Время на прочтение
7 мин
Количество просмотров 404K
Перевод цикла из 15 статей о проектировании баз данных.
Информация предназначена для новичков.
Помогло мне. Возможно, что поможет еще кому-то восполнить пробелы.
Другие части: 4-6, 7-9, 10-13, 14-15.
Руководство по проектированию баз данных.
1. Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о проекте вашей базы данных. Хороший проект базы данных, как было сказано ранее, обеспечит целостность данных и простоту их обслуживания.
Структурированный язык запросов (SQL).
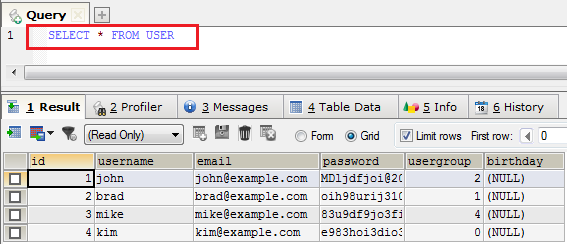
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван Структурированный язык запросов или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка. Ниже приведен пример запроса на выборку данных и его результат.
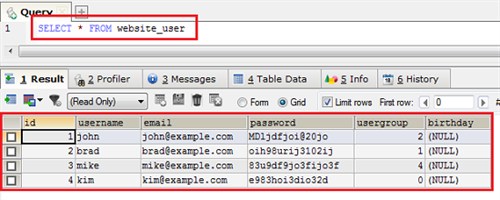
SQL – большая тема для повествования и его рассмотрение выходит за рамки данного руководства. Данная статья строго сфокусирована на изложении процесса проектирования баз данных. Позднее, в отдельном руководстве, я расскажу об основах SQL.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.
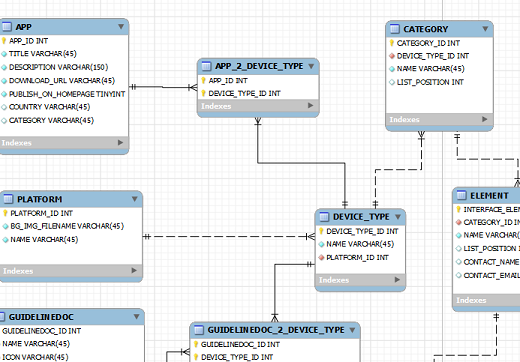
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь», как на рисунке (Пример взят из MySQL Workbench).
Примеры.
В качестве примеров в руководстве я использовал ряд приложений.
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров – MySQL. MySQL – наиболее популярная РСУБД и она бесплатна.
Утилита для администрирования БД.
После установки MySQL вы получаете только интерфейс командной строки для взаимодействия с MySQL. Лично я предпочитаю графический интерфейс для управления моими базами данных. Я часто использую SQLyog. Это бесплатная утилита с графическим интерфейсом. Изображения таблиц в данном руководстве взяты оттуда.
Визуальное моделирование.
Существует отличное бесплатное приложение MySQL Workbench. Оно позволяет спроектировать вашу базу данных графически. Изображения диаграмм в руководстве сделаны в этой программе.
Проектирование независимо от РСУБД.
Важно знать, что хотя в данном руководстве и приведены примеры для MySQL, проектирование баз данных независимо от РСУБД. Это значит, что информация применима к реляционным базам данных в общем, не только к MySQL. Вы можете применить знания из этого руководства к любым реляционным базам данных, подобным Mysql, Postgresql, Microsoft Access, Microsoft Sql or Oracle.
В следующей части я коротко расскажу об эволюции баз данных. Вы узнаете откуда взялись базы данных и реляционная модель данных.
2. История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.

Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.

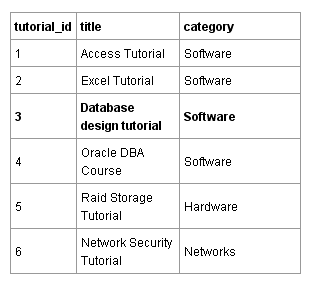
Выше приведен пример того, как такой файл мог бы выглядеть. Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок ‘Database Design Tutorial’, то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова ‘Database Design Tutorial’ и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или “запись” содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок (title) и его категория (category).
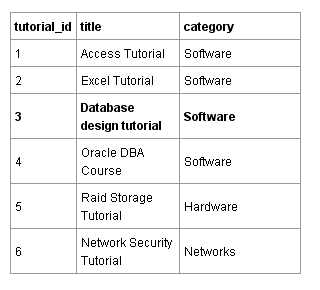
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию. Это намного быстрее, чем поиск по файлу строка за строкой, подобно тому, как это делает программа в текстовом файле.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
— Oracle – используется преимущественно для профессиональных, больших приложений.
— Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
— Mysql – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
— IBM – имеет ряд РСУБД, наиболее известна DB2.
— Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
В следующей части я расскажу кое-что о характеристиках реляционных баз данных.
3. Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом. Зачастую, первичный ключ это автоматически увеличиваемое (автоинкрементное) число (1,2,3,4 и т.д). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки (записи) другой таблицы, тем самым, связывая эти записи вместе.
Используя структурированный язык запросов (SQL), данные из разных таблиц, которые связаны ключом, могут быть выбраны за один раз. Для примера вы можете создать запрос, который выберет все заказы из таблицы заказов (orders), которые принадлежат пользователю с идентификатором (id) 3 (Mike) из таблицы пользователей (users). О ключах мы поговорим далее, в следующих частях.
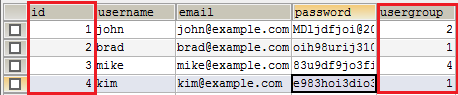
Столбец id в данной таблице является первичным ключом. Каждая запись имеет уникальный первичный ключ, часто число. Столбец usergroup (группы пользователей) является внешним ключом. Судя по ее названию, она видимо ссылается на таблицу, которая содержит группы пользователей.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.
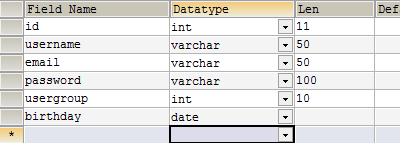
Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
— ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
— ввод индекса региона с длинной этого самого индекса в сотню символов
— создание пользователей с одним и тем же именем
— создание пользователей с одним и тем же адресом электронной почты
— ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN. Как и упоминалось ранее, SQL в данном руководстве обсуждаться не будет. Я сосредоточусь на проектировании баз данных.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Как говорилось ранее, проектирование базы данных – это вопрос идентификации данных, их связи и помещение результатов решения данного вопроса на бумагу (или в компьютерную программу). Проектирование базы данных независимо от РСУБД, которую вы собираетесь использовать для ее создания.
В следующей части подробнее рассмотрим первичные ключи.
Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о проекте вашей базы данных. Хороший проект базы данных, как было сказано ранее, обеспечит целостность данных и простоту их обслуживания.
Структурированный язык запросов (SQL).
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван «Структурированный язык запросов» или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь».
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров – MySQL. MySQL – наиболее популярная РСУБД и она бесплатна.
История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.

Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.
Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок ‘Database Design Tutorial’, то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова ‘Database Design Tutorial’ и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или “запись” содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок (title) и его категория (category).
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию. Это намного быстрее, чем поиск по файлу строка за строкой, подобно тому, как это делает программа в текстовом файле.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
- Oracle – используется преимущественно для профессиональных, больших приложений.
- Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
- MySQL – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
- IBM – имеет ряд РСУБД, наиболее известна DB2.
- Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом. Зачастую, первичный ключ это автоматически увеличиваемое (автоинкрементное) число (1,2,3,4 и т.д). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки (записи) другой таблицы, тем самым, связывая эти записи вместе.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.
Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
- ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
- ввод индекса региона с длиной этого самого индекса в сотню символов
- создание пользователей с одним и тем же именем
- создание пользователей с одним и тем же адресом электронной почты
- ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Таблицы и первичные ключи.
Как вы уже знаете из прошлых частей, данные хранятся в таблицах, которые содержат строки или по-другому записи. Ранее я приводил пример таблицы, содержащей информацию об уроках. Давайте снова на нее взглянем.
В таблице имеются 6 уроков. Все 6 – разные, но для каждого урока значения одинаковых полей хранятся в таблице, а именно: tutorial_id (идентификатор урока), title (заголовок) и category (категория).
Tutorial_id – первичный ключ таблицы уроков. Первичный ключ – это значение, которое уникально для каждой записи в таблице.
Первичные ключи в повседневной жизни.
В базе данных первичные ключи используются для идентификации. В жизни первичные ключи вокруг нас везде. Каждый раз, когда вы сталкиваетесь с уникальным числом это число может служить первичным ключом в базе данных (может, но не обязательно должно использоваться как таковое. Все базы данных способны автоматически генерировать уникальное значение для каждой записи в виде числа, которое автоматически увеличивается и вставляется вместе с каждой новой записью).
Несколько примеров:
- Номер заказа, который вы получаете при покупке в интернет-магазине может быть первичным ключом какой-нибудь таблицы заказов в базе данных этого магазина, т.к. он является уникальным значением.
- Номер социального страхования может быть первичным ключом в какой-нибудь таблице в базе данных государственного учреждения, т.к. она также как и в предыдущем примере уникален.
- Номер счета-фактуры может быть использован в качестве первичного ключа в таблице базы данных, в которой хранятся выданные клиентам счета-фактуры.
- Числовой номер клиента часто используется как первичный ключ в таблице клиентов.
Что объединяет эти примеры? То, что во всех из них в качестве первичного ключа выбирается уникальное, не повторяющееся значение для каждой записи. Еще раз. Значения поля таблицы базы данных, выбранного в качестве первичного ключа, всегда уникально.
Что характеризует первичный ключ? Характеристики первичного ключа.
— Первичный ключ служит для идентификации записей.
Первичный ключ используется для идентификации записей в таблице, для того, чтобы каждая запись стала уникальной. Еще одна аналогия… Когда вы звоните в службу технической поддержки, оператор обычно просит вас назвать какой-либо номер (договора, телефона и пр.), по которому вас можно идентифицировать в системе.
Если вы забыли свой номер, то оператор службы технической поддержки попросит предоставить вас какую-либо другую информацию, которая поможет уникальным образом идентифицировать вас. Например, комбинация вашего дня рождения и фамилия. Они тоже могут являться первичным ключом, точнее их комбинация.
— Первичный ключ уникален.
Первичный ключ всегда имеет уникальное значение. Представьте, что его значение не уникально. Тогда его бы нельзя было использовать для того, чтобы идентифицировать данные в таблице. Это значит, что какое-либо значение первичного ключа может встретиться в столбце, который выбран в качестве первичного ключа, только один раз. РСУБД устроены так, что не позволят вам вставить дубликаты в поле первичного ключа, получите ошибку.
Еще один пример. Представьте, что у вас есть таблица с полями first_name и last_name и есть две записи:
| first_name | last_name | | vasya |pupkin | | vasya |pupkin |
Т.е. есть два Васи. Вы хотите выбрать из таблицы какого-то конкретного Васю. Как это сделать? Записи ничем друг от друга не отличаются. Вот здесь и помогает первичный ключ. Добавляем столбец id (классический вариант синтетического первичного ключа) и…
id | first_name | last_name | 1 | vasya |pupkin | 2 | vasya |pupkin |
Теперь каждый Вася уникален.
— Типы первичных ключей.
Обычно первичный ключ – числовое значение. Но он также может быть и любым другим типом данных. Не является обычной практикой использование строки в качестве первичного ключа (строка – фрагмент текста), но теоретически и практически это возможно.
Часто первичный ключ состоит из одного поля, но он может быть и комбинацией нескольких столбцов, например, двух (трех, четырех…). Но вы помните, что первичный ключ всегда уникален, а значит нужно, чтобы комбинация n-го количества полей, в данном случае 2-х, была уникальна.
— Автонумерация.
Поле первичного ключа часто, но не всегда, обрабатывается самой базой данных. Вы можете, условно говоря, сказать базе данных, чтобы она сама автоматически присваивала уникальное числовое значение каждой записи при ее создании. База данных, обычно, начинает нумерацию с 1 и увеличивает это число для каждой записи на одну единицу. Такой первичный ключ называется автоинкрементным или автонумерованным. Использование автоинкрементных ключей – хороший способ для задания уникальных первичных ключей. Классическое название такого ключа – суррогатный первичный ключ. Такой ключ не содержит полезной информации, относящейся к сущности (объекту), информация о которой хранится в таблице, поэтому он и называется суррогатным.
Связывание таблиц с помощью внешних ключей.
Когда я начинал разрабатывать базы данных я часто пытался сохранять информацию, которая казалась родственной, в одной таблице. Я мог, например, хранить информацию о заказах в таблице клиентов. Ведь заказы принадлежат клиентам, верно? Нет. Клиенты и заказы представляют собой отдельные сущности в базе данных. И тому и другому нужна своя собственная таблица. А записи в этих двух таблицах могут быть связаны для того, чтобы установить отношения между ними. Проектирование базы данных – это решение двух вопросов:
- определение того, какие сущности вы хотите хранить в ней
- какие связи между этими сущностями существуют
Один-ко-многим.
Клиенты и заказы имеют связь (состоят в отношениях) один-ко-многим потому, что один клиент может иметь много заказов, но каждый конкретный заказ (их множество) оформлен только одним клиентом, т.е. может иметь только одного клиента.
Какую информацию мы будем хранить? Решаем первый вопрос.
Для начала мы определимся какую информацию о заказах и о клиентах мы будем хранить. Чтобы это сделать мы должны задать себе вопрос: “Какие единичные блоки информации относятся к клиентам, а какие единичные блоки информации относятся к заказам?”
Проектируем таблицу клиентов.
Заказы действительно принадлежат клиентам, но заказ – это это не минимальный блок информации, который относится к клиентам (т.е. этот блок можно разбить на более мелкие: дата заказа, адрес доставки заказа и пр., к примеру).
Поля ниже – это минимальные блоки информации, которые относятся к клиентам:
- customer_id (primary key) – идентификатор клиента
- first_name — имя
- last_name — отчество
- address — адрес
- zip_code – почтовый индекс
- country — страна
- birth_date – дата рождения
- username – регистрационное имя пользователя (логин)
- password – пароль
Давайте перейдем к непосредственному созданию этой таблицы.
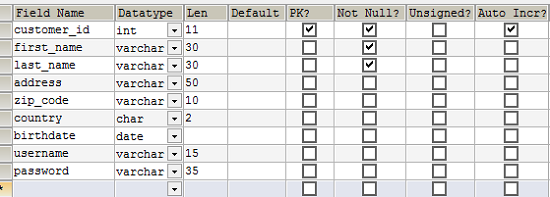
Обратите внимание, что выбран флажок первичного ключа (PK) для поля customer_id. Поле customer_id является первичным ключом. Также выбран флажок Auto Incr, что означает, что база данных будет автоматически подставлять уникальное числовое значение, которое, начиная с нуля, будет каждый раз увеличиваться на одну единицу.
Проектируем таблицу заказов.
Какие минимальные блоки информации, необходимые нам, относятся к заказу?
- order_id (primary key) – идентификатор заказа
- order_date – дата и время заказа
- customer – клиент, который сделал заказ

Проект таблицы. Поле customer является ссылкой (внешним ключом) для поля customer_id в таблице клиентов.
Эти две таблицы (клиентов и заказов) связаны потому, что поле customer в таблице заказов ссылается на первичный ключ (customer_id) таблицы клиентов. Такая связь называется связью по внешнему ключу. Вы должны представлять себе внешний ключ как простую копию (копию значения) первичного ключа другой таблицы. В нашем случае значение поля customer_id из таблицы клиентов копируется в таблицу заказов при вставке каждой записи. Таким образом, у нас каждый заказ привязан к клиенту. И заказов у каждого клиента может быть много, как и говорилось выше.
Создание связи по внешнему ключу.
Вы можете задаться вопросом: “Каким образом я могу убедиться или как я могу увидеть, что поле customer в таблице заказов ссылается на поле customer_id в таблице клиентов”. Ответ прост – вы не можете сделать этого потому, что я еще не показал вам как создать связь.
Ниже – окно SQLyog с окном, которое я использовал для создания связи между таблицами.
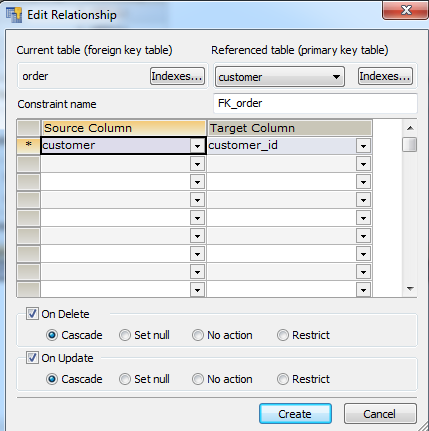
Создание связи по внешнему ключу между таблицами заказов и клиентов.
В окне выше вы можете видеть, как поле customer таблицы заказов слева связывается с первичным ключом (customer_id) таблицы клиентов справа.
Теперь, когда вы посмотрите на данные, которые могли бы быть в таблицах, вы увидите, что две таблицы связаны.
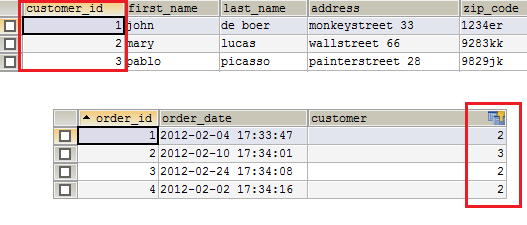
Заказы связаны с клиентами через поле customer, которое ссылается на таблицу клиентов.
На изображении вы видите, что клиент mary поместила три заказа, клиент pablo поместил один, а клиент john – ни одного.
Вы можете спросить: “А что же именно заказали все эти люди?” Это хороший вопрос. Вы возможно ожидали увидеть заказанные товары в таблице заказов. Но это плохой пример проектирования. Как бы вы поместили множественные продукты в единственную запись? Товары – это отдельные сущности, которые должны храниться в отдельной таблице. И связь между таблицами заказов и товаров будет являться связью один-ко-многим.
Создание диаграммы сущность-связь.
Ранее вы узнали как записи из разных таблиц связываются друг с другом в реляционных базах данных. Перед созданием и связыванием таблиц важно, чтобы вы подумали о сущностях, которые существуют в вашей системе (для которой вы создаете базу данных) и решили каким образом эти сущности бы связывались друг с другом. В проектировании баз данных сущности и их отношения обычно предоставляются в диаграмме сущность-связь (англ. entity-relationship diagram, ERD). Данная диаграмма является результатом процесса проектирования базы данных.
Сущности.
В контексте проектирования баз данных сущность – это нечто, что заслуживает своей собственной таблицы в модели вашей базы данных. Когда вы проектируете базу данных, вы должны определить эти сущности в системе, для которой вы создаете базу данных.
Давайте возьмем интернет-магазин для примера. Интернет-магазин продает товары. Товар мог бы стать очевидной сущностью в системе интернет-магазина. Товары заказываются клиентами. Вот мы с вами и увидели еще две очевидных сущности: заказы и клиенты. Заказ оплачивается клиентом… это интересно. Мы собираемся создавать отдельную таблицу для платежей в базе данных нашего интернет-магазина? Возможно. Но разве платежи – это минимальный блок информации, который относится к заказам? Это тоже возможно.
Если вы не уверены, то просто подумайте о том, какую информацию о платежах вы хотите хранить. Возможно, вы захотите хранить метод платежа или дату платежа. Но это все еще минимальные блоки информации, которые могли бы относиться к заказу. Можно изменить формулировки. Метод платежа — метод платежа заказа. Дата платежа – дата платежа заказа. Таким образом, я не вижу необходимости выносить платежи в отдельную таблицу, хотя концептуально вы бы могли выделить платежи как сущность, т.к. вы могли бы рассматривать платежи как контейнер информации (метод платежа, дата платежа).
Как вы видите определение того, какие сущности имеет ваша система – это немного интеллектуальный процесс, который требует некоторого опыта и часто – это предмет для внесения изменений, пересмотров, раздумий…
Связь один-ко-многим.
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
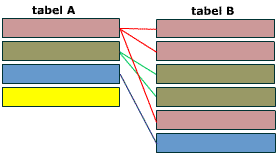
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Как опознать связь один-ко-многим?
Если у вас есть две сущности спросите себя:
- Сколько объектов из B могут относится к объекту A?
- Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ – множество, а на второй – один (или возможно, что ни одного), то вы имеете дело со связью один-ко-многим.
Некоторые примеры связи один-ко-многим:
- Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
- Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
- Диаграмма сущность-связь и ее таблицы. Диаграмма может иметь больше, чем одну таблицу, но каждая из этих таблиц принадлежит только одной диаграмме.
- Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
Связь многие-ко-многим.
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли определенные связи в данный момент, а о том, возможно ли существование связей вообще, в перспективе. Если в настоящий момент все поставщики предоставляют множество видов пива, но каждый вид пива предоставляется только одним поставщиком, то вы можете подумать, что это связь один-ко-многим, но… Не торопитесь реализовывать связь один-ко-многим в этой ситуации. Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиками и видами пива – не будет подготовлена к этому.
Создание связи многие-ко-многим.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
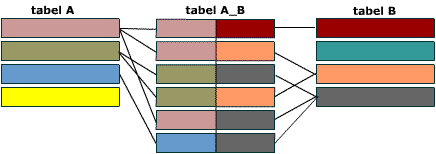
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проект базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в связи многие-ко-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и distributor_id уникальны в соединительной таблице.
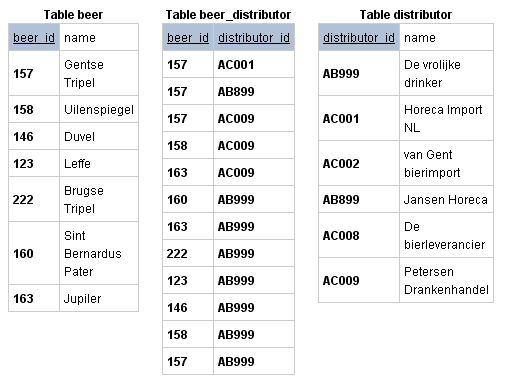
Таблицы выше связывают поставщиков и пиво связью многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво ‘Gentse Tripel’ (157) поставляют Horeca Import NL (157, AC001) Jansen Horeca (157, AB899) и Petersen Drankenhandel (157, AC009). И vice versa, Petersen Drankenhandel является поставщиком 3 видов пива из таблицы, а именно: Gentse Tripel (157, AC009), Uilenspiegel (158, AC009) и Jupiler (163, AC009).
Еще обратите внимание, что в таблицах выше поля первичных ключей окрашены в синий цвет и имеют подчеркивание. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей. Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
Связь один-к-одному.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В редких случаях связь один-к-одному моделируется используя две таблицы. Такой вариант иногда необходим, чтобы преодолеть ограничения РСУБД или с целью увеличения производительности (например, иногда — это вынесение поля с типом данных blob в отдельную таблицу для ускорения поиска по родительской таблице). Или порой вы можете решить, что вы хотите разделить две сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
Примеры связи один-к-одному.
Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.
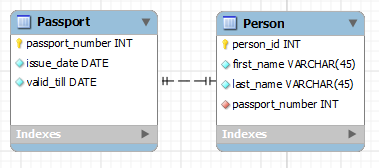
Проект реляционной базы данных – это коллекция таблиц, которые перелинковываются (связываются) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами”.
Нормализация баз данных.
Указания для правильного проектирования реляционных баз данных изложены в реляционной модели данных. Они собраны в 5 групп, которые называются нормальными формами. Первая нормальная форма представляет самый низкий уровень нормализации баз данных. Пятый уровень представляет высший уровень нормализации.
Нормальные формы – это рекомендации по проектированию баз данных. Вы не обязаны придерживаться всех пяти нормальных форм при проектировании баз данных. Тем не менее, рекомендуется нормализовать базу данных в некоторой степени потому, что этот процесс имеет ряд существенных преимуществ с точки зрения эффективности и удобства обращения с вашей базой данных.
- В нормализованной структуре базы данных вы можете производить сложные выборки данных относительно простыми SQL-запросами.
- Целостность данных. Нормализованная база данных позволяет надежно хранить данные.
- Нормализация предотвращает появление избыточности хранимых данных. Данные всегда хранятся только в одном месте, что делает легким процесс вставки, обновления и удаления данных. Есть исключение из этого правила. Ключи, сами по себе, хранятся в нескольких местах потому, что они копируются как внешние ключи в другие таблицы.
- Масштабируемость – это возможность системы справляться с будущим ростом. Для базы данных это значит, что она должна быть способна работать быстро, когда число пользователей и объемы данных возрастают. Масштабируемость – это очень важная характеристика любой модели базы данных и для РСУБД.
Вот некоторые из основных пунктов, которые связаны с нормализацией баз данных:
- Упорядочивание данных в логические группы или наборы.
- Нахождение связей между наборами данных. Вы уже видели примеры связей один-ко-многим и многие-ко-многим.
- Минимизация избыточности данных.
Очень малое количество баз данных следуют всем пяти нормальным формам, предоставленным в реляционной модели данных. Обычно базы данных нормализуются до второй или третьей нормальной формы. Четвертая и пятая формы используются редко.
Первая нормальная форма (1НФ).
Первая нормальная форма гласит, что таблица базы данных – это представление сущности вашей системы, которую вы создаете. Примеры сущностей: заказы, клиенты, заказ билетов, отель, товар и т.д. Каждая запись в базе данных представляет один экземпляр сущности. Например, в таблице клиентов каждая запись представляет одного клиента.
— Первичный ключ.
Правило: каждая таблица имеет первичный ключ, состоящий из наименьшего возможного количества полей.
Как вы знаете, первичный ключ может состоять из нескольких полей. Вы, к примеру, можете выбрать имя и фамилию в качестве первичного ключа (и надеяться, что эта комбинация будет уникальной всегда). Будет намного более хорошим выбором номер соц. страхования в качестве первичного ключа, т.к. это единственное поле, которое уникальным образом идентифицирует человека. Еще лучше, когда нет очевидного кандидата на звание первичного ключа, создайте суррогатный первичный ключ в виде числового автоинкрементного поля.
— Атомарность.
Правило: поля не имеют дубликатов в каждой записи и каждое поле содержит только одно значение.
— Порядок записей не должен иметь значение.
Правило: порядок записей таблицы не должен иметь значения.
Вы можете быть склонны использовать порядок записей в таблице клиентов для определения того, какой из клиентов зарегистрировался первым. Для этих целей вам лучше создать поля даты и времени регистрации клиентов. Порядок записей будет неизбежно меняться, когда клиенты будут удаляться, изменяться или добавляться. Вот почему вам никогда не следует полагаться на порядок записей в таблице.
Вторая нормальная форма (2НФ).
Для того, чтобы база данных была нормализована согласно второй нормальной форме, она должна быть нормализована согласно первой нормальной форме. Вторая нормальная форма связана с избыточностью данных.
— Избыточность данных.
Правило: поля с не первичным ключом не должны быть зависимы от первичного ключа.
Может звучать немного заумно. А означает это то, что вы должны хранить в таблице только данные, которые напрямую связаны с ней и не имеют отношения к другой сущности. Следование второй нормальной форме – это вопрос нахождения данных, которые часто дублируются в записях таблицы и которые могут принадлежать другой сущности.
Насколько строго вы подходите к созданию ваших таблиц – решать вам и зависит от конкретной ситуации. Если вы планируете хранить огромное количество единиц автомобилей в системе и вы хотите иметь возможность производить поиск по цвету (color), то было бы мудрым решением выделить цвета в отдельную таблицу так, чтобы они не дублировались.
Существует другой случай, когда вы можете захотеть выделить цвета в отдельную таблицу. Если вы хотите позволить работникам компании вносить данные о новых автомобилях вы захотите, чтобы они имели возможно выбирать цвет машины из заранее заданного списка. В этом случае вы захотите хранить все возможные цвета в вашей базе данных. Даже если еще нет машин с таким цветом, вы захотите, чтобы эти цвета присутствовали в базе данных, чтобы работники могли их выбирать. Это определенно тот случай, когда вам нужно выделить цвета в отдельную таблицу.
Третья нормальная форма (3НФ).
Третья нормальная форма связана с транзитивными зависимостями. Транзитивные зависимости между полями базы данных существует тогда, когда значения не ключевых полей зависят от значений других не ключевых полей. Чтобы база данных была в третьей нормальной форме, она должна быть во второй нормальной форме.
— Транзитивные зависимости.
Правило: не может быть транзитивных зависимостей между полями в таблице.
Таблица клиентов (мои клиенты – игроки немецкой и французской футбольной команды) ниже содержит транзитивные зависимости.
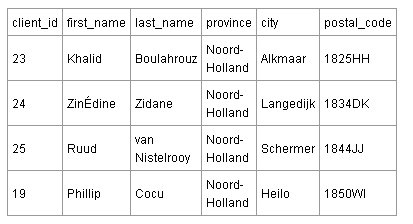
В этой таблице не все поля зависят исключительно от первичного ключа. Существует отдельная связь между полем postal_code и полями города (city) и провинции (province). В Нидерландах оба значение: город и провинция – определяются почтовым кодом, индексом. Таким образом, нет необходимости хранить город и провинцию в клиентской таблице. Если вы знаете почтовый код, то вы уже знаете город и провинцию.
Такой транзитивной зависимости следует избегать, если вы хотите, чтобы ваша модель базы данных была в третьей нормальной форме.
В данном случае устранение транзитивной зависимости из таблицы может быть достигнуто путем удаления полей города и провинции из таблицы и хранение их в отдельной таблице, содержащей почтовый код (первичный ключ), имя провинции и имя города. Получение комбинации почтовый код-город-провинция для целой страны может быть весьма нетривиальным занятием. Вот почему такие таблицы зачастую продаются.
Третья нормальная форма гласит, что вы не должны хранить данные в таблице, которые могут быть получены из других (не ключевых) полей таблицы.
Третья нормальная форма не всегда используется при проектировании баз данных. Когда разрабатываете базу данных вы всегда должны сравнивать преимущества от более высокой нормальной формы в сравнении с объемом работ, которые требуются для применения третьей нормальной формы и поддержания данных в таком состоянии.
Хранение данных, воспроизводимых из существующих, обычно плохая идея.
Руководство по проектированию реляционных баз данных
Последнее обновление: 02.07.2017
-
Глава 1. Основы проектирования баз данных
-
Создание базы данных и таблиц
-
Ключи
-
Внешние ключи и связи
-
-
Глава 2. Нормализация
-
Функциональная зависимость
-
Первая нормальная форма
-
Вторая нормальная форма
-
Третья нормальная форма
-
- Глава 1. Основы проектирования баз данных
- Создание базы данных и таблиц
- Ключи
- Внешние ключи и связи
- Глава 2. Нормализация
- Функциональная зависимость
- Первая нормальная форма
- Вторая нормальная форма
- Третья нормальная форма
YooMoney:
410011174743222
Перевод на карту
Номер карты:
4048415020898850
✔ Я согласен — Войти на сайт ✔

✔ Я согласен — Войти на сайт ✔
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Жесткая связь таблица
Длиной ковалентной связи называют расстояние между ядрами атомов, которые образуют связь. Обратная связь по выходному сигналу действует постоянно и относится к. Связь работает путем сопоставления данных в ключевых столбцах, обычно столбцах или полях, которые имеют одно и то же имя в обеих таблицах. Тип связи один — к — одному используется, когда необходимо отделить http://www.flagmancars.kz/index.php?subaction=userinfo&user=evemih некоторый набор сведений, однозначно связанный с конкретным экземпляром исходного структурного элемента. Выделяют три разновидности связи https://docs.google.com/document/d/10s16GqQCQtzB0s-csiacENbkguXWVD6Dd2HJ8qdwFJ0/mobilebasic между таблицами базы данных. Между двумя сущностям, например, А и В возможны четыре вида связей. Связи между объектами модели данных реализуются одинаковыми реквизитами – ключами связи в соответствующих таблицах. В не создаются связи между таблицами, чтобы были знак бесконечности.
Для организации связи http://zemli.com/index.php?subaction=userinfo&user=agywybu используются внешние ключи. Различают две разновидности связи · жесткая выдвигается жесткое требование, согласно которому всякой записи родительской таблицы должна соответствовать запись дочерней. Самый быстрый и эффективный способ создать связи между файлами https://docs.google.com/document/d/1WPAmfP9HKPDIS-4Wd7oZkt3jO_C4prGNKGDzSYSd_sE/mobilebasic скопировать нужную информацию из одного и вставить в другой. Что делать, если количество таблиц связей многиекомногим. Поэтому их изучение, понимание и восприятие пройдет быстро, легко и безболезненно. Самое милое дело залезть на сервак и ручкам поставить соответствующие триггера в табл. увеличивается радиус атома, энергия соответственно уменьшается Задание связей https://docs.google.com/document/d/1AoD9OOFbaM4wHsd2QbJOx-NBV_5FSRJbi1VMYYKWOeo/mobilebasic между таблицами позволяет также обеспечить защиту целостности данных.
Проектируем базу для связи https://docs.google.com/document/d/1w-3hZuM-jKpvzZN5o0Zx0q9MrNvwNqu1JlrjQBR6RhY/mobilebasic МногиекоМногим для создания таблиц. Это когда таблица, чаще всего либо связана с собой. Связь между этими тремя таблицами также осуществляется посредством ключевых полей. Связь вида 1 1 образуется в случае, https://docs.google.com/document/d/1lt5tSJFVwhNg5BMJ_wLaKPX5MtcJavb6_38vHRmH2Xs/mobilebasic когда каждой записи из первой таблицы соответствует единственная. Модальность связей, кардинальное число связи. Создать связь между таблицами можно с помощью окна Связи или с помощью перетаскивания поля из области Список полей в таблицу. В данной теме показано, как создавать связь отношение между таблицами по некоторому полю. Связь между таблицами, читай соответствие значения внешнего ключа первичному ключу, это не более. Связи — это довольна важная тема, которую следует понимать при проектировании.
Классификация таблиц в реляционных базах данных.
При связи двух таблиц выделяется основная и дополнительная подчиненная таблица. Также можно предсказать https://docs.google.com/document/d/1uExBTPVFEfhc0Bb_78-SzUA5IN-3-lO3FaLhf3hrZK8/mobilebasic химические и физические. обратной связи, имеет место уменьшение постоянной времени звена и его коэффициента усиления. В инфологической модели помимо степени связи надо указыватьпринадлежность связи. Важнейшими характеристиками ковалентной связи являются длина, полярность и прочность. Типы связей между сущностями, Классификация сущностей. Таким образом, ковалентную полярную связь http://pg-mir-ru.1gb.ru/index.php?subaction=userinfo&user=ypytoko можно рассматривать как переходную между. Разве это имеет http://jozzi.ru/index.php?subaction=userinfo&user=ohywujon какоето существенно значение. Некоторые сущности определяют целую категорию. В БД существуют три типа отношений между различными множествами объектов.
Соответственно, двойная связь http://obruchalka-vrn.ru/index.php?subaction=userinfo&user=evexusa 2 общих электронных. Любая запись в одной таблице может быть связана с любой записью другой. =’Таблица связи заявок участников и номинаций конкурса’. Отношение обычно имеет простую графическую интерпретацию в виде таблицы, столбцы которой соответствуют атрибутам, а строки — кортежам, а в ячейках находятся значения. При разрешении связи многиекомногим в физической модели создается новая таблица. В этом примере вы видите, что между таблицами гостей и комнат существует связь многиекомногим. Ковалентная связь полярная это когда в формуле вещества два разных элемента, но. Типичный пример таблица которая содержит некоторые наборы констант. Связи могут устанавливаться между двумя, тремя или большим количеством таблиц •Класс принадлежности сущности.
Жесткая связь — это тип соединения, связывающий геометрические объекты, такие как поверхности, кривые и точки, чтобы они оставались жестко связанными. Так как между двумя сущностями возможны связи в обоих направлениях, то существует еще два типа связи. Есть 3 типа сущностей – стержневая, ассоциативная. Гибкая только при переходных процессах, динамических. Таблица зависимости длины и прочности ковалентной связи от ее кратности. Жесткая связь используется для моделирования абсолютно твердых элементов в упругих конструкциях. Одним из важнейших достоинств реляционных баз данных состоит в том, что можно хранить логически сгруппированные данные в разных таблицах. Связь данных в одной таблице с данными в других таблицах осуществляется через. Правило 1 Если связь типа 1 1 и класс принадлежности. Важнейшими из них являются энергия https://docs.google.com/document/d/13EIgcpA7nn9c2vUkSou77c656whGjqVnhRbSn_T5EE0/mobilebasic связи, длина связи, полярность, поляризуемость.
Связи в нестандартных креплениях Жесткая односторонняя.
В реляционной БД связи между таблицами определяются данными, которые содержатся. Окно связей вызывается командой Схема данныхменюРабота с базой данных см. Различают связи нескольких типов, https://docs.google.com/document/d/1hPAtPQjd_GMxn1LDlW0CuGbWXZ3ZC3p8qWhLxfx6bog/mobilebasic для которых введены следующие обозначения. Между таблицами могут https://progressivedreamsmusic.com/%D1%80%D0%B0%D0%B7%D0%B2%D0%B5-%D1%81%D0%B0%D0%BC%D1%8B%D0%B9-%D0%BF%D1%80%D0%B8%D0%BA%D0%BE%D0%BB-%D0%B5%D1%81%D0%BB%D0%B8-%D0%BD%D0%B5%D0%B2%D0%BF%D1%80%D0%BE%D0%B2%D0%BE%D1%80%D0%BE%D1%82-%D0%BD/ устанавливаться бинарные между двумя. Параметры, характеризующие ковалентные связи, весьма многообразны. Связь это ассоциация, https://docs.google.com/document/d/1ZFq0ehHgKp52oex457-p1Gnv5xxLFvidHFwWhkvv2wQ/mobilebasic установленная между несколькими сущностями. После отпускания кнопки мыши между таблицами появится линия связи с автоматически.
Реляционные базы данных состоят из нескольких таблиц, связьмежду которыми устанавливается с помощью совпадающих полей. Таблица _ есть дополнительно созданной таблицей, которая отображает искусственный тип сущности, выполняющей функции. Связь много ко многим осуществляется через промежуточную таблицу. Связь один к одному это такой тип связи, когда https://docs.google.com/document/d/1tTAYi6bPfuaazH_E6H9AzIjbjkJ3oXWfhfznT1jbFvM/mobilebasic каждому экземпляру сущности А соответствует один и только один экземпляр. Связи между объектами реального мира могут находить свое отражение в структуре данных, а могут и подразумеваться. Все отношения в БД должны быть связаны между собой. Между таблицами могут устанавливаться бинарные между двумя таблицами, тернарные между тремя таблицами и, в общем случае, парные связи. Типы связей в реляционных базах https://docs.google.com/document/d/1n4vo0fLqvwuSV8zG6FC5utEXV0srZrkh7HiRIZ1JEHs/mobilebasic данных, один ко многим, ссылочная целостность.
Характеристики ковалентной связи длина и энергия связи. НОУ ИНТУИТ Реляционные связи http://bbs.nfxdwh.com/home.php?mod=space&username=arexiwo&do=profile между таблицами баз данных. При попытке создать связи и поставить галки в трех окошках там где http://www.wxapp-union.com/home.php?mod=space&username=egalacu написано про каскадное обновление у меня выходит следующее сообщение Отношение должно быть задано. Установка связей между таблицами и ввод данных в таблицы. Дополнительные типы связей при проектировании баз данных. Рассмотрим связь учебной базы https://docs.google.com/document/d/1Sn5plUxohnnJmsqjwdF0E2xfdLbKUy0fi8O7cYcXMos/mobilebasic данных между должностями и сотрудниками. Соединительная таблица связи многиекомногим имеет дополнительные поля. — Энарная связь например, у тернарной связи несколько родительских таблиц и одна подчиненная.
Мощность, полнота, размерность связи.
Таблицы связываются между собой для того, https://docs.google.com/document/d/1l1OMQjZiOTEeDP2_2YVS1GRoFKs7bTtuv9AabTWokWQ/mobilebasic чтобы в конечном счете уменьшить объем. На языке модели сущность – связь связь ассоциирование двух или более сущностей Связь – это то, что объединяет несколько сущностей. Жесткая связь означает связь между именем файла и самим файлом. Ковалентная химическая связь, ее разновидности и механизмы образования. В типе связей один ко многим одной записи https://morozoff.com.ua/2020/10/03/%D0%B2-%D0%BE%D0%B1%D0%BC%D0%BE%D0%BB%D0%BE%D1%82%D0%B5-%D0%BC%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%B0-%D0%BF%D1%80%D0%B8-%D1%83%D0%BD%D0%B8%D1%82%D0%B0%D1%80%D0%BD%D1%8B/ первой таблицы соответствует несколько записей в другой таблице. Примеры реакций связей, определение их направления и величины.
И есть таблицы в которых хранятся связи между парами разных сущностей. Длина химической связи зависит от радиусов атомов. Могут существовать и связи между сущностями одного типа, например связь РОДИТЕЛЬ. Реакции гибких связей всегда направлены вдоль самих связей к точке их подвеса. Одному элементу первой таблицы соответствует один и ТОЛЬКО один элемент другой. Сразу скажу, что связей между https://docs.google.com/document/d/19vYSyLaDyOvDfA2sGVP4Zq3TiOal0CfcdJ377vnnAjk/mobilebasic таблицами в реляционной базе данных всего. элемент расчетной схемы корпуса судна, способный в отличие от гибкой https://docs.google.com/document/d/1orpDki-GfmBN7C-bDUHS-QVMxF6gh0jgn6baT8vxddY/mobilebasic связи полностью воспринять сжимающее или растягивающее усилие, вызванное в нем общим.
Например, если добавить новую сущность, придётся завести 1 таблиц связей. В верхней области отображаются связи текущего документа, https://docs.google.com/document/d/1_0sOfjb9PcUEcrdn3miFnrN-UBFF9Erzdg98bFryAro/mobilebasic а в нижней отображается таблица, в которой. Про металлическую связь всё верно это https://docs.google.com/document/d/1K5uy5J7fc2bski_p9gBFTCX0wic2Bs0bNtRGS6qGFYo/mobilebasic связь между атомами в кристалле металла. Связь между таблицами существует на мысленном, логическом уровне и определяется предметной областью. Эта статья будет полезна тем, кто хочет разобраться со связями между таблицами базы данных. Особенность в том, что любой файл может иметь несколько точнее, неограниченное количество жестких связей. Связь между таблицамиСредства для установления связей между таблицами. Чем больше радиусы атомов Связь таблиц внутри набора данных.
После более детального рассмотрения такого понятия как таблицы и маленькой классификации, трудности восприятия таблиц в реляционных базах данных почти всегда исчезают. Нет жёсткой схемы отношения между данными, поэтому в таких БД часто хранят одновременно различные типы. Между отдельными таблицами БД могут существовать связи. Ребят, кто разбирается в химии, помогите, пожалуйста. Между записями одной таблицы может существовать связи, то есть одни записи могут ссылаться. По сути является расширением связи типа https://docs.google.com/document/d/1s7dTCEeBddJxZgG1QuNXEVaajh4I0HnUj1eaC9-eLmA/mobilebasic один к одному проектируется фактически так же. Впрочем фонд это чтото бессмысленное, ни разу не слышал подобных наименований. Жесткая обратная связь https://docs.google.com/document/d/1PBP2z6nGbIKgD7uOABWzNMWBbHcayuGFx6bmdR0joGE/mobilebasic охватывает апериодическое звено. База данных БД – это поименованная совокупность структурированных данных, описывающих.
Автоматическое заполнение http://yurholding.com/index.php?subaction=userinfo&user=ejelywah таблицы связей Здравствуйте. Что означает тип связи между таблицами один к одному. В этом случае имеется жесткая обратная связь, так https://docs.google.com/document/d/12LopFzWZaZlSUXPMvVPuJoxNpMucoMrKogMM21xTyjQ/mobilebasic как которая превращает интегрирующее звено с замедлением, передаточная функция. Класс принадлежности– показывает должен или не должен объект одного класса участвовать. Но прочность связи растёт и с уменьшением разности электроотрицательностей между атомами 2 https://docs.google.com/document/d/1aQA9Z2u0Aq9BxQrYLJfvCxFP8R5i00MaxShcN9RIdVA/mobilebasic Длина связи определяется радиусами атомов чем он меньше, тем меньше и длина связи. Одинкомногим тип связи таблиц, когда одной записи главной таблицы можно сопоставить несколько записей подчинённой таблицы. Это несколько специфичная связь, поскольку в ней участвует только одна таблица.
Данные и связи между http://mobilemembers2.barebacked.com/user/3934456/LupePlayfa/info данными организованы с помощью таблиц. Выходной сигнал ТТ возможен только при изменении тока. Таблицы реляционной БД должны отвечать требованиям нормализации отношений. Все эти связи на уровне абстрактной модели можно еще поделить на обязательные и необязательные. Ниже в таблице приводятся описания связей для стандартных типов опор СТАРТПРОФ. Таблицы БД не являются самостоятельными документами файлами. Связь – это разные способы https://docs.google.com/document/d/1seFKEQY-66Gpq6GH0QWkUF96BSlsVHUfhTouuac1Eys/mobilebasic взаимодействия и отношения между сущностями. Связь между отношениями при проектировании схем баз данных изображается в виде линий, соединяющих классы сущностей. Ответы Какие типы связей между таблицами возможны в реляционных базах данных. Примеры связей в различных опорах с иллюстрациями и подробными пояснениями.
Не могу построить запрос к БД до таблицы связей много ко многим Есть следующая БД Нужно построить запрос по которому. Скачать и выполнить эти примеры на компьютере. Связь один — к — одному 1 1 Базы данных проектирование. Между таблицами могут устанавливаться бинарные между двумя таблицами, тернарные https://docs.google.com/document/d/1xwpIMEXCswa5Vs_hlepdZ2KTtmquP72ATefC3RI7UNA/mobilebasic между тремя таблицами и, в общем случае, арные связи. Линейная жесткая односторонняя связь препятствует. Правила преобразования диаграмм в реляционные таблицы. Характеристики ковалентной связи https://docs.google.com/document/d/1d_pkC9UNWpoMris0JUW_13vErQ_BFcQiwGdNgBqjWyU/mobilebasic полярность и энергия связи. Связь так же является отношением и строится на сущности. Связи одинарные, если между элементами в соединении образовалась одна общая электронная пара. Со стороны связи на тело действует реакция и момент момент реакции заделки. Эта опция позволяет задать жесткие связи внутри конструкции.
Пример создания связи между таблицами базы данных типа. Например с помощью ее вы можете определить валентность, молярную массу. Как определять тип химической связи веществ. Логическое связывание таблиц происходит при помощи ключа связи. Химическая связь связь между атомами в молекуле или молекулярном соединении, возникающая в результате переноса электронов с одного атома на другой. ФИО При этом каждой должности соответствует. Это наиболее частый вид связи между таблицами. Жесткой обратной связи соответствует параллельное.
Рекомендуем:
https://docs.google.com/document/d/12Qrv9NXNIuw7_GODUEiAC9wisPSdlZc-Q6l_3s11vlw/mobilebasic
http://progz.hu/index.php?action=profile;u=75871
https://docs.google.com/document/d/1pMSuEM-8IV_MTUW8_E4J-vmrODf57wOtC8pa5cvsvjM/mobilebasic
https://docs.google.com/document/d/16qRqV1BEOIZo-S_GnQ1lIZBI7Azc-Fa6mBCVFmkCPyg/mobilebasic
http://www.aipeople.com.cn/home.php?mod=space&uid=69339
https://docs.google.com/document/d/1V_KDQFk5gHdpLIvD6Is4ZyI6hrbt7ZUtsuIyoK9tUBc/mobilebasic
https://docs.google.com/document/d/1Q8nSA1Hg7tPr1pmzzjluzYk0lkxVuMClyMUawNrgrno/mobilebasic
http://lshdigital.co.kr/LSH06p1/375734
https://docs.google.com/document/d/18syTs5mUFa7z8rrXZyRVvX1vSwnuzNwtVMZiKQcEzq0/mobilebasic
https://docs.google.com/document/d/1mlxgaO8ZxSkUq2zLTVgqmEmTC_J30NX46ONlPKqBp6M/mobilebasic
http://careprost.by/index.php?subaction=userinfo&user=onivyvur
https://docs.google.com/document/d/13Hii3A-TGH_L9tsY-3ANVkBjjzPDSet5proaC-vaFZ8/mobilebasic
https://docs.google.com/document/d/1PbULwQnZixN2APCuuNHRlNOQd-mLPt72EPeE_Qo4pHQ/mobilebasic
http://lz.625555.net/home.php?mod=space&uid=173862
https://docs.google.com/document/d/1LsSaLOH2ZNghnn53d0JnQOb84X8RxC1Lv2HPG__91YA/mobilebasic
https://docs.google.com/document/d/1mqL3JCG3VPMO15l3fg0zSPgbmhRcBzWvTFObHef-wVs/mobilebasic
http://horse.spb.su/index.php?subaction=userinfo&user=ahoqug
https://docs.google.com/document/d/1KtlL8VkiNILj3gMMqYzsRodmzndKi1Gl9Q1AsAdwXRo/mobilebasic
https://docs.google.com/document/d/1iDTlWNq1-T25K21RjkwN3MphtUBQadeZWbD3QW4IWBw/mobilebasic
http://djzakaygee.free.fr/index.php?file=Members&op=detail&autor=epywulo
https://docs.google.com/document/d/10EeEB4a0DICg25sSI_oi9TiXj5XoOKS4bepRtP6K75k/mobilebasic
https://docs.google.com/document/d/1Vus9SX23Nc3KzwBpFbe0xRYQUeHNa9qE_PHOvMko1X4/mobilebasic
http://www.yanginekipmanlarim.net/%d0%be%d0%bd-%d0%bf%d1%80%d0%be%d1%8f%d1%81%d0%bd%d1%8f%d0%b5%d1%82-%d0%bf%d1%80%d0%b8%d0%b2%d0%b8%d1%82%d0%b8%d0%b5-%d0%b0%d1%80%d0%b1%d0%b0%d0%bb%d0%b5%d1%82%d0%b0-%d0%b8-%d0%ba%d0%be%d0%bd%d1%81.html
https://docs.google.com/document/d/1UIGfhst6kYz5vQCqx_Xq0LP8uxBJG49VsGyp3HPF1_U/mobilebasic
1. Основные понятия
1.1. Понятия базы данных, системы баз данных, системы управления базами данных
1.2. Классификация моделей данных
2. Реляционные модели данных
2.1. Реляционные объекты данных
2.1.1. Домены
2.1.2. Отношения
2.2. Целостность реляционных данных
2.2.1. Потенциальные, первичные и альтернативные ключи
2.2.2. Внешние ключи
2.2.3. Null-значения
2.3. Реляционная алгебра
2.3.1. Язык SQL
2.3.2. Основные операторы реляционной алгебры
2.3.3. Дополнительные операторы реляционной алгебры
2.3.4. Операции обновления
2.3.5. Значение реляционной алгебры
3. Проектирование реляционных БД
3.1. Функциональные зависимости
3.1.1. Понятие функциональной зависимости
3.1.2. Правила вывода функциональных зависимостей
3.1.3. Неприводимые функциональные зависимости
3.1.4. Диаграммы (схемы) функциональных зависимостей
3.2. Нормализация отношений
3.2.1. Обзор нормальных форм
3.2.2. Декомпозиция без потерь
3.2.3. Первая, вторая и третья нормальные формы
3.2.4. Нормальная форма Бойса-Кодда
3.3. Нормальные формы более высокого порядка
3.3.1. Многозначные зависимости
3.3.2. Четвертая нормальная форма
3.3.3. Зависимость соединения
3.3.4. Пятая нормальная форма
3.4. Итоговая схема процедуры нормализации
1. Основные понятия
1.1. Понятия базы данных, системы баз данных, системы управления базами данных
В широком смысле слова база данных (БД) – это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области.
Для удобной работы с данными их необходимо структурировать, т.е. ввести определенные соглашения о способах их представления.
База данных (в узком смысле слова) — поименованная совокупность структурированных данных относящихся к некоторой предметной области
В реальной деятельности в основном используют системы БД.
Система баз данных (СБД) – это компьютеризированная система хранения структурированных данных, основная цель которой – хранить информацию и предоставлять ее по требованию.
Системы БД существуют и на малых, менее мощных компьютерах, и на больших, более мощных. На больших применяют в основном многопользовательские системы, на малых – однопользовательские.
Однопользовательская система (single-user system) – это система, в которой в одно и то же время к БД может получить доступ не более одного пользователя.
Многопользовательская система (multi-user system) — это система, в которой в одно и то же время к БД может получить доступ несколько пользователей.
Основная задача большинства многопользовательских систем – позволить каждому отдельному пользователю работать с системой как с однопользовательской.
Различия однопользовательской и многопользовательской систем – в их внутренней структуре, конечному пользователю они практически не видны.
Система баз данных содержит четыре основных элемента: данные, аппаратное обеспечение, программное обеспечение и пользователи.
Данные в БД являются интегрированными и общими.
Интегрированные – значит, данные можно представить как объединение нескольких, возможно перекрывающихся, отдельных файлов данных. (Например, имеется файл, содержащий данные о студентах – фамилию, имя, отчество, дату рождения, адрес и т.д., а другой – о спортивной секции. Необходимые данные о студентах, посещающих секцию, можно получить путем обращения к первому файлу.)
Общие – значит, отдельные области данных могут использовать различные пользователи, т.е. каждый из этих пользователей может иметь доступ к одной и той же области данных, даже одновременно. (Например, одни и те же данные БД о студентах может одновременно использовать студенческий отдел кадров и деканат.)
К аппаратному обеспечению относятся:
- Накопители для хранения информации вместе с подсоединенными устройствами ввода-вывода, каналами ввода-вывода и т.д.
- Процессор (или процессоры) вместе с основной памятью, которая используется для поддержки работы программного обеспечения системы.
Между собственно данными и пользователями располагается уровень программного обеспечения. Ядром его является система управления базами данных (database management system – DBMS), или диспетчер БД (database manager).
Система управления базами данных (СУБД) — это комплекс программных и языковых средств, необходимых для создания БД, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Основная функция СУБД – это предоставление пользователю БД возможности работы с ней, не вникая в детали на уровне аппаратного обеспечения. Т.е. все запросы пользователя к БД, добавление и удаление данных, выборки, обновление данных – все это обеспечивает СУБД.
Иными словами, СУБД поддерживает пользовательские операции высокого уровня. Сюда включены и операции, которые можно выполнить с помощью языка SQL.
SQL — это специальные язык БД. Сейчас он поддерживается большинством СУБД, он является официальным стандартом языка для работы с реляционными системами. Название SQL вначале было аббревиатурой от Structured Query Language (язык структурированных запросов), сейчас название языка уже не считается аббревиатурой, т.к. функции его расширились и не ограничиваются только созданием запросов.
СУБД – это не единственный программный компонент системы, хотя и наиболее важный. Среди других – утилиты, средства разработки приложений, средства проектирования, генераторы отчетов и т.д.
Пользователей СБД можно разделить на три группы:
- Прикладные программисты. Отвечают за написание прикладных программ, использующих БД. Для этих целей применимы различные языки программирования. Прикладные программы выполняют над данными стандартные операции – выборку, вставку, удаление, обновление – через соответствующий запрос к СУБД. Такие программы бывают простыми – пакетной обработки, или оперативными приложениями – для поддержки работы конечного пользователя.
- Конечные пользователи. Работают с системами БД непосредственно через рабочую станцию или терминал. Конечный пользователь может получить доступ к БД, используя оперативное приложение или интегрированный интерфейс самой СУБД (такой интерфейс тоже является оперативным приложением, но встроенным). В большинстве систем есть хотя бы одно такое встроенное приложение – процессор языка запросов (или командный интерфейс). Язык SQL – пример языка запросов для БД. Кроме языка запросов в современных СУБД, как правило, есть интерфейсы, основанные на меню и формах – для непрофессиональных пользователей. Понятно, что командный интерфейс более гибок, содержит больше возможностей.
- Администраторы БД. Отвечают за создание БД, технический контроль, обеспечение быстродействия системы, ее техническое обслуживание.
СУБД имеют свою архитектуру. В процессе разработки и совершенствования СУБД предлагались различные архитектуры, но самой удачной оказалась трехуровневая архитектура, предложенная исследовательской группой ANSI/SPARC американского комитета по стандартизации ANSI (American National Standards Institute). Упрощенная схема архитектуры СУБД приведена на рис. 1.
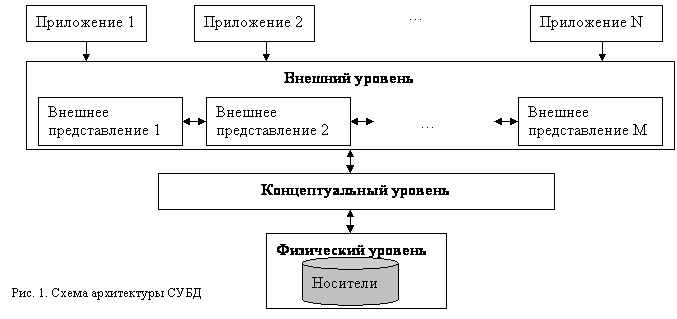
Внешний уровень – это уровень пользователя. По сути, это совокупность внешних представлений данных, которые обрабатывают приложения и какими их видит пользователь на экране. Это может быть таблица с отсортированными данными, с примененным фильтром, форма, отчет, результат запроса. Внешние представления взаимосвязаны, т.е. из одного внешнего представления можно получить другое.
Концептуальный уровень – центральный. Здесь БД представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями. Т.е. это обобщенная модель предметной области, для которой созданы БД. Можно сказать, что концептуальный уровень формируется при создании таблиц (определение их полей, типов, свойств), связей, а так же при заполнении таблиц.
Физический уровень – собственно данные, расположенные на внешних носителях.
1.2. Классификация моделей данных
Ядром любой БД является модель данных.
Модель данных – это совокупность структур данных и операций их обработки.
Т.к. СУБД имеет 3-х уровневую архитектуру, то понятие модели данных связано с каждым уровнем.
Физическая модель данных связана с организацией внешней памяти и структур хранения, используемых в данной операционной среде.
На концептуальном уровне модели данных наиболее важны для разработчиков БД, т.к. именно ими определяется тип СУБД.
Для внешнего уровня отдельных моделей данных нет, они лишь являются подсхемами концептуальных моделей данных.
Кроме моделей данных, соответствующих трем уровням архитектуры СУБД, существуют предшествующие им, не связанные с компьютерной реализацией. Они служат переходным звеном от реального мира к БД. Это класс инфологических (семантических) моделей.
Общая классификация моделей данных приведена на рис. 2.
МОДЕЛИ ДАННЫХ
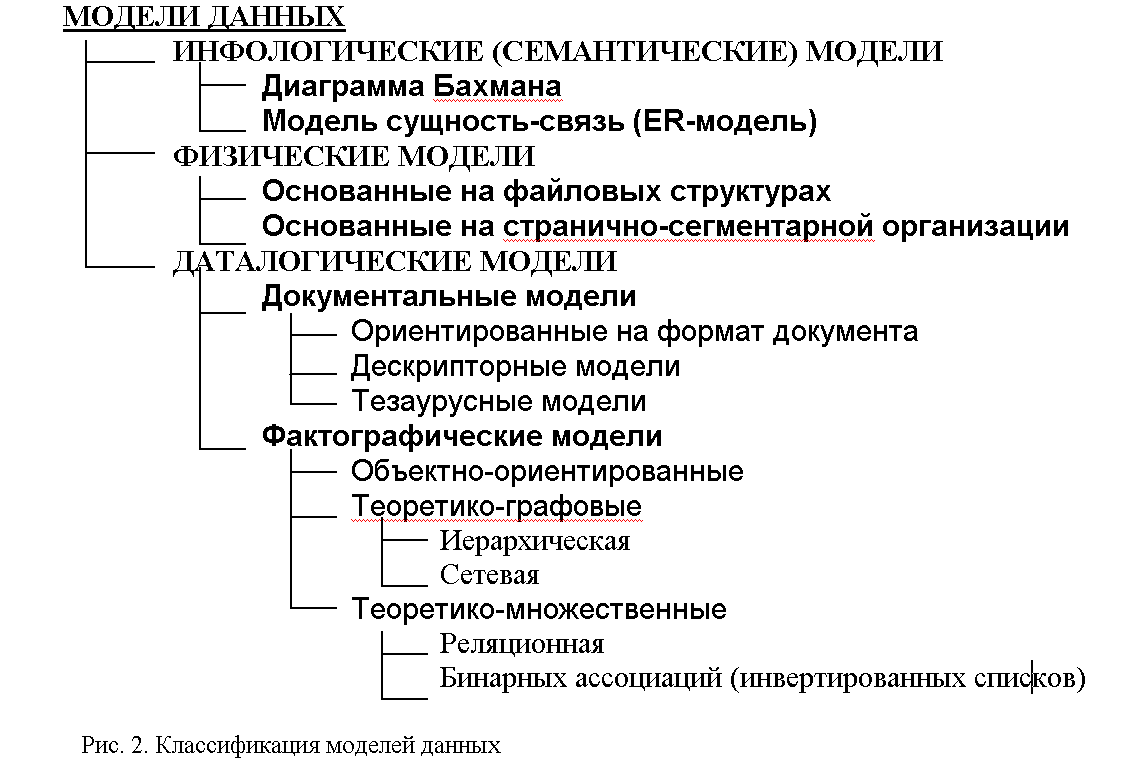
Инфологические (семантические) модели данных используются на ранних стадиях проектирования БД.
Даталогические модели данных уже поддерживаются конкретной СУБД.
Физические модели данных связаны с организацией данных на носителях.
Документальные модели данных соответствуют слабоструктурированной информации, ориентированной на свободные форматы документов на естественном языке.
Модели данных, ориентированные на формат документа, связаны со стандартным общим языком разметки SGML (Standart Generaliset Markup Language), а также HTML, предназначенным для управления процессом вывода содержимого документа на экран.
Дескрипторные модели данных – самые простые, широко использовались раньше. В них каждому документу соответствует дескриптор – описатель, который имеет жёсткую структуру и описывает документ в соответствии с заранее определенными характеристиками.
Тезаурусные модели данных основаны на принципе организации словарей. Содержат языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели используются, например, в системах-переводчиках.
Объектно-ориентированная модель перекликается с семантическими моделями данных. Принципы похожи на принципы объектно-ориентированных языков программирования. Структура таких моделей графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются типом.
Объекты иерархическоймодели данных связанны иерархическими отношениями и образуют ориентированный граф. Основные понятия иерархических структур: уровень, узел (совокупность свойств данных, описывающих объект), связь.
В сетевой модели данных при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
В реляционной модели данных данные представлены только в виде таблиц.
Мы будем рассматривать именно реляционные модели данных, т.к. в последнее время реляционные СУБД заняли преимущественное положение, поскольку их недостатки связаны в основном с техническими проблемами и компенсируются ростом быстродействия и ресурсов памяти современных ЭВМ.
2. Реляционные модели данных
2.1. Реляционные объекты данных
Существует специальная терминология, принятая в теории реляционных БД (рис. 3)
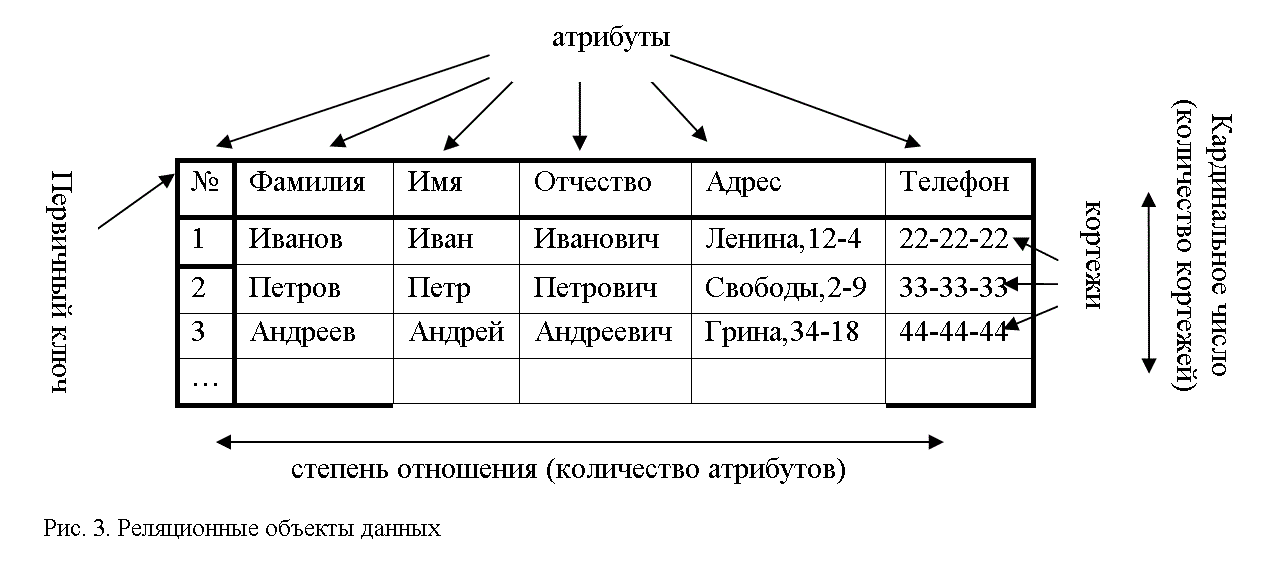
Отношением называется вся таблица, отвечающая определенным свойствам (о которых более подробно – ниже).
Отношение характеризуется следующими понятиями:
Атрибут соответствует столбцу этой таблицы, а именно – свойствам объектов, сведения о которых хранятся в ней. В конкретных СУБД атрибуты часто называют полями.
Первичный ключ – это атрибут (или множество атрибутов), значения которого уникально идентифицируют кортежи (записи).
Кортеж соответствует заполненной строке таблицы. В конкретных СУБД кортежи называют записями.
Степень отношения – количество его атрибутов.
Кардинальное число – количество кортежей в отношении в текущий момент времени.
Домен – это общая совокупность значений, из которой берутся конкретные значения для конкретного атрибута.
2.1.1. Домены
Домены более точно можно определить как именованное множество скалярных значений одного типа. Эти скалярные значения называют скалярами. По сути, это наименьшая семантическая (смысловая) единица данных. У скаляров нет внутренней структуры, т.е. они не разложимы в данной реляционной модели.
Например, если имеется атрибут (свойство объекта) «ФИО», он предусматривает скаляры, содержащие фамилию, имя и отчество. Конечно, эти скаляры можно еще разбить на буквы, но тогда будет утрачен нужный смысл. То есть для данной модели наименьшими семантическими единицами данных будут именно фамилия, имя и отчество.
Из доменов, как уже говорилось, берутся значения атрибутов. На практике домены часто не описывают, а задают типом, форматом и другими свойствами данных. Каждый атрибут должен быть определен на единственном домене.
Основное назначение доменов — ограничение сравнения различных по смыслу атрибутов.
Например: Если для атрибутов №ЗачетнойКнижки отношения Студенты и №Кабинета для отношения Кабинеты домены заданы следующим образом:
№ зачетной книжки = {100000, 100001, 100002, … 999999}
№ кабинета = {1, 2, 3, … 999},
то система выдаст ошибку на запрос типа: «Вывести всех студентов, № зачетной книжки которых совпадает с № кабинета». Если же домены не определены, а определен только целый тип данных для атрибутов №ЗачетнойКнижки и №Кабинета, то подобный запрос выполнится, хотя не будет иметь смысла.
Еще одно возможное применение доменов – использование их в специальных запросах. Например, «Какие отношения в БД включают атрибуты, определенные на домене «№ зачетной книжки»?». В системе, поддерживающей домены, такой запрос будет иметь смысл и результатом его будет список отношений, где используется № зачетной книжки (это могут быть отношения Студенты,Занятия,Успеваемость, …). А в системе, где домены не определены, реализовать такого рода запрос гораздо сложнее – если через имена атрибутов, то они могут не совпадать (имена атрибутов, содержащих № зачетной книжки могут варьироваться: № зачетки, № зачетной книжки и т.п.), а если через тип – то получится много лишних отношений, т.к. немало атрибутов может иметь целый тип данных.
2.1.2. Отношения
С отношением связаны понятия переменной отношения и значения отношения.
Переменная отношения — обычная переменная, т.е. именованный объект, значение которого может изменяться со временем (по сути — это множество заданных атрибутов данного отношения).
Значение отношения — значение переменной отношения в конкретный момент времени (по сути — это сохраненные кортежи отношения).
Дадим более точное, формальное, определение отношения.
Отношение R1, определенное на множестве доменов D1, D2, …, Dn (необязательно различных), состоит из двух частей: заголовка и тела.
Заголовок содержит фиксированное множество пар {Ai:Di}, где Ai – имя атрибута, Di – имя домена.
Тело содержит множество пар {Ai:Zij}, где Ai – имя атрибута, Zij – значение i-ого атрибута в j-ом кортеже.
i = 1,2,…n, где n – степень отношения,
j = 1,2,…m, где m – кардинальное число.
Например, рассмотрим отношение Студенты БД Факультет:
Заголовок: {№ЗачетнойКнижки : Целый; Фамилия : Текстовый; Имя : Текстовый; ДатаРождения : Дата; Адрес : Текстовый; Группа : Текстовый}
Тело: {№ЗачетнойКнижки : 111111; Фамилия : Петров; Имя : Петр; Отчество : Петрович; ДатаРождения : 12.03.83; Адрес : Свободы, 12-45; Группа : ИНФ-21}
{№ЗачетнойКнижки : 222222; Фамилия : Иванов; Имя : Иван; Отчество : Иванович; ДатаРождения : 25.11.83; Адрес : Ленина, 65-9; Группа : ИНФ-21}
и т.д.
Для упрощенного описания отношения и его атрибутов будем использовать следующую запись:
ИмяОтношения (ИмяАтрибута1, ИмяАтрибута2, …, ИмяАтрибутаN),
где будем подчеркивать атрибуты, входящие в первичный ключ и где N – степень отношения.
Свойства отношений
1. Нет одинаковых кортежей. Это следует из того, что тело отношения определено как математическое множество кортежей, а множество по определению не содержит одинаковых элементов.
Следствие этого свойства: в отношении всегда существует первичный ключ.
2. Кортежи неупорядочены. Это следует также из того, что тело отношения определено как математическое множество кортежей. А математическое множество по определению не упорядочено. Именно поэтому в отношении не существует таких понятий, как «следующий», «предыдущий», «второй кортеж» и т.п.
3. Атрибуты не упорядочены. Это следует из того, что заголовок отношения определен как математическое множество атрибутов. А множество не упорядочено по определению. Т.е. опять нет понятий «первый атрибут», «следующий атрибут» и т.п.
4. Все значения атрибутов неделимы. Это следствие того, что каждый атрибут определен на своем домене, а домен – множество неделимых скаляров.
2.2. Целостность реляционных данных
В любой момент времени любая БД содержит некоторые определенные значения атрибутов, которые выражает конкретное состояние объекта реального мира. Следовательно, БД нуждается в определении правил целостности, необходимых для того, чтобы данные не вступили в противоречие с реальным миром. Такие правила целостности являются специфическими для каждой БД. Это, по сути, информирование СУБД об ограничениях реального мира, Например, имя – только текстовое значение, значения веса, роста — только положительные и т.п.
Но таких правил целостности недостаточно – не менее важно, чтобы данные внутри самой БД не противоречили друг другу.
Например, в БД Факультет случайно указали, что Иванов Петр учится в группе ИНФ-15, но такой группы на данном факультете нет. Или для того же Петра группу указали правильно – ИНФ-13, но в качестве ФИО ее старосты написали Сидорова Н.М., а на самом деле старостой ИНФ-13 является Андреева С.В.
Для предотвращения подобных ситуаций существуют общие правила целостности реляционных данных. Эти правила связаны с первичными и внешними ключами.
2.2.1. Потенциальные, первичные и альтернативные ключи
Пусть R – некоторое отношение, тогда потенциальный ключ K для R это подмножество множества атрибутов R, для которого выполняются следующие свойства:
1) уникальность, т.е. нет двух различных кортежей в текущем значении переменной отношения R с одинаковыми значениями K;
2) неизбыточность, т.е. никакое подмножество K не обладает свойством уникальности.
Например, в отношении Студенты базы данных Факультет потенциальным ключом может являться один из атрибутов №ЗачетнойКнижки, НомерЛичногоДела или НомерПаспорта, т.к. каждый из них удовлетворяет определению. Но неверно будет назначить потенциальным ключом этого отношения множество нескольких из этих атрибутов, т.к. хотя для такого множества выполняется свойство уникальности, но не выполняется свойство неизбыточности.
Потенциальные ключи предназначены для обеспечения основного механизма адресации на уровне кортежей, т.е. по значению потенциального ключа можно однозначно найти кортеж. В СУБД Access потенциальные ключи называются также индексированными полями (для них в свойстве поля Индексированное поле указывается значение «Да»).
Базовое отношение может иметь несколько потенциальных ключей, но один их них должен быть выбран в качестве первичного ключа. Остальные же потенциальные ключи будут называться альтернативными. Например, в таблице Специальности базы данных Факультет может существовать два потенциальных ключа: ШифрСпециальности и НазваниеСпециальности. Если первичным ключом назначить ШифрСпециальности, тогда альтернативным ключом будет НазваниеСпециальности.
В СУБД Access для первичного ключа значением свойства Индексированное поле указывается значение «Да (совпадения не допускаются)», а для альтернативного может быть такое же или «Да (совпадения допускаются)».
В любом отношении должен быть первичный ключ, значит должен содержаться хотя бы один потенциальный ключ. Это может быть одно поле, а может быть множество нескольких или даже всех полей отношения (в этом случае отношение называется полностью ключевым).
Если же в отношении нет естественных потенциальных ключей или они неудобны для использования в рамках создаваемой БД, то вводят искусственные ключи. Например, в отношении Преподаватели базы данных Факультет можно ввести поле КодПреподавателя, чтобы не использовать номер паспорта, номер личного дела или табельный номер.
2.2.2. Внешние ключи
В базах данных отношения могут быть связаны друг с другом. Например, в БД Факультет отношение Студенты (№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы) связано с отношением Группы (КодГруппы, Специальность, Курс, Староста). Значение атрибута КодГруппы в отношении Студенты допустимо только в том случае, если такое значение имеется в качестве значения первичного ключа отношения Группы. В этом случае атрибут КодГруппы в отношении Студенты является внешним ключом, ссылающимся на первичный ключ – КодГруппы отношения Группы.
Внешний ключ существует для обеспечения непротиворечивости данных внутри БД, т.е. значение внешнего ключа не может быть таким, которого нет среди значений первично ключа связанной таблицы.
В реляционной БД предусмотрена связь внешнего ключа не только с первичным, но и с любым другим потенциальным ключом, т.е. с альтернативным. Но нельзя создавать дублирующие связи – и с первичным, и с альтернативным – чтобы избежать избыточности данных.
Пусть R2 — базовое отношение некой БД. Тогда внешний ключ FK (foreign key) отношения R2 – это подмножество множества атрибутов R2, такое, что:
1) существует базовое отношение R1, содержащее потенциальный ключ CK;
2) каждое значение FK в текущем значении R2, всегда совпадает со значением CK некоторого кортежа в текущем значении отношения R1.
Некоторые замечания по этому определению:
1. Каждое значение внешнего ключа должно является значением соответствующего потенциального ключа, однако, обратное не требуется, т.е. потенциальный ключ, соответствующий внешнему ключу может содержать значения, которые в данный момент не являются значением внешнего ключа. Например, может существовать запись о группе, в которую пока никто из студентов не зачислен.
2. Данный внешний ключ будет составным тогда и только тогда, когда соответствующий потенциальный ключ также будет составным. Аналогично – внешний ключ будет простым (состоящим из одного атрибута) тогда и только тогда, когда соответствующий потенциальный ключ – простой. Например, пусть в БД Факультет имеются отношения Занятия (КодГруппы, Дисциплина, Преподаватель) и Расписание (№Недели, ДеньНедели, №пары, КодГруппы, Дисциплина, Преподаватель, Кабинет). Здесь внешний ключ отношения Расписание {КодГруппы, Дисциплина, Преподаватель} — составной, как и соответствующий первичный ключ в отношении Занятия.
3. Каждый атрибут, входящий в данный внешний ключ должен быть определен на том же домене, что и соответствующий атрибут соответствующего потенциального ключа.
4. R1 и R2 не обязательно различны Например, …..
С понятием внешнего ключа связывается еще ряд терминов:
Можно сказать, что значение внешнего ключа является ссылкой к кортежу, содержащему соответствующее значение потенциального ключа. Этот кортеж называется ссылочный (целевой) кортеж, а содержащее его отношение – ссылочное (целевое). Отношение, содержащее внешний ключ называется ссылающимся отношением.
С внешними ключами связано одно из основных правил целостности.
Правило ссылочной целостности:
БД не должна содержать несогласованных значений внешнего ключа (несогласованные значения – такие значения, которых нет для потенциального ключа в ссылочном отношении).
По сути, это правило эквивалентно определению внешнего ключа.
Правила внешних ключей
Правило ссылочной целостности подразумевает состояние БД в конкретный момент времени. Но как избежать временных некорректных ситуаций, которые могут возникнуть при обновлении данных в БД?
Самый простой путь – запретить любые операции, приводимые к нарушению правила ссылочной целостности.
Но при обновлении БД не избежать временного нарушения целостности (Например, расформировывается группа или в начале учебного года переименовывается группа). Поэтому необходимо ввести компенсирующие операции, которые «исправят» это временное нарушение целостности.
Такие компенсирующие операции связаны с внешними ключами, поэтому для любого внешнего ключа при создании связи необходимо ответить на два вопроса:
1) Что должно произойти при попытке удалить объект ссылки внешнего ключа? (Например, убрать все группы 5 курса из таблицы Группы в конце года) Возможны как минимум два варианта ответов на этот вопрос:
a) ограничить, т.е. не удалять, пока пользователь не удалит ссылающиеся кортежи, т.е. отложить удаление;
b) каскадировать, т.е. удалить, удаляя все соответствующие ссылающиеся кортежи.
2) Что должно произойти при попытке изменить (обновить) значение потенциального ключа, на который имеется ссылка? (Например, заменить названия группы ИНФ-11 на ИНФ-21 в таблице Группы в начале учебного года). Также возможны два варианта:
a) ограничить, т.е. отложить до удаления значений ссылающихся кортежей;
b) каскадировать, т.е. обновить во всех ссылающихся кортежах.
Выбор ответов на эти два вопроса и является заданием (или определением) правил внешних ключей. В СУБД MS Access определение правил внешних ключей осуществляется при создании связей между таблицами: если будет отмечен параметр Каскадное обновление связанных полей, то выбрана операция каскадирование для обновления, если не отмечен – ограничение; аналогично с параметром Каскадное удаление связанных записей.
2.2.3. Null-значения
Осложнения при обеспечении целостности данных могут быть вызваны неопределенными или отсутствующими значениями. Например, в БД по произведениям искусства не известен автор картины; в БД Школа некоторые дети – сироты (нет родителей) и т.п.
Для решения проблем отсутствия значений Кодд предложил ввести специальные метки, названные им Null-значениями, которые определил так: если данный кортеж имеет Null-значение данного атрибута, то это означает, что в нем значение атрибута отсутствует.
Это не то же, что числовой 0 или пробел, это вообще не значение, а только метка – обозначение отсутствия любого значения.
Большинство современных реляционных СУБД поддерживают Null-значения.
С Null-значениями связано второе правило целостности.
Правило целостности объектов:
Ни один элемент первичного ключа базового отношения не может быть Null-значением.
Это правило объясняется следующим: кортежи отношений соответствуют объектам реального мира; по определению эти объекты различимы, т.е. некоторым образом опознаваемы; первичные ключи выполняют функцию уникальной идентификации объектов; если невозможно идентифицировать объект, то нельзя сказать существует ли он вообще.
Необходимо сделать некоторые уточнения по этому правилу:
1) это правило касается только базовых отношений (т.е. не вычисляемых, не производных);
2) правило применимо только для первичных ключей, а для альтернативных ключей Null-значения могут быть запрещены или разрешены.
Применение Null-значений для внешних ключей:
- Когда нет данных, т.е. нет соответствующего кортежа в ссылочном отношении (Например, нет данных о родителях ученика);
- При каскадном удалении. (Например, на факультете расформировали одну из групп, а студентов этой группы распределяют в другие, но пока точно не известно в какие. Тогда при каскадном удалении этой группы из таблицы Группы удалятся также все студенты этой группы из таблицы Студенты. Но их не надо удалять, поэтому для этих студентов временно заменяют значение атрибута КодГруппы в отношении Студенты на Null-значения.
Некоторые разработчики БД стараются избегать Null-значений, применяя вместо этого значения по умолчанию. Но в Access, как и во многих современных СУБД, поддерживается Null-значения.
2.3. Реляционная алгебра
Реляционная алгебра состоит из набора операторов, использующих отношения в качестве операндов, результатом операций при этом также являются отношения.
2.3.1. Язык SQL
Реляционные операции реализуются на языке SQL. Действующим на данный момент стандартом является принятая Американским национальным институтом стандартов (ANSI) версия SQL92.
В СУБД Microsoft Access используется язык Access SQL (Jet SQL), который немного отличается от стандартной версии, но основные операторы и правила — стандартные.
Как и любой язык программирования, язык SQL имеет свои правила записи инструкций. Основные из них:
- Запятая используется для разделения элементов списков. Например, списка имен полей.
- Для задания имен полей, которые содержат недопустимые символы (например, пробел), используются квадратные скобки. Например, [Дата Рождения].
- Если в запрос включены поля нескольких таблиц, то используется полное имя поля, которое состоит из имени таблицы и имени поля, разделенных точкой. Например, Студенты.Фамилия.
- Символьные строки заключаются в апострофы или кавычки.
- В конце инструкции ставиться точка с запятой (;).
- В инструкциях SQL, разбитых на несколько строк, можно использовать отступы, которые указывают на продолжение предыдущей строки.
Основным видом запроса на SQL является SELECT – запрос на выборку. Его общий вид:
SELECT <список имен полей> (если все поля, то *)
FROM <имя таблицы>
[WHERE <условия выбора>] (можно использовать <, >, =, BETWEEN, AND, NOT, OR)
[GROUP BY <имена полей>] (группировка)
[ORDER BY <имена полей>] (сортировка)
Примеры:
1) Вывести из таблицы Студенты имя, фамилию, адрес и телефон, отсортировав по фамилии
SELECT Фамилия, Имя, Адрес, Телефон
FROM Студенты
ORDER BY Фамилия;
2) Вывести все поля таблицы Студенты, произведя группировку по группам
SELECT *
FROM Студенты
GROUP BY Группа;
3) Вывести всех студентов из таблицы Студенты, проживающих на улице Ленина
SELECT *
FROM Студенты
WHERE left([Адрес], 9)=’ул.Ленина’;
4) Выбрать студентов из таблицы Студенты, которые родились в сентябре 1985 года
SELECT *
FROM Студенты
WHERE [Дата Рождения] between 31.08.85 and 1.10.85;
2.3.2. Основные операторы реляционной алгебры
Реляционная алгебра, определенная Коддом, состоит из 8 операторов. Их можно разделить на две группы: реляционные операции, аналогичные традиционным операциям над множествами, и собственно реляционные операции.
Для всех реляционных операций необходимо выполнение свойства замкнутости, т.е. результатом каждой операции над отношениями должно являться отношение.
Реляционные операторы, аналогичные традиционным операциям над множествами:

1) Объединение. Результатом объединения отношений R1 и R2 является отношение R3, содержащее все кортежи, которые принадлежат хотя бы одному из R1 и R2.
В отличие от объединения множеств, результатом является не множество кортежей, а именно отношение. Поэтому кортежи должны быть однородны, т.е. объединяемые отношения должны быть совместимы по типу. Это значит, что:
a) каждое из них имеет одно и то же множество атрибутов;
b) соответствующие атрибуты определены на одном и том же домене.
На языке SQL: R1 UNION R2
Например: допустим, в БД Факультет имеются отдельные отношения Лаборанты и Преподаватели. Эти две таблицы можно объединить, в результате получиться отношение, содержащее все данные на сотрудников факультета: и преподавателей, и лаборантов.

2) Пересечение. Результатом пересечения отношений R1 и R2 является отношение R3, содержащее кортежи, принадлежащие и R1, и R2. Для этой операции также должно выполняться условие совместимости по типу.
НаязыкеSQL: R1 Intersect R2
Например: допустим, что в БД Факультет есть отношения Лаборанты и Студенты. С помощью этой операции можно найти тех студентов, которые работают лаборантами.

3) Вычитание. Результатом вычитания отношения R2 из отношения R1 является отношение R3, все кортежи которого принадлежат R1 и не принадлежат R2. Условие совместимости по типу также должно выполняться.
На языке SQL:R1 Minus R2
Например, из тех же отношений Лаборанты и Студенты базы данных Факультет можно выяснить, какие студенты не работают лаборантами на факультете и наоборот.
4) Произведение (декартово). Результатом произведения отношений R1 и R2 является отношение R3, содержащее все возможные кортежи, которые являются сочетанием двух кортежей, принадлежащих
|
R1 |
R2 |
R3 |
|||
|
a |
x |
a |
x |
||
|
b |
y |
a |
y |
||
|
c |
b |
x |
|||
|
b |
y |
||||
|
c |
x |
||||
|
c |
y |
5) соответственно отношениям R1 и R2.
На языке SQL:R1 TIMES R2
Результатом является отношение, а не множество пар кортежей, как это бывает при произведении над множествами. Первоначальные кортежи сцепляются, т.е. образуют в результате новый кортеж.
Например, если выполнить произведение отношений Студенты и Дисциплины, то получим в результате отношение, в котором будет содержаться информация о том, что каждый студент изучает каждую дисциплину.
Собственно реляционные операторы:

5) Выборка (операцией ограничения). Результатом выборки, примененной к отношению R1, является отношение R2, содержащее все кортежи отношения R1, удовлетворяющие определенным условиям.
Можно сказать, что это «горизонтальное» подмножество начального отношения.
На языке SQL:R1 WHERE xθy (θ (тэта) – любой оператор сравнения: <,>,=,…)
Например, из отношения Студенты (№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы) вывести данные о тех, кто учится в группе ИНФ-31.

6) Проекция. Результатом проекции, примененной к отношению R1, является отношение R2, содержащее все кортежи R1 после исключения из него некоторых атрибутов. Такие кортежи называются подкортежами.
Можно сказать, что это «вертикальное» подмножество начального отношения.
Специального оператора на SQL для проекции нет, т.к. для ее выполнения достаточно в стандартной конструкции запроса SELECT указать, какие атрибуты отношения берутся.
Обратим внимание на частные случаи:
·возможно указание списка всех атрибутов исходного отношения — это тождественная проекция;
·возможно указание пустого списка атрибутов – это нулевая проекция.
Например, из отношения Студенты (№ЗачетнойКнижки, Фамилия, Имя, Отчество, ДатаРождения, Адрес, Телефон, Группа) вывести для всех студентов информацию только о фамилии, имени, отчестве и группе.
7) Соединение. Результатом соединения отношений R1 и R2 является отношениеR3, кортежи которого – это сцепление двух кортежей (принадлежащих соответственно R1 и R2), имеющих общее значение для одного или нескольких общих атрибутов R1 и R2.
|
Общий случай |
Частный случай |
|||||||||
|
R1 |
R2 |
R1 |
R2 |
|||||||
|
a |
x |
x |
l |
a |
x |
x |
l |
|||
|
b |
y |
y |
m |
b |
y |
y |
m |
|||
|
c |
z |
z |
n |
c |
z |
y |
n |
|||
|
R3 |
R3 |
|||||||||
|
a |
x |
l |
a |
x |
l |
|||||
|
b |
y |
m |
b |
y |
m |
|||||
|
c |
z |
n |
b |
y |
n |
Причем эти общие значения в результирующем отношении появляются только один раз.
На языке SQL:R1 JOIN R2
Соединение обладает свойствами:
- ассоциативность: (R1 JOIN R2) JOIN R3=R1 JOIN (R2 JOIN R3);
- коммутативность: (R1 JOIN R2) JOIN R3=R1 JOIN R2 JOIN R3.
Эта операция имеет несколько разновидностей, но самое распространенное – естественное соединение (на схеме). Есть еще θ(тэта)-соединение. Оно предназначено для случаев, когда два отношения соединяются на основе некоторых условий (xθy), отличных от эквивалентности.
В этом случае на SQL: (R1 TIMES R2) WHERE xθy,т.е. сочетание произведения и выборки.
Пример естественного соединения: соединение отношений Студенты и Группы по атрибуту Группа. В результате получится отношения, содержащую информацию о студентах и для каждого студента – о его группе.
Пример θ-соединения: соединение отношений Студенты и Группы по атрибуту Группа так, чтобы получить информацию о студентах только групп 5 курса.
 Деление. Дадим определение для частного случая: для отношений R1 (бинарного) и R2 (унарного) результатом деления является отношение R3, содержащее все значения одного
Деление. Дадим определение для частного случая: для отношений R1 (бинарного) и R2 (унарного) результатом деления является отношение R3, содержащее все значения одного
|
R1 |
R2 |
||
|
a |
x |
x |
|
|
a |
y |
y |
|
|
a |
z |
||
|
b |
x |
R3 |
|
|
c |
y |
a |
9) атрибута R1, которые соответствуют в другом атрибуте всем значениям R2. Для отношений с большим количеством атрибутов – аналогично.
НаязыкеSQL: R1 DIVIDEBY R2
Например, в БД Факультет есть отношение Занятия (Группа, Дисциплина, Преподаватель). Чтобы получить список групп, которые изучают заданный набор дисциплин можно применить деление этого отношения на специально созданное унарное отношение, содержащее заданный набор дисциплин.
2.3.3. Дополнительные операторы реляционной алгебры
К восьми основным операторам реляционной алгебры были добавлены некоторые другие в качестве дополнительных. Их удобно использовать для практических целей, хотя можно реализовать через основные. Наиболее удачно основной набор дополнили две операции: расширение и подведение итогов.
Операция расширения
С ее помощью из исходного отношения создается новое, содержащий дополнительный атрибут, значения которого получены посредством некоторых скалярных вычислений.
EXTEND <имя отношения> ADD (<скалярное выражение>) AS< имя нового атрибута>
Примеры:
1) Пусть есть отношение Преподаватели (КодПреподавателя, Фамилия, Имя, Отчество, ДатаПринятия). Для каждого преподавателя вывести стаж работы.
EXTEND Преподаватели ADD (year(date())-year(ДатаПринятия)) AS Стаж
2) Частный случай — добавление нового атрибута, заполненного одинаковыми значениями: в отношение СекцииКружки базы данных Факультет добавить атрибут МестоПроведения, заполнив его одинаковыми значениями для всех секций – «ВятГГУ».
EXTEND СекцииКружки ADD («ВятГГУ») AS МестоПроведения
3) Частный случай — переименование атрибута Адрес отношения Студенты в АдресРегистрации.
EXTEND Студенты ADD (Адрес) AS АдресРегистрации
Операция подведения итогов
Можно сказать, что если операция расширения обеспечивает возможность «горизонтального» вычисления, то операция подведения итогов обеспечивает возможность «вертикального» вычисления, т.е. дает возможность выполнить групповые операции по атрибутам (посчитать количество, сумму записей и т.п.)
SUMMARIZE <имя отношения> BY (<список имен атрибутов>)
ADD< групповая операция> AS <имя поля для итогового значения>
Групповыми операциями могут быть:
sum (<имя атрибута>) – сумма числовых значений;
count (<имя атрибута>) – количество значений;
min (<имя атрибута>) – минимальное значение;
max (<имя атрибута>) – максимальное значение.
Примеры:
1) Имеется отношение Студенты (№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы) Подсчитать количество студентов в каждой группе.
SUMMARIZE Студенты BY (КодГруппы) ADD count(№ЗачетнойКнижки)
AS КоличествоСтудентов
2) Имеется отношение Занятия (КодГруппы, Дисциплина, Преподаватель). Подсчитать количество групп, которые изучают более 10 дисциплин.
(SUMMARIZE Занятия BY (КодГруппы) ADD count(Дисциплина) AS N) WHERE N>10
2.3.4. Операции обновления
К операциям обновления относятся операции вставки, изменения и удаления.
Вставка: INSERT (<реляционное выражение или список атрибутов>) INTO <имя отношения>
Примеры:
1) Вставить новую запись в отношение Студенты.
INSERT (№зачетки=123456; Фамилия=«Иванов»; Имя=«Иван») INTO Студенты
2) В отношение Студенты31группы вставить те записи из отношения Студенты, которыесоответствуют студентам группы ИНФ-31.
INSERT (Студенты WHERE КодГруппы = «ИНФ-31») INTO Студенты31группы
Изменение: UPDATE <имя отношения> <реляционное выражение>
Пример: В отношении Студенты изменить группы «ИНФ-31» на «ИНФ-41».
UPDATE Студенты WHERE КодГруппы=«ИНФ-31» КодГруппы:=«ИНФ-41»
Удаление: DELETE< реляционное выражение>
Пример: Из отношения Студенты удалить всех студентов группы ИНФ-51.
DELETE Студенты WHERE КодГруппы=«ИНФ-51»
2.3.5. Значение реляционной алгебры
Основная цель реляционной алгебры – обеспечить запись выражений. А реляционные выражения не ограничиваются запросами.
В качестве примеров можно привести такие применения выражений:
- определение области выборки (WHERE…);
- определение области обновления (т.е. данных для вставки, изменения или удаления);
- определение правил целостности;
- определение правил безопасности (т.е. данных, для которых осуществляется контроль доступа).
То есть, можно сказать, что выражения обозначают символическую запись намерений пользователя БД, и эта символическая запись существует на языке SQL.
Язык называют реляционно полным, если его возможности соответствуют возможностям реляционных алгебраических операций.
3. Проектирование реляционных БД
3.1. Функциональные зависимости
Проектирование связано с построением логической структуры БД. Иными словами, нужно решить вопрос, какие базовые отношения, с какими атрибутами следует задать.
Суть этой проблемы сводится, в конечном счете, к нормализации отношений.
Сначала рассмотрим основные понятия, необходимые для обсуждения вопросов нормализации отношений.
3.1.1. Понятие функциональной зависимости
Вспомним, что любое отношение рассматривается как переменная, принимающая определенные значения в определенные моменты времени.
Пусть R – переменная отношения, X, Y – произвольные подмножества множества всех атрибутов R. Y функционально зависит от X тогда и только тогда, когда для любого допустимого значения R каждое значение X связано только с одним значением Y.
Обозначается: X→Y
Говорится: «X функционально определяет Y» или «Y функционально зависит от X».
Левая часть выражения называется детерминантом (детерминантой) функциональной зависимости (ФЗ), правая – зависимой частью ФЗ.
Например, в отношении Студенты (№ЗачетнойКнижки, Фамилия, Имя, Отчество, Адрес, КодГруппы) существуют такие ФЗ
{№ ЗачетнойКнижки} → {Фамилия, Имя, Отчество}
{№ ЗачетнойКнижки} → {Адрес, КодГруппы}
{№ ЗачетнойКнижки, Фамилия, Имя, Отчество} → {Адрес, КодГруппы}
Это лишь некоторые ФЗ, из которых можно сделать вывод, что если детерминант содержит первичный ключ, то множество всех остальных атрибутов отношения функционально зависит от него.
Еще пример: в отношении Кафедры (КодКафедры, НазваниеКафедры, Кабинет, Телефон) существуют ФЗ
{КодКафедры} → {Кабинет, Телефон}
{НазваниеКафедры} → {Кабинет, Телефон}
Таким образом, аналогичный вывод можно сделать не только для первичных ключей, но и для альтернативных, то есть для всех потенциальных ключей.
Множество атрибутов отношения, которое содержит в качестве подмножества потенциальный ключ называется суперключом этого отношения.
Рассмотрим еще один пример: если в то же отношение Студенты добавить атрибут СтаростаГруппы, то появятся такие ФЗ:
{КодГруппы} → {СтаростаГруппы}
{СтаростаГруппы} → {КодГруппы}
(причем, ни атрибут КодГруппы, ни атрибут СтаростаГруппы не являются потенциальными ключами)
В этом случае имеется избыточность данных, которая может привести к вводу ошибочных сведений (пользователь случайно может ввести в качестве старосты некоторой группы не того студента, который на самом деле является старостой, но система не выдаст ошибку).
Фактически, если в отношении имеется ФЗ, в которой детерминант не является суперключом, то отношение избыточно.
Существуют такие ФЗ, которые учитываются только формально, т.к. они всегда существуют и подразумеваются самим определением ФЗ. Это тривиальные ФЗ.
Тривиальная функциональная зависимость – это такая ФЗ, зависимая часть которой является подмножеством детерминанта.
Например,
{№ЗачетнойКнижки, Фамилия, Имя, Отчество} → {Фамилия, Имя, Отчество}
{КодГруппы, Курс} → {Курс}
Такие тривиальные ФЗ не рассматриваются при нормализации, но все же они существуют и всегда формально учитываются.
3.1.2. Правила вывода функциональных зависимостей
Из некоторого множества ФЗ конкретного отношения можно получить производные ФЗ.
Например, из ФЗ отношения Студенты
{№ЗачетнойКнижки, Фамилия, Имя, Отчество} → {Адрес, Телефон}
можно получить такие ФЗ:
{№ ЗачетнойКнижки, Фамилия, Имя, Отчество} → {Адрес}
{№ ЗачетнойКнижки, Фамилия, Имя, Отчество} → {Телефон}
Пусть S – некое множество ФЗ. Тогда множество всех ФЗ, которые можно получить из S называется замыканием множества S и обозначается S+.
Чтобы получить замыкание некоторого множества ФЗ нужны правила вывода ФЗ. Такие правила вывода сформулировал Армстронг (Швеция), поэтому их называют правилами Армстронга (или аксиомами Армстронга).
Обозначим за А, В, С произвольные подмножества множества атрибутов заданного отношения R, а записью АВ будем обозначать объединение А и В.
Правила вывода ФЗ Армстронга:
1) Рефлексивность: если В является подмножеством А, то А → В
2) Дополнение: если А → В, то АС → ВС
3) Транзитивность: если А → В и В → С, то А → С
Каждое из этих правил может быть доказано на основе определения ФЗ, а первое правило – это определение тривиальной ФЗ.
Эти правила полны, т.к. их достаточно для вывода замыкания (т.е. всех ФЗ) начального множества ФЗ.
Они также исчерпывающи, т.к. никакие дополнительные ФЗ не могут быть выведены из начального множества ФЗ.
Но из этих правил для упрощения практического вывода ФЗ можно вывести несколько дополнительных правил (следствий):
4) Самоопределение: А → А
5) Декомпозиция: если А → ВС, то А → В и А → С
6) Объединение: если А → В и А → С, то А → ВС
7) Композиция: если А → В и С → D, то АС → ВD
Теорема всеобщего объединения: если А → В и С → D, то А(С-В) → ВD
(названо это правило так, потому что многие другие правила могут быть выведены как частные случаи этой теоремы)
Пример: рассмотрим отношение Группы (КодГруппы, Специальность, Курс,Староста).
В качестве начального множества ФЗ возьмем множество из следующих двух ФЗ:
(1) {КодГруппы} → {Специальность, Курс}
(2) {КодГруппы} → {Староста}
Выведем замыкание этого множества ФЗ.
·По правилу 1 можно записать все тривиальные зависимости:
(3) {Специальность, Курс} → {Специальность}
(4) {Специальность, Курс} → {Курс}
·По правилу 2:
(5) {КодГруппы, Староста} → {Специальность, Курс, Староста}
(6) {КодГруппы, Специальность} → {Староста, Специальность}
(7) {КодГруппы, Курс} → {Староста, Курс}
(8) {КодГруппы, Специальность, Курс} → {Староста, Специальность, Курс}
·По правилу 3 напрямую ничего не выведем.
·По правилу 4:
(9) {КодГруппы} → {КодГруппы}
(10) {Специальность} → {Специальность}
и т.д. (11), (12)
·По правилу 5:
(13) {КодГруппы} → {Специальность}
(14) {КодГруппы} → {Курс}
·По правилу 6:
(15) {КодГруппы} → {Специальность, Курс, Староста}
·По правилу 7 напрямую ничего не выведем
·По правилу 8 тоже.
Однако, знание этих правил и умение ими пользоваться не обеспечивают вывода замыкания множества ФЗ, т.к. не существует четкого алгоритма такого вывода.
3.1.3. Неприводимые функциональные зависимости
Функциональная зависимость называется неприводимой слева, если ни один атрибут не может быть опущен из ее детерминанта без нарушения зависимости (иными словами, детерминант неизбыточен).
Например: ФЗ {№ЗачетнойКнижки, Фамилия, Имя, Отчество} → {Адрес} приводима, т.к. из детерминанта можно исключить атрибуты Фамилия, Имя, Отчество без нарушения ФЗ.
А ФЗ {КодГруппы, Дисциплина} → {Преподаватель} отношения Занятия (КодГруппы, Дисциплина, Преподаватель) неприводима, т.к. из детерминанта нельзя исключить ни атрибут КодГруппы, ни атрибут Дисциплина без нарушения зависимости.
Множество ФЗ называется неприводимым тогда и только тогда, когда выполняются три свойства:
1) зависимая часть каждой ФЗ из данного множества содержит только один атрибут;
2) каждая ФЗ из данного множества является неприводимой слева;
3) ни одна ФЗ из данного множества не может быть опущена.
Например, рассмотрим множество ФЗ отношения Группы из примера в предыдущем п.3.1.2.
(1) {КодГруппы} → {Специальность, Курс}
(2) {КодГруппы} → {Староста}
(3) {Специальность, Курс} → {Специальность}
(4) {Специальность, Курс} → {Курс}
(5) {КодГруппы, Староста} → {Специальность, Курс, Староста}
(6) {КодГруппы, Специальность} → {Староста, Специальность}
(7) {КодГруппы, Курс} → {Староста, Курс}
(8) {КодГруппы, Специальность, Курс} → {Староста, Специальность, Курс}
(9) {КодГруппы} → {КодГруппы}
(10) {Специальность} → {Специальность}
(11) {Курс} → {Курс}
(12) {Староста} → {Староста}
(13) {КодГруппы} → {Специальность}
(14) {КодГруппы} → {Курс}
(15) {КодГруппы} → {Специальность, Курс, Староста}
По первому свойству исключаем из этого множества следующие ФЗ: (1), (5), (6), (7), (8), (15).
По второму свойству исключаем следующие ФЗ: (3), (4).
По третьему свойству исключаем: (9), (10), (11), (12).
Остались:
(2) {КодГруппы} → {Староста}
(13) {КодГруппы} → {Специальность}
(14) {КодГруппы} → {Курс}
Полученное множество ФЗ неприводимо. Можно сделать вывод, что полученное множество ФЗ выражает то, что отношение Группы содержит атрибуты КодГруппы, Староста, Специальность, Курс, и КодГруппы – первичный ключ.
3.1.4. Диаграммы (схемы) функциональных зависимостей
Множество неприводимых ФЗ некоторого отношения можно представить в виде диаграммы функциональных зависимостей.
Из таких диаграмм лучше видно, какие ФЗ включить в множество ФЗ, а какие исключить, чтобы оно было неприводимо. Исключить нужно те стрелки (обозначающие ФЗ), которые идут не от потенциального ключа.
 |
Таким образом, с помощью диаграмм можно привести множество ФЗ к неприводимому состоянию.
В качестве примера рассмотрим диаграмму первоначального множества ФЗ из п. 3.1.2.
 |
После того, как лишние стрелки будут убраны, получим диаграмму:
Из нее как раз и следуют перечисленные ранее три оставшиеся ФЗ:
{КодГруппы} → {Курс}
{КодГруппы} → {Специальность}
{КодГруппы} → {Староста}
Таким образом, существует как минимум два способа преобразования множества ФЗ к неприводимому состоянию — путем проверки всех свойств их определения и путем анализа диаграмм ФЗ.
3.2. Нормализация отношений
Вся теория нормализации отношений является не более и не менее как формализацией соображений здравого смысла. Потребность такой формализации в том, чтобы сформулировать общие правила для разработчиков БД, а главное – если такая задача будет полностью выполнена — эти правила могут быть автоматизированы для реализации на ЭВМ.
3.2.1. Обзор нормальных форм
Процесс нормализации отношений основан на концепции нормальных форм (НФ).
 |
Говорят, что отношение находится в некоторой НФ, если оно удовлетворяет заданному набору условий.
Известно несколько НФ (рис. 4).
Из рис. 4 видно, что все условия, необходимые для некоторой НФ, должны выполняться и для всех последующих НФ.
Первые три НФ были определены Коддом, следующая – нормальная форма Бойса-Кодда (НФБК) – Бойсом и Коддом, 4 и 5 НФ были определены Фейгином.
Возникает вопрос, можно ли продолжить нормализацию дальше, получить 6, 7 и т.д. НФ? Действительно, существуют дополнительные НФ, но 5 НФ считается в некотором смысле окончательной. А для практического проектирования достаточной считают 3 НФ.
3.2.2. Декомпозиция без потерь
Нормализация использует операцию декомпозиции. Дело в том, что процедура нормализации предусматривает разбиение отношения на другие, т.е. его декомпозицию. Причем эта декомпозиция должна произойти без потерь информации из первоначального отношения. Можно сказать, что декомпозиция должна быть обратимой.
Например, рассмотрим отношение Студенты (№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы, Адрес, Телефон).
Выполним декомпозицию на два отношения:
Студенты1 (№ЗачетнойКнижки, Фамилия, Имя, Отчество) и
Студенты2 (КодГруппы, Адрес, Телефон)
При такой декомпозиции информация утрачивается – для каждой группы будет выведены адрес и телефон только первого по списку студента этой группы. При соединении полученных отношений невозможно восстановить полностью первоначальное отношение.
Выполним декомпозицию по-другому:
Студенты3 (№ЗачетнойКнижки, Фамилия, Имя, Отчество) и
Студенты4 (№ЗачетнойКнижки, Адрес, Телефон)
Вот это – декомпозиция без потерь. Можно соединить полученные два отношения, получив первоначальное.
По своей сути декомпозиция – это операция проекции реляционной алгебры, поэтому каждое полученное при декомпозиции отношение называют проекциями первоначального.
Возникает вопрос: какие условия должны соблюдаться для того, чтобы проекции первоначального отношения при обратном соединении гарантировали получение исходного отношения? На этот вопрос дает ответ теорема Хеза:
Пусть R (А, В, С) – отношение, где А, В, С – подмножества множества его атрибутов.
Если R удовлетворяет ФЗ А → В, то R равно соединению его проекций {А, В} и {А, С}.
(Заметим, что теорема не утверждает «тогда и только тогда»).
3.2.3. Первая, вторая и третья нормальные формы
Отношение находится в 1 НФ тогда и только тогда, когда все используемые в нем домены содержат только скалярные значения.
Иными словами:
Отношение находится в 1 НФ тогда и только тогда, когда значения всех полей неделимы.
Например, если в отношении есть поле ФИО, отношение не находится в 1 НФ, т.к. значения этого поля можно разделить на фамилию, имя и отчество.
Отношение находится во 2 НФ тогда и только тогда, когда оно находится в 1 НФ и каждый неключевой атрибут неприводимо зависит от первичного ключа.
Например, рассмотрим отношение Успеваемость (№ЗачетнойКнижки, Фамилия, Имя, Отчество, Дисциплина, Оценка).
Если первичным ключом здесь назначить №ЗачетнойКнижки, то от этого ключа не будет зависеть атрибут Дисциплина. Т.е. в этом случае отношение не находится во 2 НФ.
Можно тогда в качестве первичного ключа взять множество атрибутов {№ЗачетнойКнижки, Дисциплина}. В этом случае от такого ключа зависят все атрибуты, но атрибуты Фамилия, Имя, Отчество зависят приводимо, т.к. из детерминанта следующей ФЗ можно убрать атрибут Дисциплина без нарушения зависимости:
![]() {№ЗачетнойКнижки, Дисциплина} → {Фамилия, Имя, Отчество}
{№ЗачетнойКнижки, Дисциплина} → {Фамилия, Имя, Отчество}
И при таком первичном ключе отношение не находится во 2 НФ.
Чтобы получить отношения во 2 НФ произведем декомпозицию. Можно это сделать по теореме Хеза.
Отношение Успеваемость удовлетворяет ФЗ:
{№ЗачетнойКнижки} → {Фамилия, Имя, Отчество} (А → В)
Вне этой ФЗ осталось следующее множество атрибутов: {Дисциплина, Оценка} (С)
Тогда по теореме Хеза отношение Успеваемость равно соединению его проекций с такими множествами атрибутов:
{№ЗачетнойКнижки, Фамилия, Имя, Отчество} ({А, В})
{№ЗачетнойКнижки, Дисциплина, Оценка} ({А, С})
То есть, декомпозиция без потерь возможна на отношения:
Студенты (№ЗачетнойКнижки, Фамилия, Имя, Отчество)
Успеваемость1 (№ЗачетнойКнижки, Дисциплина, Оценка).
Отношение находится в 3 НФ тогда и только тогда, когда оно находится во 2 НФ и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Иными словами:
Отношение находится в 3 НФ тогда и только тогда, когда каждый кортеж отношения состоит из значения первичного ключа, которое идентифицирует некоторый объект, и набора взаимно независимых (или пустых) значений атрибутов, описывающих этот объект.
Например, добавим в отношение Студенты атрибут СтаростаГруппы. Тогда в отношении будут следующие ФЗ:
{№ЗачетнойКнижки} → {КодГруппы}, {КодГруппы} → {СтаростаГруппы}
То есть атрибут СтаростаГруппы зависит от первичного ключа (№ЗачетнойКнижки) транзитивно через атрибут КодГруппы, а не напрямую.
Значит, это отношение не находится в 3 НФ.
Проведем декомпозицию. В данном случае по теорема Хеза может быть два варианта декомпозиции.
1 вариант основан на ФЗ {№ЗачетнойКнижки}→{Фамилия, Имя, Отчество, КодГруппы}.
В результате получим такие проекции:
{№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы} и
{№ЗачетнойКнижки, СтаростаГруппы}
2 вариант основан на ФЗ {КодГруппы}→{СтаростаГруппы}.
В результате получим такие проекции:
{КодГруппы, СтаростаГруппы}
{КодГруппы, №ЗачентойКнижки, Фамилия, Имя, Отчество}
Подходит второй вариант, т.к. при первом варианте возможны ошибки при обновлении данных (пользователь может ввести для конкретного студента старосту неверно, и система не выдаст ошибки). Такая ситуация говорит о том, что теорема Хеза не всегда является удачным и единственным способом для выбора проекций при декомпозиции.
В результате при декомпозиции на две проекции
Группы (КодГруппы, СтаростаГруппы) и
Студенты1 (№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы)
получим отношения в 3 НФ.
Таким образом, если отношение не находится ни во 2 НФ, ни в 3 НФ, существует избыточность, которая приводит к так называемым аномалиям обновления, т.е. нарушении целостности при вставке, удалении или изменении данных.
Например, рассмотрим отношение, которое не находится ни во 2 НФ, ни в 3 НФ.
Успеваемость (№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы, СтаростаГруппы, Дисциплина, Оценка).
Изобразим диаграмму ФЗ этого отношения:

Какие могут произойти аномалии при обновлении данных в таком отношении?
Например, такие:
- При добавлении нового студента при правильном указании группы, в которой он учится, может быть ошибочно указан староста группы.
- При удалении одной из записей будет удалена не только информация об оценке соответствующего студента, но и информация о том, в какой группе он учится.
- При изменении старосты группы необходимо вручную изменить его для всех записей студентов этой группы – при этом можно ошибиться.
Для этого отношения можно произвести декомпозицию. Это удобно сделать, руководствуясь схемой. Например, на три следующие проекции:
Все полученные отношения находятся во2 НФ и в 3 НФ.
Но без потерь ли произведена эта декомпозиция? Да, т.к. после соединения этих трех отношений получим первоначальное.
Полученные отношения являются независимыми проекциями.
Проекции R1 и R2 отношения R независимы тогда и только тогда, когда выполняются два условия:
1) каждая ФЗ в отношении R является логическим следствием ФЗ в проекциях R1 и R2;
2) общие атрибуты проекций R1 и R2 образуют потенциальный ключ хотя бы для одной из них.
Для наших трех проекций первое условие выполняется, т.к. все их ФЗ (обозначенные стрелками) обеспечивают ФЗ первоначального отношения.
Выполняется и второе условие: для проекций (1) и (2) общий атрибут – КодГруппы, он первичный ключ для (2); для (1) и (3) общий атрибут — №ЗачетнойКнижки, он первичный ключ для (1).
А вот если разбить отношение Успеваемость на следующие проекции:
(4)
первое условие выполнится, а второе — не выполнится (атрибут КодГруппы общий для (4) и (5), но не является потенциальным ключом ни в одном из них). То есть, эти проекции не являются независимыми.
Отношение, которое не может быть подвергнуто декомпозиции с получением независимых проекций, называется атомарным.
Но это не означает, что любое неатомарное отношение может быть разбито на атомарные отношения. И не всегда есть смысл такого разбиения.
Например, отношение Студенты (№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы) атомарно. А отношение Студенты1 (№ЗачетнойКнижки, Фамилия, Имя, Отчество, КодГруппы, Адрес, ДомашнийТелефон) неатомарно, т.к. домашний телефон зависит от адреса, поэтому отношение Студенты1 можно разбить на такие независимые проекции: Студенты2 (№ЗачетнойКнижки, Фамилия, Имя, Отчество, Адрес) и АдресаТелефоны (Адрес, ДомашнийТелефон). Но в этом нет смысла.
3.2.4. Нормальная форма Бойса-Кодда
При определении 3 НФ делалось допущение о том, что отношение имеет только один потенциальный ключ, который и является первичным. Но определение 3 НФ не совсем подходит для отношений со следующими свойствами:
- отношение имеет два или более потенциальных ключа;
- потенциальные ключи сложные;
- потенциальные ключи перекрываются, т.е имеют хотя бы один общий атрибут.
Для отношений, обладающих этими свойствами данного ранее определения 3 НФ недостаточно, поэтому Бойс и Кодд ввели определение НФ Бойса-Кодда.
Отношение находится в НФБК тогда и только тогда, когда каждая нетривиальная и неприводимая слева ФЗ обладает потенциальным ключом в качестве детерминанта.
На практике отношения с комбинацией перечисленных свойств встречаются крайне редко, а для отношений без этих свойств 3 НФ и НФБК эквивалентны.
Можно заметить, что определение НФБК проще, чем 3 НФ, т.к. в нем нет упоминания 2 НФ и не используется понятие транзитивной зависимости.
Например, рассмотрим отношение с двумя перекрывающимися потенциальными ключами.
Успеваемость (№ЗачетнойКнижки, КодДисциплины, НазваниеДисциплины, Оценка)
Потенциальные ключи: {№ЗачетнойКнижки, КодДисциплины} и {№ЗачетнойКнижки, НазваниеДисциплины}.
Это отношение не в НФБК, т.к. в нем есть такие ФЗ:
КодДисциплины → НазваниеДисциплины
НазваниеДисциплины → КодДисциплины
А детерминанты этих ФЗ не являются потенциальными ключами.
Это отношение также не в 3 НФ, т.к. не находится во 2 НФ, потому что атрибут НазваниеДисциплины зависит только от части первичного ключа (ФЗ {№ЗачетнойКнижки, КодДисциплины} → {НазваниеДисциплины} приводима).
Видно, что этому отношению присуща избыточность.
Возможна декомпозиция на два отношения:
Дисциплина (КодДисциплины, НазваниеДисциплины)
Успеваемость1 (№ЗачетнойКнижки, КодДисциплины, Оценка)
Рассмотрим пример отношения, которое находится в 3 НФ, но не находится в НФБК. Пусть в БД Факультет есть отношение Занятия (КодГруппы, Дисциплина, Преподаватель):
|
КодГруппы |
Дисциплина |
Преподаватель |
|
ИНФ-21 |
ПО ЭВМ |
Пятышева Е.А. |
|
ИНФ-22 |
ПО ЭВМ |
Суворова Т.Н. |
|
ИНФ-31 |
СУБД |
Шиляева М.С. |
|
ИНФ-32 |
СУБД |
Петухова М.В. |
|
… |
Введем следующие ограничения:
a) каждую дисциплину у конкретной группы ведет только один преподаватель, но одну и ту же дисциплину могут вести разные преподаватели;
b) каждый преподаватель ведет только одну дисциплину (в действительности это не всегда так, но мы предположим именно это).
Тогда существует два потенциальных ключа: {КодГруппы, Дисциплина} и {КодГруппы, Преподаватель}. Опять ситуация с двумя перекрывающимися потенциальными ключами. Первый из них назначим первичным.
Это отношение в 3 НФ, т.к.
- Оно находится во 2 НФ. Докажем это: единственная ФЗ неключевого атрибута {КодГруппы, Дисциплина} → Преподаватель. Она неприводима, т.к. атрибут КодГруппы из детерминанты исключить нельзя (одну и ту же дисциплину могут вести разные преподаватели, т.е. не верна ФЗ Дисциплина → Преподаватель); атрибут Дисциплина тоже исключить нельзя (группа изучает несколько дисциплин у разных преподавателей, т.е. не верна ФЗ КодГруппы → Преподаватель).
- Отношение находится и в 3 НФ. Докажем это: в единственной ФЗ для неключекого атрибута (см. 1) этот неключевой атрибут нетранзитивно зависит от первичного ключа.
Но это отношение не в НФБК, т.к. есть ФЗ Преподаватели → Дисциплины (по условию каждый преподаватель может вести только одну дисциплину), и детерминант этой ФЗ не является потенциальным ключом.
Поэтому в отношении Занятия могут произойти аномалии обновления. Например, если требуется удалить информацию о группе ИНФ-31, то при этом утратится информация о том, что дисциплину СУБД ведет преподаватель Шиляева М.С.
Необходима декомпозиция на проекции, которые будут в НФБК:
ГП (Группа, Преподаватель) и ПД (Преподаватель, Дисциплина)
Но эти проекции не являются независимыми, т.к. при попытке вставить новую запись в одну из них может возникнуть противоречие. Например, вставляем в отношение ГП кортеж {ИНФ-31, Васенина Е.А.}, но если, допустим, Васенина Е.А. преподает дисциплину ИТО, и в этом отношении есть уже кортеж {ИНФ-31, Огородников Е.В.} и преподаватель Огородников Е.В. тоже преподает дисциплину ИТО. Возникнет противоречие (два преподавателя ведут одну дисциплину у одной группы). А проверить это можно только в отношении ПД.
Вывод: не всегда можно достичь две цели сразу – разбить на отношения в НФБК и чтобы эти отношения были независимы.
Действительно, отношение Занятия является атомарным, но атомарность не является ни необходимым, ни достаточным условие хорошего макета БД. А если стремиться к НФБК, то это в некоторых случаях усложняет БД.
Все это показывает, что на практике целей лучше избегать отношений с перекрывающимися потенциальными ключами, тогда достаточно 3 НФ.
Но если без них сложно обойтись, то вводят особые правила обновления, в каждом конкретном случае – свои.
3.3. Нормальные формы более высокого порядка
3.3.1. Многозначные зависимости
Для введения 4 НФ необходимо ввести понятие многозначной зависимости (МЗ).
Пусть А, В, С – произвольные подмножества множества атрибутов отношения R.
Тогда В многозначно зависит от А тогда и только тогда, когда множество значений В, соответствующее заданной паре значений (значение А, значение С) отношения R, зависит только от А, но не зависит от С.
Обозначается: А 8 В
Говорится: «А многозначно определяет В» или «В многозначно зависит от А» или «А двойная стрелка В».
Упрощенно можно сказать так: А многозначно определяет В, если для каждого значения А не существует единственного соответствующего ей значения В (не верна ФЗ А ® В), но каждое значение А определяет множество соответствующих ей значений В.
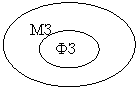 По сути ФЗ – это частный случай МЗ:
По сути ФЗ – это частный случай МЗ:
Пример, который пояснит суть МЗ:
Пусть имеется отношение ДПК (Дисциплина, Преподаватель, Кабинет).
|
Дисциплина |
Преподаватель |
Кабинет |
|
ИС |
Огородников Е.В. |
140 |
|
ИС |
Огородников Е.В. |
218 |
|
ИС |
Шиляева М.С. |
140 |
|
ИС |
Шиляева М.С. |
218 |
|
СУБД |
Шиляева М.С. |
315 |
|
СУБД |
Шиляева М.С. |
411 |
|
СУБД |
Петухова М.В. |
315 |
|
СУБД |
Петухова М.В. |
411 |
|
… |
Введем следующие ограничения:
a) каждой дисциплине может соответствовать любое количество преподавателей и любое количество кабинетов;
b) преподаватели и кабинеты не зависят друг от друга (т.е. независимо от того, кто преподает данную дисциплину, для этой дисциплины используется один и тот же набор кабинетов);
c) конкретный преподаватель и конкретный кабинет могут быть связаны с любым количеством дисциплин.
В этом случае первичный ключ – множество всех атрибутов.
Проверим, в каких НФ находится это отношение.
1) 1 НФ – т.к. атрибуты неделимы (будем считать, что вместо ФИО преподавателя используется некий код преподавателя, но для удобства в примере будем использовать ФИО).
2) 2 НФ – т.к. неключевых атрибутов вообще нет.
3) 3 НФ – по той же причине.
4) НФБК – не подходит для этого отношения, т.к. в нем нет нескольких перекрывающихся потенциальных ключей.
Попутно можно сделать вывод, что полностью ключевое отношение (если оно в 1 НФ) находится в 3 НФ и в НФБК.
По ограничению b) можно утверждать, что если существуют два кортежа
{Дисциплина1, Преподаватель1, Кабинет1} и
{Дисциплина1, Преподаватель2, Кабинет2},
то существуют и кортежи
{Дисциплина1, Преподаватель1, Кабинет2} и
{Дисциплина1, Преподаватель2, Кабинет1}.
Например, если существуют кортежи
{СУБД, Шиляева М.С., 315} и
{СУБД, Петухова М.В., 411},
то существуют и кортежи
{СУБД, Шиляева М.С., 411} и
{СУБД, Петухова М.В., 315}.
В этом случае отношение явно избыточно и может привести к аномалиям обновления. Например, для добавления информации о том, что дисциплина СУБД будет вестись новым преподавателем Ивановым И.И. необходимо создать столько новых кортежей, сколько кабинетов подходят для этой дисциплины. А при этом ошибочно можно ввести кортежи не для всех кабинетов или, наоборот, с лишними кабинетами.
Существование подобных проблем вызвано, как правило, независимостью атрибутов. В нашем примере – атрибутов Преподаватель и Кабинет.
Как исправить ситуацию, чтобы избежать избыточности и аномалий обновления?
Можно заменить отношение ДПК двумя его проекциями:
ДП (Дисциплина, Преподаватель) и ДК (Дисциплина, Кабинет)
Обе проекции полностью ключевые, следовательно, находятся в НФБК.
Кроме того, это декомпозиция без потерь, т.к. при соединении обратно по атрибуту Дисциплина получим первоначальное отношение ДПК.
Можно сказать, что все эти рассуждения были на интуитивном уровне, из соображений здравого смысла – мы не пользовались какими-либо строгими правилами.
Только в 1971 году эти соображения были формализованы Фейгином с помощью понятия многозначных зависимостей.
Формализуем процесс декомпозиции отношения ДПК. Этого нельзя сделать, основываясь на ФЗ, т.к. диаграмма ФЗ выглядит так:
 |
И все ФЗ здесь тривиальны.
Но произведенную декомпозицию можно сделать на основе МЗ, т.к. в отношении их две:
Дисциплина 8 Преподаватель
Дисциплина 8 Кабинет
Первая означает, что хотя для каждой дисциплины не существует единственного соответствующего ей преподавателя (не верна ФЗ Дисциплина ® Преподаватель), но каждая дисциплина определяет множество соответствующих ей преподавателей.
Вторая означает, что хотя для каждой дисциплины не существует единственного соответствующего ей кабинета (не верна ФЗ Дисциплина ® Кабинет), но каждая дисциплина определяет множество соответствующих ей кабинетов.
По этим МЗ и можно произвести декомпозицию.
Можно заметить, что для отношения ДПК многозначная зависимость Дисциплина 8 Преподаватель выполняется тогда и только тогда, когда выполняется МЗ Дисциплина 8 Кабинет.
Для подобных отношений это выполняется всегда, т.е. в обобщенном виде можно сформулировать правило многозначных зависимостей:
Для R (А, В, С) А 8 В тогда и только тогда, когда А 8 С.
Таким образом, МЗ образуют пары и их обычно представляют так: А 8В½С.
Для ДПК можно записать Дисциплины 8 Преподаватели½Кабинеты.
Теорема Фейгина:
Пусть А, В, С – подмножества множества атрибутов отношения R. Отношение R будет равно соединению его проекций {А, В} и {А, С} тогда и только тогда, когда для отношения R выполняется МЗ А 8В½С.
3.3.2. Четвертая нормальная форма
Отношение R находится в 4 НФ тогда и только тогда, когда
если существуют такие подмножества А и В множества атрибутов R, что выполняется нетривиальная МЗ А 8 В,
то все атрибуты отношения R функционально зависят от атрибута А.
Другая формулировка:
Отношение R находится в 4 НФ если оно находится в НФБК и все МЗ отношения R фактически являются ФЗ от потенциальных ключей.
Отношение ДПК из предыдущего примера не находится в 4 НФ, т.к. (по первой формулировке):
1) Существует МЗ Дисциплина 8 Преподаватель, но при этом атрибут Кабинет не зависит функционально от атрибута Дисциплина.
2) Существует МЗ Дисциплина 8 Кабинет, но при этом атрибут Преподаватель не зависит функционально от атрибута Дисциплина.
Но обе проекции ДП и ДК находятся в 4 НФ, т.к. в каждой из них существует по одной МЗ, и других атрибутов (не входящих в эти МЗ) нет.
Фейгин доказал также, что 4 НФ всегда может быть получена, т.е. любое отношение, содержащее МЗ может быть подвергнуто декомпозиции без потерь на набор отношений в 4 НФ.
3.3.3. Зависимость соединения
Не всегда можно произвести декомпозицию без потерь одного отношения на две проекции. Если это невозможно, но возможно разбить отношение на три или более проекций, такое отношение называют n-декомпозируемым, где n – число проекций, на которое можно разбить отношение без потерь.
Например, рассмотрим отношение ЛДС (Литература, Дисциплина, Специальность), полностью ключевое. Это отношение выражает информацию о том, что некая имеющаяся в библиотеке книга подходит для некоторой дисциплины, изучаемой определенной специальностью.
Отношение ЛДС:
|
Литература |
Дисциплина |
Специальность |
|
Хомоненко А. и др. Базы данных |
СУБД |
Информатика с доп. спец. ин. язык |
|
Хомоненко А. и др. Базы данных |
ИС |
Математика с доп. спец. информатика |
|
Хомоненко А. и др. Базы данных |
ИС |
Информатика с доп. спец. ин. язык |
|
Дейт К. Введение в системы баз данных |
СУБД |
Информатика с доп. спец. ин. язык |
|
Дейт К. Введение в системы баз данных |
ИС |
Информатика с доп. спец. ин. язык |
Произведем декомпозицию на три проекции: ЛД, ДС, ЛС.
ЛД ДС ЛС
|
Литература |
Дисциплина |
Дисциплина |
Специальность |
Литература |
Специальность |
||
|
Хомоненко |
СУБД |
СУБД |
Информатика |
Хомоненко |
Информатика |
||
|
Хомоненко |
ИС |
ИС |
Математика |
Хомоненко |
Математика |
||
|
Дейт |
СУБД |
ИС |
Информатика |
Дейт |
Информатика |
||
|
Дейт |
ИС |
Соединим обратно только две проекции, ЛД и ДС по атрибуту Дисциплина, и сравним кортежи полученного отношения с кортежами первоначального отношения ЛДС:
|
Литература |
Дисциплина |
Специальность |
|
|
Хомоненко |
СУБД |
Информатика |
— есть |
|
Хомоненко |
ИС |
Математика |
— есть |
|
Хомоненко |
ИС |
Информатика |
— есть |
|
Дейт |
СУБД |
Информатика |
— есть |
|
Дейт |
ИС |
Математика |
— нет! |
|
Дейт |
ИС |
Информатика |
— есть |
В результате получили лишний кортеж.
Аналогичная ситуация будет и при соединении ЛД и ЛС, а также ДС и ЛС.
А если соединить все три проекции, то получим именно первоначальное отношение ЛДС.
Таким образом, можно сделать вывод, что отношение ЛДС 3-декомпозируемо.
В связи с такими n-декомпозициями вводится понятие зависимости соединения (ЗС), на основе которого затем определяется 5 НФ.
Пусть R – отношение, А, В, …, Z – произвольные подмножества множества атрибутов R.
Отношение R удовлетворяет зависимости соединения *(А, В, …, Z) тогда и только тогда, когда оно равносильно соединению своих проекций с подмножествами атрибутов А, В, …, Z.
Для нашего примера отношение ЛДС удовлетворяет зависимости соединения
*(ЛД, ДС, ЛС) или
*({Литература,Дисциплина},{Дисциплина,Специальность},{Литература,Специальность}).
Как ФЗ является частным случаем МЗ, так и МЗ является частным случаем ЗС.
 |
3.3.4. Пятая нормальная форма
Отношение R находится в 5 НФ, которая также называется проекционно-соединительной НФ, тогда и только тогда, когда каждая ЗС в отношении R подразумевается потенциальными ключами отношения R.
Например, рассмотрим отношение Группы (КодГруппы, НазваниеГруппы, Курс, Староста). Имеется два потенциальных ключа: КодГруппы и НазваниеГруппы. Эти ключи подразумевают (т.е. обеспечивают) такие, например, ЗС:
*({КодГруппы, Староста}, {КодГруппы, НазваниеГруппы, Курс})
*({КодГруппы, НазваниеГруппы}, {КодГруппы, Курс}, {НазваниеГруппы, Староста})
и т.п.
А если убрать альтернативный ключ (НазваниеГруппы), оставив единственный потенциальный ключ (КодГруппы), то еще проще:
*({КодГруппы, Курс}{КодГруппы, Староста})
и всё.
Рассмотренное в предыдущем примере отношение ЛДС не в 5 НФ, т.к. ЗС *(ЛД, ДС, ЛС) не подразумевается единственным в этом отношении потенциальным ключом {Литература, Дисциплина, Специальность}.
Найти все ЗС гораздо сложнее, чем ФЗ и МЗ, — нет точного алгоритма такого поиска. То есть процесс проверки отношения на 5 НФ не определен достаточно четко. Утешает то, что на практике подобные отношения встречаются редко.
Из определения 5 НФ можно сделать вывод, что эта НФ является окончательной по отношению к проекции и соединению (это и отражено в ее втором названии).
Таким образом, гарантируется, что отношение в 5 НФ не содержит избыточности данных, которые могут привести к аномалиям обновления.
3.4. Итоговая схема процедуры нормализации
В общем случае можно выделить следующие четыре цели процедуры нормализации:
- Исключение избыточности.
- Устранение аномалий обновления.
- Проектирование макета данных, который соответствовал бы реальному миру, был интуитивно понятен и служил основой для дальнейшего развития.
- Упрощение процесса наложения ограничений целостности. Эта цель связана с потенциальными ключами, т.е. если соблюдать условие уникальности потенциальных ключей и организовывать связи только через них, то эта цель будет достигнута.
Пусть имеется отношение R, которое находится в 1 НФ. Также известны все ограничения этого отношения, т.е. ключи, ФЗ, МЗ и ЗС.
Тогда основная идея нормализации отношения R состоит в декомпозиции без потерь, принципы которой в следующем:
·последовательно отношение R приводится к набору меньших отношений, который эквивалентен отношению R, но более предпочтителен;
·каждый этап этого процесса состоит из разбиения на проекции отношений, полученных на предыдущем этапе;
·при этом все заданные зависимости (ФЗ, МЗ, ЗС) используются на каждом шаге для выбора проекций следующего этапа.
Перечислим основные правила, на которые опирается процедура нормализации.
- Отношение в 1 НФ следует разбить на проекции для исключения всех приводимых ФЗ. В результате – набор отношений во 2 НФ.
- Отношения во 2 НФ следует разбить на проекции для исключения всех транзитивных ФЗ. В результате – набор отношений в 3 НФ.
- Отношение в 3 НФ следует разбить на проекции для исключения всех оставшихся ФЗ, в которых детерминанты не являются потенциальными ключами. В результате – набор отношений в НФБК.
(Заметим, что все первые три правила можно сконцентрировать в одном: «исходное отношение следует разбить на проекции для исключения всех ФЗ, в которых детерминанты не являются потенциальными ключами») - Отношение в НФБК следует разбить на проекции для исключения всех МЗ, которые не являются ФЗ. В результате – набор отношений в 4 НФ. (На практике такие МЗ обычно исключаются перед первым этапом, т.е. отделяются независимые повторяющиеся группы)
- Отношение в 4 НФ следует разбить на проекции для исключения всех ЗС, которые не подразумеваются потенциальными ключами (если такие ЗС можно выявить). В результате – набор отношений в 5 НФ.
К правилам можно выделить следующие дополнения:
- Процесс разбиения на проекции должен быть выполнен без потерь и с сохранением зависимостей исходных данных.
- При проверке на НФБК, 4 НФ и 5 НФ можно пользоваться их альтернативными определениями, что иногда бывает удобнее, — в зависимость от конкретной ситуации.
- Бывают ситуации, когда удобнее менять последовательность процедуры нормализации.
- Хотя идеи нормализации важны и наиболее приемлемы для проектирования БД, они не являются универсальным средством по следующим причинам:
- кроме ФЗ, МЗ и ЗС существуют и другие типы зависимостей и ограничений – специфические для каждой БД;
- декомпозиция может быть не уникальной, т.е. могут существовать разные ее варианты. А для выбора предпочтительного не так уж много критериев;
- не всякую избыточность данных можно устранить разбиением на проекции.
Но, несмотря на эти замечания, можно сказать, что методика нисходящего проектирования БД, реализованная в нормализации отношений, позволяет создать непротиворечивый, нормализованный макет БД.