Время на прочтение
7 мин
Количество просмотров 404K
Перевод цикла из 15 статей о проектировании баз данных.
Информация предназначена для новичков.
Помогло мне. Возможно, что поможет еще кому-то восполнить пробелы.
Другие части: 4-6, 7-9, 10-13, 14-15.
Руководство по проектированию баз данных.
1. Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о проекте вашей базы данных. Хороший проект базы данных, как было сказано ранее, обеспечит целостность данных и простоту их обслуживания.
Структурированный язык запросов (SQL).
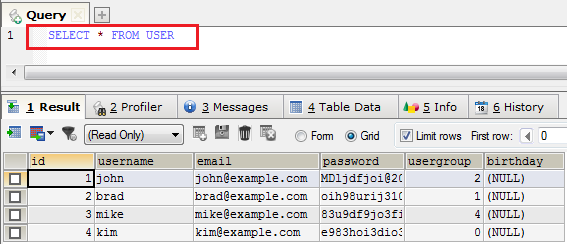
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван Структурированный язык запросов или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка. Ниже приведен пример запроса на выборку данных и его результат.
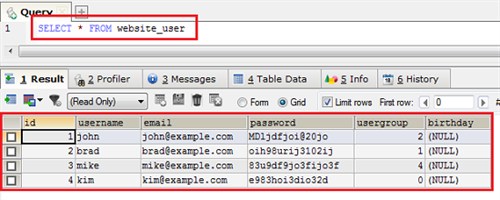
SQL – большая тема для повествования и его рассмотрение выходит за рамки данного руководства. Данная статья строго сфокусирована на изложении процесса проектирования баз данных. Позднее, в отдельном руководстве, я расскажу об основах SQL.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.
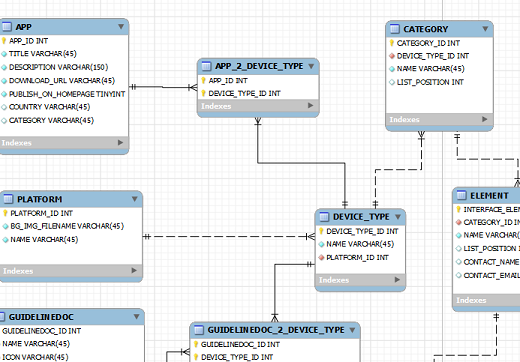
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь», как на рисунке (Пример взят из MySQL Workbench).
Примеры.
В качестве примеров в руководстве я использовал ряд приложений.
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров – MySQL. MySQL – наиболее популярная РСУБД и она бесплатна.
Утилита для администрирования БД.
После установки MySQL вы получаете только интерфейс командной строки для взаимодействия с MySQL. Лично я предпочитаю графический интерфейс для управления моими базами данных. Я часто использую SQLyog. Это бесплатная утилита с графическим интерфейсом. Изображения таблиц в данном руководстве взяты оттуда.
Визуальное моделирование.
Существует отличное бесплатное приложение MySQL Workbench. Оно позволяет спроектировать вашу базу данных графически. Изображения диаграмм в руководстве сделаны в этой программе.
Проектирование независимо от РСУБД.
Важно знать, что хотя в данном руководстве и приведены примеры для MySQL, проектирование баз данных независимо от РСУБД. Это значит, что информация применима к реляционным базам данных в общем, не только к MySQL. Вы можете применить знания из этого руководства к любым реляционным базам данных, подобным Mysql, Postgresql, Microsoft Access, Microsoft Sql or Oracle.
В следующей части я коротко расскажу об эволюции баз данных. Вы узнаете откуда взялись базы данных и реляционная модель данных.
2. История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.

Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.

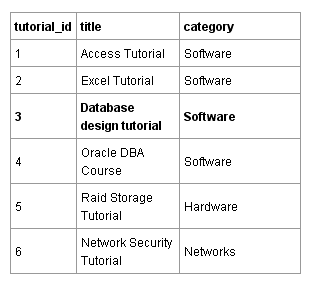
Выше приведен пример того, как такой файл мог бы выглядеть. Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок ‘Database Design Tutorial’, то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова ‘Database Design Tutorial’ и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или “запись” содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок (title) и его категория (category).
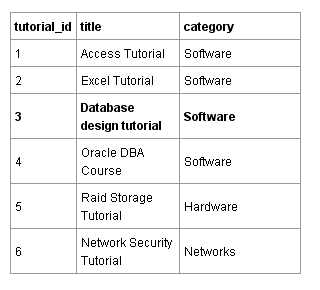
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию. Это намного быстрее, чем поиск по файлу строка за строкой, подобно тому, как это делает программа в текстовом файле.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
— Oracle – используется преимущественно для профессиональных, больших приложений.
— Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
— Mysql – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
— IBM – имеет ряд РСУБД, наиболее известна DB2.
— Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
В следующей части я расскажу кое-что о характеристиках реляционных баз данных.
3. Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом. Зачастую, первичный ключ это автоматически увеличиваемое (автоинкрементное) число (1,2,3,4 и т.д). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки (записи) другой таблицы, тем самым, связывая эти записи вместе.
Используя структурированный язык запросов (SQL), данные из разных таблиц, которые связаны ключом, могут быть выбраны за один раз. Для примера вы можете создать запрос, который выберет все заказы из таблицы заказов (orders), которые принадлежат пользователю с идентификатором (id) 3 (Mike) из таблицы пользователей (users). О ключах мы поговорим далее, в следующих частях.
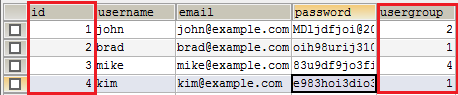
Столбец id в данной таблице является первичным ключом. Каждая запись имеет уникальный первичный ключ, часто число. Столбец usergroup (группы пользователей) является внешним ключом. Судя по ее названию, она видимо ссылается на таблицу, которая содержит группы пользователей.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.
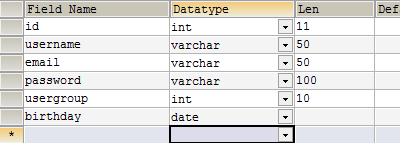
Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
— ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
— ввод индекса региона с длинной этого самого индекса в сотню символов
— создание пользователей с одним и тем же именем
— создание пользователей с одним и тем же адресом электронной почты
— ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN. Как и упоминалось ранее, SQL в данном руководстве обсуждаться не будет. Я сосредоточусь на проектировании баз данных.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Как говорилось ранее, проектирование базы данных – это вопрос идентификации данных, их связи и помещение результатов решения данного вопроса на бумагу (или в компьютерную программу). Проектирование базы данных независимо от РСУБД, которую вы собираетесь использовать для ее создания.
В следующей части подробнее рассмотрим первичные ключи.
Установка
Когда вы изучаете новый язык, самым важным аспектом является практика. Одно дело – прочитать статью и совсем другое – применить полученную информацию. Давайте начнем с установки базы данных на компьютер.
Первый шаг – установить SQL
Мы будем использовать PostgreSQL (Postgres) – достаточно распространенный SQL диалект. Для этого откроем страницу загрузки, выберем операционную систему (в моем случае Windows), и запустим установку. Если вы установите пароль для вашей базы данных, постарайтесь сразу не забыть его, он нам дальше понадобится. Поскольку наша база будет локальной, можете использовать простой пароль, например: admin.
Следующий шаг – установка pgAdmin
pgAdmin – это графический интерфейс пользователя (GUI – graphical user interface), который упрощает взаимодействие с базой данных PostgreSQL. Перейдите на страницу загрузки, выберите вашу операционную систему и следуйте указаниям (в статье используется Postgres 14 и pgAdmin 4 v6.3.).
После установки обоих компонентов открываем pgAdmin и нажимаем Add new server. На этом шаге установится соединение с существующим сервером, именно поэтому необходимо сначала установить Postgres. Я назвал свой сервер home и использовал пароль, указанный при установке.
Теперь всё готово к созданию таблиц. Давайте создадим набор таблиц, которые моделируют школу. Нам необходимы таблицы: ученики, классы, оценки. При создании модели данных необходимо учитывать, что в одном классе может быть много учеников, а у ученика может быть много оценок (такое отношение называется «один ко многим»).
Мы можем создать таблицы напрямую в pgAdmin, но вместо этого мы напишем код, который можно будет использовать в дальнейшем, например, для пересоздания таблиц. Для создания запроса, который создаст наши таблицы, нажимаем правой кнопкой мыши на postgres (пункт расположен в меню слева home → Databases (1) → postgres и далее выбираем Query Tool.
Начнем с создания таблицы классов (classrooms). Таблица будет простой: она будет содержать идентификатор id и имя учителя – teacher. Напишите следующий код в окне запроса (query tool) и запустите (run или F5).
DROP TABLE IF EXISTS classrooms CASCADE;
CREATE TABLE classrooms (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
teacher VARCHAR(100)
);
В первой строке фрагмент DROP TABLE IF EXISTS classrooms удалит таблицу classrooms, если она уже существует. Важно учитывать, что Postgres, не позволит нам удалить таблицу, если она имеет связи с другими таблицами, поэтому, чтобы обойти это ограничение (constraint) в конце строки добавлен оператор CASCADE. CASCADE – автоматически удалит или изменит строки из зависимой таблицы, при внесении изменений в главную. В нашем случае нет ничего страшного в удалении таблицы, поскольку, если мы на это пошли, значит мы будем пересоздавать всё с нуля, и остальные таблицы тоже удалятся.
Добавление DROP TABLE IF EXISTS перед CREATE TABLE позволит нам систематизировать схему нашей базы данных и создать скрипты, которые будут очень удобны, если мы захотим внести изменения – например, добавить таблицу, изменить тип данных поля и т. д. Для этого нам просто нужно будет внести изменения в уже готовый скрипт и перезапустить его.
Ничего нам не мешает добавить наш код в систему контроля версий. Весь код для создания базы данных из этой статьи вы можете посмотреть по ссылке.
Также вы могли обратить внимание на четвертую строчку. Здесь мы определили, что колонка id является первичным ключом (primary key), что означает следующее: в каждой записи в таблице это поле должно быть заполнено и каждое значение должно быть уникальным. Чтобы не пришлось постоянно держать в голове, какое значение id уже было использовано, а какое – нет, мы написали GENERATED ALWAYS AS IDENTITY, этот приём является альтернативой синтаксису последовательности (CREATE SEQUENCE). В результате при добавлении записей в эту таблицу нам нужно будет просто добавить имя учителя.
И в пятой строке мы определили, что поле teacher имеет тип данных VARCHAR (строка) с максимальной длиной 100 символов. Если в будущем нам понадобится добавить в таблицу учителя с более длинным именем, нам придется либо использовать инициалы, либо изменять таблицу (alter table).
Теперь давайте создадим таблицу учеников (students). Новая таблица будет содержать: уникальный идентификатор (id), имя ученика (name), и внешний ключ (foreign key), который будет указывать (references) на таблицу классов.
DROP TABLE IF EXISTS students CASCADE;
CREATE TABLE students (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
name VARCHAR(100),
classroom_id INT,
CONSTRAINT fk_classrooms
FOREIGN KEY(classroom_id)
REFERENCES classrooms(id)
);
И снова мы перед созданием новой таблицы удаляем старую, если она существует, добавляем поле id, которое автоматически увеличивает своё значение и имя с типом данных VARCHAR (строка) и максимальной длиной 100 символов. Также в эту таблицу мы добавили колонку с идентификатором класса (classroom_id), и с седьмой по девятую строку установили, что ее значение указывает на колонку id в таблице классов (classrooms).
Мы определили, что classroom_id является внешним ключом. Это означает, что мы задали правила, по которым данные будут записываться в таблицу учеников (students). То есть Postgres на данном этапе не позволит нам вставить строку с данными в таблицу учеников (students), в которой указан идентификатор класса (classroom_id), не существующий в таблице classrooms. Например: у нас в таблице классов 10 записей (id с 1 до 10), система не даст нам вставить данные в таблицу учеников, у которых указан идентификатор класса 11 и больше.
INSERT INTO students
(name, classroom_id)
VALUES
('Matt', 1);
/*
ERROR: insert or update on table "students" violates foreign
key constraint "fk_classrooms"
DETAIL: Key (classroom_id)=(1) is not present in table
"classrooms".
SQL state: 23503
*/
Теперь давайте добавим немного данных в таблицу классов (classrooms). Так как мы определили, что значение в поле id будет увеличиваться автоматически, нам нужно только добавить имена учителей.
INSERT INTO classrooms
(teacher)
VALUES
('Mary'),
('Jonah');
SELECT * FROM classrooms;
/*
id | teacher
-- | -------
1 | Mary
2 | Jonah
*/
Прекрасно! Теперь у нас есть записи в таблице классов, и мы можем добавить данные в таблицу учеников, а также установить нужные связи (с таблицей классов).
INSERT INTO students
(name, classroom_id)
VALUES
('Adam', 1),
('Betty', 1),
('Caroline', 2);
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
*/
Но что же случится, если у нас появится новый ученик, которому ещё не назначили класс? Неужели нам придется ждать, пока станет известно в каком он классе, и только после этого добавить его запись в базу данных?
Конечно же, нет. Мы установили внешний ключ, и он будет блокировать запись, поскольку ссылка на несуществующий id класса невозможна, но мы можем в качестве идентификатора класса (classroom_id) передать null. Это можно сделать двумя способами: указанием null при записи значений, либо просто передачей только имени.
-- явно определим значение NULL
INSERT INTO students
(name, classroom_id)
VALUES
('Dina', NULL);
-- неявно определим значение NULL
INSERT INTO students
(name)
VALUES
('Evan');
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
4 | Dina | [null]
5 | Evan | [null]
*/
И наконец, давайте заполним таблицу успеваемости. Этот параметр, как правило, формируется из нескольких составляющих – домашние задания, участие в проектах, посещаемость и экзамены. Мы будем использовать две таблицы. Таблица заданий (assignments), как понятно из названия, будет содержать данные о самих заданиях, и таблица оценок (grades), в которой мы будем хранить данные о том, как ученик выполнил эти задания.
DROP TABLE IF EXISTS assignments CASCADE;
DROP TABLE IF EXISTS grades CASCADE;
CREATE TABLE assignments (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
category VARCHAR(20),
name VARCHAR(200),
due_date DATE,
weight FLOAT
);
CREATE TABLE grades (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
assignment_id INT,
score INT,
student_id INT,
CONSTRAINT fk_assignments
FOREIGN KEY(assignment_id)
REFERENCES assignments(id),
CONSTRAINT fk_students
FOREIGN KEY(student_id)
REFERENCES students(id)
);
Вместо того чтобы вставлять данные вручную, давайте загрузим их с помощью CSV-файла. Вы можете скачать файл из этого репозитория или создать его самостоятельно. Имейте в виду, чтобы разрешить pgAdmin доступ к данным, вам может понадобиться расширить права доступа к папке (в моем случае – это папка db_data).
COPY assignments(category, name, due_date, weight)
FROM 'C:/Users/mgsosna/Desktop/db_data/assignments.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 5
Query returned successfully in 118 msec.
*/
COPY grades(assignment_id, score, student_id)
FROM 'C:/Users/mgsosna/Desktop/db_data/grades.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 25
Query returned successfully in 64 msec.
*/
Теперь давайте проверим, что мы всё сделали верно. Напишем запрос, который покажет среднюю оценку, по каждому виду заданий с группировкой по учителям.
SELECT
c.teacher,
a.category,
ROUND(AVG(g.score), 1) AS avg_score
FROM
students AS s
INNER JOIN classrooms AS c
ON c.id = s.classroom_id
INNER JOIN grades AS g
ON s.id = g.student_id
INNER JOIN assignments AS a
ON a.id = g.assignment_id
GROUP BY
1,
2
ORDER BY
3 DESC;
/*
teacher | category | avg_score
------- | --------- | ---------
Jonah | project | 100.0
Jonah | homework | 94.0
Jonah | exam | 92.5
Mary | homework | 78.3
Mary | exam | 76.0
Mary | project | 69.5
*/
Отлично! Мы установили, настроили и наполнили базу данных.
***
Итак, в этой статье мы научились:
- создавать базу данных;
- создавать таблицы;
- наполнять таблицы данными;
- устанавливать связи между таблицами;
Теперь у нас всё готово, чтобы пробовать более сложные возможности SQL. Мы начнем с возможностей синтаксиса, которые, вероятно, вам еще не знакомы и которые откроют перед вами новые границы в написании SQL-запросов. Также мы разберем некоторый виды соединений таблиц (JOIN) и способы организации запросов в тех случаях, когда они занимают десятки или даже сотни строк.
В следующей части мы разберем:
- виды фильтраций в запросах;
- запросы с условиями типа if-else;
- новые виды соединений таблиц;
- функции для работы с массивами;
Материалы по теме
- 🐘 8 лучших GUI клиентов PostgreSQL в 2021 году
- 🐍🐬 Python и MySQL: практическое введение
- 🐍🗄️ Управление данными с помощью Python, SQLite и SQLAlchemy
Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о проекте вашей базы данных. Хороший проект базы данных, как было сказано ранее, обеспечит целостность данных и простоту их обслуживания.
Структурированный язык запросов (SQL).
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван «Структурированный язык запросов» или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь».
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров – MySQL. MySQL – наиболее популярная РСУБД и она бесплатна.
История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.

Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.
Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок ‘Database Design Tutorial’, то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова ‘Database Design Tutorial’ и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или “запись” содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок (title) и его категория (category).
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию. Это намного быстрее, чем поиск по файлу строка за строкой, подобно тому, как это делает программа в текстовом файле.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
- Oracle – используется преимущественно для профессиональных, больших приложений.
- Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
- MySQL – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
- IBM – имеет ряд РСУБД, наиболее известна DB2.
- Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом. Зачастую, первичный ключ это автоматически увеличиваемое (автоинкрементное) число (1,2,3,4 и т.д). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки (записи) другой таблицы, тем самым, связывая эти записи вместе.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.
Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
- ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
- ввод индекса региона с длиной этого самого индекса в сотню символов
- создание пользователей с одним и тем же именем
- создание пользователей с одним и тем же адресом электронной почты
- ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Таблицы и первичные ключи.
Как вы уже знаете из прошлых частей, данные хранятся в таблицах, которые содержат строки или по-другому записи. Ранее я приводил пример таблицы, содержащей информацию об уроках. Давайте снова на нее взглянем.
В таблице имеются 6 уроков. Все 6 – разные, но для каждого урока значения одинаковых полей хранятся в таблице, а именно: tutorial_id (идентификатор урока), title (заголовок) и category (категория).
Tutorial_id – первичный ключ таблицы уроков. Первичный ключ – это значение, которое уникально для каждой записи в таблице.
Первичные ключи в повседневной жизни.
В базе данных первичные ключи используются для идентификации. В жизни первичные ключи вокруг нас везде. Каждый раз, когда вы сталкиваетесь с уникальным числом это число может служить первичным ключом в базе данных (может, но не обязательно должно использоваться как таковое. Все базы данных способны автоматически генерировать уникальное значение для каждой записи в виде числа, которое автоматически увеличивается и вставляется вместе с каждой новой записью).
Несколько примеров:
- Номер заказа, который вы получаете при покупке в интернет-магазине может быть первичным ключом какой-нибудь таблицы заказов в базе данных этого магазина, т.к. он является уникальным значением.
- Номер социального страхования может быть первичным ключом в какой-нибудь таблице в базе данных государственного учреждения, т.к. она также как и в предыдущем примере уникален.
- Номер счета-фактуры может быть использован в качестве первичного ключа в таблице базы данных, в которой хранятся выданные клиентам счета-фактуры.
- Числовой номер клиента часто используется как первичный ключ в таблице клиентов.
Что объединяет эти примеры? То, что во всех из них в качестве первичного ключа выбирается уникальное, не повторяющееся значение для каждой записи. Еще раз. Значения поля таблицы базы данных, выбранного в качестве первичного ключа, всегда уникально.
Что характеризует первичный ключ? Характеристики первичного ключа.
— Первичный ключ служит для идентификации записей.
Первичный ключ используется для идентификации записей в таблице, для того, чтобы каждая запись стала уникальной. Еще одна аналогия… Когда вы звоните в службу технической поддержки, оператор обычно просит вас назвать какой-либо номер (договора, телефона и пр.), по которому вас можно идентифицировать в системе.
Если вы забыли свой номер, то оператор службы технической поддержки попросит предоставить вас какую-либо другую информацию, которая поможет уникальным образом идентифицировать вас. Например, комбинация вашего дня рождения и фамилия. Они тоже могут являться первичным ключом, точнее их комбинация.
— Первичный ключ уникален.
Первичный ключ всегда имеет уникальное значение. Представьте, что его значение не уникально. Тогда его бы нельзя было использовать для того, чтобы идентифицировать данные в таблице. Это значит, что какое-либо значение первичного ключа может встретиться в столбце, который выбран в качестве первичного ключа, только один раз. РСУБД устроены так, что не позволят вам вставить дубликаты в поле первичного ключа, получите ошибку.
Еще один пример. Представьте, что у вас есть таблица с полями first_name и last_name и есть две записи:
| first_name | last_name | | vasya |pupkin | | vasya |pupkin |
Т.е. есть два Васи. Вы хотите выбрать из таблицы какого-то конкретного Васю. Как это сделать? Записи ничем друг от друга не отличаются. Вот здесь и помогает первичный ключ. Добавляем столбец id (классический вариант синтетического первичного ключа) и…
id | first_name | last_name | 1 | vasya |pupkin | 2 | vasya |pupkin |
Теперь каждый Вася уникален.
— Типы первичных ключей.
Обычно первичный ключ – числовое значение. Но он также может быть и любым другим типом данных. Не является обычной практикой использование строки в качестве первичного ключа (строка – фрагмент текста), но теоретически и практически это возможно.
Часто первичный ключ состоит из одного поля, но он может быть и комбинацией нескольких столбцов, например, двух (трех, четырех…). Но вы помните, что первичный ключ всегда уникален, а значит нужно, чтобы комбинация n-го количества полей, в данном случае 2-х, была уникальна.
— Автонумерация.
Поле первичного ключа часто, но не всегда, обрабатывается самой базой данных. Вы можете, условно говоря, сказать базе данных, чтобы она сама автоматически присваивала уникальное числовое значение каждой записи при ее создании. База данных, обычно, начинает нумерацию с 1 и увеличивает это число для каждой записи на одну единицу. Такой первичный ключ называется автоинкрементным или автонумерованным. Использование автоинкрементных ключей – хороший способ для задания уникальных первичных ключей. Классическое название такого ключа – суррогатный первичный ключ. Такой ключ не содержит полезной информации, относящейся к сущности (объекту), информация о которой хранится в таблице, поэтому он и называется суррогатным.
Связывание таблиц с помощью внешних ключей.
Когда я начинал разрабатывать базы данных я часто пытался сохранять информацию, которая казалась родственной, в одной таблице. Я мог, например, хранить информацию о заказах в таблице клиентов. Ведь заказы принадлежат клиентам, верно? Нет. Клиенты и заказы представляют собой отдельные сущности в базе данных. И тому и другому нужна своя собственная таблица. А записи в этих двух таблицах могут быть связаны для того, чтобы установить отношения между ними. Проектирование базы данных – это решение двух вопросов:
- определение того, какие сущности вы хотите хранить в ней
- какие связи между этими сущностями существуют
Один-ко-многим.
Клиенты и заказы имеют связь (состоят в отношениях) один-ко-многим потому, что один клиент может иметь много заказов, но каждый конкретный заказ (их множество) оформлен только одним клиентом, т.е. может иметь только одного клиента.
Какую информацию мы будем хранить? Решаем первый вопрос.
Для начала мы определимся какую информацию о заказах и о клиентах мы будем хранить. Чтобы это сделать мы должны задать себе вопрос: “Какие единичные блоки информации относятся к клиентам, а какие единичные блоки информации относятся к заказам?”
Проектируем таблицу клиентов.
Заказы действительно принадлежат клиентам, но заказ – это это не минимальный блок информации, который относится к клиентам (т.е. этот блок можно разбить на более мелкие: дата заказа, адрес доставки заказа и пр., к примеру).
Поля ниже – это минимальные блоки информации, которые относятся к клиентам:
- customer_id (primary key) – идентификатор клиента
- first_name — имя
- last_name — отчество
- address — адрес
- zip_code – почтовый индекс
- country — страна
- birth_date – дата рождения
- username – регистрационное имя пользователя (логин)
- password – пароль
Давайте перейдем к непосредственному созданию этой таблицы.
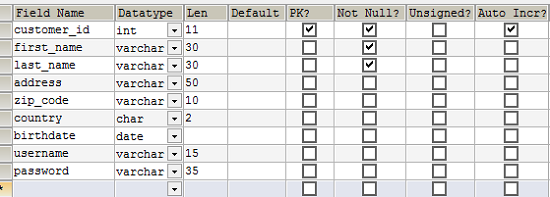
Обратите внимание, что выбран флажок первичного ключа (PK) для поля customer_id. Поле customer_id является первичным ключом. Также выбран флажок Auto Incr, что означает, что база данных будет автоматически подставлять уникальное числовое значение, которое, начиная с нуля, будет каждый раз увеличиваться на одну единицу.
Проектируем таблицу заказов.
Какие минимальные блоки информации, необходимые нам, относятся к заказу?
- order_id (primary key) – идентификатор заказа
- order_date – дата и время заказа
- customer – клиент, который сделал заказ

Проект таблицы. Поле customer является ссылкой (внешним ключом) для поля customer_id в таблице клиентов.
Эти две таблицы (клиентов и заказов) связаны потому, что поле customer в таблице заказов ссылается на первичный ключ (customer_id) таблицы клиентов. Такая связь называется связью по внешнему ключу. Вы должны представлять себе внешний ключ как простую копию (копию значения) первичного ключа другой таблицы. В нашем случае значение поля customer_id из таблицы клиентов копируется в таблицу заказов при вставке каждой записи. Таким образом, у нас каждый заказ привязан к клиенту. И заказов у каждого клиента может быть много, как и говорилось выше.
Создание связи по внешнему ключу.
Вы можете задаться вопросом: “Каким образом я могу убедиться или как я могу увидеть, что поле customer в таблице заказов ссылается на поле customer_id в таблице клиентов”. Ответ прост – вы не можете сделать этого потому, что я еще не показал вам как создать связь.
Ниже – окно SQLyog с окном, которое я использовал для создания связи между таблицами.
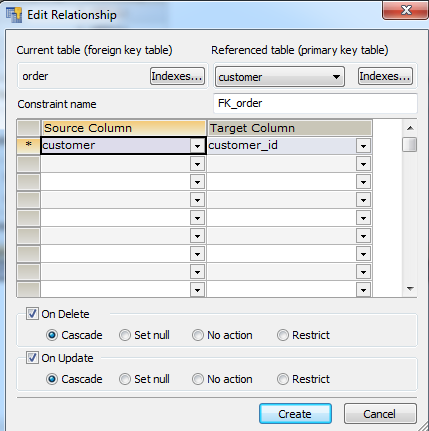
Создание связи по внешнему ключу между таблицами заказов и клиентов.
В окне выше вы можете видеть, как поле customer таблицы заказов слева связывается с первичным ключом (customer_id) таблицы клиентов справа.
Теперь, когда вы посмотрите на данные, которые могли бы быть в таблицах, вы увидите, что две таблицы связаны.
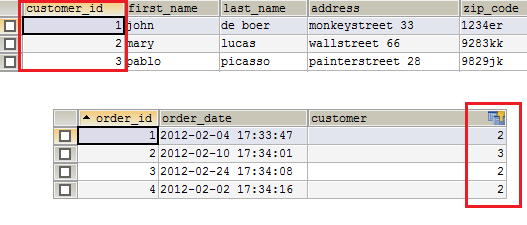
Заказы связаны с клиентами через поле customer, которое ссылается на таблицу клиентов.
На изображении вы видите, что клиент mary поместила три заказа, клиент pablo поместил один, а клиент john – ни одного.
Вы можете спросить: “А что же именно заказали все эти люди?” Это хороший вопрос. Вы возможно ожидали увидеть заказанные товары в таблице заказов. Но это плохой пример проектирования. Как бы вы поместили множественные продукты в единственную запись? Товары – это отдельные сущности, которые должны храниться в отдельной таблице. И связь между таблицами заказов и товаров будет являться связью один-ко-многим.
Создание диаграммы сущность-связь.
Ранее вы узнали как записи из разных таблиц связываются друг с другом в реляционных базах данных. Перед созданием и связыванием таблиц важно, чтобы вы подумали о сущностях, которые существуют в вашей системе (для которой вы создаете базу данных) и решили каким образом эти сущности бы связывались друг с другом. В проектировании баз данных сущности и их отношения обычно предоставляются в диаграмме сущность-связь (англ. entity-relationship diagram, ERD). Данная диаграмма является результатом процесса проектирования базы данных.
Сущности.
В контексте проектирования баз данных сущность – это нечто, что заслуживает своей собственной таблицы в модели вашей базы данных. Когда вы проектируете базу данных, вы должны определить эти сущности в системе, для которой вы создаете базу данных.
Давайте возьмем интернет-магазин для примера. Интернет-магазин продает товары. Товар мог бы стать очевидной сущностью в системе интернет-магазина. Товары заказываются клиентами. Вот мы с вами и увидели еще две очевидных сущности: заказы и клиенты. Заказ оплачивается клиентом… это интересно. Мы собираемся создавать отдельную таблицу для платежей в базе данных нашего интернет-магазина? Возможно. Но разве платежи – это минимальный блок информации, который относится к заказам? Это тоже возможно.
Если вы не уверены, то просто подумайте о том, какую информацию о платежах вы хотите хранить. Возможно, вы захотите хранить метод платежа или дату платежа. Но это все еще минимальные блоки информации, которые могли бы относиться к заказу. Можно изменить формулировки. Метод платежа — метод платежа заказа. Дата платежа – дата платежа заказа. Таким образом, я не вижу необходимости выносить платежи в отдельную таблицу, хотя концептуально вы бы могли выделить платежи как сущность, т.к. вы могли бы рассматривать платежи как контейнер информации (метод платежа, дата платежа).
Как вы видите определение того, какие сущности имеет ваша система – это немного интеллектуальный процесс, который требует некоторого опыта и часто – это предмет для внесения изменений, пересмотров, раздумий…
Связь один-ко-многим.
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
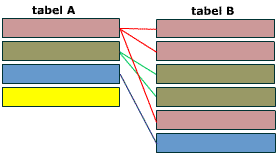
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Как опознать связь один-ко-многим?
Если у вас есть две сущности спросите себя:
- Сколько объектов из B могут относится к объекту A?
- Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ – множество, а на второй – один (или возможно, что ни одного), то вы имеете дело со связью один-ко-многим.
Некоторые примеры связи один-ко-многим:
- Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
- Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
- Диаграмма сущность-связь и ее таблицы. Диаграмма может иметь больше, чем одну таблицу, но каждая из этих таблиц принадлежит только одной диаграмме.
- Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
Связь многие-ко-многим.
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли определенные связи в данный момент, а о том, возможно ли существование связей вообще, в перспективе. Если в настоящий момент все поставщики предоставляют множество видов пива, но каждый вид пива предоставляется только одним поставщиком, то вы можете подумать, что это связь один-ко-многим, но… Не торопитесь реализовывать связь один-ко-многим в этой ситуации. Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиками и видами пива – не будет подготовлена к этому.
Создание связи многие-ко-многим.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
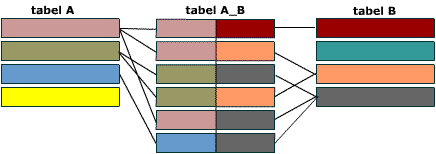
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проект базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в связи многие-ко-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и distributor_id уникальны в соединительной таблице.
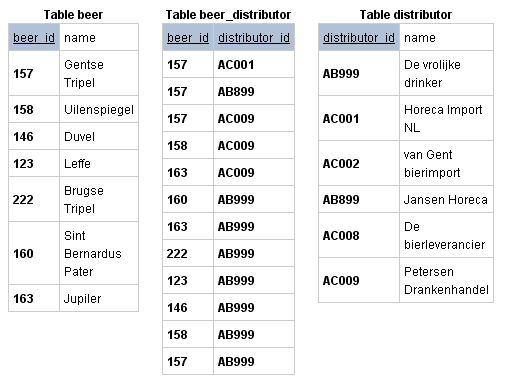
Таблицы выше связывают поставщиков и пиво связью многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво ‘Gentse Tripel’ (157) поставляют Horeca Import NL (157, AC001) Jansen Horeca (157, AB899) и Petersen Drankenhandel (157, AC009). И vice versa, Petersen Drankenhandel является поставщиком 3 видов пива из таблицы, а именно: Gentse Tripel (157, AC009), Uilenspiegel (158, AC009) и Jupiler (163, AC009).
Еще обратите внимание, что в таблицах выше поля первичных ключей окрашены в синий цвет и имеют подчеркивание. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей. Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
Связь один-к-одному.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В редких случаях связь один-к-одному моделируется используя две таблицы. Такой вариант иногда необходим, чтобы преодолеть ограничения РСУБД или с целью увеличения производительности (например, иногда — это вынесение поля с типом данных blob в отдельную таблицу для ускорения поиска по родительской таблице). Или порой вы можете решить, что вы хотите разделить две сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
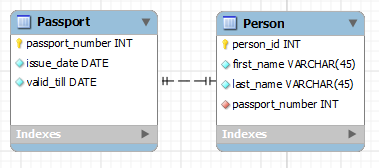
Примеры связи один-к-одному.
Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.
Проект реляционной базы данных – это коллекция таблиц, которые перелинковываются (связываются) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами”.
Нормализация баз данных.
Указания для правильного проектирования реляционных баз данных изложены в реляционной модели данных. Они собраны в 5 групп, которые называются нормальными формами. Первая нормальная форма представляет самый низкий уровень нормализации баз данных. Пятый уровень представляет высший уровень нормализации.
Нормальные формы – это рекомендации по проектированию баз данных. Вы не обязаны придерживаться всех пяти нормальных форм при проектировании баз данных. Тем не менее, рекомендуется нормализовать базу данных в некоторой степени потому, что этот процесс имеет ряд существенных преимуществ с точки зрения эффективности и удобства обращения с вашей базой данных.
- В нормализованной структуре базы данных вы можете производить сложные выборки данных относительно простыми SQL-запросами.
- Целостность данных. Нормализованная база данных позволяет надежно хранить данные.
- Нормализация предотвращает появление избыточности хранимых данных. Данные всегда хранятся только в одном месте, что делает легким процесс вставки, обновления и удаления данных. Есть исключение из этого правила. Ключи, сами по себе, хранятся в нескольких местах потому, что они копируются как внешние ключи в другие таблицы.
- Масштабируемость – это возможность системы справляться с будущим ростом. Для базы данных это значит, что она должна быть способна работать быстро, когда число пользователей и объемы данных возрастают. Масштабируемость – это очень важная характеристика любой модели базы данных и для РСУБД.
Вот некоторые из основных пунктов, которые связаны с нормализацией баз данных:
- Упорядочивание данных в логические группы или наборы.
- Нахождение связей между наборами данных. Вы уже видели примеры связей один-ко-многим и многие-ко-многим.
- Минимизация избыточности данных.
Очень малое количество баз данных следуют всем пяти нормальным формам, предоставленным в реляционной модели данных. Обычно базы данных нормализуются до второй или третьей нормальной формы. Четвертая и пятая формы используются редко.
Первая нормальная форма (1НФ).
Первая нормальная форма гласит, что таблица базы данных – это представление сущности вашей системы, которую вы создаете. Примеры сущностей: заказы, клиенты, заказ билетов, отель, товар и т.д. Каждая запись в базе данных представляет один экземпляр сущности. Например, в таблице клиентов каждая запись представляет одного клиента.
— Первичный ключ.
Правило: каждая таблица имеет первичный ключ, состоящий из наименьшего возможного количества полей.
Как вы знаете, первичный ключ может состоять из нескольких полей. Вы, к примеру, можете выбрать имя и фамилию в качестве первичного ключа (и надеяться, что эта комбинация будет уникальной всегда). Будет намного более хорошим выбором номер соц. страхования в качестве первичного ключа, т.к. это единственное поле, которое уникальным образом идентифицирует человека. Еще лучше, когда нет очевидного кандидата на звание первичного ключа, создайте суррогатный первичный ключ в виде числового автоинкрементного поля.
— Атомарность.
Правило: поля не имеют дубликатов в каждой записи и каждое поле содержит только одно значение.
— Порядок записей не должен иметь значение.
Правило: порядок записей таблицы не должен иметь значения.
Вы можете быть склонны использовать порядок записей в таблице клиентов для определения того, какой из клиентов зарегистрировался первым. Для этих целей вам лучше создать поля даты и времени регистрации клиентов. Порядок записей будет неизбежно меняться, когда клиенты будут удаляться, изменяться или добавляться. Вот почему вам никогда не следует полагаться на порядок записей в таблице.
Вторая нормальная форма (2НФ).
Для того, чтобы база данных была нормализована согласно второй нормальной форме, она должна быть нормализована согласно первой нормальной форме. Вторая нормальная форма связана с избыточностью данных.
— Избыточность данных.
Правило: поля с не первичным ключом не должны быть зависимы от первичного ключа.
Может звучать немного заумно. А означает это то, что вы должны хранить в таблице только данные, которые напрямую связаны с ней и не имеют отношения к другой сущности. Следование второй нормальной форме – это вопрос нахождения данных, которые часто дублируются в записях таблицы и которые могут принадлежать другой сущности.
Насколько строго вы подходите к созданию ваших таблиц – решать вам и зависит от конкретной ситуации. Если вы планируете хранить огромное количество единиц автомобилей в системе и вы хотите иметь возможность производить поиск по цвету (color), то было бы мудрым решением выделить цвета в отдельную таблицу так, чтобы они не дублировались.
Существует другой случай, когда вы можете захотеть выделить цвета в отдельную таблицу. Если вы хотите позволить работникам компании вносить данные о новых автомобилях вы захотите, чтобы они имели возможно выбирать цвет машины из заранее заданного списка. В этом случае вы захотите хранить все возможные цвета в вашей базе данных. Даже если еще нет машин с таким цветом, вы захотите, чтобы эти цвета присутствовали в базе данных, чтобы работники могли их выбирать. Это определенно тот случай, когда вам нужно выделить цвета в отдельную таблицу.
Третья нормальная форма (3НФ).
Третья нормальная форма связана с транзитивными зависимостями. Транзитивные зависимости между полями базы данных существует тогда, когда значения не ключевых полей зависят от значений других не ключевых полей. Чтобы база данных была в третьей нормальной форме, она должна быть во второй нормальной форме.
— Транзитивные зависимости.
Правило: не может быть транзитивных зависимостей между полями в таблице.
Таблица клиентов (мои клиенты – игроки немецкой и французской футбольной команды) ниже содержит транзитивные зависимости.
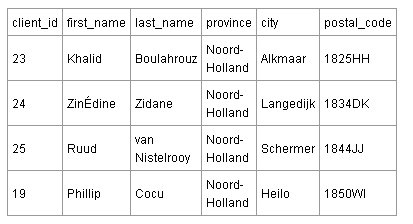
В этой таблице не все поля зависят исключительно от первичного ключа. Существует отдельная связь между полем postal_code и полями города (city) и провинции (province). В Нидерландах оба значение: город и провинция – определяются почтовым кодом, индексом. Таким образом, нет необходимости хранить город и провинцию в клиентской таблице. Если вы знаете почтовый код, то вы уже знаете город и провинцию.
Такой транзитивной зависимости следует избегать, если вы хотите, чтобы ваша модель базы данных была в третьей нормальной форме.
В данном случае устранение транзитивной зависимости из таблицы может быть достигнуто путем удаления полей города и провинции из таблицы и хранение их в отдельной таблице, содержащей почтовый код (первичный ключ), имя провинции и имя города. Получение комбинации почтовый код-город-провинция для целой страны может быть весьма нетривиальным занятием. Вот почему такие таблицы зачастую продаются.
Третья нормальная форма гласит, что вы не должны хранить данные в таблице, которые могут быть получены из других (не ключевых) полей таблицы.
Третья нормальная форма не всегда используется при проектировании баз данных. Когда разрабатываете базу данных вы всегда должны сравнивать преимущества от более высокой нормальной формы в сравнении с объемом работ, которые требуются для применения третьей нормальной формы и поддержания данных в таком состоянии.
Хранение данных, воспроизводимых из существующих, обычно плохая идея.
В современном мире нужны инструменты, которые бы позволяли хранить, систематизировать и обрабатывать большие объемы информации, с которыми сложно работать в Excel или Word.
Подобные хранилища используются для разработки информационных сайтов, интернет-магазинов и бухгалтерских дополнений. Основными средствами, реализующими данный подход, являются MS SQL и MySQL.
Продукт от Microsoft Office представляет собой упрощенную версию в функциональном плане и более понятную для неопытных пользователей. Давайте рассмотрим пошагово создание базы данных в Access 2007.

Microsoft Access 2007 – это система управления базами данных (СУБД), реализующая полноценный графический интерфейс пользователя, принцип создания сущностей и связей между ними, а также структурный язык запросов SQL. Единственный минус этой СУБД – невозможность работать в промышленных масштабах. Она не предназначена для хранения огромных объемов данных. Поэтому MS Access 2007 используется для небольших проектов и в личных некоммерческих целях.
Но прежде чем показывать пошагово создание БД, нужно ознакомиться с базовыми понятиями из теории баз данных.

Определения основных понятий
Без базовых знаний об элементах управления и объектах, использующихся при создании и конфигурации БД, нельзя успешно понять принцип и особенности настройки предметной области. Поэтому сейчас я постараюсь простым языком объяснить суть всех важных элементов. Итак, начнем:
- Предметная область – множество созданных таблиц в базе данных, которые связаны между собой с помощью первичных и вторичных ключей.
- Сущность – отдельная таблица базы данных.
- Атрибут – заголовок отдельного столбца в таблице.
- Кортеж – это строка, принимающая значение всех атрибутов.
- Первичный ключ – это уникальное значение (id), которое присваивается каждому кортежу.
- Вторичный ключ таблицы «Б» – это уникальное значение таблицы «А», использующееся в таблице «Б».
- SQL запрос – это специальное выражение, выполняющее определенное действие с базой данных: добавление, редактирование, удаление полей, создание выборок.
Теперь, когда в общих чертах есть представление о том, с чем мы будем работать, можно приступить к созданию БД.
Создание БД
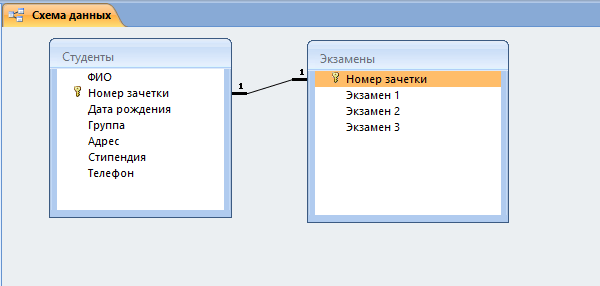
Для наглядности всей теории создадим тренировочную базу данных «Студенты-Экзамены», которая будет содержать 2 таблицы: «Студенты» и «Экзамены». Главным ключом будет поле «Номер зачетки», т.к. данный параметр является уникальным для каждого студента. Остальные поля предназначены для более полной информации об учащихся.
Итак, выполните следующее:
- Запустите MS Access 2007.
- Нажмите на кнопку «Новая база данных».
- В появившемся окне введите название БД и выберите «Создать».

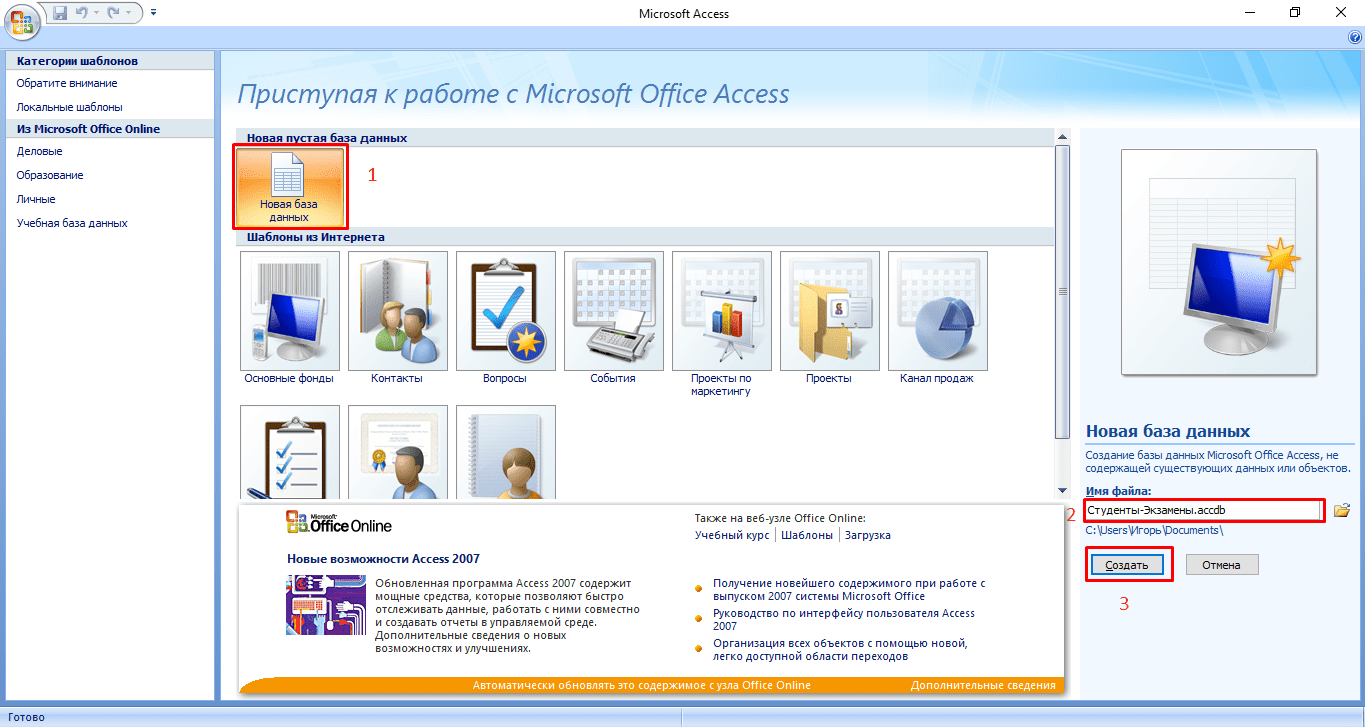
Все, теперь осталось только создать, заполнить и связать таблицы. Переходите к следующему пункту.
Создание и заполнение таблиц
После успешного создания БД на экране появится пустая таблица. Для формирования ее структуры и заполнения выполните следующее:
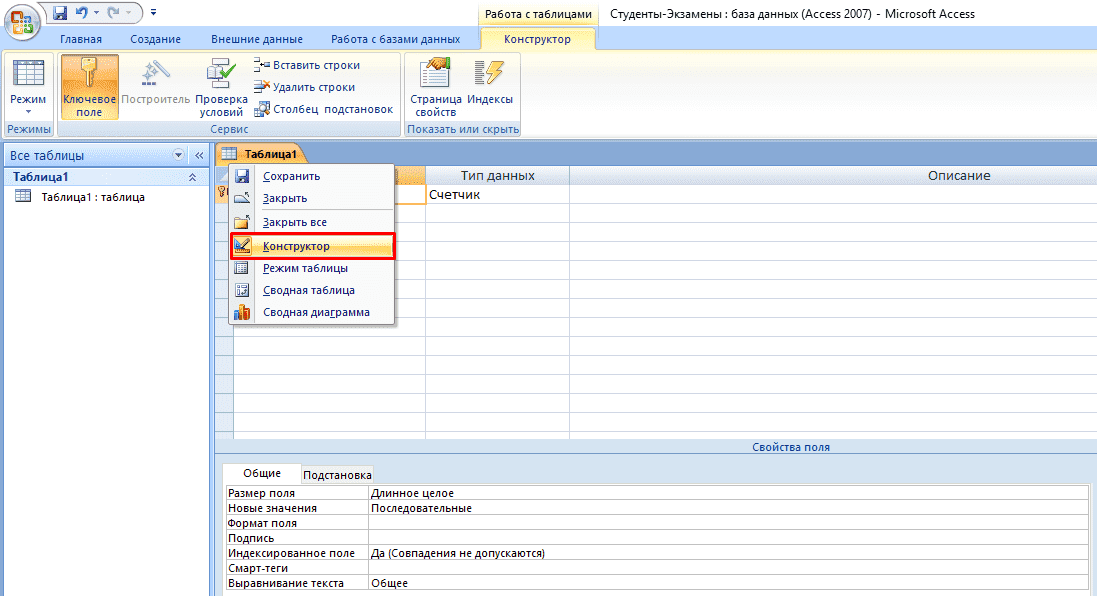
- Нажмите ПКМ по вкладке «Таблица1» и выберите «Конструктор».

- Теперь начинайте заполнять названия полей и соответствующий им тип данных, который будет использоваться.

Внимание! Первым полем принято устанавливать уникальное значение (первичный ключ). Для него предпочтительно числовое значение.
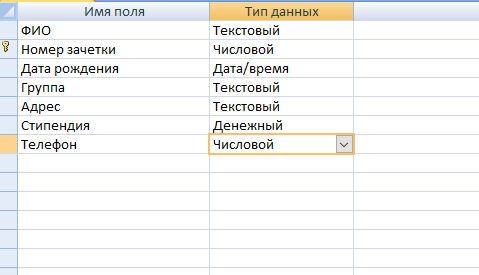
- После создания необходимых атрибутов сохраните таблицу и введите ее название.
- Снова нажмите ПКМ по вкладке с уже новым название и выберите «Режим таблицы».

- Заполните таблицу необходимыми значениями.

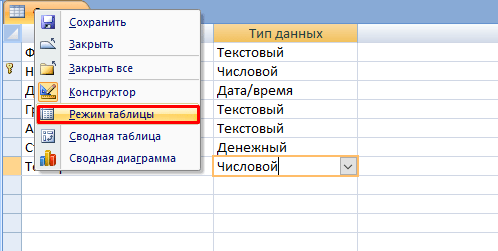

Совет! Для тонкой настройки формата данных перейдите на ленте во вкладку «Режим таблицы» и обратите внимание на блок «Форматирование и тип данных». Там можно кастомизировать формат отображаемых данных.
Создание и редактирование схем данных
Перед тем, как приступить к связыванию двух сущностей, по аналогии с предыдущим пунктом нужно создать и заполнить таблицу «Экзамены». Она имеет следующие атрибуты: «Номер зачетки», «Экзамен1», «Экзамен2», «Экзамен3».
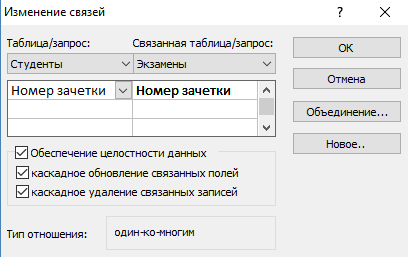
Для выполнения запросов нужно связать наши таблицы. Иными словами, это некая зависимость, которая реализуется с помощью ключевых полей. Для этого нужно:
- Перейти во вкладку «Работа с базами данных».
- Нажать на кнопку «Схема данных».
- Если схема не была создана автоматически, нужно нажать ПКМ на пустой области и выбрать «Добавить таблицы».

- Выберите каждую из сущностей, поочередно нажимая кнопку «Добавить».
- Нажмите кнопку «ОК».
Конструктор должен автоматически создать связь, в зависимости от контекста. Если же этого не случилось, то:
- Перетащите общее поле из одной таблицы в другую.
- В появившемся окне выберите необходимы параметры и нажмите «ОК».

- Теперь в окне должны отобразиться миниатюры двух таблиц со связью (один к одному).

Выполнение запросов
Что же делать, если нам нужны студенты, которые учатся только в Москве? Да, в нашей БД только 6 человек, но что, если их будет 6000? Без дополнительных инструментов узнать это будет сложно.
Именно в этой ситуации к нам на помощь приходят SQL запросы, которые помогают изъять лишь необходимую информацию.
Виды запросов
SQL синтаксис реализует принцип CRUD (сокр. от англ. create, read, update, delete — «создать, прочесть, обновить, удалить»). Т.е. с помощью запросов вы сможете реализовать все эти функции.
На выборку
В этом случае в ход вступает принцип «прочесть». Например, нам нужно найти всех студентов, которые учатся в Харькове. Для этого нужно:
- Перейти во вкладку «Создание».
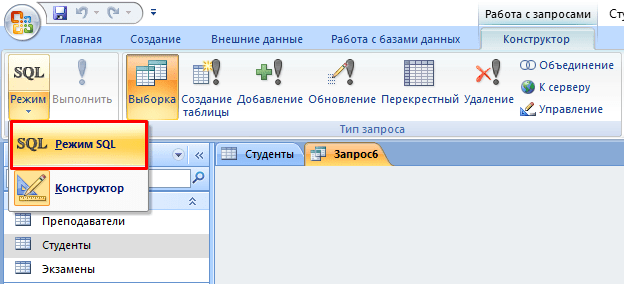
- Нажать кнопку «Конструктор запросов» в блоке «Другие».
- В новом окне нажмите на кнопку SQL.

- В текстовое поле введите команду: SELECT * FROM Студенты WHERE Адрес = “Харьков”; где «SELECT *» означает, что выбираются все студенты, «FROM Студенты» – из какой таблицы, «WHERE Адрес = “Харьков”» – условие, которое обязательно должно выполняться.
- Нажмите кнопку «Выполнить».

- На выходе мы получаем результирующую таблицу.

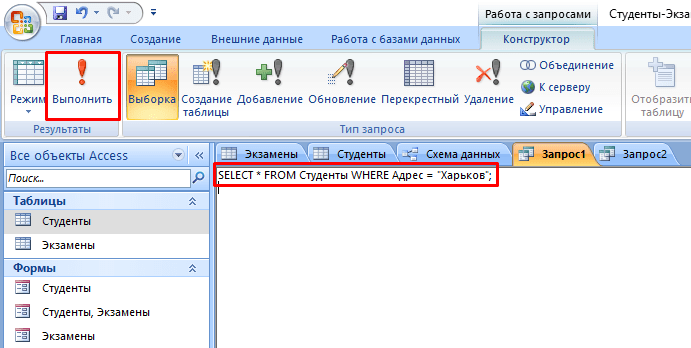
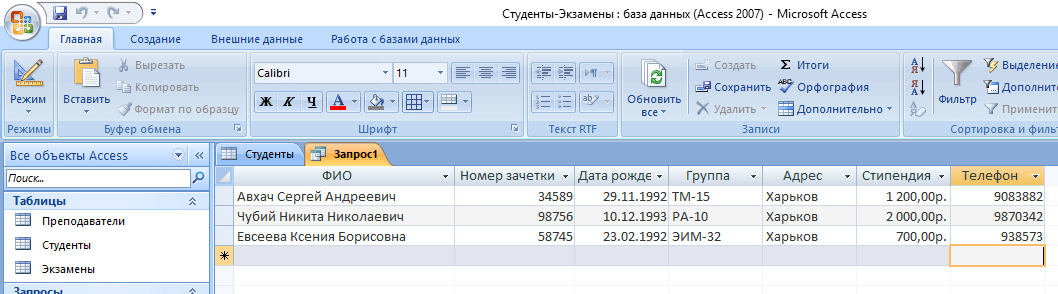
А что делать, если нас интересуют студенты из Харькова, стипендии у которых больше 1000? Тогда наш запрос будет выглядеть следующим образом:
SELECT * FROM Студенты WHERE Адрес = “Харьков” AND Стипендия > 1000;
а результирующая таблица примет следующий вид:

На создание сущности
Кроме добавления таблицы с помощью встроенного конструктора, иногда может потребоваться выполнение этой операции с помощью SQL запроса. В большинстве случаев это нужно во время выполнения лабораторных или курсовых работ в рамках университетского курса, ведь в реальной жизни необходимости в этом нет. Если вы, конечно, не занимаетесь профессиональной разработкой приложений. Итак, для создания запроса нужно:
- Перейти во вкладку «Создание».
- Нажать кнопку «Конструктор запросов» в блоке «Другие».
- В новом окне нажмите на кнопку SQL, после чего в текстовое поле введите команду:
CREATE TABLE Преподаватели
(КодПреподавателя INT PRIMARY KEY,
Фамилия CHAR(20),
Имя CHAR (15),
Отчество CHAR (15),
Пол CHAR (1),
Дата_рождения DATE,
Основной_предмет CHAR (200));
где «CREATE TABLE» означает создание таблицы «Преподаватели», а «CHAR», «DATE» и «INT» – типы данных для соответствующих значений.
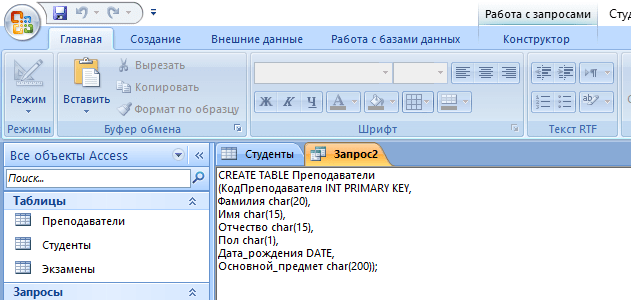
- Кликните по кнопке «Выполнить».
- Откройте созданную таблицу.

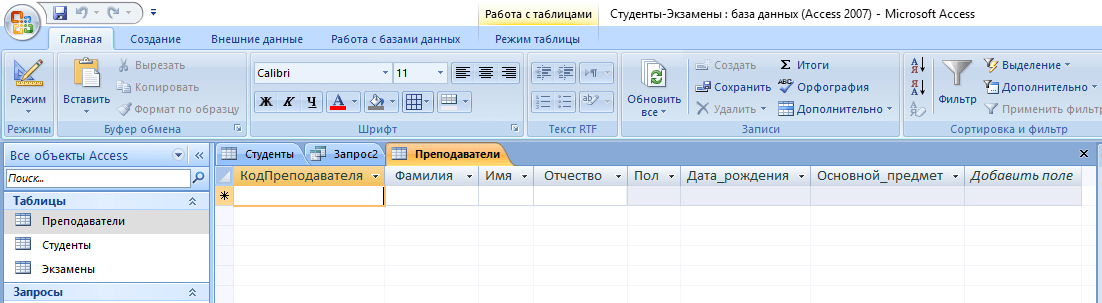
Внимание! В конце каждого запроса должен стоять символ «;». Без него выполнение скрипта приведет к ошибке.
На добавление, удаление, редактирование
Здесь все гораздо проще. Снова перейдите в поле для создания запроса и введите следующие команды:
Создание формы
При огромном количестве полей в таблице заполнять базу данных становится сложно. Можно случайно пропустить значение, ввести неверное или другого типа. В данной ситуации на помощь приходят формы, с помощью которых можно быстро заполнять сущности, а вероятность допустить ошибку минимизируется. Для этого потребуются следующие действия:
- Откройте интересующую таблицу.
- Перейдите во вкладку «Создание».
- Нажмите на необходимый формат формы из блока «Формы».

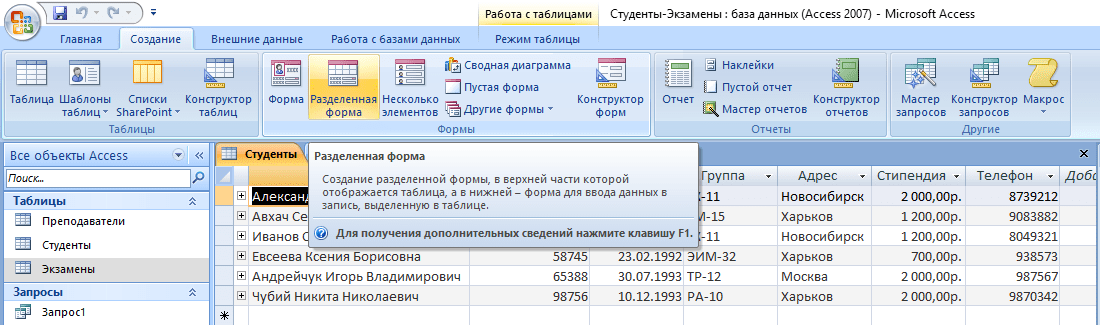
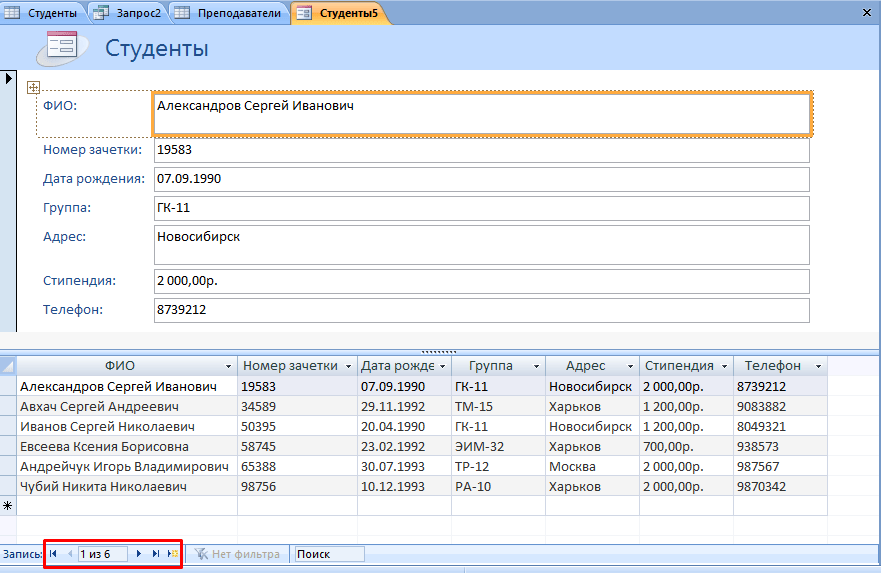
Совет! Рекомендуется использовать «Разделенную форму» – кроме самого шаблона, в нижней части будет отображаться миниатюра таблицы, которая сделает процесс редактирования еще более наглядным.
- С помощью навигационных кнопок переходите к следующей записи и вносите изменения.

Все базовые функции MS Access 2007 мы уже рассмотрели. Остался последний важный компонент – формирование отчета.
Формирование отчета
Отчет – это специальная функция MS Access, позволяющая оформить и подготовить для печати данные из базы данных. В основном это используется для создания товарных накладных, бухгалтерских отчетов и прочей офисной документации.
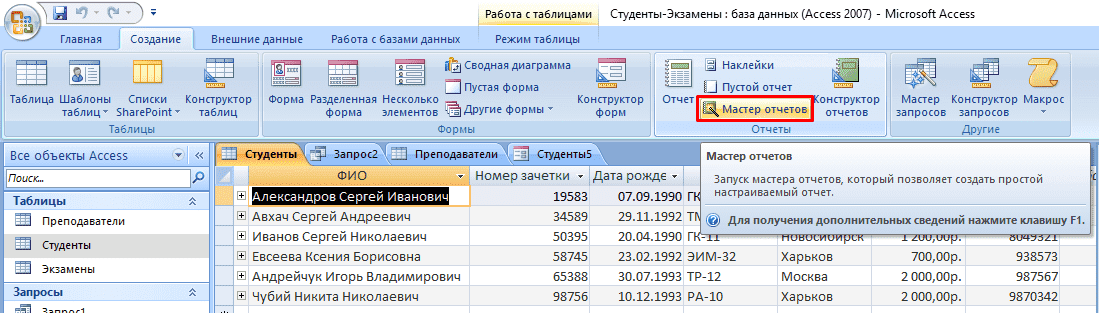
Если вы никогда не сталкивались с подобной функцией, рекомендуется воспользоваться встроенным «Мастером отчетов». Для этого сделайте следующее:
- Перейдите во вкладку «Создание».
- Нажмите на кнопку «Мастер отчетов» в блоке «Отчеты».

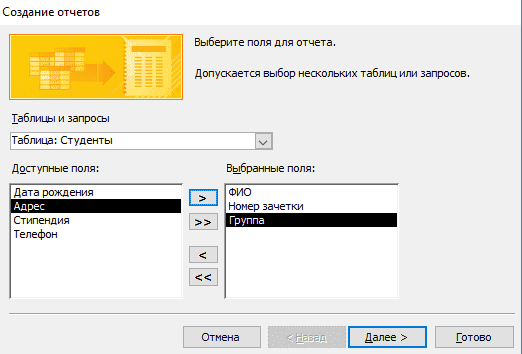
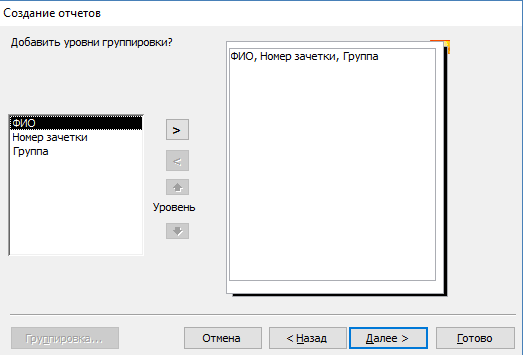
- Выберите интересующую таблицу и поля, нужные для печати.

- Добавьте необходимый уровень группировки.

- Выберите тип сортировки каждого из полей.

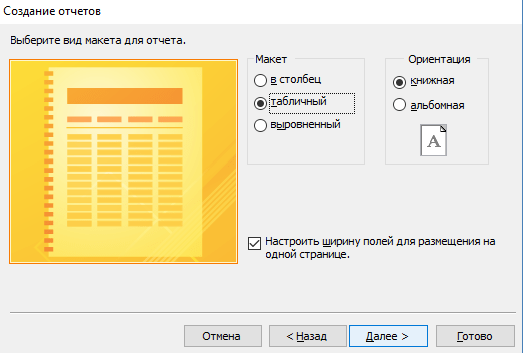
- Настройте вид макета для отчета.

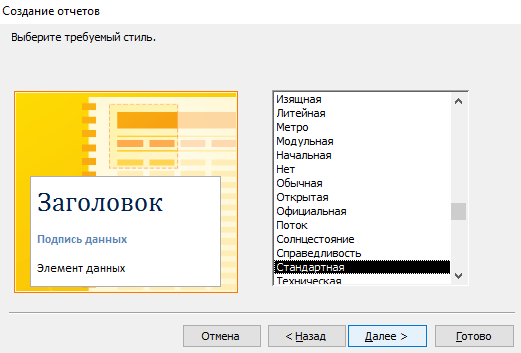
- Выберите подходящий стиль оформления.

Внимание! В официальных документах допускается только стандартный стиль оформления.
- Просмотрите созданный отчет.


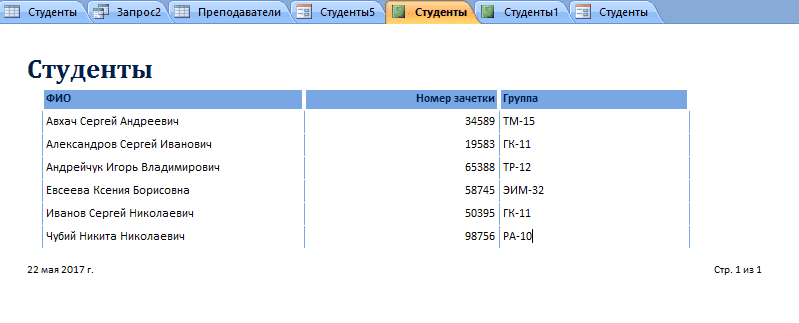
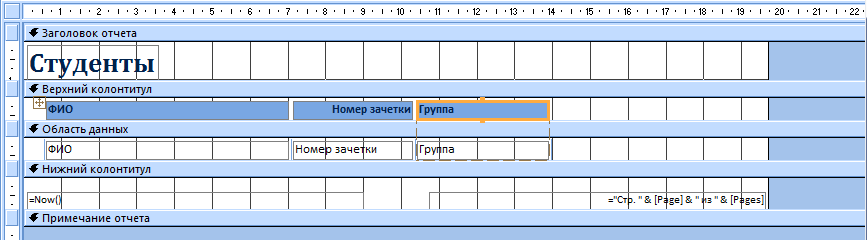
Если отображение вас не устраивает, его можно немного подкорректировать. Для этого:
- Нажмите ПКМ на вкладке отчета и выберите «Конструктор».
- Вручную расширьте интересующие столбцы.

- Сохраните изменения.
Вывод
Итак, с уверенностью можно заявить, что создание базы данных в MS Access 2007 мы разобрали полностью. Теперь вам известны все основные функции СУБД: от создания и заполнения таблиц до написания запросов на выборку и создания отчетов. Этих знаний хватит для выполнения несложных лабораторных работ в рамках университетской программы или использования в небольших личных проектах.
Для проектирования более сложных БД необходимо разбираться в объектно-ориентированном программировании и изучать такие СУБД, как MS SQL и MySQL. А для тех, кому нужна практика составления запросов, рекомендую посетить сайт SQL-EX, где вы найдете множество практических занимательных задачек.
Удачи в освоении нового материала и если есть какие-либо вопросы – милости прошу в комментарии!
Руководство по разработке структуры и проектированию базы данных
Следуя принципам, описанным в этой статье, можно создать базу данных, которая работает надлежащим образом и в будущем может быть адаптирована под новые требования. Мы рассмотрим основные принципы проектирования базы данных, а также способы ее оптимизации.
- Этапы создания базы данных
- Анализ требований: определение цели базы данных
- Структура базы данных: построение блоков
- Создание связей между сущностями
- Связь «один-к одному»
- Связь «один-ко-многим»
- Связь «многие-ко-многим»
- Обязательно или нет?
- Рекурсивные связи
- Лишние связи
- Нормализация базы данных
- Первая форма нормализации
- Вторая форма нормализации
- Третья форма нормализации
- Многомерные данные
- Правила целостности данных
- Добавление индексов и представлений
- Расширенные свойства
- SQL и UML
- Системы управления базами данных
Надлежащим образом структурированная база данных:
- Помогает сэкономить дисковое пространство за счет исключения лишних данных;
- Поддерживает точность и целостность данных;
- Обеспечивает удобный доступ к данным.
Основные этапы разработки базы данных:
- Анализ требований или определение цели базы данных;
- Организация данных в таблицах;
- Указание первичных ключей и анализ связей;
- Нормализация таблиц.
Рассмотрим каждый этап проектирования баз данных подробнее. Обратите внимание, что в этом руководстве рассматривается реляционная модель базы данных Эдгара Кодда, написанная на языке SQL (а не иерархическая, сетевая или объектная модели).
Например, если вы создаете базу данных для публичной библиотеки, нужно продумать, каким образом и читатели, и библиотекари должны получать доступ к БД.
Вот несколько способов сбора информации перед созданием базы данных:
- Опрос людей, которые будут ее использовать;
- Анализ бизнес-форм, таких как счета-фактуры, расписания, опросы;
- Рассмотрение всех существующих систем данных (включая физические и цифровые файлы).
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
Клиенты
- Имя;
- Адрес;
- Город, штат, почтовый индекс;
- Адрес электронной почты.
Товары
- Название;
- Цена;
- Количество в наличии;
- Количество под заказ.
Заказы
- Номер заказа;
- Торговый представитель;
- Дата;
- Товар;
- Количество;
- Цена;
- Стоимость.
При проектировании реляционной базы данных эта информация позже станет частью словаря данных, в котором описаны таблицы и поля БД. Разбейте информацию на минимально возможные части. Например, подумайте о том, чтобы разделить поле почтового адреса и штата, чтобы можно было фильтровать людей по штату, в котором они проживают.
После того, как вы определились с тем, какие данные будут включены в базу, откуда эти данные будут поступать, и как они будут использоваться, можно приступить к планированию фактической БД.
Следующим шагом будет визуальное представление базы данных. Для этого нужно точно знать, как структурируются реляционные БД. Внутри базы связанные данные группируются в таблицы, каждая из которых состоит из строк и столбцов.
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.

Чтобы при проектировании модели базы данных обеспечить согласованность разных записей, назначьте соответствующий тип данных для каждого столбца. К общим типам данных относятся:
- CHAR — конкретная длина текста;
- VARCHAR — текст различной длины;
- TEXT — большой объем текста;
- INT — положительное или отрицательное целое число;
- FLOAT, DOUBLE — числа с плавающей запятой;
- BLOB — двоичные данные.
Некоторые СУБД также предлагают тип данных Autonumber, который автоматически генерирует уникальный номер в каждой строке.
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:

При проектировании информационной базы данных необходимо решить, какие атрибуты будут служить в качестве первичного ключа для каждой таблицы, если таковые будут. Первичный ключ (PK) — это уникальный идентификатор для данного объекта. С его помощью вы можете выбрать данные конкретного клиента, даже если знаете только это значение.
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL (они не могут быть пустыми). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно (это называется составным ключом).
Когда придет время создавать фактическую БД, вы реализуете как логическую, так и физическую структуру через язык определения данных, поддерживаемый вашей СУБД.
Также необходимо оценить размер БД, чтобы убедиться, что можно получить требуемый уровень производительности и у вас достаточно места для хранения данных.
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:

Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:

Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:

При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:

Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:

Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи — это те, которые выражены более одного раза. Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями». Так как единственный способ, которым ученикам назначают учителей — это предметы.
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:

Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:

Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:

В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:

Также с помощью средств проектирования баз данных необходимо настроить БД с учетом возможности проверки данных на соответствие определенным правилам. Многие СУБД, такие как Microsoft Access, автоматически применяют некоторые из этих правил.
Правило целостности гласит, что первичный ключ никогда не может быть равен NULL. Если ключ состоит из нескольких столбцов, ни один из них не может быть равен NULL. В противном случае он может неоднозначно идентифицировать запись.
Правило целостности ссылок требует, чтобы каждый внешний ключ, указанный в одной таблице, сопоставлялся с одним первичным ключом в таблице, на которую он ссылается. Если первичный ключ изменяется или удаляется, эти изменения необходимо реализовать во всех объектах, на которые ссылается этот ключ в базе данных.
Правила целостности бизнес-логики обеспечивают соответствие данных определенным логическим параметрам. Например, время встречи должно быть в пределах стандартных рабочих часов.
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
После того как схема базы данных будет готова можно уточнить БД с помощью расширенных свойств, таких как справочный текст, маски ввода и правила форматирования, которые применяются к конкретной схеме, представлению или столбцу. Преимущество этого метода заключается в том, что, поскольку эти правила хранятся в самой базе, представление данных будет согласовано между несколькими программами, которые обращаются к данным.
Унифицированный язык моделирования (UML) — это еще один визуальный способ выражения сложных систем, созданных на объектно-ориентированном языке. Некоторые из концепций, упомянутых в этом руководстве, известны в UML под разными названиями. Например, объект в UML известен, как класс.
Сейчас UML используется не так часто. В наши дни он применяется академически и в общении между разработчиками программного обеспечения и их клиентами.
Проектируемая структура базы данных зависит от того, какую СУБД вы используете. Некоторые из наиболее распространенных:
- Oracle DB;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- IBM DB2.
Подходящую систему управления базами данных можно выбирать исходя из стоимости, установленной операционной системы, наличия различных функций и т. д.
Прим. перев. Предполагается, что вы уже имеете начальные знания по SQL. Если вы плохо понимаете, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, то лучше сначала изучить их, например по этим видео:
А если вы знакомы с SQL и вас не остановили предыдущие термины, на всякий случай напомним, что:
- атомарность предполагает, что значение нельзя разделить на несколько атрибутов;
- под кортежем понимается запись (строка) в таблице базы данных;
- атрибут — это колонка таблицы;
- неключевой атрибут — это атрибут, не входящий в состав никакого потенциального ключа.
***
Есть минимум два требования, которые должны быть соблюдены при проектировании структуры БД:
- Сохранить всю информацию после разделения её на таблицы.
- Минимизировать избыточность того, как эта информация хранится.
Примечание Второй пункт важен не только из-за того, что избыточность влияет на размер БД. Чаще всего при обновлении данных нужно обработать много строк. В таком случае вы рискуете просто забыть обновить некоторые из них, что приведёт к коллизиям внутри БД.
Ниже перечислены некоторые рекомендации, которые помогут добиться эффективной структуры:
- используйте хотя бы третью нормальную форму;
- создавайте ограничения для входных данных;
- не храните ФИО в одном поле, также как и полный адрес;
- установите для себя правила именования таблиц и полей.
Используйте хотя бы третью нормальную форму
Нормальные формы — это требования, которые должны соблюдаться при правильной проектировке базы данных.
Нормальных форм существует целых 6 штук, однако обычно соблюдают всего лишь 3 и для начала этого более чем достаточно.
Первая нормальная форма
Для примера будем использовать отношение сотрудники_отделы_проекты. В нём есть информация о номере сотрудника, его фамилии, номере отдела, в котором он работает, номере телефона отдела и так далее.

Это отношение, как и любое другое, автоматически находится в первой нормальной форме:
- в отношении нет одинаковых кортежей;
- кортежи не упорядочены;
- атрибуты не упорядочены и различаются по наименованию;
- все значения атрибутов атомарны.
Вторая нормальная форма
В нашем случае у таблицы выше имеется сложный (составной) ключ {Н_СОТР, Н_ПРО}. От части ключа Н_СОТР зависят неключевые атрибуты ФАМ, Н_ОТД, ТЕЛ. От части ключа Н_ПРО зависит неключевой атрибут ПРОЕКТ. А вот атрибут Н_ЗАДАН зависит от всего составного ключа, так как сотрудник может выполнять одно задание в одном проекте.
Поэтому для приведения отношения ко второй нормальной форме из отношения сотрудники_отделы_проекты нужно выделить два отношения сотрудники_отделы и проекты, а исходное отношение оставим отношением задания.

Наконец, третья нормальная форма
Отношение находится в третьей нормальной форме, когда отношение находится во второй нормальной форме и все неключевые атрибуты взаимно независимы.
Для того, чтобы устранить зависимость неключевых атрибутов, нужно произвести декомпозицию отношения ещё на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.
Отношение сотрудники_отделы не находится в третьей нормальной форме, так как имеется зависимость неключевых атрибутов, таких как зависимость номера телефона от номера отдела. Поэтому декомпозируем отношение сотрудники_отделы на два отношения — сотрудники и отделы:
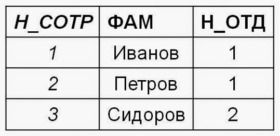
Используйте проверочные ограничения
База данных — это не просто набор таблиц. В неё встроено много инструментов, которые помогут с сохранностью и качеством данных.
В первую очередь БД поможет с ограничением значений, которые принимают поля.
Внешние ключи регламентируют отношения между таблицами. Благодаря им сильно упрощается контроль за структурой базы, уменьшается и упрощается код приложения. Правильно настроенные внешние ключи — это гарант того, что увеличится целостность данных за счёт уменьшения избыточности. Поэтому обязательно применяйте ограничение внешнего ключа при определении связей между таблицами.
Выражения ON DELETE и ON UPDATE внешних ключей используются для указания действий, которые будут выполняться при удалении строк родительской таблицы (ON DELETE) или изменении родительского ключа (ON UPDATE). Не пренебрегайте ими.
Стоит убедиться, что обязательность заполнения (NOT NULL) проверяется для полей, которые строго не должны оставаться пустыми.
Используйте CHECK, чтобы убедиться, что значения входят в диапазон (например чтобы цена не была отрицательной).
Не храните ФИО в одном поле, также как и полный адрес
Представим ситуацию, когда вам понадобится узнать, в каком городе продукт более популярен. В таком случае, если полный адрес хранится в виде цельной строки, сделать это будет очень тяжело, ведь вам нужно будет каким-то образом выделить из этой строки город. Учитывая все возможные форматы и варианты адресов, эта задача становится практически невыполнимой. Похожая ситуация и с ФИО. Даже если кажется, что это ни к чему, храните эти данные в разных полях, и в будущем вы поблагодарите себя.
Установите для себя правила именования таблиц и полей
Сложно работать с данными, которые выглядят как-то так: user.firstName, user.last_name, user.birthDate. Конечно, каждый программист в праве сам выбирать для себя стиль наименования, но для SQL рекомендуется выбрать наименование с подчёркиванием. Потому что не все SQL-движки одинаково работают с заглавными буквами, а помещать всё в кавычки бывает утомительно.
Ещё нужно определиться как будут называться таблицы — во множественном числе (users) или в единственном (user). Каждая базовая структура в БД обычно настроена на множественное число, поэтому и именовать таблицы стоит соответственно.
Не упускайте возможность сложить побольше обязанностей на базу данных, чтобы облегчить себе работу над приложением и думать о его структуре, а не о контроле табличных связей.
Всё приходит с опытом. Спроектируйте две-три схемы, и картинка сама сложится у вас в голове. Отталкивайтесь от задачи —некоторыми рекомендациями иногда можно пренебречь.
Перевод статьи «A humble guide to database schema design»