Уровень сложности
Простой
Время на прочтение
12 мин
Количество просмотров 2.4K


Автор статьи: Рустем Галиев
IBM Senior DevOps Engineer & Integration Architect. Официальный DevOps ментор и коуч в IBM
Привет Хабр! Не так давно общался с SRE в нашей команде и он рассказал мне о базовых принципах процесса управления инцидентами, теперь я поделюсь этим с вами, быть может кому‑то поможет.
Управление инцидентами включает в себя мониторинг, анализ, планирование и выполнение. SRE работают с операционными группами, экспертами по техническим вопросам, разработчиками, инженерами DevOPs, владельцами приложений и другими.
При оценке инцидентов SRE обращают внимание на такие критерии, как импакт и частота повторения — для того, чтобы определить, какие инциденты требуют дальнейшего анализа.
Есть некоторые практики, которых придерживаются в нашей команде:
-
Прежде чем произойдет инцидент, сотрудничайте с другими, настроив уведомления о предупреждениях и информационные панели, чтобы во время события уведомлялись нужные люди и предпринимались правильные действия.
-
Во время инцидента SRE несут ответственность за решение инцидента; выполнение заявок на обслуживание; мониторинг каналов событий и журналов; и анализ информационных панелей, корреляций событий, данных о тикетах и тенденциях.
-
Необходимость меняться. После разрешения инцидента дополнительные действия приводят к управлению изменениями, управлению проблемами и обновлениям управления конфигурацией, чтобы снизить вероятность возникновения подобных инцидентов в будущем.
Автоматизация, связанная с проблемами, постоянно обновляется, чтобы предотвратить повторение инцидента или быстрее решить его, если все же он произойдет снова. Ниже приведена архитектура, которой мы пользуемся (больше как референс).

Концепции управления инцидентами
-
Инфраструктура всегда в мониторинге, что выявляет отклонения от нормального поведения, такие как уменьшение времени отклика, и оповещает ops об инцидентах.
Первые респондеры, которые всегда на связи, выявляют неисправный компонент и восстанавливают обслуживание как можно быстрее. Они делают это с помощью автоматизации и runbook (скрипт, который фиксит ту или иную проблему, если совсем уж просто), чтобы устранить зависимость и риски, связанные с ручным выполнением задач.
-
В то время как первые респондеры используют информационные панели, которые обеспечивают обзор приложения, они не смотрят на консоли в ожидании сигналов тревоги. Вместо этого они уведомляются о проблемах через алерты.
Эти алерты объединяются различными системами мониторинга, сопоставляются и дополняются соответствующей информацией, такой как имя приложения, затронутые пользователи и заинтересованные стороны, а также информация о соглашении об уровне обслуживания (SLA). Эти алерты являются и должны быть действенными, в идеале с четким описанием мер по смягчению последствий. Используя call‑rotation и списки on‑call, алерт отправляется правильному первому респонденту, который предпринимает необходимые действия.
-
Оповещения, которые не могут быть быстро определены для смягчения последствий, требуют дополнительного анализа. SME в нескольких доменах сотрудничают, чтобы изолировать инцидент и определить эффективный ответ.
Такие технологии, как ChatOps, помогают в этом сотрудничестве. Инструменты DevOps и управления услугами также интегрируются через бот‑агентов. Командир инцидента (да у нас есть и такие роли) координирует эти задачи и поддерживает прозрачную связь с пострадавшими заинтересованными сторонами.
-
Целью управления инцидентами является восстановление службы. Команда не тратит время на анализ основной причины проблемы. Этот анализ проводится на следующем этапе: управление проблемами.
Подходы к управлению инцидентами включают перезапуск микросервиса, настройку балансировщика нагрузки для игнорирования отказавшего инстанса или откат к предыдущей версии. Типичные принципы DevOps, такие как blue‑green deployment (CD), упрощают реализацию этих подходов.
Инструменты процесса управления инцидентами
Целью мониторинга инцидента является обнаружение простоев, сатурация производительности и т. д. Поскольку неэффективно просто заставлять наших сотрудников постоянно следить за консолями, следующим важным элементом является настройка алертов, чтобы нужный SME уведомлялся, когда что-то идет не так. В этих случаях тулчейн играет важную роль.
SRE часто должны сотрудничать с SME, чтобы изолировать проблему и определить стратегию смягчения последствий. Вместо того, чтобы полагаться на электронную почту и телефоны, SRE используют платформы уведомлений и совместной работы, из такой практики как ChatOps.

В дополнение к мониторингу и активному исследованию служб и API SRE также должны отслеживать файлы журналов служб. Этот мониторинг может помочь выявить проблемы до того, как они повлияют на службу. Это также может ускорить этап идентификации и разрешения инцидента.
По мере увеличения нагрузки и усложнения приложений, первые респондеры начинают получать слишком много предупреждений. Они получают оповещения, связанные с симптомами и причинами. Некоторые предупреждения могут не действовать. События могут не предоставлять достаточный контекст для быстрого реагирования, например соглашение об уровне обслуживания (SLA) или данные об импакте. На этом этапе должен быть “event management” в тулчейне. Управление событиями сопоставляет связанные события, удаляет” шум”, чтобы отображались только предупреждающие действия, и дополняет эти события дополнительным контекстом.
Усовершенствованная цепочка инструментов с управлением событиями будет выглядеть так, как показано здесь.
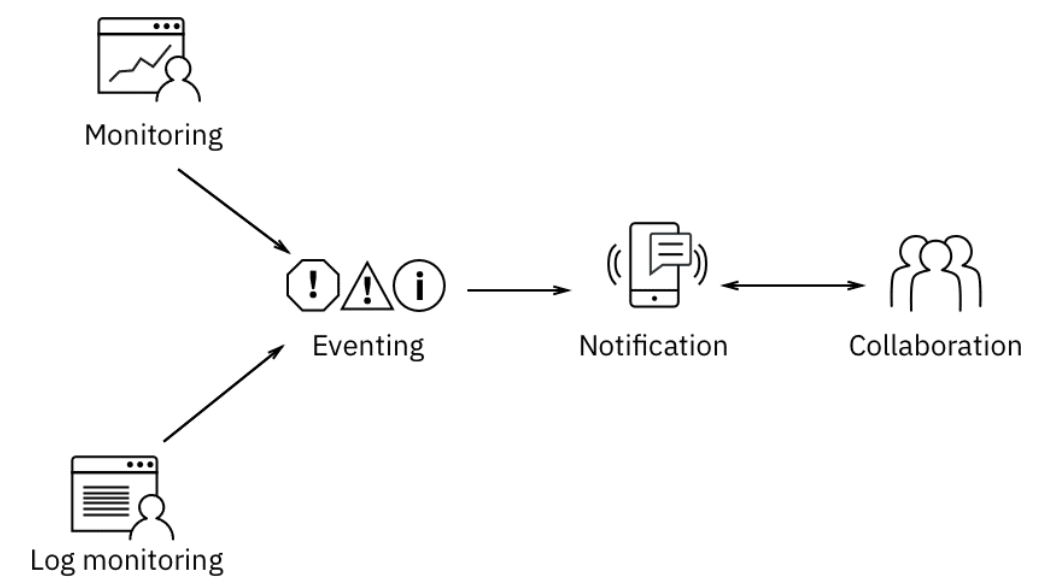
Чтобы быстро реагировать на проблемы, нужны runbook и средства автоматизации. Runbook могут вызываться автоматически либо для запуска диагностических команд, либо для устранения проблемы. Runbook также может запускаться вручную первым ответчиком и специалистом по разрешению инцидентов. Чтобы избежать ручного входа в систему и риска неправильного набора команд, автоматизированные и полуавтоматические runbook обеспечивают безопасное и согласованное выполнение.
По мере добавления новых инструментов SR-инженерам требуется обзор всего “ландшафта”. Эта видимость не заменяет существующие пользовательские интерфейсы продукта (UI), а вместо этого дополняет их и обеспечивает комбинированное представление среды на панелях управления для конкретных пользователей. В идеале в этих представлениях также отображается дополнительная информация, например действия по развертыванию или информация об уровне обслуживания.
Кроме того, информация об инцидентах постоянно отслеживается в инструментах оформления заявок, которые являются источником достоверной информации для расчета SLA. Предприятиям особенно необходимо вести журнал аудита для всех инцидентов. Отслеживаются начало и конец инцидента, а также любые важные обновления. Интеграция всей цепочки инструментов автоматизирует заполнение этого журнала действий.

Коммуникация по управлению инцидентами во время простоя
Прозрачность — ключевой аспект завоевания и поддержания доверия пользователей вашего сервиса. Поскольку предприятия полагаются на доступность и качество услуг, они заинтересованы в получении информации о любых проблемах или инцидентах, влияющих на качество этих услуг. В дополнение к незапланированным отключениям любое плановое техническое обслуживание должно следовать той же парадигме. Руководящими принципами любого сообщения о сбоях являются точность, ясность и своевременное предоставление информации.
Можно использовать правило: “How? Who? When?”
How: Поставщики услуг информируют своих пользователей об инцидентах несколькими способами:
-
Веб-страница с информацией о статусе,
-
Информация о статусе через социальные сети, такие как Twitter,
-
Эмейл,
-
Программный API (веб-хук),
-
Инженерный блог компании.
Предоставить нужно информацию об инциденте в сочетании этих каналов. Не будем думать, что пользователи всегда знают, где искать.
Who: При составлении плана передачи информации о состоянии четко определите, кто отвечает за выполнение каждой задачи. Важно определить зоны ответственности, чтобы общение осуществлялось быстро и эффективно.
Типичной ролью, отвечающей за коммуникацию и координацию, является руководитель инцидента.
-
Этот человек олицетворяет культуру прозрачности, честности и подотчетности перед клиентами в качестве руководящих принципов.
-
Сосредоточив общение в одной роли, убедитесь, что общение последовательное и не конфликтное или, что еще хуже, противоречивое.
-
Для своевременного предоставления обновлений этот человек должен иметь возможность предоставлять обновления без трудоемкого процесса утверждения.
-
Использование готовых сценариев или шаблонов постов — хорошая стратегия для заблаговременного завершения проверки и утверждения.
When: Также важно определить, когда общаться. Как только произойдет сбой, подтвердите инцидент и сообщите об этом пользователям. Пользователи в любом случае узнают об инциденте, и если предоставленная поставщиком страница состояния отображает что “все хорошо”, люди будут чувствовать, что им лгут.
После подтверждения сбоя часто обновляйте статус.
-
Найдите баланс между регулярными и содержательными обновлениями. Как только статус изменится или появится значимая информация для обмена, отправьте обновление.
-
Следующее обновление может занять некоторое время, но пользователи хотят видеть, что команда все еще работает над инцидентом.
-
Рекомендуется обновлять информацию по истечении определенного времени, например, каждые 30 минут, даже если новая информация недоступна. Однако будьте осторожны, чтобы не показывать один и тот же ответ для нескольких итераций.
-
После восстановления службы опубликуйте уведомление об окончании сбоя.
Характеристики инцидента
Каким бы надежным ни был сервис, иногда возникают проблемы, которые могут повлиять на качество и доступность. Управление инцидентами — это процесс, посредством которого мы восстанавливаем поврежденный сервис. Работая вместе в команде, мы можем определить характеристики сервиса, чтобы как можно быстрее вернуть сервис в нужное русло.
Некоторые инциденты требуют дальнейшего анализа:
-
Когда проблемы возникают более одного раза (частота),
-
Когда сбой может затронуть многих пользователей (импакт),
-
Когда система не работает так, как задумано.
Каскадный сбой — это сбой, который со временем нарастает в результате положительной обратной связи. Когда одна часть всей системы выходит из строя, возрастает вероятность того, что другие части системы также откажут.Этот шаблон может создать эффект домино или каскада, который отключает все функции службы.
Снижение производительности: падение производительности относится к службам, которые не работают должным образом. Обнаружение и устранение ухудшения производительности может быть затруднено, но SRE несут ответственность за обнаружение и устранение проблем с ухудшением производительности.
Сбой функционала: Иногда команда создает необходимую функцию, и она не работает должным образом.
Воздействие вышестоящих и нижестоящих зависимостейЗачем учитывать восходящие и нисходящие зависимости при обработке инцидента?
Для вас важно учитывать восходящие и нисходящие зависимости, влияющие на микросервис, при обработке инцидента, поскольку они имеют решающее значение для разрешения инцидента в целом.
Примеры восходящих проблем включают в себя:
-
Проблема с сетью,
-
Проблема аутентификации.
Примеры нижестоящих проблем включают:
-
Проблема с облачным объектным хранилищем,
-
Проблема с блочным хранилищем,
-
Сбой в базе данных, на которую повлияла проблема микросервиса.
Зная, какие восходящие и нисходящие зависимости находятся в микросервисе, и как исправить любые проблемы с ними, вы приблизитесь к разрешению общего инцидента.
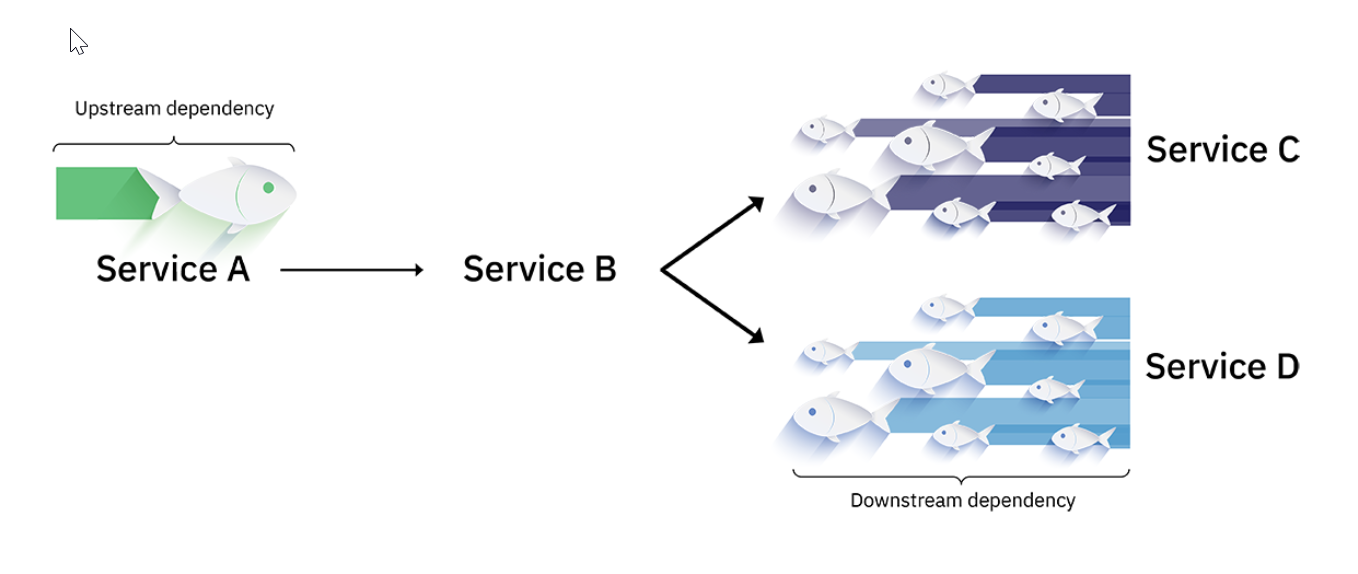
Распределенная трассировка
Один из методов, который SRE могут использовать для специального изучения зависимостей приложения — это распределенная трассировка. Его можно использовать для идентификации неудачной транзакции и отслеживания потока транзакции через приложение микрослужбы.
Распределенная трассировка — это метод, позволяющий регистрировать информацию в приложениях на основе микрослужб.
-
Уникальный идентификатор транзакции передается через цепочку вызовов каждой транзакции в распределенной топологии.
-
Одним из примеров транзакции является взаимодействие пользователя с веб-сайтом.
-
Уникальный идентификатор генерируется в точке входа транзакции.
-
Затем идентификатор передается каждой службе, используемой для завершения задания, и записывается как часть информации журнала служб.
-
Не менее важно включать временные метки в сообщения журнала вместе с идентификатором.
-
Идентификатор и отметка времени объединяются с действием, которое выполняет служба, и состоянием этого действия.
Создание Runbook для устранения неполадок и смягчения последствий распространенных инцидентов
С помощью инструментов Runbook, интегрированных с уведомлениями о событиях, SRE могут определять автоматические процедуры, которые будут выполняться при возникновении определенного события. Рассмотрим, что происходит, когда система управления событиями получает событие, указывающее на сбой службы. Система может выполнять автоматизированные действия, определенные в runbook. Например, когда система получает событие сбоя службы, сценарий runbook предлагает сделать снимок системы. SRE могут автоматизировать следующие действия:
-
Использование системного имени хоста и учетных данных для входа на сервер,
-
Получение списка процессов, памяти, использования cpu, и другой информации,
-
Извлечение любых связанных журналов и сообщений трассировки.
Результаты действий могут быть немедленно отправлены первому ответчику, как только действие будет завершено. Выявление неполадок с помощью автоматизированных runbook — это низкий барьер, поскольку команды доступны только для чтения и обычно не наносят вреда системам. Со временем команда может писать сценарии для автоматического решения проблем без ручного вмешательства.
Этапы зрелости Runbook
По мере взросления команды и приложения могут развиваться и runbook. Зрелость runbook включает следующие этапы:
Ad hoc: это начальное состояние характеризуется отдельными ручными действиями без документации или согласованности.
Repeatable: стандартные действия задокументированы и согласованы во всей организации. Эти действия по-прежнему выполняются вручную.
Defined: действия принудительно выполняются. Действия становятся доступными, поскольку сценарии и задачи предоставляются оператору в контексте инструментов управления.
Managed: система предлагает правильное действие для события. Используя базовые функции if/then, система автоматически запускает действия.
Optimized: на самом высоком уровне применяется аналитика, чтобы определить, когда и что автоматизировать.
Управление модулями Runbook
Чтобы runbook был оптимальным, SRE должны управлять его содержимым и поддерживать его. Приложение может быть обновлено до версии, требующей других действий. Технологии и инфраструктура могут измениться, что приведет к изменениям в командах runbook. При выборе решения runbook рассмотрите возможность управления отзывами пользователей, управления библиотеками, контролем доступа, API, отчетами и аудитом.
User feedback: Когда инженеры используют runbook, собирайте их отзывы.
Вы можете задать им следующие вопросы:
-
Помог ли runbook решить проблему?
-
Как можно улучшить модуль runbook?
Library management: Некоторые решения Runbook предоставляют библиотеку «строительных блоков» Runbook, которые можно использовать для создания Runbook. В зависимости от инструмента библиотека может быть предоставлена поставщиком или представлять собой набор библиотек, предоставленных другими пользователями.
Например, Red Hat® Ansible поставляется с модулями для выполнения общих задач. Разработчик может использовать модуль для более быстрой разработки Runbook.
Access control: Для средних и крупных организаций решающее значение имеет управление пользователями и ресурсами. Конкретным пользователям или группам пользователей требуется доступ для работы с определенной группой ресурсов. Если необходим аудит, аудитору может потребоваться доступ только для чтения к большей группе ресурсов.
Другой формой управления доступом является имя пользователя и пароль для средства Runbook для выполнения действий с управляемыми ресурсами. Может потребоваться несколько уровней контроля доступа.
Например, чтобы прочитать состояние сервера, используйте обычные учетные данные для входа, но для изменения конфигурации сервера учетная запись должна иметь привилегии root. Runbook могут предоставить средства безопасного делегирования привилегированных команд администраторам.
API: В рамках интеграции Runbook система управления событиями может активировать Runbook. Runbook также можно запускать в результате действия инструмента на панели мониторинга топологии, как действие из системы ChatOps или как задачу в конвейере непрерывной доставки. Решение Runbook должно предоставлять набор API, чтобы другой компонент интеграции мог вызывать правильный Runbook с соответствующими полномочиями.
Report and audit: При рассмотрении решения Runbook обратите внимание на его возможности отчетности и аудита. Полезно знать, какие Runbook выполняются чаще всего или получают самые высокие оценки при решении проблем.. Вашей организации может потребоваться аудит Runbook в рамках деятельности по обеспечению соответствия требованиям.
Информация о выполнении модуля Runbook может быть передана группе SRE из отчета, чтобы расставить приоритеты в отношении необходимых работ по улучшению приложений или инфраструктуры.
Runbook или пофиксить?
В SRE подход к решению повторяющейся проблемы заключается в устранении ее источника. Runbook может быть хорошим краткосрочным тактическим решением, когда исправление требует дополнительного времени и усилий.
SRE может использовать отчет, созданный решением Runbook, и работать с приоритетным списком исправлений. По мере реализации большего количества исправлений требуется запускать меньше Runbook. Помните, что лучше предотвратить проблему до того, как она возникнет, чем решать ее после того, как она возникла. Однако иногда runbook является решением.
Организация может инвестировать в коммерческое программное обеспечение, которое команда SRE не может изменить напрямую, или SRE может использовать решение Runbook для автоматизации повторяющихся задач, выходящих за рамки управления инцидентами.
Методы устранения неполадок и постоянное совершенствование
Устранение неполадок не зависит от удачи. Наша основная теория заключается в том, что SRE могут изучать и обучать эффективным стратегиям. Теория, лежащая в основе эффективного устранения неполадок, заключается в том, что этому можно научиться и чему можно научить.
Процесс устранения неполадок — это способность выдвигать гипотезы о причинах сбоя и тестировать решения.
Помните об этих важных моментах:
-
Не все неудачи одинаково вероятны — при прочих равных условиях наиболее вероятным решением может быть простое или очевидное решение.
-
Корреляция не является причинно-следственной связью.
Шаги в модели устранения неполадок:
-
Получаем сообщение о проблеме, что-то не так с системой.
-
Просмотрим телеметрию и логи, чтобы понять ее текущее состояние.
-
Определим некоторые возможные причины.
-
Активно «лечим» систему — то есть изменяем систему контролируемым образом и наблюдаем за результатами.
-
Повторно тестируем, пока не будет выявлена основная причина.
-
Примем меры для предотвращения повторения.
-
Напишите репорт о решении, задокументируем это.
Так и работаем.
В завершение хочу порекомендовать вам бесплатный вебинар: «Чему могут научить SRE техники? Сравнение SRE и DevOps».
На вебинаре эксперты OTUS разберут как SRE-техники могут помочь вам в построении и обслуживании систем. Вы увидите сравнение SRE с ITSM, DevOps, Platform Engineering. Также будут рассмотрены принципиально новые идеи в каждом фреймворке, какие части фреймворков прошли проверку временем, а какие не работают как ожидается и как оценивать успешность внедрения.
-
Зарегистрироваться на бесплатный урок
В работе службы поддержки компании или предприятия управление инцидентами — один из ключевых процессов. Автоматизация управления инцидентами позволяет компании быстро справляться с обнаруженными ошибками, оперативно устранять сбои в работе сервиса, сохранить высокий уровень качества предоставляемых услуг и минимизировать потери для бизнеса.
В этой статье обсуждаем само понятие управления инцидентами, рассматриваем основные роли и этапы в процессе поиска решений в работе с инцидентами ITIL на предприятии.
Что такое инцидент: история, определение
В ITIL существует четкое определение инцидента (IT Incident) — это незапланированное прерывание ИТ-услуги или снижение качества ее предоставления. Другими словами, инцидентом можно назвать любую ситуацию, которая снижает качество предоставления услуг конечному потребителю и мешает бесперебойной работе бизнеса.
Простые примеры инцидентов — не отвечает сервер, не работает бизнес-приложение, письма по электронной почте не отправляются, в личном кабинете ошибка авторизации. Каждый день служба сервис деск получает десятки похожих обращений от пользователей. Это сбои, которые влияют на бизнес, частично или полностью тормозят выполнение бизнес-процессов. У каждого происшествия есть причины и последствия. Управление инцидентами сосредоточено на борьбе с последствиями и скорейшем восстановлении сервиса.
В ITIL существует несколько классификаций инцидентов. За основу при классификации берут срочность и степень влияния инцидента на бизнес и на каждого пользователя. Грамотная классификация позволяет быстро подключать соответствующих технических специалистов, экономить время и ресурсы компании. Например, по срочности и степени влияния инциденты классифицируют на незначительные и серьезные, которые требуют немедленного реагирования, так как затрагивают работу критически важных служб и могут привести к серьезным сбоям в работе компании.
В крупных корпоративных сетях ИТ-команды получают огромное количество сообщений об инцидентах, происходящих одномоментно. Чтобы не возникало путаницы в работе специалистов, а потенциальный ущерб для компании был по возможности минимизирован, важно разделить заявки по срочности, а также степени значимости. Первостепенно устраняются инциденты, которые могут нанести серьезный урон бизнесу и повлиять на качество предоставляемого сервиса.
Сразу после обнаружения инцидента ИТ-группа должна предпринять необходимые меры, чтобы сохранить эффективность работы сети на нормальном уровне производительности. Все инциденты фиксируются и, если проблема повторяется, составляется план по исправлению системных ошибок, которые могут приводить к возникновению одной и той же проблемы.
Управление инцидентами ITIL — описание проблем и основных шагов
Цикл управления инцидентами состоит из множества действий. Главный элемент в этой цепочке — Service Desk или служба поддержки, которая выступает связующим звеном между ИТ-компанией и пользователями. Без сервис деск работа компании будет неструктурированной, ресурсы будут распределяться неравномерно, а приоритетность решения проблем будет упущена из виду.
Проблемы, которые могут возникнуть, если управление инцидентами организовано неправильно:
- Статус заявки неясен, для конечного пользователя непонятны сроки решения проблемы.
- Неправильное протоколирование прошлых инцидентов.
- Отсутствие документирования решений для повторяющихся/похожих проблем.
- Высокий риск простоев в случае серьезных инцидентов.
- Большие сроки решения проблемы.
- Снижение удовлетворенности клиентов.
Управление инцидентами ускоряет процесс поиска и предоставления решения, помогает быстро и эффективно обрабатывать заявки. При правильной организации процесса служба поддержки сервис деск может выступать как интерфейс для сбора ответов по проблемам от пользователей, агрегации необходимых данных, расстановки приоритетности и делегирования процесса разрешения проблем специалистам ИТ-команды.
В зависимости от вида произошедшего инцидента процессы управления могут быть сложными или простыми, включать решение нескольких задач или рабочих процессов.
Рассмотрим пошагово цикл по управлению IT Incident:
1. Регистрация инцидента.
Происходит через электронную почту, смс, веб-форму на сайте, портал самообслуживания, живой чат, телефон. Здесь важно четко указать, от кого поступила заявка, во сколько и какого числа, описать сам IT Incident — что случилось, какая неисправность, что работает не так или не работает вообще. Инциденту нужно присвоить уникальный идентификационный номер для простоты отслеживания.
2. Классификация инцидента.
Определяется, какую область затрагивает IT Incident, например, оборудование или сеть. Исходя из этого, ему присваивают соответствующую категорию. Если потребуется, можно создать и подкатегории. Главное, чтобы IT Incident был понятно описан и классифицирован — это необходимо для выявлений закономерностей и эффективной организации процесса по управлению проблемами, а также предупреждения похожих инцидентов в будущем.
3. Определение приоритетности.
Ориентируясь на матрицу приоритетов, по степени срочности и влияния на бизнес-процессы инциденту присваивают приоритет. Степень влияния определяют, исходя из того, как IT Incident может повлиять на бизнес и какой ущерб нанести компании или конечному потребителю услуги. Срочность указывает на временной период, за который IT Incident должен быть устранен.
Виды приоритетов: низкий, средний, высокий, критический. Если нет уверенности, какой приоритет назначать, лучше перестраховаться и назначить с округлением в большую сторону.
4. Маршрутизация инцидентов.
Когда инциденту присвоена категория и определена приоритетность, его переадресуют техническому специалисту с соответствующей квалификацией и компетенциями.
5. Создание задач.
В зависимости от сложности инцидента его можно разделить на несколько задач (действий). Создаются задачи в том случае, если для решения необходимо привлекать специалистов из разных отделов.
6. Обработка инцидента и SLA.
Обрабатывая инцидент, специалист ориентируется на требования SLA относительно приемлемого времени или периода, за который нужно предоставить ответ или решение по инциденту. Назначают SLA, ориентируясь на такие параметры, как автор заявки, срочность, вероятность влияния на бизнес в целом, категория инцидента. Если требования SLA нарушаются, инцидент может быть выведен на другой уровень или передан другому специалисту для оперативного устранения.
7. Решение по инциденту.
Устраненным IT Incident считается, когда специалист нашел и предоставил временное или окончательное решение возникшей проблемы.
8. Закрытие.
Когда IT Incident устранен, важно получить от пользователя, который обратился с заявкой, подтверждение, что решение сработало и результат его удовлетворил. После этого IT Incident можно закрывать.
После того, как IT Incident закрыт, важно задокументировать выводы, полученные в ходе работы над устранением проблемы. Эта информация поможет специалистам в будущем быстрее и эффективнее решать похожие проблемы.
Различие между проблемами и инцидентами
Выше мы упомянули инциденты и проблемы — это ИТ-определения, с которыми нередко возникает путаница. И проблемы, и инциденты связаны с процессом устранения возникшего сбоя и регистрируются в системе сервис деск, но по своей сути отличаются друг от друга и имеют разные пути решения.
- IT Incident — любой сбой в работе ИТ-системы.
- Проблема — первопричина, по которой произошел один или несколько инцидентов. Устранив проблему, можно предупредить повторные IT Incident.
Управление инцидентами — это реактивный подход, при управлении проблемами используется проактивный подход, когда ИТ-отдел борется с первопричиной возникновения инцидента, фокусируется на корневых причинах сбоя в работе сервиса и предпринимает все необходимые меры, чтобы IT Incident не возникал в принципе.
Процесс по управлению проблемами включает в себя:
- контроль проблем и ошибок;
- предотвращение повторения проблем;
- анализ основных проблем.
При контроле проблемы основная цель — обнаружить причину проблемы и выполнить следующие шаги:
- идентифицировать и зарегистрировать проблему;
- классифицировать и определить приоритетность решения проблем;
- исследовать и диагностировать причины.
Основная цель анализа проблемы — улучшение процессов управления инцидентами за счет отслеживания качества результатов работы по устранению проблем и инцидентов. Кроме этого необходимо вести контроль ошибок для быстрого исправления возникающих проблем, которые могут привести к инциденту. Для этого:
- идентифицируют и регистрируют известные ошибки;
- оценивают способы их устранения;
- расставляют приоритеты;
- закрывают ошибки, осуществляя необходимые исправления;
- мониторят известные ошибки, чтобы определить, где необходимо изменить приоритеты.
Инциденты, проблемы и ошибки формируют определенный цикл — инциденты выступают как индикаторы проблем, при обнаружении причины возникшей проблемы удается определить ошибку, а, исправив ошибки, можно предупредить повторение инцидента.
Исходя из вышесказанного, можно выделить три основных процесса, которые напрямую связаны с управлением инцидентами:
- Процесс управления инцидентами. Фокус на скорейшем восстановлении прерванного сервиса.
- Процесс контроля проблем. Фокус на определении приоритетности и определении причин или ошибок, которые привели к возникновению конкретной проблемы, поиск способов для их устранения. В этом процессе акцент сделан на определении причины и ее анализ.
- Процесс контроля ошибок. Сюда входит документирование способов устранения неисправностей, информирование о них персонала службы поддержки.
Управление инцидентами и проблемами позволяет поддерживать высокую эффективность рабочего процесса и обеспечивать наилучшие результаты предоставления услуги для конечного потребителя. Главная цель ИТ-команды — как можно быстрее восстановить работу системы и вернуть ее в нормальный рабочий режим
Подходы к управлению инцидентами
Сегодня в работе многих компаний используются различные программные продукты, поэтому потенциальных точек отказа и возникновения инцидентов больше, чем когда-либо. Последствия крупных инцидентов могут быть масштабными и привести к серьезным убыткам. Самый распространенный подход к управлению инцидентами — структурная система поддержки с многоуровневой моделью и четко распределенными ролями и зоной ответственности:
1. Основная техническая поддержка.
Первый уровень поддержки — специалисты, которые принимают заявки и предпринимают первую попытку решить проблему. Разбираться с инцидентами в соответствии с идеологией сервисного подхода должна служба поддержки или Service Desk, в задачи которой входит:
- обработка обращений от пользователей;
- получение детальной информации об инциденте, в том числе, выявление нецелевых обращений;
- регистрация, классификация, определение приоритетности;
- контроль восстановления сервиса пользователям и соблюдения заявленных параметров.
Каждой компании выгодно организовать работу сервис деск так, чтобы сократить финансовые и временные затраты, но не потерять в качестве сервиса. В работе специалисты сервис деск используют заранее определенный набор инструкций по восстановлению работы службы.
Специалисты первого уровня поддержки используют базу данных при управлении проблемами, чтобы сопоставить IT Incident с ранее происходившими и сравнить с известными ошибками. Цель первого уровня поддержки — решить до 80% инцидентов. Основная клиентская техническая поддержка — это первая точка контакта для инцидентов, но специалисты первого уровня не управляют всей командой, которая в дальнейшем работает над решением инцидента.
Если в сжатые сроки проблему решить не удается, заявку передают в группу поддержки второго уровня. Специалисты на этом уровне изучают и решают до 75% инцидентов, переданных с первого уровня. Остальные передаются на третий уровень и решаются узкими ИТ-специалистами, отвечающими за архитектурные или технические вопросы. На втором уровне специалисты документируют найденные решения и сообщают о них персоналу первого уровня. Кроме этого на втором уровне анализируют тенденции инцидентов, чтобы понять, о наличии каких проблем они сигнализируют.
Третий уровень поддержки — специалисты сетевой инфраструктуры и разработчики приложений. Зона ответственности — решение инцидентов, переданных со второго уровня, организация работ по управлению проблемами — поиск причин, которые привели к появлению инцидента, устранение ошибок.
2. Менеджер по инцидентам.
Диспетчер инцидентов отвечает за весь процесс, начиная от обнаружения проблемы, заканчивая созданием отчетов и закрытием IT Incident. При переходе проблемы из группы поддержки первого уровня к группе поддержки второго уровня менеджер по управлению инцидентами отвечает за выделение ресурсов и создание рабочей группы для работы над выявленными серьезными инцидентами.
3. ИТ-операторы.
Группа специалистов, выступающих своего рода буферами при решении инцидентов. Обеспечивают плановое обслуживание серверов, контролируют следование расписанию для критических задач, делают резервное копирования данных. Также ИТ-операторы могут привлекаться для решения проблем в случае значительного инцидента.
4. Команда по крупным инцидентам.
Этих специалистов привлекают в тех случаях, когда проблема не решилась на первых уровнях и возникший IT Incident грозит нанести серьезный урон важным бизнес-процессам компании.
Резюмируя все сказанное, Service Desk помогает создать единую точку контакта между пользователем и поставщиком ИТ-услуг. Специалисты службы поддержки принимают заявку об инциденте, представляют необходимую помощь или привлекают сотрудников ИТ-подразделений для быстрого устранений проблемы и закрытия инцидента.
Кроме четкого определения ролей важно позаботиться о равномерном распределении нагрузки и учесть компетенции специалистов. Первая линия должна быть сосредоточена на работе с простыми задачами и нецелевыми обращениями, вторая линия решать вопросы по существу, а третья — заниматься только самыми сложными вопросами, когда для решения инцидента необходимо привлекать узких ИТ-специалистов. Внутри каждой линии важно продумать распределение задач, а эффективность процесса по управлению IT Incident контролировать, опираясь на метрики — собственные KPI, принятые внутри компании.
Инструкция по управлению инцидентами
Выше мы рассмотрели, как может выглядеть цикл решения инцидентов и как правильно распределить роли отдельных исполнителей. Также собрали для вас базовые рекомендации, которые могут оказаться полезными при организации успешного решения IT Incident в вашей компании:
- Подготовьте несколько вариантов (моделей) создания заявок об инциденте, например, по телефону, на электронную почту, в чат, через портал самообслуживания.
- Сформируйте базу знаний и пополняйте ее готовыми решениями по управлению аналогичными инцидентами.
- Для эффективного сбора информации об инцидентах опубликуйте настраиваемые формы.
- Настройте автоматическую классификацию инцидентов и определение их приоритетности на основании ряда критериев в заявке.
- Создайте уникальные рабочие процессы по управлению серьезными IT Incident.
- Свяжите SLA с инцидентами на основе таких параметров, как приоритетность.
- Техническим специалистам с одинаковыми компетенциями можно автоматически назначать заявки, опираясь на такие алгоритмы, как циклический перебор и балансировка нагрузки.
- Настройте коммуникацию с пользователем на каждом этапе цикла решения инцидентов.
- Удостоверьтесь, что специалисты закрывают инциденты только после того, как найдено эффективное решение с получением обратной связи от конечного потребителя услуги.
Ключ к успешному управлению инцидентами — качественно проработанный алгоритм действий и его пошаговое выполнение.
Попробуйте наш Service Desk бесплатно!
Бесплатный доступ ко всем возможностям Service Desk системы на 14 дней
- Добавьте услуги для любых подразделений компании
- Настройте конфигурационные единицы
- Управляйте пользователями
- Назначьте ответственных и определите SLA
- Оцените возможности базы знаний и чата
Преимущества в управлении инцидентами ITIL с помощью Сервис Деск
Структурированный подход к управлению и работе с инцидентами ITIL с помощью Сервис Деск открывает перед компанией много возможностей:
- хранение всех известных инцидентов центральном репозитории;
- автоматизация классификации инцидентов на основании на таких параметрах, как срочность, отдел, влияние и приоритет;
- сопоставление требований SLA с заявками об инцидентах;
- назначение заявок ИТ-специалистам или группам специалистов;
- сохранение историй процесса изменений;
- поиск решений по IT Incident;
- документирование решений в базе данных по IT Incident и запросам на обслуживание;
- связь с конфигурационными единицами и взаимосвязи с другими инцидентами, запросами на обслуживание и проблемами;
- формирование интерактивных информационных панелей и отчетности для дальнейшего анализа и поиска эффективных решений для устранения IT Incident;
- функционал для уведомления ответственных о событиях при управлении инцидентами;
- возможность досрочного закрытия IT Incident;
- аналитика решений IT Incident по срокам, услугам, ответственным, типам;
- полная автоматизация всего процесса при управлении инцидентами — от подачи заявки до закрытия IT Incident.
Используя Service Desk КСК.ИК, вы можете хранить всю документацию в настраиваемой структуре папкой, при необходимости модифицировать «коробочный» процесс изменений, настроить уникальные процессы для решения нестандартных инцидентов.
КСК.Service Desk — система по управлению инцидентами для любой компании. Вы можете использовать КСК.Service Desk как единую точку контакта с потребителями услуги и эффективно управлять ИТ-инфраструктурой в компании.
Благодаря инструментам автоматизации процесс по управлению IT Incident становится понятным и прозрачным процессом, так как все обращения регистрируются, оперативно распределяются по ответственным специалистам. Такой подход эффективен, так как у сотрудников не возникает путаницы — за счет строгой приоритетности заявки выполняются в определенном порядке.
С помощью сервис деск вы можете автоматизировать процессы решения IT Incident — быстро отслеживать, правильно расставлять приоритеты и эффективно закрывать IT Incident.
Выводы
В управлении инцидентами ключевой критерий качества предоставления услуги — скорость. Хорошо, если удается быстро найти причину сбоя и сразу устранить ее. Но так получается не всегда и тогда необходимо предложить пользователю временное решение. А уже после закрытия инцидента специалисты ищут, анализируют и устраняют основную причину, которая вызвала сбой. Эти работы входят в процесс по управлению проблемами. Важно, чтобы специалисты вели учет всех инцидентов и проблем, вызвавших их, чтобы в случае очередного сбоя можно было обратиться к накопленному опыту и быстрее справиться с аналогичными обращениями. На основании данных, фиксируемых системой, формируются отчеты, по котором можно проверить соблюдение требований SLA. Также можно проследить число решенных инцидентов и возвращенных на доработку, в целом, проанализировать работу сотрудников по ряду показателей.
Инциденты случаются и это неизбежно. Правильно структурированный процесс управления и использование инструментов для автоматизации позволяет ускорить устранение сбоев в предоставлении услуги, сократить убытки и потери прибыли, а также повысить лояльность конечных потребителей услуги.
Процесс управления инцидентами в DevOps и SRE
При подходе DevOps или SRE к управлению инцидентами, команда, которая разрабатывает сервис, также отвечает за его работу и вносит исправления в случае сбоев. Такой подход быстро нашел свою популярность с развитием бесперебойных облачных сервисов, веб-приложений с глобальным доступом, микросервисов и программного обеспечения как услуги.
Increasingly the software you rely on for life and work is not being hosted on a server in the same physical location as you. It’s likely a web-accessed application deployed in a data center for thousands or millions of users around the globe. For teams tasked with running these services, agility and speed are paramount. Any downtime has the potential to affect thousands of organizations, not just one.
An advantage of the “you build it, you run it” approach is that it offers the flexibility agile teams need, but it can also obscure who is responsible for what and when. DevOps teams can be comfortable—and successful—with less structured development processes. But it’s best to standardize on a core set of processes for incident management so there is no question how to respond in the heat of an incident, and so you can track issues and report how they’re resolved.
Три принципа управления инцидентами в командах DevOps
- Дежурство по очереди. Обычно команды DevOps не назначают конкретных членов команды на разрешение конфликтов, а создают график дежурств и распределяют его между членами команды.
- Кто разработал, тот лучше всего подходит для внесения исправлений. Основная идея принципа «кто разработал, тот и запускает» заключается в том, что люди, которые больше знакомы с сервисом (разработчики), лучше всего подходят для исправления перебоев в его работе.
- Разрабатывайте быстро, но не забывайте сообщать о прогрессе. Когда разработчики понимают, что они и их команда теряют время при сбое в работе, появляется стимул писать более качественный код.
Такой подход обеспечивает более быстрое реагирование и обратную связь с командами, которым необходимо знать, как разработать более надежный сервис.
В нашем Справочнике по управлению инцидентами мы описываем подход к управлению инцидентами, подходящий именно командам DevOps.
Введение
Практики построения процесса управления инцидентами и событиями ИБ будут рассмотрены в разрезе международных стандартов и Методических рекомендаций по созданию ведомственных и корпоративных центров государственной системы обнаружения, предупреждения и ликвидации последствий компьютерных атак на информационные ресурсы Российской Федерации (далее – Методические рекомендации ГосСОПКА).
Этапы управления инцидентами и событиями ИБ
Снижение потенциальных рисков нарушения доступности, целостности и конфиденциальности информационных ресурсов вследствие инцидентов ИБ может быть достигнуто путем их своевременного обнаружения в комплексе с реагированием. Более того, реагирование на инциденты ИБ – часто менее дорогостоящее и более эффективное средство, чем их расследование, так как возникший инцидент ИБ может привести к сбою работоспособности систем, сервисов, сетей, и, как следствие, к длительной недоступности критичных бизнес-процессов, потере / модификации передаваемой или хранимой информации без возможности ее восстановления, репутационным рискам владельца информационных ресурсов и контрагентов.
Практический подход к построению эталонного процесса подробно описан в международных стандартах:
- ISO/IEC 27001:2005 Information security management system. Requirements – стандарт, который содержит как рекомендации по построению, внедрению, использованию и поддержке системы менеджмента ИБ в целом, так и подходы к управлению инцидентами ИБ.
- NIST SP 800-61 Computer security incident handling guide – полноценное руководство по обработке инцидентов ИБ, которое описывает различные подходы к реагированию на инциденты и их обработке.
- CMU/SEI-2004-TR-015 Defining incident management processes for CISRT – документ для оценки эффективности работы подразделения CISRT (Critical Incident Stress Response Team), обеспечивающего предотвращение, обработку и реагирование на инциденты ИБ.
- ISO/IEC TR 18044:2004 Information security incident management –документ устанавливает рекомендации к менеджменту инцидентов ИБ в отношении планирования, эксплуатации, анализа и улучшения процесса.
- NIST SP 800-83 Guide to Malware Incident Prevention and Handling – руководство по предотвращению и обработке инцидентов, связанных с заражением рабочих станций и ноутбуков вредоносным программным обеспечением.
- NIST SP 800-86 Guide to Integrating Forensic Techniques into Incident Response – руководство по техникам проведения расследований в рамках реакции на выявленные инциденты.
Практический подход в российской нормативной документации подробно описан в следующих стандартах и рекомендациях:
- Национальный стандарт РФ ГОСТ Р ИСО/МЭК ТО 18044-2007 «Информационная технология. Методы и средства обеспечения безопасности. Менеджмент инцидентов информационной безопасности» подробно описывает стадии планирования, эксплуатации, анализа и улучшения системы управления инцидентами безопасности.
- Стандарт Банка России «Обеспечение информационной безопасности организаций банковской системы Российской Федерации. Сбор и анализ технических данных при реагировании на инциденты информационной безопасности при осуществлении переводов денежных средств» (СТО БР ИББС-1.3-2016) определяет необходимость выполнения организациями банковской системы Российской Федерации деятельности по выявлению инцидентов ИБ и реагированию на инциденты ИБ.
- Методические рекомендации ГосСОПКА разработаны для органов государственной власти, принявших решение о создании ведомственных центров ГосСОПКА, государственных корпораций, операторов связи и других организаций, осуществляющих лицензируемую деятельность в области защиты информации и принявших решение о создании корпоративных центров ГосСОПКА. Рекомендации разработаны Центром защиты информации и специальной связи Федеральной службы безопасности Российской Федерации в соответствии с основными положениями следующих нормативных документов:
- Указ Президента Российской Федерации от 15 января 2013 г. № 31с «О создании государственной системы обнаружения, предупреждения и ликвидации последствий компьютерных атак на информационные ресурсы Российской Федерации»;
- «Основные направления государственной политики в области обеспечения безопасности автоматизированных систем управления производственными и технологическими процессами критически важных объектов инфраструктуры Российской Федерации» (утв. Президентом Российской Федерации 03.02.2012 № 803);
- «Концепция государственной системы обнаружения, предупреждения и ликвидации последствий компьютерных атак на информационные ресурсы Российской Федерации» (утв. Президентом Российской Федерации 12.12.2014 № К 1274).
Каждый из вышеперечисленных документов с разной степенью детализации и в различной структуре описывает полный набор мер построения процесса управления инцидентами и событиями ИБ. Выполнение любого из данных стандартов целесообразно для большинства организаций. Однако стоит выделить, что в целом Методические рекомендации ГосСОПКА являются локализацией и дополнением к вышеперечисленным международным стандартам.
В общем случае жизненный цикл управления событиями и инцидентами ИБ принято разделять на несколько основных последовательных этапов:
- Обнаружение компьютерных атак.
- Анализ данных о событиях безопасности.
- Регистрация инцидентов.
- Реагирование на инциденты и ликвидация их последствий.
- Установление причин инцидентов.
- Анализ результатов устранения последствий инцидентов.
Далее рассмотрим каждый этап процесса управления инцидентами и событиями ИБ подробнее.
Обнаружение компьютерных атак
Целью обнаружения компьютерных атак является своевременное реагирование на связанные с ними инциденты для дальнейшего принятия мер по ликвидации последствий таких инцидентов.
В ходе деятельности по обнаружению компьютерных атак реализуются следующие процессы:
- Контроль за реализацией единых правил эксплуатации средств обнаружения компьютерных атак на информационные ресурсы.
- Контроль за централизованным обновлением баз решающих правил для средств обнаружения компьютерных атак.
- Выявление ранее неизвестных компьютерных атак сетевого уровня, в том числе с применением средств анализа сетевого трафика на каналах связи.
- Выявление ранее неизвестных компьютерных атак, проводимых с использованием вредоносного программного обеспечения, в том числе с использованием методов поведенческого анализа программного обеспечения.
- Разработка решающих правил для неизвестных компьютерных атак.
Стоит отметить, что в отличие от международных практик, в соответствии с которыми организация самостоятельно определяет сегменты ответственности, вышеперечисленные процессы в Методических рекомендациях ГосСОПКА распространяются только на сегменты, находящиеся в зоне ответственности сегмента ГосСОПКА, и при обнаружении ранее неизвестных компьютерных атак центром ГосСОПКА проводятся мероприятия по реализации функции анализа угроз ИБ.
Анализ данных о событиях безопасности
Целью анализа данных о событиях безопасности является выявление инцидентов ИБ, в том числе связанных с ранее неизвестными компьютерными атаками, а также инцидентов, связанных с недостаточной эффективностью принимаемых мер защиты информации.
В соответствии с Методическими рекомендациями ГосСОПКА, для реализации анализа данных центры ГосСОПКА осуществляют сбор результатов работы всех средств защиты информации, используемых в соответствии с политикой безопасности, принятой в информационных системах. Это такие источники, как:
- Средства обнаружения атак и межсетевые экраны, применяемые на каналах связи, по которым осуществляется доступ к информационным ресурсам.
- Средства анализа сетевого трафика, использующие методы интеллектуального анализа данных.
- Средства обнаружения атак и межсетевых экранов, применяемые в локальных вычислительных сетях, в которых размещены компоненты информационных ресурсов.
- Средства поведенческого анализа программного обеспечения.
Сбор информации из указанных источников рекомендуется проводить в автоматизированном режиме. При этом реализуются правила нормализации событий ИБ. Сведения о событиях безопасности сопоставляются со сведениями об уязвимостях компонентов информационных ресурсов для прогнозирования возможных действий злоумышленника при проведении компьютерных атак.
При проведении анализа данных о событиях безопасности с использованием автоматизированных средств применяются правила корреляции. Примеры инцидентов ИБ, выявленных автоматизированной системой, приведены на рисунке 1.

Правила корреляции определяются ответственными сотрудниками или, в соответствии с Методическими рекомендациями ГосСОПКА, сотрудниками центра ГосСОПКА с учетом сведений, полученных на этапах инвентаризации и выявления уязвимостей информационных ресурсов. В процессе функционирования проводится постоянная работа по адаптации источников данных о событиях безопасности со средствами их анализа для повышения эффективности обнаружения компьютерных атак, а также работа по формированию новых правил корреляции и сигнатур.
Регистрация инцидентов
Регистрацию инцидентов рекомендуется осуществлять с использованием автоматизированных средств учета и обработки инцидентов на основе показателей, влияющих на степень негативного влияния инцидента ИБ, так как ручной процесс обработки инцидентов ИБ по мере формирования приводит к высокой ресурсоемкости кадрового состава и значительно увеличивает время реагирования на инциденты ИБ высокой критичности.
Пример построения процесса регистрации инцидентов ИБ в зависимости от степени негативного влияния с использованием средств автоматизации представлен на рисунке 2:
При выполнении одного или нескольких правил корреляции, свидетельствующих о возможной попытке реализации угроз безопасности, определенных ранее в ходе анализа угроз, в системе учета и обработки инцидентов создается карточка инцидента.
В соответствии с Методическими рекомендациями ГосСОПКА, карточка инцидента, созданная на основе сообщения пользователя или в результате анализа данных о событиях безопасности, направляется в подчиненный центр ГосСОПКА, в зоне ответственности которого находится информационный ресурс, предположительно затрагиваемый инцидентом.
В случае если инцидент затрагивает несколько информационных ресурсов, карточка инцидента направляется во все подчиненные центры ГосСОПКА, в зоне ответственности которых находятся указанные информационные ресурсы. В случае если сведения о возможном инциденте подтверждаются специалистом центра ГосСОПКА или хотя бы одним из лиц, ответственных за функционирование хотя бы одного из информационных ресурсов, инцидент признается подтвержденным и принимаются меры реагирования.
Реагирование на инциденты и ликвидация их последствий
Организацию процесса реагирования на инциденты ИБ можно разделить на десять последовательных этапов:
- Фиксация состояния и анализ объектов информационных ресурсов, вовлеченных в инцидент.
- Координация деятельности по прекращению воздействия компьютерных атак, проведение которых вызвало возникновение инцидента.
- Фиксация и анализ сетевого трафика, циркулирующего в информационном ресурсе, вовлеченном в инцидент.
- Определение причин инцидента и его возможных последствий для информационного ресурса.
- Локализация инцидента.
- Сбор сведений для последующего установления причин инцидента.
- Планирование мер по ликвидации последствий инцидента.
- Ликвидация последствий инцидента.
- Контроль ликвидации последствий.
- Формирование рекомендаций для совершенствования нормативных документов, обеспечивающих информационную безопасность информационных ресурсов.
В соответствии с Методическими рекомендациями ГосСОПКА при отсутствии в центре ГосСОПКА специалистов, обладающих необходимой квалификацией, к реагированию на инцидент могут обоснованно привлекаться специалисты центра ГосСОПКА, стоящего выше в иерархии ГосСОПКА.
Лицо, ответственное за функционирование информационного ресурса, совместно со специалистами центра ГосСОПКА организует локализацию инцидента и ликвидацию последствий в соответствии методическими рекомендациями, разработанными для инцидентов данного типа.
Установление причин инцидентов
Установление причин инцидента проводится в две стадии:
- Первичный анализ инцидента.
- Комплексный анализ инцидента.
Задачами первичного анализа инцидента являются:
- установление обстоятельств и возможных последствий инцидента;
- своевременное установление обстоятельств инцидента, выходящих за рамки стандартного порядка действий при инциденте данного типа.
Задачами комплексного анализа инцидента являются:
- установление причин инцидента;
- установление фактических последствий инцидента.
Нередко в международных практиках первичный и комплексный анализ инцидента ИБ объедены в один этап, реализуемый ответственной рабочей группой организации, в отношении которой возник инцидент ИБ. Однако в соответствии с Методическими рекомендациями ГосСОПКА, первичный анализ проводится центром ГосСОПКА, а комплексный анализ инцидента проводится одновременно с ликвидацией его последствий совместно с головным центром ГосСОПКА.
Анализ результатов устранения последствий инцидентов
Инцидент признается завершенным после принятия всех мер при условии, что установление причин инцидента показало достаточность принятых мер. Анализ результатов устранения последствий инцидента включает в себя оценку следующих аспектов:
- Вред, причиненный информационному ресурсу и его владельцу в результате инцидента.
- Недостатки в обеспечении безопасности информации, не позволившие предотвратить инцидент.
- Своевременность обнаружения инцидента.
- Действия персонала при локализации инцидента и ликвидации его последствий.
- Сроки устранения последствий инцидента.
При оценке вреда, причиненного информационному ресурсу и его владельцу в результате инцидента, принимаются в расчет:
- Трудозатраты персонала и иные затраты, связанные с ликвидацией последствий.
- Вред, причиненный общественным интересам и интересам владельца информационного ресурса, в том числе связанный с нарушением конфиденциальности.
При оценке недостатков в обеспечении безопасности информации определяются:
- Нормативные требования, невыполнение, недостаточная эффективность выполнения или отсутствие которых сделали инцидент возможным.
- Дополнительные меры защиты, которые не являются обязательными в соответствии с действующими нормативными документами, но которые могли бы предотвратить инцидент.
В соответствии с Методическими рекомендациями ГосСОПКА, по результатам анализа инцидента, связанного с ранее неизвестной компьютерной атакой, центр ГосСОПКА осуществляет самостоятельную разработку или уточнение существующих методических рекомендаций по обнаружению, предупреждению и ликвидации последствий компьютерных атак данного типа. В случае если разработка указанных рекомендаций вызывает затруднение, центр ГосСОПКА направляет запрос в главный центр ГосСОПКА на оказание методической помощи по разработке указанных рекомендаций.
Заключение
В зависимости от деятельности организации оптимальным выбором применения могут быть как международные стандарты, так и Методические рекомендации ГосСОПКА, которые описывают достаточно полный набор мер необходимый для построения процесса управления инцидентами и событиями ИБ. Однако стоит отметить, что в общем случае в отличие от международных стандартов, в Методических рекомендациях ГосСОПКА дополнительно существуют такие процессы, как:
- Взаимодействие между центрами по вертикали иерархической структуры ГосСОПКА.
- Информирование в зоне ответственности субъекта ГосСОПКА заинтересованных лиц по вопросам обнаружения, предупреждения и ликвидации последствий компьютерных атак.
Независимо от того, какая была выбрана или разработана методология управления инцидентами и событиями ИБ, она должна:
- учитывать потребности организации;
- быть максимально автоматизированной;
- выполняться непрерывно (24 часа в сутки 7 дней в неделю);
- быть применимой к организации с учетом корпоративной культуры и имеющихся ресурсов;
- отражать в виде модели реальный ландшафт угроз ИБ, актуальных для организации;
- быть прозрачной для всех заинтересованных сторон, включая руководство компании, представителей регуляторов, внешних и внутренних аудиторов.
Автор:
Владимир Дрюков, директор Центра мониторинга и реагирования на кибератаки Solar JSOC «Ростелеком-Solar».
Система защиты от утечек информации основывается в том числе на выявлении, предотвращении, регистрации и устранении последствий инцидентов информационной безопасности или событий, нарушающих регламентированные процедуры защиты ИБ. Существует ряд методик, определяющих основные параметры управления ими. Эти методики внедряются на уровне международных стандартов, устанавливающих критерии оценки качества менеджмента в компании. События или инциденты ИБ в рамках этих регламентов выявляются и регистрируются, их последствия устраняются, а на основании анализа причин их возникновения положения и методики дорабатываются.
Понятие инцидента
Международные регламенты, действующие в сфере сертификации менеджмента информационных систем, дают свое определение этому явлению. Согласно им инцидентом информационной безопасности является единичное событие нежелательного и непредсказуемого характера, которое способно повлиять на бизнес-процессы компании, скомпрометировать их или нарушить степень защиты информационной безопасности. На практике к этому понятию относятся разноплановые события, происходящие в процессе работы с информацией, существующей в электронной форме или на материальных носителях. К ним может относиться и оставление документов на рабочем столе в свободном доступе для другого персонала, и хакерская атака – оба инцидента в равной мере могут нанести ущерб интересам компании.
Среди основных типов событий присутствуют:
- нарушение порядка взаимодействия с Интернет-провайдерами, хостингами, почтовыми сервисами, облачными сервисами и другими поставщиками телекоммуникационных услуг;
- отказ оборудования по любым причинам, как технического, так и программного характера;
- нарушение работы программного обеспечения;
- нарушение любых правил обработки, хранения, передачи информации, как электронной, так и документов;
- неавторизированный или несанкционированный доступ третьих лиц к информационным ресурсам;
- выявление внешнего мониторинга ресурсов;
- выявление вирусов или других вредоносных программ;
- любая компрометация системы, например, попадание пароля от учетной записи в открытый доступ.
Все эти события должны быть классифицированы, описаны и внесены во внутренние документы компании, регламентирующие порядок обеспечения информационной безопасности. Кроме того, в регламентирующих документах необходимо установить иерархию событий, разделить их на более или менее значимые. Следует учитывать, что существенная часть инцидентов малозаметны, они происходят вне периметра внимания должностных лиц. Такие события должны быть описаны особо, и определены меры для их выявления в режиме постфактум.
При описании мер реакции следует учитывать, что изменение частоты появления и общего количества инцидентов информационной безопасности является одним из показателей качества работы систем, обеспечивающих ИБ, и само по себе классифицируется в качестве существенного события. Учащение событий может говорить о намеренной атаке на информационные системы компании, поэтому оно должно стать основанием для анализа и дальнейшего повышения уровня защиты.
Место управления инцидентами в общей системе информационной безопасности
Регламенты, определяющие порядок управления инцидентами информационной безопасности, должны стать составной частью бизнес-процессов и их регламентации. Предполагая, что инцидентом является недозволенное, несанкционированное событие, в работе нужно опираться на механизм, разделяющий события и действия на разрешенные и запрещенные, определяющий органы, имеющие права на разработку таких норм. Кроме того, регламент определяет методы и способы классификаций событий, прямо не обозначенных в документах в качестве значимых, и механизм выявления таких событий, их описания и последующего внесения в регламентирующие документы.
Например, в регламенте может быть запрещено размещение конфиденциальной информации на портативных носителях без ее кодировки или шифрования, при этом не будет прямо установлен запрет на вынос таких устройств за пределы компании. Случайная утрата компьютера в результате криминального посягательства станет инцидентом, но он не будет прямо запрещен. Соответственно, в документах должен быть установлен механизм дополнения норм и правил безопасности в ситуативном порядке без излишней бюрократии. Это позволит оперативно реагировать на новые вызовы и дорабатывать меры защиты своевременно, а не со значительным запозданием.
Система сертификации ISO 27001 в качестве одного из элементов ИБ предполагает необходимость создания отдельной процедуры управления инцидентами информационной безопасности в рамках общей системы стандартизации бизнес-процессов.
Особенности управления событиями безопасности
Несмотря на то, что стандарты прямо рекомендуют внедрять методики управления инцидентами информационной безопасности, на практике внедрение и реализация этих практик встречают множество сложностей. Отдельные процедуры управления инцидентами не внедряются. Этот показатель не говорит о том, что системы менеджмента инцидентов работают хорошо или плохо, это свидетельствует только о том, что существует определенная брешь в системе безопасности.
Управление инцидентами информационной безопасности основано на следующих действиях:
- определение. В организации отсутствует методика выявления и классификации инцидентов, описание их основных параметров, поэтому сотрудники встают перед необходимостью или самостоятельно определять критерии события, или игнорировать его. Вход в сеть под аккаунтом другого сотрудника, согласно стандартам, является инцидентом информационной безопасности, но он не будет зафиксирован в журнале, так как сотрудники считают такое поведение стандартным и дозволенным, особенно в условиях дефицита кадровых ресурсов;
- оповещение о возникновении. Даже если какое-либо событие может быть определено согласно принятым в организации методикам или личному мнению сотрудника как инцидент, чаще всего в организации не разработаны стандарты и маршруты оповещения о таких событиях. Даже если кем-то будет выявлен факт копирования документов, относящихся к коммерческой тайне, сотрудник встанет в тупик перед вопросом, кто именно и в какой форме должен быть оповещен об этом инциденте: его руководитель, служба безопасности или иное лицо;
- регистрация. Эта часть стандартов является наиболее невыполнимой для российских компаний, инциденты не идентифицируются, соответственно, не фиксируются. Отсутствует практика заведения регистров учета, в которых бы фиксировались значимые события, что впоследствии давало бы материал для их анализа и прогноза возможных атак;
- устранение причин и последствий. Любой инцидент вызывает определенные следы и последствия, которые, с одной стороны, могут мешать деятельности компании, с другой – служат материалом для проведения расследования причин его возникновения. Отсутствие регламентов устранения последствий может привести как к накоплению ошибок, так и к полному уничтожению доказательственной базы, позволяющей выявить виновника произошедшей ситуации. Любые срочные меры, предпринимаемые для восстановления стабильности, могут случайно или намеренно уничтожить следы проникновения в базу данных;
- меры реагирования на инциденты. В ряде случаев возникновение инцидента может потребовать срочных мер реагирования, например, отключения компьютера от сети, приостановки передачи информации, установки контакта с провайдером. Должны быть определены органы и должностные лица, ответственные за разработку механизма реагирования и его оперативную реализацию;
- расследование. Полномочия по расследованию должны быть переданы из ведения IT-службы в компетенцию служб безопасности. В рамках расследования должны быть изучены журналы учета, проанализированы действия всех пользователей и администраторов, которые имели доступ к системам в период возникновения чрезвычайной ситуации. Расследование должно стать одним из основных элементов управления инцидентами. На практике в российских компаниях от реализации этого этапа отказываются, ограничиваясь устранениями последствий произошедшего события. При необходимости расследование должно производиться с привлечением оперативно-следственных органов;
- реализация превентивных мер. В большинстве случаев инциденты не являются единичными, их возникновение свидетельствует о том, что в системе ИБ возникла брешь и аналогичные случаи будут повторяться. Во избежание этих рисков необходимо по результатам расследования подготовить протокол или акт комиссии, в котором определить, какие именно меры должны быть применены для предотвращения аналогичных ситуаций. Кроме того, применяются определенные меры дисциплинарной ответственности, предусмотренные Трудовым кодексом и внутренними регламентами;
- аналитика. Все события, нарушающие регламентированные процессы и могущие быть квалифицированы в качестве инцидентов информационной безопасности, должны стать основой для анализа, который поможет определить их характер, проявить системность и выработать рекомендации для совершенствования системы ИБ, действующей в компании.
Управление инцидентами в безопасности с помощью «СёрчИнформ КИБ» упрощает работу ИБ-службы компании: система экстренно реагирует на нарушения политик безопасности и снабжает ИБ-специалиста большой доказательной базой.
Основные проблемы, связанные с нарушением процедур, обусловлены неготовностью персонала в полной мере воспринимать, адаптировать и выполнять рекомендации. Касательно инцидентов информационной безопасности, сложности в восприятии и реакции вызывают моменты, связанные с совершением действий, которые прямо не регламентированы инструкциями или стандартами или вызывают ощущение излишних или избыточных.
Процедура управления
Как любая корпоративная процедура, организация управления инцидентами информационной безопасности должна пройти несколько этапов: от принятия решения о его необходимости до внедрения и аудита. На практике менеджмент большинства предприятий не осознает необходимости применения этой практики защиты информационного периметра, поэтому для возникновения инициативы о ее внедрении часто требуется аудит систем ИБ внешними консультантами, выработка ими рекомендаций, которые затем будут реализованы руководством предприятия. Таким образом, начальной точкой для реализации процедур управления инцидентами ИБ становится решение исполнительных органов или иногда более высоких звеньев системы управления компании, например, Совета директоров.
Общее решение обычно принимается в русле модернизации существующей системы ИБ. Система управления инцидентами является ее основной частью. На уровне принятия решения необходима его локализация в общей парадигме целей компании. Оптимально, если функционирование системы ИБ становится одной из бизнес-целей организации, а качество ее работы подкрепляется установлением ключевых показателей эффективности для ответственных сотрудников компании. После определения статуса функционирования системы необходимо перейти к разработке внутренней документации, опосредующей связанные с ней отношения в компании.
Для придания значимости методикам управления информационной безопасностью они должны быть утверждены на уровне исполнительного органа (генерального директора, правления или совета директоров). С данными документа необходимо ознакомить всех сотрудников, имеющих отношение к работе с информацией, существующей в электронных формах или на материальных носителях.
В структуре документа, оформляемого в виде положения или регламента, должны выделяться следующие подразделы:
- определение событий, признаваемых инцидентами применительно к системе безопасности конкретной компании. Так, пользование внешней электронной почтой может быть нарушением ИБ для государственной компании и рядовым событием для частной;
- порядок оповещения о событии. Должны быть определены формат уведомления (устный, докладная записка, электронное сообщение), перечень лиц, которые должны быть оповещены, и дублирующие их должности в случае их отсутствия, перечень лиц, до которых также доносится информация о событии (руководство компании), срок уведомления после получения информации об инциденте;
- перечень мероприятий по устранению последствий инцидента и порядок их реализации;
- порядок расследования, в котором определяются ответственные за него должностные лица, механизм сбора и фиксации доказательств, возможные действия по выявлению виновника;
- порядок привлечения виновных лиц к дисциплинарной ответственности;
- меры усиления безопасности, которые должны быть применены по итогам расследования инцидента;
- порядок минимизации вреда и устранения последствий инцидентов.
При разработке регламентов, опосредующих систему управления событиями ИБ, желательно опираться на уже созданные и показавшие свою эффективность методики и документы, включая формы отчетов, журналы регистрации, уведомления о событии.
Устранение причин и последствий события, его расследование
Непосредственно после уведомления соответствующих должностных лиц о произошедшем инциденте и его фиксации необходимо совершить действия реагирования, а именно устранения причин и последствий события. Все этапы этих процессов должны найти свое отражение в регламентах. Там описываются перечни общих действий для отдельных наиболее значимых событий, конкретные шаги и сроки применения мер. Необходимо также предусмотреть ответственность за неприменение установленных мер или недостаточно эффективное их применение.
На этапе расследования от должностных лиц организации требуется:
- определить причины возникновения инцидента и недостатки регламентирующих документов и методик, сделавших возможным его возникновение;
- установить ответственных и виновных лиц;
- собрать и зафиксировать доказательства;
- установить мотивы совершения инцидента и круг лиц, причастных к нему помимо персонала компании, выявить заказчика.
Если предполагается в дальнейшем возбуждение судебного преследования по факту инцидента на основании совершения преступления в сфере информационной безопасности или нарушения режима коммерческой тайны, к расследованию уже на начальном этапе необходимо привлечь оперативно-следственные органы. Собранные самостоятельно факты без соблюдения процессуальных мер не будут признаны надлежащими доказательствами и приобщены к делу.
Как расследовать утечки информации с помощью DLP-системы? Читать.
Превентивные меры, изменения стандартов и ликвидация последствий
Непосредственно после выявления инцидента предпринимаются оперативные меры по устранению его последствий. На следующем этапе необходим анализ причин его возникновения и совершение комплекса действий, направленных на предотвращение возможного повторения аналогичного события. Сегодня основным регламентирующим документом, предлагающим стандарты реакции на инциденты, стал ISO/IEC 27000:2016, это последняя версия совместной разработки ISO и Энергетической комиссии. В России на основе более ранних версий ISO/IEC разработаны ГОСТы. В рамках ISO/IEC 27000:2016 предлагается создать специальную службу поддержки, Service Desk, на которую должны быть возложены функции управления инцидентами.
Аудит соблюдения стандартов
При получении сертификата соответствия по стандарту ISO 27001, а также при проверке соблюдений требований стандарта проводится аудит выполнения методик управления инцидентами информационной безопасности. При проведении аудита часто выясняется, что даже при внедрении стандартов возникает существенное количество проблем и недопониманий, связанных с регистрацией инцидентов и расследованием событий, послуживших причиной для их возникновения. Расследования осложняются тем, что под одной учетной записью могут входить несколько операторов или администраторов, что затрудняет их аутентификацию. На контроллере серверов в большинстве случаев не заводятся и не ведутся журналы учета событий. Отсутствие контролируемой системы идентификации пользователей, характерное для большинства российских компаний, позволяет в произвольном режиме менять информацию, останавливать серверы или модифицировать их работу. ИБ, внедренные в большинстве российских компаний, не позволяют контролировать действия администраторов.
Рекомендуется проведение аудита не реже чем раз в полгода. Его результатами должны стать обновление перечня событий, признаваемых инцидентами, доработка перечня необходимых действий по их устранению, изменение программных средств, обеспечивающих защиту информационного периметра. Если в компании установлены DLP-системы и SIEM-системы, то с учетом проведенного анализа инцидентов, произошедших за определенный период, и результатов аудита они могут быть доработаны.
Аудит не должен быть единственным фактором, выявляющим недостатки работы системы. Еще на этапе ее внедрения должны быть разработаны системы контроля качества процессов, результаты работы которых должны обрабатываться в регулярном режиме.
ПОПРОБУЙТЕ «СЁРЧИНФОРМ КИБ»!
Полнофункциональное ПО без ограничений по пользователям и функциональности.