Прочитав статью, вы познакомитесь с особенностями языка Python, основными типами данных, условными операторы, циклами и работой с файлами. В заключении приведена подборка литературы и каналов на YouTube, а также бесплатных курсов.
***
Python в Ubuntu предустановлен. Чтобы узнать версию Python, откроем терминал комбинацией клавиш Ctrl + Alt + T и введем следующую команду:
python3 --version
Для Windows нужно скачать Python с официального сайта и установить как обычную программу.
Установка редактора кода
Для работы нам понадобится редактор кода (IDE). Самые популярные:
- PyCharm
- Atom
- Visual Studio Code
- Sublime Text
Для установки Atom в Ubuntu введем в терминале:
wget -qO - https://packagecloud.io/AtomEditor/atom/gpgkey | sudo apt-key add -
sudo sh -c 'echo "deb [arch=amd64] https://packagecloud.io/AtomEditor/atom/any/ any main" > /etc/apt/sources.list.d/atom.list'
sudo apt-get update
sudo apt-get install atom
Для Windows скачаем Atom с официального сайта. После установки редактора кода установим для него плагин run-python-simply (есть и другие) для запуска Python. Два способа установки:
- Перейдем на страничку плагина и нажмем кнопку
Install. - Откроем Atom, перейдем во вкладку
File→Settings→Install, введем в поле поискаrun-python-simplyи установим его.
Создание проекта
Создадим проект, в котором будем хранить код и другие файлы. Для этого перейдем во вкладку File → Add Project Folder и выберем любую свободную папку.
Онлайн-редакторы кода
Если под рукой только смартфон, воспользуемся бесплатными онлайн-редакторами кода:
- repl.it
- onlinegdb.com
- tutorialspoint.com
- paiza.io
- onecompiler.com
1. Синтаксис
Python использует отступы, чтобы обозначить начало блока кода:
if 3 > 1:
print("Три больше единицы") # Три больше единицы
Python выдаст ошибку, если вы пропустите отступ:
if 3 > 1:
print("Три больше единицы") # Ошибка: IndentationError: expected an indented block
Рекомендуется использовать отступ, равный четырем пробелам.
2. Hello, World
Создадим файл example.py, где example – имя файла, .py – расширение, которое означает, что программа написана на языке программирования Python.
Напишем в example.py следующую строчку:
print('Hello, World') # Hello, World
У нас установлен плагин run-python-simply и запустить код мы можем двумя способами:
- перейти во вкладку
Packages→Run Python Simply→Toggle F5; - или нажать на клавишу
F5.
После запуска кода появится окно терминала с результатом или ошибкой.
В нашем случае в терминале отобразится фраза Hello, World.
Здесь:
print() – функция, выводящая на экран фразу Hello, World.
'Hello, World' – строка (заключена в кавычки).
Также можно использовать переменную word, которой присвоим значение 'Hello, World':
word = 'Hello, World'
print(word) # Hello, World
Python – язык с динамической типизацией, то есть нам не нужно заранее объявлять тип переменной, является ли она строкой, числом и так далее.
О функциях поговорим в конце статьи, сейчас разберемся со строками и другими типами данных.
3. Типы данных
3.1. Строки
Строка – упорядоченная последовательность символов, заключенная в одинарные или двойные кавычки:
"Cat and dog" # пример записи строки
'Cat and giraffe'
Операции со строками
Изменение регистра первого символа к верхнему регистру с помощью метода title():
string = 'cat'
print(string.title()) # Cat
Преобразование всех символов к верхнему и нижнему регистру методами upper() и lower() соответственно:
string = 'cat'
print(string.upper()) # CAT
string = 'DOG'
print(string.lower()) # dog
Объединение строк (конкатенация). Строки объединяются с помощью знака сложения +:
first_animal = 'cat'
second_animal = 'dog'
all_animals = first_animal + ',' + ' ' + second_animal
print(all_animals) # cat, dog
Повторение строки:
animal = 'Cat'
print(animal * 5) # CatCatCatCatCat
Вычисление длины строки. Чтобы определить длину строки воспользуемся встроенной функцией len() (сокращённое от англ. length):
animal = 'Cat'
print(len(animal)) # 3

Индексация начинается с 0. В нашем случае символ C имеет индекс 0, a – 1, t – 2.
Для получения элемента по индексу воспользуемся квадратными скобками []:
animal = 'Cat'
print(animal[0]) # C
В предыдущем примере по индексу мы получали один элемент строки. По срезу можно получить несколько элементов:
animal = 'CatDog'
print(animal[1:3]) # at
print(animal[0:6:2]) # Cto – выводится нулевой элемент и каждый второй после него
Как формируется срез:
list_name[start:stop:step], где start – начало среза, stop – конец среза, step – шаг среза.
Получим с помощью среза последний элемент:
animal = 'CatDog'
print(animal[-1]) # g
Все элементы, кроме первого:
animal = 'CatDog'
print(animal[1:]) # atDog
Все элементы, кроме последнего:
animal = 'CatDog'
print(animal[0:5]) # CatDo
print(animal[:5]) # CatDo
print(animal[:-1]) # CatDo
Создание копии строки через срез:
animal = 'CatDog'
animal_copy = animal[:]
print(animal_copy) # CatDog
Методом replace() заменим символы в строке:
animal = 'CatDog'
print(animal.replace('Cat', 'Dog')) # DogDog
В скобках метода replace() указана дополнительная информация: Cat – элемент, подлежащий замене на элемент Dog.
Для удаление пробелов слева и справа применяется метод strip(), только справа – rstrip(), только слева – lstrip():
animal = ' CatDog '
print(animal.strip()) # CatDog
print(animal.rstrip()) # CatDog – здесь остался пробел слева
print(animal.lstrip()) # CatDog – здесь остался пробел справа
Преобразование строки в список индивидуальных символов:
animal = 'CatDog '
print(list(animal)) # ['C', 'a', 't', 'D', 'o', 'g', ' ']
3.2. Числа
Целые числа (int) не имеют дробной части:
print(25 + 0 - 24) # 1
Число с плавающей точкой (float) имеет дробную часть:
print(2.8 + 4.1) # 6.8999999999999995
Операции над числами:
print(2 + 3) # Сложение: 5
print(5 - 4) # Вычитание: 1
print(5 * 5) # Умножение: 25
print(4 / 2) # Деление: 2.0
print(4 ** 4) # Возведение в степень: 256
Порядок операций. Выражение в скобках будет просчитываться в первую очередь:
print(3*4 + 5) # 17
print(3*(4 + 5)) # 27
Чтобы преобразовать число с плавающей точкой в целое воспользуемся функцией int(), а для обратного преобразования – функцией float():
print(int(5.156)) # 5
print(float(4)) # 4.0
3.3. Списки
Список (англ. list) – набор упорядоченных элементов произвольных типов. Списки задаются квадратными скобками [] и содержат объекты любого типа: строки, числа, другие списки и так далее. Элементы можно менять по индексу.
Создадим список animals и выведем его на экран:
animals = ['cat', 'dog', 'giraffe']
print(animals) # ['cat', 'dog', 'giraffe']
Обратимся к второму элементу списка:
animals = ['cat', 'dog', 'giraffe']
print(animals[1]) # dog
Чтобы изменить элемент списка, обратимся к нему по индексу и присвоим новое значение:
animals = ['cat', 'dog', 'giraffe']
print(animals) # ['cat', 'dog', 'giraffe']
animals[2] = 'orangutan' # меняем третий элемент
print(animals) # ['cat', 'dog', 'orangutan']
animals[2] = ['orangutan']
print(animals) # ['cat', 'dog', ['orangutan']] – список внутри списка, вложенный список
Для добавления элемента в конец списка воспользуемся методом append():
animals = ['cat', 'dog', 'giraffe']
animals.append('tyrannosaurus')
print(animals) # ['cat', 'dog', 'giraffe', 'tyrannosaurus']
Метод insert() вставляет элемент по индексу:
animals = ['cat', 'dog', 'giraffe']
animals.insert(1, 43)
print(animals) # ['cat', 43, 'dog', 'giraffe']
Число 43 вставляется на место с индексом 1, остальные элементы сдвигаются вправо. Первый элемент остается на прежнем месте.
Для удаления элемента из списка, обратимся к элементу по индексу, используя команду del:
animals = ['cat', 'dog', 'giraffe']
del animals[2]
print(animals) # ['cat', 'dog']
Другой способ удаления – метод pop():
animals = ['cat', 'dog', 'giraffe']
animals.pop(2)
print(animals) # ['cat', 'dog']
В двух предыдущих примерах мы удаляли элемент по его индексу. Теперь удалим элемент по его значению с помощью метода remove():
animals = ['cat', 'dog', 'giraffe']
animals.remove('dog')
print(animals) # ['cat', 'giraffe']
Чтобы упорядочить список по алфавиту используем метод sort():
animals = ['giraffe', 'cat', 'dog']
animals.sort()
print(animals) # ['cat', 'dog', 'giraffe']
Список в обратном порядке выводится методом reverse():
animals = ['cat', 'dog', 'giraffe']
animals.reverse()
print(animals) # [giraffe', 'dog', 'cat']
Для определения длины списка воспользуемся функцией len():
animals = ['cat', 'dog', 'giraffe']
print(len(animals)) # 3
3.4. Кортежи

Кортеж (англ. tuple), как и список хранит элементы, только в отличие от списка, элементы кортежа не изменяются. Кортеж задается круглыми скобками ():
animals = ('cat', 'dog', 'giraffe')
print(animals[0]) # Получение элемента кортежа с индексом 0: cat
Одноэлементный кортеж задается с помощью запятой после первого элемента. Без запятой получим строку. Чтобы узнать какой тип данных мы получаем на выходе воспользуемся функцией type():
animals = ('cat',)
print(animals) # ('cat',)
print(type(animals)) # <class 'tuple'> – кортеж
animals = ('cat')
print(animals) # cat
print(type(animals)) # <class 'str'> – строка
Конкатенация кортежей:
print(('cat',) + ('dog', 2)) # ('cat', 'dog', 2)
Повторение кортежа:
print(('cat', 'dog', 4) * 2) # ('cat', 'dog', 4, 'cat', 'dog', 4)
Срез кортежа:
animals = ('cat', 'dog', 'giraffe')
print(animals[0:1]) # ('cat',)
print(animals[0:2]) # ('cat', 'dog')
Чтобы создать список из элементов кортежа применим функцию list():
animals_tuple = ('cat', 'dog', 33)
animals_list = list(animals_tuple)
print(animals_list) # ['cat', 'dog', 33]
3.5. Словари
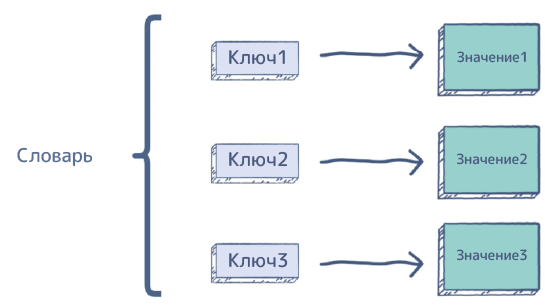
Словарь – неупорядоченная коллекция произвольных элементов, состоящих из пар «ключ-значение». Словарь объявляется через фигурные скобки {}: dictionary = {‘pets‘: ‘cat‘, ‘numbers‘: (1, 2)}, где pets и numbers – ключи, а cat, (1, 2) – значения. Если в списке мы получаем объект по его индексу, то в словаре по ключу.
Получим по ключам соответствующие значения из словаря dictionary:
dictionary = {'pets': 'cat', 'numbers': (1, 2)}
print(dictionary['pets']) # cat
print(dictionary['numbers']) # (1, 2)
print(dictionary['numbers'][1]) # 2
Чтобы добавить новую пару «ключ-значение» используем следующую запись словарь['новый_ключ'] = новое_значение:
dictionary = {'pets': 'cat', 'numbers': (1, 2)}
dictionary['dinosaur'] = 'tyrannosaurus', 'pterodactylus'
print(dictionary) # {'pets': 'cat', 'numbers': (1, 2), 'dinosaur': ('tyrannosaurus', 'pterodactylus')}
Изменение существующего значения похоже на добавление нового значения словарь['существующий_ключ'] = новое_значение:
dictionary = {'pets': 'cat', 'numbers': (1, 2)}
dictionary['pets'] = 'dog'
print(dictionary) # {'pets': 'dog', 'numbers': (1, 2)}
Командой del можно удалить ключ со значением:
dictionary = {'pets': 'cat', 'numbers': (1, 2)}
del dictionary['pets']
print(dictionary) # {'numbers': (1, 2)}
3.6. Множества
Множества – неупорядоченные последовательности не повторяющихся элементов. Множество задается через фигурные скобки {}:
animals_and_numbers = {'cat', 'dog', 99, 100}
print(animals_and_numbers) # {'cat', 99, 100, 'dog'}
Операции над множествами:
animals_and_numbers = {'cat', 'dog', 99, 100}
numbers = {555, 99}
animals = {'cat', 'dog'}
print(animals_and_numbers.union(numbers)) # {'cat', 99, 100, 'dog', 555} – добавляет в множество animals_and_numbers элементы множества numbers
print(animals_and_numbers.intersection(numbers)) # {99} – возвращает множество, являющееся пересечением множеств animals_and_numbers и numbers
print(animals_and_numbers.difference(numbers)) # {'cat', 'dog', 100} – Возвращает разность множеств animals_and_numbers и numbers
print(animals_and_numbers.issuperset(animals)) # True – Возвращает True, если animals является подмножеством animals_and_numbers.
3.7. Файлы
С помощью функции open() мы создаем файловый объект для работы с файлами. Создадим в папке с python-файлом текстовой файл example.txt, напишем в нем слово test, сохраним и закроем. Следующий код открывает и выводит на экран содержимое текстового файла example.txt:
with open('example.txt', 'r') as file:
for line in file:
print(line)
Здесь:
example.txt – путь к файлу и его имя. В нашем случае файл расположен в папке с выполняемой программой.
r – режим работы «только чтение».
Попробуем дозаписать числа в конец файла:
numbers = ['0', '1', '2', '3']
with open('example.txt', 'a') as file:
for number in numbers:
file.write(number + 'n')
0 # в файл запишется последовательность чисел, каждое число с новой строчки
1
2
3
Здесь:
numbers – список чисел.
a – режим записи «в конец текстового файла».
n – перенос на новую строчку.
Без переноса строки результат будет следующий:
numbers = ['0', '1', '2', '3']
with open('example.txt', 'a') as file:
for number in numbers:
file.write(number)
0123 # результат записи без переноса строки
4. Ввод данных
Для ввода данных применяется функция input():
input_word = input('Введите какое-нибудь слово: ')
print('Слово: ' + input_word)
5. Условные инструкции
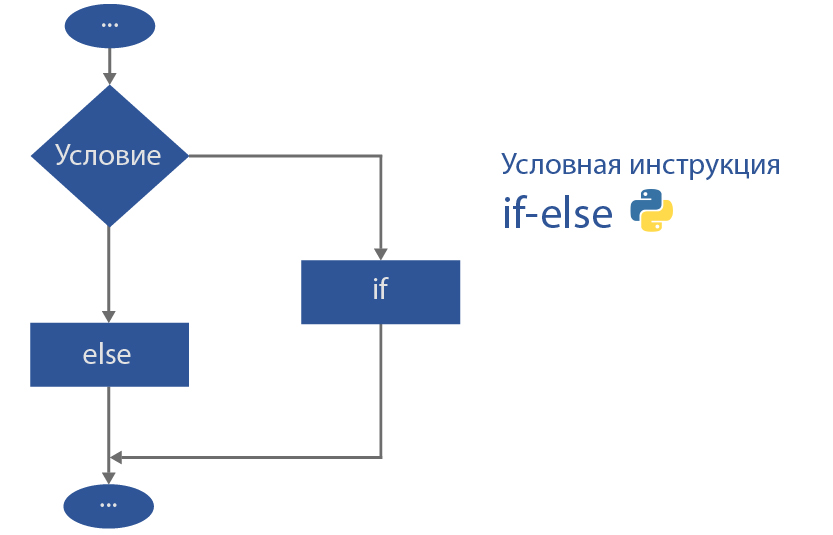
Оператор if выполняет код в зависимости от условия. Проверим, если число три меньше пяти, то выведем на экран слово true:
if 3 < 5:
print('true') # true
Попробуем оператор if-else. else переводится как «в другом случае». Когда условие if не выполняется, то идет выполнение кода после else:
if 3 > 5:
print('true')
else:
print('false') # false
elif = else + if – код выполняется, если предыдущее условие ложно, а текущее истинно:
number = 15
if number < 3:
print('число меньше трех')
elif 4 < number < 10:
print('число в промежутке от 4 до 10')
elif number > 10:
print('число больше 10') # число больше 10
6. Цикл while
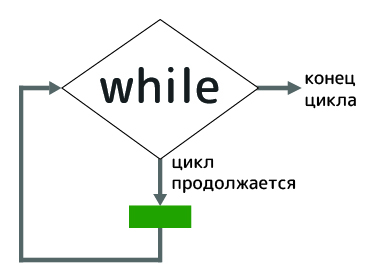
Напишем цикл, который 5 раз выведет на экран слово hello:
x = 0
while x < 5:
print('hello')
x += 1
# получаем пять раз слово hello
hello
hello
hello
hello
hello
Здесь:
while – обозначение цикла.
x < 5 – условие, которое записывается после while. Каждый раз после выполнения цикла (после одной итерации) проверяется это условие. Если оно становится ложным, цикл прекращает работу.
print('hello') – вывести на экран слово hello.
x += 1 – это сокращенный способ записи x = x + 1. То есть при каждой итерации значение x увеличивается на единицу.
Бесконечный цикл записывается с помощью while True:
while True:
print('hello')
hello
hello
hello
hello
hello
…
7. Цикл for
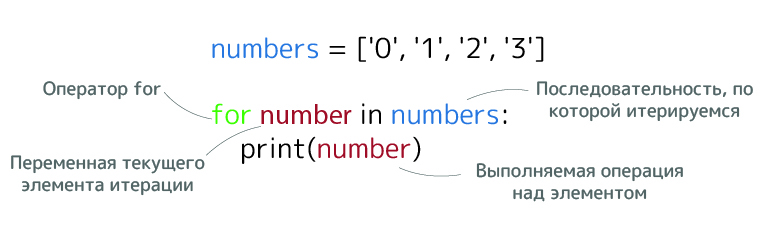
Цикл for перебирает элементы последовательности:
numbers = ['0', '1', '2', '3']
for i in range(0, len(numbers)):
print(numbers[i])
# на экран выводятся числа 0, 1, 2 и 3
0
1
2
3
Здесь:
i – переменная, которая принимает значение из диапазона значений range(0, len(numbers)).
range(0, len(numbers)) – последовательность чисел от 0 до значения длины списка numbers.
print(numbers[i]) – тело цикла, выводит на экран i-й элемент списка numbers.
Второй вариант записи:
numbers = ['0', '1', '2', '3']
for number in numbers:
print(number)
# идентичный результат
0
1
2
3
8. Функции
Функция выполняет одну конкретную задачу и имеет имя. Напишем функцию greeting(), которая выводит на экран приветствие:
def greeting(): # объявление функции
print('hello') # тело функции
greeting() # запуск функции
Здесь:
def – создает объект функции и присваивает ей имя greeting. В скобках можно указать аргументы (см. следующий пример). В нашем случае аргументов нет и скобки пустые.
print('hello') – выводит на экран слово hello.
Напишем функцию summation(), которая складывает два числа:
def summation (a, b):
return print(a + b)
summation(3, 8) # 11
Здесь:
a и b – аргументы функции.
return возвращает значение функции.
9. Модули
Модуль – файл, содержащий функции, классы и данные, которые можно использовать в других программах.
from math import trunc
print(trunc(3.9)) # 3
Здесь:
from math import trunc – из встроенного в Python модуля math импортируем функцию trunc, которая отбрасывает дробную часть числа.
Это был импорт отдельной функции. Теперь импортируем весь модуль и обратимся к функции через модуль.имя_функции():
import math
print(math.trunc(3.9)) # 3
10. Комментарии
Комментирование кода помогает объяснить логику работы программы. Однострочный комментарий начинается с хеш-символа #:
a = 45 # комментарий к коду
Многострочный комментарий заключается с обеих сторон в три кавычки:
"""
a = 45
b = 99
"""
Литература
- «Изучаем Python», Марк Лутц
- «Программируем на Python», Майкл Доусон
- «Изучаем программирование на Python», Пол Бэрри
- «Начинаем программировать на Python», Тонни Гэддис
- «Простой Python. Современный стиль программирования», Билл Любанович
Шпаргалки
- Шпаргалка по Python3 (.pdf)
- Python Cheat Sheet (.pdf)
- Beginners Python Cheat Sheet (.pdf)
- Essential Python Cheat Sheet
- Python Conditions Cheat Sheet
Больше шпаргалок в нашей группе ВКонтакте.
YouTube-каналы и курсы
Бесплатные курсы на русском и английском языках в YouTube и на образовательных ресурсах:
На английском:
- Programming with Mosh
- freeСodeСamp.org
- Microsoft Developer
- Introduction To Python Programming (Udemy)
На русском:
- Python с нуля
- Python для начинающих
- Python с нуля от А до Я
- Программирование на Python (Stepik)
- Python: основы и применение (Stepik)
- Питонтьютор (онлайн-тренажер)
Python в «Библиотеке Программиста»
- подписывайтесь на тег Python, чтобы получать уведомления о новых постах на сайте;
- телеграм-канал «Библиотека питониста»;
- телеграм-канал для поиска работы «Python jobs — вакансии по питону, Django, Flask».
***
Мы кратко познакомились с основными понятиями Python: команды, функции, операторы и типы данных. У этого языка низкий порог вхождения, простой синтаксис, поэтому вероятность освоить его человеку, который никогда не занимался программированием – высокая (по моей субъективной оценке – 90%).
***

Мне кажется, IT — это не для меня. Как понять, что я на правильном пути?
Вы сделали самое важное, что необходимо новичку в IT, — первый шаг. Самообучение требует огромной мотивации, желания и трудолюбия. Здорово, если всё это есть. В противном случае первые шаги могут стать последними.
Важно, чтобы обучение доставляло удовольствие, приносило пользу и было реальным стартом в новой профессии. На курсе онлайн-университета Skypro «Python-разработчик» начинающим айтишникам помогают мягко погрузиться в индустрию. Вы научитесь:
- писать код в Colab, PyCharm и GitHub;
- работать с базами данных SQLite, PostgreSQL, SQLAlchemy;
- использовать фреймворки Django, Flask;
- разрабатывать веб-сервисы и телеграм-боты.
У Skypro гарантия трудоустройства прописана в договоре, поэтому вам реально вернут деньги, если вы не устроитесь на работу в течение четырех месяцев после окончания обучения.
В данной статье мы затронем основы Python. Мы все ближе и ближе к цели, в общем, скоро приступим к работе с основными библиотеками для Data Science и будем использовать TensorFlow (для написания и развертывания нейросетей, тобишь Deep Learning).
Установка
Python можно скачать с python.org. Однако если он еще не установлен, то вместо
него рекомендую дистрибутивный пакет Anaconda, который уже включает в себя большинство библиотек, необходимых для работы в области науки о данных.
Если вы не используете дистрибутив Anaconda, то не забудьте установить менеджер пакетов pip, позволяющий легко устанавливать сторонние пакеты, поскольку некоторые из них нам понадобятся. Стоит также установить намного более удобную для работы интерактивную оболочку IPython. Следует учитывать, что дистрибутив Anaconda идет вместе с pip и IPython.
Пробельные символы
Во многих языках программирования для разграничения блоков кода используются
фигурные скобки. В Python используются отступы:
# пример отступов во вложенных циклах for
for i in [ 1, 2, 3, 4, 5] :
print (i) # первая строка в блоке for i
for j in (1, 2, З, 4, 5 ] :
print ( j ) # первая строка в блоке for j
print (i + j) # последняя строка в блоке for j
print (i) # последняя строка в блоке for i
print ( "циклы закончились ")Это делает код легко читаемым, но в то же время заставляет следить за форматированием. Пробел внутри круглых и квадратных скобок игнорируется, что облегчает написание многословных выражений:
# пример многословного выражения
long_winded_computation = (1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 +
11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20) и легко читаемого кода:
# список списков
list_of_lists = [ [ 1 , 2, 3 ) , [4, 5, 6 ] , [ 7 , 8, 9 ] ]
# такой список списков легче читается
easy_to_read_list_of_lists = [1, 2, 3 ) ,
[4, 5, 6 ) ,
[7, 8, 9 ) ] Для продолжения оператора на следующей строке используется обратная косая черта, впрочем, такая запись будет применяться редко:
two_plus_three = 2 +
3В следствие форматирования кода пробельными символами возникают трудности при копировании и вставке кода в оболочку Python. Например, попытка скопировать следующий код:
for i in [ 1, 2, 3, 4, 5] :
# обратите внимание на пустую строку
print (1)в стандартную оболочку Python вызовет ошибку:
# Ошибка нарушения отступа : ожидается блок с отступом
IndentationError : expected an indented blосkпотому что для интерпретатора пустая строка свидетельствует об окончании блока кода с циклом for.
Оболочка IPython располагает «волшебной» функцией %paste, которая правильно вставляет все то, что находится в буфере обмена, включая пробельные символы.
Модули (Импортирование библиотек)
Некоторые библиотеки среды программирования на основе Python не загружаются по умолчанию. Для того чтобы эти инструменты можно было использовать, необходимо импортировать модули, которые их содержат.
Один из подходов заключается в том, чтобы просто импортировать сам модуль:
import re
my_regex = re.compile ("[0-9]+",re.I)Здесь re — это название модуля, содержащего функции и константы для’ работы с регулярными выражениями. Импортировав таким способом весь модуль, можно обращаться к функциям, предваряя их префиксом re.
Если в коде переменная с именем re уже есть, то можно воспользоваться псевдонимом модуля:
import re as regex
my_regex = regex.compile("[0-9)+",regex.I)Псевдоним используют также в тех случаях, когда импортируемый модуль имеет громоздкое имя или когда в коде происходит частое обращение к модулю.
Например, при визуализации данных на основе модуля matplotlib для него обычно
используют следующий стандартный псевдоним:
import matplotlib.pyplot as pltЕсли из модуля нужно получить несколько конкретных значений, то их можно импортировать в явном виде и использовать без ограничений:
from collections import defaultdict , Counter
lookup = defaultdict(int)
my_counter = Counter() Функции
Функция — это правило, принимающее ноль или несколько входящих аргументов и возвращающее соответствующий результат. В Python функции обычно определяются при помощи оператора def:
def double(х) :
"""здесь, когда нужно, размещают
многострочный документирующий комментарий docstring,
который поясняет, что именно функция вычисляет.
Например, данная функция умножает входящее значение на 2"""
return х * 2Функции в Python рассматриваются как объекты первого класса. Это означает, что их можно присваивать переменным и передавать в другие функции так же, как любые другие аргументы:
# применить функцию f к единице
def apply_to_one(f):
'""'вызывает функцию f с единицей в качестве аргумента """
return f(1)
my _ double = double # ссылка на ранее определенную функцию
х = apply_to_one(my_double) # = 2Кроме того, можно легко создавать короткие анонимные функции или лямбда выражения:
у = apply_to_one(lambda х: х + 4) # = 5Лямбда-выражения можно присваивать переменным. Однако рекомендуют пользоваться оператором def:
another double = lаmbdа х: 2 * х # так не делать
def another_double (x) : return 2 * х # лучше такПараметрам функции, помимо этого, можно передавать аргументы по умолчанию, которые следует указывать только тогда, когда ожидается значение, отличающееся от значения по умолчанию:
def my_print (message="мoe сообщение по умолчанию" ):
print (message )
my_print ( "пpивeт") # напечатает 'привет'
my_print () # напечатает 'мое сообщение по умолчанию'Иногда целесообразно указывать аргументы по имени:
# функция вычитания
def subtract ( a=0, Ь=0 ) :
return а - b
subtract (10, 5)# возвращает 5
subtract (0, 5)# возвращает -5
subtract (b=5 )# то же, что и в предыдущем примереВ дальнейшем функции будут использоваться очень часто.
Строки
Символьные строки (или последовательности символов) с обеих сторон ограничиваются одинарными или двойными кавычками (они должны совпадать):
single_quoted_string = ' наука о данных ' # одинарные
double_quoted_string = "наука о данных" # двойныеОбратная косая черта используется для кодирования специальных символов. Например:
tab_string = "t" # обозначает символ табуляции
len (tab_string)# = 1
Если требуется непосредственно сама обратная косая черта, которая встречается
в именах каталогов в операционной системе Windows, то при помощи r ‘»‘ можно создать неформатированную строку:
not_tab_string = r"t" # обозначает символы ' ' и ' t '
len (not_tab_string) # = 2
Многострочные блоки текста создаются при помощи тройных одинарных (или
двойных) кавычек:
multi_line_string = """Это первая строка .
это вторая строка
а это третья строка """Исключения
Когда что-то идет не так, Python вызывает исключение. Необработанные исключения приводят к непредвиденной остановке программы. Исключения обрабатываются при помощи операторов try и except:
try:
print (0 / 0)
except ZeroDivisionError :
рrint ( "нельзя делить на ноль ")Хотя во многих языках программирования использование исключений считается плохим стилем программирования, в Python нет ничего страшного, если он используется с целью сделать код чище, и мы будем иногда поступать именно так.
Списки
Наверное, наиважнейшей структурой данных в Python является список. Это просто упорядоченная совокупность (или коллекция), похожая на массив в других языках программирования, но с дополнительными функциональными возможностями.
integer_list = [1, 2, З] # список целых чисел
heterogeneous_list = ["строка", 0.1 , True] # разнородный список
list_of_lists = [integer_list, heterogeneous_list, [] ] # список списков
list_length = len(integer_list) #длина списка = 3
list_sum = sum(integer_list)#сумма значений в списке = 6Устанавливать значение и получать доступ к n-му элементу списка можно при помощи квадратных скобок:
х = list(range (10)) # задает список {0, 1 , . . . , 9]
zero = х [0] # = 0 , списки нуль-индексные, т. е . индекс 1-го элемента = 0
one = x [1] # = 1
nine = х [-1] # = 9, по-питоновски взять последний элемент
eight = х [-2] # = 8, по-питоновски взять предпоследний элемент
х [0] = -1 # теперь х = { - 1 , 1 , 2, 3, . . . , 9]Помимо этого, квадратные скобки применяются для «нарезки» списков:
first_three = х[:З] # первые три = [-1 , 1, 2]
three_to_end = х[3:] #с третьего до конца = {3, 4, ... , 9]
one_to_four = х[1:5] # с первого по четвертый = {1 , 2, 3, 4]
last_three = х[-3:] # последние три = { 7, 8, 9]
without_first_and_last = x[1:-1] # без первого и последнего = {1 , 2, ... , 8]
сору_ of _х = х[:] # копия списка х= [ -1, 1, 2, ... , 91В Python имеется оператор ln, который проверяет принадлежность элемента списку:
1 ln [1, 2, 3] #True
0 ln [1, 2, 3] #FalseПроверка заключается в поочередном просмотре всех элементов, поэтому пользоваться им стоит только тогда, когда точно известно, что список небольшой или неважно, сколько времени уйдет на проверку.
Списки легко сцеплять друг с другом:
х = [1, 2, 3]
х. extend ( [ 4, 5, 6] ) # теперь х = {1, 2, 3, 4, 5, 6}Если нужно оставить список х без изменений, то можно воспользоваться сложением списков:
х = [1, 2, 3]
у = х + [4, 5, 6] #у= (1, 2, 3, 4, 5, 6] ; х не изменилсяОбычно к спискам добавляют по одному элементу за одну операцию:
х = [1, 2, 3]
x.append (0)# теперь х = [1,2,3,0]
у= х [-1] # = 0
z = len (x)# = 4Нередко бывает удобно распаковать список, если известно, сколько элементов в нем содержится:
х, у = [1, 2] # теперь х = 1, у = 2Если с обеих сторон выражения число элементов не одинаково, то будет выдано сообщение об ошибке ValueError.
Для отбрасываемого значения обычно используется символ подчеркивания:
_, у = [1, 2] # теперь у == 2, первый элемент не нужен
Кортежи
Кортежи — это неизменяемые (или иммутабельные) двоюродные братья списков.
Практически все, что можно делать со списком, не внося в него изменения, можно делать и с кортежем. Вместо квадратных скобок кортеж оформляют круглымискобками, или вообще обходятся без них:
my_list = [1, 2] # задать список
my_tuple = (1, 2) # задать кортеж
other_tuple = 3, 4 # еще один кортеж
my_list [1] = 3 # теперь my_list = [1 , 3]
try:
my_tuple [1] = 3
except ТypeError :
print ( "кортеж изменять нель зя" )Кортежи обеспечивают удобный способ для возвращения из функций нескольких значений:
# функция возвращает сумму и произведение двух параметров
def sum_and_product (x, у ) :
return (х + у) , (х * у)
sp = sum_and_product (2, 3) # = (5, 6)
s, р = sum_and_product (S, 10) # s = 15, р = 50 Кортежи (и списки) также используются во множественном присваивании:
х, у = 1, 2 # теперь х = 1, у = 2
х, у = у, х # обмен переменными по-питоновски; теперь х = 2, у = 1
Словари
Словарь или ассоциативный список — это еще одна основная структура данных.
В нем значения связаны с ключами, что позволяет быстро извлекать значение, соответствующее конкретному ключу:
empty_dict = {} # задать словарь по-питоновски
empty_dict2 = dict () # не совсем по-питоновски
grades = { "Grigoriy" : 80, "Tim" : 95 } # литерал словаря (оценки за экзамены)Доступ к значению по ключу можно получить при помощи квадратных скобок:
rigory_aleksee = grades[ "Grigoriy"] # = 80При попытке запросить значение, которое в словаре отсутствует, будет выдано сообщение об ошибке KeyError:
try:
kates_grade = grades [ "Kate "]
except КeyError:
рrint ( "оценки для Кэйт отсутствуют ! " )Проверить наличие ключа можно при помощи оператора in:
grigoriy_has_grade = "Grigoriy" in grades #true
kate_has_grade = "Kate" in grades #falseСловари имеют метод get(), который при поиске отсутствующего ключа вместо вызова исключения возвращает значение по умолчанию:
grigoriy_grade = grades. get ( "Grigoriy ", 0) # =80
kates_grade = grades.get ("Kate" , 0) # = 0
no_ones_grade = grades.get ( "No One" ) # значение по умолчанию = NoneПрисваивание значения по ключу выполняется при помощи тех же квадратных скобок:
grades [ "Tim" ] = 99 # заменяет старое значение
grades [ "Kate"] = 100 # добавляет третью запись
num_students = len(grades) # = 3
Словари часто используются в качестве простого способа представить структурные
данные:
tweet = {
"user" : " grinaleks",
"text" : "Наука о данных - потрясающая тема",
" retweet_count" : 100,
"hashtags " : [ "# data", " #science", " #datascience " , " #awesome", "#yolo" ] }Помимо поиска отдельных ключей можно обратиться ко всем сразу:
tweet_keys = tweet.keys() # список ключей
tweet_values = tweet.values() # список значений
tweet_items = tweet.items() # список кортежей (ключ, значение)
"user" in tweet_keys # True, но использует медленное in списка
"user" in tweet # по-питоновски, использует быстрое in словаря
"grinaleks" in tweet_values # TrueКлючи должны быть неизменяемыми; в частности, в качестве ключей нельзя использовать списки. Если нужен составной ключ, то лучше воспользоваться кортежем или же найти способ, как преобразовать ключ в строку.
Словарь defaultdict
Пусть в документе необходимо подсчитать слова. Очевидным решением задачи является создание словаря, в котором ключи — это слова, а значения — частотности слов (или количества вхождений слов в текст). Во время проверки слов в случае, если текущее слово уже есть в словаре, то его частотность увеличивается, а если отсутствует, то оно добавляется в словарь:
# частотности слов
word_ counts = { }
document = { } # некий документ; здесь он пустой
for word in document :
if word in word counts:
word_counts [word] += 1
else :
word_counts [word] = 1Кроме этого, можно воспользоваться nриемом под названием «лучше просить прощения, чем разрешения» и перехватывать ошибку при попытке обратиться к отсутствующему ключу:
word_ counts = { }
for word in document :
try:
word_counts [word] += 1
except КeyError :
word_counts [word] = 1Третий прием — использовать метод get(), который изящно выходит из ситуации с отсутствующими ключами:
word_counts = { }
for word in document :
previous_count = word_counts.get (word, 0)
word_counts [word] = previous_count + 1Все перечисленные приемы немного громоздкие, и по этой причине целесообразно использовать словарь defaultdict (который еще называют словарем со: значением по умолчанию). Он похож на обычный словарь за исключением одной особенности — при попытке обратиться к ключу, которого в нем нет, он сперва добавляет для него значение, используя функцию без аргументов, которая предоставляется при его создании. Чтобы воспользоваться словарями defaultdict, их необходимо импортировать из модуля collections:
from collections import defaultdict
word_counts = defaultdict(int) # int () возвращает 0
for word in document :
word_counts[word] += 1Кроме того, использование словарей defaultdict имеет практическую пользу во время работы со списками, словарями и даже с пользовательскими функциями:
dd_list = defaultdict (list)# list () возвращает пустой список
dd_list [2].append (l) # теперь dd_list содержит (2: {1] }
dd_dict = defaultdict (dict ) # dict () возвращает пустой словарь dict
dd_dict ["Grigoriy"] [ "City" ] = "Seattle" # { "Grigoriy" : { "City" : Seattle"}
dd_pair = defaultdict (lambda: [0,0] )
dd_pair [2][1] = 1 # теперь dd_pair содержит (2 : {0,1] }
Эти возможности понадобятся, когда словари будут использоваться для «сбора»
результатов по некоторому ключу и когда необходимо избежать повторяющихся
проверок на присутствие ключа в словаре.
Словарь Counter
Подкласс словарей counter трансформирует последовательность значений в похожий на словарь defaultdict(int) объект, где ключам поставлены в соответствие частотности или, выражаясь более точно, ключи отображаются (map) в частотности.
Он в основном будет применяться при создании гистограмм:
from collections import Counter
с = Counter([0,1,2,0]) # в результате с = { 0 : 2, 1 : 1, 2 : 1 }Его функционал позволяет достаточно легко решить задачу подсчета частотностей слов:
# лучший вариант подсчета частотностей слов
word_counts = Counter (document)Словарь counter располагает методом most_common( ), который нередко бывает полезен:
# напечатать 10 наиболее встречаемых слов и их частотность (встречаемость)
for word, count in word_counts.most_common(10) :
print (word, count )
Множества
Структура данных set или множество представляет собой совокупность неупорядоченных элементов без повторов:
s = set ()# задать пустое множество
s.add (1) # теперь s = { 1 }
s.add (2) # теперь s = { 1, 2 }
s.add (2) # s как и прежде = { 1, 2 }
х = len (s) # = 2
у = 2 in s # = True
z = 3 in s # = FalseМножества будут использоваться по двум причинам. Во-первых, операция in на множествах очень быстрая. Если необходимо проверить большую совокупность элементов на принадлежность некоторой последовательности, то структура данных set подходит для этого лучше, чем список:
# список стоп-слов
stopwords_list = [ "a", "an" , "at "] + hundreds_of_other_words + [ "yet ", " you"]
" zip" in stopwords_list # False, но проверяется каждый элемент
# множество стоп-слов
stopwords_set = set(stopwords_list)
" zip" in stopwords_set # очень быстрая проверкаВторая причина — получение уникальных элементов в наборе данных:
item_list = [1, 2, 3, 1, 2, 3] # список
num_items = len( item_list) # количество = 6
item_set = set(item_list) # вернет множество (1, 2, 3}
num_distinct_items = len(item_set) # число недублирующихся = 3
distinct_item_list = list(item_set) # назад в список = [1,2,3]Множества будут применяться намного реже словарей и списков.
Управляющие конструкции
Как и в большинстве других языков программирования, действия можно выполнять по условию, применяя оператор if:
if 1 > 2:
message "если 1 была бы больше 2 . . . "
elif 1 > 3:
message "elif означает 'else if '"
else:
message = " когда все предыдущие условия не выполняются, используется else "Кроме того, можно воспользоваться однострочным трехместным оператором if-then-else, который будет иногда использоваться в дальнейшем:
parity = "четное" if х % 2 === О else "нечетное "В Python имеется цикл whlle:
х = 0
while х < 10:
print (x, "меньше 10")
х += 1Однако чаще будет использоваться цикл for совместно с оператором in:
for х in range (lO) :
print (x, "меньше 10" )
51Если требуется более сложная логика управления циклом, то можно воспользоваться операторами
continue и break:
for х 1n range (10) :
1f х == 3:
continue # перейти сразу к следующей итерации
if х == 5:
break
print (x)
# выйти из циклаВ результате будет напечатано 0, 1, 2 и 4.
Истинность
Булевы переменные в Python работают так же, как и в большинстве других языков программирования лишь с одним исключением — они пишутся с заглавной буквы:
one_is_less_than_two = 1 < 2 #True
true_equals_false = True == False #FalseДля обозначения несуществующего значения применяется специальный объект None, который соответствует значению null в других языках:
х = None
print (x == None )# напечатает True, но это не по-питоновски
print ( х is None ) # напечатает True по-питоновски В Python может использоваться любое значение там, где ожидается логический тип Boolean. Все следующие элементы имеют логическое значение False:
- False; .
- None;
- set() (множество):
- [] (пустой список);
- {} (пустой словарь);
Практически все остальное рассматривается как True. Это позволяет легко применять операторы if для проверок на наличие пустых списков. пустых строк, пустых словарей и т. д. Иногда, правда, это приводит к труднораспознаваемым ошибкам, если не учитывать следующее:
s = some_function_that_returns_a_string () # возвращает строковое значение
if s:
first_char = s [0] # первый символ в строке
else:
first char = ""Вот более простой способ сделать то же самое:
first_char = s and s [0] поскольку логический оператор and возвращает второе значение, в случае если первое истинное, и первое значение, в случае если оно ложное. Аналогичным образом, если х в следующем ниже выражении является либо числом, либо, возможно, None, то результат так или иначе будет числом:
safe х = х or 0 # безопасный способВстроенная функция all языка Python берет список и возвращает True только тогда, когда каждый элемент списка истинен, а встроенная функция any возвращает тrue, когда истинен хотя бы один элемент:
all ( [True, 1, { 3 }]) # True
all ( [True, 1, {}] ) # False, {} = ложное
any ( [ True, 1, {}]) # True, True = истинное
all ( [] ) # True, ложные элементы в списке отсутствуют
any ( [ ] ) # False, истинные элементы в списке отсутствуют 
Хендбук по Python поможет овладеть основным синтаксисом и принципами языка. Для этого не потребуется специальной подготовки — достаточно знаний по информатике, логике и математике на уровне школьной программы. Кроме основных конструкций в учебнике рассмотрены разные подходы к программированию, реализованные на Python. А в последней главе вы прикоснётесь к главной суперсиле языка — большому количеству прикладных библиотек.
-
1. Введение
-
2. Базовые конструкции Python
-
3. Коллекции и работа с памятью
-
4. Функции и их особенности в Python
-
5. Объектно-ориентированное программирование
-
6. Библиотеки для получения и обработки данных