Моделирование данных: зачем нужно и как реализовать
Время на прочтение
8 мин
Количество просмотров 29K
Моделирование данных ощутимо упрощает взаимодействие между разработчиками, аналитиками и маркетологами, как и сам процесс создания отчетов. Поэтому я перевела статью IBM Cloud Education о ценности моделирования и от себя добавила инфо о способах трансформации данных для моделирования.
Моделирование данных
Узнайте, как моделирование данных использует абстракцию для представления и лучшего понимания природы данных в информационной системе предприятия.
Что такое моделирование данных
Моделирование данных — это создание визуального представления о всей информационной системе либо ее части. Цель в том, чтобы проиллюстрировать типы данных, которые используются и хранятся в системе, отношения между этими типами данных, способы группировки и организации данных, их форматы и атрибуты.
Модели данных строятся на основе бизнес-потребностей. Правила и требования к модели данных определяются заранее на основе обратной связи с бизнесом, поэтому их можно включить в разработку новой системы или адаптировать к существующей.
Данные можно моделировать на различных уровнях абстракции. Процесс начинается со сбора бизнес-требований от заинтересованных сторон и конечных пользователей. Эти бизнес-правила затем преобразуются в структуры данных. Модель данных можно сравнить с дорожной картой, планом архитектора или любой формальной схемой, которая способствует более глубокому пониманию того, что разрабатывается.
Моделирование данных использует стандартизированные схемы и формальные методы. Это обеспечивает последовательный и предсказуемый способ управления данными в организации или за ее пределами.
В идеале модели данных — это живые документы, которые развиваются вместе с потребностями бизнеса. Они играют важную роль в поддержке бизнес-процессов и планировании ИТ-архитектуры и стратегии. Моделями данных можно делиться с поставщиками, партнерами и коллегами.
Преимущества моделирования данных
Моделирование упрощает просмотр и понимание взаимосвязей между данными для разработчиков, архитекторов данных, бизнес-аналитиков и других заинтересованных лиц. Кроме того, моделирование данных помогает:
-
Уменьшить количество ошибок при разработке программного обеспечения и баз данных.
-
Унифицировать документацию на предприятии.
-
Повысить производительность приложений и баз данных.
-
Упростить отображение данных по всей организации.
-
Улучшить взаимодействие между разработчиками и командами бизнес-аналитики.
-
Упростить и ускорить процесс проектирования базы данных на концептуальном, логическом и физическом уровнях.
Типы моделей данных
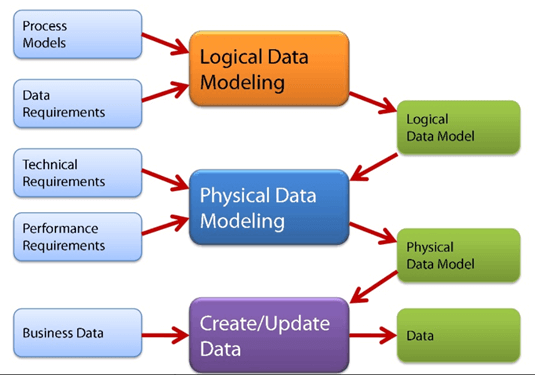
Разработка баз данных и информационных систем начинается с высокого уровня абстракции и с каждым шагом становится все точнее и конкретнее. В зависимости от степени абстракции модели данных можно разделить на три категории. Процесс начинается с концептуальной модели, переходит к логической модели и завершается физической моделью.
-
Концептуальные модели данных. Также они называются моделями предметной области и описывают общую картину: что будет содержать система, как она будет организована и какие бизнес-правила будут задействованы. Концептуальные модели обычно создаются в процессе сбора исходных требований к проекту. Как правило, они включают классы сущностей (вещи, которые бизнесу важно представить в модели данных), их характеристики и ограничения, отношения между сущностями, требования к безопасности и целостности данных. Любые обозначения обычно просты.


-
Логические модели данных уже не так абстрактны и предоставляют более подробную информацию о концепциях и взаимосвязях в рассматриваемой области. Они содержат атрибуты данных и показывают отношения между сущностями. Логические модели данных не определяют никаких технических требований к системе. Этот этап часто пропускается в agile или DevOps-практиках. Логические модели данных могут быть полезны для проектов, ориентированных на данные по своей природе. Например, для проектирования хранилища данных или разработки системы отчетности.
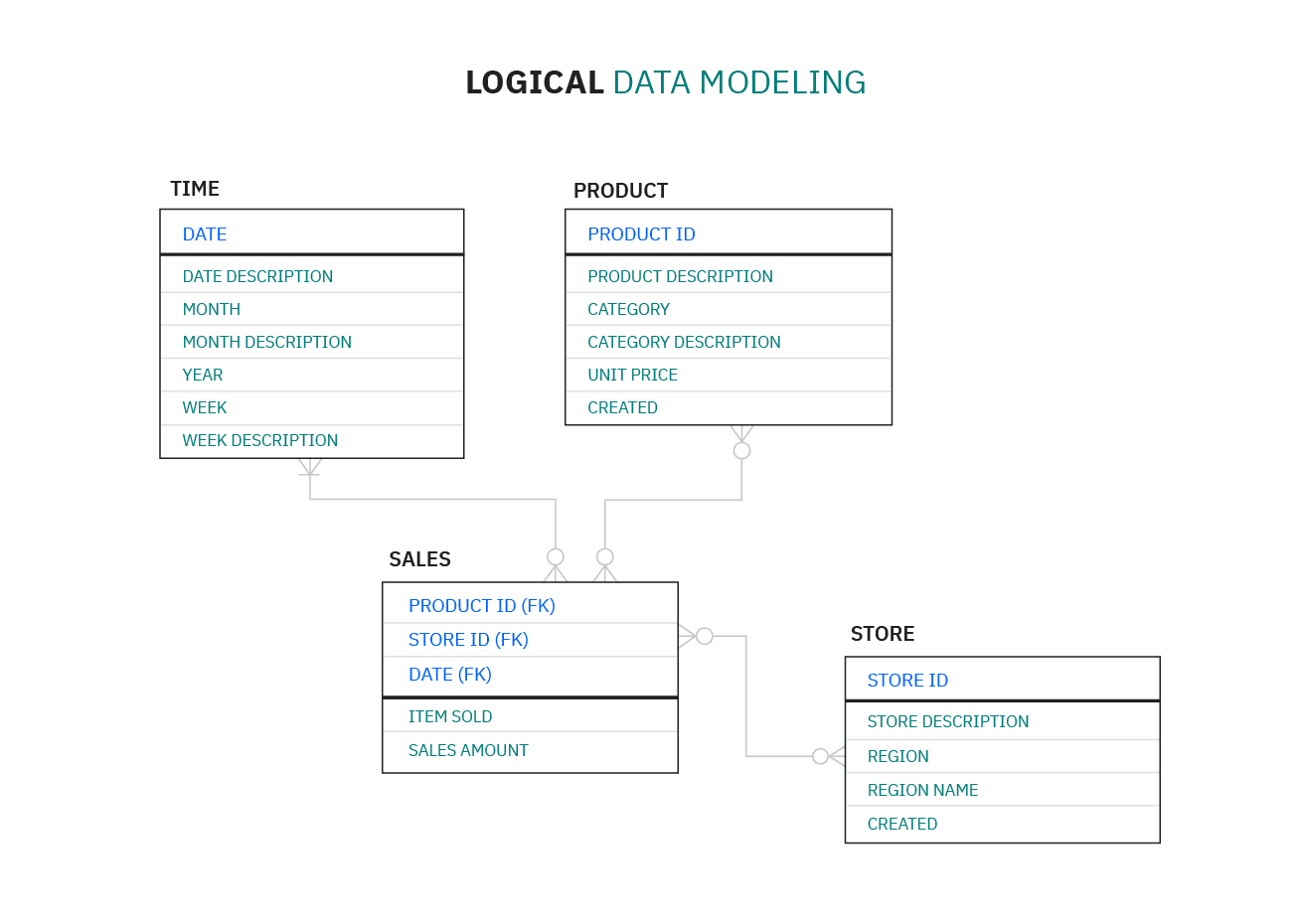
-
Физические модели данных представляют схему того, как данные будут храниться в базе. По сути, это наименее абстрактные из всех моделей. Они предлагают окончательный дизайн, который может быть реализован как реляционная база данных, включающая ассоциативные таблицы, которые иллюстрируют отношения между сущностями, а также первичные и внешние ключи для связи данных.


Процесс моделирования данных
Моделирование данных начинается с договоренности о том, какие символы используются для представления данных, как размещаются модели и как передаются бизнес-требования. Это формализованный рабочий процесс, включающий ряд задач, которые должны выполняться итеративно. Сам процесс обычно выглядят так:
-
Определите сущности. На этом этапе идентифицируем объекты, события или концепции, представленные в наборе данных, который необходимо смоделировать. Каждая сущность должна быть целостной и логически отделенной от всех остальных.
-
Определите ключевые свойства каждой сущности. Каждый тип сущности можно отличить от всех остальных, поскольку он имеет одно или несколько уникальных свойств, называемых атрибутами. Например, сущность «клиент» может обладать такими атрибутами, как имя, фамилия, номер телефона и т.д. Сущность «адрес» может включать название и номер улицы, город, страну и почтовый индекс.
-
Определите связи между сущностями. Самый ранний черновик модели данных будет определять характер отношений, которые каждая сущность имеет с другими. В приведенном выше примере каждый клиент «живет по» адресу. Если бы эта модель была расширена за счет включения сущности «заказы», каждый заказ также был бы отправлен на адрес. Эти отношения обычно документируются с помощью унифицированного языка моделирования (UML).
-
Полностью сопоставьте атрибуты с сущностями. Это гарантирует, что модель отражает то, как бизнес будет использовать данные. Широко используются несколько формальных шаблонов (паттернов) моделирования данных. Объектно-ориентированные разработчики часто применяют шаблоны для анализа или шаблоны проектирования, в то время как заинтересованные стороны из других областей бизнеса могут обратиться к другим паттернам.
-
Назначьте ключи по мере необходимости и определите степень нормализации. Нормализация — это метод организации моделей данных, в которых числовые идентификаторы (ключи) назначаются группам данных для установления связей между ними без повторения данных. Например, если каждому клиенту назначен ключ, этот ключ можно связать как с его адресом, так и с историей заказов, без необходимости повторять эту информацию в таблице с именами клиентов. Нормализация помогает уменьшить объем дискового пространства, необходимого для базы данных, но может сказываться на производительности запросов.
-
Завершите и проверьте модель данных. Моделирование данных — это итеративный процесс, который следует повторять и совершенствовать под потребности бизнеса.
Типы моделирования данных
Моделирование данных развивалось вместе с системами управления базами данных (СУБД), при этом типы моделей усложнялись по мере роста потребностей предприятий в хранении данных.
Иерархические модели данных представляют отношения «один ко многим» в древовидном формате. В модели этого типа каждая запись имеет единственный корень или родительский элемент, который сопоставляется с одной или несколькими дочерними таблицами. Эта модель была реализована в IBM Information Management System (IMS) в 1966 году и быстро нашла широкое применение, особенно в банковской сфере. Хотя этот подход менее эффективен, чем недавно разработанные модели баз данных, он все еще используется в системах расширяемого языка разметки (XML) и географических информационных системах (ГИС).
Реляционные модели данных были предложены исследователем IBM Э. Ф. Коддом в 1970 году. Они до сих пор встречаются во многих реляционных базах данных, обычно используемых в корпоративных вычислениях. Реляционное моделирование не требует детального понимания физических свойств используемого хранилища данных. В нем сегменты данных объединяются с помощью таблиц, что упрощает базу данных.
Реляционные базы данных часто используют язык структурированных запросов (SQL) для управления данными. Эти базы подходят для поддержания целостности данных и минимизации избыточности. Они часто используются в кассовых системах, а также для других типов обработки транзакций.
В ER-моделях данных используют диаграммы для представления взаимосвязей между сущностями в базе данных. ER-модель представляет собой формальную конструкцию, которая не предписывает никаких графических средств её визуализации. В качестве стандартной графической нотации, с помощью которой можно визуализировать ER-модель, была предложена диаграмма «сущность-связь» (Entity-Relationship diagram). Однако для визуализации ER-моделей могут использоваться и другие графические нотации, либо визуализация может вообще не применяться (например, только текстовое описание).
Объектно-ориентированные модели данных получили распространение как объектно-ориентированное программирование и стали популярными в середине 1990-х годов. Вовлеченные «объекты» — это абстракции сущностей реального мира. Объекты сгруппированы в иерархии классов и имеют связанные черты. Объектно-ориентированные базы данных могут включать таблицы, но могут также поддерживать более сложные связи. Этот подход часто используется в мультимедийных и гипертекстовых базах данных.
Размерные модели данных разработал Ральф Кимбалл для быстрого поиска данных в хранилище. Реляционные и ER-модели делают упор на эффективное хранение и уменьшают избыточность данных, а размерные модели упорядочивает данные таким образом, чтобы легче было извлекать информацию и создавать отчеты. Это моделирование обычно используется в системах OLAP.
Две популярные размерные модели данных — это схемы «звезда» и «снежинка». В схеме «звезда» данные организованы в факты (измеримые элементы) и измерения (справочная информация), где каждый факт окружен связанными с ним измерениями в виде звездочки. Схема «снежинка» напоминает схему «звезда», но включает дополнительные слои связанных измерений, что усложняет схему ветвления.
Инструменты для моделирования данных
Сегодня широко используются многочисленные коммерческие и CASE-решения с открытым исходным кодом, в том числе различные инструменты моделирования данных, построения диаграмм и визуализации. Вот несколько примеров:
-
erwin Data Modeler — это инструмент моделирования данных, основанный на языке IDEF1X, который теперь поддерживает и другие нотации, включая нотацию для размерного моделирования.
-
Enterprise Architect — это инструмент визуального моделирования и проектирования, который поддерживает моделирование корпоративных информационных систем и архитектур, программных приложений и баз данных. Он основан на объектно-ориентированных языках и стандартах.
-
ER/Studio — это программа для проектирования баз данных, совместимая с некоторыми из самых популярных СУБД. Она поддерживает как реляционное, так и размерное моделирование данных.
-
Бесплатные инструменты моделирования данных включают решения с открытым исходным кодом, такие как Open ModelSphere.
Для того, чтобы преобразовать данные в структуру, которая соответствует требованиям модели, можно использовать встроенный механизм регулярных запросов, которые выполняются в Google BigQuery, Scheduled Queries и AppScript. Их легко можно освоить, потому что это привычный SQL, но проводить отладку в Scheduled Queries практически нереально. Особенно, если это какой-то сложный запрос или каскад запросов.
Есть специализированные инструменты для управления SQL-запросами, например, dbt и Dataform.
dbt (data build tool) — это фреймворк с открытым исходным кодом для выполнения, тестирования и документирования SQL-запросов, который позволяет привнести элемент программной инженерии в процесс анализа данных. Он помогает оптимизировать работу с SQL-запросами: использовать макросы и шаблоны JINJA, чтобы не повторять в сотый раз одни и те же фрагменты кода.
Главная проблема, которую решают специализированные инструменты — это уменьшение времени, необходимого на поддержку и обновление. Это достигается за счет удобства отладки.
В основе моделирования баз данных лежит идея создания структуры базы данных, которая определяет, как можно получить доступ к хранимой информации, классифицировать ее и манипулировать ею. Это сама основа проектирования базы данных, а конкретная модель данных, используемая при проектировании, определяет диаграмму базы данных и общие усилия по разработке. Читайте дальше, чтобы узнать, почему моделирование является инженерным императивом, а также некоторые из наиболее популярных методов моделирования данных.
Моделирование базы данных 101
По сути, база данных должна быть простой в использовании и должна поддерживать целостность данных в безопасном режиме. Мощная модель базы данных также позволит использовать различные способы управления, контроля и организации хранимой информации для эффективного выполнения множества ключевых задач. На этапе проектирования диаграммы базы данных будут содержать необходимую документацию о ссылках на данные, которые облегчают функциональность базы данных.
Типы методов моделирования баз данных
Ниже приведен список наиболее распространенных методов моделирования баз данных. Обратите внимание, что в зависимости от типа данных и потребностей конечного пользователя при доступе к базе данных можно использовать несколько моделей для создания более сложного дизайна базы данных. Разумеется, в обоих сценариях для установления и поддержания высоких эксплуатационных стандартов потребуется создание диаграмм базы данных. К счастью, готовые под ключ диагностические и дизайнерские инструменты, такие как Creately, могут сделать это усилие легким ветерком.
Из приведенных ниже моделей реляционная модель является наиболее часто используемой моделью для большинства проектов баз данных. Но в некоторых особых случаях другие модели могут быть более выгодными. К счастью, Creately поддерживает все модели 🙂 .
- Реляционная модель: Основанная на математической теории, эта модель базы данных выводит хранение и поиск информации на новый уровень, так как она предлагает способ поиска и понимания различных взаимосвязей между данными. Рассматривая, как различные переменные могут изменить соотношение между данными, можно получить новые перспективы по мере изменения представления информации, сосредоточившись на различных атрибутах или областях. Эти модели часто можно найти в системах бронирования авиабилетов или в базах данных банков.

Метод реляционного проектирования, наиболее популярный метод проектирования баз данных
- Модель графика: модель графика – еще одна модель, которая набирает популярность. Эти базы данных созданы на основе теории графов и используют узлы и ребра для представления данных. Структура несколько похожа на объектно-ориентированные приложения. Базы данных графиков, как правило, легче масштабировать и обычно быстрее работают с ассоциативными наборами данных.
- Иерархическая модель: Как и общая организационная схема, используемая для организации компаний, эта модель базы данных имеет тот же древовидный вид и часто используется для структурирования XML документов. При рассмотрении эффективности данных это идеальная модель, в которой данные содержат вложенную и отсортированную информацию, но она может быть неэффективной, когда данные не имеют восходящей связи с основной точкой данных или субъектом. Данная модель хорошо работает для системы управления информацией сотрудников в компании, которая стремится ограничить или назначить использование оборудования определенным лицам и/или отделам.

Иерархический метод, самая первая модель проектирования базы данных
- Сетевая модель: Используя записи и наборы данных, эта модель использует подход “от одного к другому” к записям данных. Несколько ветвей выделяются для структур нижнего уровня и ветвей, которые затем соединяются несколькими узлами, представляющими собой структуры верхнего уровня внутри информации. Этот метод моделирования базы данных обеспечивает эффективный способ получения информации и организации данных таким образом, чтобы их можно было рассматривать несколькими способами, обеспечивая средство для увеличения производительности бизнеса и времени отклика. Это жизнеспособная модель для планирования дорожных, железнодорожных или коммунальных сетей.

Сетевая модель, в которой узел может иметь несколько родительских узлов
- Размерная модель: Это является адаптацией реляционной модели и часто используется в сочетании с ней путем добавления “размерности” фактов к точкам данных. Эти факты могут быть использованы в качестве измерительных палочек для других данных для определения того, как размер группы или время группы повлияли на определенные результаты. Это может помочь бизнесу принимать более эффективные стратегические решения и помочь им узнать свою целевую аудиторию. Эти модели могут быть полезны организациям с анализом продаж и прибыли.
- Объектная реляционная модель: Эти модели создали совершенно новый тип базы данных, который сочетает в себе дизайн базы данных с прикладной программой для решения конкретных технических задач, используя при этом лучшее из обоих миров. На сегодняшний день базы данных объектов все еще нуждаются в доработке для достижения большей стандартизации. Применение этой модели в реальном мире часто включает в себя технические или научные области, такие как инженерия и молекулярная биология.


Диаграммы базы данных и выбор модели
Независимо от того, какой метод моделирования базы данных вы выберете, необходимо разработать соответствующие диаграммы для визуализации желаемого потока и функциональности, чтобы база данных была спроектирована наиболее эффективным и действенным образом. Правильная диаграмма уменьшит количество исправлений и доработок, потому что вы можете протестировать предложенный проект перед тем, как вложить в него время и затраты на его реальное создание. Диаграммы также являются высокоэффективным инструментом коммуникации, особенно для больших команд, поскольку они способствуют четкому и быстрому общению.
Независимо от того, предпочитаете ли вы настольное программное обеспечение, Google App или веб-приложение, Creately имеет все необходимое для упрощения совместного создания диаграмм, включая бесплатные шаблоны диаграмм баз данных и примеры любых типов диаграмм, таких как блок-схемы, диаграммы разума, проводные диаграммы и UML. Creately также предоставляет плагины для популярных платформ, включая Confluence, JIRA и FogBugz, чтобы расширить их возможности для поддержки разработки диаграмм базы данных.
Источники:
- http://docs.oracle.com/cd/B13789_01/appdev.101/b10828/sdo_net_concepts.htm
- http://infolab.stanford.edu/~ullman/focs/ch08.pdf
- http://docs.oracle.com/cd/B28359_01/olap.111/b28124/overview.htm
Моделирование и проектирование данных
Конспект DAMA DMBOK2 на русском языке
Глоссарий проекта и вебинар-обсуждение
Конспект каждой главы мы сопровождаем онлайн-дискуссией с экспертами по теме
Понятие и цель моделирования данных
Моделирование данных заключается в последовательном выявлении, анализе и формулировании основных требований к данным и их последующим представлением и распространением в виде модели данных
Наиболее часто используются следующие схемы представления данных:
→ реляционная
→ многомерная (dimensional)
→ объектно-ориентированная
→ основанная на фактах (fact-based)
→ хронологическая (time-based)
→ NoSQL2
Модели данных во всех этих схемах представляются на трех уровнях детализации — концептуальном, логическом и физическом. Каждая модель содержит набор компонентов (примеры компонентов — сущности, связи, факты, ключи, атрибуты).
Модели данных важны, потому что —
→ определяют единую общую терминологию во всем, что касается данных
→ собирают и документируют точные знания о данных и информационных системах организации
→ служат основным средством коммуникации в процессе реализации проектов
→ являются отправной точкой при настройке, интеграции или даже замене приложений
Главная цель моделирования данных — подтвердить и документально зафиксировать понимание различных аспектов организации данных, которое обеспечит создание приложений, наиболее точно соответствующих текущим и будущим потребностям бизнеса, а также заложить фундамент для успешной реализации широкомасштабных инициатив, таких как программы управления основными данными и руководства данными
![]()
Формализация
Модель данных документирует краткое и четкое определение структур данных и связей между ними. Она позволяет оценивать, как влияют на данные реализованные бизнес-правила (как для текущих, так и для будущих целевых состояний)
![]()
Определение области применения
Модель данных помогает объяснить границы контекста данных, а также границы внедрения приобретенного программного обеспечения и области охвата проектов, инициатив и существующих систем

Сохранение и документирование знаний
Модель данных может сохранять корпоративную память о какой-либо системе или проекте, фиксируя знания в четко определенной форме. Она служит документацией для будущих проектов в качестве версии «как есть»
Основные концепции моделирования
Модель — это представление чего-либо, что уже существует, или примерный образец того, что предстоит создать. Модель данных либо описывает данные на текущий момент, либо отражает желаемое состояние данных
NB: Данные в покое и в движении. Что это?
Как правило, модели данных включают «данные в покое» (data at rest), т.е. статичные данные, находящиеся в местах хранения. Однако «данные в движении» (data in motion) (динамичные, перемещающиеся данные) также можно моделировать: например, с помощью описаний системных решений, включая протоколы, а также специфических схем для систем обмена сообщениями и систем на основе событий (event-based systems).
Предмет, о котором организация собирает информацию
Альтернативные наименования (aliases) понятия «сущность»
Общий термин сущность иногда может фигурировать под иными наименованиями. Чаще всего при этом используется понятие тип сущности, как тип чего-то, что должно быть представлено
Используемые компоненты модели данных могут называться по-разному, в зависимости от типа модели данных. Например, для обозначения понятия «сущность» могут использоваться:
- в реляционных схемах — сущность
- в многомерных схемах — таблица фактов (fact table) и таблица измерений (dimension table)
- в объектно-ориентированных схемах — термины класс (class) или объект (object)
- в хронологических схемах — термины концентратор (или хаб — hub), сателлит (satellite) и связь (link)
- в схемах NoSQL — такие термины, как документ (document) или узел (node)
Отношение между сущностями. Связи фиксируют информацию о взаимодействиях между концептуальными сущностями, детализированные взаимодействия между логическими сущностями и взаимные ограничения при взаимодействии физических сущностей
Мощность (cardinality) связи
Определяет, сколько экземпляров одной сущности и сколько экземпляров другой могут быть связаны друг с другом. Мощность отображается специальными символами на обоих концах линии связи.
Характеристика сущности, позволяющая ее идентифицировать, описать или измерить. Для атрибута может быть определен домен (domain) — совокупность возможных значений. На физическом уровне атрибуту сущности может соответствовать столбец, поле, тег или узел (место пересечения) в таблице, представлении, документе, графе или файле
Идентификатор
(или ключ — key)
Атрибут или набор атрибутов, уникальным образом определяющий экземпляр сущности.
Ключи могут быть:
→ простыми
→ составными
→ композитными
→ потенциальными
Исчерпывающе описанный набор, диапазон или множество значений, которые могут быть присвоены атрибуту. Определение домена — одно из средств стандартизации характеристик атрибутов. Пример домена: Дата
Домены атрибутов задаются наложением ограничений следующих видов:
→ Типы данных
→ Форматы данных
→ Списки
→ Допустимые интервалы
→ Реализация правил
Схемы представления данных при моделировании
Выбор схемы зависит отчасти от характера создаваемой базы данных, поскольку некоторые из них ориентированы на определенные технологии
Концептуальная модель данных (Conceptual Data Model, CDM)
Фиксирует высокоуровневые требования к данным как к набору взаимосвязанных понятий. Она содержит только базовые и критически важные для бизнеса сущности в рассматриваемой функциональной области с описанием каждой сущности и связей между ними
Логическая модель данных (Logical Data Model, LDM)
Детально отражает требования к данным, обычно в контексте их конкретного применения — например, с точки зрения потребностей в данных пользовательских приложений. На логическом уровне модель данных всё еще независима от каких-либо технологических ограничений, которые возникают и учитываются лишь на стадии реализации. Обычно логическая модель, по крайней мере поначалу, строится как детализирующее расширение концептуальной модели данных. В реляционных схемах логическая модель данных строится путем добавления атрибутов к объектам концептуальной модели
Физическая модель данных (Physical Data Model, PDM)
Отражает детализированное техническое решение, за основу которого обычно берется логическая модель данных, а затем доводится до состояния полной совместимости с комплексом аппаратного и программного обеспечения и сетевого оборудования. Физические модели данных разрабатываются в расчете на конкретные технологии. Реляционные базы данных, например, проектируются с учетом функциональной специфики СУБД, которую планируется использовать
Виртуальная таблица, служащая средством просмотра данных из одной или многих таблиц, содержащих фактические атрибуты и/или ссылки на них. Обычное представление в процессе его использования запускает SQL-запросы к базе данных, обеспечивающие получение и отображение текущих значений входящих в представление атрибутов
Секционирование (partitioning)
Вертикальное (по столбцам) или горизонтальное (по строкам) разделение таблицы с целью упрощения архивирования или ускорения извлечения данных
Денормализация (denormalization) данных
Намеренное внесение в физические таблицы, создаваемые на основе нормализованной логической модели, избыточных или дублирующих друг друга полей данных (т.е. подразумевается умышленное размещение одного и того же атрибута в двух или более местах).
Зачем нужна денормализация?
Основная причина — повышение производительности за счет использования следующих приемов:
→ Предварительная заготовка сводных таблиц данных из множества других таблиц во избежание необходимости затратного по времени и аппаратным ресурсам многократного повторного объединения одних и тех же данных во время выполнения приложения
→ Создание предварительно отфильтрованных выборочных копий данных с целью снижения затрат времени на операционные расчеты и/или сканирование больших таблиц
→ Предварительное проведение и сохранение результатов ресурсоемких расчетов с использованием базовых данных с целью снижения конкуренции процессов за системные ресурсы во время выполнения
Нормализация (normalization) данных
Заключается в применении наборов правил, позволяющих упорядочить всё разнообразие необходимых для ведения бизнеса данных в стабильные структуры (по сути — сделать так, чтобы каждый атрибут содержался строго в одном месте во избежание избыточности данных и, как следствие, их возможной противоречивости).
→ Первая нормальная форма (1NF).
→ Вторая нормальная форма (2NF)
→ Третья нормальная форма (3NF)
→ Нормальная форма Бойса — Кодда (BCNF)
→ Четвертая нормальная форма (4NF)
→ Пятая нормальная форма (5NF)
Удаление из модели излишних деталей, с тем чтобы ее можно было применять к максимально широкому классу ситуаций, при сохранении всех важных свойств, проистекающих от природы, концепции и/или предметов модели.
Проектируя модели, разработчики часто опираются на богатый практический опыт анализа и моделирования данных — как собственный, так и накопленный коллегами. Они могут изучать существующие модели и базы данных, выверять свои действия по опубликованным стандартам, рассматривать и учитывать всевозможные требования к данным.
Прямое проектирование — forward engineering. Построение нового приложения, начиная с выяснения предъявляемых к нему требований. Cначала создается CMD, чтобы понять границы и состав предстоящих работ, выработать и согласовать ключевую терминологию. Затем создается LMD, документирующая бизнес-решение, и наконец — PMD, документирующая техническое решение.
Создание концептуального моделирования данных (CMD) включает:
- Выбор схемы
- Выбор нотации
- Создание исходной CMD
- Учет корпоративной терминологии
- Окончательное согласование
Логическое моделирование данных. Логические модели данных требуют модификаций и адаптации с целью получения итогового проектного решения, обеспечивающего эффективную работу в среде конкретной СУБД.
- Анализ информационных потребностей
- Анализ имеющейся документации
- Добавление ассоциативных сущностей
- Добавление атрибутов
- Определение доменов
- Определение ключей
Физическое моделирование данных включает:
- Разрешение логических абстракций
- Добавление детальной информации об атрибутах
- Добавление объектов справочных данных
- Определение суррогатных ключей
- Повышение производительности за счет денормализации
- Повышение производительности за счет индексирования
- Повышение производительности за счет секционирования
- Создание представлений данных
Обратное проектирование (или реверс-инжиниринг — reverse engineering). Это процесс документирования существующей базы данных. Первым делом составляется PMD с целью понять техническое устройство имеющейся системы, затем создается LMD с целью документирования решаемых ею бизнес-задач, и, наконец, подготавливается CMD для документирования области применения системы и используемой терминологии.
Рекомендации в области именования содержатся в международном стандарте ISO 11 179 «Регистры метаданных».
- Модель данных и стандарты присвоения имен элементам данных должны быть опубликованы.
- Стандартизация наименований особенно важна для сущностей, таблиц, атрибутов, ключей, представлений и индексов.
- Имя каждого такого элемента должно быть уникальным и в то же время максимально информативным.
- В логической модели имена должны быть осмысленными с точки зрения бизнес-пользователей, поэтому следует по возможности избегать любых сокращений
- В физической модели имена не должны превышать максимально допустимой для выбранной СУБД длины
- Стандарты наименований должны быть по возможности едиными для всех рабочих сред.
- Следует минимизировать рассогласование имен элементов в различных средах — тестовой, обеспечения качества или эксплуатационной.
Также, есть стандарт проектирования баз данных PRISM.
- Performance: Производительность и простота использования
- Reusability: Возможность повторного использования
- Integrity: Целостность (все без исключения данные должны быть корректными и непротиворечивыми вне зависимости от контекста, а также обязаны точно отражать фактическую ситуацию в бизнесе)
- Security: Безопасность (достоверные и точные данные должны быть всегда доступны авторизованным пользователям, но надежно защищены от несанкционированного доступа)
- Maintainability: Удобство сопровождения (Весь комплекс работ по сопровождению данных должен быть окупаемым, т. е. суммарные затраты на создание, хранение, ведение, использование и ликвидацию данных должны быть ниже суммарной оценки выгод, которые эти данные приносят организации)
Управление качеством моделей и проектных решений
Проектные команды должны регулярно проводить обзорные проверки выполнения требований в сопоставлении с концептуальной и логической моделями данных, а также физическим проектом базы данных. Такие проверки нужно проводить с участием экспертов в предметных областях, обладающих различным опытом и навыками и представляющих различные профессиональные интересы, ожидания и мнения. Участники должны иметь возможность высказывать и обсуждать различные точки зрения и приходить к групповому консенсусу без персональных конфликтов, поскольку все они преследуют общую цель — содействие выработке наиболее практичных и эффективных проектных решений.
Управление версиями и интеграцией моделей данных
Почему проект или ситуация потребовали внесения изменения?
Что и Как именно было изменено?
С точным описанием добавленных, удаленных или измененных столбцов и связанных с ними изменений
Когда было утверждено решение о внесении изменения и когда оно было внесено в модель?
Подписывайтесь на новые выпуски проекта
Получайте обновления конспекта DMBOK2 себе на почту по мере их публикации
Диганг модельный гид
- Предварительное моделирование DW, BL и моделирования измерений
-
- Таблица фактов для измерения
-
- Таблица фактов с одним событием
- Процесс таблицы фактов
- Хранение таблицы фактов
- Таблица измерений, используемая для описания окружающей среды
-
- Три -уровень каталог
Предварительное моделирование DW, BL и моделирования измерений
Часть ссылки и (Этот исходный текст:https://blog.csdn.net/mcajax/article/details/104376168)
Таблица фактов для измерения
Результаты бизнес -процесса организации по хранению таблиц в модели измерения модели измерения указывают на вес бизнеса.

Факты таблицы фактов соответствуют одному событию измерения. Каждое событие измерения имеет одно соотношение с соответствующей линией таблицы событий
Таблица фактов с одним событием
Для каждого мероприятия по бизнесу, разрабатывайте таблицу фактов, которая записывает только факты и статус инцидента. Принимая заказ пользователя и взяв автомобиль в качестве примера, процесс заказа включает в себя заказы пользователя, заказы на получение драйверов, оплату пассажиров и Другие процессы и другие процессы

Процесс таблицы фактов
Для основного органа бизнес -процесса разработайте таблицу фактов, отслеживая факты и статус всего процесса.

Хранение таблицы фактов
(1) Увеличение хранения
Только данные об инкрементной части инкрементной части за цикл, данные, которые не изменяются в состоянии, являются более уместными
(2) Полный снимок
Состояние меняется, но текущие данные снимка хранятся каждый день, и объем данных может быть использован для количества данных в контролируемом диапазоне. Если пространство и стоимость хранения являются приемлемыми, полное хранилище сохраняется, чтобы гарантировать, что его можно отследить до повседневного статуса истории истории. Если пространство для хранения ограничено, учитывая данные мобильных исторических снимков на холодный диск, он может быть восстановленным, когда это необходимо использовать. Рассмотрим удаление части, например, сохранение данных снимка последнего дня каждого месяца
(3) Часы с волнами
Для большого количества данных, но меняется медленно, вам необходимо отслеживать исторический статус, который похож на медленное размер выпуска. Часы на молнии подходят для небольшого количества данных, которые изменяются ежедневно.
Таблица измерений, используемая для описания окружающей среды
Таблица измерений содержит текстовую среду, связанную с чрезмерным количеством бизнеса
Измерение обеспечивает вход в данные, обеспечивая окончательную идентификацию и группировку всего анализа DW/BI
Три -уровень каталог
Что такое моделирование данных?
Моделирование данных (моделирование данных) – это процесс создания модели данных для хранения данных в базе данных. Эта модель данных представляет собой концептуальное представление объектов данных, связей между различными объектами данных и правилами. Моделирование данных помогает визуально представлять данные и обеспечивает соблюдение бизнес-правил, нормативных требований и государственных политик в отношении данных. Модели данных обеспечивают согласованность в соглашениях об именах, значениях по умолчанию, семантике, безопасности при обеспечении качества данных.
Модель данных подчеркивает, какие данные необходимы и как они должны быть организованы, а не какие операции должны выполняться с данными. Модель данных похожа на план здания архитектора, который помогает построить концептуальную модель и установить отношения между элементами данных.
Два типа методов моделей данных:
- Модель отношений сущностей (ER)
- UML (унифицированный язык моделирования)
Мы обсудим их подробно позже.
В этом уроке вы узнаете больше о
- Зачем использовать модель данных?
- Типы моделей данных
- Концептуальная модель
- Логическая модель данных
- Физическая модель данных
- Преимущества и недостатки модели данных
Зачем использовать модель данных?
Основная цель использования модели данных:
- Обеспечивает точное представление всех объектов данных, необходимых для базы данных. Пропуск данных приведет к созданию ошибочных отчетов и даст неправильные результаты.
- Модель данных помогает проектировать базу данных на концептуальном, физическом и логическом уровнях.
- Структура модели данных помогает определить реляционные таблицы, первичные и внешние ключи и хранимые процедуры.
- Он обеспечивает четкое представление о базовых данных и может использоваться разработчиками базы данных для создания физической базы данных.
- Также полезно определить отсутствующие и избыточные данные.
- Несмотря на то, что первоначальное создание модели данных является трудоемким и длительным, в конечном итоге это делает обновление и обслуживание ИТ-инфраструктуры дешевле и быстрее.
Типы моделей данных
Существует в основном три различных типа моделей данных:
- Концептуальный: эта модель данных определяет ЧТО система содержит. Эта модель обычно создается заинтересованными сторонами и архитекторами данных. Цель состоит в том, чтобы организовать, охватить и определить бизнес-концепции и правила.
- Логический: определяет, КАК система должна быть реализована независимо от СУБД. Эта модель обычно создается архитекторами данных и бизнес-аналитиками. Целью является разработка технической карты правил и структур данных.
- Физические : Эта модель данных описывает КАК система будет реализована с использованием конкретной системы СУБД. Эта модель обычно создается администратором базы данных и разработчиками. Цель – фактическая реализация базы данных.
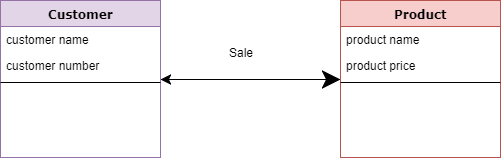
Концептуальная модель
Основная цель этой модели – установить сущности, их атрибуты и их взаимосвязи. На этом уровне моделирования данных едва ли есть какая-либо подробная информация о фактической структуре базы данных.
3 основных арендатора модели данных
Entity : реальная вещь
Атрибут : характеристики или свойства объекта
Отношения : Зависимость или связь между двумя объектами
Например:
- Клиент и Продукт – это две сущности. Номер и имя клиента являются атрибутами объекта «Клиент»
- Название продукта и цена являются атрибутами объекта продукта
- Продажа – это отношения между клиентом и продуктом
Характеристики концептуальной модели данных
- Предлагает общеорганизационный охват бизнес-концепций.
- Этот тип моделей данных предназначен для бизнес-аудитории.
- Концептуальная модель разрабатывается независимо от технических характеристик оборудования, таких как емкость хранилища данных, расположение или спецификации программного обеспечения, таких как поставщик СУБД и технологии. Цель состоит в том, чтобы представлять данные так, как их увидит пользователь в «реальном мире».
Концептуальные модели данных, известные как доменные модели, создают общий словарь для всех заинтересованных сторон, устанавливая основные понятия и объем.
Логическая модель данных
Логические модели данных добавляют дополнительную информацию к элементам концептуальной модели. Он определяет структуру элементов данных и устанавливает отношения между ними.
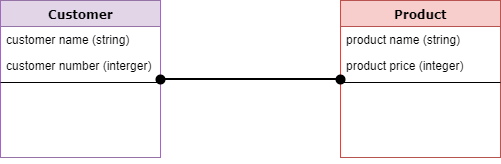
Преимущество логической модели данных состоит в том, чтобы обеспечить основу для формирования физической модели. Тем не менее, структура моделирования остается общей.
На этом уровне моделирования данных первичный или вторичный ключ не определен. На этом уровне моделирования данных необходимо проверить и настроить детали соединителя, которые были установлены ранее для отношений.
Характеристики логической модели данных
- Описывает потребности в данных для одного проекта, но может интегрироваться с другими логическими моделями данных в зависимости от объема проекта.
- Разработан и разработан независимо от СУБД.
- Атрибуты данных будут иметь типы данных с точной точностью и длиной.
- Процесс нормализации к модели применяется обычно до 3NF.
Физическая модель данных
Физическая модель данных описывает специфическую для базы данных реализацию модели данных. Он предлагает абстракцию базы данных и помогает создавать схемы. Это связано с богатством метаданных, предлагаемых физической моделью данных.
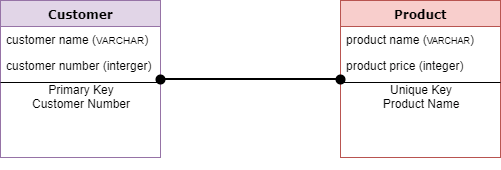
Этот тип модели данных также помогает визуализировать структуру базы данных. Это помогает моделировать ключи столбцов базы данных, ограничения, индексы, триггеры и другие функции РСУБД.
Характеристики физической модели данных:
- Физическая модель данных описывает потребность в данных для одного проекта или приложения, хотя она может быть интегрирована с другими физическими моделями данных на основе объема проекта.
- Модель данных содержит отношения между таблицами, которые обращаются к количеству и обнуляемости отношений.
- Разработано для конкретной версии СУБД, местоположения, хранилища данных или технологии, которая будет использоваться в проекте.
- Столбцы должны иметь точные типы данных, назначенные длины и значения по умолчанию.
- Определены первичные и внешние ключи, представления, индексы, профили доступа, авторизации и т. Д.
Преимущества и недостатки модели данных:
Преимущества модели данных:
- Основная цель разработки модели данных – обеспечить точное представление объектов данных, предлагаемых функциональной группой.
- Модель данных должна быть достаточно подробной, чтобы ее можно было использовать для построения физической базы данных.
- Информация в модели данных может использоваться для определения отношений между таблицами, первичным и внешним ключами и хранимыми процедурами.
- Модель данных помогает бизнесу общаться внутри и между организациями.
- Модель данных помогает документировать отображения данных в процессе ETL
- Help to recognize correct sources of data to populate the model
Disadvantages of Data model:
- To develop Data model one should know physical data stored characteristics.
- This is a navigational system produces complex application development, management. Thus, it requires a knowledge of the biographical truth.
- Even smaller change made in structure require modification in the entire application.
- There is no set data manipulation language in DBMS.
Conclusion
- Data modeling is the process of developing data model for the data to be stored in a Database.
- Data Models ensure consistency in naming conventions, default values, semantics, security while ensuring quality of the data.
- Data Model structure helps to define the relational tables, primary and foreign keys and stored procedures.
- There are three types of conceptual, logical, and physical.
- The main aim of conceptual model is to establish the entities, their attributes, and their relationships.
- Logical data model defines the structure of the data elements and set the relationships between them.
- A Physical Data Model describes the database specific implementation of the data model.
- The main goal of a designing data model is to make certain that data objects offered by the functional team are represented accurately.
- The biggest drawback is that even smaller change made in structure require modification in the entire application.