Профилирование: измерение и анализ
Время на прочтение
13 мин
Количество просмотров 14K

Привет, я Тони Альбрехт (Tony Albrecht), инженер в Riot. Мне нравится профилировать и оптимизировать. В этой статье я расскажу об основах профилирования, а также проанализирую пример С++-кода в ходе его профилирования на Windows-машине. Мы начнём с самого простого и будем постепенно углубляться в потроха центрального процессора. Когда нам встретятся возможности оптимизировать — мы внедрим изменения, а в следующей статье разберём реальные примеры из кодовой базы игры League of Legends. Поехали!
Обзор кода
Сначала взглянем на код, который собираемся профилировать. Наша программа — это простой маленький OpenGL-рендерер, объектно ориентированное, иерархические дерево сцены (scene tree). Я находчиво назвал основной объект Object’ом — всё в сцене наследуется от одного из этих базовых классов. В нашем коде от Object’а наследуются лишь Node, Cube и Modifier.

Cube — это Object, который рендерит себя на экране в виде куба. Modifier — это Object, который «живёт» в дереве сцены и, будучи Updated, преобразует добавленные нему Object’ы. Node — это Object, который может содержать другие Object’ы.
Система спроектирована так, что вы можете создавать иерархию объектов, добавляя кубики в ноды, а также одни ноды к другим нодам. Если вы преобразуете ноду (посредством модификатора), то будут преобразованы и все содержащиеся в ноде объекты. С помощью этой простой системы я создал дерево из кубов, вращающихся друг вокруг друга.

Согласен, предложенный код — не лучшая реализация дерева сцены, но ничего страшного: этот код нужен именно для последующей оптимизации. По сути, это прямое портирование примера для PlayStation3®, который я написал в 2009-м для анализа производительности в работе Pitfalls of Object Oriented Programming. Можно отчасти сравнить нашу сегодняшнюю статью со статьёй 9-летней давности и посмотреть, применимы ли к современным аппаратным платформам те уроки, что мы извлекли когда-то для PS3.
Но вернёмся к нашим кубикам. На приведённой выше гифке показаны около 55 тысяч вращающихся кубиков. Обратите внимание, что я профилирую не рендеринг сцены, а только анимацию и отбрасывание (culling) при передаче на рендеринг. Библиотеки, задействованные для создания примера: Dear Imgui и Vectormath от Bullet, обе бесплатны. Для профилирования я использовал AMD Code XL и простой контрольно-измерительный (instrumented) профилировщик, на скорую руку сооружённый для этой статьи.
Прежде чем переходить к делу
Единицы измерения
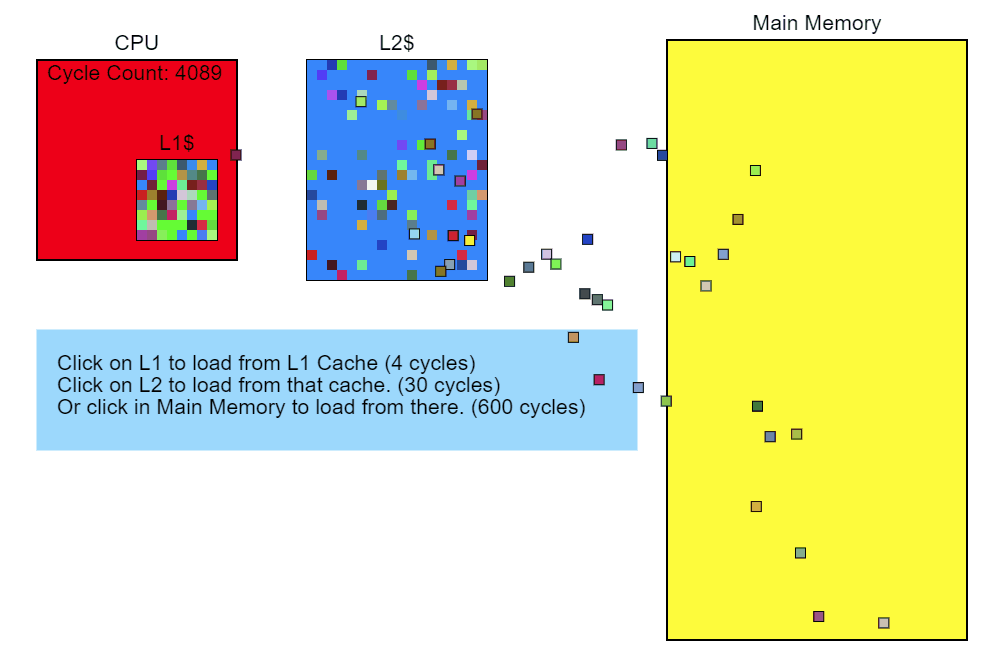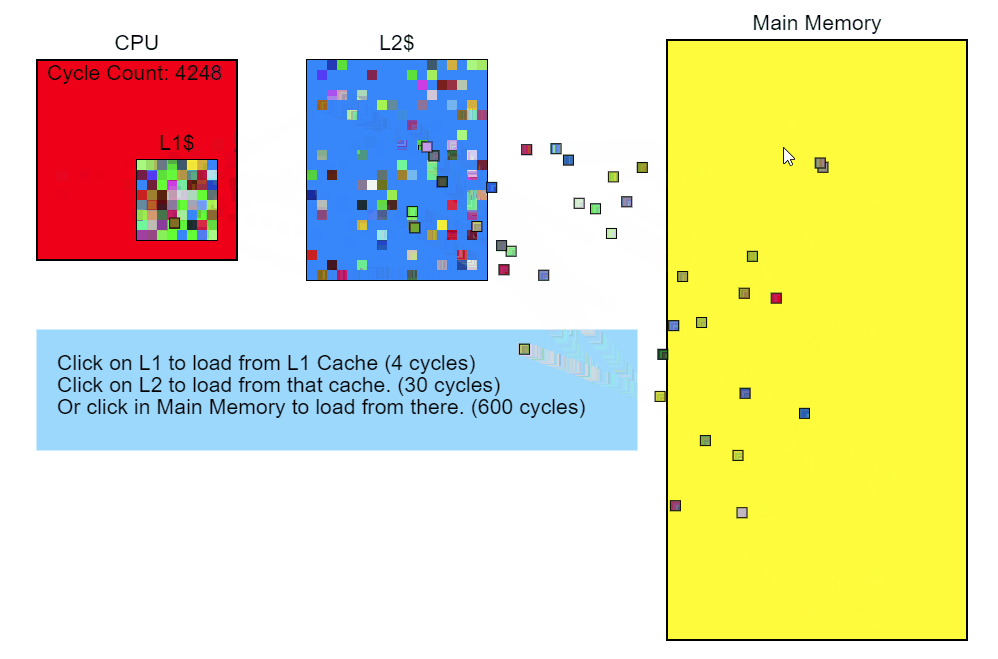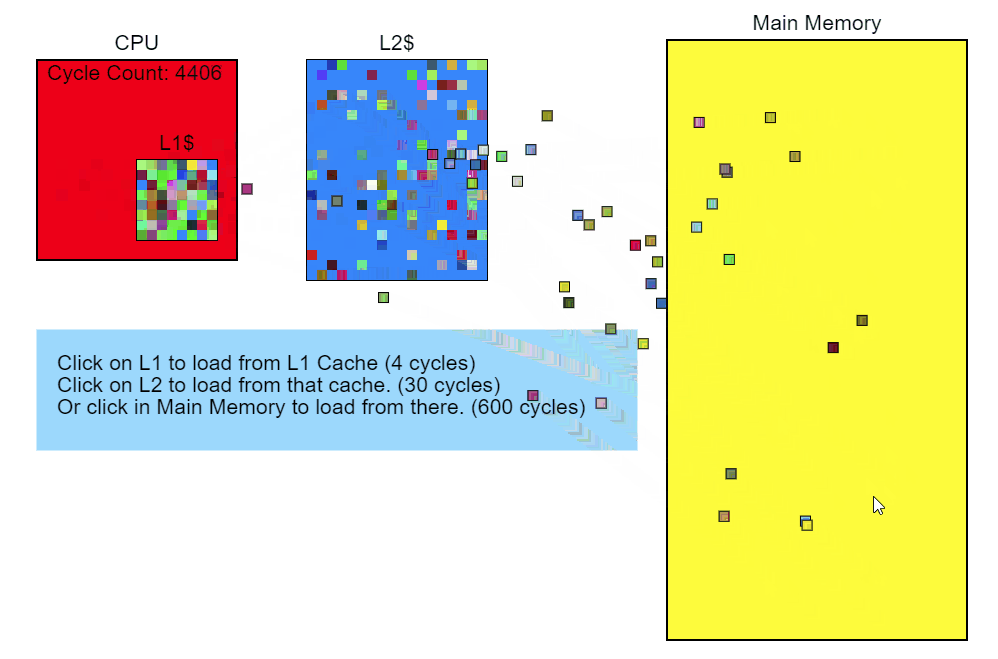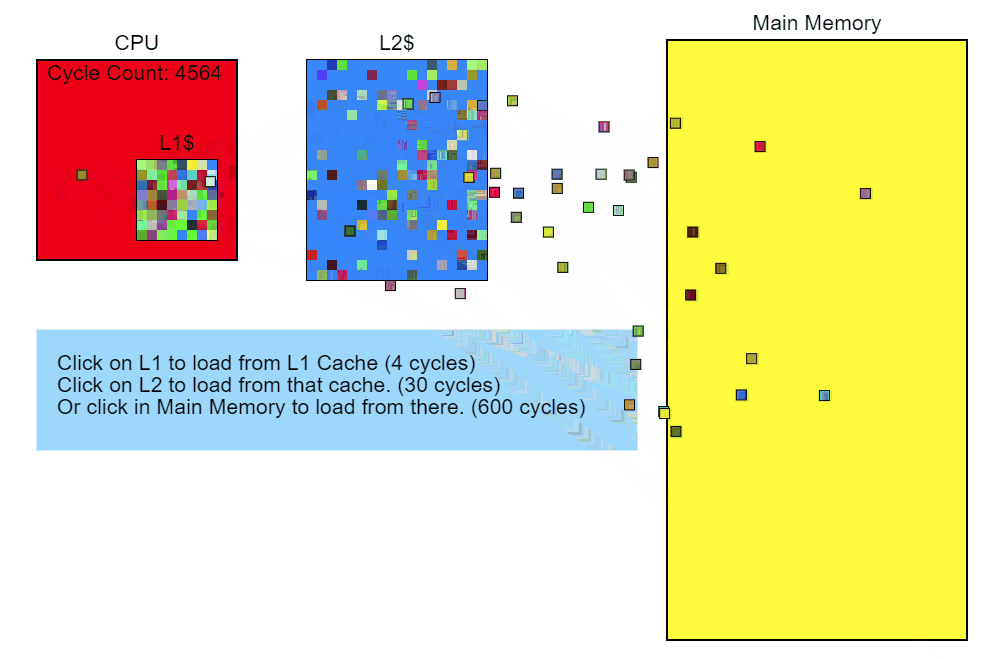
Сначала я хочу обсудить измерение производительности. Зачастую в играх в качестве метрики используются кадры в секунду (FPS). Это неплохой индикатор производительности, однако он бесполезен при анализе частей кадра или сравнении улучшений от разных оптимизаций. Допустим, «игра теперь работает на 20 кадров в секунду быстрее!» — это вообще насколько быстрее?
Зависит от ситуации. Если у нас было 60 FPS (или 1000/60 = 16,666 миллисекунд на кадр), а теперь стало 80 FPS (1000/80 = 12,5 мс на кадр), то наше улучшение равно 16,666 мс – 12,5 мс = 4,166 мс на кадр. Это хороший прирост.
Но если у нас было 20 FPS, а теперь стало 40 FPS, то улучшение уже равно (1000/20 – 1000/40) = 50 мс – 25 мс = 25 мс на кадр! Это мощный прирост производительности, который может превратить игру из «неиграбельной» в «приемлемую». Проблема метрики FPS в том, что она относительна, так что мы будем всегда использовать миллисекунды. Всегда.
Проведение замеров
Существует несколько типов профилировщиков, каждый со своими достоинствами и недостатками.
Контрольно-измерительные профилировщики
Для контрольно-измерительных (instrumented) профилировщиков программист должен вручную пометить фрагмент кода, производительность которого нужно измерить. Эти профилировщики засекают и сохраняют время начала и окончания работы профилируемого фрагмента, ориентируясь на уникальные маркеры. Например:
void Node::Update()
{
FT_PROFILE_FN
for(Object* obj : mObjects)
{
obj->Update();
}
}В данном случае FT_PROFILE_FN создаёт объект, фиксирующий время своего создания, а затем и уничтожения при выпадении из области видимости. Эти моменты времени вместе с именем функции хранятся в каком-нибудь массиве для последующего анализа и визуализации. Если постараться, то можно реализовать визуализацию в коде или — чуть проще — в инструменте вроде Chrome tracing.
Контрольно-измерительное профилирование великолепно подходит для визуального отображения производительности кода и выявления её всплесков. Если характеристики производительности приложения представить в виде иерархии, то можно сразу увидеть, какие функции в целом работают медленнее всего, какие вызывают больше всего других функций, у каких больше всего варьируется длительность исполнения и т. д.
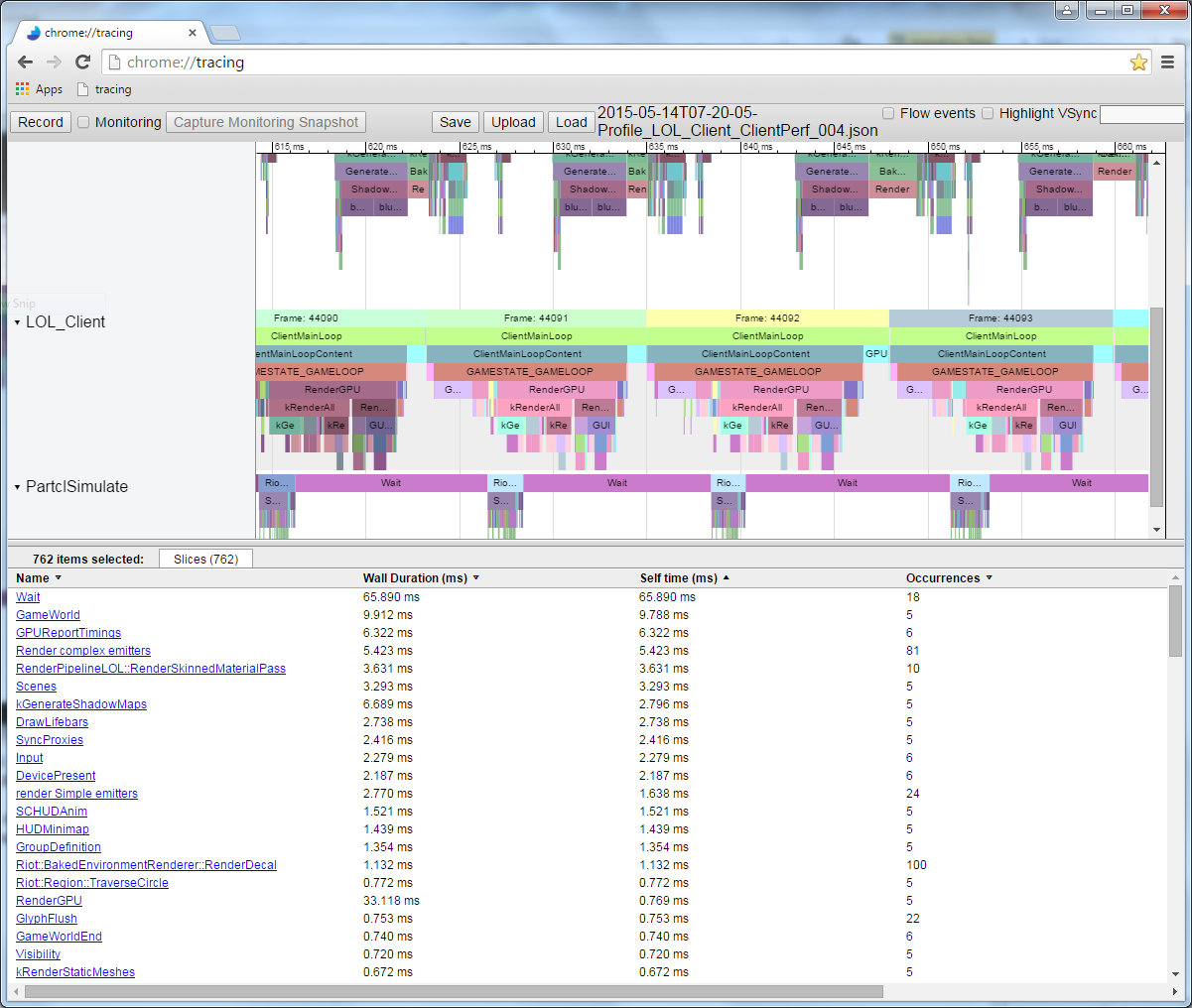
На этой иллюстрации каждая цветная плашка соответствует какой-то функции. Плашки, расположенные непосредственно под другими плашками, обозначают функции, которые вызываются «вышерасположенными» функциями. Длина плашки пропорциональна длительности исполнения функции.
Хотя контрольно-измерительное профилирование даёт ценную визуальную информацию, у него всё же есть недостатки. Оно замедляет исполнение программы: чем больше вы измеряете, тем медленнее становится программа. Поэтому при написании контрольно-измерительного профилировщика постарайтесь минимизировать его влияние на производительность приложения. Если пропустите медленную функцию, то появится большой разрыв в профиле. Также вы не получите информацию о скорости работы каждой строки кода: достаточно легко можно помечать лишь области видимости, но накладные расходы контрольно-измерительного профилирования обычно сводят на нет вклад отдельных строк, так что измерять их просто бесполезно.
Семплирующие профилировщики
Семплирующие (sampling) профилировщики запрашивают состояние исполнения того процесса, который вы хотите профилировать. Они периодически сохраняют счётчик программы (Program Counter, PC), показывающий, какая инструкция сейчас исполняется, а также сохраняют стек, благодаря чему можно узнать, какие функции вызвала та функция, что содержит текущую инструкцию. Вся эта информация полезна, поскольку функция или строки с наибольшим количеством семплов окажутся самой медленной функцией или строками. Чем дольше работает семплирующий профилировщик, тем больше собирается семплов инструкций и стеков, что улучшает результаты.

Семплирующие профилировщики позволяют собирать очень низкоуровневые характеристики производительности программы и не требуют ручного вмешательства, как в случае с контрольно-измерительными профилировщиками. Кроме того, они автоматически покрывают всё состояние исполнения вашей программы. У этих профилировщиков есть два основных недостатка: они не слишком полезны для определения всплесков по каждому кадру, а также не позволяют узнать, когда была вызвана определённая функция относительно других функций. То есть мы получаем меньше информации об иерархических вызовах по сравнению с хорошим контрольно-измерительным профилировщиком.
Специализированные профилировщики
Эти профилировщики предоставляют специфическую информацию о процессах. Обычно они связаны с аппаратными элементами вроде центрального процессора или видеокарты, которые способны генерировать конкретные события, если происходит что-то вас интересующее, к примеру промах кеша или ошибочное предсказание ветвления. Производители оборудования встраивают возможность измерения этих событий, чтобы нам легче было выяснять причины низкой производительности; следовательно, для понимания этих профилей нужны знания об используемой аппаратной части.
Профилировщики, предназначенные для конкретных игр
На гораздо более общем уровне профилировщики, предназначенные для конкретных игр, могут подсчитывать, скажем, количество миньонов на экране или количество видимых частиц в поле зрения персонажа. Такие профилировщики тоже очень полезны, они помогут выявить высокоуровневые ошибки в игровой логике.
Профилирование
Профилирование приложения без сравнительного эталона не имеет смысла, поэтому при оптимизации необходимо иметь под рукой надёжный тестовый сценарий. Это не так просто, как кажется. Современные компьютеры выполняют не одно лишь ваше приложение, а одновременно десятки, если не сотни других процессов, постоянно переключаясь между ними. То есть другие процессы могут замедлить профилируемый вами процесс в результате конкуренции за обращение к устройствам (например, несколько процессов пытаются считать с диска) или за ресурсы процессора/видеокарты. Так что для получения хорошей отправной точки вам нужно прогнать код через несколько операций профилирования, прежде чем вы хотя бы приступите к задаче. Если результаты прогонов будут сильно различаться, то придётся разобраться в причинах и избавиться от вариативности или хотя бы снизить её.
Добившись наименьшего возможного разброса результатов, не забывайте, что небольшие улучшения (меньше имеющейся вариативности) будет трудно измерить, потому что они могут затеряться в «шуме» системы. Допустим, конкретная сцена в игре отображается в диапазоне 14—18 мс на кадр, в среднем это 16 мс. Вы потратили две недели на оптимизацию какой-нибудь функции, перепрофилировали и получили 15,5 мс на кадр. Стало ли быстрее? Чтобы выяснить точно, вам придётся прогнать игру много раз, профилируя эту сцену и вычисляя среднеарифметическое значение и строя график тренда. В описанном здесь приложении мы измеряем сотни кадров и усредняем результаты, чтобы получить достаточно надёжное значение.
Кроме того, многие игры выполняются в несколько потоков, порядок которых определяется вашим оборудованием и ОС, что может привести к недетерминированному поведению или как минимум к разной длительности исполнения. Не забывайте о влиянии этих факторов.
В связи со сказанным я собрал небольшой тестовый сценарий для профилирования и оптимизации. Он прост для понимания, но достаточно сложен, чтобы иметь ресурс значительного улучшения производительности. Обратите внимание, что ради упрощения я при профилировании отключил рендеринг, так что мы видим только те вычислительные расходы, что связаны с центральным процессором.
Профилируем код
Ниже приведён код, который мы будем оптимизировать. Помните, что один пример лишь научит нас профилированию. Вы обязательно столкнётесь с неожиданными трудностями при профилировании собственного кода, и я надеюсь, что эта статья поможет вам создать собственный диагностический фреймворк.
{
FT_PROFILE("Update");
mRootNode->Update();
}
{
FT_PROFILE("GetWBS");
BoundingSphere totalVolume = mRootNode->GetWorldBoundingSphere(Matrix4::identity());
}
{
FT_PROFILE("cull");
uint8_t clipFlags = 63;
mRootNode->Cull(clipFlags);
}
{
FT_PROFILE("Node Render");
mRootNode->Render(mvp);
}Я добавил в разные области видимости контрольный макрос FT_PROFILE(), чтобы измерять длительность исполнения разных частей кода. Ниже мы подробнее поговорим о назначении каждого фрагмента.
Когда я выполнил код и записал данные из измеренного профиля, то получил в Chrome://tracing такую картину:

Это профиль одного кадра. Здесь мы видим относительную длительность работы каждого вызова функции. Обратите внимание, что можно посмотреть и порядок выполнения. Если бы я измерил функции, которые вызываются этими вызовами функций, то они отобразились бы под плашками родительских функций. К примеру, я измерил Node::Update() и получил такую рекурсивную структуру вызовов:

Длительность исполнения одного кадра этого кода при измерении различается на пару миллисекунд, так что мы берём среднеарифметическое как минимум по нескольким сотням кадров и сравниваем с исходным эталоном. В данном случае измерено 297 кадров, среднее значение — 17,5 мс, одни кадры выполнялись до 19 мс, а другие — чуть меньше 16,5 мс, хотя в каждом из них выполняется практически одно и то же. Такова неявная вариативность кадров. Многократный прогон и сравнение результатов устойчиво дают нам около 17,5 мс, так что это значение можно считать надёжной исходной точкой.

Если отключить в коде контрольные метки и прогнать его через семплирующий профилировщик AMD CodeXL, то получим такую картину:

Если мы проанализируем пять самых «востребованных» функций, то получим:

Похоже, самая медленная функция — матричное умножение. Звучит логично, поскольку для всех этих вращений функции приходится выполнять кучу вычислений. Если внимательно присмотреться к иерархии стека парой иллюстраций выше, то можно заметить, что оператор матричного умножения вызывается посредством Modifier::Update(), Node::Update(), GetWorldBoundingSphere() и Node::Render(). Он вызывается так часто и из такого количества мест — так что этот оператор можно считать хорошим кандидатом на оптимизацию.
Matrix::operator*
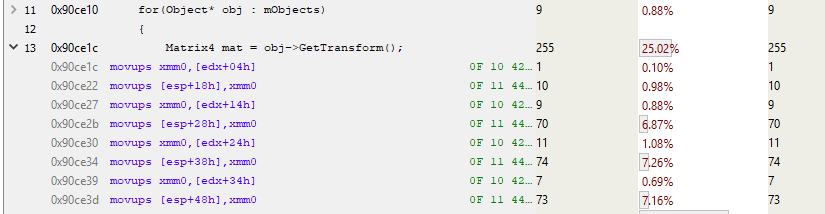
Если с помощью семплирующего профилировщика проанализировать код, отвечающий за умножение, то можно выяснить «стоимость» выполнения каждой строки.

К сожалению, длина кода матричного умножения — всего одна строка (ради эффективности), так что нам этот результат мало что даёт. Или всё-таки не так уж мало?
Если взглянуть на ассемблер, можно выявить пролог и эпилог функции.

Это стоимость внутренней инструкции вызова функции. В прологе задаётся новое пространство стека (ESP — текущий указатель стека, EBP — базовый указатель для текущего фрейма стека), а в эпилоге выполняется очистка и возврат. При каждом вызове функции, которая не инлайнена и использует какое-либо пространство стека (т. е. имеет локальную переменную), все эти инструкции могут быть вставлены и вызваны.
Давайте развернём остальную часть функции и посмотрим, что на самом деле выполняет матричное умножение.

Ого, куча кода! И это лишь первая страница. Полная функция занимает больше килобайта кода с 250—300 инструкциями! Проанализируем начало функции.

Строка над выделенной синим цветом занимает около 10 % общего времени выполнения. Почему она выполняется гораздо медленнее соседних? Эта MOVSS-инструкция берёт из памяти по адресу eax+34h значение с плавающей запятой и кладёт в регистр xmm4. Строкой выше то же самое делается с регистром xmm1, но гораздо быстрее. Почему?
Всё дело в промахе кеша.
Разберёмся подробнее. Семплирование отдельных инструкций применимо в самых разных ситуациях. Современные процессоры в любой момент выполняют несколько инструкций, и в течение одного тактового цикла немало инструкций может быть пересортировано (retire). Даже семплирование на основе событий может приписывать события не той инструкции. Так что при анализе семплирования ассемблера необходимо руководствоваться какой-то логикой. В нашем примере наиболее семплированная инструкция может не быть самой медленной. Мы лишь можем с определённой долей уверенности говорить о медленной работе чего-то, относящегося к этой строке. А поскольку процессор выполняет ряд MOV’ов в память и из неё, то предположим, что как раз эти MOV’ы и виноваты в низкой производительности. Чтобы удостовериться в этом, можно прогнать профиль с включённым семплированием на основе событий для промахов кеша и посмотреть на результат. Но пока что доверимся инстинктам и прогоним профиль исходя из гипотезы о промахе кеша.
Пропуск кеша L3 занимает более 100 циклов (в некоторых случаях — несколько сотен циклов), а промах кеша L2 — около 40 циклов, хотя всё это сильно зависит от процессора. К примеру, x86-инструкции занимают от 1 примерно до 100 циклов, при этом большинство — менее 20 циклов (некоторые инструкции деления на некотором железе работают довольно медленно). На моём Core i7 инструкции умножения, сложения и даже деления занимали по несколько циклов. Инструкции попадают в конвейер, так что одновременно обрабатывается несколько инструкций. Это значит, что один промах кеша L3 — загрузка напрямую из памяти — по времени может занимать исполнение сотен инструкций. Проще говоря, чтение из памяти — очень медленный процесс.
Modifier::Update()
Итак, мы видим, что обращение к памяти замедляет исполнение нашего кода. Давайте вернёмся назад и посмотрим, что в коде приводит к этому обращению. Контрольно-измерительный профилировщик показывает, что Node::Update() выполняется медленно, а из отчёта семплирующего профилировщика о стеке очевидно, что функция Modifier::Update() особенно нетороплива. С этого и начнём оптимизацию.
void Modifier::Update()
{
for(Object* obj : mObjects)
{
Matrix4 mat = obj->GetTransform();
mat = mTransform*mat;
obj->SetTransform(mat);
}
}Modifier::Update() проходит через вектор указателей к Object’ам, берёт их матрицу преобразования (transform matrix), умножает её на матрицу mTransform Modifier’а, а затем применяет это преобразование к Object’ам. В приведённом выше коде преобразование копируется из объекта в стек, умножается, а затем копируется обратно.
GetTransform() просто возвращает копию mTransform, при этом SetTransform() копирует в mTransform новую матрицу и задаёт состояние mDirty этого объекта:
void SetDirty(bool dirty)
{
if (dirty && (dirty != mDirty))
{
if (mParent)
mParent->SetDirty(dirty);
}
mDirty = dirty;
}
void SetTransform(Matrix4& transform)
{
mTransform = transform;
SetDirty(true);
}
inline const Matrix4 GetTransform() const { return mTransform; } Внутренний слой данных этого Object’а выглядит так:
protected:
Matrix4 mTransform;
Matrix4 mWorldTransform;
BoundingSphere mBoundingSphere;
BoundingSphere mWorldBoundingSphere;
bool m_IsVisible = true;
const char* mName;
bool mDirty = true;
Object* mParent;
};Для ясности я раскрасил записи в памяти объекта Node:
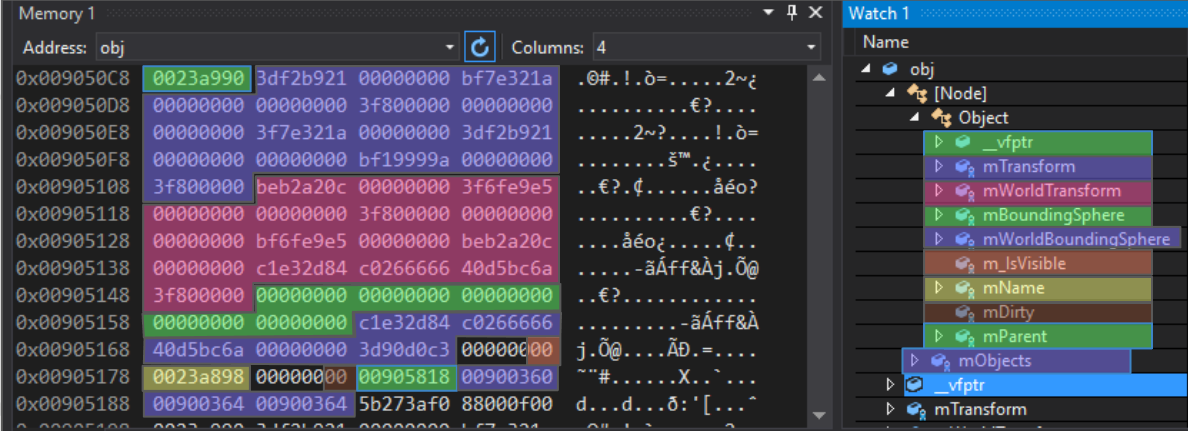
Первая запись — указатель виртуальной таблицы (virtual table pointer). Это часть реализации наследования в С++: указатель на массив указателей функций, которые выступают в роли виртуальных функций для этого конкретного полиморфного объекта. Для Object, Node, Modifier и любого класса, унаследованного от базового, существуют разные виртуальные таблицы.
После этого 4-байтного указателя идёт 64-байтный массив чисел с плавающей запятой. За матрицей mTransform идёт матрица mWorldTransform, а затем две ограничивающие сферы (bounding spheres). Обратите внимание, что следующая запись, m_IsVisible, однобайтная, она занимает 4 полных байта. Это нормально, поскольку следующая запись — указатель, который должен иметь как минимум 4-байтное выравнивание. Если после m_IsVisible положить другое булево значение, то оно было бы упаковано в доступные 3 байта. Далее идёт указатель mName (с 4-байтным выравниванием), затем булево mDirty (также неплотно упакованное), потом указатель на родительский Object. Всё это — характерные для Object данные. Последующий вектор mObjects относится уже к Node-вектору и занимает на этой платформе 12 байтов, хотя на иных платформах может быть другого размера.
Если мы рассмотрим код Modifier::Update(), то увидим, что может быть причиной промаха кеша.
void Modifier::Update()
{
for(Object* obj : mObjects)
{Для начала отметим: вектор mObjects — это массив указателей на Object’ы, которые размещаются в памяти динамически. Итерирование по этому вектору хорошо работает с кешем (красные стрелки на иллюстрации ниже), поскольку указатели следуют один за другим. Там есть несколько промахов, но они указывают на что-то, вероятно, не адаптированное для работы с кешем. А поскольку каждый Object размещается в памяти с новым указателем, то можно сказать лишь, что наша помеха находится где-то в памяти.

Когда мы получаем указатель на Object, вызываем GetTransform():
Matrix4 mat = obj->GetTransform();Эта инлайновая функция просто возвращает копию mTransform Object’а, так что предыдущая строка эквивалентна этой:
Matrix4 mat = obj->mTransform;Как вы можете видеть на диаграмме, Object’ы, на которые ссылаются указатели в массиве mObjects, разбросаны по памяти. Каждый раз, когда мы добавляем новый Object и вызываем GetTransform(), это наверняка приводит к промаху кеша при загрузке в mTransform и помещению в стек. На используемом мной оборудовании кеш-строка занимает 64 байта, так что если повезёт и объект начнётся за 4 байта до 64-байтной границы, то mTransform будет загружен в кеш целиком за раз. Но более вероятна ситуация, когда загрузка mTransform приведёт к двум промахам кеша. Из семплирующего профиля Modifier::Update() очевидно, что выравнивание матрицы выполняется произвольно.
В этом фрагменте edx является расположением Object’а. А как мы знаем, mTransform начинается за 4 байта до начала объекта. Так что этот код копирует mTransform в стек (MOVUPS копирует в регистр 4 невыравненных значения с плавающей запятой). Обратите на 7 % обращений к трём MOVUPS-инструкциям. Это говорит о том, то промахи кеша также встречаются и в случае с MOV’ами. Не знаю, почему первый MOVUPS в стек занимает не столько же времени, сколько остальные. Мне кажется, «затраты» просто переносятся на последующие MOVUPS из-за особенностей конвейеризации инструкций. Но в любом случае мы получили доказательство высокой стоимости обращения к памяти, так что будем с этим работать.
void Modifier::Update()
{
for(Object* obj : mObjects)
{
Matrix4 mat = obj->GetTransform();
mat = mTransform*mat;
obj->SetTransform(mat);
}
}После умножения матрицы вызываем Object::SetTransform(), которая берёт результат умножения (свежепомещённый в стек) и копирует его в экземпляр Object’а. Копирование проходит быстро, потому что преобразование уже закешировано, но SetDirty() работает медленно, потому что считывает флаг mDirty, его, вероятно, нет в кеше. Так что для тестирования и, возможно, определения этого одного байта процессору приходится считывать окружающие 63 байта.
Заключение
Если дочитали до конца — молодцы! Знаю, поначалу это бывает сложно, особенно если вы не знакомы с ассемблером. Но очень рекомендую найти время и посмотреть, что компиляторы делают с кодом, который они пишут. Для этого можно воспользоваться Compiler Explorer.
Мы собрали ряд доказательств, что главная причина проблем с производительностью в нашем примере кода — это указатели доступа к памяти. Дальше минимизируем затраты на доступ к памяти, а затем снова измерим производительность, чтобы понять, удалось ли добиться улучшения. Этим мы и займёмся в следующий раз.
При использовании Unity Profiler для профилирования приложения существует три основных способа записи данных:
- Профилируйте свое приложение в проигрывателе на целевой платформе
- Профилируйте свое приложение в режиме воспроизведения в редакторе Unity
- Профиль редактора Unity
Лучший способ получить точное время для вашего приложения – это профилировать его на конечной платформе, на которой вы собираетесь его публиковать. Это дает вам точные данные о том, что влияет на производительность вашего приложения.
Однако создание приложения каждый раз, когда вы хотите улучшить его производительность, может занять много времени. Чтобы быстро оценить производительность вашего приложения, вы можете профилировать его прямо в режиме Play в Редакторе. Профилирование в режиме воспроизведения не дает точного представления о том, как выглядит производительность вашего приложения на реальном устройстве, но это полезный инструмент, позволяющий быстро проверить, улучшают ли внесенные вами изменения производительность вашего приложения после первоначального профилирования на конечная платформа.
Редактор Unity может повлиять на производительность вашего приложения, поскольку он использует те же ресурсы, что и ваше приложение, когда оно работает в режиме воспроизведения, поэтому вы также можете отдельно профилировать редактор, чтобы определить, какие ресурсы он использует. Это особенно полезно, если ваше приложение предназначено для работы только в режиме воспроизведения, например для создания фильмов.
Профилируйте свое приложение на целевой платформе
Чтобы профилировать приложение на целевой платформе выпуска, подключите целевое устройство к сети или напрямую к компьютеру с помощью кабеля. Вы также можете подключиться к устройству через IP-адрес. Вы можете профилировать свое приложение только как разрабатываемую сборку. Чтобы настроить это, перейдите в Настройки сборки (меню: Файл > Настройки сборки) и выберите целевую платформу вашего приложения. Включите параметр Разработка. Когда вы включаете этот параметр, становятся доступными две настройки, связанные с Profiler: Autoconnect Profiler и Поддержка глубокого профилирования.
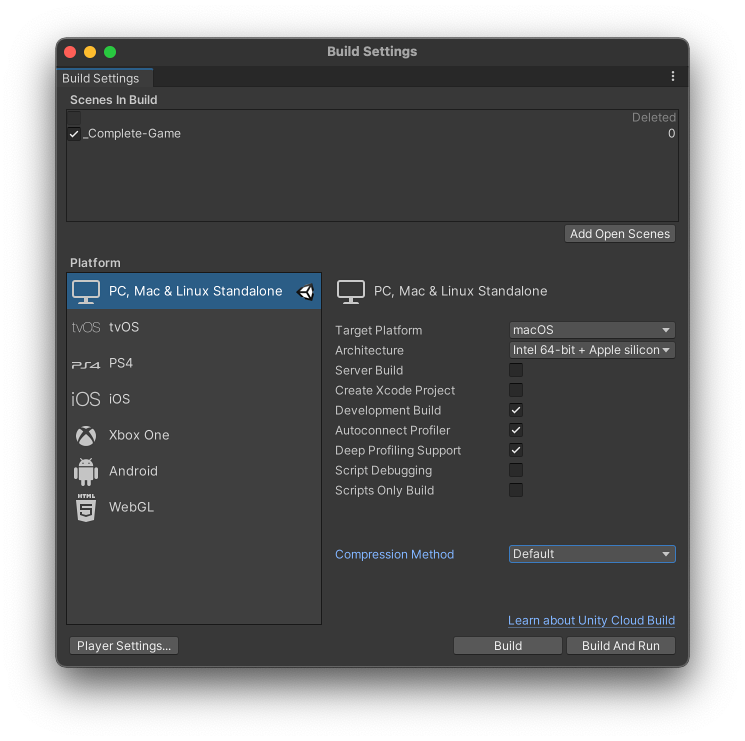
Если вы включите параметр Автоподключение Profiler, редактор Unity запишет свой IP-адрес во встроенный проигрыватель в процессе сборки. Когда вы запускаете проигрыватель, он пытается подключиться к профилировщику в редакторе, расположенному по запеченному IP-адресу.
Если вы также включите параметр Поддержка глубокого профилирования, Unity будет выполнять глубокое профилирование при запуске встроенного проигрывателя. , что означает, что окно Profiler поможет вам оптимизировать игру. Он показывает, сколько времени вы тратите на различные области вашей игры. Например, он может сообщать о проценте времени, затраченном на рендеринг, анимацию или игровую логику. Подробнее
Смотрите в Словарь каждую часть вашего кода, а не только тайминги кода в явном виде. завернутые в ProfilerMarkers. Это полезно для получения информации Deep Profiling о времени запуска вашего приложения, однако это добавляет небольшие накладные расходы к вашей сборке.
Подключение к проигрывателю в окне Profiler
Если вы не включили параметр Autoconnect Profiler в настройках сборки, вы можете вручную подключиться к платформе, на которой запущено ваше приложение. Пока ваше приложение работает в проигрывателе, этот проигрыватель отображается в раскрывающемся списке Присоединить к проигрывателю окна Profiler. В раскрывающемся списке Присоединить к проигрывателю показаны все проигрыватели Unity, работающие в вашей локальной сети. Вы можете идентифицировать этих проигрывателей по типу проигрывателя и имени хоста, на котором работает проигрыватель (например, «iPhonePlayer (Toms iPhone)»).
Вы также можете подключиться к игроку напрямую через его IP-адрес. Для этого выберите меню Прикрепить к проигрывателю, а затем в раскрывающемся списке выберите <Введите IP>. Появится диалоговое окно, в котором вы можете ввести IP-адрес и (необязательно) порт проигрывателя, к которому вы хотите подключиться.

Чтобы начать сбор информации о профилировании вашего приложения, выберите проигрыватель в раскрывающемся меню и нажмите Записать. Для непрерывного сбора данных во время работы приложения включите параметр Запускать в фоновом режиме в настройках проигрывателя (меню: Правка > Настройки проекта > Плеер > Разрешение и представление). Когда вы включаете этот параметр, Profiler собирает данные, даже если вы оставляете свое приложение работающим в фоновом режиме. Если вы отключите его, профилировщик будет собирать данные только тогда, когда приложение работает в активном окне.
Руководство по профилированию для конкретных платформ
Разные платформы ведут себя по-разному, когда вы подключаете их к Unity Profiler. В следующих разделах приводятся рекомендации по некоторым общим функциям, характерным для каждой платформы:
WebGL
Вы можете использовать Unity Profiler в WebGL, но вы не можете подключиться к работающему проигрывателю, созданному с помощью WebGL, через редактор. Это связано с тем, что WebGL использует для связи WebSockets, что не позволяет входящие соединения на стороне браузера. Чтобы подключиться к работающему проигрывателю, необходимо установить флажок Автоподключение профилировщика в Настройки сборки (меню: Файл > Настройки сборки). Unity не может профилировать вызовы отрисовки для WebGL.
Профилирование на мобильных устройствах
Обе iOSмобильная операционная система Apple. Подробнее
См. в Словарь, а устройства Android поддерживают удаленное профилирование по сети. Если вы используете брандмауэр, откройте порты с 54998 по 55511 в исходящих правилах брандмауэра. Это порты, которые Unity использует для удаленного профилирования.
Иногда при настройке удаленного профилирования Редактор Unity может не подключаться к устройству автоматически. В этом случае вы можете инициировать подключение Profiler вручную. Для этого выберите раскрывающееся меню Присоединить к проигрывателю в окне Профилировщика и выберите соответствующее устройство.
Вы также можете подключить целевое устройство напрямую к компьютеру, чтобы избежать проблем с сетью или подключением.
Удаленное профилирование iOS
Чтобы включить удаленное профилирование на устройствах iOS, выполните следующие действия:
- Подключите устройство iOS к сети Wi-Fi. Profiler использует локальную сеть Wi-Fi для отправки данных профилирования с вашего устройства в редактор Unity.
- Подключите устройство к компьютеру с помощью кабеля. Перейдите к настройкам сборки (меню: Файл > Настройки сборки), установите флажки Разработка сборки и Профилировщик автоподключения. , затем выберите Сборка и запуск.
- Когда приложение запустится на устройстве, откройте окно Profiler в редакторе Unity (меню: Окно > Анализ > Profiler).
Удаленное профилирование Android
Устройства Android поддерживают два метода удаленного профилирования: через WiFi или через Android Debug Bridge (adb ).
Для профилирования Wi-Fi выполните следующие действия:
- Отключите мобильные данные на устройстве Android.
- Подключите устройство Android к сети Wi-Fi. Profiler использует локальную сеть Wi-Fi для отправки данных профилирования с вашего устройства в редактор Unity.
- Подключите устройство к компьютеру с помощью кабеля. Перейдите к настройкам сборки (меню: Файл > Настройки сборки), установите флажки Разработка сборки и Профилировщик автоподключения. , затем выберите Сборка и запуск.
- Когда приложение запустится на устройстве, откройте окно Profiler в редакторе Unity (меню: Окно > Анализ > Profiler).
Примечание. Устройство Android и хост-компьютер, на котором запущен редактор Unity, должны находиться в одной подсети, чтобы определение устройства работало.
Для профилирования Android Debug Bridge (adb) выполните следующие действия:
- Убедитесь, что устройство находится в режиме разработки и включите параметр Отладка USB
- Подключите устройство к компьютеру с помощью кабеля и убедитесь, что оно отображается в adbмосте отладки Android (ADB) . Вы можете использовать ADB для развертывания пакета Android (APK) вручную после сборки. Подробнее
См. в Словарь. - Перейдите к настройкам сборки (меню: Файл > Настройки сборки), установите флажок Разработка сборки, а затем выберите Собери и запусти.
- Когда приложение запустится на устройстве, откройте окно Profiler в редакторе Unity (меню: Окно > Анализ > Profiler).
- В раскрывающемся меню Прикрепить к проигрывателю выберите AndroidProfiler(ADB@127.0.0.1:34999). Запись в раскрывающемся меню отображается только в том случае, если выбрана цель Android.
.
Редактор Unity автоматически создает туннель adb для вашего приложения, когда вы выбираете Build & Run. Если вы хотите профилировать другое приложение или перезапустить сервер adb, вам необходимо настроить этот туннель вручную. Для этого откройте окно терминала или командную строку и введите следующее:
-
Требуется, когда соединение Editor-to-Android установлено через USB-кабель
adb forward tcp:34999 localabstract:Unity-{вставьте здесь идентификатор пакета} -
Необходимо, если соединение Android-Editor установлено через USB-кабель
обратный TCP:34998 TCP:34999
Чтобы использовать Deep Profiling со сборкой Android, необходимо включить параметр Mono Scripting Backend в Настройках проигрывателя Android (меню: Редактировать > Настройки проекта > Игрок > Android > Другие настройки) и введите следующее, чтобы запустить игру через команда adb:
~$ adb shell am start -n {insert bundle identifier here}/com.unity3d.player.UnityPlayerActivity -e 'unity' '-deepprofiling'
Удаленное профилирование Android Chrome OS
Unity не может автоматически обнаруживать устройства Chrome OS. Чтобы инициировать подключение, подключитесь к устройству через Android Debug Bridge (adb) по его IP-адресу, а затем выберите в разделе Подключить к проигрывателю раскрывающееся меню и введите IP-адрес устройства. После подключения вы можете профилировать свое приложение как обычно.
Когда вы используете окно Profiler для запуска и профилирования вашего приложения в редакторе, результаты являются лишь приблизительным представлением поведения вашего приложения, когда оно запускается на целевой платформе. Это связано с тем, что режим воспроизведения работает в том же процессе, что и редактор, поэтому вы не можете полностью изолировать использование процессора, графического процессора и памяти вашего приложения от использования редактора Unity. Это искажает полученные данные профилирования.
Чтобы получить лучшие результаты профилирования, вы всегда должны профилировать свое приложение на целевом устройстве и профилировать только в редакторе, чтобы быстро перебирать проблемы, которые вы уже определили на устройстве.
Вы также можете профилировать в режиме воспроизведения или профилировать редактор, чтобы выявить проблемы, не связанные с производительностью вашего приложения, например, замедляет ли время итерации длительное время загрузки или неотвечающий редактор, или если ваше приложение плохо работает в режиме воспроизведения.
Каждый раз, когда вы профилируете в редакторе, убедитесь, что вы открываете режим воспроизведения в развернутом виде и уменьшаете количество открытых окон редактора. Это гарантирует, что другие окна редактора не используют время потока рендеринга и графического процессора и, следовательно, не влияют на данные о производительности. Когда режим воспроизведения находится в развернутом виде, ваше приложение запускается с разрешением, более близким к разрешению вашего целевого устройства, что напрямую влияет на проблемы с производительностью, например связанные с скоростью заполнения.
Профилирование в режиме воспроизведения
Целью профилировщика по умолчанию является режим воспроизведения, который записывает действия, когда редактор работает в режиме воспроизведения. Профилирование в режиме воспроизведения полезно для проверки быстрых изменений без пересборки проигрывателя, но его не следует использовать в качестве замены для проверки сборок на целевой платформе и устройствах вашего приложения. Это связано с тем, что режим воспроизведения работает в том же приложении и в том же основном потоке, что и редактор, а это означает, что при профилировании в режиме воспроизведения системы редактора, такие как UI(User Interface) Позволяет пользователю взаимодействовать с вашим приложением. Подробнее
См. в Словарь, ИнспекторыОкно Unity, в котором отображается информация о текущем выбранном игровом объекте, активе или настройках проекта, что позволяет вам проверять и редактировать значения. Подробнее
См. в Словарь, СценаСцена содержит окружение и меню вашей игры. Думайте о каждом уникальном файле сцены как об уникальном уровне. В каждой сцене вы размещаете свое окружение, препятствия и декорации, по сути проектируя и создавая свою игру по частям. Подробнее
См. в Словарь Просмотр рендерингПроцесс вывода графики на экран (или текстуры рендеринга). По умолчанию основная камера в Unity отображает изображение на экране. Подробнее
См. в Словарь, и управление активами влияет на показатели производительности и профилирования памяти вашего приложение.
Для эффективного профилирования в режиме воспроизведения вам следует регулярно создавать сборки своего приложения и развертывать их на ряде целевых устройств (как с высокими, так и с низкими характеристиками), а также тестировать и профилировать свое приложение на этих устройствах. Если вы обнаружите проблемы с производительностью вашего приложения на этих устройствах, сузьте область, которая требует наибольшего внимания.
Затем вы можете профилировать свое приложение в режиме воспроизведения и быстро повторять любые изменения, которые вы вносите в свое приложение. Вы можете использовать информацию, полученную при профилировании вашего приложения на целевых устройствах, чтобы определить, есть ли подобное поведение после профилирования вашего приложения в режиме воспроизведения. Затем вы можете снова внести изменения в свое приложение и профиль в режиме воспроизведения, чтобы быстро увидеть результаты ваших изменений. Когда вы будете удовлетворены внесенными изменениями, снова создайте и разверните приложение на целевых устройствах, чтобы проверить изменения.
Примеры PlayerLoop и EditorLoop
Чтобы уменьшить количество шумов и вводящих в заблуждение измерений в данных профилирования, которые редактор создает во время работы в режиме воспроизведения, модули CPU и GPU Profiler разделяют свои тайминги на те, которые происходят в PlayerLoop, и те, которые которые происходят в EditorLoop. Unity присваивает выборки профилировщиканабор данных, связанных с маркером профилировщика, которые профайлер записал и собрал.
См. в Словарь этих типов с Маркеры PlayerLoop и EditorLoop.
Когда Profiler выбирает режим воспроизведения, он собирает только выборки времени, которые произошли внутри PlayerLoop.
Unity классифицирует все образцы EditorLoop как Другие в диаграммах модуля CPU Profiler. В результате образцы EditorLoop вносят наибольший вклад в эту категорию. Если вы хотите увидеть, что редактор делает в это время, а также получить более подробную информацию о том, что еще вносит свой вклад в категорию Другие, вместо этого измените цель профилировщика на редактор.
Важно! Если вы используете Глубокое профилирование и нацеливаете режим воспроизведения, это влияет на производительность каждого вызова функции. как в PlayerLoop, так и в EditorLoop. Это связано с тем, что Deep Profiling перехватывает начало и конец любого вызова метода сценария при перезагрузке домена и не определяет, какие части никогда не вызываются из PlayerLoop. Вызовы методов, происходящие в цикле EditorLoop, не несут всех накладных расходов, связанных с созданием сэмпла, но они все же проверяют, должны ли они выдавать его, что вызывает меньшие, но все же существующие накладные расходы.
Профилирование редактора
Когда вы меняете цель Profiler на Editor, все образцы, которые ранее были скрыты под маркером EditorLoop, добавляются в соответствующие категории. Это означает, что информация на панели сведений модуля CPU Profiler и в его диаграммах существенно меняется.
Чтобы профилировать время запуска редактора, запустите редактор с параметром командной строки -profiler-enable.
Чтобы уменьшить влияние окна Profiler на производительность редактора, вы можете использовать автономный Profiler, который открывает окно Profiler в своем собственном процессе. Это особенно полезно, если вы выбираете редактор в качестве цели профилирования или выполняете глубокое профилирование своего приложения, поскольку само окно профилировщика обычно использует ресурсы, которые могут исказить производительность. данные.
Рекомендации по профилированию вашего приложения
При профилировании своего приложения вы можете сделать несколько вещей, чтобы обеспечить согласованность между сеансами профилирования и убедиться, что процессы, которые использует Unity, не влияют на ваши данные профилирования:
- Добавляйте в окно Profiler только модули Profiler, относящиеся к области, которую вы хотите исследовать. Чтобы добавить или удалить модули в Profiler, выберите раскрывающийся список в левом верхнем углу окна Profiler.
- Избегайте использования глубокого профилирования, так как при его использовании возникают большие накладные расходы. Если вы хотите просмотреть дополнительные сведения о примерах с такими маркерами, как GC.Alloc или JobFence.Complete, перейдите в окно Profiler на панель инструментов Ряд кнопок и основных элементов управления в верхней части редактора Unity, который позволяет вам взаимодействовать с редактором различными способами (например, масштабирование, перевод). Подробнее
Посмотрите в Словарь и включите Настройка стеков вызовов. Это обеспечивает полный стек вызовов примера, который дает вам необходимую информацию, не неся накладные расходы на глубокое профилирование. - Отключите параметр «В режиме реального времени», если вам не нужно видеть обновление представления «Иерархия» или «Временная шкала» по мере сбора данных профилировщиком. Остановите запись, чтобы увидеть обновление данных в окне.
- Используйте сочетание клавиш F9, чтобы включить или отключить профилировщик. Вы можете использовать этот ярлык для сбора данных о производительности без открытия окна Profiler. Если у вас открыт автономный профилировщик, использование этого ярлыка запускает запись в этом окне.
- Добавлена поддержка глубокого профилирования в 2019.3
Хороший сайт должен быть не только красивым и удобным, но и быстрым. Если ваш сайт стал работать медленнее, но причин такого поведения быстро найти не удается — помочь определить проблемы в его коде сможет профилировщик.
Что такое профилировщик?
Профилировщик (или профайлер, от английского profiler) — это специальное программное обеспечение, которое дает возможность оценить:
- где именно;
- на какие операции;
- в каких объемах
тратятся ресурсы при выполнении скриптов. Эта информация полезна разработчикам, которые с ее помощью могут оптимизировать работу своих программ, уменьшить использование аппаратных ресурсов и сократить время работы скриптов.
Данные, которые собирает профилировщик, могут быть разными: количество использованной во время выполнения скрипта памяти, частота и продолжительность вызовов функций, время ответа на конкретный запрос и так далее.
Для проектов, написанных на PHP, наибольшей популярностью пользуются профилировщики XHProf и Tideways — бесплатные решения с открытым исходным кодом, которые можно использовать на нашем хостинге: мы сделали простую установку профилировщика и интерфейса для работы с ним прямо из Панели управления, чтобы нашим пользователям не приходилось тратить время и силы на его подключение.
Как установить профилировщик на сайт?
Установить профилировщик на сайт можно из раздела «Сайты» Панели управления: напротив доменного имени, прилинкованного к нужному сайту, кликните по иконке  «Управление профилировщиком».
«Управление профилировщиком».
В открывшемся окне будет доступна справочная информация о том, какие действия необходимо будет предпринять после включения профилировщика для генерации отчета, а также кнопка «Включить».
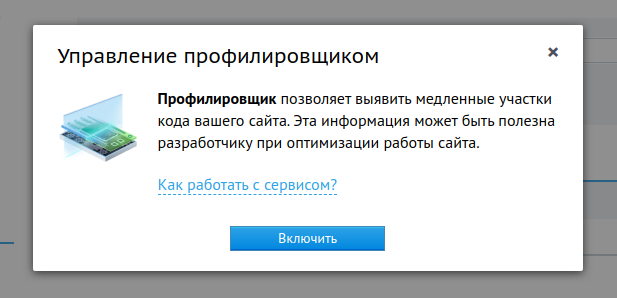
По нажатию кнопки «Включить» запустится установка профилировщика и графического интерфейса для просмотра результатов профилирования. Профилировщик будет включен для сайта практически мгновенно, для установки интерфейса понадобится некоторое время: текущий статус установки будет отображаться в окне состояния профилировщика.
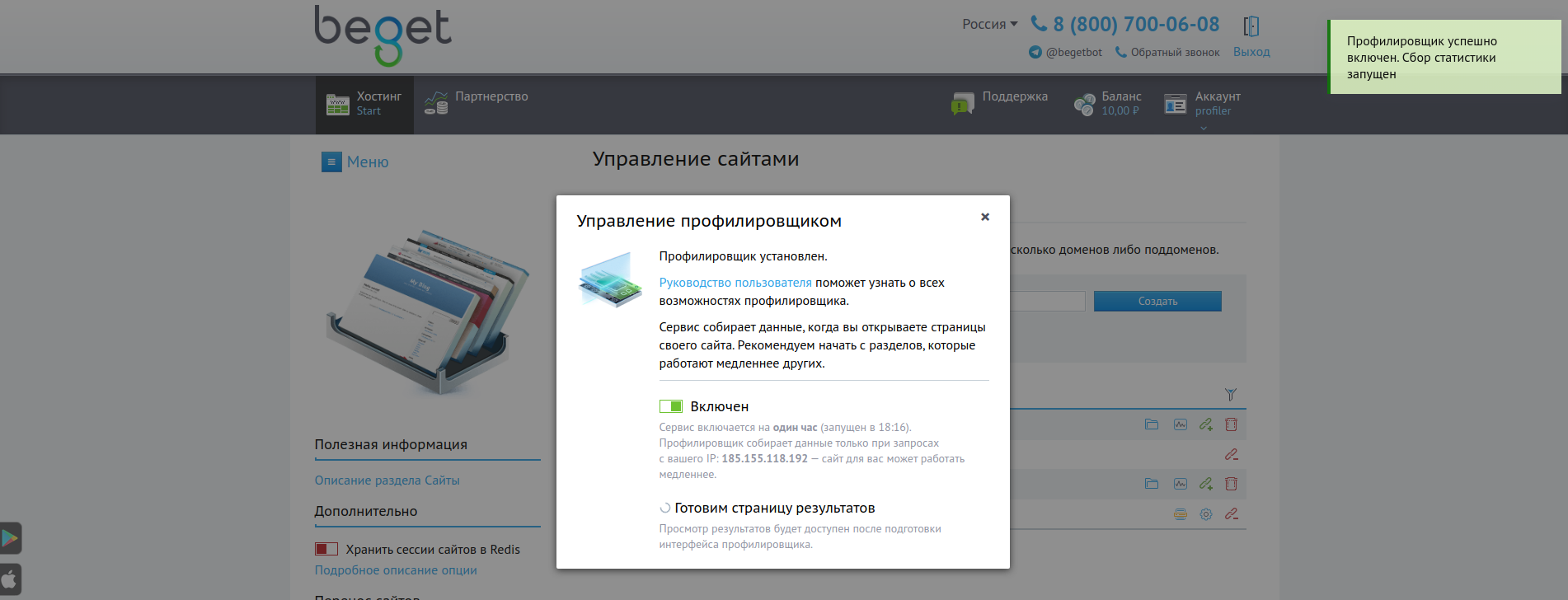
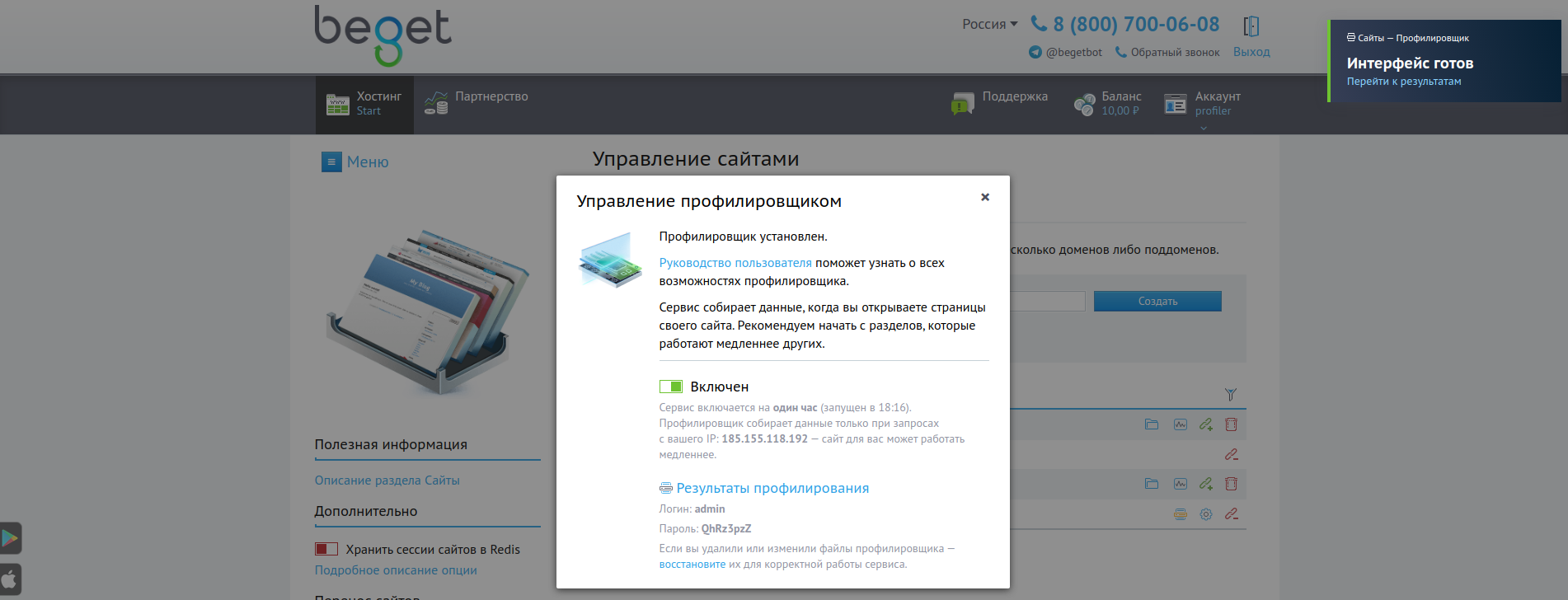
После завершения установки интерфейса в Панели управления появится соответствующее уведомление, а в окне настроек будут доступны логин и пароль для доступа к нему. Если Вы по какой-то причине удалили или изменили файлы графического интерфейса профилировщика — из этого же окна можно одним кликом восстановить данные для его корректной работы.
Как использовать профилировщик?
При включении профилировщик генерирует отчеты о работе вашего сайта, когда вы открываете его страницы. Каждую страницу сайта, для которой необходим отчет, вам нужно открыть самостоятельно: профилировщик запускается только для вашего IP-адреса. Посещения сайта другими пользователями не запускают профилирование, отчеты в таком случае создаваться не будут.
После генерации отчетов они будут доступны в интерфейсе — ссылка на него доступна в окне управления профилировщиком.
Главное окно
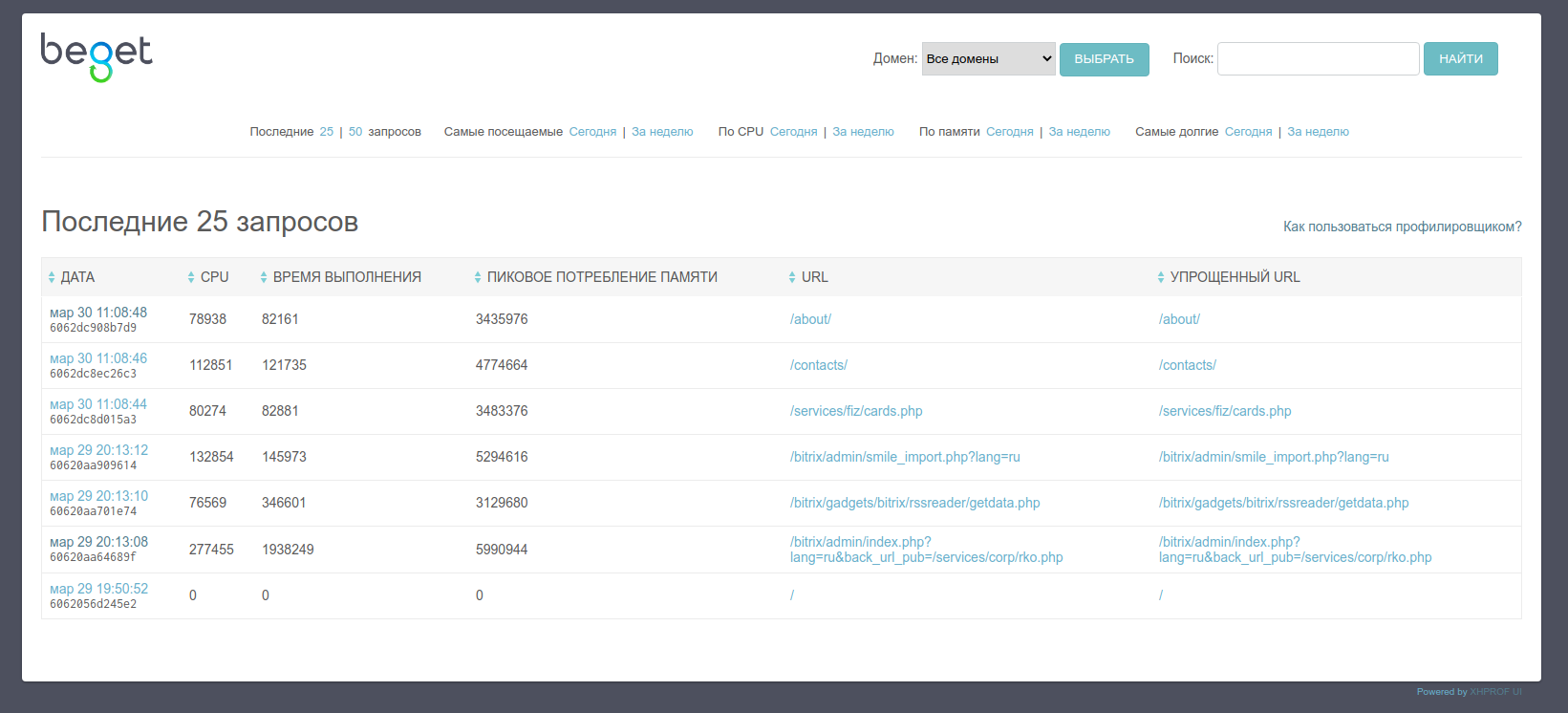
В главном окне интерфейса можно выбрать количество последних запросов, для которых собрана статистика, а также включить фильтр результатов по нескольким критериям: посещаемости страницы, нагрузки на CPU, используемой памяти и времени выполнения.

Если профилировщик включен для нескольких сайтов — в выпадающем списке можно выбрать конкретный домен, для которого нужно отобразить результаты.
Для каждого отчета в таблице выводится информация о времени выполнения скрипта (в микросекундах), процессорному времени и пиковом потреблении памяти (в байтах). По клику по дате отчета откроется подробная информация о результатах профилирования.

Отчет о результатах
Каждый отчет профилировщика состоит из нескольких частей:
- общая информация о результатах профилирования — статистика общего выполнения скрипта, информация о Cookie и параметрах GET- и POST-запросов;
- подробная информация о результатах профилирования — статистика по каждой вызываемой скриптом функции;
- граф вызовов функций — визуальное отображение связи функций, выполняемых скриптом.
Общая информация об отчете
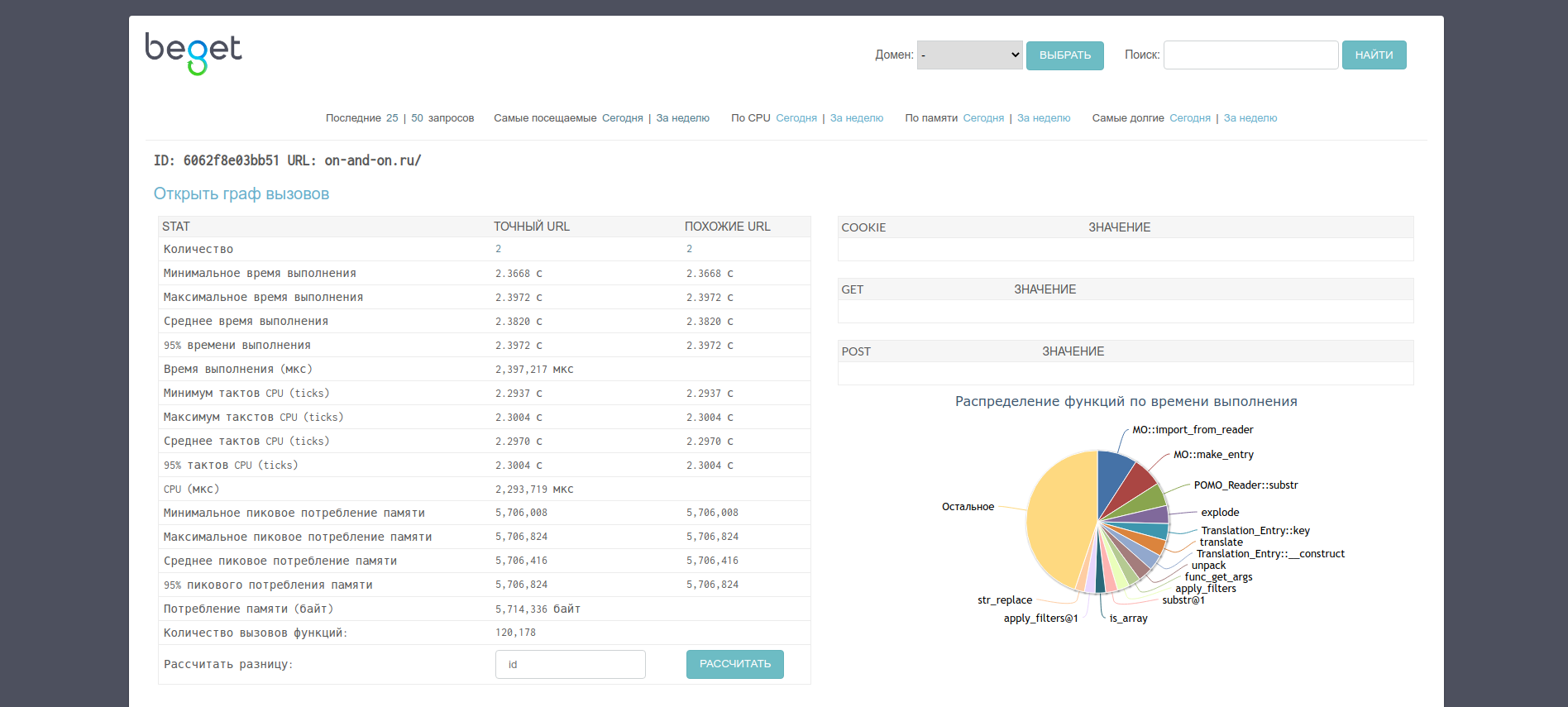
Первая часть отчета содержит общую информацию о работе скрипта, для которого запускалось профилирование. Если профилирование для скрипта запускалось несколько раз — интерфейс отобразит это: соответствующие счетчики будут отображены в графе «Точный URL» (в случае, когда отчеты собирались при посещении одной и той же страницы сайта) и «Похожие URL» (когда есть результаты профилирования страниц, адрес которых похож на адрес из текущего отчета).
Интерфейс отображает следующие данные статистики:
- Время выполнения скрипта (в микросекундах);
- Процессорное время, потраченное на работу скрипта (в микросекундах);
- Потребление памяти во время выполнения (в байтах);
- Количество вызовов функций внутри скрипта.
Также предоставляются следующие данные (при их наличии):
- информация о Cookie;
- информация о GET- и POST-запросах.
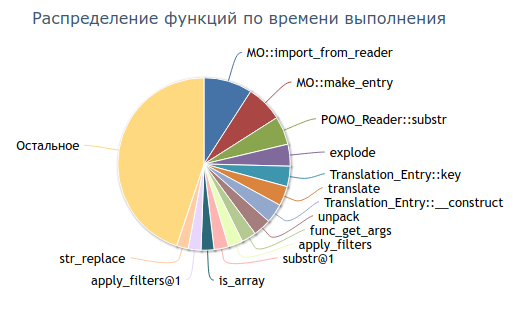
В общую информацию включена и диаграмма распределения функций, вызываемых в скрипте, по времени их выполнения: при наведении на сектор диаграммы отобразится название функции и потраченное на ее выполнение время.
Подробная информация об отчете (таблица)
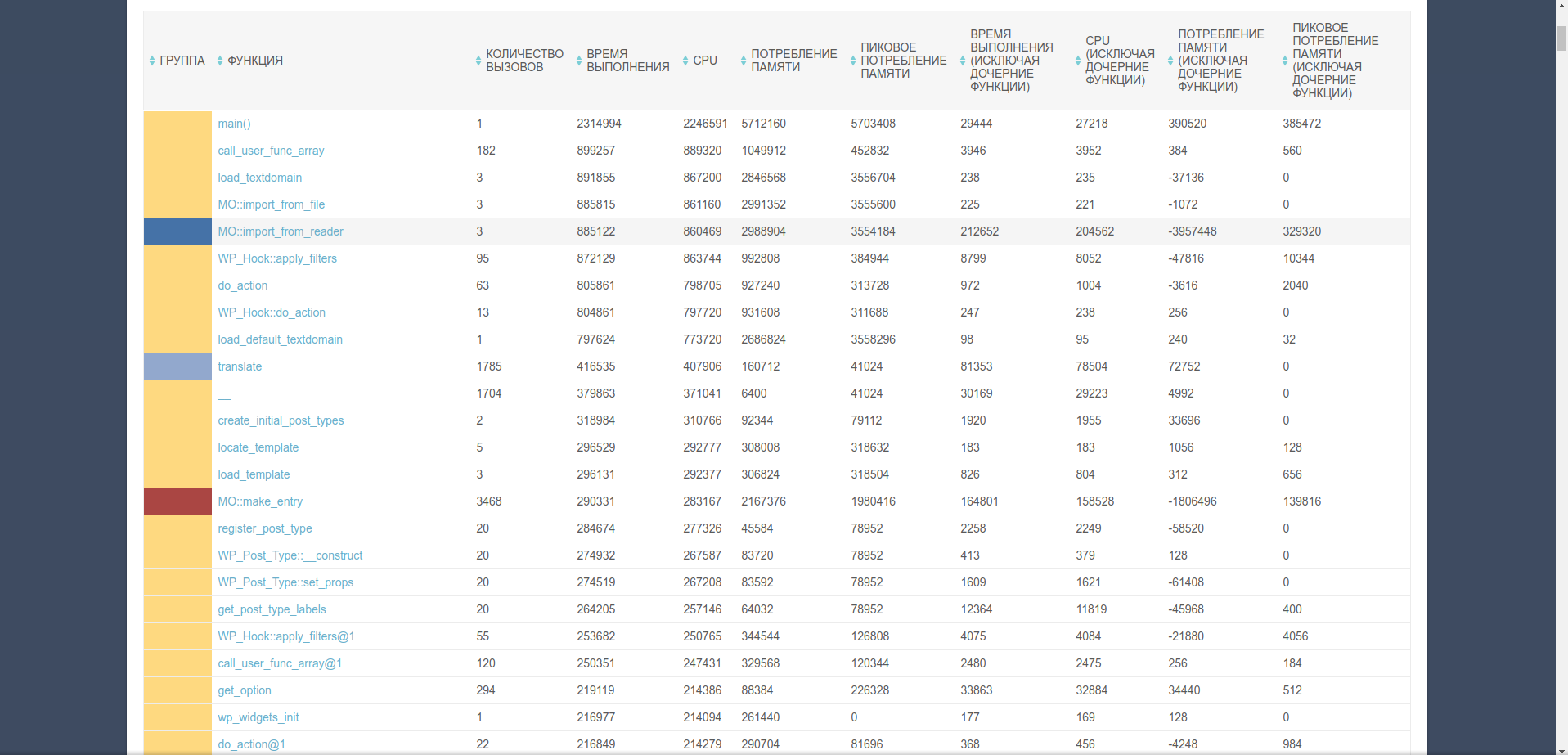
В таблице подробной информации отображается статистика по каждой функции, вызванной в ходе работы скрипта. Цвет ячейки в колонке «Группа» соответствует цвету сектора на диаграмме распределения функций по времени выполнения — это позволяет быстро найти функцию, которая выполнялась дольше всего, не изменяя сортировку таблицы.
Таблица отображает следующие данные статистики:
- Количество вызовов функции за время работы скрипта;
- Время в микросекундах, потраченное на выполнение функции (как с учетом выполнения других функций внутри, так и без);
- Процессорное время в микросекундах, использованное на выполнение функции (как с учетом выполнения дочерних функций, так и без)
- Среднее и пиковое потребление памяти в байтах (также с учетом и без учета дочерних функций).
По клику на имя функции откроется расширенная статистика ее профилирования.
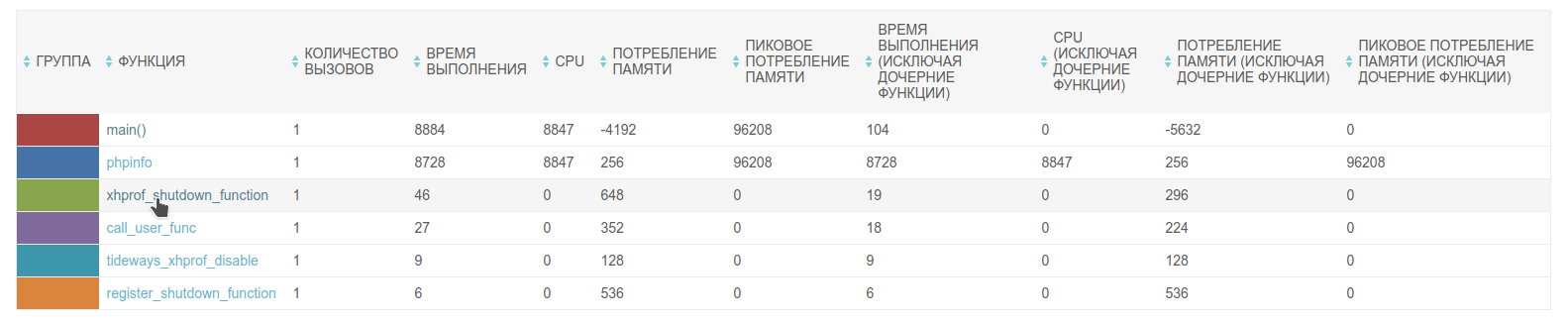
В расширенной статистике доступна информация как о самой функции, так и о родительских (тех функциях, которые в ходе своей работы вызывали исследуемую нами) и дочерних (тех функциях, которые вызывала исследуемая нами функция). Статистика собирается по следующим данным:
- количеству вызовов;
- времени выполнения в микросекундах;
- процессорному времени в микросекундах;
- потреблению памяти в байтах (как среднему, так и пиковому).
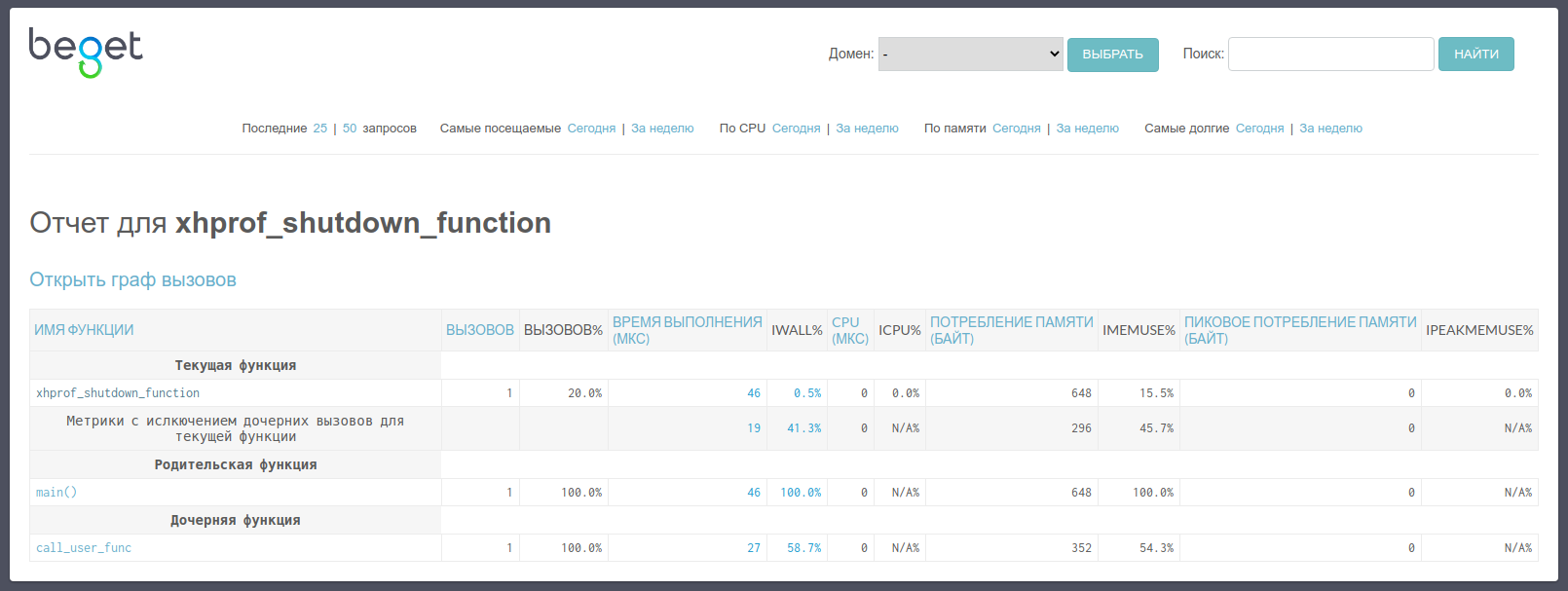
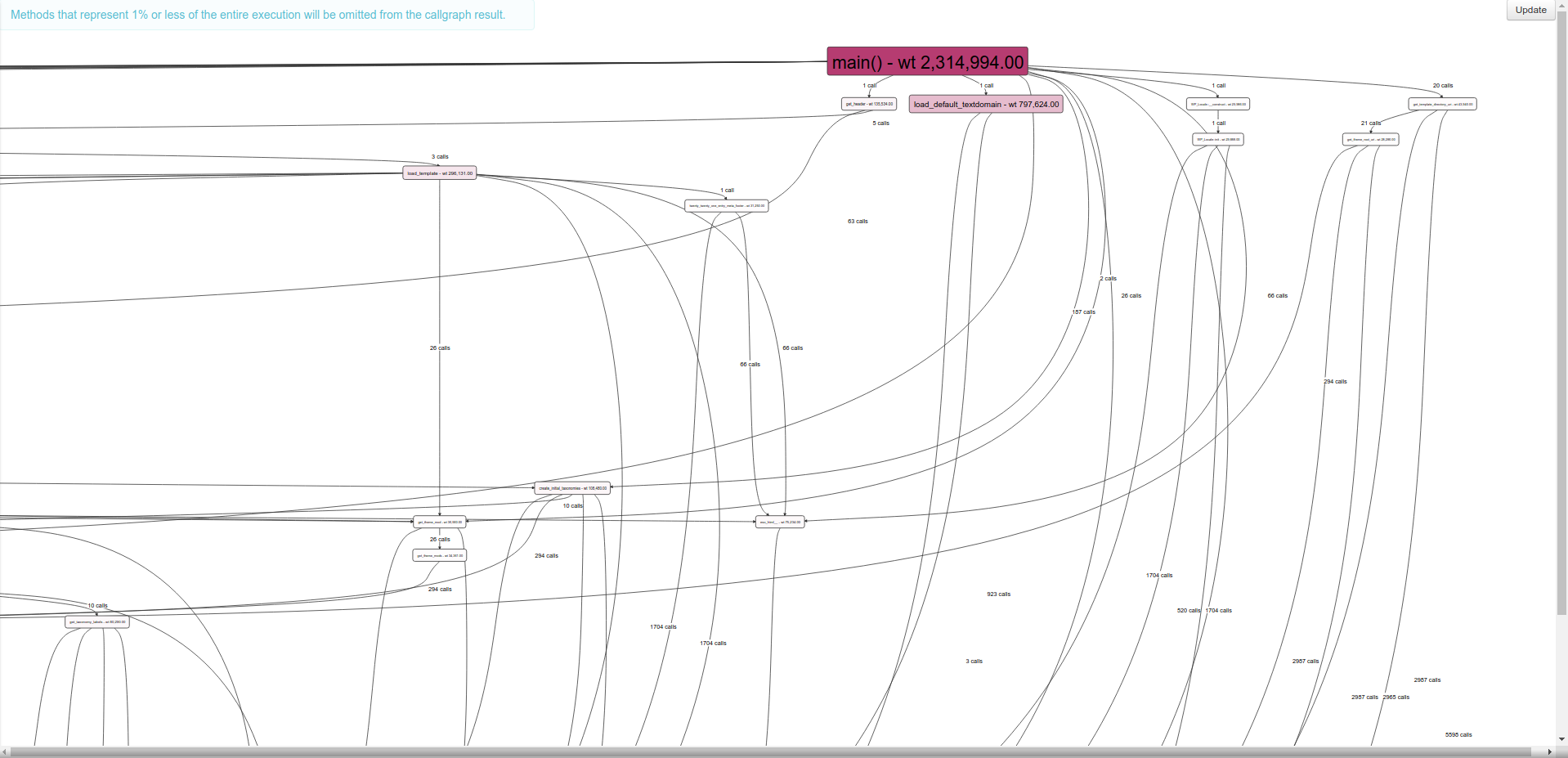
Граф вызовов
Интерфейс позволяет построить визуальное отображение вызовов всех функций во время работы скрипта — граф вызовов. Просмотреть его можно, кликнув по соответствующей ссылке в собранном отчете. Цветом в графе вызовов выделены функции, время выполнения которых было наибольшим, рядом со связью родительской и дочерней функции отображается количество вызовов.
Заключение
Профилирование — это важный метод оптимизации программного обеспечения, который предоставляет подробную информацию о вашем приложении на уровне кода. С помощью профилировщика вы сможете найти проблемные части вашего кода и оптимизировать его работу, а также отслеживать влияние изменений кода на производительность приложения — а наша моментальная установка из Панели управления позволит быстрее приступить к работе.

Нередко во время печати на принтере возникают проблемы, связанные с некорректной передачей цветов относительно монитора. Для устранения подобной «не состыковки» следует выполнить профилирование принтера.
Что такое цветовой профиль?
Вообще, цветовые профили представляют собой файлы, которые содержат описания характеристик того или иного оборудования, а также параметры настроек, предназначенных для работы с цветами. Подобные данные определенным образом отражаются при воспроизведении готового изображения на бумаге.
Все файлы цветопрофилей имеют следующие расширения: .icm и .icc. Аббревиатура профиль icc расшифровывается как «International Color Consortium». Данное наименование было получено благодаря образованному в 1993-м году консорциуму по цвету. Участие в нем приняли несколько известных компаний, а именно: Kodak, Adobe, Apple, Agfa и некоторые другие. Именно благодаря сотрудничеству и плодотворной работе этих компаний и появились icc профили, заметно облегчающие печать качественных и хорошо обработанных снимков.
Заводские установки
Для начала следует сказать, что вы можете использовать заводской цветовой профиль принтера. Обычно он записан на компакт-диск вместе с ПО и идет в одном комплекте с девайсом. Если его на диске нет, то откройте официальный сайт производителя и загрузите уже настроенный цветовой профиль оттуда. Но нет полной уверенности в том, что данный цветопрофиль будет обеспечивать оптимальную передачу цвета во время печати изображений, даже в том случае, если вы будете использовать исключительно оригинальные расходные материалы, которые рекомендуются производителем. Ключевой причиной того, что использование заводского профиля принтера может вылиться в не корректную цветопередачу, заключается в том, что в этом случае нет учета индивидуальных особенностей девайса. Но в целом, если вы не планируете распечатывать какие-то высококачественные фотографии, где очень важно соответствие всех тонов с теми, что отображаются на мониторе, то заводские установки должны устроить вас.
Создание цветопрофиля: способы
Если же вы хотите создать или установить индивидуальные настройки, чтобы калибровка цветопередачи полностью устраивала вас, то в таком случае отнеситесь к решению данной задачи серьезно и ответственно. Чтобы калибровка прошла действительно так, как этого вам хочется, и цвет печати в конечном итоге удовлетворил вас, то скачайте плагин Color DarkRoom, предназначенный для ПО Adobe Photoshop. Данный способ, позволяющий сделать изменение в профилировании принтера, заключается в том, что пользователю для достижения нужного результата нужно поочередного распечатывать тестовую шкалу и менять на свое усмотрение расположение каналов и кривых RGB.
Итак, чтобы выполнить настройку цветового профиля принтера таким способом, запустите ПО Photoshop и откройте т.н. цветовую карту, при помощи которой вы планируете редактировать свой профиль цветовой. Для этого выберите «Файл»=>«Открыть»=>«…..Color DarkRoomColor_Card». Но стоит отметить, что данный плагин работает только с файлами, имеющими расширение * icm. Поэтому заранее измените расширение *icc на данное. Далее для калибровки выполните все следующие шаги:
- Зайдите через «Пуск» в меню «Устройства и принтеры», чтобы в свойства девайсах узнать о том, какой профиль используется им в данный момент. В свойствах устройства откройте управление цветом и нажмите на одноименную кнопку. Найдите свой девайс и запомните наименование цветопрофиля, которое отобразится ниже. В папке «System32spooldriverscolor» найдите данный профиль, скопируйте его и переименуйте – таким образом вы создадите основу для нового цветопрофиля.
- Выполните распечатку цветовой карты для того, чтобы знать, какие цвета нужно будет калибровать. В настройках обязательно укажите «цветом управляет принтер», т.к. распечатка будет осуществляться с помощью цветофильтра принтера.
- Зайдите в ПО Photoshop с вышеназванным плагином и открытой серой картой. Откройте «Фильтр» и перейдите там из «AMS» в «Color DarkRoom». Через открывшееся окошко выполните добавление своего профиля, который вы создали ранее.
- Теперь можно заняться выполнением такой задачи, как калибровка профиля. Для этого найдите в меню «Цвета печати» кнопку «Graph» и нажмите на нее. Далее перед вами откроется ваш профиль, представленный в виде графика, состоящего в виде кривых красного, зеленого и синего цвета.
- Выполните настройки профиля на свое усмотрение. Очень важно, чтобы и вначале, и в конце данного графика, все линии цветом сходились в одну точку. Сохраните откалиброванный профиль.
- Чтобы решить задачу типа «как установить цветовой профиль», откройте свойства печатающего устройства, нажмите на «Управление цветом» и одноименную кнопку. Далее в пункте выбора профиля нажмите на «добавить». После чего выберите из открывшегося списка нужный профиль и нажмите «ОК». Выделите его и установите «по умолчанию».
Другой способ решения задачи, связанной с тем, как настроить оптимальные параметры передачи цвета принтера заключается в использовании сканера. Суть такого метода заключается в том, что для начала нужно распечатать тестовую мишень, т.е. профильную карту, после чего без предварительной обработки цвета отсканировать ее. Полученный после этой процедуры файл необходимо загрузить в Adobe Photoshop, а если быть точнее – в плагине Pantone Colorvision Profilerplus. Данный плагин выполнит генерацию нового цветопрофиля в полуавтоматическом режиме. За основу будет взята разница в исходном файле и цвета эталонного изображения профильной карты.
Но данный способ решения задачи «как изменить цвет передачи принтера» имеет недостаток, которым является возможное отклонение передачи цвета сканера. Приблизить результаты к максимально подходящим можно будет с помощью плагина, используемого при первом способе профилирования принтера.
Коротко о том, как выполнить профилирование монитора
Кроме калибровки цветопередачи принтера, очень важно решить задачу, связанную с тем, как откалибровать монитор. Без налаженной связи монитор-принтер добиться оптимальных результатов будет очень сложно или и вовсе невозможно. Чтобы выполнить эту задачу можете воспользоваться заводскими настройками, установив ПО своего монитора.
Если такой профиль вам не подойдет, то для ручного создания нового варианта нужно воспользоваться калибратором (колориметром). Данная процедура состоит из замера внешнего освещения и установки первоначальных настроек с помощью регуляторов дисплея, а именно: яркости, контраста и цветовой температуры. Затем нужно сравнить те цвета, что реально воспроизводятся на экране с эталонными значениями. В конце необходимо выполнить генерацию индивидуального профиля для своего монитора, приняв во внимание внешнее освещение. Таким образом, настраивать цветопередачу дисплея под конкретные условия не так уж легко.
Профилирование со сверхсветовой скоростью: теория и практика. Часть 1 +26
Программирование, Высокая производительность, Java, Assembler, Блог компании Райффайзенбанк
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/
Привет! Из заголовка вы уже поняли, о чём я собираюсь рассказать. Тут будет много хардкора:
мы обсудим Java, С, С++, ассемблер, немного Linux, немного ядра операционной системы. А ещё разберём практический кейс, поэтому статья будет в трёх больших частях (достаточно объёмных).
В первой мы попробуем выжать всё возможное из существующих профилировщиков.
Во второй части сделаем собственный маленький профилировщик, а в третьей посмотрим, как же профилировать то, что профилировать не принято, потому что существующие инструменты не очень для этого подходят. Если готовы пройти этот путь — жду вас под катом 
Содержание
- Время и средство постижения — профилировщик
- Как работают сэмплирующие профилировщики
- С какой частотой нам нужно сэмплировать
- Выбираем профилировщик
- Учим perf собирать профиль Java-приложения
- Увеличиваем частоту сэмплирования perf’а
- Используем (явно) аппаратные события PMU/PEBS
- Короткое резюме
Время и средство постижения — профилировщик
С житейской точки зрения, 1 секунда — это очень мало. Но мы-то знаем, что 1 секунда — это целый миллиард наносекунд. И пускай за 1 наносекунду всего лишь исполняется около 4 тактов процессора, за 1 секунду в компьютере выполняется очень много всего, что может улучшить или ухудшить нам жизнь.
Допустим, мы разрабатываем приложение, которое само по себе достаточно критично к быстродействию, а для некоторых фрагментов кода это вообще критично. Эти кусочки исполняются, скажем, сотни микросекунд — достаточно быстро, но они [участки кода] напрямую влияют на успешность нашего приложения и на количество зарабатываемых или теряемых денег. Например,
при отправке ордеров на заключение биржевых сделок задержка в 100 мкс может стоить бирже 1 млн. рублей и более на каждой сделке, которых в день проходит не одна, и не две, и даже не сто.
И мне была поставлена задача: с одной стороны, нужно отправить все ордеры одновременно, а с другой стороны — отправить их так, чтобы дисперсия между первым и последним была минимальна. То есть необходимо было отпрофилировать функцию, которая отправляет ордеры на биржу. Типичная задача, кроме одного маленького нюанса: характерное время исполнения этой функции существенно меньше 100 мкс.
Давайте подумаем, как нам профилировать эти 100 мкс, чтобы понять, что происходит внутри.
Что необходимо учитывать, выбирая этот инструмент?
- Интересующий нас участок кода исполняется достаточно редко, то есть 100 мкс исполняются где-то раз в секунду. И это в тестовом стенде, а в production и того реже.
- Этот кусочек кода достаточно сложно будет выделить в микробенчмарк, потому что он затрагивает заметную часть проекта, да еще и ввод/вывод через сеть.
- И наконец, самое важное, хочется, чтобы полученный профиль соответствовал тому поведению, которое будет на наших production-серверах.
Как же нам учесть все эти нюансы и правильно отпрофилировать интересующий метод?
Концептуально, все профилировщики можно разделить на две группы профилировщиков инструментирующие или сэмплирующие. Рассмотрим каждую группу в отдельности.
Инструментирующие профилировщики вносят достаточно большие накладные расходы, потому что они модифицируют наш байт-код и вставляют в него запись таймингов. Отсюда ключевой недостаток таких профилировщиков: они могут существенно влиять на исполняемый код. В результате будет трудно сказать, насколько полученный профиль соответствует поведению на production-серверах: какие-то оптимизации могут работать иначе, какие-то случаются, а какие-то нет. Возможно, в других масштабах времени, — секунды, минуты, часы, — мы получим репрезентативные данные. Но в масштабе 100 мкс сработавшая или не сработавшая оптимизация может привести к тому, что профиль окажется совершенно не репрезентативен. Поэтому давайте присмотримся к другой группе профилировщиков.
Сэмплирующие профилировщики вносят либо минимальные, либо умеренные накладные расходы. Эти инструменты не влияют напрямую на исполняемый код, а их использование требует от вас чуть больше внимания. Поэтому остановимся именно на сэмпиирующих профилировщиках. Давайте посмотрим, какие данные и в каком виде мы будем получать от них.
Как работают сэмплирующие профилировщики?
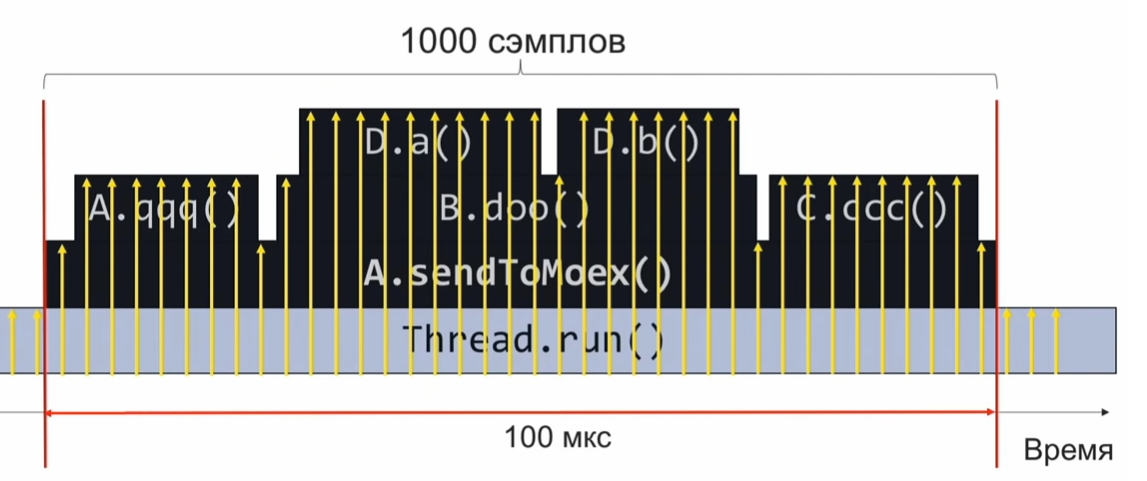
Для того, чтобы понять, как работает сэмплирующий профилировщик, рассмотрим следующий пример — метод sendToMoex вызывает несколько других методов. Смотрим:
void sendToMoex() {
a.qqq();
b.doo();
c.ccc()
}
void doo() {
d.a();
d.b();
}
Если мы будем наблюдать за состоянием стека вызовов в момент выполнения этого участка программы и периодически его записывать, то получим информацию в примерно таком виде:

Это набор стеков вызовов. Если предположить, что сэмплы распределены достаточно равномерно, то количество одинаковых стеков свидетельствует об относительном времени выполнения того метода, который находится на вершине стека.
В данном примере, метод D.a выполнялся столько же, сколько метод C.ccc, и это в 2 раза больше, чем метод D.b. Однако предположение о равномерности распределения сэмплов может оказаться не совсем верным, и тогда оценка времени выполнения будет некорректной.
С какой частотой нам нужно сэмплировать?
Допустим, мы хотим за 100 мкс взять 1000 сэмплов, чтобы понять, что там внутри исполнялось. Далее простой пропорцией вычисляем, что если нам нужно делать 1000 сэмплов в 100мкс, то это 10 млн. сэмплов за 1 секунду или 10.000.000 сэмплов/с.
Если мы будем сэмплировать на такой скорости, то за одно исполнение кода мы соберём 1000 сэмплов, агрегируем и поймём, что работало быстро или медленно. После этого будем анализировать производительность и корректировать код.
Однако частота 10 млн. сэмплов в секунду — это много. А если нам не удастся добиться такой скорости профилирования с самого начала? Допустим, мы собрали за 100 мкс всего лишь 10 сэмплов, а не 1000. В таком случае нам остается подождать следующего исполнения профилируемого кода, которое произойдет через 1 секунду (ведь профилируемый код выполняется раз в секунду). Так мы наберем ещё 10 сэмплов. Поскольку они у нас равномерно распределены, их можно объединять в общий набор. Достаточно подождать, пока профилируемый код исполнится 1000/10 = 100 раз, и мы наберём необходимые 1000 сэмплов (по 10 сэмплов каждый из 100 раз).
Выбираем профилировщик
Вооружившись этими теоретическими знаниями, давайте перейдём к практике.
Возьмём Async-profiler. Отличный инструмент (использует вызов виртуальной машины AsyncGetCallTrace), который собирает стек вызовов с точностью до инструкции байт кода виртуальной машины Java. Штатная частота сэмплирования async-profiler’а — 1000 сэмплов в секунду.
Решим простую пропорцию: 10.000.000сэмплов/сек — 1 секунда, 1000сэмплов/с — Х секунд.
Мы получим, что на штатной частоте сэмплирования async-profiler’а профилирование займет около 3 часов. Это долго. В идеале хочется собирать профиль максимально быстро, прямо-таки со сверхсветовой скоростью.
Попробуем разогнать Async-profiler. Для этого в readme находим флаг -i, который задаёт интервал сбора сэмплов. Попробуем установить флаг -i1 (1 наносекунда), или вообще -i0, чтобы профилировщик сэмплировал без остановки. У меня получилась частота около 2,5 тыс. сэмплов в секунду. В этом случае суммарная длительность профилирования составит порядка 1 часа. Конечно, не 3 часа, но и не особо быстро. Кажется, чтобы достичь требуемых скоростей профилирования нужно сделать что-то качественно другое, выйти на новый уровень.
Чтобы достичь существенно больших частот, придётся отказаться от вызова AsyncGetCallTrace и воспользоваться perf — штатным профилировщиком Linux, который есть в каждом дистрибутиве Linux’а. Однако perf ничего не знает про Java, и нам еще предстоит обучить perf работать с Java. А пока попробуем запустить perf вот таким страшным образом:
$ perf record –F 10000 -p PID -g -- sleep 1
[ perf record: Woken up 1 times to write data ]
[ perf record: .. 0.215 MB perf.data (4032 samples) ]Подробнее об обозначениях
- perf record означает, что мы хотим записать профиль.
- Флаг
-Fи аргумент 10 000 — это частота сэмплирования. - Флаг
-pговорит о том, что мы хотим профилировать только конкретный PID нашего Java-процесса. - Флаг
-gотвечает за сбор стеков вызовов. - Наконец, с помощью sleep 1 мы ограничиваем запись профиля 1 секундой.
Для чего нам нужно собирать стеки вызова? Мы профилируем всё подряд, а потом из собранных данных вытаскиваем ту часть, которая нас интересует (метод, отвечающий за формирование и отправку ордеров). Маркером, что собранный сэмпл принадлежит к интересующим нас данным, является наличие стекового кадра вызова метода sendToMoex.
Учим perf собирать профиль Java-приложения
Выполним команду perf record …, подождем 1 секунду и запустим perf script, чтобы посмотреть, что же напрофилировалось? И увидим что-то не очень понятное:
$ perf script
java 8079 2008793.746571: 3745505 cycles:uppp:
7fa1e88b53f8 [unknown] (/tmp/perf-11038.map)
java 8079 2008793.747565: 3728336 cycles:uppp:
7fa1e88b5372 [unknown] (/tmp/perf-11038.map)
java 8079 2008793.748613: 3731147 cycles:uppp:
7fa1e88b53ef [unknown] (/tmp/perf-11038.map)
Вроде бы это адреса, но нет имён Java-методов. Значит, нужно научить perf сопоставлять эти адреса с названиями методов.
В мире С и С++ для сопоставления адресов и имен функций используется так называемая отладочная информация. В специальной секции исполняемого файла хранится соответствие: по таким-то адресам лежит один метод, по другим адресам — другой метод. Perf эту информацию подтягивает и делает сопоставление.
Очевидно, что JIT-компилятор виртуальной машины не генерирует отладочную информацию в таком формате. Нам остается другой способ — записать данные о соответствии адресов и имен методов в специальный perf-map файл, который perf будет трактовать как дополнение к прочитанной отладочной информации. Этот perf-map файл должен лежать в папке tmp и иметь такую структуру данных:
Первая колонка — это адрес начала кода метода, вторая — его длина, третья колонка — имя метода.
Итак, нам нужно сгенерировать подобный файл. Очевидно, что сделать это вручную не получится (откуда мы знаем, по каким адреcам JIT-компилятор разместит код), поэтому воспользуемся скриптом create-java-perf-map.sh из проекта perf-map-agent, передав ему PID нашего Java-процесса. Файл готов, проверяем его содержимое, ещё раз запускаем perf-script.
$ perf script
java 8080 1895245.867498: cycles:uppp:
7fb2dd10f527 Loop3.doRecursiveCall (/tmp/perf-8079.map)
java 8080 1895245.868176: 2127960 cycles:uppp:
7fb2dd10f57f Loop3.doRecursiveCall (/tmp/perf-8079.map)
java 8080 1895245.868737: 1959990 cycles:uppp:
7fb2dd10f627 Loop3.doRecursiveCall (/tmp/perf-8079.map)Вуаля! Мы видим имена java-методов! Что же только что произошло: мы научили профилировщик perf, который ничего не знает про Java, профилировать обычное Java-приложение и видеть горячие java-методы этого приложения!
Однако для анализа производительности интерсующего нас куска программы нам не хватает call-stack’а, чтобы отфильтровать интересующие данные от всех собранных сэмплов.
Как получить стек вызовов?
Теперь нужно ещё что-то сделать с perf или виртуальной машиной, чтобы получить стеки вызовов. Чтобы понять, что же нужно сделать, давайте сделаем шаг назад и посмотрим, как вообще работает стек. Представим, что у нас есть три функции f1, f2, f3. Причем f1 вызывает f2, а f2 вызывает f3.
void f1() {
f2();
}
void f2() {
f3();
}
void f3() {
...
}
В момент исполнения функции f3 посмотрим, в каком состоянии находится стек. Мы видим регистр rsp, который указывает на вершину стека. Также мы знаем, что в стеке есть адрес предыдущего стекового кадра. А как можно получить call-stack?
Если бы мы могли как-то получить адрес этой области, то мы бы могли представить стек как односвязный список и понять ту последовательность вызовов, которая нас привела в текущую точку исполнения.
Что же нам для этого нужно? Нам нужен дополнительный регистр rbp, который будет указывать на желтую область. Получается, что регистр rbp позволяет perf получить стек вызовов, понять последовательность, которая нас привела в текущую точку. Подробнее эти детали рекомендую прочитать в System V Application Binary Interface. Там описано, как происходит вызов методов в Linux.

Мы поняли, в чем наша проблема. Нам нужно заставить виртуальную машину использовать регистр rbp по его изначальному назначению — в качестве указателя на начало стекового кадра. Именно так JIT-компилятор должен использовать регистр rbp. Для этого в вирутальной машине есть флажок PreserveFramePointer. Когда мы передадим виртуальной машине этот флаг, то виртуальная машина начнет использовать регистр rbp по его традиционному назначению. И тогда Perf сможет раскрутить стек. И мы получим в профиле настоящий колл-стек. Флажок был законтрибьючен небезызвестным Бренданом Греггом всего лишь в JDK8u60.
Запускаем виртуальную машину с новым флагом. Выполняем create-java-perf-map, затем perf record и perf script. Теперь мы умеем собирать точный профиль со стеками вызовов:
$ perf script
java 18657 1901247.601878: 979583 cycles:uppp:
7fbfd1101edc Loop3.doRecursiveCall (...)
7fbfd1101edc Loop3.doRecursiveCall (...)
7fbfd1101edc Loop3.doRecursiveCall (...)
7fbfd1101edc Loop3.doRecursiveCall (...)
7f285d007b10 Interpreter (...)
7f285d0004e7 call_stub (...)
67d0db [unknown] (... libjvm.so)
...
708c start_thread (... libpthread-2.26.so)
Мы научили профилировщик perf, входящий в комплект большинства дистрибутивов Linux, работать с Java-приложениями. Поэтому теперь мы можем видеть не только горячие участки кода, но и ту последовательность вызовов, которая привела к текущему горячему месту. Отличное достижение, если учесть, что профилировщик perf ничего не знает про java. Всему этому мы только что научили perf!
Увеличиваем частоту сэмплирования perf’а
Попробуем разогнать perf до 10 млн сэмплов в секунду. Сейчас у нас частота существенно меньше.
Чтобы автоматизировать все задачи, которые мы только что делали, можно воспользоваться скриптом perf-java-record-stack из проекта perf-map-agent. У него есть замечательная ручка — переменная окружения perf_record-freq, с помощью которой можно задать частоту сэмплирования. Сначала зададим 100 тыс. сэмплов в секунду и попробуем запустить. В консоли появляется грозное сообщение, что мы превысили максимально дозволенную частоту сэмплирования:
$ PERF_RECORD_FREQ=100000 ./bin/perf-java-record-stack PID
...
Maximum frequency rate (30000) reached.
Please use -F freq option with lower value or consider
tweaking /proc/sys/kernel/perf_event_max_sample_rate.
...
В моем случае лимит был в 30 тыс. сэмплов в секунду. Perf сразу говорит, какой аргумент ядра нужно поправить, что мы и сделаем либо с помощью echo sudo tee в нужный файл, либо напрямую через sysctl. Так:
$ echo '1000000' |
sudo tee /proc/sys/kernel/perf_event_max_sample_rate или так:
$ sudo sysctl kernel.perf_event_max_sample_rate=1000000
Сейчас мы говорим ядру, что верхний предел частоты теперь 1 млн. сэмплов в секунду. Запускаем профилировщик ещё раз и указываем частоту 200 тыс. сэмплов в секунду. Профилировщик проработает 15 секунд и выдаст нам 1 млн. сэмплов. Вроде бы всё хорошо. По крайней мере никаких грозных сообщений об ошибках. Но какую же частоту мы получили на самом деле? Оказывается, всего лишь 70 тыс. сэмплов в секунду. Что же пошло не так?
Давайте посмотрим вывод команды dmesg:
[84430.412898] perf: interrupt took too long (1783 > 200), lowering kernel.perf_event_max_sample_rate to 89700
...
[84431.618452] perf: interrupt took too long (2229 > 2228), lowering kernel.perf_event_max_sample_rate to 71700
Это вывод ядра ОС Linux. Оно поняло, что мы сэмплируем слишком часто, и это занимает слишком много времени, поэтому ядро понижает частоту. Получается, нам нужно выкрутить ещё одну ручку в ядре — она называется kernel.perf_cpu_time_max_percent и регулирует количество времени, которое ядро может тратить на прерывания от perf.
Закажем частоту сэмплирования 200 тыс. сэмплов в секунду. И через 15 секунд мы получаем 3 млн. сэмплов — 200 тыс. сэмплов в секунду.
$ PERF_RECORD_FREQ=200000 ./bin/perf-java-record-stack PID
Recording events for 15 seconds ...
...
[ perf record: Captured ... (2.961.252 samples) ]
Теперь посмотрим профиль. Запускаем perf script:
$ perf script
...
java ... native_write_msr (/.../vmlinux)
java ... Loop2.main (/tmp/perf-29621.map)
java ... native_write_msr (/.../vmlinux)
...
Видим странные функции и исполняемый модуль vmlinux — ядро Linux. Это точно не наш код. Что же произошло? Частота оказалась настолько большой, что в сэмплы начал попадать код ядра. То есть чем выше мы будем поднимать частоту, тем больше будет сэмплов, которые относятся не к нашему коду, а к ядру Linux.
Тупик.
Используем (явно) аппаратные события PMU/PEBS
Тогда я решил попробовать воспользоваться аппаратной технологией PMU/PEBS — Performance Monitoring Unit, Precise Event Based Sampling. Она позволяет получать уведомления о том, что какое-то событие произошло заданное количество раз. Это называется «период». Например, мы можем получать уведомления об исполнении процессором каждой 20-й инструкции. Давайте посмотрим это на примере. Пусть сейчас исполняется инструкция xor, а PMU-счётчик получает значение 18; затем идёт инструкция mov — счётчик равен 19; и следующую инструкцию, add %r14, %r13, PMU будет показывать как «горячую».
Дальше начинается новый цикл: исполняется inc — PMU сбрасывается до 1. Проходит ещё несколько итераций цикла. В итоге мы останавливаемся на инструкции mov, PMU отщелкивает 19. Следующая инструкция add, и опять мы помечаем её как «горячую». Смотрим листинг:
mov aaa, bbbb
xor %rdx, %rdx
L_START:
mov $0x0(%rbx, %rdx),%r14
add %r14, %r13 ; (PMU будет показывать только эту инструкцию как "горячую")
cmp %rdx,100000000
jne L_STARTНе замечаете странностей? Цикл из пяти инструкций, но каждый раз мы помечаем одну и ту же инструкцию как горячую. Очевидно, что это неправда: все инструкции «горячие». На них тоже тратится время, а мы помечаем только одну. Дело в том, что у нас между периодом и счетчиком количества инструкций в итерации есть общий делитель 4. Получается, каждую четвёртую итерацию мы будем помечать одну и ту же инструкцию как «горячую». Чтобы избежать такого поведения, нужно в качестве периода выбирать такое число, при котором минимизируется вероятность появления общего делителя между количеством итераций в цикле и самим счётчиком. В идеале период должен быть простым числом, т.е. делиться только на себя и на единицу. Для примера выше: следовало бы выбрать период равный 23. Тогда бы мы поровну помечали все инструкции в этом цикле как «горячие».
Технология PMU/PEBS поддерживается в современном виде как минимум с 2009 года, то есть она есть почти на любых компьютерах. Чтобы применить ее явно, давайте модифицируем скрипт perf-java-record-stack. Заменим флаг -F на -e, который явным образом задаёт использование PMU/PEBS.
...
sudo perf record -F $PERF_RECORD_FREQ ...
...Перевоплощаем скрипт:
...
sudo perf record -e cycles –c 10007 ...
...Вы уже знаете, какими свойствами должен обладать период — нам нужно простое число. Для нашего случая это будет период 10007.
Запустили модифицированный скрипт perf-java-record-stack и за 15 секунд получили 4,5 млн. сэмплов — это почти 300 тыс. в секунду, по одному сэмплу каждые 3 мкс. То есть за одно исполнение нашего профилированного кода, за 100 мкс мы будем набирать 33 сэмпла. При такой частоте общая длительность сбора профиля составит всего лишь 30 секунд. Даже чашку кофе не выпить! В реальности же всё немного сложнее. Что будет, если наш код станет исполняться не раз в секунду, а раз в 5 секунд? Тогда длительность профилирования вырастет до 2,5 минут, что тоже вполне достойный результат.
Итак, за 30 секунд можно получить профиль, который полностью покроет все наши потребности в исследовании. Победа?
Но меня не покидало ощущение какого-то подвоха. Вернемся к ситуации, при которой наш код исполняется раз в 5 секунд. Тогда профилирование займёт 150 секунд, за это время мы соберем около 45 млн. сэмплов. Из них нам нужны лишь 1000, то есть 0,002 % собранных данных. Всё остальное — мусор, который замедляет работу других инструментов и добавляет накладные расходы. Да, задача решена, но решена в лоб, грязно, тупой силой.
И в тот вечер, когда я впервые получил с помощью perf’а такой подробный профиль, у меня появилась мечта. Я шел с работы домой и думал, а вот бы было хорошо, если железо умело само собирать профиль да еще и с точностью до инфтрукций и микросекунд, а мы бы только анализировали результаты. Сбудется ли моя мечта? Как вы думаете?
Короткое резюме:
- Чтобы собрать профиль Java-приложения с помощью perf’а необходимо сгенерировать файл с информацией о символах с помощью скриптов из проекта perf-map-agent
- Чтобы собирать информацию не только про горячие участки кода, но и стеки, нужно запускать виртуальную машину с флагом -XX:+PreserveFramePointer
- Если хочется увеличить частоту сэмплирования, стоит обратить внимание на sysctl’и kernel.perf_cpu_time_max_percent и kernel.perf_event_max_sample_rate.
- Если в профиль начали попадать сэмплы из ядра, не относящиеся к приложению, стоит задуматься о явном указании периода PMU/PEBS.
Эта статья (и последующие её части) является расшифровкой доклада, адаптированного в текстовом виде. Если хочется не только прочитать, но и послушать про профилирование, ссылочка на выступление.