Несмотря на критически важную роль в высокоскоростных схемах, компоновка печатной платы часто является одним из последних этапов проектирования. Эта тема имеет множество аспектов, по ней было написано много литературы. В данной статье компоновка рассматривается с практической точки зрения. Основная цель в том, чтобы заострить внимание новичков на многих различных тонкостях, которые им необходимо учитывать при компоновке печатных плат для высокоскоростных схем. Но статья также предназначена для освежения знаний тех, кто какое-то время не занимался компоновкой плат. Не все темы могут быть детально рассмотрены в рамках такой небольшой статьи, но мы обратимся к ключевым областям, способным принести наибольшую пользу в улучшении характеристик схемы, сокращении времени проектирования и минимизации трудоемких доработок.

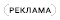
Хотя основное внимание уделяется схемам с высокоскоростными операционными усилителями (ОУ), обсуждаемые здесь темы и методы в целом применимы к компоновке большинства других высокоскоростных аналоговых схем. Когда ОУ работает в области ВЧ, характеристики устройства сильно зависят от компоновки платы. Высококачественная конструкция, которая хорошо выглядит «на бумаге», может показать посредственные характеристики из-за небрежной компоновки. Стараясь все продумывать заранее и обращая внимание на существенные детали в процессе компоновки, можно почти гарантировать, что устройство будет работать так, как ожидалось.
Принципиальная схема
Хотя нет никакой гарантии, но хорошая компоновка начинается с хорошо нарисованной схемы. Будьте внимательны при рисовании схемы, сопровождайте ее большим количеством пометок и учитывайте направление прохождения сигнала. Схема, имеющая естественное и общепринятое направление прохождения сигнала слева направо, как правило, будет иметь хорошее прохождение сигнала и на плате. Поместите на схему как можно больше полезной информации. Проектировщики, техники и инженеры, которые будут работать с вашей схемой, будут вам очень признательны, включая и нас; время от времени клиенты просят нас помочь со схемой, потому что ее проектировщика больше нет.
Какая информация содержится на схеме, помимо привычных позиционных обозначений, рассеиваемых мощностей и допусков? Вот несколько советов, которые могут превратить обычную схему в суперсхему. Добавьте временные диаграммы сигналов; информацию механического характера о корпусе или экране, длине дорожек, областях без трассировки; обозначьте, какие компоненты должны находиться на верхней стороне платы; включите туда информацию о настройке, диапазоны значений компонентов, информацию о тепловых характеристиках, о согласованных линиях передачи, примечания, краткое описание работы схемы… (список можно продолжать).
Никому не доверять
Если вы не занимаетесь компоновкой платы собственноручно, обязательно уделите достаточно времени обсуждению предстоящей работы с человеком, ответственным за компоновку. На этом этапе унция профилактики стоит больше, чем фунт лечения! Не надейтесь, что компоновщик способен читать ваши мысли. Ваше техническое задание и рекомендации наиболее важны в начале процесса компоновки. Чем больше информации вы можете предоставить, и чем сильнее вы вовлечены в этот процесс, тем лучше выйдет плата. Обозначьте проектировщику платы точки промежуточных этапов, на которых вы хотите ознакомиться с ходом компоновки. Такая организация рабочего процесса предотвращает слишком большое отклонение компоновки от намеченной и сводит к минимуму переделки платы.
Ваши указания разработчику платы должны включать в себя:
- краткое описание функций схемы;
- эскиз платы, на котором показано расположение входов и выходов сигнала;
- строение платы «в разрезе» (т.е., какой будет ее толщина, количество слоев, подробное описание сигнальных аналоговых, цифровых и ВЧ слоев и сплошных слоев питания и земли);
- какие сигналы должны проходить в каждом слое;
- где должны располагаться критически важные компоненты;
- точное расположение компонентов развязки;
- какие дорожки имеют решающее значение;
- какие дорожки должны составлять согласованные линии передачи;
- какие дорожки должны иметь одинаковую длину;
- размеры компонентов;
- какие дорожки следует располагать рядом, либо дальше друг от друга (это же относится и к цепям, и к компонентам);
- какие компоненты должны находиться сверху и снизу платы.
На вас никогда не пожалуются за то, что вы предоставили кому-то слишком много информации; а вот если слишком мало – то да.
Личный опыт: около 10 лет назад, я проектировал многослойную плату поверхностного монтажа с компонентами на обеих сторонах. Плата крепилась в позолоченный алюминиевый корпус множеством винтов (чтобы обеспечить требуемую стойкость к вибрации). Сквозь плату проходили контакты, соединявшиеся с ней проводами. Сборка была трудоемкой. Некоторые компоненты должны были подбираться при тестировании, но я не уточнил, где следовало их расположить. Как вы думаете, где были расположены некоторые из них? Правильно, снизу! Инженеры-технологи и техники были не очень довольны, когда им пришлось все это разбирать, устанавливать компоненты с нужными номиналами и затем собрать обратно. Больше я таких ошибок не совершал.
Расположение, расположение и еще раз расположение
Как и в сфере недвижимости, главное здесь — расположение. Где на плате расположена та или иная цепь, где располагаются ее отдельные компоненты и какие другие цепи расположены поблизости — все это имеет решающее значение.
Как правило, места ввода-вывода сигналов и подключения питания определены, но пространство между ними целиком в вашем распоряжении. Именно здесь внимание к деталям компоновки принесет ощутимый результат. Начните с размещения компонентов, важнейших как с точки зрения отдельных цепей, так и платы в целом. Указание с самого начала положения этих компонентов и путей трассировки сигнальных дорожек почти гарантирует, что устройство будет работать так, как задумано. Правильное выполнение с первого раза сокращает расходы и стресс, а также время проектирования.
Развязка по питанию
Шунтирование выводов питания усилителя для минимизации помех является важнейшим аспектом разработки платы — как для быстродействующих ОУ, так и для остальных высокоскоростных схем. Для высокоскоростных ОУ обычно используются два метода шунтирования.
От шин питания к земле: в этом методе, который в большинстве случаев работает лучше всего, используются несколько параллельно соединенных конденсаторов, включенных прямо между выводами питания ОУ и землей. Обычно достаточно двух параллельных конденсаторов, но некоторые схемы лучше работают с дополнительными параллельными конденсаторами.
Параллельное включение конденсаторов различной емкости позволяет гарантировать, что импеданс между выводами питания усилителя будет оставаться низким в широком диапазоне частот. Это особенно важно на тех частотах, где подавление помех по питанию (power-supply rejection, PSR) операционного усилителя становится низким. Конденсаторы позволяют компенсировать это снижение PSR. Поддержание низкого импеданса шунтирующей цепи в пределах многих декад изменения частоты помогает избежать проникновения нежелательных помех по цепям питания ОУ На Рисунке 1 показано преимущество параллельного соединения нескольких конденсаторов. На более низких частотах низкоимпедансный путь к земле обеспечивают конденсаторы с большей емкостью. Когда частота достигает частоты собственного резонанса конденсатора, его импеданс меняется с емкостного на индуктивный. Вот почему так важно использовать несколько конденсаторов: когда импеданс одного из них начинает расти, импеданс другого все еще остается низким, что обеспечивает малый общий импеданс в широком диапазоне частот.
 |
|
| Рисунок 1. | Частотная зависимость импеданса конденсатора. |
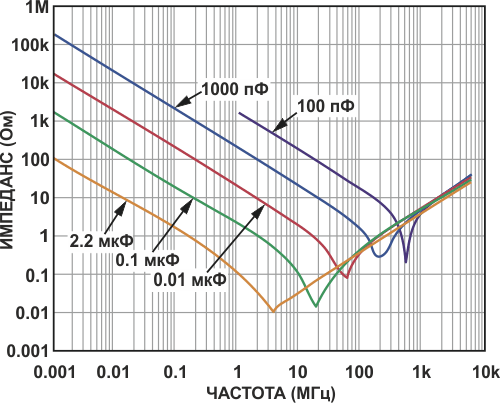
Начинаем непосредственно с выводов питания ОУ; самый миниатюрный конденсатор наименьшей емкости следует расположить на той же стороне платы, что и ОУ, как можно ближе к нему. Другой вывод конденсатора должен подключаться к земляному слою проводником минимальной длины. Чтобы свести к минимуму помехи между шинами питания и землей, это подключение делается как можно ближе к нагрузке ОУ. Этот метод показан на Рисунке 2.
 |
|
| Рисунок 2. | Шунтирование шин питания на землю параллельно соединенными конденсаторами. |
Эту процедуру следует повторить для следующего конденсатора большей емкости. Хорошей отправной точкой для выбора конденсаторов будет 0.01 мкФ для наименьшего значения и электролитический low ESR конденсатор 2.2 мкФ (или больше) для следующего. Конденсаторы 0.01 мкФ типоразмера 0508 имеют низкую последовательную индуктивность и отличные частотные характеристики.
Между шинами питания: в альтернативной конфигурации используется один или несколько конденсаторов, включенных между положительной и отрицательной шинами питания ОУ. Этот метод обычно используется в том случае, когда трудно подключить к цепи все четыре конденсатора, как в предыдущем методе. Недостаток метода состоит в том, что может потребоваться конденсатор с бóльшим размером корпуса, поскольку теперь он работает при напряжении, удвоенном по сравнению с предыдущим методом. Однако такой способ может улучшить PSR и снизить искажения.
Поскольку все схемы и их компоновки различны, конфигурация, количество и номиналы конденсаторов определяются фактическими требованиями к схеме.
Паразитные параметры
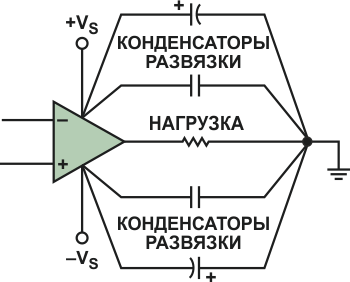
Паразитные параметры — это те маленькие мерзкие гремлины, которые проникают в вашу печатную плату (в буквальном смысле) и сеют хаос в вашей схеме. Это неявные паразитные емкости и индуктивности, проникающие в высокоскоростные цепи. К ним относятся индуктивности выводов компонентов и излишне длинных дорожек. емкости между основанием микросхемы и земляным слоем, слоем питания или дорожками. взаимодействия с переходными отверстиями и еще много другого. На Рисунке 3а показана типичная схема неинвертирующего ОУ. Однако, если бы были учтены паразитные параметры, та же схема выглядела бы, как на Рисунке 3б.
 |
|
| Рисунок 3. | Типичная схема на ОУ (а) и она же с паразитными параметрами (б). |
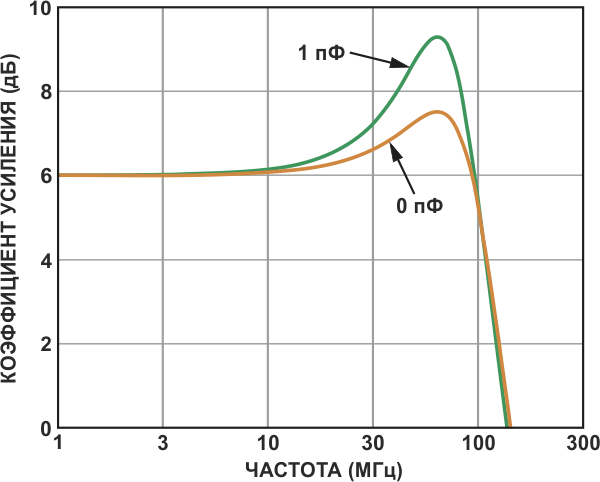
Чтобы нарушить работу высокоскоростных схем, не требуется значительных величин паразитных параметров. Иногда достаточно всего нескольких десятых пикофарады. Показательный пример: если цепь, идущая к инвертирующему входу ОУ, имеет паразитную емкость всего 1 пФ, это может вызвать подъем коэффициента усиления на высоких частотах почти на 2 дБ (Рисунок 4). При достаточной емкости это может привести к потере устойчивости и возбуждению.
 |
|
| Рисунок 4. | Выброс на АЧХ, обусловленный паразитной емкостью. |
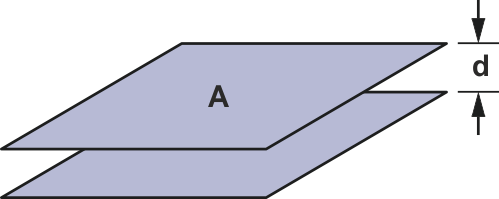
Несколько основных формул для нахождения величин паразитных параметров помогут при поиске причин неудовлетворительной работы схемы. Формула 1 выражает емкость конденсатора с параллельными плоскими обкладками. (См. Рисунок 5).
 |
|
| Рисунок 5. | Емкость между двумя плоскими пластинами. |
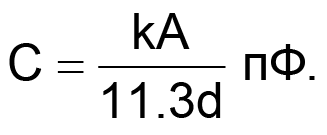 |
(1) |
Здесь
C — емкость,
A — площадь пластины в см2,
k — относительная диэлектрическая проницаемость материала платы,
d — расстояние между пластинами в сантиметрах.
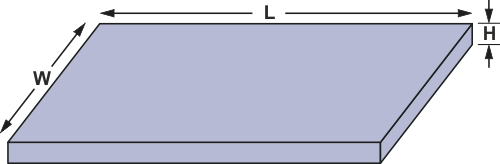
Следует учитывать еще один паразитный параметр — индуктивность дорожек, обусловленную их чрезмерной длиной и отсутствием слоя земли. Формула 2 выражает индуктивность дорожки LT через ее геометрические размеры. (См. Рисунок 6).
 |
|
| Рисунок 6. | Индуктивность участка печатной дорожки. |
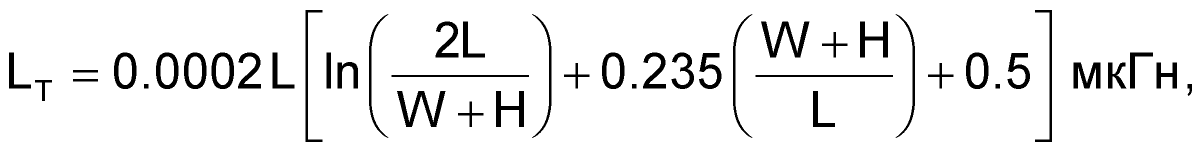 |
(2) |
где
W — ширина дорожки,
L — ее длина,
H — толщина.
Все величины выражены в миллиметрах.
Колебания на Рисунке 7 иллюстрируют влияние дорожки длиной 2.54 см, идущей к неинвертирующему входу высокоскоростного ОУ. Эквивалентная паразитная индуктивность этой дорожки составляет 29 нГн, чего достаточно, чтобы вызвать устойчивые колебания малой амплитуды, сохраняющиеся в течение всего переходного процесса. На Рисунке 7 также показано, как ослабляет влияние паразитной индуктивности использование земляного слоя.
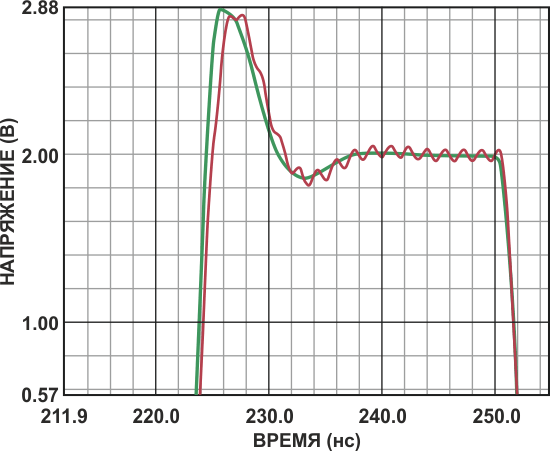 |
|
| Рисунок 7. | Переходная характеристика при наличии и отсутствии земляного слоя. |
Переходные отверстия являются еще одним источником паразитных параметров; они могут добавлять как индуктивность, так и емкость. Формула 3 позволяет найти величину паразитной индуктивности (см. Рисунок 8).
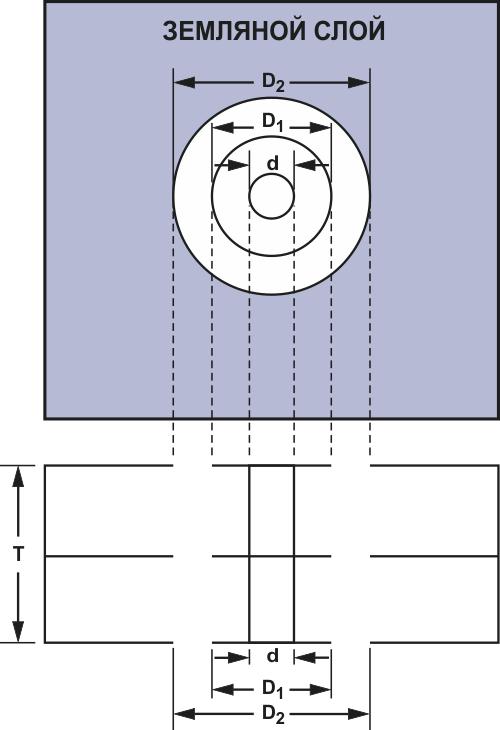 |
|
| Рисунок 8. | Размеры переходного отверстия. |
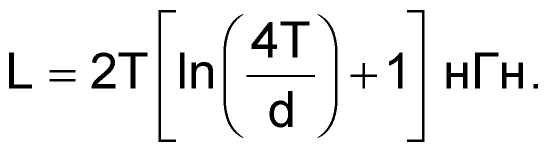 |
(3) |
Здесь
T — толщина платы в сантиметрах,
d — диаметр отверстия в сантиметрах.
Формула 4 позволяет найти паразитную емкость отверстия (см. Рисунок 8).
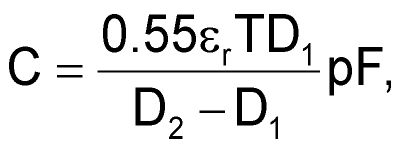 |
(4) |
где
εr — относительная диэлектрическая проницаемость материала платы,
T — толщина платы,
D1 — диаметр контактной площадки вокруг отверстия,
D2 — диаметр выреза в земляном слое
Все величины выражены в сантиметрах.
Одиночное переходное отверстие в плате толщиной 0.157 см может внести 1.2 нГн и 0.5 пФ; вот почему при компоновке плат необходимо постоянно быть внимательным, чтобы свести к минимуму паразитные параметры.
Система компоновки данных
Система компоновки данных представляет собой механизм, основанный на декларативном описании отчетов. Он предназначен для построения отчетов, а также вывода информации, имеющей сложную структуру и содержащий произвольный набор таблиц и диаграмм.
Устройство системы компоновки данных
Система компоновки данных позволяет реализовать следующие возможности:
- создание отчета без программирования;
- использование автоматически генерируемых форм просмотра и настройки отчета;
- разбиение исполнения отчета на этапы;
- исполнение отдельных этапов построения отчета на различных компьютерах;
- независимое использование отдельных частей системы компоновки данных;
- программное управление процессом выполнения отчета.
Основные элементы системы компоновки данных представлены на следующей схеме:
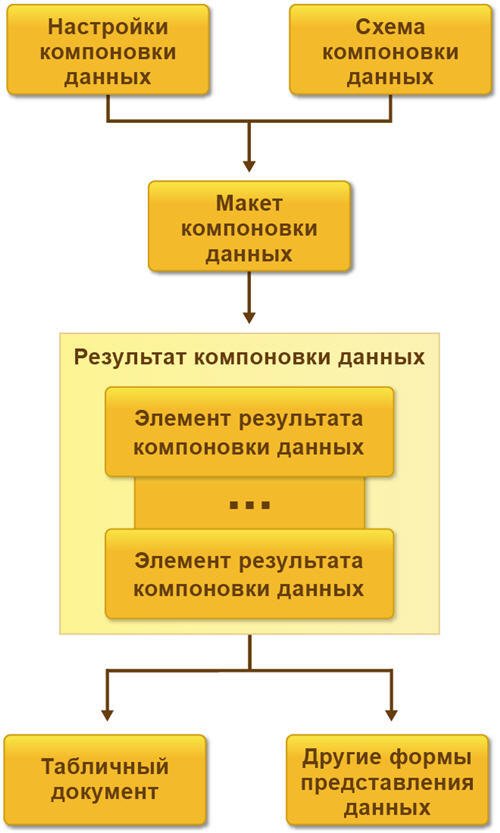
Схема компоновки данных
Схема компоновки данных описывает суть данных, которые предоставляются отчету (откуда получать данные и как можно управлять компоновкой данных). Представляет собой базу, на основе которой могут быть сформированы всевозможные отчеты. Схема компоновки данных может содержать:
- текст запроса с инструкциями системы компоновки данных;
- описание нескольких наборов данных;
- подробное описание доступных полей;
- описание связей между несколькими наборами данных;
- описание параметров получения данных;
- описание макетов полей и группировок;
- и др.
Настройки компоновки данных
Настройки компоновки данных описывают все, что может настроить разработчик или пользователь в некоторой установленной схеме компоновки данных. Настройки компоновки данных могут содержать:
- отбор;
- упорядочивание;
- условное оформление;
- структуру отчета (составные части будущего отчета);
- параметры получения данных;
- параметры вывода данных;
- и др.
Макет компоновки данных
Макет компоновки данных представляет собой уже готовое описание того, как должен быть сформирован отчет. В нем соединяется схема компоновки и настройки компоновки. Фактически макет компоновки данных представляет собой результат применения конкретных настроек к схеме компоновки и является готовым заданием процессору компоновки на формирование отчета нужной структуры с учетом конкретных настроек.
Элемент результата компоновки данных
Результат компоновки данных представляется набором элементов результата компоновки данных. Как самостоятельная логическая сущность результат компоновки данных не существует, существуют только его элементы. Элементы результата компоновки данных можно вывести в табличный документ для представления их пользователю, или в другие виды документов. Также имеется возможность программного вывода элементов результата компоновки в объекты вида Дерево значений или Таблица значений.
Работа с системой компоновки данных в конфигурации
Система компоновки данных интегрирована в объект конфигурации Отчет. Это позволяет создавать отчеты без программирования.
У объекта конфигурации Отчет реализовано свойство «Основная схема компоновки данных»:
При нажатии кнопки открытия для этого свойства, вызывается конструктор макета, который позволяет создать макет отчета, содержащий схему компоновки данных:
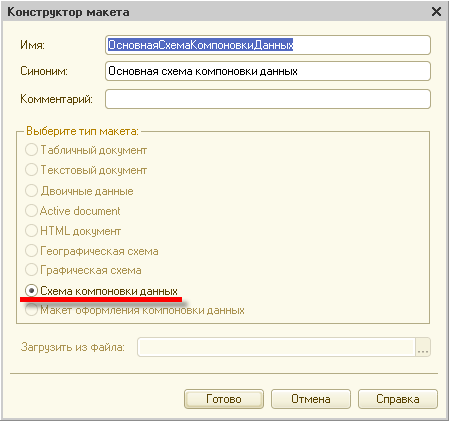
После нажатия кнопки «Готово» будет открыт конструктор схемы компоновки данных.
Конструктор схемы компоновки данных позволяет описать исходные данные, которые будет использовать отчет: наборы данных, связи между наборами данных, вычисляемые поля, ресурсы и т. д.
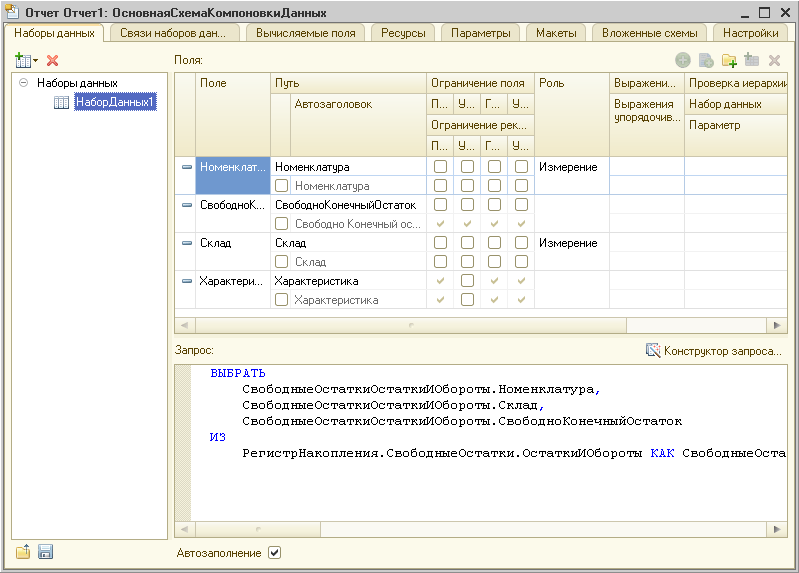
Также конструктор схемы компоновки данных предоставляет возможность описать настройки компоновки данных, которые будут использоваться по умолчанию (в том случае, если пользователь не задаст собственные настройки). Настройки компоновки данных могут быть созданы с помощью специального конструктора настроек компоновки данных, или вручную:
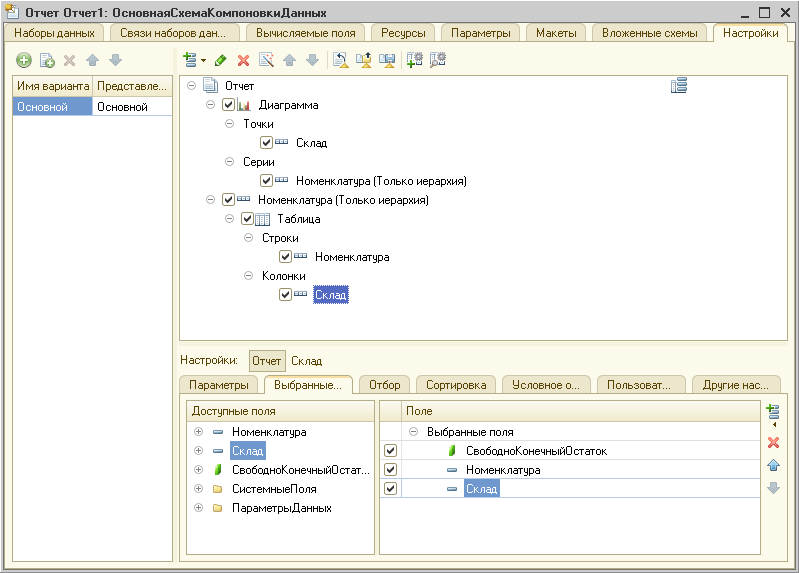
После выполнения этих действий отчет готов. В режиме 1С:Предприятие система автоматически, на основании схемы компоновки данных, содержащейся в отчете, может создать форму отчета и форму настроек отчета.
Таким образом пользователь просто запускает отчет и получает результат в соответствии с теми настройками, которые описал разработчик:
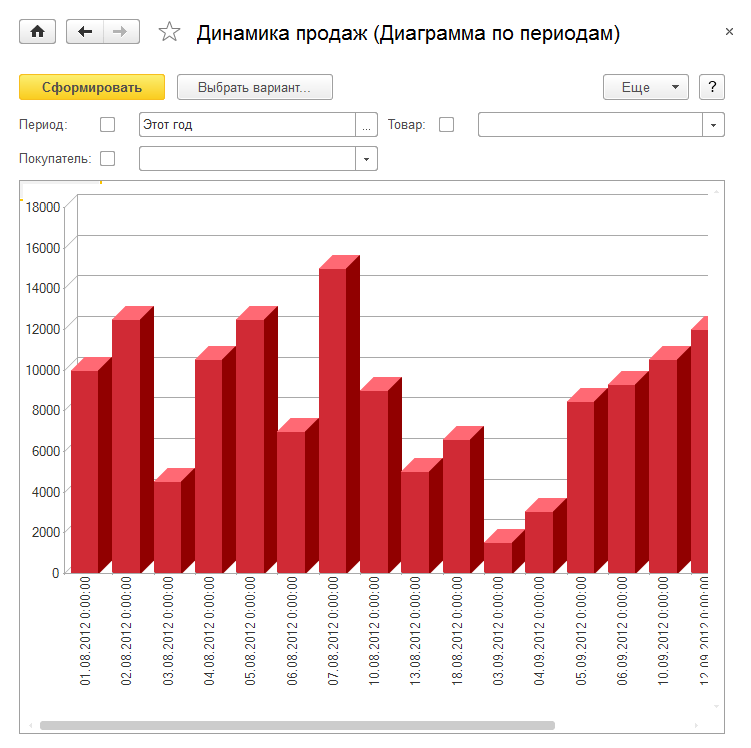
При необходимости пользователь может открыть форму настроек отчета и отредактировать их, изменить структуру отчета и т. д. аналогично тому, как это делает разработчик в режиме конфигуратора.
Консоль системы компоновки данных
Внешний отчет «Консоль системы компоновки данных» предназначен для специалистов, желающих подробнее узнать об устройстве системы компоновки данных. Консоль позволяет выполнять отдельные шаги компоновки данных с просмотром промежуточных результатов в виде XML. Подробнее…
David Drysdale, Beginner’s guide to linkers (http://www.lurklurk.org/linkers/linkers.html).
Цель данной статьи — помочь C и C++ программистам понять сущность того, чем занимается компоновщик. За последние несколько лет я объяснил это большому количеству коллег и наконец решил, что настало время перенести этот материал на бумагу, чтоб он стал более доступным (и чтоб мне не пришлось объяснять его снова). [Обновление в марте 2009: добавлена дополнительная информация об особенностях компоновки в Windows, а также более подробно расписано правило одного определения (one-definition rule).
Типичным примером того, почему ко мне обращались за помощью, служит следующая ошибка компоновки:
g++ -o test1 test1a.o test1b.o
test1a.o(.text+0x18): In function `main':
: undefined reference to `findmax(int, int)'
collect2: ld returned 1 exit status
Если Ваша реакция — ‘наверняка забыл extern «C»’, то Вы скорее всего знаете всё, что приведено в этой статье.
Содержание
- Определения: что находится в C файле?
- Что делает C компилятор
- Что делает компоновщик: часть 1
- Что делает операционная система
- Что делает компоновщик: часть 2
- C++ для дополнения картины
- Динамически загружаемые библиотеки
- Дополнительно
Определения: что находится в C файле?
Эта глава — краткое напоминание о различных составляющих C файла. Если всё в листинге, приведённом ниже, имеет для Вас смысл, то скорее всего Вы можете пропустить эту главу и сразу перейти к следующей.
Сперва надо понять разницу между объявлением и определением. Определение связывает имя с реализацией, что может быть либо кодом либо данными:
- Определение переменной побуждает компилятор зарезервировать некоторую область памяти, возможно задав ей некоторое определённое значение.
- Определение функции заставляет компилятор сгенерировать код для этой функции
Объявление говорит компилятору, что определение функции или переменной (с определённым именем) существует в другом месте программы, вероятно в другом C файле. (Заметьте, что определение также является объявлением — фактически это объявление, в котором «другое место» программы совпадает с текущим).
Для переменных существует определения двух видов:
- глобальные переменные, которые существуют на протяжении всего жизненного цикла программы («статическое размещение») и которые доступны в различных функциях;
- локальные переменные, которые существуют только в пределах некоторой исполняемой функции («локальное размещение») и которые доступны только внутри этой самой функции.
При этом под термином «доступны» следует понимать «можно обратиться по имени, ассоциированным с переменной в момент определения».
Существует пара частных случаев, которые с первого раза не кажутся очевидными:
- статичные (
static) локальные переменные на самом деле являются глобальными, потому что существуют на протяжении всей жизни программы, даже если они видимы только в пределах одной функции. - статичные глобальные переменные также являются глобальными с той лишь разницей, что они доступны только в пределах одного файла, где они определены.
Стоит отметить, что, определяя функцию статичной, просто сокращается количество мест, из которых можно обратиться к данной функции по имени.
Для глобальных и локальных переменных, мы можем различать инициализирована переменная или нет, т.е. будет ли пространство, отведённое для переменной в памяти, заполнено определённым значением.
И наконец, мы можем сохранять информацию в памяти, которая динамически выделена посредством malloc или new. В данном случае нет возможности обратиться к выделенной памяти по имени, поэтому необходимо использовать указатели — именованные переменные, содержащие адрес неименованной области памяти. Эта область памяти может быть также освобождена с помощью free или delete. В этом случае мы имеем дело с «динамическим размещением».
Подытожим:
| Код | Данные | |||||
| Глобальные | Локальные | Динамические | ||||
| Инициа- лизиро- ванные |
Неинициа- лизиро- ванные |
Инициа- лизиро- ванные |
Неинициа- лизиро- ванные |
|||
| Объяв- ление |
int fn(int x); |
extern int x; |
extern int x; |
N/A | N/A | N/A |
| Опреде- ление |
int fn(int x) { ... } |
int x = 1;(область действия — файл) |
int x;(область действия — файл) |
int x = 1;(область действия — функция) |
int x;(область действия — функция) |
int* p = malloc(sizeof(int)); |
Вероятно более лёгкий путь усвоить — это просто посмотреть на пример программы.
/* Определение неинициализированной глобальной переменной */
int x_global_uninit;
/* Определение инициализированной глобальной переменной */
int x_global_init = 1;
/* Определение неинициализированной глобальной переменной, к которой
* можно обратиться по имени только в пределах этого C файла */
static int y_global_uninit;
/* Определение инициализированной глобальной переменной, к которой
* можно обратиться по имени только в пределах этого C файла */
static int y_global_init = 2;
/* Объявление глобальной переменной, которая определена где-нибудь
* в другом месте программы */
extern int z_global;
/* Объявлени функции, которая определена где-нибудь другом месте
* программы (Вы можете добавить впереди "extern", однако это
* необязательно) */
int fn_a(int x, int y);
/* Определение функции. Однако будучи помеченной как static, её можно
* вызвать по имени только в пределах этого C файла. */
static int fn_b(int x)
{
return x+1;
}
/* Определение функции. */
/* Параметр функции считается локальной переменной. */
int fn_c(int x_local)
{
/* Определение неинициализированной локальной переменной */
int y_local_uninit;
/* Определение инициализированной локальной переменной */
int y_local_init = 3;
/* Код, который обращается к локальным и глобальным переменным,
* а также функциям по имени */
x_global_uninit = fn_a(x_local, x_global_init);
y_local_uninit = fn_a(x_local, y_local_init);
y_local_uninit += fn_b(z_global);
return (x_global_uninit + y_local_uninit);
}
Что делает C компилятор
Работа компилятора C заключается в конвертировании текста, (обычно) понятного человеку, в нечто, что понимает компьютер. На выходе компилятор выдаёт объектный файл. На платформах UNIX эти файлы имеют обычно суффикс .o; в Windows — суффикс .obj. Содержание объектного файла — в сущности две вещи:
- код, соответствующий определению функции в C файле
- данные, соответствующие определению глобальных переменных в C файле (для инициализированных глобальных переменных начальное значение переменной тоже должно быть сохранено в объектном файле).
Код и данные, в данном случае, будут иметь ассоциированные с ними имена — имена функций или переменных, с которыми они связаны определением.
Объектный код — это последовательность (подходящим образом составленных) машинных инструкций, которые соответствуют C инструкциям, написанных программистом: все эти if‘ы и while‘ы и даже goto. Эти заклинания должны манипулировать информацией определённого рода, а информация должна быть где-нибудь находится — для этого нам и нужны переменные. Код может также ссылаться на другой код (в частности на другие C функции в программе).
Где бы код ни ссылался на переменную или функцию, компилятор допускает это, только если он видел раньше объявление этой переменной или функции. Объявление — это обещание, что определение существует где-то в другом месте программы.
Работа компоновщика проверить эти обещания. Однако, что компилятор делает со всеми этими обещаниями, когда он генерирует объектный файл?
По существу компилятор оставляет пустые места. Пустое место (ссылка) имеет имя, но значение соответствующее этому имени пока не известно.
Учитывая это, мы можем изобразить объектный файл, соответствующей программе, приведённой выше, следующим образом:
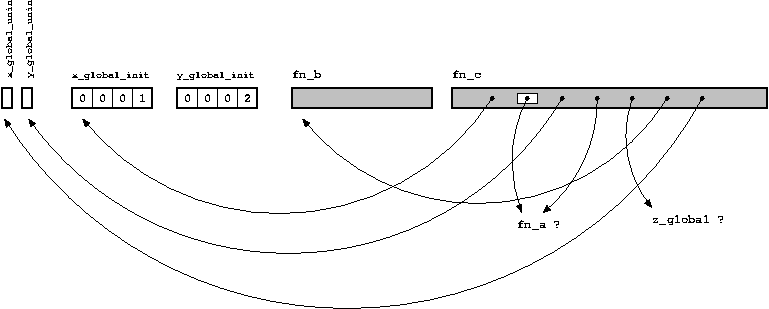
Анализирование объектного файла
До сих пор мы рассматривали всё на высоком уровне. Однако полезно посмотреть, как это работает на практике. Основным инструментом для нас будет команда nm, которая выдаёт информацию о символах объектного файла на платформе UNIX. Для Windows команда dumpbin с опцией /symbols является приблизительным эквивалентом. Также есть портированные под Windows инструменты GNU binutils, которые включают nm.exe.
Давайте посмотрим, что выдаёт nm для объектного файла, полученного из нашего примера выше:
Symbols from c_parts.o:
Name Value Class Type Size Line Section
fn_a | | U | NOTYPE| | |*UND*
z_global | | U | NOTYPE| | |*UND*
fn_b |00000000| t | FUNC|00000009| |.text
x_global_init |00000000| D | OBJECT|00000004| |.data
y_global_uninit |00000000| b | OBJECT|00000004| |.bss
x_global_uninit |00000004| C | OBJECT|00000004| |*COM*
y_global_init |00000004| d | OBJECT|00000004| |.data
fn_c |00000009| T | FUNC|00000055| |.text
Результат может выглядеть немного по разному на разных платформах (обратитесь к man‘ам, чтобы получить соответствующую информацию), но ключевыми сведениями являются класс каждого символа и его размер (если присутствует). Класс может иметь различны значения:
- Класс U обозначает неопределённые ссылки, те самые «пустые места», упомянутые выше. Для этого класса существует два объекта:
fn_aиz_global. (Некоторые версииnmмогут выводить секцию, которая была бы*UND*илиUNDEFв этом случае.) - Классы t и T указывают на код, который определён; различие между t и T заключается в том, является ли функция локальной (t) в файле или нет (T), т.е. была ли функция объявлена как
static. Опять же в некоторых системах может быть показана секция, например.text. - Классы d и D содержат инициализированные глобальные переменные. При этом статичные переменные принадлежат классу d. Если присутствует информация о секции, то это будет .data.
- Для неинициализированных глобальных переменных, мы получаем b, если они статичные и B или C иначе. Секцией в этом случае будет скорее всего .bss или *COM*.
Также можно увидеть символы, которые не являются частью исходного C кода. Мы не будем заострять наше внимание на этом, так как это обычно часть внутреннего механизма компилятора, для того чтобы Ваша программа всё-таки смогла быть потом скомпонована.
Что делает компоновщик: часть 1
Ранее мы обмолвились, что объявление функции или переменной — это обещание компилятору, что где-то в другом месте программы есть определение этой функции или переменной, и что работа компоновщика заключается в осуществлении этого обещания. Глядя на диаграмму объектного файла, мы можем описать этот процесс, как «заполнение пустых мест».
Проиллюстрируем это на примере, рассматривая ещё один C файл в дополнение к тому, что был приведён выше.
/* Инициализированная глобальная переменная */
int z_global = 11;
/* Вторая глобальная переменная с именем y_global_init, но они обе static */
static int y_global_init = 2;
/* Объявление другой глобальной переменной */
extern int x_global_init;
int fn_a(int x, int y)
{
return(x+y);
}
int main(int argc, char *argv)
{
const char *message = "Hello, world";
return fn_a(11,12);
}
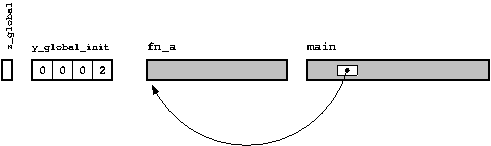
Исходя из обоих диаграмм, мы можем видеть, что все точки могут быть соединены (если нет, то компоновщик выдал бы сообщение об ошибке). Каждая вещь имеет своё место, и каждое место имеет свою вещь. Также компоновщик может заполнить все пустые места как показано здесь (на системах UNIX процесс компоновки обычно вызывается командой ld).

Также как и для объектных файлов, мы можем использовать nm для исследования конечного исполняемого файла.
Symbols from sample1.exe:
Name Value Class Type Size Line Section
_Jv_RegisterClasses | | w | NOTYPE| | |*UND*
__gmon_start__ | | w | NOTYPE| | |*UND*
__libc_start_main@@GLIBC_2.0 | U | FUNC|000001ad| |*UND*
_init |08048254| T | FUNC| | |.init
_start |080482c0| T | FUNC| | |.text
__do_global_dtors_aux|080482f0| t | FUNC| | |.text
frame_dummy |08048320| t | FUNC| | |.text
fn_b |08048348| t | FUNC|00000009| |.text
fn_c |08048351| T | FUNC|00000055| |.text
fn_a |080483a8| T | FUNC|0000000b| |.text
main |080483b3| T | FUNC|0000002c| |.text
__libc_csu_fini |080483e0| T | FUNC|00000005| |.text
__libc_csu_init |080483f0| T | FUNC|00000055| |.text
__do_global_ctors_aux|08048450| t | FUNC| | |.text
_fini |08048478| T | FUNC| | |.fini
_fp_hw |08048494| R | OBJECT|00000004| |.rodata
_IO_stdin_used |08048498| R | OBJECT|00000004| |.rodata
__FRAME_END__ |080484ac| r | OBJECT| | |.eh_frame
__CTOR_LIST__ |080494b0| d | OBJECT| | |.ctors
__init_array_end |080494b0| d | NOTYPE| | |.ctors
__init_array_start |080494b0| d | NOTYPE| | |.ctors
__CTOR_END__ |080494b4| d | OBJECT| | |.ctors
__DTOR_LIST__ |080494b8| d | OBJECT| | |.dtors
__DTOR_END__ |080494bc| d | OBJECT| | |.dtors
__JCR_END__ |080494c0| d | OBJECT| | |.jcr
__JCR_LIST__ |080494c0| d | OBJECT| | |.jcr
_DYNAMIC |080494c4| d | OBJECT| | |.dynamic
_GLOBAL_OFFSET_TABLE_|08049598| d | OBJECT| | |.got.plt
__data_start |080495ac| D | NOTYPE| | |.data
data_start |080495ac| W | NOTYPE| | |.data
__dso_handle |080495b0| D | OBJECT| | |.data
p.5826 |080495b4| d | OBJECT| | |.data
x_global_init |080495b8| D | OBJECT|00000004| |.data
y_global_init |080495bc| d | OBJECT|00000004| |.data
z_global |080495c0| D | OBJECT|00000004| |.data
y_global_init |080495c4| d | OBJECT|00000004| |.data
__bss_start |080495c8| A | NOTYPE| | |*ABS*
_edata |080495c8| A | NOTYPE| | |*ABS*
completed.5828 |080495c8| b | OBJECT|00000001| |.bss
y_global_uninit |080495cc| b | OBJECT|00000004| |.bss
x_global_uninit |080495d0| B | OBJECT|00000004| |.bss
_end |080495d4| A | NOTYPE| | |*ABS*
Он содержит символы обоих объектных файлов и все неопределённые ссылки исчезли. Символы переупорядочены так, что похожие типы находятся вместе. А также существует немного дополнений, чтобы помочь ОС иметь дело с такой штукой, как исполняемый файл.
Существует достаточное количество сложных деталей, загромождающих вывод, но если вы выкинете всё, что начинается с подчёркивания, то станет намного проще.
Повторяющиеся символы
В предыдущей главе было упомянуто, что компоновщик выдаёт сообщение об ошибке, если не может найти определение для символа, на который найдена ссылка. А что случится, если найдено два определения для символа во время компоновки?
В C++ решение прямолинейное. Язык имеет ограничение, известное как правило одного определения, которое гласит, что должно быть только одно определение для каждого символа, встречающегося во время компоновки, ни больше, ни меньше. (Соответствующей главой стандарта C++ является 3.2, которая также упоминает некоторые исключения, которые мы рассмотрим несколько позже.)
Для C положение вещей менее очевидно. Должно быть точно одно определение для любой функции и инициализированной глобальной переменной, но определение неинициализированной переменной может быть трактовано как предварительное определение. Язык C таким образом разрешает (или по крайней мере не запрещает) различным исходным файлам содержать предварительное определение одного и того же объекта.
Однако, компоновщики должны уметь обходится также и с другими языками кроме C и C++, для которых правило одного определения не обязательно соблюдается. Например, для Fortran’а является нормальным иметь копию каждой глобальной переменной в каждом файле, который на неё ссылается. Компоновщику необходимо тогда убрать дубликаты, выбрав одну копию (самого большого представителя, если они отличаются в размере) и выбросить все остальные. Эта модель иногда называется «общей моделью» компоновки из-за ключевого слова COMMON (общий) языка Fortran.
Как результат, вполне распространённо для UNIX компоновщиков не ругаться на наличие повторяющихся символов, по крайней мере, если это повторяющиеся символы неинициализированных глобальных переменных (эта модель компоновки иногда называется «моделью с ослабленной связью» [прим. перев. это мой вольный перевод relaxed ref/def model. Более удачные предложения приветствуются]). Если это Вас волнует (вероятно и должно волновать), обратитесь к документации Вашего компоновщика, чтобы найти опцию --работай-правильно, которая усмиряет его поведение. Например, в GNU тулчейне опция компилятора -fno-common заставляет поместить неинициализированную переменную в сегмент BBS вместо генерирования общих (COMMON) блоков.
Что делает операционная система
Теперь, когда компоновщик произвёл исполняемый файл, присвоив каждой ссылке на символ подходящее определение, можно сделать короткую паузу, чтобы понять, что делает операционная система, когда Вы запускаете программу на выполнение.
Запуск программы разумеется влечёт за собой выполнение машинного кода, т.е. ОС очевидно должна перенести машинный код исполняемого файла с жёстокого диска в операционную память, откуда CPU сможет его забрать. Эти порции называются сегментом кода (code segment или text segment).
Код без данных сам по себе бесполезен. Следовательно всем глобальным переменным тоже необходимо место в памяти компьютера. Однако, существует разница между инициализированными и неинициализированными глобальными переменными. Инициализированные переменные имеют определённые стартовые значения, которые тоже должны храниться в объектных и исполняемом файлах. Когда программа запускается на старт, ОС копирует эти значения в виртуальное пространство программы, в сегмент данных.
Для неинициализированных переменных ОС может предположить, что они все имеют 0 в качестве начального значения, т.е. нет надобности копировать какие-либо значения. Кусок памяти, который инициализируется нулями, известен как bss сегмент.
Это означает, что место под глобальные переменные может быть отведено в выполняемом файле, хранящемся на диске; для инициализированных переменных должны быть сохранены их начальные значения, но для неинициализированных нужно только сохранить их размер.
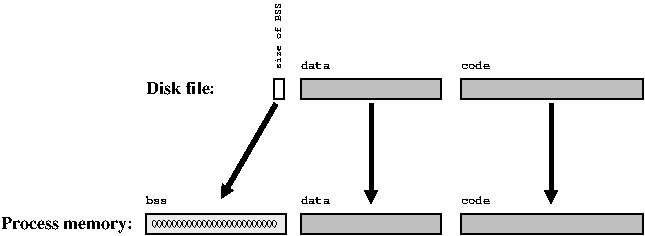
Как Вы могли заметить, до сих пор во всех рассуждениях об объектных файлах и компоновщике речь заходила только о глобальных переменных; при этом мы не упоминались локальные переменные и динамически занимаемая память, упомянутые раньше.
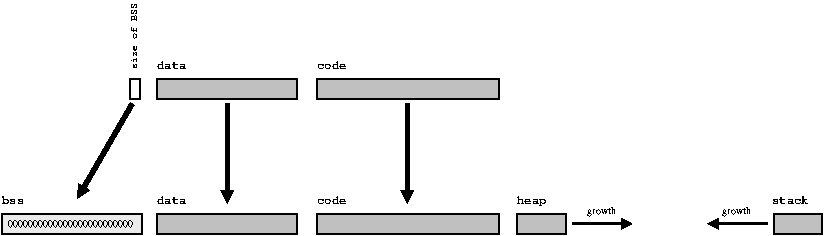
Эти данные не нуждаются во вмешательстве компоновщика, потому что время их жизни начинается и заканчивается во время исполнения программы — гораздо позже того, как компоновщик уже сделал своё дело. Однако, для полноты описания, мы коротко укажем, что:
- локальные переменные располагаются в области памяти, называемым стеком, который растёт и сужается по мере вызова и выполнения различных функций.
- динамически выделяемая память берётся из области памяти, известной как куча, и функция malloc контролирует доступ к свободному пространству в этой области.
Для полноты картины стоит добавить, как выглядит пространство памяти выполняемого процесса. Так как куча и стек могут изменять свои размеры динамически, вполне распространенным является факт, что стек растёт в одном направлении, а куча обратном. Таким образом, программа выдаст ошибку отсутствия свободной памяти, только если стек и куча встретятся где-нибудь в середине (в этом случае пространство памяти программы будет действительно заполнено).
Что делает компоновщик; часть 2
Теперь, после того как мы рассмотрели основы основ того, что делает компоновщик, мы можем погрузиться в описание более сложных деталей — примерно в том хронологическом порядке, как они были добавлены к компоновщику.
Главное наблюдение, которое затрагивает функции компоновщика следующее: если ряд различных программ делают примерно одни и те же вещи (вывод на экран, чтение файлов с жёсткого диска и т.д.), тогда очевидно имеет смысл обособить этот код в определённом месте и дать другим программам его использовать.
Одним из возможных решений было бы использование одних и тех же объектных файлов, однако было бы гораздо удобнее держать всю коллекцию… объектных файлов в одном легко доступном месте: библиотеке.
Техническое отступление: Эта глава полностью опускает важное свойство компоновщика: переадресация (relocation). Разные программы имеют различные размеры, т.е. если разделяемая библиотека отображается в адресное пространство различных программ, она будет иметь различные адреса. Это в свою очередь означает, что все функции и переменные в библиотеке будут на различных местах. Теперь, если все обращения к адресам относительные («значение +1020 байта отсюда») нежели абсолютные («значение в 0x102218BF»), то это не проблема, однако так бывает не всегда. В таких случаях всем абсолютным адресам необходимо прибавить подходящий офсет — это и есть relocation. Я не собираюсь возвращается к этой теме снова, однако добавлю, что так как это практически всегда скрыто от C/C++ программиста — очень редко проблемы компоновки вызваны трудностями переадресации.
Статические библиотеки
Самое простое воплощение библиотеки — это статическая библиотека. В предыдущей главе было упомянуто, что можно разделять (share), код просто повторно используя объектные файлы; это и есть суть статичных библиотек.
В системах UNIX командой для сборки статичной библиотеки обычно является ar, и библиотечный файл, который при этом получается, имеет расширение *.a. Также эти файлы обычно имеют префикс «lib» в своём названии и они передаются компоновщику с опцией «-l» с последующим именем библиотеки без префикса и расширения (т.е. «-lfred» подхватит файл «libfred.a»).
(Раньше программа, называемая ranlib, также была нужна для статических библиотек, чтобы сгенерировать список символов вначале библиотеки. В наши дни инструменты ar делают это сами.)
В системе Windows статические библиотеки имеют расширение .LIB и собираются инструментами LIB, однако этот факт может ввести в заблуждение, так как такое же расширение используется и для «import library», которая содержит в себе только список того, что имеется в DLL — смотрите главу о Windows DLL
По мере того как компоновщик перебирает коллекцию объектных файлов, чтобы объединить их вместе, он ведёт список символов, которые не могут быть пока реализованы. Как только все явно указанные объектные файлы обработаны, у компоновщика теперь есть новое место для поиска символов, которые остались в списке — в библиотеке. Если нереализованный символ определён в одном из объектов библиотеки, тогда объект добавляется, точно также как если бы он был бы добавлен в список объектных файлов пользователем, и компоновка продолжается.
Обратите внимание на гранулярность того, что добавляется из библиотеки: если необходимо определение некоторого символа, тогда весь объект, содержащий определение символа, будет включён. Это означает, что этот процесс может быть как шагом вперёд, так и шагом назад — свеже добавленный объект может как и разрешить неопределённую ссылку, так и привнести целую коллекцию новых неразрешённых ссылок.
Другая важная деталь — это порядок событий; библиотеки привлекаются только, когда нормальная компоновка завершена, и они обрабатываются в порядке слева на право. Это значит, что если объект, извлекаемый из библиотеки в последнюю очередь, требует наличие символа из библиотеки, стоящей раньше в строке команды компоновки, то компоновщик не найдёт его автоматически.
Приведём пример, чтоб прояснить ситуацию; предположим у нас есть следующие объектные файлы и строка команды компоновки, которая содержит a.o, b.o, -lx и -ly.
| Файл | a.o |
b.o |
libx.a |
liby.a |
||||
| Объект | a.o |
b.o |
x1.o |
x2.o |
x3.o |
y1.o |
y2.o |
y3.o |
| Опредe- ления |
a1, a2, a3 |
b1, b2 |
x11, x12, x13 |
x21, x22, x23 |
x31, x32 |
y11, y12 |
y21, y22 |
y31, y32 |
| Неразре- шённые ссылки |
b2, x12 |
a3, y22 |
x23, y12 |
y11 |
y21 |
x31 |
Как только компоновщик обработал a.o и b.o, ссылки на b2 и a3 будут разрешены, в то время как x12 и y22 будут всё ещё неразрешёнными. В этот момент компоновщик проверяет первую библиотеку libx.a на наличие недостающих символов и находит, что он может включить x1.o, чтобы компенсировать ссылку на x12; однако делая это, x23 и y12 добавляются в список неопределённых ссылок (теперь список выглядит как y22, x23, y12).
Компоновщик всё ещё имеет дело с libx.a, поэтому ссылка на x23 легко компенсируется, включая x2.o из libx.a. Однако это добавляет y11 к списку неопределённых (который стал y22, y12, y11). Ни одна из этих ссылок не может быть разрешена использованием libx.a, таким образом компоновщик принимается за liby.a.
Здесь происходит примерно тоже самое и компоновщик включает y1.o и y2.o. Первым объектом добавляется ссылка на y21, но так как y2.o всё равно будет включено, эта ссылка разрешается просто. Результатом этого процесса является то, что все неопределённые ссылки разрешены, и некоторые (но не все) объекты библиотек включены в конечный исполняемый файл.
Заметьте, что ситуация несколько изменяется, если скажем b.o тоже имел бы ссылку на y32. Если это было бы так, то компоновка libx.a происходила бы также, но обработка liby.a повлекла бы включение y3.o. Включением этого объекта мы добавим x31 к списку неразрешённых символов и эта ссылка останется неразрешённой — на этой стадии компоновщик уже завершил обработку libx.a и поэтому уже не найдёт определение этого символа (в x3.o).
(Между прочим этот пример имеет циклическую зависимость между библиотеками libx.a и liby.a; обычно это плохо особенно под Windows)
Динамические разделяемые библиотеки
Для популярных библиотек таких как стандартная библиотека C (обычно libc) быть статичной библиотекой имеет явный недостаток — каждая исполняемая программа будет иметь копию одного и того же кода. Действительно, если каждый исполняемый файл будет иметь копию printf, fopen и тому подобных, то будет занято неоправданно много дискового пространства.
Менее очевидный недостаток это то, что в статически скомпонованной программе код фиксируется навсегда. Если кто-нибудь найдёт и исправит баг в printf, то каждая программа должна будет скомпонована заново, чтобы заполучить исправленный код.
Чтоб избавиться от этих и других проблем, были представлены динамически разделяемые библиотеки (обычно они имеют расширение .so или .dll в Windows и .dylib в Mac OS X). Для этого типа библиотек компоновщик не обязательно соединяет все точки. Вместо этого компоновщик выдаёт купон типа «IOU» (I owe you = я тебе должен) и откладывает обналичивание этого купона до момента запуска программы.
Всё это сводится к тому, что если компоновщик обнаруживает, что определение конкретного символа находится в разделяемой библиотеке, то он не включает это определение в конечный исполняемый файл. Вместо этого компоновщик записывает имя символа и библиотеки, откуда этот символ должен предположительно появится.
Когда программа вызывается на исполнение, ОС заботится о том, чтобы оставшиеся части процесса компоновки были выполнены вовремя до начала работы программы. Прежде чем будет вызвана функция main, малая версия компоновщика (часто называемая ld.so) проходится по списку обещания и выполняет последний акт компоновки прямо на месте — помещает код библиотеки и соединяет все точки.
Это значит, что ни один выполняемый файл не содержит копии кода printf. Если новая версия printf будет доступна, то её можно использовать просто изменив libc.so — при следующем запуске программы вызовется новая printf.
Существует другое большое отличие между тем, как динамические библиотеки работают по сравнению со статическими и это проявляется в гранулярности компоновки. Если конкретный символ берётся из конкретной динамической библиотеки (скажем printf из libc.so), то всё содержимое библиотеки помещается в адресное пространство программы. Это основное отличие от статических библиотек, где добавляются только конкретные объекты, относящиеся к неопределённому символу.
Сформулируем иначе, разделяемые библиотеки сами получаются как результат работы компоновщика (а не как формирование большой кучи объектов, как это делает ar), содержащий ссылки между объектами в самой библиотеке. Повторю ещё, nm — полезный инструмент для иллюстрации происходящего: для приведённого выше примера он выдаст множество исходов для каждого объектного файла в отдельности, если этот инструмент запустить на статической версии библиотеки, но для разделяемой версии библиотеки liby.so имеет только один неопределённый символ x31. Также в примере с порядком включения библиотек в конце предыдущей главы тоже никаких проблем не будет: добавление ссылки на y32 в b.c не повлечёт никаких изменений, так как всё содержимое y3.o и x3.o уже было задействовано.
Так между прочим, другой полезный инструмент — это ldd; на платформе Unix он показывает все разделяемые библиотеки, от которых зависит исполняемый бинарник (или же другая разделяемая библиотека), вместе с указанием, где эти библиотеки можно найти. Для того чтобы программа удачно запустилась, загрузчику необходимо найти все эти библиотеки вместе со всеми их зависимостями. (Обычно загрузчик ищет библиотеки в списке директорий, указанных в переменной окружения LD_LIBRARY_PATH.)
/usr/bin:ldd xeyes
linux-gate.so.1 => (0xb7efa000)
libXext.so.6 => /usr/lib/libXext.so.6 (0xb7edb000)
libXmu.so.6 => /usr/lib/libXmu.so.6 (0xb7ec6000)
libXt.so.6 => /usr/lib/libXt.so.6 (0xb7e77000)
libX11.so.6 => /usr/lib/libX11.so.6 (0xb7d93000)
libSM.so.6 => /usr/lib/libSM.so.6 (0xb7d8b000)
libICE.so.6 => /usr/lib/libICE.so.6 (0xb7d74000)
libm.so.6 => /lib/libm.so.6 (0xb7d4e000)
libc.so.6 => /lib/libc.so.6 (0xb7c05000)
libXau.so.6 => /usr/lib/libXau.so.6 (0xb7c01000)
libxcb-xlib.so.0 => /usr/lib/libxcb-xlib.so.0 (0xb7bff000)
libxcb.so.1 => /usr/lib/libxcb.so.1 (0xb7be8000)
libdl.so.2 => /lib/libdl.so.2 (0xb7be4000)
/lib/ld-linux.so.2 (0xb7efb000)
libXdmcp.so.6 => /usr/lib/libXdmcp.so.6 (0xb7bdf000)
Причина большей гранулярности заключается в том, что современные операционные системы достаточно интеллигентны, чтобы позволить делать больше, чем просто сэкономить сохранение повторяющихся элементов на диске, чем страдают статические библиотеки. Различные исполняемые процессы, которые используют одну и туже разделяемую библиотеку, также могут совместно использовать сегмент кода (но не сегмент данных или сегмент bss — например, два различных процесса могут находится в различных местах при использовании, скажем, strtok). Чтобы этого достичь, вся библиотека должна быть адресована одним махом, чтобы все внутренние ссылки были выстроены однозначным образом. Действительно, если один процесс подхватывает a.o и c.o, а другой b.o и c.o, то ОС не сможет использовать никаких совпадений.
Windows DLL
Несмотря на то, что общие принципы разделяемых библиотек примерно одинаковы как на платформах Unix, так и на Windows, всё же есть несколько деталей, на которые могут подловиться новички.
Экспортируемые символы
Самое большое отличие заключается в том, что в библиотеках Windows символы не экспортируются автоматически. В Unix все символы всех объектных файлов, которые были подлинкованы к разделяемой библиотеке, видны пользователю этой библиотеки. В Windows, программист должен явно делать некоторые символы видимыми, т.е. экспортировать их.
Есть три способа как экспортировать символ и Windows DLL (и все эти три способа можно перемешивать в одной и той же библиотеке).
- В исходном коде объявить символ как
__declspec(dllexport), примерно так:__declspec(dllexport) int my_exported_function(int x, double y) - При выполнении команды компоновщика использовать опцию
LINK.EXEexport:symbol_to_exportLINK.EXE /dll /export:my_exported_function - Скормить компоновщику файл определения модуля (DEF) (используя опцию
/DEF:def_file), включив в этот файл секциюEXPORT, которая содержит символы, подлежащие экспортированию.EXPORTS my_exported_function my_other_exported_function
Как только к этой мешанине подключается C++, первая из этих опций становится самой простой, так как в этом случае компилятор берёт на себя обязательства позаботиться о декорировании имён
.LIB и другие относящиеся к библиотеке файлы
Мы подошли ко второй трудности, связанной с библиотеками Windows: информация об экспортируемых символах, которые компоновщик должен связать с остальными символам, не содержится в самом DLL. Вместо этого данная информация содержится в соответствующем .LIB файле.
.LIB файл, ассоциированный с DLL описывает какие (экспортируемые) символы находятся в DLL вместе с их расположением. Любой бинарник, который использует DLL, должен обращаться к .LIB файлу, чтобы связать символы корректно.
Чтобы сделать всё ещё более запутанным, расширение .LIB также используется для статических библиотек.
На самом деле существует целый ряд различных файлов, которые могут относиться каким-либо образом к библиотекам Windows. Наряду с .LIB файлом, а также (опциональным) .DEF файлом Вы можете увидеть все нижеперечисленные файлы, ассоциированные с Вашей Windows библиотекой.
- Файлы на выходе компоновки
- library
.DLL: собственно код библиотеки; этот файл нужен (во время исполнения) любому бинарнику, использующему библиотеку. - library
.LIB: файл «импортирования библиотеки», который описывает где и какой символ находится в результирующейDLL. Этот файл генерируется, если толькоDLLэкспортирует некоторые её символы. Если символы не экспортируются, то смысла в.LIBфайле нет. Этот файл нужен во время компоновки. - library
.EXP: «Экспорт файл» компилируемой библиотеки, который нужен если имеет место компоновка бинарников с циклической зависимостью. - library
.ILK: Если опция/INCREMENTALбыла применена во время компоновки, которая активирует инкрементную компоновку, то этот файл содержит в себе статус инкрементной компоновки. Он нужен для будущих инкрементных компоновок с этой библиотекой. - library
.PDB: Если опция/DEBUGбыла применена во время компоновки, то этот файл является программной базой данных, содержащей отладочную информацию для библиотеки. - library
.MAP: Если опция/MAPбыла применена во время компоновки, то этот файл содержит описание внутреннего формата библиотеки.
- library
- Файлы на входе компоновки:
- library
.LIB: Файл «импорта библиотеки», которые описывает где и какие символы находятся в другихDLL, которые нужны для компоновки. - library
.LIB: Статическая библиотека, которая содержит коллекцию объектов, необходимых при компоновке. Обратите внимание на неоднозначное использование расширения.LIB - library
.DEF: Файл «определений», который позволяет управлять различными деталями скомпонованной библиотеки, включая экспорт символов. - library
.EXP: Файл экспорта компонуемой библиотеки, который может сигнализировать, что предыдущее выполнениеLIB.EXEуже создало файл.LIBдля библиотеки. Имеет значение при компоновке бинарников с циклическими зависимостями. - library
.ILK: Файл состояния инкрементной компоновки; см. выше. - library
.RES: Файл ресурсов, который содержит информацию о различных GUI виджетах, используемых исполняемым файлом. Эти ресурсы включаются в конечный бинарник.
- library
Это является большим отличием к Unix, где почти вся информация, содержащаяся в этих всех дополнительных файлах, просто добавляется в саму библиотеку.
Импортируемые символы
Вместе с требованием к DLL явно объявлять экспортируемые символы, Windows также разрешает бинарникам, которые используют код библиотеки, явно объявлять символы, подлежащие импортированию. Это не является обязательным, но даёт некоторую оптимизацию по скорости, вызванную историческими свойствами 16-ти битных окон.
Для этого объявляем символ как __declspec(dllimport) в исходном коде примерно так:
__declspec(dllimport) int function_from_some_dll(int x, double y);
__declspec(dllimport) extern int global_var_from_some_dll;
При этом индивидуальное объявление функций или глобальных переменных в одном заголовочном файле является хорошим тоном программирования на C. Это приводит к некоторому ребусу: код в DLL, содержащий определение функции/переменной должен экспортировать символ, но любой другой код, использующий DLL, должен импортировать символ.
Стандартный выход из этой ситуации — это использование макросов препроцессора.
#ifdef EXPORTING_XYZ_DLL_SYMS
#define XYZ_LINKAGE __declspec(dllexport)
#else
#define XYZ_LINKAGE __declspec(dllimport)
#endif
XYZ_LINKAGE int xyz_exported_function(int x);
XYZ_LINKAGE extern int xyz_exported_variable;
Файл с исходниками в DLL, который определяет функцию и переменную гарантирует, что переменная препроцессора EXPORTING_XYZ_DLL_SYMS определена (по средством #define) до включения соответствующего заголовочного файла и таким образом экспортирует символ. Любой другой код, который включает этот заголовочный файл не определяет этот символ и таким образом импортирует его.
Циклические зависимости
Ещё одной трудностью, связанной с использованием DLL, является тот факт, что Windows относится строже к требованию, что каждый символ должен быть разрешён во время компоновки. В Unix вполне возможно скомпоновать разделяемую библиотеку, которая содержит неразрешённые символы, т.е. символы, определение которых неведомо компоновщику В этой ситуации любой другой код, использующий эту разделяемую библиотеку, должен будет предоставить определение незразрешённых символов, иначе программа не будет запущена. Windows не допускает такой распущенности.
Для большинства систем — это не проблема. Выполняемые файлы зависят от высокоуровевых библиотек, высокоуровневые библиотеки зависят от библиотек низкого уровня, и всё компонуется в обратном порядке — сначала библиотеки низкого уровня, потом высокого, а затем и выполняемый файл, который зависит от всех остальных
Однако, если имеет место циклическая зависимость между бинарниками, тогда всё немного усложняется. Если X.DLL нуждается в символе из Y.DLL, а Y.DLL нуждается в символе из X.DLL, тогда необходимо решить задачу про курицу и яйцо: какая бы библиотека ни компоновалась бы первой, она не сможет найти разрешение ко всем символам.
Windows предоставил обходной приём примерно следующего содержания.
- Сначала имитируем компоновку библиотеки X. Запускаем
LIB.EXE(неLINK.EXE), чтобы получить файлX.LIBточно такой же, какой был бы получен сLINK.EXE. При этомX.DLLне будет сгенерирован, но вместо него будет получен файлX.EXP. - Компонуем библиотеку
Yкак обычно, используяX.LIB, полученную на предыдущем шаге, и получаем на выходе какY.DLLтак иY.LIB. - В конце концов компонуем библиотеку
Xтеперь уже полноценно. Это происходит почти как обычно, используя дополнительно файлX.EXP, полученный на первом шаге. Обычное в этом шаге то, что компоновщик используетY.LIBи производитX.DLL. Необычное — компоновщик пропускает шаг созданияX.LIB, так как этот файл был уже создан на первом шаге, чему свидетельствует наличие.EXPфайла.
Но несомненно лучше всё же реорганизовать библиотеки таким образом, чтоб избежать любых циклических зависимостей…
C++ для дополнения картины
C++ предлагает ряд дополнительных возможностей сверх того, что доступно в C, и часть этих возможностей влияет на работу компоновщика. Так было не всегда — первые реализации C++ появились в качестве внешнего интерфейса к компилятору C, поэтому о совместимости работы компоновщика не было нужды. Однако со временем были добавлены более продвинутые особенности языка, так что компоновщик уже должен был быть изменён, чтобы их поддерживать.
Перегрузка функций и декорирование имён
Первое отличие C++ заключается в том, что функции могут быть перегружены, то есть одновременно могут существовать функции с одним и тем же именем, но с различными принимаемыми типами (различной сигнатурой функции):
int max(int x, int y)
{
if (x>y) return x;
else return y;
}
float max(float x, float y)
{
if (x>y) return x;
else return y;
}
double max(double x, double y)
{
if (x>y) return x;
else return y;
}
Такое положение вещей определённо затрудняет работу компоновщика: если какой-нибудь код обращается к функции max, какая именно имелась в виду?
Решение к этой проблеме названо декорированием имён (name mangling), потому что вся информация о сигнатуре функции переводится (to mangle = искажать, деформировать, прим.пер.) в текстовую форму, которая становится собственно именем символа с точки зрения компоновщика. Различные сигнатуры переводятся в различные имена. Таким образом проблема уникальности имён решена.
Я не собираюсь вдаваться в детали используемых схем декорирования (которые к тому же отличаются от платформы к платформе), но беглый взгляд на объектный файл, соответствующий коду выше, даст идею, как всё это понимать (запомните, nm — Ваш друг!):
Symbols from fn_overload.o:
Name Value Class Type Size Line Section
__gxx_personality_v0| | U | NOTYPE| | |*UND*
_Z3maxii |00000000| T | FUNC|00000021| |.text
_Z3maxff |00000022| T | FUNC|00000029| |.text
_Z3maxdd |0000004c| T | FUNC|00000041| |.text
Здесь мы видим три функции max, каждая из которых получила отличное имя в объектном файле, и мы можем проявить смекалку и предположить, что две следующие буквы после «max» обозначают типы входящих параметров — «i» как int, «f» как float и «d» как double (однако всё значительно усложняется, если классы, пространства имён, шаблоны и перегруженные операторы вступают в игру!).
Также стоит отметить, что обычно есть способ конвертирования между именами, видимых программисту и именами, видимых компоновщику. Это может быть и отдельная программа (например, c++filt) или опция в командной строке (например --demangle для GNU nm), которая выдаёт что-то похожее на это:
Symbols from fn_overload.o:
Name Value Class Type Size Line Section
__gxx_personality_v0| | U | NOTYPE| | |*UND*
max(int, int) |00000000| T | FUNC|00000021| |.text
max(float, float) |00000022| T | FUNC|00000029| |.text
max(double, double) |0000004c| T | FUNC|00000041| |.text
Область, где схемы декорирования чаще всего заставляют ошибиться, находится в месте переплетения C и C++. Все символы, произведённые C++ компилятором, декорированы; все символы, произведённые C компилятором, выглядят так же, как и в исходном коде. Чтобы обойти это, язык C++ разрешает поместить extern "C" вокруг объявления и определения функций. По сути этим мы сообщаем C++ компилятору, что определённое имя не должно быть декорировано — либо потому что это определение C++ функции, которая будет вызываться кодом C, либо потом что это определение C функции, которая будет вызываться кодом C++.
Возвращаясь к примеру в самом начале статьи, можно легко заметить, что существует достаточно большая вероятность, что кто-то забыл использовать extern "C" при компоновке C и C++ объектов.
g++ -o test1 test1a.o test1b.o
test1a.o(.text+0x18): In function `main':
: undefined reference to `findmax(int, int)'
collect2: ld returned 1 exit status
Большой подсказкой является то, что сообщение об ошибке содержит сигнатуру функции — это не просто сообщение о том, что findmax не найдено. Другими словами C++ код ищет что-то вроде "_Z7findmaxii", а находит только "findmax". Поэтому возникает ошибка компоновки.
Кстати заметьте, что объявление extern "C" игнорируется для функций-членов классов (§7.5.4 стандарта С++)
Инициализация статических объектов
Следующее выходящее за рамки С свойство C++, которое затрагивает работу компоновщика, — это существование конструкторов объектов. Конструктор — это кусок кода, который задаёт начальное состояние объекта. По сути его работа концептуально эквивалентна инициализации значения переменной, однако с той важной разницей, что речь идёт о произвольных фрагментах кода.
Вспомним из первой главы, что глобальные переменные могут начать своё существование уже с определённым значением. В C конструкция начального значения такой глобальной переменной — дело простое: определённое значение просто копируется из сегмента данных выполняемого файла в соответствующее место в памяти программы, которая вот-вот-начнёт-выполняться.
В C++ процесс инициализации может быть гораздо сложнее, чем просто копирование фиксированных значений; весь код в различных конструкторах по всей иерархии классов должен быть выполнен, прежде чем сама программа фактически начнёт выполняться.
Чтобы с этим справиться, компилятор помещает немного дополнительной информации в объектный файл для каждого C++ файла; а именно это список конструкторов, которые должны быть вызваны для конкретного файла. Во время компоновки компоновщик объединяет все эти списки в один большой список, а также помещает код, которые проходит через весь этот список, вызывая конструкторы всех глобальных объектов.
Обратим внимание, что порядок, в котором конструкторы глобальных объектов вызываются не определён — он полностью находится во власти того, что именно компоновщик намерен делать. (См. «Эффективный C++» Скотта Майерса для дальнейших деталей — заметка 47 во второй редакции, заметка 4 в третьей редакции)
Мы можем проследить за этими списками, опять же прибегнув к помощи nm. Рассмотрим следующий C++ файл:
class Fred {
private:
int x;
int y;
public:
Fred() : x(1), y(2) {}
Fred(int z): x(z), y(3) {}
};
Fred theFred;
Fred theOtherFred(55);
Для этого кода (недекорированный) вывод nm выглядит так:
Symbols from global_obj.o:
Name Value Class Type Size Line Section
__gxx_personality_v0| | U | NOTYPE| | |*UND*
__static_initialization_and_destruction_0(int, int)
|00000000| t | FUNC|00000039| |.text
Fred::Fred(int) |00000000| W | FUNC|00000017| |.text._ZN4FredC1Ei
Fred::Fred() |00000000| W | FUNC|00000018| |.text._ZN4FredC1Ev
theFred |00000000| B | OBJECT|00000008| |.bss
theOtherFred |00000008| B | OBJECT|00000008| |.bss
global constructors keyed to theFred
|0000003a| t | FUNC|0000001a| |.text
Как обычно, мы можем увидеть здесь кучу разных вещей, но одна из них наиболее интересна для нас это записи с классом W (что означает «слабый» символ («weak» symbol)) а также записи именем секции типа «.gnu.linkonce.t.stuff«. Это маркеры для конструкторов глобальных объектов и мы видим, что соответствующее поле «Name» показывает то, что мы собственно и могли там ожидать — каждый из двух конструкторов задействованы.
Шаблоны
Ранее мы приводили пример с тремя различными реализациями функции max, каждая из которых принимала аргументы различных типов. Однако, мы видим, что код тела функции во всех трёх случаях идентичен. А мы знаем, что дублировать один и тот же код — это дурной тон программирования.
C++ вводит понятия шаблона (templates), который позволяет использовать код, приведённый ниже, сразу для всех случаев. Мы можем создать заголовочный файл max_template.h с только одной копией кода функции max:
template <class T>
T max(T x, T y)
{
if (x>y) return x;
else return y;
}
и включим этот файл в исходный файл, чтобы испробовать шаблонную функцию:
#include "max_template.h"
int main()
{
int a=1;
int b=2;
int c;
c = max(a,b); // Компилятор автоматически определяет, что нужно именно max<int>(int,int)
double x = 1.1;
float y = 2.2;
double z;
z = max<double>(x,y); // Компилятор не может определить, поэтому требуем max<double>(double,double)
return 0;
}
Этот написанный на C++ код использует max<int>(int,int) и max<double>(double,double). Однако, какой-нибудь другой код мог бы использовать и другие инстанции этого шаблона. Ну, скажем, max<float>(float,float) или даже max<MyFloatingPointClass>(MyFloatingPointClass,MyFloatingPointClass).
Каждая из этих различных инстанций порождает различный машинный код. Таким образом на то время, когда программа будет окончательна скомпонована, компилятор и компоновщик должны гарантировать, что код каждого используемого экземпляра шаблона включён в программу (и ни один неиспользуемый экземпляр шаблона не включён, чтобы не раздуть размер программы).
Как же это делается? Обычно есть два пути действия: либо прореживание повторяющихся инстанций либо откладывание инстанциирования до стадии компоновки (я обычно называю эти подходы как разумный путь и путь компании Sun).
Способ прореживания повторяющихся инстанций подразумевает, что каждый объектный файл содержит код всех повстречавшихся шаблонов. Например, для приведённого выше файла, содержимое объектного файла выглядит так:
Symbols from max_template.o:
Name Value Class Type Size Line Section
__gxx_personality_v0 | | U | NOTYPE| | |*UND*
double max<double>(double, double) |00000000| W | FUNC|00000041| |.text _Z3maxIdET_S0_S0_
int max<int>(int, int) |00000000| W | FUNC|00000021| |.text._Z3maxIiET_S0_S0_
main |00000000| T | FUNC|00000073| |.text
И мы видим присутствие обоих инстанций max<int>(int,int) и max<double>(double,double).
Оба определения помечены как слабые символы, и это значит, что компоновщик при создании конечного выполняемого файла может выкинуть все повторяющиеся инстанции одного и того же шаблона и оставить только одну (и если он посчитает нужным, то он может проверить действительно ли все повторяющиеся инстанции шаблона отображаются в один и тот же код). Самый большой минус в этом подходе — это увеличение размеров каждого отдельного объектного файла.
Другой подход (который используется в Solaris C++) — это не включать шаблонные определения в объектные файлы вообще, а пометить их как неопределённые символы. Когда дело доходит до стадии компоновки, то компоновщик может собрать все неопределённые символы, которые собственно относятся к шаблонным инстанциям, и потом сгенерировать машинный код для каждой из них.
Это определённо редуцирует размер каждого объектного файла, однако минус этого подхода проявляется в том, что компоновщик должен отслеживать где исходной код находится и должен уметь запускать C++ компилятор во время компоновки (что может замедлить весь процесс)
Динамически загружаемые библиотеки
Последняя особенность, которую мы здесь обсудим, — это динамическая загрузка разделяемых библиотек. В предыдущей главе мы видели, как использование разделяемых библиотек откладывает конечную компоновку до момента, когда программа собственно запускается. В современных ОС это даже возможно на более поздних стадиях.
Это осуществляется парой системных вызовов dlopen и dlsym (примерные эквиваленты в Windows соответственно называются LoadLibrary и GetProcAddress). Первый берёт имя разделяемой библиотеки и догружает её в адресное пространство запущенного процесса. Конечно, эта библиотека может также иметь неразрешённые символы, поэтому вызов dlopen может повлечь за собой подгрузку других разделяемых библиотек.
dlopen предлагает на выбор либо ликвидировать все неразрешённости сразу, как только библиотека загружена, (RTLD_NOW) либо разрешать символы по мере необходимости (RTLD_LAZY). Первый способ означает, что вызов dlopen может занять достаточно времени, однако второй способ закладывает определённый риск, что во время выполнения программы будет обнаружена неопределённая ссылка, которая не может быть разрешена — в этот момент программа будет завершена.
Конечно же, символы из динамически загружаемой библиотеки не могут иметь имени. Однако, это просто решается, также как решаются и другие программистские задачки, добавлением дополнительного уровня обходных путей. В этом случае используется указатель на пространство символа. Вызов dlsym принимает литеральный параметр, который сообщает имя символа, который нужно найти, и возвращает указатель на его местоположение (или NULL, если символ не найден).
Взаимодействие с C++
Процесс динамической загрузки достаточно прямолинеен, но как он взаимодействует с различными особенностями C++, которые воздействуют на всё поведение компоновщика?
Первое наблюдение касается декорирования имён. При вызове dlsym, передаётся имя символа, который нужно найти. Значит это должно быть версия имени, видимая компоновщику, т.е. декорированное имя.
Так как процесс декорирования может меняться от платформы к платформе и от компилятора к компилятору, это означает, что практически невозможно динамически найти C++ символ универсальным методом. Даже если Вы работаете только с одним компилятором и углубляетесь в его внутренний мир, существуют и другие проблемы — кроме простых C-подобных функций, есть куча других вещей (таблицы виртуальных методов и тому подобное), о которых тоже надо заботиться.
Подводя итог изложенному выше, отметим следующее: обычно лучше иметь одну заключённую в extern "C" точку вхождения, которая может быть найдена dlsym‘ом. Эта точка вхождения может быть фабричным методом, который возвращает указатели на все инстанции C++ класса, разрешая доступ ко всем прелестям C++.
Компилятор вполне может разобраться с конструкторами глобальных объектов в библиотеке, подгружаемой dlopen, так как есть парочка специальных символов, которые могут быть добавлены в библиотеку, и которые будут вызваны компоновщиком (неважно во время загрузки или исполнения), если библиотека динамически догружается или выгружается — то есть необходимые вызовы конструкторов или деструкторов могут произойти здесь. В Unix это функции _init и _fini, или для более новых систем, использующих GNU инструментарий существуют функции, маркированные как __attribute__((constructor)) или __attribute__((destructor)). В Windows соответствующая функция — DllMain с параметром DWORD fdwReason равным DLL_PROCESS_ATTACH или DLL_PROCESS_DETACH.
И в заключении добавим, что динамическая загрузка справляется отлично с «прореживанием повторяющихся инстанций», если речь идёт об инстанциировании шаблонов; и всё выглядит неоднозначно с «откладыванием инстанциирования», так как «стадия компоновки» наступает после того, как программа уже запущена (и вполне вероятно на другой машине, которая не хранит исходники). Обращайтесь к документации компилятора и компоновщика, чтобы найти выход из такой ситуации.
Дополнительно
В этой статье были намеренно пропущены многие детали о том, как компоновщик работает, потому что я считаю, что содержимое написанного покрывает 95% повседневных проблем, с которыми программист имеет дело при компоновке своей программы.
Если Вы хотите узнать больше, то можно почерпнуть информацию из ниже приведённых ссылок:
- John Levine, Linkers and Loaders: содержит огромнейшее количество информации о тонкостях работы компоновщика и загрузчика, включая все вещи, пропущенные в этой статье. Также существует онлайн-версия этой книги (или её черновик) здесь.
- Отличная ссылка на описание формата Mach-O для бинарников на Mac OS X.
- Peter Van Der Linden, Expert C Programming: отличная книга, включающая больше информации о том, как код, написанный на C, трансформируется в запускаемую программу, чем любой другой труд о C, прочитанный мной.
- Scott Meyers, More Effective C++: заметка 34 описывает ловушки, встречающиеся на пути комбинирования C и C++ в одной программе (касается не только работы компоновщика)
- Bjarne Stroustrup, The Design and Evolution of C++: в главе 11.3 обсуждается компоновка в C++ и как это происходит.
- Margaret A. Ellis & Bjarne Stroustrup, The Annotated C++ Reference Manual: глава 7.2c описывает конкретную схему декорирования имён
- ELF format reference [PDF]
- Две интересные статьи о создании легковесных выполняемых файлов в Linux и о минимальном Hello World в частности.
- «How To Write Shared Libraries» [PDF] небезызвестного Ulrich Drepper содержит больше деталей о ELF и переадресации.
Many thanks to Mike Capp and Ed Wilson for useful suggestions about this page.
Copyright © 2004-2005,2009-2010 David Drysdale
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1 or any later version published by the Free Software Foundation; with no Invariant Sections, with no Front-Cover Texts, and with no Back-Cover Texts. A copy of the license is available here.
Система компоновки данных 1С 8.3 для начинающих: первый отчёт на СКД
Автор уроков и преподаватель школы: Владимир Милькин
Если вы не читали введение к этому модулю — пожалуйста, прочтите его: ссылка.
Оглавление
- Готовим рабочее место
- Ставим цель
- Создаём отчёт
- Создаём схему компоновки данных внутри отчёта
- Пишем запрос через конструктор
- Настраиваем представление данных
- Сохраняем отчёт в виде файла
- Проверяем отчёт в режиме пользователя
Готовим рабочее место
Для выполнения уроков вам понадобится 1С 8.3 (не ниже 8.3.13.1644) .
Если у вас уже есть установленная 1С версии 8.3 — используйте её. Если нет — скачайте и установите учебную версию, которую фирма 1С выпускает специально для образовательных целей: ссылка на инструкцию по скачиванию и установке 1С.
На вашем рабочем столе должен появиться вот такой ярлык:

Готово!
Для всех уроков из этого цикла мы будем использовать подготовленную мной базу данных «Гастроном». Она полностью совпадает с базой, которую мы использовали в четвёртом и пятом модулях школы при изучении запросов. Поэтому я рассчитываю, что вы знакомы с её справочниками и документами.
Если вы её удалили — скачайте заново по следующей ссылке, распакуйте и подключите в список баз.
Наконец, рабочее место настроено и сейчас мы вместе создадим наш первый отчёт при помощи системы компоновки данных. Он будет очень простым, чтобы продемонстрировать общие возможности системы компоновки данных (сокращенно СКД).
Ставим цель
Цель этого урока — создать отчёт, который в режиме пользователя выводит список клиентов со следующими полями:
- Имя
- Пол
- Любимый цвет клиента.
Отчёт должен быть внешним. Это значит, что он будет создан и настроен в конфигураторе, а затем сохранен в виде отдельного (внешнего) файла на компьютере.
Чтобы сформировать такой отчет в 1С пользователю нужно будет запустить базу в режиме пользователя, открыть этот файл и нажать кнопку «Сформировать».
Поехали! ![]()
Создаём отчёт
Запускаем конфигуратор для базы «Гастроном»:

Из главного меню выбираем пункт «Файл»->»Новый…»:

Выбираем «Внешний отчет»:

Создаём схему компоновки данных внутри отчёта
Открылось окно создания внешнего отчёта. В качестве имени вводим: «Урок1«, а затем жмём кнопку «Открыть схему компоновки данных«:

Запустился конструктор создания схемы. Соглашаемся с именем по умолчанию «ОсновнаяСхемаКомпоновкиДанных» и жмём кнопку «Готово«:

Открылось основное рабочее окно, с множеством закладок и полей, в котором мы и будем настраивать нашу схему компоновки данных.
Не нужно пугаться — возможностей здесь действительно много, но далеко не все из них нам нужны. Особенно на первом уроке.
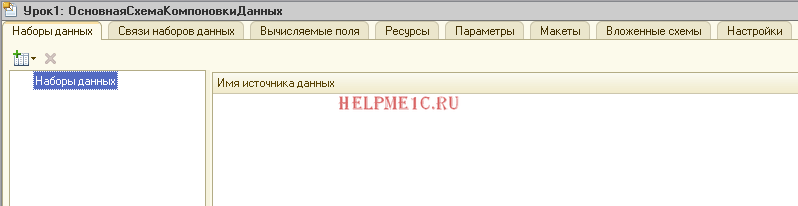
Сейчас мы находимся на закладке «Наборы данных«. На ней и останемся.
Пишем запрос через конструктор
Система компоновки данных (сокращенно СКД) требует от нас данные, которые она будет выводить пользователю.
Самый простой способ — написать запрос к базе. В предыдущих модулях школы мы научились писать и понимать запросы — поэтому я рассчитываю, что вы обладаете соответствующими навыками.
Нажимаем на зелёный плюсик и в раскрывшемся списке выбираем пункт «Добавить набор данных — запрос«:

Добавился набор данных с именем «НаборДанных1«, но мы видим, что поле «Запрос» в нижней части окна пока пустое:
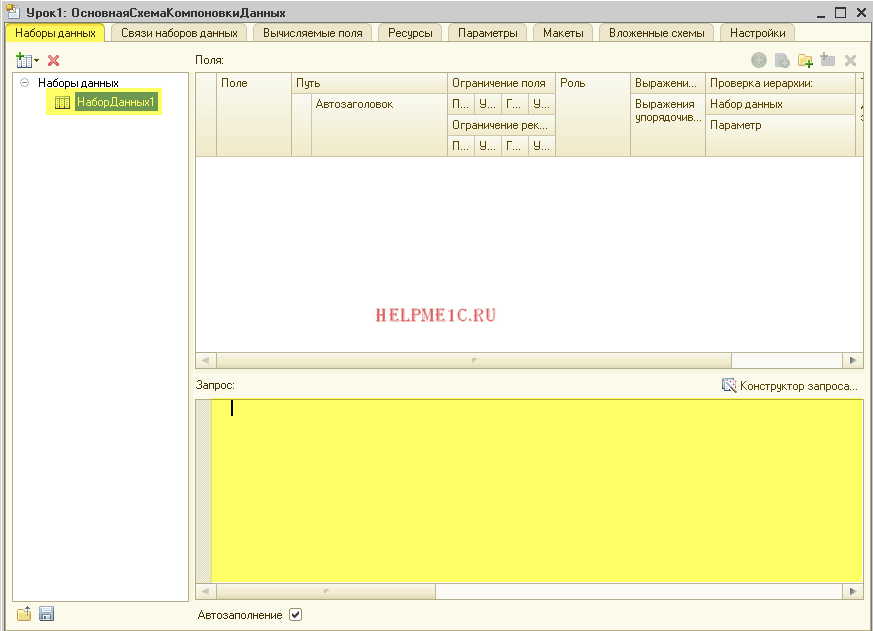
Наша задача написать в это поле текст запроса. Вы ещё не забыли как это делается? ![]()
Я вам подскажу:
ВЫБРАТЬ Наименование, Пол, ЛюбимыйЦвет ИЗ Справочник.Клиенты
В этом запросе мы выбрали три поля («Наименование«, «Пол» и «ЛюбимыйЦвет«) из таблицы «Справочник.Клиенты«.
Но не торопитесь писать этот текст в поле «Запрос» вручную.
Сейчас мы создадим тот же самый запрос визуально, только при помощи мышки. Этот способ называется «Конструктор запроса«.
Чтобы вызвать этот конструктор нажмём кнопку «Конструктор запроса…» в верхней правой части поля «Запрос»:

В открывшемся окне перетащим таблицу «Клиенты» из первого столбца во второй, чтобы указать, что именно из этой таблицы мы будем запрашивать данные:
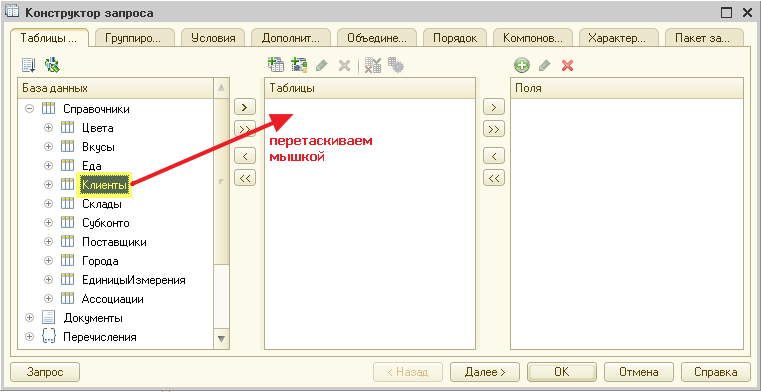
Получилось вот так:
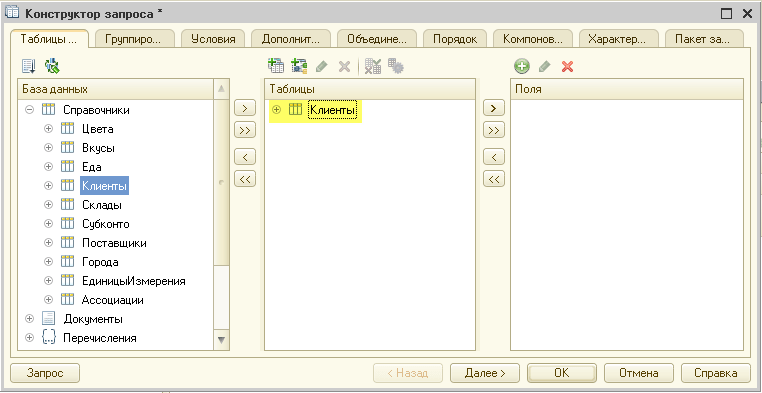
Далее раскроем таблицу «Клиенты» во втором столбце по знаку «Плюс«, чтобы увидеть все её поля и перетащим поле «Наименование» из второго столбца в третий, чтобы указать, что из этой таблицы нам нужно запрашивать поле «Наименование»:
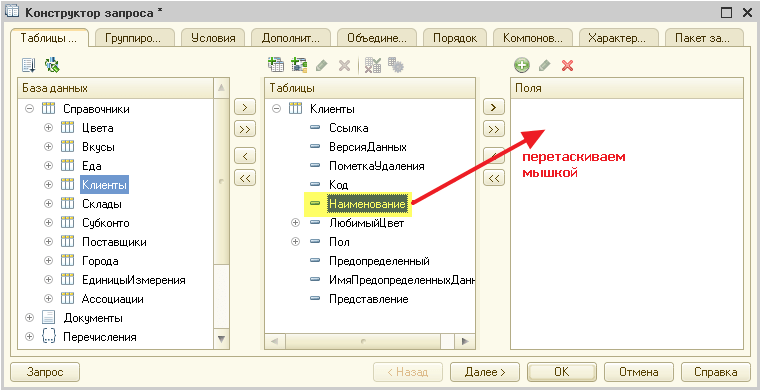
Получилось вот так:
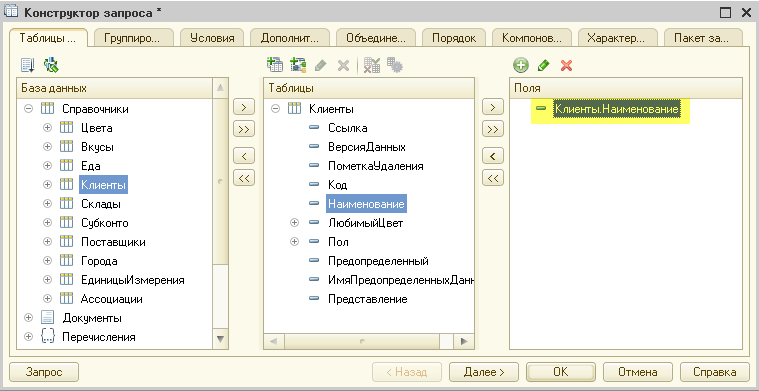
Поступим точно так же с полями «Пол» и «ЛюбимыйЦвет«. Результат будет таким:
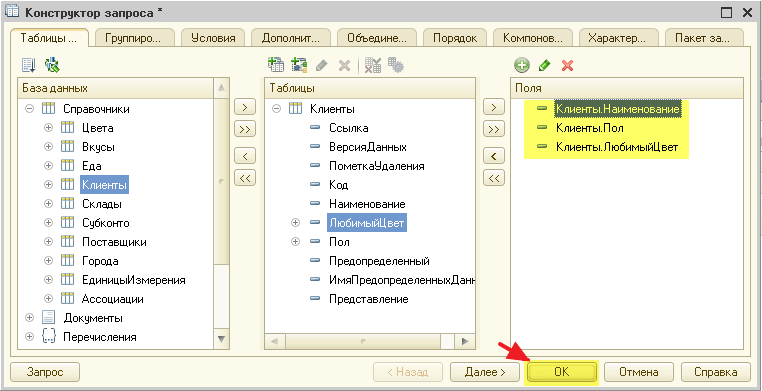
Нажмём кнопку «ОК», чтобы выйти из конструктора запроса и увидим, что текст запроса автоматически добавился в поле «Запрос».
Более того на основании текста запроса 1С сама вытащила имена полей (область выше запроса), которые будут использоваться схемой компоновки данных:

Теперь, когда мы составили запрос, СКД знает каким образом получать данные для отчёта.
Настраиваем представление данных
Осталось как-то визуализировать эти данные для пользователя в виде печатной формы. И вот тут СКД может творить чудеса! ![]()
Чтобы сотворить такое чудо перейдём на вкладку «Настройки» и нажмём кнопку конструктора настроек (волшебная палочка):

В открывшемся окне укажем тип отчёта «Список» и нажмём «Далее«:

В следующем окне выберем (путём перетаскивания) поля, которые нужно будет отобразить в списке (перетащим все из доступных нам: «ЛюбимыйЦвет«, «Наименование» и «Пол«):

Получим вот такой результат и нажмём кнопку «ОК«:
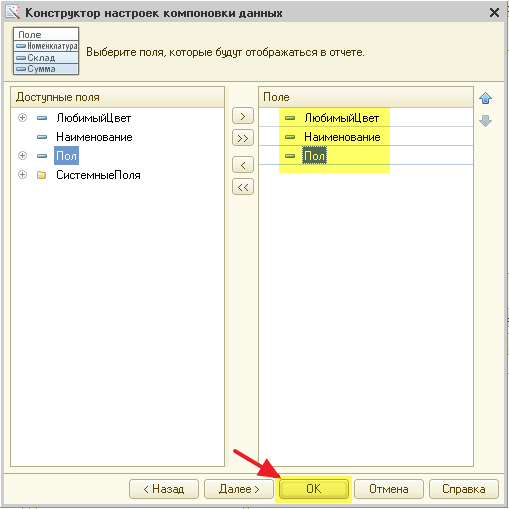
Конструктор настроек закрылся и появился пункт «Детальные записи«:
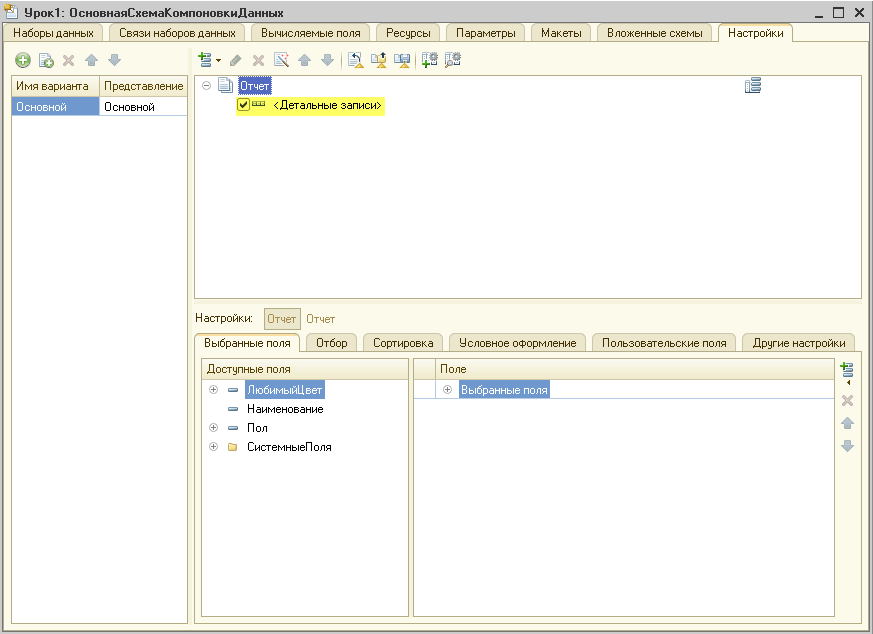
Отчёт готов, давайте же его проверим. Для этого вначале сохраним отчет в виде внешнего файла.
Сохраняем отчёт в виде файла
Откроем пункт главного меню «Файл«->»Сохранить«:

Я сохраню его на рабочий стол под именем «Урок1«:

Проверяем отчёт в режиме пользователя
Наконец, закроем конфигуратор и зайдём в нашу базу в режиме пользователя:

Имя пользователя «Администратор», пароля нет:

Через меню выберем пункт «Файл«->»Открыть…»:

И укажем файл отчёта (я сохранял его на рабочий стол под именем «Урок1.erf»:

Открылась форма отчёта, нажмём кнопку «Сформировать«:

Готово! Вот она наша печатная форма со списком клиентов, их любимым цветом и полом:

Печатную форму можно легко распечатать. Для этого достаточно выбрать в меню пункт «Файл«->»Печать…«:

Вот так просто, без программирования нам удалось создать полноценный отчёт, который пользователи смогут открывать в своих базах, формировать и распечатывать.
То ли ещё будет, наберитесь терпения ![]()
Эталонная обработка, после выполнения всех шагов этого урока
Прибегайте к изучению эталонного варианта только после самостоятельного выполнения всех шагов.
Содержание:
1. Инструмент Компоновщик данных
2. Пример работы с компоновщиком данных в 1С
1. Инструмент Компоновщик данных
В данной статье будет рассмотрен такое инструмент как компоновщик данных, а также дан пример схемы по компоновке данных в 1С. Будет описано, как происходит связка между схемой по компоновке данных и компоновщиком настроек. Для более понятного и подробного описания за основу будет взят пример.
2. Пример работы с компоновщиком данных в 1С
Создадим и рассмотрим следующий пример: пусть существуют два справочника – это «Склады» и «Товары». В справочнике с товарами находится таблица «Перечень складов», где прописываются товары по складам, а также максимальное количество заданного товара на том или ином складе.
Пусть нужно сделать групповую обработку, чтобы прописать наибольшее количество продукции по складам. В таблице тогда будет находится два древа со значениями, а заполняться они будут при помощи отбора по складу и товару.
Чтобы реализовать данный отбор – нужно будет воспользоваться формами с управлением. Итоговая обработка для 1С:Предприятие будет выглядеть как показано на скриншоте ниже:

Рис. 1 Обработка для 1С:Предприятие
Далее надо решить, как будет проходить реализация. Так как нам нужно оперировать отборами, то первое – это настройка схемы по компоновке данных. Для этого делаем обработку с добавлением макета «Схема компоновки данных», а также формы, как показано на скриншоте ниже:

Рис. 2 Обработка с добавлением макета Схема компоновки данных
В схеме, которая отвечает за компоновку данных нужно прибавить следующий запрос, который продемонстрирован ниже:

Рис. 3 Запрос в Схеме компоновки данных
После этого нужно произвести настройку схемы компоновки данных:

Рис. 4 Настройка схемы компоновки данных
Далее нужно будет спроектировать форму. Для этого делаем отбор: добавляем реквизит в форму и выбираем типы, которые можно к нему применить. Получаем, что в списке находится лишь один тип – «КомпоновщикНастроекКомпоновкиДанных». Он как раз подходит для необходимой обработки по отбору.

Рис. 5 Обработка по отбору с типом КомпоновщикНастроекКомпоновкиДанных
Далее, как только выбор вышеуказанного типа осуществлён, открываем «Настройки» для типа «НастройкиКомпоновкиДанных» и ищем пункт «Отбор», после чего вставляем его в форму. Дальше вставляем реквизит типа «ДеревоЗначений» и делаем столбцы по схеме по компоновке данных. После всех вышеуказанных действий окно примет такой вид:

Рис. 6 Столбцы схемы компоновки данных

Рис. 7 Использование реквизита ДеревоЗначений
При помощи кода программы произведем заполнение отбора по настройкам в компоновщике настроек, основываясь на отбор в схеме по компоновке данных. Далее организовываем реализацию по заполнению древа с значениями, учитывая приведённый выше отбор. Код будет выглядеть следующим образом:

Рис. 8 Код после отбора по настройкам

Рис. 9 Код для работы схемы компоновки данных

Рис. 10 Код с заполнением ДеревоЗначений
По коду выше – в процедуре «ПриСозданииНаСервере()» реализуем отбор по компоновщику настроек. При похождении инициализации в компоновщике настроек в схеме по компоновке данных получаем, что схему по компоновке данных необходимо сначала переместить в хранилище временного типа, при помощи «ПоместитьВоВременноеХранилище()», а далее – как только все отборы были установлены – можно приступить к заполнению таблицы и древа значений.
Рассмотрим подробнее формировку макета, которая прописана в этом месте:

Рис. 11 Формировка макеты схемы компоновки данных
Формирование макета конструктором схемы компоновки данных происходит на основании схемы компоновки данных, а также согласно настройкам по компоновке данных. Так как в рассматриваемом примере отбор по форме относится не к схеме компоновки, а к компоновщику по настройкам, оттуда и берём настройки. Также стоит отметить, что внутри метода «Выполнить()» во время генерирования макета нужно в виде параметра добавить Тип(«ГенераторМакетаКомпоновкиДанныхДляКоллекцииЗначений»).
Специалист компании «Кодерлайн»
Айдар Фархутдинов