Базовые подходы к парсингу
Время на прочтение
4 мин
Количество просмотров 25K
Вступление
У меня бывают ситуации на проектах, когда нужна база данных какой-то статической информации. Но увы, пошарив в интернетах, какого то публичного хранилища найти не удалось, но тем не менее, я вижу кучу ресурсов, которые это используют.
В моем случае мне понадобилась база данных пород кошек, но среди этих примеров может быть что угодно, от базы данных имен, названия городов, областей и т.д. Эта статья о базовых подходах и практиках парсинга данных с веб ресурсов.
Хочу подметить, что хоть в моих жилах течет дотнет, в этом примере я буду использовать Node JS, потому что так быстрее, и удобнее в плане парсинга. Чем именно удобней — я расскажу позже в статье.
Можем ли мы спарсить?
Да, к сожалению (или счастью) веб — он не однообразен, и каждый ресурс может быть уникален по своему, но в нашем деле, ключевым моментом будет то, есть ли на этом ресурсе Server-Side Rendering (SSR), или там Client-Side Rendering и важная для нас информация подтягивается позже с помощью JS.
К примеру, нативные апки на React или тот же Angular by default есть CSR. И что бы прикрутить там SSR нужно порой очень сильно попотеть. Тем не менее, большинство сайтов с топ серч результатов любой поисковой системы будут поддерживать именно SSR, потому что таков мир SEO оптимизаций.
В моем примере, страница, которую будем парсить — это простая вики страница:
https://uk.m.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%BA%D0%BE%D1%82%D1%8F%D1%87%D0%B8%D1%85_%D0%BF%D0%BE%D1%80%D1%96%D0%B4
Мы можем видеть, что эта страница использует SSR, ибо в первом запросе, мы видим, что информация о породах уже есть в ответе от сервера.
Как будем парсить?
Перед тем, как начать парсить, давайте сначала определимся, что именно будем парсить. В моем примере — мне нужны были названия и фото пород. Названия я потом переводил на английский и русский, а фотки сохранял в директории с приложением. К слову, потом это все перегонялось в Postgres похожим скриптом.
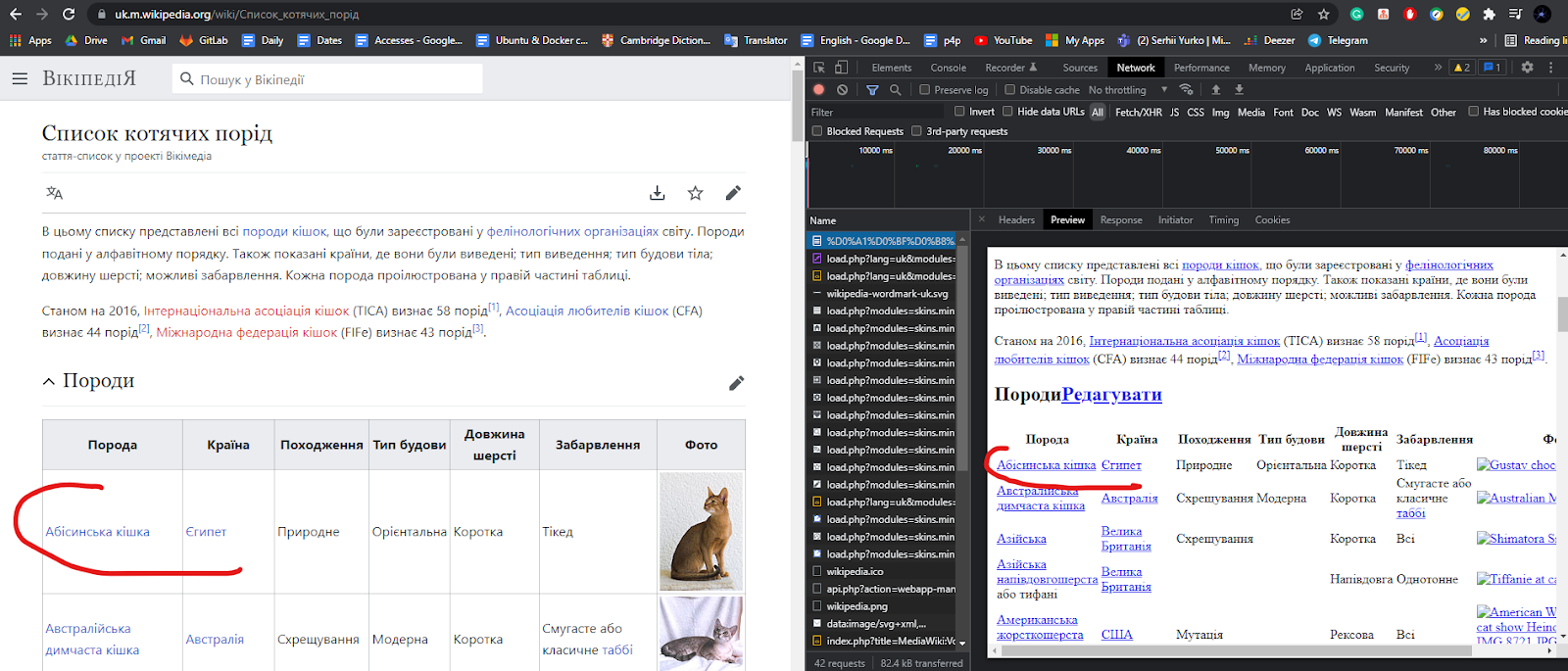
Первое, что нужно сделать — это заинспектить нужные элементы страницы через тулзы браузера (в моем случае хром).


Кликаем на выбранный элемент и смотрим HTML в сайдбаре тулзов.

Как вы видите, мы имеем дело со стандартной таблицей, и для парсинга названия породы все, что нам нужно сделать — это спарсить необходимые нам <td> для каждого <tr>.

Фото также находится на одном из <td> тегов. Убеждаемся, что сорс фото валидный, и у нас есть доступ туда без никакой авторизации и прочих вещей.
Начнём парсить!
Создадим папку с проектом и в руте создадим main.js.
Потом с рута проекта открываем терминал и пишем:
npm init

Можете пропустить все, что спрашивается там, это неважно в нашем случае.
Для нашего апликейшена нам будут нужны axios для HTTP запросов, node-html-parser, чтобы парсить html, fs.promises для асинхронных колов файловой системы, google-translate-api, для перевода с украинского.
В терминале пишем следующую команду:
npm install axios node-html-parser @vitalets/google-translate-api --save
Дальше пишем такой код в нашем мейн файле:
Как вы видите, мы определили наши константы, библиотеки, которые собираемся использовать и асинхронный мейн, чтобы писать чистый и асинхронный код.
Теперь, чтобы спарсить контент с этой страницы, мы должны ее как-то получить. Мы просто сделаем GET запрос к ней и получим наш HTML.
Дальше, что мы можем сделать с нашим HTML? Есть несколько вариантов парсинга: XPath и нативные JS querySelector & getElementsBy. Я использовал querySelector ибо это упрощает написание парсера, потому что это легче тестировать (чуть ниже я покажу каким образом), лично мне больше понятен его синтаксис нежели синтаксис XPath.
Что же, давайте попробуем написать селектор для нашего имени. И вот тут и проявляется вся прелесть выбора querySelector, потому что мы просто идем в тулзы для девов в браузере, и там все это тестируем.
Тут я выпарсил все <tr>.

Как только “подобрали” правильный селектор, просто копипастим это в апку в какую-то константу.
Как мы видим, мы должны исключить первый и последний элемент.


Давайте теперь напишем ещё вспомогательный метод, который будет проверять, существует ли папка или файл по заданному пути, ну и добавим нашу константу.
Следом за этим — напишем логику, которая будет парсить все наши строки:
В коде выше — мы создали директорию для фото, взяли HTML через риквест на CAT_URL, и потом спарсили все <tr> теги. Теперь в Promise.all мы можем отдельно парсить каждую строку.
Теперь давайте поиграем с селекторами еще, чтобы взять имя породы:

Как вы видите, внутри <tr> тега мы должны следовать за <td> тегом и взять текст тега <a>.

Посмотрим, что мы можем использовать для парсинга фото:


Как же мы можем быть уверены, что можем это спарсить с нашей хтмл?
Мы можем скачать эту HTML любым удобным способом (cURL, Postman) и проверить, есть ли там фотка.
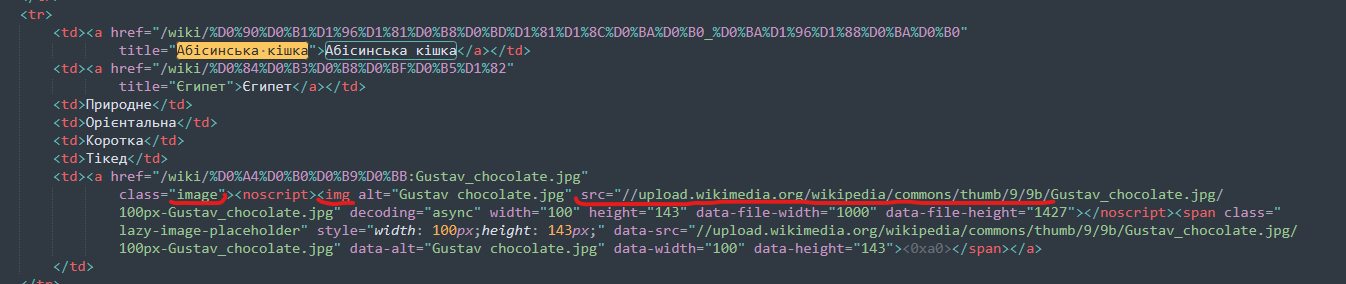
И конечно же, там нету элемента с классом ‘.image-lazy-loaded’. Но как решение, мы можем взять элемент с классом ‘.image’ потом взять тег <noscript> и из его дочернего элемента взять сорс фото.
Добавим нужные селекторы в код:
В коде, мы проверяем, есть ли уже у нас фото с названием породы (возможно апка будет запускаться множество раз, чтобы лишний раз не делать риквест на вики), и если нету мы скачиваем фото в локальную директорию.
Так же проверяем, есть ли фотка у породы вообще, потому что ее может не быть

Теперь создадим метод, который будет скачивать. Так же нам понадобиться юзерагент википедии, потому что после нескольких скачиваний, у меня начали падать ошибки, и они пофиксились добавлением этого хедера.
Последнее, что нужно сделать, после того, как мы скачали фото — это перевести название породы, сохранить это название в файлике.
Я также отделил создание новой строки в отдельный метод, потому что это платформ специфик штука.
Попробуем же это все запустить с командой:
node main.js
Весь код солюшна:
Результаты

Перевод не такой классный, как мог бы быть, но это уже не проблема парсинга, а проблема процессинга.
Я еще сделал видео, демонстрирующее написанное в статьи, если хочется увидеть процесс вживую — вот ссылка.
Меня зовут Максим Кульгин и моя компания xmldatafeed занимается парсингом сайтов в России порядка четырех лет. Ежедневно мы парсим более 500 крупнейших интернет-магазинов в России и на выходе мы отдаем данные в формате Excel/CSV и делаем готовую аналитику для маркетплейсов. Тема парсинга в последнее время становится все более востребованной и в этой статье мы хотим дать общий обзор подходов и механизмов парсинга данных, учитывая правовые особенности.
За последнее десятилетие данные стали ресурсом для развития бизнеса, а Интернет — их основным источником благодаря пяти миллиардам пользователей, формирующим миллиарды фрагментов данных каждую секунду. Анализ данных Всемирной паутины может помочь компаниям выявлять скрытые закономерности, позволяющие им добиваться выполнения своих целей. Однако сбор большого объема данных — непростая для компаний задача, особенно для тех, которые думают, что кнопка «Экспортировать в Excel» (если такая присутствует) и обработка данных вручную — единственные способы сбора данных.
Парсинг веб-сайтов позволяет компаниям автоматизировать процессы сбора данных во Всемирной паутине, используя ботов или автоматические скрипты, называемые «обходчиками» веб-страниц, автоматическими сборщиками данных или веб-сборщиками (web crawlers). В этой статье раскрыты все важные аспекты парсинга веб-сайтов, включая понятие парсинга, почему он важен, как он работает, варианты применения, а также сведения о поставщиках парсеров и руководство по доступным к покупке программным продуктам и услугам.
Что такое парсинг веб-сайтов?
Парсинг веб-сайтов, который также называют сбором/извлечением данных, скрейпингом данных или содержимого экрана, добычей данных/интернет-данных и иногда обходом/сканированием Всемирной паутины, — это процесс извлечения данных из веб-сайтов.
Процесс парсинга веб-сайтов включает в себя отправку запросов на получение веб-страницы и извлечение из нее машиночитаемой информации.
Всё более широкое использование аналитики данных и автоматизации — существенные тенденции бизнеса. Парсинг веб-сайтов может стать движущей силой для обеих тенденций. Помимо этих причин, у парсинга веб-сайтов есть множество применений, которые могут повлиять на все отрасли. Парсинг веб-сайтов дает компаниям возможность:
- автоматизировать процессы сбора данных в необходимом масштабе;
- получить доступ к источникам данных во Всемирной паутине, которые могут повысить эффективность вашего бизнеса;
- принимать решения, опираясь на данные.
Эти факторы объясняют возрастающий интерес к парсингу веб-сайтов, который можно наблюдать в Google Trends на представленном выше изображении.
Как осуществляется парсинг веб-сайтов?
Обычно процесс парсинга веб-сайтов состоит из следующих последовательных шагов:
- Идентификация целевых URL-адресов.
- Если веб-сайт, сканируемый для сбора данных, использует инструменты противодействия парсингу, то парсеру, возможно, придется выбрать подходящий прокси-сервер, чтобы получить новый IP-адрес, через который парсер будет отправлять свой запрос.
- Отправка запросов на эти URL-адреса для получения HTML-кода.
- Использование указателей для обнаружения местонахождения данных в HTML-коде.
- Аналитический разбор строки данных, которая содержит нужную информацию.
- Преобразование собранных данных в желаемый формат.
- Передача собранных данных в выбранное хранилище данных.
Для чего применяется парсинг веб-сайтов?
Распространенные варианты применения парсинга веб-сайтов перечислены ниже.
- Аналитика данных и наука о данных (data science).Сбор «тренировочных» данных для машинного обучения.Наполнение корпоративных баз данных.
- Маркетинг и продажи.Сравнение цен (особенно актуально в электронной коммерции).Извлечение описания товаров.Отслеживание в поисковых системах конкурентов и текущего состояния компаний в рамках усилий по поисковой оптимизации (SEO).Лидогенерация.Тестирование веб-сайтов.Отслеживание потребительских настроений.
- PR.Агрегация новостей о компании.
- Торговля.Сбор финансовых данных.
- Стратегическое планирование.Исследование рынка.
Как выглядит сфера парсинга веб-сайтов?
Чтобы называться компаний по парсингу веб-сайтов, поставщик подобных программных решений должен предоставлять возможность извлечения данных из множества интернет-ресурсов и возможность экспорта извлеченных данных в различные форматы. Да, сфера парсинга веб-сайтов переполнена, и есть разные способы решения задач по парсингу веб-сайтов на корпоративном уровне.
Инструменты
Решения с открытым исходным кодом
Фреймворки с открытым исходным кодом делают парсинг веб-сайтов дешевле и проще для личного использования. Наиболее широко используемые инструменты: Scrapy, Selenium, BeautifulSoup и Puppeteer.
Пользователи могут собирать информацию, используя библиотеки наподобие Selenium, чтобы автоматизировать этот процесс. Когда на веб-странице есть список, то чаще всего есть и другие страницы, помимо той, которая сразу отображается пользователю. Пример — веб-страницы с «бесконечной прокруткой». Например, предположим, что вы просматриваете веб-страницы YouTube. На веб-странице, которую вы просматриваете, среди всех перечисленных видео не оказалось такого, который вы бы захотели посмотреть. Затем вам нужно прокрутить список вниз, чтобы появились следующие видео. Selenium позволяет пользователям автоматизировать перемещение по последующим страницам списка и сканирование требуемой информации о каждом элементе списка. Далее пользователи могут сформировать набор данных, содержащий информацию о каждом элементе списка, представленного на веб-сайте. Например, можно создать набор данных о фильмах, в который будут входить наименования, рейтинги IMDb, актеры и позиции фильмов в топе 250 IMDb, сканируя список лучших фильмов по версии IMDb с помощью инструментов с открытым исходным кодом наподобие Scrapy.
Проприетарные программные решения
Хотя на рынке есть различные проприетарные решения, продукты разделены на два типа:
- Решения, для взаимодействия с которыми нужно писать программный код. Поставщики таких решений предоставляют ключ API для доступа к данным.
- Решения без кода, для использования которых необязательно обладать навыками программирования и которые предоставляют инструменты, делающие сканирование веб-сайтов более доступным.
Облачные (SaaS) решения
Хотя парсить данные со своего собственного веб-сайта нетрудно, эта задача будет более сложной на веб-сайтах, стремящихся противодействовать сканированию своего контента роботами, которые не относятся к роботам поисковых систем. Как следствие, передовые парсеры собирают данные с использованием набора различных IP-адресов и цифровых подписей, действуя не как автоматический программный робот, а как группа пользователей, просматривающих веб-сайт.
Управляемые услуги
Полностью управляемые услуги по парсингу веб-сайтов, также называемые «данные-как-услуга» (data-as-a-service, DaaS), будут более удобны для компаний, которым нужен широкомасштабный сбор данных. Работа с веб-сервисами, предоставляющими такие услуги, обычно выглядит так:
- Клиент отправляет требования, как например: перечень сканируемых веб-сайтов, извлекаемые поля и частота сбора данных.
- Компания-поставщик управляемых услуг проверяет, возможно ли выполнить эти требования, и подготавливает к работе программных роботов, которые будут собирать данные.
- Компания использует лучшие методы «очистки» данных, преобразует их в нужный формат и отправляет клиенту.
Такие компании, как Yipitdata, PromptCloud и ScrapeHero, — некоторые из поставщиков, предлагающих полностью управляемые услуги по парсингу веб-сайтов.
Собственные внутриорганизационные решения
Используя готовое существующее программное обеспечение (ПО) с открытым или закрытым исходным кодом и навыки программирования, любая компания может создавать качественные парсеры веб-сайтов. При условии, что у компании есть технический персонал для осуществления этой задачи, и что парсинг необходим для реализации стратегически важного проекта, собственную разработку можно считать оптимальным вариантом.
Выбор подходящего инструмента или веб-сервиса для сбора данных во Всемирной паутине зависит от различных факторов, включая тип проекта, бюджет и наличие технического персонала. Чтобы кратко охарактеризовать представленную выше схему принятия решения, правильный ход мыслей при выборе автоматического сборщика данных должен быть таким:
- Собираетесь ли вы собирать данные только для личного использования? Если да, то выберите инструмент с открытым исходным кодом или его community-версию, что позволит вам собирать данные бесплатно.
- Если нет, то работает ли ваша IT-компания над стратегически важными проектами, которые дифференцируют ваши продукты или услуг?
- Если да, то сформируйте в компании команду, которая будет предотвращать сбор ваших данных сторонними компаниями.
- Если нет, то позволяет ли ваш бюджет инвестировать более $10 000?
- Если да, то отдайте предпочтение управляемым услугам, поскольку системы парсинга данных требуют существенных усилий по их поддержке. Возможно, что вам не захочется, чтобы команда вашей компании была сосредоточена на поддержке проекта, который не является стратегически важным.
- Если нет, то есть ли у вас навыки программирования? Если есть, то отдайте предпочтение решениям с открытым исходным кодом или недорогим проприетарным решениям. Разработка своего парсера может быть эффективнее, чем использование решений, не требующих написания программного кода, поскольку разработанное решение может предложить более высокий уровень автоматизации.
- Если их нет, то сделайте выбор в пользу решений, которыми можно пользоваться без программирования. Большинство из них проприетарные, но их можно приобрести и с ограниченным бюджетом.
Законно ли заниматься парсингом?
Коротко говоря, если: при парсинге собираются общедоступные данные, парсинг не наносит вред компании-владельцу данных, среди собранных данных нет персональных и при повторной публикации собранных данных добавляется ссылка на источник, то, по всей видимости, заниматься парсингом законно. Однако это не юридическое заключение, поэтому, пожалуйста, обратитесь к профессиональному юристу за конкретной консультацией.
Персональные данные
Законность парсинга ранее долгое время была неоднозначной, но сейчас в этом вопросе больше ясности. В настоящее время нормативно-правовые акты, регулирующие конфиденциальность персональных данных, наподобие GDPR Европейского союза и CCPA в Калифорнии не препятствуют парсингу веб-сайтов. В России недавно приняли дополнительные поправки в закон об Персональных данных. Просто убедитесь, что:
- Собираются общедоступные данные.
- Персональные данные хранятся в надежных условиях и в соответствии с передовыми методиками.
- Данные не продаются или не передаются посторонним, если только на это не было получено согласие отдельного пользователя.
Данные, которые не относятся к персональным
Говоря о компаниях, Апелляционный суд девятого округа США после иска LinkedIn против hiQ постановил, что автоматический парсинг общедоступных данных, очевидно, не нарушает Закон о компьютерном мошенничестве и злоупотреблении (Computer Fraud and Abuse Act, CFAA).
Ограничения
Тем не менее при использовании парсинга веб-сайтов действуют ограничения.
- Извлечение данных не должно причинять какой-либо ущерб владельцам данных.
- Парсер не может публиковать данные без указания их источника. Это было бы неэтично и незаконно.
Примеры
При оценке законности парсинга учтите также, что каждый результат поиска, который вы видите на страницах поисковых систем, был собран ею. Помимо этого, сообщается, что хедж-фонды тратят миллиарды на сбор данных, чтобы принимать более эффективные инвестиционные решения. Поэтому парсинг — это не сомнительная практика, которую применяют только небольшие компании.
Почему владельцы веб-сайтов хотят защитить их от парсинга?
Отчет 2020 от imperva о нежелательных программных роботах, собирающих данные
- Сборщики данных могут значительно ухудшить производительность веб-сайта. Роботы, включая поисковых, составляют 24% веб-трафика согласно Imperva — поставщику ПО для обеспечения информационной безопасности.
- Конкуренты могут собирать и анализировать данные на страницах веб-сайта. Например, это позволяет им посредством уведомлений оперативно узнавать о новых клиентах, партнерских связях или возможностях конкурентов.
- Кроме того, внутренние непубличные данные владельцев веб-сайта могут быть собраны конкурентами, создающими аналогичные продукты или конкурирующие услуги, уменьшая спрос на услуги владельцев веб-сайта.
- Защищенный авторским правом контент владельцев веб-сайта может быть скопирован и процитирован без ссылок на источник, приводя к потере дохода у создателей контента.
Какие сложности могут возникнуть при парсинге веб-сайтов?
- Веб-сайты со сложной структурой: большинство веб-страниц основаны на использовании HTML, и структура одной веб-страницы может сильно отличаться от структуры другой. Следовательно, когда вам нужно спарсить несколько веб-сайтов, для каждого из них придется создать свой парсер.
- Поддержка парсера может быть дорогой: веб-сайты всё время меняют дизайн веб-страницы. Если местоположение собираемых данных меняется, то программный код сборщиков данных необходимо снова доработать.
- Используемые веб-сайтами инструменты противодействия парсингу: такие инструменты позволяют веб-разработчикам управлять контентом, который отображается роботам и людям, а также ограничивать роботам возможность собирать данные на веб-сайте. Некоторые из методов защиты от парсинга: блокировка IP-адресов, captcha (Completely Automated Public Turing test to tell Computers and Humans Apart — полностью автоматический тест Тьюринга для различения компьютеров и людей) и ловушки в виде приманок для парсеров.
- Необходимость авторизации: чтобы собрать во Всемирной паутине определенную информацию, возможно, вам сначала потребуется пройти авторизацию. Поэтому когда веб-сайт требует войти в систему, нужно убедиться, что парсер сохраняет файлы cookie, которые были отправлены вместе с запросом, чтобы веб-сайт воспринимал парсер в качестве авторизованного ранее посетителя.
- Медленная или нестабильная скорость загрузки: когда веб-сайты загружают контент медленно или не отвечают на запросы, может помочь обновление страницы, хотя парсер, возможно, не знает, что делать в такой ситуации.
Какие приемы парсинга веб-сайтов считаются лучшими?
Распространенные и наиболее успешные приемы парсинга веб-сайтов:
Использование прокси-серверов
Многие администраторы крупных веб-сайтов применяют инструменты для защиты от роботов. Роботам приходится обходить их, чтобы просканировать большое количество HTML-страниц. Использование прокси-серверов и отправка запросов через разные IP-адреса могут помочь преодолеть эти трудности.
Использование динамического IP-адреса
Переход от статического IP-адреса на динамический также может оказаться полезным для того, чтобы парсер не обнаружили и не заблокировали.
Замедление процесса сбора данных
Следует ограничить частоту отправки запросов на один и тот же веб-сайт по двум причинам:
- веб-сборщиков данных легче обнаружить, если они делают запросы быстрее людей;
- сервер веб-сайта может перестать отвечать, если он получает слишком много запросов одновременно. Кроме того, эту проблему поможет решить программирование сборщика данных на взаимодействие с веб-страницей и планирование сеансов сбора данных таким образом, чтобы они начинались не в периоды пиковой нагрузки на веб-сайты.
Соблюдение требований GDPR
Согласно GDPR, незаконно собирать личную информацию (personally identifiable information, PII) резидентов ЕС, если только у вас нет их явного на это согласия.
Бойтесь пользовательских соглашений
Если вы собираетесь собирать данные на веб-сайте, где требуется проходить авторизацию, вам нужно принять пользовательское соглашение (Terms & Conditions), чтобы зарегистрироваться там. Некоторые пользовательские соглашения включают в себя принципы компаний, связанные с парсингом данных, в соответствии с которыми вам не разрешается парсить любые данные на веб-сайте.
Однако даже несмотря на то, что пользовательское соглашение LinkedIn однозначно запрещает парсинг данных, как упоминалось выше, парсинг LinkedIn пока еще не нарушает закон. Мы не дает юридическое заключение и не беремся однозначно разъяснять смысл пользовательских соглашений компаний.
Что сулит будущее для парсинга веб-сайтов?
Парсинг превращается в игру в кошки-мышки между владельцами контента и его сборщиками — обе стороны тратят миллиарды на преодоление мер, разработанных другой стороной. Можно ожидать, что обе стороны будут использовать машинное обучение для создания более продвинутых систем.
Открытый исходный код играет важную роль в разработке ПО, в том числе в области разработки парсеров. Кроме того, популярность Python растет, и она уже довольно высока. Можно ожидать, что библиотеки с открытым исходным кодом, как например: Selenium, Scrapy и Beautiful Soup, которые работают на Python, будут в ближайшем будущем формировать подходы к парсингу веб-сайтов.
Вместе с библиотеками с открытым исходным кодом интерес к искусственному интеллекту (ИИ) делает будущее более радужным, поскольку системы на основе ИИ в значительной степени полагаются на данные, а автоматизация сбора данных может содействовать различным вариантам применения ИИ с тренировкой на общедоступных данных.
#статьи
- 28 окт 2022
-

0
Рассказываем и показываем, как запросто вытянуть данные из сайта и «разговорить» его без утюга, паяльника и мордобоя.
Иллюстрация: Катя Павловская для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Для парсинга используют разные языки программирования: Python, JavaScript или даже Go. На самом деле инструмент не так важен, но некоторые языки делают парсинг удобнее за счёт наличия специальных библиотек — например, Beautiful Soup в Python.
В этой статье разберёмся в основах парсинга — вспомним про структуру HTML-запроса и спарсим сведения о погоде с сервиса «Яндекса». А ещё поделимся записью мастер-класса, на котором наш эксперт в веб-разработке покажет, как с нуля написать веб-парсер.
Парсинг (от англ. parsing — разбор, анализ), или веб-скрейпинг, — это автоматизированный сбор информации с интернет-сайтов. Например, можно собрать статьи с заголовками с любого сайта, что полезно для журналистов или социологов. Программы, которые собирают и обрабатывают информацию из Сети, называют парсерами (от англ. parser — анализатор).
Сам парсинг используется для решения разных задач: с его помощью телеграм-боты могут получать информацию, которую затем показывают пользователям, маркетологи — подтягивать данные из социальных сетей, а бизнесмены — узнавать подробности о конкурентах.
Существуют различные подходы к парсингу: можно забирать информацию через API, который предусмотрели создатели сервиса, или получать её напрямую из HTML-кода. В любом из этих случаев важно помнить, как вообще мы взаимодействуем с серверами в интернете и как работают HTTP-запросы. Начнём с этого!
HTTP (HyperText Transfer Protocol, протокол передачи гипертекста) — протокол для передачи произвольных данных между клиентом и сервером. Он называется так, потому что изначально использовался для обмена гипертекстовыми документами в формате HTML.
Для того чтобы понять, как работает HTTP, надо помнить, что это клиент-серверная структура передачи данных․ Клиент, например ваш браузер, формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передаётся обратно клиенту. В нашем примере клиент — это браузер.
Запрос состоит из трёх частей:
- Строка запроса (request line): указывается метод передачи, версия HTTP и сам URL, к которому обращается сервер.
- Заголовок (message header): само сообщение, передаваемое серверу, его параметры и дополнительная информация).
- Тело сообщения (entity body): данные, передаваемые в запросе. Это необязательная часть.
Посмотрим на простой HTTP-запрос, которым мы воспользуемся для получения прогноза погоды:
_GET /https://yandex.com.am/weather/ HTTP/1.1_
В этом запросе можно выделить три части:
- _GET — метод запроса. Метод GET позволяет получить данные с ресурса, не изменяя их.
- /https://yandex.com.am/weather/ — URL сайта, к которому мы обращаемся.
- HTTP/1.1_ — указание на версию HTTP.
Ответ на запрос также имеет три части: _HTTP/1.1 200 OK_. В начале указывается версия HTTP, цифровой код ответа и текстовое пояснение. Существующих ответов несколько десятков. Учить их не обязательно — можно воспользоваться документацией с пояснениями.
Сам HTTP-запрос может быть написан в разных форматах. Рассмотрим два самых популярных: XML и JSON.
JSON (англ. JavaScript Object Notation) — простой формат для обмена данными, созданный на основе JavaScript. При этом используется человекочитаемый текст, что делает его лёгким для понимания и написания:
({
<font color="#069">"firstName"</font> : <font color="#069">"Антон"</font>,
<font color="#069">"lastName"</font> : <font color="#069">"Яценко"</font>
});
Для того чтобы получить информацию в формате JSON, необходимо подготовить правильный HTTP-запрос:
var requestURL = 'test.json'; var request = new XMLHttpRequest(); request.open('GET', requestURL); request.responseType = 'json'; request.send();
В его структуре можно выделить пять логических частей:
- var requestURL — переменная с указанием на URL-адреса с необходимой информацией;
- var request = new XMLHttpRequest () — создание нового экземпляра объекта запроса из конструктора XMLHttpRequest с помощью ключевого слова new;
- request.open (‘GET’, requestURL) — открытие нового запроса с использованием метода GET. Обязательно указываем нашу переменную с URL-адресом;
- request.responseType = ‘json’ — явно обозначаем получаемый формат данных как JSON;
- request.send () — отправляем запрос на получение информации.
XML — язык разметки, который определяет набор правил для кодирования документов, записанных в текстовом формате. От JSON отличается большей сложностью — проще всего увидеть это на примере:
<font color="#069"><person></font> <font color="#069"><firstname></font>Антон<font color="#069"></firstname></font> <font color="#069"><lastname></font>Яценко<font color="#069"></lastname></font> <font color="#069"></person></font>
Чтобы получить информацию, хранящуюся на сервере как XML или HTML, потребуется воспользоваться той же библиотекой, как и в случае с JSON, но в качестве responseType следует указать Document.
var requestURL = 'test.txt'; var request = new XMLHttpRequest(); request.open('GET', requestURL); request.responseType = 'document'; request.send();
Какой из форматов лучше выбрать? Кажется, что JSON легче для восприятия. Но выбор между определённым форматом HTTP-запроса зависит и от решаемой задачи. Подробно обсудим это в будущих материалах.
А сегодня разберёмся с основами веб-скрейпинга — используем стандартные библиотеки Python и научимся работать с различными полезными инструментами.
Самый простой способ разобраться в парсинге — что-то спарсить. Создадим программу, которая будет показывать информацию о погоде в вашем городе.
Для этого пройдём через три последовательных шага:
- Подключим библиотеки, которые помогут нам спарсить информацию с помощью Python (как установить Python на Windows, macOS и Linux — смотрите в нашей статье).
- Зайдём на сайт, с которого мы планируем парсить информацию, и изучим его исходный код. Важно будет найти те элементы, которые содержат нужную информацию.
- Напишем код и спарсим данные.
Подключаем библиотеки
Подключаем библиотеки
В разных языках программирования есть свои библиотеки для парсинга информации с сайтов. Например, в JavaScript используется библиотека Puppeteer, а на Python популярна библиотека Beautiful Soup. Принципы их работы похожи. Но сначала нужно разобраться с запуском Python на компьютере.
Просто так написать код в текстовом документе не получится. Можно воспользоваться одним из способов:
- Использовать терминал на macOS или Linux, или воспользоваться командной строкой в Windows. Для этого предварительно потребуется установить Python в систему. Мы подробно писали об этом в отдельном материале.
- Воспользоваться одним из онлайн-редакторов, позволяющих работать с кодом на Python без его установки: Google Colab, python.org, onlineGDB или другим.
После установки на свой компьютер Python или запуска онлайн-редактора кода можно переходить к импорту библиотек.
BeautifulSoup — библиотека, которая позволяет работать с HTML- и XML-кодом. Подключить её очень просто:
from bs import BeautifulSoup
Дополнительно потребуется библиотека requests, которая помогает сделать запрос на нужный нам адрес сайта. Импортируется она в одну строку:
import requests
Всё. Все библиотеки готовы к работе — они помогут получить исходный код сайта и найти в нём нужную информацию.
Важно! Библиотека Beautiful Soup чаще всего предустановлена в используемой среде разработке или в Jupyter Notebook, но иногда её нет. Если при попытке её импорта вы получаете ошибку, то выполните команду для её установки, а потом повторите запросы на импорт:
pip3 install bs4
В качестве источника прогнозы погоды будем использовать сайт «Яндекс.Погода». Перейдём на него и в строке поиска найдём свой город. В нашем случае это будет Москва.
Посмотрите внимательно на адресную строку — она ещё пригодится нам в дальнейшем: https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526.
Обычно в адресной строке там нет названия города, а есть географические координаты точки, для которой показана текущая погода (у нас это центр Москвы).
Теперь посмотрим на исходный код страницы и найдём место, где хранится текущая температура. Нас интересует обведённый на скриншоте сайта блок:
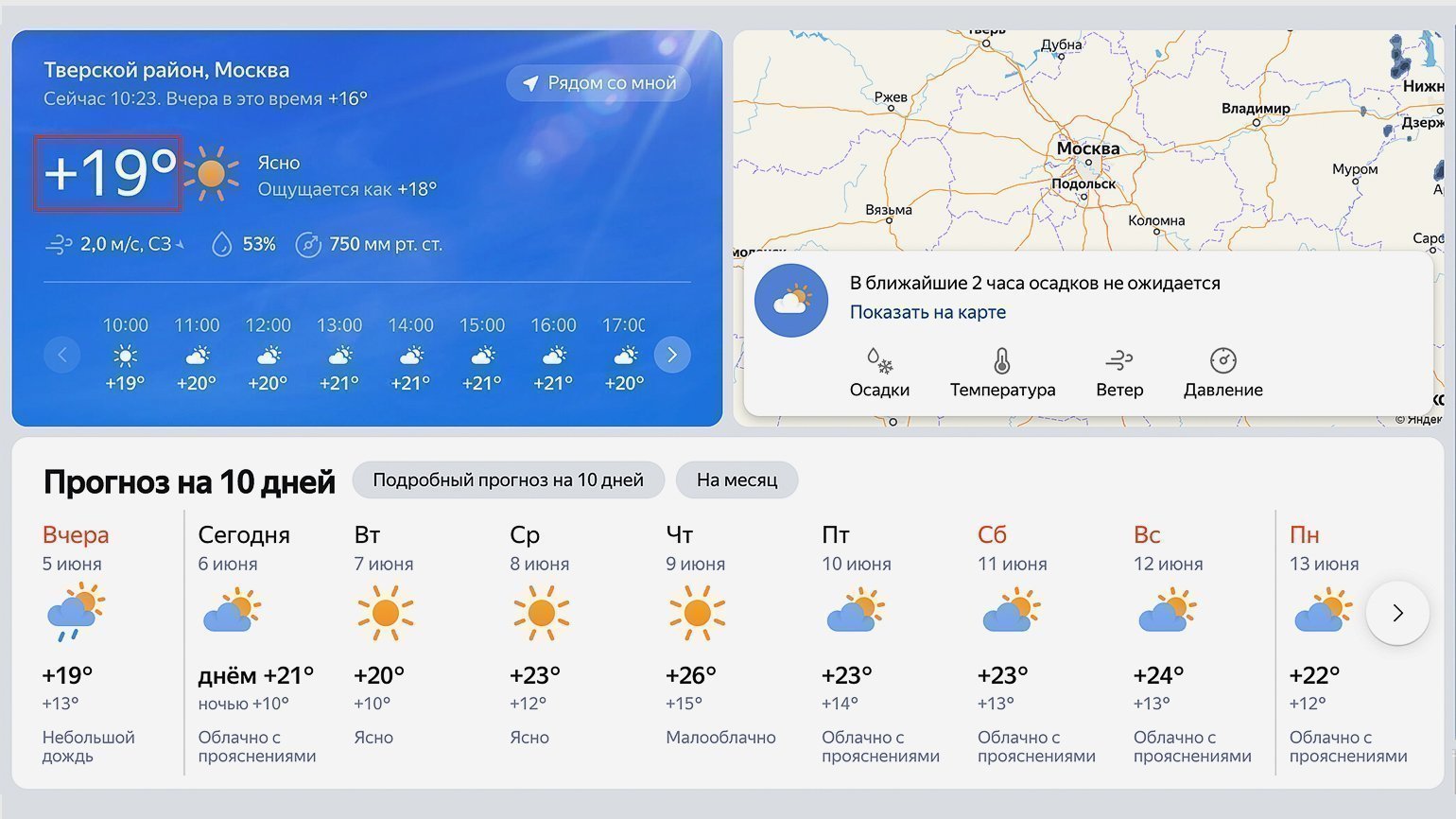
Для просмотра HTML-кода откроем «Инспектор кода». Для этого можно использовать комбинации горячих клавиш: в Google Chrome на macOS — ⌥ + ⌘ + I, на Windows — Сtrl + Shift + I или F12. Инспектор кода выглядит как дополнительное окно в браузере с несколькими вкладками:
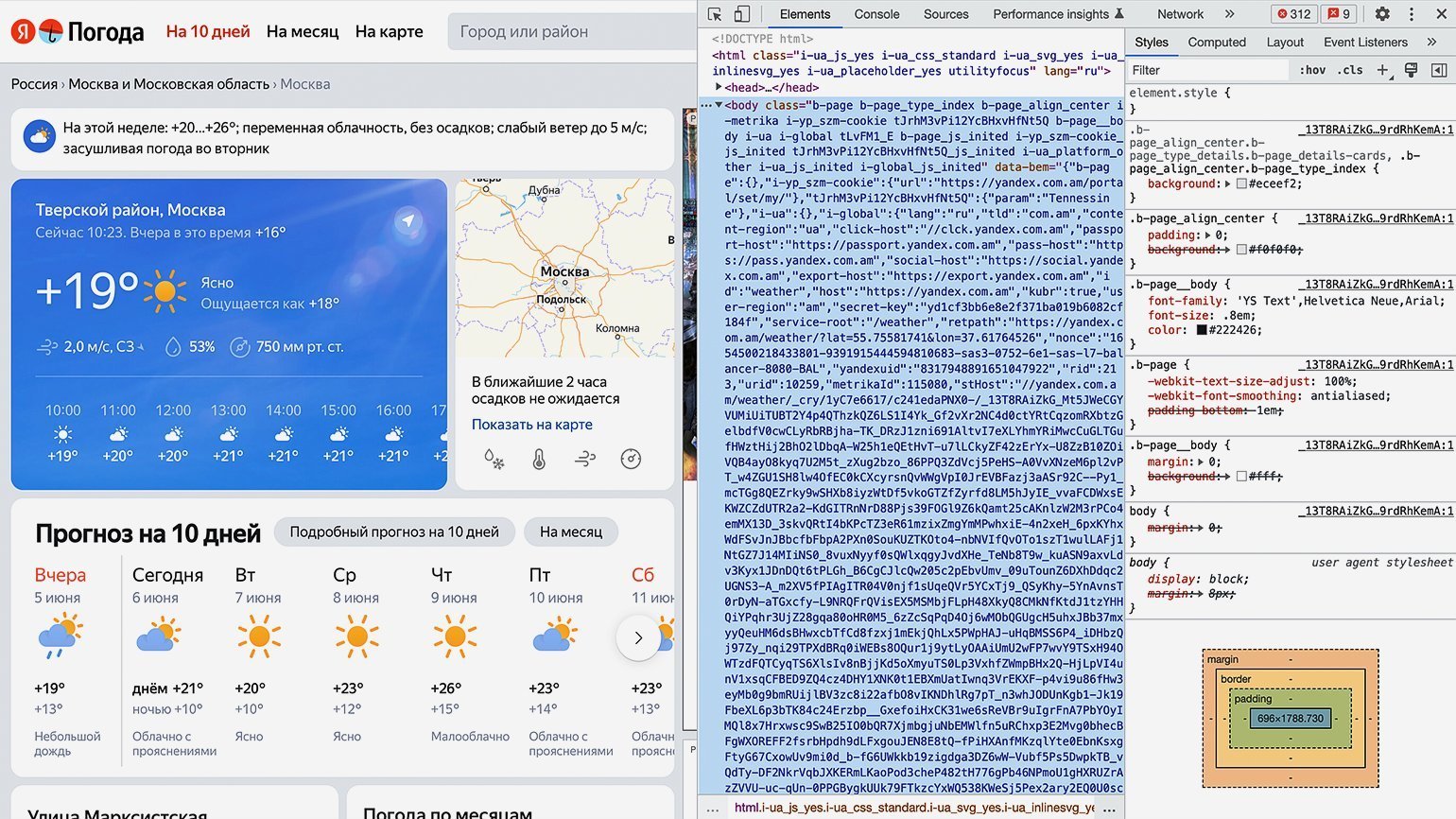
Переключаться между вкладками не надо, так как вся необходимая информация уже есть на первой.
Теперь найдём блок в коде, где хранится значение температуры. Для этого следует последовательно разворачивать блоки кода, располагающиеся внутри тега <body>. Сделать это можно, нажимая на символ ▶.
Как понять, что мы на правильном пути? Инспектор кода при наведении на блок кода подсвечивает на сайте ту область, за которую он отвечает. Переходим последовательно вглубь HTML-кода и находим нужный нам элемент.
В нашем случае пришлось проделать большой путь: элемент с классом «b‑page__container» → первый элемент с классом «content xKNTdZXiT5r0Tp0FJZNQIGlNu xIpbRdHA» → элемент с классом «xKNTdZXiT5r0vvENJ» → элемент с классом «fact card card_size_big» → элемент с классом «fact__temp-wrap xFNjfcG6O4pAfvHM» → элемент с классом «link fact__basic fact__basic_size_wide day-anchor xIpbRdHA» → элемент с классом «temp fact__temp fact__temp_size_s». Именно последнее название класса нам потребуется на следующем шаге.
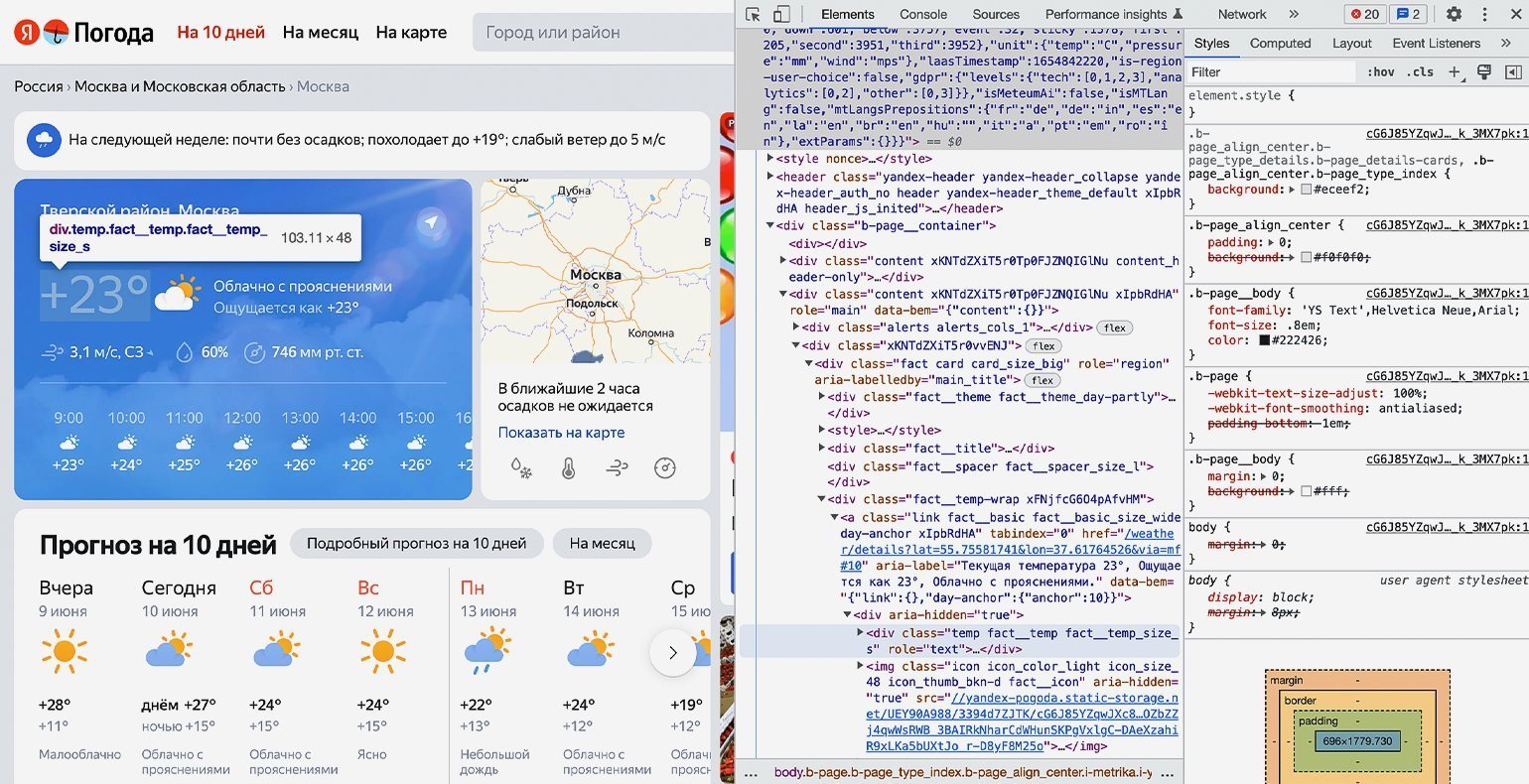
Продолжаем писать команды в терминал, командную строку, IDE или онлайн-редактор кода Python. На этом шаге нам остаётся использовать подключённые библиотеки и достать значения температуры из элемента <span=»temp fact__temp fact__temp_size_s»>. Но для начала надо проверить работу библиотек.
Сохраняем в переменную URL-адрес страницы, с которой мы планируем парсить информацию:
url = 'https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526'
Создадим к ней запрос и посмотрим, что вернёт сервер:
response = requests.get(url) print(response)
В нашем случае получаем ответ:
<Response [200]>
Отлично. Ответ «200» значит, что библиотека requests работает правильно и сервер отдаёт нам информацию со страницы.
Теперь получим исходный код, используя библиотеку Beautiful Soup и сразу выведем результат на экран:
bs = BeautifulSoup(response.text,"lxml") print(bs)
После выполнения на экране виден код всей страницы полностью:

Но весь код нам не нужен — мы должны выводить только тот блок кода, где хранится значение температуры. Напомним, что это <span=»temp fact__temp fact__temp_size_s»>. Найдём его значение с помощью функции find() библиотеки Beautiful Soup.
Функция find() принимает два аргумента:
- указание на тип элемента HTML-кода, в котором происходит поиск;
- наименование этого элемента.
В нашем случае код будет следующим:
temp = bs.find('span', 'temp__value temp__value_with-unit')
И сразу выведем результат на экран с помощью print:
print(temp)
Получаем:
<span class="temp__value temp__value_with-unit">+17</span>
Получилось! Но кроме нужной нам информации есть ещё HTML-тег с классом — а он тут лишний. Избавимся от него и оставим только значения температуры с помощью свойства text:
print(temp.text)
Результат:
+17
Всё получилось. Мы смогли узнать текущую температуру в городе с сайта «Яндекс.Погода», используя библиотеку Beautiful Soup для Python. Её можно использовать для своих задач — например, передавая в виджет на своём сайте, — или создать бота для погоды.
Если вы совсем новичок в веб-скрапинге, но хотите написать свой парсер (например, для автоматической генерации отчётов в Excel), рекомендуем посмотреть вебинар от Михаила Овчинникова — ведущего инженера-программиста из Badoo. Он на понятном примере объясняет основы языка Python и принципы веб-скрапинга. Уже в начале видеоурока вы запустите простой парсер и научитесь читать данные в формате HTML и JSON.
Бесплатная библиотека Selenium позволяет эмулировать работу веб-браузера — то есть «маскировать» веб-запросы скрипта под действия человека в Google Chrome или Safari. Почему это важно? Сайты умеют распознавать ботов и блокируют IP-адреса, с которых отправляются автоматические запросы.
Избежать «бана» можно двумя способами: изучить HTTP, принципы работы Python с вебом и написать свой эмулятор с нуля или воспользоваться готовым инструментом. Во втором случае Selenium — одно из лучших и самых удобных решений.
О том, как работать с библиотекой, рассказал Михаил Овчинников:
Парсинг помогает получить нужную информацию с любого сайта. Для него можно использовать разные языки программирования, но некоторые из них содержат стандартные библиотеки для веб-скрейпинга, например Beautiful Soup на Python.
А ещё мы рекомендуем внимательно изучить официальную документацию по библиотекам, которые мы использовали для парсинга. Например, можно углубиться в возможности и нюансы использования библиотеки Beautiful Soup на Python.
Исходные данные – это фундамент для успешной работы в области анализа и обработки данных. Существует множество источников данных, и веб-сайты являются одним из них. Часто они могут быть вторичным источником информации, например: сайты агрегации данных (Worldometers), новостные сайты (CNBC), социальные сети (Twitter), платформы электронной коммерции (Shopee) и так далее. Эти веб-сайты предоставляют информацию, необходимую для проектов по анализу и обработке данных.
Но как нужно собирать данные? Мы не можем копировать и вставлять их вручную, не так ли? В такой ситуации решением проблемы будет парсинг сайтов на Python. Этот язык программирования имеет мощную библиотеку BeautifulSoup, а также инструмент для автоматизации Selenium. Они оба часто используются специалистами для сбора данных разных форматов. В этом разделе мы сначала познакомимся с BeautifulSoup.
ШАГ 1. УСТАНОВКА БИБЛИОТЕК
Прежде всего, нам нужно установить нужные библиотеки, а именно:
- BeautifulSoup4
- Requests
- pandas
- lxml
Для установки библиотеки вы можете использовать pip install [имя библиотеки] или conda install [имя библиотеки], если у вас Anaconda Prompt.
«Requests» — это наша следующая библиотека для установки. Ее задача — запрос разрешения у сервера, если мы хотим получить данные с его веб-сайта. Затем нужно установить pandas для создания фрейма данных и lxml, чтобы изменить HTML на формат, удобный для Python.
ШАГ 2. ИМПОРТИРОВАНИЕ БИБЛИОТЕК
После установки библиотек давайте откроем вашу любимую среду разработки. Мы предлагаем использовать Spyder 4.2.5. Позже на некоторых этапах работы мы столкнемся с большими объемами выводимых данных и тогда Spyder будет удобнее в использовании чем Jupyter Notebook.
Итак, Spyder открыт и мы можем импортировать необходимую библиотеку:
# Import library
from bs4 import BeautifulSoup
import requests
ШАГ 3. ВЫБОР СТРАНИЦЫ
В этом проекте мы будем использовать webscraper.io. Поскольку данный веб-сайт создан на HTML, код легче и понятнее даже новичкам. Мы выбрали эту страницу для парсинга данных:
Она является прототипом веб-сайта онлайн магазина. Мы будем парсить данные о компьютерах и ноутбуках, такие как название продукта, цена, описание и отзывы.
ШАГ 4. ЗАПРОС НА РАЗРЕШЕНИЕ
После выбора страницы мы копируем ее URL-адрес и используем request, чтобы запросить разрешение у сервера на получение данных с их сайта.
# Define URL
url = ‘https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops'#
Ask hosting server to fetch url
requests.get(url)
Результат <Response [200]> означает, что сервер позволяет нам собирать данные с их веб-сайта. Для проверки мы можем использовать функцию request.get.
pages = requests.get(url)
pages.text
Когда вы выполните этот код, то на выходе получите беспорядочный текст, который не подходит для Python. Нам нужно использовать парсер, чтобы сделать его более читабельным.
# parser-lxml = Change html to Python friendly format
soup = BeautifulSoup(pages.text, ‘lxml’)
soup

ШАГ 5. ПРОСМОТР КОДА ЭЛЕМЕНТА
Для парсинга сайтов на Python мы рекомендуем использовать Google Chrome, он очень удобен и прост в использовании. Давайте узнаем, как с помощью Chrome просмотреть код веб-страницы. Сначала нужно щелкнуть правой кнопкой мыши страницу, которую вы хотите проверить, далее нажать Просмотреть код и вы увидите это:
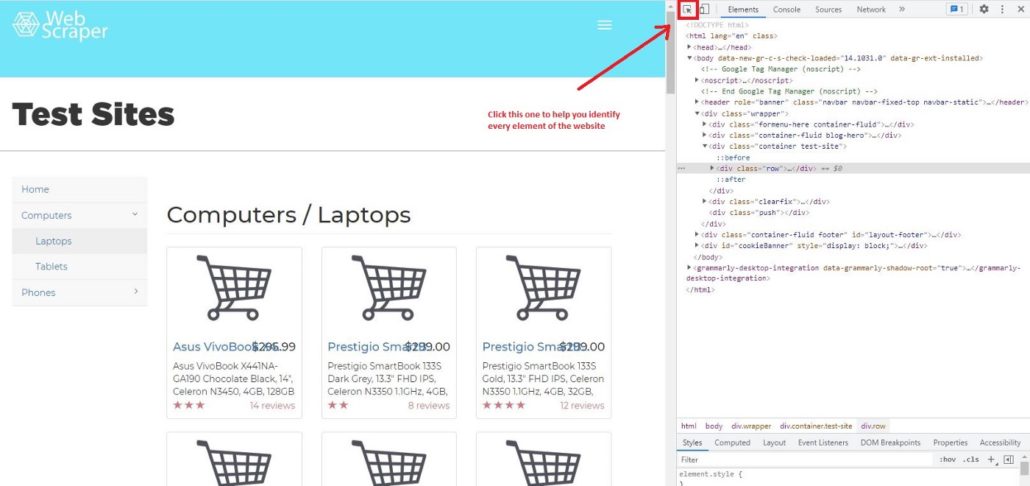
Затем щелкните Выбрать элемент на странице для проверки и вы заметите, что при перемещении курсора к каждому элементу страницы, меню элементов показывает его код.
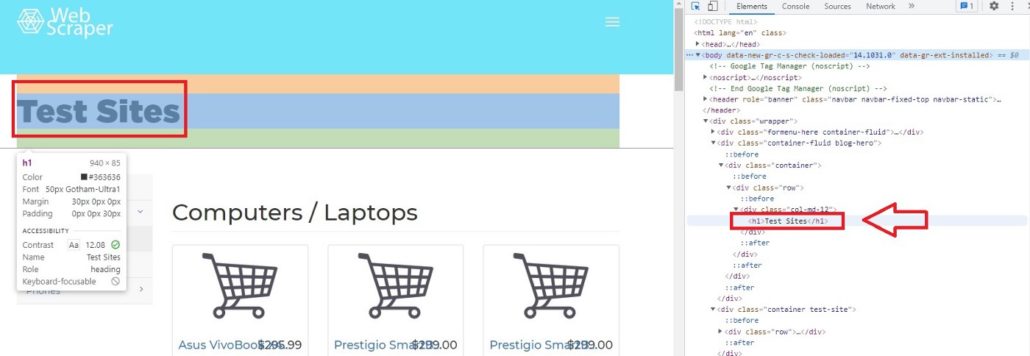
Например, если мы переместим курсор на Test Sites, элемент покажет, что Test Sites находится в теге h1. В Python, если вы хотите просмотреть код элементов сайта, можно вызывать теги. Характерной чертой тегов является то, что они всегда имеют < в качестве префикса и часто имеют фиолетовый цвет.
Как выбрать решение для парсинга сайтов: классификация и большой обзор программ, сервисов и фреймворков
ШАГ 6. ДОСТУП К ТЕГАМ
Если мы, к примеру, хотим получить доступ к элементу h1 с помощью Python, мы можем просто ввести:
# Access h1 tag
soup.h1
Результат будет:
soup.h1
Out[11]: <h1>Test Sites</h1>
Вы можете получить доступ не только к однострочным тегам, но и к тегам класса, например:
# Access header tagsoup.header#Access div tag soup.div
Не забудьте перед этим определить soup, поскольку важно преобразовать HTML в удобный для Python формат.
Вы можете получить доступ к определенному из вложенных тегов. Вложенные теги означают теги внутри тегов. Например, тег <p> находится внутри другого тега <header>. Но когда вы получаете доступ к определенному тегу из <header>, Python всегда покажет результаты из первого индекса. Позже мы узнаем, как получить доступ к нескольким тегам из вложенных.
# Access string from nested tags
soup.header.p
Результат:
soup.header.p
Out[10]: <p>Web Scraper</p>
Вы также можете получить доступ к строке вложенных тегов. Нужно просто добавить в код string.
# Access string from nested tags
soup.header.p
soup.header.p.string
Результат:
soup.header.p
soup.header.p.string
Out[12]: ‘Web Scraper’
Следующий этап парсинга сайтов на Python — это получение доступа к атрибутам тегов. Для этого мы можем использовать функциональную возможность BeautifulSoup attrs. Как результат применения attrs мы получим словарь.
# Access ‘a’ tag in <header>
a_start = soup.header.a
a_start#
Access only the attributes using attrs
a_start.attrs
Результат:
Out[16]:{‘data-toggle’: ‘collapse-side’,
‘data-target’: ‘.side-collapse’,
‘data-target-2’: ‘.side-collapse-container’}
Мы можем получить доступ к определенному атрибуту. Учтите, что Python рассматривает атрибут как словарь, поэтому data-toggle, data-target и data-target-2 являются ключом. Вот пример получение доступа к ‘data-target:
a_start[‘data-target’]
Результат:
a_start[‘data-target’]
Out[17]: ‘.side-collapse’
Мы также можем добавить новый атрибут. Имейте в виду, что изменения влияют только на веб-сайт локально, а не на веб-сайт в мировом масштабе.
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Результат:
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Out[18]:
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</a>
Парсинг таблицы с сайта на Python: Пошаговое руководство
ШАГ 7. ДОСТУП К КОНКРЕТНЫМ АТРИБУТАМ ТЕГОВ
Мы узнали, что в теге может быть больше чем один вложенный тег. Например, если мы запустим soup.header.div, <div> будет иметь много вложенных тегов. Учтите, что мы вызываем только <div> внутри <header >, поэтому другой тег внутри <header> не будет показан.
Результат:
soup.header.div
Out[26]:
<div class=”container”><div class=”navbar-header”>
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</div>
Как мы видим, в одном теге находится много атрибутов и вопрос заключается в том, как получить доступ только к тому атрибуту, который нам нужен. В BeautifulSoup есть функция ‘find’ и ‘find_all’. Чтобы было понятнее, мы покажем вам, как использовать обе функции и чем они отличаются друг от друга. В качестве примера найдем цену каждого товара. Чтобы увидеть код элемента цены, просто наведите курсор на индикатор цены.
После перемещения курсора мы можем определить, что цена находится в теге h4, значение класса pull-right price.
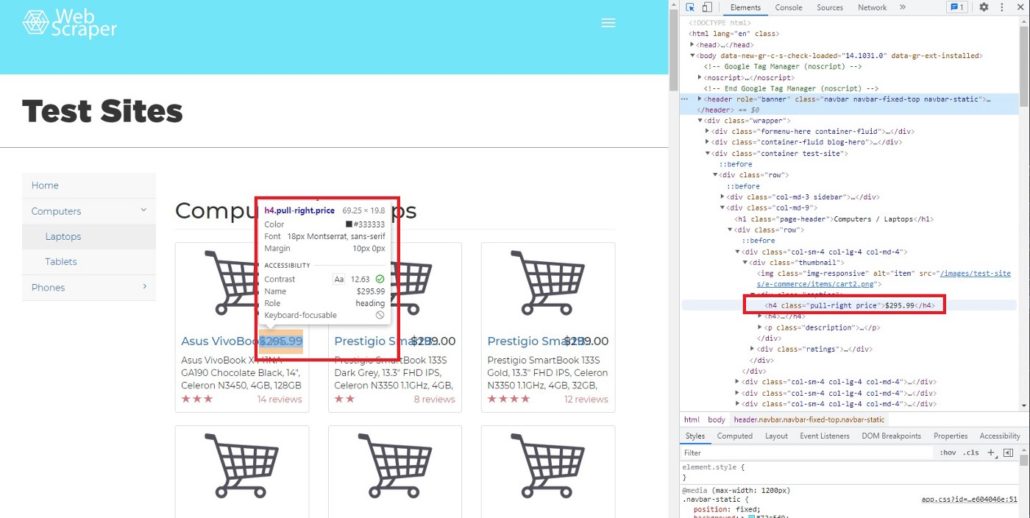
Далее мы хотим найти строку элемента h4, используя функцию find:
# Searching specific attributes of tags
soup.find(‘h4’, class_= ‘pull-right price’)
Результат:
Out[28]: <h4 class=”pull-right price”>$295.99</h4>
Как видно, $295,99 — это атрибут (строка) h4. Но что будет, если мы используем find_all.
# Using find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)
Результат:
Out[29]:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>,
<h4 class=”pull-right price”>$356.49</h4>,
....
</h4>]
Вы заметили разницу между find и find_all?
Да, все верно, find нужно использовать для поиска определенных атрибутов, потому что он возвращает только один результат. Для парсинга больших объемов данных (например, цена, название продукта, описание и т. д.), используйте find_all.
Кроме того, можем получить часть результата функции find_all. В данном случае мы хотим видеть только индексы с 3-го до 5-го.
# Slicing the results of find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)[2:5]
Результат:
Out[32]:[<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>]
[!] Не забывайте, что в Python индекс первого элемента в списке — 0, а последний не учитывается.
ШАГ 8. ИСПОЛЬЗОВАНИЕ ФИЛЬТРА
При необходимости мы можем найти несколько тегов:
# Using filter to find multiple tagssoup.find_all(['h4', 'a', 'p'])soup.find_all(['header', 'div'])
soup.find_all(id = True) # class and id are special attribute so it can be written like this
soup.find_all(class_= True)
Поскольку class и id являются специальными атрибутами, поэтому можно писать class_ и id вместо ‘class’ или ‘id’.
Использование фильтра поможет нам получить необходимые данные с веб-сайта. В нашем случае это название, цена, отзывы и описания. Итак, сначала определим переменные.
# Filter by name name = soup.find_all(‘a’, class_=’title’) # Filter by priceprice = soup.find_all(‘h4’, class_ = ‘pull-right price’)# Filter by reviews reviews = soup.find_all(‘p’, class_ = ‘pull-right’)# Filter by description description = soup.find_all(‘p’, class_ =’description’)
Фильтр по названию:
[<a class=”title” href=”/test-sites/e-commerce/allinone/product/545" title=”Asus VivoBook X441NA-GA190">Asus VivoBook X4…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/546" title=”Prestigio SmartBook 133S Dark Grey”>Prestigio SmartB…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/547" title=”Prestigio SmartBook 133S Gold”>Prestigio SmartB…</a>,
...
</a>]
Фильтр по цене:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$306.99</h4>,
...
</h4>]
Фильтр по отзывам:
[<p class=”pull-right”>14 reviews</p>,<p class=”pull-right”>8 reviews</p>,
<p class=”pull-right”>12 reviews</p>,<p class=”pull-right”>2 reviews</p>,
...
</p>]
Фильтр по описанию:
[<p class=”description”>Asus VivoBook X441NA-GA190 Chocolate Black, 14", Celeron N3450, 4GB, 128GB SSD, Endless OS, ENG kbd</p>,
<p class=”description”>Prestigio SmartBook 133S Dark Grey, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
<p class=”description”>Prestigio SmartBook 133S Gold, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
...
</p>]
ШАГ 9. ОЧИСТКА ДАННЫХ
Очевидно, результаты все еще в формате HTML, поэтому нам нужно очистить их и получить только строку элемента. Используем для этого функцию text.
Text может служить для сортировки строк HTML кода, однако нужно определить новую переменную, например:
# Try to call priceprice1 = soup.find(‘h4’, class_ = ‘pull-right price’)
price1.text
Результат:
Out[55]: ‘$295.99’
На выходе получается только строка из кода, но этого недостаточно. На следующем этапе мы узнаем, как парсить все строки и сделать из них список.
ШАГ 10. ИСПОЛЬЗОВАНИЕ ЦИКЛА FOR ДЛЯ СОЗДАНИЯ СПИСКА СТРОК
Чтобы сделать список из всех строк, необходимо создать цикл for.
# Create for loop to make string from find_all list
product_name_list = []
for i in name:
name = i.text
product_name_list.append(name)price_list = []
for i in price:
price = i.text
price_list.append(price)
review_list = []
for i in reviews:
rev = i.text
review_list.append(rev)
description_list = []
for i in description:
desc = i.text
description_list.append(desc)ШАГ 11. СОЗДАНИЕ ФРЕЙМА ДАННЫХ
После того, как мы создали цикл for и все строки были добавлены в списки, остается заключительный этап парсинга сайтов на Python — построить фрейм данных. Для этой цели нам нужно импортировать библиотеку pandas.
# Create dataframe# Import library import pandas as pdtabel = pd.DataFrame({‘Product Name’:product_name_list, ‘Price’: price_list, ‘Reviews’:review_list, ‘Description’:description_list})
Теперь эти данные можно использовать для работы в проектах по анализу и обработке данных, в машинном обучении, для получения другой ценной информации.

Надеюсь, это руководство будет вам полезно, особенно для тех, кто изучает парсинг сайтов на Python. До новых встреч в следующем проекте.
Если у вас возникнут сложности с парсингом сайтов на Python или с парсингом приложений, обращайтесь в компанию iDatica — напишите письмо или заполните заявку указав все детали задачи по парсингу.
Парсинг —
руководство для новичков
Оглавление
- Предисловие
- Что такое парсинг?
- Как работает парсинг?
- Продвинутые методы в парсинге. Автоматизация.
- Для чего используется парсинг?
- Как начать парсинг?
- Бесплатные инструменты для парсинга
- Вывод. Кратко о сказанном
Предисловие
Вы когда-нибудь задумывались над тем, как парсинг может раскрыть потенциал вашего бизнеса?
В первую очередь вы сразу же подумаете о препятствиях, связанных с парсингом — вы можете быть заблокированы, как трудно получить данные, как сложно их масштабировать, даже если вы можете начать, как поддерживать? Даже если вы начнете извлекать данные, изменения в структуре сайта могут полностью помешать вам. Это то, что мешает вам заниматься этим самостоятельно, верно?
Не беспокойтесь!
Мы составили Руководство для начинающих по парсингу в интернете. Имея лишь некоторые, или вовсе не имея каких-либо технических знаний, вы можете начать использовать это руководство. Данное руководство позволит вам изучить парсинг и поможет вам получить конкурентное преимущество перед другими. Давайте начнем!
Что такое парсинг?
Парсинг сайтов — это автоматический способ извлечения больших объемов данных с сайтов, которые затем можно сохранить в файле на вашем компьютере или сетевом диске в виде электронной таблицы.
Зайдя на любой сайт вы можете только просматривать данные, но не можете их выгрузить. Да, вы можете вручную скопировать и сохранить некоторые из них, но это отнимает много времени и сил. Парсинг позволяет автоматизировать этот процесс и быстро извлечь точные данные, которые можно использовать для любого рода аналитики.
Вы можете собирать огромное количество данных, а также различные типы данных. Это могут быть текст, изображения, электронная почта, номера телефонов, видео и так далее. Для конкретных проектов вам могут потребоваться данные, относящиеся к конкретному ресурсу, такие как информация о товаре или услуге, обзоры, цены или данные о конкурентах. В конце процесса вы получите все это в формате таблицы XLS или CSV файла, который вы можете использовать по своему усмотрению далее.
Как работает парсинг?
Итак, позвольте нам показать вам, как на самом деле работает парсинг. Хотя есть много разных способов, мы расскажем самый простой и легкий из возможных способов сбора данных. Вот как это работает.
1. Запрос-ответ
Первый и самый простой шаг в любом созданном парсере по сбору данных — запросить у целевого веб-сайта содержимое определенного количества URL. В ответ ваш парсер получает запрошенную информацию в формате HTML. Помните, HTML — это тип файла, используемый для отображения всей текстовой информации на веб-странице.
2. Разбор и извлечение
Проще говоря, HTML — это язык разметки с простой структурой. Когда дело доходит до парсинга, это обычно относится к процессу восприятия кода как текста и создания структуры в памяти, которую компьютер может понимать и работать с ней.
Проще говоря, парсер в основном принимает HTML-код и извлекает соответствующую информацию, такую как заголовок страницы, абзацы на странице, иные заголовки на странице, ссылки, текст и так далее. Все, что вам нужно, это задать регулярные выражения (Regex или Regexp, англ. Regular expressions), где группа регулярных выражений определяет регулярный язык и механизм регулярных выражений, автоматически генерирующий синтаксический анализатор для этого языка, позволяющий сопоставлять шаблоны и извлекать нужный текст.
3. Скачать данные
В заключительной части вы загружаете и сохраняете данные в CSV или XML, чтобы их можно было использовать в любой другой программе (например Excel).
Благодаря этому вы можете извлекать конкретные данные из Интернета и сохранять их, как правило, в локальной базе данных для последующего поиска или анализа. Вот и все. Вот как работает парсинг!
Продвинутые методы в парсинге. Автоматизация.
В настоящее время автоматизация процесса парсинга используется для идентификации нужной информации на сайте путем визуального распознавания страниц, как это делает человек своими глазами.
Как это работает ? Довольно просто. В автоматическом режиме настроенный парсер обычно присваивает каждой из своих классификаций показатель достоверности, который является мерой статистической вероятности того, что классификация является правильной, с учетом закономерностей, обнаруженных в данных. Пока сложно для восприятия? Дальше будет понятнее.
Если показатель доверия слишком низок, система автоматически генерирует запрос, предназначенный для получения текстов, которые могут содержать данные, которые парсер пытается извлечь.
Затем парсер пытается извлечь соответствующие данные вначале из одного, а после по аналогии из новых текстов и сверяет результаты с результатами его первоначального извлечения. Если показатель достоверности остается достаточно низким, он переходит к следующему найденному тексту, и так далее.
Для чего используется парсинг?
Парсинг в сети имеет множество вариантов применения. Он может быть использован в любой известной области, но мы расскажем о самых востребованных. Сейчас по порядку.
1. Мониторинг цен
В сфере онлайн-торговли компании используют конкурентные цены в качестве стратегии. Чтобы преуспеть в таком бизнесе, нужно отслеживать ценовую стратегию конкурентов. По данным ценообразования вы можете самостоятельно определить лучшую цену. Вы будете удивлены тем, как парсинг может помочь вам получить преимущество над другими, когда дело доходит до мониторинга цен. Немного о фактах и факторах.
Цена на сегодняшний день является решающим фактором в таких сферах, как торговля в онлайне. Компании, занимающиеся продажей товаров в онлайне и офлайне, хотели бы отслеживать цены своих конкурентов и соответственно зная их цены устанавливать более конкурентные, чтобы получить стратегическое преимущество, а как следствие получить клиента.
Более того, это не разовое дело. Цены постоянно меняются, и компаниям, занимающимся торговлей, требуется оперативная информация об изменениях цен, происходящих на сайтах их конкурентов.
Вот где парсинг информации может дать вам большие преимущества. С помощью парсинга вы можете постоянно проверять цены и отслеживать ценовые стратегии ваших конкурентов.
2. Ведущее положение
Для любого бизнеса маркетинг имеет первостепенное значение. Для маркетинга вам нужны контактные данные тех, кому вы отправляете свои коммерческие предложения через ныне популярные рассылки. С помощью парсинга вы можете получить невероятно большое количество данных, из которых вы создадите бесчисленное количество потенциальных клиентов. Вот как это работает:
Когда вы думаете об ускорении вашей маркетинговой кампании, что вам нужно в первую очередь? Конечно информация!
Она нужна вам оптом – сотни, тысячи таких данных как электронная почта, телефонные номера потенциальных клиентов, цены сайтов конкурентов и т. д. Нет способа получить информацию вручную с сайтов, расположенных по всему интернету.
Хорошо созданный парсер может извлечь эти адреса электронной почты и номера телефонов, любую другую необходимую информацию с хирургической точностью. Это будет не просто точно, но и быстро. Вы получаете это за малую долю времени, нежели сравнить с тем, сколько потребуется времени и сил чтобы сделать это вручную.
Вы также получаете результаты парсинга в удобном формате, который вы можете легко использовать для дальнейшей обработки. Вы также можете интегрировать его в свои инструменты продаж (всевозможные CRM) или выгрузить на собственный сайт.
3. Конкурентный анализ
В эпоху конкурентной борьбы вам нужно очень хорошо знать своих конкурентов и понимать их стратегии, сильные и слабые стороны. Для этого вам нужно много-много данных. Вот где может помочь парсинг. Вот как это работает:
Вам определенно необходимо время от времени проводить конкурентный анализ. Но нужные вам данные разбросаны здесь, там и везде. Как вы получите к ним доступ? Это то, где парсинг может создать для вас преимущество. Вы можете быстро собрать нужные данные из нескольких источников и использовать их для конкурентного анализа.
Чем быстрее и эффективнее у вас есть инструменты для парсинга, тем лучше будет конкурентный анализ. Это так просто!
4. Загрузка изображений и описание продукта
Каждому новому интернет-магазину нужны описания продуктов и изображения десятков, сотен, а может даже и тысяч товаров, которые должны быть показаны на вашем сайте. Как написать описания продукта и создать новые изображения для большого количества продуктов за ночь? Парсинг данных может помочь вам и здесь:
Допустим, у вас есть интернет-магазин. Вам понадобятся изображения и описания товаров, не так ли?
Конечно, вы можете попросить кого-нибудь скопировать и вставить все вручную с другого сайта. Скорее всего это займет вечность. Вместо этого, парсинг может автоматизировать процесс извлечения изображений и описания товаров, а как следствие выполнить задачу в кратчайшие сроки!
Так что, если вы хотите заняться бизнесом в области онлайн-торговли, не важно будет это ваш сайт, маркетплейс на который вы поставляете товары или доска объявлений — парсинг может быть вашим верным помощником в этом не легком деле, вы согласны?
Как начать парсинг?
На данный момент, вы, вероятно, задаетесь вопросом:
«Хорошо, я готов попробовать парсить. Как мне начать?
1. Кодируй сам
- Это вариант означает, что вам придется самостоятельно создать свой парсер.
- Вы можете использовать несколько простых в использовании продуктов с открытым исходным кодом, которые помогут вам начать работу.
- Тогда вам нужен сервер, который может позволить вашему парсеру работать круглосуточно.
- Вам также нужна надежная серверная инфраструктура, которая может быть расширена в соответствии с вашими требованиями. Это также необходимо для хранения и доступа к извлеченным данным.
- Основным преимуществом является то, что парсер изготовлен на заказ, и, следовательно, вы можете извлекать данные по своему усмотрению. Другими словами, вы имеете полный контроль над процессом.
- С другой стороны, это требует огромных ресурсов, чтобы сделать это самостоятельно таким образом.
- Это также потребует постоянного мониторинга, так как вам может потребоваться вносить изменения, модификации и время от времени обновлять вашу систему.
- Для простого одноразового проекта это может сработать!
2. Инструменты для парсинга
- Ну, здесь все, что вам нужно, это использовать уже существующие инструменты на рынке.
- Вы можете немного инвестировать и исследовать, как вы можете использовать доступные инструменты / программное обеспечение / сервис веб-поиска.
- Если вы сможете найти действительно жизнеспособный вариант в этом сегменте, который является доступным и масштабируемым, вы действительно сможете воспользоваться преимуществами парсинга гораздо быстрее и эффективнее.
- Это будет зависеть от того, сколько вы можете потратить, хотите ли вы выбрать только бесплатные инструменты или сколько данных вам нужно собрать. Соответственно, вы можете определить инструменты и посмотреть, как они работают.
- Вы также можете изучить бесплатные инструменты для парсинга, которые позволяют бесплатно собрать первые 10-20 страниц.
3. Внештатный разработчик
- Ну, есть и средний путь, который вы можете попробовать!
- Вы можете обратиться к внештатному разработчику и заказать у него разработку инструмента парсинга для ваших конкретных потребностей.
- Это освободит вас как от статуса «сделай сам», так и от значительных инвестиций, которые могут вам понадобиться для инструментов.
- Если вы сможете найти такого внештатного разработчика, который сможет понять ваши потребности и придумать что-то стоящее, это стоит попробовать!
Бесплатные инструменты для парсинга
Допустим, вы немного ограничены в средствах или не хотите вкладывать средства в инструменты на данный момент, вы все еще можете изучить несколько бесплатных программ и посмотреть, работает ли он для вас так как нужно. Вот пара бесплатных инструментов, которые вы можете попробовать:
1. Парсер-расширение Chrome
- Это расширение Chrome для парсинга простых сайтов.
- Он может извлекать данные из таблиц и преобразовывать их в структурированный формат.
- Это простой инструмент, но довольно ограниченный как инструмент расширения для интеллектуального анализа данных. Он может помочь вам в онлайн-исследованиях, когда вам нужно быстро получить данные в форме электронной таблицы.
- Если вы являетесь опытным и у вас есть навыки подбора XPath выражений, это простой в использовании инструмент, который вы можете иметь в своем портфеле!
2. Scrapy (с открытым кодом)
- Scrapy — это платформа для работы с открытым исходным кодом, которая может помочь вам собрать данные, необходимые для получения с разных веб-сайтов.
- По сути, это прикладная среда для парсинга сайтов и извлечения структурированных данных, которые можно использовать для самых разных потребностей, таких как анализ и обработка данных.
- По сравнению со всеми другими инструментами с открытым исходным кодом, извлечение данных с использованием Scrapy происходит намного быстрее. Таким образом, он идеально подходит для требований к сбору больших объемов данных. Это эффективно, масштабируемо и гибко.
- Вы также получаете встроенную поддержку генерации экспорта файлов в нескольких форматах (JSON, CSV, XML) и хранения их в нескольких бэкэндах (FTP, S3, локальная файловая система).
- Он работает в системах Linux, Mac OS и Windows.
Вывод. Кратко о сказанном
Как вы можете видеть, парсинг является мощным методом извлечения данных, который может помочь вам получить конкурентное преимущество над вашими коллегами или конкурентами. С помощью парсинга вы можете получить объективные, полные данные без ошибок, которые могут повысить эффективность вашей бизнес-аналитики и привести к неограниченному потенциалу роста.
Все, что вам нужно сделать, это начать изучать технологии парсинга как можно скорее. Если вы приложите некоторые усилия, есть способы начать это с минимальными знаниями.
Мы рассказали о том, что есть инструменты, которые могут использовать новички и без опыта. Для начала, есть бесплатные инструменты, которые вы можете использовать на старте работы с парсингом.
Ну а если для вас это сложно или нецелесообразно, вы ограничены во времени, мы сделаем эту работу за вас в самый короткий срок. Только помните о том, что мы не продаем знания и инструменты, мы продаем и добываем информацию разрабатывая свои методы сбора данных.