О чем данный учебник
Данный учебник представляет собой что-то типа «штампа моей памяти» по языку SQL (DDL, DML), т.е. это информация, которая накопилась по ходу профессиональной деятельности и постоянно хранится в моей голове. Это для меня достаточный минимум, который применяется при работе с базами данных наиболее часто. Если встает необходимость применять более полные конструкции SQL, то я обычно обращаюсь за помощью в библиотеку MSDN расположенную в интернет. На мой взгляд, удержать все в голове очень сложно, да и нет особой необходимости в этом. Но знать основные конструкции очень полезно, т.к. они применимы практически в таком же виде во многих реляционных базах данных, таких как Oracle, MySQL, Firebird. Отличия в основном состоят в типах данных, которые могут отличаться в деталях. Основных конструкций языка SQL не так много, и при постоянной практике они быстро запоминаются. Например, для создания объектов (таблиц, ограничений, индексов и т.п.) достаточно иметь под рукой текстовый редактор среды (IDE) для работы с базой данных, и нет надобности изучать визуальный инструментарий заточенный для работы с конкретным типом баз данных (MS SQL, Oracle, MySQL, Firebird, …). Это удобно и тем, что весь текст находится перед глазами, и не нужно бегать по многочисленным вкладкам для того чтобы создать, например, индекс или ограничение. При постоянной работе с базой данных, создать, изменить, а особенно пересоздать объект при помощи скриптов получается в разы быстрее, чем если это делать в визуальном режиме. Так же в скриптовом режиме (соответственно, при должной аккуратности), проще задавать и контролировать правила наименования объектов (мое субъективное мнение). К тому же скрипты удобно использовать в случае, когда изменения, делаемые в одной базе данных (например, тестовой), необходимо перенести в таком же виде в другую базу (продуктивную).
Язык SQL подразделяется на несколько частей, здесь я рассмотрю 2 наиболее важные его части:
- DDL – Data Definition Language (язык описания данных)
- DML – Data Manipulation Language (язык манипулирования данными), который содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
Т.к. я являюсь практиком, как таковой теории в данном учебнике будет мало, и все конструкции будут объясняться на практических примерах. К тому же я считаю, что язык программирования, а особенно SQL, можно освоить только на практике, самостоятельно пощупав его и поняв, что происходит, когда вы выполняете ту или иную конструкцию.
Данный учебник создан по принципу Step by Step, т.е. необходимо читать его последовательно и желательно сразу же выполняя примеры. Но если по ходу у вас возникает потребность узнать о какой-то команде более детально, то используйте конкретный поиск в интернет, например, в библиотеке MSDN.
При написании данного учебника использовалась база данных MS SQL Server версии 2014, для выполнения скриптов я использовал MS SQL Server Management Studio (SSMS).
Кратко о MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) — утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. Данный текст частично позаимствован с википедии.
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:
Для смены текущей базы данных можно использовать выпадающий список:
Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.
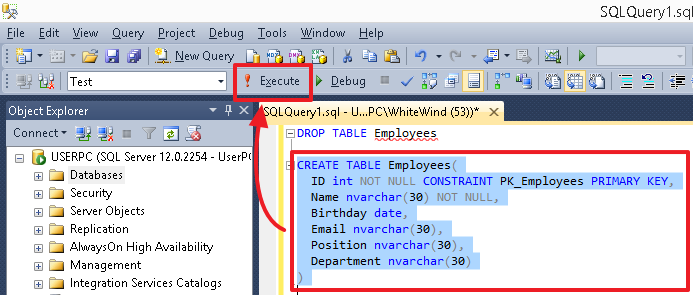
После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.

Собственно, это все, что нам необходимо будет знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории
Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой. Если говорить грубо, то БД – файл в котором данные хранятся в структурированном виде.
СУБД – Система Управления этими Базами Данных, т.е. это комплекс инструментов для работы с конкретным типом БД (MS SQL, Oracle, MySQL, Firebird, …).
Примечание
Т.к. в жизни, в разговорной речи, мы по большей части говорим: «БД Oracle», или даже просто «Oracle», на самом деле подразумевая «СУБД Oracle», то в контексте данного учебника иногда будет употребляться термин БД. Из контекста, я думаю, будет понятно, о чем именно идет речь.
Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица – это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи – тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.
Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов.
Для справки – в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
SQL — язык позволяющий осуществлять запросы в БД посредством СУБД. В конкретной СУБД, язык SQL может иметь специфичную реализацию (свой диалект).
DDL и DML — подмножество языка SQL:
- Язык DDL служит для создания и модификации структуры БД, т.е. для создания/изменения/удаления таблиц и связей.
- Язык DML позволяет осуществлять манипуляции с данными таблиц, т.е. с ее строками. Он позволяет делать выборку данных из таблиц, добавлять новые данные в таблицы, а так же обновлять и удалять существующие данные.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
-- однострочный комментарий
и
/*
многострочный
комментарий
*/
Собственно, все для теории этого будет достаточно.
DDL – Data Definition Language (язык описания данных)
Для примера рассмотрим таблицу с данными о сотрудниках, в привычном для человека не являющимся программистом виде:
| Табельный номер | ФИО | Дата рождения | Должность | Отдел | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | i.ivanov@test.tt | Директор | Администрация |
| 1001 | Петров П.П. | 03.12.1983 | p.petrov@test.tt | Программист | ИТ |
| 1002 | Сидоров С.С. | 07.06.1976 | s.sidorov@test.tt | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | 17.04.1982 | a.andreev@test.tt | Старший программист | ИТ |
В данном случае столбцы таблицы имеют следующие наименования: Табельный номер, ФИО, Дата рождения, E-mail, Должность, Отдел.
Каждый из этих столбцов можно охарактеризовать по типу содержащемся в нем данных:
- Табельный номер – целое число
- ФИО – строка
- Дата рождения – дата
- E-mail – строка
- Должность – строка
- Отдел – строка
Тип столбца – характеристика, которая говорит о том какого рода данные может хранить данный столбец.
Для начала будет достаточно запомнить только следующие основные типы данных используемые в MS SQL:
| Значение | Обозначение в MS SQL | Описание |
|---|---|---|
| Строка переменной длины | varchar(N) и nvarchar(N) |
При помощи числа N, мы можем указать максимально возможную длину строки для соответствующего столбца. Например, если мы хотим сказать, что значение столбца «ФИО» может содержать максимум 30 символов, то необходимо задать ей тип nvarchar(30). Отличие varchar от nvarchar заключается в том, что varchar позволяет хранить строки в формате ASCII, где один символ занимает 1 байт, а nvarchar хранит строки в формате Unicode, где каждый символ занимает 2 байта. Тип varchar стоит использовать только в том случае, если вы на 100% уверены, что в данном поле не потребуется хранить Unicode символы. Например, varchar можно использовать для хранения адресов электронной почты, т.к. они обычно содержат только ASCII символы. |
| Строка фиксированной длины | char(N) и nchar(N) |
От строки переменной длины данный тип отличается тем, что если длина строка меньше N символов, то она всегда дополняется справа до длины N пробелами и сохраняется в БД в таком виде, т.е. в базе данных она занимает ровно N символов (где один символ занимает 1 байт для char и 2 байта для типа nchar). На моей практике данный тип очень редко находит применение, а если и используется, то он используется в основном в формате char(1), т.е. когда поле определяется одним символом. |
| Целое число | int | Данный тип позволяет нам использовать в столбце только целые числа, как положительные, так и отрицательные. Для справки (сейчас это не так актуально для нас) – диапазон чисел который позволяет тип int от -2 147 483 648 до 2 147 483 647. Обычно это основной тип, который используется для задания идентификаторов. |
| Вещественное или действительное число | float | Если говорить простым языком, то это числа, в которых может присутствовать десятичная точка (запятая). |
| Дата | date | Если в столбце необходимо хранить только Дату, которая состоит из трех составляющих: Числа, Месяца и Года. Например, 15.02.2014 (15 февраля 2014 года). Данный тип можно использовать для столбца «Дата приема», «Дата рождения» и т.п., т.е. в тех случаях, когда нам важно зафиксировать только дату, или, когда составляющая времени нам не важна и ее можно отбросить или если она не известна. |
| Время | time | Данный тип можно использовать, если в столбце необходимо хранить только данные о времени, т.е. Часы, Минуты, Секунды и Миллисекунды. Например, 17:38:31.3231603 Например, ежедневное «Время отправления рейса». |
| Дата и время | datetime | Данный тип позволяет одновременно сохранить и Дату, и Время. Например, 15.02.2014 17:38:31.323 Для примера это может быть дата и время какого-нибудь события. |
| Флаг | bit | Данный тип удобно применять для хранения значений вида «Да»/«Нет», где «Да» будет сохраняться как 1, а «Нет» будет сохраняться как 0. |
Так же значение поля, в том случае если это не запрещено, может быть не указано, для этой цели используется ключевое слово NULL.
Для выполнения примеров создадим тестовую базу под названием Test.
Простую базу данных (без указания дополнительных параметров) можно создать, выполнив следующую команду:
CREATE DATABASE Test
Удалить базу данных можно командой (стоит быть очень осторожным с данной командой):
DROP DATABASE Test
Для того, чтобы переключиться на нашу базу данных, можно выполнить команду:
USE Test
Или же выберите базу данных Test в выпадающем списке в области меню SSMS. При работе мною чаще используется именно этот способ переключения между базами.
Теперь в нашей БД мы можем создать таблицу используя описания в том виде как они есть, используя пробелы и символы кириллицы:
CREATE TABLE [Сотрудники](
[Табельный номер] int,
[ФИО] nvarchar(30),
[Дата рождения] date,
[E-mail] nvarchar(30),
[Должность] nvarchar(30),
[Отдел] nvarchar(30)
)
В данном случае нам придется заключать имена в квадратные скобки […].
Но в базе данных для большего удобства все наименования объектов лучше задавать на латинице и не использовать в именах пробелы. В MS SQL обычно в данном случае каждое слово начинается с прописной буквы, например, для поля «Табельный номер», мы могли бы задать имя PersonnelNumber. Так же в имени можно использовать цифры, например, PhoneNumber1.
На заметку
В некоторых СУБД более предпочтительным может быть следующий формат наименований «PHONE_NUMBER», например, такой формат часто используется в БД ORACLE. Естественно при задании имя поля желательно чтобы оно не совпадало с ключевыми словами используемые в СУБД.
По этой причине можете забыть о синтаксисе с квадратными скобками и удалить таблицу [Сотрудники]:
DROP TABLE [Сотрудники]
Например, таблицу с сотрудниками можно назвать «Employees», а ее полям можно задать следующие наименования:
- ID – Табельный номер (Идентификатор сотрудника)
- Name – ФИО
- Birthday – Дата рождения
- Email – E-mail
- Position – Должность
- Department – Отдел
Очень часто для наименования поля идентификатора используется слово ID.
Теперь создадим нашу таблицу:
CREATE TABLE Employees(
ID int,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Для того, чтобы задать обязательные для заполнения столбцы, можно использовать опцию NOT NULL.
Для уже существующей таблицы поля можно переопределить при помощи следующих команд:
-- обновление поля ID
ALTER TABLE Employees ALTER COLUMN ID int NOT NULL
-- обновление поля Name
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
На заметку
Общая концепция языка SQL для большинства СУБД остается одинаковой (по крайней мере, об этом я могу судить по тем СУБД, с которыми мне довелось поработать). Отличие DDL в разных СУБД в основном заключаются в типах данных (здесь могут отличаться не только их наименования, но и детали их реализации), так же может немного отличаться и сама специфика реализации языка SQL (т.е. суть команд одна и та же, но могут быть небольшие различия в диалекте, увы, но одного стандарта нет). Владея основами SQL вы легко сможете перейти с одной СУБД на другую, т.к. вам в данном случае нужно будет только разобраться в деталях реализации команд в новой СУБД, т.е. в большинстве случаев достаточно будет просто провести аналогию.Чтобы не быть голословным, приведу несколько примеров тех же команд для СУБД ORACLE:
-- создание таблицы CREATE TABLE Employees( ID int, -- в ORACLE тип int - это эквивалент(обертка) для number(38) Name nvarchar2(30), -- nvarchar2 в ORACLE эквивалентен nvarchar в MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- обновление полей ID и Name (здесь вместо ALTER COLUMN используется MODIFY(…)) ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- добавление PK (в данном случае конструкция выглядит как и в MS SQL, она будет показана ниже) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);Для ORACLE есть отличия в плане реализации типа varchar2, его кодировка зависит настроек БД и текст может сохраняться, например, в кодировке UTF-8. Помимо этого длину поля в ORACLE можно задать как в байтах, так и в символах, для этого используются дополнительные опции BYTE и CHAR, которые указываются после длины поля, например:
NAME varchar2(30 BYTE) -- вместимость поля будет равна 30 байтам NAME varchar2(30 CHAR) -- вместимость поля будет равна 30 символовКакая опция будет использоваться по умолчанию BYTE или CHAR, в случае простого указания в ORACLE типа varchar2(30), зависит от настроек БД, так же она иногда может задаваться в настройках IDE. В общем порой можно легко запутаться, поэтому в случае ORACLE, если используется тип varchar2 (а это здесь порой оправдано, например, при использовании кодировки UTF-8) я предпочитаю явно прописывать CHAR (т.к. обычно длину строки удобнее считать именно в символах).
Но в данном случае если в таблице уже есть какие-нибудь данные, то для успешного выполнения команд необходимо, чтобы во всех строках таблицы поля ID и Name были обязательно заполнены. Продемонстрируем это на примере, вставим в таблицу данные в поля ID, Position и Department, это можно сделать следующим скриптом:
INSERT Employees(ID,Position,Department) VALUES
(1000,N'Директор',N'Администрация'),
(1001,N'Программист',N'ИТ'),
(1002,N'Бухгалтер',N'Бухгалтерия'),
(1003,N'Старший программист',N'ИТ')
В данном случае, команда INSERT также выдаст ошибку, т.к. при вставке мы не указали значения обязательного поля Name.
В случае, если бы у нас в первоначальной таблице уже имелись эти данные, то команда «ALTER TABLE Employees ALTER COLUMN ID int NOT NULL» выполнилась бы успешно, а команда «ALTER TABLE Employees ALTER COLUMN Name int NOT NULL» выдала сообщение об ошибке, что в поле Name имеются NULL (не указанные) значения.
Добавим значения для полю Name и снова зальем данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Так же опцию NOT NULL можно использовать непосредственно при создании новой таблицы, т.е. в контексте команды CREATE TABLE.
Сначала удалим таблицу при помощи команды:
DROP TABLE Employees
Теперь создадим таблицу с обязательными для заполнения столбцами ID и Name:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Можно также после имени столбца написать NULL, что будет означать, что в нем будут допустимы NULL-значения (не указанные), но этого делать не обязательно, так как данная характеристика подразумевается по умолчанию.
Если требуется наоборот сделать существующий столбец необязательным для заполнения, то используем следующий синтаксис команды:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Или просто:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Так же данной командой мы можем изменить тип поля на другой совместимый тип, или же изменить его длину. Для примера давайте расширим поле Name до 50 символов:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Первичный ключ
При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки – по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» — пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).
Создать первичный ключ к уже существующей таблице можно при помощи команды:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
Где «PK_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK_» после которого идет имя таблицы.
Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1,поле2,…)
Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.
Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
DROP TABLE Employees
А затем создадим ее, используя следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
CONSTRAINT PK_Employees PRIMARY KEY(ID) -- описываем PK после всех полей, как ограничение
)
После создания зальем в таблицу данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Если первичный ключ в таблице состоит только из значений одного столбца, то можно использовать следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- указываем как характеристику поля
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK__Employee__3214EC278DA42077»):
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
PRIMARY KEY(ID)
)
Или:
CREATE TABLE Employees(
ID int NOT NULL PRIMARY KEY,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.
Подытожим
На данный момент мы рассмотрели следующие команды:
- CREATE TABLE имя_таблицы (перечисление полей и их типов, ограничений) – служит для создания новой таблицы в текущей БД;
- DROP TABLE имя_таблицы – служит для удаления таблицы из текущей БД;
- ALTER TABLE имя_таблицы ALTER COLUMN имя_столбца … – служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL);
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1, поле2,…) – добавление первичного ключа к уже существующей таблице;
- ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения – удаление ограничения из таблицы.
Немного про временные таблицы
Вырезка из MSDN. В MS SQL Server существует два вида временных таблиц: локальные (#) и глобальные (##). Локальные временные таблицы видны только их создателям до завершения сеанса соединения с экземпляром SQL Server, как только они впервые созданы. Локальные временные таблицы автоматически удаляются после отключения пользователя от экземпляра SQL Server. Глобальные временные таблицы видны всем пользователям в течение любых сеансов соединения после создания этих таблиц и удаляются, когда все пользователи, ссылающиеся на эти таблицы, отключаются от экземпляра SQL Server.
Временные таблицы создаются в системной базе tempdb, т.е. создавая их мы не засоряем основную базу, в остальном же временные таблицы полностью идентичны обычным таблицам, их так же можно удалить при помощи команды DROP TABLE. Чаще используются локальные (#) временные таблицы.
Для создания временной таблицы можно использовать команду CREATE TABLE:
CREATE TABLE #Temp(
ID int,
Name nvarchar(30)
)
Так как временная таблица в MS SQL аналогична обычной таблице, ее соответственно так же можно удалить самому командой DROP TABLE:
DROP TABLE #Temp
Так же временную таблицу (как собственно и обычную таблицу) можно создать и сразу заполнить данными возвращаемые запросом используя синтаксис SELECT … INTO:
SELECT ID,Name
INTO #Temp
FROM Employees
На заметку
В разных СУБД реализация временных таблиц может отличаться. Например, в СУБД ORACLE и Firebird структура временных таблиц должна быть определена заранее командой CREATE GLOBAL TEMPORARY TABLE с указанием специфики хранения в ней данных, дальше уже пользователь видит ее среди основных таблиц и работает с ней как с обычной таблицей.
Нормализация БД – дробление на подтаблицы (справочники) и определение связей
Наша текущая таблица Employees имеет недостаток в том, что в полях Position и Department пользователь может ввести любой текст, что в первую очередь чревато ошибками, так как он у одного сотрудника может указать в качестве отдела просто «ИТ», а у второго сотрудника, например, ввести «ИТ-отдел», у третьего «IT». В итоге будет непонятно, что имел ввиду пользователь, т.е. являются ли данные сотрудники работниками одного отдела, или же пользователь описался и это 3 разных отдела? А тем более, в этом случае, мы не сможем правильно сгруппировать данные для какого-то отчета, где, может требоваться показать количество сотрудников в разрезе каждого отдела.
Второй недостаток заключается в объеме хранения данной информации и ее дублированием, т.е. для каждого сотрудника указывается полное наименование отдела, что требует в БД места для хранения каждого символа из названия отдела.
Третий недостаток – сложность обновления данных полей, в случае если изменится название какой-то должности, например, если потребуется переименовать должность «Программист», на «Младший программист». В данном случае нам придется вносить изменения в каждую строчку таблицы, у которой Должность равняется «Программист».
Чтобы избежать данных недостатков и применяется, так называемая, нормализация базы данных – дробление ее на подтаблицы, таблицы справочники. Не обязательно лезть в дебри теории и изучать что из себя представляют нормальные формы, достаточно понимать суть нормализации.
Давайте создадим 2 таблицы справочники «Должности» и «Отделы», первую назовем Positions, а вторую соответственно Departments:
CREATE TABLE Positions(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
CREATE TABLE Departments(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
Заметим, что здесь мы использовали новую опцию IDENTITY, которая говорит о том, что данные в столбце ID будут нумероваться автоматически, начиная с 1, с шагом 1, т.е. при добавлении новых записей им последовательно будут присваиваться значения 1, 2, 3, и т.д. Такие поля обычно называют автоинкрементными. В таблице может быть определено только одно поле со свойством IDENTITY и обычно, но необязательно, такое поле является первичным ключом для данной таблицы.
На заметку
В разных СУБД реализация полей со счетчиком может делаться по своему. В MySQL, например, такое поле определяется при помощи опции AUTO_INCREMENT. В ORACLE и Firebird раньше данную функциональность можно было съэмулировать при помощи использования последовательностей (SEQUENCE). Но насколько я знаю в ORACLE сейчас добавили опцию GENERATED AS IDENTITY.
Давайте заполним эти таблицы автоматически, на основании текущих данных записанных в полях Position и Department таблицы Employees:
-- заполняем поле Name таблицы Positions, уникальными значениями из поля Position таблицы Employees
INSERT Positions(Name)
SELECT DISTINCT Position
FROM Employees
WHERE Position IS NOT NULL -- отбрасываем записи у которых позиция не указана
То же самое проделаем для таблицы Departments:
INSERT Departments(Name)
SELECT DISTINCT Department
FROM Employees
WHERE Department IS NOT NULL
Если теперь мы откроем таблицы Positions и Departments, то увидим пронумерованный набор значений по полю ID:
SELECT * FROM Positions
| ID | Name |
|---|---|
| 1 | Бухгалтер |
| 2 | Директор |
| 3 | Программист |
| 4 | Старший программист |
SELECT * FROM Departments
| ID | Name |
|---|---|
| 1 | Администрация |
| 2 | Бухгалтерия |
| 3 | ИТ |
Данные таблицы теперь и будут играть роль справочников для задания должностей и отделов. Теперь мы будем ссылаться на идентификаторы должностей и отделов. В первую очередь создадим новые поля в таблице Employees для хранения данных идентификаторов:
-- добавляем поле для ID должности
ALTER TABLE Employees ADD PositionID int
-- добавляем поле для ID отдела
ALTER TABLE Employees ADD DepartmentID int
Тип ссылочных полей должен быть каким же, как и в справочниках, в данном случае это int.
Так же добавить в таблицу сразу несколько полей можно одной командой, перечислив поля через запятую:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Теперь пропишем ссылки (ссылочные ограничения — FOREIGN KEY) для этих полей, для того чтобы пользователь не имел возможности записать в данные поля, значения, отсутствующие среди значений ID находящихся в справочниках.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID
FOREIGN KEY(PositionID) REFERENCES Positions(ID)
И то же самое сделаем для второго поля:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID
FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Теперь пользователь в данные поля сможет занести только значения ID из соответствующего справочника. Соответственно, чтобы использовать новый отдел или должность, он первым делом должен будет добавить новую запись в соответствующий справочник. Т.к. должности и отделы теперь хранятся в справочниках в одном единственном экземпляре, то чтобы изменить название, достаточно изменить его только в справочнике.
Имя ссылочного ограничения, обычно является составным, оно состоит из префикса «FK_», затем идет имя таблицы и после знака подчеркивания идет имя поля, которое ссылается на идентификатор таблицы-справочника.
Идентификатор (ID) обычно является внутренним значением, которое используется только для связей и какое значение там хранится, в большинстве случаев абсолютно безразлично, поэтому не нужно пытаться избавиться от дырок в последовательности чисел, которые возникают по ходу работы с таблицей, например, после удаления записей из справочника.
Так же в некоторых случаях ссылку можно организовать по нескольким полям:
ALTER TABLE таблица ADD CONSTRAINT имя_ограничения
FOREIGN KEY(поле1,поле2,…) REFERENCES таблица_справочник(поле1,поле2,…)
В данном случае в таблице «таблица_справочник» первичный ключ представлен комбинацией из нескольких полей (поле1, поле2,…).
Собственно, теперь обновим поля PositionID и DepartmentID значениями ID из справочников. Воспользуемся для этой цели DML командой UPDATE:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Посмотрим, что получилось, выполнив запрос:
SELECT * FROM Employees
| ID | Name | Birthday | Position | Department | PositionID | DepartmentID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | Директор | Администрация | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | Программист | ИТ | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | Бухгалтер | Бухгалтерия | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | Старший программист | ИТ | 4 | 3 |
Всё, поля PositionID и DepartmentID заполнены соответствующие должностям и отделам идентификаторами надобности в полях Position и Department в таблице Employees теперь нет, можно удалить эти поля:
ALTER TABLE Employees DROP COLUMN Position,Department
Теперь таблица у нас приобрела следующий вид:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | 4 | 3 |
Т.е. мы в итоге избавились от хранения избыточной информации. Теперь, по номерам должности и отдела можем однозначно определить их названия, используя значения в таблицах-справочниках:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON d.ID=e.DepartmentID
LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
|---|---|---|---|
| 1000 | Иванов И.И. | Директор | Администрация |
| 1001 | Петров П.П. | Программист | ИТ |
| 1002 | Сидоров С.С. | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | Старший программист | ИТ |
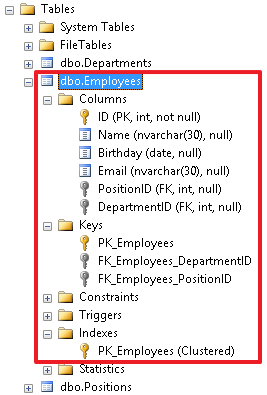
В инспекторе объектов мы можем увидеть все объекты, созданные для в данной таблицы. Отсюда же можно производить разные манипуляции с данными объектами – например, переименовывать или удалять объекты.
Так же стоит отметить, что таблица может ссылаться сама на себя, т.е. можно создать рекурсивную ссылку. Для примера добавим в нашу таблицу с сотрудниками еще одно поле ManagerID, которое будет указывать на сотрудника, которому подчиняется данный сотрудник. Создадим поле:
ALTER TABLE Employees ADD ManagerID int
В данном поле допустимо значение NULL, поле будет пустым, если, например, над сотрудником нет вышестоящих.
Теперь создадим FOREIGN KEY на таблицу Employees:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID
FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Давайте, теперь создадим диаграмму и посмотрим, как выглядят на ней связи между нашими таблицами:
В результате мы должны увидеть следующую картину (таблица Employees связана с таблицами Positions и Depertments, а так же ссылается сама на себя):
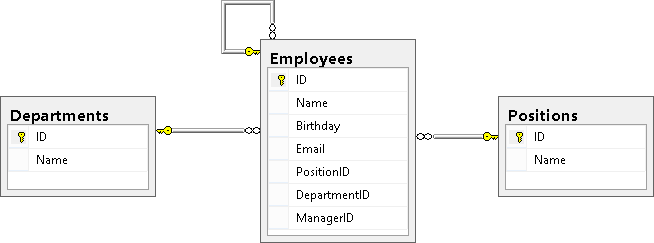
Напоследок стоит сказать, что ссылочные ключи могут включать дополнительные опции ON DELETE CASCADE и ON UPDATE CASCADE, которые говорят о том, как вести себя при удалении или обновлении записи, на которую есть ссылки в таблице-справочнике. Если эти опции не указаны, то мы не можем изменить ID в таблице справочнике у той записи, на которую есть ссылки из другой таблицы, так же мы не сможем удалить такую запись из справочника, пока не удалим все строки, ссылающиеся на эту запись или, же обновим в этих строках ссылки на другое значение.
Для примера пересоздадим таблицу с указанием опции ON DELETE CASCADE для FK_Employees_DepartmentID:
DROP TABLE Employees
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
ON DELETE CASCADE,
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
)
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
Удалим отдел с идентификатором 3 из таблицы Departments:
DELETE Departments WHERE ID=3
Посмотрим на данные таблицы Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Сидоров С.С. | 1976-06-07 | NULL | 1 | 2 | 1000 |
Как видим, данные по отделу 3 из таблицы Employees так же удалились.
Опция ON UPDATE CASCADE ведет себя аналогично, но действует она при обновлении значения ID в справочнике. Например, если мы поменяем ID должности в справочнике должностей, то в этом случае будет производиться обновление DepartmentID в таблице Employees на новое значение ID которое мы задали в справочнике. Но в данном случае это продемонстрировать просто не получится, т.к. у колонки ID в таблице Departments стоит опция IDENTITY, которая не позволит нам выполнить следующий запрос (сменить идентификатор отдела 3 на 30):
UPDATE Departments
SET
ID=30
WHERE ID=3
Главное понять суть этих 2-х опций ON DELETE CASCADE и ON UPDATE CASCADE. Я применяю эти опции очень в редких случаях и рекомендую хорошо подумать, прежде чем указывать их в ссылочном ограничении, т.к. при нечаянном удалении записи из таблицы справочника это может привести к большим проблемам и создать цепную реакцию.
Восстановим отдел 3:
-- даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(3,N'ИТ')
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments OFF
Полностью очистим таблицу Employees при помощи команды TRUNCATE TABLE:
TRUNCATE TABLE Employees
И снова перезальем в нее данные используя предыдущую команду INSERT:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
Подытожим
На данным момент к нашим знаниям добавилось еще несколько команд DDL:
- Добавление свойства IDENTITY к полю – позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы;
- ALTER TABLE имя_таблицы ADD перечень_полей_с_характеристиками – позволяет добавить новые поля в таблицу;
- ALTER TABLE имя_таблицы DROP COLUMN перечень_полей – позволяет удалить поля из таблицы;
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY(поля) REFERENCES таблица_справочник(поля) – позволяет определить связь между таблицей и таблицей справочником.
Прочие ограничения – UNIQUE, DEFAULT, CHECK
При помощи ограничения UNIQUE можно сказать что значения для каждой строки в данном поле или в наборе полей должно быть уникальным. В случае таблицы Employees, такое ограничение мы можем наложить на поле Email. Только предварительно заполним Email значениями, если они еще не определены:
UPDATE Employees SET Email='i.ivanov@test.tt' WHERE ID=1000
UPDATE Employees SET Email='p.petrov@test.tt' WHERE ID=1001
UPDATE Employees SET Email='s.sidorov@test.tt' WHERE ID=1002
UPDATE Employees SET Email='a.andreev@test.tt' WHERE ID=1003
А теперь можно наложить на это поле ограничение-уникальности:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Теперь пользователь не сможет внести один и тот же E-Mail у нескольких сотрудников.
Ограничение уникальности обычно именуется следующим образом – сначала идет префикс «UQ_», далее название таблицы и после знака подчеркивания идет имя поля, на которое накладывается данное ограничение.
Соответственно если уникальной в разрезе строк таблицы должна быть комбинация полей, то перечисляем их через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE(поле1,поле2,…)
При помощи добавления к полю ограничения DEFAULT мы можем задать значение по умолчанию, которое будет подставляться в случае, если при вставке новой записи данное поле не будет перечислено в списке полей команды INSERT. Данное ограничение можно задать непосредственно при создании таблицы.
Давайте добавим в таблицу Employees новое поле «Дата приема» и назовем его HireDate и скажем что значение по умолчанию у данного поля будет текущая дата:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
Или если столбец HireDate уже существует, то можно использовать следующий синтаксис:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
Здесь я не указал имя ограничения, т.к. в случае DEFAULT у меня сложилось мнение, что это не столь критично. Но если делать по-хорошему, то, думаю, не нужно лениться и стоит задать нормальное имя. Делается это следующим образом:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
Та как данного столбца раньше не было, то при его добавлении в каждую запись в поле HireDate будет вставлено текущее значение даты.
При добавлении новой записи, текущая дата так же будет вставлена автоматом, конечно если мы ее явно не зададим, т.е. не укажем в списке столбцов. Покажем это на примере, не указав поле HireDate в перечне добавляемых значений:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Сергеев С.С.','s.sergeev@test.tt')
Посмотрим, что получилось:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Сергеев С.С. | NULL | s.sergeev@test.tt | NULL | NULL | NULL | 2015-04-08 |
Проверочное ограничение CHECK используется в том случае, когда необходимо осуществить проверку вставляемых в поле значений. Например, наложим данное ограничение на поле табельный номер, которое у нас является идентификатором сотрудника (ID). При помощи данного ограничения скажем, что табельные номера должны иметь значение от 1000 до 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
Ограничение обычно именуется так же, сначала идет префикс «CK_», затем имя таблицы и имя поля, на которое наложено это ограничение.
Попробуем вставить недопустимую запись для проверки, что ограничение работает (мы должны получить соответствующую ошибку):
INSERT Employees(ID,Email) VALUES(2000,'test@test.tt')
А теперь изменим вставляемое значение на 1500 и убедимся, что запись вставится:
INSERT Employees(ID,Email) VALUES(1500,'test@test.tt')
Можно так же создать ограничения UNIQUE и CHECK без указания имени:
ALTER TABLE Employees ADD UNIQUE(Email)
ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Но это не очень хорошая практика и лучше задавать имя ограничения в явном виде, т.к. чтобы разобраться потом, что будет сложнее, нужно будет открывать объект и смотреть, за что он отвечает.
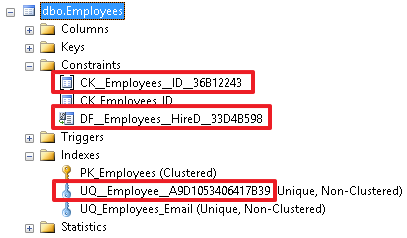
При хорошем наименовании много информации об ограничении можно узнать непосредственно по его имени.
И, соответственно, все эти ограничения можно создать сразу же при создании таблицы, если ее еще нет. Удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL DEFAULT SYSDATETIME(), -- для DEFAULT я сделаю исключение
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT UQ_Employees_Email UNIQUE (Email),
CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3)
Немного про индексы, создаваемые при создании ограничений PRIMARY KEY и UNIQUE
Как можно увидеть на скриншоте выше, при создании ограничений PRIMARY KEY и UNIQUE автоматически создались индексы с такими же названиями (PK_Employees и UQ_Employees_Email). По умолчанию индекс для первичного ключа создается как CLUSTERED, а для всех остальных индексов как NONCLUSTERED. Стоит сказать, что понятие кластерного индекса есть не во всех СУБД. Таблица может иметь только один кластерный (CLUSTERED) индекс. CLUSTERED – означает, что записи таблицы будут сортироваться по этому индексу, так же можно сказать, что этот индекс имеет непосредственный доступ ко всем данным таблицы. Это так сказать главный индекс таблицы. Если сказать еще грубее, то это индекс, прикрученный к таблице. Кластерный индекс – это очень мощное средство, которое может помочь при оптимизации запросов, пока просто запомним это. Если мы хотим сказать, чтобы кластерный индекс использовался не в первичном ключе, а для другого индекса, то при создании первичного ключа мы должны указать опцию NONCLUSTERED:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения
PRIMARY KEY NONCLUSTERED(поле1,поле2,…)
Для примера сделаем индекс ограничения PK_Employees некластерным, а индекс ограничения UQ_Employees_Email кластерным. Первым делом удалим данные ограничения:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
А теперь создадим их с опциями CLUSTERED и NONCLUSTERED:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID)
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Теперь, выполнив выборку из таблицы Employees, мы увидим, что записи отсортировались по кластерному индексу UQ_Employees_Email:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
|---|---|---|---|---|---|---|
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 |
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 |
До этого, когда кластерным индексом был индекс PK_Employees, записи по умолчанию сортировались по полю ID.
Но в данном случае это всего лишь пример, который показывает суть кластерного индекса, т.к. скорее всего к таблице Employees будут делаться запросы по полю ID и в каких-то случаях, возможно, она сама будет выступать в роли справочника.
Для справочников обычно целесообразно, чтобы кластерный индекс был построен по первичному ключу, т.к. в запросах мы часто ссылаемся на идентификатор справочника для получения, например, наименования (Должности, Отдела). Здесь вспомним, о чем я писал выше, что кластерный индекс имеет прямой доступ к строкам таблицы, а отсюда следует, что мы можем получить значение любого столбца без дополнительных накладных расходов.
Кластерный индекс выгодно применять к полям, по которым выборка идет наиболее часто.
Иногда в таблицах создают ключ по суррогатному полю, вот в этом случае бывает полезно сохранить опцию CLUSTERED индекс для более подходящего индекса и указать опцию NONCLUSTERED при создании суррогатного первичного ключа.
Подытожим
На данном этапе мы познакомились со всеми видами ограничений, в их самом простом виде, которые создаются командой вида «ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения …»:
- PRIMARY KEY – первичный ключ;
- FOREIGN KEY – настройка связей и контроль ссылочной целостности данных;
- UNIQUE – позволяет создать уникальность;
- CHECK – позволяет осуществлять корректность введенных данных;
- DEFAULT – позволяет задать значение по умолчанию;
- Так же стоит отметить, что все ограничения можно удалить, используя команду «ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения».
Так же мы частично затронули тему индексов и разобрали понятие кластерный (CLUSTERED) и некластерный (NONCLUSTERED) индекс.
Создание самостоятельных индексов
Под самостоятельностью здесь имеются в виду индексы, которые создаются не для ограничения PRIMARY KEY или UNIQUE.
Индексы по полю или полям можно создавать следующей командой:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Так же здесь можно указать опции CLUSTERED, NONCLUSTERED, UNIQUE, а так же можно указать направление сортировки каждого отдельного поля ASC (по умолчанию) или DESC:
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
При создании некластерного индекса опцию NONCLUSTERED можно отпустить, т.к. она подразумевается по умолчанию, здесь она показана просто, чтобы указать позицию опции CLUSTERED или NONCLUSTERED в команде.
Удалить индекс можно следующей командой:
DROP INDEX IDX_Employees_Name ON Employees
Простые индексы так же, как и ограничения, можно создать в контексте команды CREATE TABLE.
Для примера снова удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями и индексами одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1,NULL),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3,1003),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2,1000),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3,1000)
Дополнительно стоит отметить, что в некластерный индекс можно включать значения при помощи указания их в INCLUDE. Т.е. в данном случае INCLUDE-индекс чем-то будет напоминать кластерный индекс, только теперь не индекс прикручен к таблице, а необходимые значения прикручены к индексу. Соответственно, такие индексы могут очень повысить производительность запросов на выборку (SELECT), если все перечисленные поля имеются в индексе, то возможно обращений к таблице вообще не понадобится. Но это естественно повышает размер индекса, т.к. значения перечисленных полей дублируются в индексе.
Вырезка из MSDN. Общий синтаксис команды для создания индексов
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Подытожим
Индексы могут повысить скорость выборки данных (SELECT), но индексы уменьшают скорость модификации данных таблицы, т.к. после каждой модификации системе будет необходимо перестроить все индексы для конкретной таблицы.
Желательно в каждом случае найти оптимальное решение, золотую середину, чтобы и производительность выборки, так и модификации данных была на должном уровне. Стратегия по созданию индексов и их количества может зависеть от многих факторов, например, насколько часто изменяются данные в таблице.
Заключение по DDL
Как можно увидеть, язык DDL не так сложен, как может показаться на первый взгляд. Здесь я смог показать практически все его основные конструкции, оперируя всего тремя таблицами.
Главное — понять суть, а остальное дело практики.
Удачи вам в освоении этого замечательного языка под названием SQL.
Часть вторая — habrahabr.ru/post/255523
Установка
Когда вы изучаете новый язык, самым важным аспектом является практика. Одно дело – прочитать статью и совсем другое – применить полученную информацию. Давайте начнем с установки базы данных на компьютер.
Первый шаг – установить SQL
Мы будем использовать PostgreSQL (Postgres) – достаточно распространенный SQL диалект. Для этого откроем страницу загрузки, выберем операционную систему (в моем случае Windows), и запустим установку. Если вы установите пароль для вашей базы данных, постарайтесь сразу не забыть его, он нам дальше понадобится. Поскольку наша база будет локальной, можете использовать простой пароль, например: admin.
Следующий шаг – установка pgAdmin
pgAdmin – это графический интерфейс пользователя (GUI – graphical user interface), который упрощает взаимодействие с базой данных PostgreSQL. Перейдите на страницу загрузки, выберите вашу операционную систему и следуйте указаниям (в статье используется Postgres 14 и pgAdmin 4 v6.3.).
После установки обоих компонентов открываем pgAdmin и нажимаем Add new server. На этом шаге установится соединение с существующим сервером, именно поэтому необходимо сначала установить Postgres. Я назвал свой сервер home и использовал пароль, указанный при установке.
Теперь всё готово к созданию таблиц. Давайте создадим набор таблиц, которые моделируют школу. Нам необходимы таблицы: ученики, классы, оценки. При создании модели данных необходимо учитывать, что в одном классе может быть много учеников, а у ученика может быть много оценок (такое отношение называется «один ко многим»).
Мы можем создать таблицы напрямую в pgAdmin, но вместо этого мы напишем код, который можно будет использовать в дальнейшем, например, для пересоздания таблиц. Для создания запроса, который создаст наши таблицы, нажимаем правой кнопкой мыши на postgres (пункт расположен в меню слева home → Databases (1) → postgres и далее выбираем Query Tool.
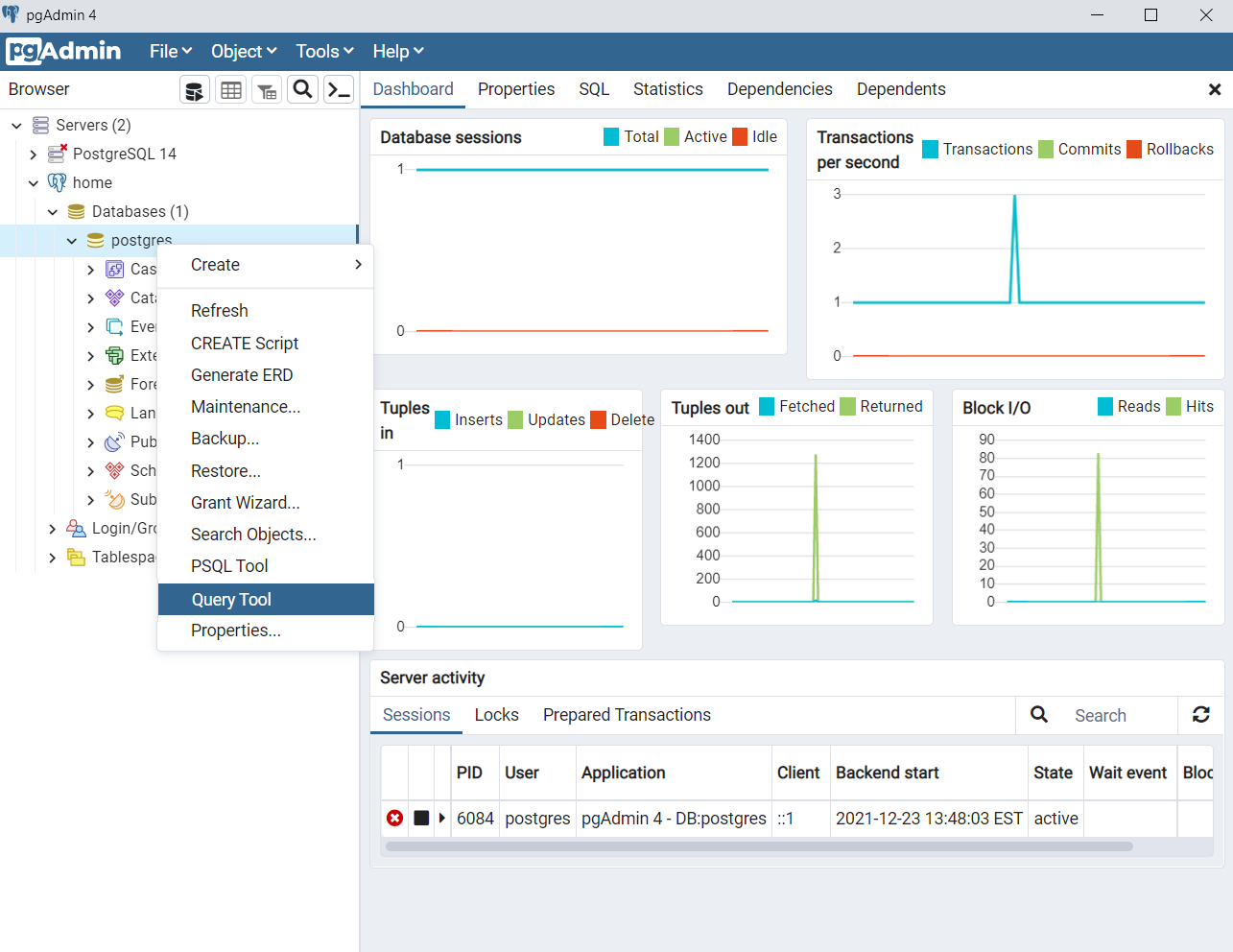
Начнем с создания таблицы классов (classrooms). Таблица будет простой: она будет содержать идентификатор id и имя учителя – teacher. Напишите следующий код в окне запроса (query tool) и запустите (run или F5).
DROP TABLE IF EXISTS classrooms CASCADE;
CREATE TABLE classrooms (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
teacher VARCHAR(100)
);
В первой строке фрагмент DROP TABLE IF EXISTS classrooms удалит таблицу classrooms, если она уже существует. Важно учитывать, что Postgres, не позволит нам удалить таблицу, если она имеет связи с другими таблицами, поэтому, чтобы обойти это ограничение (constraint) в конце строки добавлен оператор CASCADE. CASCADE – автоматически удалит или изменит строки из зависимой таблицы, при внесении изменений в главную. В нашем случае нет ничего страшного в удалении таблицы, поскольку, если мы на это пошли, значит мы будем пересоздавать всё с нуля, и остальные таблицы тоже удалятся.
Добавление DROP TABLE IF EXISTS перед CREATE TABLE позволит нам систематизировать схему нашей базы данных и создать скрипты, которые будут очень удобны, если мы захотим внести изменения – например, добавить таблицу, изменить тип данных поля и т. д. Для этого нам просто нужно будет внести изменения в уже готовый скрипт и перезапустить его.
Ничего нам не мешает добавить наш код в систему контроля версий. Весь код для создания базы данных из этой статьи вы можете посмотреть по ссылке.
Также вы могли обратить внимание на четвертую строчку. Здесь мы определили, что колонка id является первичным ключом (primary key), что означает следующее: в каждой записи в таблице это поле должно быть заполнено и каждое значение должно быть уникальным. Чтобы не пришлось постоянно держать в голове, какое значение id уже было использовано, а какое – нет, мы написали GENERATED ALWAYS AS IDENTITY, этот приём является альтернативой синтаксису последовательности (CREATE SEQUENCE). В результате при добавлении записей в эту таблицу нам нужно будет просто добавить имя учителя.
И в пятой строке мы определили, что поле teacher имеет тип данных VARCHAR (строка) с максимальной длиной 100 символов. Если в будущем нам понадобится добавить в таблицу учителя с более длинным именем, нам придется либо использовать инициалы, либо изменять таблицу (alter table).
Теперь давайте создадим таблицу учеников (students). Новая таблица будет содержать: уникальный идентификатор (id), имя ученика (name), и внешний ключ (foreign key), который будет указывать (references) на таблицу классов.
DROP TABLE IF EXISTS students CASCADE;
CREATE TABLE students (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
name VARCHAR(100),
classroom_id INT,
CONSTRAINT fk_classrooms
FOREIGN KEY(classroom_id)
REFERENCES classrooms(id)
);
И снова мы перед созданием новой таблицы удаляем старую, если она существует, добавляем поле id, которое автоматически увеличивает своё значение и имя с типом данных VARCHAR (строка) и максимальной длиной 100 символов. Также в эту таблицу мы добавили колонку с идентификатором класса (classroom_id), и с седьмой по девятую строку установили, что ее значение указывает на колонку id в таблице классов (classrooms).
Мы определили, что classroom_id является внешним ключом. Это означает, что мы задали правила, по которым данные будут записываться в таблицу учеников (students). То есть Postgres на данном этапе не позволит нам вставить строку с данными в таблицу учеников (students), в которой указан идентификатор класса (classroom_id), не существующий в таблице classrooms. Например: у нас в таблице классов 10 записей (id с 1 до 10), система не даст нам вставить данные в таблицу учеников, у которых указан идентификатор класса 11 и больше.
INSERT INTO students
(name, classroom_id)
VALUES
('Matt', 1);
/*
ERROR: insert or update on table "students" violates foreign
key constraint "fk_classrooms"
DETAIL: Key (classroom_id)=(1) is not present in table
"classrooms".
SQL state: 23503
*/
Теперь давайте добавим немного данных в таблицу классов (classrooms). Так как мы определили, что значение в поле id будет увеличиваться автоматически, нам нужно только добавить имена учителей.
INSERT INTO classrooms
(teacher)
VALUES
('Mary'),
('Jonah');
SELECT * FROM classrooms;
/*
id | teacher
-- | -------
1 | Mary
2 | Jonah
*/
Прекрасно! Теперь у нас есть записи в таблице классов, и мы можем добавить данные в таблицу учеников, а также установить нужные связи (с таблицей классов).
INSERT INTO students
(name, classroom_id)
VALUES
('Adam', 1),
('Betty', 1),
('Caroline', 2);
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
*/
Но что же случится, если у нас появится новый ученик, которому ещё не назначили класс? Неужели нам придется ждать, пока станет известно в каком он классе, и только после этого добавить его запись в базу данных?
Конечно же, нет. Мы установили внешний ключ, и он будет блокировать запись, поскольку ссылка на несуществующий id класса невозможна, но мы можем в качестве идентификатора класса (classroom_id) передать null. Это можно сделать двумя способами: указанием null при записи значений, либо просто передачей только имени.
-- явно определим значение NULL
INSERT INTO students
(name, classroom_id)
VALUES
('Dina', NULL);
-- неявно определим значение NULL
INSERT INTO students
(name)
VALUES
('Evan');
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
4 | Dina | [null]
5 | Evan | [null]
*/
И наконец, давайте заполним таблицу успеваемости. Этот параметр, как правило, формируется из нескольких составляющих – домашние задания, участие в проектах, посещаемость и экзамены. Мы будем использовать две таблицы. Таблица заданий (assignments), как понятно из названия, будет содержать данные о самих заданиях, и таблица оценок (grades), в которой мы будем хранить данные о том, как ученик выполнил эти задания.
DROP TABLE IF EXISTS assignments CASCADE;
DROP TABLE IF EXISTS grades CASCADE;
CREATE TABLE assignments (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
category VARCHAR(20),
name VARCHAR(200),
due_date DATE,
weight FLOAT
);
CREATE TABLE grades (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
assignment_id INT,
score INT,
student_id INT,
CONSTRAINT fk_assignments
FOREIGN KEY(assignment_id)
REFERENCES assignments(id),
CONSTRAINT fk_students
FOREIGN KEY(student_id)
REFERENCES students(id)
);
Вместо того чтобы вставлять данные вручную, давайте загрузим их с помощью CSV-файла. Вы можете скачать файл из этого репозитория или создать его самостоятельно. Имейте в виду, чтобы разрешить pgAdmin доступ к данным, вам может понадобиться расширить права доступа к папке (в моем случае – это папка db_data).
COPY assignments(category, name, due_date, weight)
FROM 'C:/Users/mgsosna/Desktop/db_data/assignments.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 5
Query returned successfully in 118 msec.
*/
COPY grades(assignment_id, score, student_id)
FROM 'C:/Users/mgsosna/Desktop/db_data/grades.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 25
Query returned successfully in 64 msec.
*/
Теперь давайте проверим, что мы всё сделали верно. Напишем запрос, который покажет среднюю оценку, по каждому виду заданий с группировкой по учителям.
SELECT
c.teacher,
a.category,
ROUND(AVG(g.score), 1) AS avg_score
FROM
students AS s
INNER JOIN classrooms AS c
ON c.id = s.classroom_id
INNER JOIN grades AS g
ON s.id = g.student_id
INNER JOIN assignments AS a
ON a.id = g.assignment_id
GROUP BY
1,
2
ORDER BY
3 DESC;
/*
teacher | category | avg_score
------- | --------- | ---------
Jonah | project | 100.0
Jonah | homework | 94.0
Jonah | exam | 92.5
Mary | homework | 78.3
Mary | exam | 76.0
Mary | project | 69.5
*/
Отлично! Мы установили, настроили и наполнили базу данных.
***
Итак, в этой статье мы научились:
- создавать базу данных;
- создавать таблицы;
- наполнять таблицы данными;
- устанавливать связи между таблицами;
Теперь у нас всё готово, чтобы пробовать более сложные возможности SQL. Мы начнем с возможностей синтаксиса, которые, вероятно, вам еще не знакомы и которые откроют перед вами новые границы в написании SQL-запросов. Также мы разберем некоторый виды соединений таблиц (JOIN) и способы организации запросов в тех случаях, когда они занимают десятки или даже сотни строк.
В следующей части мы разберем:
- виды фильтраций в запросах;
- запросы с условиями типа if-else;
- новые виды соединений таблиц;
- функции для работы с массивами;
Материалы по теме
- 🐘 8 лучших GUI клиентов PostgreSQL в 2021 году
- 🐍🐬 Python и MySQL: практическое введение
- 🐍🗄️ Управление данными с помощью Python, SQLite и SQLAlchemy
Данный документ поможет пользователю в настройке и использовании MySQL.
Начало работы с MySQL
Введение
MySQL — это популярный сервер баз данных, используемый в разных приложениях. SQL означает язык структурированных запросов — (S)tructured (Q)uery (L)anguage, который MySQL использует для коммуникации с другими программами. Сверх того, MySQL имеет свои собственные расширенные функции SQL для того чтобы обеспечить пользователям дополнительный функционал. В этом документе мы рассмотрим как провести первоначальную установку MySQL, настроить базы данных и таблицы, и создать новых пользователей. Давайте начнем с установки.
Установка MySQL
Сначала убедитесь что MySQL установлен на вашу систему. В случае если вам требуется определенная функциональность MySQL, убедитесь, что установлены необходимые USE-флаги, так как они помогут в тонкой настройке инсталляции.
По завершении установки, вы увидите следующее уведомление:
КОД Сообщение einfo MySQL
You might want to run: "emerge --config =dev-db/mysql-[version]" if this is a new install.
Так как это новая установка, мы запустим эту команду. Вам надо нажать ENTER по запросу во время конфигурации базы данных MySQL. В процессе конфигурации устанавливается основная база данных MySQL, которая содержит служебную информацию, такую как базы данных, таблицы, пользователи, разрешения и т.д. В процессе конфигурации рекомендуется чтобы вы изменили свой пароль root так быстро, как это возможно. Мы определенно это сделаем, иначе кто-нибудь сможет волей случая появиться и взломать сервер MySQL, настроенный по умолчанию.
root #emerge --config =dev-db/mysql-[version]
* MySQL DATADIR is /var/lib/mysql * Press ENTER to create the mysql database and set proper * permissions on it, or Control-C to abort now... Preparing db table Preparing host table Preparing user table Preparing func table Preparing tables_priv table Preparing columns_priv table Installing all prepared tables To start mysqld at boot time you have to copy support-files/mysql.server to the right place for your system PLEASE REMEMBER TO SET A PASSWORD FOR THE MySQL root USER ! To do so, issue the following commands to start the server and change the applicable passwords: /etc/init.d/mysql start /usr/bin/mysqladmin -u root -h pegasos password 'new-password' /usr/bin/mysqladmin -u root password 'new-password' Depending on your configuration, a -p option may be needed in the last command. See the manual for more details.
Заметка
Если предыдущая команда не выполнится из-за того, что имя хоста установлено в localhost, измените его на другое имя, например gentoo. Обновите файл /etc/conf.d/hostname и перезапустите /etc/init.d/hostname.
Некоторая нехарактерная для ebuild-файлов информация MySQL удалена отсюда, чтобы содержать этот документ настолько последовательным, насколько возможно.
Важно
Начиная с mysql-4.0.24-r2, пароли вводятся во время этапа конфигурации, что делает пароль root более надежным.
Сценарий конфигурации уже вывел команды, которые нам нужно запустить, чтобы настроить наш пароль, поэтому нам сейчас надо их выполнить.
Если вы используете OpenRC, выполните данную команду:
root #/etc/init.d/mysql start
* Re-caching dependency info (mtimes differ)... * Starting mysqld (/etc/mysql/my.cnf) ... [ ok ]
Если вы используете systemd, вместо этого используйте следующую команду:
root #systemctl restart mysqld.service
With >=dev-db/mariadb-10.1.18, use:
root #systemctl restart mariadb.service
После этого установите пароль root:
root #/usr/bin/mysqladmin -u root -h localhost password 'new-password'
Теперь вы можете проверить, что пароль root был успешно настроен, попытавшись войти на MySQL-сервер:
user $mysql -u root -h localhost -p
Enter password: Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 4 to server version: 4.0.25 Type 'help;' or 'h' for help. Type 'c' to clear the buffer. mysql>
Параметр -u указывает пользователя, который будет выполнять вход. Параметр -h указывает хост. Обычно это будет localhost, если только вы не настраиваете удаленный сервер. И, наконец, -p сообщает клиенту mysql что вы будете вводить пароль для доступа к базе данных. Обратите внимание на приглашение mysql>. Это то место, где вы будете вводить все ваши команды. Теперь, когда мы в командной строке mysql в качестве пользователя root, мы можем начать настраивать нашу базу данных.
Важно
Установка mysql по умолчанию приемлема для систем разработки. Для более безопасных значений по умолчанию можно запустить /usr/bin/mysql_secure_installation
Настройка Базы Данных
Создание Базы Данных
Мы вошли и приглашение mysql показано на экране. Сначала, давайте рассмотрим базы данных, которые у нас имеются в настоящий момент. Чтобы это сделать, мы используем команду SHOW DATABASES.
mysql>SHOW DATABASES;
+----------+ | Database | +----------+ | mysql | | test | +----------+ 2 rows in set (0.09 sec)
Важно
Пожалуйста, запомните что команды MySQL должны оканчиваться точкой с запятой — ;
Вопреки тому факту, что тестовая база данных уже создана, мы собираемся создать нашу собственную. Базы данных создаются с использованием команды CREATE DATABASE. Мы создадим одну из них под названием gentoo.
mysql>CREATE DATABASE gentoo;
Query OK, 1 row affected (0.08 sec)
Ответ позволяет нам узнать, что команда была выполнена без ошибок. В этом случае, одна строка была изменена. Это является отсылкой к основной базе данных mysql, которая содержит список всех баз данных. Вам не нужно сильно беспокоиться о второстепенных деталях. Последнее число является характеристикой того, насколько быстро был выполнен запрос. Мы можем проверить, что база данных была создана, запустив команду SHOW DATABASES снова.
mysql>SHOW DATABASES;
+----------+ | Database | +----------+ | gentoo | | mysql | | test | +----------+ 3 rows in set (0.00 sec)
В самом деле, наша база данных была создана. Для того чтобы работать с созданием таблиц для нашей новой базы данных gentoo, нам надо выбрать ее в качестве текущей базы данных. Чтобы это сделать, мы используем команду USE. Команда USE принимает имя базы данных, которую вы хотите использовать в качестве текущей. Другой возможностью является ее установка в командной строке после параметра -D. Давайте продолжим и переключимся к базе данных gentoo.
mysql>USE gentoo;
Database changed
Сейчас, текущей базой данных является созданная нами ранее база данных gentoo. Теперь, когда мы ей пользуемся, мы можем начать создавать таблицы и заполнять их информацией.
Работа с таблицами в MySQL
Создание таблицы
В структуру MySQL входят базы данных, таблицы, записи, и поля. Базы данных объединяют таблицы, таблицы объединяют записи, записи объединяют поля, которые содержат действительную информацию. Такая структура позволяет пользователям выбирать как они хотят обращаться к своей информации. На данный момент, мы разобрались с базами данных, теперь давайте поработаем с таблицами. Во-первых, таблицы могут быть перечислены, подобно базам данных, с использованием команды SHOW TABLES. Сейчас, в базе данных gentoo не имеется таблиц, как и показывает нам следующая команда:
mysql>SHOW TABLES;
Empty set (0.00 sec)
Это означает нам надо создать какие-либо таблицы. Чтобы это сделать, мы используем команду CREATE TABLE. Однако, эта команда достаточно отличается от простой команды CREATE DATABASE тем что принимает список аргументов. Формат команды следует ниже:
КОД Синтаксис CREATE TABLE
CREATE TABLE [table_name] ([field_name] [field_data_type]([size]));
table_name — это имя таблицы, которую мы хотим создать. В данном случае, давайте создадим таблицу с именем developers . Эта таблица будет хранить имя разработчика, email адрес и его должность.
field_name будет хранить имя поля. В этом случае мы имеем три требуемых имени: имя разработчика, email адрес, и должность.
field_data_type — это то, какой тип информации будет сохранен. Различные доступные форматы могут быть найдены по адресу MySQL Column Types Page . Для наших целей, мы будем использовать тип данных VARCHAR для всех наших полей. VARCHAR — это один из простейших типов данных, когда дело касается работы со строками.
size — это то, как много данных будет хранить одно поле. В нашем случае, мы будем использовать 128. Это означает, что поле будет иметь данные типа VARCHAR, которые занимают 128 байт. В настоящий момент, вы можете спокойно думать об этом как о 128 символах, хотя существует более техническое объяснение, которое вам предоставит сайт, указанный выше. Теперь, когда мы знаем как мы создадим таблицу, давайте это сделаем.
mysql>CREATE TABLE developers ( name VARCHAR(128), email VARCHAR(128), job VARCHAR(128));
Query OK, 0 rows affected (0.11 sec)
Похоже, наша таблица была успешно создана. Давайте проверим это командой SHOW TABLES:
mysql>SHOW TABLES;
+------------------+ | Tables_in_gentoo | +------------------+ | developers | +------------------+ 1 row in set (0.00 sec)
Да, наша таблица существует. Однако, она, по-видимому, не имеет никакой информации о типах полей, которые мы создали. Для этого, мы используем команду DESCRIBE (или, кратко, DESC), которая принимает имя таблицы в качестве своих аргументов. Давайте посмотрим что она нам даст для нашей таблицы developers.
mysql>DESCRIBE developers;
+-------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+-------+ | name | varchar(128) | YES | | NULL | | | email | varchar(128) | YES | | NULL | | | job | varchar(128) | YES | | NULL | | +-------+--------------+------+-----+---------+-------+ 3 rows in set (0.00 sec)
Показаны разные поля и их типы. Также показано несколько дополнительных атрибутов, которые находятся за рамками данного руководства. Пожалуйста, обратитесь за подробностями к Справочному Руководству MySQL . Теперь у нас есть таблица для работы с ней. Давайте продолжим и заполним ее.
Заполнение Базы Данных MySQL
Мы заполним таблицу (или добавим в нее данные), используя команду INSERT. Подобно команде CREATE TABLE, она также имеет особый формат:
КОД Синтаксис INSERT
INSERT INTO table (col1, col2, ...) VALUES('value1', 'value2', ...);
Эта команда используется для вставки записи в таблицу. table содержит таблицу MySQL, в которую мы хотим ввести информацию. Имя таблицы может сопровождаться списком столбцов для вставки данных, VALUES() хранит значения, которые вы хотите вставить в таблицу. Вы можете опустить список столбцов, если вы вставляете значение в каждый из них и если Вы пишете значения в том же порядке, в котором определены столбцы. В данном случае, мы хотим вставить данные в таблицу developers. Давайте добавим примеры записей:
mysql>INSERT INTO developers VALUES('Joe Smith', 'joesmith@gentoo.org', 'toolchain');
Query OK, 1 row affected (0.06 sec)
## (Если вы не знаете порядок столбцов в таблице или хотите вставить неполную запись)
mysql> INSERT INTO developers (job, name) VALUES('outsourced', 'Jane Doe');
Query OK, 1 row affected (0.01 sec)
В соответствии с полученным результатом, кажется, запись была вставлена правильно. Что если мы хотим ввести больше, чем просто одну запись? Это тот случай, когда команда LOAD DATA вступает в действие. Она загружает записи из файла, разделенного символами табуляции. Давайте это попробуем, отредактировав файл в домашнем каталоге пользователя и добавив в него записи. Мы назовем этот файл records.txt . Здесь приведен пример:
КОД ~/records.txt
John Doe johndoe@gentoo.org portage Chris White chriswhite@gentoo.org documentation Sam Smith samsmith@gentoo.org amd64
Важно
Убедитесь, что вы знаете, с какими данными вы будете работать. Очень небезопасно использовать LOAD DATA, когда вы не уверены насчет содержимого файла!
Команда LOAD DATA имеет в каком-то смысле пространное определение, но здесь мы используем ее самую простую форму.
КОД Синтаксис LOAD DATA
LOAD DATA LOCAL INFILE '/path/to/filename' INTO TABLE table;
/path/to/filename — это каталог и имя файла, которые будут использоваться. table — это имя нашей таблицы. В этом случае, наш файл — ~/records.txt, а имя таблицы — developers.
mysql>LOAD DATA LOCAL INFILE '~/records.txt' INTO TABLE developers;
Query OK, 3 rows affected (0.00 sec) Records: 3 Deleted: 0 Skipped: 0 Warnings: 0
Важно
Если вы обнаружили какое-либо странное поведение, убедитесь, что поля разделены символами табуляции. Если вы вставите информацию в ваш исходный файл из другого источника, это может конвертировать символы табуляции в пробелы.
Сработало хорошо. Однако, это просто вставляет записи, и не дает вам какого-либо контроля над MySQL. Множество веб-приложений используют скрипты sql для того чтобы настроить MySQL быстро и легко. Если вы хотите использовать скрипты sql, вам нужно запустить mysql в пакетном режиме, или использовать файл в качестве источника команд. Здесь приведен пример запуска mysql в пакетном режиме:
user $mysql -u root -h localhost -p < sqlfile
Как и в случае с LOAD DATA, убедитесь, что вы можете сказать что делает файл sqlfile. Невозможность этого может скомпрометировать вашу базу данных! Другим способом выполнения этого является использование команды source. Эта команда запустит команды из файла sql, находясь в интерактивном режиме mysql. Здесь показано как использовать sql file в качестве источника команд:
Если вы видите, что веб-приложение требует запуск sql файла, две команды выше могут быть использованы для выполнения данной задачи. Мы настроили нашу таблицу, как же нам проверить наши поля? Мы выполним это поиском в нашей таблице с помощью запросов.
Запросы к Таблицам MySQL
Запросы являются одной из основных функций любой базы данных SQL. Они помогают превратить данные в таблицах во что-то полезное. Большинство запросов выполняются командой SELECT . Команда SELECT — довольно сложна, и мы рассмотрим только три основных формы этой команды в данном документе.
КОД Виды команды SELECT
## (Выбрать все записи в таблице) SELECT * FROM table; ## (Выбрать определенные записи в таблице) SELECT * FROM table WHERE field=value; ## (Выбрать определенные поля) SELECT field1,field2,field3 FROM table [WHERE field=value];
Давайте-ка быстро рассмотрим первую форму команды. Она относительно проста и дает общее представление о вашей таблице. Мы продолжим и запустим ее, чтобы посмотреть какие данные у нас есть в настоящий момент.
mysql>SELECT * FROM developers;
+-------------+-----------------------+----------------+ | name | email | job | +-------------+-----------------------+----------------+ | Joe Smith | joesmith@gentoo.org | toolchain | | John Doe | johndoe@gentoo.org | portage | | Chris White | chriswhite@gentoo.org | documentation | | Sam Smith | samsmith@gentoo.org | amd64 | | Jane Doe | NULL | Outsourced job | +-------------+-----------------------+----------------+ 5 rows in set (0.00 sec)
Мы видим как данные, которые мы добавили с INSERT, так и вставленные LOAD DATA. Теперь, давайте предположим что мы просто хотим посмотреть запись для Chris White. Мы можем сделать это с помощью второй формы команды select, как показано ниже.
mysql>SELECT * FROM developers WHERE name = 'Chris White';
+-------------+-----------------------+---------------+ | name | email | job | +-------------+-----------------------+---------------+ | Chris White | chriswhite@gentoo.org | documentation | +-------------+-----------------------+---------------+ 1 row in set (0.08 sec)
Как предполагалось, выбрана отдельная запись, которую мы искали. Теперь, предположим, мы только хотели узнать должность и email адрес данной персоны, но не ее имя. Мы можем это выполнить с помощью третьей формы SELECT , как здесь и показано.
mysql>SELECT email,job FROM developers WHERE name = 'Chris White';
+-----------------------+---------------+ | email | job | +-----------------------+---------------+ | chriswhite@gentoo.org | documentation | +-----------------------+---------------+ 1 row in set (0.04 sec)
Этот способ выбора намного легче в управлении, особенно с большими объемами информации, как мы увидим позже. А сейчас, будучи mysql пользователем root, мы обладаем неограниченными разрешениями делать с базой данных MySQL то, что мы захотим. В среде выполнения сервера, наличие пользователя с такими привилегиями может вызвать немало проблем. Для того, чтобы контролировать кто и что может делать с базами данных, мы установим привилегии.
Привилегии MySQL
Привилегии — это то, каким доступом обладают пользователи к базам данных, таблицам, почти ко всему. На данный момент в базе данных gentoo, учетная запись MySQL root — это единственная учетная запись, которая может получить к ней доступ, учитывая ее разрешения. Теперь, давайте создадим двух обычных пользователей, guest и admin, которые получат доступ к базе данных gentoo и будут работать с информацией, хранящейся в ней. Учетная запись guest будет ограниченной в правах. Все, что он сможет сделать, это получить информацию из базы данных, и только это. admin будет иметь те же самые права на управление, что и root, но только к базе данных gentoo (а не основным базам данных mysql). Перед тем как начать, давайте рассмотрим подробнее этот, в некотором смысле, упрощенный формат команды GRANT.
Creating users
The CREATE USER SQL statement will define users and set the authentication method, commonly by password but other plugins may be available.
An example CREATE USER command is:
КОД CREATE USER Syntax
CREATE USER '[user]'@'[host]' IDENTIFIED BY '[password]';
user is the name of the user and host is the hostname the user will be accessing from. In most cases, this will be localhost. To create our users for this example:
(admin)
mysql>CREATE USER 'admin'@'localhost' IDENTIFIED BY 'password';
(guest)
mysql>CREATE USER 'guest'@'localhost' IDENTIFIED BY 'password';
Важно
A host of ‘localhost’ does not mean DNS localhost (127.0.0.1) to MySQL. Instead, it refers to the UNIX socket connection and not TCP/IP.
Предоставление Привилегий Командой GRANT
Let’s have a closer look at this somewhat simplified format of the GRANT command.
КОД Синтаксис команды GRANT
GRANT [privileges] ON database.* TO '[user]'@'[host]' IDENTIFIED BY '[password]';
Во-первых, мы имеем привилегии, которые мы хотим назначить. Исходя из того что мы выучили на данный момент, имеются несколько привилегий, которые вы можете установить:
ALL— Дает полный контроль базы данных со всеми привилегиямиCREATE— Позволяет пользователям создавать таблицыSELECT— Позволяет пользователям делать запросы к таблицамINSERT— Позволяет пользователям вставлять данные в таблицуSHOW DATABASES— Позволяет пользователям просматривать список баз данныхUSAGE— Пользователь не имеет привилегийGRANT OPTION— Позволяет пользователям предоставлять привилегии
Заметка
Если вы запустили MySQL чтобы передавать данные веб-приложению, CREATE, SELECT, INSERT (обсуждалось здесь же), DELETE и UPDATE (для получения дальнейшей информации посмотрите раздел Справочного Руководства MySQL — Синтаксис GRANT и REVOKE) — это единственные разрешения, которые вам, скорее всего, понадобятся. Большинство делает ошибку, предоставляя все разрешения, когда в этом нет действительной необходимости. Сверьтесь с разработчиками приложения, чтобы посмотреть, не вызовут ли такие разрешения проблемы в общей работе.
Для пользователя admin, подойдет уровень ALL. Для пользователя guest, SELECT будет достаточно для доступа только на чтение. database — это база данных, над которой пользователь, как мы того желаем, должен иметь эти разрешения. В этом примере, базой данных является gentoo. .* означает все таблицы. Если бы вы хотели, вы могли бы установить права доступа для каждой из таблиц. user — это имя пользователя, а host — имя хоста, с которого пользователь будет получать доступ. В большинстве случаев, это будет localhost. И наконец, password — это пароль пользователя. Учитывая эту информацию, давайте продолжим и создадим наших пользователей.
mysql>GRANT ALL ON gentoo.* TO 'admin'@'localhost' IDENTIFIED BY 'password';
mysql>GRANT SELECT ON gentoo.* TO 'guest'@'localhost' IDENTIFIED BY 'password';
Теперь, когда мы настроили наших пользователей, давайте их протестируем. Сначала, мы завершим работу mysql, введя quit в командной строке:
Теперь мы снова в консоли. Сейчас, когда пользователи созданы, давайте продолжим и посмотрим что они могут делать.
Проверка Пользовательских Разрешений
Сейчас мы должны попытаться войти в качестве пользователя guest. В настоящий момент, пользователь guest имеет только привилегии SELECT. Это, просто-напросто, сводится к способности поиска в базе данных, и ничему другому. Продолжайте и войдите как пользователь guest.
user $mysql -u guest -h localhost -p
Enter password: Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 6 to server version: 4.0.25 Type 'help;' or 'h' for help. Type 'c' to clear the buffer. mysql>
Теперь мы должны протестировать пользовательские ограничения. Давайте переключимся к базе данных gentoo:
mysql>USE gentoo;
Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed
Давайте попробуем сделать что-нибудь, что мы, как предполагается, не должны. Мы попытаемся создать таблицу.
mysql>CREATE TABLE test (test VARCHAR(20), foobar VARCHAR(2));
ERROR 1044: Access denied for user: 'guest@localhost' to database 'gentoo'
Как видите, эта функция не сработала, так как наш пользователь не имеет соответствующих прав доступа. Однако, одной из привилегий, которую мы предоставили, является выражение SELECT. Давайте попробуем:
mysql>SELECT * FROM developers;
+-------------+-----------------------+----------------+ | name | email | job | +-------------+-----------------------+----------------+ | Joe Smith | joesmith@gentoo.org | toolchain | | John Doe | johndoe@gentoo.org | portage | | Chris White | chriswhite@gentoo.org | documentation | | Sam Smith | samsmith@gentoo.org | amd64 | | Jane Doe | NULL | Outsourced job | +-------------+-----------------------+----------------+ 5 rows in set (0.00 sec)
Команда завершилась успешно, и мы мельком увидели, что могут делать пользовательские разрешения. Мы, однако же, также создали и учетную запись admin. Она была создана для того чтобы показать, что даже пользователи, которым предоставлены все права, все же могут иметь ограничения. Завершите работу MySQL и войдите под учетной записью admin.
user $mysql -u admin -h localhost -p
Enter password: Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 7 to server version: 4.0.25 Type 'help;' or 'h' for help. Type 'c' to clear the buffer. mysql>
Для начала, мы попытаемся создать новую базу данных от учетной записи admin. Этот пользователь будет иметь права доступа схожие с учетной записью root в MySQL, и будет способен выполнить любые изменения выбранной базы данных gentoo. Это протестирует права доступа данного пользователя к главной базе данных MySQL. Вспомните, что ранее мы установили разрешения только для определенной базы данных.
mysql>CREATE DATABASE gentoo2;
ERROR 1044: Access denied for user: 'admin@localhost' to database 'gentoo2'
В самом деле, пользователь admin не может создавать базы данных в основной базе данных MySQL, вопреки всем своим разрешениям к базе данных gentoo. Однако, мы все еще способны использовать учетную запись admin для изменения базы данных gentoo, как показано на этом примере вставки данных.
mysql>USE gentoo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> INSERT INTO developers VALUES('Bob Simmons', 'bobsimmons@gentoo.org', 'python');
Query OK, 1 row affected (0.08 sec)
Пользователь admin может получить доступ к базе данных по желанию. Иногда, мы должны избавиться от пользовательских разрешений. Примером может быть все что угодно, от пользователя, вызывающего проблемы, до уволенного сотрудника. Давайте рассмотрим как отключить пользовательские разрешения командой REVOKE.
Удаление Прав Доступа Пользователя Командой REVOKE
Команда REVOKE позволяет нам запретить доступ пользователю. Мы можем запретить или все права на доступ, или определенные права. В действительности, формат весьма схож с командой GRANT .
КОД Синтаксис REVOKE
REVOKE [privileges] ON database.* FROM '[user]'@'[host]';
Здесь, параметры объясняются в разделе команды GRANT . Однако же, в этом разделе, мы собираемся запретить пользователю доступ полностью. Давайте предположим, мы обнаружили, что учетная запись guest вызывает некоторые проблемы с безопасностью. Мы решаем отозвать все привилегии. Мы заходим под учетной записью root и делаем то, что необходимо.
mysql>REVOKE ALL ON gentoo.* FROM 'guest'@'localhost';
Query OK, 0 rows affected (0.00 sec)
Заметка
В данном случае, права доступа пользователя достаточно просты, поэтому их удаление из базы данных не является проблемой. Однако, в более общем случае, вы, скорее всего, использовали бы *.* вместо gentoo.* для того чтобы удалить права доступа пользователя ко всем другим базам данных.
Давайте теперь выйдем и попытаемся зайти в качестве пользователя guest.
user $mysql -u guest -h localhost -p
Enter password: Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 9 to server version: 4.0.25 Type 'help;' or 'h' for help. Type 'c' to clear the buffer. mysql>
Хотя мы и были способны выполнить вход, наши права доступа к gentoo теперь исчезли.
mysql>USE gentoo;
ERROR 1044: Access denied for user: 'guest@localhost' to database 'gentoo'
И наш проблемный пользователь больше не может получить доступ к базе данных gentoo. Пожалуйста, заметьте, что пользователь все еще может выполнить вход. Это потому что он остается в основной базе данных MySQL. Давайте рассмотрим как полностью удалить учетную запись командой DELETE и взглянем на таблицу пользователей MySQL.
Удаление Учетных Записей с Использованием DELETE
Таблица пользователей MySQL является перечислением всех пользователей и информации о них. Убедитесь, что вы выполнили вход под root. Затем продолжайте и используйте основную базу данных MySQL.
DROP USER will delete the record in the user table and all privilege tables. Let’s go ahead and do that:
mysql>DROP USER 'guest'@'localhost';
Query OK, 1 row affected (0.07 sec)
Кажется, сработало на отлично. Давайте это протестируем, выйдя и попытаясь войти как пользователь guest.
user $mysql -u guest -h localhost -p
Enter password: ERROR 1045: Access denied for user: 'guest@localhost' (Using password: YES)
Наш пользователь успешно удален!
Заключение
В то время как это руководство сфокусировано, в основном, на настройке MySQL из командной строки, доступно несколько альтернатив с графическим интерфейсом:
- phpMyAdmin — Популярный инструмент администрирования MySQL, основанный на php.
- mysqlnavigator — Интерфейс QT к MySQL.
- gmyclient — MySQL клиент, основанный на GNOME.
- knoda — клиент MySQL для KDE.
Это завершает вводное руководство к MySQL. Я надеюсь это дало вам лучшее понимание основ MySQL и настройки базы данных.
This page is based on a document formerly found on our main website gentoo.org.
The following people contributed to the original document: Chris White, Shyam Mani, Xavier Neys
They are listed here because wiki history does not allow for any external attribution. If you edit the wiki article, please do not add yourself here; your contributions are recorded on each article’s associated history page.
![]()
Загрузить PDF
![]()
Загрузить PDF
Microsoft Access — это программа для создания баз данных, которая позволяет с легкостью управлять и редактировать базы данных. Она подходит буквально для всего, начиная от небольших проектов и заканчивая крупным бизнесом, она очень наглядна. Это делает ее прекрасным помощником для ввода и хранения данных, поскольку пользователю не нужно иметь дело с таблицами и графиками. Приступайте к чтению, чтобы научиться использовать Microsoft Access максимально эффективно.
-

1
Во вкладке «Файл» выберите «Новая». В базах данных можно хранить информацию различных форм. Вы можете создать пустую базу данных, пустую веб-базу данных, или выбрать любую из широкого ассортимента шаблонов.
- Пустая база данных — это стандартная база данных программы Access, отлично подходит для локального использования. Создание пустой базы данных также приводит к созданию одной таблицы.
- Веб-базы данных разработаны для применения вместе со встроенными инструментами Access для публикации в интернете. Создание пустой базы данных также приводит к созданию одной таблицы.
- Шаблоны — это заранее построенные базы данных широкого спектра применения. Выбирайте шаблоны, если вы не хотите тратить слишком много времени, сводя структуру баз данных в единое целое.
-
2
Назовите свою базу данных. Выбрав тип базы данных, назовите ее согласно предназначению. Это будет особенно полезно, если вы работаете одновременно с несколькими разными базами данных. Введите название в поле «Имя файла». Нажмите «Создать», чтобы сгенерировать новую базу данных.
Реклама


-
1
Определите лучшую структуру для хранения вашей информации. Если создаете пустую базу данных, вам стоит заранее подумать, как организовать хранение своей информации и заранее добавить необходимую структуру. Существует несколько вариантов, как вы можете изменять и взаимодействовать со своими данными в Access:
- Таблицы — основной вид хранения информации. Таблицы можно сравнить с таблицами Excel: все данные распределяются по строкам и столбцам. Именно поэтому импортировать информацию из Excel или других табличных редакторов относительно просто.
- Формы — это способ внесения информации в базу данных. Используя таблицы, информацию в базу данных можно вносить напрямую, однако формы позволяют делать это более быстро и наглядно.
- Отчеты позволяют подсчитывать и выводить информацию из базы данных. Отчеты нужны для анализа информации и для получения ответов на необходимые вопросы, например сколько прибыли было получено, или где находятся клиенты. Как правило, их используют для распечатки в бумажном виде.
- Запросы необходимы для получения и сортировки информации. Запросами можно пользоваться для поиска определенных записей из нескольких таблиц. Их также можно использовать для создания и обновления информации.
-
2
Создайте свою первую таблицу. Если речь идет о создании пустой базы данных, автоматически будет создана пустая таблица. Вводить туда данные можно вручную или копируя и вставляя из другого источника.
- Каждую часть данных нужно вставлять в отдельную колонку (поле), в то время как каждую запись нужно начинать с новой строки. Например, каждая строка — это клиент, а каждая колонка — это отдельная информация об этом клиенте (имя, фамилия, электронная почта, телефон и прочее).
- Вы можете переименовывать названия колонок, чтобы было понятнее, какое поле для чего предназначено. Дважды щелкните по заголовку колонки, чтобы изменить его название.
-
3
Импортируйте информацию из другого источника. Если вы хотите импортировать информацию из файла поддерживаемого формата или определенного места, вы можете настроить Access на импорт информации и добавление в вашу базу данных. Это полезно для импорта информации с веб-сервера или из другого открытого источника.
- Перейдите на вкладку «Внешние данные».
- Выберите тип файла, который собираетесь импортировать. В разделе «Импорт и объединение» вы найдете несколько вариантов для выбора. Нажмите кнопку «больше», чтобы открыть еще больше вариантов выбора. ODBC — это протокол для подключения баз данных, например таких как SQL.
- Укажите место расположения файла. Если файл расположен на сервере, вам нужно будет ввести адрес сервера.
- В следующем окне выберите «Указать, как и где вы хотите сохранять данные в текущей базе данных». Нажмите «ОК». Следуйте инструкциям для импорта необходимой информации.
-
4
Добавьте еще таблицу. Разные записи следует хранить в разных базах данных. Так базы данных будут работать безошибочно. Например, в одной таблице будет содержаться информация о клиентах, в другой — о заказах. Затем вы сможете связать таблицу о клиентах с информацией в таблице о заказах.
- В разделе «Создание» вкладки «Домой» нажмите кнопку создания таблицы. Новая таблица появится в вашей базе данных. Внесите нужную информацию так же, как делали это в первой таблице.
Реклама




-
1
Узнайте, как работают ключи. В каждой таблице есть уникальный ключ для каждой записи. По умолчанию Access создает колонку имен, которая растет с каждым вводом. Это и есть первичный ключ. Таблицы также могут иметь внешние ключи. Это поля, связанные с другой таблицей в базе данных. Связанные поля содержат одну и ту же информацию.
- Например, в таблице заказов у вас может быть поле «Имя клиента» для отслеживания, кто именно заказал определенный продукт. Вы можете создать связь этого поля с полем «Имя» в вашей таблице клиентов.
- Создание связей позволяет улучшить целостность, эффективность и удобство чтения информации.
-
2
Нажмите на вкладку «Работа с базами данных». Выберите «Схема данных». Откроется окно с обзором всех таблиц в базе данных. Каждое поле будет указано под названием его таблицы.
- Прежде чем создавать связь, необходимо создать поле для внешних ключей. Например, если вы хотите использовать «Идентификатор клиента» в таблице заказов, создайте поле под именем «Клиент» и оставьте его пустым. Оно должно быть такого же формата, как и то, с которым вы устанавливаете связь (в этом случае числа).
-
3
Перетащите поле, которое вы хотите использовать как внешний ключ. Переместите его в заранее приготовленное поле для внешнего ключа. Нажмите «Создание» в появившемся окне, чтобы создать связь между полями. Появится линия между двух таблиц, связав тем самым поля.
- При создании связей установите флажок в графе «Обеспечить целостность данных». Данная функция позволяет вносить изменения во второе поле при изменении первого, что исключает неточность данных.
Реклама



-
1
Поймите роль запросов. Запрос — это действие, которое позволяет быстро посмотреть, добавить или изменить информацию в базе данных. Существует большой выбор запросов, начиная от простого поиска и заканчивая созданием новых таблиц, основанных на имеющейся информации. Запросы — это необходимый инструмент для подготовки отчетов.[1]
- Запросы разделяются на два главных вида: «Выбор» или «Действие». Запросы на выборку позволяют извлекать информацию из таблиц и делать вычисления. Запросы действия позволяют добавлять, изменять и удалять данные из таблиц.
-
2
Воспользуйтесь мастером запросов, чтобы создать запрос на выборку. Если вы хотите создать базовый запрос на выборку, воспользуйтесь мастером запросов, чтобы он шаг за шагом помог вам в этом. Вы можете найти мастер запросов во вкладке «Создание». Он позволяет находить нужные поля в таблице.
Реклама


Создание запроса на выборку по критериям
-
1
Откройте инструмент «Конструктор запросов». Вы можете использовать критерии поиска, чтобы сузить выбор и выводить только нужную информацию. Для начала нажмите на вкладку «Создание» и выберите инструмент «Конструктор запросов».
-
2
Выберите таблицу. Откроется окно выбора таблиц. Дважды щелкните по нужной таблице для запроса, а затем нажмите «Закрыть».
-
3
Добавляйте поля, из которых нужно получить данные. Дважды щелкните по каждому полю, чтобы добавить их в запрос. Эти поля будут добавляться в сетку конструктора.
-
4
Добавьте собственные критерии. Вы можете использовать разные виды критериев, такие как текст или функции. Например, если вы хотите отобразить цены выше, чем 5000 рублей в поле «Цены», введите
>=5000, чтобы добавить этот критерий. Если вы хотите найти клиентов только из России, введитеРоссияв поле критериев.- В одном запросе можно использовать несколько критериев.
-
5
Нажмите «Выполнить», чтобы увидеть результаты. Кнопка «Выполнить» в виде восклицательного знака находится во вкладке «Конструктор». Результаты запроса будут выведены в отдельное окно. Нажмите Ctrl + S, чтобы сохранить результаты запроса.
Реклама





Создание выборного запроса по параметрам
-
1
Откройте инструмент «Конструктор запросов». Запрос по параметрам позволит вам установить, какие именно результаты вы хотите видеть каждый раз, когда делаете запрос. Например, если в вашей базе данных есть клиенты из разных городов, вы можете настроить запрос по параметрам, чтобы выводить результаты для определенного города.
-
2
Создайте запрос на выборку и выберите таблицу(-ы). Добавляйте поля для отбора путем двойного клика в общем обзоре таблицы.
-
3
Добавляйте параметр в раздел критериев. Параметры разделены между собой скобками «[]». Текст внутри скобок будет выведен в строку, которая появится во время проведения запроса. Например, для запроса города кликните по ячейке критериев в поле города и введите
[Какой город?].- Параметр может заканчиваться на «?» или «:», но не «!» или «.»
-
4
Сделайте запрос по множеству параметров. Вы можете использовать несколько параметров , чтобы создать поисковый запрос. Например, в поле «Дата» можно ввести диапазон дат, введя
Между [Введите начальную дату:] И [Введите дату окончания:]. В результате запроса вы получите две строки. [2]
Реклама




Создание запроса на создание таблицы
-
1
Во вкладке «Создание» нажмите «Конструктор запросов». Вы можете использовать запросы для получения выбранной информации из уже существующих таблиц или можете создавать новые таблицы с этой информацией. Это будет особенно полезно, если вы хотите поделиться какой-либо частью базы данных или создать особые формы для подразделов вашей базы данных. Для начала вам нужно создать обычный запрос на выборку.
-
2
Выберите таблицу(-ы) из которых вы хотите извлечь данные. Дважды щелкните по таблице, из которой необходимо извлечь информацию. Вы можете использовать сразу несколько таблиц, если требуется.
-
3
Выберите поля, из которых нужно извлечь данные. Дважды щелкните по каждому полю для добавления. Оно будет добавлено в сетку запросов.
-
4
Выставьте необходимые критерии. Если вам нужна определенная информация из полей, установите фильтр по критериям. Перейдите в раздел «Создание запроса на выборку по критериям» выше за более подробной информацией.
-
5
Протестируйте запрос, чтобы убедиться, что он выводит нужные результаты. Прежде чем создать таблицу, выполните запрос, чтобы убедиться, что он извлекает необходимую вам информацию. Настраивайте критерии и поля, пока не получите нужный вам результат.
-
6
Сохраните запрос. Нажмите Ctrl + S, чтобы сохранить запрос для дальнейшего использования. Он появится в колонке навигации в левой части экрана. Если вы нажмете на этот запрос, вы сможете использовать его снова, затем перейдите на вкладку «Конструктор».
-
7
Нажмите на кнопку «Создать таблицу» в группе выбора типа запроса. Появится окно, запрашивающее имя новой таблицы. Введите имя таблицы и нажмите «ОК».
-
8
Нажмите кнопку «Выполнить». Согласно установленным запросам будет создана новая таблица. Таблица появится в колонке навигации слева.
Реклама








Создание запроса на добавление
-
1
Откройте ранее созданный запрос. Вы можете использовать запрос на добавление, чтобы добавить информацию в таблицу, которая уже создана в другой таблице. Это полезно, когда необходимо добавить больше данных в готовую таблицу, созданную по запросу создания таблицы.
-
2
Нажмите кнопку «Добавление» во вкладке «Конструктор». Откроется диалоговое окно. Выберите в нем таблицу, которую нужно дополнить.
-
3
Измените критерии запроса, чтобы они соответствовали добавляемой информации. Например, если вы создали таблицу с критерием «2010» в поле «Год», измените это значение согласно добавляемой информации, например «2011».
-
4
Выберите, куда именно вы хотите добавить информацию. Убедитесь, что добавляете данные в подходящие поля для каждой добавляемой колонки. Например, если вы вносите изменения, приведенные выше, информацию следует добавить в поле «Год» на каждой строчке.
-
5
Выполните запрос. Нажмите кнопку «Выполнить» на вкладке «Конструктор». Запрос будет проведен и информация будет добавлена в таблицу. Вы можете открыть таблицу, чтобы убедиться в правильности введенных данных.
Реклама





-
1
Выберите таблицу, для которой вы хотите создать форму. Формы отображают данные по каждому полю и позволяют с легкостью переключаться между записями или создавать новые. Формы — необходимый инструмент при длительных периодах ввода информации; большинство пользователей считают, что пользоваться формами гораздо проще, чем таблицами.
-
2
Нажмите кнопку «Форма» во вкладке «Создание». Будет автоматически создана форма, основанная на данных из таблице. Программа Access автоматически создает поля с нужным размером, но по желанию их всегда можно изменить или сдвинуть.
- Если вы не хотите отображать определенное поле в форме, вызовите контекстное меню правой кнопкой мыши и нажмите «Удалить».
- Если таблицы связаны между собой, над каждой записью появится описание, отображающее объединенные данные. Так редактировать эти данные гораздо проще. Например, каждому торговому представителю можно приписать базу клиентов.
-
3
Перемещайтесь по новой форме. Указатели в форме стрелок позволяют перемещаться от одной записи к другой. Поля будут заполнены вашими данными в момент переключения между ними. Вы можете воспользоваться кнопками по краям, чтобы сразу перейти к первой или последней записи.
-
4
Нажмите кнопку описания, чтобы воспользоваться таблицей. Она находится в верхнем левом углу и позволяет изменять значения выбранной таблицы с помощью форм.
-
5
Внесите изменения в существующие записи. Вы можете изменять текст в любом поле каждой записи, чтобы изменить информацию в таблице. Все изменения автоматически отобразятся в таблице, то же произойдет и во всех связанных таблицах.
-
6
Вносите новые записи. Нажмите «Добавить запись» возле кнопок навигации, чтобы добавить новую запись в конце списка. Затем вы сможете использовать поля для внесения данных в пустые записи внутри таблицы. Это гораздо проще, чем добавлять новые данные через табличный вид.
-
7
Сохраните форму, когда закончите работу с ней. Убедитесь, что сохранили форму, нажав Ctrl + S; вы сможете с легкостью войти в нее снова позже. Она появится в колонке навигации в левой части экрана.[3]
Реклама







-
1
Выберите таблицу или запрос. Отчеты позволяют быстро отобразить сводку по нужным данным. Их часто используют для создания отчетов по выручке или для отчетов по доставке, но их можно настроить почти для любой области использования. Отчеты используют данные из таблиц или запросов, созданных вами ранее.
-
2
Нажмите вкладку «Создание». Выберите тип необходимого отчета. Существует несколько разных путей создания отчетов. Access может сделать отчет для вас автоматически, либо создайте его самостоятельно.
- Отчет — будет создан автоотчет, использующий всю доступную информацию из вашего источника. Ничего не будет сгруппировано, но для небольших баз данных вполне подойдет.
- Пустой отчет — будет создан пустой отчет, который вы сами сможете заполнить нужными данными. Вы сможете выбирать информацию из любого доступного поля, чтобы создать необходимый отчет.
- Мастер отчетов поможет вам пройти через процесс создания отчета, позволяя выбирать и группировать данные, а затем редактировать подходящим образом.
-
3
Выберите источник для пустого отчета. Если вы выбрали создание пустого отчета, вам нужно указать для него источник. Сначала нажмите вкладку «Упорядочить», а затем перейдите в «Свойства». Для этого также можно нажать Alt + Enter.
- Нажмите на стрелочку рядом с полем «Источник записей». Появится список всех доступных таблиц и запросов. Выберите один, и он будет отнесен к отчету.
-
4
Добавьте поля в отчет. Указав источник, добавьте поля из него в свой отчет. Нажмите вкладку «Формат», затем нажмите «Добавить существующие поля». Список полей доступен в правой части.
- Нажмите и переместите поля, которые необходимо добавить в раздел «Конструктор». Запись появится в отчете. При добавлении дополнительных полей они будут добавляться автоматически к уже существующим.
- Вы можете изменять размер полей путем нажатия на грани и перемещения указателя.
- Удаляйте поля из отчета, выделив заголовок и нажав кнопку «Удалить».
-
5
Добавляйте группы в свой отчет. Группы позволяют быстро разбираться в информации из отчета, поскольку все подается в организованном виде. К примеру, если вам необходимо создать группы для продаж по региону или с привязкой к продавцу, все это можно сделать с помощью группировки.
- На вкладке «Конструктор», выберите «Группировка».
- Правой кнопкой мыши щелкните по части поля, которое вы хотите добавить в группу. Выберите «Сгруппировать» из меню.
- Появится заголовок для группы. Вы можете изменять заголовок на любой желаемый.
-
6
Сохраните и поделитесь своим отчетом. Как только отчет будет готов, вы можете сохранить его и распечатать как любой документ. Используйте его, чтобы рассказать об эффективности компании инвесторам, поделиться контактной информацией с работниками и для других целей.
Реклама






Советы
- Microsoft Access открывается в режиме скрытой информации, в котором находятся опции, позволяющие вам открывать существующие базы данных, создавать новые и получать доступ к командам для редактирования любых ваших баз.
Реклама
Предупреждения
- Некоторые возможности Access не всегда доступны — все зависит от типа созданной вами базы данных. Например, нельзя предоставить доступ к базе данных, созданной для использования оффлайн, а некоторые возможности оффлайн баз, например, суммарное число запросов, не будут работать в веб-базе данных.
Реклама
Источники
Об этой статье
Эту страницу просматривали 289 290 раз.