Решил начать цикл статей по ассемблеру, и, в частности, по MASM32. Пригодятся эти мануалы с примерами тем, кто хочет поднять свои навыки программирования и развить умение программировать на ассемблере. Пакет MASM32 — это не просто голый ассемблер. В нём есть огромное множество облегчающих разработку софта вещей — пользовательские макросы, встроенные функции и макросы, дебаггер и прочее, и обо всём этом я буду рассказывать. Конечно, читать такие статьи будет гораздо легче тем, кто уже умеет программировать на каком-нибудь языке. Если вы программируете на каком-нибудь говне вроде Visual Basic, или фанатеете от перетаскивания компонентов и кнопочек на формы в дельфи или Borland C++ — не расстраивайтесь, я расскажу, как можно перетаскивать кнопочки и в ассемблере. Разумеется, никаких стандартных облегчающих жизнь компонентов здесь не будет, но это побудит разобраться с WinAPI — огромной кладезью полезных функций, которые способны делать всё, начиная от чтения данных из сокета и заканчивая отображением окон.
Собственно, эту статью я начну с примера простого GUI-приложения на MASM. Конечно, проектировать дизайн окна мы будем визуально (я же обещал). Для этого сначала следует скачать визуальный редактор ресурсов ResEd. Запускаем его и видим интерфейс:
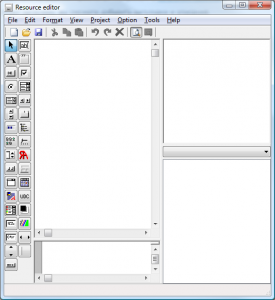
Создаем новый файл ресурсов (File — New Project и вводим имя). В правой верхней панели появляется значок папки и имя файла. Кликаем по ней правой кнопкой и нажимаем «Add Dialog». Теперь мы можем визуально спроектировать интерфейс окна и изменить его настройки. Я создал простое окно TEST_DIALOG с двумя кнопками TEST_BTN и EXIT_BTN:

Если вы успели обрадоваться — не спешите: здесь нельзя программировать, можно только делать дизайн интерфейса. Теперь необходимо добавить в наш файл ресурсов еще пару вещей. Первое — это include-файл с определениями всех констант, который будет необходим компилятору ресурсов MASM32. Как и раньше, нажимаем правой кнопкой мыши по значку папки, выбираем «Include file», «Add» и вводим путь. У меня это C:masm32includeRESOURCE.H. У вас может быть и другой, зависит от папки установки masm32 (как? вы еще не установили его?).
Теперь еще одна вещь. Пусть наше окно и кнопки выглядят в современном XP-стиле. Для этого необходимо добавить к файлу ресурсов XP Manifest. Добавляется он аналогично предыдущим пунктам (Add XP Manifest).
Теперь сохраняем файл ресурсов. Он должен выглядеть примерно таким образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#define MANIFEST 24 #define TEST_DIALOG 1000 #define TEST_BTN 1001 #define EXIT_BTN 1002 #define IDR_XPMANIFEST1 1 #include «C:/masm32/include/RESOURCE.H» TEST_DIALOG DIALOGEX 6,6,134,51 CAPTION «Test Dialog» FONT 8,«MS Sans Serif»,0,0,0 STYLE WS_VISIBLE|WS_CAPTION|WS_SYSMENU BEGIN CONTROL «Тест»,TEST_BTN,«Button»,WS_CHILD|WS_VISIBLE|WS_TABSTOP,6,18,54,13 CONTROL «Выход»,EXIT_BTN,«Button»,WS_CHILD|WS_VISIBLE|WS_TABSTOP,72,18,54,13 END IDR_XPMANIFEST1 MANIFEST «xpmanifest.xml» |
Осталось написать программу. Я в качестве редактора предпочитаю обычный Блокнот Windows. Сначала я приведу полный листинг, а потом прокомментирую его построчно:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
.386 .model flat, stdcall option casemap :none include masm32includewindows.inc include masm32macrosmacros.asm uselib kernel32, user32, masm32, comctl32 WndProc PROTO :DWORD,:DWORD,:DWORD,:DWORD TEST_DIALOG = 1000 TEST_BTN = 1001 EXIT_BTN = 1002 .data? hInstance dd ? hWnd dd ? icce INITCOMMONCONTROLSEX <> .code start: mov icce.dwSize, SIZEOF INITCOMMONCONTROLSEX mov icce.dwICC, ICC_DATE_CLASSES or ICC_INTERNET_CLASSES or ICC_PAGESCROLLER_CLASS or ICC_COOL_CLASSES invoke InitCommonControlsEx, offset icce invoke GetModuleHandle, NULL mov hInstance, eax invoke DialogBoxParam, hInstance, TEST_DIALOG, 0, offset WndProc, 0 invoke ExitProcess,eax WndProc proc hWin :DWORD, uMsg :DWORD, wParam :DWORD, lParam :DWORD switch uMsg case WM_INITDIALOG invoke SendMessage, hWin, WM_SETICON, 1, FUNC(LoadIcon, NULL, IDI_ASTERISK) case WM_COMMAND switch wParam case TEST_BTN invoke MessageBox, hWin, chr$(«Hello, world!»), chr$(«Test»), 0 case EXIT_BTN jmp exit_program endsw case WM_CLOSE exit_program: invoke EndDialog, hWin, 0 endsw xor eax,eax ret WndProc ENDP end start |
Итак, начнем:
|
.386 .model flat, stdcall option casemap :none |
Эти директивы говорят о том, что мы пишем код под 386 архитектуру процессора (это так и будет всегда), вторая говорит о том, что модель памяти мы используем плоскую и вызовы функций по стандарту stdcall. Этот стандарт подразумевает, что аргументы функциям передаются через стек в обратном порядке, и функция сама должна удалять их оттуда. Кроме того, функции сохраняют регистры ebx, edi и esi и возвращают значение в регистре eax. Если вы сейчас ничерта не поняли — не расстраивайтесь, это всё прекрасно разъяснено в гугле — и про регистры, и про стек. Если вы занимаетесь программированием, то понять это не составит труда.
|
include masm32includewindows.inc include masm32macrosmacros.asm uselib kernel32, user32, masm32, comctl32 |
Здесь мы подключаем необходимые библиотеки. kernel32 содержит функцию ExitProcess, user32 — всякие GUI-функции, comctl32 — функции работы с common controls, masm32 — библиотека встроенных функций masm32, я не знаю, зачем я ее здесь подключил, потому что она все равно в этом простом проекте не используется. Ну, лишнего объема, как в дельфи, это не добавит, если функции из библиотеки не используются. Я расскажу о ней в будущем. uselib — это макрос masm32, который всё необходимое позволяет одной строкой подключить. Только представьте, эти три строки эквивалентны следующему коду:
|
include masm32includewindows.inc include masm32macrosmacros.asm include masm32includeuser32.inc include masm32includekernel32.inc include masm32includemasm32.inc include masm32includecomctl32.inc includelib masm32libuser32.lib includelib masm32libkernel32.lib includelib masm32libmasm32.lib includelib masm32libcomctl32.lib |
Как узнать, из какой библиотеки функция? Смотреть msdn.
Идем дальше…
|
WndProc PROTO :DWORD,:DWORD,:DWORD,:DWORD |
Эта строка представляет собой прототип процедуры. Если вы программируете на C или C++, то знаете, что это такое, если нет — я поясню. Функцию нельзя вызывать до того, как она будет объявлена, поэтому в начало файла часто пишутся прототипы функций, расположенных в других файлах или ниже места первого вызова функции.
|
TEST_DIALOG = 1000 TEST_BTN = 1001 EXIT_BTN = 1002 |
Этими строками мы просто объявили некоторые значения из нашего файла ресурсов new.rc. Можно было бы этого и не делать, но с ними программа будет более читаемой.
|
.data? hInstance dd ? icce INITCOMMONCONTROLSEX <> |
В этом куске кода у нас объявляются глобальные переменные в секции неинициализированных данных. Что это такое? Это просто переменные, не имеющие начального значения. Они не занимают места в получающемся после компиляции exe-файле. В hInstance мы будем хранить указатель на модуль нашей программы (зачем — позже поясню), а в icce — структуру INITCOMMONCONTROLSEX (также объясню позже). dd — он же DWORD — тип данных «двойное слово». В C++ такой тип имеют int, long и все указатели, но C и C++ являются более типизированными языками, а в ассемблере всё сводится к двойным словам (4 байта).
Чтобы объявить секцию инициализированных данных и глобальные переменные в ней, пишут так:
|
.data vasya dd 0 some_string db «hello, world», 0 ;строковая переменная, состоящая из db — байтов (он же BYTE) |
В нашей программе тоже будет секция инициализированных данных, просто она неявно объявляется, далее я расскажу об этом.
|
.code start: mov icce.dwSize, SIZEOF INITCOMMONCONTROLSEX mov icce.dwICC, ICC_DATE_CLASSES or ICC_INTERNET_CLASSES or ICC_PAGESCROLLER_CLASS or ICC_COOL_CLASSES invoke InitCommonControlsEx, offset icce invoke GetModuleHandle, NULL mov hInstance, eax invoke DialogBoxParam, hInstance, TEST_DIALOG, 0, offset WndProc, 0 invoke ExitProcess, eax |
Что же происходит здесь? Здесь мы уже объявляем секцию исполняемого кода и метку start, которую потом объявим точкой входа.
Мы инициализируем объявленную ранее структуру icce и вызываем функцию InitCommonControlsEx. Инструкция mov загружает данные в регистр или ячейку памяти. Представьте, что мы пишем
|
icce.dwSize = SIZEOF(INITCOMMONCONTROLSEX); icce.dwICC = ICC_DATE_CLASSES | ICC_INTERNET_CLASSES | ICC_PAGESCROLLER_CLASS | ICC_COOL_CLASSES; InitCommonControlsEx(&icce); |
… и всё станет понятнее. Встроенный макрос invoke используется для вызовы любых функций, у которых есть прототип (а прототипы всех WinAPI прописаны в заголовочных файлах MASM32, которые мы подключили в самом начале программы). Sizeof возвращает размер структуры в байтах, offset позволяет получить смещение в памяти какого-либо байта. Есть еще addr, позволяющая получить смещение какого-то байта, размещенного в памяти по заранее неизвестному адресу (например, для локальных переменных в процедурах).
Теперь дальше — мы получаем указатель на начало нашего исполняемого модуля. Опять-таки, представьте, что мы пишем
|
hInstance = GetModuleHandle(NULL); |
Все stdcall-функции возвращают значение в регистре eax, как я уже говорил, а GetModuleHandle как раз stdcall WinAPI. Ах да, у вас, вероятно, есть вопросы по этим функциям, если вы впервые слышите про WinAPI? Ну так вбейте название непонятной функции в гугл, и получите ссылку на msdn с подробнейшим описанием.

И, как вы уже могли догадаться, мы создаем диалоговое окно функцией DialogBoxParam с указанием идентификатора диалога из файла ресурса (TEST_DIALOG = 1000). Эта функция начинает цикл сообщений windows с использованием функции WndProc, на которую мы передали указатель. Это типизированная функция, далее я опишу ее, но пока что — пара слов о цикле сообщений. Каждое окно в Windows получает множество сообщений от системы или других приложений, от других окон или от своего же в непрерывном цикле. Процедура WndProc будет эти сообщения получать, а мы будем в ней обрабатывать часть сообщений. которые нужны нам.
Далее я распишу код с комментариями:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
;WndProc — это процедура, которая принимает 4 параметра ;hWin — хендл окна, которому передается сообщение ;uMsg — тип сообщения ;wParam и lParam — по сути, дополнительные данные, ;различные для каждого сообщения WndProc proc hWin :DWORD, uMsg :DWORD, wParam :DWORD, lParam :DWORD ;switch — такой же, как во всех языках. Это макрос MASM32, удобно, не так ли? switch uMsg ;WM_INITDIALOG отсылается диалогу 1 раз — когда форма загружается case WM_INITDIALOG ;Давайте установим диалогу иконку «Инфо» ;Для этого мы пошлем ему самому сообщение ;WM_SETICON с указателем на иконку ;которую загрузим функцией LoadIcon invoke SendMessage, hWin, WM_SETICON, 1, FUNC(LoadIcon, NULL, IDI_ASTERISK) ;FUNC — еще один удобный макрос MASM32 ;он вызывает функцию и возвращает ее возвращаемое значение ;теперь — к обработке нажатий на кнопки ;за это ответственно сообщение WM_COMMAND case WM_COMMAND ;идентификатор кнопки будет в wParam ;не верите — вбейте в гугл «WM_COMMAND» switch wParam ;если нажали на TEST_BTN case TEST_BTN ;выведем сообщение Hello, World invoke MessageBox, hWin, chr$(«Hello, world!»), chr$(«Test»), 0 ;здесь chr$(«строка») — еще один удобный макрос MASM32 ;он создает строку в инициализированной секции данных ;и возвращает указатель на нее ;это эквивалентно записи: ;.data ;some_name db «Hello, world!»,0 ;… ;invoke MessageBox, hWin, offset some_name, … ;Если нажали Выход case EXIT_BTN jmp exit_program ;переходим на выход ;ДА! Ассемблер — это язык, где никто не будет ;ругаться за использование в программе GOTO! endsw ;WM_CLOSE посылается окну при нажатии на крестик или при Alt+F4 case WM_CLOSE exit_program: invoke EndDialog, hWin, 0 ;закрываем диалог endsw xor eax,eax ;всегда возвращаем 0 ret WndProc ENDP |
Ну и последнее:
Здесь мы устанавливаем точку входа на метку start, т.е. с нее начнется выполнение программы.
Ну что же, сохраним код как new.asm, закинем в одну папку new.rc, new.asm и xpmanifest.xml и скомпилируем всё следующим bat-файлом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
@echo off cls REM ну сюда впишите свои пути SET PATH=C:Masm32bin SET INCLUDE=C:Masm32INCLUDE SET LIB=C:Masm32LIB REM компилируем ресурсы Rc.exe /v %1.rc REM компилируем исходник ML /nologo —c —coff %1.asm if errorlevel 1 goto terminate REM линкуем всё в exe REM !!!!!! файл 64stub.exe можно взять отсюда: REM http://kaimi.io/2009/08/пакет-для-компиляции-masm32 REM и положить его в папку с батником и проектом LINK /nologo %1.obj %1.res /SUBSYSTEM:WINDOWS /STUB:64stub.exe /FILEALIGN:512 /VERSION:4.0 /MERGE:.rdata=.text /MERGE:.data=.text /SECTION:.text,EWR /ignore:4078 /RELEASE /BASE:0x400000 REM ключей тут много, я описывать их не буду, вот самый примитивный вариант линкования: rem LINK32 /nologo %1.obj /SUBSYSTEM:WINDOWS if errorLevel 1 goto terminate echo OK :terminate |
После компиляции и линкования получаем программу размером 2.5 кб, которая еще и работает. Ну не прелесть ли?

Надеюсь, эта статья была вам полезна. Хотя о чем это я… Если вы дочитали до этого момента, то явно почерпнули для себя что-то полезное. Надеюсь, вам уже хочется писать свои GUI-программы на ассемблере с использованием MASM32, наполняя их функционалом, ну или хотя бы немного заинтересовала эта тема. В следующей статье я напишу что-нибудь более полезное, чем простой «Hello, world!», и представлю Вашему вниманию.
И последнее. Если после прочтения вы будете находиться в состоянии, подобном этому — не расстраивайтесь, у вас ещё все впереди! 
Руководство по проектированию макросов в MASM32
Руководство по проектированию макросов в MASM32 — Архив WASM.RU
Руководство по проектированию макросов в MASM32
Edmond / HI-TECH
Руководство по проектированию макросов в MASM32
Пойми в Хаосе Разное, и стань человеком.
Осознай Единое в Различном – и будь Богом.Автор
I. От автора
I.1. Для тех, кто впервые
I.2. Примечания (обо всём понемногу)
I.3. Особенности терминологии
I.4. БлагодарностиII. Лень – двигатель Макро
III. Макромир MASMIII.1. Функционирование макросов
III.2. Определение макро переменных и строк
III.3.
Обработка выражения в MASM
III.4. Целочисленные выражения MASM
III.5. Вычисление рекурсивных выражений
III.6. Встроенные макрофункции и директивы
III.7. Символ макроподстановки
III.8. Макроблоки
III.9. Отладка макроопределений и заключение
III.10. Абстрактный алгоритм анализа строки MASM (Дополнение)I. От автора
В этом руководстве раскрывается тема создания, использования (а главное –
проектирования) макросов и макрофункций в проектах на MASM32.Что не так важно в ЯВУ, то очень важно в программировании на ассемблере.
Если выстроить по приоритетам недостатки программирования на ассемблере,
то первым
недостатком будет не объём строк написанного кода (как нестранно), а отсутствие
средств, обеспечивающих хороший стиль написания кода.Что значит стиль? А что значит плохой или хороший? Это можно быстро понять
на простом примере.Допустим, у вас есть процедура объёмом на несколько экранов. Вы её написали
месяц назад, а теперь вам нужно несколько изменить её поведение. Для того,
чтобы сделать
это, вам необходимо:
- Вспомнить её алгоритм (если забыли)
- Вспомнить особенности реализации (у вас должны быть комментарии)
- Вспомнить какой участок кода, чем занимается.
Если код процедуры был прооптимизирован, вероятней всего вам захочется,
чтобы после модификации он остался настолько же оптимальным,
а поэтому вы должны
вспомнить все тонкости кода, или только того участка, который
подлежит модификации.А это не так то просто, даже если исходник написан вами, в вашем
неповторимом стиле.Если этот стиль будет хорошим, вы потратите меньшее время,
если бы стиль был бы плохим.Хороший стиль программирования – это сэкономленное время, которое
можно потратить на понимание, модификацию или, как это называют, сопровождение
кода.
Стиль программирования – это архитектура исходного кода – не только его
внешнее оформление, но и использование констант, разбиения кода на функции
или процедуры, способы вызова функций и процедур, согласованность структур,
их потенциал к расширению, гибкость алгоритмов и многое другое. Стиль программирования
сложно отделить от архитектуры самой программы, так как хорошо спроектированная
программа не может иметь плохого стиля программирования.Конечно же, на ЯВУ легче писать качественно оформленные программы, хотя бы,
потому что ЯВУ уже имеет готовые средства выражения, и шаблоны мышления.Что такое шаблоны мышления? Всё чем вы так активно пользуетесь:
— типы
— функции
— классы
— массивы
— указатели на типы
— пространства имён
— шаблоны (С++)
Всё это направляет ваше понимание программирования как пространства сотканного
из таких абстракций.Недавно я прочёл следующую мысль на форуме WASM.RU:
Да, зачем вы пишите программы на asm под Win32, лучше уже писать
под DOS, там хоть нет этого бесконечно однообразного кода создания окон
и обработки сообщений.Такое заявление говорит, что программист не желает писать проекты более чем
на 6 000 строк (или 3 000). Вместо того чтобы извлечь великую выгоду из
единообразия кода,
мы ругаем его. А ведь это первый звонок к автоматизации программирования.Неужели программирование asm может быть похоже на Delphi (ох
как его не любят некоторые)? Снова интегрированная среда? Конечно!!! (Жаль,
её всё-таки нет!) Но это не значит, что она играет отрицательную роль.
Хотя о средствах автоматизации и их создании мы поговорим в другой работе.Ассемблер не определяет шаблонов мышления, и практически не имеет средств
выражения каких либо шаблонов (из-за чего автор пользуется им).Очень сложно назвать директиву proc средством выражение процедурной
модели программирования.Однако я могу ручаться, если вы научитесь писать качественно стилизированные
программы на ассемблере, то на ЯВУ…Об искусстве стилизации или проектировании архитектуры написано слишком мало,
а рассказать хотелось бы слишком много. Только нельзя объять необъятное, и
потому цель этого руководства рассказать об использовании макросов в MASM32,
а также
о том, как их можно либо нужно использовать, чтобы более качественно стилизировать
код.I.1 Для тех, кто впервые…
Если вы ещё не работали с макросами, или работали, но очень мало, я спешу
признаться, что это руководство не предназначалось для начинающих. Но благодаря
рекомендациям и советам TheSvin/HI-TECH я решился добавить в него вырезки
и упражнения, которые позволят вам быстро войти во вкус макромира MASM32.
Если же вы уже
имеете дело
с макросами, тогда это руководство укрепит ваши знания и представления по
данной теме.Для исследования макромира MASM мы воспользуемся директивой echo, которая
позволит вывести нам на экран то, что творится в препроцессоре MASM. Очень
удобно, а главное
наглядно. Я уверен, что вы быстро усвоите этот материал.I.2. Примечания (обо всём понемногу)
В данной работе я часто пишу: «Препроцессор ML». Кто-то из умников (или просто
жаждущих подловить «на горячем») воскликнет: «Да какой же такой ML.EXE – препроцессор?
Наглая ложь». На всякий случай оговорю, что здесь имеется ввиду не утверждение
«ML – препроцессор», а именование его подсистемы – препроцессор.Всё, что есть в этом руководстве не взято с потолка, и не является вымышленным.
Весь код проверен, и работает именно так как описано, если только автор случайно
не ошибся, что так же случается.Многое из того, что написано в этом руководстве недокументированно (или плохо
документировано) в официальном. Поэтому вы всегда должны помнить, что если
в следующих версиях ML (например, 8.0) что-то не будет работать, никто не
виноват.Если вы думаете, что я дизассемблировал ML.EXE – то ошибаетесь. Алгоритмы
работы, приведённые здесь, получены логическим путём на основе знаний работы
компиляторов,
а поэтому их не следует воспринимать как истинные. Важна сама логика работы,
понимание которой, поможет вам безболезненно использовать макро, допуская
меньшее количество ошибок.На самом деле MASM очень плохо документирован, и видно MS совсем не относится
к нему как к продукту (что вполне очевидно). Хотя уже в MSDN
2002 был
внесён раздел MASM Reference, и всё равно – вы не найдёте лучше описания
чем в
MASM32 by Hutch.Когда вы прочтете, то воскликните: «Да, зачем мне такой ML?». Есть NASM и FASM – главная надежда мира ассемблерщиков. Однако и теперь ML всё
ещё выигрывает
у них по удобству эксплуатации, большей частью видимо благодаря Хатчу,
и многим
замечательным людям, поддерживающим MASM32. Кто знает, может после
этой статьи кто-то воскликнет: «Я знаю, какой должен быть компилятор
мечты асмовцев!». И напишет новый компилятор. (Автор шутит ?)Уверен, что программисты из MS вряд ли прочтут эту статью (они плохо
знакомы с русским), и оно к лучшему. Возможно, такая статья могла
бы их огорчить,
а я не люблю портить настроение людям, трудами которых пользуюсь.
(Снова шутит,
только
про что?)И наконец-то мне в свою очередь хочется порадоваться, что многие
вопросы по макросам в MASM закрыты на долгое время, во всяком случае,
для русскоязычной
аудитории.
(Шутит, или нет? Гм…)I.3. Особенности терминологии
Терминология этой статьи различается от терминологии принятой в MASM.
В частности автором было предложено называть:
MacroConstant EQU 123 ;; Числовая макроконстанта
MacroVar = 123 ;; Числовая макропеременная
MacroText EQU <string> ;; строковая макропеременная
MacroText TEXTEQU <string> ;; строковая макропеременнаяВ MASM:
MacroConstant EQU 123 ;; numeric equates
MacroVar = 123 ;; numeric equates
MacroText EQU <string> ;; text macro
MacroText TEXTEQU <string> ;; text macroМожно было бы попросту выбрать терминологию MASM, однако последняя не позволяет
объяснять материал систематически. То есть все четыре вида выражений – по сути,
являются переменными или константами. Однако в терминологии MASM два последних
определения называются текстовыми макро, подчёркивая их связь с макросами.Если пойти этим путём, то тогда и первые два определения – являются упрощёнными
определениями макро. Если разработчики желали подчеркнуть, что сама суть
внутренней реализации
ML представляет текстовые макросы как макро, то тогда не ясны те все эффекты
функциональности, обсуждаемые в этой статье.Что имеет ввиду автор?
Посмотрите что такое макроопределение – это некий текст, который как бы
«вставляется» препроцессором в исходный текст программы в месте вызова
макро.
А что такое в терминологии MASM numeric equates, или text macro – это некоторые
переменные, значения которых «подставляются» в исходный текст программы
во время компиляции вместо имён этих переменных.
Таким образом, можно сказать, что определения представленные выше – макро,
но в упрощённом их виде.Этот спор не решаем, что не так и важно. Поэтому автор отдаёт предпочтение
двум терминам для «text macro»: «текстовой макро» и «строковая макропеременная».Понятие: «numeric equates» является общим для первых двух случаев, и разрывает
смысловую связь с двумя последними определениями. Поэтому я пользуюсь своим
вариантом терминологии, который подчёркивает, что определения:MacroConstant EQU 123 ;; Числовая макроконстанта
MacroVar = 123 ;; Числовая макропеременнаяявляются подобными макро. А, кроме того, первое из низ – константа, а второе
– переменная.I.4. Благодарности
Не могу не написать этот пункт, ибо не только автору обязана эта статья.
Она обязана замечательной версии Win98 с инсталляцией от 2000, которая отформатировала
весь мой винчестер, и унесла в небытие первый вариант настоящей статьи.Не малая заслуга в вопросе терминологии MASM, и его разрешении принадлежит
Four-F, который как он сам мне признался, съел на макросах
собаку, при чём без солиКогда я думаю, чтобы было бы без самого Маниакального редактора в Inet,
CyberManiacа, то понимаю: без его правок мои статьи приводили
бы в ужас, и лишали разума
всех морально неустойчивых читателей. CyberManiac: «Только такой замечательный
безумец
как ты может выдержать ЭТО!!!»FatMoon, Rustam, The Svin – вы дали понять мне то, что такая статья действительно
нужна, и это, наверное, самое главное. Вряд ли я бы так долго работал
над ней, если бы меня никто не подталкивал.Всех кого я забыл поблагодарить здесь, и кого не забыл, жду в условном
месте в условное время для раздачи благодарностей.С уважением, Edmond/HI-TECH
II. Лень – двигатель Макро
Когда говорят, что лень – это двигатель прогресса, видимо лицемерят или преувеличивают.
Скорее это нежелание выполнять одну и ту же работу очень часто. Первая парадигма
к созданию макро звучит так:Если есть что-то похожее, что нужно делать очень часто, я могу оформить
это как макроопределение.Ассемблер, дающий программисту полную свободу в использовании методик программирования,
совершенно лишает его средств для выражения этих методик. Например, ООП. В
MASM32 нет классов, конструкторов и других механизмов, поддерживающих эту абстракцию.
Зато вместо ООП Вы можете придумать множество других методик и абстракций (как,
например модель серверов).Та или иная методика программирования обязательно состоит из каких-либо компонентов,
которые являются подобными друг другу. Например, следующие макро очень любимы
в примерах пакета MASM32:m2m MACRO M1, M2 push M2 pop M1 ENDM return MACRO arg mov eax, arg ret ENDMПредположим, что кому-то так надоело писать:
push переменная2
pop переменная1И он решил придумать макро для этого. Эта пара команд осуществляет пересылку
данных из одной ячейки памяти в другую. То есть теперь в программе, когда вы
захотите написать push/pop, вы можете заменить это некой m2m операнд1,
операнд2.
Посмотрите на эти два участка кода:mov wc.cbWndExtra, NULL
m2m wc.hInstance, hInst
mov wc.hbrBackground, COLOR_BTNFACE+1
-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
mov wc.cbWndExtra, NULL
push hInst
pop wc.hInstance,
mov wc.hbrBackground, COLOR_BTNFACE+1Первый вариант не только занимает меньше строк (что тоже важно), но и намного
понятнее, чем push/pop (если вы, знаете что такое m2m). Конечно, если говорить
о макро m2m, то он имеет и очень важный недостаток.Мощь макро была бы сказочной, если бы MASM умел следить за
кодом, или ему можно было бы указать, что, например, сейчас регистр ebx
== 0, или eax никем не используется. Хотя мы попробуем достичь подобного
эффекта самостоятельно.Этот недостаток потеря контроля над оптимальностью кода. Например, более быстрыми,
по сравнению с парой команд push/pop, являются mov eax,… Употребляя макро m2m,
вы получаете худший код, если стремитесь оптимизировать по скорости. И здесь
есть две стороны проектирования кода:
- Эффективность кода
- Совершенство стилистики
Используя макро m2m, вы повышаете уровень стилистики, так как сокращаете
время на понимание исходного кода (вами же или другим программистом). Однако
с другой
стороны вы теряете эффективность.Это одна из вечных задач архитектора – найти баланс между эффективностью
в коде и совершенством стилистики.Другая парадигма использования макро звучит так:
Если, объединяя что-то в одно целое, я улучшаю стиль кода – это можно
сделать в виде макроопределения.Эта парадигма отличается от предыдущей тем, что создание макроопределения
обуславливается только улучшением стилизации кода, и не имеет особой практической
ценности. Например, я объявил такие макро для определения кода начала и конца
в главном модуле программы:$$$WIN32START macro
PUBLIC l$_ExitProgram
_start:
xor ebx,ebx
endm$$$WIN32END
macro
l$_ExitProgram:
push $$$__null
call ExitProcess
end _startendmВ этих макро нет по сути никакой пользы, кроме эстетической. Зато, глядя на
код, можно сразу понять, что это не что иное, как начало программы нечто вроде
main() в C++.И последняя парадигма использования макро:
Если ты используешь технологию программирования – попытайся заключить
её в комплекс макроопределений.Например, для модульного программирования нужно создать макросы для
определения модуля, его частей, кода и данных.Наиболее важная часть использования макро. Посмотрите, например, файл Objects.INC из пакета MASM32 в папке oop (NaN & Thomas).
Мы начнём создание первых макро со следующей задачи.Наверное, вы знаете, что EXE приложения всегда могут загружаться по адресу
равному:PROGRAM_IMAGE_BASE EQU 400000hВо-первых, это даёт нам право убрать из приложения всю Relock секцию, тем
самым, уменьшив объём образа (если эта секция нужна для систем плагинов, её
можно держать отдельно).Во-вторых мы можем более не вызывать функцию GetModuleHandle, что так же
полезно для нас. Использование константы PROGRAM_IMAGE_BASE очень удобно.
Однако, что
будет значить это удобство, если всё-таки PROGRAM_IMAGE_BASE не определено?
Это будет означать, что мы обязаны переписать весь код. А если этого кода
много?Определённо об этом нужно позаботится заранее. Давайте же будем решать эту
проблему при помощи макро! Для этого нам станут необходимыми некоторые знания
о том, как
обрабатывается макро, и что это такое.III. Макромир MASM
Макрос представляет собой именованный участок исходного текста программы,
который обрабатывается компилятором каждый раз в том месте, где вызывается
макрос.
Пример:
Создайте небольшой модуль с именем macro.asm.
И напишите в нём несколько строчек.386 .data .code echo Hello!!! echo Ты должен увидеть во время компиляции endТак действует директива echo. С помощью неё можно подсмотреть значения
переменных.Mycount = 1 %echo @CatStr(%Mycount)Если вы не знаете, как это работает, не волнуйтесь, обо всём будет рассказано.
А пока несколько экспериментов:Напишите:
MyMacro macro reg dec reg endm .code mov eax,5 MyMacro eax MyMacro ebxВзгляните на код программы под отладчиком. Что у вас получилось? Что
будет, если вы измените текст внутри макроопределения?Теперь напишите:
MyVar = 1 MyMacro macro MyVar = MyVar+1 %echo MyVar = @CatStr(%MyVar) endm MyMacro MyMacro MyMacro MyMacroКаким будет вывод на экран во время компиляции?
С этого момента вам придётся различать в ассемблере ML две подсистемы: препроцессор
и компилятор. Если компилятор переводит код мнемоник в машинный код, вычисляет
значения меток и смещений, то препроцессор занимается вычислением выражений
этапа компиляции, и что самое важное – процессом раскрытия макросов.Подобно многим объектам мира программирования макро имеет два состояния в
исходном тексте: определение, и использование.Таким образом, мы будем иметь дело с определением макроса (макроопределением),
и его вызовом (использованием макроса).
Макроопределением называется любой текст, заключённый между ключевыми словами:MacroName macro paramlist
макроопределение
endmПри каждом вызове макро, а именно:
…
MacroName
или
mov eax, MacroName()
…Будет анализироваться и исполнятся текст, заключённый в макро. Именно так
это и реализовано в ML. Поскольку текст в макроопределении не компилируется,
то естественно, вы не увидите сообщений об ошибке, даже если с точки зрения
ассемблера эта ошибка будет в теле макроопределения. Однако ошибка появится
при попытке вызова макроопределения, её могут выдать вам, либо сам препроцессор,
либо компилятор, если текст, сгенерированный препроцессором является неверным
с точки зрения компилятора.Каждый раз, когда препроцессор встречает макроопределение, он помещает его
имя в специальную таблицу, и копирует его тело к себе в память (это не обязательно
именно так, но вам должна быть понятна суть). Встретив макроопределение, препроцессор
не проверяет, а есть ли макро с таким же именем. Это значит, что макро можно
переопределять.MyMacro macro echo Это макро 1 endm MyMacro macro echo Это макро 2 endm MyMacroВы можете самостоятельно удалять макроопределения, из памяти препроцессора
используя директиву PURGE:PURGE macronameЭта директива удаляет тело макроопределения, однако не удаляет имя макро из
таблицы имён. Таким образом, в данном случае:MyMacro macro mov eax,ebx endm PURGE MyMacro ;; После этой директивы, MyMacro эквивалентен: ;; MyMacro macro ;; endm ;; Определению пустого макро. MyMacro ;; Ничего не произойдёт.Разработчики ML задумывали эту директиву для разрешения конфликтов
между файлами с множеством макросов, однако мне совершенно не ясно как ей можно
воспользоваться.
Если вы хотите получить эффект «удаления» макро, лучше применять следующий
метод:<Имя макро, который нужно «удалить»> macro
.ERR <Попытка вызова макро, который не существует>
endmВ этом случае при попытке воспользоваться таким макро, компилятор выдаст
ошибку, и вы будете проинформированы о его вызове, что намного лучше неведения.
Поэтому просто запомните: «Не нужно использовать директиву PURGE».Конечно же, использование макро не было бы столь полезным, если бы макро
не имел формальных параметров. При вызове макро, препроцессор заменяет все
имена
формальных параметров
их непосредственными значениями в теле макроопределения. Список формальных
параметров разделяется запятой, и может иметь вид:MyMacro macro param0, param1:REQ, param2 := <0>,param3:VARARGЗдесь:
Param0 – пример определения параметра.
Param1:REQ – ключевое слово REQ указывает на то, что этот параметр обязательный.
То есть, если он не будет указан, вы получите ошибку этапа компиляции.
Param2:=<0> – пример параметра, который имеет значение по умолчанию.
То есть если этот параметр не будет указан при вызове макро, он будет равен
этому значению.Заметьте, что при вызове макро параметр может быть не определён:
MyMacro param1,,param3Значение второго параметра неопределенно.
Param3:vararg – становится именем параметра, который воспринимает всё остальное
как строку. При этом запятые между параметрами так же попадают в строку, а
значит число параметров макроса в принципе неограниченно.Ограничениям являются особенности архитектуры компилятора.
Так, например, компилятор имеет ограничение на длину логической строки,
которая равна 512 байтам.Конечно же, после параметра с директивой vararg не возможно объявить другие
параметры.Обратите внимание, что если при определении формального
параметра в макро нет директивы – он считается необязательным параметром.
Более подробно о вызове макро и значении параметров я расскажу далее.
Пример:
Так что же происходит с формальными параметрами?
Посмотрите, как работает препроцессор ML:MyMacro macro param1,param2 mov eax, param1 mov ebx, param2 endm MyMacro var, 1231. Препроцессор берёт текст внутри макро, и заменяет
в нём все
слова param1, param2, на их значения:
«
mov eax, var
mov ebx, 123
»2. Полученный текст вставляет на место вызова макро, и передаёт компилятору.
Вот интересно, а что будет если:
MyMacro macro param1,param2 MyMacro2 macro param1 mov eax, param1 mov ebx, param2 endm endm MyMacro var, 123Можно различать два вида макро – макропроцедуры и макрофункции.
В официальном руководстве MASM различается четыре основных
вида макро.
Text macros – текстовый макрос
Macro procedures – макро-процедура
Repeat blocks – блок повторения
Macro functions – макро-функция
Однако автор считает, что разделение макро на два вида – лучше систематизирует
материал, и отражает суть темы.Макрофункции в отличие от макропроцедур могут возвращать результат, и получают
список формальных параметров в скобках, подобно функциям в С. Например:mov eax,@GetModuleHandle()Заметьте, что к макрофункции невозможно обратится как к макро, вы всегда должны
заключать формальные параметры макрофункции между «()», иначе MASM не будет
распознавать её как макрофункцию:mov eax,@GetModuleHandle
error A2148: invalid symbol type in expression : @GetModuleHandleПрепроцессор MASM анализирует текст макроопределения на наличие директивы
exitm, и помечает макрос как макрофункцию.Ключевое слово exitm <retval>, аналогично оператору return в C++, выполнение
макро заканчивается, и возвращается необязательный параметр retval. Этот параметр
– строка, которую должен вернуть макрос.
Если в макро директива EXITM употребляется без параметров:
EXITM
То препроцессор считает, что это макропроцедура, а не макрофункция.
Если в макроопределении есть два вида EXITM с параметром и без, то ML выдаст
ошибку о недопустимом использовании директивы EXITM.
EXITM <>
EXITM
: error A2126: EXITM used inconsistently
Это подчёркивает тот факт, что макрофункцией считается только макро, который
возвращает значение (хотя бы пустое), а директива EXITM без параметров
не возвращает никакого значения, что недопустимо в макрофункции.Таким образом, окончательно будем считать, что макро, которые не возвращают
значение – это макропроцедуры, а макро, которые возвращают значение
(хотя бы пустую строку) – это макрофункции.;####################################################### @GetModuleHandle macro Invoke GetModuleHandle,0 exitm endm .code ; Это макрофункция так нельзя @GetModuleHandle ;;– ошибка ; Так можно @GetModuleHandle() ;######################################################## @GetModuleHandle macro Invoke GetModuleHandle,0 endm .code ; Это макрос. Так правильно @GetModuleHandle ; Так можно, но всё равно это вызывает ошибку ? ; warning A4006: too many arguments in macro call @GetModuleHandle() ; Это макро, а не макрофункция так нельзя!!! mov eax,@GetModuleHandle ; И так нельзя mov eax,@GetModuleHandle() ;########################################################Что касается директивы endm, которая заканчивает каждое макроопределение,
в руководстве написано, что при помощи неё так же можно указать возвращаемый
параметр:
endm <retvalue>
Однако на практике это не так. ? Очень странно, хотя об этом чётко написано
в руководстве.Заметьте, что макропроцедура может быть вызвана только в начале строки:
@GetModuleHandle
;; Но не так:
mov eax,@MyMacroМакрофункция может быть вызвана в любых выражениях:
;; Так:
mov eax,@GetModuleHandle()
;; И так:
@FunMacro()
;; И так:
@GetModuleHandle() EQU eaxIII.1. Функционирование макросов
Чтобы строить макросы, важно понимать, как они работают, и как их обрабатывает
MASM. Давайте рассмотрим типичный макро, и этапы его обработки.MyMacro macro param1,param2,param3:VARARG echo param1 echo param2 echo param3 endm MyMacro Параметр 1, Параметр 2, Параметр 3, Параметр 4 ;; Вывод -=-=-=-=-=-=-=-= Параметр 1 Параметр 2 Параметр 3,Параметр 41. Компилятор встречает лексему MyMacro
2. Он проверяет, содержится ли эта лексема в словаре ключевых слов
3. Если нет, то он проверяет, содержится ли эта лексема в списке макросов.
4. Если да, он передаёт текст, содержащийся в макро препроцессору. Препроцессор
заменяет все вхождения формальных параметров в этом тексте на их значения.
В данном случае мы имеем:echo Параметр 1
echo Параметр 2
echo Параметр 3,Параметр 45. Препроцессор возвращает компилятору обработанный текст, который после компилируется.
Обратите внимание на пункт 4 и 5. Они ключевые. Очень часто при работе с макроопределениями
появляются ошибки из-за неверного понимания порядка генерирования макро текста.
Например:PROGRAM_IMAGE_BASE EQU 400000h FunMacro macro exitm <Параметр 3,параметр 4> endm MyMacro macro param1,param2,param3:VARARG echo param1 echo param2 echo param3 endm MyMacro PROGRAM_IMAGE_BASE, FunMacro(),Параметр 5А теперь самостоятельно опишите порядок действий компилятора при вызове этого
макро. Запишите его себе куда-нибудь, так чтобы сравнить, и смотрите на вывод:PROGRAM_IMAGE_BASE
Параметр 3, Параметр 4
Параметр 5Прежде чем объяснять действительный порядок, я оговорюсь, что директива echoникогда не обрабатывает определённые константы, такие как PROGRAM_IMAGE_BASE.
Это утверждение справедливо даже тогда, когда перед директивой echo стоит
оператор %, который может раскрывать только текстовые макроопределения.
То есть выражение:echo FunMacro()Даст результат:
FunMacro()Теперь, когда мы немного порассуждали можно привести тот текст, который генерируется
из макро:echo PROGRAM_IMAGE_BASE
echo Параметр 3, Параметр 4
echo Параметр 5Это означает следующее:
- При вызове макро, значение формальных параметров воспринимается как
текст, и передаётся в макро как строка.- Исключение составляют лишь макрофункции, результат выполнения которых
вычисляется и присваивается значению параметра.Специальный оператор % заставляет ассемблер вычислять текстовую строку,
следующую за ним, и только потом подставлять в правое выражение.
Например, если мы
перепишем макровызов так:MyMacro %PROGRAM_IMAGE_BASE, FunMacro,Параметр 5То получим вывод:
4194304 ;; Значение PROGRAM_IMAGE_BASE
Параметр 3, Параметр 4
Параметр 5Давайте рассмотрим ещё один пример, который хорошо показывает, как работает
макро. Например, вы определили макропроцедуру (именно его, а не макрофункцию).
То когда вы пишите такое:@Macro что-то, что придёт вам в голову [символ возврата каретки]Что делает препроцессор ML:
1. Считывает всю строку до символа возврата каретки;
2. Смотрит, как вы определили параметры в макро;
3. Сканирует строку на наличие символа «,» или «<», «>»;
Вам может показаться странным, но препроцессору всё равно,
какие символы идут во время вызова макро. То есть вы можете вызвать макро
так:@MyMacro Привет, это кириллица в файле, и ML не будет на неё ругаться
или
@MyMacro `!@#$%^&*(){}[]Посмотрите как СИльно (от буквы CИ)
будет выглядеть макро в MASM:MyMacro{Это что С++?}
MyMacro[Нет, это MASM]4. Назначает формальным параметрам (любого типа, кроме VARARG) макро участки
строк, которые были определены разделителями запятыми (предварительно очистив
от хвостовых и начальных пробелов, если только строка не была определена в
угловых кавычках <>);5. Если макро содержит формальный параметр типа VARARG, то ML сперва
инициализирует значениями (согласно пункту 4) обычные формальные параметры,
и только потом
назначает параметру типа VARARG (который может быть только один в
конце списка параметров) всю строку до конца.
Если вы пишите макровызов как
@Macro Param1 , Param2
То значение параметров будут:
param1 = «Param1»
param2 = «Param2»
Если вы хотите передать сами значения строк, то должны заключит их в угловые
кавычки:
@Macro < Param1 >,< Param2 >6. Препроцессор разрешает все вызовы макрофункций, если они есть в лексемах
параметра, и присваивает их результат соответствующему параметру. Если лексему
в строке параметра предваряет символ %, то он вычисляет её значение до того,
как передаст строку внутрь макро.
Благодаря именно такому порядку:
1. Разделение строки на макропараметры
2. Поиск и Вызов макрофункций в значениях макропараметров
3. Присвоение результатов соответствующему макропараметрув следующем случае:
MyMacro macro param1,param2,param3 echo param1 endm -------------------------------------- FunMacro macro param:VARARG exitm param endm MyMacro FunMacro(param1, param2, param3) OUT: param1, param2, param3 --------------------------------------строка, возращаемая макрофункцией присваивается параметру param1, а не
param2, param3Теперь вы в состоянии объяснить следующую ситуацию:
MyMacro macro … endm MyMacro() Предупреждение при компиляции: : warning A4006: too many arguments in macro callКак нужно было бы изменить этот макро (именно макро, а не макрофункцию), чтобы
предупреждение не выдавалось? А почему оно происходит?Если вы с лёгкостью ответили на этот вопрос, значит, материал усвоен, иначе
советую ещё раз прочитать его, и ответить на следующий вопрос.Как должен понять компилятор следующий код:
MyMacro macro param1 param1 endm MyMacro = 2Естественно отвечать на этот вопрос вы должны без помощи компилятора (то есть
проверить компиляцией). Если вы не можете ответить на этот вопрос, или неуверенны
в верности ответа, я поменяю задание:MyMacro macro param1 echo param1 endm MyMacro = 2Запустите его в ML. Если и теперь вы сомневаетесь – перечитайте этот пункт
снова и снова, продолжая экспериментировать.III.2. Определение макро переменных и строк
Я бы назвал следующее:
Param = 0
Constant EQU 123
WASM EQU <One Wonderful Wonderful ASM>
WASM_RU TEXTEQU <http://www.wasm.ru>макропеременными (с тем фактом, что переменная может иметь константный тип).
В терминологии MASM:
WASM EQU <One Wonderful Wonderful ASM>
WASM_RU TEXTEQU <http://www.wasm.ru> ;; Такие определения называются текстовыми макро. ;; В этой статье вы встретите два варианта определенийПотому что под термином «переменная» понимается:
var dd 123Переменные являются частью программы, а макропеременные живут только на
этапе компиляции. По сути, они есть более простым видом макроопределений, и
поэтому их стоит понимать как специальные макро, которые так же раскрываются
препроцессором.Макропеременная может иметь только три типа – целочисленная макропеременная
INEGER4 (dword), целочисленная макроконстанта или текстовой макро (строковая
макропеременная).Автор считает значительным упущением отсутствия возможности
определять тип макропеременной. Это очень сильно ограничивает возможности
макропрепроцессора. Но что поделать.При чём, в зависимости от вида определения макропеременной ML считает, что:
Param = 0 ;; Param – это целочисленная макропеременная Constant EQU 123 ;; Макроконстанта
;; Текстовой макро (Макропеременная строкового типа)
;; (Это не так в руководстве MASM)
Var EQU qwer
;; Текстовой макро (Макропеременная строкового типа)
WASM EQU <One Wonderful Wonderful ASM>
;; Текстовой макро (Макропеременная строкового типа)
WASM_RU TEXTEQU <http://www.wasm.ru>Как вы уже догадались, каждое макроопределение обладает своими свойствами
и возможностями.
- Целочисленная макропеременная. Имеет тип INT (dword). Может участвовать
во всех арифметических выражениях MASM. Как переменная она может изменять
своё значение.- Макроконстанта может иметь целочисленное значение. Её значение не может
быть повторно изменено.- Текстовой макро может быть любой строкой не более 255 символов. Поскольку
он имеет статус переменной, его значение может быть изменено.А теперь подробнее. Если с целочисленными макропеременными в достаточной степени
ясно. То с определениями EQU полный бардак.Как и в случае с вызовами макро, автор попытается построить алгоритм анализа
EQU выражений:1. Анализируем правую часть. В анализе правой части препроцессор выделяет
лексемы, которые классифицирует как числа, строки. Так, например, в выражении:qqqq EQU 1234567890 string1 23456789012390 macrofun()«1234567890» – это лексема число, а «string1» – это строка, «macrofun()» –
это всё равно строка (а не макрофункция!!!).
Именно по этому такое определение будет давать ошибку:
qqqq EQU 156n7
: error A2048: nondigit in number2. Если правая часть является верным определением числа в MASM, то есть 123
или 123h или 0101b – выполнить шаг три, иначе шаг четыре.
Обратите внимание, что числа с плавающей запятой в этом случае
считаются строкой.Такое поведение связано с внутренней организацией препроцессора ML,
который просто «не понимает» чисел с плавающей запятой, и не умеет
с ними работать.То есть тип макропеременной Float:
Float EQU 1.2345будет не числовой, а строковой
3. Если полученное число имеет значение, не превышающее диапазон значений
для dword – это целочисленная макроконстанта.
Если правая часть для EQU является верным числом более 25 символов,
выдаётся ошибка:
: error A2071: initializer magnitude too large for specified sizeПри чём такая ошибка появляется даже в том случае, если выражение содержит
другие символы через пробел:qqqq EQU 1234567890123456789012390 dfdgЭто объясняется действиями в пункте 1, когда ML анализирует лексемы.
Кроме того, если числовая лексема не соответствует правилам определения
чисел в ML, то есть в середине числа появляется символ A-Z, либо другие
символы, не входящие в разряд разделителей – то такая лексема порождает
ошибку, даже если она содержит число большее dword диапазона.4. Иначе – это строковая макропеременная.
Теперь попробуйте самостоятельно определить тип макроопределения:
qqqq EQU 0x123234
qqqq EQU 123234h
qqqq EQU 012323
qqqq EQU 0.123234
qqqq EQU 123234 342
qqqq EQU 4294967296В данном примере только второй и третий вариант – макроконстанта, остальные
– текстовые макро. Последний вариант таким не является, так как превышает диапазон
значений для dword.Замете, что поскольку препроцессор в правой части выделяет корректные выражения,
правая часть не может состоять из недопустимых символов. Но при этом она может
состоять из директивы определения литерала: «<>» – угловых кавычек.Директива <текст> – определяет литерал, таким образом, указывая препроцессору
ML, что он должен воспринимать нечто как строку символов. При этом сами «<>»
– в строку не попадают. Директива <> – является единственной директивой
для препроцессора ML, которая определяет литералы.Именно по этой причине, все виды кавычек – двойные, одинарные,
` – вот такие одинарные, воспринимаются как простые символы, и как следствие
проходят к значениям параметров макро. То есть, например:
MyMacro “Привет, это строка в двойных кавычках”
MyMacro ‘Привет, это строка в одинарных кавычках’
MyMacro `Привет, это строка в специальных кавычках`
MyMacro «Привет, это строка»‘И это’И замете, что во всех случаях кавычки так же попадают в значения формального
параметра макро. Вы можете использовать этот факт, например, для того,
чтобы менять поведение макро, в зависимости от типа кавычек обрамляющих
строку.Кроме директивы, определяющей литерал, препроцессор ML имеет свой ESC-символ
(символ отмены). В отличие от С этот символ – «!». Он отменяет
действие других символов (<, >, «, ‘, %, ; , а так же символ запятой),
которые могут иметь функциональность в том, или ином выражении. Если вы хотите
получить «!»,
вы должны использовать последовательность «!!».К сожалению, не обходится без проблем и с символом отмены «!». Восстановить
точный алгоритм работы мне не удалось. Единственное, что возможно – это
привести несколько
примеров с непонятными эффектами при его использовании:literal EQU <!> ;; Пустая строка
;; Ошибка – ;;: error A2045: missing angle bracket or brace in literal
literal EQU <!!>
;; Один символ «!»
literal EQU <!!!!>
;; Не имеют эффекта
literal EQU <Привет!" fgd!">
literal EQU <Привет" fgd">
;; Один символ «>»
literal EQU <!!!>> ;; literal = «>»
literal EQU <Текст!!!>> ;; literal = «Текст>»
;; Хотя при вызове макро, «!» ведёт себя нормально
;; а так же он ведёт себя нормально в директиве TEXTEQU
Char <Текст!>>Вывод – не пользуйтесь директивой EQU для определения литералов, для этого
есть другая директива – TEXTEQU.Для директивы TEXTEQU алгоритм несколько отличен от алгоритма EQU, так как
в TEXTEQU обрабатывается правое выражение на наличие символа %. То есть
вы можете
определить этот код:literal TEXTEQU %FunMacro()Или
literal TEXTEQU %(10-5)*30 ;; literal = “150”На самом деле как вы видите, внутренняя работа TEXTEQU значительно отличается
от EQU <>. Видимо по этому разработчики ML решили её ввести.В руководстве MASM32 написано:
———————————————————————————————
The TEXTEQU directive acts like the EQU directive with text equates but
performs macro substitution at assembly and does not require angle brackets.
The TEXTEQU directive will also resolve the value of an expression preceded
by a percent sign (%). The EQU directive does not perform macro substitution
or expression evaluation for strings.
———————————————————————————————Теперь вы должны понимать, что это не совсем так. Является ли это ошибкой
разработчиков ML? Видимо да. В частности EQU не должна была переводить
в статус переменных литералов определения типа:NOLITERAL EQU dbИ конструкция ниже должна была бы вызывать ошибку:
literal EQU db literal EQU dwНо ошибка не появляется, более того значение literal меняется на dw
В заключении к этому пункту, вы должны осознать, что тип определений невозможно
изменить. То есть переменная не может стать целочисленной константой:literal EQU string
literal EQU 123 ;; Это текстовой макроВторое переопределение символа literal, не изменит его тип на тип целочисленной
константы.Думаю, у Вас возник вопрос:
– Что такое? Недокументированные возможности MASM?У меня есть веские основания считать это ничем иным, как
ошибкой разработчиков. Давайте предположим, что все макропеременные хранятся
компилятором в памяти в виде массива структур. Не вдаваясь в подробности,
пусть эта
структура будет такая:macrodefine struct type dd ? ;; тип макроконстанты value dd ? endsКак видно из структуры, значение макроконстанты может быть только dword’ом.
Если это строка, то в поле value может быть записан указатель на строку
(например, ASCIIZ).Поле type может принимать только два значения, которое описывает тип
value: либо value – содержит числовое значение макропеременной (константы).Если определяется числовая константа то, вызывается одна функция (назовём
её setmacrodefine_val()), которая добавляет в таблицу макроконстанту.Это конечно предположение. И в действительности всё может быть ещё
проще или ещё сложнее. Однако вероятность того, что свойства макропеременных
хранятся именно подобным образом близка к единице. Теперь если
вы немного подумаете, то поймёте:string EQU <string> ;; Строковая макропеременная string TEXTEQU string ;; Строковая макропеременная string EQU string ;; Должна была быть константойПоследний случай записывается в таблицу, как строковая макропеременная
по той простой причине, что string не может быть записано в поле value,
а поле type не имеет специального значения, чтобы указать, что value – это константный указатель на строку (помните C++?).В конце концов, совершенно не важно угадал ли автор причину,
или нет. Важно другое – что ошибка достаточно явная. А, кроме того, так
и
не была исправлена
до сих пор (версия 7.0). Зато теперь вы сможет с пониманием отнестись к таким
неожиданным эффектам.Видимо разработчики не задумываются о том, что кто-то будет использовать
определения MASM, иначе, нежели это написано в руководстве. И кому-то взбредёт
в голову
проверить, а можно ли переопределить EQU.А подумайте, к каким бы серьёзным неуловимым ошибкам произвела бы эта
халатность, если бы на MASM писали сложные приложения. Но как видно
их никто не пишет.Свои особенности имеют так же целочисленные выражения с оператором «=». В
таких выражениях перед их выполнением осуществляется полная замена всех макроконстант,
макропеременных на их значения, и вызов всех макрофункций.Как вы думаете, что будет в следующем примере:
literal EQU Something
literal = 1234Варианты ответа:
- Произойдёт ошибка переопределения константы.
- literal = 1234.
Второй вариант ответа мы должны откинуть сразу, потому что в этом пункте
чётко определили, что данное переопределение невозможно. Первый вариант
ответа больше
похож на правду.… Однако не соответствует истине. Что же произошло? А
произошло следующее:
- Препроцессор нашёл лексемы «literal» и «1234».
- Обнаружил, что «literal» является текстовым макро, и именно поэтому
выполнил замену лексемы «literal» на её строковое значение.- Проанализировал строку: «Something = 1234».
Этот факт может быть легко доказан, следующим тестом:
literal EQU Something literal = 1234 %echo @CatStr(%Something) ============================ Вывод: 1234Если вас сбил с толку этот пример, не отчаивайтесь. Всё дело в том, что препроцессор
ML в разных выражениях по-разному заменяет макропеременные. Вот об этом мы
и поговорим в следующем пункте.А пока подумайте, что должно случится в этом примере:
num EQU number
num EQU 123
num = 1234На этом можно было бы закончить данный пункт, если бы не одна особенность
использования строк в вызове макро. А точнее приоритет анализа кавычек и директивы
определения литерала <>. Не смотря на описанный выше алгоритм поведения
макро, оказывается, что препроцессор при вызове макро выполняет определение
литерала в кавычках, но что самое интересное, как было отмечено, выше сами
кавычки попадают в строку. Если вам нужно передать макро одиночную кавычку
вы должны воспользоваться символом отмены «!». Однако самое неприятное таится
в том, что символы «<>» и кавычки конкурируют между собой в определениях
строк. Например, попробуйте сказать, что должно было бы получиться в этом случае:%echo @CatStr(<Раз">,<"Два>)
OUT:
Раз">,<"ДваА можно было бы подумать, что ML должен принять операторы <> и запятую.
Данное место – источник многих сложно обнаруживаемых ошибок. Например:FORC char,<str>
m$__charcode = @InStr (1,<@ABCDEFGHIJKLMNOPQRSTUVWXYZ>,<char>)
…Если в строке попадается символ кавычки, а макропеременная char заменяется
на значение кавычки, имеем:m$__charcode = @InStr (1,<@ABCDEFGHIJKLMNOPQRSTUVWXYZ>,<”>)В этом случае мы получаем ошибку:
missing single or double quotation mark in stringТак и должно быть, потому что кавычки имеют высший приоритет анализа, чем
оператор <>. Более того, угловые кавычки <> имеют самый низкий
приоритет по отношению ко всем спец. символам, что согласуется с MASM Reference.
Посмотрите на Дополнение к статье: пункт 3.a.i, который подозрительно выделен
«жирным». В частности, следующее выражение, которое работает без проблем:TEXT TEXTEQU <"> ;; Это работает?
TEXT TEXTEQU <;> ;; И это???Появляется закономерный вопрос: для чего символ отмены «!»?
Данный пример демонстрирует скрытые глубины анализатора ML. А точнее его архитектурное
несовершенство. Так как выражения с TEXTEQU как видно обрабатываются отдельной
функцией, которая проверяет в первую очередь наличие угловых скобок «<>».
Все другие выражения ML обрабатываются другой стандартной функцией, которая
была написана задолго до появления TEXTEQU.Замечательная наука всем программистам, которая демонстрирует,
во что выливается халатность архитектора при дальнейших попытках расширения
продукта.Зато благодаря TEXTEQU пример с поиском символа в строке имеет решение:
m$__char TEXTEQU <char>
m$__charcode = @InStr (1,<@ABCDEFGHIJKLMNOPQRSTUVWXYZ>,%m$__char)Единственно, отчего не может помочь данный код – это от вылавливания в строке
символов «> или <». Для этого можно использовать специальную проверку
в условных блоках на наличие символа «>», но при этом придётся отказаться
от микроблока FORC.III.3. Обработка выражения в MASM
MASM обрабатывает выражения в правой и левой части в зависимости от контекста.
Там, где вам необходима предварительная обработка выражений, используется оператор
«%». Он заставляет препроцессор ML сначала вычислить выражение
после оператора
% (то есть выражение в правой части относительно %), и только
потом продолжить анализ всей строки. Например, если вы хотите, чтобы при вызове
макро:num TEXTEQU <123>
FunMacro numмакропараметр был бы равен не строке «num», а значению текстового макро num,
вы должны поставить оператор % перед num. Например:FunMacro %num
;;или
FunMacro %(1+2*num)Но и с оператором % не всё гладко.
Оказывается препроцессор ML, различает два (фактически три) вида выражений, в
которых используется оператор %. Первый вид выражений – Арифметические:Все выражения, содержащие операторы +,-,*, а так же сдвиговые и битовые
операцииСтроковые выражения:
Все выражения результат вычисления которых – строка.
Примеры:
;Арифметические выражения
%(num shl 3)
%num = 2134 shl 3 + 2*6
;Всё равно арифметическое выражение
%(num shl 3 @CatStr(num))
;Строковое выражение
%(@CatStr(num shl 3))
;Строковое выражение
%PROGRAM IMAGEТак вот что интересно.
В арифметических выражениях происходит полная замена правой части: вызовы
макрофункций, значение макроконстант, макропеременных любых типов, как
строковых, так и целочисленных.
Так же в левой части выражения: замена строковых макропеременных, и вызов
макрофункций.То есть:
Левая часть = Правая часть
(Вызвать все макрофункции, и заменить все строковые макропеременные) =
(Вызвать все макрофункции, и заменить все строковые и целочисленные макропеременные
и константы)В строковых выражениях происходит замена только строковых макропеременных
(текстовых макро) (замете, что в ML нет строковых макроконстант). Это значит
что в случае:%echo PROGRAM_IMAGE_BASEПоявится: «PROGRAM_IMAGE_BASE», а не его числовое значение.
Однако есть и третий частный случай, когда оператор % относится только к
одному литералу:%literalВ этом случае происходит полный комплекс подстановок:
- Вызываются макрофункции.
- Заменяются все макропеременные или макроконстанты.
Например:
FunMacro %literalЗначение literal будет подставлено в вызов макро, в независимости от того,
какой тип имеет literal.
-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
temp TEXTEQU %(SIZEOF array / LENGTHOF array)
% ECHO Bytes per element: tempNote that you cannot get the same results simply by putting the % at
the beginning of the first echo line, because % expands only text macros,
not numeric equates or constant expressions.
-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=Следует так же отметить, что в выражениях с exitm оператор % работает
точно
так же, как с выражениями в TEXTEQU.III.4. Целочисленные выражения MASM
Целочисленные, побитовые операции так же необходимы разработчику макроопределений.
Они дают возможность скрыть обработку битовых полей, или вычисление сложных
выражений. Например, как это сделано в макрофункции $$$MAKELANGID.$$$MAKELANGID macro p:REQ,s:REQ
m$__langid = (s SHL 10) or p
EXITM <m$__langid>
endmВы всегда должны помнить, что препроцессор MASM не различается знаковые и
беззнаковые числа (подобно тому, как это делает x86), и значение числа
не может выходить
за диапазон dword. Препроцессор MASM не выдаёт предупреждений при переполнении.
Следующий пример демонстрирует такое поведение:myint = 0ffffffffh myint = myint + 1 ;; myint = 0 %echo @CatStr(%myint) ================================= OUT: 0 ;; Ещё один пример с умножением: myint = 0ffffffffh ;; ;; 0ffffffffh * 2 = (dword)1FFFFFFFEh = 4294967294 myint = myint * 2 %echo @CatStr(%myint) ================================= OUT: 4294967294В следующей статье мы поговорим про то, как работать с 64-bits макропеременными,
используя данный факт.Ниже приводится список операций, которые могут участвовать в целочисленных
выражениях MASM.
Оператор Пример Описание AND res = op1 AND op2 Операция логического «И» над каждым битом операндов op1 и op2. OR res = op1 OR op2 Операция логического «ИЛИ» над каждым битом операндов op1, op2 NOT res = NOT op1 Операция логического «НЕ» над каждым битом операнда op1 XOR res = op1 XOR op2 Операция XOR между операндами op1, op2 SHL res = op1 SHL count Выполняет побитовый сдвиг влево (наподобие команды x86 shl) операнда
op1, на количество бит, указанное в операнде count.SHR res = op1 SHL count Выполняет побитовый сдвиг вправо операнда op1, на число бит, указанное
в операнде count.+,-,*,/ Основные математические операции MOD res = op1 MOD op2 Возвращает остаток от деления операнда op1 на операнд op2 [] res = op1[op2] Операция: «Смещение». Выполняет сложение операндов op1 и op2 III.5. Вычисление рекурсивных выражений
Теперь, когда мы рассмотрели правила анализа и вычисления выражений в MASM,
остаётся раскрыть важный вопрос: «Как происходит анализ выражений, если
они
состоят из других выражений?».Обычно это называется короче: вложенные выражения.
Вложенное выражение – это такое выражение, элементы
которого сами являются выражениями, которые так же могут иметь
вложенность.Замороченное определение, похожее на «Иди туда, не знаю куда,
возьми то, не знаю что» – пример старинной народной русской рекурсии,
которая так часто встречается в нашей жизни.Например, вызов макрофункции при вызове макро – это вложенное выражение:
MyMacro FunMacro(Мой парамерт) ;;Или это: %echo FunMacro(Мой параметр) ;;Или это: MyMacro FunMacro(Fun2(Привет))Вложенность характеризуется параметром количества уровней вложенности. В недавнем
примере уровень вложенности был равен двум. При чём вызов Fun2() можно называть
выражением низшего уровня вложенности, а вызов макро MyMacro – выражением верхнего
уровня.После анализа выражений, и получения их многоуровневой структуры вложенности,
препроцессор начинает вычислять результат выражения самого низшего уровня.
Потом подставляет его результат в выражение следующего уровня, и так далее.Например, для случая:
Fun2 macro param
exitm <MyCount = param>
endm
FunMacro(Fun2(%(12+34)))Порядок вычислений такой:
- %(12+34) = 46
- Fun2(46)
- FunMacro(MyCount = 46)
- Результат выполнения FunMacro(MyCount = 46)
А иначе препроцессор не смог бы. Если бы он начал вычисления
выражений с верхнего уровня, то это то же самое, как если бы он попытался
выполнить народную русскую рекурсию:
«Пойди туда, не знаю куда…, вычисли то, не знаю что»
или
FunMacro(???)То есть: Вложенные выражения вычисляются последовательно от низшего уровня
к верхнему, и результаты вычисления каждого уровня становятся материалом для
выражений следующего уровня.Это правило называется рекурсивным вычислением выражений. Оно используется
везде, кроме мест вычисления значений макропараметров при вызове макро
(как макросов,
так и макрофункций). В этом случае действует правило: результат вложенного
выражения присваивается макропараметру и не анализируется повторно. Это
значит, что в данном
примере:myvar EQU <123> MyMacro macro param1,param2,param3 echo param1 endm FunMacro macro param:VARARG exitm <param> endm MyMacro FunMacro(var,@CatStr(<%>,myvar),var4)вывод будет таким:
var,myvar,var4То есть препроцессор не будет снова вычислять выражение для второго макропараметра
функции FunMacro(). Если бы он сделал это, то тогда вывод был бы таким, как
в этом случае:%echo FunMacro(var,@CatStr(<%>,myvar),var4)
Вывод:
var,123,var4Теперь, когда вы знаете все тонкости вычисления выражений в MASM, настало
время рассмотреть Встроенные макрофункции и директивы, которые участвуют в
этих выражениях.III.6. Встроенные макрофункции и директивы
Несмотря на то, что этот пункт не касается самих макросов в MASM, он необходим,
для того, чтобы строить макросы, и манипулировать выражениями, возникающими
внутри макросов.MASM обладает несколькими встроенными макрофункциями, макропеременными и
макроконстантами, которые работают так, как если бы они были макро, определённые
вами. Вот список
этих предопределений:
Имя макроопределения, его тип Описание
Определения Даты и Времени @Date,
текстовое макроопределение (не макрофункция)Возвращает строку вида MM/ДД/ГГ
Где:
MM – месяц, две цифры
ДД – день, две
цифры
ГГ – год, две цифры@Time,
текстовое макроопределение (не макрофункция)Возвращает текущее время в 24-х часовом формате вида ЧЧ:ММ:СС
ЧЧ – часы,
два числа
ММ – минуты, два числа
СС – секунды, два числаИнформация об окружении @Cpu, числовая макроконстанта Битовая маска, определяющая режим работы процессора. Никакой информации
о полях этой маски нет.@Environ(env), макрофункция Возвращает строковое значение переменной среды окружения. Например:
%echo @Environ(TEMP)Вывод: F:Tempasm
@Interface, целочисленная макроконстанта Информация о языковых параметрах вызова. @Version, строковая макроконстанта Возвращает версию ML.
Например:
%echo Version = @Version Вывод: Version = 614Или 615 в MASM 6.15Информация о файле @FileCur, строковая макропеременная Возвращает имя файла и путь к нему (если есть), так как был подан этот
файл в командной строке компилятору ML.Пример:
%echo FileCur = @FileCur Вывод: FileCur = .start.asm@FileName, строковая макропеременная Возвращает имя файла, без его расширения. То есть для модуля start.asm:
%echo FileName = @FileName Вывод:FileName = START@Line, целочисленная макроконстанта Возвращает номер текущей строки в файле.
Пример:
%echo Line = @CatStr(%@Line) Вывод:Line = 31Строковые макрофункции @CatStr( string1 [[, string2…]] ), макрофункция Возвращает строку, созданную объединением строк параметров функции.
Пример:
%echo @CatStr(<my>,var) Вывод:Myvar@InStr( [[position]], string1, string2 ), макрофункция Возвращает позицию вхождения строки string2 в строку string1. Если параметр
position определён, тогда поиск начинается именно с этой позиции. Отсчёт
позиции начинается с единицы. В случае, если вхождение не найдено макрофункция
возвращает значение 0. Параметр position должен быть целым числом больше
нуля, но не равным нулю.Пример:
%echo @InStr(1,asdfg,s) Вывод:02@SizeStr( string ) макрофункция Возвращает число, характеризующее длину строки, или, что тоже самое
количество символов в строке. Функция возвращает число, однако, поскольку
это макрофункция то тип возвращаемого значения – строка.@SubStr( string, position [[, length]] ) макрофункция Возвращает подстроку строки string, начиная с позиции, указанной в параметре
position (отсчёт начинается с 1). Если необязательный параметр length задан,
он ограничивает размер возвращаемой строки. Параметр length не может быть
меньше нуля, и не может быть строкой.Пример:
%echo @SubStr(1234567890,2) %echo @SubStr(1234567890,1,5) Вывод: 234567890 12345Информация о сегментах @code, строковая макропеременная Возвращает имя сегмента кода. @data, строковая макропеременная Возвращает модель памяти.
Пример:
%echo data = @data Вывод:data = FLAT@fardata?, строковая макропеременная Равен имени сегмента FARDATA? @WordSize, численная константа Содержит размер слова в байтах.
Для 16-bits – 2.
Для 32-bits – 4.@CodeSize, численная константа Содержит идентификатор типа памяти.
0 – TINY, SMALL, COMPACT, FLAT.
1
– MEDIUM, LARGE, HUGE@Model, численная константа 1 – TINY
2 – SMALL
3 – COMPACT
4 – MEDIUM
5
– LARGE
6 – HUGE
7 – FLAT@CurSeg, строковая макропеременная Хранит имя текущего сегмента. @fardata, @stack, строковая макропеременная Содержат соответствующие имена сегментов Кроме знания макрофункций, нам так же понадобятся знания о блоках ветвлений
или просто IF блоках. Эти блоки позволяют исполнять тот или иной участок исходного
кода в зависимости от того, выполняется какое-либо условие или нет. Часто это
называют «Условным ассемблированием (компиляцией)», однако для MASM это нечто
большее, нежели простое управление компилятором, так как, вы уже поняли, мы
имеем дело, как с кодом машины, так и с макрокодом, который вычисляется и живёт
только во время компиляции.Условный блок в MASM имеет следующий общий вид:
[IFDIRECTIVE] условие
...
[ELSEDIRECTIVE] условие
...
ELSE
...
ENDIFЕсли выражение «Условие» равно истине, то выполняется блок кода, идущий после
условной директивы, иначе управление передаётся на следующий оператор за блоком.
[IFDIRECTIVE]/[ELSEDIRECTIVE] – могут быть той или иной директивой
условия. Стандартные директивы IF/ELSEIF/ELSE требуют,
чтобы выражение, стоящее при них, было целочисленным. Если вам необходимо проверять
другие условия, то для этого
в MASM предусмотрены специальные директивы.Список [IFDIRECTIVE]/[ELSEDIRECTIVE]:
Блок Условие выполнения блока IF выражение
ELSEIF выражение
ELSEесли выражение равно истине IF1
ELSEIF1если ассемблер выполняет первый проход IF2
ELSEIF2если ассемблер выполняет второй проход (устарело) IFE выражение
ELSEIFE выражениеесли выражение равно нулю IFDEF выражение
ELSEIFDEF выражениеесли идентификатор, который является результатом выражения, определен.
Идентификатором может быть макро, макропеременная, переменная, макроконстанта,
любой другой идентификатор.При помощи этой директивы, можно проверить была ли определена та или
иная переменная, макро, константа.IFDEF PROGRAM_IMAGE_BASE
;; Выполняем действия если PROGRAM_IMAGE_BASE
;; определена
ELSE
…IFNDEF выражение
ELSEIFNDEF выражениеесли идентификатор не определён. IFB строка
ELSEIFB строкаесли строка пустая.
Строка считается пустой, если её длинна равна нулю,
либо она содержит одни пробелы. С помощью этой директивы можно определяет
присутствие/отсутствие необязательных макропараметров.MyMacro macro param1,param2
IFB <param2>
;; Если макропараметр не определён,
;; генерируем ошибку
.ERR <Не определён параметр param2>IFNB строка
ELSEIFNB строкаесли строка не пуста. IFDIF str1,str2
ELSEIFDIF str1,str2если строки различны.
IFDIF <String>,<string> echo Этот код выполнится echo потому что строки различны ENDIFIFDIFI str1,str2
ELSEIFDIFI str1,str2если строки различны (без учёта различий в регистре букв).
IFDIF <String1>,<string2>
echo Этот код не выполнится
echo потому что строки Одинаковы
ENDIFIFIDN str1,str2
ELSEIFIDN str1,str2если строки одинаковы.
IFDIF <String1>,<string2>
echo Этот код не выполнится
echo потому что строки Различны
ENDIFIFIDN str1,str2
ELSEIFIDN str1,str2если строки одинаковы (без учёта различий в регистре букв).
IFDIF <String1>,<string2>
echo Этот код выполнится
echo потому что строки Одинаковы
ENDIFНа протяжении всей статьи я часто пользовался следующей директивой, которая
позволяет выводить текст на консоль во время компиляции. Эта директива echo.
Как мы узнаем позже, она оказалось просто незаменимой при проектировании макро.Вы уже, наверное, убедились насколько полезна эта директива, позволяющая
заглянуть, а что именно происходит в недрах макроса, или посмотреть значения
макропеременных.Кроме этого, есть ещё одна группа директив, без которой мы не сможем обойтись.
Не сможем потому, что макрофункции, или макросы, которые мы собираемся создавать
должны быть слегка умными, иначе говоря, иметь «защиту от дурака».Если кто-то неправильно использует макрос, то код, полученный таким образом
может быть неправильным с точки зрения программиста, но не вызовет подозрений
у компилятора.
Поэтому макро не просто должен завершится, а и каким-то образом остановить
компиляцию программы с выдачей сообщения об ошибке.Именно для этого и существует простой набор директив условной генерации
ошибки. Действуют они подобно условным блокам и директиве echo. Пример
безусловной
генерации ошибки:.ERR <Ошибочка вышла, гражданин начальник>Условная генерация ошибки, имеют ту же форму, что и IFDIRECTIVE в таблице
выше, однако последним дополнительным параметром является строка сообщения.
Например:.ERRE выражение,<ошибка, если выражение равно нулю>
.ERRNZ выражение,<ошибка, если выражение не равно нулю>
.ERRDEF id,<ошибка, если id определен>
.ERRB строка,<ошибка, если строка пуста>
.ERRNB строка,<ошибка, если строка не пуста>
.ERRDIF str1,str2,<ошибка, если строки различны>
.ERRDIFI str1,str2,<ошибка, если строки различны (без учёта регистра)>
.ERRIDN str1,str2,<ошибка, если строки одинаковы>
.ERRIDNI str1,str2,<ошибка, если строки одинаковы (без учёта регистра)>III.7. Символ макроподстановки
Ещё раз вернёмся к формальным параметрам макро. Как было сказано, при раскрытии
макроопределения препроцессор заменяет в теле макро формальные названия на
их величины. В MASM32 предусмотрено ещё одно средство подстановки макропараметров
– внутри строкового литерала.Предположим нам нужно, чтобы макро генерировал строку: «label_xx». Где xx – это формальный параметр макро. Это можно сделать двумя способами:
@CatStr(label_,xx) ;;Вызов макрофункции конкантенации строк или
label_&xx& ;;Использование символа макроподстановкиТо есть если во время генерации макро, препроцессор встречает в его теле символ
«&», он анализирует строку после него. Если эта строка однозначно определяет
один из макропараметров, препроцессор заменяет выражение &макропараметр& на
значение макропараметра.Следует отметить, что если макропараметр начинает или заканчивает литерал,
то
можно использовать только один символ «&»:label_&xx
;;или ещё пример
label_&xx&&xx2 ;; Замена для двух макропараметров xx и xx2III.8. Макроблоки
И, наконец, у читателя должен остаться единственный вопрос: «А как обрабатывать
переменные типа VARARG»? Например, рассмотрим возможный макро для вызова функций
– STDCALL:stdcall macro funname,params:VARARG endmЭтот макро должен генерировать код вызова функции согласно конвенции STDCALL:
- Поместить параметры в стек в обратном порядке их определению.
- Вызвать функцию funname, предварительно видоизменив её имя по правилам
STDCALL.Получить видоизмененное имя функции по значению параметра funname можно
было бы при помощи символа макроподстановки.call _&funname@(количество параметров * 4)Но непонятно, как распознать параметры функции, которые представляют собой
строку, где значения разделены символом «,». Более того, не понятно,
как вообще можно получить эти параметры, и посчитать их число, ведь макропараметр
params – это одна строка. То есть при вызове макро:stdcall win32fun,1,2,3Мы должны как-то определить количество параметров, а потом их значения.
Именно для решения этой задачи в MASM предусмотрены несколько специальных
макроопределений, которые можно назвать макроблоками.Первый из них FOR позволяет получить значения элементов, разделённых в строке
символом «,».FOR parameter[:REQ | :=default], string
statements
ENDMВспоминая С конструкцию FOR, вы сразу поймёте что это цикл, где значение parameter последовательно принимает значения элементов списка string.
Вот вам wonderful пример:
FOR parameter, <It’s, wonderful, wonderful, asm>
echo parameter
ENDM
ВЫВОД:
-=-=-=-=-=-=
It's
wonderful
wonderful
asm
-=-=-=--=-=-А вот пример макрофункции, который подсчитывает число аргументов VARARG:
@ArgCount MACRO parmlist:VARARG
count = 0
FOR param, <parmlist>
count = count + 1
ENDM
EXITM count
ENDMВот в принципе, уже на основе этих знаний можно было бы организовать макрос
stdcall:stdcall macro funname,params:VARARG
count = 0
FOR param, <parmlist>
count = count + 1 ;; Считаем число параметров
push param ;; Помещаем их в стек
ENDM
;;Вызываем функцию
call ??? ;;А вот как это сделать?
endmЕщё несколько минут необходимо для того, чтобы понять, что этот макро работает
неправильно. Хотя бы потому, что параметры помещаются в стек не так. Нужно
было бы помещать их от последнего к первому, а не от первого к последнему.
А, кроме того, ведь символ макроподстановки нельзя употреблять к макропеременной
count, потому что это не макропараметр, это макропеременная.К сожалению, в MASM нет обратной конструкции FOR. Поэтому самый простой выход,
который напрашивается сам собой – это изменить порядок параметров в списке,
а потом только генерировать команды push.Вторую проблему можно легко решить, воспользовавшись макрофункцией конкатенации
строк:call @CatStr(_,funname,@,%(count*4))С параметрами в стек будет посложнее. В принципе я бы решил эту задачу, если
бы MASM поддерживал бы такой тип макропеременных как массив. Но хотя MASM и
не поддерживает этот тип, его можно эмулировать.count = 0
FOR param, <paramlist>
count = count + 1 ;; Считаем число параметров
@CatStr(var,%count) TEXTEQU <param>
ENDMКак вы можете догадаться, в этом примере создаются макропеременные varXX,
которым присваиваются значения параметров. Теперь с той же лёгкостью можно
работать с этими переменными. Можно снова использовать цикл FOR, однако в данном
случае, было бы грамотней воспользоваться значением count, и выполнить цикл
столько раз, сколько записано в нашем счётчике параметров. Для этого мы воспользуемся
ещё одним макроблоком rept, о котором скажем позже:nparams = count REPT nparams ;; Начало блока push @CatStr(var,%count) count = count - 1 ENDMБлок REPT выполняется столько раз, сколько указано в nparams. Я ввёл эту дополнительную
макропеременную, для того, чтобы значение, указанное в REPT осталось неизменным.
Однако этого не нужно. Можно было бы написать и так:REPT count ;; Начало блока
push @CatStr(var,%count)
count = count - 1
ENDMЗначение макропеременной count инициализирует цикл только один раз вначале,
после чего, она может, как угодно менять значение.И ещё один макроблок, без которого нам невозможно будет реализовать макрос
для определения строк уникода, или макрос, который позволяет писать строки
OEM в
редакторе использующий кодировку win cp-1251 (например, при создании консольных
приложений).Этот макроблок FORC:
FORC char, string
;;блок
ENDMБлок FORC выполняется столько раз, сколько символов в строке string, при этом
макропараметр char равен текущему символу из строки.
Например, посчитать количество символов в строке можно было бы так:count = 0
FORC char, <Сколько тут символов?>
count = count + 1
ENDM
%echo @CatStr(%count)А вот так, можно было бы посчитать количество пробельных символов.
count = 0
FORC char, <Сколько тут символов?>
IFB <char>
count = count + 1
ENDIF
ENDM
%echo @CatStr(%count)Упражнение:
TheSvin‘у, как и любому программисту, который часто имеет дело с битами,
было бы удобно записывать значения бит по группам, через пробел.;;Вот так неудобно и ненаглядно mov eax,011110111011b ;;Вот так удобно и наглядно, но компилятор выдаст ошибку ;;Вариант1 mov eax, 0111 101 1101 1b ;;А вот так вообще замечательно, только ML неправильно поймёт ;;Вариант2 mov eax, [0111] [101] [1101] [1]bХорошо бы было написать некую макрофункцию, которая смогла бы позволить записывать
эти выражения:mov eax,nf(0111 101 1101 1b)Напишите такую макрофункцию, которая позволила бы это делать. Напишите её
для первого и второго вариантов исполнения.III.9. Отладка макроопределений и заключение
А напоследок… остаётся маленькая деталь.
И эта деталь не самая приятная. Отладка макроопределений и их испытания невозможны
под отладчиком. А, кроме того, если при генерации макро возникает ошибка,
то ML выдаёт её в жутком виде:.start.asm(84) : error A2008: syntax error : in directive
MacroLoop(3): iteration 8: Macro Called From
.start.asm(84): Main Line CodeТо есть он выдаёт относительную строку в макро MacroLoop(3), где эта ошибка
появилась. А если ещё макровызовы будут вложенными, то вам лучше не видеть
этой замечательной картины.Единственной возможностью качественно и относительно легко отлаживать макро
– это употребление директивы echo.На протяжении статьи вы не раз наблюдали примеры её использования. Но я снова
повторюсь:;; Для макропараметров
echo macroparam
;; Для макропеременных типа строка или текстовых макро
%echo macrovar_string
;; Для целочисленных макропеременных, или макроконстант
%echo @CatStr(%macro_num)Заметьте, чтобы вывести значение целочисленной макропеременной необходимо
воспользоваться макрофункцией @CatStr(), и перед аргументом указать оператор
%. Почему именно так обсуждалась в пункте III.2. Определение макро переменных
и строк.Теперь вы знакомы с теорией использования макроопределений в MASM32, и сможете
смело приступать к разработке макро. Именно этим мы и займёмся в следующей
практической части нашего руководства, а так же заполним некоторые пробелы,
на которые не
обратили внимания здесь.III.10. Абстрактный алгоритм анализа строки MASM (Дополнение)
1. Определены таблицы элементов:
Таблица переменных Хранит сведения о всех переменных модуля Таблица меток Хранит список меток в коде. Таблица процедур Хранит таблицу и прототип процедур Список ключевых слов KEYLIST Хранит список ключевых слов, на которые реагирует ML Таблица макрофункций Хранит тело всех макро, их имена и тип: макрофункция, или макро. Список
макропараметровТаблица макросов -=- Таблица макропеременных, или переменных времени компиляции Хранит тип макропеременной и её значение. Всё остальное, что не включено 2. Начальное состояние анализа строки.
3. Читать поток символов, пока не встретится символ возврата каретки без предыдущего
символа «/». Игнорировать часть строки после «;»a. Определить наличие лексем первого уровня в строке:
i. Выделить все строковые литералы в кавычках, если только это не
выражение с TEXTEQU и символ комментария «;»
ii. Строковые литералы: <текст>
iii. Численные литералы: 1234, 1234h, 01011b
iv. Правильные литералы: строка из символов «A-Z,a-z,_0-9», но не
начинающаяся на цифру
v. Литералы разделители: «,.»
vi. Управляющие Литералы: «+-*» Правильные литералы: строка из символов
«A-Z,a-z,_0-9», но не начинающаяся на цифруb. Проверить правильные литералы на совпадение в списке ключевых слов,
и определить схему выражения. В зависимости от схемы выражения, выполнить
или
пропустить:i. Проверить правильные литералы на совпадение в списке макро (в зависимости
от способа вызова в списке макрофункций, или макросов)
ii. Проверить на наличие имени правильного литерала в таблице макропеременных.
iii. Осуществить вызов и замену макро и макропеременных, в соответствии
с выражением строки.
iv. Вычислить все выражения допустимые в ML (+-*).c. Осуществить разбор схемы.
i. Если это определение процедуры, записать в таблице процедур имя
и прототип новой процедуры
ii. Если это макроопределение: анализировать его тело. Если найден
возвращаемый параметр, записать макроопределение в таблицу макрофункций,
иначе в таблицу
макросов.
iii. Если это определение EQU вычислить правую часть.1. Если эта макропеременная уже есть в таблице макропеременных,
и её тип – числовой, выдать ошибку. Если эта макропеременная
имеет строковый
тип,
изменить
строку, на которую указывает свойство value этой макропеременной.
2. Если правая часть числовой литерал – записать EQU определение
в таблицу, и пометить его тип как числовой константы. Записать
в свойство
макропеременной
value значение указателя на строку. Записать свойство value
равным числу.
3. иначе EQU – переменная, имеющая указатель на строку. Записать
в значения свойства value указатель на строку.iv. Если это выражение с «=» или подобное, выполнить замену
всех литералов на макроконстанты, переменные, вызов всех
макрофункций,
и только потом
выполнять выражение.4. Перейти к анализу следующей строки.
 ). Вместо того чтобы извлечь великую выгоду из
). Вместо того чтобы извлечь великую выгоду из
archive
New Member
- Регистрация:
- 27 фев 2017
- Публикаций:
- 532

Генерация кода
Вступление
Генерация кода — это процесс перевода промежуточного представления, в частности абстрактного синтаксического дерева, в выходной код на некотором языке, в том числе и на языке ассемблера.
Мы не будем рассматривать генерацию машинных кодов, потому что они имеют очень много тонкостей, которые выходят за рамки этой главы. Мы остановимся на генерации в ассемблерный код. В качестве ассемблера выберем MASM (Macro Assembler).
Задача генерации кода, в нашем случае, будет состоять в переводе AST в ассемблерный код!
В первую очередь мы поговорим о самом ассемблере, о том, как он работает, как на нем писать простейшие конструкции, а также как его компилировать в исполняемый файл. Я буду показывать только самые необходимые вещи, так что некоторые, неважные в рамках этой статьи, могут остаться вне поля зрения.
Ассемблер (MASM)
Ассемблер — это низкоуровневый язык программирования. Все команды в нем, являются более удобными заменами двоичного представления команд процессора.
Сам ассемблер не является сложным языком в плане синтаксиса, у него простая структура и небольшой набор доступных команд. Однако ассемблер сложен тем, что такие вещи как циклы, условия не существуют, как готовые языковые конструкции, они описываются вручную с помощью определенного набора доступных команд. Это довольно непривычно, но мы разберем все основные конструкции на примерах.
Установка компилятора для MASM
Для того, чтобы исходный код на ассемблере преобразовывать в готовые для запуска, исполняемые файлы, нам понадобится компилятор ассемблера. Для masm существует набор инструментов под общим названием masm32, который включает в себя компилятор.
Инструкция по установке:
- Переходим по ссылке на официальный сайт и выбираем любой из вариантов для скачивания;
- Открываем архив и запускаем файл
install.exe; - Далее нажимаем кнопку
installи следуем дальнейшим инструкциям. Процесс установки довольно долгий, так что придется подождать. После установки откроется редактор, его можно спокойно закрывать; - Теперь необходимо добавить путь к папке с установленным
masm32в переменную окруженияPath. Откройте проводник и вставьте в адресную строкуControl PanelSystem and SecuritySystemи нажмитеEnter; - Дальше в меню слева выберите пункт
Расширенные настройки системы; - В появившемся окне кликнете на кнопку
Переменные среды; - В верхней таблице найдите запись у которой первый столбец имеет значение
Pathи кликнете по ней два раза; - В проводнике, найдите папку, в которую вы установили MASM (обычно это папка
masm32на диске, который вы выбрали в начале установки); - Скопируйте путь до папки
binв папке, где установлен MASM.; - В появившемся ранее окне нажмите на пустое место, и в появившееся поле вставьте скопированный путь. Это необходимо, чтобы получить быстрый доступ к таким программам, как
ml.exeиlink.exe, которые понадобятся для компиляции; - Нажмите ОК и еще раз ОК;
- Откройте PowerShell (воспользуйтесь поиском Window, для быстрого поиска) и введите команду
ml, если ошибки нет, значит компилятор для MASM установлен верно.
Первая программа на ассемблере
Теперь, когда компилятор установлен, давайте скомпилируем небольшую тестовую программу, которая будет выводить "Hello World!" в консоль.
В папке, где вы пишите код компилятора, создайте папку с любым названием, например, test_asm.
Для дальнейших действий вы можете использовать любую консоль, будь то PowerShell или стандартную консоль Windows. Я буду показывать все в PowerShell, хотя все действия полностью идентичны.
Откроем PowerShell. Скопируем полный путь до папки test_asm и пропишем следующую команду в консоли:
где [path_to_test_asm] заменим на путь к папке.
Выполните команду нажатием клавиши Enter. Эта команда сменит текущий каталог, на каталог который был прописан на месте [path_to_test_asm], тем самым мы перейдем в каталог в котором будет файл, где мы будем писать ассемблерный код. Это удобно, так как, не надо прописывать длинный путь к файлу с ассемблерным кодом, а достаточно указать его название: test.asm.
Важно!
Весь код, который рассматривается в этой главе должен быть сохранен в кодировке ASCII или другой кодировке на основе ASCII (например, windows-1251).
Время добавить этот файл с ассемблерным кодом. Создайте файл test.asm со следующим содержанием:
Далее, последовательно введите в PowerShell две команды:
Если все верно, то вы должны получить файл test.exe. Если вы его запустите, то увидите надпись Hello World!.
Если вы получаете ошибку на подобии этой:
то это означает, что есть проблемы с установкой masm32. Возможно вы не прописали путь в переменной окружения Path, которая описана в 7 пункте инструкции по установке. Если проблема все еще существует, попробуйте перезапустить PowerShell с правами администратора.
Теперь давайте разберем, что это за команды:
Первая команда отвечает за компиляцию программы в объектный файл. Это файл еще не является исполняемым, поэтому, чтобы сделать из него исполняемый, мы используем линкер с помощью второй командой:
В результате мы получим готовый исполняемый файл, который можем запустить.
Итак, теперь мы умеем компилировать ассемблерный код.
Давайте выделим основное:
Чтобы скомпилировать ассемблерный код, нужно в первую очередь перейти в каталог с исходным кодом, чтобы не прописывать длинные пути, с помощью команды
cd [путь_до_папки], а затем выполнить следующие две команды:Первая из которых скомпилирует ассемблерный код в объектный файл, а вторая создаст на его основе исполняемый файл.
Лайфхак
Прописывать эти команды каждый раз, долго. Однако есть способ избежать этого. Для этого создадим в папке файл run.bat со следующим содержанием:
Это те же команды, что мы прописывали в консоли, однако добавилась еще одна команда, которая будет запускать полученный исполняемый файл. Это избавит нас от лишнего действия.
И теперь, чтобы перекомпилировать ассемблерный код, достаточно запустить файл run.bat двойным кликом.
Если вы хотите компилировать файл с названием отличным от
test.asm, просто поменяйте название во всех командах на необходимое.
Основы ассемблера
Основа программ на ассемблере — это команды. Команды выполняются одна за другой до тех пор, пока не будет встречен конец программы. Благодаря некоторым конструкциям языка, мы можем переходить к любому месту в программе при необходимости, это позволяет создавать все возможные конструкции циклов или условий.
Пустая программа
Давайте рассмотрим «костяк» любой программы на ассемблере. Это код можно просто копировать из программы в программу, он везде будет одинаков.
Рассмотрим код по-блочно:
Первый блок — это блок определений для ассемблера.
В первой строке обозначается набор используемых инструкций, в данном случае мы используем i586 набор, который является достаточно универсальным для процессоров Intel и AMD.
Во второй строке задается модель памяти программы, а также модель вызова процедур. Так как мы программируем под WIndows, то модель памяти должна быть flat, а модель вызова процедур — stdcall.
В данный момент примем это, как данность и будем просто копировать из программы в программу.
Следующий блок, это сегмент данных:
Сегмент данных используется для задания всех необходимых в программе переменных. Объявлять переменные вне этого сегмента нельзя.
Следующий блок, это сегмент команд:
Сегмент команд может называться любым именем, но стандартно его называют text. Сегмент команд — это то место в коде, где пишутся все исполняемые команды программы. Писать команды вне сегмента команд нельзя.
В сегменте команд обязательна начальная метка (о том, что это такое мы поговорим дальше) :
Эта метка должны быть закрыта, сразу же после завершения сегмента команд:
Данная метка, как функция main в С/С++, с нее начинается выполнение команд, то есть программа начнет свое исполнение с первой команды после метки __main:.
В нашем случае это команда ret. Сейчас не будем вдаваться в подробности, эта команда завершает выполнение программы.
Однако команды можно писать и до метки __main:, но тогда они не будут исполнены, в нормальном течении программы. Так как команды выполняются друг за другом, пока не будет встречен конец.
До метки __main обычно пишут функции, которые вызываются командами после метки __main:. Об этом мы поговорим в разделе про функции.
Это все блоки, которые понадобятся нам в написании нашего ассемблерного кода.
Отмечу еще один факт, большая часть ассемблера не учитывает регистр, поэтому записи:
равноценны. Однако некоторые части являются регистрозависимыми, в этом случае, это будет указано явно.
Подведем итоги:
Переменные определяются между
data segmentиdata ends! Этот блок называется сегментом данных!Весь код программы пишется между
text segmentиtext ends(этот блок называется сегментом команд) после метки__main:! Однако если задается функция, то она обычно пишется до метки:Весь остальной код, можно просто копировать из программы в программу, он не изменяется!
Комментарии начинаются с символа точка с запятой
;Большая часть ассемблера не учитывает регистр, поэтому записи:
равноценны. Однако некоторые части являются регистрозависимыми, в этом случае, это будет указано явно!
Регистры
Следующее, что мы рассмотрим — это регистры.
Регистры — это специальные ячейки памяти расположенные прямо в процессоре. Работа с ними происходит намного быстрее, чем с оперативной памятью, поэтому они предпочтительнее для большинства операций, чем переменные.
Регистры по сути такие же переменные, в которые можно записывать и считывать данные.
Регистров не так много, ниже приведена сводная таблица:
| Название | Разрядность | Основное назначение |
|---|---|---|
EAX |
32 | Аккумулятор |
EBX |
32 | База |
ECX |
32 | Счётчик |
EDX |
32 | Регистр данных |
EBP |
32 | Указатель базы |
ESP |
32 | Указатель стека |
ESI |
32 | Индекс источника |
EDI |
32 | Индекс приёмника |
EFLAGS |
32 | Регистр флагов |
EIP |
32 | Указатель инструкции (команды) |
CS |
16 | Сегментный регистр |
DS |
16 | Сегментный регистр |
ES |
16 | Сегментный регистр |
FS |
16 | Сегментный регистр |
GS |
16 | Сегментный регистр |
SS |
16 | Сегментный регистр |
Регистры EAX, EBX, ECX, EDX — это регистры общего назначения. Они имеют определённое историческое назначение, однако в них можно хранить любую информацию. Они имеют размер 32 бита или 4 байта, что очень похоже на переменные типа int, которые также занимают 4 байта.
Регистры EBP, ESP, ESI, EDI— это также регистры общего назначения. Однако они имеют уже более конкретное назначение, поэтому использовать их нужно аккуратно. Они имеют размер также 32 бита или 4 байта.
Регистр флагов и сегментные регистры мы оставим на потом, так как их описание довольно большое и сложное.
Регистры можно рассматривать, как обычные переменные с предопределенными именами и имеющие размер 4 байта.
Регистры общего назначения также можно использовать не полностью, можно использовать их первые 16 бит или использовать первые 8 бит и вторые 8 бит, это сделано для совместимости со старыми процессорами, однако использовать это мы не будет.
Давайте выделим основное:
Регистр — это ячейка в памяти процессора, которую можно рассматривать, как переменную с предопределенным именем. Есть 4 регистра (
EAX,EBX,ECX,EDX), которые можно свободно использовать для своих целей, каждый из которых имеет размер 32 бита или 4 байта.
Переменные
Переменные в ассемблере не отличаются от переменных в привычных нам языках. Помните в каком сегменте они задаются? Правильно в сегменте данных:
Числовые
Числовые переменные могут быть следующих типов:
| Директива | Название | Размер |
|---|---|---|
DB |
Byte |
1 байт |
DW |
Word |
2 байта |
DD |
DoubleWord |
4 байта |
DQ |
QuadWord |
8 байт |
DT |
TWord |
10 байт |
Переменные объявляются следующим образом:
Если начального значения нет, то необходимо поставить на его место знак вопроса (?)
Давайте посмотрим на объявление нескольких переменных:
Массивы
В ассемблере массивы можно задавать несколькими способами, мы рассмотрим два варианта, как набор значений через запятую, и как массив n-размера заполненный каким-то значением.
Первый вариант имеет следующий синтаксис:
Давайте посмотрим на объявление некоторых массивов:
Второй вариант имеет следующий синтаксис:
Ключевое слово dup задает массив определенного размера заполненный некоторым значением.
Давайте посмотрим на объявление некоторых массивов:
А что, если попробовать объявить массив однобайтных символов? Например такой:
И так и правда можно, таким образом мы задали строку World! Обратите внимание на ноль, он будет говорить программе, что эта строка завершена. Вспомните, в Си все строки заканчиваются нулем терминатором по-умолчанию. Ассемблер же сам не вставляет в конец нуль-терминатор, поэтому его нужно объявлять явно, с помощью еще одного элемента массива в виде нуля.
Однако так задавать строки очень неудобно, поэтому в ассемблере есть более удобный синтаксис для задания строк.
Строки
Синтаксис задания строки следующий:
Здесь тип DB обязателен, так как мы задаем строку с однобайтными символами. Не стоит забывать, что строки, как и в Си хранятся в виде массива, на что явно указывал способ объявления выше. Ноль после строки выполняет ту же роль, что была обозначена выше.
Давайте объявим несколько строк:
А помните, пример вывода Hello World! в самом начале, когда мы только изучали компиляцию? Там как раз таки в сегменте данных были объявлены две строки:
Выделим самое основное:
- Числовые переменные могут быть следующих типов:
Директива Название Размер DBByte1 байт DWWord2 байта DDDoubleWord4 байта DQQuadWord8 байт DTTWord10 байт
Синтаксис объявления численной переменной:
Массивы можно задавать двумя способами:
Строки задаются следующим образом:
После строки обязательно надо поставить ноль, чтобы явно обозначить завершение строки!
Метки
Очень важной частью программирования на ассемблере являются метки и переходы к ним.
Метка — это конструкция языка, которая имеет уникальное имя, после которого идет двоеточие (:) и перенос строки, позволяющая переходить между исполняемыми командами:
Метки ставятся в любом месте сегмента команд. Метка — это место в коде, в которое можно перейти и начать исполнение команд непосредственно с этой метки, то есть вне зависимости от места где сейчас исполняется код, можно перейти к метке и продолжить выполнять команды расположенные после этой метки.
Помните начальную метку __main:, с которой начинается выполнение команд? Эта также метка, только переход к ней происходит в автоматическом режиме при запуске программы.
Рассмотрим пример использования метки:
Команды
Дальше мы переходим к основной части ассемблера, а именно к командам. Однако изучать сухую теорию не очень весело, поэтому сейчас мы создадим тестовый стенд, где сможем выводить значение регистра eax, после использования каких-то команд. Тем самым мы сразу будем видеть результат выполнения команды.
Для начала, изменим содержание нашего файл test.asm на следующее:
В дальнейшем, я буду описывать только код между enter 0, 0 и push eax. Пока что не заморачивайтесь, что здесь написано, главное, что эта программа будет выводить значение регистра eax (помните, что регистры — это переменные? Так что мы выводим просто значение переменной, ничего сложного).
Теперь попробуем скомпилировать программу. Для этого используем наш файл run.bat, запустим его двойным щелчком. Если все хорошо, то в консоли будет выведено случайное число. (Посмотрите, что будет, если несколько раз подряд запустить программу?).
Теперь переходим к командам.
[] в описании команды, означает, что на этом месте будет что-либо. Конкретное описание того, что там может быть будет в описании команды.
MOV [приемник], [источник]
Первая команда, это команда mov, расшифровывается, как move, что переводится как «перемещать».
Эта команда перемещает значение из источника в приемник.
- Приемником может быть регистр или переменная;
- Источником может быть регистр, переменная или константа.
Итак, давайте поиграем с этой командой. Помните, что мы изменяем только код между enter 0, 0 и push eax? Если да, то начинаем.
Давайте напишем следующий код:
Сохраним и запустим компиляцию файлом run.bat. В выводе должно появится число 100. (Помните, что мы выводим значение eax?) Таким образом, мы поместили значение 100 в регистр eax. Здорово, не правда ли? А теперь давайте поместим значение в другой регистр, и значение этого регистра поместим в eax:
После компиляции в выводе должно быть число 200. То есть, здесь, мы сначала поместили в регистр ebx значение 200, а затем значение ebx (которое равно 200) мы поместили в регистр eax. Держите в голове тот факт, что регистр можно рассматривать, как переменную.
Следующие команды описывают команды для арифметических действий с числами. Пришло время посчитать.
ADD [приемник], [источник]
Команда add расшифровывается, как addition, что переводится как «сложение».
Эта команда складывает значения из приемника со значением источника и кладет его в приемник.
- Приемником может быть регистр или переменная;
- Источником может быть регистр, переменная или константа.
Давайте напишем следующий код:
Здесь мы сначала поместили значение 100 в регистр eax, а затем прибавили к значению eax число 5. Тем самым на выводе мы должны получить число 105. Так и есть.
Все просто, а что если сначала поместить значение в ebx, затем в eax, а затем сложить eax и ebx? Это ваше задание, напишите такую программу, значения могут быть любыми.
Если вы не знаете, как это написать, попробуйте написать по подобию примеров, это не так сложно, однако именно практика дает 50% запоминания и понимания материала, так что обязательно делайте эти небольшие задания.
SUB [приемник], [источник]
Команда sub расшифровывается, как subtraction, что переводится как «вычитание».
Эта команда вычитает значение источника из значения приемника и кладет его в приемник.
- Приемником может быть регистр или переменная;
- Источником может быть регистр, переменная или константа.
Мы уже умеем складывать, теперь пробуем вычитать:
У нас есть такой код, скажите, как вы думаете, что должно быть выведено? Правильно, 95. Ничего сложного, все как и со сложением.
А если написать такой код, то что выведется?
Да, выведется 0, так как мы из eax вычитаем eax.
Теперь, когда мы знаем две операции, напишите программу, которая посчитает значение выражения:
На выходе вы должны получить 12.
IMUL [приемник], [источник]
Команда imul расшифровывается, как integer multiplication, что переводится как «умножение целых чисел».
Эта команда перемножает значение источника со значением приемника и кладет результат в приемник.
- Приемником может быть регистр или переменная;
- Источником может быть регистр, переменная или константа.
Наконец то мы добрались до умножения. Здесь все также очень похоже на две команды выше.
Что должно быть выведено в итоге? Правильно, 400.
Теперь, когда вы знаете 3 арифметические операции, ваша задача написать код, который будет рассчитывать дискриминант.
Формула дискриминанта:
Значения, a, b, c можно взять любыми. Главное, чтобы результат был выведен на экран. (Не забывайте, мы выводим регистр eax, поэтому результат должен быть именно в нем).
DIV [источник]
Команду для деления мы пока что разбирать не будем, так как она слишком сложная, на этом этапе изучения ассемблере. Вернемся к ней позже.
Следующие команды, это команды для сравнения и условных переходов.
Условные переходы — это переходы в какую-то метку программы, в зависимости от того, какой результат был получен в результате последней команды cmp.
CMP [значение_1], [значение_2]
Команда cmp расшифровывается, как compare, что переводится как «сравнить».
Эта команда сравнивает значение 1 со значением 2, а результат записывает в регистр флагов. О регистре флагов мы поговорим дальше, сейчас просто поймите это, как то, что результат записывается в регистре флагов и мы можем его использовать с помощью следующих команд.
- Значение 1 может быть регистром, переменной или константой;
- Значение 2 может быть регистром, переменной или константой.
Например:
Следующие команды описывают условные переходы. То есть эти команды переходят к меткам в зависимости от результата предыдущей команды, например, команды cmp.
JNE [имя_метки]
Команда jne расшифровывается, как jump if not equal, что переводится как «прыгнуть если НЕравно».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был НЕравен второму
Давайте попробуем использовать эту и предыдущую команды и попробуем создать цикл:
Данный код описывает простой цикл, в нем значение ebx увеличивается на 1, а затем проверяется на равенство ecx. Таким образом, переход к метке loop_start будет происходить до тех пор, пока значения ebx и ecx не станут равными, тогда код продолжит выполнять код за пределами данного отрывка (помним, что мы описываем не весь код, а его часть, дальше идет вывод значения eax).
Если вы запустите код, вы должны получить 512. Таким образом мы написали расчет степени двойки, чтобы поменять расчетную степень, надо изменить первоначальное значение ecx.
Ваша задача написать на основе этого кода программу, которая будет рассчитывать степень числа 5. Ответ в приложении.
JE [имя_метки]
Команда je расшифровывается, как jump if equal, что переводится как «прыгнуть если равно».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был равен второму
Сейчас мы рассмотрим простейшую реализацию конструкции if else. Предположим, что нам нужно сравнить значение ebx и ecx и в случае равенства вывести 1, а в обратном случае — 0.
Казалось бы, вроде все верно, если равно, то переходим к одной метке, если нет — к другой. Но здесь проявляется особенность ассемблера, он выполняет команды одну за другой, несмотря ни на что. Поэтому в данном случае, если числа будут равны, eax станет равным 1, но после этого же, ему будет присвоен 0 и в результате работы будет выведен 0.
Чтобы избежать такого, создают специальную метку, в случае, если числа равны, эта метка будет переходить к коду после команд, которые должны были быть выполнены в случае неравенства.
Для этого используется команды jmp, давайте отвлечемся на ее описание, а после вернемся к примеру.
JMP [имя_метки]
Команда jmp расшифровывается, как jump, что переводится как «прыгнуть».
Эта команда переходит к метке, вне зависимости от чего-либо. Это безусловный переход.
Теперь вернемся к нашему примеру и добавим эту метку и переход к ней:
Теперь, если числа равны, то программа перейдет к метке if_equal, а потом «перепрыгнет» команды, так как встретит безусловный перед к метке if_end, таким образом команды которые должны были выполнится в случае неравенства будут пропущены.
В случае же неравенства, программа перейдет к метке if_not_equal и продолжит выполнять программу до конца, метка if_end в данном случае будет просто пропущена.
JG [имя_метки]
Команда jg расшифровывается, как jump if greater, что переводится как «прыгнуть если больше».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был строго больше второму.
JL [имя_метки]
Команда jl расшифровывается, как jump if less, что переводится как «прыгнуть если меньше».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был строго меньше второму.
JGE [имя_метки]
Команда jge расшифровывается, как jump if greater or equal, что переводится как «прыгнуть если больше или равно».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был больше или равен второму.
JLE [имя_метки]
Команда jle расшифровывается, как jump if less or equal, что переводится как «прыгнуть если меньше или равно».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был меньше или равен второму.
Все эти команды работают также как и предыдущие 3, поэтому не будем на них обращать пристальное внимание.
Однако, у вас есть задача. Предыдущий цикл будет корректно работать только в том случае, если в результате прибавления, ebx когда то станет равным ecx, но если мы поменяем приращение на 2, то мы получим бесконечный цикл, так как значения никогда не будут равны и программа будет постоянно переходить к метке.
Вам нужно исправить этот код, используя команды выше, чтобы он не уходил в бесконечный цикл.
Ответ в приложении.
На этом основные команды закончены.
Стек
Мы переходим к одной из самых сложных частей ассемблера — стеку. В первую очередь, давайте рассмотрим, что вообще такое стек, как структура данных.
Стек — это структура данных, при использовании которой возможны только две операции:
- Поместить на вершину стека значение;
- Извлечь значение из вершины стека.
Таким образом, если мы поместили в стек 3 значения, то получить доступ мы можем только к последнему добавленному элементу, а чтобы получить доступ к элементу посередине, нужно сначала извлечь все элементы до него.
Стек можно сравнить со стопкой тарелок. Если вы хотите достать тарелку из середины, то вам нужно сначала убрать все тарелки над ней. Также, когда вы добавляете новую тарелку, вы кладете ее на вершину стопки.
Если говорить о том, что такое стек в программе, то — это область программы для временного хранения произвольных данных.
Конечно, можно хранить все данные в сегменте памяти, в виде переменных, но это увеличивает размер программы и количество используемых имен.
Память в стеке используется многократно, что удобно, так как занимает меньше памяти.
Для работы со стеком есть две основных команды:
PUSH [значение]
Команда push переводится как «протолкнуть».
Эта команда добавляет значение в стек.
Значение может быть регистром, переменной или константой;
POP [приемник]
Команда pop переводится как «вытолкнуть».
Эта команда извлекает значение вершины стека и помещает его в приемник.
Приемник может быть регистром или переменной;
Давайте попробуем написать что-нибудь с использованием стека:
Предположим у нас есть 5 чисел:
10, 5, 6, 3, 2
Наша задача сложить их. Но мы не сможем их задать одновременно, так как регистров у нас только 4, а чисел 5. Конечно, здесь можно использовать и переменные, но давайте реализуем это с помощью стека:
В первую очередь помещаем все наши значения в стек:
После того, как значения в стеке, нам надо 5 раз достать значение из стека и прибавить его к eax:
Таким непритязательным кодом, мы реализовали нашу задачу. Однако у вас будет задача чуть сложнее, она будет охватывать и все предыдущие команды.
Ваша задача написать программу, которая в самом начале поместит в стек числа от 100 до 1, а потом извлечет их и сложит. Нужно использовать циклы из прошлых команд, а также стек. Ответ, как всегда, в приложении.
Регистрыesp и ebp
Помните в самом начале мы рассматривали вторую четверку общих регистров? И было сказано, что у них есть конкретные назначения. Так вот два из них используются в стеке. Это регистры esp и ebp. Это регистры-указатели, то есть их значения трактуются, как адреса. Ассемблер работает с ними, предполагая, что в них хранится адрес, вне зависимости от тог, что там находится в реальности. Это означает, что если вы поместите в них число 4, то при разыменовании будет обращение к памяти по адресу 4, а если эта память недоступна, то вы получите ошибку.
Давайте посмотрим, на что они указывают, когда программа только запущена:
![]()
Оба указателя находятся под стеком, то есть указывают на элемент под стеком.
Когда мы помещаем значение в стек, регистр esp начинает указывать на верхний, то есть на последний добавленный элемент в стеке:

Если мы добавим еще один элемент, то esp вновь будет указывать на вершину стека:

Таким образом, с помощью регистра esp мы можем получить доступ к последнему добавленному элементу стека, а также к произвольному значению в стеке. Для того, чтобы получить значение по некоторому адресу используется синтаксис разыменования.
Разыменование указателей
Для того, чтобы разыменовать указатель нужно заключить регистр в квадратные скобки:
mov eax, [esp]
Таким образом в eax будет помещено значение по адресу esp. Если написать просто:
mov eax, esp
То тогда в регистре eax будет адрес, который хранится в esp, но однако никто не запрещает разыменовать и его:
mov eax, [eax]
Давайте попробуем поместить в стек пару значений и получить значение элемента после самого последнего:
В последней строке мы используем разыменование, но однако до этого мы сдвигаем указатель на 4 байта, такой синтаксис корректен, он означает, что начала из адреса вычитается 4, а потом происходит разыменование. В итоге, мы получим в выводе 20, так как адрес esp + 4 указывает на следующий, после вершины стека, элемент.
Однако, вас может смутить, почему для того, чтобы получить элемент под верхним, нужно прибавлять 4, а не отнимать. Дело в том, что адреса в стеке уменьшаются снизу вверх:

Поэтому для получения элементов ниже последнего нужно прибавлять, а выше — вычитать.
Но почему именно 4? Дело в том, что мы помещаем в стек 4 байтные значения по-умолчанию, и чтобы обратится именно к следующему элементу нужно прибавить 4. Если вы попробуете прибавить, например, 2, то вы получите число, которое описывается 4 байтами, начиная с текущего, то есть программа просто возьмет 32 бита из стека и поместит их в eax абсолютно не думая о том, что это могут быть не те данные, обычно это приведет к ошибкам.
Функции
Следующая очень важная тема, это функции. Функции в ассемблере задаются с помощью ключевого слова PROC (регистр не важен, см. введение).
Так, например, объявление функции выглядит следующим образом:
Каждая функция должна заканчиваться командой ret для явного выхода из функции.
Вызвать функцию можно с помощью команд условного и безусловного перехода, но для этого есть более специализированные команды.
Для вызова функции используется команда call.
CALL [имя_функции]
Команда call переводится как «вызвать».
Эта команда помещает в стек адрес возврата (адрес следующей, после этой, команды) и переходит к началу функции. Адрес возврата нужен, чтобы после завершения выполнения перейти к команде, которые должны быть выполнены после вызова функции.
Пролог функции (Начало функции)
Каждая функция начинается с так называемого пролога процедуры.
Пролог процедуры — это фрагмент кода, нужный для того, чтобы сохранить текущее состояние стека, то есть сохранить адрес последнего элемента стека в момент вызова функции.
Код пролога следующий:
В первой строке мы помещаем в стек ebp, чтобы потом, после того, как функция завершит свою работу восстановить изначальное значение. Это нужно, так как в следующей строке мы кладем значение esp в ebp. Но что это означает на деле.
Предположим, у нас в стеке лежит два значения. Мы вызываем функцию с помощью команды call. В стек кладется адрес возврата (см. описание функции call):

После того, как мы выполним первую команду пролога, стек будет следующим:

То есть мы помещаем ebp в стек, при этом esp указывает на последний элемент, то есть на значение ebp, которое было только что добавлено. Сам регистр ebp все еще указывает на дно стека.
После того, как мы выполним вторую команду пролога, стек будет следующим:

Все что изменилось, это то, что ebp стало равным esp.
Таким образом, после пролога, в ebp будет хранится адрес вершины стека (или верхнего элемента стека) в момент вызова функции. Это нужно, чтобы, когда мы в функции будем добавлять элементы в стек, то в ebp адрес все еще будет указывать на начальный для esp в начале функции:

Это нужно, чтобы можно было обращаться к элементам стека, которые были до вызова функции по фиксированным сдвигам. Так, например, если мы хотим получить значение 20 то достаточно прибавить 8 к ebp, а вот для esp необходимо сначала вычесть количество добавленных в функции новых значений и только потом вычесть 8, что намного сложнее. Поэтому мы будем использовать ebp для доступа к элементам стека, которые были добавлены до вызова функции, это понадобится нам в дальнейшем для передачи аргументов.
Эпилог функции (Конец функции)
После того, как функция завершена, выполняется так называемый эпилог процедуры. Эпилог процедуры восстанавливает значение ebp, которое мы сохранили в стек в прологе.
Код эпилога следующий:
Стек после эпилога будет следующий:

То есть теперь ebp будет вновь указывать на дно стека (будет иметь первоначальное значение, которые мы сохранили в прологе), а значение из стека будет изъято. Теперь на вершине стека лежит адрес возврата. Встречая команду ret, из стека извлекается значение и трактуется, как адрес возврата, то есть в виде адреса команды, с которой нужно продолжить выполнение программы после того, как функция закончена.
Например, у вас есть следующий код:
Когда функция someFunction вызывается, то в стек помещается адрес следующей команды, то есть в нашем случае адрес команды mov.
После того, как функция закончила работу, из стека извлекается этот адрес и выполнение продолжается, начиная с команды по этому адресу, то есть с команды mov.
Проблема при работе со стеком в функции
Однако здесь таится большая возможная проблема, а что если мы в функции поместили в стек какое-то значение?
И после добавления у нас идет эпилог функции. Тогда в ebp будет помещено значение из вершины стека, где у нас лежит значение 5.

Теперь ebp указывает на неизвестно что, а на вершине стека лежит адрес ebp, который мы поместили еще в прологе. Теперь, так как после пролога идет команда ret, будет извлечено значение из стека и оно будет рассматриваться, как адрес возврата, но это не адрес возврата, а адрес ebp. Поэтому мы получим ошибку, так как пытаемся получить доступ к памяти, которая нам недоступна.
Чтобы этого избежать, нужно тщательно следить за стеком!
Если вы в функции добавляете какие-то значения в стек, то их обязательно нужно извлечь оттуда до пролога!
Дневники чайника. Чтива 0, виток0
Знакомство с MASM32 и Win32-программированием
Мне приходит довольно много писем с просьбами рассказать о MASM’е больше. И я решил слегка переделать эту главу.
Кроме того, я уже написал справочные статьи для тех, кто не застал времена MS-DOS. Если интересно, загляните в следующий виток
Как получаются программы?
До сих пор мы писали все примеры в Hiew’e, но этот способ крайне извращенный.
Я использовал его только для того, чтобы вы увидели настоящий Асм.
Вначале очень трудно отличить высокоуровневые наслоения от самого языка Ассемблер,
и некоторое время я сам путал команды процессора и директивы.
Но теперь, когда вы видели язык во всей его наготе, можно слегка приодеть его.
Нормальные программы пишут в обычном текстовом виде, а не как мы раньше (каждую строку сразу транслировали в машинную команду).
Такой текстовый вид называется исходным, а файлы — исходниками, или сырцами (от английского source).
Текст исходника можно писать где угодно, хоть в Ворде (при установленном фильтре простого текста).
На вкус, на цвет…
Я пишу в RadAsm’e. Это целая среда для разработки приложений, очень удобно.
Однако на первых порах рекомендую писать просто в редакторе Far’а, можно подключить к нему специальный плагин Colorer.
Этот плаг подсвечивает синтаксис многих языков программирования. Но всё это не обязательно. Тут каждый сам себе берлогу выстилает.
Когда исходный текст набран и сохранён, его можно компилировать.
За процесс получения готовой программы отвечает компилятор, и состоит этот процесс из двух основных этапов.
- Исходный текст преобразуется в промежуточный файл. Это делает транслятор (в случае с MASM’ом он называется ml.exe).
- Затем создаётся готовый исполняемый модуль в определённом формате. То есть программа.
Это делает линковщик (в случае с MASM’ом он называется link.exe).
Значит, для того чтобы делать программы, нужно иметь текстовый редактор и компилятор,
который состоит из двух основных частей — транслятор и линковщик.
Всё остальное не обязательно, однако реальные программы Win32 используют
внешние функции, стандартные константы и переменные, ресурсы и много другое.
Всё это требует дополнительных файлов, которые мы и видим в…
MASM32 SDK
Это очень распространённый пакет, собранный Стивеном Хатчисоном (Hutch).
Важно понять, что MASM32 вовсе не компилятор, а сборник для программирования под Win32,
в который входит 32-битный компилятор MASM.
Сегодня (С наступающим, 2012-м, годом!) я использую пакет MASM32 версии 10.
Описывать всё, что входит в пакет MASM32 SDK, — не вижу смысла. Лучше сосредоточиться на самом компиляторе.
Матрос, мы сегодня выходим из гравитационного пояса Солнечной системы.
Перед гиперскачком нужно проверить и настроить всё оборудование.
Из чего состоит компилятор MASM?
Основных файлов всего два:
ml.exe — транслятор. Он преобразует исходный текст в obj-файл (объектного формата COFF или OMF),
link.exe — линковщик. Создаёт готовый исполняемый exe или dll модуль (в формате для DOS, Windows…).
Эти файлы включены в основной состав MS Visual Studio (и в .NET).
При желании можно скачать в открытом доступе самые новые версии вместе с Visual Studio Express (или в обновлениях) на сайте MS.
Правда, я не вижу в этом особого смысла (в следующем витке описана причина).
Установка и настройка MASM32
Ну, для начала хорошо бы его иметь. Можно скачать с wasm.ru или с сайта автора.
1. Перед установкой отключите чрезмерно бдительные антивирусы (Каспер в первую очередь).
2. Устанавливать пакет советую на тот диск, где будут ваши исходники.
Теперь полезно прописать в системе путь к файлам компилятора.
В Win7 это можно сделать так:
В меню «пуск» правый клик на «Компьютер» > Свойства > Дополнительные параметры системы > закладка «Дополнительно» > Переменные среды.
Здесь в списке системных переменных нужно изменить значение переменной «PATH». Дописать в конце строки:
;D:MASM32bin
(не пропустите точку с запятой и вместо «D» укажите букву диска на котором установлен MASM32).
Поскольку редактор исходных файлов Quick Editor я не использую (уж больно он убогий),
на этом можно считать подготовку MASM32 к работе завершенной.
Было бы неплохо знать, как вообще проходит процесс написания программы.
Здесь я могу рассуждать только теоретически, так как сам не написал еще ни одной серьёзной программы. :)))
Однако кое-что об этом знаю и с радостью поделюсь своими представлениями.
Реальный процесс разработки программы
Знающие люди говорят, что это творческий процесс. Из чего можно сделать вывод, что дело это крайне личное.
Но общие правила здесь тоже имеются.
- Постановка задачи
- Создание алгоритма (в той или иной степени)
- Кодирование на конкретном языке
- Попытка компиляции. Если счетчик ошибок не ноль, прыг на шаг 3 или даже 2
- Удивление, что оно хоть как-то заработало
- Если счетчик найденных ошибок не ноль, то прыг на шаг 1
- Я пока так оставлю, а потом ещё доделаю
- Если обстоятельства (обычно лень) не позволяют продолжить — проект умирает. Или на шаг 1
Примерно так я делал небольшую программку для личного пользования.
Научить вас ставить задачи я даже пытаться не буду, сам не умею.
Создавать алгоритмы вас научит Кнут, это его стихия, а я могу только восхищаться.
Дональд Эрвин Кнут — Великий Автор, его трёхтомник можно взять на сайте
int3.net (после регистрации).
Мне кажется, человек, который не читал Кнута, программистом себя называть не имеет права (сам я, кстати, тоже не читал :).
А если серьёзно, то абсолютное большинство существующих учебников и литературы о программировании не может выжить и семи лет,
потому что такие книги ориентированы на изучение возможностей того или иного языка (как мои статьи).
Кнут же на протяжении полувека(!) учит создавать реальные программы, а не оболочки для простого ввода/вывода.
Думаю, вы поняли, что его книгу хорошо бы купить. Цена, правда, хорошая, но трёхтомник того стоит.
Итак, вернёмся к бренной жизни.
Кодирование на конкретном языке — вот о чем мы тут толкуем.
Правда не надо забывать, что программа ещё должна работать под конкретной системой.
Win32
Многие считают, что мир форточек устроен по законам Майкрософт, но это лишь очень поверхностный взгляд.
Как бы ни старались специалисты этой конторы,
они тоже вынуждены подчиняться правилам Intel. Так что главное отличие DOS-среды от Windows —
это то, что последняя опирается на защищённый режим процессора (Protected Mode — PM).
Кардинальное отличие PM от Real Mode — новый (довольно хитрый) механизм работы с памятью, и он сильно изменил жизнь программистов.
Win32 использует страничную адресацию памяти, которая является надстройкой над сегментной адресацией защищённого режима.
Несмотря на то, что работа с памятью в PM устроена сложно и запутанно, внешне всё выглядит элементарно.
По крайней мере в Windows адресацию сделали довольно удобной.
В данном случае советую всем начать именно с внешнего осмотра.
Ну если, конечно, вы самые смелые, самые умные и уже готовы разбирать всё по винтикам изнутри,
тогда берите учебник по i80386 процессору и читайте про селекторы,
таблицы дискрипторов, разбирайтесь, как в PM при страничной адресации формируется физический адрес из линейного.
Лучше, конечно, начать с рассылки Broken Sword’a.
Но что-то мне подсказывает, что вам пока рано браться даже за популярное изложение особенностей PM :).
Сам я уже год как пытаюсь подступиться к этой теме, просветление уже где-то рядом.
Внешний осмотр Win32.
Что же мы имеем после загрузки форточек:
- Каждая программа загружается в собственное изолированное виртуальное адресное пространство (Виртуальное Пространство Процесса).
- Адреса в таком ВПП могут быть от 00000000 до FFFFFFFF (4Gb), будем называть их виртуальными.
- При загрузке и далее при выполнении в эту виртуальность проецируется всё необходимое для работы программы
(код и данные операционной системы, динамические части самой программы, файлы и т.п.). - Программа, кроме собственных вычислений, практически ничего самостоятельно сделать не может.
Ей приходится просить ОС вывести что-либо или предоставить в её ВПП. Для этого она вызывает нужные API-функции. - Файлы с машинным кодом и данными у Win32-программ устроены в соответствии с PE-форматом,
который довольно сильно связан с особенностями защищённого режима процессора.
Исполняемые файлы PE-формата делятся на секции. Должна быть минимум одна секция (секция кода),
но файл может иметь и другие секции для разных целей (данные, ресурсы, служебные секции и т.д.).
А ещё нужно знать, что в защищённом режиме существуют 4 уровня привилегий. Нулевой самый сильный,
3-й самый слабый. Эти уровни называют кольцами (ring0,1,2,3).
Win32 использует только ring0 для ядра и драйверов и ring3 для прикладных программ.
Таких поверхностных данных вполне достаточно, чтобы мы могли дальше разумно изучать программирование на Ассемблере,
и приступить к программированию WinAPI.
По крайней мере сам я о защищённом режиме и о том, как его используют форточки знаю немногим больше :(.
Так что будем учиться вместе.
Первый пример Windows-программы
Давайте рассмотрим, как может выглядеть маленькая программа для Win32, написанная под MASM.
prax05.asm:
.386
.model flat, stdcall
option casemap :none ; case sensitive
;#########################################################################
include masm32includewindows.inc
include masm32includeuser32.inc
include masm32includekernel32.inc
includelib masm32libuser32.lib
includelib masm32libkernel32.lib
;#########################################################################
.data
MsgBoxCaption db "It's the first your program for Win32",0
MsgBoxText db "Assembler language for Windows is a fable!",0
;#########################################################################
.code
start:
invoke MessageBox, NULL, addr MsgBoxText, addr MsgBoxCaption, MB_OK
invoke ExitProcess, NULL
end start
Языка Ассемблер здесь нет! Этот текст будет преобразован в запускаемый файл формата PE (Portable Executable — портируемый exe-формат).
То есть стандартную программу для форточек.
Попробуйте набрать в файл «prax05.asm» все эти строки, большая часть которых, кстати сказать, — директивы MASM’a.
…Хотя это как раз можно и не набирать, ещё успеете натыкаться :), возьмите мой файл.
Компилировать программу новичку проще всего так (читатели меня всё-таки убедили =):
1. Открыть редактор исходных файлов «Quick Editor» (икона «MASM32 Editor» на рабочем столе).
2. Открыть или набрать в нём пример.
3. После всех изменений обязательно нужно сохранить пример и обязательно на тот диск где установлен MASM32.
4. Для самой компиляции нужно выполнить пункт меню Project > Build All.
5. Должно появиться консольное окошко с отчётом компилятора (если консоли нет, значит, по какой-то причине компиляции не было).
Запустить пример можно из того же Quick Editor’a кнопкой «Run File» или пунктом меню Project > Run Program.
Если вы планируете работать с компилятором на разных дисках, то самый грубый, но быстрый и универсальный, способ решить проблему компиляции – тупо скопировать папку MASM32 в корень всех дисков, где будет проходить компиляция программ.
Хочу предостеречь юные умы от выражений типа «иконка открывает MASM».
В корне неправильные слова влекут неправильные выводы и действия.
Ещё раз обращаю ваше внимание: MASM – это компилятор, он состоит из двух частей (ml.exe и link.exe). Обе части не имеют другого способа общения с пользователем кроме как через командную строку. А иконка на рабочем столе открывает программу-посредник под названием «Quick Editor», которая для компиляции всего лишь запускает файл build.bat.
И тут мы переходим к следующему уровню пользования компилятором.
Другой способ компиляции программ — использовать файл build.bat без посредника (описание в следующем витке).
В командной строке ОСи (В Far’e внизу или в «Пуск > Все программы > Стандартные > Командная строка») набираем следующее:
build prax05
! Разумеется, текущей папкой должна быть папка с исходником.
! Имя файла в командной строке пишите без расширения.
! Расширение у файла должно быть asm.
! файл должен быть на диске с пакетом MASM32 в корне.
После нажатия Enter вызовется бат-файл. Его задача превратить текстовый файл (исходник) в готовую программу (бинарник). Для этого он выполняет ml.exe с параметрами
"/c /coff prax05.asm"
Если в исходнике нет явных ошибок, появится файл prax05.obj.
И далее выполнится link.exe, который и создаст готовую Win-программу.
На выходе мы имеем два файла. Один — объектный, он нам не пригодится, это для нас промежуточный файл.
Второй — exe, сами знаете, что с ним делать.
Ошибки будут — это я гарантирую. Опечатки обычно быстро находятся, так как компилятор сообщает тип ошибки и строку, которая её вызывает.
Однако это далеко не всегда означает, что ошибка именно в этой строке.
Тут нужно головой думать. Подозреваю, что она у вас работает хорошо, раз мы с вами добрались до Windows.
Но если у вас недостаточно знаний пользователя и из-за этого не собирается даже пример prax05.asm, — не расстраивайтесь.
Прочитайте главу следующего витка.
Должно помочь и уж, по крайней мере, поднимет ваш «уровень юзера». Да, да, у вас всё получится…
Поздравляю, матрос! Мы в гиперпространстве.
Полноценная программа для Windows. Её уже не исследуешь в CodeView. Для отладки форточных программ мы запаслись OllyDbg.
Хорошо бы настроить и его (цвета, шрифты, размер и пути в ini-файле).
Это у вас займёт некоторое время, ко всему надо привыкнуть.
Я всё-таки надеюсь, вас не испугает такая небольшая программка весом в 2Mb,
ведь вы наверняка настраивали и более навороченные приложения. Кроме того, недавно хорошие ребята,
потрудившись наславу, сделали русский help, который можно взять тут.
Спасибо: deNULL, HyPeR, name, Wenden.
Exe-файл формата PE содержит кучу всякой ерунды, которая, впрочем, необходима для запуска Win32-программы.
Сложного там ничего нет, позже вы скорее всего познакомитесь с устройством PE-формата, а сейчас нужно понять лишь одно.
На начало исполняемого кода программы в памяти указывает Entry Point (EP — точки входа).
В разных программах она может указывать на разные адреса.
Но в простых примерах, собранных build.bat’ом, адрес первой команды будет 401000h.
Значение EntryPoint в таком случае будет = 1000h, плюс Image base 400000h = 401000h.
Про PE-формат мы, наверное, ещё поговорим, и даже очень плотно, ну а сейчас…
Откройте prax05.exe в OllyDbg. Для этого достаточно загрузить Olly и открыть программу как обычный документ в форточках.
После работы Win-загрузчика Олли покажет вам первую инструкцию в окне кода (ориентируясь именно на EP).
Исследовать этот пример вам пока не надо, через регистры здесь слишком трудно разобраться.
- В верхней левой части — вся программа, которая выводит на экран сообщение типа Message Box.
Вы видите, нет ни одной строчки из исходного файла prax05.asm, потому что это уже Ассемблер! - Вверху справа — регистры процессора (заметьте, EBX стоит четвёртым, рядом с регистрами-указателями, и флаги выглядят по-другому).
Как я уже сказал, регистры селекторов (сегментные регистры ES-GS) нас не волнуют, даже не обращайте на них внимание. - Внизу слева — байты памяти (Olly сразу же показывает секцию данных программы).
- Внизу справа отображается содержимое стека (о нём следующая глава).
Нужно заметить, несмотря на то, что Ollydbg выглядит как обычная программа,
это всё-таки отладчик и у него есть свои ограничения.
Рекомендую, например, закрывать его каждый раз, как вам понадобится загрузить новую программу.
Мы узнаем, как работает этот пример, но прежде остановимся на исходнике.
Весь код из исходника, кроме двух строк, будет во всех программах Win32 под MASM’ом, поэтому вы должны знать, что он означает.
Но не воспринимайте это слишком серьёзно. Там будет много длинно-умных слов. За такими словами очень часто прячется дребедень.
Хочу, чтобы вы поняли одну простую вещь. Совсем скоро вы будете знать команды Асма,
и если вы поймёте основы программирования, а затем познаете интерес математики :), то каждый из вас сможет написать собственный компилятор
для программ Ассемблера, возможно, не хуже MASM’a или FASM’a. Вы сможете сами придумывать всякие директивы,
псевдокоманды, макросы, плагины и новые удобные фишки. Но команды процессора — совсем другое дело.
Кроме того, что они в процессоре и изменить их нельзя (уточнение), большинство из команд имеет под собой математическое основание,
заложенное в структуру цифровых технологий. Поэтому приоритет нужно отдавать в пользу команд процессора.
А директивы MASM’a и все страшные слова за ними воспринимайте поверхностно.
Я бы вообще не объяснял их (как Калашников в первых уроках), если б не знал,
как сильно отвлекает внимание новичка непонятная строка в исходнике.
Теперь можно приступать к разбору этих самых директив.
Писать каждый раз такой код заново не надо. Это каркас программы для форточек.
Мало того, к этому каркасу будут добавляться такие же постоянно повторяющиеся вещи.
Создали один раз файл-заготовку — и далее можно вписывать туда только полезный код.
;#########################################################################
Я уже не раз говорил, что после точки с запятой идёт комментарий. Значит, MASM такую информацию не воспринимает.
Можно писать всё что хочется.
.386
Это директива, указывающая компилятору, что в программе будут использоваться команды процессора i80x386.
В exe эта информация записывается в самом начале после заголовка PE. Если интересно, найдите в exe-файле буквы PE.
Потом идут два нулевых байта, так как заголовок PE — это dword (4 байта).
В следующем слове (двух байтах) как раз и будет информация о командах процессора, которые используются программой.
Всё, от 386-го до сегодняшних 32-битных Intel-совместимых процессоров, обозначается кодом 014Сh. Для нас такая информация бесполезна,
а вот директива «.386» обязывает нас не использовать новые команды, иначе программа не соберётся,
пока мы не исправим эту директиву на «.486» или «.586» :).
.model flat, stdcall
Директива «.model» задаёт модель памяти flat для нашей программы. Модель flat лучше переводить: сплошная модель,
а не плоская, как многие пишут.
Stdcall — это «уговор» о том, кто будет чистить параметры (функция, которую вызвали, или сам вызывающий).
Мы всегда будем использовать вариант «функция чистит свои параметры».
Он и называется stdcall. Однако такое объяснение далеко не полное, и я вернусь к параметру stdcall при объяснении вызова функций.
К этому моменту вы уже будете знать, что такое стек.
От директивы .model явным образом зависит скомпилированный код в объектном файле и также зависит формат получившегося исполняемого файла.
option casemap :none ; case sensitive
Это просто. Всё уже объяснено в комментарии. В этой строке включается чувствительность к ПРОПИСНЫМ или строчным символам.
То есть «МЕТКА» и «метка», «Имя» и «имя» будут уже не одно и то же!
На exe это никак не отражается.
;#########################################################################
include masm32includewindows.inc
include masm32includeuser32.inc
include masm32includekernel32.inc
includelib masm32libuser32.lib
includelib masm32libkernel32.lib
Include — директива для подключения файлов (их расширение не обязательно должно быть inc).
В подключаемых файлах может быть всё то же самое, что и в основном файле.
То есть исходный код программы, данные, макросы (тоже код), комментарии и т.д.
Причём вы можете вставлять инклуды, например, в середине кода, а продолжать программу уже в том файле.
В этих трёх inc-файлах в текстовом виде содержатся описания констант, структур и прототипов функций Windows.
Далее я всё объясню, и вы поймёте, что это очень просто — как словарь или каталог товаров.
Вы можете перенести нужные описания в наш файл, и подключать inc’и не придётся, только это неудобно.
Includelib — директива для подключения файлов импорта. Я сам только что в первый раз задумался: а что в lib-файлах?
Думаю, что вам сегодня объяснять это не нужно.
Просто там информация о системных библиотеках, на основе которой будет сформирован вызов API-функций в нашей программе.
В exe-файл в данном случае из inc’ов не попадёт ни строчки кода,
но компилятору они нужны для преобразования двух полезных строк (invoke) в машинный код.
А из lib-файлов будут взяты две строки кода и данные, которые в exe запишутся в директорию импорта (всё тот же PE-формат).
;#########################################################################
.data
Вот это очень интересная строка. Тоже директива.
Чтобы разделить код и разного рода данные, в exe-файлах существуют секции.
У каждой секции свои атрибуты и они тоже напрямую связаны с защищённым режимом.
Это позволяет стабилизировать работу программ и упорядочить процесс написания.
Считается, что машинный код менять не нужно, значит, для него подойдёт атрибут read only (только чтение).
А данные (как теперь считается) выполнять не нужно, значит, можно в секции данных выключить атрибут исполняемого кода.
Слава Богу, что всё это только теоретически (пока). Любая секция может содержать и код, и данные, и соответствующие атрибуты.
Так что сейчас можно воспринимать секции только как полезную для программистов вещь.
Итак, секция данных объявляется директивой «.data», и это выставляет в ней нужные для данных атрибуты.
Так же, как мы вписывали строки текста в конце файла (после кода программы), эта секция по умолчанию будет размещаться в exe-файле после кода.
MsgBoxCaption db "It's the first your program for Win32",0 MsgBoxText db "Assembler language for Windows is a fable!",0
Здесь от MASM’a только db. Перед ним идут названия переменных. После db идёт содержание переменной, то есть текстовые или цифровые данные.
Если данные текстовые, то они помещаются в кавычках или апострофах. А если данные просто байты, то так и пишут через запятую.
Добавьте в этой секции вот такую строку:
LaLa db 00,0FFh, 11d, 0ABh, 01010101b
Теперь соберите файл ещё раз (старые obj и exe будут стёрты build.bat’om).
Несмотря на то, что переменная LaLa в коде не использовалась, в готовой программе будут эти байты:
00 FF 0B AB 55
Найдите их, загрузив пример в отладчик OllyDbg.
Я уже говорил, что обычно мы будем заканчивать строку текста нулевым байтом.
Теперь вы видите, как это пишется в синтаксисе MASM’а.
Str1 db "строка",0
или так:
Str2 db 'строка',00h
В файле будет одно и то же: байты символов и 00.
А Str1, Str2 — это имена переменных, они могут быть любые, лишь бы не нарушали правил, описанных в help-файлах MASM’a.
Осталось объяснить, что такое db — одна из ряда однотипных директив инициализации данных и их резервирования.
Длинные слова, мало что значат.
DB — сокращение от Data in Bytes (данные в байтах).
Есть ещё DW (Data in Words), и DD (Data in Dwords), и ещё несколько аналогичных, побольше.
Суть только в том, что запятая в DB разделяет байт, а в DD запятая разделяет 4 байта. Пример.
В исходнике так:
Str1 dd 0, 1, 0FFFFFFFFh
В файле будет:
00 00 00 00 01 00 00 00 FF FF FF FF
В исходнике так:
Str1 db 0, 1, 0FFh
В файле будет:
00 01 FF
А строка
Str1 db 0,1,0FFFFFFFFh
вызовет ошибку при сборке файла — размер в последней запятой не тот.
Вот и все основные премудрости представления целочисленных данных без знака (то есть положительных целых чисел) в MASM’e.
Хотя нет, забыл сказать, что можно ещё объявлять резерв. Данные, которые на момент старта программы ещё не появились.
Для чего это делается?
Допустим, в программе много промежуточных данных. Вписывая их в секцию неинициализированных данных (.data?),
мы экономим в размере файла. Пока программа не стартовала, никаких данных в этой секции нет,
а вот во время загрузки OS выделяет память сразу под все данные.
На первых порах можно спокойно писать все данные в секцию .data. Файл от этого больше не станет,
а наоборот, будет только меньше. В PE-формате есть много всяких тонкостей, одна из них — это выравнивание секций.
В большинстве программ в конце каждой секции есть нули, посмотрите в Hiew’e, и вы увидите, сколько места пропадает.
Если я ничего не путаю, то секция должна быть кратна 512 байтам (200h).
Значит, если у вас нет данных на эту сумму, то лучше не заводить новую секцию «.data?» а писать всё в «.data».
Здесь закончилась секция данных…
.code
…и началась секция кода.
Это единственная секция, без которой программу не собрать.
Но я ещё раз повторяю: «.code» вовсе не означает, что данных сюда класть нельзя.
Правда, если данные изменяются и они в секции кода — это вызовет проблему (не те атрибуты секции). Хотя руками можно всё :).
start:
Вот мы и добрались до нашей первой метки. Метки в exe-файл не идут.
Первая метка начинает код программы. Можно написать хоть «tuki_puki:», лишь бы в конце кода было «end tuki_puki».
Что и сообщит MASM’у, где кончилась программа, а самое главное — где она началась.
Далее мы всё время будем использовать метки. Они начинают строки, к которым нам нужно прыгать.
При сборке программы компилятор подставляет адреса команд в памяти вместо обращений к меткам. Это гораздо удобнее, чем писать:
JMP 00
Такая команда будет ошибочна, так как, я уже сказал, EP будет указывать на разные адреса в разных программах.
Пока что адрес в памяти для первой инструкции будет 401000, а если код программы усложнится, то адрес может стать другим. Если вы запишете:
JMP start
то больше об адресах беспокоиться не надо. В exe окажется правильная маш.команда, а на Асме она будет выглядеть «JMP 00401000» или куда укажет метка.
invoke MessageBox, NULL, addr MsgBoxText, addr MsgBoxCaption, MB_OK invoke ExitProcess, NULL
В этих двух строчках и скрывается сама программа.
Первая строка вызывает API-функцию MessageBox и передаёт ей необходимые параметры.
Вторая строка выполняет действие, похожее на int 20 в DOS. Это завершающий код с параметром NULL.
На самом деле в коде будет не NULL, а нулевой байт (00h). Это значит, что и здесь можно писать:
invoke MessageBox, 0, addr MsgBoxText, addr MsgBoxCaption, 0 invoke ExitProcess, 0
Подробный разбор содержания этих двух строк будет уже в следующей Чтиве.
Она была написана год назад, я тогда в первый раз увидел в WinXP код программы на Асме, поэтому дотошно описывал всё новое (но с таким количеством ошибок! :/).
end start
Найдя оператор END в этом случае, компилятор MASM’a сочтёт, что метка «start» будет точкой входа в программу.
Потому что больше заканчивать в этом файле нечего. Именно со строки
END первая метка
начнётся трансляция полезного кода в файл :).
В любой программе под форточки используется стек, и в следующей главе я расскажу о нём.
Bitfry
<<предыдущая глава следующая глава>>
Вернуться на главную
— Фирма Интел после всем известной ошибки Пентимума
разработала специальную утилиту для «конечных» пользователей,
благодаря которой можно изменять код микропрограммного блока управления в процессорах «выше» Пентиума.
То есть у нас с вами теоретически есть возможность менять свойства инструкций процессора.
Некоторую информацию вы можете получить в популярной статье iXbt, а также здесь.
![]()
Оглавление
Исходники
Программы
Справочник

Разминка. Первая программа
Итак, приступим. Нам понадобится сам MASM32, который легко найти в Интернете.
Для своих проектов создадим папку, но, желательно не внутри MASM32. Назовем ее, но так,
чтобы в названии были только английские буквы — компилятор, гад, по-русски не понимает и
при компилляции будут трудности. Если имя не придумывается, то назовем просто ASM. Получилось? Тогда начнем. Немножко теории. В ассемблере
любая программа содержит сегмент данных — он отмечается символом .data, сегмент констант
— .const и сегмент кода — .code. В сегмент данных заносятся переменные, которые будут
доступны из любой точки программы (глобальные переменные). То же самое относится и к
сегменту констант. Тогда в общем виде структура программы имеет вид:
.data — глобальные переменные
.const — константы (по ходу дела не меняются)
.code — исполняемый код прогаммы
start: — его начало и наконец,
end start — его окончание.
MASM32 использует плоскую модель памяти — никаких сегментов памяти нет,
она, в принципе, доступна вся. Об этом — в самом начале программы мы должны
сообщить компиллятору (который сделает их нашего текста исполняемый .ехе файл):
.386 ; процессор
.model flat, stdcall ; 32 разрядная модель памяти
option casemap :none ; различает строчные
и заглавные буквы
Накопленный человечеством опыт собран в библиотеках. Опыт программистов
также собран в библиотеках — динамических и статических. Нам не нужно изобретать
велосипед заново — воспользуемся
тем, что уже есть (по крайней мере, на первых порах).
Windows содержит огромное количество функций в библиотеках динамической компоновки (DLL — dynamic link library),
эти функции часто называют API(Application Programming Interface).
Подключим к нашему проекту библиотеки. Это делается помощью include и includelib так:
include masm32includeuser32.inc
includelib masm32libuser32.lib
Если мы впишем в текст программы эти строки, то к нашему проекту будет подключена
библиотека user32. Одной библиотекой, как правило, не обойтись, чаще всего стандартный набор
выглядит так:
; Подключаемые файлы.
include masm32includewindows.inc
include masm32includemasm32.inc
include masm32includegdi32.inc
include masm32includeuser32.inc
include masm32includekernel32.inc
include masm32includeComctl32.inc
include masm32includecomdlg32.inc
include masm32includeshell32.inc
include MASM32includeoleaut32.inc
; Подключаемые библиотеки.
includelib masm32libmasm32.lib
includelib masm32libgdi32.lib
includelib masm32libuser32.lib
includelib masm32libkernel32.lib
includelib masm32libComctl32.lib
includelib masm32libcomdlg32.lib
includelib masm32libshell32.lib
includelib masm32liboleaut32.lib
Все понятно? Если не все (или все не) — ничего страшного, потом разберемся.
Едем дальше. Наша первая программа:
———————————————Линия отреза———————————————
.386
.model flat, stdcall
option casemap :none
include masm32includewindows.inc
include masm32includeuser32.inc
include masm32includekernel32.inc
includelib masm32libuser32.lib
includelib masm32libkernel32.lib
.data
TitleMsg db «Первая программа»,0
TextMsg db «Пишем здесь чаво-нибудь, типа — это я сам сделал(а)!» ,0
.code
start:
invoke MessageBox, NULL,ADDR TextMsg,ADDR TitleMsg, MB_OK
invoke ExitProcess, NULL
end start
uild
————————————-Линия отреза——————————————————
Аккуратно копируем то, что между линиями отреза (они не должны попасть в копируемую область!),
откравыем MASM32 editor, в меню File выбираем пункт New и вставляем туда скопированное. Теперь сохраним созданный файл
в нашей папке под каким-нибудь название, и, что очень важно, с расширением .asm, ну, например, first.asm. Получилось?
Если нет — то повторим все еще раз (или не раз, пока не получится). Теперь — компиляция, т.е. создание .ехе-файла. В меню
редактора выбираем пункт Project и в нем — пункт Build All. Выдохнули и нажали. Если все сделано правильно, через
какое-то время на экране появится что-то вроде:
Если картинка похожа, то .ехе-файл создан. Открываем нашу папку и находим его. Если папка была сначала
пустой, то после компиляции там три файла — один first.asm — это наш исходник, другой, похожий на использованную
туалетную бумагу — first.obj, и наконец, наш файл first.exe. Щелкаем по нему мышкой. Работает? Если не работает —
ищем, что сделано неправильно, а если работает — то еще похожий пример:
———————————————Линия отреза———————————————
.386
.model flat, stdcall
option casemap :none
include masm32includewindows.inc
include masm32includemasm32.inc
include masm32includeuser32.inc
include masm32includekernel32.inc
includelib masm32libmasm32.lib
includelib masm32libuser32.lib
includelib masm32libkernel32.lib
.data
TextMsg1 db «Здесь — текст, типа — это я сам сделал(а)!» ,0
TextMsg2 db» (чтобы показывать друзьям и знакомым )»,0
TextMsg3 db «Copyright © А здесь — свою ФИО., «,13,10,»(полностью, чтобы они поверили)»,13,10,»ну и, конечно, -All Right Reserved»,0
.code
start:
invoke AboutBox,NULL,NULL,NULL,ADDR TextMsg1,ADDR TextMsg2,ADDR TextMsg3
invoke ExitProcess, NULL
end start
end start
————————————-Линия отреза——————————————————
Повторим все то, что мы сделали раньше. Запускается? Для тех, у кого рука дрожит и текст
не копируется, исходники — пример 1 и пример 2
Ну вот, разминка закончена. Тот, кто понял, что MASM32 он уже полностью освоил, может
расслабиться, а для остальных — продолжение на следующей странице…
В начало
Дальше
MASM32 и OpenGL