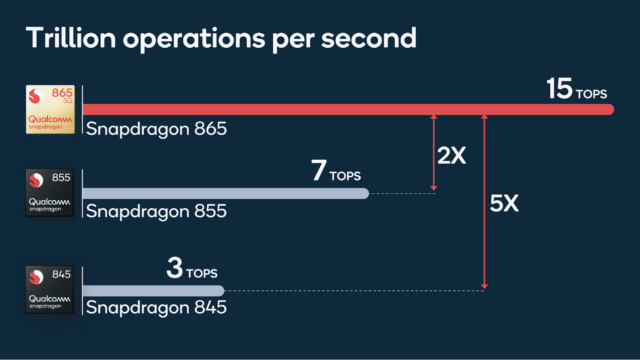
- скорость очень мощного CPU (AMD Ryzen Threadripper 3990X) — 3 триллиона операций в секунду;
- GPU — 20 триллионов операций в секунду;
- NPU — 480 триллионов операций в секунду.

Нейропроцессоры необязательно должны быть большими: есть и маленькие чипы, которые можно вставить в смартфон. Чаще всего это тензорные процессоры — те, которые рассчитаны на работу с библиотекой машинного обучения TensorFlow CCSLRF, но необязательно. Ещё они могут быть сопроцессорами — дополнительными модулями, которые встроены в основной чип для облегчения вычислений.
Сейчас почти у каждого крупного производителя чипов для телефонов есть свои нейропроцессоры:
- Apple: Apple Bionic с сопроцессором Neural Engine;
- Huawei: Kirin 970 со встроенным NPU (Neural Network Processing Unit);
- Oppo: MariSilicon X;
- Samsung: Exynos 9 Series 9820.
Что делают нейросети в телефонах
Задача нейросетей в телефоне — сделать нашу жизнь проще и удобнее. Для этого нейронки:
- слушают ваш голос в ожидании команды «Алиса»;
- распознают голос и переводят его в текст и наоборот;
- определяют лица и предметы на фотографиях;
- занимаются вычислительной фотографией, чтобы сделать красивое размытие на фотках, поменять фон, исправить дефекты лица, перерисовать освещение, исправить заваленные тени или пересвет;
- помогают нарисовать дополненную реальность;
- переводят с одного языка на другой.
Что дальше
В следующий раз мы посмотрим на нейропроцессоры с точки зрения разработчика — какие бывают, чем различаются, что нужно учесть при работе. Будет сложно, поэтому всё сделаем поэтапно.
Вёрстка:
Кирилл Климентьев
![]()
![]()
Видео
Архитектура нейронных процессоров

Андрей Иванов
Сохранить в закладки
3160
23
Сохранить в закладки
IT-специалист Андрей Иванов о soft-процессорах, сверточной нейронной сети и системе обучения нейронных процессоров
14.02.2020
Над материалом работали
Андрей Иванов
кандидат технических наук, Сколковский институт науки и технологий

Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
Видео
2734
История предсказания будущего интернета

Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
ПРОМО Вы нужны нам: как поддержать ПостНауку

Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
Видео
4400
Первые определения кристаллических структур
Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
Как умирают звезды?

Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
Видео
59082
19
Двигательные центры мозга

Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
Видео
10555
Латентная семантическая модель

Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
FAQ Почему Вселенную называют плоской?

Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
Видео
41965
Квазары и релятивистские струи

Добавить в закладки
Вы сможете увидеть эту публикацию в личном кабинете
Видео
5716
Иерархическое обучение с подкреплением
В настоящее время нейропроцессоры по-прежнему остаются одним из наиболее перспективных направлений развития электроники. Конечно, им еще очень далеко до совершенства. Однако технологии не стоят на месте, и способности современных нейропроцессоров оказываются весьма впечатляющими. В данной статье кратко рассказывается об истории нейропроцессоров, раскрываются различия между нейропроцессорами и процессорами с традиционной архитектурой, анализируются основные принципы работы и обучения нейропроцессоров на примере микросхемы NM500 от NeuroMem.

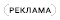
Несмотря на все достижения современных технологий, человеческий мозг остается самой совершенной вычислительной системой на Земле. Конечно, любой, даже самый простой 8-битный микроконтроллер без проблем опередит профессора математики на соревнованиях по арифметике, однако он вряд ли сможет разобраться с неформализованными задачами.
Удивительная универсальность мозга давно является мечтой для разработчиков процессорных систем. Попытки создать машинный аналог нейронов предпринимались еще в 60-х годах прошлого века. В качестве примера можно привести персептрон Марк-1, разработанный Фрэнком Розенблаттом. Первые варианты электронных нейронов по своим возможностям были очень далеки от биологического оригинала, и интерес к данной задаче был не очень высоким. Однако в 1980-е годы интегральные технологии позволили создать сложные процессоры, объединяющие миллионы транзисторов, а их топологические нормы оказались меньше, чем размеры реальных биологических нейронов. В то же время по своей эффективности при решении неформализованных задач эти процессоры по-прежнему значительно уступали мозгу. Именно это противоречие и стало толчком к развитию нейропроцессорных технологий. При этом речь шла как о создании специализированных архитектур, так и о проработке теоретических вопросов [1].
В чем разница между нейропроцессором и традиционным процессором?
Чем же нейропроцессоры отличаются от традиционных процессорных систем, таких как микроконтроллеры (МК), процессоры (ЦП), цифровые сигнальные процессоры (ЦСП), графические процессоры (ГП) и т.д. Главное отличие заключается в архитектуре. Традиционные процессоры состоят из обособленных блоков, выполняющих разные функции (вычислительные и периферийные блоки, память). Нейропроцессоры имеют более «однородную» структуру, включающую множество нейронов – одинаковых и относительно простых вычислительных ячеек со встроенной памятью. Это различие хорошо видно даже на фотографии (Рисунок 1).
 |
|
| Рис. 1. | Увеличенная фотография структуры традиционного процессора и нейропроцессора [2]. |
Таким образом, архитектура нейропроцессора по определению оказывается многоядерной, ведь каждый нейрон – это самостоятельное вычислительное ядро. В результате многие операции, такие как распознавание изображений, фильтрация и т.д., выполняются очень быстро. Конечно, современные процессоры также могут иметь многоядерную структуру (в первую очередь графические процессоры), но решение неформализованных задач для них по-прежнему оказывается затруднено. Другие важные отличия в возможностях процессоров представлены в Таблице 1.
| Таблица 1. Сравнение процессоров с традиционной архитектурой и нейропроцессоров | ||||||||||||||||
|
Развитие нейропроцессоров, также как и развитие обычных процессоров, тесно связано с совершенствованием интегральных технологий. Чем меньше топологические нормы, тем больше можно уместить нейронов на кристалле, сохранив при этом низкий уровень потребления (Рисунок 2).
 |
|
| Рис. 2. | Развитие интегральных технологий определяет развитие нейропроцессоров [2]. |
В настоящее время существует множество примеров более и менее удачных реализаций нейропроцессоров. Многие из предлагаемых решений разрабатывались для решения узкого круга задач и не всегда становились доступными для широкого круга разработчиков. Впрочем, судя по всему, появление доступных и дружелюбных к пользователям нейропроцессоров не за горами. В качестве примера можно привести процессоры CM1K и NM500 от компании NeuroMem.
Как устроена нейронная сеть в нейропроцессоре?
Рассмотрим устройство и принцип работы нейропроцессоров на примере CM1K и NM500 от компании NeuroMem. Эти процессоры, с одной стороны, хорошо раскрывают суть нейровычислений, а с другой стороны обладают достаточно простой и прозрачной архитектурой.
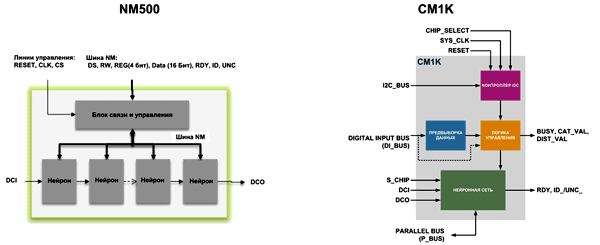
CM1K – нейропроцессор, изготовленный по технологии 130 нм и содержащий сеть из 1024 нейронов (Таблица 2). CM1K не имеет встроенного супервизора (встроенного управляющего сопроцессора) – все вычисления производятся параллельными нейронами, подключенными к параллельной шине и работающими на частоте до 27 МГц (Рисунок 3). При этом общее потребление системы оказывается достаточно низким (от 0.5 Вт). CM1K имеет корпусное исполнение TQFP 16×16 мм.
NM500 – новый нейропроцессор от NeuroMem, выполненный по технологии 110 нм, и объединяющий 576 нейронов (Таблица 2). Так же как и у CM1K, у NM500 нет какого-либо встроенного супервизора (Рисунок 3). Габариты корпуса данного процессора 4×4 мм (WCSP64), а потребление составляет менее 153 мВт в активном режиме.
 |
|
| Рис. 3. | Структура нейропроцессоров CM1K и NM500 оказывается достаточно простой [2]. |
| Таблица 2. Сравнение характеристик нейропроцессоров C1MK, QuarkSE/Curie и NM500 [2] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Отсутствие встроенного супервизора говорит о том, что для работы с CM1K и NM500 требуется внешний управляющий процессор, который будет снабжать нейроны данными. При этом связь осуществляется по параллельной двунаправленной 26-битной шине. По сути, NM500 представляет собой цепочку одинаковых нейронов, которые подключены к общей параллельной шине и имеют связи между собой (Рисунок 4).
 |
|
| Рис. 4. | Упрощенная структура NM500 [3]. |
Как работает нейронная сеть в нейропроцессоре?
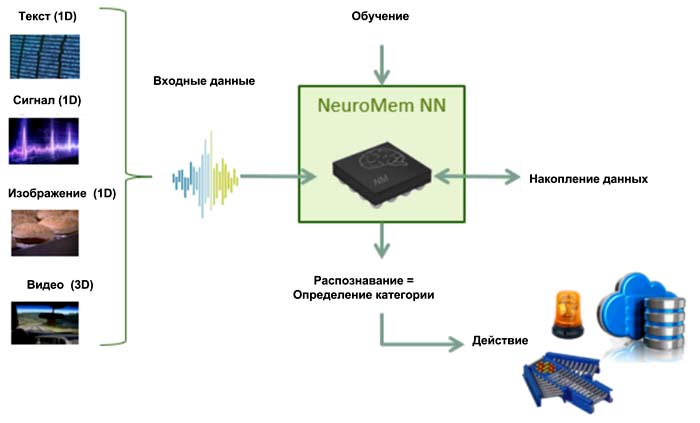
CM1K и NM500 способны работать в двух основных режимах: обучение и распознавание (Рисунок 5). При этом речь может идти об абсолютно разных по природе данных: текстах, изображениях, звуковых сигналах, видео и т.д. Далее (исключительно для простоты!) будем полагать, что нейропроцессор используется для распознавания изображений. Поток данных формирует внешний управляющий процессор, а обработка производится нейронами.
 |
|
| Рис. 5. | CM1K и NM500 могут работать в двух основных режимах: обучение и распознавание [2]. |
Каждый нейрон NM500 имеет собственную программируемую память: основную 256 байт (шаблон), контекст (8 бит), категорию (16 бит). Категория используется для классификации объектов, а контекст для разделения нейронов на подсети. Кроме того, у каждого нейрона есть собственный 24-битный идентификатор NID (neuron ID). Программирование памяти нейронов отличается от программирования обычных процессоров. В обычном процессоре программа записывается перед началом работы. Во многих нейропроцессорах (но не во всех!) программирование может осуществляться прямо в процессе работы и называется обучением.
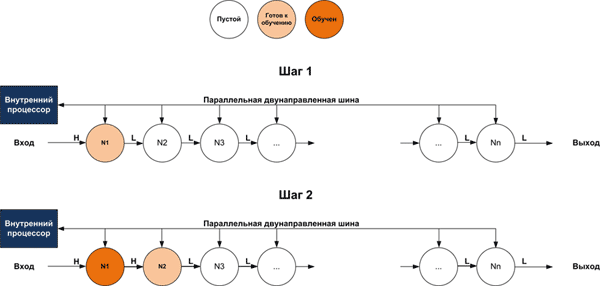
На Рисунке 6 представлен процесс обучения NM500. На первом шаге все нейроны не обучены и находятся в состоянии «пуст» (кроме первого нейрона). У них на выходе присутствует низкий сигнал «L». Первый нейрон находится в состоянии «готов к обучению». После того, как управляющий процессор проведет заполнение внутренней памяти (по параллельной шине), первый нейрон перейдет в состояние «обучен» и получит идентификатор NID=1, на его выходе установится высокий сигнал «H». При этом второй нейрон перейдет в состояние «готов к обучению». Таким образом могут быть последовательно обучены и автоматически идентифицированы все нейроны (NID=2, NID=3…). Такой подход позволяет каскадировать процессоры NM500, наращивая число нейронов практически до бесконечности.
 |
|
| Рис. 6 | Обучение нейронов NM500 происходит последовательно [3]. |
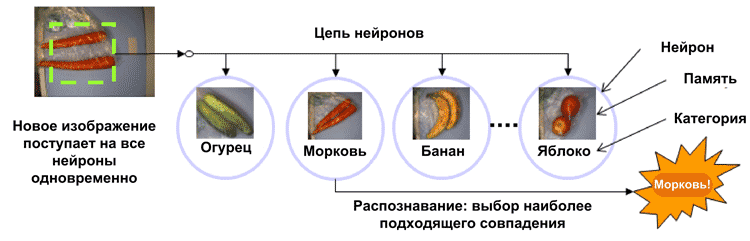
В качестве примера проанализируем работу NM500 в составе кассового терминала с функцией распознавания продуктов (Рисунок 7). В процессе обучения в основную память нейронов (256 байт) были записаны шаблонные изображения продуктов, а в поле категории (16 бит) закодирован их тип: огурец, банан, морковь и т.д. Далее в процессе работы камера делает цифровую фотографию продукта. Управляющий процессор по параллельной шине передает изображение всем нейронам одновременно. Нейроны, используя встроенные алгоритмы распознавания, сравнивают содержимое своей памяти и полученное изображение. Далее нейроны сообщают управляющему процессору о результатах совпадения. Если совпадение найдено, значит, задача успешно решена. Если нет, то управляющий контроллер самостоятельно или с помощью оператора может создать новый шаблон и поместить его в свободный нейрон.
 |
|
| Рис. 7. | Использование NM500 для распознавания продуктов [3]. |
Нейроны могут использоваться для распознавания различных свойств объекта, например формы, цвета и т.д. В таких случаях нейроны удобно разделять на отдельные подсети с помощью поля контекст. Тогда в процессе распознавания активными остаются только те нейроны, чей контекст совпадает с глобальным контекстом, задаваемым управляющим процессором.
В приведенном примере не рассмотрены наиболее сложные аспекты работы нейропроцессора. В частности, как нейрон выполняет сравнение? Как оценивается сходство? Каким образом решаются спорные вопросы? Например, что было бы, если в этом примере камера зафиксировала зеленый неспелый банан, похожий на огурец? Возникла бы коллизия между 1-м и 3-м нейронами? Рассмотрим эти вопросы отдельно.
Зачем нейропроцессор измеряет дистанцию в битах?
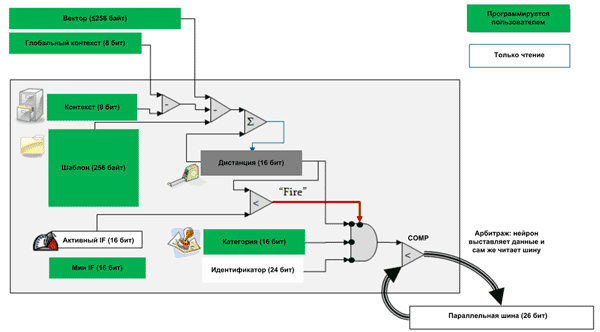
Чтобы понять, каким образом оценивается степень сходства, следует обратиться к структуре нейрона в NM500 (Рисунок 8). В процессе сравнения исходное изображение проходит обработку с использованием специализированных алгоритмов (о них речь пойдет далее) и шаблона (256 байт), хранящегося в памяти нейрона. Результатом сравнения становится 16-битное число, которое помещается в регистр «Дистанция». Другими словами нейрон формирует результат не в форме «совпал» – не «совпал», а в виде 16-битного числа – дистанции, которое является мерой «похожести». Чем меньше дистанция, тем ближе исследуемое изображение к шаблону.
 |
|
| Рис. 8. | Процесс распознавания в нейроне NM500 [3]. |
После расчета дистанции происходит ее сравнение со значением регистра поля интересов (influence field, IF). Если дистанция оказывается меньше, значит, объект имеет высокое сходство с шаблоном. В таком случае нейрон переходит в возбужденное состояние (fire) и начинает передавать значение дистанции, а потом, если требуется, категорию (16 бит) и идентификатор нейрона (NID) управляющему процессору.
Существует возможность того, что исследуемый объект одновременно попадет в поле интересов нескольких нейронов как зеленый банан, который похож и на банан, и на огурец. Для таких случаев в NM500 реализован запатентованный механизм неразрушающего арбитража.
Для осуществления арбитража используется блок сравнения COMP. На один его вход поступают данные от нейрона, а на второй текущее состояние шины. При этом выходные линии D[0…15] блока сравнения имеют тип открытый коллектор и подключены к этой же шине. Таким образом, каждый из нейронов не только передает данные на шину, но и отслеживает ее состояние. Если оказывается, что какой-то из нейронов сообщает о меньшей дистанции (большем сходстве), то нейрон с меньшим сходством автоматически отключается и выбывает из «гонки» на максимальное сходство.
Если управляющему процессору после чтения дистанции требуется чтение категории (16 бит) и идентификатор нейрона (NID), то используется тот же механизм арбитража. Поэтому, если два нейрона имеют равную дистанцию, но у одного из них значение категории меньше, то именно он и выиграет «гонку» арбитража и продолжит передачу данных.
Этот принцип арбитража называется «Winner-Takes-All», что обычно переводят, как «победитель получает все».
Описанный выше алгоритм работы соответсвует механизму радиально-базисных функций (Radial Basis Function, RBF). Его главным преимуществом является максимальная временная детерминированность – управляющий процессор узнает о совпадении (или о его отсутствии) за 19 тактов (37 тактов с вычитыванием категории). В NM500 также поддерживается механизм «K ближайших соседей» (K-Nearest Neighbor, KNN).
При использовании механизма «K ближайших соседей» (K-Nearest Neighbor, KNN) значение регистра поля интересов игнорируется, и все нейроны в любом случае переходят в возбужденное состояние. В дальнейшем управляющий процессор вычитывает значения дистанций всех нейронов, что занимает гораздо больше времени. Как было сказано выше, чтение дистанции одного нейрона занимает 19 тактов, тогда, например, для считывания дистанций 50 нейронов понадобится 950 тактов.
Зачем нужны разные алгоритмы обработки?
Необходимо также пару слов сказать о самих алгоритмах сравнения. Таких алгоритмов существует много, в частности NM500 поддерживает алгоритмы L1 (Manhattan) и Lsup (Рисунок 9). Выбор алгоритма зависит от конкретной задачи:
- Lsup позволяет обнаруживать максимальное отклонение исходных данных от шаблона. Очевидно, что такой алгоритм идеально подходит для фильтрации, а также для обнаружения аномалий.
- L1 позволяет определять отклонение всех составляющих массива данных от соответствующих составляющих шаблона. Такой алгоритм востребован в операциях майнинга.
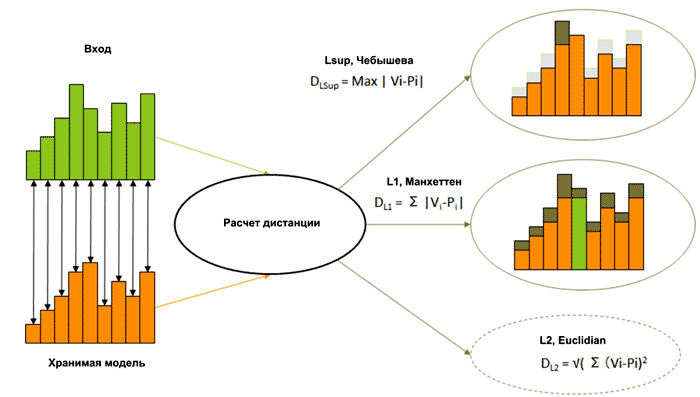 |
|
| Рис. 9. | Для вычисления дистанции NM500 использует алгоритмы L1 (Manhattan) и Lsup [3]. |
Работа нейропроцессора на пальцах, в картинках и таблицах
Теперь, когда общие вопросы были рассмотрены, пришло время подробно разобрать пару конкретных примеров.
Пример 1. Распознавание одномерных массивов из двух чисел
В данном примере предполагается использовать три нейрона. Для этого их память заполняется следующим образом:
- 1 нейрон: шаблон = (11, 11), поле интересов AIF = 16, категория CAT = 55, идентификатор NID=1;
- 2 нейрон: шаблон = (15, 15), поле интересов AIF = 16, категория CAT = 33, идентификатор NID=2;
- 3 нейрон: шаблон = (30, 30), поле интересов AIF = 20, категория CAT = 100, идентификатор NID=3.
Этот пример удобно проиллюстрировать в виде двухмерной графической модели (Рисунок 10). Каждый нейрон представляется в виде сферы с радиусом, равным полю интересов AIF. При этом несложно отметить наличие перекрытий полей интересов.
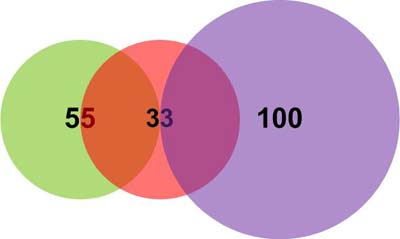 |
|
| Рис. 10. | Пример 1. Графическое представление исходных данных. |
Рассмотрим реакцию системы на входные векторы.
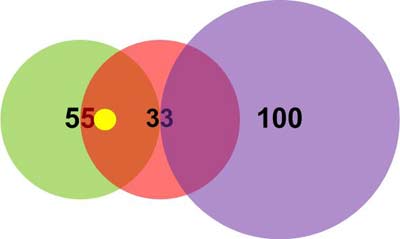
Вектор (12, 12). Расчетная дистанция между нейроном 1 и вектором 1 (по алгоритму L1) вычисляется как сумма разностей составляющих вектора и шаблона: (12-11) + (12-11) = 2.
Аналогичным образом:
- Дистанция до нейрона 2: (15-12) + (15-12) = 6.
- Дистанция до нейрона 3: (30-12) + (30-12) = 36.
Таким образом, вектор (12, 12) попадает в поле интересов нейрона 1 и нейрона 2 (возбуждает их), но не попадает в поле интересов нейрона 3 (Рисунок 11).
В итоге, при чтении результата по механизму «победитель получает все» управляющий процессор получит данные о совпадении от нейрона 1, так как именно у нейрона 1 минимальная дистанция, то есть максимальное совпадение.
 |
|
| Рис. 11. | Положение вектора (12,12). |
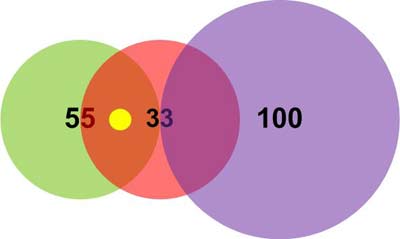
Вектор (13, 13). Расчетные дистанции до вектора:
- Дистанция до нейрона 1: (13-11) + (13-11) = 4.
- Дистанция до нейрона 2: (15-13) + (15-13) = 4.
- Дистанция до нейрона 3: (30-13) + (30-13) = 34.
Таким образом, вектор (13, 13) попадает в поле интересов нейрона 1 и нейрона 2 (возбуждает их), но не попадает в поле интересов нейрона 3 (Рисунок 12). В то же время дистанция до 1 и 2 нейронов одинакова. Однако, так как категория нейрона 2 меньше, именно он выиграет гонку по принципу «победитель получает все». Управляющий процессор получит данные о совпадении от нейрона 2.
 |
|
| Рис. 12. | Пример 1. Положение вектора (13,13). |
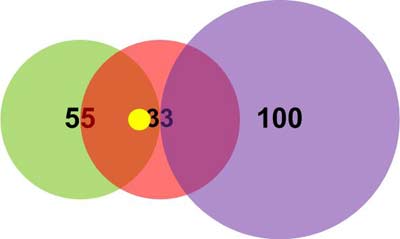
Вектор (14, 14). Расчетные дистанции до вектора:
- Дистанция до нейрона 1: (14-11) + (14-11) = 6.
- Дистанция до нейрона 2: (15-14) + (15-14) = 4.
- Дистанция до нейрона 3: (100-14) + (100-14) = 32.
Таким образом, вектор (14, 14) попадает в поле интересов нейрона 1 и нейрона 2 (возбуждает их), но управляющий процессор получит данные о совпадении от победителя – нейрона 2 (Рисунок 13).
 |
|
| Рис. 13. | Пример 1. Положение вектора (14,14). |
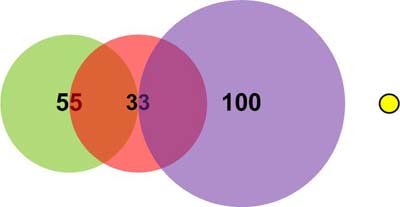
Вектор (200, 200). Расчетные дистанции до вектора:
- Дистанция до нейрона 1: (200-11) + (200-11) = 378.
- Дистанция до нейрона 2: (200-15) + (200-15) = 370.
- Дистанция до нейрона 3: (200-30) + (200-30) = 340.
Таким образом, вектор (200, 200) не попадает в поле интересов ни одного из нейронов (Рисунок 14). В таких случаях процессор может инициировать запись этого вектора в незанятый нейрон и классифицировать его самостоятельно.
 |
|
| Рис. 14. | Пример 1. Положение вектора (200,200). |
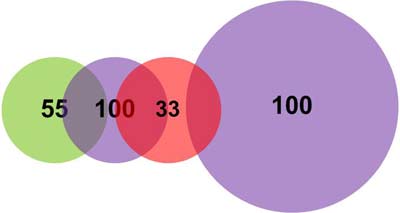
Обучение новому вектору (13, 13). Допустим, требуется «выучить» новый вектор (13,13) с категорией 100. Как было показано, выше он находится на равной дистанции от нейрона 1 и нейрона 2. По этой причине при записи этого вектора нейроны автоматически сузят поля интересов до значения AIF = 8. Таким образом, реализуется самообучение нейронов.
 |
|
| Рис. 15. | Пример 1. Самообучение нейронов при добавлении нового вектора заключается в сужении поля интересов. |
Пример 2. Обучение и работа двухнейронной сети с массивом из 10 чисел
В данном примере повторяются вычисления аналогичные из Примера 1. Главное отличие заключается в том, что обучение ведется между распознаваниями и серьёзно влияет на результаты.
Процесс представлен в виде Таблицы 3.
| Таблица 3. Пример 2. Поведение нейропроцессора при работе с массивом из 10 чисел | ||||||||||||||||||||||||||||||||||||||||
|
Что делать если не хватает нейронов?
Возникает вопрос. 576 нейронов и 256 байт памяти – это много или мало? Очевидно, что ответ зависит от требований конкретного приложения. Для простых задач этого хватит, а для более сложных приложений может потребоваться и более мощный инструмент. Тем не менее, процессоры NM500 оказываются очень простыми и доступными для широкого круга пользователей, что без сомнений является их большим достоинством.
Как уже было сказано выше, при необходимости нейронная сеть на базе процессоров NM500 может быть расширена. Для этого используется каскадирование микросхем (Рисунок 16). При этом выход DCO одного процессора должен подключаться к входу DCI следующего процессора. Количество последовательно включенных микросхем не ограничено, или скорее ограничено возможностями печатной платы сохранять целостность сигналов при работе на частотах до 20 МГц.
 |
|
| Рис. 16. | Расширение нейронной сети за счет каскадирования процессоров NM500. |
Как ознакомится с возможностями NM500?
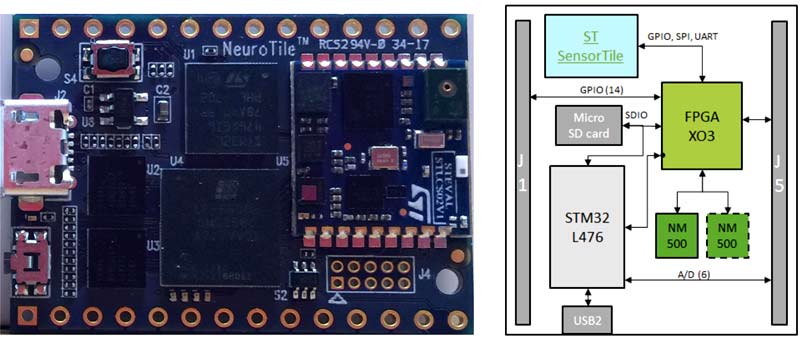
Одна из целей создания NM500 заключалась в продвижении нейропроцессоров в народные массы. Действуя в рамках этой стратегии, компания NeuroMem пошла логичным путем и выпустила Arduino-совместимый отладочный модуль NeuroTile, который делает нейропроцессор максимально доступным как для профессиональных разработчиков, так и для простых любителей электроники.
На борту у NeuroTile присутствует один или два процессора NM500, производительный и малопотребляющий микроконтроллер STM32F476 с процессорным ядром ARM Cortex-M4, ПЛИС XO3 от Lattice, Bluetooth, 6-осевой инерциальный модуль (гироскоп + акселерометр), 6-осевой инерциальный модуль (магнитометр + акселерометр), датчик давления, микрофон, слот для карты памяти, микросхема заряда Li-ion аккумуляторов, USB, Arduino-совместимый стек для штыревых разъемов (Рисунок 17).
 |
|
| Рис. 17. | Внешний вид и структура отладочной платы NeuroTile [2]. |
Существуют Arduino-совместимые отладочные модули с NM500 от сторонних производителей, например ProdigyBoard от корейской компании nepes (Рисунок 18). Отличительными чертами ProdigyBoard являются: два процессора NM500, 1 Гбайт DDR3, FPGA с загрузочной Flash 20 МБит, камера, микрофон, Micro SD, USB.
 |
|
| Рис. 18. | Внешний вид и структура отладочной платы ProdigyBoard [2]. |
Заключение
В отличие от традиционных процессоров, нейропроцессоры обеспечивают высокую производительность и низкое потребление при выполнении сложных неформализованных задач. Они могут использоваться в широком спектре приложений, начиная от контроля качества продуктов и заканчивая обработкой изображения и звука.
Появление простых и дружелюбных к пользователям нейропроцессоров NM500 может стать большим шагом для популяризации неропроцессорных технологий.
Характеристики нейропроцессора NM500:
- Число нейронов: 576;
- Объем памяти нейрона: 256 байт;
- Режим работы: радиально-симметричные функции (RadialBasisFunction, RBF) и «K ближайших соседей» (K-NearestNeighbor, KNN);
- Выходные состояния: определен, не полное совпадение, неизвестен;
- Расчет дистанции: L1 (Manhattan), Lsup;
- Рабочая частота: 37 МГц (одиночный процессор), 18 МГц (при параллельном включении процессоров);
- Коммуникационные интерфейсы: параллельная шина (26 линий);
- Напряжения питания: 3.3 В I/O и 1.2 В ядра;
- Потребление (активная работа): <153 мВт;
- Корпус: CSP-64 4.5×4.5×0.5 мм.
Посмотреть технические характеристики контроллеров и процессоров компании NeuroMem