В языке Transact-SQL в одном ряду с такими операциями как INSERT (вставка), UPDATE (обновление), DELETE (удаление) стоит операция MERGE (слияние), которая в некоторых случаях может быть полезна, но некоторые почему-то о ней не знают и не пользуются ею, поэтому сегодня мы рассмотрим данную операцию и разберем примеры.

Начнем мы, конечно же, с небольшой теории.
Заметка! Начинающим рекомендую посмотреть мой видеокурс по T-SQL.
Содержание
- Что такое MERGE в T-SQL?
- Исходные данные для примеров операции MERGE
- Пример 1 – обновление и добавление данных с помощью MERGE
- Пример 2 – синхронизация таблиц с помощью MERGE
- Пример 3 – операция MERGE с дополнительным условием
MERGE – операция в языке T-SQL, при которой происходит обновление, вставка или удаление данных в таблице на основе результатов соединения с данными другой таблицы или SQL запроса. Другими словами, с помощью MERGE можно осуществить слияние двух таблиц, т.е. синхронизировать их.
В операции MERGE происходит объединение по ключевому полю или полям основной таблицы (в которой и будут происходить все изменения) с соответствующими полями другой таблицы или результата запроса. В итоге если условие, по которому происходит объединение, истина (WHEN MATCHED), то мы можем выполнить операции обновления или удаления, если условие не истина, т.е. отсутствуют данные (WHEN NOT MATCHED), то мы можем выполнить операцию вставки (INSERT добавление данных), также если в основной таблице присутствуют данные, которое отсутствуют в таблице (или результате запроса) источника (WHEN NOT MATCHED BY SOURCE), то мы можем выполнить обновление или удаление таких данных.
В дополнение к основным перечисленным выше условиям можно указывать «Дополнительные условия поиска», они указываются через ключевое слово AND.
Упрощённый синтаксис MERGE
MERGE <Основная таблица>
USING <Таблица или запрос источника>
ON <Условия объединения>
[ WHEN MATCHED [ AND <Доп. условие> ]
THEN <UPDATE или DELETE>
[ WHEN NOT MATCHED [ AND Доп. условие> ]
THEN <INSERT> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <Доп. условие> ]
THEN <UPDATE или DELETE> ] [ ...n ]
[ OUTPUT ]
;
Важные моменты при использовании MERGE:
- В конце инструкции MERGE обязательно должна идти точка с запятой (;) иначе возникнет ошибка;
- Должно быть, по крайней мере, одно условие MATCHED;
- Операцию MERGE можно использовать совместно с CTE (обобщенным табличным выражением);
- В инструкции MERGE можно использовать ключевое слово OUTPUT, для того чтобы посмотреть какие изменения были внесены. Для идентификации операции здесь в OUTPUT можно использовать переменную $action;
- На все операции к основной таблице, которые предусмотрены в MERGE (удаления, вставки или обновления), действуют все ограничения, определенные для этой таблицы;
- Функция @@ROWCOUNT, если ее использовать после инструкции MERGE, будет возвращать общее количество вставленных, обновленных и удаленных строк;
- Для того чтобы использовать MERGE необходимо разрешение на INSERT, UPDATE или DELETE в основной таблице, и разрешение SELECT для таблицы источника;
- При использовании MERGE необходимо учитывать, что все триггеры AFTER на INSERT, UPDATE или DELETE, определенные для целевой таблицы, будут запускаться.
А теперь переходим к практике. И для начала давайте определимся с исходными данными.
Исходные данные для примеров операции MERGE
У меня в качестве SQL сервера будет выступать Microsoft SQL Server 2016 Express. На нем есть тестовая база данных, в которой я создаю тестовые таблицы, например, с товарами: TestTable – это у нас будет целевая таблица, т.е. та над которой мы будем производить все изменения, и TestTableDop – это таблица источник, т.е. данные в соответствии с чем, мы будем производить изменения.
Запрос для создания таблиц.
--Целевая таблица
CREATE TABLE dbo.TestTable(
ProductId INT NOT NULL,
ProductName VARCHAR(50) NULL,
Summa MONEY NULL,
CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC)
)
--Таблица источник
CREATE TABLE dbo.TestTableDop(
ProductId INT NOT NULL,
ProductName VARCHAR(50) NULL,
Summa MONEY NULL,
CONSTRAINT PK_TestTableDop PRIMARY KEY CLUSTERED (ProductId ASC)
)
Далее я их наполняю тестовыми данными.

--Добавляем данные в основную таблицу
INSERT INTO dbo.TestTable
(ProductId,ProductName,Summa)
VALUES
(1, 'Компьютер', 0)
GO
INSERT INTO dbo.TestTable
(ProductId,ProductName,Summa)
VALUES
(2, 'Принтер', 0)
GO
INSERT INTO dbo.TestTable
(ProductId,ProductName,Summa)
VALUES
(3, 'Монитор', 0)
GO
--Добавляем данные в таблицу источника
INSERT INTO dbo.TestTableDop
(ProductId,ProductName,Summa)
VALUES
(1, 'Компьютер', 500)
GO
INSERT INTO dbo.TestTableDop
(ProductId,ProductName,Summa)
VALUES
(2, 'Принтер', 300)
GO
INSERT INTO dbo.TestTableDop
(ProductId,ProductName,Summa)
VALUES
(4, 'Монитор', 400)
GO
Посмотрим на эти данные.
SELECT * FROM dbo.TestTable SELECT * FROM dbo.TestTableDop
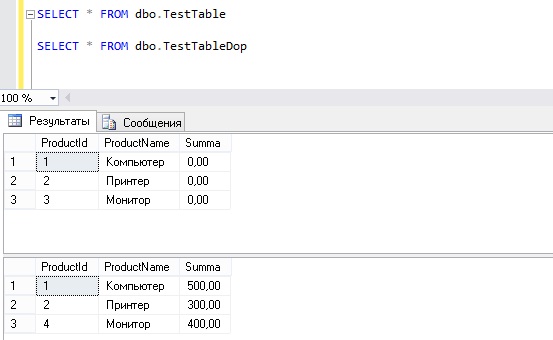
Видно, что в целевой таблице значение поля Summa = 0, а также есть несоответствие некоторых идентификаторов, т.е. у нас есть товары, которые есть в одной таблице, при этом они отсутствуют в другой.
Пример 1 – обновление и добавление данных с помощью MERGE
Это, наверное, классический вариант использования MERGE, когда мы по условию объединения обновляем данные, а если таких данных нет, то добавляем их. Для наглядности в конце инструкции MERGE я укажу ключевое слово OUTPUT, для того чтобы посмотреть какие именно изменения мы произвели, а также сделаю выборку итоговых данных.
MERGE dbo.TestTable AS T_Base --Целевая таблица
USING dbo.TestTableDop AS T_Source --Таблица источник
ON (T_Base.ProductId = T_Source.ProductId) --Условие объединения
WHEN MATCHED THEN --Если истина (UPDATE)
UPDATE SET ProductName = T_Source.ProductName, Summa = T_Source.Summa
WHEN NOT MATCHED THEN --Если НЕ истина (INSERT)
INSERT (ProductId, ProductName, Summa)
VALUES (T_Source.ProductId, T_Source.ProductName, T_Source.Summa)
--Посмотрим, что мы сделали
OUTPUT $action AS [Операция], Inserted.ProductId,
Inserted.ProductName AS ProductNameNEW,
Inserted.Summa AS SummaNEW,
Deleted.ProductName AS ProductNameOLD,
Deleted.Summa AS SummaOLD; --Не забываем про точку с запятой
--Итоговый результат
SELECT * FROM dbo.TestTable
SELECT * FROM dbo.TestTableDop
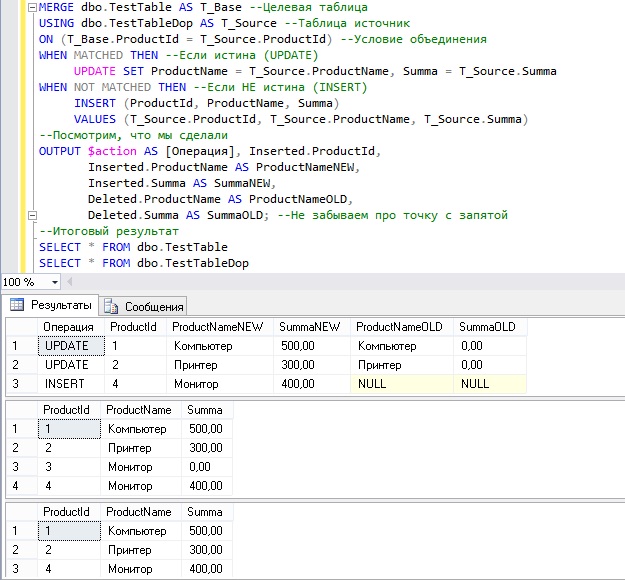
Мы видим, что у нас было две операции UPDATE и одна INSERT. Так оно и есть, две строки из таблицы TestTable соответствуют двум строкам в таблице TestTableDop, т.е. у них один и тот же ProductId, у данных строк в таблице TestTable мы обновили поля ProductName и Summa. При этом в таблице TestTableDop есть строка, которая отсутствует в TestTable, поэтому мы ее и добавили через INSERT.
Пример 2 – синхронизация таблиц с помощью MERGE
Теперь, допустим, нам нужно синхронизировать таблицу TestTable с таблицей TestTableDop, для этого мы добавим еще одно условие WHEN NOT MATCHED BY SOURCE, суть его в том, что мы удалим строки, которые есть в TestTable, но нет в TestTableDOP. Но для начала, для того чтобы у нас все три условия отработали (в частности WHEN NOT MATCHED) давайте в таблице TestTable удалим строку, которую мы добавили в предыдущем примере. Также здесь я в качестве источника укажу запрос, чтобы Вы видели, как можно использовать запросы в качестве источника.
--Удаление строки с ProductId = 4
--для того чтобы отработало условие WHEN NOT MATCHED
DELETE dbo.TestTable WHERE ProductId = 4
--Запрос MERGE для синхронизации таблиц
MERGE dbo.TestTable AS T_Base --Целевая таблица
--Запрос в качестве источника
USING (SELECT ProductId, ProductName, Summa
FROM dbo.TestTableDop) AS T_Source (ProductId, ProductName, Summa)
ON (T_Base.ProductId = T_Source.ProductId) --Условие объединения
WHEN MATCHED THEN --Если истина (UPDATE)
UPDATE SET ProductName = T_Source.ProductName, Summa = T_Source.Summa
WHEN NOT MATCHED THEN --Если НЕ истина (INSERT)
INSERT (ProductId, ProductName, Summa)
VALUES (T_Source.ProductId, T_Source.ProductName, T_Source.Summa)
--Удаляем строки, если их нет в TestTableDOP
WHEN NOT MATCHED BY SOURCE THEN
DELETE
--Посмотрим, что мы сделали
OUTPUT $action AS [Операция], Inserted.ProductId, Inserted.ProductName AS ProductNameNEW,
Inserted.Summa AS SummaNEW,Deleted.ProductName AS ProductNameOLD,
Deleted.Summa AS SummaOLD; --Не забываем про точку с запятой
--Итоговый результат
SELECT * FROM dbo.TestTable
SELECT * FROM dbo.TestTableDop

В итоге мы видим, что у нас таблицы содержат одинаковые данные. Для этого мы выполнили две операции UPDATE, одну INSERT и одну DELETE. При этом мы использовали всего одну инструкцию MERGE.
Пример 3 – операция MERGE с дополнительным условием
Сейчас давайте выполним запрос похожий на запрос, который мы использовали в примере 1, только добавим дополнительное условие на обновление данных, например, мы будем обновлять TestTable только в том случае, если поле Summa, в TestTableDop, содержит какие-нибудь данные (например, мы не хотим использовать некорректные значения для обновления). Для того чтобы было видно, как отработало это условие, давайте предварительно очистим у одной строки в таблице TestTableDop поле Summa (поставим NULL).
--Очищаем поле сумма у одной строки в TestTableDop
UPDATE dbo. TestTableDop SET Summa = NULL
WHERE ProductId = 2
--Запрос MERGE
MERGE dbo.TestTable AS T_Base --Целевая таблица
USING dbo.TestTableDop AS T_Source --Таблица источник
ON (T_Base.ProductId = T_Source.ProductId) --Условие объединения
--Если истина + доп. условие отработало (UPDATE)
WHEN MATCHED AND T_Source.Summa IS NOT NULL THEN
UPDATE SET ProductName = T_Source.ProductName, Summa = T_Source.Summa
WHEN NOT MATCHED THEN --Если НЕ истина (INSERT)
INSERT (ProductId, ProductName, Summa)
VALUES (T_Source.ProductId, T_Source.ProductName, T_Source.Summa)
--Посмотрим, что мы сделали
OUTPUT $action AS [Операция], Inserted.ProductId,
Inserted.ProductName AS ProductNameNEW,
Inserted.Summa AS SummaNEW,
Deleted.ProductName AS ProductNameOLD,
Deleted.Summa AS SummaOLD; --Не забываем про точку с запятой
--Итоговый результат
SELECT * FROM dbo.TestTable
SELECT * FROM dbo.TestTableDop
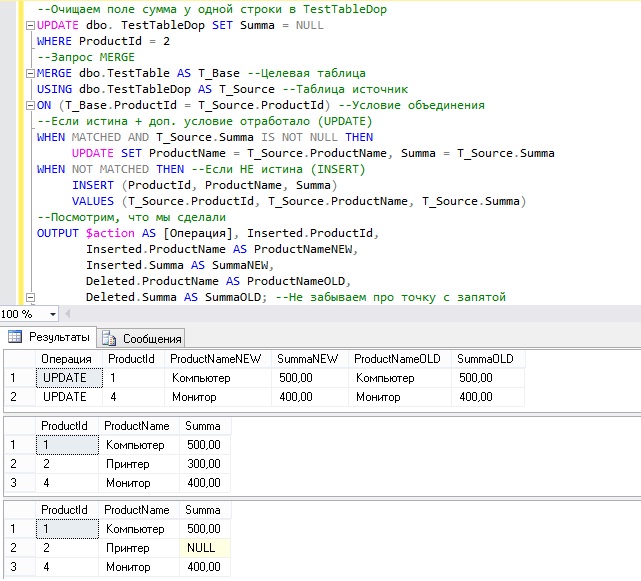
В итоге у меня обновилось всего две строки, притом, что все три строки успешно выполнили условие объединения, но одна строка не обновилась, так как сработало дополнительное условие Summa IS NOT NULL, потому что поле Summa у строки с ProductId = 2, в таблице TestTableDop, не содержит никаких данных, т.е. NULL.
Заметка! Для комплексного изучения языка SQL и T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, которые помогут Вам «с нуля» научиться работать с SQL и программировать на T-SQL в Microsoft SQL Server.
На этом у меня все, удачи!
MERGE — conditionally insert, update, or delete rows of a table
Synopsis
[ WITHwith_query[, ...] ] MERGE INTO [ ONLY ]target_table_name[ * ] [ [ AS ]target_alias] USINGdata_sourceONjoin_conditionwhen_clause[...] wheredata_sourceis: { [ ONLY ]source_table_name[ * ] | (source_query) } [ [ AS ]source_alias] andwhen_clauseis: { WHEN MATCHED [ ANDcondition] THEN {merge_update|merge_delete| DO NOTHING } | WHEN NOT MATCHED [ ANDcondition] THEN {merge_insert| DO NOTHING } } andmerge_insertis: INSERT [(column_name[, ...] )] [ OVERRIDING { SYSTEM | USER } VALUE ] { VALUES ( {expression| DEFAULT } [, ...] ) | DEFAULT VALUES } andmerge_updateis: UPDATE SET {column_name= {expression| DEFAULT } | (column_name[, ...] ) = ( {expression| DEFAULT } [, ...] ) } [, ...] andmerge_deleteis: DELETE
Description
MERGE performs actions that modify rows in the target_table_name, using the data_source. MERGE provides a single SQL statement that can conditionally INSERT, UPDATE or DELETE rows, a task that would otherwise require multiple procedural language statements.
First, the MERGE command performs a join from data_source to target_table_name producing zero or more candidate change rows. For each candidate change row, the status of MATCHED or NOT MATCHED is set just once, after which WHEN clauses are evaluated in the order specified. For each candidate change row, the first clause to evaluate as true is executed. No more than one WHEN clause is executed for any candidate change row.
MERGE actions have the same effect as regular UPDATE, INSERT, or DELETE commands of the same names. The syntax of those commands is different, notably that there is no WHERE clause and no table name is specified. All actions refer to the target_table_name, though modifications to other tables may be made using triggers.
When DO NOTHING is specified, the source row is skipped. Since actions are evaluated in their specified order, DO NOTHING can be handy to skip non-interesting source rows before more fine-grained handling.
There is no separate MERGE privilege. If you specify an update action, you must have the UPDATE privilege on the column(s) of the target_table_name that are referred to in the SET clause. If you specify an insert action, you must have the INSERT privilege on the target_table_name. If you specify an delete action, you must have the DELETE privilege on the target_table_name. Privileges are tested once at statement start and are checked whether or not particular WHEN clauses are executed. You will require the SELECT privilege on the data_source and any column(s) of the target_table_name referred to in a condition.
MERGE is not supported if the target_table_name is a materialized view, foreign table, or if it has any rules defined on it.
Parameters
target_table_name-
The name (optionally schema-qualified) of the target table to merge into. If
ONLYis specified before the table name, matching rows are updated or deleted in the named table only. IfONLYis not specified, matching rows are also updated or deleted in any tables inheriting from the named table. Optionally,*can be specified after the table name to explicitly indicate that descendant tables are included. TheONLYkeyword and*option do not affect insert actions, which always insert into the named table only. target_alias-
A substitute name for the target table. When an alias is provided, it completely hides the actual name of the table. For example, given
MERGE INTO foo AS f, the remainder of theMERGEstatement must refer to this table asfnotfoo. source_table_name-
The name (optionally schema-qualified) of the source table, view, or transition table. If
ONLYis specified before the table name, matching rows are included from the named table only. IfONLYis not specified, matching rows are also included from any tables inheriting from the named table. Optionally,*can be specified after the table name to explicitly indicate that descendant tables are included. source_query-
A query (
SELECTstatement orVALUESstatement) that supplies the rows to be merged into thetarget_table_name. Refer to the SELECT statement or VALUES statement for a description of the syntax. source_alias-
A substitute name for the data source. When an alias is provided, it completely hides the actual name of the table or the fact that a query was issued.
join_condition-
join_conditionis an expression resulting in a value of typeboolean(similar to aWHEREclause) that specifies which rows in thedata_sourcematch rows in thetarget_table_name.Warning
Only columns from
target_table_namethat attempt to matchdata_sourcerows should appear injoin_condition.join_conditionsubexpressions that only referencetarget_table_namecolumns can affect which action is taken, often in surprising ways. when_clause-
At least one
WHENclause is required.If the
WHENclause specifiesWHEN MATCHEDand the candidate change row matches a row in thetarget_table_name, theWHENclause is executed if theconditionis absent or it evaluates totrue.Conversely, if the
WHENclause specifiesWHEN NOT MATCHEDand the candidate change row does not match a row in thetarget_table_name, theWHENclause is executed if theconditionis absent or it evaluates totrue. condition-
An expression that returns a value of type
boolean. If this expression for aWHENclause returnstrue, then the action for that clause is executed for that row.A condition on a
WHEN MATCHEDclause can refer to columns in both the source and the target relations. A condition on aWHEN NOT MATCHEDclause can only refer to columns from the source relation, since by definition there is no matching target row. Only the system attributes from the target table are accessible. merge_insert-
The specification of an
INSERTaction that inserts one row into the target table. The target column names can be listed in any order. If no list of column names is given at all, the default is all the columns of the table in their declared order.Each column not present in the explicit or implicit column list will be filled with a default value, either its declared default value or null if there is none.
If
target_table_nameis a partitioned table, each row is routed to the appropriate partition and inserted into it. Iftarget_table_nameis a partition, an error will occur if any input row violates the partition constraint.Column names may not be specified more than once.
INSERTactions cannot contain sub-selects.Only one
VALUESclause can be specified. TheVALUESclause can only refer to columns from the source relation, since by definition there is no matching target row. merge_update-
The specification of an
UPDATEaction that updates the current row of thetarget_table_name. Column names may not be specified more than once.Neither a table name nor a
WHEREclause are allowed. merge_delete-
Specifies a
DELETEaction that deletes the current row of thetarget_table_name. Do not include the table name or any other clauses, as you would normally do with a DELETE command. column_name-
The name of a column in the
target_table_name. The column name can be qualified with a subfield name or array subscript, if needed. (Inserting into only some fields of a composite column leaves the other fields null.) Do not include the table’s name in the specification of a target column. OVERRIDING SYSTEM VALUE-
Without this clause, it is an error to specify an explicit value (other than
DEFAULT) for an identity column defined asGENERATED ALWAYS. This clause overrides that restriction. OVERRIDING USER VALUE-
If this clause is specified, then any values supplied for identity columns defined as
GENERATED BY DEFAULTare ignored and the default sequence-generated values are applied. DEFAULT VALUES-
All columns will be filled with their default values. (An
OVERRIDINGclause is not permitted in this form.) expression-
An expression to assign to the column. If used in a
WHEN MATCHEDclause, the expression can use values from the original row in the target table, and values from thedata_sourcerow. If used in aWHEN NOT MATCHEDclause, the expression can use values from thedata_source. DEFAULT-
Set the column to its default value (which will be
NULLif no specific default expression has been assigned to it). with_query-
The
WITHclause allows you to specify one or more subqueries that can be referenced by name in theMERGEquery. See Section 7.8 and SELECT for details.
Outputs
On successful completion, a MERGE command returns a command tag of the form
MERGE total_count
The total_count is the total number of rows changed (whether inserted, updated, or deleted). If total_count is 0, no rows were changed in any way.
Notes
The following steps take place during the execution of MERGE.
-
Perform any
BEFORE STATEMENTtriggers for all actions specified, whether or not theirWHENclauses match. -
Perform a join from source to target table. The resulting query will be optimized normally and will produce a set of candidate change rows. For each candidate change row,
-
Evaluate whether each row is
MATCHEDorNOT MATCHED. -
Test each
WHENcondition in the order specified until one returns true. -
When a condition returns true, perform the following actions:
-
Perform any
BEFORE ROWtriggers that fire for the action’s event type. -
Perform the specified action, invoking any check constraints on the target table.
-
Perform any
AFTER ROWtriggers that fire for the action’s event type.
-
-
-
Perform any
AFTER STATEMENTtriggers for actions specified, whether or not they actually occur. This is similar to the behavior of anUPDATEstatement that modifies no rows.
In summary, statement triggers for an event type (say, INSERT) will be fired whenever we specify an action of that kind. In contrast, row-level triggers will fire only for the specific event type being executed. So a MERGE command might fire statement triggers for both UPDATE and INSERT, even though only UPDATE row triggers were fired.
You should ensure that the join produces at most one candidate change row for each target row. In other words, a target row shouldn’t join to more than one data source row. If it does, then only one of the candidate change rows will be used to modify the target row; later attempts to modify the row will cause an error. This can also occur if row triggers make changes to the target table and the rows so modified are then subsequently also modified by MERGE. If the repeated action is an INSERT, this will cause a uniqueness violation, while a repeated UPDATE or DELETE will cause a cardinality violation; the latter behavior is required by the SQL standard. This differs from historical PostgreSQL behavior of joins in UPDATE and DELETE statements where second and subsequent attempts to modify the same row are simply ignored.
If a WHEN clause omits an AND sub-clause, it becomes the final reachable clause of that kind (MATCHED or NOT MATCHED). If a later WHEN clause of that kind is specified it would be provably unreachable and an error is raised. If no final reachable clause is specified of either kind, it is possible that no action will be taken for a candidate change row.
The order in which rows are generated from the data source is indeterminate by default. A source_query can be used to specify a consistent ordering, if required, which might be needed to avoid deadlocks between concurrent transactions.
There is no RETURNING clause with MERGE. Actions of INSERT, UPDATE and DELETE cannot contain RETURNING or WITH clauses.
When MERGE is run concurrently with other commands that modify the target table, the usual transaction isolation rules apply; see Section 13.2 for an explanation on the behavior at each isolation level. You may also wish to consider using INSERT ... ON CONFLICT as an alternative statement which offers the ability to run an UPDATE if a concurrent INSERT occurs. There are a variety of differences and restrictions between the two statement types and they are not interchangeable.
Examples
Perform maintenance on customer_accounts based upon new recent_transactions.
MERGE INTO customer_account ca USING recent_transactions t ON t.customer_id = ca.customer_id WHEN MATCHED THEN UPDATE SET balance = balance + transaction_value WHEN NOT MATCHED THEN INSERT (customer_id, balance) VALUES (t.customer_id, t.transaction_value);
Notice that this would be exactly equivalent to the following statement because the MATCHED result does not change during execution.
MERGE INTO customer_account ca USING (SELECT customer_id, transaction_value FROM recent_transactions) AS t ON t.customer_id = ca.customer_id WHEN MATCHED THEN UPDATE SET balance = balance + transaction_value WHEN NOT MATCHED THEN INSERT (customer_id, balance) VALUES (t.customer_id, t.transaction_value);
Attempt to insert a new stock item along with the quantity of stock. If the item already exists, instead update the stock count of the existing item. Don’t allow entries that have zero stock.
MERGE INTO wines w USING wine_stock_changes s ON s.winename = w.winename WHEN NOT MATCHED AND s.stock_delta > 0 THEN INSERT VALUES(s.winename, s.stock_delta) WHEN MATCHED AND w.stock + s.stock_delta > 0 THEN UPDATE SET stock = w.stock + s.stock_delta WHEN MATCHED THEN DELETE;
The wine_stock_changes table might be, for example, a temporary table recently loaded into the database.
Compatibility
This command conforms to the SQL standard.
The WITH clause and DO NOTHING action are extensions to the SQL standard.
| title | description | author | ms.author | ms.reviewer | ms.date | ms.service | ms.subservice | ms.topic | f1_keywords | helpviewer_keywords | dev_langs | monikerRange | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
MERGE (Transact-SQL) |
MERGE (Transact-SQL) |
mstehrani |
emtehran |
wiassaf |
05/24/2022 |
sql |
t-sql |
reference |
|
|
TSQL |
=azuresqldb-current||=azuresqldb-mi-current||>=sql-server-2016||>=sql-server-linux-2017||azure-sqldw-latest |
MERGE (Transact-SQL)
[!INCLUDE SQL Server SQL Database]
Runs insert, update, or delete operations on a target table from the results of a join with a source table. For example, synchronize two tables by inserting, updating, or deleting rows in one table based on differences found in the other table.
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
[!NOTE]
Change the product version selector for important content on MERGE specific to Azure Synapse Analytics. To change document version to Azure Synapse Analytics: Azure Synapse Analytics.
Performance Tip: The conditional behavior described for the MERGE statement works best when the two tables have a complex mixture of matching characteristics. For example, inserting a row if it doesn’t exist, or updating a row if it matches. When simply updating one table based on the rows of another table, improve the performance and scalability with basic INSERT, UPDATE, and DELETE statements. For example:
INSERT tbl_A (col, col2) SELECT col, col2 FROM tbl_B WHERE NOT EXISTS (SELECT col FROM tbl_A A2 WHERE A2.col = tbl_B.col);
::: moniker-end
::: moniker range=»=azure-sqldw-latest»
[!NOTE]
MERGE is now Generally Available in Synapse Dedicated SQL Pool with version ‘10.0.17829.0’ or above. Connect to your dedicated SQL pool (formerly SQL DW) and runSELECT @@VERSION. A pause and resume may be required to ensure your instance gets the latest version.
[!TIP]
The conditional behavior described for the MERGE statement works best when the two tables have a complex mixture of matching characteristics. For example, inserting a row if it doesn’t exist, or updating a row if it matches. When simply updating one table based on the rows of another table, consider using basic INSERT, UPDATE, and DELETE statements for better query performance and scalability. For example:INSERT tbl_A (col, col2) SELECT col, col2 FROM tbl_B WHERE NOT EXISTS (SELECT col FROM tbl_A A2 WHERE A2.col = tbl_B.col);
::: moniker-end
:::image type=»icon» source=»../../includes/media/topic-link-icon.svg» border=»false»::: Transact-SQL syntax conventions
Syntax
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
-- SQL Server and Azure SQL Database
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] <target_table> [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source> [ [ AS ] table_alias ]
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
;
<target_table> ::=
{
[ database_name . schema_name . | schema_name . ]
target_table
}
<merge_hint>::=
{
{ [ <table_hint_limited> [ ,...n ] ]
[ [ , ] INDEX ( index_val [ ,...n ] ) ] }
}
<merge_search_condition> ::=
<search_condition>
<merge_matched>::=
{ UPDATE SET <set_clause> | DELETE }
<merge_not_matched>::=
{
INSERT [ ( column_list ) ]
{ VALUES ( values_list )
| DEFAULT VALUES }
}
<clause_search_condition> ::=
<search_condition>
[!INCLUDEsql-server-tsql-previous-offline-documentation]
::: moniker-end
::: moniker range=»=azure-sqldw-latest»
-- MERGE for Azure Synapse Analytics
[ WITH <common_table_expression> [,...n] ]
MERGE
[ INTO ] <target_table> [ [ AS ] table_alias ]
USING <table_source> [ [ AS ] table_alias ]
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
; -- The semi-colon is required, or the query will return a syntax error.
<target_table> ::=
{
[ database_name . schema_name . | schema_name . ]
target_table
}
<merge_search_condition> ::=
<search_condition>
<merge_matched>::=
{ UPDATE SET <set_clause> | DELETE }
<merge_not_matched>::=
{
INSERT [ ( column_list ) ]
VALUES ( values_list )
}
<clause_search_condition> ::=
<search_condition>
::: moniker-end
Arguments
WITH <common_table_expression>
Specifies the temporary named result set or view, also known as common table expression, that’s defined within the scope of the MERGE statement. The result set derives from a simple query and is referenced by the MERGE statement. For more information, see WITH common_table_expression (Transact-SQL).
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
TOP (expression* ) [ PERCENT ]
Specifies the number or percentage of affected rows. expression can be either a number or a percentage of the rows. The rows referenced in the TOP expression aren’t arranged in any order. For more information, see TOP (Transact-SQL).
The TOP clause applies after the entire source table and the entire target table join and the joined rows that don’t qualify for an insert, update, or delete action are removed. The TOP clause further reduces the number of joined rows to the specified value. The insert, update, or delete actions apply to the remaining joined rows in an unordered way. That is, there’s no order in which the rows are distributed among the actions defined in the WHEN clauses. For example, specifying TOP (10) affects 10 rows. Of these rows, 7 may be updated and 3 inserted, or 1 may be deleted, 5 updated, and 4 inserted, and so on.
Without filters on the source table, the MERGE statement may perform a table scan or clustered index scan on the source table, as well as a table scan or clustered index scan of target table. Therefore, I/O performance is sometimes affected even when using the TOP clause to modify a large table by creating multiple batches. In this scenario, it’s important to ensure that all successive batches target new rows.
::: moniker-end
database_name
The name of the database in which target_table is located.
schema_name
The name of the schema to which target_table belongs.
target_table
The table or view against which the data rows from <table_source> are matched based on <clause_search_condition>. target_table is the target of any insert, update, or delete operations specified by the WHEN clauses of the MERGE statement.
If target_table is a view, any actions against it must satisfy the conditions for updating views. For more information, see Modify Data Through a View.
target_table can’t be a remote table. target_table can’t have any rules defined on it.
Hints can be specified as a <merge_hint>.
::: moniker range=»=azure-sqldw-latest»
Note that merge_hints aren’t supported for [!INCLUDEssazuresynapse-md].
::: moniker-end
[ AS ] table_alias
An alternative name to reference a table for the target_table.
USING <table_source>
Specifies the data source that’s matched with the data rows in target_table based on <merge_search condition>. The result of this match dictates the actions to take by the WHEN clauses of the MERGE statement. <table_source> can be a remote table or a derived table that accesses remote tables.
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
<table_source> can be a derived table that uses the [!INCLUDEtsql] table value constructor to construct a table by specifying multiple rows.
::: moniker-end
::: moniker range=»=azure-sqldw-latest»
<table_source> can be a derived table that uses SELECT ... UNION ALL to construct a table by specifying multiple rows.
::: moniker-end
[ AS ] table_alias
An alternative name to reference a table for the table_source.
For more information about the syntax and arguments of this clause, see FROM (Transact-SQL).
ON <merge_search_condition>
Specifies the conditions on which <table_source> joins with target_table to determine where they match.
[!CAUTION]
It’s important to specify only the columns from the target table to use for matching purposes. That is, specify columns from the target table that are compared to the corresponding column of the source table. Don’t attempt to improve query performance by filtering out rows in the target table in the ON clause; for example, such as specifyingAND NOT target_table.column_x = value. Doing so may return unexpected and incorrect results.
WHEN MATCHED THEN <merge_matched>
Specifies that all rows of *target_table, which match the rows returned by <table_source> ON <merge_search_condition>, and satisfy any additional search condition, are either updated or deleted according to the <merge_matched> clause.
The MERGE statement can have, at most, two WHEN MATCHED clauses. If two clauses are specified, the first clause must be accompanied by an AND <search_condition> clause. For any given row, the second WHEN MATCHED clause is only applied if the first isn’t. If there are two WHEN MATCHED clauses, one must specify an UPDATE action and one must specify a DELETE action. When UPDATE is specified in the <merge_matched> clause, and more than one row of <table_source> matches a row in target_table based on <merge_search_condition>, [!INCLUDEssNoVersion] returns an error. The MERGE statement can’t update the same row more than once, or update and delete the same row.
WHEN NOT MATCHED [ BY TARGET ] THEN <merge_not_matched>
Specifies that a row is inserted into target_table for every row returned by <table_source> ON <merge_search_condition> that doesn’t match a row in target_table, but satisfies an additional search condition, if present. The values to insert are specified by the <merge_not_matched> clause. The MERGE statement can have only one WHEN NOT MATCHED [ BY TARGET ] clause.
WHEN NOT MATCHED BY SOURCE THEN <merge_matched>
Specifies that all rows of *target_table, which don’t match the rows returned by <table_source> ON <merge_search_condition>, and that satisfy any additional search condition, are updated or deleted according to the <merge_matched> clause.
The MERGE statement can have at most two WHEN NOT MATCHED BY SOURCE clauses. If two clauses are specified, then the first clause must be accompanied by an AND <clause_search_condition> clause. For any given row, the second WHEN NOT MATCHED BY SOURCE clause is only applied if the first isn’t. If there are two WHEN NOT MATCHED BY SOURCE clauses, then one must specify an UPDATE action and one must specify a DELETE action. Only columns from the target table can be referenced in <clause_search_condition>.
When no rows are returned by <table_source>, columns in the source table can’t be accessed. If the update or delete action specified in the <merge_matched> clause references columns in the source table, error 207 (Invalid column name) is returned. For example, the clause WHEN NOT MATCHED BY SOURCE THEN UPDATE SET TargetTable.Col1 = SourceTable.Col1 may cause the statement to fail because Col1 in the source table is inaccessible.
AND <clause_search_condition>
Specifies any valid search condition. For more information, see Search Condition (Transact-SQL).
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
<table_hint_limited>
Specifies one or more table hints to apply on the target table for each of the insert, update, or delete actions done by the MERGE statement. The WITH keyword and the parentheses are required.
NOLOCK and READUNCOMMITTED aren’t allowed. For more information about table hints, see Table Hints (Transact-SQL).
Specifying the TABLOCK hint on a table that’s the target of an INSERT statement has the same effect as specifying the TABLOCKX hint. An exclusive lock is taken on the table. When FORCESEEK is specified, it applies to the implicit instance of the target table joined with the source table.
[!CAUTION]
Specifying READPAST with WHEN NOT MATCHED [ BY TARGET ] THEN INSERT may result in INSERT operations that violate UNIQUE constraints.
INDEX ( index_val [ ,…n ] )
Specifies the name or ID of one or more indexes on the target table for doing an implicit join with the source table. For more information, see Table Hints (Transact-SQL).
<output_clause>
Returns a row for every row in target_table that’s updated, inserted, or deleted, in no particular order. $action can be specified in the output clause. $action is a column of type nvarchar(10) that returns one of three values for each row: ‘INSERT’, ‘UPDATE’, or ‘DELETE’, according to the action done on that row. The OUTPUT clause is the recommended way to query or count rows affected by a MERGE. For more information about the arguments and behavior of this clause, see OUTPUT Clause (Transact-SQL).
::: moniker-end
OPTION ( <query_hint> [ ,…n ] )
Specifies that optimizer hints are used to customize the way the Database Engine processes the statement. For more information, see Query Hints (Transact-SQL).
<merge_matched>
Specifies the update or delete action that’s applied to all rows of target_table that don’t match the rows returned by <table_source> ON <merge_search_condition>, and which satisfy any additional search condition.
UPDATE SET <set_clause>
Specifies the list of column or variable names to update in the target table and the values with which to update them.
For more information about the arguments of this clause, see UPDATE (Transact-SQL). Setting a variable to the same value as a column isn’t supported.
DELETE
Specifies that the rows matching rows in target_table are deleted.
<merge_not_matched>
Specifies the values to insert into the target table.
(column_list)
A list of one or more columns of the target table in which to insert data. Columns must be specified as a single-part name or else the MERGE statement will fail. column_list must be enclosed in parentheses and delimited by commas.
VALUES ( values_list)
A comma-separated list of constants, variables, or expressions that return values to insert into the target table. Expressions can’t contain an EXECUTE statement.
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
DEFAULT VALUES
Forces the inserted row to contain the default values defined for each column.
For more information about this clause, see INSERT (Transact-SQL).
::: moniker-end
<search_condition>
Specifies the search conditions to specify <merge_search_condition> or <clause_search_condition>. For more information about the arguments for this clause, see Search Condition (Transact-SQL).
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
<graph search pattern>
Specifies the graph match pattern. For more information about the arguments for this clause, see MATCH (Transact-SQL)
::: moniker-end
Remarks
::: moniker range=»=azure-sqldw-latest»
[!NOTE]
In Azure Synapse Analytics, the MERGE command has following differences compared to SQL server and Azure SQL database.
- Using MERGE to update a distribution key column is not supported in builds older than
10.0.17829.0. If unable to pause or force-upgrade, use the ANSIUPDATE FROM ... JOINstatement as a workaround until on version10.0.17829.0.- A MERGE update is implemented as a delete and insert pair. The affected row count for a MERGE update includes the deleted and inserted rows.
- MERGE…WHEN NOT MATCHED INSERT is not supported for tables with IDENTITY columns.
- Table value constructor can’t be used in the USING clause for the source table. Use
SELECT ... UNION ALLto create a derived source table with multiple rows.- The support for tables with different distribution types is described in this table:
MERGE CLAUSE in Azure Synapse Analytics Supported TARGET distribution table Supported SOURCE distribution table Comment WHEN MATCHED All distribution types All distribution types NOT MATCHED BY TARGET HASH All distribution types Use UPDATE/DELETE FROM…JOIN to synchronize two tables. NOT MATCHED BY SOURCE All distribution types All distribution types
[!TIP]
If you’re using the distribution hash key as the JOIN column in MERGE and performing just an equality comparison, you can omit the distribution key from the list of columns in theWHEN MATCHED THEN UPDATE SETclause, as this is a redundant update.
[!IMPORTANT]
In Azure Synapse Analytics the MERGE command on builds older than10.0.17829.0may, under certain conditions, leave the target table in an inconsistent state, with rows placed in the wrong distribution, causing later queries to return wrong results in some cases. This problem may happen in 2 cases:
Scenario Comment Case 1
Using MERGE on a HASH distributed TARGET table that contains secondary indices or a UNIQUE constraint.— Fixed in Synapse SQL version 10.0.15563.0 and higher.
— IfSELECT @@VERSIONreturns a lower version than 10.0.15563.0, manually pause and resume the Synapse SQL pool to pick up this fix.
— Until the fix has been applied to your Synapse SQL pool, avoid using the MERGE command on HASH distributed TARGET tables that have secondary indices or UNIQUE constraints.Case 2
Using MERGE to update a distribution key column of a HASH distributed table.— Fixed in Synapse SQL version 10.0.17829.0 and higher.
— IfSELECT @@VERSIONreturns a lower version than 10.0.17829.0, manually pause and resume the Synapse SQL pool to pick up this fix.
— Until the fix has been applied to your Synapse SQL pool, avoid using the MERGE command to update distribution key columns.Note that the updates in both scenarios do not repair tables already affected by previous MERGE execution. Use scripts below to identify and repair any affected tables manually.
To check which hash distributed tables in a database may be of concern (if used in the Cases above), run this statement
-- Case 1 select a.name, c.distribution_policy_desc, b.type from sys.tables a join sys.indexes b on a.object_id = b.object_id join sys.pdw_table_distribution_properties c on a.object_id = c.object_id where b.type = 2 and c.distribution_policy_desc = 'HASH'; -- Subject to Case 2, if distribution key value is updated in MERGE statement select a.name, c.distribution_policy_desc from sys.tables a join sys.pdw_table_distribution_properties c on a.object_id = c.object_id where c.distribution_policy_desc = 'HASH';To check if a hash distributed table for MERGE is affected by either Case 1 or Case 2, follow these steps to examine if the tables have rows landed in wrong distribution. If ‘no need for repair’ is returned, this table is not affected.
if object_id('[check_table_1]', 'U') is not null drop table [check_table_1] go if object_id('[check_table_2]', 'U') is not null drop table [check_table_2] go create table [check_table_1] with(distribution = round_robin) as select <DISTRIBUTION_COLUMN> as x from <MERGE_TABLE> group by <DISTRIBUTION_COLUMN>; go create table [check_table_2] with(distribution = hash(x)) as select x from [check_table_1]; go if not exists(select top 1 * from (select <DISTRIBUTION_COLUMN> as x from <MERGE_TABLE> except select x from [check_table_2]) as tmp) select 'no need for repair' as result else select 'needs repair' as result go if object_id('[check_table_1]', 'U') is not null drop table [check_table_1] go if object_id('[check_table_2]', 'U') is not null drop table [check_table_2] goTo repair affected tables, run these statements to copy all rows from the old table to a new table.
if object_id('[repair_table_temp]', 'U') is not null drop table [repair_table_temp]; go if object_id('[repair_table]', 'U') is not null drop table [repair_table]; go create table [repair_table_temp] with(distribution = round_robin) as select * from <MERGE_TABLE>; go -- [repair_table] will hold the repaired table generated from <MERGE_TABLE> create table [repair_table] with(distribution = hash(<DISTRIBUTION_COLUMN>)) as select * from [repair_table_temp]; go if object_id('[repair_table_temp]', 'U') is not null drop table [repair_table_temp]; go
::: moniker-end
At least one of the three MATCHED clauses must be specified, but they can be specified in any order. A variable can’t be updated more than once in the same MATCHED clause.
Any insert, update, or delete action specified on the target table by the MERGE statement are limited by any constraints defined on it, including any cascading referential integrity constraints. If IGNORE_DUP_KEY is ON for any unique indexes on the target table, MERGE ignores this setting.
The MERGE statement requires a semicolon (;) as a statement terminator. Error 10713 is raised when a MERGE statement is run without the terminator.
When used after MERGE, @@ROWCOUNT (Transact-SQL) returns the total number of rows inserted, updated, and deleted to the client.
MERGE is a fully reserved keyword when the database compatibility level is set to 100 or higher. The MERGE statement is available under both 90 and 100 database compatibility levels; however, the keyword isn’t fully reserved when the database compatibility level is set to 90.
[!CAUTION]
Don’t use the MERGE statement when using queued updating replication. The MERGE and queued updating trigger aren’t compatible. Replace the MERGE statement with an insert or an update statement.
::: moniker range=»=azure-sqldw-latest»
Troubleshooting
In certain scenarios, a MERGE statement may result in the error "CREATE TABLE failed because column <> in table <> exceeds the maximum of 1024 columns.", even when neither Target nor Source table has 1024 columns. This scenario can arise when all the below conditions are met:
- Multiple columns are specified in an UPDATE SET or INSERT operation within MERGE (not specific to any WHEN [NOT] MATCHED clause)
- Any column in the JOIN condition has a Non-Clustered Index (NCI)
If this error is found, the suggested workaround is to remove the Non-Clustered Index (NCI) from the JOIN columns, or join on columns without an NCI. If you later update the underlying tables to include an NCI on the JOIN columns, your MERGE statement may be susceptible to this error at runtime. See DROP INDEX to learn how to drop the Non-Clustered Index.
::: moniker-end
Trigger implementation
For every insert, update, or delete action specified in the MERGE statement, [!INCLUDEssNoVersion] fires any corresponding AFTER triggers defined on the target table, but doesn’t guarantee on which action to fire triggers first or last. Triggers defined for the same action honor the order you specify. For more information about setting trigger firing order, see Specify First and Last Triggers.
If the target table has an enabled INSTEAD OF trigger defined on it for an insert, update, or delete action done by a MERGE statement, it must have an enabled INSTEAD OF trigger for all of the actions specified in the MERGE statement.
If any INSTEAD OF UPDATE or INSTEAD OF DELETE triggers are defined on target_table, the update or delete operations aren’t run. Instead, the triggers fire and the inserted and deleted tables then populate accordingly.
If any INSTEAD OF INSERT triggers are defined on target_table, the insert operation isn’t performed. Instead, the table populates accordingly.
[!NOTE]
Unlike separate INSERT, UPDATE, and DELETE statements, the number of rows reflected by @@ROWCOUNT inside of a trigger may be higher. The @@ROWCOUNT inside any AFTER trigger (regardless of data modification statements the trigger captures) will reflect the total number of rows affected by the MERGE. For example, if a MERGE statement inserts one row, updates one row, and deletes one row, @@ROWCOUNT will be three for any AFTER trigger, even if the trigger is only declared for INSERT statements.
Permissions
Requires SELECT permission on the source table and INSERT, UPDATE, or DELETE permissions on the target table. For more information, see the Permissions section in the SELECT, INSERT, UPDATE, and DELETE articles.
Index best practices
By using the MERGE statement, you can replace the individual DML statements with a single statement. This can improve query performance because the operations are performed within a single statement, therefore, minimizing the number of times the data in the source and target tables are processed. However, performance gains depend on having correct indexes, joins, and other considerations in place.
To improve the performance of the MERGE statement, we recommend the following index guidelines:
- Create indexes to facilitate the join between the source and target of the MERGE:
- Create an index on the join columns in the source table that has keys covering the join logic to the target table. If possible, it should be unique.
- Also, create an index on the join columns in the target table. If possible, it should be a unique clustered index.
- These two indexes ensure that the data in the tables is sorted, and uniqueness aids performance of the comparison. Query performance is improved because the query optimizer doesn’t need to perform extra validation processing to locate and update duplicate rows and additional sort operations aren’t necessary.
- Avoid tables with any form of columnstore index as the target of MERGE statements. As with any UPDATEs, you may find performance better with columnstore indexes by updating a staged rowstore table, then performing a batched DELETE and INSERT, instead of an UPDATE or MERGE.
Concurrency considerations for MERGE
In terms of locking, MERGE is different from discrete, consecutive INSERT, UPDATE, and DELETE statements. MERGE still executes INSERT, UPDATE, and DELETE operations, however using different locking mechanisms. It may be more efficient to write discrete INSERT, UPDATE, and DELETE statements for some application needs. At scale, MERGE may introduce complicated concurrency issues or require advanced troubleshooting. As such, plan to thoroughly test any MERGE statement before deploying to production.
MERGE statements are a suitable replacement for discrete INSERT, UPDATE, and DELETE operations in (but not limited to) the following scenarios:
- ETL operations involving large row counts be executed during a time when other concurrent operations aren’t* expected. When heavy concurrency is expected, separate INSERT, UPDATE, and DELETE logic may perform better, with less blocking, than a MERGE statement.
- Complex operations involving small row counts and transactions unlikely to execute for extended duration.
- Complex operations involving user tables where indexes can be designed to ensure optimal execution plans, avoiding table scans and lookups in favor of index scans or — ideally — index seeks.
Other considerations for concurrency:
- In some scenarios where unique keys are expected to be both inserted and updated by the MERGE, specifying the HOLDLOCK will prevent against unique key violations. HOLDLOCK is a synonym for the SERIALIZABLE transaction isolation level, which doesn’t allow for other concurrent transactions to modify data that this transaction has read. SERIALIZABLE is the safest isolation level but provides for the least concurrency with other transactions that retains locks on ranges of data to prevent phantom rows from being inserted or updated while reads are in progress. For more information on HOLDLOCK, see Hints and SET TRANSACTION ISOLATION LEVEL (Transact-SQL).
JOIN best practices
To improve the performance of the MERGE statement and ensure correct results are obtained, we recommend the following join guidelines:
- Specify only search conditions in the ON <merge_search_condition> clause that determine the criteria for matching data in the source and target tables. That is, specify only columns from the target table that are compared to the corresponding columns of the source table.
- Don’t include comparisons to other values such as a constant.
To filter out rows from the source or target tables, use one of the following methods.
- Specify the search condition for row filtering in the appropriate WHEN clause. For example,
WHEN NOT MATCHED AND S.EmployeeName LIKE 'S%' THEN INSERT.... - Define a view on the source or target that returns the filtered rows and reference the view as the source or target table. If the view is defined on the target table, any actions against it must satisfy the conditions for updating views. For more information about updating data by using a view, see Modifying Data Through a View.
- Use the
WITH <common table expression>clause to filter out rows from the source or target tables. This method is similar to specifying additional search criteria in the ON clause and may produce incorrect results. We recommend that you avoid using this method or test thoroughly before implementing it.
The join operation in the MERGE statement is optimized in the same way as a join in a SELECT statement. That is, when SQL Server processes join, the query optimizer chooses the most efficient method (out of several possibilities) of processing the join. When the source and target are of similar size and the index guidelines described previously are applied to the source and target tables, a merge join operator is the most efficient query plan. This is because both tables are scanned once and there’s no need to sort the data. When the source is smaller than the target table, a nested loops operator is preferable.
You can force the use of a specific join by specifying the OPTION (<query_hint>) clause in the MERGE statement. We recommend that you don’t use the hash join as a query hint for MERGE statements because this join type doesn’t use indexes.
Parameterization best practices
If a SELECT, INSERT, UPDATE, or DELETE statement is executed without parameters, the SQL Server query optimizer may choose to parameterize the statement internally. This means that any literal values that are contained in the query are substituted with parameters. For example, the statement INSERT dbo.MyTable (Col1, Col2) VALUES (1, 10), may be implemented internally as INSERT dbo.MyTable (Col1, Col2) VALUES (@p1, @p2). This process, called simple parameterization, increases the ability of the relational engine to match new SQL statements with existing, previously compiled execution plans. Query performance may be improved because the frequency of query compilations and recompilations are reduced. The query optimizer doesn’t apply the simple parameterization process to MERGE statements. Therefore, MERGE statements that contain literal values may not perform and individual INSERT, UPDATE, or DELETE statements because a new plan is compiled each time the MERGE statement is executed.
To improve query performance, we recommend the following parameterization guidelines:
- Parameterize all literal values in the
ON <merge_search_condition>clause and in theWHENclauses of the MERGE statement. For example, you can incorporate the MERGE statement into a stored procedure replacing the literal values with appropriate input parameters. - If you can’t parameterize the statement, create a plan guide of type
TEMPLATEand specify thePARAMETERIZATION FORCEDquery hint in the plan guide. For more information, see Specify Query Parameterization Behavior by Using Plan Guides. - If MERGE statements are executed frequently on the database, consider setting the PARAMETERIZATION option on the database to FORCED. Use caution when setting this option. The
PARAMETERIZATIONoption is a database-level setting and affects how all queries against the database are processed. For more information, see Forced Parameterization. - As a newer and easier alternative to plan guides, consider a similar strategy with Query Store hints. For more information, see Query Store hints.
TOP Clause best practices
In the MERGE statement, the TOP clause specifies the number or percentage of rows that are affected after the source table and the target table are joined, and after rows that don’t qualify for an insert, update, or delete action are removed. The TOP clause further reduces the number of joined rows to the specified value and the insert, update, or delete actions are applied to the remaining joined rows in an unordered fashion. That is, there’s no order in which the rows are distributed among the actions defined in the WHEN clauses. For example, specifying TOP (10) affects 10 rows; of these rows, 7 may be updated and 3 inserted, or 1 may be deleted, 5 updated, and 4 inserted and so on.
It’s common to use the TOP clause to perform data manipulation language (DML) operations on a large table in batches. When using the TOP clause in the MERGE statement for this purpose, it’s important to understand the following implications.
-
I/O performance may be affected.
The MERGE statement performs a full table scan of both the source and target tables. Dividing the operation into batches reduces the number of write operations performed per batch; however, each batch will perform a full table scan of the source and target tables. The resulting read activity may affect the performance of the query and other concurrent activity on the tables.
-
Incorrect results can occur.
It’s important to ensure that all successive batches target new rows or undesired behavior such as incorrectly inserting duplicate rows into the target table can occur. This can happen when the source table includes a row that wasn’t in a target batch but was in the overall target table. To ensure correct results:
- Use the ON clause to determine which source rows affect existing target rows and which are genuinely new.
- Use an additional condition in the WHEN MATCHED clause to determine if the target row has already been updated by a previous batch.
- Use an additional condition in the WHEN MATCHED clause and SET logic to verify the same row can’t be updated twice.
Because the TOP clause is only applied after these clauses are applied, each execution either inserts one genuinely unmatched row or updates one existing row.
Bulk Load best practices
The MERGE statement can be used to efficiently bulk load data from a source data file into a target table by specifying the OPENROWSET(BULK…) clause as the table source. By doing so, the entire file is processed in a single batch.
To improve the performance of the bulk merge process, we recommend the following guidelines:
-
Create a clustered index on the join columns in the target table.
-
Disable other non-unique, nonclustered indexes on the target table during the bulk load MERGE, enable them afterwards. This is common and useful for nightly bulk data operations.
-
Use the ORDER and UNIQUE hints in the
OPENROWSET(BULK…)clause to specify how the source data file is sorted.By default, the bulk operation assumes the data file is unordered. Therefore, it’s important that the source data is sorted according to the clustered index on the target table and that the ORDER hint is used to indicate the order so that the query optimizer can generate a more efficient query plan. Hints are validated at runtime; if the data stream doesn’t conform to the specified hints, an error is raised.
These guidelines ensure that the join keys are unique and the sort order of the data in the source file matches the target table. Query performance is improved because additional sort operations aren’t necessary and unnecessary data copies aren’t required.
Measuring and diagnosing MERGE performance
The following features are available to assist you in measuring and diagnosing the performance of MERGE statements.
- Use the merge stmt counter in the sys.dm_exec_query_optimizer_info dynamic management view to return the number of query optimizations that are for MERGE statements.
- Use the
merge_action_typeattribute in the sys.dm_exec_plan_attributes dynamic management view to return the type of trigger execution plan used as the result of a MERGE statement. - Use an Extended Events Session to gather troubleshooting data for the MERGE statement in the same way you would for other data manipulation language (DML) statements. For more information on Extended Events, see Quick Start: Extended events in SQL Server and SSMS XEvent Profiler.
Examples
A. Using MERGE to do INSERT and UPDATE operations on a table in a single statement
A common scenario is updating one or more columns in a table if a matching row exists. Or, inserting the data as a new row if a matching row doesn’t exist. You usually do either scenario by passing parameters to a stored procedure that contains the appropriate UPDATE and INSERT statements. With the MERGE statement, you can do both tasks in a single statement. The following example shows a stored procedure in the [!INCLUDEssSampleDBnormal] database that contains both an INSERT statement and an UPDATE statement. The procedure is then modified to run the equivalent operations by using a single MERGE statement.
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
CREATE PROCEDURE dbo.InsertUnitMeasure @UnitMeasureCode nchar(3), @Name nvarchar(25) AS BEGIN SET NOCOUNT ON; -- Update the row if it exists. UPDATE Production.UnitMeasure SET Name = @Name WHERE UnitMeasureCode = @UnitMeasureCode -- Insert the row if the UPDATE statement failed. IF (@@ROWCOUNT = 0 ) BEGIN INSERT INTO Production.UnitMeasure (UnitMeasureCode, Name) VALUES (@UnitMeasureCode, @Name) END END; GO -- Test the procedure and return the results. EXEC InsertUnitMeasure @UnitMeasureCode = 'ABC', @Name = 'Test Value'; SELECT UnitMeasureCode, Name FROM Production.UnitMeasure WHERE UnitMeasureCode = 'ABC'; GO -- Rewrite the procedure to perform the same operations using the -- MERGE statement. -- Create a temporary table to hold the updated or inserted values -- from the OUTPUT clause. CREATE TABLE #MyTempTable (ExistingCode nchar(3), ExistingName nvarchar(50), ExistingDate datetime, ActionTaken nvarchar(10), NewCode nchar(3), NewName nvarchar(50), NewDate datetime ); GO ALTER PROCEDURE dbo.InsertUnitMeasure @UnitMeasureCode nchar(3), @Name nvarchar(25) AS BEGIN SET NOCOUNT ON; MERGE Production.UnitMeasure AS tgt USING (SELECT @UnitMeasureCode, @Name) as src (UnitMeasureCode, Name) ON (tgt.UnitMeasureCode = src.UnitMeasureCode) WHEN MATCHED THEN UPDATE SET Name = src.Name WHEN NOT MATCHED THEN INSERT (UnitMeasureCode, Name) VALUES (src.UnitMeasureCode, src.Name) OUTPUT deleted.*, $action, inserted.* INTO #MyTempTable; END; GO -- Test the procedure and return the results. EXEC InsertUnitMeasure @UnitMeasureCode = 'ABC', @Name = 'New Test Value'; EXEC InsertUnitMeasure @UnitMeasureCode = 'XYZ', @Name = 'Test Value'; EXEC InsertUnitMeasure @UnitMeasureCode = 'ABC', @Name = 'Another Test Value'; SELECT * FROM #MyTempTable; -- Cleanup DELETE FROM Production.UnitMeasure WHERE UnitMeasureCode IN ('ABC','XYZ'); DROP TABLE #MyTempTable; GO
::: moniker-end
::: moniker range=»=azure-sqldw-latest»
CREATE PROCEDURE dbo.InsertUnitMeasure @UnitMeasureCode nchar(3), @Name nvarchar(25) AS BEGIN SET NOCOUNT ON; -- Update the row if it exists. UPDATE Production.UnitMeasure SET Name = @Name WHERE UnitMeasureCode = @UnitMeasureCode -- Insert the row if the UPDATE statement failed. IF (@@ROWCOUNT = 0 ) BEGIN INSERT INTO Production.UnitMeasure (UnitMeasureCode, Name) VALUES (@UnitMeasureCode, @Name) END END; GO -- Test the procedure and return the results. EXEC InsertUnitMeasure @UnitMeasureCode = 'ABC', @Name = 'Test Value'; SELECT UnitMeasureCode, Name FROM Production.UnitMeasure WHERE UnitMeasureCode = 'ABC'; GO -- Rewrite the procedure to perform the same operations using the -- MERGE statement. ALTER PROCEDURE dbo.InsertUnitMeasure @UnitMeasureCode nchar(3), @Name nvarchar(25) AS BEGIN SET NOCOUNT ON; MERGE Production.UnitMeasure AS tgt USING (SELECT @UnitMeasureCode, @Name) as src (UnitMeasureCode, Name) ON (tgt.UnitMeasureCode = src.UnitMeasureCode) WHEN MATCHED THEN UPDATE SET Name = src.Name WHEN NOT MATCHED THEN INSERT (UnitMeasureCode, Name) VALUES (src.UnitMeasureCode, src.Name); END; GO -- Test the procedure and return the results. EXEC InsertUnitMeasure @UnitMeasureCode = 'ABC', @Name = 'New Test Value'; EXEC InsertUnitMeasure @UnitMeasureCode = 'XYZ', @Name = 'Test Value'; EXEC InsertUnitMeasure @UnitMeasureCode = 'ABC', @Name = 'Another Test Value'; -- Cleanup DELETE FROM Production.UnitMeasure WHERE UnitMeasureCode IN ('ABC','XYZ'); GO
::: moniker-end
B. Using MERGE to do UPDATE and DELETE operations on a table in a single statement
The following example uses MERGE to update the ProductInventory table in the [!INCLUDEssSampleDBnormal] sample database, daily, based on orders that are processed in the SalesOrderDetail table. The Quantity column of the ProductInventory table is updated by subtracting the number of orders placed each day for each product in the SalesOrderDetail table. If the number of orders for a product drops the inventory level of a product to 0 or less, the row for that product is deleted from the ProductInventory table.
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
CREATE PROCEDURE Production.usp_UpdateInventory @OrderDate datetime AS MERGE Production.ProductInventory AS tgt USING (SELECT ProductID, SUM(OrderQty) FROM Sales.SalesOrderDetail AS sod JOIN Sales.SalesOrderHeader AS soh ON sod.SalesOrderID = soh.SalesOrderID AND soh.OrderDate = @OrderDate GROUP BY ProductID) as src (ProductID, OrderQty) ON (tgt.ProductID = src.ProductID) WHEN MATCHED AND tgt.Quantity - src.OrderQty <= 0 THEN DELETE WHEN MATCHED THEN UPDATE SET tgt.Quantity = tgt.Quantity - src.OrderQty, tgt.ModifiedDate = GETDATE() OUTPUT $action, Inserted.ProductID, Inserted.Quantity, Inserted.ModifiedDate, Deleted.ProductID, Deleted.Quantity, Deleted.ModifiedDate; GO EXECUTE Production.usp_UpdateInventory '20030501';
::: moniker-end
::: moniker range=»=azure-sqldw-latest»
CREATE PROCEDURE Production.usp_UpdateInventory @OrderDate datetime AS MERGE Production.ProductInventory AS tgt USING (SELECT ProductID, SUM(OrderQty) FROM Sales.SalesOrderDetail AS sod JOIN Sales.SalesOrderHeader AS soh ON sod.SalesOrderID = soh.SalesOrderID AND soh.OrderDate = @OrderDate GROUP BY ProductID) as src (ProductID, OrderQty) ON (tgt.ProductID = src.ProductID) WHEN MATCHED AND tgt.Quantity - src.OrderQty <= 0 THEN DELETE WHEN MATCHED THEN UPDATE SET tgt.Quantity = tgt.Quantity - src.OrderQty, tgt.ModifiedDate = GETDATE(); GO EXECUTE Production.usp_UpdateInventory '20030501';
::: moniker-end
C. Using MERGE to do UPDATE and INSERT operations on a target table by using a derived source table
The following example uses MERGE to modify the SalesReason table in the [!INCLUDEssSampleDBnormal] database by either updating or inserting rows.
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
When the value of NewName in the source table matches a value in the Name column of the target table, (SalesReason), the ReasonType column is updated in the target table. When the value of NewName doesn’t match, the source row is inserted into the target table. The source table is a derived table that uses the [!INCLUDEtsql] table value constructor to specify multiple rows for the source table. For more information about using the table value constructor in a derived table, see Table Value Constructor (Transact-SQL).
The OUTPUT clause can be useful to query the result of MERGE statements, for more information, see OUTPUT Clause. The example also shows how to store the results of the OUTPUT clause in a table variable. And, then you summarize the results of the MERGE statement by running a simple select operation that returns the count of inserted and updated rows.
-- Create a temporary table variable to hold the output actions. DECLARE @SummaryOfChanges TABLE(Change VARCHAR(20)); MERGE INTO Sales.SalesReason AS tgt USING (VALUES ('Recommendation','Other'), ('Review', 'Marketing'), ('Internet', 'Promotion')) as src (NewName, NewReasonType) ON tgt.Name = src.NewName WHEN MATCHED THEN UPDATE SET ReasonType = src.NewReasonType WHEN NOT MATCHED BY TARGET THEN INSERT (Name, ReasonType) VALUES (NewName, NewReasonType) OUTPUT $action INTO @SummaryOfChanges; -- Query the results of the table variable. SELECT Change, COUNT(*) AS CountPerChange FROM @SummaryOfChanges GROUP BY Change;
::: moniker-end
::: moniker range=»=azure-sqldw-latest»
When the value of NewName in the source table matches a value in the Name column of the target table, (SalesReason), the ReasonType column is updated in the target table. When the value of NewName doesn’t match, the source row is inserted into the target table. The source table is a derived table that uses SELECT ... UNION ALL to specify multiple rows for the source table.
MERGE INTO Sales.SalesReason AS tgt USING (SELECT 'Recommendation','Other' UNION ALL SELECT 'Review', 'Marketing' UNION ALL SELECT 'Internet', 'Promotion') as src (NewName, NewReasonType) ON tgt.Name = src.NewName WHEN MATCHED THEN UPDATE SET ReasonType = src.NewReasonType WHEN NOT MATCHED BY TARGET THEN INSERT (Name, ReasonType) VALUES (NewName, NewReasonType);
::: moniker-end
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
D. Inserting the results of the MERGE statement into another table
The following example captures data returned from the OUTPUT clause of a MERGE statement and inserts that data into another table. The MERGE statement updates the Quantity column of the ProductInventory table in the [!INCLUDEssSampleDBnormal] database, based on orders that are processed in the SalesOrderDetail table. The example captures the updated rows and inserts them into another table that’s used to track inventory changes.
CREATE TABLE Production.UpdatedInventory (ProductID INT NOT NULL, LocationID int, NewQty int, PreviousQty int, CONSTRAINT PK_Inventory PRIMARY KEY CLUSTERED (ProductID, LocationID)); GO INSERT INTO Production.UpdatedInventory SELECT ProductID, LocationID, NewQty, PreviousQty FROM ( MERGE Production.ProductInventory AS pi USING (SELECT ProductID, SUM(OrderQty) FROM Sales.SalesOrderDetail AS sod JOIN Sales.SalesOrderHeader AS soh ON sod.SalesOrderID = soh.SalesOrderID AND soh.OrderDate BETWEEN '20030701' AND '20030731' GROUP BY ProductID) AS src (ProductID, OrderQty) ON pi.ProductID = src.ProductID WHEN MATCHED AND pi.Quantity - src.OrderQty >= 0 THEN UPDATE SET pi.Quantity = pi.Quantity - src.OrderQty WHEN MATCHED AND pi.Quantity - src.OrderQty <= 0 THEN DELETE OUTPUT $action, Inserted.ProductID, Inserted.LocationID, Inserted.Quantity AS NewQty, Deleted.Quantity AS PreviousQty) AS Changes (Action, ProductID, LocationID, NewQty, PreviousQty) WHERE Action = 'UPDATE'; GO
E. Using MERGE to do INSERT or UPDATE on a target edge table in a graph database
In this example, you create node tables Person and City and an edge table livesIn. You use the MERGE statement on the livesIn edge and insert a new row if the edge doesn’t already exist between a Person and City. If the edge already exists, then you just update the StreetAddress attribute on the livesIn edge.
-- CREATE node and edge tables CREATE TABLE Person ( ID INTEGER PRIMARY KEY, PersonName VARCHAR(100) ) AS NODE GO CREATE TABLE City ( ID INTEGER PRIMARY KEY, CityName VARCHAR(100), StateName VARCHAR(100) ) AS NODE GO CREATE TABLE livesIn ( StreetAddress VARCHAR(100) ) AS EDGE GO -- INSERT some test data into node and edge tables INSERT INTO Person VALUES (1, 'Ron'), (2, 'David'), (3, 'Nancy') GO INSERT INTO City VALUES (1, 'Redmond', 'Washington'), (2, 'Seattle', 'Washington') GO INSERT livesIn SELECT P.$node_id, C.$node_id, c FROM Person P, City C, (values (1,1, '123 Avenue'), (2,2,'Main Street')) v(a,b,c) WHERE P.id = a AND C.id = b GO -- Use MERGE to update/insert edge data CREATE OR ALTER PROCEDURE mergeEdge @PersonId integer, @CityId integer, @StreetAddress varchar(100) AS BEGIN MERGE livesIn USING ((SELECT @PersonId, @CityId, @StreetAddress) AS T (PersonId, CityId, StreetAddress) JOIN Person ON T.PersonId = Person.ID JOIN City ON T.CityId = City.ID) ON MATCH (Person-(livesIn)->City) WHEN MATCHED THEN UPDATE SET StreetAddress = @StreetAddress WHEN NOT MATCHED THEN INSERT ($from_id, $to_id, StreetAddress) VALUES (Person.$node_id, City.$node_id, @StreetAddress) ; END GO -- Following will insert a new edge in the livesIn edge table EXEC mergeEdge 3, 2, '4444th Avenue' GO -- Following will update the StreetAddress on the edge that connects Ron to Redmond EXEC mergeEdge 1, 1, '321 Avenue' GO -- Verify that all the address were added/updated correctly SELECT PersonName, CityName, StreetAddress FROM Person , City , livesIn WHERE MATCH(Person-(livesIn)->city) GO
::: moniker-end
See also
::: moniker range=»= azuresqldb-current || = azuresqldb-mi-current || >= sql-server-2016 || >= sql-server-linux-2017″
- SELECT (Transact-SQL)
- INSERT (Transact-SQL)
- UPDATE (Transact-SQL)
- DELETE (Transact-SQL)
- OUTPUT Clause (Transact-SQL)
- MERGE in Integration Services Packages
- FROM (Transact-SQL)
- Table Value Constructor (Transact-SQL)
::: moniker-end
::: moniker range=»=azure-sqldw-latest»
- SELECT (Transact-SQL)
- INSERT (Transact-SQL)
- UPDATE (Transact-SQL)
- DELETE (Transact-SQL)
- MERGE in Integration Services Packages
- FROM (Transact-SQL)
- Table Value Constructor (Transact-SQL)
::: moniker-end
Предыдущие части
- Часть первая — habrahabr.ru/post/255361
- Часть вторая — habrahabr.ru/post/255523
- Часть третья — habrahabr.ru/post/255825
- Часть четвертая — habrahabr.ru/post/256045
В данной части мы рассмотрим
Здесь мы в общих чертах рассмотрим работу с операторами модификации данных:
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- SELECT … INTO … – сохранить результат запроса в новой таблице
- MERGE – слияние данных
- Использование конструкции OUTPUT
- TRUNCATE TABLE – DDL-операция для быстрой очистки таблицы
В самом конце вас ждут «Приложение 1 – бонус по оператору SELECT» и «Приложение 2 – OVER и аналитические функции», в которых будут показаны некоторые расширенные конструкции:
- PIVOT
- UNPIVOT
- GROUP BY ROLLUP
- GROUP BY GROUPING SETS
- использование приложения OVER
Операции модификации данных очень сильно связаны с конструкциями оператора SELECT, т.к. по сути выборка модифицируемых данных идет при помощи них. Поэтому для понимания данного материала, важное место имеет уверенное владение конструкциями оператора SELECT.
Данная часть, как я и говорил, будет больше обзорная. Здесь я буду описывать только те основные формы операторов модификации данных, которыми я сам регулярно пользуюсь. Поэтому на полноту изложения рассчитывать не стоит, здесь будут показан только необходимый минимум, который новички могут использовать как направление для более глубокого изучения. За более подробной информацией по каждому оператору обращайтесь в MSDN. Хотя кому-то возможно и в таком объеме информации будет вполне достаточно.
Т.к. прямая модификация информации в РБД требует от человека большой ответственности, а также потому что пользователи обычно модифицируют информацию БД посредством разных АРМ, и не имеют полного доступа к БД, то данная часть больше посвящается начинающим ИТ-специалистам, и я буду здесь очень краток. Но конечно, если вы смогли освоить оператор SELECT, то думаю, и операторы модификации вам будут под силу, т.к. после оператора SELECT здесь нет ничего сверхсложного, и по большей части должно восприниматься на интуитивном уровне. Но порой сложность представляют не сами операторы модификации, а то что они должны выполняться группами, в рамках одной транзакции, т.е. когда дополнительно нужно учитывать целостность данных. В любом случае можете почитать и попытаться проделать примеры в ознакомительных целях, к тому же в итоге вы сможете получить более детальную базу, на которой можно будет отработать те или иные конструкции оператора SELECT.
Проведем изменения в структуре нашей БД
Давайте проведем небольшое обновление структуры и данных таблицы Employees:
-- информацию по ЗП решено хранить до 2-х знаков после запятой
ALTER TABLE Employees ALTER COLUMN Salary numeric(20,2)
-- информацию по процентам решено хранить только в целых числах
ALTER TABLE Employees ALTER COLUMN BonusPercent tinyint
А также для демонстрационных целей расширим схему нашей БД, а за одно повторим DDL. Назначения таблиц и полей указаны в комментариях:
-- история изменений ЗП у сотрудников
CREATE TABLE EmployeesSalaryHistory(
EmployeeID int NOT NULL, -- ссылка на ID сотрудника
DateFrom date NOT NULL, -- с какой даты
DateTo date, -- по какую дату. Содержит NULL если это последняя установленная ЗП.
Salary numeric(20,2) NOT NULL, -- сумма ЗП за этот период
CONSTRAINT PK_EmployeesSalaryHistory PRIMARY KEY(EmployeeID,DateFrom),
CONSTRAINT FK_EmployeesSalaryHistory_EmployeeID FOREIGN KEY(EmployeeID) REFERENCES Employees(ID)
)
GO
-- таблица для хранения истории начислений по ЗП
CREATE TABLE EmployeesSalary(
EmployeeID int NOT NULL,
SalaryDate date NOT NULL, -- дата начисления
SalaryAmount numeric(20,2) NOT NULL, -- сумма начисления
Note nvarchar(50), -- примечание
-- здесь сумма ЗП может фиксироваться по человеку 1 раз в день
CONSTRAINT PK_EmployeesSalary PRIMARY KEY(EmployeeID,SalaryDate),
-- связь с таблицей Employees
CONSTRAINT FK_EmployeesSalary_EmployeeID FOREIGN KEY(EmployeeID) REFERENCES Employees(ID)
)
GO
-- справочник по типам бонусов
CREATE TABLE BonusTypes(
ID int IDENTITY(1,1) NOT NULL,
Name nvarchar(30) NOT NULL,
CONSTRAINT PK_BonusTypes PRIMARY KEY(ID)
)
GO
-- таблица для хранения истории начислений бонусов
CREATE TABLE EmployeesBonus(
EmployeeID int NOT NULL,
BonusDate date NOT NULL, -- дата начисления
BonusAmount numeric(20,2) NOT NULL, -- сумма начисления
BonusTypeID int NOT NULL,
BonusPercent tinyint,
Note nvarchar(50), -- примечание
-- бонус одного типа может фиксироваться по человеку 1 раз в день
CONSTRAINT PK_EmployeesBonus PRIMARY KEY(EmployeeID,BonusDate,BonusTypeID),
-- связь с таблицей Employees и BonusTypes
CONSTRAINT FK_EmployeesBonus_EmployeeID FOREIGN KEY(EmployeeID) REFERENCES Employees(ID),
CONSTRAINT FK_EmployeesBonus_BonusTypeID FOREIGN KEY(BonusTypeID) REFERENCES BonusTypes(ID)
)
GO
Вот такой полигон мы должны были получить в итоге:

Кстати, потом этот полигон (когда он будет наполнен данными) вы и можете использовать для того чтобы опробовать на нем разнообразные запросы – здесь можно опробовать и разнообразные JOIN-соединения, и UNION-объединения, и группировки с агрегированием данных.
INSERT – вставка новых данных
Данный оператор имеет 2 основные формы:
- INSERT INTO таблица(перечень_полей) VALUES(перечень_значений) – вставка в таблицу новой строки значения полей которой формируются из перечисленных значений
- INSERT INTO таблица(перечень_полей) SELECT перечень_значений FROM … – вставка в таблицу новых строк, значения которых формируются из значений строк возвращенных запросом.
В диалекте MS SQL слово INTO можно отпускать, что мне очень нравится и я этим всегда пользуюсь.
К тому же стоит отметить, что первая форма в диалекте MS SQL с версии 2008, позволяет вставить в таблицу сразу несколько строк:
INSERT таблица(перечень_полей) VALUES
(перечень_значений1),
(перечень_значений2),
…
(перечень_значенийN)
INSERT – форма 1. Переходим сразу к практике
Наполним таблицу EmployeesSalaryHistory предоставленными нам данными:
INSERT EmployeesSalaryHistory(EmployeeID,DateFrom,DateTo,Salary)
VALUES
-- Иванов И.И.
(1000,'20131101','20140531',4000),
(1000,'20140601','20141230',4500),
(1000,'20150101',NULL,5000),
-- Петров П.П.
(1001,'20131101','20140630',1300),
(1001,'20140701','20140930',1400),
(1001,'20141001',NULL,1500),
-- Сидоров С.С.
(1002,'20140101',NULL,2500),
-- Андреев А.А.
(1003,'20140601',NULL,2000),
-- Николаев Н.Н.
(1004,'20140701','20150131',1400),
(1004,'20150201','20150131',1500),
-- Александров А.А.
(1005,'20150101',NULL,2000)
Таким образом мы вставили в таблицу EmployeesSalaryHistory 11 новых записей.
SELECT *
FROM EmployeesSalaryHistory
| EmployeeID | DateFrom | DateTo | Salary |
|---|---|---|---|
| 1000 | 2013-11-01 | 2014-05-31 | 4000.00 |
| 1000 | 2014-06-01 | 2014-12-30 | 4500.00 |
| 1000 | 2015-01-01 | NULL | 5000.00 |
| 1001 | 2013-11-01 | 2014-06-30 | 1300.00 |
| 1001 | 2014-07-01 | 2014-09-30 | 1400.00 |
| 1001 | 2014-10-01 | NULL | 1500.00 |
| 1002 | 2014-01-01 | NULL | 2500.00 |
| 1003 | 2014-06-01 | NULL | 2000.00 |
| 1004 | 2014-07-01 | 2015-01-31 | 1400.00 |
| 1004 | 2015-02-01 | 2015-01-31 | 1500.00 |
| 1005 | 2015-01-01 | NULL | 2000.00 |
Хоть мы в этом случае могли и не указывать перечень полей, т.к. мы вставляем данные всех полей и в таком же виде, как они перечислены в таблице, т.е. мы могли бы написать:
INSERT EmployeesSalaryHistory
VALUES
-- Иванов И.И.
(1000,'20131101','20140531',4000),
(1000,'20140601','20141230',4500),
(1000,'20150101',NULL,5000),
…
Но я бы не рекомендовал использовать такой подход, особенно если данный запрос будет использоваться регулярно, например, вызываясь из какого-то АРМ. Опять же это чревато тем, что структура таблицы может изменяться, в нее могут быть добавлены новые поля, или же последовательность полей может быть изменена, что еще опасней, т.к. это может привести к появлению логических ошибок во вставленных данных. Поэтому лучше лишний раз не полениться и перечислить явно все поля, в которые вы хотите вставить значение.
Несколько заметок про INSERT:
- Порядок перечисления полей не имеет значения, вы можете написать и (EmployeeID,DateFrom,DateTo,Salary) и (DateFrom,DateTo, EmployeeID,Salary). Здесь важно только то, чтобы он совпадал с порядком значений, которые вы перечисляете в скобках после ключевого слова VALUES.
- Так же важно, чтобы при вставке были заданы значения для всех обязательных полей, которые помечены в таблице как NOT NULL.
- Можно не указывать поля у которых была указана опция IDENTITY или же поля у которых было задано значение по умолчанию при помощи DEFAULT, т.к. в качестве их значения подставится либо значение из счетчика, либо значение, указанное по умолчанию. Такие вставки мы уже делали в первой части.
- В случаях, когда значение поля со счетчиком нужно задать явно используйте опцию IDENTITY_INSERT.
В предыдущих частях мы периодически использовали опцию IDENTITY_INSERT. Давайте и здесь воспользуемся данной опцией для создания строк в таблице BonusTypes, у которой поле ID указано с опцией IDENTITY:
-- даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT BonusTypes ON
INSERT BonusTypes(ID,Name)VALUES
(1,N'Ежемесячный'),
(2,N'Годовой'),
(3,N'Индивидуальный')
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT BonusTypes OFF
Давайте вставим информацию по начислению сотрудникам ЗП, любезно предоставленную нам бухгалтером:
|
|
|
|
|
|
Думаю, приводить содержимое таблицы уже нет смысла.
INSERT – форма 2
Данная форма позволяет вставить в таблицу данные полученные запросом.
Для демонстрации наполним таблицу с начислениями бонусов одним большим запросом:
INSERT EmployeesBonus(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent)
-- расчет ежемесячных бонусов
SELECT hist.EmployeeID,bdate.BonusDate,hist.Salary/100*emp.BonusPercent,1 BonusTypeID,emp.BonusPercent
FROM EmployeesSalaryHistory hist
JOIN
(
VALUES -- весь период работы компании - последние дни месяцев
('20131130'),
('20131231'),
('20140131'),
('20140228'),
('20140331'),
('20140430'),
('20140531'),
('20140630'),
('20140731'),
('20140831'),
('20140930'),
('20141031'),
('20141130'),
('20141230'),
('20150131'),
('20150228'),
('20150331')
) bdate(BonusDate)
ON bdate.BonusDate BETWEEN hist.DateFrom AND ISNULL(hist.DateTo,'20991231')
JOIN Employees emp ON hist.EmployeeID=emp.ID
WHERE emp.BonusPercent IS NOT NULL AND emp.BonusPercent>0
AND NOT EXISTS( -- исключаем сотрудников, которым по какой-то причине не дали бонус в указанный период
SELECT *
FROM
(
VALUES
(1001,'20140115'),
(1001,'20140430'),
(1001,'20141031'),
(1001,'20141130'),
(1001,'20150228')
) exclude(EmployeeID,BonusDate)
WHERE exclude.EmployeeID=emp.ID
AND exclude.BonusDate=bdate.BonusDate
)
UNION ALL
-- годовой бонус за 2014 год - всем кто проработал больше полугода
SELECT
hist.EmployeeID,
'20141231' BonusDate,
hist.Salary/100*
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount,
2 BonusTypeID,
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusPercent
FROM EmployeesSalaryHistory hist
JOIN Employees emp ON hist.EmployeeID=emp.ID
WHERE CAST('20141231' AS date) BETWEEN hist.DateFrom AND ISNULL(hist.DateTo,'20991231')
AND emp.HireDate<='20140601'
UNION ALL
-- индивидуальные бонусы
SELECT EmployeeID,BonusDate,BonusAmount,3 BonusTypeID,NULL BonusPercent
FROM
(
VALUES
(1001,'20140930',300),
(1002,'20140331',500),
(1002,'20140630',500),
(1002,'20140930',500),
(1002,'20141230',500),
(1002,'20150331',500),
(1004,'20140831',200)
) indiv(EmployeeID,BonusDate,BonusAmount)
В таблицу EmployeesBonus должно было вставиться 50 записей.
Результат каждого запроса объединенных конструкциями UNION ALL вы можете проанализировать самостоятельно. Если вы хорошо изучили базовые конструкции, то вам должно быть все понятно, кроме возможно конструкции с VALUES (конструктор табличных значений), которая появилась с MS SQL 2008.
Пара слов про конструкцию VALUES
SELECT EmployeeID,BonusDate,BonusAmount,3 BonusTypeID,NULL BonusPercent
FROM
(
VALUES
(1001,'20140930',300),
(1002,'20140331',500),
(1002,'20140630',500),
(1002,'20140930',500),
(1002,'20141230',500),
(1002,'20150331',500),
(1004,'20140831',200)
) indiv(EmployeeID,BonusDate,BonusAmount)
В случае необходимости, данную конструкцию можно заменить, аналогичным запросом, написанным через UNION ALL:
SELECT 1001 EmployeeID,'20140930' BonusDate,300 BonusAmount,3 BonusTypeID,NULL BonusPercent
UNION ALL
SELECT 1002,'20140331',500,3,NULL
UNION ALL
SELECT 1002,'20140630',500,3,NULL
UNION ALL
SELECT 1002,'20140930',500,3,NULL
UNION ALL
SELECT 1002,'20141230',500,3,NULL
UNION ALL
SELECT 1002,'20150331',500,3,NULL
UNION ALL
SELECT 1004,'20140831',200,3,NULL
Думаю, комментарии излишни и вам не составит большого труда разобраться с этим самостоятельно.
Так что, идем дальше.
INSERT + CTE-выражения
Совместно с INSERT можно применять CTE выражения. Для примера перепишем тот же запрос перенеся все подзапросы в блок WITH.
Для начала полностью очистим таблицу EmployeesBonus при помощи операции TRUNCATE TABLE:
TRUNCATE TABLE EmployeesBonus
Теперь перепишем запрос вынеся запросы в блок WITH:
WITH cteBonusType1 AS(
-- расчет ежемесячных бонусов
SELECT hist.EmployeeID,bdate.BonusDate,hist.Salary/100*emp.BonusPercent BonusAmount,1 BonusTypeID,emp.BonusPercent
FROM EmployeesSalaryHistory hist
JOIN
(
VALUES -- весь период работы компании - последние дни месяцев
('20131130'),
('20131231'),
('20140131'),
('20140228'),
('20140331'),
('20140430'),
('20140531'),
('20140630'),
('20140731'),
('20140831'),
('20140930'),
('20141031'),
('20141130'),
('20141230'),
('20150131'),
('20150228'),
('20150331')
) bdate(BonusDate)
ON bdate.BonusDate BETWEEN hist.DateFrom AND ISNULL(hist.DateTo,'20991231')
JOIN Employees emp ON hist.EmployeeID=emp.ID
WHERE emp.BonusPercent IS NOT NULL AND emp.BonusPercent>0
AND NOT EXISTS( -- исключаем сотрудников, которым по какой-то причине не дали бонус в указанный период
SELECT *
FROM
(
VALUES
(1001,'20140115'),
(1001,'20140430'),
(1001,'20141031'),
(1001,'20141130'),
(1001,'20150228')
) exclude(EmployeeID,BonusDate)
WHERE exclude.EmployeeID=emp.ID
AND exclude.BonusDate=bdate.BonusDate
)
),
cteBonusType2 AS(
-- годовой бонус за 2014 год - всем кто проработал больше полугода
SELECT
hist.EmployeeID,
'20141231' BonusDate,
hist.Salary/100*
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount,
2 BonusTypeID,
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusPercent
FROM EmployeesSalaryHistory hist
JOIN Employees emp ON hist.EmployeeID=emp.ID
WHERE CAST('20141231' AS date) BETWEEN hist.DateFrom AND ISNULL(hist.DateTo,'20991231')
AND emp.HireDate<='20140601'
),
cteBonusType3 AS(
-- индивидуальные бонусы
SELECT EmployeeID,BonusDate,BonusAmount,3 BonusTypeID,NULL BonusPercent
FROM
(
VALUES
(1001,'20140930',300),
(1002,'20140331',500),
(1002,'20140630',500),
(1002,'20140930',500),
(1002,'20141230',500),
(1002,'20150331',500),
(1004,'20140831',200)
) indiv(EmployeeID,BonusDate,BonusAmount)
)
INSERT EmployeesBonus(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent)
SELECT *
FROM cteBonusType1
UNION ALL
SELECT *
FROM cteBonusType2
UNION ALL
SELECT *
FROM cteBonusType3
Как видим вынос больших подзапросов в блок WITH упростил основной запрос – сделал его более понятным.
UPDATE – обновление данных
Данный оператор в MS SQL имеет 2 формы:
- UPDATE таблица SET … WHERE условие_выборки – обновлении строк таблицы, для которых выполняется условие_выборки. Если предложение WHERE не указано, то будут обновлены все строки. Это можно сказать классическая форма оператора UPDATE.
- UPDATE псевдоним SET … FROM … – обновление данных таблицы участвующей в предложении FROM, которая задана указанным псевдонимом. Конечно, здесь можно и не использовать псевдонимов, используя вместо них имена таблиц, но с псевдонимом на мой взгляд удобнее.
Давайте при помощи первой формы приведем даты приема каждого сотрудника в порядок. Выполним 6 отдельных операций UPDATE:
-- приведем даты приема в порядок
UPDATE Employees SET HireDate='20131101' WHERE ID=1000
UPDATE Employees SET HireDate='20131101' WHERE ID=1001
UPDATE Employees SET HireDate='20140101' WHERE ID=1002
UPDATE Employees SET HireDate='20140601' WHERE ID=1003
UPDATE Employees SET HireDate='20140701' WHERE ID=1004
-- а здесь еще почистим поле FirstName
UPDATE Employees SET HireDate='20150101',FirstName=NULL WHERE ID=1005
Вторую форму, где применялся псевдоним, мы уже тоже успели использовать в первой части, когда обновляли поля PositionID и DepartmentID, на значения возвращаемые подзапросами:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Сейчас конечно данный и следующий запрос не сработают, т.к. поля Position и Department мы удалили из таблицы Employees. Вот так можно было бы представить этот запрос при помощи операций соединений:
UPDATE e
SET
PositionID=p.ID,
DepartmentID=d.ID
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
Надеюсь суть обновления здесь понятна, тут обновляться будут строки таблицы Employees.
Сначала вы можете сделать выборку, чтобы посмотреть какие данные будут обновлены и на какие значения:
SELECT
e.ID,
e.PositionID,e.DepartmentID, -- старые значения
e.Position,e.Department,
p.ID,d.ID, -- новые значения
p.Name,d.Name
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
А потом переписать это в UPDATE:
UPDATE e
SET
PositionID=p.ID,
DepartmentID=d.ID
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
Эх, не могу я так, все-таки давайте посмотрим, как это работает наглядно.
Для этого опять вспомним DDL и временно создадим поля Position и Department в таблице Employees:
ALTER TABLE Employees ADD Position nvarchar(30),Department nvarchar(30)
Зальем в них данные, предварительно посмотрев при помощи SELECT, что получится:
SELECT
e.ID,
e.Position,
p.Name NewPosition,
e.Department,
d.Name NewDepartment
FROM Employees e
LEFT JOIN Positions p ON p.ID=e.PositionID
LEFT JOIN Departments d ON d.ID=e.DepartmentID
Теперь перепишем и выполним обновление:
UPDATE e
SET
e.Position=p.Name,
e.Department=d.Name
FROM Employees e
LEFT JOIN Positions p ON p.ID=e.PositionID
LEFT JOIN Departments d ON d.ID=e.DepartmentID
Посмотрите, что получилось (должны были появиться значения в 2-х полях – Position и Department, находящиеся в конце таблицы):
SELECT *
FROM Employees
Теперь и этот запрос:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
И этот:
UPDATE e
SET
PositionID=p.ID,
DepartmentID=d.ID
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
Отработают успешно.
Не забудьте только предварительно посмотреть (это очень полезная привычка):
SELECT
e.ID,
e.PositionID,e.DepartmentID, -- старые значения
e.Position,e.Department,
p.ID,d.ID, -- новые значения
p.Name,d.Name
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
И конечно же можете использовать здесь условие WHERE:
UPDATE e
SET
PositionID=p.ID,
DepartmentID=d.ID
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
WHERE d.ID=3 -- обновить только данные по ИТ-отделу
Все, убедились, что все работает. Если хотите, то можете снова удалить поля Position и Department.
Вторую форму можно так же использовать с подзапросом:
UPDATE e
SET
HireDate='20131101',
MiddleName=N'Иванович'
FROM (SELECT MiddleName,HireDate FROM Employees WHERE ID=1000) e
В данном случае подзапрос должен возвращать в явном виде строки таблицы Employees, которые будут обновлены. В подзапросе нельзя использовать группировки или предложения DISTINCT, т.к. в этом случае мы не получим явных строк таблицы Employees. И соответственно все обновляемые поля должны содержаться в предложении SELECT, если конечно вы не указали «SELECT *».
Так же с UPDATE вы можете использовать CTE-выражения. Для примера перенесем наш подзапрос в блок WITH:
WITH cteEmp AS(
SELECT MiddleName,HireDate FROM Employees WHERE ID=1000
)
UPDATE cteEmp
SET
HireDate='20131101',
MiddleName=N'Иванович'
Идем дальше.
DELETE – удаление данных
Принцип работы DELETE похож на принцип работы UPDATE, и так же в MS SQL можно использовать 2 формы:
- DELETE таблица WHERE условие_выборки – удаление строк таблицы, для которых выполняется условие_выборки. Если предложение WHERE не указано, то будут удалены все строки. Это можно сказать классическая форма оператора DELETE (только в некоторых СУБД нужно писать DELETE FROM таблица WHERE условие_выборки).
- DELETE псевдоним FROM … – удаление данных таблицы участвующей в предложения FROM, которая задана указанным псевдонимом. Конечно, здесь можно и не использовать псевдонимов, используя вместо них имена таблиц, но с псевдонимом на мой взгляд удобнее.
Для примера при помощи первого варианта:
-- удалим неиспользуемые должности Логист и Кладовщик
DELETE Positions WHERE ID IN(6,7)
При помощи второго варианта удалим остальные неиспользуемые должности. В целях демонстрации запрос намеренно излишне усложнен. Сначала посмотрим, что именно удалиться (всегда старайтесь делать проверку, а то ненароком можно удалить лишнее, а то и всю информацию из таблицы):
SELECT pos.*
FROM
(
SELECT DISTINCT PositionID
FROM Employees
) emp
RIGHT JOIN Positions pos ON pos.ID=emp.PositionID
WHERE emp.PositionID IS NULL -- нет среди должностей указанных в Employees
Убедились, что все нормально. Переписываем запрос на DELETE:
DELETE pos -- удалить из этой таблицы
FROM
(
SELECT DISTINCT PositionID
FROM Employees
) emp
RIGHT JOIN Positions pos ON pos.ID=emp.PositionID
WHERE emp.PositionID IS NULL -- нет среди должностей указанных в Employees
В качестве таблицы Positions может выступать и подзапрос, главное, чтобы он однозначно возвращал строки, которые будут удаляться. Давайте добавим для демонстрации в таблицу Positions мусора:
INSERT Positions(Name) VALUES('Test 1'),('Test 2')
Теперь для демонстрации используем вместо таблицы Positions, подзапрос, в котором отбираются только определенные строки из таблицы Positions:
DELETE pos -- удалить из этой таблицы
FROM
(
SELECT DISTINCT PositionID
FROM Employees
) emp
RIGHT JOIN
(
SELECT ID
FROM Positions
WHERE ID>4 -- отбираем должности по условию
) pos
ON pos.ID=emp.PositionID
WHERE emp.PositionID IS NULL -- нет среди должностей указанных в Employees
Так же мы можем использовать CTE выражения (подзапросы, оформленные в блоке WITH). Давайте снова добавим для демонстрации в таблицу Positions мусора:
INSERT Positions(Name) VALUES('Test 1'),('Test 2')
И посмотрим на тот же запрос с CTE-выражением:
WITH ctePositionc AS(
SELECT ID
FROM Positions
WHERE ID>4 -- отбираем должности по условию
)
DELETE pos -- удалить из этой таблицы
FROM
(
SELECT DISTINCT PositionID
FROM Employees
) emp
RIGHT JOIN ctePositionc pos ON pos.ID=emp.PositionID
WHERE emp.PositionID IS NULL -- нет среди должностей указанных в Employees
Заключение по INSERT, UPDATE и DELETE
Вот по сути и все, что я хотел рассказать вам про основные операторы модификации данных – INSERT, UPDATE и DELETE.
Я считаю, что данные операторы очень легко понять интуитивно, когда умеешь пользоваться конструкциями оператора SELECT. Поэтому рассказ о операторе SELECT растянулся на 3 части, а рассказ о операторах модификации был написан в такой беглой форме.
И как вы увидели, с операторами модификации тоже полет фантазии не ограничен. Но все же старайтесь писать, как можно проще и понятней, обязательно предварительно проверяя, какие записи будут обработаны при помощи SELECT, т.к. обычно модификация данных, это очень большая ответственность.
В дополнение скажу, что в диалекте MS SQL cо всеми операциями модификации можно использовать предложение TOP (INSERT TOP …, UPDATE TOP …, DELETE TOP …), но мне пока ни разу не приходилось прибегать к такой форме, т.к. здесь непонятно какие именно TOP записей будут обработаны.
Если уж нужно обработать TOP записей, то я, наверное, лучше воспользуюсь указанием опции TOP в подзапросе и применю в нем нужным мне образом ORDER BY, чтобы явно знать какие именно TOP записей будут обработаны. Для примера снова добавим мусора:
INSERT Positions(Name) VALUES('Test 1'),('Test 2')
И удалим 2 последние записи:
DELETE emp
FROM
(
SELECT TOP 2 * -- 2. берем только 2 верхние записи
FROM Positions
ORDER BY ID DESC -- 1. сортируем по убыванию
) emp
Я здесь привожу примеры больше в целях демонстрации возможностей языка SQL. В реальных запросах старайтесь выражать свои намерения очень точно, дабы выполнение вашего запроса не привело к порче данных. Еще раз скажу – будьте очень внимательны, и не ленитесь делать предварительные проверки.
SELECT … INTO … – сохранить результат запроса в новой таблице
Данная конструкция позволяет сохранить результат выборки в новой таблице. Она представляет из себя что-то промежуточное между DDL и DML.
Типы колонок созданной таблицы будут определены на основании типов колонок набора, полученного запросом SELECT. Если в выборке присутствуют результаты выражений, то им должны быть заданы псевдонимы, которые будут служить в роли имен колонок.
Давайте отберем следующие данные и сохраним их в таблице EmployeesBonusTarget (перед FROM просто пишем INTO и указываем имя новой таблицы):
SELECT
bonus.EmployeeID,
bonus.BonusDate,
bonus.BonusAmount-bonus.BonusAmount BonusAmount, -- обнулим значения
bonus.BonusTypeID,
bonus.BonusPercent,
bonus.Note
INTO EmployeesBonusTarget -- сохраним результат в новой таблице EmployeesBonusTarget
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
WHERE emp.DepartmentID=3
Можете обновить список таблиц в инспекторе объектов и увидеть новую таблицу EmployeesBonusTarget:

На самом деле я специально создал таблицу EmployeesBonusTarget, я ее буду использовать для демонстрации оператора MERGE.
Еще пара слов про конструкцию SELECT … INTO …
Данную конструкцию иногда удобно применять при формировании очень сложных отчетов, которые требуют выборки из множества таблиц. В этом случае данные обычно сохраняют во временных таблицах (#). Т.е. предварительно при помощи запросов, мы сбрасываем данные во временные таблицы, а затем используем эти временные таблицы в других запросах, которые формируют окончательный результат:
SELECT
ID,
CONCAT(LastName,' ',FirstName,' ',MiddleName) FullName, -- используем псевдоним FullName
Salary,
BonusPercent,
Salary/100*ISNULL(BonusPercent,0) Bonus -- используем псевдоним Bonus
INTO #EmployeesBonus -- сохранить результат во временной таблице
FROM Employees
SELECT …
FROM #EmployeesBonus b
JOIN …
Иногда данную конструкцию удобно использовать, чтобы сделать полную копию всех данных текущей таблицы:
SELECT *
INTO EmployeesBackup
FROM Employees
Это можно использовать, например, для подстраховки, перед тем как вносить серьезные изменения в структуру таблицы Employees. Вы можете сохранить копию либо всех данных таблицы, либо только тех данных, которых коснется модификация. Т.е. если что-то пойдет не так, вы сможете восстановить данные таблицы Employees с этой копии. В таких случаях конечно хорошо сделать предварительный бэкап БД на текущий момент, но это бывает не всегда возможно из-за огромных объемов, срочности и т.п.
Чтобы не засорять основную базу, можно создать новую БД и сделать копию таблицы туда:
CREATE DATABASE TestTemp
GO
SELECT *
INTO TestTemp.dbo.EmployeesBackup -- используем префикс ИмяБаза.Схема.
FROM Employees
Для того чтобы увидеть новую БД TestTemp, соответственно, обновите в инспекторе объектов список баз данных, в ней и уже можете найти данную таблицу.
На заметку.
В БД Oracle так же есть конструкция для сохранения результата запроса в новую таблицу, выглядит она следующим образом:CREATE TABLE EMPLOYEES_BACK -- сохранить результат в новой таблице с именем EMPLOYEES_BACK AS SELECT * FROM EMPLOYEES
MERGE – слияние данных
Данный оператор хорошо подходит для синхронизации данных 2-х таблиц. Такая задача может понадобится при интеграции разных систем, когда данные передаются порциями из одной системы в другую.
В нашем случае, допустим, что стоит задача синхронизации таблицы EmployeesBonusTarget с таблицей EmployeesBonus.
Давайте добавим в таблицу EmployeesBonusTarget какого-нибудь мусора:
INSERT EmployeesBonusTarget(EmployeeID,BonusDate,BonusAmount,BonusTypeID,Note)VALUES
(9999,'20150101',9999.99,0,N'это мусор'),
(9999,'20150201',9999.99,0,N'это мусор'),
(9999,'20150301',9999.99,0,N'это мусор'),
(9999,'20150401',9999.99,0,N'это мусор'),
(9999,'20150501',9999.99,0,N'это мусор'),
(9999,'20150601',9999.99,0,N'это мусор')
Теперь при помощи оператора MERGE добьемся того, чтобы данные в таблице EmployeesBonusTarget стали такими же, как и в EmployeesBonus, т.е. сделаем синхронизацию данных.
Синхронизацию мы будем осуществлять на основании сопоставления данных входящих в первичный ключ таблицы EmployeesBonus (EmployeeID, BonusDate, BonusTypeID):
- Если для строки таблицы EmployeesBonusTarget соответствия по ключу не нашлось, то нужно сделать удаление таких строк из EmployeesBonusTarget
- Если соответствие нашлось, то нужно обновить строки EmployeesBonusTarget данными соответствующей строки из EmployeesBonus
- Если строка есть в EmployeesBonus, но ее нет в EmployeesBonusTarget, то ее нужно добавить в EmployeesBonusTarget
Сделаем реализацию всей этой логики при помощи инструкции MERGE:
MERGE EmployeesBonusTarget trg -- таблица приемник
USING EmployeesBonus src -- таблица источник
ON trg.EmployeeID=src.EmployeeID AND trg.BonusDate=src.BonusDate AND trg.BonusTypeID=src.BonusTypeID -- условие слияния
-- 1. Строка есть в trg но нет сопоставления со строкой из src
WHEN NOT MATCHED BY SOURCE THEN
DELETE
-- 2. Есть сопоставление строки trg со строкой из источника src
WHEN MATCHED THEN
UPDATE SET
trg.BonusAmount=src.BonusAmount,
trg.BonusPercent=src.BonusPercent,
trg.Note=src.Note
-- 3. Строка не найдена в trg, но есть в src
WHEN NOT MATCHED BY TARGET THEN -- предложение BY TARGET можно отпускать, т.е. NOT MATCHED = NOT MATCHED BY TARGET
INSERT(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent,Note)
VALUES(src.EmployeeID,src.BonusDate,src.BonusAmount,src.BonusTypeID,src.BonusPercent,src.Note);
Данная конструкция должна оканчиваться «;».
После выполнения запроса сравните 2 таблицы, их данные должны быть одинаковыми.
Конструкция MERGE чем-то напоминает условный оператор CASE, она так же содержит блоки WHEN, при выполнении условий которых происходит то или иное действие, в данном случае удаление (DELETE), обновление (UPDATE) или добавление (INSERT). Модификация данных производится в таблице приемнике.
В качестве источника может выступать запрос. Например, синхронизируем только данные по отделу 3 и для примера исключаем блок «NOT MATCHED BY SOURCE», чтобы данные не удались в случае не совпадения:
MERGE EmployeesBonusTarget trg -- таблица приемник
USING
(
SELECT bonus.*
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
WHERE emp.DepartmentID=3
) src -- источник
ON trg.EmployeeID=src.EmployeeID AND trg.BonusDate=src.BonusDate AND trg.BonusTypeID=src.BonusTypeID -- условие слияния
-- 2. Есть сопоставление строки trg со строкой из источника src
WHEN MATCHED THEN
UPDATE SET
trg.BonusAmount=src.BonusAmount,
trg.BonusPercent=src.BonusPercent,
trg.Note=src.Note
-- 3. Строка не найдена в trg, но есть в src
WHEN NOT MATCHED BY TARGET THEN -- предложение BY TARGET можно отпускать, т.е. NOT MATCHED = NOT MATCHED BY TARGET
INSERT(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent,Note)
VALUES(src.EmployeeID,src.BonusDate,src.BonusAmount,src.BonusTypeID,src.BonusPercent,src.Note);
Я показал работу конструкции MERGE в самом общем ее виде. При помощи нее можно реализовывать более разнообразные схемы для слияния данных, например, можно включать в блоки WHEN дополнительные условия (WHEN MATCHED AND … THEN). Это очень мощная конструкция, позволяющая в подходящих случаях сократить объем кода и совместить в рамках одного оператора функционал всех трех операторов – INSERT, UPDATE и DELETE.
И естественно с конструкцией MERGE так же можно применять CTE-выражения:
WITH cteBonus AS(
SELECT bonus.*
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
WHERE emp.DepartmentID=3
)
MERGE EmployeesBonusTarget trg -- таблица приемник
USING cteBonus src -- источник
ON trg.EmployeeID=src.EmployeeID AND trg.BonusDate=src.BonusDate AND trg.BonusTypeID=src.BonusTypeID -- условие слияния
-- 2. Есть сопоставление строки trg со строкой из источника src
WHEN MATCHED THEN
UPDATE SET
trg.BonusAmount=src.BonusAmount,
trg.BonusPercent=src.BonusPercent,
trg.Note=src.Note
-- 3. Строка не найдена в trg, но есть в src
WHEN NOT MATCHED BY TARGET THEN -- предложение BY TARGET можно отпускать, т.е. NOT MATCHED = NOT MATCHED BY TARGET
INSERT(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent,Note)
VALUES(src.EmployeeID,src.BonusDate,src.BonusAmount,src.BonusTypeID,src.BonusPercent,src.Note);
В общем, я постарался вам задать направление, более подробнее, в случае необходимости, изучайте уже самостоятельно.
Использование конструкции OUTPUT
Конструкция OUTPUT дает возможность получить информацию по строкам, которые были добавлены, удалены или изменены в результате выполнения DML команд INSERT, DELETE, UPDATE и MERGE. Данная конструкция, представляет расширение для операций модификации данных и в каждой СУБД может быть реализовано по-своему, либо вообще отсутствовать.
Конструкция OUTPUT имеет 2 основные формы:
- OUTPUT перечень_выражений – используется для возврата результата в виде набора
- OUTPUT перечень_выражений INTO принимающая_таблица(список_полей) – используется для вставки результата в указанную таблицу
Рассмотрим первую форму
Добавим в таблицу Positions новые записи:
INSERT Positions(Name)
OUTPUT inserted.*
VALUES
(N'Test 1'),
(N'Test 2'),
(N'Test 3')
После выполнения данной операции, записи будут вставлены в таблицу Positions и в добавок мы увидим информацию по добавленным строкам на экране.
Ключевое слово «inserted» дает нам доступ к значениям добавленных строк. В данном случае использование «inserted.*» вернет нам информацию по всем полям, которые есть в таблице Positions (ID и Name).
Так же после OUTPUT вы можете явно указать возвращаемый на экран перечень полей посредством «inserted.имя_поля», также вы можете использовать разные выражения:
INSERT Positions(Name)
OUTPUT inserted.ID,inserted.Name,'I'
VALUES
(N'Test 4'),
(N'Test 5'),
(N'Test 6')
При использовании DML команды DELETE, доступ к значениям измененных строк получается при помощи ключевого слова «deleted»:
DELETE Positions
OUTPUT deleted.ID,deleted.Name,'D'
WHERE Name LIKE N'Test%'
При использовании DML команды UPDATE, мы можем использовать ключевое слово:
- deleted – для того, чтобы получить доступ к значениям строки, которые были до обновления (старые значения)
- inserted – для того, чтобы получить новые значения строки
Продемонстрируем на таблице Employees:
UPDATE Employees
SET
LastName=N'Александров',
FirstName=N'Александр'
OUTPUT
deleted.ID,
deleted.LastName [Старая Фамилия],
deleted.FirstName [Старое Имя],
inserted.ID,
inserted.LastName [Новая Фамилия],
inserted.FirstName [Новое Имя]
WHERE ID=1005
| ID | Старая Фамилия | Старое Имя | ID | Новая Фамилия | Новое Имя |
|---|---|---|---|---|---|
| 1005 | NULL | NULL | 1005 | Александров | Александр |
В случае MERGE мы можем так же использовать «inserted» и «deleted» для доступа к значениям обработанных строк.
Давайте для примера создадим таблицу PositionsTarget, на которой после будет показан пример с MERGE:
SELECT
CAST(ID AS int) ID, -- чтобы поле создалось без опции IDENTITY
Name+'-old' Name -- изменим название
INTO PositionsTarget
FROM Positions
WHERE ID=2 -- вставим только одну должность
Добавим в PositionsTarget мусора:
INSERT PositionsTarget(ID,Name)VALUES
(100,N'Qwert'),
(101,N'Asdf')
Выполним команду MERGE с конструкцией OUTPUT:
MERGE PositionsTarget trg -- таблица приемник
USING Positions src -- таблица источник
ON trg.ID=src.ID -- условие слияния
-- 1. Строка есть в trg но нет сопоставления со строкой из src
WHEN NOT MATCHED BY SOURCE THEN
DELETE
-- 2. Есть сопоставление строки trg со строкой из источника src
WHEN MATCHED THEN
UPDATE SET
trg.Name=src.Name
-- 3. Строка не найдена в trg, но есть в src
WHEN NOT MATCHED BY TARGET THEN -- предложение BY TARGET можно отпускать, т.е. NOT MATCHED = NOT MATCHED BY TARGET
INSERT(ID,Name)
VALUES(src.ID,src.Name)
OUTPUT
deleted.ID Old_ID,
deleted.Name Old_Name,
inserted.ID New_ID,
inserted.Name New_Name,
CASE
WHEN deleted.ID IS NOT NULL AND inserted.ID IS NOT NULL THEN 'U'
WHEN deleted.ID IS NOT NULL THEN 'D'
WHEN inserted.ID IS NOT NULL THEN 'I'
END OperType;
| Old_ID | Old_Name | New_ID | New_Name | OperType |
|---|---|---|---|---|
| NULL | NULL | 1 | Бухгалтер | I |
| 2 | Директор-old | 2 | Директор | U |
| NULL | NULL | 3 | Программист | I |
| NULL | NULL | 4 | Старший программист | I |
| 100 | Qwert | NULL | NULL | D |
| 101 | Asdf | NULL | NULL | D |
Думаю, назначение первой формы понятно – сделать модификацию и получить результат в виде набора, который можно вернуть пользователю.
Рассмотрим вторую форму
У конструкции OUTPUT, есть и более важное предназначение – она позволяет не только получить, но и зафиксировать (OUTPUT … INTO …) информацию о том, что уже произошло по факту, то есть после выполнения операции модификации. Она может оказаться полезна в случае логированния произошедших действий. В некоторых случаях, ее можно использовать как хорошую альтернативу тригерам (для прозрачности действий).
Давайте создадим демонстрационную таблицу, для логирования изменений по таблице Positions:
CREATE TABLE PositionsLog(
LogID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_PositionsLog PRIMARY KEY,
ID int,
Old_Name nvarchar(30),
New_Name nvarchar(30),
LogType char(1) NOT NULL,
LogDateTime datetime NOT NULL DEFAULT SYSDATETIME()
)
А теперь сделаем при помощи конструкции (OUTPUT … INTO …) запись в эту таблицу:
-- добавление
INSERT Positions(Name)
OUTPUT inserted.ID,inserted.Name,'I' INTO PositionsLog(ID,New_Name,LogType)
VALUES
(N'Test 1'),
(N'Test 2')
-- обновление
UPDATE Positions
SET
Name+=' - new' -- обратите внимание на синтаксис "+=", аналогично Name=Name+' - new'
OUTPUT
deleted.ID,
deleted.Name,
inserted.Name,
'U'
INTO PositionsLog(ID,Old_Name,New_Name,LogType)
WHERE Name LIKE N'Test%'
-- удаление
DELETE Positions
OUTPUT deleted.ID,deleted.Name,'D' INTO PositionsLog(ID,Old_Name,LogType)
WHERE Name LIKE N'Test%'
Посмотрите, что получилось:
SELECT * FROM PositionsLog
TRUNCATE TABLE – DDL-операция для быстрой очистки таблицы
Данный оператор является DDL-операцией и служит для быстрой очистки таблицы – удаляет все строки из нее. За более детальными подробностями обращайтесь в MSDN.
Некоторые вырезки из MSDN. TRUNCATE TABLE – удаляет все строки в таблице, не записывая в журнал удаление отдельных строк. Инструкция TRUNCATE TABLE похожа на инструкцию DELETE без предложения WHERE, однако TRUNCATE TABLE выполняется быстрее и требует меньших ресурсов системы и журналов транзакций.
Если таблица содержит столбец идентификаторов (столбец с опцией IDENTITY), счетчик этого столбца сбрасывается до начального значения, определенного для этого столбца. Если начальное значение не задано, используется значение по умолчанию, равное 1. Чтобы сохранить столбец идентификаторов, используйте инструкцию DELETE.
Инструкцию TRUNCATE TABLE нельзя использовать если на таблицу ссылается ограничение FOREIGN KEY. Таблицу, имеющую внешний ключ, ссылающийся сам на себя, можно усечь.
Пример:
TRUNCATE TABLE EmployeesBonusTarget
Заключение по операциям модификации данных
Здесь я наверно повторю, все что писал ранее.
Старайтесь в первую очередь написать запрос на модификацию как можно проще, в первую очередь попытайтесь выразить свое намерение при помощи базовых конструкций и в последнюю очередь прибегайте к использованию подзапросов.
Прежде чем запустить запрос на модификацию данных по условию, убедитесь, что он выбирает именно необходимые записи, а не больше и не меньше. Для этой цели воспользуйтесь операцией SELECT.
Не забывайте перед очень серьезными изменениями делать резервные копии, хотя бы той информации, которая будет подвергнута модификации, это можно сделать при помощи SELECT … INTO …
Помните, что модификация данных это очень серьезно.
Приложение 1 – бонус по оператору SELECT
Подумав, я решил дописать этот раздел для тех, кто дошел до конца.
В данном разделе я дам примеры с использованием некоторых расширенных конструкций:
- PIVOT
- UNPIVOT
- GROUP BY ROLLUP
- GROUP BY GROUPING SETS
Попробуйте разобрать каждый из следующих примеров самостоятельно, анализируя результаты выполнения запросов. Обращайте внимание на комментарии, которые я указал в текстах запросов, некоторые важные вещи указаны в них.
Получение сводных отчетов при помощи GROUP BY+CASE и конструкции PIVOT
Для начала давайте посмотрим, как можно создать сводный отчет при помощи конструкции GROUP BY и CASE-условий. Можно сказать, это классический способ создания сводных отчетов:
-- получение сводной таблицы при помощи GROUP BY
SELECT
EmployeeID,
SUM(CASE WHEN MONTH(BonusDate)=1 THEN BonusAmount END) BonusAmount1,
SUM(CASE WHEN MONTH(BonusDate)=2 THEN BonusAmount END) BonusAmount2,
SUM(CASE WHEN MONTH(BonusDate)=3 THEN BonusAmount END) BonusAmount3,
SUM(CASE WHEN MONTH(BonusDate)=4 THEN BonusAmount END) BonusAmount4,
SUM(CASE WHEN MONTH(BonusDate)=5 THEN BonusAmount END) BonusAmount5,
SUM(CASE WHEN MONTH(BonusDate)=6 THEN BonusAmount END) BonusAmount6,
SUM(CASE WHEN MONTH(BonusDate)=7 THEN BonusAmount END) BonusAmount7,
SUM(CASE WHEN MONTH(BonusDate)=8 THEN BonusAmount END) BonusAmount8,
SUM(CASE WHEN MONTH(BonusDate)=9 THEN BonusAmount END) BonusAmount9,
SUM(CASE WHEN MONTH(BonusDate)=10 THEN BonusAmount END) BonusAmount10,
SUM(CASE WHEN MONTH(BonusDate)=11 THEN BonusAmount END) BonusAmount11,
SUM(CASE WHEN MONTH(BonusDate)=12 THEN BonusAmount END) BonusAmount12,
SUM(BonusAmount) TotalBonusAmount
FROM EmployeesBonus
WHERE BonusDate BETWEEN '20140101' AND '20141231' -- отберем данные за 2014 год
GROUP BY EmployeeID
Теперь рассмотрим, как получить эти же данные при помощи конструкции PIVOT:
-- получение сводной таблицы при помощи PIVOT
SELECT
EmployeeID,
[1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12],
ISNULL([1],0)+ISNULL([2],0)+ISNULL([3],0)+ISNULL([4],0)+
ISNULL([5],0)+ISNULL([6],0)+ISNULL([7],0)+ISNULL([8],0)+
ISNULL([9],0)+ISNULL([10],0)+ISNULL([11],0)+ISNULL([12],0) TotalBonusAmount
FROM
(
/*
в данном подзапросе мы отберем только необходимые для свода данные:
- поля BonusMonth и BonusAmount будут задействованы в конструкции PIVOT
- прочие поля, в данном случае это только EmployeeID, будут использованны для группировки данных
*/
SELECT
EmployeeID,
MONTH(BonusDate) BonusMonth,
BonusAmount
FROM EmployeesBonus
WHERE BonusDate BETWEEN '20140101' AND '20141231'
) q
PIVOT(SUM(BonusAmount) FOR BonusMonth IN([1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])) p
В конструкции PIVOT кроме SUM, как вы думаю догадались, можно использовать и другие агрегатные функции (COUNT, AVG, MIN, MAX, …).
Конструкция UNPIVOT
Давайте теперь рассмотрим, как работает конструкция UNPIVOT. Для демонстрации сбросим сводный результат в таблицу DemoPivotTable:
SELECT
EmployeeID,
SUM(CASE WHEN MONTH(BonusDate)=1 THEN BonusAmount END) BonusAmount1,
SUM(CASE WHEN MONTH(BonusDate)=2 THEN BonusAmount END) BonusAmount2,
SUM(CASE WHEN MONTH(BonusDate)=3 THEN BonusAmount END) BonusAmount3,
SUM(CASE WHEN MONTH(BonusDate)=4 THEN BonusAmount END) BonusAmount4,
SUM(CASE WHEN MONTH(BonusDate)=5 THEN BonusAmount END) BonusAmount5,
SUM(CASE WHEN MONTH(BonusDate)=6 THEN BonusAmount END) BonusAmount6,
SUM(CASE WHEN MONTH(BonusDate)=7 THEN BonusAmount END) BonusAmount7,
SUM(CASE WHEN MONTH(BonusDate)=8 THEN BonusAmount END) BonusAmount8,
SUM(CASE WHEN MONTH(BonusDate)=9 THEN BonusAmount END) BonusAmount9,
SUM(CASE WHEN MONTH(BonusDate)=10 THEN BonusAmount END) BonusAmount10,
SUM(CASE WHEN MONTH(BonusDate)=11 THEN BonusAmount END) BonusAmount11,
SUM(CASE WHEN MONTH(BonusDate)=12 THEN BonusAmount END) BonusAmount12,
SUM(BonusAmount) TotalBonusAmount
INTO DemoPivotTable -- сбросим сводный результат в таблицу
FROM EmployeesBonus
WHERE BonusDate BETWEEN '20140101' AND '20141231'
GROUP BY EmployeeID
Первым делом посмотрите, как у нас выглядят данные в данной таблице:
SELECT *
FROM DemoPivotTable
Теперь применим к данной таблице конструкцию UNPIVOT:
-- демонстрация UNPIVOT
SELECT
*,
CAST(REPLACE(ColumnLabel,'BonusAmount','') AS int) BonusMonth
FROM DemoPivotTable
UNPIVOT(BonusAmount FOR ColumnLabel IN(BonusAmount1,BonusAmount2,BonusAmount3,BonusAmount4,
BonusAmount5,BonusAmount6,BonusAmount7,BonusAmount8,
BonusAmount9,BonusAmount10,BonusAmount11,BonusAmount12)) u
Обратите внимание, что NULL значения не войдут в результат.
Как вы наверно догадались, на месте таблицы может стоять и подзапрос с заданным для него псевдонимом.
GROUP BY ROLLUP и GROUP BY GROUPING SETS
Данные конструкции позволяют подбить промежуточные итоги по строкам.
Пример первый:
-- GROUP BY ROLLUP и функция GROUPING
SELECT
--GROUPING(YEAR(bonus.BonusDate)) g1,
--GROUPING(bonus.EmployeeID) g2,
--GROUPING(emp.Name) g3,
CASE
WHEN GROUPING(YEAR(bonus.BonusDate))=1 THEN 'Общий итог'
WHEN GROUPING(bonus.EmployeeID)=1 THEN 'Итого за '+CAST(YEAR(bonus.BonusDate) AS varchar(4))+' год'
END RowTitle,
emp.Name,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=1 THEN bonus.BonusAmount END) BonusAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=2 THEN bonus.BonusAmount END) BonusAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=3 THEN bonus.BonusAmount END) BonusAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=4 THEN bonus.BonusAmount END) BonusAmountQ4,
SUM(bonus.BonusAmount) TotalBonusAmount
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
GROUP BY ROLLUP(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)
-- исключаем ненужный итог обрабатывая GROUPING
HAVING NOT(GROUPING(YEAR(bonus.BonusDate))=0 AND GROUPING(bonus.EmployeeID)=0 AND GROUPING(emp.Name)=1)
Чтобы понять, как работает функции GROUPING, раскомментируйте поля g1, g2 и g3, чтобы они попали в результирующий набор, а также закомментируйте предложение HAVING.
Пример второй:
-- GROUP BY ROLLUP и функция GROUPING_ID
SELECT
/*
GROUPING_ID (a, b, c) input = GROUPING(a) + GROUPING(b) + GROUPING(c)
бинарное 001 = десятичное 1
бинарное 011 = десятичное 3
бинарное 111 = десятичное 7
*/
--GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name) gID,
CASE GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)
WHEN 7 THEN 'Общий итог'
WHEN 3 THEN 'Итого за '+CAST(YEAR(bonus.BonusDate) AS varchar(4))+' год'
END RowTitle,
emp.Name,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=1 THEN bonus.BonusAmount END) BonusAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=2 THEN bonus.BonusAmount END) BonusAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=3 THEN bonus.BonusAmount END) BonusAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=4 THEN bonus.BonusAmount END) BonusAmountQ4,
SUM(bonus.BonusAmount) TotalBonusAmount
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
GROUP BY ROLLUP(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)
-- исключаем ненужный итог обрабатывая GROUPING_ID
HAVING GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)<>1
Здесь для понимания, можете так же раскомментировать поле gID и закомментировать предложение HAVING.
Пример третий:
-- GROUP BY GROUPING SETS и функция GROUPING_ID
SELECT
/*
GROUPING_ID (a, b, c) input = GROUPING(a) + GROUPING(b) + GROUPING(c)
бинарное 001 = десятичное 1
бинарное 011 = десятичное 3
бинарное 111 = десятичное 7
*/
--GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name) gID,
CASE GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)
WHEN 7 THEN 'Общий итог'
WHEN 3 THEN 'Итого за '+CAST(YEAR(bonus.BonusDate) AS varchar(4))+' год'
END RowTitle,
emp.Name,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=1 THEN bonus.BonusAmount END) BonusAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=2 THEN bonus.BonusAmount END) BonusAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=3 THEN bonus.BonusAmount END) BonusAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=4 THEN bonus.BonusAmount END) BonusAmountQ4,
SUM(bonus.BonusAmount) TotalBonusAmount
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
GROUP BY GROUPING SETS(
(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name), -- Имя сотрудника
(YEAR(bonus.BonusDate)), -- Сумма по годам
() -- Общий итог
)
При помощи GROUPING SET можно явно указать какие именно итоги нам нужны, поэтому здесь можно обойтись без предложения HAVING.
Т.е. можно сказать, что GROUP BY ROLLUP частный случай GROUP BY GROUPING SETS, когда делается вывод всех итогов.
Пример использования FULL JOIN
Здесь для примера выведем для каждого сотрудника сводные данные по начислениям бонусов и ЗП, поквартально:
-- пример использования FULL JOIN
WITH cteBonus AS(
SELECT
YEAR(BonusDate) BonusYear,
EmployeeID,
SUM(CASE WHEN DATEPART(QUARTER,BonusDate)=1 THEN BonusAmount END) BonusAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,BonusDate)=2 THEN BonusAmount END) BonusAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,BonusDate)=3 THEN BonusAmount END) BonusAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,BonusDate)=4 THEN BonusAmount END) BonusAmountQ4,
SUM(BonusAmount) TotalBonusAmount
FROM EmployeesBonus
GROUP BY YEAR(BonusDate),EmployeeID
),
cteSalary AS(
SELECT
YEAR(SalaryDate) SalaryYear,
EmployeeID,
SUM(CASE WHEN DATEPART(QUARTER,SalaryDate)=1 THEN SalaryAmount END) SalaryAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,SalaryDate)=2 THEN SalaryAmount END) SalaryAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,SalaryDate)=3 THEN SalaryAmount END) SalaryAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,SalaryDate)=4 THEN SalaryAmount END) SalaryAmountQ4,
SUM(SalaryAmount) TotalSalaryAmount
FROM EmployeesSalary
GROUP BY YEAR(SalaryDate),EmployeeID
)
SELECT
ISNULL(s.SalaryYear,b.BonusYear) AccYear,
ISNULL(s.EmployeeID,b.EmployeeID) EmployeeID,
s.SalaryAmountQ1,s.SalaryAmountQ2,s.SalaryAmountQ3,s.SalaryAmountQ4,
s.TotalSalaryAmount,
b.BonusAmountQ1,b.BonusAmountQ2,b.BonusAmountQ3,b.BonusAmountQ4,
b.TotalBonusAmount,
ISNULL(s.TotalSalaryAmount,0)+ISNULL(b.TotalBonusAmount,0) TotalAmount
FROM cteSalary s
FULL JOIN cteBonus b ON s.EmployeeID=b.EmployeeID AND s.SalaryYear=b.BonusYear
Попробуйте самостоятельно разобрать, почему я здесь применил именно FULL JOIN. Посмотрите на результаты, которые дают запросы размещенные в блоке WITH.
Приложение 2 – OVER и аналитические функции
Предложение OVER служит для проведения дополнительных вычислений, на окончательном наборе, полученном оператором SELECT (в подзапросах или запросах). Поэтому предложения OVER может быть применено только в блоке SELECT, т.е. его нельзя использовать, например, в блоке WHERE.
Выражения с использованием OVER могут в некоторых ситуациях значительно сократить запрос. В данном приложении я постарался привести самые основные моменты с использованием данной конструкции. Надеюсь, что самостоятельная проработка каждого приведенного здесь запроса и их результатов, поможет вам разобраться с особенностями конструкции OVER и вы сможете применять ее по назначению (не злоупотребляя ими чрезмерно там, где можно обойтись без них и наоборот) при написании своих запросов.
Для демонстрационных целей, для получения более наглядных результатов, добавим немного новых данных:
-- добавим новые должности
SET IDENTITY_INSERT Positions ON
INSERT Positions(ID,Name)VALUES
(10,N'Маркетолог'),
(11,N'Логист')
SET IDENTITY_INSERT Positions OFF
-- новые сотрудники
INSERT Employees(ID,Name,DepartmentID,PositionID,HireDate,Salary,Email)VALUES
(1006,N'Антонов А.А.',4,10,'20150215',1800,'a.antonov@test.tt'),
(1007,N'Максимов М.М.',5,11,'20150405',1200,'m.maksimov@test.tt'),
(1008,N'Данилов Д.Д.',5,11,'20150410',1200,'d.danolov@test.tt'),
(1009,N'Остапов О.О.',5,11,'20150415',1200,'o.ostapov@test.tt')
Предложение OVER дает возможность делать агрегатные вычисления, без применения группировки
SELECT
ID,
Name,
DepartmentID,
Salary,
-- получаем сумму ЗП всех сотрудников
SUM(Salary) OVER() AllSalary,
-- получаем сумму ЗП сотрудников этого же отдела
SUM(Salary) OVER(PARTITION BY DepartmentID) DepartmentSalary,
-- процент ЗП сотрудника от суммы ЗП всего отдела
CAST(Salary/SUM(Salary) OVER(PARTITION BY DepartmentID)*100 AS numeric(20,3)) SalaryPercentOfDepSalary,
-- кол-во всех сотрудников
COUNT(*) OVER() AllEmplCount,
-- кол-во сотрудников в отделе
COUNT(*) OVER(PARTITION BY DepartmentID) DepEmplCount
FROM Employees
| ID | Name | DepartmentID | Salary | AllSalary | DepartmentSalary | SalaryPercentOfDepSalary | AllEmplCount | DepEmplCount |
|---|---|---|---|---|---|---|---|---|
| 1005 | Александров А.А. | NULL | 2000.00 | 19900.00 | 2000.00 | 100.000 | 10 | 1 |
| 1000 | Иванов И.И. | 1 | 5000.00 | 19900.00 | 5000.00 | 100.000 | 10 | 1 |
| 1002 | Сидоров С.С. | 2 | 2500.00 | 19900.00 | 2500.00 | 100.000 | 10 | 1 |
| 1003 | Андреев А.А. | 3 | 2000.00 | 19900.00 | 5000.00 | 40.000 | 10 | 3 |
| 1004 | Николаев Н.Н. | 3 | 1500.00 | 19900.00 | 5000.00 | 30.000 | 10 | 3 |
| 1001 | Петров П.П. | 3 | 1500.00 | 19900.00 | 5000.00 | 30.000 | 10 | 3 |
| 1006 | Антонов А.А. | 4 | 1800.00 | 19900.00 | 1800.00 | 100.000 | 10 | 1 |
| 1007 | Максимов М.М. | 5 | 1200.00 | 19900.00 | 3600.00 | 33.333 | 10 | 3 |
| 1008 | Данилов Д.Д. | 5 | 1200.00 | 19900.00 | 3600.00 | 33.333 | 10 | 3 |
| 1009 | Остапов О.О. | 5 | 1200.00 | 19900.00 | 3600.00 | 33.333 | 10 | 3 |
Предложение «PARTITION BY» позволяет сделать разбиение данных по группам, можно сказать выполняет здесь роль «GROUP BY».
Можно задать группировку по нескольким полям, использовать выражения, например, «PARTITION BY DepartmentID,PositionID», «PARTITION BY DepartmentID,YEAR(HireDate)».
Поэкспериментируйте и с другими агрегатными функциями, которые мы разбирали – AVG, MIN, MAX, COUNT с DISTINCT.
Нумерация и ранжирование строк
Для цели нумерации строк используется функция ROW_NUMBER.
Пронумеруем сотрудников по полю Name и по нескольким полям LastName,FirstName,MiddleName:
SELECT
ID,
Name,
-- нумирация в порядке значений Name
ROW_NUMBER() OVER(ORDER BY Name) EmpNoByName,
-- нумирация в порядке значений LastName,FirstName,MiddleName
ROW_NUMBER() OVER(ORDER BY LastName,FirstName,MiddleName) EmpNoByFullName
FROM Employees
ORDER BY Name
| ID | Name | EmpNoByName | EmpNoByFullName |
|---|---|---|---|
| 1005 | Александров А.А. | 1 | 6 |
| 1003 | Андреев А.А. | 2 | 7 |
| 1006 | Антонов А.А. | 3 | 1 |
| 1008 | Данилов Д.Д. | 4 | 2 |
| 1000 | Иванов И.И. | 5 | 8 |
| 1007 | Максимов М.М. | 6 | 3 |
| 1004 | Николаев Н.Н. | 7 | 4 |
| 1009 | Остапов О.О. | 8 | 5 |
| 1001 | Петров П.П. | 9 | 9 |
| 1002 | Сидоров С.С. | 10 | 10 |
Здесь для задания порядка в OVER используется предложение «ORDER BY».
Для разбиения на группы, здесь так же в OVER можно использовать предложение «PARTITION BY»:
SELECT
emp.ID,
emp.Name EmpName,
dep.Name DepName,
-- нумирация сотрудников в разрезе отделов, в порядке значений Name
ROW_NUMBER() OVER(PARTITION BY dep.ID ORDER BY emp.Name) EmpNoInDepByName
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
ORDER BY dep.Name,emp.Name
| ID | EmpName | DepName | EmpNoInDepByName |
|---|---|---|---|
| 1005 | Александров А.А. | NULL | 1 |
| 1000 | Иванов И.И. | Администрация | 1 |
| 1002 | Сидоров С.С. | Бухгалтерия | 1 |
| 1003 | Андреев А.А. | ИТ | 1 |
| 1004 | Николаев Н.Н. | ИТ | 2 |
| 1001 | Петров П.П. | ИТ | 3 |
| 1008 | Данилов Д.Д. | Логистика | 1 |
| 1007 | Максимов М.М. | Логистика | 2 |
| 1009 | Остапов О.О. | Логистика | 3 |
| 1006 | Антонов А.А. | Маркетинг и реклама | 1 |
Ранжирование строк – это можно сказать нумерация, только группами. Есть 2 вида нумерации, с дырками (RANK) и без дырок (DENSE_RANK).
SELECT
emp.ID,
emp.Name EmpName,
emp.PositionID,
-- кол-во сотрудников в разрезе должностей
COUNT(*) OVER(PARTITION BY emp.PositionID) EmpCountInPos,
-- ранжирование с дырками - следующий номер зависит от кол-ва записей в предыдущей группе
RANK() OVER(ORDER BY emp.PositionID) RankValue,
-- ранжирование без дырок – плотная нумерация (последовательная)
DENSE_RANK() OVER(ORDER BY emp.PositionID) DenseRankValue
FROM Employees emp
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
| ID | EmpName | PositionID | EmpCountInPos | RankValue | DenseRankValue |
|---|---|---|---|---|---|
| 1005 | Александров А.А. | NULL | 1 | 1 | 1 |
| 1002 | Сидоров С.С. | 1 | 1 | 2 | 2 |
| 1000 | Иванов И.И. | 2 | 1 | 3 | 3 |
| 1001 | Петров П.П. | 3 | 2 | 4 | 4 |
| 1004 | Николаев Н.Н. | 3 | 2 | 4 | 4 |
| 1003 | Андреев А.А. | 4 | 1 | 6 | 5 |
| 1006 | Антонов А.А. | 10 | 1 | 7 | 6 |
| 1007 | Максимов М.М. | 11 | 3 | 8 | 7 |
| 1008 | Данилов Д.Д. | 11 | 3 | 8 | 7 |
| 1009 | Остапов О.О. | 11 | 3 | 8 | 7 |
Аналитические функции: LAG() и LEAD(), FIRST_VALUE() и LAST_VALUE()
Данные функции позволяют получить значения другой строки относительно текущей строки.
Рассмотрим LAG() и LEAD():
SELECT
ID CurrEmpID,
Name CurrEmpName,
-- значения предыдущей строки
LAG(ID) OVER(ORDER BY ID) PrevEmpID,
LAG(Name) OVER(ORDER BY ID) PrevEmpName,
LAG(ID,2) OVER(ORDER BY ID) PrevPrevEmpID,
LAG(Name,2,'not found') OVER(ORDER BY ID) PrevPrevEmpName,
-- значения следующей строки
LEAD(ID) OVER(ORDER BY ID) NextEmpID,
LEAD(Name) OVER(ORDER BY ID) NextEmpName,
LEAD(ID,2) OVER(ORDER BY ID) NextNextEmpID,
LEAD(Name,2,'not found') OVER(ORDER BY ID) NextNextEmpName
FROM Employees
ORDER BY ID
| CurrEmpID | CurrEmpName | PrevEmpID | PrevEmpName | PrevPrevEmpID | PrevPrevEmpName | NextEmpID | NextEmpName | NextNextEmpID | NextNextEmpName |
|---|---|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | NULL | not found | 1001 | Петров П.П. | 1002 | Сидоров С.С. |
| 1001 | Петров П.П. | 1000 | Иванов И.И. | NULL | not found | 1002 | Сидоров С.С. | 1003 | Андреев А.А. |
| 1002 | Сидоров С.С. | 1001 | Петров П.П. | 1000 | Иванов И.И. | 1003 | Андреев А.А. | 1004 | Николаев Н.Н. |
| 1003 | Андреев А.А. | 1002 | Сидоров С.С. | 1001 | Петров П.П. | 1004 | Николаев Н.Н. | 1005 | Александров А.А. |
| 1004 | Николаев Н.Н. | 1003 | Андреев А.А. | 1002 | Сидоров С.С. | 1005 | Александров А.А. | 1006 | Антонов А.А. |
| 1005 | Александров А.А. | 1004 | Николаев Н.Н. | 1003 | Андреев А.А. | 1006 | Антонов А.А. | 1007 | Максимов М.М. |
| 1006 | Антонов А.А. | 1005 | Александров А.А. | 1004 | Николаев Н.Н. | 1007 | Максимов М.М. | 1008 | Данилов Д.Д. |
| 1007 | Максимов М.М. | 1006 | Антонов А.А. | 1005 | Александров А.А. | 1008 | Данилов Д.Д. | 1009 | Остапов О.О. |
| 1008 | Данилов Д.Д. | 1007 | Максимов М.М. | 1006 | Антонов А.А. | 1009 | Остапов О.О. | NULL | not found |
| 1009 | Остапов О.О. | 1008 | Данилов Д.Д. | 1007 | Максимов М.М. | NULL | NULL | NULL | not found |
В данных функциях вторым параметром можно указать сдвиг относительно текущей строки, а третьим параметром можно указать возвращаемое значение для случая если для указанного смещения строки не существует.
Для разбиения данных по группам, попробуйте самостоятельно добавить предложение «PARTITION BY» в OVER, например, «OVER(PARTITION BY emp.DepartmentID ORDER BY emp.ID)».
Рассмотрим FIRST_VALUE() и LAST_VALUE():
SELECT
ID CurrEmpID,
Name CurrEmpName,
DepartmentID,
-- первое значение в группе
FIRST_VALUE(ID) OVER(PARTITION BY DepartmentID ORDER BY ID) FirstEmpID,
FIRST_VALUE(Name) OVER(PARTITION BY DepartmentID ORDER BY ID) FirstEmpName,
-- последнее значение в группе
LAST_VALUE(ID) OVER(PARTITION BY DepartmentID ORDER BY ID RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) LastEmpID,
LAST_VALUE(Name) OVER(PARTITION BY DepartmentID ORDER BY ID RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) LastEmpName
FROM Employees
ORDER BY DepartmentID,ID
| CurrEmpID | CurrEmpName | DepartmentID | FirstEmpID | FirstEmpName | LastEmpID | LastEmpName |
|---|---|---|---|---|---|---|
| 1005 | Александров А.А. | NULL | 1005 | Александров А.А. | 1005 | Александров А.А. |
| 1000 | Иванов И.И. | 1 | 1000 | Иванов И.И. | 1000 | Иванов И.И. |
| 1002 | Сидоров С.С. | 2 | 1002 | Сидоров С.С. | 1002 | Сидоров С.С. |
| 1001 | Петров П.П. | 3 | 1001 | Петров П.П. | 1004 | Николаев Н.Н. |
| 1003 | Андреев А.А. | 3 | 1001 | Петров П.П. | 1004 | Николаев Н.Н. |
| 1004 | Николаев Н.Н. | 3 | 1001 | Петров П.П. | 1004 | Николаев Н.Н. |
| 1006 | Антонов А.А. | 4 | 1006 | Антонов А.А. | 1006 | Антонов А.А. |
| 1007 | Максимов М.М. | 5 | 1007 | Максимов М.М. | 1009 | Остапов О.О. |
| 1008 | Данилов Д.Д. | 5 | 1007 | Максимов М.М. | 1009 | Остапов О.О. |
| 1009 | Остапов О.О. | 5 | 1007 | Максимов М.М. | 1009 | Остапов О.О. |
Думаю, здесь все понятно. Стоит только объяснить, что такое RANGE.
Параметры RANGE и ROWS
При помощи дополнительных параметров «RANGE» и «ROWS», можно изменить область работы функции, которая работает с предложением OVER. У каждой функции по умолчанию используется какая-то своя область действия. Такая область обычно называется окном.
Важное замечание. В разных СУБД для одних и тех же функций область по умолчанию может быть разной, поэтому нужно быть внимательным и смотреть справку конкретной СУБД по каждой отдельной функции.
Можно создавать окна по двум критериям:
- по диапазону (RANGE) значений данных
- по смещению (ROWS) относительно текущей строки
Общий синтаксис этих опций выглядит следующим образом:
Вариант 1:
{ROWS | RANGE} {{UNBOUNDED | выражение} PRECEDING | CURRENT ROW}Вариант 2:
{ROWS | RANGE}
BETWEEN
{{UNBOUNDED PRECEDING | CURRENT ROW |
{UNBOUNDED | выражение 1}{PRECEDING | FOLLOWING}}
AND
{{UNBOUNDED FOLLOWING | CURRENT ROW |
{UNBOUNDED | выражение 2}{PRECEDING | FOLLOWING}}
Здесь проще понять если проанализировать в Excel результат запроса:
SELECT
ID,
Salary,
SUM(Salary) OVER() Sum1,
-- сумма всех строк - "все предыдущие" и "все последующие"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN unbounded preceding AND unbounded following) Sum2,
-- сумма строк до текущей строки включительно - "все предыдущие" и "текущая строка"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN unbounded preceding AND current row) Sum3,
-- сумма всех последующих от текущей строки включительно - "текущая строка" и "все последующие"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN current row AND unbounded following) Sum4,
-- сумма следующих трех строк - "1 следующую" и "3 следующие"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN 1 following AND 3 following) Sum5,
-- сумма трех строк - "1 предыдущая" и "1 следующую"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN 1 preceding AND 1 following) Sum6,
-- сумма предыдущих "трех предыдущих" и "текущей"
SUM(Salary) OVER(ORDER BY ID ROWS 3 preceding) Sum7,
-- сумма "всех предыдущих" и "текущей"
SUM(Salary) OVER(ORDER BY ID ROWS unbounded preceding) Sum8
FROM Employees
ORDER BY ID
| ID | Salary | Sum1 | Sum2 | Sum3 | Sum4 | Sum5 | Sum6 | Sum7 | Sum8 |
|---|---|---|---|---|---|---|---|---|---|
| 1000 | 5000.00 | 19900.00 | 19900.00 | 5000.00 | 19900.00 | 6000.00 | 6500.00 | 5000.00 | 5000.00 |
| 1001 | 1500.00 | 19900.00 | 19900.00 | 6500.00 | 14900.00 | 6000.00 | 9000.00 | 6500.00 | 6500.00 |
| 1002 | 2500.00 | 19900.00 | 19900.00 | 9000.00 | 13400.00 | 5500.00 | 6000.00 | 9000.00 | 9000.00 |
| 1003 | 2000.00 | 19900.00 | 19900.00 | 11000.00 | 10900.00 | 5300.00 | 6000.00 | 11000.00 | 11000.00 |
| 1004 | 1500.00 | 19900.00 | 19900.00 | 12500.00 | 8900.00 | 5000.00 | 5500.00 | 7500.00 | 12500.00 |
| 1005 | 2000.00 | 19900.00 | 19900.00 | 14500.00 | 7400.00 | 4200.00 | 5300.00 | 8000.00 | 14500.00 |
| 1006 | 1800.00 | 19900.00 | 19900.00 | 16300.00 | 5400.00 | 3600.00 | 5000.00 | 7300.00 | 16300.00 |
| 1007 | 1200.00 | 19900.00 | 19900.00 | 17500.00 | 3600.00 | 2400.00 | 4200.00 | 6500.00 | 17500.00 |
| 1008 | 1200.00 | 19900.00 | 19900.00 | 18700.00 | 2400.00 | 1200.00 | 3600.00 | 6200.00 | 18700.00 |
| 1009 | 1200.00 | 19900.00 | 19900.00 | 19900.00 | 1200.00 | NULL | 2400.00 | 5400.00 | 19900.00 |
С RANGE все тоже самое, только здесь смещения идут не относительно строк, а относительно их значений. Поэтому в данном случае в ORDER BY допустимы значения только типа дата или число.
SELECT
PositionID,
Salary,
SUM(Salary) OVER(PARTITION BY PositionID) Sum1,
-- сумма ЗП для всех значений PositionID - "все меньшие" и "все большие"
SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN unbounded preceding AND unbounded following) Sum2,
-- сумма ЗП для значений меньших PositionID до текущего значения включительно - "все меньшие" и "текущее значение" (значения<=PositionID)
SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN unbounded preceding AND current row) Sum3,
-- сумма ЗП для всех больших значений от текущего значения включительно - "текущее значение" и "все большие" (значения>=PositionID)
SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN current row AND unbounded following) Sum4,
/*
Увы следующие комбинации для RANGE в MS SQL не работают, хотя в Oracle они работают.
Вырезки из MSDN:
Предложение RANGE не может использоваться со <спецификацией неподписанного значения> PRECEDING или со <спецификацией неподписанного значения> FOLLOWING.
<спецификация неподписанного значения> PRECEDING
Указывается с <беззнаковым указанием значения> для обозначения числа строк или значений перед текущей строкой.
Эта спецификация не допускается в предложении RANGE.
<спецификация неподписанного значения> FOLLOWING
Указывается с <беззнаковым указанием значения> для обозначения числа строк или значений после текущей строки.
Эта спецификация не допускается в предложении RANGE.
*/
-- сумма ЗП для трех значений - "+1" и "+3" (значение BETWEEN PositionID+1 AND PositionID+3)
--SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN 1 following AND 3 following) Sum5,
-- сумма ЗП для трех значений - "-1" и "+1" (значение BETWEEN PositionID-1 AND PositionID+1)
--SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN 1 preceding AND 1 following) Sum6,
-- сумма ЗП для предыдущих трех значений - "-3" и "текущее" (значение BETWEEN PositionID-3 AND PositionID)
--SUM(Salary) OVER(ORDER BY PositionID RANGE 3 preceding) Sum7,
-- сумма ЗП для "всех предыдущих значений" и "текущего" (значения<=PositionID)
SUM(Salary) OVER(ORDER BY PositionID RANGE unbounded preceding) Sum8
FROM Employees
ORDER BY PositionID
| PositionID | Salary | Sum1 | Sum2 | Sum3 | Sum4 | Sum8 |
|---|---|---|---|---|---|---|
| NULL | 2000.00 | 2000.00 | 19900.00 | 2000.00 | 19900.00 | 2000.00 |
| 1 | 2500.00 | 2500.00 | 19900.00 | 4500.00 | 17900.00 | 4500.00 |
| 2 | 5000.00 | 5000.00 | 19900.00 | 9500.00 | 15400.00 | 9500.00 |
| 3 | 1500.00 | 3000.00 | 19900.00 | 12500.00 | 10400.00 | 12500.00 |
| 3 | 1500.00 | 3000.00 | 19900.00 | 12500.00 | 10400.00 | 12500.00 |
| 4 | 2000.00 | 2000.00 | 19900.00 | 14500.00 | 7400.00 | 14500.00 |
| 10 | 1800.00 | 1800.00 | 19900.00 | 16300.00 | 5400.00 | 16300.00 |
| 11 | 1200.00 | 3600.00 | 19900.00 | 19900.00 | 3600.00 | 19900.00 |
| 11 | 1200.00 | 3600.00 | 19900.00 | 19900.00 | 3600.00 | 19900.00 |
| 11 | 1200.00 | 3600.00 | 19900.00 | 19900.00 | 3600.00 | 19900.00 |
Заключение
Вот и все, уважаемые читатели, на этом я оканчиваю свой учебник по SQL (DDL, DML).
Надеюсь, что вам было интересно провести время за прочтением данного материала, а главное надеюсь, что он принес вам понимание самых важных базовых конструкций языка SQL.
Учитесь, практикуйтесь, добивайтесь получения правильных результатов.
Спасибо за внимание! На этом пока все.
PS. Отдельное спасибо всем, кто помогал сделать данный материал лучше, указывая на опечатки или давая дельные советы!