Related articles
- Install Arch Linux on LVM
- LVM on software RAID
- dm-crypt/Encrypting an entire system#LVM on LUKS
- dm-crypt/Encrypting an entire system#LUKS on LVM
- Resizing LVM-on-LUKS
- Create root filesystem snapshots with LVM
From Wikipedia:Logical Volume Manager (Linux):
- Logical Volume Manager (LVM) is a device mapper framework that provides logical volume management for the Linux kernel.
Background
LVM building blocks
Logical Volume Management utilizes the kernel’s device-mapper feature to provide a system of partitions independent of underlying disk layout. With LVM you abstract your storage and have «virtual partitions», making extending/shrinking easier (subject to potential filesystem limitations).
Virtual partitions allow addition and removal without worry of whether you have enough contiguous space on a particular disk, getting caught up fdisking a disk in use (and wondering whether the kernel is using the old or new partition table), or, having to move other partitions out of the way.
Basic building blocks of LVM:
- Physical volume (PV)
- Unix block device node, usable for storage by LVM. Examples: a hard disk, an MBR or GPT partition, a loopback file, a device mapper device (e.g. dm-crypt). It hosts an LVM header.
- Volume group (VG)
- Group of PVs that serves as a container for LVs. PEs are allocated from a VG for a LV.
- Logical volume (LV)
- «Virtual/logical partition» that resides in a VG and is composed of PEs. LVs are Unix block devices analogous to physical partitions, e.g. they can be directly formatted with a file system.
- Physical extent (PE)
- The smallest contiguous extent (default 4 MiB) in the PV that can be assigned to a LV. Think of PEs as parts of PVs that can be allocated to any LV.
Example:
Physical disks
Disk1 (/dev/sda):
┌──────────────────────────────────────┬─────────────────────────────────────┐
│ Partition1 50 GiB (Physical volume) │ Partition2 80 GiB (Physical volume) │
│ /dev/sda1 │ /dev/sda2 │
└──────────────────────────────────────┴─────────────────────────────────────┘
Disk2 (/dev/sdb):
┌──────────────────────────────────────┐
│ Partition1 120 GiB (Physical volume) │
│ /dev/sdb1 │
└──────────────────────────────────────┘
LVM logical volumes
Volume Group1 (/dev/MyVolGroup/ = /dev/sda1 + /dev/sda2 + /dev/sdb1):
┌─────────────────────────┬─────────────────────────┬──────────────────────────┐
│ Logical volume1 15 GiB │ Logical volume2 35 GiB │ Logical volume3 200 GiB │
│ /dev/MyVolGroup/rootvol │ /dev/MyVolGroup/homevol │ /dev/MyVolGroup/mediavol │
└─────────────────────────┴─────────────────────────┴──────────────────────────┘
Note: Logical volumes are accessible at both /dev/VolumeGroupName/LogicalVolumeName and /dev/mapper/VolumeGroupName-LogicalVolumeName. However, lvm(8) § VALID NAMES recommends the former format for «software and scripts» (e.g. fstab) since the latter is intended for «internal use» and subject to possible «change between releases and distributions».
Advantages
LVM gives you more flexibility than just using normal hard drive partitions:
- Use any number of disks as one big disk.
- Have logical volumes stretched over several disks.
- Create small logical volumes and resize them «dynamically» as they get filled up.
- Resize logical volumes regardless of their order on disk. It does not depend on the position of the LV within VG, there is no need to ensure surrounding available space.
- Resize/create/delete logical and physical volumes online. File systems on them still need to be resized, but some (such as ext4) support online resizing.
- Online/live migration of LV being used by services to different disks without having to restart services.
- Snapshots allow you to backup a frozen copy of the file system, while keeping service downtime to a minimum.
- Support for unlocking separate volumes without having to enter a key multiple times on boot (make LVM on top of LUKS).
- Built-in support for caching of frequently used data (lvmcache(7)).
Disadvantages
- Additional steps in setting up the system, more complicated. Requires (multiple) daemons to constantly run.
- If dual-booting, note that Windows does not support LVM; you will be unable to access any LVM partitions from Windows. 3rd Party software may allow to mount certain kinds of LVM setups. [1]
- If your physical volumes are not on a RAID-1, RAID-5 or RAID-6 losing one disk can lose one or more logical volumes if you span (or extend) your logical volumes across multiple non-redundant disks.
- You cannot (easily) shrink the space used by the logical volume manager, meaning the physical volumes used for the logical volumes. If the physical extents are scattered across the physical volume until the end, it is not possible to shrink the physical volume with the scripts provided on the Arch Wiki. If you want to dual-boot with other operating systems (e.g. with Microsoft Windows), the only space left on the device for Microsoft Windows is the space not used by LVM / not used as physical volume.
Installation
Make sure the lvm2 package is installed.
If you have LVM volumes not activated via the initramfs, enable lvm2-monitor.service, which is provided by the lvm2 package.
Volume operations
Physical volumes
Creating
To create a PV on /dev/sda1, run:
# pvcreate /dev/sda1
You can check the PV is created using the following command:
# pvs
Growing
After extending or prior to reducing the size of a device that has a physical volume on it, you need to grow or shrink the PV using pvresize(8).
To expand the PV on /dev/sda1 after enlarging the partition, run:
# pvresize /dev/sda1
This will automatically detect the new size of the device and extend the PV to its maximum.
Note: This command can be done while the volume is online.
Shrinking
To shrink a physical volume prior to reducing its underlying device, add the --setphysicalvolumesize size parameters to the command, e.g.:
# pvresize --setphysicalvolumesize 40G /dev/sda1
The above command may leave you with this error:
/dev/sda1: cannot resize to 25599 extents as later ones are allocated. 0 physical volume(s) resized / 1 physical volume(s) not resized
Indeed pvresize will refuse to shrink a PV if it has allocated extents after where its new end would be. One needs to run pvmove beforehand to relocate these elsewhere in the volume group if there is sufficient free space.
Move physical extents
Before moving free extents to the end of the volume, one must run pvdisplay -v -m to see physical segments. In the below example, there is one physical volume on /dev/sdd1, one volume group vg1 and one logical volume backup.
# pvdisplay -v -m
Finding all volume groups.
Using physical volume(s) on command line.
--- Physical volume ---
PV Name /dev/sdd1
VG Name vg1
PV Size 1.52 TiB / not usable 1.97 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 399669
Free PE 153600
Allocated PE 246069
PV UUID MR9J0X-zQB4-wi3k-EnaV-5ksf-hN1P-Jkm5mW
--- Physical Segments ---
Physical extent 0 to 153600:
FREE
Physical extent 153601 to 307199:
Logical volume /dev/vg1/backup
Logical extents 1 to 153599
Physical extent 307200 to 307200:
FREE
Physical extent 307201 to 399668:
Logical volume /dev/vg1/backup
Logical extents 153601 to 246068
One can observe FREE space are split across the volume. To shrink the physical volume, we must first move all used segments to the beginning.
Here, the first free segment is from 0 to 153600 and leaves us with 153601 free extents. We can now move this segment number from the last physical extent to the first extent. The command will thus be:
# pvmove --alloc anywhere /dev/sdd1:307201-399668 /dev/sdd1:0-92467
/dev/sdd1: Moved: 0.1 % /dev/sdd1: Moved: 0.2 % ... /dev/sdd1: Moved: 99.9 % /dev/sdd1: Moved: 100.0 %
Note:
- This command moves 399668 — 307201 + 1 = 92468 PEs from the last segment to the first segment. This is possible as the first segment encloses 153600 free PEs, which can contain the 92467 — 0 + 1 = 92468 moved PEs.
- The
--alloc anywhereoption is used as we move PEs inside the same partition. In case of different partitions, the command would look something like this:# pvmove /dev/sdb1:1000-1999 /dev/sdc1:0-999
- This command may take a long time (one to two hours) in case of large volumes. It might be a good idea to run this command in a tmux or GNU Screen session. Any unwanted stop of the process could be fatal.
- Once the operation is complete, run fsck to make sure your file system is valid.
Resize physical volume
Once all your free physical segments are on the last physical extents, run vgdisplay with root privileges and see your free PE.
Then you can now run again the command:
# pvresize --setphysicalvolumesize size PhysicalVolume
See the result:
# pvs
PV VG Fmt Attr PSize PFree /dev/sdd1 vg1 lvm2 a-- 1t 500g
Resize partition
Last, you need to shrink the partition with your favorite partitioning tool.
Volume groups
Creating a volume group
To create a VG MyVolGroup with an associated PV /dev/sdb1, run:
# vgcreate MyVolGroup /dev/sdb1
You can check the VG MyVolGroup is created using the following command:
# vgs
You can bind multiple PVs when creating a VG like this:
# vgcreate MyVolGroup /dev/sdb1 /dev/sdb2
Activating a volume group
Note: You can restrict the volumes that are activated automatically by setting the auto_activation_volume_list in /etc/lvm/lvm.conf. If in doubt, leave this option commented out.
# vgchange -a y MyVolGroup
By default, this will reactivate the volume group when applicable. For example, if you had a drive failure in a mirror and you swapped the drive; and ran (1) pvcreate, (2) vgextend and (3) vgreduce --removemissing --force.
Repairing a volume group
To start the rebuilding process of the degraded mirror array in this example, you would run:
# lvconvert --repair /dev/MyVolGroup/mirror
You can monitor the rebuilding process (Cpy%Sync Column output) with:
# lvs -a -o +devices
Deactivating a volume group
Just invoke
# vgchange -a n MyVolGroup
This will deactivate the volume group and allow you to unmount the container it is stored in.
Renaming a volume group
Use the vgrename(8) command to rename an existing volume group.
Either of the following commands renames the existing volume group MyVolGroup to my_volume_group
# vgrename /dev/MyVolGroup /dev/my_volume_group
# vgrename MyVolGroup my_volume_group
Make sure to update all configuration files (e.g. /etc/fstab or /etc/crypttab) that reference the renamed volume group.
Add physical volume to a volume group
You first create a new physical volume on the block device you wish to use, then extend your volume group
# pvcreate /dev/sdb1 # vgextend MyVolGroup /dev/sdb1
This of course will increase the total number of physical extents on your volume group, which can be allocated by logical volumes as you see fit.
Note: It is considered good form to have a partition table on your storage medium below LVM. Use the appropriate partition type: 8e for MBR, and E6D6D379-F507-44C2-A23C-238F2A3DF928 for GPT partitions.
Remove partition from a volume group
If you created a logical volume on the partition, remove it first.
All of the data on that partition needs to be moved to another partition. Fortunately, LVM makes this easy:
# pvmove /dev/sdb1
If you want to have the data on a specific physical volume, specify that as the second argument to pvmove:
# pvmove /dev/sdb1 /dev/sdf1
Then the physical volume needs to be removed from the volume group:
# vgreduce MyVolGroup /dev/sdb1
Or remove all empty physical volumes:
# vgreduce --all MyVolGroup
For example: if you have a bad disk in a group that cannot be found because it has been removed or failed:
# vgreduce --removemissing --force MyVolGroup
And lastly, if you want to use the partition for something else, and want to avoid LVM thinking that the partition is a physical volume:
# pvremove /dev/sdb1
Logical volumes
Note: lvresize(8) provides more or less the same options as the specialized lvextend(8) and lvreduce(8) commands, while allowing to do both types of operation. Notwithstanding this, all those utilities offer a -r/--resizefs option which allows to resize the file system together with the LV using fsadm(8) (ext2, ext3, ext4, ReiserFS and XFS supported). Therefore it may be easier to simply use lvresize for both operations and use --resizefs to simplify things a bit, except if you have specific needs or want full control over the process.
Warning: While enlarging a file system can often be done on-line (i.e. while it is mounted), even for the root partition, shrinking will nearly always require to first unmount the file system so as to prevent data loss. Make sure your file system supports what you are trying to do.
Tip: If a logical volume will be formatted with ext4, leave at least 256 MiB free space in the volume group to allow using e2scrub(8). After creating the last volume with -l 100%FREE, this can be accomplished by reducing its size with lvreduce -L -256M volume_group/logical_volume.
Creating a logical volume
To create a LV homevol in a VG MyVolGroup with 300 GiB of capacity, run:
# lvcreate -L 300G MyVolGroup -n homevol
or, to create a LV homevol in a VG MyVolGroup with the rest of capacity, run:
# lvcreate -l 100%FREE MyVolGroup -n homevol
The new LV will appear as /dev/MyVolGroup/homevol. Now you can format the LV with an appropriate file system.
You can check the LV is created using the following command:
# lvs
Renaming a logical volume
To rename an existing logical volume, use the lvrename(8) command.
Either of the following commands renames logical volume old_vol in volume group MyVolGroup to new_vol.
# lvrename /dev/MyVolGroup/old_vol /dev/MyVolGroup/new_vol
# lvrename MyVolGroup old_vol new_vol
Make sure to update all configuration files (e.g. /etc/fstab or /etc/crypttab) that reference the renamed logical volume.
Resizing the logical volume and file system in one go
Note: Only ext2, ext3, ext4, ReiserFS and XFS file systems are supported. For a different type of file system see #Resizing the logical volume and file system separately.
Extend the logical volume mediavol in MyVolGroup by 10 GiB and resize its file system all at once:
# lvresize -L +10G --resizefs MyVolGroup/mediavol
Set the size of logical volume mediavol in MyVolGroup to 15 GiB and resize its file system all at once:
# lvresize -L 15G --resizefs MyVolGroup/mediavol
If you want to fill all the free space on a volume group, use the following command:
# lvresize -l +100%FREE --resizefs MyVolGroup/mediavol
See lvresize(8) for more detailed options.
Resizing the logical volume and file system separately
For file systems not supported by fsadm(8) will need to use the appropriate utility to resize the file system before shrinking the logical volume or after expanding it.
To extend logical volume mediavol within volume group MyVolGroup by 2 GiB without touching its file system:
# lvresize -L +2G MyVolGroup/mediavol
Now expand the file system (ext4 in this example) to the maximum size of the underlying logical volume:
# resize2fs /dev/MyVolGroup/mediavol
To reduce the size of logical volume mediavol in MyVolGroup by 500 MiB, first calculate the resulting file system size and shrink the file system (ext4 in this example) to the new size:
# resize2fs /dev/MyVolGroup/mediavol NewSize
When the file system is shrunk, reduce the size of logical volume:
# lvresize -L -500M MyVolGroup/mediavol
To calculate the exact logical volume size for ext2, ext3, ext4 file systems, use a simple formula: LVM_EXTENTS = FS_BLOCKS × FS_BLOCKSIZE ÷ LVM_EXTENTSIZE.
# tune2fs -l /dev/MyVolGroup/mediavol | grep Block
Block count: 102400000 Block size: 4096 Blocks per group: 32768
# vgdisplay MyVolGroup | grep "PE Size"
PE Size 4.00 MiB
Note: The file system block size is in bytes. Make sure to use the same units for both block and extent size.
102400000 blocks × 4096 bytes/block ÷ 4 MiB/extent = 100000 extents
Passing --resizefs will confirm that the correctness.
# lvreduce -l 100000 --resizefs /dev/MyVolGroup/mediavol
... The filesystem is already 102400000 (4k) blocks long. Nothing to do! ... Logical volume sysvg/root successfully resized.
See lvresize(8) for more detailed options.
Removing a logical volume
Warning: Before you remove a logical volume, make sure to move all data that you want to keep somewhere else; otherwise, it will be lost!
First, find out the name of the logical volume you want to remove. You can get a list of all logical volumes with:
# lvs
Next, look up the mountpoint of the chosen logical volume:
$ lsblk
Then unmount the filesystem on the logical volume:
# umount /mountpoint
Finally, remove the logical volume:
# lvremove volume_group/logical_volume
For example:
# lvremove MyVolGroup/homevol
Confirm by typing in y.
Make sure to update all configuration files (e.g. /etc/fstab or /etc/crypttab) that reference the removed logical volume.
You can verify the removal of the logical volume by typing lvs as root again (see first step of this section).
Snapshots
LVM supports CoW (Copy-on-Write) snapshots. A CoW snapshot initially points to the original data. When data blocks are overwritten, the original copy is left intact and the new blocks are written elsewhere on-disk. This has several desirable properties:
- Creating snapshots is fast, because it does not copy data (just the much shorter list of pointers to the on-disk locations).
- Snapshots require just enough free space to hold the new data blocks (plus a negligible amount for the pointers to the new blocks). For example, a snapshot of 35 GiB of data, where you write only 2 GiB (on both the original and snapshot), only requires 2 GiB of free space.
LVM snapshots are at the block level. They make a new block device, with no apparent relationship to the original except when dealing with the LVM tools. Therefore, deleting files in the original copy does not free space in the snapshots. If you need filesystem-level snapshots, you rather need btrfs, ZFS or bcache.
Warning:
- A CoW snapshot is not a backup, because it does not make a second copy of the original data. For example, a damaged disk sector that affects original data also affects the snapshots. That said, a snapshot can be helpful while using other tools to make backups, as outlined below.
- Btrfs expects different filesystems to have different UUIDs. If you snapshot a LVM volume that contains a btrfs filesystem, make sure to change the UUID of the original or the copy, before both are mounted (or made visible to the kernel, for example if an unrelated daemon triggers a btrfs device scan). For details see btrfs wiki Gotcha’s.
Configuration
You create snapshot logical volumes just like normal ones.
# lvcreate --size 100M --snapshot --name snap01vol /dev/MyVolGroup/lvol
With that volume, you may modify less than 100 MiB of data, before the snapshot volume fills up.
Reverting the modified lvol logical volume to the state when the snap01vol snapshot was taken can be done with
# lvconvert --merge /dev/MyVolGroup/snap01vol
In case the origin logical volume is active, merging will occur on the next reboot (merging can be done even from a LiveCD).
Note: The snapshot will no longer exist after merging.
Also multiple snapshots can be taken and each one can be merged with the origin logical volume at will.
Backups
A snapshot provides a frozen copy of a file system to make backups. For example, a backup taking two hours provides a more consistent image of the file system than directly backing up the partition.
The snapshot can be mounted and backed up with dd or tar. The size of the backup file done with dd will be the size of the files residing on the snapshot volume.
To restore just create a snapshot, mount it, and write or extract the backup to it. And then merge it with the origin.
See Create root filesystem snapshots with LVM for automating the creation of clean root file system snapshots during system startup for backup and rollback.
![]() This article or section needs expansion.
This article or section needs expansion.![]()
Reason: Show scripts to automate snapshots of root before updates, to rollback… updating menu.lst to boot snapshots (maybe in a separate article?) (Discuss in Talk:LVM)
Encryption
See dm-crypt/Encrypting an entire system#LUKS on LVM and dm-crypt/Encrypting an entire system#LVM on LUKS for the possible schemes of combining LUKS with LVM.
Cache
From lvmcache(7):
- The cache logical volume type uses a small and fast LV to improve the performance of a large and slow LV. It does this by storing the frequently used blocks on the faster LV. LVM refers to the small fast LV as a cache pool LV. The large slow LV is called the origin LV. Due to requirements from dm-cache (the kernel driver), LVM further splits the cache pool LV into two devices — the cache data LV and cache metadata LV. The cache data LV is where copies of data blocks are kept from the origin LV to increase speed. The cache metadata LV holds the accounting information that specifies where data blocks are stored (e.g. on the origin LV or on the cache data LV). Users should be familiar with these LVs if they wish to create the best and most robust cached logical volumes. All of these associated LVs must be in the same VG.
Create cache
Convert your fast disk (/dev/fastdisk) to PV and add to your existing VG (MyVolGroup):
# vgextend MyVolGroup /dev/fastdisk
Create a cache pool with automatic meta data on /dev/fastdisk and convert the existing LV MyVolGroup/rootvol to a cached volume, all in one step:
# lvcreate --type cache --cachemode writethrough -l 100%FREE -n root_cachepool MyVolGroup/rootvol /dev/fastdisk
Tip: Instead of using -l 100%FREE to allocate 100% of available space from PV /dev/fastdisk, you can use -L 20G instead to allocate only 20 GiB for cachepool.
Cachemode has two possible options:
writethroughensures that any data written will be stored both in the cache pool LV and on the origin LV. The loss of a device associated with the cache pool LV in this case would not mean the loss of any data;writebackensures better performance, but at the cost of a higher risk of data loss in case the drive used for cache fails.
If a specific --cachemode is not indicated, the system will assume writethrough as default.
Remove cache
If you ever need to undo the one step creation operation above:
# lvconvert --uncache MyVolGroup/rootvol
This commits any pending writes still in the cache back to the origin LV, then deletes the cache. Other options are available and described in lvmcache(7).
RAID
LVM may be used to create a software RAID. It is a good choice if the user does not have hardware RAID and was planning on using LVM anyway. From lvmraid(7):
- lvm(8) RAID is a way to create a Logical Volume (LV) that uses multiple physical devices to improve performance or tolerate device failures. In LVM, the physical devices are Physical Volumes (PVs) in a single Volume Group (VG).
LVM RAID supports RAID 0, RAID 1, RAID 4, RAID 5, RAID 6 and RAID 10. See Wikipedia:Standard RAID levels for details on each level.
Warning: When using the lvm2 mkinitcpio hook, make sure to include the RAID kernel modules in the initramfs. This must be done regardless whether the root volume is on LVM RAID or not, as after boot pvscan will not retry activating devices it could not activate in the initramfs phase. See FS#71385.
Tip: mdadm may also be used to create a software RAID. It is arguably simpler, more popular, and easier to setup.
Setup RAID
Create physical volumes:
# pvcreate /dev/sda2 /dev/sdb2
Create volume group on the physical volumes:
# vgcreate MyVolGroup /dev/sda2 /dev/sdb2
Create logical volumes using lvcreate --type raidlevel, see lvmraid(7) and lvcreate(8) for more options.
# lvcreate --type RaidLevel [OPTIONS] -n Name -L Size VG [PVs]
For example:
# lvcreate --type raid1 --mirrors 1 -L 20G -n myraid1vol MyVolGroup /dev/sda2 /dev/sdb2
will create a 20 GiB mirrored logical volume named «myraid1vol» in VolGroup00 on /dev/sda2 and /dev/sdb2.
Thin provisioning
Note: When mounting a thin LV file system, always remember to use the discard option or to use fstrim regularly, to allow the thin LV to shrink as files are deleted.
From lvmthin(7):
- Blocks in a standard lvm(8) Logical Volume (LV) are allocated when the LV is created, but blocks in a thin provisioned LV are allocated as they are written. Because of this, a thin provisioned LV is given a virtual size, and can then be much larger than physically available storage. The amount of physical storage provided for thin provisioned LVs can be increased later as the need arises.
Example: implementing virtual private servers
Here is the classic use case. Suppose you want to start your own VPS service, initially hosting about 100 VPSes on a single PC with a 930 GiB hard drive. Hardly any of the VPSes will actually use all of the storage they are allotted, so rather than allocate 9 GiB to each VPS, you could allow each VPS a maximum of 30 GiB and use thin provisioning to only allocate as much hard drive space to each VPS as they are actually using. Suppose the 930 GiB hard drive is /dev/sdb. Here is the setup.
Prepare the volume group, MyVolGroup.
# vgcreate MyVolGroup /dev/sdb
Create the thin pool LV, MyThinPool. This LV provides the blocks for storage.
# lvcreate --type thin-pool -n MyThinPool -l 95%FREE MyVolGroup
The thin pool is composed of two sub-volumes, the data LV and the metadata LV. This command creates both automatically. But the thin pool stops working if either fills completely, and LVM currently does not support the shrinking of either of these volumes. This is why the above command allows for 5% of extra space, in case you ever need to expand the data or metadata sub-volumes of the thin pool.
For each VPS, create a thin LV. This is the block device exposed to the user for their root partition.
# lvcreate -n SomeClientsRoot -V 30G --thinpool MyThinPool MyVolGroup
The block device /dev/MyVolGroup/SomeClientsRoot may then be used by a VirtualBox instance as the root partition.
Use thin snapshots to save more space
Thin snapshots are much more powerful than regular snapshots, because they are themselves thin LVs. See Red Hat’s guide [2] for a complete list of advantages thin snapshots have.
Instead of installing Linux from scratch every time a VPS is created, it is more space-efficient to start with just one thin LV containing a basic installation of Linux:
# lvcreate -n GenericRoot -V 30G --thinpool MyThinPool MyVolGroup *** install Linux at /dev/MyVolGroup/GenericRoot ***
Then create snapshots of it for each VPS:
# lvcreate -s MyVolGroup/GenericRoot -n SomeClientsRoot
This way, in the thin pool there is only one copy the data common to all VPSes, at least initially. As an added bonus, the creation of a new VPS is instantaneous.
Since these are thin snapshots, a write operation to GenericRoot only causes one COW operation in total, instead of one COW operation per snapshot. This allows you to update GenericRoot more efficiently than if each VPS were a regular snapshot.
Example: zero-downtime storage upgrade
There are applications of thin provisioning outside of VPS hosting. Here is how you may use it to grow the effective capacity of an already-mounted file system without having to unmount it. Suppose, again, that the server has a single 930 GiB hard drive. The setup is the same as for VPS hosting, only there is only one thin LV and the LV’s size is far larger than the thin pool’s size.
# lvcreate -n MyThinLV -V 16T --thinpool MyThinPool MyVolGroup
This extra virtual space can be filled in with actual storage at a later time by extending the thin pool.
Suppose some time later, a storage upgrade is needed, and a new hard drive, /dev/sdc, is plugged into the server. To upgrade the thin pool’s capacity, add the new hard drive to the VG:
# vgextend MyVolGroup /dev/sdc
Now, extend the thin pool:
# lvextend -l +95%FREE MyVolGroup/MyThinPool
Since this thin LV’s size is 16 TiB, you could add another 15.09 TiB of hard drive space before finally having to unmount and resize the file system.
Note: You will probably want to use reserved blocks or a disk quota to prevent applications from attempting to use more physical storage than there actually is.
Troubleshooting
LVM commands do not work
- Load proper module:
# modprobe dm_mod
The dm_mod module should be automatically loaded. In case it does not, explicitly load the module at boot.
- Try preceding commands with lvm like this:
# lvm pvdisplay
Logical Volumes do not show up
If you are trying to mount existing logical volumes, but they do not show up in lvscan, you can use the following commands to activate them:
# vgscan # vgchange -ay
LVM on removable media
Symptoms:
# vgscan
Reading all physical volumes. This may take a while... /dev/backupdrive1/backup: read failed after 0 of 4096 at 319836585984: Input/output error /dev/backupdrive1/backup: read failed after 0 of 4096 at 319836643328: Input/output error /dev/backupdrive1/backup: read failed after 0 of 4096 at 0: Input/output error /dev/backupdrive1/backup: read failed after 0 of 4096 at 4096: Input/output error Found volume group "backupdrive1" using metadata type lvm2 Found volume group "networkdrive" using metadata type lvm2
Cause: removing an external LVM drive without deactivating the volume group(s) first. Before you disconnect, make sure to:
# vgchange -an volume group name
Fix: assuming you already tried to activate the volume group with vgchange -ay vg, and are receiving the Input/output errors:
# vgchange -an volume group name
Unplug the external drive and wait a few minutes:
# vgscan # vgchange -ay volume group name
Suspend/resume with LVM and removable media
![]() The factual accuracy of this article or section is disputed.
The factual accuracy of this article or section is disputed.![]()
Reason: Provided solution will not work in more complex setups like LUKS on LVM. (Discuss in Talk:LVM#LVM on removable media)
In order for LVM to work properly with removable media – like an external USB drive – the volume group of the external drive needs to be deactivated before suspend. If this is not done, you may get buffer I/O errors on the dm device (after resume). For this reason, it is not recommended to mix external and internal drives in the same volume group.
To automatically deactivate the volume groups with external USB drives, tag each volume group with the sleep_umount tag in this way:
# vgchange --addtag sleep_umount vg_external
Once the tag is set, use the following unit file for systemd to properly deactivate the volumes before suspend. On resume, they will be automatically activated by LVM.
/etc/systemd/system/ext_usb_vg_deactivate.service
[Unit] Description=Deactivate external USB volume groups on suspend Before=sleep.target [Service] Type=oneshot ExecStart=-/etc/systemd/system/deactivate_sleep_vgs.sh [Install] WantedBy=sleep.target
and this script:
/etc/systemd/system/deactivate_sleep_vgs.sh
#!/bin/sh
TAG=@sleep_umount
vgs=$(vgs --noheadings -o vg_name $TAG)
echo "Deactivating volume groups with $TAG tag: $vgs"
# Unmount logical volumes belonging to all the volume groups with tag $TAG
for vg in $vgs; do
for lv_dev_path in $(lvs --noheadings -o lv_path -S lv_active=active,vg_name=$vg); do
echo "Unmounting logical volume $lv_dev_path"
umount $lv_dev_path
done
done
# Deactivate volume groups tagged with sleep_umount
for vg in $vgs; do
echo "Deactivating volume group $vg"
vgchange -an $vg
done
Finally, enable the unit.
Resizing a contiguous logical volume fails
If trying to extend a logical volume errors with:
" Insufficient suitable contiguous allocatable extents for logical volume "
The reason is that the logical volume was created with an explicit contiguous allocation policy (options -C y or --alloc contiguous) and no further adjacent contiguous extents are available.[3]
To fix this, prior to extending the logical volume, change its allocation policy with lvchange --alloc inherit logical_volume. If you need to keep the contiguous allocation policy, an alternative approach is to move the volume to a disk area with sufficient free extents. See [4].
Command «grub-mkconfig» reports «unknown filesystem» errors
Make sure to remove snapshot volumes before generating grub.cfg.
Thinly-provisioned root volume device times out
With a large number of snapshots, thin_check runs for a long enough time so that waiting for the root device times out. To compensate, add the rootdelay=60 kernel boot parameter to your boot loader configuration. Or, make thin_check skip checking block mappings (see [5]) and regenerate the initramfs:
/etc/lvm/lvm.conf
thin_check_options = [ "-q", "--clear-needs-check-flag", "--skip-mappings" ]
Delay on shutdown
If you use RAID, snapshots or thin provisioning and experience a delay on shutdown, make sure lvm2-monitor.service is started. See FS#50420.
Hibernating into a thinly-provisioned swap volume
See Power management/Suspend and hibernate#Hibernation into a thinly-provisioned LVM volume.
See also
- LVM2 Resource Page on SourceWare.org
- Gentoo:LVM
- Red Hat Enterprise 9: Configuring and managing logical volumes
- Ubuntu LVM Guide Part 1Part 2 details snapshots
 Обновлено: 29.04.2021
Обновлено: 29.04.2021
Опубликовано: 23.03.2019
Тематические термины: LVM, Linux.
В статье описаны основные моменты использования LVM для организации дисковой системы в Linux. Она поможет как чайникам разобраться с принципами ее работы, так и уже знающим LVM в качестве шпаргалки.
Используемые команды одинаково подойдут как для систем Red Hat / CentOS, так и Debian / Ubuntu.
Уровни абстракции
Установка LVM
Создание разделов
Инициализация (pvcreate)
Создание групп (vgcreate)
Создание логического тома (lvcreate)
Файловая система и монтирование
Создание файловой системы
Монтирование тома
Просмотр информации об LVM
Увеличение томов
Расширение физического раздела
Добавление диска к группе
Увеличение логического тома
Изменение размера файловой системы
Уменьшение томов
Удаление томов
Зеркалирование
Снапшоты
Импорт диска из другой системы
Работа с LVM в Windows
Возможные ошибки
Уровни абстракции
Работа с томами с помощью LVM происходит на 3-х уровнях абстракции:
- Физический уровень (PV). Сначала диск инициализируется командой pvcreate — в начале диска создается дескриптор группы томов. При этом важно заметить, что диск не обязательно должен быть физическим — мы можно отметить на использование обычный раздел диска.
- Группа томов (VG). С помощью команды vgcreate создается группа томов из инициализированных на предыдущем этапе дисков.
- Логический том (LV). Группы томов нарезаются на логические тома командой lvcreate.
Схематично, уровни можно представить так:

Установка
Для работы с LVM необходима установка одноименной утилиты. В системе Linux она может быть установлена по умолчанию. Но если ее нет, выполняем инструкцию ниже.
Если используем системы на безе deb (Ubuntu, Debian, Mint):
apt-get install lvm2
Если используем системы на безе RPM (Red Hat, CentOS, Fedora):
yum install lvm2
Создание разделов
Рассмотрим пример создания томов из дисков sdb и sdc с помощью LVM.
1. Инициализация
Помечаем диски, что они будут использоваться для LVM:
pvcreate /dev/sdb /dev/sdc
* напомним, что в качестве примера нами используются диски sdb и sdc.
Посмотреть, что диск может использоваться LMV можно командой:
pvdisplay
В нашем случае мы должны увидеть что-то на подобие:
«/dev/sdb» is a new physical volume of «1,00 GiB»
— NEW Physical volume —
PV Name /dev/sdb
VG Name
PV Size 1,00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID rR8qya-eJes-7AC5-wuxv-CT7a-o30m-bnUrWa
«/dev/sdc» is a new physical volume of «1,00 GiB»
— NEW Physical volume —
PV Name /dev/sdc
VG Name
PV Size 1,00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID 2jIgFd-gQvH-cYkf-9K7N-M7cB-WWGE-9dzHIY
* где
- PV Name — имя диска.
- VG Name — группа томов, в которую входит данный диск (в нашем случае пусто, так как мы еще не добавили его в группу).
- PV Size — размер диска.
- Allocatable — распределение по группам. Если NO, то диск еще не задействован и его необходимо для использования включить в группу.
- PE Size — размер физического фрагмента (экстента). Пока диск не добавлен в группу, значение будет 0.
- Total PE — количество физических экстентов.
- Free PE — количество свободных физических экстентов.
- Allocated PE — распределенные экстенты.
- PV UUID — идентификатор физического раздела.
2. Создание групп томов
Инициализированные на первом этапе диски должны быть объединены в группы.
Группа может быть создана:
vgcreate vg01 /dev/sdb /dev/sdc
* где vg01 — произвольное имя создаваемой группы; /dev/sdb, /dev/sdc — наши диски.
Просмотреть информацию о созданных группах можно командой:
vgdisplay
На что мы получим, примерно, следующее:
— Volume group —
VG Name vg01
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 1,99 GiB
PE Size 4,00 MiB
Total PE 510
Alloc PE / Size 0 / 0
Free PE / Size 510 / 1,99 GiB
VG UUID b0FAUz-wlXt-Hzqz-Sxs4-oEgZ-aquZ-jLzfKz
* где:
- VG Name — имя группы.
- Format — версия подсистемы, используемая для создания группы.
- Metadata Areas — область размещения метаданных. Увеличивается на единицу с созданием каждой группы.
- VG Access — уровень доступа к группе томов.
- VG Size — суммарный объем всех дисков, которые входят в группу.
- PE Size — размер физического фрагмента (экстента).
- Total PE — количество физических экстентов.
- Alloc PE / Size — распределенное пространство: колическтво экстентов / объем.
- Free PE / Size — свободное пространство: колическтво экстентов / объем.
- VG UUID — идентификатор группы.
3. Создание логических томов
Последний этап — создание логического раздела их группы томов командой lvcreate. Ее синтаксис:
lvcreate [опции] <имя группы томов>
Примеры создания логических томов:
lvcreate -L 1G vg01
* создание тома на 1 Гб из группы vg01.
lvcreate -L50 -n lv01 vg01
* создание тома с именем lv01 на 50 Мб из группы vg01.
lvcreate -l 40%VG vg01
* при создании тома используется 40% от дискового пространства группы vg01.
lvcreate -l 100%FREE -n lv01 vg01
* использовать все свободное пространство группы vg01 при создании логического тома.
* также можно использовать %PVS — процент места от физического тома (PV); %ORIGIN — размер оригинального тома (применяется для снапшотов).
Посмотрим информацию о созданном томе:
lvdisplay
— Logical volume —
LV Path /dev/vg01/lv01
LV Name lv01
VG Name vg01
LV UUID 4nQ2rp-7AcZ-ePEQ-AdUr-qcR7-i4rq-vDISfD
LV Write Access read/write
LV Creation host, time vln.dmosk.local, 2019-03-18 20:01:14 +0300
LV Status available
# open 0
LV Size 52,00 MiB
Current LE 13
Segments 1
Allocation inherit
Read ahead sectors auto
— currently set to 8192
Block device 253:2
* где:
- LV Path — путь к устройству логического тома.
- LV Name — имя логического тома.
- VG Name — имя группы томов.
- LV UUID — идентификатор.
- LV Write Access — уровень доступа.
- LV Creation host, time — имя компьютера и дата, когда был создан том.
- LV Size — объем дискового пространства, доступный для использования.
- Current LE — количество логических экстентов.
Создание файловой системы и монтирование тома
Чтобы начать использовать созданный том, необходимо его отформатировать, создав файловую систему и примонтировать раздел в каталог.
Файловая система
Процесс создания файловой системы на томах LVM ничем не отличается от работы с любыми другими разделами.
Например, для создания файловой системы ext4 вводим:
mkfs.ext4 /dev/vg01/lv01
* vg01 — наша группа томов; lv01 — логический том.
Для создания, например, файловой системы xfs вводим:
mkfs.xfs /dev/vg01/lv01
Монтирование
Как и в случае с файловой системой, процесс монтирования не сильно отличается от разделов, созданных другими методами.
Для разового монтирования пользуемся командой:
mount /dev/vg01/lv01 /mnt
* где /dev/vg01/lv01 — созданный нами логический том, /mnt — раздел, в который мы хотим примонтировать раздел.
Для постоянного монтирования раздела добавляем строку в fstab:
vi /etc/fstab
/dev/vg01/lv01 /mnt ext4 defaults 1 2
* в данном примере мы монтируем при загрузке системы том /dev/vg01/lv01 в каталог /mnt; используется файловая система ext4.
Проверяем настройку fstab, смонтировав раздел:
mount -a
Проверяем, что диск примонтирован:
df -hT
Просмотр информации
Разберемся, как получить информацию о дисковых накопителях в системе.
1. Для общего представления дисков, разделов и томов вводим:
lsblk
Мы получим что-то на подобие:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 30G 0 disk
sda1 8:1 0 1G 0 part /boot
sda2 8:2 0 29G 0 part
sys-root 253:0 0 27G 0 lvm /
sys-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 1G 0 disk
vg01-lv01-real 253:3 0 1G 0 lvm
vg01-lv01 253:2 0 1G 0 lvm /mnt
vg01-sn01 253:5 0 1G 0 lvm
sdc 8:32 0 1G 0 disk
vg01-lv01-real 253:3 0 1G 0 lvm
vg01-lv01 253:2 0 1G 0 lvm /mnt
vg01-sn01 253:5 0 1G 0 lvm
vg01-sn01-cow 253:4 0 500M 0 lvm
vg01-sn01 253:5 0 1G 0 lvm
sdd 8:48 0 1G 0 disk
* как видим, команда отображает корневое блочное устройство, какие разделы из него сделаны и в какие логические тома организованы из некоторых из разделов.
2. Получить информацию о проинициализированных для LVM дисков:
Кратко:
pvs
Подробно:
pvdisplay
pvdisplay /dev/sdb
3. Посмотреть информацию о группах LVM.
Кратко:
vgs
Подробно:
vgdisplay
vgdisplay vg01
4. Посмотреть информацию о логических томах можно также двумя способами — краткая информация:
lvs
* команда покажет все логические разделы.
Для более подробной информации о логических томах вводим:
lvdisplay
lvdisplay /dev/vg01/lv01
5. Для поиска всех устройств, имеющих отношение к LVM, вводим:
lvmdiskscan
Увеличение томов
Увеличение размера тома может выполняться с помощью добавления еще одного диска или при увеличении имеющихся дисков (например, увеличение диска виртуальной машины). Итак, процедура выполняется в 4 этапа:
1. Расширение физического тома
Расширение физического раздела можно сделать за счет добавление нового диска или увеличение дискового пространства имеющегося (например, если диск виртуальный).
а) Если добавляем еще один диск.
Инициализируем новый диск:
pvcreate /dev/sdd
* в данном примере мы инициализировали диск sdd.
Проверяем объем физического тома:
pvdisplay
б) Если увеличиваем дисковое пространство имеющегося диска.
Увеличиваем размер физического диска командой:
pvresize /dev/sda
* где /dev/sda — диск, который был увеличен.
Проверяем объем физического тома:
pvdisplay
2. Добавление нового диска к группе томов
Независимо от способа увеличения физического тома, расширяем группу томов командой:
vgextend vg01 /dev/sdd
* данная команда расширит группу vg01 за счет добавленого или расширенного диска sdd.
Результат можно увидеть командой:
vgdisplay
3. Увеличение логического раздела
Выполняется одной командой.
а) все свободное пространство:
lvextend -l +100%FREE /dev/vg01/lv01
* данной командой мы выделяем все свободное пространство группы томов vg01 разделу lv01.
б) определенный объем:
lvextend -L+30G /dev/vg01/lv01
* данной командой мы добавляем 30 Гб от группы томов vg01 разделу lv01.
в) до нужного объема:
lvextend -L500G /dev/vg01/lv01
* данной командой мы доводим наш раздел до объема в 500 Гб.
Результат можно увидеть командой:
lvdisplay
Обратить внимание нужно на опцию LV Size:
…
LV Status available
# open 1
LV Size <2,99 GiB
Current LE 765
…
4. Увеличение размера файловой системы
Чтобы сама система увидела больший объем дискового пространства, необходимо увеличить размер файловой системы.
Посмотреть используемую файловую систему:
df -T
Для каждой файловой системы существуют свои инструменты.
ext2/ext3/ext4:
resize2fs /dev/vg01/lv01
XFS:
xfs_growfs /dev/vg01/lv01
Reiserfs:
resize_reiserfs /dev/vg01/lv01
Уменьшение томов
Размер некоторый файловых систем, например, XFS уменьшить нельзя. Из положения можно выйти, создав новый уменьшенный том с переносом на него данных и последующим удалением.
LVM также позволяет уменьшить размер тома. Для этого необходимо выполнить его отмонтирование, поэтому для уменьшения системного раздела безопаснее всего загрузиться с Linux LiveCD. Далее выполняем инструкцию ниже.
Отмонтируем раздел, который нужно уменьшить:
umount /mnt
Выполняем проверку диска:
e2fsck -fy /dev/vg01/lv01
Уменьшаем размер файловой системы:
resize2fs /dev/vg01/lv01 500M
Уменьшаем размер тома:
lvreduce -L-500 /dev/vg01/lv01
На предупреждение системы отвечаем y:
WARNING: Reducing active logical volume to 524,00 MiB.
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce vg01/lv01? [y/n]: y
Готово.
Очень важно, чтобы сначала был уменьшен размер файловой системы, затем тома. Также важно не уменьшить размер тома больше, чем файловой системы. В противном случае данные могут быть уничтожены. Перед выполнением операции, обязательно создаем копию важных данных.
Удаление томов
Если необходимо полностью разобрать LVM тома, выполняем следующие действия.
Отмонтируем разделы:
umount /mnt
* где /mnt — точка монтирования для раздела.
Удаляем соответствующую запись из fstab (в противном случае наша система может не загрузиться после перезагрузки):
vi /etc/fstab
#/dev/vg01/lv01 /mnt ext4 defaults 1 2
* в данном примере мы не удалили, а закомментировали строку монтирования диска.
Смотрим информацию о логичеких томах:
lvdisplay
Теперь удаляем логический том:
lvremove /dev/vg01/lv01
На вопрос системы, действительно ли мы хотим удалить логических том, отвечаем да (y):
Do you really want to remove active logical volume vg01/lv01? [y/n]: y
* если система вернет ошибку Logical volume contains a filesystem in use, необходимо убедиться, что мы отмонтировали том.
Смотрим информацию о группах томов:
vgdisplay
Удаляем группу томов:
vgremove vg01
Убираем пометку с дисков на использование их для LVM:
pvremove /dev/sd{b,c,d}
* в данном примере мы деинициализируем диски /dev/sdb, /dev/sdc, /dev/sdd.
В итоге мы получим:
Labels on physical volume «/dev/sdb» successfully wiped.
Labels on physical volume «/dev/sdc» successfully wiped.
Labels on physical volume «/dev/sdd» successfully wiped.
Создание зеркала
С помощью LVM мы может создать зеркальный том — данные, которые мы будем на нем сохранять, будут отправляться на 2 диска. Таким образом, если один из дисков выходит из строя, мы не потеряем свои данные.
Зеркалирование томов выполняется из группы, где есть, минимум, 2 диска.
1. Сначала инициализируем диски:
pvcreate /dev/sd{d,e}
* в данном примере sdd и sde.
2. Создаем группу:
vgcreate vg02 /dev/sd{d,e}
3. Создаем зеркальный том:
lvcreate -L200 -m1 -n lv-mir vg02
* мы создали том lv-mir на 200 Мб из группы vg02.
В итоге:
lsblk
… мы увидим что-то на подобие:
sdd 8:16 0 1G 0 disk
vg02-lv—mir_rmeta_0 253:2 0 4M 0 lvm
vg02-lv—mir 253:6 0 200M 0 lvm
vg02-lv—mir_rimage_0 253:3 0 200M 0 lvm
vg02-lv—mir 253:6 0 200M 0 lvm
sde 8:32 0 1G 0 disk
vg02-lv—mir_rmeta_1 253:4 0 4M 0 lvm
vg02-lv—mir 253:6 0 200M 0 lvm
vg02-lv—mir_rimage_1 253:5 0 200M 0 lvm
vg02-lv—mir 253:6 0 200M 0 lvm
* как видим, на двух дисках у нас появились разделы по 200 Мб.
Работа со снапшотами
Снимки диска позволят нам откатить состояние на определенный момент. Это может послужить быстрым вариантом резервного копирования. Однако нужно понимать, что данные хранятся на одном и том же физическом носителе, а значит, данный способ не является полноценным резервным копированием.
Создание снапшотов для тома, где уже используется файловая система XFS, имеет некоторые нюансы, поэтому разберем разные примеры.
Создание для не XFS:
lvcreate -L500 -s -n sn01 /dev/vg01/lv01
* данная команда помечает, что 500 Мб дискового пространства устройства /dev/vg01/lv01 (тома lv01 группы vg01) будет использоваться для snapshot (опция -s).
Создание для XFS:
xfs_freeze -f /mnt; lvcreate -L500 -s -n sn01 /dev/vg01/lv01; xfs_freeze -u /mnt
* команда xfs_freeze замораживает операции в файловой системе XFS.
Посмотрим список логических томов:
lvs
Получим что-то на подобие:
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lv01 vg01 owi-aos— 1,00g
sn01 vg01 swi-a-s— 500,00m lv01 2,07
* поле Origin показывает, к какому оригинальному логическому тому относится LV, например, в данной ситуации наш раздел для снапшотов относится к lv01.
Также можно посмотреть изменения в томах командой:
lsblk
Мы должны увидеть что-то подобное:
sdc 8:32 0 1G 0 disk
vg01-lv01-real 253:3 0 1G 0 lvm
vg01-lv01 253:2 0 1G 0 lvm /mnt
vg01-sn01 253:5 0 1G 0 lvm
vg01-sn01-cow 253:4 0 500M 0 lvm
vg01-sn01 253:5 0 1G 0 lvm
С этого момента все изменения пишутся в vg01-sn01-cow, а vg01-lv01-real фиксируется только для чтения и мы может откатиться к данному состоянию диска в любой момент.
Содержимое снапшота можно смонтировать и посмотреть, как обычный раздел:
mkdir /tmp/snp
Монтирование не XFS:
mount /dev/vg01/sn01 /tmp/snp
Монтирование XFS:
mount -o nouuid,ro /dev/vg01/sn01 /tmp/snp
Для выполнения отката до снапшота, выполняем команду:
lvconvert —merge /dev/vg01/sn01
Импорт диска из другой системы
Если мы перенесли LVM-диск с другого компьютера или виртуальной машины и хотим подключить его без потери данных, то нужно импортировать том.
Если есть возможность, сначала нужно на старом компьютере отмонтировать том и сделать его экспорт:
umount /mnt
* предположим, что диск примонтирован в /mnt.
Деактивируем группу томов:
vgchange -an vg_test
* в данном примере наша группа называется vg_test.
Делаем экспорт:
vgexport vg_test
После переносим диск на новый компьютер.
На новой системе сканируем группы LVM следующей командой:
pvscan
… система отобразит все LVM-тома (подключенные и нет), например:
PV /dev/sdb VG vg_test lvm2 [1020,00 MiB / 0 free]
PV /dev/sda5 VG ubuntu-vg lvm2 [11,52 GiB / 0 free]
Total: 2 [12,52 GiB] / in use: 2 [12,52 GiB] / in no VG: 0 [0 ]
* в данном примере найдено два диска с томами LVM — /dev/sdb (группа vg_test) и /dev/sda5 (группа ubuntu-vg).
В моем примере новый диск с группой vg_test — будум импортировать его. Вводим команду:
vgimport vg_test
Возможны два варианта ответа:
1) если мы экспортировали том:
Volume group «vg_test» successfully imported
2) если не экспортировали:
Volume group «vg_test» is not exported
Так или иначе, группа томов должна появиться в нашей системе — проверяем командой:
vgdisplay
… мы должны увидеть что-то на подобие:
— Volume group —
VG Name vg_test
System ID
Format lvm2
…
Активируем его:
vgchange -ay vg_test
Готово. Для монтирования раздела, смотрим его командой:
lvdisplay
… и монтируем в нужный каталог, например:
mount /dev/vg_test/lvol0 /mnt
* в данном примере мы примонтируем раздел lvol0 в группе томов vg_test к каталогу /mnt.
Работа с LVM из под Windows
По умолчанию, система Windows не умеет работать с томами LVM. Для реализации такой возможности, необходимо установить утилиту Virtual Volumes.
На данный момент на сайте разработчика имеется предупреждение, что программное обеспечение на тестировании и его не следует применять для разделов, где есть важные данные без резервных копий. В противном случае, данные можно потерять.
Возможные ошибки
Рассмотрим ошибки, с которыми можно столкнуться при работе с LVM.
Device /dev/sdX excluded by a filter
Данную ошибку можно встретить при попытке инициализировать диск командой pvcreate.
Причина: либо диск не полностью чист, либо раздел не имеет нужный тип.
Решение: в зависимости от типа проблемы, рассмотрим 2 варианта.
а) если добавляем целый диск.
Удаляем все метаданные с диска командой:
wipefs -a /dev/sdX
* где вместо X (или sdX) подсталвляем имя диска.
б) если добавляем раздел.
Открываем диск с помощью команды fdisk:
fdisk /dev/sdX
* где вместо X (или sdX) подсталвляем имя диска.
Смотрим список созданных на диске разделов:
: p
Задаем тип раздела:
: t
Выбираем номер раздела (например, раздел номер 3):
: 3
Командой L можно посмотреть список всех типов, но нас интересует конкретный — LVM (8e):
: 8e
Сохраняем настройки:
: w
Материал из Xgu.ru
Перейти к: навигация, поиск
Повесть о Linux и LVM (Logical Volume Manager).
+ дополнения
- Автор: Иван Песин
- Автор: Игорь Чубин (автор дополнений)
В основу этой страницы положена работа «Повесть о Linux и LVM» Ивана Песина, которая, в свою очередь, написана на основе Linux LVM HOWTO.
Она дополнена новыми ссылками и небольшими уточнениями, а также углублённым рассмотрением нескольких дополнительных вопросов.
Один из вопросов это использование kpartx из пакета multipath-tools для построения карты устройства (device map) и рекурсивного доступа к томам LVM (когда LVM развёрнут на разделах, созданных внутри логического тома LVM более низкого уровня). Это может быть полезно при использовании LVM совместно с системами виртуализации.
Второй вопрос — это использование постоянных снимков (persistent snapshot) для быстрого клонирования разделов. Эта возможность может быть полезна как при выполнении резервного копирования, так и при быстром создании виртуальных машин в системах виртуализации (вопрос создания снимков затрагивался и в повести, но здесь он рассмотрен более детально).
Третий вопрос — это сравнение LVM и файловой системой ZFS, набирающей в последнее время большую популярность. На первый взгляд такое сравнение может показаться странным, ведь ZFS — это файловая система, а LVM — система управления томами, то есть нечто, что находится на уровень ниже файловой системы. В действительности, сравнение вполне имеет право на существование, поскольку ZFS это не просто файловая система, а нечто большее. В ней присутствует уровень «storage pool», который берёт на себя те же задачи, что и LVM.
Содержание
- 1 Введение
- 1.1 Терминология
- 1.2 Работа с LVM
- 1.3 Инициализация дисков и разделов
- 1.4 Создание группы томов
- 1.5 Активация группы томов
- 1.6 Удаление группы томов
- 1.7 Добавление физических томов в группу томов
- 1.8 Удаление физических томов из группы томов
- 1.9 Создание логического тома
- 1.10 Удаление логических томов
- 1.11 Увеличение логических томов
- 1.11.1 ext2/ext3/ext4
- 1.11.2 jfs
- 1.11.3 reiserfs
- 1.11.4 xfs
- 1.12 Уменьшение размера логического тома
- 1.12.1 ext2
- 1.12.2 ext2/ext3/ext4
- 1.12.3 reiserfs
- 1.12.4 xfs
- 1.13 Перенос данных с физического тома
- 2 Примеры
- 2.1 Настройка LVM на трех SCSI дисках
- 2.2 Создание логического тома
- 2.3 Создание файловой системы
- 2.4 Тестирование файловой системы
- 2.5 Создание логического тома с «расслоением»
- 2.6 Добавление нового диска
- 2.7 Резервное копирование при помощи «снапшотов»
- 2.8 Удаление диска из группы томов
- 2.9 Перенос группы томов на другую систему
- 2.10 Конвертация корневой файловой системы в LVM
- 2.11 Организация корневой файловой системы в LVM для дистрибутива ALT Master 2.2
- 3 Заключение
- 4 Дополнительные вопросы по LVM
- 4.1 Дисковые разделы и LVM внутри LVM
- 4.2 Создание зашифрованных томов LVM
- 4.3 Сравнение LVM и ZFS
- 4.4 Восстановления LVM после сбоя
- 4.5 Слияние LVM
- 4.6 Thin Provisioning
- 4.7 Поддержка LVM в NetBSD
- 4.8 Работа с LVM в FreeBSD
- 4.9 Работа с LVM в Windows
- 4.10 Альтернативы LVM
- 4.11 Графические инструменты администрирования LVM
- 4.12 Ограничение скорости доступа к LVM-томам
- 5 Приложения
- 5.1 Список команд для работы с LVM
- 6 Дополнительная информация
- 7 Примечания
[править] Введение
Цель статьи — описать процесс установки и использования менеджера логических томов на Linux-системе. LVM (Logical Volume Manager), менеджер логических томов — это система управления дисковым пространством, абстрагирующаяся от физических устройств. Она позволяет эффективно использовать и легко управлять дисковым пространством. LVM обладает хорошей масштабируемостью, уменьшает общую сложность системы. У логических томов, созданных с помощью LVM, можно легко изменить размер, а их названия могут нести большую смысловую нагрузку, в отличие от традиционных /dev/sda, /dev/hda …
Реализации менеджеров логических томов существуют практически во всех UNIX-подобных операционных системах. Зачастую они сильно отличаются в реализации, но все они основаны на одинаковой идее и преследуют аналогичные цели. Одна из основных реализаций была выполнена Open Software Foundation (OSF) и сейчас входит в состав многих систем, например IBM AIX, DEC Tru64, HP/UX. Она же послужила и основой для Linux-реализации LVM.
Данная статья является переработкой и дополнением LVM-HOWTO.
[править] Терминология
Поскольку система управления логическими томами использует собственную модель представления дискового пространства, нам необходимо определиться с терминами и взаимосвязями понятий. Рассмотрим схему, основанную на диаграмме Эрика Бегфорса (Erik Bеgfors), приведенную им в списке рассылки linux-lvm. Она демонстрирует взаимосвязь понятий системы LVM:
sda1 sda2 sdb sdc <-- PV
| | | |
| | | |
+--------+- VG00 -+-------+ <-- VG
|
+-------+-------+---------+
| | | |
root usr home var <-- LV
| | | |
ext3 reiserfs reiserfs xfs <-- Файловые системы
Обозначения и понятия:
- PV, Physical volume, физический том. Обычно это раздел на диске или весь диск. В том числе, устройства программного и аппаратного RAID (которые уже могут включать в себя несколько физических дисков). Физические тома входят в состав группы томов.
- VG, Volume group, группа томов. Это самый верхний уровень абстрактной модели, используемой системой LVM. С одной стороны группа томов состоит из физических томов, с другой — из логических и представляет собой единую административную единицу.
- LV, Logical volume, логический том. Раздел группы томов, эквивалентен разделу диска в не-LVM системе. Представляет собой блочное устройство и, как следствие, может содержать файловую систему.
- PE, Physical extent, физический экстент. Каждый физический том делится на порции данных, называющиеся физическими экстентами. Их размеры те же, что и у логических экстентов.
- LE, Logical extent, логический экстент. Каждый логический том делится на порции данных, называющиеся логическими экстентами. Размер логических экстентов не меняется в пределах группы томов.
Давайте теперь соединим все эти понятия в общую картину. Пусть у нас имеется группа томов VG00 с размером физического экстента 4Мб. В эту группу мы добавляем два раздела, /dev/hda1 и /dev/hdb1. Эти разделы становятся физическими томами, например PV1 и PV2 (символьные имена присваивает администратор, так что они могут быть более осмысленными). Физические тома делятся на 4-х мегабайтные порции данных, т.к. это размер физического экстента. Диски имеют разный размер: PV1 получается размером в 99 экстентов, а PV2 — размером в 248 экстентов. Теперь можно приступать к созданию логических томов, размером от 1 до 347 (248+99) экстентов. При создании логического тома, определяется отображение между логическими и физическими экстентами. Например, логический экстент 1 может отображаться в физический экстент 51 тома PV1. В этом случае, данные, записанные в первые 4Мб логического экстента 1, будут в действительности записаны в 51-й экстент тома PV1.
Администратор может выбрать алгоритм отображения логических экстентов в физические. На данный момент доступны два алгоритма:
1. Линейное отображение последовательно назначает набор физических экстентов области логического тома, т.е. LE 1 — 99 отображаются на PV1, а LE 100 — 347 — на PV2.
2. «Расслоенное» (striped) отображение разделяет порции данных логических экстентов на определенное количество физических томов. То есть:
1-я порция данных LE[1] -> PV1[1],
2-я порция данных LE[1] -> PV2[1],
3-я порция данных LE[1] -> PV3[1],
4-я порция данных LE[1] -> PV1[2], и т.д.
Похожая схема используется в работе RAID нулевого уровня. В некоторых ситуациях этот алгоритм отображения позволяет увеличить производительность логического тома. Однако он имеет значительное ограничение: логический том с данным отображением не может быть расширен за пределы физических томов, на которых он изначально и создавался.
Великолепная возможность, предоставляемая системой LVM — это «снапшоты». Они позволяют администратору создавать новые блочные устройства с точной копией логического тома, «замороженного» в какой-то момент времени. Обычно это используется в пакетных режимах. Например, при создании резервной копии системы. Однако при этом вам не будет нужно останавливать работающие задачи, меняющие данные на файловой системе. Когда необходимые процедуры будут выполнены, системный администратор может просто удалить устройство-«снапшот». Ниже мы рассмотрим работу с таким устройством.
[править] Работа с LVM
Давайте теперь рассмотрим задачи, стоящие перед администратором LVM системы. Помните, что для работы с системой LVM ее нужно инициализировать командами:
%# vgscan %# vgchange -ay
Первая команда сканирует диски на предмет наличия групп томов, вторая активирует все найденные группы томов. Аналогично для завершения всех работ, связанных с LVM, нужно выполнить деактивацию групп:
%# vgchange -an
Первые две строки нужно будет поместить в скрипты автозагрузки (если их там нет), а последнюю можно дописать в скрипт shutdown.
[править] Инициализация дисков и разделов
Перед использованием диска или раздела в качестве физического тома необходимо его инициализировать:
Для целого диска:
%# pvcreate /dev/hdb
Эта команда создает в начале диска дескриптор группы томов.
Если вы получили ошибку инициализации диска с таблицей разделов — проверьте, что работаете именно с нужным диском, и когда полностью будете уверены в том, что делаете, выполните следующие команды
%# dd if=/dev/zero of=/dev/diskname bs=1k count=1 %# blockdev --rereadpt /dev/diskname
Эти команды уничтожат таблицу разделов на целевом диске.
Для разделов:
Установите программой fdisk тип раздела в 0x8e.
%# pvcreate /dev/hdb1
Команда создаст в начале раздела /dev/hdb1 дескриптор группы томов.
[править] Создание группы томов
Для создания группы томов используется команда ‘vgcreate’
%# vgcreate vg00 /dev/hda1 /dev/hdb1
|
|
Если вы используете devfs важно указывать полное имя в devfs, а не ссылку в каталоге /dev. Таким образом приведенная команда должна выглядеть в системе с devfs так: # vgcreate vg00 /dev/ide/host0/bus0/target0/lun0/part1 /dev/ide/host0/bus0/target1/lun0/part1 |
Кроме того, вы можете задать размер экстента при помощи ключа «-s», если значение по умолчанию в 4Мб вас не устраивает. Можно, также, указать ограничения возможного количества физических и логических томов.
[править] Активация группы томов
После перезагрузки системы или выполнения команды vgchange -an, ваши группы томов и логические тома находятся в неактивном состоянии. Для их активации необходимо выполнить команду
%# vgchange -a y vg00
[править] Удаление группы томов
Убедитесь, что группа томов не содержит логических томов. Как это сделать, показано в следующих разделах.
Деактивируйте группу томов:
%# vgchange -a n vg00
Теперь можно удалить группу томов командой:
%# vgremove vg00
[править] Добавление физических томов в группу томов
Для добавления предварительно инициализированного физического тома в существующую группу томов используется команда ‘vgextend’:
%# vgextend vg00 /dev/hdc1
^^^^^^^^^ новый физический том
[править] Удаление физических томов из группы томов
Убедитесь, что физический том не используется никакими логическими томами. Для этого используйте команду ‘pvdisplay’:
%# pvdisplay /dev/hda1 --- Physical volume --- PV Name /dev/hda1 VG Name vg00 PV Size 1.95 GB / NOT usable 4 MB [LVM: 122 KB] PV# 1 PV Status available Allocatable yes (but full) Cur LV 1 PE Size (KByte) 4096 Total PE 499 Free PE 0 Allocated PE 499 PV UUID Sd44tK-9IRw-SrMC-MOkn-76iP-iftz-OVSen7
Если же физический том используется, вам нужно будет перенести данные на другой физический том при помощи команды pvmove.
%# pvmove /dev/hda1
Затем можно использовать ‘vgreduce’ для удаления физических томов:
%# vgreduce vg00 /dev/hda1
После этого используя pvremove можно удалить устройство, в котором больше нет необходимости, заполняя его метаданные нулями.
Эта процедура будет описана в следующих разделах.
[править] Создание логического тома
Для того, чтобы создать логический том «lv00», размером 1500Мб, выполните команду:
%# lvcreate -L1500 -n lv00 vg00
Без указания суффикса размеру раздела используется множитель «мегабайт» (в системе СИ равный 106 байт), что и продемонстрировано в примере выше. Суффиксы в верхнем регистре (KMGTPE) соответствуют единицам в системе СИ (с основанием 10), например, G — гигабайт равен 109 байт, а суффиксы в нижнем регистре (kmgtpe) соответствуют единицам в системе IEC (с основанием 2), например g — гибибайт равен 230 байт.
Для создания логического тома размером в 100 логических экстентов с расслоением по двум физическим томам и размером блока данных 4 KB:
%# lvcreate -i2 -I4 -l100 -n lv01 vg00
Если вы хотите создать логический том, полностью занимающий группу томов, выполните команду vgdisplay, чтобы узнать полный размер группы томов, после чего используйте команду lvcreate.
%# vgdisplay vg00 | grep "Total PE" Total PE 10230 %# lvcreate -l 10230 vg00 -n lv02
Эти команды создают логический том lv02, полностью заполняющий группу томов.
Тоже самое можно реализовать командой
%# lvcreate -l100%FREE vg00 -n lv02
[править] Удаление логических томов
Логический том должен быть размонтирован перед удалением:
%# umount /dev/vg00/home %# lvremove /dev/vg00/home lvremove -- do you really want to remove "/dev/vg00/home"? [y/n]: y lvremove -- doing automatic backup of volume group "vg00" lvremove -- logical volume "/dev/vg00/home" successfully removed
[править] Увеличение логических томов
Для увеличения логического тома вам нужно просто указать команде lvextend до какого размера вы хотите увеличить том:
%# lvextend -L12G /dev/vg00/home lvextend -- extending logical volume "/dev/vg00/home" to 12 GB lvextend -- doing automatic backup of volume group "vg00" lvextend -- logical volume "/dev/vg00/home" successfully extended
В результате /dev/vg00/home увеличится до 12Гбайт.
%# lvextend -L+1G /dev/vg00/home lvextend -- extending logical volume "/dev/vg00/home" to 13 GB lvextend -- doing automatic backup of volume group "vg00" lvextend -- logical volume "/dev/vg00/home" successfully extended
Эта команда увеличивает размер логического тома на 1Гб.
%# lvextend -l +100%FREE /dev/vg00/home lvextend -- extending logical volume "/dev/vg00/home" to 68.59 GB lvextend -- doing automatic backup of volume group "vg00" lvextend -- logical volume "/dev/vg00/home" successfully extended
А эта команда увеличивает размер логического тома до максимально доступного.
После того как вы увеличили логический том, необходимо соответственно увеличить размер файловой системы. Как это сделать зависит от типа используемой файловой системы.
По умолчанию большинство утилит изменения размера файловой системы увеличивают ее размер до размера соответствующего логического тома. Так что вам не нужно беспокоится об указании одинаковых размеров для всех команд.
[править] ext2/ext3/ext4
Если вы не пропатчили ваше ядро патчем ext2online, вам будет необходимо размонтировать файловую систему перед изменением размера:
%# umount /dev/vg00/home %# resize2fs /dev/vg00/home %# mount /dev/vg00/home /home
Если у вас нет пакета e2fsprogs 1.19 его можно загрузить с сайта ext2resize.sourceforge.net.
Для файловой системы ext2 есть и другой путь. В состав LVM входит утилита e2fsadm, которая выполняет и lvextend, и resize2fs (она также выполняет и уменьшение размера файловой системы, это описано в следующем разделе). Так что можно использовать одну команду:
%# e2fsadm -L+1G /dev/vg00/home
что эквивалентно двум следующим:
%# lvextend -L+1G /dev/vg00/home %# resize2fs /dev/vg00/home
|
|
вам все равно нужно будет размонтировать файловую систему перед выполнением e2fsadm. |
[править] jfs
mount -o remount,resize /home
[править] reiserfs
Увеличивать размер файловых систем Reiserfs можно как в смонтированном, так и в размонтированном состоянии.
Увеличить размер смонтированной файловой системы:
%# resize_reiserfs -f /dev/vg00/home
Увеличить размер размонтированной файловой системы:
%# umount /dev/vg00/homevol %# resize_reiserfs /dev/vg00/homevol %# mount -treiserfs /dev/vg00/homevol /home
[править] xfs
Размер файловой системы XFS можно увеличить только в смонтированном состоянии. Кроме того, утилите в качестве параметра нужно передать точку монтирования, а не имя устройства:
%# xfs_growfs /home
[править] Уменьшение размера логического тома
Логические тома могут быть уменьшены в размере, точно также как и увеличены. Однако очень важно помнить, что нужно в первую очередь уменьшить размер файловой системы, и только после этого уменьшать размер логического тома. Если вы нарушите последовательность, вы можете потерять данные.
[править] ext2
При использовании файловой системы ext2, как уже указывалось ранее, можно использовать команду e2fsadm:
# umount /home # e2fsadm -L-1G /dev/vg00/home # mount /home
Если вы хотите выполнить операцию по уменьшению логического тома вручную, вам нужно знать размер тома в блоках:
# umount /home # resize2fs /dev/vg00/home 524288 # lvreduce -L-1G /dev/vg00/home # mount /home
[править] ext2/ext3/ext4
Способ применимый в более современных системах.
$ sudo umount /home $ sudo e2fsck -f /dev/vg00/home $ sudo resize2fs /dev/vg00/home 11G
Указываем размер явно и с некоторым с запасом:
$ sudo lvreduce -L 12G /dev/vg00/home $ sudo e2fsck -f /dev/vg00/home $ sudo mount /home
[править] reiserfs
При уменьшении размера файловой системы Reiserfs, ее нужно размонтировать:
# umount /home # resize_reiserfs -s-1G /dev/vg00/home # lvreduce -L-1G /dev/vg00/home # mount -treiserfs /dev/vg00/home /home
[править] xfs
Уменьшить размер файловой системы XFS нельзя.
Примечание: обратите внимание на то, что для уменьшения размера файловых систем, необходимо их размонтировать. Это вносит определенные трудности, если вы желаете уменьшить размер корневой файловой системы. В этом случае можно применить следующий метод: загрузится с CD дистрибутива, поддерживающего LVM. Перейти в командный режим (обычно это делается нажатием клавиш Alt+F2) и выполнить команды сканирования и активации группы томов:
%# vgscan %# vgchange -a y
Теперь вы имеете доступ к логическим томам и можете изменять их размеры:
%# resize_reiserfs -s-500M /dev/vg00/root %# lvreduce -L-500M /dev/vg00/root %# reboot
[править] Перенос данных с физического тома
Для того, чтобы можно было удалить физический том из группы томов, необходимо освободить все занятые на нем физические экстенты. Это делается путем перераспределения занятых физических экстентов на другие физические тома. Следовательно, в группе томов должно быть достаточно свободных физических экстентов. Описание операции удаления физического тома приведено в разделе примеров.
[править] Примеры
[править] Настройка LVM на трех SCSI дисках
В первом примере мы настроим логический том из трех SCSI дисков. Устройства дисков: /dev/sda, /dev/sdb и /dev/sdc.
Перед добавлением в группу томов диски нужно инициализировать:
%# pvcreate /dev/sda %# pvcreate /dev/sdb %# pvcreate /dev/sdc
После выполнения этих команд в начале каждого диска создастся область дескрипторов группы томов.
Теперь создадим группу томов vg01, состоящую из этих дисков:
%# vgcreate vg01 /dev/sda /dev/sdb /dev/sdc
Проверим статус группы томов командой vgdisplay:
%# vgdisplay --- Volume Group --- VG Name vg01 VG Access read/write VG Status available/resizable VG # 1 MAX LV 256 Cur LV 0 Open LV 0 MAX LV Size 255.99 GB Max PV 256 Cur PV 3 Act PV 3 VG Size 1.45 GB PE Size 4 MB Total PE 372 Alloc PE / Size 0 / 0 Free PE / Size 372/ 1.45 GB VG UUID nP2PY5-5TOS-hLx0-FDu0-2a6N-f37x-0BME0Y
Обратите внимание на первые три строки и строку с общим размером группы томов. Она должна соответствовать сумме всех трех дисков. Если всё в порядке, можно переходить к следующей задаче.
[править] Создание логического тома
После успешного создания группы томов, можно начать создавать логические тома в этой группе. Размер тома может быть любым, но, естественно, не более всего размера группы томов. В этом примере мы создадим один логический том размером 1 Гб. Мы не будем использовать «расслоение», поскольку при этом невозможно добавить диск в группу томов после создания логического тома, использующего данный алгоритм.
%# lvcreate -L1G -nusrlv vg01 lvcreate -- doing automatic backup of "vg01" lvcreate -- logical volume "/dev/vg01/usrlv" successfully created
[править] Создание файловой системы
Создадим на логическом томе файловую систему ext2:
%# mke2fs /dev/vg01/usrlv mke2fs 1.19, 13-Jul-2000 for EXT2 FS 0.5b, 95/08/09 Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) 131072 inodes, 262144 blocks 13107 blocks (5.00%) reserved for the super user First data block=0 9 block groups 32768 blocks per group, 32768 fragments per group 16384 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376 Writing inode tables: done Writing superblocks and filesystem accounting information: done
[править] Тестирование файловой системы
Смонтируйте логический том и проверьте все ли в порядке:
%# mount /dev/vg01/usrlv /mnt %# df Filesystem 1k-blocks Used Available Use% Mounted on /dev/hda1 1311552 628824 616104 51% / /dev/vg01/usrlv 1040132 20 987276 0% /mnt
Если вы все сделали правильно, у вас должен появиться логический том с файловой системой ext2, смонтированный в точке /mnt.
[править] Создание логического тома с «расслоением»
Рассмотрим теперь вариант логического тома, использующего алгоритм «расслоения». Как уже указывалось выше, минусом этого решения является невозможность добавления дополнительного диска.
Процедура создания данного типа логического тома также требует инициализации устройств и добавления их в группу томов, как это уже было показано.
Для создания логического тома с «расслоением» на три физических тома с блоком данных 4Кб выполните команду:
%# lvcreate -i3 -I4 -L1G -nvarlv vg01 lvcreate -- rounding 1048576 KB to stripe boundary size 1056768 KB / 258 PE lvcreate -- doing automatic backup of "vg01" lvcreate -- logical volume "/dev/vg01/varlv" successfully created
После чего можно создавать файловую систему на логическом томе.
[править] Добавление нового диска
Рассмотрим систему со следующей конфигурацией:
%# pvscan pvscan -- ACTIVE PV "/dev/sda" of VG "dev" [1.95 GB / 0 free] pvscan -- ACTIVE PV "/dev/sdb" of VG "sales" [1.95 GB / 0 free] pvscan -- ACTIVE PV "/dev/sdc" of VG "ops" [1.95 GB / 44 MB free] pvscan -- ACTIVE PV "/dev/sdd" of VG "dev" [1.95 GB / 0 free] pvscan -- ACTIVE PV "/dev/sde1" of VG "ops" [996 MB / 52 MB free] pvscan -- ACTIVE PV "/dev/sde2" of VG "sales" [996 MB / 944 MB free] pvscan -- ACTIVE PV "/dev/sdf1" of VG "ops" [996 MB / 0 free] pvscan -- ACTIVE PV "/dev/sdf2" of VG "dev" [996 MB / 72 MB free] pvscan -- total: 8 [11.72 GB] / in use: 8 [11.72 GB] / in no VG: 0 [0] %# df Filesystem 1k-blocks Used Available Use% Mounted on /dev/dev/cvs 1342492 516468 757828 41% /mnt/dev/cvs /dev/dev/users 2064208 2060036 4172 100% /mnt/dev/users /dev/dev/build 1548144 1023041 525103 66% /mnt/dev/build /dev/ops/databases 2890692 2302417 588275 79% /mnt/ops/databases /dev/sales/users 2064208 871214 1192994 42% /mnt/sales/users /dev/ops/batch 1032088 897122 134966 86% /mnt/ops/batch
Как видно из листинга, группы томов «dev» и «ops» практически заполнены. В систему добавили новый диск /dev/sdg. Его необходимо разделить между группами «ops» и «dev», поэтому разобьем его на разделы:
%# fdisk /dev/sdg Device contains neither a valid DOS partition table, nor Sun or SGI disklabel Building a new DOS disklabel. Changes will remain in memory only, until you decide to write them. After that, of course, the previous content won't be recoverable. Command (m for help): n Command action e extended p primary partition (1-4) p Partition number (1-4): 1 First cylinder (1-1000, default 1): Using default value 1 Last cylinder or +size or +sizeM or +sizeK (1-1000, default 1000): 500 Command (m for help): n Command action e extended p primary partition (1-4) p Partition number (1-4): 2 First cylinder (501-1000, default 501): Using default value 501 Last cylinder or +size or +sizeM or +sizeK (501-1000, default 1000): Using default value 1000 Command (m for help): t Partition number (1-4): 1 Hex code (type L to list codes): 8e Changed system type of partition 1 to 8e (Unknown) Command (m for help): t Partition number (1-4): 2 Hex code (type L to list codes): 8e Changed system type of partition 2 to 8e (Unknown) Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. WARNING: If you have created or modified any DOS 6.x partitions, please see the fdisk manual page for additional information.
Перед тем как добавить разделы в группу томов, их необходимо инициализировать:
%# pvcreate /dev/sdg1 pvcreate -- physical volume "/dev/sdg1" successfully created # pvcreate /dev/sdg2 pvcreate -- physical volume "/dev/sdg2" successfully created
Теперь можно добавлять физические тома в группы томов:
%# vgextend ops /dev/sdg1 vgextend -- INFO: maximum logical volume size is 255.99 Gigabyte vgextend -- doing automatic backup of volume group "ops" vgextend -- volume group "ops" successfully extended # vgextend dev /dev/sdg2 vgextend -- INFO: maximum logical volume size is 255.99 Gigabyte vgextend -- doing automatic backup of volume group "dev" vgextend -- volume group "dev" successfully extended # pvscan pvscan -- reading all physical volumes (this may take a while...) pvscan -- ACTIVE PV "/dev/sda" of VG "dev" [1.95 GB / 0 free] pvscan -- ACTIVE PV "/dev/sdb" of VG "sales" [1.95 GB / 0 free] pvscan -- ACTIVE PV "/dev/sdc" of VG "ops" [1.95 GB / 44 MB free] pvscan -- ACTIVE PV "/dev/sdd" of VG "dev" [1.95 GB / 0 free] pvscan -- ACTIVE PV "/dev/sde1" of VG "ops" [996 MB / 52 MB free] pvscan -- ACTIVE PV "/dev/sde2" of VG "sales" [996 MB / 944 MB free] pvscan -- ACTIVE PV "/dev/sdf1" of VG "ops" [996 MB / 0 free] pvscan -- ACTIVE PV "/dev/sdf2" of VG "dev" [996 MB / 72 MB free] pvscan -- ACTIVE PV "/dev/sdg1" of VG "ops" [996 MB / 996 MB free] pvscan -- ACTIVE PV "/dev/sdg2" of VG "dev" [996 MB / 996 MB free] pvscan -- total: 10 [13.67 GB] / in use: 10 [13.67 GB] / in no VG: 0 [0]
Наконец, увеличим размеры логических томов и расширим файловые системы до размеров логических томов:
%# umount /mnt/ops/batch %# umount /mnt/dev/users # export E2FSADM_RESIZE_CMD=ext2resize # e2fsadm /dev/ops/batch -L+500M e2fsck 1.18, 11-Nov-1999 for EXT2 FS 0.5b, 95/08/09 Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/ops/batch: 11/131072 files (0.0<!-- non-contiguous), 4127/262144 blocks lvextend -- extending logical volume "/dev/ops/batch" to 1.49 GB lvextend -- doing automatic backup of volume group "ops" lvextend -- logical volume "/dev/ops/batch" successfully extended ext2resize v1.1.15 - 2000/08/08 for EXT2FS 0.5b e2fsadm -- ext2fs in logical volume "/dev/ops/batch" successfully extended to 1.49 GB # e2fsadm /dev/dev/users -L+900M e2fsck 1.18, 11-Nov-1999 for EXT2 FS 0.5b, 95/08/09 Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/dev/users: 12/262144 files (0.0% non-contiguous), 275245/524288 blocks lvextend -- extending logical volume "/dev/dev/users" to 2.88 GB lvextend -- doing automatic backup of volume group "dev" lvextend -- logical volume "/dev/dev/users" successfully extended ext2resize v1.1.15 - 2000/08/08 for EXT2FS 0.5b e2fsadm -- ext2fs in logical volume "/dev/dev/users" successfully extended to 2.88 GB
Нам осталось смонтировать системы и посмотреть их размеры:
%# mount /dev/ops/batch %# mount /dev/dev/users %# df Filesystem 1k-blocks Used Available Use% Mounted on /dev/dev/cvs 1342492 516468 757828 41% /mnt/dev/cvs /dev/dev/users 2969360 2060036 909324 69% /mnt/dev/users /dev/dev/build 1548144 1023041 525103 66% /mnt/dev/build /dev/ops/databases 2890692 2302417 588275 79% /mnt/ops/databases /dev/sales/users 2064208 871214 1192994 42% /mnt/sales/users /dev/ops/batch 1535856 897122 638734 58% /mnt/ops/batch
[править] Резервное копирование при помощи «снапшотов»
Развивая приведенный пример, предположим, что нам нужно выполнить резервирование базы данных. Для этой задачи мы будем использовать устройство-«снапшот».
Этот тип устройства представляет собой доступную только на чтение (при использовании опции —permission r) копию другого тома на момент выполнения процедуры «снапшот». Это дает возможность продолжать работу не заботясь о том, что данные могут измениться в момент резервного копирования. Следовательно, нам не нужно останавливать работу базы данных на время выполнения резервного копирования. Остановка нужна только на момент создания устройства-«снапшот», который значительно короче самого копирования.
В группе томов ops у нас осталось около 600Мб свободного места, его мы и задействуем для «снапшот»-устройства. Размер «снапшот»-устройства не регламентируется, но должен быть достаточен для сохранения всех изменений, которые могут произойти с томом, с которого он сделан, за время жизни снапшота. 600Мб должно хватить для наших целей:
%# lvcreate -L592M -s -n dbbackup -p r /dev/ops/databases lvcreate -- WARNING: the snapshot must be disabled if it gets full lvcreate -- INFO: using default snapshot chunk size of 64 KB for "/dev/ops/dbbackup" lvcreate -- doing automatic backup of "ops" lvcreate -- logical volume "/dev/ops/dbbackup" successfully create
Если вы делаете «снапшот» файловой системы XFS, нужно выполнить на смонтированной файловой системе команду xfs_freeze, и лишь после этого создавать «снапшот»:
%# xfs_freeze -f /mnt/point; lvcreate -L592M -s -n dbbackup /dev/ops/databases; xfs_freeze -u /mnt/point
|
|
Если устройство-«снапшот» полностью заполняется, оно автоматически деактивируется. В этом случае «снапшот» не может более использоваться, потому крайне важно выделять достаточное пространство для него. |
После того как мы создали «снапшот», его нужно смонтировать:
%# mkdir /mnt/ops/dbbackup %# mount /dev/ops/dbbackup /mnt/ops/dbbackup mount: block device /dev/ops/dbbackup is write-protected, mounting read-only
Если вы работаете с файловой системой XFS, вам будет нужно при монтировании указать опцию nouuid:
%# mount -o nouuid,ro /dev/ops/dbbackup /mnt/ops/dbbackup
Выполним резервное копирование раздела:
%# tar -cf /dev/rmt0 /mnt/ops/dbbackup tar: Removing leading `/' from member names
После выполнения необходимых процедур, нужно удалить устройство-«снапшот»:
%# umount /mnt/ops/dbbackup %# lvremove /dev/ops/dbbackup lvremove -- do you really want to remove "/dev/ops/dbbackup"? [y/n]: y lvremove -- doing automatic backup of volume group "ops" lvremove -- logical volume "/dev/ops/dbbackup" successfully removed
|
|
Запись данных на том, с которого сделан снимок, очень сильно замедлена |
Элементарное сравнение производительности, наглядно демонстрирующее разницу
между скоростью работы с томом, у которого нет снапшотов (смонтирован в /data/lv3/xxxx),
и с томом, на котором есть снапшот (смонтирован в /data/lv4/qqqq).
%# dd if=/dev/zero of=/data/lv3/xxxx count=100 bs=1024k 100+0 records in 100+0 records out 104857600 bytes (105 MB) copied, 0.827104 s, 127 MB/s %# dd if=/dev/zero of=/data/lv4/qqqq count=100 bs=1024k 100+0 records in 100+0 records out 104857600 bytes (105 MB) copied, 5.77779 s, 18.1 MB/s
Подробнее о снапшотах:
- Consistent backup with Linux Logical Volume Manager (LVM) snapshots (англ.)
- Back Up (And Restore) LVM Partitions With LVM Snapshots (англ.)
- Linux Kernel Documentation: device-mapper/snapshot.txt (англ.)
Резервное копирование MySQL и LVM:
- Using LVM for MySQL Backup and Replication Setup (англ.)
- MySQL Backups using LVM Snapshots (англ.)
- mylvmbackup (англ.)
[править] Удаление диска из группы томов
Скажем, вы хотите освободить один диск из группы томов. Для этого необходимо выполнить процедуру переноса использующихся физических экстентов. Естественно, что на других физических томах должно быть достаточно свободных физических экстентов.
Выполните команду:
%# pvmove /dev/hdb pvmove -- moving physical extents in active volume group "vg00" pvmove -- WARNING: moving of active logical volumes may cause data loss! pvmove -- do you want to continue? [y/n] y pvmove -- 249 extents of physical volume "/dev/hdb" successfully moved
Учтите, что операция переноса физических экстентов занимает много времени. Если вы хотите наблюдать за процессом переноса экстентов, укажите в команде ключ -v .
После окончания процедуры переноса, удалите физический том из группы томов:
%# vgreduce vg00 /dev/hdb vgreduce -- doing automatic backup of volume group "vg00" vgreduce -- volume group "vg00" successfully reduced by physical volume: vgreduce -- /dev/hdb
Теперь данный диск может быть физически удален из системы или использован в других целях. Например, добавлен в другую группу томов.
[править] Перенос группы томов на другую систему
Физический перенос группы томов на другую систему организовывается при помощи команд vgexport и vgimport.
Сперва необходимо размонтировать все логические тома группы томов и деактивировать группу:
%# unmount /mnt/design/users %# vgchange -an design vgchange -- volume group "design" successfully deactivated
После этого экспортируем группу томов. Процедура экспорта запрещает доступ к группе на данной системе и готовит ее к удалению:
%# vgexport design vgexport -- volume group "design" sucessfully exported
Теперь можно выключить машину, отсоединить диски, составляющие группу томов и подключить их к новой системе. Остается импортировать группу томов на новой машине и смонтировать логические тома:
%# pvscan pvscan -- reading all physical volumes (this may take a while...) pvscan -- inactive PV "/dev/sdb1" is in EXPORTED VG "design" [996 MB / 996 MB free] pvscan -- inactive PV "/dev/sdb2" is in EXPORTED VG "design" [996 MB / 244 MB free] pvscan -- total: 2 [1.95 GB] / in use: 2 [1.95 GB] / in no VG: 0 [0] # vgimport design /dev/sdb1 /dev/sdb2 vgimport -- doing automatic backup of volume group "design" vgimport -- volume group "design" successfully imported and activated %# mkdir -p /mnt/design/users %# mount /dev/design/users /mnt/design/users
Все! Группа томов готова к использованию на новой системе.
[править] Конвертация корневой файловой системы в LVM
В данном примере имеется установленная система на двух разделах: корневом и /boot. Диск размером 2Гб разбит на разделы следующим образом:
/dev/hda1 /boot /dev/hda2 swap /dev/hda3 /
Корневой раздел занимает все пространство, оставшееся после выделения swap и /boot разделов. Главное требование, предъявляемое к корневому разделу в нашем примере: он должен быть более чем на половину пуст. Это нужно, чтобы мы могли создать его копию. Если это не так, нужно будет использовать дополнительный диск. Процесс при этом останется тот же, но уменьшать корневой раздел будет не нужно.
Для изменения размера файловой системы мы будем использовать утилиту GNU parted.
Загрузитесь в однопользовательском режиме, это важно. Запустите программу parted для уменьшения размера корневого раздела. Ниже приведен пример диалога с утилитой parted:
# parted /dev/hda (parted) p . . .
Изменим размер раздела:
(parted) resize 3 145 999
Первое число — это номер раздела (hda3), второе — начало раздела hda3, не меняйте его. Последнее число — это конец раздела. Укажите приблизительно половину текущего размера раздела.
Создадим новый раздел:
(parted) mkpart primary ext2 1000 1999
Этот раздел будет содержать LVM. Он должен начинаться после раздела hda3 и заканчиваться в конце диска.
Выйдите из утилиты parted:
(parted) q
Перезагрузите систему. Убедитесь, что ваше ядро содержит необходимые установки. Для поддержки LVM должны быть включены параметры CONFIG_BLK_DEV_RAM и CONFIG_BLK_DEV_INITRD.
Для созданного раздела необходимо изменить тип на LVM (8e). Поскольку parted не знает такого типа, воспользуемся утилитой fdisk:
%# fdisk /dev/hda Command (m for help): t Partition number (1-4): 4 Hex code (type L to list codes): 8e Changed system type of partition 4 to 8e (Unknown) Command (m for help): w
Инициализируем LVM, физический том; создаем группу томов и логический том для корневого раздела:
%# vgscan %# pvcreate /dev/hda4 %# vgcreate vg /dev/hda4 %# lvcreate -L250M -n root vg
Создадим теперь файловую систему на логическом томе и перенесем туда содержимое корневого каталога:
%# mke2fs /dev/vg/root %# mount /dev/vg/root /mnt/ %# find / -xdev | cpio -pvmd /mnt
Отредактируйте файл /mnt/etc/fstab на логическом томе соответствующем образом. Например, строку:
/dev/hda3 / ext2 defaults 1 1
замените на:
/dev/vg/root / ext2 defaults 1 1
Создаем образ initrd, поддерживающий LVM:
%# lvmcreate_initrd Logical Volume Manager 1.0.6 by Heinz Mauelshagen 25/10/2002 lvmcreate_initrd -- make LVM initial ram disk /boot/initrd-lvm-2.4.20-inp1-up-rootlvm.gz lvmcreate_initrd -- finding required shared libraries lvmcreate_initrd -- stripping shared libraries lvmcreate_initrd -- calculating initrd filesystem parameters lvmcreate_initrd -- calculating loopback file size lvmcreate_initrd -- making loopback file (6491 kB) lvmcreate_initrd -- making ram disk filesystem (19125 inodes) lvmcreate_initrd -- mounting ram disk filesystem lvmcreate_initrd -- creating new /etc/modules.conf lvmcreate_initrd -- creating new modules.dep lvmcreate_initrd -- copying device files to ram disk lvmcreate_initrd -- copying initrd files to ram disk lvmcreate_initrd -- copying shared libraries to ram disk lvmcreate_initrd -- creating new /linuxrc lvmcreate_initrd -- creating new /etc/fstab lvmcreate_initrd -- ummounting ram disk lvmcreate_initrd -- creating compressed initrd /boot/initrd-lvm-2.4.20-inp1-up-rootlvm.gz
Внимательно изучите вывод команды. Обратите внимание на имя
нового образа и его размер. Отредактируйте файл /etc/lilo.conf. Он
должен выглядеть приблизительно следующим образом:
image = /boot/KERNEL_IMAGE_NAME label = lvm root = /dev/vg/root initrd = /boot/INITRD_IMAGE_NAME ramdisk = 8192
KERNEL_IMAGE_NAME — имя ядра, поддерживающего LVM. INITRD_IMAGE_NAME — имя образа initrd, созданного командой lvmcreate_initrd. Возможно, вам будет нужно увеличить значение ramdisk, если у вас достаточно большая конфигурация LVM, но значения 8192 должно хватить в большинстве случаев. Значение по умолчанию параметра ramdisk равно 4096. Если сомневаетесь, проверьте вывод команды lvmcreate_initrd в строке lvmcreate_initrd — making loopback file (6189 kB).
После этого файл lilo.conf нужно скопировать и на логический том:
%# cp /etc/lilo.conf /mnt/etc/
Выполните команду lilo:
%# lilo
Перезагрузитесь и выберите образ lvm. Для этого введите «lvm» в ответ на приглашение LILO. Система должна загрузится, а корневой раздел будет находиться на логическом томе.
После того как вы убедитесь, что все работает нормально, образ lvm нужно сделать загружаемым по умолчанию. Для этого укажите в конфигурационном файле LILO строку default=lvm, и выполните команду lilo.
Наконец, добавьте оставшийся старый корневой раздел в группу томов. Для этого измените тип раздела утилитой fdisk на 8е, и выполните команды:
%# pvcreate /dev/hda3 %# vgextend vg /dev/hda3
[править] Организация корневой файловой системы в LVM для дистрибутива ALT Master 2.2
При установке данного дистрибутива оказалось невозможным разместить корневой раздел в системе LVM. Связано это с тем, как выяснилось позже, что в ядре, поставляемом с данным дистрибутивом, поддержка файловой системы ext2 организована в виде загружаемого модуля. Образ же initrd использует файловую систему romfs, поддержка которой вкомпилирована в ядро. При выполнении команды lvmcreate_initrd генерируется файл-образ initrd с системой ext2. Если после этого вы попытаетесь загрузиться, то получите примерно следующее:
Kernel panic: VFS: Unable to mount root fs on 3a:00
Первое, что вам нужно будет сделать — это скомпилировать ядро со встроенной поддержкой файловой системы ext2, установить его и проверить. После этого снова выполните команду lvmcreate_initrd. Дальнейшие действия зависят от вашей конфигурации. Смонтируйте созданный образ:
%# gzip -d /boot/initrd-lvm-2.4.20-inp1-up-rootlvm.gz %# mount -o loop /boot/initrd-lvm-2.4.20-inp1-up-rootlvm /mnt/initrd
И копируйте туда модули, необходимые для работы с вашими дисковыми накопителями и файловыми системами (если они не вкомпилированы в ядро). Так, для системы с RAID-контроллером ICP-Vortex и корневой файловой системой reiserfs нужны модули: gdth.o mod_scsi.o sd_mod.o reiserfs.o. Добавьте их загрузку в файл /mnt/initrd/linuxrc.
Обратите внимание на оставшееся свободное место на образе:
Filesystem Size Used Avail Use% Mounted on
…
/boot/initrd-lvm-2.4.20-inp1-up-rootlvm
4.0M 3.9M 0.1M 100% /mnt/initrd
В файловой системе должно быть свободно еще 200-300Кб, в зависимости от вашей LVM-конфигурации. Если же у вас ситуация похожа на приведенную в листинге, будет необходимо создать новый образ, с большим размером файловой системы и повторить операции добавления модулей.
Наконец, отмонтируйте образ, сожмите его, запустите программу lilo и перезагрузитесь:
%# umount /mnt/initrd %# gzip /boot/initrd-lvm-2.4.20-inp1-up-rootlvm %# lilo %# reboot
[править] Заключение
Система управления логическими томами особенно полезна в работе с серверами, поскольку обеспечивает масштабируемость и удобное управление дисковым пространством. Она упрощает планирование дискового пространства и предотвращает проблемы, возникающие при неожиданно быстром росте занятого места в разделах. LVM не предназначен для обеспечения отказоустойчивости или высокой производительности. Потому он часто используется в сочетании с системами RAID.
Использованные источники:
- LVM-HOWTO
- http://www.gweep.net/~sfoskett/linux/lvmlinux.html
[править] Дополнительные вопросы по LVM
[править] Дисковые разделы и LVM внутри LVM
LVM может находиться рекурсивно внутри логического
тома LVM.
Например, пусть есть три логических тома: LV1, LV2 и LV3.
Один из которых, LV2 разбит на разделы,
каждый из которых является физическим томом LVM,
который в свою очередь объединены в группу томов,
на которых созданы логические тома и так далее.
LV1 LV2 LV3
...--++----------------------------+ +--....
||+-------------------------+ | |
||| LVM | | |
||+-------------------------+ | |
...--++----------------------------+ +--.....
Такая ситуация очень легко может возникнуть
при использовании виртуальных машин,
например в том случае, если том LV2
выдан как диск виртуальной машине Xen или эмулятору QEMU.
Может возникнуть необходимость залезть
внутрь системы томов, которые установлены внутрь логического тома.
Например, это может произойти в случае, когда
виртуальная машина (в результате сбоя или по какой-то другой причине),
не загружается, а нужно добраться до её данных
(напомним, что всё это при условии, что LVM используется не только
снаружи, то есть в домене 0, но и внутри, то есть в домене U).
Решение, если говорить кратко, заключается в том,
чтобы использовать kpartx из пакета multipath-tools,
которая даёт возможность строить карты устройств
(device maps) для разделов.
Далее процедура использования kpartx
описывается подробно.
Блочное устройство, внутри которого находятся
тома LVM может быть любым, в частности,
это может быть том LVM, том EVMS, простой дисковый раздел или физическое устройство.
Убедитесь что пакет multipath-tools установлен:
%# apt-get install multipath-tools
Посмотрите как выполнено разбинение на разделы:
dom0:~ # fdisk -l /dev/evms/san2/vm3
Disk /dev/evms/san2/vm3: 5368 MB, 5368708096 bytes
255 heads, 63 sectors/track, 652 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/evms/san2/vm3p1 * 1 9 72261 83 Linux
/dev/evms/san2/vm3p2 10 652 5164897+ f W95 Ext'd (LBA)
/dev/evms/san2/vm3p5 10 75 530113+ 82 Linux swap / Solaris
/dev/evms/san2/vm3p6 76 493 3357553+ 83 Linux
/dev/evms/san2/vm3p7 494 652 1277136 83 Linux
Создайте карту устройств для блочного устройства:
dom0:~ # kpartx -a /dev/evms/san2/vm3
Карты находятся здесь:
%# ls -l /dev/mapper total 0 lrwxrwxrwx 1 root root 16 Aug 26 16:28 control -> ../device-mapper brw------- 1 root root 253, 1 Aug 26 16:28 mpath1 brw------- 1 root root 253, 0 Aug 26 16:28 mpath2 brw------- 1 root root 253, 13 Aug 29 08:55 san2|vm3p1 brw------- 1 root root 253, 14 Aug 29 08:55 san2|vm3p2 brw------- 1 root root 253, 15 Aug 29 08:55 san2|vm3p5 brw------- 1 root root 253, 16 Aug 29 08:55 san2|vm3p6 brw------- 1 root root 253, 17 Aug 29 08:55 san2|vm3p7
Имена выглядят несколько странно, но вообще это нормально.
Можно попробовать смонтировать раздел:
%# mount -o rw /dev/mapper/san2|vm3p6 /mnt
В данном случае была смонтирована корневая файловая система
виртуальной машины:
%# ls -l /mnt total 96 dr-xr-xr-x 3 root root 4096 Aug 28 10:12 automount drwxr-xr-x 2 root root 4096 Aug 25 16:51 bin drwxr-xr-x 2 root root 4096 Aug 25 16:45 boot drwxr-xr-x 5 root root 4096 Aug 25 16:45 dev drwxr-xr-x 69 root root 8192 Aug 29 08:53 etc drwxr-xr-x 2 root root 4096 May 4 01:43 home drwxr-xr-x 11 root root 4096 Aug 25 17:10 lib drwx------ 2 root root 16384 Aug 25 16:45 lost+found drwxr-xr-x 2 root root 4096 May 4 01:43 media drwxr-xr-x 3 root root 4096 Aug 28 15:08 mnt drwxr-xr-x 4 root root 4096 Aug 25 16:49 opt drwxr-xr-x 2 root root 4096 Aug 25 16:45 proc drwx------ 10 root root 4096 Aug 28 14:56 root drwxr-xr-x 3 root root 8192 Aug 25 16:52 sbin drwxr-xr-x 4 root root 4096 Aug 25 16:45 srv -rw-r--r-- 1 root root 0 Aug 29 08:53 success drwxr-xr-x 3 root root 4096 Aug 25 16:45 sys drwxrwxrwt 6 root root 4096 Aug 29 08:49 tmp drwxr-xr-x 12 root root 4096 Aug 25 16:50 usr drwxr-xr-x 3 root root 4096 Aug 25 16:54 var
Аналогичным образом монтируем остальные разделы:
%# mount -o rw /dev/mapper/san2|vm3p1 /mnt/boot %# mount -o rw /dev/mapper/san2|vm3p7 /mnt/var
С разделами можно работать как обычно.
По завершению работы нужно
- размонтировать разделы;
- удалить карты устройств.
|
|
Размонтировать разделы и удалить карту устройств |
%# umount /mnt/var %# umount /mnt/boot %# umount /mnt %# kpartx -d /dev/evms/san2/vm3 %# ls -l /dev/mapper total 0 lrwxrwxrwx 1 root root 16 Aug 26 16:28 control > ../device-mapper brw------- 1 root root 253, 1 Aug 26 16:28 mpath1 brw------- 1 root root 253, 0 Aug 26 16:28 mpath2
При условии что разделы находятся не на блочном устройстве,
а в обычно файле, сначала нужно воспользоваться
программой losetup.
В данном примере loop0 это первое свободное loopback-устройство,
но возможно, что оно будет занято, и тогда вместо loop0 нужно будет использовать loopX с более выскоим номерм X:
%# cd /etc/xen/images
%# losetup /dev/loop0 /xen/images/vm1.img
%# losetup -a
/dev/loop0: [6806]:318859 (vm1.img)
%# fdisk -l /dev/loop0
Disk /dev/loop0: 1638 MB, 1638400000 bytes
255 heads, 63 sectors/track, 199 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/loop0p1 * 1 9 72261 83 Linux
/dev/loop0p2 10 199 1526175 5 Extended
/dev/loop0p5 10 26 136521 82 Linux swap / Solaris
/dev/loop0p6 27 151 1004031 83 Linux
/dev/loop0p7 152 199 385528+ 83 Linux
%# kpartx -a /dev/loop0
%# ls -l /dev/mapper/
total 0
lrwxrwxrwx 1 root root 16 Sep 12 15:38 control -> ../device-mapper
brw------- 1 root root 253, 15 Sep 30 13:19 loop0p1
brw------- 1 root root 253, 16 Sep 30 13:19 loop0p2
brw------- 1 root root 253, 17 Sep 30 13:19 loop0p5
brw------- 1 root root 253, 18 Sep 30 13:19 loop0p6
brw------- 1 root root 253, 19 Sep 30 13:19 loop0p7
Можно монтировать, копировать, восстанавливать, форматировать
эти разделы, короче, делать с ними всё, что делается с обычными дисковыми разделами.
%# mount /dev/mapper/loop0p6 /mnt %# mount /dev/mapper/loop0p1 /mnt/boot %# mount /dev/mapper/loop0p7 /mnt/var %# mount -snip- /dev/mapper/loop0p6 on /mnt type ext3 (rw) /dev/mapper/loop0p1 on /mnt/boot type ext2 (rw) /dev/mapper/loop0p7 on /mnt/var type ext3 (rw)
Другое решение:
%# lomount -diskimage vm1.img -partition 1 /mnt %# mount -snip- /xen/images/vm1.img on /mnt type ext2 (rw,loop=/dev/loop0,offset=32256)
С одной стороны при таком подходе:
- не нужно вручную подключать loopback-устройства;
- не нужно использовать kpartx;
Но с другой стороны:
- это решение позволяет смонтировать только простые разделы, размещённые внутри тома LVM.
Если внутри логического тома выполнено другое разбиение,
такой подход не поможет.
Если внутри тома находится расширенный раздел, подход работает,
но требует дополнительных манипуляций:
%# fdisk -l -u /xen/images/vm1.img You must set cylinders. You can do this from the extra functions menu. Disk vm1.img: 0 MB, 0 bytes 255 heads, 63 sectors/track, 0 cylinders, total 0 sectors Units = sectors of 1 * 512 = 512 bytes Device Boot Start End Blocks Id System vm1.img1 * 63 144584 72261 83 Linux vm1.img2 144585 3196934 1526175 5 Extended vm1.img5 144648 417689 136521 83 Linux vm1.img6 417753 2425814 1004031 83 Linux vm1.img7 2425878 3196934 385528+ 83 Linux
Найти начало интересующего раздела можно путём
умножения значения поля Start (показанного fdiks) на 512.
417753*512=213889536
Если мы хотим смонтировать корневой раздел:
%# mount -o loop,offset=213889536 /xen/images/vm1.img /mnt %# mount -snip- /xen/images/vm1.img on /mnt type ext3 (rw,loop=/dev/loop0,offset=213889536)
[править] Создание зашифрованных томов LVM
Пример создания зашифрованного тома:
%# cryptsetup -y -s 256 -c aes-cbc-essiv:sha256 luksFormat /dev/hda3 %# cryptsetup luksOpen /dev/hda3 lukspace %# pvcreate /dev/mapper/lukspace %# vgcreate vg /dev/mapper/lukspace %# lvcreate -L10G -n root vg %# lvcreate -l 100%FREE -n myspace vg
Подробнее:
- How to set up an encrypted filesystem in several easy steps (англ.)
- Resizing Encrypted Filesystems (англ.)
- How To Migrate to a full encrypted LVM system (англ.)
[править] Сравнение LVM и ZFS
- Основная страница: ZFSvsLVM
На первый взгляд такое сравнение может показаться странным,
ведь ZFS — это файловая система, а LVM — система для управления томами,
то есть нечто, что находится на уровень ниже файловой системы.
В действительности, сравнение вполне имеет право на существование,
поскольку ZFS это не просто файловая система, а нечто большее.
В ней присутствует уровень «storage pool»,
который берёт на себя те же задачи, что и LVM.
В таком случае возникает вопрос,
а какую функциональность ZFS может дать сама,
без применения LVM, и если что-то она делает лучше,
то что именно?
[править] Восстановления LVM после сбоя
- Recover Data From RAID1 LVM Partitions With Knoppix Linux LiveCD (англ.)
- LVM Recovery Tale (англ.)
- Recovery of RAID and LVM2 Volumes (англ.)
[править] Слияние LVM
В августе 2008 появился патч для ядра Linux,
который позволяет делать слияние снимка и тома:
изменения, которые делаются на снимке,
при желании можно перенести на том.
Снимок при этом перестаёт существовать.
Начиная с ядра 2.6.33 [1]
необходимый код присутствует в составе ядра Linux. Для того чтобы использовать его, необходим пакет LVM версии не менее
2.02.58 [2].
Пример использования:
%# lvconvert --merge /dev/VG0/lv1_snap
После выполнения этой команды изменения, сделанные в снимке lv1_snap будут перенесены в родительский том
/dev/VG0/lv1, а снимок перестанет существовать.
Подробнее:
- http://kerneltrap.org/Linux/LVM_Snapshot_Merging
- Merging Snapshot Volumes (англ.)
[править] Thin Provisioning
Начиная с 2012 года (полноценно с ядра Linux 3.4; май 2012)
LVM поддерживает такую возможность как thin provisioning. Это возможность использовать какое-либо внешнее блочное устройство в режиме только для чтения как основу для создания новых логических томов LVM.
Такие разделы при создании уже будут выглядеть так будто они
заполнены данными исходного блочного устройства. Операции с томами изменяются налету таким образом, что чтение данных выполняется с исходного блочного устройства (или с тома если данные уже отличаются), а запись — на том.
Такая возможность может быть полезна, например, при создании множества однотипых виртуальных машин или для решения других аналогичных задач, т.е. задач где нужно получить несколько изменяемых копий одних и тех же исходных данных.
Подробнее:
- New LVM2 release 2.02.89: Thinly-provisioned logical volumes (англ.)
- https://github.com/jthornber/linux-2.6/blob/thin-stable/Documentation/device-mapper/thin-provisioning.txt (англ.)
[править] Поддержка LVM в NetBSD
В 2008 году в NetBSD появилась[1] начальная поддержка LVM.
Та часть, которая интегрируется в ядро,
была написана с нуля и распространяется по лицензии BSD.
Другая (большая) часть, которая работает в пространстве пользователя (userland),
взята из Linux и осталась под лицензией GPL.
Пока что не работают такие вещи как создание снимков (snapshots),
не работает pvmove и нет возможности совместной работы с LVM
в кластере, как это можно делать с помощью CLVM (однако, использовать независимые логические тома в кластере, конечно же, можно).
Подробнее:
- How to use lvm on NetBSD (англ.)
- The NetBSD Logical Volume Manager (англ.)
- LVM Volume Manager on NetBSD (англ.) — пример использования LVM в NetBSD
[править] Работа с LVM в FreeBSD
- Автор: Владимир Чижиков (Skif), [3]
Для монтирования LVM с EXT2/EXT3 файловой системой необходимо скомпилировать
ядро с поддержкой EXT2FS:
options EXT2FS
либо добавить /boot/loader.conf строку:
ext2fs_load="YES"
Если после перезагрузки сервера необходимости в подключении данного диска не
будет, тогда достаточно просто подгрузить модуль ядра
kldload ext2fs
Для подключения LVM разделов необходимо перекомпилировать ядро с опцией:
option GEOM_LINUX_LVM
либо добавить /boot/loader.conf
geom_linux_lvm_load="YES"
вручную можно произвести загрузку следующим образом
geom linux_lvm load
посмотреть результат (пример):
# geom linux_lvm list
Geom name: skdeb5-home.bsd
Providers:
1. Name: linux_lvm/skdeb5-home.bsd-swap_1
Mediasize: 1551892480 (1.4G)
Sectorsize: 512
Mode: r0w0e0
2. Name: linux_lvm/skdeb5-home.bsd-root
Mediasize: 38205915136 (36G)
Sectorsize: 512
Mode: r1w1e1
Consumers:
1. Name: ad2s2
Mediasize: 39761003520 (37G)
Sectorsize: 512
Mode: r1w1e2
в /etc/fstab прописать следующим образом:
cat /etc/fstab | grep linux_lvm
/dev/linux_lvm/skdeb5-home.bsd-root /mnt/ad2s2.ext2 ext2fs rw 0 0
PS: Для монтирования LVM-раздела с другой FS, отличной от EXT2/EXT3 необходимо
перекомпилировать ядро или загрузить соответствующие данной ФС модули ядра.
[править] Работа с LVM в Windows
LVM это чуждая для Windows система, и её поддержка в Windows отсутствует.
Не предполагается, что вы будете работать с LVM из-под Windows.
Однако, в некоторых случаях такая потребность всё же может возникнуть:
- В случае, когда у вас на компьютере установлено две системы (dual boot), одна из которых Linux, а вторая Windows;
- В случае, когда на переносном диске у вас LVM, внутри ценные файлы, а рядом только Windows-машины.
Программа Virtual Volumes
позволяет обращаться к логическому тому LVM изнутри Windows-машины.
Программа находится в процессе разработки. Пока она имеет некоторые ограничения.
Подробнее:
- http://www.chrysocome.net/virtualvolumes (англ.)
[править] Альтернативы LVM
LVM сегодня — это главная система управления томами, существующая в Linux.
Раньше главным её конкурентом считалась система EVMS,
но затем, после того как LVM была включена в ядро, а EVMS нет,
конкуренция закончилась в пользу LVM.
Сейчас главными конкурентами LVM можно считать файловые системы с возможностями
систем управления томами, такие как btrfs и ZFS[2].
Кроме этого существует система Zumastor, которая отличается от LVM
лучшей поддержкой управления снимками (snapshotting) и удалённой репликацией.
Особенно печальным для LVM создатели Zumastor считают следующий факт:
если в LVM сделать много снимков с одного тома, а потом в оригинальном томе изменить какой-то блок,
то оригинальная информация будет копироваться теперь для каждого снимка[3].
Можно представить, какая будет производительность и расточительность при записи в оригинальный том,
особенно в случае большого количества снимков с него. Большим недостатком Zumastor является то, что его развитие приостановлено несколько лет назад[4].
Проблема неэффективных снапшотов в LVM считается одной из важнейших проблем LVM на сегодняшний день
и работа по её устранению относится к одной из наиболее приоритетных[5]. Другой приоритетной задачей является поддержка снапшотов бесконечной глубины, то есть, возможность создания снапшотов со снапшотов[6].
Другие попытки решить эту задачу: [4], [5].
[править] Графические инструменты администрирования LVM

![]()
system-config-lvm в действии
Есть несколько графических инструментов, помогающих использовать LVM.
В частности:
- LVM GUI Project[7];
- system-config-lvm.
Первый уже давно не развивается.
Второй является основным графическим инструментом для администрирования LVM в Redhat-подобных дистрибутивах.
Он может быть установлен и в других.
Например, в Debian[8]:
%# apt-get install system-config-lvm
Вызвать его можно командой:
%# system-config-lvm
Дополнительная информация:
- Using the LVM utility system-config-lvm (англ.) — подробно об использовании system-config-lvm
[править] Ограничение скорости доступа к LVM-томам
Ограничение делается на уровне cgroup:
mount -t tmpfs cgroup_root /sys/fs/cgroup mkdir -p /sys/fs/cgroup/blkio mount -t cgroup -o blkio none /sys/fs/cgroup/blkio
После этого:
mkdir -p /sys/fs/cgroup/blkio/limit1M/ echo "X:Y 1048576" > /sys/fs/cgroup/blkio/limit1M/blkio.throttle.write_bps_device
В качестве X:Y используются мажорный и минорный номер соответствующего тома.
Подробнее:
- How to Throttle per process I/O to a max limit? (англ.)
- Throttling IO with Linux (англ.)
- Which I/O controller is the fairest of them all? (англ.) — немного о blkio-cgroup, io-band и других механизмах регулирования скорости доступа к дисковой подсистеме
- blkio-cgroup: Introduction (англ.)
[править] Приложения
[править] Список команд для работы с LVM
- lvchange
- Изменить атрибуты логического тома
- lvcreate
- Создать логический том
- lvdisplay
- Показать информацию о логическом томе
- lvextend
- Добавить места в логический том
- lvmchange
- (команда устарела, её лучше не использовать)
- lvmdiskscan
- Показать список устройств, которые могут быть использованы как физический том
- lvmsadc
- Собрать данные об активности использования LVM
- lvmsar
- Создать отчёт об активности использования LVM
- lvreduce
- Уменьшить размер логического тома
- lvremove
- Удалить логический том из системы
- lvrename
- Переименовать логический том
lvrename vg00 lv_old lv_new
- lvresize
- Изменить размер логического тома
- lvs
- Показать информацию о логическом томе
- lvscan
- Показать список логических томов во всех группах томов
- pvchange
- Изменить атрибуты физического тома
- pvcreate
- Инициализировать физический том для использования в LVM
- pvdata
- Показать информацию (из метаданных на диске) о физическом томе
- pvdisplay
- Показать информацию о физическом томе
- pvmove
- Переместить эстенты с одного физического тома на другой.
- 1. Переместить все эстенты находящиеся на устройстве /dev/hd_source:
pvmove /dev/hd_source
- 2. Переместить эстенты тома lv_name находящиеся на устройстве /dev/hd_source на /dev/hd_target:
pvmove -n lv_name /dev/hd_source /dev/hd_target
- pvremove
- Удалить метку LVM с физического тома
- pvresize
- Изменить размер физического тома, использующегося в группе томов
- pvs
- Показать информацию о физическом томе
- pvscan
- Показать список всех физических томов
- vgcfgbackup
- Сделать резервную копию конфигурации группы томов
- vgcfgrestore
- Восстановить из резервной копии конфигурацию группы томов
- vgchange
- Изменить атрибуты группы томов
- vgck
- Проверить целостность группы томов
- vgconvert
- Изменить формат метаданных группы томов
- vgcreate
- Создать группу томов
- vgdisplay
- Показать информацию о группе томов
- vgexport
- Разрегистрировать группу томов в системе
- vgextend
- Добавить физический том в группу томов
- vgimport
- Зарегистрировать эскпортированную группу томов в системе
- vgmerge
- Объединить группы томов
vgmerge -v vg_target vg_source
- vgmknodes
- Создать файлы устройств для групп томов в каталоге /dev/
- vgreduce
- Удалить физический том из группы томов
- vgremove
- Удалить группу томов
- vgrename
- Переименовать группу томов
- vgs
- Показать информацию о группах томов
- vgscan
- Выполнить поиск групп томов
- vgsplit
- Переместить физический том в новую группу томов
[править] Дополнительная информация
- LVM-HOWTO (англ.)
- LVM2 Resource Page (англ.)
- Повесть о Linux и LVM (Logical Volume Manager), Иван Песин
- LVM в Википедии
- LVM в Wikipedia (англ.)
- «Руководство администратора LVM» на docs.redhat.com
Xen и LVM:
- (Xen-users) Xen with LVM (англ.)
- Mount/access Files Residing on Xen Virtual Machines (англ.)
[править] Примечания
- ↑ http://mail-index.netbsd.org/tech-kern/2008/08/28/msg002554.html
- ↑ Только вот btrfs пока находится в процессе разработки, а ZFS не поддерживается толком в Linux, поэтому конкуренция здесь
получается не более чем умозрительная - ↑ Zumastor HOWTO, Snapshots
- ↑ http://groups.google.com/group/zumastor/browse_thread/thread/72846703af4ef5d3
- ↑ http://www.redhat.com/archives/linux-lvm/2010-January/msg00012.html
- ↑ http://osdir.com/ml/linux-lvm/2011-01/msg00010.html
- ↑ http://www.xs4all.nl/~mmj/lvm/
- ↑ Или в Ubuntu: http://ubuntuforums.org/showthread.php?t=216117
 |
|
|---|
Что такое диспетчер логических томов LVM?
LVM аккумулирует пространство, взятое из разделов или целых дисков, чтобы сформировать логический контейнер (Группа томов). Группа томов далее делится на логические разделы, называемые логическими томами.
Проще говоря, LVM группирует все ваше пространство хранения в пул и позволяет вам создавать тома (логические тома) из этого пула.
Преимущество использования LVM перед стандартным разделом заключается в том, что LVM предлагает вам больше гибкости и возможностей. Он позволяет онлайн изменять размеры логических групп и логических томов. Поэтому, если в каком-либо из ваших логических разделов закончилось место, вы можете легко увеличить размер раздела, используя свободное место в пуле.
Вы также можете экспортировать и импортировать разделы. LVM также поддерживает зеркалирование и создание моментальных снимков логических томов.
Слои абстракции в LVM
LVM обеспечивает абстракцию между физическим хранилищем и файловой системой, позволяя изменять размер файловой системы, охватывать несколько физических дисков и использовать произвольное дисковое пространство.
LVM использует три уровня абстракции для создания разделов.
- Физический том,
- Группа томов,
- Логический том.
Физический том
Все начинается с физического диска. Физический том – это первый уровень абстракции, который LVM использует для идентификации диска, помеченного для операций LVM. Проще говоря, если вы хотите работать с LVM, ваш диск должен быть инициализирован как физический том. Это может быть целый диск или стандартные разделы, созданные на этом диске.
Группа томов
Группа томов – это комбинация всех физических томов. Допустим, у вас есть пять отдельных дисков размером 1 ТБ каждый. Сначала вы инициализируете пять дисков как физический том, а затем добавите их в группу томов.
Группа томов будет содержать 5 ТБ пространства, которое является пространством, доступным для всех физических томов. Из группы томов можно создать логические разделы.
Логические тома
Из пула пространства (группа томов) можно создать логические тома. Считайте, что это эквивалентно стандартному разделу диска.
Я использую сервер Ubuntu, запущенный в virtualbox для демонстрации. Если вы изучаете LVM впервые, проведите тестирование на любой виртуальной машине.
Внимание: Команды LVM требуют привилегий root. Выполняйте все команды либо от имени пользователя root, либо с привилегией sudo.
Шаг 1 – Инициализация физического тома
Я добавил три диска разного размера, в общей сложности 10G.
sudo lsblk /dev/sd[b-e] NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdb 8:16 0 2G 0 disk sdc 8:32 0 3G 0 disk sdd 8:48 0 5G 0 disk
Для инициализации любого диска как физического тома используйте команду pvcreate с именем устройства в качестве аргумента.
sudo pvcreate /dev/sdb /dev/sdc /dev/sdd Physical volume "/dev/sdb" successfully created. Physical volume "/dev/sdc" successfully created. Physical volume "/dev/sdd" successfully created.
Чтобы проверить список физических томов, вы можете выполнить любую из следующих команд. Каждая команда даст разные результаты.
PVDISPLAY – Команда pvdisplay даст вам подробную информацию о каждом физическом томе, под какой группой томов он находится, уникальный ID и доступный размер.
sudo pvdisplay
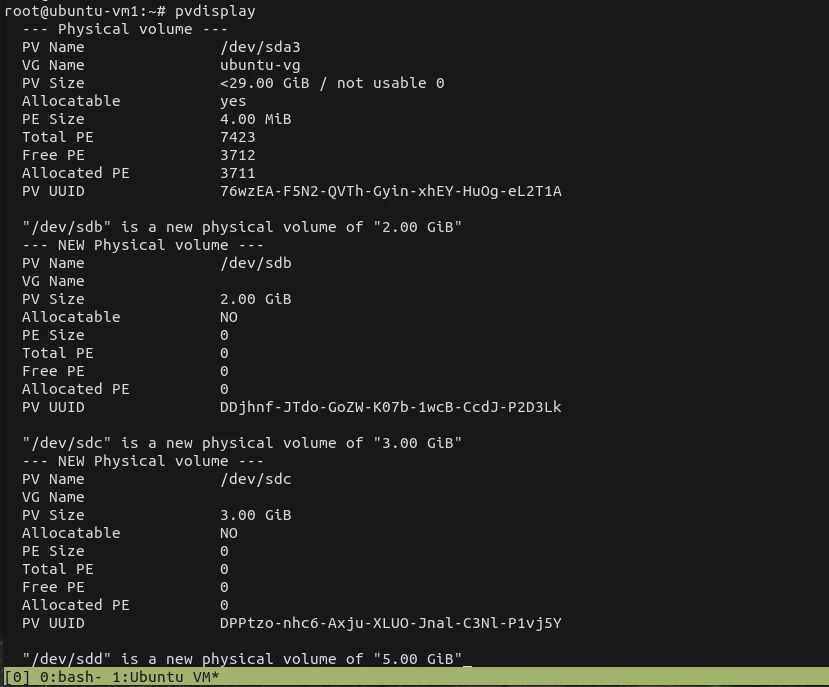
PVS & PVSCAN – Эти две команды показывают информацию, как физический объем, группа томов, выделенный и свободный размер.
sudo pvs
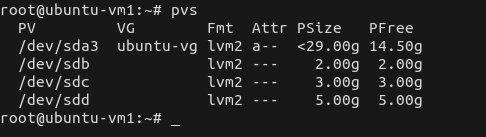
sudo pvscan

Шаг 2 – Создание группы томов
Теперь у меня есть три диска, инициализированные как физический том общим размером 10 ГБ. Эти физические тома должны быть добавлены в пул хранения, известный как группа томов.
Выполните команду vgcreate для создания группы томов. Вы должны передать имя для группы томов. Здесь я использую «myDisk» в качестве имени группы томов.
sudo vgcreate myDisk /dev/sd[b-d] Volume group "myDisk" successfully created
Выполните любую из следующих команд для проверки сведений о группе томов.
sudo vgdisplay
или
sudo vgdisplay <имя группы томов>
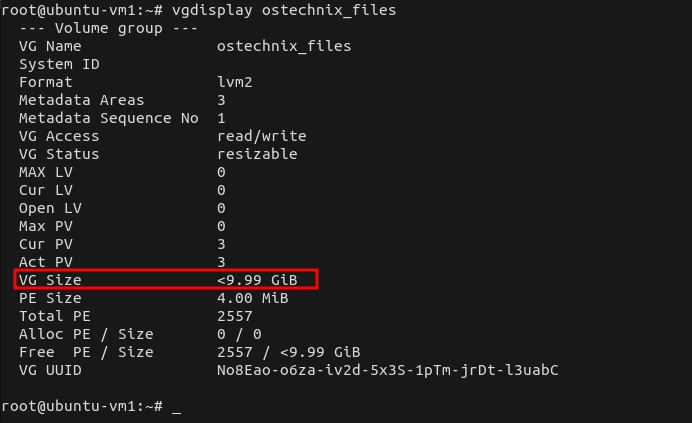
Шаг 3 – Отображение сведений о группе томов
Команды vgs и vgscan предоставят вам информацию обо всех доступных группах томов, количестве физических томов и количестве логических томов, выделенных и свободных размерах группы томов.
sudo vgs sudo vgscan
Шаг 4 – Создание логических томов
Как я уже говорил, логический том похож на разделы диска. Теперь у нас есть почти 10 ГБ свободного места в пуле «myDisk» (группа томов). На основе этой группы томов мы создадим логические тома, отформатируем том с файловой системой ext4, смонтируем и будем использовать том.
Для создания логического тома можно использовать команду lvcreate. Общий синтаксис команды lvcreate приведен ниже.
sudo lvcreate -L <volume-size> -n <logical-volume-name> <volume-group>
Здесь,
-L=> размер в KB, MB, GB-n=> Имя для вашего тома=> Какая группа томов будет использоваться Сейчас я создаю логический том размером 3GB. Я назвал логический том «guides «.
sudo lvcreate -L 3GB -n guides myDisk Logical volume "guides" created.
Шаг 5 – Просмотр информации о логических томах
Для просмотра информации о логических томах можно использовать любую из следующих команд.
Команда *lvdisplay* предоставляет подробную информацию о логическом томе, связанной с ним группе томов, размере тома, пути к логическому тому и т.д.
lvdisplay
Или укажите имя логического тома явно:
lvdisplay guides
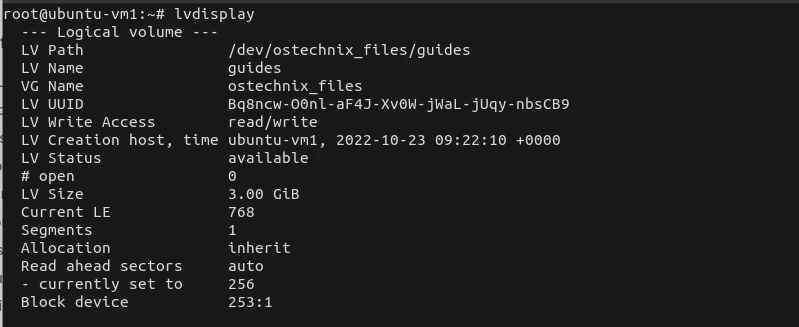
Команды lvscan и lvs также предоставят некоторую базовую информацию о логических томах.
lvscan lvs

Шаг 6 – Форматирование и монтирование логических томов
Вам нужно отформатировать логический том с файловой системой и смонтировать его. Здесь я форматирую том с файловой системой ext4 и монтирую его в каталог /mnt/.
Вы должны увидеть файл устройства для логического тома под /dev/volume-group/logical-volume. В моем случае файл устройства будет /dev/myDisk/guides.
sudo mkfs.ext4 /dev/myDisk/guides
Creating filesystem with 786432 4k blocks and 196608 inodes
Filesystem UUID: a477d1b6-e806-451f-ab34-4be9978c1328
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
Для монтирования каталога выполните следующую команду. Вы можете смонтировать каталог в любое место по своему усмотрению.
sudo mount /dev/ostechnix_files/guides /mnt/
Для просмотра смонтированных томов выполните:
mount | grep -i guides /dev/mapper/myDisk-guides on /mnt type ext4 (rw,relatime)
Вы также можете выполнить команду df, чтобы проверить информацию о смонтированной файловой системе. Вы можете увидеть, что файловая система названа именем тома. Вам будет довольно легко понять, что это за том и его группа с таким названием.
df -h /mnt/ Filesystem Size Used Avail Use% Mounted on /dev/mapper/myDisk-guides 2.9G 9.0M 2.8G 1% /mnt
Чтобы сделать монтирование постоянным при перезагрузках, вы должны добавить запись в fstab. Если вы не имеете представления о fstab, я советую вам ознакомиться с нашей подробной статьей о fstab.
Что такое Fstab в Linux
Похожие статьи
- Понимание файла /etc/mtab в системе Linux
Not to be confused with LLVM.
LVM (Logical Volume Manager) allows administrators to create meta devices that provide an abstraction layer between a file system and the physical storage that is used underneath. The meta devices (on which file systems are placed) are logical volumes, which use storage from storage pools called volume groups. A volume group is provisioned with one or more physical volumes which are the true devices on which the data is stored.
Physical volumes can be partitions, whole hard drives grouped as JBOD (Just a Bunch Of Disks), RAID systems, iSCSI, Fibre Channel, eSATA etc.
Installation
LVM is handled by both kernel-level drivers and user space applications to manage the LVM configuration.
Kernel
Activate the following kernel options:
KERNEL linux-4.9 Enabling LVM
Device Drivers --->
Multiple devices driver support (RAID and LVM) --->
<*> Device mapper support
<*> Crypt target support
<*> Snapshot target
<*> Mirror target
<*> Multipath target
<*> I/O Path Selector based on the number of in-flight I/Os
<*> I/O Path Selector based on the service time
USE flags
USE flags for
sys-fs/lvm2
User-land utilities for LVM2 (device-mapper) software
lvm
|
Build all of LVM2 including daemons and tools like lvchange, not just the device-mapper library (for other packages to use). If your system uses LVM2 for managing disks and partitions, enable this flag. |
readline
|
Enable support for libreadline, a GNU line-editing library that almost everyone wants |
sanlock
|
Enable lvmlockd with support for sanlock |
selinux
|
!!internal use only!! Security Enhanced Linux support, this must be set by the selinux profile or breakage will occur |
static
|
!!do not set this during bootstrap!! Causes binaries to be statically linked instead of dynamically |
static-libs
|
Build static versions of dynamic libraries as well |
systemd
|
Enable use of systemd-specific libraries and features like socket activation or session tracking |
thin
|
Support for thin volumes |
udev
|
Enable virtual/udev integration (device discovery, power and storage device support, etc) |
valgrind
|
Make Valgrind (dev-util/valgrind) aware of LVM2’s pool allocator. |
Important
For all instructions requiring the use of the lvm, pv*, vg*, or lv* commands in this article as well as access of LVM volumes, the lvm USE flag is required to be enabled.
Emerge
Make sure to enable USE=lvm for sys-fs/lvm2:
FILE /etc/portage/package.use
# Enable support for the LVM daemon and related tools sys-fs/lvm2 lvmAfter reviewing the USE flags, ask Portage to install the sys-fs/lvm2 package:
root #emerge --ask sys-fs/lvm2Configuration
Configuring LVM is done on several levels:
- LV, PV and VG management through the management utilities;
- LVM subsystem fine-tuning through the configuration file;
- Service management at the distribution level;
- Setup through an initial ram file system (initramfs).
Management of the logical and physical volumes as well as the volume groups is handled through the Usage chapter.
LVM configuration file
LVM has an extensive configuration file at /etc/lvm/lvm.conf. Most users will not need to modify settings in this file in order to start using LVM.
Service management
Gentoo provides the LVM service to automatically detect and activate the volume groups and logical volumes.
The service can be managed through the init system.
openrc
To start LVM manually:
root #/etc/init.d/lvm startTo start LVM at boot time:
root #rc-update add lvm bootsystemd
To start lvm manually:
root #systemctl start lvm2-monitor.serviceTo start LVM at boot time:
root #systemctl enable lvm2-monitor.serviceUsing LVM in an initramfs
Most bootloaders cannot boot from LVM directly — neither GRUB Legacy nor LILO can. GRUB2 can boot from an LVM linear logical volume, mirrored logical volume and possibly some kinds of RAID logical volumes. No bootloader currently supports thin logical volumes.
For that reason, it is recommended to use a non-LVM /boot partition and mount the LVM root from an initramfs. An initramfs can be generated automatically through Genkernel, Dracut or manually as Custom Initramfs:
- genkernel can boot from all types except thin volumes (as it neither builds nor copies the sys-block/thin-provisioning-tools binaries from the build host) and maybe RAID10 (RAID10 support requires LVM2 2.02.98, but genkernel builds 2.02.89, however if static binaries are available it can copy those);
- dracut should boot all types, but only includes thin support in the initramfs if the host being run on has a thin root.
Genkernel
Emerge sys-kernel/genkernel. The static USE flag may also be enabled on the package sys-fs/lvm2 so that genkernel will use the system binaries (otherwise it will build its own private copy). The following example will build only an initramfs (not an entire kernel) and enable support for LVM.
root #genkernel --lvm initramfs
The genkernel manpage outlines other options depending on system requirements.
The initrd will require parameters to tell it how to start LVM, and they are supplied the same way as other kernel parameters. For example:
FILE /etc/default/grubAdding dolvm as a kernel boot parameter
GRUB_CMDLINE_LINUX="dolvm"Dracut
The sys-kernel/dracut package was ported from the RedHat project and serves a similar tool for generating an initramfs. For details, please refer to Dracut page. Generally, the following command will generate a usable default initramfs.
The initrd will require parameters to tell it how to start LVM, and they are supplied the same way as other kernel parameters. For example:
FILE
/etc/default/grubAdding LVM support to the kernel boot parametersGRUB_CMDLINE_LINUX="rd.lvm.vg=vol00"For a comprehensive list of LVM options within dracut please see the section in the Dracut Manual.
Usage
LVM organizes storage in three different levels as follows:
- hard drives, partitions, RAID systems or other means of storage are initialized as physical volumes (PVs)
- Physical Volumes (PV) are grouped together in Volume Groups (VG)
- Logical Volumes (LV) are managed in Volume Groups (VG)
PV (Physical Volume)
Physical Volumes are the actual hardware or storage system LVM builds up upon.
Partitioning
Note
Using separate partitions for provisioning storage to volume groups is only needed if it is not desired to use the entire disk for a single LVM volume group. If the entire disk can be used, then skip this and initialize the entire hard drive as a physical volume.
The partition type for LVM is 8e (Linux LVM).
For instance, to set the type through fdisk for a partition on /dev/sda:
In fdisk, create partitions using the n key and then change the partition type with the t key to 8e.
Create PV
Physical volumes can be created / initialized with the pvcreate command.
For instance, the following command creates a physical volume on the first primary partition of /dev/sda and /dev/sdb:
root #pvcreate /dev/sd[ab]1
List PV
With the pvdisplay command, an overview of all active physical volumes on the system can be obtained.
root #pvdisplay
--- Physical volume --- PV Name /dev/sda1 VG Name volgrp PV Size 160.01 GiB / not usable 2.31 MiB Allocatable yes PE Size 4.00 MiB Total PE 40962 Free PE 4098 Allocated PE 36864 PV UUID 3WHAz3-dh4r-RJ0E-5o6T-9Dbs-4xLe-inVwcV --- Physical volume --- PV Name /dev/sdb1 VG Name volgrp PV Size 160.01 GiB / not usable 2.31 MiB Allocatable yes PE Size 4.00 MiB Total PE 40962 Free PE 40962 Allocated PE 0 PV UUID b031x0-6rej-BcBu-bE2C-eCXG-jObu-0Boo0x
If more physical volumes should be displayed, then pvscan can detect inactive physical volumes and activate those.
root #pvscan
PV /dev/sda1 VG volgrp lvm2 [160.01 GiB / 16.01 GiB free] PV /dev/sdb1 VG volgrp lvm2 [160.01 GiB / 160.01 GiB free] Total: 2 [320.02 GB] / in use: 2 [320.02 GiB] / in no VG: 0 [0]
Remove PV
LVM automatically distributes the data onto all available physical volumes (unless told otherwise) but in a linear approach. If a requested logical volume (within a volume group) is smaller than the amount of free space on a single physical volume, then all space for the logical volume is claimed on that (single) physical volume in a contiguous manner. This is done for performance reasons.
If a physical volume needs to be removed from a volume group, the data first needs to be moved away from the physical volume. With the pvmove command, all data on a physical volume is moved to other physical volumes within the same volume group.
root #pvmove -v /dev/sda1
Such an operation can take a while depending on the amount of data that needs to be moved. Once finished, there should be no data left on the device. Verify with pvdisplay that the physical volume is no longer used by any logical volume.
The next step is to remove the physical volume from the volume group using vgreduce after which the device can be «deselected» as a physical volume using pvremove:
root #vgreduce vg0 /dev/sda1 && pvremove /dev/sda1
VG (Volume Group)
A volume group (VG) groups a number of physical volumes and show up as /dev/VG_NAME in the device file system. The name of a volume group is chosen by the administrator.
Create VG
The following command creates a volume group called vg0 with two physical volumes assigned to it: /dev/sda1 and /dev/sdb1.
root #vgcreate vg0 /dev/sd[ab]1
List VG
To list all active volume groups, use the vgdisplay command:
root #vgdisplay
--- Volume group --- VG Name vg0 System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 8 VG Access read/write VG Status resizable MAX LV 0 Cur LV 6 Open LV 6 Max PV 0 Cur PV 1 Act PV 1 VG Size 320.02 GiB PE Size 4.00 MiB Total PE 81924 Alloc PE / Size 36864 / 144.00 GiB Free PE / Size 45056 /176.01 GiB VG UUID mFPXj3-DdPi-7YJ5-9WKy-KA5Y-Vd4S-Lycxq3
If volume groups are missing, use the vgscan command to locate volume groups:
root #vgscan
Reading all physical volumes. This may take a while... Found volume group "vg0" using metadata type lvm2
Extend VG
Volume groups group physical volumes, allowing administrators to use a pool of storage resources to allocate to file systems. When a volume group does not hold enough storage resources, it is necessary to extend the volume group with additional physical volumes.
The next example extends the volume group vg0 with a physical volume at /dev/sdc1:
root #vgextend vg0 /dev/sdc1
Remember that the physical volume first needs to be initialized as such!
Reduce VG
If physical volumes need to be removed from the volume group, all data still in use on the physical volume needs to be moved to other physical volumes in the volume group. As seen before, this is handled through the pvmove command, after which the physical volume can be removed from the volume group using vgreduce:
root #pvmove -v /dev/sdc1
root #vgreduce vg0 /dev/sdc1
Remove VG
If a volume group is no longer necessary (or, in other words, the storage pool that it represents is no longer used and the physical volumes in it need to be freed for other purposes) then the volume group can be removed with vgremove. This only works if no logical volume is defined for the volume group, and all but one physical volume have already been removed from the pool.
LV (Logical Volume)
Logical volumes are the final meta devices which are made available to the system, usually to create file systems on. They are created and managed in volume groups and show up as /dev/VG_NAME/LV_NAME. Like with volume groups, the name used for a logical volume is decided by the administrator.
Create LV
To create a logical volume, the lvcreate command is used. The parameters to the command consist out of the requested size for the logical volume (which cannot be larger than the amount of free space in the volume group), the volume group from which the space is to be claimed and the name of the logical volume to be created.
In the next example, a logical volume named lvol1 is created from the volume group named vg0 and with a size of 150MB:
root #lvcreate -L 150M -n lvol1 vg0
It is possible to tell lvcreate to use all free space inside a volume group. This is done through the -l option which selects the amount of extents rather than a (human readable) size. Logical volumes are split into logical extents which are data chunks inside a volume group. All extents in a volume group have the same size. With the -l option lvcreate can be asked to allocate all free extents:
root #lvcreate -l 100%FREE -n lvol1 vg0
Next to FREE the VG key can be used to denote the entire size of a volume group.
List LV
To list all logical volumes, use the lvdisplay command:
If logical volumes are missing, then the lvscan command can be used to scan for logical volumes on all available volume groups.
Extend LV
When a logical volume needs to be expanded, then the lvextend command can be used to grow the allocated space for the logical volume.
For instance, to extend the logical volume lvol1 to a total of 500 MB:
root #lvextend -L500M /dev/vg0/lvol1
It is also possible to use the size to be added rather than the total size:
root #lvextend -L+350MB /dev/vg0/lvol1
An extended volume group does not immediately provide the additional storage to the end users. For that, the file system on top of the volume group needs to be increased in size as well. Not all file systems allow online resizing, so check the documentation for the file system in question for more information.
For instance, to resize an ext4 file system to become 500MB in size:
root #resize2fs /dev/vg0/lvol1 500M
For certain file systems, lvresize extends the logical volume and the file system in one step. For instance, to extend the logical volume lvol1 and resize the ext4 file system:
root #lvresize --resizefs --size +350GB /dev/vg0/lvol1
Reduce LV
If a logical volume needs to be reduced in size, first shrink the file system itself. Not all file systems support online shrinking.
For instance, ext4 does not support online shrinking so the file system needs to be unmounted first. It is also recommended to do a file system check to make sure there are no inconsistencies:
root #umount /mnt/data
root #e2fsck -f /dev/vg0/lvol1
root #resize2fs /dev/vg0/lvol1 150M
With a reduced file system, it is now possible to reduce the logical volume as well:
root #lvreduce -L150M /dev/vg0/lvol1
LV Permissions
LVM supports permission states on the logical volumes.
For instance, a logical volume can be set to read only using the lvchange command:
root #lvchange -p r /dev/vg0/lvol1
root #mount -o remount /dev/vg0/lvol1
The remount is needed as the change is not enforced immediately.
To mark the logical volume as writable again, use the rw permission bit:
root #lvchange -p rw /dev/vg0/lvol1 && mount -o remount /dev/vg0/lvol1
Remove LV
Before removing a logical volume, make sure it is no longer mounted:
root #umount /dev/vg0/lvol1
Deactivate the logical volume so that no further write activity can take place:
root #lvchange -a n /dev/vg0/lvol1
With the volume unmounted and deactivated, it can now be removed, freeing the extents allocated to it for use by other logical volumes in the volume group:
root #lvremove /dev/vg0/lvol1
Features
LVM provides quite a few interesting features for storage administrators, including (but not limited to)
- thin provisioning (over-committing storage)
- snapshot support
- volume types with different storage allocation methods
Thin provisioning
Make sure to enable USE=thin for sys-fs/lvm2:
FILE /etc/portage/package.use
# Enable support for the LVM daemon and related tools sys-fs/lvm2 lvm # Enable thin support sys-fs/lvm2 thinRecent versions of LVM2 (2.02.89) support «thin» volumes. Thin volumes are to block devices what sparse files are to file systems. Thus, a thin logical volume within a pool can be «over-committed»: its presented size can be larger than the allocated size — it can even be larger than the pool itself. Just like a sparse file, the extents are allocated as the block device gets populated. If the file system has discard support extents are freed again as files are removed, reducing space utilization of the pool.
Within LVM, such a thin pool is a special type of logical volume, which itself can host logical volumes.
Creating a thin pool
Warning
If an overflow occurs within the thin pool metadata, then the pool will be corrupted. LVM cannot recover from this.Note
If the thin pool gets exhausted, any process that would cause the thin pool to allocate more (unavailable) extents will be stuck in «killable sleep» state until either the thin pool is extended or the process receives SIGKILL.Each thin pool has metadata associated with it, which is added to the thin pool size. LVM will compute the size of the metadata based on the size of the thin pool as the minimum of pool_chunks * 64 bytes or 2 MiB, whichever is larger. The administrator can select a different metadata size as well.
To create a thin pool, add the
--type thin-pool --thinpool thin_pooloptions to lvcreate:
root #lvcreate -L 150M --type thin-pool --thinpool thin_pool vg0The above example creates a thin pool called thin_pool with a total size of 150 MB. This is the real allocated size for the thin pool (and thus the total amount of actual storage that can be used).
To explicitly ask for a certain metadata size, use the
--metadatasizeoption:
root #lvcreate -L 150M --poolmetadatasize 2M --type thin-pool --thinpool thin_pool vg0Due to the metadata that is added to the thin pool, the intuitive way of using all available size in a volume group for a logical volume does not work (see LVM bug 812726):
root #lvcreate -l 100%FREE --type thin-pool --thinpool thin_pool vg0Insufficient suitable allocatable extents for logical volume thin_pool: 549 more requiredNote the thin pool does not have an associated device node like other LV’s.
Creating a thin logical volume
A thin logical volume is a logical volume inside the thin pool (which itself is a logical volume). As thin logical volumes are sparse, a virtual size instead of a physical size is specified using the
-Voption:
root #lvcreate -T vg0/thin_pool -V 300M -n lvol1In this example, the (thin) logical volume lvol1 is exposed as a 300MB-sized device, even though the underlying pool only holds 150MB of real allocated storage.
It is also possible to create both the thin pool as well as the logical volume inside the thin pool in one command:
root #lvcreate -T vg0/thin_pool -V 300M -L150M -n lvol1Listing thin pools and thin logical volumes
Thin pools and thin logical volumes are special types of logical volumes, and as such as displayed through the lvdisplay command. The lvscan command will also detect these logical volumes.
Extending a thin pool
Warning
As of LVM2 2.02.89, the metadata size of the thin pool cannot be expanded, it is fixed at creationThe thin pool is expanded like a non-thin logical volume using lvextend. For instance:
root #lvextend -L500M vg0/thin_poolExtending a thin logical volume
A thin logical volume is expanded just like a regular one:
root #lvextend -L1G vg0/lvol1Note that the lvextend command uses the
-Loption (or-lif extent counts are used) and not a «virtual size» option as was used during the creation.Reducing a thin pool
Currently, LVM cannot reduce the size of the thin pool. See LVM bug 812731.
Reducing a thin logical volume
Thin logical volumes are reduced just like regular logical volumes.
For instance:
root #lvreduce -L300M vg0/lvol1lNote that the lvreduce command uses the
-Loption (or-lif extent counts are used) and not a «virtual size» option as was used during the creation.Removing thin pools
Thin pools cannot be removed until all the thin logical volumes inside it are removed.
When a thin pool no longer services any thin logical volume, it can be removed through the lvremove command:
root #lvremove vg0/thin_poolLVM2 snapshots and thin snapshots
A snapshot is a logical volume that acts as copy of another logical volume. It displays the state of the original logical volume at the time of snapshot creation.
Warning
Since the logical snapshot volume also gets the same filesystem LABEL and UUID, be sure the /etc/fstab file or initramfs does not contain entries for these filesystems using theLABEL=orUUID=syntax. Otherwise the system might end up with the snapshot being mounted instead of the (intended) original logical volume.Creating a snapshot logical volume
A snapshot logical volume is created using the
-soption to lvcreate. Snapshot logical volumes are still given allocated storage as LVM «registers» all changes made to the original logical volume and stores these changes in the allocated storage for the snapshot. When querying the snapshot state, LVM will start from the original logical volume and then check all changes registered, «undoing» the changes before showing the result to the user.A snapshot logical volume henceforth «growths» at the rate that changes are made on the original logical volume. When the allocated storage for the snapshot is completely used, then the snapshot will be removed automatically from the system.
root #lvcreate -l 10%VG -s -n 20140412_lvol1 /dev/vg0/lvol1The above example creates a snapshot logical volume called 20140412_lvol1, based on the logical volume lvol1 in volume group vg0. It uses 10% of the space (extents actually) allocated to the volume group.
Accessing a snapshot logical volume
Snapshot logical volumes can be mounted like regular logical volumes. They are even not restricted to read-only operations — it is possible to modify snapshots and thus use it for things such as testing changes before doing these on a «production» file system.
As long as snapshot logical volumes exist, the regular/original logical volume cannot be reduced in size or removed.
LVM thin snapshots
Note
A thin snapshot can only be taken on a thin pool for a thin logical volume. The thin device mapper target supports thin snapshots of read-only non-thin logical volumes, but the LVM2 tooling does not support this. However, it is possible to create a regular (non-thin) snapshot logical volume of a thin logical volume.To create a thin snapshot, the lvcreate command is used with the
-soption. No size declaration needs to be passed on:
root #lvcreate -s -n 20140413_lvol1 /dev/vg0/lvol1Thin logical volume snapshots have the same size as their original thin logical volume, and use a physical allocation of 0 just like all other thin logical volumes.
Important
If -l or -L is specified, a snapshot will still be created, but the resulting snapshot will be a regular snapshot, not a thin snapshot.It is also possible to take snapshots of snapshots:
root #lvcreate -s -n 1_20140413_lvol1 /dev/vg0/20140413_lvol1Thin snapshots have several advantages over regular snapshots. First, thin snapshots are independent of their original logical volume once created. The original logical volume can be shrunk or deleted without affecting the snapshot. Second, thin snapshots can be efficiently created recursively (snapshots of snapshots) without the «chaining» overhead of regular recursive LVM snapshots.
Rolling back to snapshot state
To rollback the logical volume to the version of the snapshot, use the following command:
root #lvconvert --merge /dev/vg0/20140413_lvol1This might take a couple of minutes, depending on the size of the volume. Please note that the rollback will only happen once the parent logical volume is offline. Hence a reboot might be required.
Important
The snapshot will disappear and this change is not revertibleRolling back thin snapshots
For thin volumes, lvconvert —merge does not work. Instead, delete the original logical volume and rename the snapshot:
root #umount /dev/vg0/lvol1
root #lvremove /dev/vg0/lvol1
root #lvrename vg0/20140413_lvol1 lvol1Different storage allocation methods
LVM supports different allocation methods for storage:
- Linear volumes (which is the default);
- Mirrored volumes (in a more-or-less active/standby setup);
- Striping (RAID0);
- Mirrored volumes (RAID1 — which is more an active/active setup);
- Striping with parity (RAID4 and RAID5);
- Striping with double parity (RAID6);
- Striping and mirroring (RAID10).
Linear volumes
Linear volumes are the most common kind of LVM volumes. LVM will attempt to allocate the logical volume to be as physically contiguous as possible. If there is a physical volume large enough to hold the entire logical volume, then LVM will allocate it there, otherwise it will split it up into as few pieces as possible.
The commands introduced earlier on to create volume groups and logical volumes create linear volumes.
Because linear volumes have no special requirements, they are the easiest to manipulate and can be resized and relocated at will. If a logical volume is allocated across multiple physical volumes, and any of the physical volumes become unavailable, then that logical volume cannot be started anymore and will be unusable.
Mirrored volumes
LVM supports mirrored volumes, which provide fault tolerance in the event of drive failure. Unlike RAID1, there is no performance benefit — all reads and writes are delivered to a single side of the mirror.
To keep track of the mirror state, LVM requires a log to be kept. It is recommended (and often even mandatory) to position this log on a physical volume that does not contain any of the mirrored logical volumes. There are three kind of logs that can be used for mirrors:
- Disk is the default log type. All changes made are logged into extra metadata extents, which LVM manages. If a device fails, then the changes are kept in the log until the mirror can be restored again.
- Mirror logs are disk logs that are themselves mirrored.
- Core mirror logs record the state of the mirror in memory only. LVM will have to rebuild the mirror every time it is activated. This type is useful for temporary mirrors.
To create a logical volume with a single mirror, pass the -m 1 argument (to select standard mirroring) with optionally --mirrorlog to select a particular log type:
root #lvcreate -m 1 --mirrorlog mirror -l 40%VG --nosync -n lvol1 vg0
The -m 1 tells LVM to create one (additional) mirror, so requiring 2 physical volumes. The --nosync option is an optimization — without it LVM will try synchronize the mirror by copying empty sectors from one logical volume to another.
It is possible to create a mirror of an existing logical volume:
root #lvconvert -m 1 -b vg0/lvol1
The -b option does the conversion in the background as this can take quite a while.
To remove a mirror, set the number of mirrors (back) to 0:
root #lvconvert -m0 vg0/lvol1
If part of the mirror is unavailable (usually because the disk containing the physical volume has failed), the volume group will need to be brought up in degraded mode:
root #vgchange -ay --partial vg0
On the first write, LVM will notice the mirror is broken. The default policy («remove») is to automatically reduce/break the mirror according to the number of pieces available. A 3-way mirror with a missing physical volume will be reduced to 2-way mirror; a 2-way mirror will be reduced to a regular linear volume. If the failure is only transient, and the missing physical volume returns after LVM has broken the mirror, the mirrored logical volume will need to be recreated on it.
To recover the mirror, the failed physical volume needs to be removed from the volume group, and a replacement physical volume needs to be added (or if the volume group has a free physical volume, it can be created on that one). Then the mirror can be recreated with lvconvert at which point the old physical volume can be removed from the volume group:
root #vgextend vg0 /dev/sdc1
root #lvconvert -b -m 1 --mirrorlog disk vg0/lvol1
root #vgreduce --removemissing vg0
It is possible to have LVM recreate the mirror with free extents on a different physical volume if one side fails. To accomplish that, set mirror_image_fault_policy to allocate in lvm.conf.
Thin mirrors
It is not (yet) possible to create a mirrored thin pool or thin volume. It is possible to create a mirrored thin pool by creating a normal mirrored logical volume and then converting the logical volume to a thin pool with lvconvert. 2 logical volumes are required: one for the thin pool and one for the thin metadata; the conversion process will merge them into a single logical volume.
Warning
LVM 2.02.98 or above is required for this to work properly. Prior versions are either not capable or will segfault and corrupt the volume group. Also, conversion of a mirror into a thin pool destroys all existing data in the mirror!
root #lvcreate -m 1 --mirrorlog mirrored -l40%VG -n thin_pool vg0
root #lvcreate -m 1 --mirrorlog mirrored -L4MB -n thin_meta vg0
root #lvconvert --thinpool vg0/thin_pool --poolmetadata vg0/thin_meta
Striping (RAID0)
Instead of a linear volume, where multiple contiguous physical volumes are appended, it possible to create a striped or RAID0 volume for better performance. This will alternate storage allocations across the available physical volumes.
To create a striped volume over three physical volumes:
root #lvcreate -i 3 -l 20%VG -n lvol1_stripe vg0
Using default stripesize 64.00 KiB
The -i option indicates over how many physical volumes the striping should be done.
It is possible to mirror a stripe set. The -i and -m options can be combined to create a striped mirror:
root #lvcreate -i 2 -m 1 -l 10%VG vg0
This creates a 2 physical volume stripe set and mirrors it on 2 different physical volumes, for a total of 4 physical volumes. An existing stripe set can be mirrored with lvconvert.
A thin pool can be striped like any other logical volume. All the thin volumes created from the pool inherit that settings — do not specify it manually when creating a thin volume.
It is not possible to stripe an existing volume, nor reshape the stripes across more/less physical volumes, nor to convert to a different RAID level/linear volume. A stripe set can be mirrored. It is possible to extend a stripe set across additional physical volumes, but they must be added in multiples of the original stripe set (which will effectively linearly append a new stripe set).
Mirroring (RAID1)
Unlike RAID0, which is striping, RAID1 is mirroring, but implemented differently than the original LVM mirror. Under RAID1, reads are spread out across physical volumes, improving performance. RAID1 mirror failures do not cause I/O to block because LVM does not need to break it on write.
Any place where an LVM mirror could be used, a RAID1 mirror can be used in its place. It is possible to have LVM create RAID1 mirrors instead of regular mirrors implicitly by setting mirror_segtype_default to raid1 in lvm.conf.
Warning
LVM RAID1 mirroring is not supported by GRUB before version 2.02. Ensure the latest version is installed with grub-install or the system may become unbootable if the grub files are contained in the LVM RAID1.
To create a logical volume with a single mirror:
root #lvcreate -m 1 --type raid1 -l 40%VG --nosync -n lvm_raid1 vg0
Note the difference for creating a mirror: There is no mirrorlog specified, because RAID1 logical volumes do not have an explicit mirror log — it built-in to the logical volume.
It is possible to convert an existing logical volume to RAID1:
root #lvconvert -m 1 --type raid1 -b vg0/lvol1
To remove a RAID1 mirror, set the number of mirrors to 0:
root #lvconvert -m0 vg0/lvm_raid1
If part of the RAID1 is unavailable (usually because the disk containing the physical volume has failed), the volume group will need to be brought up in degraded mode:
root #vgchange -ay --partial vg0
Unlike an LVM mirror, writing does NOT break the mirroring. If the failure is only transient, and the missing physical volume returns, LVM will resync the mirror by copying cover the out-of-date segments instead of the entire logical volume. If the failure is permanent, then the failed physical volume needs to be removed from the volume group, and a replacement physical volume needs to be added (or if the volume group has a free physical volume, it can be created on a different PV). The mirror can then be repaired with lvconvert, and the old physical volume can be removed from the volume group:
root #vgextend vg0 /dev/sdc1
root #lvconvert --repair -b vg0/lvm_raid1
root #vgreduce --removemissing vg0
Thin RAID1
It is not (yet) possible to create a RAID1 thin pool or thin volume. It is possible to create a RAID1 thin pool by creating a normal mirrored logical volume and then converting the logical volume to a thin pool with lvconvert. 2 logical volumes are required: one for the thin pool and one for the thin metadata; the conversion process will then merge them into a single logical volume.
Warning
LVM 2.02.98 or above is required for this to work properly. Prior versions are either not capable or will segfault and corrupt the VG. Also, conversion of a RAID1 into a thin pool destroys all existing data in the mirror!
root #lvcreate -m 1 --type raid1 -l40%VG -n thin_pool vg0
root #lvcreate -m 1 --type raid1 -L4MB -n thin_meta vg0
root #lvconvert --thinpool vg0/thin_pool --poolmetadata vg00/thin_meta
Striping with parity (RAID4 and RAID5)
Note
Striping with parity requires at least 3 physical volumes.
RAID0 is not fault-tolerant — if any of the physical volumes fail then the logical volume is unusable. By adding a parity stripe to RAID0 the logical volume can still function if a physical volume is missing. A new physical volume can then be added to restore fault tolerance.
Stripsets with parity come in 2 flavors: RAID4 and RAID5. Under RAID4, all the parity stripes are stored on the same physical volume. This can become a bottleneck because all writes hit that physical volume, and it gets worse the more physical volumes are in the array. With RAID5, the parity data is distributed evenly across the physical volumes so none of them become a bottleneck. For that reason, RAID4 is rare and is considered obsolete/historical. In practice, all stripesets with parity are RAID5.
root #lvcreate --type raid5 -l 20%VG -i 2 -n lvm_raid5 vg0
Only the data physical volumes are specified with -i, LVM adds one to it automatically for the parity. So for a 3 physical volume RAID5, -i 2 is passed on and not -i 3.
When a physical volume fails, then the volume group will need to be brought up in degraded mode:
root #vgchange -ay --partial vg0
The volume will work normally at this point, however this degrades the array to RAID0 until a replacement physical volume is added. Performance is unlikely to be affected while the array is degraded — although it does need to recompute its missing data via parity, it only requires simple XOR for the parity block with the remaining data. The overhead is negligible compared to the disk I/O.
To repair the RAID5:
root #lvconvert --repair vg0/lvm_raid5
root #vgreduce --removemissing vg0
It is possible to replace a still working physical volume in RAID5 as well:
root #lvconvert --replace /dev/sdb1 vg0/lvm_raid5
root #vgreduce vg0 /dev/sdb1
The same restrictions of stripe sets apply to stripe sets with parity as well: it is not possible to enable striping with parity on an existing volume, nor reshape the stripes with parity across more/less physical volumes, nor to convert to a different RAID level/linear volume. A stripe set with parity can be mirrored. It is possible to extend a stripe set with parity across additional physical volumes, but they must be added in multiples of the original stripe set with parity (which will effectively linearly append a new stripe set with parity).
Thin RAID5 logical volumes
It is not (yet) possible to create stripe set with parity (RAID5) thin pools or thin logical volumes. It is possible to create a RAID5 thin pool by creating a normal RAID5 logical volume and then converting the logical volume into a thin pool with lvconvert. 2 logical volumes are required: one for the thin pool and one for the thin metadata; the conversion process will merge them into a single logical volume.
Warning
LVM 2.02.98 or above is required for this to work properly. Prior versions are either not capable or will segfault and corrupt the VG. Also, coversion of a RAID5 LV into a thin pool destroys all existing data in the LV!
root #lvcreate --type raid5 -i 2 -l20%VG -n thin_pool vg0
root #lvcreate --type raid5 -i 2 -L4MB -n thin_meta vg0
root #lvconvert --thinpool vg0/thin_pool --poolmetadata vg00/thin_meta
Striping with double parity (RAID6)
Note
RAID6 requires at least 5 physical volumes.
RAID6 is similar to RAID5, however RAID6 can survive up to two physical volume failures, thus offering more fault tolerance than RAID5 at the expense of extra physical volumes.
root #lvcreate --type raid6 -l 20%VG -i 3 -n lvm_raid6 vg00
Like RAID5, the -i option is used to specify the number of physical volumes to stripe, excluding the 2 physical volumes for parity. So for a 5 physical volume RAID6, pass on -i 3 and not -i 5.
Recovery for RAID6 is the same as RAID5.
Note
Unlike RAID5 where parity block is cheap to recompute vs disk I/O, this is only half true in RAID6. RAID6 uses 2 parity stripes: One stripe is computed the same way as RAID5 (simple XOR). The second parity stripe is much harder to compute — see [https://www.kernel.org/pub/linux/kernel/people/hpa/raid6.pdf
Thin RAID6 logical volumes
It is not (yet) possible to create a RAID6 thin pool or thin volumes. It is possible to create a RAID6 thin pool by creating a normal RAID6 logical volume and then converting the logical volume into a thin pool with lvconvert. 2 logical volumes are required: one for the thin pool and one for the thin metadata; the conversion process will merge them into a single logical volume.
Warning
LVM 2.02.98 or above is required for this to work properly. Prior versions are either not capable or will segfault and corrupt the VG. Also, conversion of a RAID6 LV into a thin pool destroys all existing data in the LV!
root #lvcreate --type raid6 -i 2 -l20%VG -n thin_pool vg0
root #lvcreate --type raid6 -i 2 -L4MB -n thin_meta vg0
root #lvconvert --thinpool vg0/thin_pool --poolmetadata vg0/thin_meta
LVM RAID10
Note
RAID10 requires at least 4 physical volumes. Also LVM syntax requires the number of physical volumes be multiple of the numbers stripes and mirror, even though RAID10 format does not
RAID10 is a combination of RAID0 and RAID1. It is more powerful than RAID0+RAID1 as the mirroring is done at the stripe level instead of the logical volume level, and therefore the layout doesn’t need to be symmetric. A RAID10 volume can tolerate at least a single missing physical volume, and possibly more.
Note
LVM currently limits RAID10 to a single mirror.
root #lvcreate --type raid10 -l 1020 -i 2 -m 1 --nosync -n lvm_raid10 vg0
Both the -i and -m options are specified: -i is the number of stripes and -m is the number of mirrors. Two stripes and 1 mirror requires 4 physical volumes.
Thin RAID10
It is not (yet) possible to create a RAID10 thin pool or thin volumes. It is possible to create a RAID10 thin pool by creating a normal RAID10 logical volume and then converting the logical volume into a thin pool with lvconvert. 2 logical volumes are required: one for the thin pool and one for the thin metadata; the conversion process will merge them into a single logical volume.
Warning
Conversion of a RAID10 logical volume into a thin pool destroys all existing data in the logical volume!
root #lvcreate -i 2 -m 1 --type raid10 -l 1012 -n thin_pool vg0
root #lvcreate -i 2 -m 1 --type raid10 -l 6 -n thin_meta vg0
root #lvconvert --thinpool vg0/thin_pool --poolmetadata vg0/thin_meta
Experimenting with LVM
It is possible to experiment with LVM without using real storage devices. To accomplish this, loopback devices are created.
First make sure to have the loopback module loaded.
root #modprobe -r loop && modprobe loop max_part=63
Note
If loopback support is built into the kernel, then use loop.max_part=63 as boot option.
Next configure LVM to not use udev to scan for devices:
FILE /etc/lvm/lvm.confDisabling udev in LVM config
obtain_device_list_from_udev = 0Important
This is for testing only, make sure to change the setting back when dealing with real devices since it is much faster to use udev!Create some image files which will become the storage devices. The next example uses five files for a total of about ~10GB of real hard drive space:
root #mkdir /var/lib/lvm_img
root #dd if=/dev/null of=/var/lib/lvm_img/lvm0.img bs=1024 seek=2097152
root #dd if=/dev/null of=/var/lib/lvm_img/lvm1.img bs=1024 seek=2097152
root #dd if=/dev/null of=/var/lib/lvm_img/lvm2.img bs=1024 seek=2097152
root #dd if=/dev/null of=/var/lib/lvm_img/lvm3.img bs=1024 seek=2097152
root #dd if=/dev/null of=/var/lib/lvm_img/lvm4.img bs=1024 seek=2097152Check which loopback devices are available:
Assuming all loopback devices are available, next create the devices:
root #losetup /dev/loop0 /var/lib/lvm_img/lvm0.img
root #losetup /dev/loop1 /var/lib/lvm_img/lvm1.img
root #losetup /dev/loop2 /var/lib/lvm_img/lvm2.img
root #losetup /dev/loop3 /var/lib/lvm_img/lvm3.img
root #losetup /dev/loop4 /var/lib/lvm_img/lvm4.imgThe /dev/loop[0-4] devices are now available to use as any other hard drive in the system (and thus be perfect for physical volumes).
Note
On the next reboot, all the loopback devices will be released and the folder /var/lib/lvm_img can be deleted.Troubleshooting
LVM has a few features that already provide some level of redundancy. However, there are situations where it is possible to restore lost physical volumes or logical volumes.
vgcfgrestore utility
By default, on any change to a LVM physical volume, volume group, or logical volume, LVM2 create a backup file of the metadata in /etc/lvm/archive. These files can be used to recover from an accidental change (like deleting the wrong logical volume). LVM also keeps a backup copy of the most recent metadata in /etc/lvm/backup. These can be used to restore metadata to a replacement disk, or repair corrupted metadata.
To see what states of the volume group are available to be restored (partial output to improve readability):
root #vgcfgrestore --list vg00File: /etc/lvm/archive/vg0_00042-302371184.vg VG name: vg0 Description: Created *before* executing 'lvremove vg0/lvm_raid1' Backup Time: Sat Jul 13 01:41:32 201Recovering an accidentally deleted logical volume
Assuming the logical volume lvm_raid1 was accidentally removed from volume group vg0, it is possible to recover it as follows:
root #vgcfgrestore -f /etc/lvm/archive/vg0_00042-302371184.vg vg0Important
vgcfgrestore only restores LVM metadata, not the data inside the logical volume. However pvremove, vgremove, and lvremove only wipe metadata, leaving any data intact. Ifissue_discardsis set in /etc/lvm/lvm.conf though, then these command are destructive to data.Replacing a failed physical volume
It possible to do a true «replace» and recreate the metadata on the new physical volume to be the same as the old physical volume:
root #vgdisplay --partial --verbose--- Physical volumes --- PV Name /dev/loop0 PV UUID iLdp2U-GX3X-W2PY-aSlX-AVE9-7zVC-Cjr5VU PV Status allocatable Total PE / Free PE 511 / 102 PV Name unknown device PV UUID T7bUjc-PYoO-bMqI-53vh-uxOV-xHYv-0VejBY PV Status allocatable Total PE / Free PE 511 / 102The important line here is the UUID «unknown device».
root #pvcreate --uuid T7bUjc-PYoO-bMqI-53vh-uxOV-xHYv-0VejBY --restorefile /etc/lvm/backup/vg0 /dev/loop1Couldn't find device with uuid T7bUjc-PYoO-bMqI-53vh-uxOV-xHYv-0VejBY. Physical volume "/dev/loop1" successfully createdThis recreates the physical volume metadata, but not the missing logical volume or volume group data on the physical volume.
root #vgcfgrestore -f /etc/lvm/backup/vg0 vg0Restored volume group vg0This now reconstructs all the missing metadata on the physical volume, including the logical volume and volume group data. However it doesn’t restore the data, so the mirror is out of sync.
root #vgchange -ay vg0device-mapper: reload ioctl on failed: Invalid argument 1 logical volume(s) in volume group "vg0" now active
root #lvchange --resync vg0/lvm_raid1Do you really want to deactivate logical volume lvm_raid1 to resync it? [y/n]: yThis will resync the mirror. This works with RAID 4,5 and 6 as well.
Deactivating a logical volume
It is possible to deactivate a logical volume with the following command:
root #umount /dev/vg0/lvol1
root #lvchange -a n /dev/vg0/lvol1It is not possible to mount the logical volume anywhere before it gets reactivated:
root #lvchange -a y /dev/vg0/lvol1See also
- Device-mapper
- Raid1 with LVM from scratch
External resources
- LVM2 sourceware.org
- LVM tldp.org
- LVM2 Wiki redhat.com
- Shrinking root logical volume on-line
Содержание
Logical Volume Manager (LVM) — это очень мощная система управления томами с данными для Linux. Она позволяет создавать поверх физических разделов (или даже неразбитых винчестеров) логические тома, которые в самой системе будут видны как обычные блочные устройства с данными (т.е. как обычные разделы). Основные преимущества LVM в том, что во-первых одну группу логических томов можно создавать поверх любого количества физических разделов, а во-вторых размер логических томов можно легко менять прямо во время работы. Кроме того, LVM поддерживает механизм снапшотов, копирование разделов «на лету» и зеркалирование, подобное RAID-1.
Если планируются большие работы с LVM, то можно запустить специальную «оболочку» командой sudo lvm. Команда help покажет список команд.
Создание и удаление
Как уже отмечалось, LVM строится на основе разделов жёсткого диска и/или целых жёстких дисков. На каждом из дисков/разделов должен быть создан физический том (physical volume). К примеру, мы используем для LVM диск sda и раздел sdb2:
pvcreate /dev/sda pvcreate /dev/sdb2
На этих физических томах создаём группу томов, которая будет называться, скажем, vg1:
vgcreate -s 32M vg1 /dev/sda /dev/sdb2
Посмотрим информацию о нашей группе томов:
vgdisplay vg1
Групп можно создать несколько, каждая со своим набором томов. Но обычно это не требуется.
Теперь в группе томов можно создать логические тома lv1 и lv2 размером 20 Гбайт и 30 Гбайт соответствено:
lvcreate -n lv1 -L 20G vg1 lvcreate -n lv2 -L 30G vg1
Теперь у нас есть блочные устройства /dev/vg1/lv1 и /dev/vg1/lv2.
Осталось создать на них файловую систему. Тут различий с обычными разделами нет:
mkfs.ext4 /dev/vg1/lv1 mkfs.reiserfs /dev/vg1/lv2
Удаление LVM (или отдельных его частей, например, логических томов или групп томов) происходит в обратном порядке — сначала нужно отмонтировать разделы, затем удалить логические тома (lvremove), после этого можно удалить группы томов (vgremove) и ненужные физические тома (pvremove).
Добавление физических томов
Чтобы добавить новый винчестер sdc в группу томов, создадим физический том:
pvcreate /dev/sdc
И добавим его в нашу группу:
vgextend vg1 /dev/sdc
Теперь можно создать ещё один логический диск (lvcreate) или увеличить размер существующего (lvresize).
Удаление физических томов
Чтобы убрать из работающей группы томов винчестер sda сначала перенесём все данные с него на другие диски:
pvmove /dev/sda
Затем удалим его из группы томов:
vgreduce vg1 /dev/sda
И, наконец, удалим физический том:
pvremove /dev/sda
Вообще-то, последняя команда просто убирает отметку о том, что диск является членом lvm, и особой пользы не приносит. После удаления из LVM для дальнейшего использования диск придётся переразбивать/переформатировать.
Изменение размеров
LVM позволяет легко изменять размер логических томов. Для этого нужно сначала изменить сам логический том:
lvresize -L 40G vg1/lv2
а затем файловую систему на нём:
resize2fs /dev/vg1/lv2 resize_reiserfs /dev/vg1/lv2
Изменение размеров физического тома — задача весьма сложная и обычно не применяется. Целесообразнее и безопаснее удалить физический том, изменить размер раздела и создать том заново.
Как просто попробовать
Если LVM устанавливается не для дальнейшего использования, а «напосмотреть», то диски и разделы можно заменить файлами. Не понадобятся ни дополнительные диски, ни виртуальные машины. Мы создадим виртуальные накопители и будем с ними работать. Например, можно создать 4 диска по 1 Гбайт, но можно создать другое количество большего или меньшего размера как вам хочется.
Создаем сами файлы, имитирующие устройства:
mkdir /mnt/sdc1/lvm cd /mnt/sdc1/lvm dd if=/dev/zero of=./d01 count=1 bs=1G dd if=/dev/zero of=./d02 count=1 bs=1G dd if=/dev/zero of=./d03 count=1 bs=1G dd if=/dev/zero of=./d04 count=1 bs=1G
Создаем loopback устройства из файлов:
losetup -f --show ./d01 losetup -f --show ./d02 losetup -f --show ./d03 losetup -f --show ./d04
Дальше поступаем так же, как если бы ми создавали LVM на реальных дисках. Обратите внимание на названия loop-устройств — они могут отличаться от приведённых здесь.
pvcreate /dev/loop0 pvcreate /dev/loop1 pvcreate /dev/loop2 pvcreate /dev/loop3 vgcreate -s 32M vg /dev/loop0 /dev/loop1 /dev/loop2 /dev/loop3 lvcreate -n first -L 2G vg lvcreate -n second -L 400M vg ...
Снапшоты
Одна из важнейших особенностей LVM — это поддержка механизма снапшотов. Снапшоты позволяют сделать мгновенный снимок логического тома и использовать его в дальнейшем для работы с данными.
Примеры использования
LVM активно используется, когда необходим механизм снапшотов. Например, этот механизм крайне важен при бекапе постоянно меняющихся файлов. LVM позволяет заморозить некоторое состояние ФС и скопировать с неё все нужные данные, при этом на оригинальной ФС останавливать запись не нужно.
Также снапшоты можно применить для организации поддержки файловым сервером с Samba механизма архивных копий, об этом в соответствующей статье:
LVM с LiveCD
Если у вас возникла необходимость работать с LVM с LiveCD Ubuntu, то вам придётся выполнить несколько дополнительных действий, поскольку по умолчанию утилит для работы с LVM нет.
Сначала вам нужно установить эти утилиты:
sudo apt-get install lvm2
Далее посмотрите командами
sudo vgscan sudo vgdisplay YOUR_VGNAME
доступность ваших групп томов. Ну а дальше запустите все группы командой
sudo vgchange -a y
Эта команда должна сообщить о том, что все ваши логические тома активированы. Теперь можно работать с ними обычным образом.
Ссылки
Red Hat Enterprise Linux 6
Руководство администратора LVM
Редакция 1
Аннотация
В данном документе приведена информация об управлении логическими томами, в том числе и в кластерном окружении.
Введение
1. Об этом руководстве
В данном документе рассматривается управление логическими томами (LVM, Logical Volume Manager) в кластерном окружении.
2. Целевая аудитория
Материал ориентирован на опытных администраторов Red Hat Enterprise Linux 6 со знаниями GFS2.
3. Версии
Таблица 1. Версии
| Название | Описание |
|---|---|
|
RHEL 6 |
RHEL 6 или более поздние версии |
|
GFS2 |
GFS2 для RHEL6 и последующих версий |
5. Отзывы и предложения
Если вы обнаружили опечатку, или у вас есть предложения по усовершенствованию руководства, создайте запрос в Bugzilla (http://bugzilla.redhat.com/) для выпуска Red Hat Enterprise Linux 6 и компонента . Укажите идентификатор: Logical_Volume_Manager_Administration(EN)-6 (2011-05-19-15:20).
Если у вас есть предложения по улучшению руководства, постарайтесь подробно их описать. Для облегчения идентификации ошибок и опечаток укажите номер раздела и окружающий текст.
Глава 1. Обзор
В этой главе приведена общая информация об LVM и его основных характеристиках в Red Hat Enterprise Linux 6.
1.1. Новые и обновленные возможности
Эта секция содержит перечень новых и измененных функций LVM в Red Hat Enterprise Linux 6.
1.1.1. Изменения в Red Hat Enterprise Linux 6.0
Ниже перечислены основные изменения LVM в Red Hat Enterprise Linux 6.0.
-
Параметры
mirror_image_fault_policyиmirror_log_fault_policyв секцииactivationфайлаlvm.confпозволяют настроить поведение зеркального тома в случае сбоя устройства. Еслиmirror_image_fault_policyимеет значениеremove, система попытается исключить проблемное устройство и продолжить работу. Значениеallocateопределяет, что после удаления устройства необходимо выделить пространство для нового устройства. При отсутствии подходящей заменыallocateработает аналогичноremove(см. Раздел 4.4.3.1, «Правила работы при сбое зеркального тома»). -
Стек ввода-вывода Linux стал распознавать ограничения ввода-вывода, заданные производителем, что позволяет оптимизировать размещение и доступ к данным. Отключать эту функциональность не рекомендуется, но при необходимости это можно сделать с помощью параметров
data_alignment_detectionиdata_alignment_offset_detectionвlvm.conf.Информацию о выравнивании данных в LVM и изменении
data_alignment_detectionиdata_alignment_offset_detectionможно можно найти в документации к/etc/lvm/lvm.conf(см. Приложение B, Файлы конфигурации LVM). Общие сведения о стеке ввода-вывода и его ограничениях в Red Hat Enterprise Linux 6 можно найти в руководстве по управлению накопителями. -
Device-mapper напрямую поддерживает интеграцию
udev, что позволяет синхронизировать проекции устройств, в том числе и для устройств LVM (см. Раздел A.3, «Поддержка udev»). -
Для восстановления зеркала после сбоя диска можно использовать
lvconvert --repair(см. Раздел 4.4.3.3, «Восстановление зеркального устройства»). -
lvconvert --mergeпозволяет объединить снимок с исходным томом (см. Раздел 4.4.5, «Объединение снимка с оригиналом»). -
lvconvert --splitmirrorsпозволяет разделить образ зеркального тома на части, тем самым состав новый том (см. Раздел 4.4.3.2, «Разбиение образа зеркального тома»). -
Теперь можно создать журнал для зеркального логического устройства, для которого также создано зеркало. Для этого используется параметр
--mirrorlog mirroredкомандыlvcreate(см. Раздел 4.4.3, «Создание зеркальных томов»).
1.1.2. Изменения в Red Hat Enterprise Linux 6.1
Ниже перечислены основные изменения LVM в Red Hat Enterprise Linux 6.1.
-
Допускается создание снимков зеркальных логических томов аналогично тому, как создаются снимки обычных томов (см. Раздел 4.4.4, «Создание снимков»).
-
При увеличении размера тома LVM можно использовать параметр
--alloc clingкомандыlvextend. При этом место будет выбираться в пределах тех же физических томов, где расположен последний сегмент увеличиваемого тома. Если места не хватает, будет проверен файлlvm.confи выбраны диски с тем же тегом.Раздел 4.4.12.2, «Увеличение логического тома в режиме
cling» содержит описание наращивания зеркальных томов с помощью--alloc cling. -
Допускается многократное указание аргументов
--addtagи--deltagв командахpvchange,vgchangeиlvchange(см. Раздел C.1, «Добавление и удаление тегов»). -
Теперь теги объектов LVM могут содержать «/», «=», «!», «:», «#», «&» (см. Приложение C, Теги объектов LVM).
-
Логический том теперь может состоять из комбинаций RAID0 и RAID1. Если при создании тома было указано число зеркал (
--mirrors X) и звеньев (--stripes Y), то будет создано зеркальное устройство с чередующимися составляющими (см. Раздел 4.4.3, «Создание зеркальных томов»). -
Для создания резервной копии кластерного логического тома теперь можно специально активировать том и создать его снимок (см. Раздел 4.7, «Активация логических томов на отдельных узлах кластера»).
1.2. Логический том
LVM добавляет дополнительный уровень абстракции над физическими дисками, позволяя создавать на их основе логические тома, что обеспечивает бóльшую гибкость по сравнению с управлением физических дисков напрямую. Аппаратная конфигурация накопителей спрятана от программ, поэтому их можно переносить или изменять размер без необходимости остановки приложений и отключения файловых систем.
Преимущества логических томов:
-
Возможность изменения размера.
Размер файловых систем логических томов не ограничивается одним диском, так как том может располагаться на разных дисках и разделах.
-
Изменение размера.
С помощью простых команд можно изменить размер логических томов без необходимости переформатирования или переразбиения физических дисков в их основе.
-
Перемещение данных в активной системе.
С целью создания новых, более быстрых и устойчивых подсистем хранения допускается перемещать данные в активной системе. Данные можно переносить, даже если к дискам выполняется обращение. Например, можно на ходу освободить заменяемый диск перед его удалением из набора.
-
Простота присвоения имен устройствам.
Логические тома могут объединяться в группы для облегчения управления. Группам могут присваиваться произвольные имена.
-
Чередование дисков.
Для повышения пропускной способности можно создать логический том с чередованием данных на нескольких дисках.
-
Зеркалирование томов.
Использование логических томов позволяет создать зеркальные копии данных.
-
Снимки томов.
Снимки томов представляют собой их точные копии и могут использоваться для тестирования, не подвергая риску исходный том.
Перечисленные возможности будут рассмотрены в этом документе.
1.3. Обзор архитектуры LVM
На смену исходному механизму LVM1, впервые появившемуся в RHEL4, пришел LVM2, архитектура которого более универсальна. LVM2 обладает следующими преимуществами:
-
гибкая емкость;
-
эффективное хранение метаданных;
-
улучшенный формат восстановления;
-
новый формат метаданных ASCII;
-
выборочное изменение метаданных;
-
поддержка избыточных копий метаданных.
LVM2 обратно совместим с LVM1 (за исключением снимков и кластерной поддержки). Группу томов LVM1 можно преобразовать в LVM2 с помощью команды vgconvert. Информацию о преобразовании формата метаданных можно найти на справочной странице vgconvert(8).
В основе логического тома лежит блочное устройство — раздел или целый диск. Это устройство инициализируется как физический том.
Физические тома объединяются в группы томов, тем самым создавая единое пространство для организации логических томов. Этот процесс аналогичен разбиению дисков на разделы. Логический том будет доступен файловым системам и приложениям.
Рисунок 1.1, «Компоненты логического тома» демонстрирует примеры логических томов.

Рисунок 1.1. Компоненты логического тома
Глава 2, Компоненты LVM содержит подробную информацию о составляющих логического тома.
1.4. CLVM
Кластерное управление логическими томами (CLVM, Clustered Logical Volume Manager) представляет собой набор кластерных расширений для LVM, позволяющих кластеру управлять общим пространством хранения, например в сети SAN. CLVM входит в состав комплекта отказоустойчивого хранилища RHEL 6.
Выбор CLVM также определяется требованиями, перечисленными ниже.
-
Если доступ к хранилищу необходим лишь одному узлу, можно ограничиться возможностями LVM. Создаваемые логические тома будут локальными.
-
Если для восстановления после отказа используется кластерная структура, где только один узел может обращаться к хранилищу в заданный момент времени, потребуются агенты HA-LVM (High Availability Logical Volume Management). Подробную информацию можно найти в документе под названием Конфигурация и управление кластером Red Hat.
-
Если пространство хранения должно быть доступно нескольким активным компьютерам, потребуется прибегнуть к помощи CLVM. CLVM позволит пользователю настроить логические тома в общем хранилище, блокируя доступ к физическому хранилищу во время настройки логического тома и используя кластерные службы блокирования для управления доступом.
Для работы CLVM необходимо, чтобы в системе работали комплекты высокой готовности и отказоустойчивого хранилища. На всех компьютерах в кластере должен выполняться процесс clvmd, который является главным кластерным расширением LVM. clvmd передает компьютерам обновления метаданных LVM, тем самым поддерживая постоянную структуру логических томов. Подробную информацию об комплекте высокой готовности можно найти в руководстве Конфигурация и управление кластером Red Hat.
Чтобы проверить, был ли запущен процесс clmvd во время загрузки компьютера, выполните:
# chkconfig clvmd on
Если clvmd не выполняется, для запуска выполните:
# service clvmd start
Создание логических томов в кластере аналогично созданию томов на одном узле (см. Глава 4, Администрирование LVM в текстовом режиме и Глава 7, Администрирование LVM в графическом режиме). Чтобы активировать созданные в кластере тома, необходимо, чтобы функционировала инфраструктура кластера.
По умолчанию логические тома, созданные в общем хранилище с помощью CLVM, будут видны всем компьютерам, у которых есть доступ к этому хранилищу. Можно создать целые группы томов, устройства хранения которых будут видны только одному компьютеру в кластере. Дополнительно можно изменить статус группы с «локальной» на «кластерную» (см. Раздел 4.3.2, «Создание групп томов в кластере» и Раздел 4.3.7, «Изменение параметров группы томов»).
При создании групп томов в общем хранилище с помощью CLVM необходимо убедиться, что у всех компьютеров в кластере есть доступ к физическим томам в составе группы. Асимметричные схемы кластеров с неравномерными правами доступа к хранилищу не поддерживаются.
Рисунок 1.2, «Структура CLVM» демонстрирует CLVM в кластере Red Hat.

Рисунок 1.2. Структура CLVM
Для блокирования в пределах кластера потребуется внести изменения в lvm.conf. Информацию о настройке кластерного блокирования можно найти в файле lvm.conf (см. Приложение B, Файлы конфигурации LVM).
1.5. Содержание документа
Содержание:
-
Глава 2, Компоненты LVM описывает составляющие компоненты логического тома.
-
Глава 3, Обзор администрирования LVM содержит обзор основных шагов по настройке логических томов с помощью команд или графического интерфейса LVM.
-
Глава 4, Администрирование LVM в текстовом режиме содержит обзор некоторых административных задач по созданию и управлению логическими томами.
-
Глава 5, Примеры конфигурации LVM приводит примеры конфигурации LVM.
-
Глава 6, Диагностика проблем содержит описание методов диагностики и решения типичных проблем LVM.
-
Глава 7, Администрирование LVM в графическом режиме содержит обзор графического интерфейса LVM.
-
Приложение A, Device Mapper содержит описание модуля Device-mapper, который LVM использует для создания соответствий между логическими и физическими томами.
-
Приложение B, Файлы конфигурации LVM содержит описание файлов конфигурации LVM.
-
Приложение C, Теги объектов LVM рассказывает о тегах объектов и узлов LVM.
-
Приложение D, Метаданные группы томов рассматривает структуру метаданных групп томов и приводит их образец.
Глава 2. Компоненты LVM
В этой главе рассматриваются компоненты LVM.
2.1. Физический том
В основе логического тома лежит блочное устройство — раздел или целый диск. Устройство инициализируется как физический том. В начале тома размещается специальная метка.
Метка LVM по умолчанию размещается во втором 512-байтном секторе. По желанию ее можно разместить в любом из первых четырех секторов, что позволяет томам использовать эти сектора параллельно с другими пользователями.
Метка определяет порядок устройств, так как очередность их обнаружения в процессе загрузки может меняться. Она не изменяется между перезагрузками в пределах кластера.
Метка идентифицирует устройство как физический том, содержит случайный уникальный идентификатор (UUID), размер устройства (в байтах) и расположение метаданных LVM на устройстве.
Метаданные LVM содержат настройки групп томов в системе. По умолчанию в секции метаданных каждого физического тома в группе хранится копия метаданных. Метаданные не занимают много места и хранятся в формате ASCII.
В настоящее время LVM позволяет сохранить 1-2 копии метаданных в каждом физическом томе. По умолчанию сохраняется одна копия. Задав число копий один раз, его нельзя будет изменить. Первая копия хранится в начале устройства — вскоре после метки. Вторая копия (если она существует) располагается в конце устройства. Если область в начале диска была случайно перезаписана, вторая копия поможет восстановить метаданные.
Приложение D, Метаданные группы томов содержит подробную информацию.
2.1.1. Структура физического тома
Рисунок 2.1, «Структура физического тома» демонстрирует организацию физического тома. Метка LVM расположена во втором секторе, за ней следует область метаданных. Остальное пространство доступно для использования.
В этом документе предполагается, что размер секторов составляет 512 байт (как и в ядре Linux).

Рисунок 2.1. Структура физического тома
2.1.2. Диски с несколькими разделами
LVM позволяет создавать физические тома на основе дисковых разделов. В этом случае рекомендуется создать единственный раздел, охватывающий весь диск, и присвоить ему метку физического тома. Достоинства такого подхода:
-
Облегчение администрирования.
Так намного легче следить за отдельными дисками, особенно в случае сбоя. Кроме того, несколько физических томов на одном диске при загрузке приведут к появлению предупреждения во время загрузки о неизвестных типах разделов.
-
Производительность при чередовании.
LVM не различает, расположены ли два физических тома на одном и том же диске. Если логический том с чередованием был создан на основе двух физических томов, расположенных на одном диске, может оказаться так, что области чередования расположены в различных разделах одного диска. Это приведет к снижению производительности вместо ожидаемой оптимизации.
Хоть это и не рекомендуется, но может случиться так, что диск все же необходимо разделить на несколько физических томов. Например, в системе с несколькими дисками может понадобиться перенести данные между разделами при миграции существующей системы в формат LVM. При наличии диска большого размера потребуется разбить его на разделы, если на его основе планируется создать несколько групп томов. Если есть такой диск с несколькими разделами, и разделы принадлежат одной группе томов, при создании томов с чередованием уделите особое внимание тому, какие разделы будут включены в логический том.
2.2. Группа томов
Физические тома объединяются в группы, что позволяет создать единое дисковое пространство, из которого будет выделяться место для логических томов.
В пределах группы пространство разделяется на блоки фиксированного размера — экстенты. Размер экстента является минимальным размером, который может быть выделен тому. На уровне физических томов используется понятие физических экстентов.
Логическому тому будут выделяться логические экстенты, размер которых равен размеру физических экстентов. То есть размер экстентов всегда один и тот же для всех логических томов в группе. Группа томов определяет соответствие логических экстентов физическим.
2.3. Логический том
Группа состоит из логических томов. Существует три типа логических томов: линейные, с чередованием и зеркальные.
2.3.1. Линейный том
Линейный том объединяет несколько физических томов. Например, при наличии двух дисков размером 60 гигабайт можно создать логический том размером 120 гигабайт.
При создании линейного тома ему выделяется непрерывный диапазон физических экстентов. Например, как иллюстрирует Рисунок 2.2, «Организация экстентов», логические экстенты с 1 до 99 могут принадлежать одному физическому тому, а логические экстенты с 100 до 198 — второму. С точки зрения приложения существует только одно устройство размером 198 экстентов.

Рисунок 2.2. Организация экстентов
Физические тома, на основе которых строится логический том, могут быть разных размеров. Рисунок 2.3, «Линейный том с физическими томами разного размера» демонстрирует группу VG1, размер физических экстентов которой равен 4 МБ. Эта группа включает физические тома PV1 и PV2, которые в свою очередь разделены на блоки размером 4 МБ (в соответствии с размером экстентов). Так, PV1 включает 100 экстентов (общий размер — 400 МБ), а PV2 — 200 экстентов (общий размер — 800 МБ). На их основе можно создать линейный том размером 4—1200 МБ, содержащий от 1 до 300 экстентов. В этом примере том LV1 содержит 300 экстентов.

Рисунок 2.3. Линейный том с физическими томами разного размера
На основе доступных физических экстентов можно создать один или несколько логических томов произвольного размера. Рисунок 2.4, «Несколько логических томов» демонстрирует ту же группу, что и Рисунок 2.3, «Линейный том с физическими томами разного размера», но в этом примере в группе создано два логических тома — LV1 (250 экстентов, общий размер — 1000 МБ) и LV2 (50 экстентов, общий размер — 200 МБ).

Рисунок 2.4. Несколько логических томов
2.3.2. Том с чередованием
При записи данных в логический том файловая система размещает их в физических томах в его основе. Чередование позволяет повысить производительность при выполнении большого объема последовательных операций ввода-вывода.
При чередовании данные последовательно распределяются между заранее определенным числом физических томов, поэтому операции ввода и вывода могут выполняться параллельно. В некоторых случаях производительность даже может сравниться с линейной организацией.
Приведенная ниже схема демонстрирует чередование данных между тремя физическими томами:
-
первая секция данных записывается на PV1;
-
вторая секция данных записывается на PV2;
-
третья секция данных записывается на PV3;
-
четвертая секция данных записывается на PV1.
Размер сегментов чередования не может превышать размер экстента.

Рисунок 2.5. Чередование данных между тремя физическими томами
В конец существующего набора томов с чередованием можно добавлять дополнительные физические тома. Прежде чем приступить к увеличению размера, необходимо убедиться, что физические тома обладают достаточным свободным пространством. К примеру, если используется двухстороннее чередование для целой группы томов, одного дополнительного тома будет недостаточно — надо добавить как минимум два физических тома (см. Раздел 4.4.12.1, «Увеличение тома с чередованием»).
2.3.3. Зеркальный том
Зеркало содержит устройства с идентичными копиями данных. При записи данных на одно устройство их копия также записывается на другое, что облегчает восстановление в случае выхода из строя одного из устройств. В случае сбоя одной составляющей зеркала логический том будет преобразован в линейный и продолжит работу.
При создании зеркала LVM записывает копию данных в отдельный физический том. LVM позволяет создать несколько зеркал для логических томов.
LVM подразделяет зеркалируемое устройство на секции, размер которых обычно составляет 512 КБ и ведет журнал синхронизации секций с зеркалами. Журнал может храниться на диске (в таком случае он будет сохраняться между перезагрузками) или временно находиться в памяти.
Рисунок 2.6, «Зеркальный логический том» демонстрирует логический том с одним зеркалом. Его журнал хранится на диске.

Рисунок 2.6. Зеркальный логический том
Раздел 4.4.3, «Создание зеркальных томов» содержит информацию о создании и изменении зеркал.
2.3.4. Снимки
LVM позволяет создавать снимки — виртуальные образы устройств в любой момент, не прибегая к остановке служб. Если исходное устройство было изменено после создания снимка, будет создана копия измененных данных, чтобы впоследствии можно было воссоздать состояние устройства.
Создание снимков в кластерных группах томов не поддерживается.
Создание снимков для зеркальных логических томов не поддерживается.
Поскольку копируются только те данные, которые были изменены уже после создания снимка, для хранения снимков не требуется много пространства. Например, для хранения снимка редко обновляемого устройства будет достаточно 3-5% от его исходного размера.
Снимки не являются полнофункциональными резервными копиями, а всего лишь виртуальными. Поэтому заменять резервное копирование они не могут.
Размер снимка определяет объем пространства, который должен быть отведен для хранения будущих изменений. Например, если том был полностью перезаписан после создания снимка, размер копии изменений будет равен размеру исходного тома. Поэтому при расчете пространства для снимка следует учитывать ожидаемый объем изменений. Так, для снимка практически неизменяемого тома /usr потребуется меньше пространства, чем для /home, который подвергается изменениям довольно часто.
Если снимок полностью заполнен, он не сможет регистрировать будущие изменения исходного тома. Рекомендуется периодически проверять размер снимка и увеличивать его при необходимости. И наоборот, если вы обнаружили, что размер снимка слишком большой, можно его уменьшить и освободить место.
При создании файловой системы снимка права чтения и записи к исходному тому сохраняются. Если же часть снимка изменена, она будет отмечена и в дальнейшем уже не будет копироваться из исходного тома.
Когда же используются снимки?
-
Если необходимо создать резервную копию логического тома, не останавливая систему, данные в которой постоянно обновляются.
-
Для проверки целостности файловой системы исходного тома можно выполнить
fsckв файловой системе снимка. -
Так как снимок доступен для чтения и записи, в его рамках можно тестировать приложения. При этом действительные данные остаются нетронутыми.
-
В окружении виртуализации снимки виртуальных систем могут создаваться для их последующей модификации и создания на их основе других гостей. Руководство по виртуализации Red Hat Enterprise Linux содержит подробную информацию.
Раздел 4.4.4, «Создание снимков» содержит информацию о создании и изменении снимков
Начиная с Red Hat Enterprise Linux 6, команда lvconvert включает параметр --merge, предназначенный для слияния снимка с исходным томом. Это может использоваться для создания точки восстановления системы. Восстановленному путем слияния логическому тому будет присвоено имя исходного тома, его вспомогательный номер и UUID, а снимок будет удален (см. Раздел 4.4.5, «Объединение снимка с оригиналом»).
Глава 3. Обзор администрирования LVM
Данная глава содержит обзор настройки логических томов LVM. Глава 5, Примеры конфигурации LVM рассматривает более детальные примеры.
Глава 4, Администрирование LVM в текстовом режиме включает описание команд, используемых для администрирования LVM. Глава 7, Администрирование LVM в графическом режиме содержит обзор графического интерфейса.
3.1. Создание томов LVM в кластере
Для создания логических томов в кластерном окружении используется набор расширений CLVM, которые позволяют управлять общим хранилищем кластера. Для работы CLVM необходимо, чтобы в системе работали комплекты высокой готовности и отказоустойчивого хранилища. В процессе загрузки на всех компьютерах в кластере должна быть запущена служба clvmd (см. Раздел 1.4, «CLVM»).
Процесс создания логических томов LVM в кластерном окружении аналогичен созданию томов на отдельном компьютере. Используемые команды не отличаются, и при работе с графическим интерфейсом ничего не меняется. Для активации созданных томов требуется, чтобы была активна кластерная инфраструктура, а для кластера определен кворум.
Для блокирования в пределах кластера потребуется внести изменения в lvm.conf. Информацию о настройке кластерного блокирования можно найти в самом файле lvm.conf (см. Приложение B, Файлы конфигурации LVM).
По умолчанию логические тома, созданные в общем хранилище с помощью CLVM, будут доступны всем компьютерам, у которых есть доступ к этому хранилищу. Можно создать целые группы томов, устройства хранения которых будут видны только одному узлу в кластере. Также можно изменить статус группы с «локальной» на «кластерную» (см. Раздел 4.3.2, «Создание групп томов в кластере» и Раздел 4.3.7, «Изменение параметров группы томов»).
При создании групп томов в общем хранилище с помощью CLVM необходимо убедиться, что у всех компьютеров в кластере есть доступ к физическим томам в составе группы. Асимметричные конфигурации кластеров с неравномерными правами доступа к хранилищу не поддерживаются.
Информацию об установке комплекта высокой степени готовности и настройке кластера можно найти в руководстве по администрированию кластера.
Раздел 5.5, «Создание зеркального логического тома в кластере» содержит пример создания тома в кластере.
3.2. Создание логического тома
Далее приведен порядок действий при создании логического тома.
-
Инициализация физических томов, на основе которых будет создан логический том.
-
Создание группы томов.
-
Создание логического тома.
После создания логического тома можно создать и подключить файловую систему. Приводимые в данном документе примеры подразумевают использование файловой системы GFS2.
GFS2 может быть создана отдельно в одной системе или как часть кластерной конфигурации, но Red Hat Enterprise Linux 6 не поддерживает GFS2 в отдельных системах. Их поддержка Red Hat ограничивается подключением снимков кластерных файловых систем с целью создания резервных копий.
-
С помощью
gfs_mkfsсоздайте файловую систему GFS2 на логическом томе. -
С помощью
mkdirсоздайте точку подключения. В кластерной системе точку подключения надо создать на каждом узле. -
Подключите файловую систему. Для каждого узла в кластере можно добавить отдельную строчку в файле
fstab.
Перечисленные действия также можно выполнить в окне графического интерфейса LVM.
Процесс создания томов не зависит от оборудования, так как информация о настройках LVM расположена в физических томах, а не на компьютере, где создается том. Использующие хранилище серверы обычно содержат локальные копии, но имеют возможность их воссоздания из содержимого физических томов. Физические тома можно подключить к другому серверу при условии совместимости их версий LVM.
3.3. Увеличение файловой системы логического тома
Порядок действий для увеличения файловой системы логического тома.
-
Создайте новый физический том.
-
Добавьте его в группу томов, в которую входит увеличиваемый логический том.
-
Увеличьте размер логического тома, чтобы он включал новый физический том.
-
Увеличьте размер файловой системы.
Если группа томов обладает достаточным объемом нераспределенного пространства, шаги 1 и 2 можно опустить.
3.4. Резервное копирование логического тома
Резервные копии и архивы метаданных создаются автоматически при изменении настроек логического тома и группы (это можно отключить в файле lvm.conf). Копия метаданных по умолчанию сохраняется в /etc/lvm/backup, а архивы — в /etc/lvm/archive. Параметры в lvm.conf определяют продолжительность хранения архивов в /etc/lvm/archive и число хранимых файлов. Ежедневная резервная копия должна включать содержимое каталога /etc/lvm.
Обратите внимание, что резервная копия метаданных не содержит системные данные и данные пользователя в логических томах.
Создать архив метаданных в /etc/lvm/backup можно с помощью команды vgcfgbackup. Восстановить метаданные можно с помощью vgcfgrestore (см. Раздел 4.3.12, «Создание резервной копии метаданных группы томов»).
3.5. Журнал событий
Вывод сообщений обрабатывается модулем журналирования. При этом события подразделяются на следующие категории:
-
стандартный вывод или ошибка;
-
syslog;
-
файл журнала;
-
внешняя функция журнала.
Уровни журналирования задаются в /etc/lvm/lvm.conf (см. Приложение B, Файлы конфигурации LVM).
Глава 4. Администрирование LVM в текстовом режиме
В этой главе приведены наборы команд для решения некоторых практических задач управления LVM.
Для управления томами в кластерном окружении необходимо, чтобы выполнялся процесс clvmd (см. Раздел 3.1, «Создание томов LVM в кластере»).
4.1. Использование команд
Сначала стоит упомянуть об основных возможностях команд LVM.
Если аргумент команды содержит величину объема информации, единицы можно указать вручную. Если единицы не указаны, по умолчанию будут подразумеваться килобайты или мегабайты. Сами значения должны быть целыми числами.
По умолчанию регистр единиц не имеет значения. Например, М и m эквивалентны, а сами значения будут кратны 1024. Но если задан аргумент --units, то обозначение единиц в нижнем регистре будет означать, что они кратны 1024, а в верхнем — 1000.
Если команды в качестве аргументов принимают имена отдельных томов или целых групп, можно указать их полный путь. Например, том lvol0 в группе vg0 можно определить как vg0/lvol0. Если ожидается список групп, но при этом он не указан, по умолчанию будет подставлен список ВСЕХ групп томов. Если команда ожидает список томов, но при этом задана группа томов, будет выполнена подстановка всех логических томов в заданной группе. К примеру, команда lvdisplay vg0 покажет список всех логических томов в группе vg0.
Аргумент -v усиливает степень подробности вывода. Его можно использовать каскадно для увеличения детализации. К примеру, стандартный вывод lvcreate выглядит так:
# lvcreate -L 50MB new_vg
Rounding up size to full physical extent 52.00 MB
Logical volume "lvol0" created
lvcreate с аргументом -v:
# lvcreate -v -L 50MB new_vg
Finding volume group "new_vg"
Rounding up size to full physical extent 52.00 MB
Archiving volume group "new_vg" metadata (seqno 4).
Creating logical volume lvol0
Creating volume group backup "/etc/lvm/backup/new_vg" (seqno 5).
Found volume group "new_vg"
Creating new_vg-lvol0
Loading new_vg-lvol0 table
Resuming new_vg-lvol0 (253:2)
Clearing start of logical volume "lvol0"
Creating volume group backup "/etc/lvm/backup/new_vg" (seqno 5).
Logical volume "lvol0" created
Степень подробности вывода можно усилить, указав -vv, -vvv или даже -vvvv. Максимально подробный вывод будет достигнут при указании -vvvv. Следующий пример демонстрирует лишь несколько первых строк вывода lvcreate -vvvv:
# lvcreate -vvvv -L 50MB new_vg
#lvmcmdline.c:913 Processing: lvcreate -vvvv -L 50MB new_vg
#lvmcmdline.c:916 O_DIRECT will be used
#config/config.c:864 Setting global/locking_type to 1
#locking/locking.c:138 File-based locking selected.
#config/config.c:841 Setting global/locking_dir to /var/lock/lvm
#activate/activate.c:358 Getting target version for linear
#ioctl/libdm-iface.c:1569 dm version OF [16384]
#ioctl/libdm-iface.c:1569 dm versions OF [16384]
#activate/activate.c:358 Getting target version for striped
#ioctl/libdm-iface.c:1569 dm versions OF [16384]
#config/config.c:864 Setting activation/mirror_region_size to 512
...
Для просмотра краткой справки по интересующей команде используется аргумент --help.
commandname --help
man открывает справочную страницу команды:
man commandname
Например, man lvm покажет информацию об LVM.
В рамках LVM обращение к объектам осуществляется при помощи уникального идентификатора UUID, который назначается при создании объектов. Например, представим, что из группы томов удален физический том /dev/sdf. При повторном его подключении он будет определен как /dev/sdk. LVM корректно его определит, так как для его идентификации используется UUID, а не имя устройства. Раздел 6.4, «Восстановление метаданных физического тома» содержит информацию о присвоении идентификаторов физическим томам при их создании.
4.2. Управление физическими томами
В этой секции рассматриваются команды управления физическими томами.
4.2.1. Создание физических томов
Далее рассматриваются команды, используемые для создания физических томов.
4.2.1.1. Настройка типов разделов
Если физический том занимает весь диск, на этом диске НЕ должно быть таблицы разделов. Разделам DOS соответствует идентификатор 0x8e (задается с помощью fdisk, cfdisk или их аналога). При удалении таблицы разделов данные на диске будут удалены автоматически. Существующую таблицу можно удалить путем заполнения первого сектора нулями:
dd if=/dev/zero of=физический_том bs=512 count=1
4.2.1.2. Инициализация физических томов
pvcreate позволяет инициализировать блочное устройство как физический том. Принципиально инициализация подобна форматированию файловой системы.
Команда инициализации /dev/sdd1, /dev/sde1 и /dev/sdf1 выглядит так:
pvcreate /dev/sdd1 /dev/sde1 /dev/sdf1
Для инициализации отдельных разделов применяется команда pvcreate. Следующий пример инициализирует /dev/hdb1 как физический том для дальнейшего включения в логический том LVM.
pvcreate /dev/hdb1
4.2.1.3. Поиск блочных устройств
С помощью lvmdiskscan можно выполнить поиск блочных устройств для создания физических томов на их основе. Пример:
# lvmdiskscan
/dev/ram0 [ 16.00 MB]
/dev/sda [ 17.15 GB]
/dev/root [ 13.69 GB]
/dev/ram [ 16.00 MB]
/dev/sda1 [ 17.14 GB] LVM physical volume
/dev/VolGroup00/LogVol01 [ 512.00 MB]
/dev/ram2 [ 16.00 MB]
/dev/new_vg/lvol0 [ 52.00 MB]
/dev/ram3 [ 16.00 MB]
/dev/pkl_new_vg/sparkie_lv [ 7.14 GB]
/dev/ram4 [ 16.00 MB]
/dev/ram5 [ 16.00 MB]
/dev/ram6 [ 16.00 MB]
/dev/ram7 [ 16.00 MB]
/dev/ram8 [ 16.00 MB]
/dev/ram9 [ 16.00 MB]
/dev/ram10 [ 16.00 MB]
/dev/ram11 [ 16.00 MB]
/dev/ram12 [ 16.00 MB]
/dev/ram13 [ 16.00 MB]
/dev/ram14 [ 16.00 MB]
/dev/ram15 [ 16.00 MB]
/dev/sdb [ 17.15 GB]
/dev/sdb1 [ 17.14 GB] LVM physical volume
/dev/sdc [ 17.15 GB]
/dev/sdc1 [ 17.14 GB] LVM physical volume
/dev/sdd [ 17.15 GB]
/dev/sdd1 [ 17.14 GB] LVM physical volume
7 disks
17 partitions
0 LVM physical volume whole disks
4 LVM physical volumes
4.2.2. Просмотр физических томов
Для просмотра информации о физических томах LVM используются команды pvs, pvdisplay и pvscan.
pvs позволяет настроить формат вывода, показывая по одному тому в каждой строке (см. Раздел 4.8, «Настройка отчетов LVM»).
pvdisplay формирует подробный отчет для каждого физического тома, включая информацию о размере, экстентах, группе томов и пр. Формат вывода фиксирован.
Пример вывода pvdisplay для одного тома:
# pvdisplay
--- Physical volume ---
PV Name /dev/sdc1
VG Name new_vg
PV Size 17.14 GB / not usable 3.40 MB
Allocatable yes
PE Size (KByte) 4096
Total PE 4388
Free PE 4375
Allocated PE 13
PV UUID Joqlch-yWSj-kuEn-IdwM-01S9-XO8M-mcpsVe
pvscan проверяет все поддерживаемые блочные устройства в системе на предмет наличия физических томов.
Пример:
# pvscan
PV /dev/sdb2 VG vg0 lvm2 [964.00 MB / 0 free]
PV /dev/sdc1 VG vg0 lvm2 [964.00 MB / 428.00 MB free]
PV /dev/sdc2 lvm2 [964.84 MB]
Total: 3 [2.83 GB] / in use: 2 [1.88 GB] / in no VG: 1 [964.84 MB]
Чтобы выборочно проверить устройства, можно создать фильтр в lvm.conf (см. Раздел 4.5, «Определение устройств LVM с помощью фильтров»).
4.2.3. Запрет выделения пространства физического тома
Команда pvchange позволяет запретить выделение свободных физических экстентов, что может потребоваться в случае ошибок диска или при удалении физического тома.
Следующая команда запрещает выделение экстентов на /dev/sdk1:
pvchange -x n /dev/sdk1
Аргументы -xy разрешат выделение экстентов там, где раньше это было запрещено.
4.2.4. Изменение размера физического тома
pvresize изменяет размер физического тома, если изменился размер блочного устройства в его основе.
4.2.5. Удаление физических томов
pvremove удаляет устройство, в котором больше нет необходимости, заполняя его метаданные нулями.
Если удаляемый том входит в состав группы, сначала исключите его из группы с помощью vgreduce (см. Раздел 4.3.6, «Удаление физических томов из группы»).
# pvremove /dev/ram15
Labels on physical volume "/dev/ram15" successfully wiped
4.3. Управление группами
В этой секции описываются команды администрирования групп томов.
4.3.1. Создание групп томов
Команда vgcreate создаст новую группу томов с заданным именем и добавит в нее как минимум один физический том.
Следующая команда создаст группу vg1, включающую в свой состав физические тома /dev/sdd1 и /dev/sde1.
vgcreate vg1 /dev/sdd1 /dev/sde1
Если группа создается на основе физических томов, их пространство по умолчанию подразделяется на экстенты размером 4 мегабайт. Этот размер и определяет минимальную величину изменения размера логического тома. Число экстентов не оказывает влияния на эффективность ввода-вывода для логического тома.
Размер экстента можно задать с помощью аргумента -s команды vgcreate. Дополнительно можно ограничить число томов в группе — для этого используется -p (для физических томов) или -l (для логических томов).
По умолчанию группа томов выделяет физические экстенты согласно стандартным правилам, то есть чередующиеся секции не будут располагаться на одном физическом томе. Стандартная политика распределения обозначена как normal. Аргумент --alloc команды vgcreate позволяет изменить значение на contiguous, anywhere или cling.
contiguous требует, чтобы новые экстенты размещались следом за существующими. Если есть достаточное число экстентов, чтобы удовлетворить запрос выделения пространства, а политика normal не может их использовать, можно выбрать anywhere. Экстенты будут заняты, даже если при этом чередующиеся сегменты будут включены в один том, тем самым оказав отрицательный эффект на производительность. Команда vgchange позволяет изменить метод выделения экстентов.
Раздел 4.4.12.2, «Увеличение логического тома в режиме cling» содержит информацию о cling и выборе томов с помощью тегов.
В целом, любой метод, отличный от normal, используется только в особых, нестандартных случаях.
Файлы групп томов и их логических томов расположены в /dev. Путь:
/dev/vg/lv/
Например, если есть группы myvg1 и myvg2 с томами lvo1, lvo2 и lvo3 в составе каждой из них, им будет соответствовать шесть файлов:
/dev/myvg1/lv01 /dev/myvg1/lv02 /dev/myvg1/lv03 /dev/myvg2/lv01 /dev/myvg2/lv02 /dev/myvg2/lv03
Максимально допустимый размер устройства с LVM — 8 эксабайт для 64-битных процессоров.
4.3.2. Создание групп томов в кластере
Группы томов в кластерном окружении можно создать с помощью vgcreate.
По умолчанию группы, созданные с помощью CLVM в общем хранилище, доступны всем компьютерам, обладающим доступом к этому хранилищу. В принципе, можно создать локальные группы томов, которые будут видны только одному компьютеру в кластере. Для этого используется vgcreate с опцией -c n.
Следующая команда создаст локальную группу vg1 с томами /dev/sdd1 и /dev/sde1.
vgcreate -c n vg1 /dev/sdd1 /dev/sde1
vgchange -с позволяет изменить тип группы с локальной на кластерную (см. Раздел 4.3.7, «Изменение параметров группы томов»).
Тип группы можно проверить с помощью команды vgs. Приведенная далее команда вернет атрибуты групп VolGroup00 и testvg1. В этом примере testvg1 является кластерной группой, а VolGroup00 — нет, о чем свидетельствует значение c в столбце Attr.
[root@doc-07]# vgs
VG #PV #LV #SN Attr VSize VFree
VolGroup00 1 2 0 wz--n- 19.88G 0
testvg1 1 1 0 wz--nc 46.00G 8.00M
Раздел 4.3.4, «Просмотр групп томов», Раздел 4.8, «Настройка отчетов LVM» и справочная страница vgs содержат подробную информацию о vgs.
4.3.3. Добавление физических томов в группу
vgextend позволяет добавить физические тома в существующую группу, тем самым увеличив ее размер.
Команда добавления тома /dev/sdf1 в группу vg1:
vgextend vg1 /dev/sdf1
4.3.4. Просмотр групп томов
vgs и vgdisplay позволяют просмотреть информацию о группах томов LVM.
Основной целью команды vgscan является поиск групп на дисках и создание файла кэша LVM, но с ее помощью можно дополнительно показать список групп томов (см. Раздел 4.3.5, «Поиск групп томов на дисках»).
Команда vgs выведет информацию для каждой группы в отдельной строке. Формат вывода можно изменять, что широко применяется в сценариях (см. Раздел 4.8, «Настройка отчетов LVM»).
vgdisplay показывает параметры группы в фиксированном формате: размер, экстенты, число физических томов и пр. Приведенный далее пример демонстрирует вывод vgdisplay для группы new_vg. Если группа не указана, будет показана информация для всех групп.
# vgdisplay new_vg
--- Volume group ---
VG Name new_vg
System ID
Format lvm2
Metadata Areas 3
Metadata Sequence No 11
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 0
Max PV 0
Cur PV 3
Act PV 3
VG Size 51.42 GB
PE Size 4.00 MB
Total PE 13164
Alloc PE / Size 13 / 52.00 MB
Free PE / Size 13151 / 51.37 GB
VG UUID jxQJ0a-ZKk0-OpMO-0118-nlwO-wwqd-fD5D32
4.3.5. Поиск групп томов на дисках
vgscan проверяет все поддерживаемые дисковые устройства в системе на предмет наличия физических томов и групп томов. При этом будет создан файл /etc/lvm/.cache, содержащий перечень текущих устройств LVM.
LVM выполняет vgscan автоматически при загрузке системы, при запуске vgcreate и при обнаружении несоответствий LVM.
Если конфигурация оборудования была изменена, можно выполнить vgscan вручную. Это необходимо, например, при добавлении новых дисков в систему из SAN или при горячем подключении нового диска, отмеченного как физический том.
В lvm.conf можно определить фильтр для исключения устройств из проверки (см. Раздел 4.5, «Определение устройств LVM с помощью фильтров»).
Пример вывода vgscan:
# vgscan
Reading all physical volumes. This may take a while...
Found volume group "new_vg" using metadata type lvm2
Found volume group "officevg" using metadata type lvm2
4.3.6. Удаление физических томов из группы
Команда vgreduce удаляет неиспользуемые физические тома из группы, тем самым уменьшая ее размер. Освобожденные физические тома могут быть удалены или добавлены в другие группы.
Прежде чем удалить физический том из группы, надо убедиться, что он не используется логическими томами. Это можно сделать с помощью pvdisplay.
# pvdisplay /dev/hda1
-- Physical volume ---
PV Name /dev/hda1
VG Name myvg
PV Size 1.95 GB / NOT usable 4 MB [LVM: 122 KB]
PV# 1
PV Status available
Allocatable yes (but full)
Cur LV 1
PE Size (KByte) 4096
Total PE 499
Free PE 0
Allocated PE 499
PV UUID Sd44tK-9IRw-SrMC-MOkn-76iP-iftz-OVSen7
Если физический том все еще используется, надо перенести данные в другой том (с помощью pvmove). После этого можно будет уменьшить размер тома с помощью vgreduce.
Следующая команда удалит том /dev/hda1 из my_volume_group:
# vgreduce my_volume_group /dev/hda1
4.3.7. Изменение параметров группы томов
vgchange позволяет включить и отключить группы томов (см. Раздел 4.3.8, «Активация и деактивация групп томов»), а также изменить некоторые параметры.
Следующая команда изменяет максимально допустимое число логических томов для группы vg00, устанавливая его значение в 128:
vgchange -l 128 /dev/vg00
Справочная страница vgchange(8) содержит описание доступных параметров.
4.3.8. Активация и деактивация групп томов
При создании группы томов она будет активна по умолчанию, то есть логические тома в ее составе будут сразу доступны.
Существует множество причин, по которым может понадобиться отключить группу томов. Для это цели служит аргумент -a (--available) команды vgchange.
Пример отключения группы my_volume_group:
vgchange -a n my_volume_group
Если включено кластерное блокирование, добавьте «e» для активации или деактивации группы на выбранном узле в кластере или «I» — только на локальном узле. Логические тома со снимком на одном узле всегда активируются отдельно.
Отключение отдельных логических томов осуществляется с помощью lvchange (см. Раздел 4.4.8, «Изменение параметров группы логических томов»). Раздел 4.7, «Активация логических томов на отдельных узлах кластера» содержит информацию об активации логических томов на индивидуальных узлах кластера.
4.3.9. Удаление групп томов
Команда vgremove позволяет удалить пустую группу томов.
# vgremove officevg
Volume group "officevg" successfully removed
4.3.10. Разбиение группы томов
Чтобы разделить физические тома в группе с целью создания новой группы, используется команда vgsplit.
Логические тома, принадлежащие разным группам, не могут быть разделены. Каждый логический том должен полностью принадлежать физическим томам, входящим в состав либо уже существующей, либо новой группы томов. Для принудительного разбиения используется pvmove.
Следующий пример отделяет новую группу томов smallvg от bigvg.
# vgsplit bigvg smallvg /dev/ram15
Volume group "smallvg" successfully split from "bigvg"
4.3.11. Объединение групп томов
Для объединения двух групп в одну используется команда vgmerge. Возможно объединение двух неактивных томов, если размеры их физических экстентов равны и общий объем физических и логических томов обеих групп не превышает допустимый размер полученной группы.
Следующая команда добавит неактивную группу my_vg в группу databases с выводом отчета о процессе выполнения.
vgmerge -v databases my_vg
4.3.12. Создание резервной копии метаданных группы томов
Резервные копии и архивы метаданных по умолчанию создаются автоматически в случае изменения конфигурации логического тома или группы. Это можно отключить в lvm.conf. Резервная копия метаданных сохраняется в /etc/lvm/backup, а архивы — в /etc/lvm/archives. Команда vgcfgbackup позволяет создать резервную копию метаданных в /etc/lvm/backup в любое время.
vgcfrestore восстанавливает метаданные группы томов из архива и размещает их на всех физических томах в группах.
Раздел 6.4, «Восстановление метаданных физического тома» содержит пример использования vgcfgrestore для восстановления метаданных.
4.3.13. Переименование группы томов
Для переименования существующей группы томов используется команда vgrename.
Обе приведенные команды изменяют имя группы vg02 на my_volume_group.
vgrename /dev/vg02 /dev/my_volume_group
vgrename vg02 my_volume_group
4.3.14. Перенос группы томов в другую систему
С помощью vgexport и vgimport можно осуществлять перемещение целых групп томов между системами.
vgexport закрывает доступ к неактивной группе томов, что позволяет отключить ее физические тома, а vgimport снова разрешает доступ.
Порядок действий при переносе группы томов между системами:
-
Убедитесь, что пользователи не обращаются к файлам в пределах активных томов в группе, затем отключите логические тома.
-
Чтобы отметить группу томов как неактивную, выполните команду
vgchangeс аргументом-a n. -
vgexportпозволяет экспортировать группу, что закроет к ней доступ из системы, откуда она будет удалена.После завершения экспортирования группы, когда вы запустите команду
pvscan, будет видно, что физический том принадлежит экспортируемой группе. Пример:[root@tng3-1]#
pvscanPV /dev/sda1 is in exported VG myvg [17.15 GB / 7.15 GB free] PV /dev/sdc1 is in exported VG myvg [17.15 GB / 15.15 GB free] PV /dev/sdd1 is in exported VG myvg [17.15 GB / 15.15 GB free] ...После следующего выключения системы можно отсоединить диски, на основе которых была построена эта группа томов, и переподключить их в новую систему.
-
Подключив диски в новую систему, выполните
vgimportдля импорта группы томов, тем самым открыв к ней доступ из системы. -
Аргумент
-a yкомандыvgchangeпозволяет активировать группу томов. -
Подключите файловую систему.
4.3.15. Восстановление каталога группы томов
Чтобы воссоздать каталог группы томов и специальные файлы логических томов, используется команда vgmknodes. Она проверяет специальные файлы LVM2 в каталоге /dev, необходимые для работы активных логических томов. При этом будут созданы недостающие специальные файлы, а лишние файлы будут удалены.
Аналогичного результата можно добиться с помощью vgscan, указав аргумент --mknodes.
4.4. Управление логическими томами
В этой секции будут рассмотрены команды управления логическими томами.
4.4.1. Создание линейных логических томов
Новый логический том можно создать с помощью lvcreate. Если имя тома не указано, по умолчанию будет использоваться обозначение lvol#, где # — внутренний номер логического тома.
Для нового линейного тома выделяются свободные экстенты из группы физических томов. Обычно логические тома используют все доступное пространство. При изменении размера логического тома экстенты в их основе будут переорганизованы или освобождены.
Следующая команда создаст логический том размером 10 гигабайт в группе vg1.
lvcreate -L 10G vg1
Приведенная далее команда создаст линейный том testlv размером 1500 мегабайт в группе testvg. При этом будет создано блочное устройство /dev/testvg/testlv.
lvcreate -L1500 -n testlv testvg
Далее из свободных экстентов в группе vg0 будет создан логический том gfslv размером 50 гигабайт.
lvcreate -L 50G -n gfslv vg0
lvcreate -l позволяет задать размер логического тома в экстентах. Также можно указать процентную часть группы томов, используемую для создания логического тома. Приведенная ниже команда создаст том mylv, занимающий 60% группы testvol.
lvcreate -l 60%VG -n mylv testvg
С помощью -l можно также указать процент свободного пространства группы, которое будет занято логическим томом. Например, команда создания тома yourlv, который займет все свободное пространство группы testvol будет выглядеть так:
lvcreate -l 100%FREE -n yourlv testvg
С помощью -l можно также создать логический том, который будет использовать целую группу томов. Другой способ создания логического тома, занимающего всю группу, состоит в передаче команде lvcreate значения «Total PE», найденного с помощью vgdisplay.
Пример создания логического тома mylv, который полностью заполнит группу testvg:
#vgdisplay testvg | grep "Total PE"Total PE 10230 #lvcreate -l 10230 testvg -n mylv
При создании логического тома на основе физических томов стоит учесть вероятность того, что в будущем физический том может потребоваться удалить (см. Раздел 4.3.6, «Удаление физических томов из группы»).
Чтобы создать логический том на основе определенных физических томов в группе, надо их перечислить в командной строке lvcreate. Далее будет создан логический том testlv на основе физического тома /dev/sdg1 в группе testvg.
lvcreate -L 1500 -ntestlv testvg /dev/sdg1
Можно указать, какие экстенты будут задействованы для образования логического тома. В следующем примере будет создан линейный том, в состав которого войдут экстенты 0 — 24 физического тома /dev/sda1 и 50 — 124 тома /dev/sdb1. Оба физических тома принадлежат группе testvg.
lvcreate -l 100 -n testlv testvg /dev/sda1:0-24 /dev/sdb1:50-124
Следующий пример демонстрирует создание линейного тома на основе экстентов 0 — 25 физического тома /dev/sda1 и затем продолжая с экстента 100.
lvcreate -l 100 -n testlv testvg /dev/sda1:0-25:100-
По умолчанию правила выделения экстентов наследуются от группы томов (inherit). Это можно изменить с помощью lvchange (см. Раздел 4.3.1, «Создание групп томов»).
4.4.2. Создание томов с чередованием
Для обработки больших объемов последовательных операций чтения и записи рекомендуется использовать логические тома с чередованием, так как при этом можно достичь высокой эффективности чтения и записи (см. Раздел 2.3.2, «Том с чередованием»).
При создании тома с чередованием число сегментов (физических томов) задается с помощью аргумента -i команды lvcreate. Это значение не должно превышать общее число физических томов в группе (за исключением использования --alloc anywhere).
Если размеры физических устройств, на основе которых создан логический том, отличаются, то максимальный объем тома с чередованием будет определяться размером наименьшего устройства. Например, если используются два физических тома, максимальный размер логического тома будет равен удвоенному размеру наименьшего устройства. Если же используются три тома, максимальный размер будет равен утроенному размеру наименьшего устройства.
Следующая команда создаст том gfslv размером 50 ГБ на основе двух физических томов в группе vg0; при этом размер сегмента чередования будет равен 64 КБ.
lvcreate -L 50G -i2 -I64 -n gfslv vg0
Так же как и в случае с линейными томами, можно явно указать число выделяемых экстентов. В следующем примере на основе двух физических томов будет создан том stripelv, содержащий 100 экстентов. Этот том будет входить в состав группы testvg и занимать секторы 0 — 49 тома /dev/sda1 и 50 — 99 тома /dev/sdb1.
# lvcreate -l 100 -i2 -nstripelv testvg /dev/sda1:0-49 /dev/sdb1:50-99
Using default stripesize 64.00 KB
Logical volume "stripelv" created
4.4.3. Создание зеркальных томов
Создание зеркального логического тома в кластере осуществляется по тем же правилам, что и на отдельном компьютере. Отличия состоят в том, что в кластере должна работать кластерная инфраструктура, кластер должен обладать кворумом, а тип блокирования в lvm.conf должен разрешать кластерное блокирование. Раздел 5.5, «Создание зеркального логического тома в кластере» содержит примеры создания зеркального тома в кластере.
Одновременные попытки выполнения команд создания и преобразования зеркал с разных компьютеров в кластере могут привести к их задержкам и сбоям. Поэтому команды создания зеркал рекомендуется выполнять с одного компьютера.
При создании зеркального тома необходимо указать число копий, для чего служит аргумент -m команды lvcreate. Так, -m1 создаст одно зеркало, то есть в файловой системе будет две копии — линейный логический том и его копия. Аналогичным образом, если указать -m2, будет создано два зеркала (всего три копии).
Ниже приведен пример создания тома mirrorlv размером 50 гигабайт с одним зеркалом. Пространство будет выделено из группы vg0.
lvcreate -L 50G -m1 -n mirrorlv vg0
Копируемое устройство разбивается на сегменты, размер которых по умолчанию составляет 512 килобайт. Аргумент -R команды lvcreate позволяет указать другой размер в мегабайтах, или его можно изменить напрямую с помощью параметра mirror_region_size в файле lvm.conf.
В силу ограничений кластерной инфраструктуры, размер сегментов зеркала, размер которого превышает 1.5 ТБ, должен быть больше 512 МБ. В противном случае может нарушиться функциональность LVM.
Размер сегмента рассчитывается так: размер зеркала в терабайтах округляется до следующего значения, кратного 2. Так, например, для зеркала размером 1.5 ТБ можно указать -R 2, для 3 ТБ — -R 4, для 5 ТБ — -R 8.
Следующая команда создаст зеркальный том с сегментами размером 2 МБ:
lvcreate -m1 -L 2T -R 2 -n mirror vol_group
LVM поддерживает краткий журнал синхронизации сегментов с зеркалами. По умолчанию журнал хранится на диске и сохраняется между перезагрузками. Если же требуется, чтобы журнал находился в памяти, используйте аргумент --corelog. Это отменяет необходимость в устройстве журналирования, но в то же время требует полной синхронизации зеркала при каждой перезагрузке.
Ниже будет создан логический том ondiskmirvol с одним зеркалом в группе bigvg. Размер тома равен 12 МБ, а журнал зеркала хранится в памяти.
# lvcreate -L 12MB -m1 --mirrorlog core -n ondiskmirvol bigvg
Logical volume "ondiskmirvol" created
Журнал зеркала будет создан на отдельном устройстве. Возможно создание журнала на том же устройстве, где расположена секция зеркала, — для этого служит аргумент --alloc anywhere команды vgcreate. Это может отрицательно сказаться на производительности, но позволит создать зеркало даже при наличии всего двух устройств.
Ниже приведен пример создания тома mirrorlv размером 50 МБ с одним зеркалом на основе группы томов vg0. При этом журнал зеркала расположен на том же устройстве, что и составляющая зеркала. Группа томов vg0 состоит из двух устройств.
lvcreate -L 500M -m1 -n mirrorlv -alloc anywhere vg0
В кластерном окружении управление журналами зеркал осуществляется компьютером с наименьшим кластерным идентификатором. Если отдельные узлы кластера потеряли доступ к устройству, где хранится журнал, функциональность зеркала не нарушится при условии, что журнал доступен компьютеру с наименьшим идентификатором. Но если компьютер с наименьшим идентификатором потеряет доступ к журналу, процедура восстановления начнется, даже если журнал доступен с других узлов.
Для создания зеркала журнала служит аргумент --mirrorlog mirrored. Приведенная ниже команда создаст том twologvol с одним зеркалом в группе bigvg. Размер тома равен 12 МБ, а журналы зеркал хранятся на отдельных устройствах.
# lvcreate -L 12MB -m1 --mirrorlog mirrored -n twologvol bigvg
Logical volume "twologvol" created
Параметр --alloc anywhere позволяет хранить копии журнала на том же устройстве, где расположено звено зеркала. Как уже упоминалось, это может отрицательно сказаться на производительности, но позволит создать дополнительный журнал, даже если общее число журналов превышает число физических дисков.
Составляющие зеркала синхронизируются в момент его создания. В зависимости от их размера процесс синхронизации может занять некоторое время. Если создается новое зеркало, синхронизация которого необязательна, можно добавить параметр nosync.
Можно явно указать, на каких устройствах будут располагаться журналы, и какие экстенты будут заняты зеркалом. Чтобы разместить журнал на конкретном диске, укажите всего ОДИН экстент на этом диске. LVM игнорирует порядок, в котором перечислены устройства. Если в списке присутствуют физические устройства, они и будут использоваться для выделения пространства; занятые физические экстенты будут пропущены.
Далее приведен пример создания зеркального тома mirrorlv размером 500 МБ с одним зеркалом и одним журналом. Том будет создан в группе vg0. Одна часть зеркала будет располагаться на устройстве /dev/sda1, вторая — на /dev/sdb1, а журнал будет храниться на /dev/sdc1.
lvcreate -L 500M -m1 -n mirrorlv vg0 /dev/sda1 /dev/sdb1 /dev/sdc1
Следующая команда создаст том mirrorlv размером 500 МБ с одним зеркалом. Том будет создан в составе группы vg0. Одна часть зеркала будет занимать экстенты 0 — 499 на /dev/sda1, вторая — экстенты 0 — 499 на /dev/sdb1, а журнал будет храниться на /dev/sdc1, начиная с нулевого экстента. Размер экстента равен 1 МБ. Если указанные экстенты уже заняты, они будут пропущены.
lvcreate -L 500M -m1 -n mirrorlv vg0 /dev/sda1:0-499 /dev/sdb1:0-499 /dev/sdc1:0
Начиная с Red Hat Enterprise Linux 6.1, допускается объединять массивы RAID0 и RAID1 в один логический том. Если при создании логического тома указано число зеркал (--mirrors X) и число секций (--stripes Y), будет создано зеркальное устройство с чередующимися составляющими.
4.4.3.1. Правила работы при сбое зеркального тома
Поведение зеркального тома в случае сбоя устройства можно определить с помощью параметров mirror_image_fault_policy и mirror_log_fault_policy в секции activation файла lvm.conf. Если этим параметрам присвоено значение remove, неисправные устройства будут исключены из системы. Значение allocate означает, что после исключения устройства будет предпринята попытка выделения пространства на другом устройстве. Если пространство выделить не удалось, allocate работает так же как remove.
По умолчанию mirror_log_fault_policy имеет значение allocate, то есть синхронизация поддерживается между перезагрузками и в случае сбоя. Если задан режим remove, то в случае сбоя устройства, где хранится журнал, зеркало будет поддерживать журнал в памяти без сохранения его между перезагрузками. Как следствие, после сбоя зеркало надо будет синхронизировать полностью.
По умолчанию mirror_image_fault_policy имеет значение remove, то есть если после сбоя звена зеркала осталась только одна копия, зеркало будет преобразовано в другой тип. allocate приводит к повторной синхронизации устройств с сохранением характеристик зеркала, что может занять некоторое время.
При выходе из строя устройства в составе зеркала начнется процесс восстановления. Сначала проблемные устройства будут исключены, что может привести к тому, что зеркало превратится в обычное линейное устройство. Далее начнется замена этих устройств при условии, что параметр mirror_log_fault_policy имеет значение allocate. Однако нет гарантий, что на втором этапе не будут выбраны устройства, которые раньше служили причиной сбоя зеркала.
Раздел 6.3, «Восстановление после сбоя зеркала» содержит дальнейшую информацию о восстановлении зеркал вручную.
4.4.3.2. Разбиение образа зеркального тома
Образ зеркального тома можно разделить на части с целью создания нового тома. Для этой цели служит lvconvert --splitmirrors с указанием числа копий. Аргумент --name задает имя нового тома.
В следующем примере от тома vg/lv будет отделен новый том copy, содержащий две копии зеркала. LVM сам выбирает, какие именно устройства будут отделены.
lvconvert --splitmirrors 2 --name copy vg/lv
Можно отдельно указать устройства. Ниже приведена команда отделения нового тома copy от vg/lv. Составляющие зеркала будут располагаться на двух устройствах: /dev/sdc1 и /dev/sde1.
lvconvert --splitmirrors 2 --name copy vg/lv /dev/sd[ce]1
4.4.3.3. Восстановление зеркального устройства
Команда lvconvert --repair поможет восстановить зеркало после сбоя диска. lvconvert --repair выполняется в интерактивном режиме, предлагая подтвердить замену сбойных устройств.
-
Чтобы пропустить запросы подтверждения и заменить все проблемные устройства, добавьте параметр
-y. -
Чтобы пропустить все запросы и не заменять устройства, добавьте параметр
-f. -
Чтобы пропустить запросы, но при этом включить доступные режимы замены для зеркального образа и журнала, укажите аргумент
--use-policies. Он получает значенияmirror_log_fault_policyиmirror_device_fault_policyизlvm.conf.
4.4.3.4. Изменение конфигурации зеркальных томов
Преобразование зеркального тома в линейный и наоборот осуществляется с помощью команды lvconvert. Она также позволяет изменить параметры существующих логических томов.
При преобразовании логического тома в зеркальный, в сущности, вы просто создаете составляющие зеркала для уже существующего тома. Группа томов должна иметь достаточно устройств и пространства для организации зеркал и хранения журнала.
Если по какой-то причине одна из составляющих зеркала перестала работать, LVM осуществит преобразование тома в линейный, чтобы сохранить доступ к его содержимому. После замены звена зеркало можно восстановить с помощью lvconvert (см. Раздел 6.3, «Восстановление после сбоя зеркала»).
Следующая команда преобразует линейный том vg00/lvol1 в зеркальный.
lvconvert -m1 vg00/lvol1
Команда преобразования зеркального логического тома vg00/lvol1 в линейный с удалением зеркального компонента будет выглядеть так:
lvconvert -m0 vg00/lvol1
4.4.4. Создание снимков
Команда lvcreate с аргументом -s позволяет создать том-снимок с разрешениями записи.
Создание снимков в кластерной группе томов не поддерживается. Но в Red Hat Enterprise Linux 6.1 можно отдельно активировать кластерный том и создать его снимок (см. Раздел 4.7, «Активация логических томов на отдельных узлах кластера»).
В Red Hat Enterprise Linux 6.1 добавлена поддержка снимков для зеркальных логических томов.
Ниже будет создан снимок /dev/vg00/snap для тома /dev/vg00/lvol1 размером 100 МБ. Если исходный том содержит файловую систему, можно будет подключить снимок в любой каталог, тем самым получив доступ к содержимому файловой системы для создания резервной копии, в то время как исходная файловая система будет продолжать обновление.
lvcreate --size 100M --snapshot --name snap /dev/vg00/lvol1
Выполнив lvdisplay для логических томов, можно получить список его снимков и их статус (активный или неактивный).
Ниже показано состояние тома /dev/new_vg/lvol0, для которого был создан снимок /dev/new_vg/newvgsnap.
# lvdisplay /dev/new_vg/lvol0
--- Logical volume ---
LV Name /dev/new_vg/lvol0
VG Name new_vg
LV UUID LBy1Tz-sr23-OjsI-LT03-nHLC-y8XW-EhCl78
LV Write Access read/write
LV snapshot status source of
/dev/new_vg/newvgsnap1 [active]
LV Status available
# open 0
LV Size 52.00 MB
Current LE 13
Segments 1
Allocation inherit
Read ahead sectors 0
Block device 253:2
Команда lvs по умолчанию показывает исходный том и процентную часть снимка. Следующий пример демонстрирует стандартный вывод lvs для системы с логическим томом /dev/new_vg/lvol0 с соответствующим ему снимком /dev/new_vg/newvgsnap.
# lvs
LV VG Attr LSize Origin Snap% Move Log Copy%
lvol0 new_vg owi-a- 52.00M
newvgsnap1 new_vg swi-a- 8.00M lvol0 0.20
Так как размер снимка увеличивается по мере изменения исходного тома, важно следить за его заполнением. Для этого можно использовать команду lvs. При заполнении снимка на 100% он будет потерян, так как запись в неизменяемые участки исходного тома повредит сам снимок.
4.4.5. Объединение снимка с оригиналом
В Red Hat Enterprise Linux 6 добавлена возможность объединения снимка с его исходным томом с помощью lvconvert --merge. Если не открыт ни снимок, ни исходный том, их слияние будет выполнено автоматически. В противном случае слияние начнется, как только один из томов станет активен или по факту закрытия обоих томов. Объединение снимка с томом, который не может быть закрыт (например, если он содержит корневую файловую систему), будет отложено до момента следующей активации исходного тома. Полученному в результате объединения тому будет присвоено имя исходного тома, его вторичный номер и UUID. Во время слияния все операции чтения и записи исходного тома будут представлены так, как будто они предназначаются снимку. После завершения снимок будет удален.
Следующая команда объединит снимок vg00/lvol1_snap с его исходным томом.
lvconvert --merge vg00/lvol1_snap"
В команде можно указать несколько снимков или их метки. Так, в приведенном ниже примере томам vg00/lvol1, vg00/lvol2 и vg00/lvol3 соответствует метка @some_tag. Команда последовательно осуществит слияние их снимков. Дополнительный параметр --background начнет объединение снимков параллельно.
lvconvert --merge @some_tag"
Приложение C, Теги объектов LVM содержит сведения о присвоении меток объектам LVM. Информацию о lvconvert --merge можно найти на справочной странице lvconvert(8).
4.4.6. Постоянные номера устройств
Старший и младший номер присваивается динамически при загрузке модуля. Производительность некоторых приложений оптимальна при условии, что оба номера остаются неизменными. Их можно задать с помощью команд lvcreate и lvchange:
--persistent y --major старший --minor младший
В качестве младшего номера используйте достаточно большое число, чтобы гарантировать, что этот номер не будет назначен устройству автоматически.
Если файловая система подключается по NFS, то указание в файле экспорта параметра fsid поможет избежать необходимости в обеспечении постоянства номера устройства в пределах LVM.
4.4.7. Изменение размера логических томов
С помощью команды lvreduce можно уменьшить размер логического тома. Если том содержит файловую систему, сначала необходимо уменьшить ее размер, чтобы размер логического тома был эквивалентен размеру файловой системы.
Следующая команда уменьшает размер тома lvol1 в группе vg00 на три логических экстента.
lvreduce -l -3 vg00/lvol1
4.4.8. Изменение параметров группы логических томов
С помощью команды lvchange можно изменить параметры логического тома. Полный список параметров можно найти на справочной странице lvchange(8).
lvchange также можно использовать для активации и деактивации логических томов. Одновременная активация ВСЕХ логических томов в группе осуществляется с помощью vgchange (см. Раздел 4.3.7, «Изменение параметров группы томов»).
Следующая команда ограничивает доступ к тому lvol1 в группе vg00 только чтением.
lvchange -pr vg00/lvol1
4.4.9. Переименование логических томов
Чтобы переименовать существующий логический том, используйте команду lvrename.
Обе приведенные команды изменят имя логического тома lvold в группе vg02 на lvnew.
lvrename /dev/vg02/lvold /dev/vg02/lvnew
lvrename vg02 lvold lvnew
Раздел 4.7, «Активация логических томов на отдельных узлах кластера» содержит информацию об активации логических томов на отдельных узлах кластера.
4.4.10. Удаление логических томов
Удалить неактивный логический том можно с помощью команды lvremove. Сначала выполните umount для его отключения из файловой системы. В кластерном окружении необходимо выключить том перед его удалением.
Приведенная далее команда удалит /dev/testvg/testlv из группы testvg. В этом примере логический том не был выключен.
[root@tng3-1 lvm]#lvremove /dev/testvg/testlvDo you really want to remove active logical volume "testlv"? [y/n]:yLogical volume "testlv" successfully removed
Том можно отключить отдельно с помощью lvchange -an — тогда предупреждение об удалении активного тома не появится.
4.4.11. Просмотр логических томов
Для просмотра сведений о логических томах используются команды lvs, lvdisplay и lvscan.
lvs позволяет настроить формат полученных данных и выводит по одному тому на каждой строке, что может применяться при создании сценариев (см. Раздел 4.8, «Настройка отчетов LVM»).
Вывод команды lvdisplay будет содержать информацию о томе в фиксированном формате.
Следующая команда покажет атрибуты тома lvol2 в группе vg00. Вывод также будет содержать список снимков выбранного тома и их статус (активен или неактивен).
lvdisplay -v /dev/vg00/lvol2
lvscan покажет список логических томов в системе. Пример:
# lvscan
ACTIVE '/dev/vg0/gfslv' [1.46 GB] inherit
4.4.12. Увеличение размера логических томов
lvextend позволяет увеличить размер логического тома.
Можно задать объем для увеличения тома или точный размер тома уже после увеличения.
Пример увеличения логического тома /dev/myvg/homevol до 12 гигабайт:
# lvextend -L12G /dev/myvg/homevol
lvextend -- extending logical volume "/dev/myvg/homevol" to 12 GB
lvextend -- doing automatic backup of volume group "myvg"
lvextend -- logical volume "/dev/myvg/homevol" successfully extended
Следующая команда добавит еще один гигабайт в /dev/myvg/homevol.
# lvextend -L+1G /dev/myvg/homevol
lvextend -- extending logical volume "/dev/myvg/homevol" to 13 GB
lvextend -- doing automatic backup of volume group "myvg"
lvextend -- logical volume "/dev/myvg/homevol" successfully extended
Аргумент -l позволяет указать число экстентов для добавления в том. Также можно указать процент от общего размера группы томов или незанятого пространства. Приведенная ниже команда увеличит том testlv, выделив ему все нераспределенное пространство в группе myvg.
[root@tng3-1 ~]# lvextend -l +100%FREE /dev/myvg/testlv
Extending logical volume testlv to 68.59 GB
Logical volume testlv successfully resized
После увеличения тома необходимо увеличить размер его файловой системы.
Большинство стандартных утилит файловой системы по умолчанию нарастят файловую систему так, чтобы ее размер соответствовал размеру логического тома.
4.4.12.1. Увеличение тома с чередованием
Чтобы увеличить размер логического тома, использующего чередование, необходимо иметь достаточно пространства на физических томах в его основе. К примеру, в случае двухстороннего чередования, в котором занята целая группа томов, добавление нового физического тома в группу не позволит увеличить размер сегмента чередования — придется добавить как минимум два физических тома.
Возьмем в качестве примера группу vg, состоящую из двух физических томов.
# vgs
VG #PV #LV #SN Attr VSize VFree
vg 2 0 0 wz--n- 271.31G 271.31G
Новый сегмент чередования может занимать все доступное в группе место.
#lvcreate -n stripe1 -L 271.31G -i 2 vgUsing default stripesize 64.00 KB Rounding up size to full physical extent 271.31 GB Logical volume "stripe1" created #lvs -a -o +devicesLV VG Attr LSize Origin Snap% Move Log Copy% Devices stripe1 vg -wi-a- 271.31G /dev/sda1(0),/dev/sdb1(0)
После этого в группе не останется свободного пространства.
# vgs
VG #PV #LV #SN Attr VSize VFree
vg 2 1 0 wz--n- 271.31G 0
Следующая команда добавит новый физический том в группу, тем самым увеличив ее размер на 135 гигабайт.
# vgextend vg /dev/sdc1 Volume group "vg" successfully extended # vgs VG #PV #LV #SN Attr VSize VFree vg 3 1 0 wz--n- 406.97G 135.66G
На данном этапе увеличить объем тома с чередованием до максимального размера группы нельзя, так как для организации чередования необходимо два физических устройства.
# lvextend vg/stripe1 -L 406G
Using stripesize of last segment 64.00 KB
Extending logical volume stripe1 to 406.00 GB
Insufficient suitable allocatable extents for logical volume stripe1: 34480
more required
Надо добавить еще один физический том и уже после этого можно будет увеличить размер логического тома.
#vgextend vg /dev/sdd1Volume group "vg" successfully extended #vgsVG #PV #LV #SN Attr VSize VFree vg 4 1 0 wz--n- 542.62G 271.31G #lvextend vg/stripe1 -L 542GUsing stripesize of last segment 64.00 KB Extending logical volume stripe1 to 542.00 GB Logical volume stripe1 successfully resized
Если в вашем распоряжении нет необходимого числа физических устройств, все же можно увеличить объем логического тома, не используя при этом чередование. При наращивании тома по умолчанию используются параметры чередования последнего сегмента существующего логического тома, что можно переопределить. Следующий пример расширяет существующий том так, чтобы в случае неудачи команды lvextend использовалось все свободное пространство.
#lvextend vg/stripe1 -L 406GUsing stripesize of last segment 64.00 KB Extending logical volume stripe1 to 406.00 GB Insufficient suitable allocatable extents for logical volume stripe1: 34480 more required #lvextend -i1 -l+100%FREE vg/stripe1
4.4.12.2. Увеличение логического тома в режиме cling
При увеличении размера тома можно использовать механизм cling (параметр --alloc cling команды lvextend). При этом место будет выбираться в пределах тех же физических томов, где расположен последний сегмент увеличиваемого тома. Если места не хватает, но файл lvm.conf содержит список тегов, для увеличения тома будет выбран физический том с тем же тегом.
Например, при наличии логических томов с зеркалами, расположенными в той же группе, им можно присвоить теги @site1 и @site2, а в lvm.conf добавить следующее выражение:
cling_tag_list = [ "@site1", "@site2" ]
Приложение C, Теги объектов LVM содержит подробную информацию о присвоении тегов.
В следующем примере lvm.conf изменен так:
cling_tag_list = [ "@A", "@B" ]
В этом примере группа taft состоит из физических томов /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, /dev/sdf1, /dev/sdg1, /dev/sdh1, которые обозначены как A, B и C. Физические тома для организации составляющих зеркала будут выбираться по тегу.
[root@taft-03 ~]# pvs -a -o +pv_tags /dev/sd[bcdefgh]1
PV VG Fmt Attr PSize PFree PV Tags
/dev/sdb1 taft lvm2 a- 135.66g 135.66g A
/dev/sdc1 taft lvm2 a- 135.66g 135.66g B
/dev/sdd1 taft lvm2 a- 135.66g 135.66g B
/dev/sde1 taft lvm2 a- 135.66g 135.66g C
/dev/sdf1 taft lvm2 a- 135.66g 135.66g C
/dev/sdg1 taft lvm2 a- 135.66g 135.66g A
/dev/sdh1 taft lvm2 a- 135.66g 135.66g A
Теперь в группе taft будет создан зеркальный том размером 100 гигабайт.
[root@taft-03 ~]# lvcreate -m 1 -n mirror --nosync -L 100G taft
Следующая команда покажет список устройств в составе зеркала.
[root@taft-03 ~]# lvs -a -o +devices
LV VG Attr LSize Log Copy% Devices
mirror taft Mwi-a- 100.00g mirror_mlog 100.00
mirror_mimage_0(0),mirror_mimage_1(0)
[mirror_mimage_0] taft iwi-ao 100.00g /dev/sdb1(0)
[mirror_mimage_1] taft iwi-ao 100.00g /dev/sdc1(0)
[mirror_mlog] taft lwi-ao 4.00m /dev/sdh1(0)
Ниже приведен пример увеличения размера зеркального тома в режиме cling, то есть для наращивания звеньев зеркала будут использоваться физические тома с тем же тегом.
[root@taft-03 ~]# lvextend --alloc cling -L +100G taft/mirror
Extending 2 mirror images.
Extending logical volume mirror to 200.00 GiB
Logical volume mirror successfully resized
Следующая команда покажет результат добавления физических томов с тем же тегом, что и исходный том. Устройства с тегом C будут проигнорированы.
[root@taft-03 ~]# lvs -a -o +devices
LV VG Attr LSize Log Copy% Devices
mirror taft Mwi-a- 200.00g mirror_mlog 50.16
mirror_mimage_0(0),mirror_mimage_1(0)
[mirror_mimage_0] taft Iwi-ao 200.00g /dev/sdb1(0)
[mirror_mimage_0] taft Iwi-ao 200.00g /dev/sdg1(0)
[mirror_mimage_1] taft Iwi-ao 200.00g /dev/sdc1(0)
[mirror_mimage_1] taft Iwi-ao 200.00g /dev/sdd1(0)
[mirror_mlog] taft lwi-ao 4.00m /dev/sdh1(0)
4.4.13. Уменьшение размера логических томов
Чтобы уменьшить размер логического тома, сначала надо отключить файловую систему, а уже затем с помощью команды lvreduce сжать том. Завершив, снова подключите файловую систему.
Сначала надо уменьшить размер файловой системы, после чего можно уменьшить сам том. В противном случае данные могут быть потеряны.
Освобожденное пространство может быть выделено другим томам в группе.
Следующая команда уменьшит размер тома lvol1 в группе vg00 на три логических экстента.
lvreduce -l -3 vg00/lvol1
4.5. Определение устройств LVM с помощью фильтров
При запуске системы выполняется команда vgscan, которая выполнит поиск меток LVM на блочных устройствах с целью определения того, какие из них представляют собой физические тома, а также получения метаданных и создания списков групп томов. Названия физических томов хранятся в файле /etc/lvm/.cache на каждом узле. Команды будут обращаться к этому файлу во избежание необходимости повторного сканирования.
С помощью фильтров в lvm.conf можно управлять тем, какие устройства будут проверяться. Фильтр содержит набор регулярных выражений, применяемых к устройствам в каталоге /dev.
Ниже приведены примеры фильтров. Следует отметить, что некоторые примеры не являются лучшими решениями, так как регулярные выражения свободно сопоставляются с полными путями. Например, a/.*loop.*/ соответствует a/loop/ и /dev/solooperation/lvol1.
Следующий фильтр добавит все обнаруженные устройства, что делается по умолчанию в случае, если фильтры не заданы.
filter = [ "a/.*/" ]
Следующий фильтр исключит CD-ROM, если он не содержит диск, что позволит избежать задержек.
filter = [ "r|/dev/cdrom|" ]
Фильтр для добавления всех петлевых устройств и удаления всех блочных устройств будет выглядеть так:
filter = [ "a/loop.*/", "r/.*/" ]
Пример фильтра, добавляющего все IDE и петлевые устройства и удаляющего остальные блочные устройства:
filter =[ "a|loop.*|", "a|/dev/hd.*|", "r|.*|" ]
Пример фильтра, добавляющего только восьмой раздел на первом диске IDE и удаляющего все остальные блочные устройства:
filter = [ "a|^/dev/hda8$|", "r/.*/" ]
Приложение B, Файлы конфигурации LVM и справочная страница lvm.conf(5) содержат подробную информацию о lvm.conf.
4.6. Перенос данных в активной системе
Команда pvmove позволяет перемещать данные в активной системе.
pvmove разбивает данные на секции и создает временное зеркало для переноса каждой секции. Справочная страница pvmove(8) содержит подробную информацию.
Следующая команда переназначит все незанятое пространство физического тома /dev/sdc1 другим томам в группе:
pvmove /dev/sdc1
Следующая команда перенесет экстенты логического тома MyLV.
pvmove -n MyLV /dev/sdc1
Поскольку процесс переноса может быть достаточно длительным, можно его запустить в фоновом режиме. Приведенная далее команда переместит все распределенные сегменты тома /dev/sdc1 на /dev/sdf1 в фоновом режиме.
pvmove -b /dev/sdc1 /dev/sdf1
Следующая команда будет сообщать о прогрессе (в процентах) с пятисекундным интервалом:
pvmove -i5 /dev/sdd1
4.7. Активация логических томов на отдельных узлах кластера
В кластерном окружении может понадобиться эксклюзивно активировать логические тома на одном узле.
Для этой цели служит команда lvchange -aey, а lvchange -aly активирует логические тома на локальном узле, но не эксклюзивно.
Активировать логические тома на конкретных узлах также можно с помощью тегов LVM (см. Приложение C, Теги объектов LVM) или в файле конфигурации (см. Приложение B, Файлы конфигурации LVM).
4.8. Настройка отчетов LVM
С помощью pvs, lvs, vgs можно создавать отчеты о состоянии объектов LVM. Каждая строка в отчете содержит информацию об одном объекте. Вывод можно отфильтровать по физическим томам, по группе томов, по логическим томам, сегментам физических или логических томов.
Далее будет рассмотрено:
-
Обзор аргументов, используемых для настройки формата генерируемого отчета.
-
Перечень полей, которые можно выбрать для каждого объекта LVM.
-
Обзор аргументов для сортировки генерируемого отчета.
-
Определение единиц в отчете.
4.8.1. Изменение формата
Независимо от того, используете ли вы pvs, lvs или vgs, выбранная команда по умолчанию отображает стандартный набор полей, что можно переопределить с помощью различных опций.
-
Аргумент
-oпозволяет выбрать поля для вывода. Например, стандартный вывод командыpvsвыглядит так:#
pvsPV VG Fmt Attr PSize PFree /dev/sdb1 new_vg lvm2 a- 17.14G 17.14G /dev/sdc1 new_vg lvm2 a- 17.14G 17.09G /dev/sdd1 new_vg lvm2 a- 17.14G 17.14GСледующая команда покажет только имя и размер физических томов.
#
pvs -o pv_name,pv_sizePV PSize /dev/sdb1 17.14G /dev/sdc1 17.14G /dev/sdd1 17.14G -
Дополнительное поле можно добавить с помощью знака «+» в комбинации с «-o».
Пример добавления идентификатора UUID в стандартный отчет:
#
pvs -o +pv_uuidPV VG Fmt Attr PSize PFree PV UUID /dev/sdb1 new_vg lvm2 a- 17.14G 17.14G onFF2w-1fLC-ughJ-D9eB-M7iv-6XqA-dqGeXY /dev/sdc1 new_vg lvm2 a- 17.14G 17.09G Joqlch-yWSj-kuEn-IdwM-01S9-X08M-mcpsVe /dev/sdd1 new_vg lvm2 a- 17.14G 17.14G yvfvZK-Cf31-j75k-dECm-0RZ3-0dGW-UqkCS -
Добавление
-vпозволяет включить другие поля. Например,pvs -vпокажет не только стандартные поля, но иDevSizeиPV UUID.#
pvs -vScanning for physical volume names PV VG Fmt Attr PSize PFree DevSize PV UUID /dev/sdb1 new_vg lvm2 a- 17.14G 17.14G 17.14G onFF2w-1fLC-ughJ-D9eB-M7iv-6XqA-dqGeXY /dev/sdc1 new_vg lvm2 a- 17.14G 17.09G 17.14G Joqlch-yWSj-kuEn-IdwM-01S9-XO8M-mcpsVe /dev/sdd1 new_vg lvm2 a- 17.14G 17.14G 17.14G yvfvZK-Cf31-j75k-dECm-0RZ3-0dGW-tUqkCS -
--noheadingsспрячет строку заголовков, что используется при создании сценариев.Следующий пример использует аргумент
--noheadingsв комбинации сpv_nameдля отображения списка всех физических томов.#
pvs --noheadings -o pv_name/dev/sdb1 /dev/sdc1 /dev/sdd1 -
--separator разделительпозволяет отделить поля друг от друга.В следующем примере поля вывода команды
pvsразделены знаком равенства.#
pvs --separator =PV=VG=Fmt=Attr=PSize=PFree /dev/sdb1=new_vg=lvm2=a-=17.14G=17.14G /dev/sdc1=new_vg=lvm2=a-=17.14G=17.09G /dev/sdd1=new_vg=lvm2=a-=17.14G=17.14GДля выравнивания полей при использовании разделителя, можно дополнительно указать
--aligned.#
pvs --separator = --alignedPV =VG =Fmt =Attr=PSize =PFree /dev/sdb1 =new_vg=lvm2=a- =17.14G=17.14G /dev/sdc1 =new_vg=lvm2=a- =17.14G=17.09G /dev/sdd1 =new_vg=lvm2=a- =17.14G=17.14G
Для добавления в отчет списка неисправных томов используется параметр -P команд lvs и vgs (см. Раздел 6.2, «Получение информации о неисправных устройствах»).
Справочные страницы pvs(8), vgs(8) и lvs(8) содержат полный перечень параметров.
Поля группы томов могут быть смешаны с полями физического или логического тома (или их сегментов), но поля физического тома не могут быть смешаны с полями логического тома. Например, следующая команда покажет по одному физическому тому в строке:
# vgs -o +pv_name
VG #PV #LV #SN Attr VSize VFree PV
new_vg 3 1 0 wz--n- 51.42G 51.37G /dev/sdc1
new_vg 3 1 0 wz--n- 51.42G 51.37G /dev/sdd1
new_vg 3 1 0 wz--n- 51.42G 51.37G /dev/sdb1
4.8.2. Выбор объектов
Далее приведены таблицы с полями вывода команд pvs, vgs, lvs.
Префикс может быть опущен, если он соответствует стандартному имени, используемому командой. Например, при указании name с командой pvs подразумевается pv_name, а с vgs — vg_name.
Выполнение следующей команды эквивалентно pvs -o pv_free.
# pvs -o +free
PFree
17.14G
17.09G
17.14G
4.8.2.1. Команда pvs
Таблица 4.1, «Поля вывода pvs» содержит список аргументов команды pvs с названиями полей и их описанием.
Таблица 4.1. Поля вывода pvs
| Аргумент | Столбец | Описание |
|---|---|---|
dev_size |
DevSize | Размер устройства в основе физического тома |
pe_start |
1st PE | Смещение первого физического экстента физического устройства |
pv_attr |
Attr | Статус физического тома: (a)llocatable или e(x)ported |
pv_fmt |
Fmt | Формат метаданных физического тома (lvm2 или lvm1) |
pv_free |
PFree | Свободное место в пределах физического тома |
pv_name |
PV | Имя физического тома |
pv_pe_alloc_count |
Alloc | Число занятых физических экстентов |
pv_pe_count |
PE | Число физических экстентов |
pvseg_size |
SSize | Размер сегмента физического тома |
pvseg_start |
Start | Начальный физический экстент сегмента физического тома |
pv_size |
PSize | Размер физического тома |
pv_tags |
PV Tags | Теги физического тома |
pv_used |
Used | Занятое пространство физического тома |
pv_uuid |
PV UUID | UUID физического тома |
По умолчанию pvs отображает поля pv_name, vg_name, pv_fmt, pv_attr, pv_size, pv_free, упорядоченные по pv_name.
# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 17.14G 17.14G
/dev/sdc1 new_vg lvm2 a- 17.14G 17.09G
/dev/sdd1 new_vg lvm2 a- 17.14G 17.13G
Параметр -v команды pvs добавит поля dev_size, pv_uuid.
# pvs -v
Scanning for physical volume names
PV VG Fmt Attr PSize PFree DevSize PV UUID
/dev/sdb1 new_vg lvm2 a- 17.14G 17.14G 17.14G onFF2w-1fLC-ughJ-D9eB-M7iv-6XqA-dqGeXY
/dev/sdc1 new_vg lvm2 a- 17.14G 17.09G 17.14G Joqlch-yWSj-kuEn-IdwM-01S9-XO8M-mcpsVe
/dev/sdd1 new_vg lvm2 a- 17.14G 17.13G 17.14G yvfvZK-Cf31-j75k-dECm-0RZ3-0dGW-tUqkCS
pvs --segments покажет информацию о каждом сегменте физического тома. Сегмент представляет собой набор экстентов. Просмотр сегментов может помочь при определении фрагментации логического тома.
pvs --segments по умолчанию отобразит поля pv_name, vg_name, pv_fmt, pv_attr, pv_size, pv_free, pvseg_start, pvseg_size. Вывод будет отсортирован по pv_name и pvseg_size для каждого физического тома.
# pvs --segments
PV VG Fmt Attr PSize PFree Start SSize
/dev/hda2 VolGroup00 lvm2 a- 37.16G 32.00M 0 1172
/dev/hda2 VolGroup00 lvm2 a- 37.16G 32.00M 1172 16
/dev/hda2 VolGroup00 lvm2 a- 37.16G 32.00M 1188 1
/dev/sda1 vg lvm2 a- 17.14G 16.75G 0 26
/dev/sda1 vg lvm2 a- 17.14G 16.75G 26 24
/dev/sda1 vg lvm2 a- 17.14G 16.75G 50 26
/dev/sda1 vg lvm2 a- 17.14G 16.75G 76 24
/dev/sda1 vg lvm2 a- 17.14G 16.75G 100 26
/dev/sda1 vg lvm2 a- 17.14G 16.75G 126 24
/dev/sda1 vg lvm2 a- 17.14G 16.75G 150 22
/dev/sda1 vg lvm2 a- 17.14G 16.75G 172 4217
/dev/sdb1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sdc1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sdd1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sde1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sdf1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sdg1 vg lvm2 a- 17.14G 17.14G 0 4389
Для просмотра обнаруженных устройств, которые не были инициализированы в виде физических томов можно использовать команду pvs -a.
# pvs -a
PV VG Fmt Attr PSize PFree
/dev/VolGroup00/LogVol01 -- 0 0
/dev/new_vg/lvol0 -- 0 0
/dev/ram -- 0 0
/dev/ram0 -- 0 0
/dev/ram2 -- 0 0
/dev/ram3 -- 0 0
/dev/ram4 -- 0 0
/dev/ram5 -- 0 0
/dev/ram6 -- 0 0
/dev/root -- 0 0
/dev/sda -- 0 0
/dev/sdb -- 0 0
/dev/sdb1 new_vg lvm2 a- 17.14G 17.14G
/dev/sdc -- 0 0
/dev/sdc1 new_vg lvm2 a- 17.14G 17.09G
/dev/sdd -- 0 0
/dev/sdd1 new_vg lvm2 a- 17.14G 17.14G
4.8.2.2. Команда vgs
Таблица 4.2, «Поля вывода vgs» содержит список аргументов vgs и названия полей.
Таблица 4.2. Поля вывода vgs
| Аргумент | Столбец | Описание |
|---|---|---|
lv_count |
#LV | Число логических томов в группе |
max_lv |
MaxLV | Максимально допустимое число логических томов в группе (0, если не ограничено) |
max_pv |
MaxPV | Максимально допустимое число томов в группе (0, если не ограничено) |
pv_count |
#PV | Число физических томов в основе группы |
snap_count |
#SN | Число снимков в группе томов |
vg_attr |
Attr | Статус группы томов. Допустимые значения: (w)riteable, (r)eadonly, resi(z)eable, e(x)ported, (p)artial, (c)lustered |
vg_extent_count |
#Ext | Число физических экстентов в группе томов |
vg_extent_size |
Ext | Размер физических экстентов в группе томов |
vg_fmt |
Fmt | Формат метаданных группы томов (lvm2 или lvm1) |
vg_free |
VFree | Объем свободного пространства в группе томов |
vg_free_count |
Free | Число свободных физических экстентов в группе томов |
vg_name |
VG | Имя группы томов |
vg_seqno |
Seq | Версия группы томов |
vg_size |
VSize | Размер группы томов |
vg_sysid |
SYS ID | Системный идентификатор LVM1 |
vg_tags |
VG Tags | LVM-теги группы томов |
vg_uuid |
VG UUID | UUID группы томов |
vgs по умолчанию показывает поля vg_name, pv_count, lv_count, snap_count, vg_attr, vg_size, vg_free. Вывод отсортирован по vg_name.
# vgs
VG #PV #LV #SN Attr VSize VFree
new_vg 3 1 1 wz--n- 51.42G 51.36G
vgs -v позволяет дополнительно показать поля vg_extent_size, vg_uuid.
# vgs -v
Finding all volume groups
Finding volume group "new_vg"
VG Attr Ext #PV #LV #SN VSize VFree VG UUID
new_vg wz--n- 4.00M 3 1 1 51.42G 51.36G jxQJ0a-ZKk0-OpMO-0118-nlwO-wwqd-fD5D32
4.8.2.3. Команда lvs
Таблица 4.3, «Поля вывода lvs» содержит список аргументов команды lvs с названиями полей и их описанием.
Таблица 4.3. Поля вывода lvs
| Аргумент | Столбец | Описание | ||||||
|---|---|---|---|---|---|---|---|---|
|
Chunk | Размер сегментов снимка | ||||||
copy_percent |
Copy% | Процентная часть синхронизации зеркального логического тома. Также используется при перемещении физических экстентов с помощью pv_move |
||||||
devices |
Devices | Устройства в основе логического тома: физические устройства, логические тома и начальные физические и логические экстенты | ||||||
lv_attr |
Attr | Статус логического тома. Его составляющие:
|
||||||
lv_kernel_major |
KMaj | Действующий основной номер устройства логического тома (-1, если устройство неактивно) | ||||||
lv_kernel_minor |
KMIN | Действующий вспомогательный номер устройства логического тома (-1, если неактивно) | ||||||
lv_major |
Maj | Постоянный основной номер устройства логического тома (-1, если не задан) | ||||||
lv_minor |
Min | Постоянный вспомогательный номер устройства логического тома (-1, если не задан) | ||||||
lv_name |
LV | Имя логического тома | ||||||
lv_size |
LSize | Размер логического тома | ||||||
lv_tags |
LV Tags | Теги логического тома | ||||||
lv_uuid |
LV UUID | UUID логического тома | ||||||
mirror_log |
Log | Устройство, где размещен журнал зеркала | ||||||
modules |
Modules | Модуль ядра соответствий устройств | ||||||
move_pv |
Move | Исходный физический том, на основе которого создан временный логический том с помощью pvmove |
||||||
origin |
Origin | Исходное устройство снимка | ||||||
|
Region | Размер сегментов зеркального логического тома | ||||||
seg_count |
#Seg | Число сегментов логического тома | ||||||
seg_size |
SSize | Размер сегментов логического тома | ||||||
seg_start |
Start | Смещение сегментов логического тома | ||||||
seg_tags |
Seg Tags | LVM-теги сегментов логического тома | ||||||
segtype |
Type | Тип сегмента логического тома (например, mirror, striped, linear) | ||||||
snap_percent |
Snap% | Процентная часть занятого пространства снимка | ||||||
stripes |
#Str | Число сегментов чередования или зеркал логического тома | ||||||
|
Stripe | Размер сегментов чередования |
По умолчанию вывод lvs будет содержать поля lv_name, vg_name, lv_attr, lv_size, origin, snap_percent, move_pv, mirror_log, copy_percent, отсортированные по vg_name и lv_name в пределах группы.
# lvs
LV VG Attr LSize Origin Snap% Move Log Copy%
lvol0 new_vg owi-a- 52.00M
newvgsnap1 new_vg swi-a- 8.00M lvol0 0.20
Параметр -v команды lvs добавляет в таблицу поля seg_count, lv_major, lv_minor, lv_kernel_major, lv_kernel_minor, lv_uuid.
# lvs -v
Finding all logical volumes
LV VG #Seg Attr LSize Maj Min KMaj KMin Origin Snap% Move Copy% Log LV UUID
lvol0 new_vg 1 owi-a- 52.00M -1 -1 253 3 LBy1Tz-sr23-OjsI-LT03-nHLC-y8XW-EhCl78
newvgsnap1 new_vg 1 swi-a- 8.00M -1 -1 253 5 lvol0 0.20 1ye1OU-1cIu-o79k-20h2-ZGF0-qCJm-CfbsIx
lvs --segments показывает стандартный набор столбцов с информацией о сегментах. При этом префикс seg указывать не обязательно. Так, lvs --segments по умолчанию покажет поля lv_name, vg_name, lv_attr, stripes, segtype, seg_size, отсортированные по vg_name, lv_name в пределах группы томов и по seg_start — в пределах логического тома. Если логические тома фрагментированы, вывод будет содержать соответствующую информацию.
# lvs --segments
LV VG Attr #Str Type SSize
LogVol00 VolGroup00 -wi-ao 1 linear 36.62G
LogVol01 VolGroup00 -wi-ao 1 linear 512.00M
lv vg -wi-a- 1 linear 104.00M
lv vg -wi-a- 1 linear 104.00M
lv vg -wi-a- 1 linear 104.00M
lv vg -wi-a- 1 linear 88.00M
Параметр -v добавляет поля seg_start, stripesize, chunksize.
# lvs -v --segments
Finding all logical volumes
LV VG Attr Start SSize #Str Type Stripe Chunk
lvol0 new_vg owi-a- 0 52.00M 1 linear 0 0
newvgsnap1 new_vg swi-a- 0 8.00M 1 linear 0 8.00K
Следующий пример демонстрирует стандартный вывод команды lvs в системе с одним логическим томом, а также вывод lvs с аргументом segments.
#lvsLV VG Attr LSize Origin Snap% Move Log Copy% lvol0 new_vg -wi-a- 52.00M #lvs --segmentsLV VG Attr #Str Type SSize lvol0 new_vg -wi-a- 1 linear 52.00M
4.8.3. Форматирование вывода
Обычно вывод команд lvs, vgs, pvs сохраняется и отдельно форматируется. Аргумент --unbuffered покажет исходный вывод сразу после его генерации.
С помощью -O можно указать порядок столбцов. При этом включение этих столбцов в вывод необязательно.
Пример вывода pvs, содержащего имена физических томов, их размер и свободное пространство:
# pvs -o pv_name,pv_size,pv_free
PV PSize PFree
/dev/sdb1 17.14G 17.14G
/dev/sdc1 17.14G 17.09G
/dev/sdd1 17.14G 17.14G
Пример аналогичного вывода, отсортированного по объему свободного пространства:
# pvs -o pv_name,pv_size,pv_free -O pv_free
PV PSize PFree
/dev/sdc1 17.14G 17.09G
/dev/sdd1 17.14G 17.14G
/dev/sdb1 17.14G 17.14G
В следующем примере вывод отсортирован по размеру свободного пространства; при этом поле pv_free не будет показано.
# pvs -o pv_name,pv_size -O pv_free
PV PSize
/dev/sdc1 17.14G
/dev/sdd1 17.14G
/dev/sdb1 17.14G
Чтобы изменить порядок сортировки, перед полем, которое служит критерием сортировки, надо указать -.
# pvs -o pv_name,pv_size,pv_free -O -pv_free
PV PSize PFree
/dev/sdd1 17.14G 17.14G
/dev/sdb1 17.14G 17.14G
/dev/sdc1 17.14G 17.09G
4.8.4. Выбор единиц
Аргумент --units позволяет указать единицы объема данных. Допустимые значения: (b)ytes, (k)ilobytes, (m)egabytes, (g)igabytes, (t)erabytes, (e)xabytes, (p)etabytes и (h)uman-readable. По умолчанию используется формат (h)uman-readable, что можно переопределить в файле lvm.conf, изменив параметр units в секции global.
Пример вывода pvs, использующего в качестве единиц мегабайты:
# pvs --units m
PV VG Fmt Attr PSize PFree
/dev/sda1 lvm2 -- 17555.40M 17555.40M
/dev/sdb1 new_vg lvm2 a- 17552.00M 17552.00M
/dev/sdc1 new_vg lvm2 a- 17552.00M 17500.00M
/dev/sdd1 new_vg lvm2 a- 17552.00M 17552.00M
По умолчанию числовые значения кратны 1024, что можно заменить на 1000, указав единицы в верхнем регистре (B, K, M, G, T, H).
Пример стандартного вывода (значения кратны 1024):
# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 17.14G 17.14G
/dev/sdc1 new_vg lvm2 a- 17.14G 17.09G
/dev/sdd1 new_vg lvm2 a- 17.14G 17.14G
Значения, кратные 1000:
# pvs --units G
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 18.40G 18.40G
/dev/sdc1 new_vg lvm2 a- 18.40G 18.35G
/dev/sdd1 new_vg lvm2 a- 18.40G 18.40G
В качестве единиц также можно использовать сектора (s), размер которых равен 512 байт, или даже произвольные единицы.
Пример, где в качестве единиц используются сектора:
# pvs --units s
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 35946496S 35946496S
/dev/sdc1 new_vg lvm2 a- 35946496S 35840000S
/dev/sdd1 new_vg lvm2 a- 35946496S 35946496S
Пример, где в качестве единиц используются блоки размером 4 мегабайт:
# pvs --units 4m
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 4388.00U 4388.00U
/dev/sdc1 new_vg lvm2 a- 4388.00U 4375.00U
/dev/sdd1 new_vg lvm2 a- 4388.00U 4388.00U
Глава 5. Примеры конфигурации LVM
В этой главе приведены простые примеры конфигурации LVM.
5.1. Создание логического тома на трех дисках
Данный пример демонстрирует создание логического тома new_logical_volume на дисках /dev/sda1, /dev/sdb1, /dev/sdc1.
5.1.1. Создание физических томов
Для использования дисков необходимо обозначить их как физические тома.
Следующая команда удалит все данные на /dev/sda1, /dev/sdb1, /dev/sdc1.
[root@tng3-1 ~]# pvcreate /dev/sda1 /dev/sdb1 /dev/sdc1
Physical volume "/dev/sda1" successfully created
Physical volume "/dev/sdb1" successfully created
Physical volume "/dev/sdc1" successfully created
5.1.2. Создание группы томов
Команда создания группы томов new_vol_group:
[root@tng3-1 ~]# vgcreate new_vol_group /dev/sda1 /dev/sdb1 /dev/sdc1
Volume group "new_vol_group" successfully created
С помощью vgs можно просмотреть атрибуты новой группы:
[root@tng3-1 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
new_vol_group 3 0 0 wz--n- 51.45G 51.45G
5.1.3. Создание логического тома
В следующем примере будет выделен логический том new_logical_volume размером 2 гигабайта из группы томов new_vol_group.
[root@tng3-1 ~]# lvcreate -L2G -n new_logical_volume new_vol_group
Logical volume "new_logical_volume" created
5.1.4. Создание файловой системы
Теперь для нового тома можно создать файловую систему.
[root@tng3-1 ~]#mkfs.gfs2 -plock_nolock -j 1 /dev/new_vol_group/new_logical_volumeThis will destroy any data on /dev/new_vol_group/new_logical_volume. Are you sure you want to proceed? [y/n]yDevice: /dev/new_vol_group/new_logical_volume Blocksize: 4096 Filesystem Size: 491460 Journals: 1 Resource Groups: 8 Locking Protocol: lock_nolock Lock Table: Syncing... All Done
Следующие команды подключат логический том в файловую систему и покажут информацию об использовании дискового пространства.
[root@tng3-1 ~]#mount /dev/new_vol_group/new_logical_volume /mnt[root@tng3-1 ~]#dfFilesystem 1K-blocks Used Available Use% Mounted on /dev/new_vol_group/new_logical_volume 1965840 20 1965820 1% /mnt
5.2. Создание логического тома с чередованием
В этом примере будет создан логический том new_vol_group, данные которого чередуются между дисками /dev/sda1, /dev/sdb1, /dev/sdc1.
5.2.1. Создание физических томов
Сначала надо обозначить диски как физические тома LVM.
Следующая команда удалит все данные на /dev/sda1, /dev/sdb1, /dev/sdc1.
[root@tng3-1 ~]# pvcreate /dev/sda1 /dev/sdb1 /dev/sdc1
Physical volume "/dev/sda1" successfully created
Physical volume "/dev/sdb1" successfully created
Physical volume "/dev/sdc1" successfully created
5.2.2. Создание группы томов
Затем можно создать группу volgroup01:
[root@tng3-1 ~]# vgcreate volgroup01 /dev/sda1 /dev/sdb1 /dev/sdc1
Volume group "volgroup01" successfully created
С помощью vgs можно просмотреть атрибуты новой группы:
[root@tng3-1 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
volgroup01 3 0 0 wz--n- 51.45G 51.45G
5.2.3. Создание логического тома
Далее в группе volgroup01 будет создан том striped_logical_volume общим размером 2 гигабайта с сегментами, размер которых равен 4 килобайта.
[root@tng3-1 ~]# lvcreate -i3 -I4 -L2G -nstriped_logical_volume volgroup01
Rounding size (512 extents) up to stripe boundary size (513 extents)
Logical volume "striped_logical_volume" created
5.2.4. Создание файловой системы
Теперь для нового тома можно создать файловую систему.
[root@tng3-1 ~]#mkfs.gfs2 -plock_nolock -j 1 /dev/volgroup01/striped_logical_volumeThis will destroy any data on /dev/volgroup01/striped_logical_volume. Are you sure you want to proceed? [y/n]yDevice: /dev/volgroup01/striped_logical_volume Blocksize: 4096 Filesystem Size: 492484 Journals: 1 Resource Groups: 8 Locking Protocol: lock_nolock Lock Table: Syncing... All Done
Следующие команды подключат логический том в файловую систему и покажут информацию об использовании дискового пространства.
[root@tng3-1 ~]#mount /dev/volgroup01/striped_logical_volume /mnt[root@tng3-1 ~]#dfFilesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/VolGroup00-LogVol00 13902624 1656776 11528232 13% / /dev/hda1 101086 10787 85080 12% /boot tmpfs 127880 0 127880 0% /dev/shm /dev/volgroup01/striped_logical_volume 1969936 20 1969916 1% /mnt
5.3. Разбиение группы томов
Если в группе томов достаточно незанятого пространства, то новая группа может быть добавлена без необходимости добавления новых дисков. В качестве примера рассмотрим группу, в состав которой входит 3 физических тома.
Изначально логический том mylv создается из группы myvol, которая включает физические тома /dev/sda1, /dev/sdb1, /dev/sdc1.
После разбиения группа myvg будет состоять из /dev/sda1 и /dev/sdb1, а /dev/sdc1 будет включен в состав группы yourvg.
5.3.1. Определение наличия свободного пространства
С помощью команды pvscan можно определить объем незанятого пространства в группе томов.
[root@tng3-1 ~]# pvscan
PV /dev/sda1 VG myvg lvm2 [17.15 GB / 0 free]
PV /dev/sdb1 VG myvg lvm2 [17.15 GB / 12.15 GB free]
PV /dev/sdc1 VG myvg lvm2 [17.15 GB / 15.80 GB free]
Total: 3 [51.45 GB] / in use: 3 [51.45 GB] / in no VG: 0 [0 ]
5.3.2. Перемещение данных
Для переноса занятых физических экстентов с /dev/sdc1 на /dev/sdb1 используется команда pvmove. Процесс может занять достаточно много времени.
[root@tng3-1 ~]# pvmove /dev/sdc1 /dev/sdb1
/dev/sdc1: Moved: 14.7%
/dev/sdc1: Moved: 30.3%
/dev/sdc1: Moved: 45.7%
/dev/sdc1: Moved: 61.0%
/dev/sdc1: Moved: 76.6%
/dev/sdc1: Moved: 92.2%
/dev/sdc1: Moved: 100.0%
После перемещения данных убедитесь, что все пространство /dev/sdc1 теперь свободно:
[root@tng3-1 ~]# pvscan
PV /dev/sda1 VG myvg lvm2 [17.15 GB / 0 free]
PV /dev/sdb1 VG myvg lvm2 [17.15 GB / 10.80 GB free]
PV /dev/sdc1 VG myvg lvm2 [17.15 GB / 17.15 GB free]
Total: 3 [51.45 GB] / in use: 3 [51.45 GB] / in no VG: 0 [0 ]
5.3.3. Разделение группы томов
С помощью vgsplit разделим группу myvg и создадим новую группу yourvg.
Прежде чем приступить к разделению группы томов, сначала необходимо убедиться, что файловая система отключена, а затем отключить сам логический том.
Отключить том можно с помощью lvchange и vgchange. Приведенная команда отключает том mylv, затем выделяет пространство для группы yourvg из myvg и переносит физический том /dev/sdc1 в yourvg.
[root@tng3-1 ~]#lvchange -a n /dev/myvg/mylv[root@tng3-1 ~]#vgsplit myvg yourvg /dev/sdc1Volume group "yourvg" successfully split from "myvg"
Атрибуты обеих групп можно просмотреть с помощью vgs.
[root@tng3-1 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
myvg 2 1 0 wz--n- 34.30G 10.80G
yourvg 1 0 0 wz--n- 17.15G 17.15G
5.3.4. Создание логического тома
После создания группы можно создать логический том yourlv:
[root@tng3-1 ~]# lvcreate -L5G -n yourlv yourvg
Logical volume "yourlv" created
5.3.5. Создание файловой системы и подключение нового логического тома
Теперь для нового логического тома можно создать файловую систему.
[root@tng3-1 ~]#mkfs.gfs2 -plock_nolock -j 1 /dev/yourvg/yourlvThis will destroy any data on /dev/yourvg/yourlv. Are you sure you want to proceed? [y/n]yDevice: /dev/yourvg/yourlv Blocksize: 4096 Filesystem Size: 1277816 Journals: 1 Resource Groups: 20 Locking Protocol: lock_nolock Lock Table: Syncing... All Done [root@tng3-1 ~]#mount /dev/yourvg/yourlv /mnt
5.3.6. Активация и подключение исходного логического тома
Поскольку том mylv был отключен, его нужно снова подключить.
root@tng3-1 ~]#lvchange -a y mylv[root@tng3-1 ~]#mount /dev/myvg/mylv /mnt[root@tng3-1 ~]#dfFilesystem 1K-blocks Used Available Use% Mounted on /dev/yourvg/yourlv 24507776 32 24507744 1% /mnt /dev/myvg/mylv 24507776 32 24507744 1% /mnt
5.4. Удаление диска из логического тома
Данный пример демонстрирует удаление диска из логического тома либо с целью его замены, либо при его переносе в другой том. Чтобы удалить диск, сначала необходимо переместить экстенты на другой диск или набор дисков.
5.4.1. Перенос экстентов в другой физический том
В этом примере логический том расположен на четырех физических томах группы myvg.
[root@tng3-1]# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda1 myvg lvm2 a- 17.15G 12.15G 5.00G
/dev/sdb1 myvg lvm2 a- 17.15G 12.15G 5.00G
/dev/sdc1 myvg lvm2 a- 17.15G 12.15G 5.00G
/dev/sdd1 myvg lvm2 a- 17.15G 2.15G 15.00G
Предположим, что требуется перенести экстенты с /dev/sdb1 и затем его удалить из группы томов.
Если на других физических томах в группе достаточно свободных экстентов, на удаляемом устройстве можно выполнить pvmove без аргументов, чтобы перераспределить свободные экстенты между другими устройствами.
[root@tng3-1 ~]# pvmove /dev/sdb1
/dev/sdb1: Moved: 2.0%
...
/dev/sdb1: Moved: 79.2%
...
/dev/sdb1: Moved: 100.0%
После завершения pvmove распределение экстентов будет выглядеть так:
[root@tng3-1]# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda1 myvg lvm2 a- 17.15G 7.15G 10.00G
/dev/sdb1 myvg lvm2 a- 17.15G 17.15G 0
/dev/sdc1 myvg lvm2 a- 17.15G 12.15G 5.00G
/dev/sdd1 myvg lvm2 a- 17.15G 2.15G 15.00G
С помощью vgreduce можно удалить том /dev/sdb1 из группы.
[root@tng3-1 ~]# vgreduce myvg /dev/sdb1
Removed "/dev/sdb1" from volume group "myvg"
[root@tng3-1 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda1 myvg lvm2 a- 17.15G 7.15G
/dev/sdb1 lvm2 -- 17.15G 17.15G
/dev/sdc1 myvg lvm2 a- 17.15G 12.15G
/dev/sdd1 myvg lvm2 a- 17.15G 2.15G
Теперь диск можно отсоединить или использовать его для других целей.
5.4.2. Перенос экстентов на новый диск
В следующем примере логический том расположен на трех физических томах группы myvg:
[root@tng3-1]# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda1 myvg lvm2 a- 17.15G 7.15G 10.00G
/dev/sdb1 myvg lvm2 a- 17.15G 15.15G 2.00G
/dev/sdc1 myvg lvm2 a- 17.15G 15.15G 2.00G
Допустим, надо переместить экстенты /dev/sdb1 на новое устройство /dev/sdd1.
5.4.2.1. Создание физического тома
На основе /dev/sdd1 создадим физический том:
[root@tng3-1 ~]# pvcreate /dev/sdd1
Physical volume "/dev/sdd1" successfully created
5.4.2.2. Добавление физического тома в группу
Добавим /dev/sdd1 в группу myvg.
[root@tng3-1 ~]#vgextend myvg /dev/sdd1Volume group "myvg" successfully extended [root@tng3-1]#pvs -o+pv_usedPV VG Fmt Attr PSize PFree Used /dev/sda1 myvg lvm2 a- 17.15G 7.15G 10.00G /dev/sdb1 myvg lvm2 a- 17.15G 15.15G 2.00G /dev/sdc1 myvg lvm2 a- 17.15G 15.15G 2.00G /dev/sdd1 myvg lvm2 a- 17.15G 17.15G 0
5.4.2.3. Перемещение данных
С помощью pvmove переместим данные с /dev/sdb1 на /dev/sdd1:
[root@tng3-1 ~]#pvmove /dev/sdb1 /dev/sdd1/dev/sdb1: Moved: 10.0% ... /dev/sdb1: Moved: 79.7% ... /dev/sdb1: Moved: 100.0% [root@tng3-1]#pvs -o+pv_usedPV VG Fmt Attr PSize PFree Used /dev/sda1 myvg lvm2 a- 17.15G 7.15G 10.00G /dev/sdb1 myvg lvm2 a- 17.15G 17.15G 0 /dev/sdc1 myvg lvm2 a- 17.15G 15.15G 2.00G /dev/sdd1 myvg lvm2 a- 17.15G 15.15G 2.00G
5.4.2.4. Удаление физического тома из группы
Завершив перенос данных с /dev/sdb1, его можно удалить из группы.
[root@tng3-1 ~]# vgreduce myvg /dev/sdb1
Removed "/dev/sdb1" from volume group "myvg"
Теперь можно переназначить диск другой группе или удалить его из системы.
5.5. Создание зеркального логического тома в кластере
Создание зеркального логического тома в кластере осуществляется по тем же правилам, что и на отдельном компьютере. Отличия состоят в том, что в кластере должны работать необходимые кластерные службы, кластер должен обладать кворумом, а тип блокирования в lvm.conf должен разрешать кластерное блокирование. Раздел 5.5, «Создание зеркального логического тома в кластере» содержит примеры создания зеркального тома в кластере.
Далее будет создан зеркальный логический том. Предварительно будет проверено, выполняются ли необходимые кластерные службы.
-
Чтобы создать общий зеркальный логический том, который будет доступен всем узлам в кластере, на каждом узле необходимо определить нужный тип блокирования в файле
lvm.conf.#
/sbin/lvmconf --enable-cluster -
Следующая команда проверит факт выполнения службы
clvmdна текущем узле:[root@doc-07 ~]#
ps auxw | grep clvmdroot 17642 0.0 0.1 32164 1072 ? Ssl Apr06 0:00 clvmd -T20 -t 90Далее будут показаны сведения о состоянии кластера:
[root@example-01 ~]#
cman_tool servicesfence domain member count 3 victim count 0 victim now 0 master nodeid 2 wait state none members 1 2 3 dlm lockspaces name clvmd id 0x4104eefa flags 0x00000000 change member 3 joined 1 remove 0 failed 0 seq 1,1 members 1 2 3 -
Убедитесь, что пакет
cmirrorустановлен. -
Запустите
cmirrord.[root@hexample-01 ~]#
service cmirrord startStarting cmirrord: [ OK ] -
Далее будет создано три физических тома. Два будут использоваться для организации зеркала, а на третьем будет храниться журнал зеркала.
[root@doc-07 ~]#
pvcreate /dev/xvdb1Physical volume "/dev/xvdb1" successfully created [root@doc-07 ~]#pvcreate /dev/xvdb2Physical volume "/dev/xvdb2" successfully created [root@doc-07 ~]#pvcreate /dev/xvdc1Physical volume "/dev/xvdc1" successfully created -
Все три тома будут добавлены в группу
vg001.[root@doc-07 ~]#
vgcreate vg001 /dev/xvdb1 /dev/xvdb2 /dev/xvdc1Clustered volume group "vg001" successfully createdВывод
vgcreateдемонстрирует, что группа томов является кластерной (атрибут «c»). Командаvgsтакже может это проверить.[root@doc-07 ~]#
vgs vg001VG #PV #LV #SN Attr VSize VFree vg001 3 0 0 wz--nc 68.97G 68.97G -
В следующем примере будет создан логический том
mirrorlvс одним зеркалом из группыvg001. Выделяемые экстенты будут указаны явно.[root@doc-07 ~]#
lvcreate -l 1000 -m1 vg001 -n mirrorlv /dev/xvdb1:1-1000 /dev/xvdb2:1-1000 /dev/xvdc1:0Logical volume "mirrorlv" createdС помощью
lvsможно наблюдать за прогрессом создания зеркала (столбец Copy%).[root@doc-07 log]#
lvs vg001/mirrorlvLV VG Attr LSize Origin Snap% Move Log Copy% Convert mirrorlv vg001 mwi-a- 3.91G vg001_mlog 47.00 [root@doc-07 log]#lvs vg001/mirrorlvLV VG Attr LSize Origin Snap% Move Log Copy% Convert mirrorlv vg001 mwi-a- 3.91G vg001_mlog 91.00 [root@doc-07 ~]#lvs vg001/mirrorlvLV VG Attr LSize Origin Snap% Move Log Copy% Convert mirrorlv vg001 mwi-a- 3.91G vg001_mlog 100.00Сообщение об успешном создании зеркала будет зарегистрировано в системном журнале:
May 10 14:52:52 doc-07 [19402]: Monitoring mirror device vg001-mirrorlv for events May 10 14:55:00 doc-07 lvm[19402]: vg001-mirrorlv is now in-sync
-
Для просмотра структуры зеркала можно выполнить
lvsс параметрами-o +devices. В приведенном ниже примере логический том состоит из двух линейных томов и одного журнала.[root@doc-07 ~]#
lvs -a -o +devicesLV VG Attr LSize Origin Snap% Move Log Copy% Convert Devices mirrorlv vg001 mwi-a- 3.91G mirrorlv_mlog 100.00 mirrorlv_mimage_0(0),mirrorlv_mimage_1(0) [mirrorlv_mimage_0] vg001 iwi-ao 3.91G /dev/xvdb1(1) [mirrorlv_mimage_1] vg001 iwi-ao 3.91G /dev/xvdb2(1) [mirrorlv_mlog] vg001 lwi-ao 4.00M /dev/xvdc1(0)Параметр
seg_pe_rangesпокажет диапазон физических экстентов.[root@doc-07 ~]#
lvs -a -o +seg_pe_ranges --segmentsPE Ranges mirrorlv_mimage_0:0-999 mirrorlv_mimage_1:0-999 /dev/xvdb1:1-1000 /dev/xvdb2:1-1000 /dev/xvdc1:0-0
Раздел 6.3, «Восстановление после сбоя зеркала» содержит инструкции по восстановлению зеркала в случае выхода из строя его составляющих.
Глава 6. Диагностика проблем
Этот раздел содержит инструкции по исправлению различных проблем с LVM.
6.1. Диагностика
Если команда не функционирует как ожидается, осуществить сбор информации можно перечисленными ниже способами.
-
Использовать параметры
-v,-vv,-vvv,-vvvvдля усиления степени детализации вывода исполняемой команды. -
Если проблема связана с активацией логического тома, в секции «log» файла конфигурации укажите ‘activation = 1’, затем выполните команду с параметром
-vvvv. Проверив вывод, не забудьте сбросить значение переменной в 0, чтобы избежать возможных проблем с блокировкой машины в случае нехватки памяти. -
Выполните команду
lvmdump. Ее вывод будет содержать информацию, которая может помочь при определении проблем (см. страницу помощиlvmdump(8)). -
Команды
lvs -v,pvs -a,dmsetup info -cпозволяют получить дополнительную информацию о системе. -
Просмотрите последнюю резервную копию метаданных в
/etc/lvm/backupи архивы в/etc/lvm/archive. -
Команда
lvm dumpconfigпозволит проверить текущую конфигурацию. -
Файл
.cacheв/etc/lvmдолжен включать список устройств, на которых расположены физические тома.
6.2. Получение информации о неисправных устройствах
Аргумент -P команд lvs и vgs покажет информацию о сбойном томе. К примеру, если в составе группы vg перестало функционировать одно устройство, следующая команда поможет его определить:
[root@link-07 tmp]# vgs -o +devices
Volume group "vg" not found
vgs -P покажет информацию о сбойном устройстве, даже если группа томов, в состав которой это устройство входит, недоступна.
[root@link-07 tmp]# vgs -P -o +devices
Partial mode. Incomplete volume groups will be activated read-only.
VG #PV #LV #SN Attr VSize VFree Devices
vg 9 2 0 rz-pn- 2.11T 2.07T unknown device(0)
vg 9 2 0 rz-pn- 2.11T 2.07T unknown device(5120),/dev/sda1(0)
В этом примере выход из строя одного устройства привел к сбою линейного тома и тома с чередованием в группе. lvs без аргумента -P покажет:
[root@link-07 tmp]# lvs -a -o +devices
Volume group "vg" not found
-P добавит в вывод список неисправных логических томов.
[root@link-07 tmp]# lvs -P -a -o +devices
Partial mode. Incomplete volume groups will be activated read-only.
LV VG Attr LSize Origin Snap% Move Log Copy% Devices
linear vg -wi-a- 20.00G unknown device(0)
stripe vg -wi-a- 20.00G unknown device(5120),/dev/sda1(0)
Следующие примеры демонстрируют вывод pvs и lvs с аргументом -P.
root@link-08 ~]# vgs -a -o +devices -P
Partial mode. Incomplete volume groups will be activated read-only.
VG #PV #LV #SN Attr VSize VFree Devices
corey 4 4 0 rz-pnc 1.58T 1.34T my_mirror_mimage_0(0),my_mirror_mimage_1(0)
corey 4 4 0 rz-pnc 1.58T 1.34T /dev/sdd1(0)
corey 4 4 0 rz-pnc 1.58T 1.34T unknown device(0)
corey 4 4 0 rz-pnc 1.58T 1.34T /dev/sdb1(0)
[root@link-08 ~]# lvs -a -o +devices -P
Partial mode. Incomplete volume groups will be activated read-only.
LV VG Attr LSize Origin Snap% Move Log Copy% Devices
my_mirror corey mwi-a- 120.00G my_mirror_mlog 1.95 my_mirror_mimage_0(0),my_mirror_mimage_1(0)
[my_mirror_mimage_0] corey iwi-ao 120.00G unknown device(0)
[my_mirror_mimage_1] corey iwi-ao 120.00G /dev/sdb1(0)
[my_mirror_mlog] corey lwi-ao 4.00M /dev/sdd1(0)
6.3. Восстановление после сбоя зеркала
В этой секции рассматривается пример восстановления после выхода из строя компонента зеркального логического тома как следствие сбоя физического тома в его основе. При этом параметр mirror_log_fault_policy имеет значение remove (см. Раздел 6.3, «Восстановление после сбоя зеркала»).
LVM преобразует зеркальный том в линейный, сохранив функциональность, но уже без избыточности. После этого можно добавить новое устройство и пересоздать зеркало.
Следующая команда создаст физические тома, на основе которых впоследствии будет создано зеркало.
[root@link-08 ~]# pvcreate /dev/sd[abcdefgh][12]
Physical volume "/dev/sda1" successfully created
Physical volume "/dev/sda2" successfully created
Physical volume "/dev/sdb1" successfully created
Physical volume "/dev/sdb2" successfully created
Physical volume "/dev/sdc1" successfully created
Physical volume "/dev/sdc2" successfully created
Physical volume "/dev/sdd1" successfully created
Physical volume "/dev/sdd2" successfully created
Physical volume "/dev/sde1" successfully created
Physical volume "/dev/sde2" successfully created
Physical volume "/dev/sdf1" successfully created
Physical volume "/dev/sdf2" successfully created
Physical volume "/dev/sdg1" successfully created
Physical volume "/dev/sdg2" successfully created
Physical volume "/dev/sdh1" successfully created
Physical volume "/dev/sdh2" successfully created
Далее создадим vg и зеркальный том groupfs:
[root@link-08 ~]#vgcreate vg /dev/sd[abcdefgh][12]Volume group "vg" successfully created [root@link-08 ~]#lvcreate -L 750M -n groupfs -m 1 vg /dev/sda1 /dev/sdb1 /dev/sdc1Rounding up size to full physical extent 752.00 MB Logical volume "groupfs" created
С помощью lvs можно проверить структуру зеркального тома, устройств в его основе и журнала зеркала. В первом примере (см. ниже) синхронизация зеркала еще не завершена, поэтому сначала надо дождаться, пока индикатор прогресса Copy% не достигнет 100.00.
[root@link-08 ~]#lvs -a -o +devicesLV VG Attr LSize Origin Snap% Move Log Copy% Devices groupfs vg mwi-a- 752.00M groupfs_mlog 21.28 groupfs_mimage_0(0),groupfs_mimage_1(0) [groupfs_mimage_0] vg iwi-ao 752.00M /dev/sda1(0) [groupfs_mimage_1] vg iwi-ao 752.00M /dev/sdb1(0) [groupfs_mlog] vg lwi-ao 4.00M /dev/sdc1(0) [root@link-08 ~]#lvs -a -o +devicesLV VG Attr LSize Origin Snap% Move Log Copy% Devices groupfs vg mwi-a- 752.00M groupfs_mlog 100.00 groupfs_mimage_0(0),groupfs_mimage_1(0) [groupfs_mimage_0] vg iwi-ao 752.00M /dev/sda1(0) [groupfs_mimage_1] vg iwi-ao 752.00M /dev/sdb1(0) [groupfs_mlog] vg lwi-ao 4.00M i /dev/sdc1(0)
В этом примере предполагается, что произошел сбой основного звена зеркала /dev/sda1. Попытки записи в зеркальный том приводят к определению неисправного зеркала, в случае чего LVM преобразует его в один линейный том. Команда dd начнет преобразование.
[root@link-08 ~]# dd if=/dev/zero of=/dev/vg/groupfs count=10
10+0 records in
10+0 records out
Чтобы убедиться, что устройство теперь является линейным, используйте команду lvs. Как следствие наличия неисправного диска, вывод будет сообщать об ошибке ввода-вывода.
[root@link-08 ~]# lvs -a -o +devices
/dev/sda1: read failed after 0 of 2048 at 0: Input/output error
/dev/sda2: read failed after 0 of 2048 at 0: Input/output error
LV VG Attr LSize Origin Snap% Move Log Copy% Devices
groupfs vg -wi-a- 752.00M /dev/sdb1(0)
Том можно продолжать использовать, но уже как линейный.
После подключения нового устройства можно пересоздать физический том, а затем сам зеркальный том. При попытке использования того же диска в процессе выполнения pvcreate появятся предупреждающие сообщения.
[root@link-08 ~]#pvcreate /dev/sdi[12]Physical volume "/dev/sdi1" successfully created Physical volume "/dev/sdi2" successfully created [root@link-08 ~]#pvscanPV /dev/sdb1 VG vg lvm2 [67.83 GB / 67.10 GB free] PV /dev/sdb2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdc1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdc2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdd1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdd2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sde1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sde2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdf1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdf2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdg1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdg2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdh1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdh2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdi1 lvm2 [603.94 GB] PV /dev/sdi2 lvm2 [603.94 GB] Total: 16 [2.11 TB] / in use: 14 [949.65 GB] / in no VG: 2 [1.18 TB]
Далее надо добавить созданный том в группу.
[root@link-08 ~]#vgextend vg /dev/sdi[12]Volume group "vg" successfully extended [root@link-08 ~]#pvscanPV /dev/sdb1 VG vg lvm2 [67.83 GB / 67.10 GB free] PV /dev/sdb2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdc1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdc2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdd1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdd2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sde1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sde2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdf1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdf2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdg1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdg2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdh1 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdh2 VG vg lvm2 [67.83 GB / 67.83 GB free] PV /dev/sdi1 VG vg lvm2 [603.93 GB / 603.93 GB free] PV /dev/sdi2 VG vg lvm2 [603.93 GB / 603.93 GB free] Total: 16 [2.11 TB] / in use: 16 [2.11 TB] / in no VG: 0 [0 ]
Теперь можно преобразовать линейный том в зеркальный.
[root@link-08 ~]# lvconvert -m 1 /dev/vg/groupfs /dev/sdi1 /dev/sdb1 /dev/sdc1
Logical volume mirror converted.
Убедитесь, что зеркало было восстановлено.
[root@link-08 ~]# lvs -a -o +devices
LV VG Attr LSize Origin Snap% Move Log Copy% Devices
groupfs vg mwi-a- 752.00M groupfs_mlog 68.62 groupfs_mimage_0(0),groupfs_mimage_1(0)
[groupfs_mimage_0] vg iwi-ao 752.00M /dev/sdb1(0)
[groupfs_mimage_1] vg iwi-ao 752.00M /dev/sdi1(0)
[groupfs_mlog] vg lwi-ao 4.00M /dev/sdc1(0)
6.4. Восстановление метаданных физического тома
Представим, что область метаданных группы томов была случайно перезаписана или повреждена. В этом случае появится сообщение об ошибке в области метаданных или о неудачной попытке нахождения физического тома с заданным UUID. Чтобы не потерять данные физического тома, можно попробовать заново переписать область метаданных, включив прежний UUID метаданных.
Не следует это делать, если логический том активно используется, так как в случае указания неверного UUID все данные будут потеряны.
Пример вывода в случае потери или повреждения области метаданных:
[root@link-07 backup]# lvs -a -o +devices
Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.
Couldn't find all physical volumes for volume group VG.
Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.
Couldn't find all physical volumes for volume group VG.
...
Перезаписанный UUID можно найти в файле ГруппаТомов_xxxx.vg в каталоге /etc/lvm/archive.
Другой способ определения идентификатора UUID состоит в отключении тома и установке параметра -P (partial).
[root@link-07 backup]# vgchange -an --partial
Partial mode. Incomplete volume groups will be activated read-only.
Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.
Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.
...
С помощью аргументов --uuid и --restorefile команды pvcreate можно восстановить физический том. В приведенном далее примере устройству /dev/sdh1 соответствует UUID FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk. Команда восстановит информацию о метаданных из последнего успешного архива метаданных VG_00050.vg. pvcreate перезапишет только область метаданных, что не окажет влияния на существующие данные.
[root@link-07 backup]# pvcreate --uuid "FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk" --restorefile /etc/lvm/archive/VG_00050.vg /dev/sdh1
Physical volume "/dev/sdh1" successfully created
Затем с помощью vgcfgrestore можно восстановить метаданные.
[root@link-07 backup]# vgcfgrestore VG
Restored volume group VG
После этого можно получить доступ логическим томам.
[root@link-07 backup]# lvs -a -o +devices
LV VG Attr LSize Origin Snap% Move Log Copy% Devices
stripe VG -wi--- 300.00G /dev/sdh1 (0),/dev/sda1(0)
stripe VG -wi--- 300.00G /dev/sdh1 (34728),/dev/sdb1(0)
Первая команда выполнит активацию тома, а вторая покажет список активных томов.
[root@link-07 backup]#lvchange -ay /dev/VG/stripe[root@link-07 backup]#lvs -a -o +devicesLV VG Attr LSize Origin Snap% Move Log Copy% Devices stripe VG -wi-a- 300.00G /dev/sdh1 (0),/dev/sda1(0) stripe VG -wi-a- 300.00G /dev/sdh1 (34728),/dev/sdb1(0)
vgcfgrestore может восстановить физический том, если метаданные были полностью перезаписаны. Если область перезаписи вышла за пределы области метаданных, возможна потеря данных. Попробуйте их восстановить с помощью fsck.
6.5. Замена физического тома
Для замены физического тома можно придерживаться той же последовательности действий, что и при восстановлении метаданных (см. Раздел 6.4, «Восстановление метаданных физического тома»). Используйте аргументы --partial и --verbose команды vgdisplay для определения UUID и размера уже исключенных физических томов. Если же вашей целью является замена физического тома другим томом того же размера, для инициализации нового устройства с тем же UUID используйте аргументы --restorefile и --uuid команды pvcreate. Затем с помощью vgcfgrestore можно восстановить метаданные группы.
6.6. Удаление физических томов из группы
В случае выхода из строя одного физического тома можно активировать остальные тома в группе с помощью аргумента --partial команды vgchange. Аргумент --removemissing команды vgreduce позволяет удалить из группы все логические тома, использующие этот физический том.
Рекомендуется сначала выполнить vgreduce с параметром --test, чтобы знать, что именно будет удалено.
Результат команды vgreduce обратим, если сразу же выполнить vgcfgrestore для восстановления метаданных. Например, если вы выполнили vgreduce с аргументом --removemissing, не указав при этом --test, логические тома будут удалены. В этом случае можно заменить физический том и выполнить vgcfgrestore для восстановления группы.
6.7. Нехватка свободных экстентов для логического тома
Если для создания логического тома не хватает экстентов, хотя вывод vgdisplay и vgs показывает обратное, появится сообщение «Insufficient free extents». Дело в том, что обе команды округляют значения для облегчения чтения. Чтобы указать точный размер, используйте число свободных физических экстентов вместо байтов.
Вывод vgdisplay по умолчанию включает число свободных физических экстентов:
# vgdisplay
--- Volume group ---
...
Free PE / Size 8780 / 34.30 GB
Или же можно передать параметры vg_free_count и vg_extent_count команде vgs для вывода числа свободных экстентов и их общего числа.
[root@tng3-1 ~]# vgs -o +vg_free_count,vg_extent_count
VG #PV #LV #SN Attr VSize VFree Free #Ext
testvg 2 0 0 wz--n- 34.30G 34.30G 8780 8780
Всего свободно 8780 экстентов. Теперь можно выполнить следующую команду («l» использует экстенты в качестве единиц вместо байтов):
# lvcreate -l8780 -n testlv testvg
Том займет все свободные экстенты в группе томов.
# vgs -o +vg_free_count,vg_extent_count
VG #PV #LV #SN Attr VSize VFree Free #Ext
testvg 2 1 0 wz--n- 34.30G 0 0 8780
Можно нарастить логический том так, чтобы он использовал процент незанятого пространства в группе. Для этого используется аргумент -l команды lvcreate (см. Раздел 4.4.1, «Создание линейных логических томов»).
Глава 7. Администрирование LVM в графическом режиме
Помимо текстового интерфейса LVM предоставляет графический интерфейс (GUI, Graphical User Interface) для настройки логических томов LVM. Для запуска графической утилиты выполните system-config-lvm. В главе «LVM» в руководстве по развертыванию Red Hat Enterprise Linux приведены пошаговые инструкции по настройке логического тома.
Приложение A. Device Mapper
Device Mapper — драйвер ядра, реализующий основную инфраструктуру для управления томами. Он позволяет создавать проекции устройств, которые могут использоваться в качестве логических томов. Device Mapper не обладает информацией о группах томов и форматах метаданных.
Device Mapper служит основой для некоторых технологий высокого уровня и активно используется командами dmraid и dm-multipath.
Device Mapper используется для активации логических томов. Логический том преобразуется в проецируемое устройство, а каждому сегменту будет соответствовать строка с таблице соответствий. Device Mapper поддерживает прямое проецирование, проецирование с чередованием или проецирование с учетом ошибок. Так, два диска могут быть объединены в один логический том с двумя линейными соответствиями — по одному на диск. При создании тома LVM будет также создана проекция, для обращения к которой используется dmsetup. Раздел A.1, «Таблица соответствий» содержит описание форматов устройств в таблице соответствий, а Раздел A.2, «dmsetup» предоставляет информацию об dmsetup.
A.1. Таблица соответствий
Проекции устройств определяются в таблице, которая содержит соответствия для диапазонов логических секторов. Формат строк в таблице:
начало длина проекция[параметры...]
Параметр начало обычно равен 0. Сумма параметров начало и длина в одной строке должна быть равна величине начало в следующей строке. Параметры зависят от типа проекции.
Размеры указываются в секторах (размер сектора — 512 байт).
Если в параметрах проецирования указано устройство, в файловой системе к нему можно обращаться и по имени (например, /dev/hda), и по номеру в формате основной:вспомогательный.
Пример таблицы соответствий, в которой определены 4 линейные составляющие:
0 35258368 linear 8:48 65920 35258368 35258368 linear 8:32 65920 70516736 17694720 linear 8:16 17694976 88211456 17694720 linear 8:16 256
Первые два параметра обозначают начальный блок и длину сегмента. Следующий параметр определяет тип проецирования (linear).
Тип может принимать следующие значения:
-
linear;
-
striped;
-
mirror;
-
snapshot и snapshot-origin;
-
error;
-
zero;
-
multipath;
-
crypt.
A.1.1. Тип linear
Создает линейное соответствие между непрерывным диапазоном блоков и другим блочным устройством.
начало длинаlinearустройство смещение
начало-
первый блок виртуального устройства
длина-
длина сегмента
устройство-
блочное устройство, которое можно указать по имени или по номеру в формате
основной:вспомогательный смещение-
смещение проекции
В следующем примере будет создана линейная проекция общей длиной 1638400. При этом основной и вспомогательный номера — 8:2, а смещение устройства — 41146992.
0 16384000 linear 8:2 41156992
Линейное соответствие для устройства /dev/hda:
0 20971520 linear /dev/hda 384
A.1.2. Тип striped
Тип striped обеспечивает чередование между несколькими физическими устройствами и в качестве аргументов принимает число устройств и размер чередующихся сегментов, за которым следуют пары имен устройств и секторов. Формат:
начало длинаstriped#число размер_сегмента устройство1 смещение1 ... устройствоN смещениеN
Каждому сегменту чередования соответствует одна пара значений устройство и смещение.
начало-
первый блок виртуального устройства
длина-
длина сегмента
число-
число чередующихся сегментов для организации виртуального устройства
размер_сегмента-
число секторов, которые будут записаны на одном устройстве, прежде чем будет выполнен переход к следующему. Должно быть кратно 2, а общий размер должен быть не меньше размера страницы ядра.
устройство-
блочное устройство, заданное с помощью имени или пары
основной:вспомогательный. смещение-
смещение проекции
Следующий пример демонстрирует чередование на трех устройствах. При этом размер сегмента равен 128 блокам:
0 73728 striped 3 128 8:9 384 8:8 384 8:7 9789824
- 0
-
первый блок виртуального устройства
- 73728
-
длина сегмента
- striped 3 128
-
чередование на трех устройствах с размером сегмента равным 128 блокам
- 8:9
-
основной и вспомогательный номера первого устройства
- 384
-
смещение на первом устройстве
- 8:8
-
основной и вспомогательный номера второго устройства
- 384
-
смещение на втором устройстве
- 8:7
-
основной и вспомогательный номера третьего устройства
- 9789824
-
смещение на третьем устройстве
В следующем примере будет организовано чередование на двух устройствах; при этом размер сегмента будет равен 256 КиБ, а устройства будут заданы с помощью имен.
0 65536 striped 2 512 /dev/hda 0 /dev/hdb 0
A.1.3. Тип mirror
Тип mirror поддерживает проецирование зеркальных логических устройств. Формат:
начало длинаmirrorтип_журнала #число_аргументов аргумент1 ... аргументN #число_устройств устройство1 смещение1 ... устройствоN смещениеN
начало-
первый блок виртуального устройства
длина-
длина сегмента
тип_журнала-
Возможные значения:
core-
Журнал локального зеркала хранится в основной памяти. Этот тип принимает от одного до трех аргументов:
размер_сектора [[
no]sync] [block_on_error] disk-
Журнал зеркала хранится на локальном диске. Этот тип принимает от двух до четырех аргументов:
устройство размер_сегмента [[
no]sync] [block_on_error] clustered_core-
Журнал кластерного зеркала хранится в основной памяти. Этот тип принимает от двух до четырех аргументов:
размер_секции UUID [[
no]sync] [block_on_error] clustered_disk-
Журнал кластерного зеркала хранится на диске. Этот тип принимает от трех до пяти аргументов:
устройство размер UUID [[
no]sync] [block_on_error]
LVM поддерживает небольшой журнал, где регистрируется информация о синхронизации регионов с зеркалом. Размер определяет размер регионов.
В кластерном окружении UUID определяет уникальный идентификатор устройства, где расположен журнал.
Аргумент
[no]syncне является обязательным; его целью является определение состояния зеркала как «in-sync» или «out-of-sync». Аргументblock_on_errorзаставит зеркало отвечать на ошибки, а не игнорировать их. #число_аргументов-
общее число аргументов журнала
аргумент1...аргументN-
аргументы журнала зеркала. Число аргументов определяется параметром
#число_аргументов, а допустимые аргументы определяются параметромтип_журнала. #число_устройств-
число составляющих зеркала. Для каждого элемента задается устройство и смещение.
устройство-
блочное устройство в основе звена зеркала. Задается с помощью имени устройства или пары номеров
основной:вспомогательный. смещение-
исходное смещение. Блочное устройство и смещение задаются для каждого элемента зеркала.
Следующий пример демонстрирует проецирование для кластерного зеркала с поддержкой журнала на диске.
0 52428800 mirror clustered_disk 4 253:2 1024 UUID block_on_error 3 253:3 0 253:4 0 253:5 0
- 0
-
первый блок виртуального устройства
- 52428800
-
длина сегмента
- mirror clustered_disk
-
зеркало и тип журнала, который в данном случае подразумевает, что он хранится на диске.
- 4
-
далее следуют четыре аргумента
- 253:2
-
основной и вспомогательный номера
- 1024
-
размер региона, где будет регистрироваться информация о синхронизации
UUID-
UUID устройства с журналами кластера
block_on_error-
зеркало должно реагировать на ошибки
- 3
-
число составляющих элементов зеркала
- 253:3 0 253:4 0 253:5 0
-
основной и вспомогательный номера и смещение
A.1.4. Тип snapshot и snapshot-origin
При создании первого снимка тома используются четыре устройства Device Mapper:
-
Устройство с линейным проецированием (
linear), содержащее изначальную таблицу соответствий для исходного тома. -
Устройство с линейным проецированием, используемое в качестве устройства CoW (copy-on-write) для исходного тома. При каждой операции записи данные сохраняются и на COW-устройство, тем самым синхронизируя содержимое (до тех пор пока COW-устройство не заполнится).
-
Устройство с проецированием
snapshot, совмещающим типы 1 и 2, которое представляет собой видимый снимок тома. -
Исходный том. Таблица этого тома заменяется соответствием «snapshot-origin» из первого устройства.
При создании этих устройств используется фиксированная схема присвоения имен. Например, команды создания тома base и его снимка snap будут выглядеть так:
#lvcreate -L 1G -n base volumeGroup#lvcreate -L 100M --snapshot -n snap volumeGroup/base
В результате будет получено 4 устройства:
#dmsetup table|grep volumeGroupvolumeGroup-base-real: 0 2097152 linear 8:19 384 volumeGroup-snap-cow: 0 204800 linear 8:19 2097536 volumeGroup-snap: 0 2097152 snapshot 254:11 254:12 P 16 volumeGroup-base: 0 2097152 snapshot-origin 254:11 #ls -lL /dev/mapper/volumeGroup-*brw------- 1 root root 254, 11 29 ago 18:15 /dev/mapper/volumeGroup-base-real brw------- 1 root root 254, 12 29 ago 18:15 /dev/mapper/volumeGroup-snap-cow brw------- 1 root root 254, 13 29 ago 18:15 /dev/mapper/volumeGroup-snap brw------- 1 root root 254, 10 29 ago 18:14 /dev/mapper/volumeGroup-base
Формат snapshot-origin:
начало длинаsnapshot-originисходный
начало-
первый блок виртуального устройства
длина-
длина сегмента
исходный-
исходный том, для которого создается снимок
Исходный том snapshot-origin обычно имеет один или несколько снимков. При чтении проецирование будет осуществляться напрямую. При записи исходные данные будут сохранены в COW-устройство каждого снимка. Это делается с целью буферизации изменений, до тех пор пока COW-устройство не будет заполнено.
Формат snapshot:
начало длинаsnapshotисходный COW-устройствоP|Nразмер_секции
начало-
первый блок виртуального устройства
длина-
длина сегмента
исходный-
исходный том, для которого создается снимок
COW-устройство-
Устройство, где будут сохраняться измененные секции данных
- P|N
-
P (Persistent) или N (Not persistent) определяют, будет ли сохраняться снимок после перезагрузки. Значение P сохраняет снимок, а N — не сохраняет, в случае чего метаданные будут храниться в памяти.
размер_секции-
Размер изменяемых секций на COW-устройстве (в секторах).
Следующий пример демонстрирует snapshot-origin для устройства с номером 254:11.
0 2097152 snapshot-origin 254:11
В следующем примере исходное устройство — 254:11, COW-устройство — 254:12. Снимок будет сохраняться между перезагрузками, а размер секций данных, сохраняемых в COW-устройстве, равен 16 секторам.
0 2097152 snapshot 254:11 254:12 P 16
A.1.5. Тип error
Тип «error» завершает неудачей любые запросы ввода и вывода к заданному сектору.
«error» обычно используется для тестирования. Скажем, надо проверить поведение устройства в случае сбоя. Для этого просто создается соответствие с поврежденным сектором где-нибудь посередине или работающий компонент зеркала специально заменяется поврежденным.
Проекция «error» может использоваться вместо поврежденного устройства во избежание задержек обращения или при реорганизации метаданных LVM в случае сбоя.
error требует указания только двух параметров — начало и конец.
Пример:
0 65536 error
A.1.6. Тип zero
Для подстановки соответствия zero используется блочное устройство /dev/zero. Запросы чтения будут возвращать блоки нулей, а запись хоть и будет завершена успешно, но записываемые данные не будут сохранены. zero принимает два параметра — начало и длина.
Пример создания соответствия zero для устройства размером 16 ТБ:
0 65536 zero
A.1.7. Тип multipath
Тип «multipath» обеспечивает сопоставление для многопутевых устройств. Формат:
начало длинаmultipath#число_функций [функция1 ... функцияN] #число_аргументов [аргумент1 ... аргументN] #число_групп след_группа аргументы_группы1 ... аргументы_группыN
Каждой группе путей соответствует один набор аргументы_группы.
начало-
первый блок виртуального устройства
длина-
длина сегмента
#число_функций-
Число функций с их последующим списком. Если равно нулю, далее сразу будет следовать
#число_аргументов. В настоящее время поддерживается лишь одна функция —queue_if_no_path, которая ставит запросы ввода-вывода в очередь при отсутствии доступных путей.К примеру, если параметр
no_path_retryв файлеmultipath.confставит операции ввода и вывода в очередь до тех пор, пока все пути не будут отмечены как сбойные после заданного числа попыток, соответствие будет выглядеть так:0 71014400 multipath 1 queue_if_no_path 0 2 1 round-robin 0 2 1 66:128 1000 65:64 1000 round-robin 0 2 1 8:0 1000 67:192 1000
После того как все проверки путей завершились неудачей, соответствие будет выглядеть так:
0 71014400 multipath 0 0 2 1 round-robin 0 2 1 66:128 1000 65:64 1000 round-robin 0 2 1 8:0 1000 67:192 1000
#число_аргументов-
Число аргументов аппаратного обработчика с последующим списком аргументов. Обработчик определяет модуль для выполнения операций, связанных с оборудованием, при изменении групп путей или при обработке ошибок ввода-вывода. Если значение равно нулю, дальше сразу будет следовать
число_групп. #число_групп-
Число групп маршрутов. Группа маршрутов представляет собой набор маршрутов, используемых многопутевым устройством для распределения нагрузки. Каждой группе соответствует один набор параметров
аргументы_группы. след_группа-
Следующая группа маршрутов.
аргументы_группы-
Каждой группе соответствуют следующие аргументы:
алгоритм #число_аргументов #число_маршрутов #число_аргументов устройство1 число_запросов1 ... устройствоN число_запросовNКаждому маршруту соответствует один набор аргументов.
алгоритм-
Алгоритм выбора пути для обработки следующего запроса ввода-вывода.
#число_аргументов-
Число аргументов. По умолчанию равно 0.
#число_маршрутов-
Число маршрутов в группе.
#число_аргументов-
Число аргументов для каждого маршрута. По умолчанию равно 1 (единственный аргумент
ioreqs). устройство-
Номер устройства маршрута в формате
основной:вспомогательный. ioreqs-
Число запросов ввода и вывода, которые будут переданы этому маршруту, прежде чем будет выбран следующий путь.
Рисунок A.1, «Соответствие multipath» демонстрирует проекцию с двумя группами маршрутов.

Рисунок A.1. Соответствие multipath
Следующий пример демонстрирует определение резервного устройства на случай сбоя многопутевого устройства. Цель включает четыре группы путей, но только один путь в группе может быть открыт.
0 71014400 multipath 0 0 4 1 round-robin 0 1 1 66:112 1000 round-robin 0 1 1 67:176 1000 round-robin 0 1 1 68:240 1000 round-robin 0 1 1 65:48 1000
Ниже приведен пример того же устройства, но в этом случае используется лишь одна группа маршрутов, между которыми нагрузка будет распределена равномерно.
0 71014400 multipath 0 0 1 1 round-robin 0 4 1 66:112 1000 67:176 1000 68:240 1000 65:48 1000
Документ DM-Multipath содержит дальнейшую информацию.
A.1.8. Тип crypt
crypt обеспечит шифрование передаваемых через заданное устройство данных. При этом используется API Crypto.
Формат:
начало длинаcryptкод ключ смещение_IV устройство смещение
начало-
первый блок виртуального устройства
длина-
длина сегмента
код-
Формат кода:
cipher[-режим]-ivmode[:iv параметры].код-
Список кодов можно найти в файле
/proc/crypto(например,aes). режим-
Надо указать
cbc, а неebc, так какebcне использует исходный вектор (IV). ivmode[:iv параметры]-
IV — вектор инициализации, позволяющий изменить метод шифрования. Режим IV может принимать значения
plainилиessiv:hash. Методplainиспользует номер сектора (плюс смещение IV) в качестве IV, в то время как-essivпредставляет собой расширение для усиления защиты от атак Watermarking.
ключ-
Ключ шифрования в шестнадцатеричной форме
смещение_IV-
Смещение вектора инициализации
устройство-
блочное устройство, которое можно указать по имени или по номеру в формате
основной:вспомогательный смещение-
смещение проекции
Пример:
0 2097152 crypt aes-plain 0123456789abcdef0123456789abcdef 0 /dev/hda 0
A.2. dmsetup
Для работы с модулем Device Mapper используется команда dmsetup с параметрами info, ls, status и deps. Они будут рассмотрены ниже.
За информацией о параметрах обратитесь к справочной странице dmsetup(8).
A.2.1. dmsetup info
Команда dmsetup info устройство позволяет получить информацию об устройствах Device Mapper. Если устройство не указано, будут показаны сведения о всех настроенных устройствах Device Mapper.
Формат вывода dmsetup info:
Name-
Имя устройства в формате «группа_томов-логический_том». Если исходное имя содержит дефис, он будет указан дважды.
State-
Возможные значения статуса:
SUSPENDED,ACTIVE,READ-ONLY. Например для перевода устройства в состояниеSUSPENDEDвыполнитеdmsetup suspend, что приостановит все операции ввода и вывода.dmsetup resumeснова активирует устройство, изменив его статус наACTIVE. Read Ahead-
Число блоков данных, которые система будет считывать заранее для каждого открытого файла. Значение можно изменить с помощью параметра
--readaheadкомандыdmsetup. Tables present-
Допустимые значения:
LIVE,INACTIVE.INACTIVEобозначает, что загружена неактивная таблица, а когда командаdmsetup resumeвосстановит работу устройства (переведет вACTIVE), ее статус изменится наLIVE. Более подробную информацию можно найти на справочной страницеdmsetup. Open count-
Счетчик попыток открыть устройство с помощью
mount. Event number-
Число полученных событий.
dmsetup wait nпозволит дождаться события с номером n, заблокировав вызов до тех пор, пока оно не будет получено. Major, minor-
Основной и вспомогательный номера устройства.
Number of targets-
Число фрагментов в составе устройства. Например, линейное устройство, в основу которого положено 3 диска, будет иметь 3 фрагмента, а линейное устройство, включающее начало и конец диска, будет иметь 2 фрагмента.
UUID-
Идентификатор UUID.
Пример частичного вывода dmsetup info:
[root@ask-07 ~]# dmsetup info
Name: testgfsvg-testgfslv1
State: ACTIVE
Read Ahead: 256
Tables present: LIVE
Open count: 0
Event number: 0
Major, minor: 253, 2
Number of targets: 2
UUID: LVM-K528WUGQgPadNXYcFrrf9LnPlUMswgkCkpgPIgYzSvigM7SfeWCypddNSWtNzc2N
...
Name: VolGroup00-LogVol00
State: ACTIVE
Read Ahead: 256
Tables present: LIVE
Open count: 1
Event number: 0
Major, minor: 253, 0
Number of targets: 1
UUID: LVM-tOcS1kqFV9drb0X1Vr8sxeYP0tqcrpdegyqj5lZxe45JMGlmvtqLmbLpBcenh2L3
A.2.2. dmsetup ls
С помощью команды dmsetup ls можно просмотреть список проекций устройств. dmsetup ls --target тип покажет устройства, в основе которых лежит по крайней мере один компонент указанного типа. Другие параметры dmsetup ls можно просмотреть на справочной странице dmsetup.
Получение списка устройств:
[root@ask-07 ~]# dmsetup ls
testgfsvg-testgfslv3 (253, 4)
testgfsvg-testgfslv2 (253, 3)
testgfsvg-testgfslv1 (253, 2)
VolGroup00-LogVol01 (253, 1)
VolGroup00-LogVol00 (253, 0)
Получение списка зеркальных устройств:
[root@grant-01 ~]# dmsetup ls --target mirror
lock_stress-grant--02.1722 (253, 34)
lock_stress-grant--01.1720 (253, 18)
lock_stress-grant--03.1718 (253, 52)
lock_stress-grant--02.1716 (253, 40)
lock_stress-grant--03.1713 (253, 47)
lock_stress-grant--02.1709 (253, 23)
lock_stress-grant--01.1707 (253, 8)
lock_stress-grant--01.1724 (253, 14)
lock_stress-grant--03.1711 (253, 27)
Конфигурация LVM может быть довольно сложной. Параметр --tree покажет связи устройств в виде дерева.
# dmsetup ls --tree
vgtest-lvmir (253:13)
├─vgtest-lvmir_mimage_1 (253:12)
│ └─mpathep1 (253:8)
│ └─mpathe (253:5)
│ ├─ (8:112)
│ └─ (8:64)
├─vgtest-lvmir_mimage_0 (253:11)
│ └─mpathcp1 (253:3)
│ └─mpathc (253:2)
│ ├─ (8:32)
│ └─ (8:16)
└─vgtest-lvmir_mlog (253:4)
└─mpathfp1 (253:10)
└─mpathf (253:6)
├─ (8:128)
└─ (8:80)
A.2.3. dmsetup status
dmsetup status устройство покажет статус всех составляющих заданного устройства. Если устройство не указано, будет приведена информация для всех настроенных устройств. dmsetup status --target тип покажет статус устройств, в основе которых лежит по крайней мере один компонент указанного типа.
Получение статуса всех настроенных устройств:
[root@ask-07 ~]# dmsetup status
testgfsvg-testgfslv3: 0 312352768 linear
testgfsvg-testgfslv2: 0 312352768 linear
testgfsvg-testgfslv1: 0 312352768 linear
testgfsvg-testgfslv1: 312352768 50331648 linear
VolGroup00-LogVol01: 0 4063232 linear
VolGroup00-LogVol00: 0 151912448 linear
A.2.4. dmsetup deps
Команда dmsetup deps устройство покажет список основных и вспомогательных номеров устройств, входящих в таблицу соответствий для заданного устройства. Если устройство не указано, будет показана информация обо всех устройствах.
Просмотр зависимостей для всех настроенных устройств:
[root@ask-07 ~]# dmsetup deps
testgfsvg-testgfslv3: 1 dependencies : (8, 16)
testgfsvg-testgfslv2: 1 dependencies : (8, 16)
testgfsvg-testgfslv1: 1 dependencies : (8, 16)
VolGroup00-LogVol01: 1 dependencies : (8, 2)
VolGroup00-LogVol00: 1 dependencies : (8, 2)
Получение зависимостей для устройства lock_stress-grant--02.1722:
[root@grant-01 ~]# dmsetup deps lock_stress-grant--02.1722
3 dependencies : (253, 33) (253, 32) (253, 31)
A.3. Поддержка udev
Основной задачей менеджера устройств udev является обслуживание файлов устройств в каталоге /dev. Создание файлов устройств осуществляется в соответствии с правилами udev в пространстве пользователя. При добавлении, удалении и изменении устройств ядро генерирует события, которые будут обработаны правилами udev.
udev может создавать не только файлы устройств, но и символьные ссылки, предоставляя тем самым свободу действий в выборе имен устройств и организации каталогов внутри /dev.
Событие udev содержит информацию об устройстве — имя, подсистема, которой оно принадлежит, тип устройства, основной и второстепенный номер и тип события. На основе этой информации и данных из /sys можно создать фильтры для правил.
udev предоставляет централизованный механизм настройки доступа к файлам устройств. Пользователь может определить собственный набор правил доступа к устройствам.
Правила могут содержать вызовы других программ. В свою очередь, программы могут экспортировать переменные окружения. Полученные результаты могут быть переданы правилам для дальнейшей обработки.
Обработка событий может осуществляться не только службой udev, но и другими программами, использующими библиотеку udev.
A.3.1. Интеграция udev с Device Mapper
В RHEL 6 обработка событий udev синхронизируется с Device Mapper. Синхронизация необходима, так как udev применяет правила параллельно с программой, запрашивающей изменение устройства (например, dmsetup или LVM). В противном случае могло бы оказаться так, что пользователь пытается удалить устройство, которое еще используется службой udev.
RHEL 6 обеспечивает поддержку правил udev для устройств Device Mapper. Правила располагаются в /lib/udev/rules.d (см. Таблица A.1, «Правила udev»).
Таблица A.1. Правила udev
| Файл | Описание | ||
|---|---|---|---|
10-dm.rules |
|
||
11-dm-lvm.rules |
|
||
13-dm-disk.rules |
Содержит правила для обработки устройств Device Mapper и создает символьные ссылки в каталогах /dev/disk/by-id, /dev/disk/by-uuid и /dev/disk/by-uuid. |
||
95-dm-notify.rules |
Содержит правило для уведомления ожидающего процесса. Уведомление будет отправлено после завершения обработки udev, то есть после применения всех правил. После этого процесс продолжит работу. |
Дополнительные правила доступа можно добавить в 12-dm-permissions.rules. Этот файл не устанавливается в /lib/udev/rules по умолчанию и изначально расположен в каталоге /usr/share/doc/device-mapper-версия. Он содержит шаблон для настройки доступа на базе примера. Отредактировав файл, переместите его в /etc/udev/rules.d.
Указанные правила определяют основные переменные, которые могут использоваться другими правилами.
Переменные в 10-dm.rules:
-
DM_NAME: имя проекции устройства; -
DM_UUID: идентификатор проекции устройства; -
DM_SUSPENDED: устройство приостановлено; -
DM_UDEV_RULES_VSN: версия. Проверяется другими правилами, чтобы убедиться, что указанные выше переменные определены официальными правилами Device Mapper.
Переменные в 11-dm-lvm.rules:
-
DM_LV_NAME: логический том; -
DM_VG_NAME: группа томов; -
DM_LV_LAYER: уровень LVM.
Для настройки доступа к конкретному устройству Device Mapper перечисленные переменные можно добавить в файл 12-dm-permissions.rules.
A.3.2. Команды для работы с udev
Таблица A.2, «Команды dmsetup для работы с udev» содержит список команд dmsetup для работы с udev.
Таблица A.2. Команды dmsetup для работы с udev
| Команда | Описание |
|---|---|
dmsetup udevcomplete |
Сообщает о завершении обработки правил и разрешает продолжение ожидающего процесса (вызывается из 95-dm-notify.rules). |
dmsetup udevcomplete_all |
Используется при отладке для возобновления всех ожидающих процессов. |
dmsetup udevcookies |
Используется при отладке для просмотра существующих cookie-файлов. |
dmsetup udevcreatecookie |
Используется для создания cookie-файлов вручную. |
dmsetup udevreleasecookie |
Ожидает завершения обработки всех процессов для выбранного cookie. |
Ниже приведен список параметров для перечисленных команд.
--udevcookie-
Обязательный параметр. Используется вместе с
udevcreatecookieиudevreleasecookie:COOKIE=$(dmsetup udevcreatecookie) dmsetup команда --udevcookie $COOKIE .... dmsetup команда --udevcookie $COOKIE .... .... dmsetup команда --udevcookie $COOKIE .... dmsetup udevreleasecookie --udevcookie $COOKIE
Дополнительно можно экспортировать переменную в окружение процесса:
export DM_UDEV_COOKIE=$(dmsetup udevcreatecookie) dmsetup команда ... dmsetup команда ... ... dmsetup команда ...
--noudevrules-
Отключает правила udev. За создание файлов и ссылок будет отвечать
libdevmapper. Этот аргумент используется для отладкиudev. --noudevsync-
Отключает синхронизацию
udev. Используется для отладки.
Более подробную информацию о dmsetup можно найти на справочной странице dmsetup(8).
Команды LVM поддерживают следующие параметры для интеграции с udev:
-
--noudevrules: отключает правилаudev. -
--noudevsync: отключает синхронизациюudev.
Ниже перечислены параметры, которые могут быть добавлены в lvm.conf.
-
udev_rules: включает и отключаетudev_rulesдля всех команд LVM2. -
udev_sync: включает и отключает синхронизациюudevдля всех команд LVM.
lvm.conf содержит подробные комментарии.
Приложение B. Файлы конфигурации LVM
При запуске системы из каталога, заданного переменной окружения LVM_SYSTEM_DIR (по умолчанию установлена в /etc/lvm) будет загружен файл конфигурации lvm.conf.
В lvm.conf могут быть указаны дополнительные файлы конфигурации. Последующие настройки будут переопределять предыдущие. Чтобы отобразить текущие настройки, выполните lvm dumpconfig.
Раздел C.2, «Теги узлов» содержит инструкции по добавлению других файлов конфигурации.
B.1. Файлы конфигурации LVM
Далее перечислены файлы конфигурации LVM.
- /etc/lvm/lvm.conf
-
Основной файл конфигурации, к которому обращаются утилиты.
- etc/lvm/lvm_тег_узла.conf
-
Каждому тегу соответствует отдельный файл
lvm_тег_узла.conf. Если он содержит другие теги, тогда имена соответствующих файлов конфигурации будут добавлены в список для последующего чтения (см. Раздел C.2, «Теги узлов»).
Также используются следующие файлы:
- /etc/lvm/.cache
-
файл кэширования фильтров имен устройств (может быть изменен).
- /etc/lvm/backup/
-
каталог, где хранятся автоматически созданные резервные копии метаданных групп томов (может быть изменен).
- /etc/lvm/archive/
-
каталог, где хранятся архивы автоматически созданных резервных копий метаданных групп томов (настраивается в зависимости от длины истории архивации и пути)
- /var/lock/lvm/
-
В структуре с одним узлом файлы блокировки предотвращают повреждение данных при параллельной работе программ. В кластере будет использоваться блокирование DLM.
B.2. Пример lvm.conf
Пример lvm.conf:
# This is an example configuration file for the LVM2 system.
# It contains the default settings that would be used if there was no
# /etc/lvm/lvm.conf file.
#
# Refer to 'man lvm.conf' for further information including the file layout.
#
# To put this file in a different directory and override /etc/lvm set
# the environment variable LVM_SYSTEM_DIR before running the tools.
# This section allows you to configure which block devices should
# be used by the LVM system.
devices {
# Where do you want your volume groups to appear ?
dir = "/dev"
# An array of directories that contain the device nodes you wish
# to use with LVM2.
scan = [ "/dev" ]
# If several entries in the scanned directories correspond to the
# same block device and the tools need to display a name for device,
# all the pathnames are matched against each item in the following
# list of regular expressions in turn and the first match is used.
# preferred_names = [ ]
# Try to avoid using undescriptive /dev/dm-N names, if present.
preferred_names = [ "^/dev/mpath/", "^/dev/mapper/mpath", "^/dev/[hs]d" ]
# A filter that tells LVM2 to only use a restricted set of devices.
# The filter consists of an array of regular expressions. These
# expressions can be delimited by a character of your choice, and
# prefixed with either an 'a' (for accept) or 'r' (for reject).
# The first expression found to match a device name determines if
# the device will be accepted or rejected (ignored). Devices that
# don't match any patterns are accepted.
# Be careful if there there are symbolic links or multiple filesystem
# entries for the same device as each name is checked separately against
# the list of patterns. The effect is that if any name matches any 'a'
# pattern, the device is accepted; otherwise if any name matches any 'r'
# pattern it is rejected; otherwise it is accepted.
# Don't have more than one filter line active at once: only one gets used.
# Run vgscan after you change this parameter to ensure that
# the cache file gets regenerated (see below).
# If it doesn't do what you expect, check the output of 'vgscan -vvvv'.
# By default we accept every block device:
filter = [ "a/.*/" ]
# Exclude the cdrom drive
# filter = [ "r|/dev/cdrom|" ]
# When testing I like to work with just loopback devices:
# filter = [ "a/loop/", "r/.*/" ]
# Or maybe all loops and ide drives except hdc:
# filter =[ "a|loop|", "r|/dev/hdc|", "a|/dev/ide|", "r|.*|" ]
# Use anchors if you want to be really specific
# filter = [ "a|^/dev/hda8$|", "r/.*/" ]
# The results of the filtering are cached on disk to avoid
# rescanning dud devices (which can take a very long time).
# By default this cache is stored in the /etc/lvm/cache directory
# in a file called '.cache'.
# It is safe to delete the contents: the tools regenerate it.
# (The old setting 'cache' is still respected if neither of
# these new ones is present.)
cache_dir = "/etc/lvm/cache"
cache_file_prefix = ""
# You can turn off writing this cache file by setting this to 0.
write_cache_state = 1
# Advanced settings.
# List of pairs of additional acceptable block device types found
# in /proc/devices with maximum (non-zero) number of partitions.
# types = [ "fd", 16 ]
# If sysfs is mounted (2.6 kernels) restrict device scanning to
# the block devices it believes are valid.
# 1 enables; 0 disables.
sysfs_scan = 1
# By default, LVM2 will ignore devices used as components of
# software RAID (md) devices by looking for md superblocks.
# 1 enables; 0 disables.
md_component_detection = 1
# By default, if a PV is placed directly upon an md device, LVM2
# will align its data blocks with the md device's stripe-width.
# 1 enables; 0 disables.
md_chunk_alignment = 1
# Default alignment of the start of a data area in MB. If set to 0,
# a value of 64KB will be used. Set to 1 for 1MiB, 2 for 2MiB, etc.
# default_data_alignment = 1
# By default, the start of a PV's data area will be a multiple of
# the 'minimum_io_size' or 'optimal_io_size' exposed in sysfs.
# - minimum_io_size - the smallest request the device can perform
# w/o incurring a read-modify-write penalty (e.g. MD's chunk size)
# - optimal_io_size - the device's preferred unit of receiving I/O
# (e.g. MD's stripe width)
# minimum_io_size is used if optimal_io_size is undefined (0).
# If md_chunk_alignment is enabled, that detects the optimal_io_size.
# This setting takes precedence over md_chunk_alignment.
# 1 enables; 0 disables.
data_alignment_detection = 1
# Alignment (in KB) of start of data area when creating a new PV.
# md_chunk_alignment and data_alignment_detection are disabled if set.
# Set to 0 for the default alignment (see: data_alignment_default)
# or page size, if larger.
data_alignment = 0
# By default, the start of the PV's aligned data area will be shifted by
# the 'alignment_offset' exposed in sysfs. This offset is often 0 but
# may be non-zero; e.g.: certain 4KB sector drives that compensate for
# windows partitioning will have an alignment_offset of 3584 bytes
# (sector 7 is the lowest aligned logical block, the 4KB sectors start
# at LBA -1, and consequently sector 63 is aligned on a 4KB boundary).
# But note that pvcreate --dataalignmentoffset will skip this detection.
# 1 enables; 0 disables.
data_alignment_offset_detection = 1
# If, while scanning the system for PVs, LVM2 encounters a device-mapper
# device that has its I/O suspended, it waits for it to become accessible.
# Set this to 1 to skip such devices. This should only be needed
# in recovery situations.
ignore_suspended_devices = 0
# During each LVM operation errors received from each device are counted.
# If the counter of a particular device exceeds the limit set here, no
# further I/O is sent to that device for the remainder of the respective
# operation. Setting the parameter to 0 disables the counters altogether.
disable_after_error_count = 0
# Allow use of pvcreate --uuid without requiring --restorefile.
require_restorefile_with_uuid = 1
}
# This section allows you to configure the way in which LVM selects
# free space for its Logical Volumes.
#allocation {
# When searching for free space to extend an LV, the "cling"
# allocation policy will choose space on the same PVs as the last
# segment of the existing LV. If there is insufficient space and a
# list of tags is defined here, it will check whether any of them are
# attached to the PVs concerned and then seek to match those PV tags
# between existing extents and new extents.
# Use the special tag "@*" as a wildcard to match any PV tag.
#
# Example: LVs are mirrored between two sites within a single VG.
# PVs are tagged with either @site1 or @site2 to indicate where
# they are situated.
#
# cling_tag_list = [ "@site1", "@site2" ]
# cling_tag_list = [ "@*" ]
#}
# This section that allows you to configure the nature of the
# information that LVM2 reports.
log {
# Controls the messages sent to stdout or stderr.
# There are three levels of verbosity, 3 being the most verbose.
verbose = 0
# Should we send log messages through syslog?
# 1 is yes; 0 is no.
syslog = 1
# Should we log error and debug messages to a file?
# By default there is no log file.
#file = "/var/log/lvm2.log"
# Should we overwrite the log file each time the program is run?
# By default we append.
overwrite = 0
# What level of log messages should we send to the log file and/or syslog?
# There are 6 syslog-like log levels currently in use - 2 to 7 inclusive.
# 7 is the most verbose (LOG_DEBUG).
level = 0
# Format of output messages
# Whether or not (1 or 0) to indent messages according to their severity
indent = 1
# Whether or not (1 or 0) to display the command name on each line output
command_names = 0
# A prefix to use before the message text (but after the command name,
# if selected). Default is two spaces, so you can see/grep the severity
# of each message.
prefix = " "
# To make the messages look similar to the original LVM tools use:
# indent = 0
# command_names = 1
# prefix = " -- "
# Set this if you want log messages during activation.
# Don't use this in low memory situations (can deadlock).
# activation = 0
}
# Configuration of metadata backups and archiving. In LVM2 when we
# talk about a 'backup' we mean making a copy of the metadata for the
# *current* system. The 'archive' contains old metadata configurations.
# Backups are stored in a human readeable text format.
backup {
# Should we maintain a backup of the current metadata configuration ?
# Use 1 for Yes; 0 for No.
# Think very hard before turning this off!
backup = 1
# Where shall we keep it ?
# Remember to back up this directory regularly!
backup_dir = "/etc/lvm/backup"
# Should we maintain an archive of old metadata configurations.
# Use 1 for Yes; 0 for No.
# On by default. Think very hard before turning this off.
archive = 1
# Where should archived files go ?
# Remember to back up this directory regularly!
archive_dir = "/etc/lvm/archive"
# What is the minimum number of archive files you wish to keep ?
retain_min = 10
# What is the minimum time you wish to keep an archive file for ?
retain_days = 30
}
# Settings for the running LVM2 in shell (readline) mode.
shell {
# Number of lines of history to store in ~/.lvm_history
history_size = 100
}
# Miscellaneous global LVM2 settings
global {
# The file creation mask for any files and directories created.
# Interpreted as octal if the first digit is zero.
umask = 077
# Allow other users to read the files
#umask = 022
# Enabling test mode means that no changes to the on disk metadata
# will be made. Equivalent to having the -t option on every
# command. Defaults to off.
test = 0
# Default value for --units argument
units = "h"
# Since version 2.02.54, the tools distinguish between powers of
# 1024 bytes (e.g. KiB, MiB, GiB) and powers of 1000 bytes (e.g.
# KB, MB, GB).
# If you have scripts that depend on the old behaviour, set this to 0
# temporarily until you update them.
si_unit_consistency = 1
# Whether or not to communicate with the kernel device-mapper.
# Set to 0 if you want to use the tools to manipulate LVM metadata
# without activating any logical volumes.
# If the device-mapper kernel driver is not present in your kernel
# setting this to 0 should suppress the error messages.
activation = 1
# If we can't communicate with device-mapper, should we try running
# the LVM1 tools?
# This option only applies to 2.4 kernels and is provided to help you
# switch between device-mapper kernels and LVM1 kernels.
# The LVM1 tools need to be installed with .lvm1 suffices
# e.g. vgscan.lvm1 and they will stop working after you start using
# the new lvm2 on-disk metadata format.
# The default value is set when the tools are built.
# fallback_to_lvm1 = 0
# The default metadata format that commands should use - "lvm1" or "lvm2".
# The command line override is -M1 or -M2.
# Defaults to "lvm2".
# format = "lvm2"
# Location of proc filesystem
proc = "/proc"
# Type of locking to use. Defaults to local file-based locking (1).
# Turn locking off by setting to 0 (dangerous: risks metadata corruption
# if LVM2 commands get run concurrently).
# Type 2 uses the external shared library locking_library.
# Type 3 uses built-in clustered locking.
# Type 4 uses read-only locking which forbids any operations that might
# change metadata.
locking_type = 1
# Set to 0 to fail when a lock request cannot be satisfied immediately.
wait_for_locks = 1
# If using external locking (type 2) and initialisation fails,
# with this set to 1 an attempt will be made to use the built-in
# clustered locking.
# If you are using a customised locking_library you should set this to 0.
fallback_to_clustered_locking = 1
# If an attempt to initialise type 2 or type 3 locking failed, perhaps
# because cluster components such as clvmd are not running, with this set
# to 1 an attempt will be made to use local file-based locking (type 1).
# If this succeeds, only commands against local volume groups will proceed.
# Volume Groups marked as clustered will be ignored.
fallback_to_local_locking = 1
# Local non-LV directory that holds file-based locks while commands are
# in progress. A directory like /tmp that may get wiped on reboot is OK.
locking_dir = "/var/lock/lvm"
# Whenever there are competing read-only and read-write access requests for
# a volume group's metadata, instead of always granting the read-only
# requests immediately, delay them to allow the read-write requests to be
# serviced. Without this setting, write access may be stalled by a high
# volume of read-only requests.
# NB. This option only affects locking_type = 1 viz. local file-based
# locking.
prioritise_write_locks = 1
# Other entries can go here to allow you to load shared libraries
# e.g. if support for LVM1 metadata was compiled as a shared library use
# format_libraries = "liblvm2format1.so"
# Full pathnames can be given.
# Search this directory first for shared libraries.
# library_dir = "/lib"
# The external locking library to load if locking_type is set to 2.
# locking_library = "liblvm2clusterlock.so"
# Treat any internal errors as fatal errors, aborting the process that
# encountered the internal error. Please only enable for debugging.
abort_on_internal_errors = 0
# If set to 1, no operations that change on-disk metadata will be permitted.
# Additionally, read-only commands that encounter metadata in need of repair
# will still be allowed to proceed exactly as if the repair had been
# performed (except for the unchanged vg_seqno).
# Inappropriate use could mess up your system, so seek advice first!
metadata_read_only = 0
}
activation {
# Set to 0 to disable udev synchronisation (if compiled into the binaries).
# Processes will not wait for notification from udev.
# They will continue irrespective of any possible udev processing
# in the background. You should only use this if udev is not running
# or has rules that ignore the devices LVM2 creates.
# The command line argument --nodevsync takes precedence over this setting.
# If set to 1 when udev is not running, and there are LVM2 processes
# waiting for udev, run 'dmsetup udevcomplete_all' manually to wake them up.
udev_sync = 1
# Set to 0 to disable the udev rules installed by LVM2 (if built with
# --enable-udev_rules). LVM2 will then manage the /dev nodes and symlinks
# for active logical volumes directly itself.
# N.B. Manual intervention may be required if this setting is changed
# while any logical volumes are active.
udev_rules = 1
# How to fill in missing stripes if activating an incomplete volume.
# Using "error" will make inaccessible parts of the device return
# I/O errors on access. You can instead use a device path, in which
# case, that device will be used to in place of missing stripes.
# But note that using anything other than "error" with mirrored
# or snapshotted volumes is likely to result in data corruption.
missing_stripe_filler = "error"
# How much stack (in KB) to reserve for use while devices suspended
reserved_stack = 256
# How much memory (in KB) to reserve for use while devices suspended
reserved_memory = 8192
# Nice value used while devices suspended
process_priority = -18
# If volume_list is defined, each LV is only activated if there is a
# match against the list.
# "vgname" and "vgname/lvname" are matched exactly.
# "@tag" matches any tag set in the LV or VG.
# "@*" matches if any tag defined on the host is also set in the LV or VG
#
# volume_list = [ "vg1", "vg2/lvol1", "@tag1", "@*" ]
# Size (in KB) of each copy operation when mirroring
mirror_region_size = 512
# Setting to use when there is no readahead value stored in the metadata.
#
# "none" - Disable readahead.
# "auto" - Use default value chosen by kernel.
readahead = "auto"
# 'mirror_image_fault_policy' and 'mirror_log_fault_policy' define
# how a device failure affecting a mirror is handled.
# A mirror is composed of mirror images (copies) and a log.
# A disk log ensures that a mirror does not need to be re-synced
# (all copies made the same) every time a machine reboots or crashes.
#
# In the event of a failure, the specified policy will be used to determine
# what happens. This applies to automatic repairs (when the mirror is being
# monitored by dmeventd) and to manual lvconvert --repair when
# --use-policies is given.
#
# "remove" - Simply remove the faulty device and run without it. If
# the log device fails, the mirror would convert to using
# an in-memory log. This means the mirror will not
# remember its sync status across crashes/reboots and
# the entire mirror will be re-synced. If a
# mirror image fails, the mirror will convert to a
# non-mirrored device if there is only one remaining good
# copy.
#
# "allocate" - Remove the faulty device and try to allocate space on
# a new device to be a replacement for the failed device.
# Using this policy for the log is fast and maintains the
# ability to remember sync state through crashes/reboots.
# Using this policy for a mirror device is slow, as it
# requires the mirror to resynchronize the devices, but it
# will preserve the mirror characteristic of the device.
# This policy acts like "remove" if no suitable device and
# space can be allocated for the replacement.
#
# "allocate_anywhere" - Not yet implemented. Useful to place the log device
# temporarily on same physical volume as one of the mirror
# images. This policy is not recommended for mirror devices
# since it would break the redundant nature of the mirror. This
# policy acts like "remove" if no suitable device and space can
# be allocated for the replacement.
mirror_log_fault_policy = "allocate"
mirror_image_fault_policy = "remove"
# 'snapshot_autoextend_threshold' and 'snapshot_autoextend_percent' define
# how to handle automatic snapshot extension. The former defines when the
# snapshot should be extended: when its space usage exceeds this many
# percent. The latter defines how much extra space should be allocated for
# the snapshot, in percent of its current size.
#
# For example, if you set snapshot_autoextend_threshold to 70 and
# snapshot_autoextend_percent to 20, whenever a snapshot exceeds 70% usage,
# it will be extended by another 20%. For a 1G snapshot, using up 700M will
# trigger a resize to 1.2G. When the usage exceeds 840M, the snapshot will
# be extended to 1.44G, and so on.
#
# Setting snapshot_autoextend_threshold to 100 disables automatic
# extensions. The minimum value is 50 (A setting below 50 will be treated
# as 50).
snapshot_autoextend_threshold = 100
snapshot_autoextend_percent = 20
# While activating devices, I/O to devices being (re)configured is
# suspended, and as a precaution against deadlocks, LVM2 needs to pin
# any memory it is using so it is not paged out. Groups of pages that
# are known not to be accessed during activation need not be pinned
# into memory. Each string listed in this setting is compared against
# each line in /proc/self/maps, and the pages corresponding to any
# lines that match are not pinned. On some systems locale-archive was
# found to make up over 80% of the memory used by the process.
# mlock_filter = [ "locale/locale-archive", "gconv/gconv-modules.cache" ]
# Set to 1 to revert to the default behaviour prior to version 2.02.62
# which used mlockall() to pin the whole process's memory while activating
# devices.
use_mlockall = 0
# Monitoring is enabled by default when activating logical volumes.
# Set to 0 to disable monitoring or use the --ignoremonitoring option.
monitoring = 1
# When pvmove or lvconvert must wait for the kernel to finish
# synchronising or merging data, they check and report progress
# at intervals of this number of seconds. The default is 15 seconds.
# If this is set to 0 and there is only one thing to wait for, there
# are no progress reports, but the process is awoken immediately the
# operation is complete.
polling_interval = 15
}
####################
# Advanced section #
####################
# Metadata settings
#
# metadata {
# Default number of copies of metadata to hold on each PV. 0, 1 or 2.
# You might want to override it from the command line with 0
# when running pvcreate on new PVs which are to be added to large VGs.
# pvmetadatacopies = 1
# Default number of copies of metadata to maintain for each VG.
# If set to a non-zero value, LVM automatically chooses which of
# the available metadata areas to use to achieve the requested
# number of copies of the VG metadata. If you set a value larger
# than the the total number of metadata areas available then
# metadata is stored in them all.
# The default value of 0 ("unmanaged") disables this automatic
# management and allows you to control which metadata areas
# are used at the individual PV level using 'pvchange
# --metadataignore y/n'.
# vgmetadatacopies = 0
# Approximate default size of on-disk metadata areas in sectors.
# You should increase this if you have large volume groups or
# you want to retain a large on-disk history of your metadata changes.
# pvmetadatasize = 255
# List of directories holding live copies of text format metadata.
# These directories must not be on logical volumes!
# It's possible to use LVM2 with a couple of directories here,
# preferably on different (non-LV) filesystems, and with no other
# on-disk metadata (pvmetadatacopies = 0). Or this can be in
# addition to on-disk metadata areas.
# The feature was originally added to simplify testing and is not
# supported under low memory situations - the machine could lock up.
#
# Never edit any files in these directories by hand unless you
# you are absolutely sure you know what you are doing! Use
# the supplied toolset to make changes (e.g. vgcfgrestore).
# dirs = [ "/etc/lvm/metadata", "/mnt/disk2/lvm/metadata2" ]
#}
# Event daemon
#
dmeventd {
# mirror_library is the library used when monitoring a mirror device.
#
# "libdevmapper-event-lvm2mirror.so" attempts to recover from
# failures. It removes failed devices from a volume group and
# reconfigures a mirror as necessary. If no mirror library is
# provided, mirrors are not monitored through dmeventd.
mirror_library = "libdevmapper-event-lvm2mirror.so"
# snapshot_library is the library used when monitoring a snapshot device.
#
# "libdevmapper-event-lvm2snapshot.so" monitors the filling of
# snapshots and emits a warning through syslog when the use of
# the snapshot exceeds 80%. The warning is repeated when 85%, 90% and
# 95% of the snapshot is filled.
snapshot_library = "libdevmapper-event-lvm2snapshot.so"
# Full path of the dmeventd binary.
#
# executable = "/sbin/dmeventd"
}
Приложение E. История изменений
| История переиздания | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Издание 1-3.400 | 2013-10-31 | |||||||||||||||||||||||
|
Rebuild with publican 4.0.0 |
||||||||||||||||||||||||
| Издание 1-3 | 2012-07-18 | Anthony Towns | ||||||||||||||||||||||
|
Rebuild for Publican 3.0 |
||||||||||||||||||||||||
| Издание 2.0-1 | Thu May 19 2011 | Steven Levine | ||||||||||||||||||||||
|
Исходная версия документа для Red Hat Enterprise Linux 6.1
|
||||||||||||||||||||||||
| Издание 1.0-1 | Wed Nov 10 2010 | Steven Levine | ||||||||||||||||||||||
|
Исходная версия для Red Hat Enterprise Linux 6 |
Предметный указатель
Символы
- /lib/udev/rules.d directory, Интеграция udev с Device Mapper
- административные процедуры, Обзор администрирования LVM
- активация групп томов
-
- отдельные узлы, Активация и деактивация групп томов
- только на локальном узле, Активация и деактивация групп томов
- активация группы томов, Активация и деактивация групп томов
- активация логических томов
-
- отдельные узлы, Активация логических томов на отдельных узлах кластера
- архивный файл, Резервное копирование логического тома
- блочное устройство
-
- поиск, Поиск блочных устройств
- ведение журнала, Журнал событий
- возможности, новые и обновленные, Новые и обновленные возможности
- выделение пространства
-
- ограничение, Запрет выделения пространства физического тома
- правила, Создание групп томов
- группа томов
-
- активация, Активация и деактивация групп томов
- деактивация, Активация и деактивация групп томов
- изменение параметров, Изменение параметров группы томов
- команда vgs, Команда vgs
- наращивание, Добавление физических томов в группу
- объединение, Объединение групп томов
- определение, Группа томов
- переименование, Переименование группы томов
- перенос между системами, Перенос группы томов в другую систему
- просмотр, Просмотр групп томов, Настройка отчетов LVM, Команда vgs
- разделение, Разбиение группы томов
-
- пример, Разбиение группы томов
- сжатие, Удаление физических томов из группы
- слияние, Объединение групп томов
- создание в кластере, Создание групп томов в кластере
- увеличение, Добавление физических томов в группу
- удаление, Удаление групп томов
- уменьшение, Удаление физических томов из группы
- управление, общие принципы, Управление группами
- группы томов
-
- создание, Создание групп томов
- деактивация групп томов
-
- на единственном узле, Активация и деактивация групп томов
- только на локальном узле, Активация и деактивация групп томов
- деактивация группы томов, Активация и деактивация групп томов
- диагностика проблем, Диагностика проблем
- единицы в командах, Использование команд
- единицы, командная строка, Использование команд
- зеркальный логический том
-
- восстановление, Восстановление после сбоя зеркала
- изменение настроек, Изменение конфигурации зеркальных томов
- кластерный, Создание зеркального логического тома в кластере
- определение, Зеркальный том
- политика сбоя, Правила работы при сбое зеркального тома
- преобразование в линейный, Изменение конфигурации зеркальных томов
- создание, Создание зеркальных томов
- изменение размера
-
- логический том, Изменение размера логических томов
- физический том, Изменение размера физического тома
- инициализация
-
- разделы, Инициализация физических томов
- физический том, Инициализация физических томов
- каталог rules.d, Интеграция udev с Device Mapper
- каталог специальных файлов устройств, Создание групп томов
- кластерное окружение, CLVM, Создание томов LVM в кластере
- команда lvchange, Изменение параметров группы логических томов
- команда lvconvert, Изменение конфигурации зеркальных томов
- команда lvcreate, Создание линейных логических томов
- команда lvdisplay, Просмотр логических томов
- команда lvextend, Увеличение размера логических томов
- команда lvmdiskscan, Поиск блочных устройств
- команда lvreduce, Изменение размера логических томов, Уменьшение размера логических томов
- команда lvremove, Удаление логических томов
- команда lvrename, Переименование логических томов
- команда lvs, Настройка отчетов LVM, Команда lvs
-
- аргументы вывода, Команда lvs
- команда lvscan, Просмотр логических томов
- команда pvdisplay, Просмотр физических томов
- команда pvmove, Перенос данных в активной системе
- команда pvremove, Удаление физических томов
- команда pvresize, Изменение размера физического тома
- команда pvs, Настройка отчетов LVM
-
- аргументы, Команда pvs
- команда pvscan, Просмотр физических томов
- команда vgcfbackup, Создание резервной копии метаданных группы томов
- команда vgcfrestore, Создание резервной копии метаданных группы томов
- команда vgchange, Изменение параметров группы томов
- команда vgcreate, Создание групп томов, Создание групп томов в кластере
- команда vgdisplay, Просмотр групп томов
- команда vgexport, Перенос группы томов в другую систему
- команда vgextend, Добавление физических томов в группу
- команда vgimport, Перенос группы томов в другую систему
- команда vgmerge, Объединение групп томов
- команда vgmknodes, Восстановление каталога группы томов
- команда vgreduce, Удаление физических томов из группы
- команда vgrename, Переименование группы томов
- команда vgs, Настройка отчетов LVM
-
- аргументы, Команда vgs
- команда vgscan, Поиск групп томов на дисках
- команда vgsplit, Разбиение группы томов
- линейный логический том
-
- определение, Линейный том
- преобразование в зеркальный, Изменение конфигурации зеркальных томов
- создание, Создание линейных логических томов
- логический том
-
- зеркальный, Создание зеркальных томов
- изменение параметров, Изменение параметров группы логических томов
- изменение размера, Изменение размера логических томов
- команда lvs, Команда lvs
- линейный, Создание линейных логических томов
- локальный доступ, Активация логических томов на отдельных узлах кластера
- монопольный доступ, Активация логических томов на отдельных узлах кластера
- наращивание, Увеличение размера логических томов
- определение, Логический том, Логический том
- переименование, Переименование логических томов
- пример создания, Создание логического тома на трех дисках
- просмотр, Просмотр логических томов, Настройка отчетов LVM, Команда lvs
- с чередованием, Создание томов с чередованием
- сжатие, Уменьшение размера логических томов
- снимок, Создание снимков
- создание, Создание линейных логических томов
- увеличение, Увеличение размера логических томов
- удаление, Удаление логических томов
- уменьшение, Уменьшение размера логических томов
- управление, общие принципы, Управление логическими томами
- логический том с чередованием
-
- наращивание, Увеличение тома с чередованием
- определение, Том с чередованием
- пример создания, Создание логического тома с чередованием
- создание, Создание томов с чередованием
- увеличение, Увеличение тома с чередованием
- логический том-снимок
-
- создание, Создание снимков
- менеджер устройств udev, Поддержка udev
- метаданные
-
- восстановление, Восстановление метаданных физического тома
- резервное копирование, Резервное копирование логического тома, Создание резервной копии метаданных группы томов
- номера устройств
-
- младший, Постоянные номера устройств
- постоянные, Постоянные номера устройств
- старший, Постоянные номера устройств
- обзор
-
- возможности, новые и обновленные, Новые и обновленные возможности
- окно справки, Использование команд
- определение устройств, фильтры, Определение устройств LVM с помощью фильтров
- отзывы
-
- контактная информация, Отзывы и предложения
- параметр mirror_image_fault_policy, Правила работы при сбое зеркального тома
- параметр mirror_log_fault_policy, Правила работы при сбое зеркального тома
- переименование
-
- группа томов, Переименование группы томов
- логический том, Переименование логических томов
- перенос данных в работающей системе, Перенос данных в активной системе
- перенос данных, онлайн, Перенос данных в активной системе
- подробный вывод, Использование команд
- поиск
-
- блочные устройства, Поиск блочных устройств
- постоянные номера устройств, Постоянные номера устройств
- правила udev, Интеграция udev с Device Mapper
- примеры конфигурации, Примеры конфигурации LVM
- просмотр
-
- группы томов, Просмотр групп томов, Команда vgs
- логический том, Просмотр логических томов, Команда lvs
- физический том, Просмотр физических томов, Команда pvs
- форматирование вывода, Форматирование вывода
- просмотр справочной страницы, Использование команд
- пути, Использование команд
- пути к устройствам, Использование команд
- разделы
-
- несколько, Диски с несколькими разделами
- размер устройства, Создание групп томов
- резервное копирование
-
- метаданные, Резервное копирование логического тома, Создание резервной копии метаданных группы томов
- файл, Резервное копирование логического тома
- сбойные устройства
-
- просмотр, Получение информации о неисправных устройствах
- служба clvmd, CLVM
- снимок
-
- определение, Снимки
- создание
-
- группа томов, Создание групп томов в кластере
- группы томов, Создание групп томов
- логический том, Создание линейных логических томов
- логический том с чередованием, пример, Создание логического тома с чередованием
- логический том, пример, Создание логического тома на трех дисках
- тома LVM в кластере, Создание томов LVM в кластере
- физический том, Создание физических томов
- создание томов LVM
-
- обзор, Создание логического тома
- сообщение о нехватке свободных экстентов, Нехватка свободных экстентов для логического тома
- тип раздела, настройка, Настройка типов разделов
- увеличение файловой системы
-
- логический том, Увеличение файловой системы логического тома
- удаление
-
- диска из логического тома, Удаление диска из логического тома
- логический том, Удаление логических томов
- физический том, Удаление физических томов
- файл archive, Создание резервной копии метаданных группы томов
- файл backup, Создание резервной копии метаданных группы томов
- файл кэша
-
- создание, Поиск групп томов на дисках
- файловая система
-
- увеличение логического тома, Увеличение файловой системы логического тома
- физический том
-
- аргументы команды pvs, Команда pvs
- восстановление, Замена физического тома
- добавление в группу томов, Добавление физических томов в группу
- изменение размера, Изменение размера физического тома
- инициализация, Инициализация физических томов
- определение, Физический том
- пример, Структура физического тома
- просмотр, Просмотр физических томов, Настройка отчетов LVM, Команда pvs
- создание, Создание физических томов
- структура, Структура физического тома
- удаление, Удаление физических томов
- удаление из группы, Удаление физических томов из группы
- удаление из группы томов, Удаление физических томов из группы
- управление, общие принципы, Управление физическими томами
- физический экстент
-
- запрет выделения, Запрет выделения пространства физического тома
- фильтры, Определение устройств LVM с помощью фильтров
- фильтры определения устройств, Определение устройств LVM с помощью фильтров
- формат отчета, устройства LVM, Настройка отчетов LVM
- экстент
-
- выделение пространства, Создание групп томов
- определение, Группа томов, Создание групп томов
L
- LVM
-
- ведение журнала, Журнал событий
- группа томов, определение, Группа томов
- история, Обзор архитектуры LVM
- кластерный, CLVM
- компоненты, Обзор архитектуры LVM, Компоненты LVM
- метка, Физический том
- обзор архитектуры, Обзор архитектуры LVM
- справка, Использование команд
- структура каталогов, Создание групп томов
- управление логическими томами, Управление логическими томами
- управление физическими томами, Управление физическими томами
- физический том, определение, Физический том
- формат отчета, Настройка отчетов LVM
- LVM1, Обзор архитектуры LVM
- LVM2, Обзор архитектуры LVM
Юридическое уведомление
Copyright © 2011 Red Hat, Inc. and others.
This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed.
Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law.
Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.
Время на прочтение
4 мин
Количество просмотров 560K
Собственно, хочется просто и доступно рассказать про такую замечательную вещь как Logical Volume Management или Управление Логическими Томами.
Поскольку уже давно пользуюсь LVM-ом, расскажу что он значит именно для меня, не подглядывая в мануалы и не выдёргивая цитаты из wiki, своими словами, чтобы было понятно именно тем кто ничего о нем не знает. Постараюсь сразу не рассказывать о всяческих «продвинутых» функциях типа страйпов, снапшотов и т.п.
LVM — это дополнительный слой абстракции от железа, позволяющий собрать кучи разнородных дисков в один, и затем снова разбить этот один именно так как нам хочется.
есть 3 уровня абстракции:
1. PV (Physical Volume) — физические тома (это могут быть разделы или целые «неразбитые» диски)
2. VG (Volume Group) — группа томов (объединяем физические тома (PV) в группу, создаём единый диск, который будем дальше разбивать так, как нам хочется)
3. LV (Logical Volume) — логические разделы, собственно раздел нашего нового «единого диска» ака Группы Томов, который мы потом форматируем и используем как обычный раздел, обычного жёсткого диска.
это пожалуй вся теория.  теперь практика:
теперь практика:
для работы нужны пакеты lvm2 и возможность работать с привелегиями root поэтому:
$ sudo bash
# apt-get install lvm2
допустим у нас в компе есть жёсткий диск на 40Гб и нам удалось наскрести немного денег и наконец-то купить себе ТЕРАБАЙТНИК! :))) Система уже стоит и работает, и первый диск разбит одним разделом (/dev/sda1 как / ), второй — самый большой, который мы только подключили — вообще не разбит /dev/sdb…
Предлагаю немножко разгрузить корневой диск, а заодно ускорить (новый диск работает быстрее старого) и «обезопасить» систему с помощью lvm.
Можно делать на втором диске разделы и добавлять их в группы томов (если нам нужно несколько групп томов),
а можно вообще не делать на диске разделы и всё устройство сделать физическим разделом (PV)
root@ws:~# pvcreate /dev/sdb
Physical volume «/dev/sdb» successfully created
Создаём группу томов с говорящим названием, например по имени машины «ws», чтобы когда мы перетащим данный диск на другую машину небыло конфликтов с именами групп томов:
root@ws:~# vgcreate ws /dev/sdb
Volume group «vg0» successfully created
желательно внести с корневого раздела такие папки как /usr /var /tmp /home, чтобы не дефрагментировать лишний раз корневой раздел и ни в коем случае его не переполнить, поэтому создаём разделы:
root@ws:~# lvcreate -n usr -L10G ws # здесь мы создаём раздел с именем «usr», размером 10Gb
Logical volume «usr» created
по аналогии делаем то же для /var, /tmp, /home:
root@ws:~# lvcreate -n var -L10G ws
root@ws:~# lvcreate -n tmp -L2G ws
root@ws:~# lvcreate -n home -L500G ws
у нас ещё осталось немного свободного места в группе томов (например для будущего раздела под бэкап)
посмотреть сколько именно можно командой:
root@ws:~# vgdisplay
информацию по созданным логическим томам
root@ws:~# lvdisplay
информацию по физическим томам
root@ws:~# pvdisplay
разделы что мы создали появятся в папке /dev/[имя_vg]/, точнее там будут ссылки на файлы,
lrwxrwxrwx 1 root root 22 2009-08-10 18:35 swap -> /dev/mapper/ws-swap
lrwxrwxrwx 1 root root 21 2009-08-10 18:35 tmp -> /dev/mapper/ws-tmp
lrwxrwxrwx 1 root root 21 2009-08-10 18:35 usr -> /dev/mapper/ws-usr
lrwxrwxrwx 1 root root 21 2009-08-10 18:35 var -> /dev/mapper/ws-var
и т.д…
дальше lvm уже почти кончается… форматируем наши разделы в любимые файловые системы:
root@ws:~# mkfs.ext2 -L tmp /dev/ws/tmp
root@ws:~# mkfs.ext4 -L usr /dev/ws/usr
root@ws:~# mkfs.ext4 -L var /dev/ws/var
root@ws:~# mkfs.ext4 -L home /dev/ws/home
кстати, не плохо было бы сделать раздел подкачки:
root@ws:~# lvcreate -n swap -L2G ws
root@ws:~# mkswap -L swap /dev/ws/swap
root@ws:~# swapon /dev/ws/swap
создаём папку и подключая по очереди новообразовавшиеся тома, копируем в них нужное содержимое:
root@ws:~# mkdir /mnt/target
root@ws:~# mount /dev/ws/home /mnt/target
копируем туда всё из папки /home своим любимым файловым менеджером (с сохранением прав доступа), например так ;):
root@ws:~# cp -a /home/* /mnt/target/
root@ws:~# umount /mnt/target/
кстати, для папки temp необходимо только поправить права, копировать туда что-либо необязательно:
root@ws:~# mount /dev/ws/tmp /mnt/target && chmod -R a+rwx /mnt/target && umount /mnt/target/
добавляем нужные строчки в /etc/fstab, например такие:
/dev/mapper/ws-home /home ext4 relatime 0 2
/dev/mapper/ws-tmp /tmp ext2 noatime 0 2
/dev/mapper/ws-swap none swap sw 0 0
и перезагружаемся… (продвинутые господа могут обойтись без перезагрузки ;))
На вкусное, хочу предложить более продвинутую штуку:
допустим у нас есть система с разделом на LVM, а жёсткий диск начал сбоить, тогда мы можем без перезагрузки переместить всю систему на другой жёсткий диск/раздел:
# On-line добавление/удаление жёстких дисков с помощью LVM (пример)
root@ws:~# pvcreate /dev/sda1 # наш эмулятор сбойного диска
Physical volume «/dev/sda1» successfully created
root@ws:~# pvcreate /dev/sdb1 # наш эмулятор спасательного диска
Physical volume «/dev/sdb1» successfully created
root@ws:~# vgcreate vg0 /dev/sda1 # создаю группу томов vg0
Volume group «vg0» successfully created
root@ws:~# lvcreate -n test -L10G vg0 #создаю раздел для «важной» инфы
Logical volume «test» created
root@ws:~# mkfs.ext2 /dev/vg0/test # создаю файловую систему на разделе
root@ws:~# mount /dev/mapper/vg0-test /mnt/tmp/ #монтирую раздел
… # заполняю его информацией, открываю на нем несколько файлов и т.п.
root@ws:~# vgextend vg0 /dev/sdb1 # расширяю нашу групу томов на «спасательный» диск
Volume group «vg0» successfully extended
root@work:~# pvmove /dev/sda1 /dev/sdb1 #передвигаю содержимое с «умирающего» диска на «спасательный»
/dev/sda1: Moved: 0.9%
/dev/sda1: Moved: 1.8%
…
/dev/sda1: Moved: 99.7%
/dev/sda1: Moved: 100.0%
root@work:~# vgreduce vg0 /dev/sda1 # убираю «умирающий» диск из группы томов.
Removed «/dev/sda1» from volume group «vg0»
Итого:
Я создал логический раздел, отформатировал его, примонтировал и заполнил нужными данными, затем переместил его с одного устройства на другое, при этом раздел остался примонтирован и данные всё время оставались доступны!
Подобным образом мне удавалось без перезагрузки перенести всю систему с умирающего диска на рэид-массив.
А это моя любимая ссылка по LVM: xgu.ru/wiki/LVM
P.S. Прошу простить за опечатки, меня постоянно отвлекали =))
P.P.S. Ах, да!!! Самое главное и самый большой минус LVM — он не читается grub’ом
поэтому раздел /boot должен находиться вне LVM на отдельном разделе жёсткого диска,
иначе система не загрузится.