Аннотация
В статье рассмотрен режим работы Vivado, позволяющий вносить изменения в проект на уровне редактирования списка соединений (в дальнейшем – нетлиста). Описаны как сам режим ECO, так и некоторые нюансы, которые появляются во время работы в нём. Приведён демонстрационный пример и описана полная последовательность действий для получения результата, в работоспособности которой может убедиться каждый желающий. Статья будет полезна для «общего развития» FPGA-разработчикам, а особенно — тем, кто часто отлаживает проекты в Logic Analyzer. Надеюсь, работа в этом режиме вызовет интерес у разработчиков, работающих с большими кристаллами, время компиляции в которых может достигать часов (а то и десятков часов), поскольку в этом режиме время, затрачиваемое на имплементацию, при внесении изменений в нетлист может сократиться до буквально пары минут.

Оглавление
Скрытый текст
- Аннотация
- Введение
- 1. ECO: краткий обзор
- 2. Design Сheckpoint
- 3. Разработка тестового проекта
- 3.1. Создание проекта
- 3.2. Создание и добавление HDL файлов в проект
- 3.3.Создание проекта MicroBlaze и работа в IP Integrator
- 3.4.Синтез и имплементация
- 3.5.Написание программы для MicroBlaze
- 3.6.Запуск программы и отладка
- 4. Переход в режим ECO
- 5. ECO: описание интерфейса
- 6. Внесение изменений в проект
- 6.1. Создание новых элементов в нетлисте
- 6.2. Изменение свойств/параметров компонентов
- 6.3. Подключение других цепей к пробникам и ILA
- 6.4. Замена портов ввода/вывода
- 7. Сравнительный анализ
- 8. Заключение
- 9. Домашнее задание
- Библиографический список
В статье очень много картинок не в спойлерах (140 штук). Пожалуйста, будьте внимательны, если заходите с телефона
Введение
Зачастую, когда мне приходится читать лекцию или вести семинар, я всегда стараюсь рассказать несколько больше, нежели предполагает программа. Так было на последних трёх семинарах, посвящённых работе с одноядерными Zynq-7000S. В этот раз было интересно посмотреть, насколько аудитория знает о некоторых «скрытых» режимах работы с Vivado. Вопрос был достаточно прост: «Кто-нибудь из присутствующих знает про режим ECO Flow?» Сразу за вопросом последовал, что называется, «лес рук, чему я особенно не удивился.
Желание несколько просветить разработчиков хотя бы о наличии этого режима в Vivado, не говоря уже о демонстрации работы в нём, появилась у меня очень давно. Но по какой-то загадочной причине, я «впрягся» в написание руководств по сборке проектов с использованием MicroBlaze и работе с ним. Однако, после недавних семинаров стало очевидно, что писать про ECO Flow всё таки нужно.
Цель статьи – дать общее представление о режиме ECO в среде Vivado [1], предоставляемой компанией Xilinx для своих кристаллов и показать на реальном примере работу в этом режиме, стараясь указать «тонкие» моменты и проанализировать его достоинства и недостатки.
Задачи, которые поставлены в этой статье:
- разработать тестовый пример, по возможности содержащий и демонстрирующий все (или хотя бы большинство) возможностей работы в режиме ECO;
- выполнить имплементацию проекта;
- пояснить понятие Design Checkpoint;
- описать переход в режим работы ECO;
- внести правки в нетлист и получить файл прошивки FPGA;
- убедиться в корректности внесенных изменений;
- составить сводную таблицу времени, затрачиваемого на стандартное внесение изменений в проект и сравнить его со временем, затрачиваемым в режиме ECO, а также инкрементной имплементации.
К сожалению, физически проверить методологию на достаточно «тяжёлом» кристалле (например, Virtex UltraScale) у меня возможности нет. Но, думаю, даже тот пример, который будет приведен – с проверкой на скромном Artix-7, установленном на плате Arty [2], окажется достаточно показательным. В процессе написания я буду опираться на несколько основных документов, в которых описан режим ECO [3], [4], [5]. Используемая версия Vivado (и, соответственно, документации) – 2017.4.
Небольшое отступление: да в руководстве много картинок и «банальщины» о том, как создать проект, собрать процессорную систему на MicroBlaze, работе в IP Integrator, отладке и т.д. Если Вы опытны и просто хотите прочитать об ECO – пожалуйста, перейдите сразу к главе 4: «Переход в режим ECO». Если же Вы не знаете, как собирать проект на MicroBlaze, ни разу не работали в IP Integrator, или любите руководства в стиле пошаговых иллюстраций – буду только рад, если Вы уделите дополнительные 75-90 минут представленному материалу. И, всё же, я надеюсь, что кто-нибудь выполнит руководство полностью, с проверкой в железе.
1. ECO: краткий обзор
ECO – Engineering change orders [6] («порядок внесения инженерных изменений») – это режим, в котором возможно внести изменения в нетлист, синтезированного или имплементированного проекта с минимальным влиянием на исходный нетлист. В Vivado имеется режим ECO, в котором возможно изменять так называемые Design Checkpoint проекта(см. далее), имплементировать внесённые изменения, выполнять генерацию необходимых отчётов для изменённого нетлиста и генерировать по нему файл прошивки FPGA.
Наиболее типичное применение данного режима:
- Изменение пробников и подключаемых линий логических анализаторов (ILA – IntegratedLogicAnalyzer) при отладке проекта. Пользователь может изменить набор подключаемых к ILA линий, избежав при этом полной повторной имплементации проекта.
- Переназначение цепей, подключенных к ножкам ПЛИС. В случае, если разработчиком проекта, схемотехником или разработчиком печатной платы была допущена ошибка в назначении ножек (например, rx перепутан с tx), а проект на FPGA уже был имплементирован, таким способом можно выполнить переназначение портов в нетлисте, избежав повторной полной имплементации (т. е. синтеза, мапинга, оптимизации, размещения, трассировки – со всеми сопутствующими затратами машинного времени и ресурсов) проекта.
- Выполнение анализа «Что_если?» (редактирование содержимого памяти, изменение функционала LUT, улучшение таймингов и т.д.)
Основная задача работы в режиме ECO – экономия времени и избегание повторной имплементации проекта, при внесении изменений на этапе настройки или отладки проекта. Многие знакомы с режимом инкрементной имплементации, который в ECO также используется, однако в ECO, по сравнению с инкрементной имплементацией, быстрее удаётся получить файл прошивки и быстрее выполнить текущую итерацию отладки.
Примечание: работа в режиме ECO возможна только с Design Сheckpoint.
2. Design Сheckpoint
Маршрут проектирования делится на несколько составных частей:, включая синтез и имплементацию. Имплементация в свою очередь делится на подэтапы: различные оптимизации, размещение и трассировку. Промежуточные этапы маршрута проектирования при этом сохраняются в некий «контейнер», который называется Design Checkpoint (DCP) [7]. Это файл, имеющий расширение «.dcp». Design Checkpoint содержит:
- Текущий нетлист (в зависимости от этапа маршрута проектирования), включая все оптимизации, выполненные до записи dcp-файла.
- Ограничения, наложенные на проект (design constraints).
По умолчанию, Vivado создаёт четыре файла dcp: один – на этапе синтеза модуля верхнего уровня проекта (если выполняется синтез в режиме out-of-context, то для всех модулей, которые синтезируются в out-of-context, создается свой файл dcp) и три – на этапе имплементации. Эти файлы можно найти в папках:
«Название_проекта.runs/название_синтеза/название_топ_модуля.dcp»
«Название_проекта.runs/название_импелементации/».
На рис. 1 показан пример расположения и файлы .dcp, которые создаются по умолчанию для некоторого абстрактного проекта.
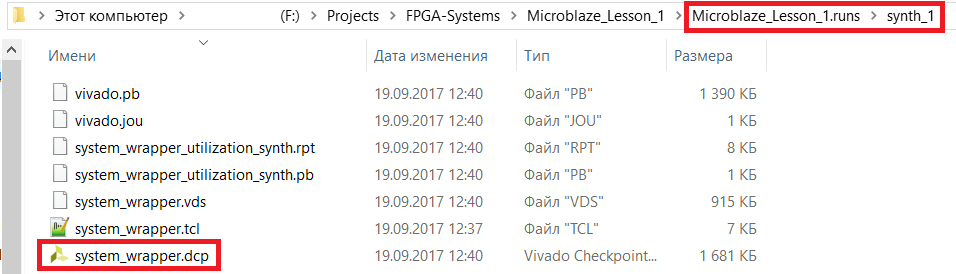
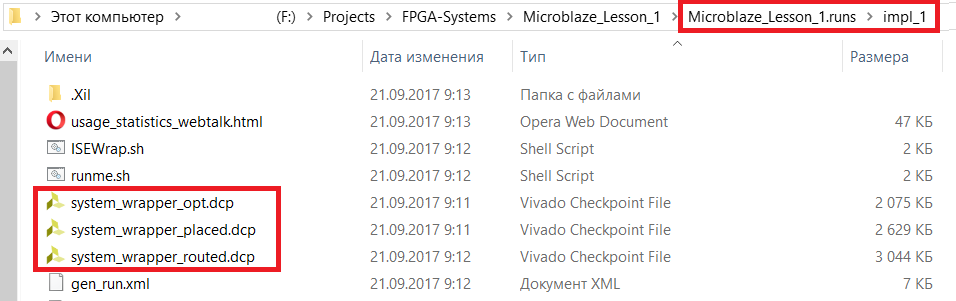
Рисунок 1 – создаваемые по умолчанию dcp-файлы (1 – «постсинтез-» и 3 – «постимплемент-»: после оптимизации (_opt), после размещения (_placed) и после трассировки (_routed))
В проектном режиме работы с Vivado (Project Mode [8]) файлы .dcp создаются автоматически. Но при работе в непроектном режиме (Non-ProjectMode [8]) пользователь сам должен следить за тем, чтобы «снимки» текущего состояния проекта записывались. Для этого следует использовать соответствующие Tcl команды [9, 10].:
write_checkpoint <file_name>.dcp
read_checkpoint <file_name>.dcp
О том, зачем, как и какие файлы dcp следует открывать, будет рассказано далее.
3. Разработка тестового проекта
Чтобы продемонстрировать на тестовом проекте возможности ECO, он должен содержать следующее:
- Элементы, которых нет в исходном нетлисте или элементы, у которых можно изменять функционал. Например, завести светодиод на кнопку – и в исходном проекте он будет загораться по нажатию, а в измененном – по нажатию он будет гаснуть. То есть нужно будет добавить в нетлист инвертор, которого нет в исходном проекте.
- Элементы, у которых можно менять содержимое. Например, таблица истинности в LUT или содержимое блочной памяти. Причём изменение содержимого блочной памяти тут будет более предпочтительным, поскольку изменение LUT мы уже выполним в п.1, когда будем создавать дополнительный инвертор.
- ILA – для возможности замены подключённых цепей на другие цепи. То есть, не трогая сам ILA, мы попробуемчерез нетлист заменить подключенные к нему выбранные в исходном проекте цепи на другие.
- Перепутанные выводы. Предположим, что при проектировании печатной платы ее разработчик выполнил pin-swap двух выводов для удобства разводки, не согласовав это с разработчиком FPGA, т.е. внёс ошибку путаницы rx с tx UART. В режиме ECO мы должны будем восстановить правильность подключения.
3.1. Создание проекта
Находим иконку Vivado и кликаем по ней два раза, откроется окно приветствия (рис. 2)
Рисунок 2 – Окно приветствия Vivado
Для создания нового проекта нажимаем кнопку Create Project. Нажатие кнопки вызывает мастер создания нового проекта. После его появления нажимаем кнопку Next (рис. 3).
Рисунок 3 – Окно мастера создания нового проекта
Вводим название проекта, в поле Project Name пишем «eco_flow». Указываем, где будет располагаться проект: в поле Project location укажите директорию с проектом. У меня она будет «F:/Projects/FPGA-Systems/eco_flow/projects/vivado». Если установить галочку «create project subdirectory» – будет создана дополнительная папка с именем проекта. Нажимаем Next (рис. 4).

Рисунок 4 – Ввод имени проекта и его расположения
Создаем мы обыкновенный проект, поэтому просто выбираем тип проекта RTL. На текущем этапе не будем добавлять какие-либо файлы в проект, поэтому поставим галку “Do not specify sources at this time” и нажимаем Next (рис. 5).
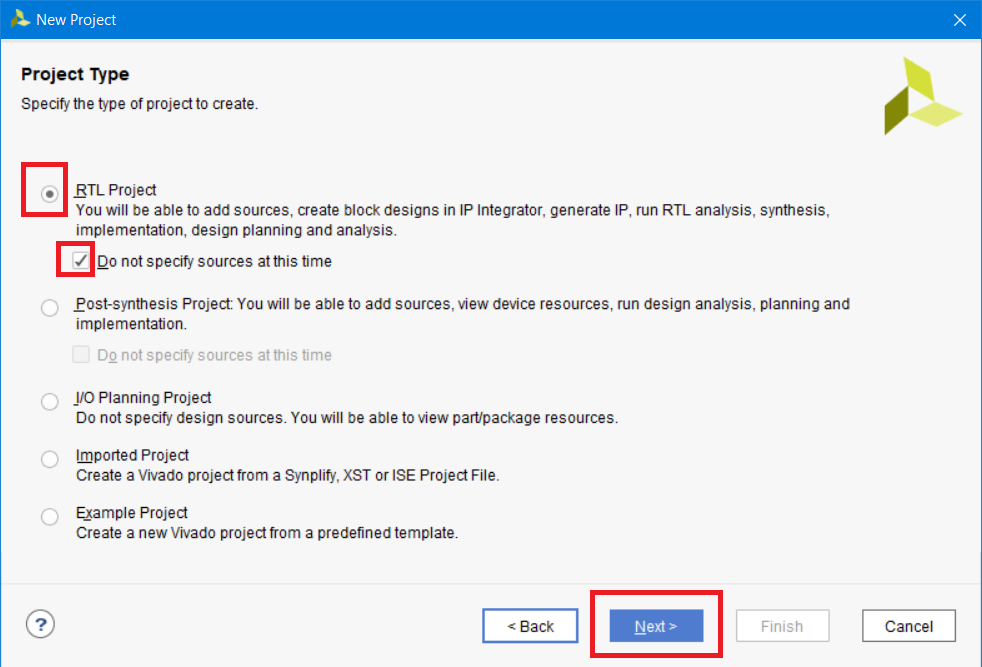
Рисунок 5 – Выбор типа создаваемого проекта
Работать мы будем с платой Arty [2], поэтому выберем кристалл, который на ней установлен: xc7a35tcsg324-1. Нажимаем Next (рис. 6).
Примечание: я специально не выбираю готовую плату из шаблона доступных плат. Это сделано для того, чтобы можно было вручную делать ошибки, которые потом мы будем исправлять.

Рисунок 6 – Выбор кристалла xc7a35tcsg324-1
Заключительным в мастере настройки нового проекта будет окно Summary создаваемого проекта. Нажимаем Finish (рис. 7).
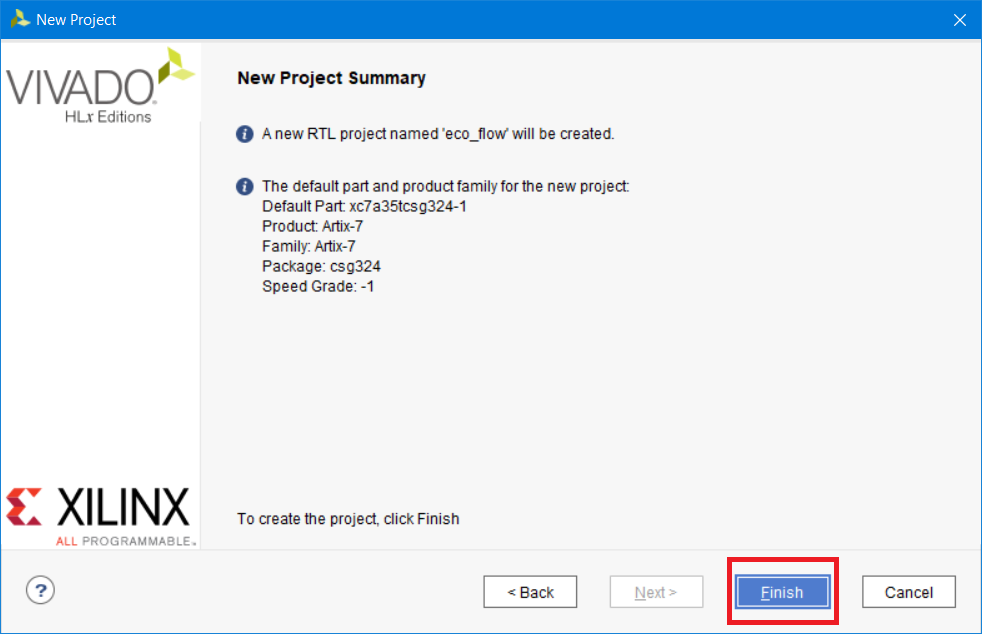
Рисунок 7 – Окно кратких сведений создаваемого проекта
3.2. Создание и добавление HDL файлов в проект
Здесь мы создадим два модуля: просто мигающий светодиод и блочную память, которая постоянно считывается (фактически, это имитация памяти коэффициентов фильтра, значения которых мы потом попробуем изменить).
Для создания и добавления нового файла в проект воспользуемся мастером, который вызывается по нажатию на синий плюс (рис. 8).
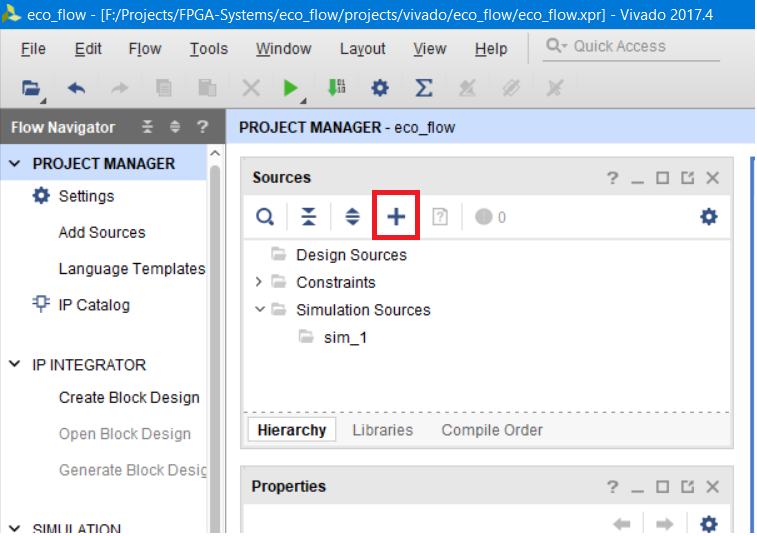
Рисунок 8 – Вызов мастера создания добавления файлов в проект
В появившемся окне выбираем «Add or create design sources» и кликаем Next (рис. 9).
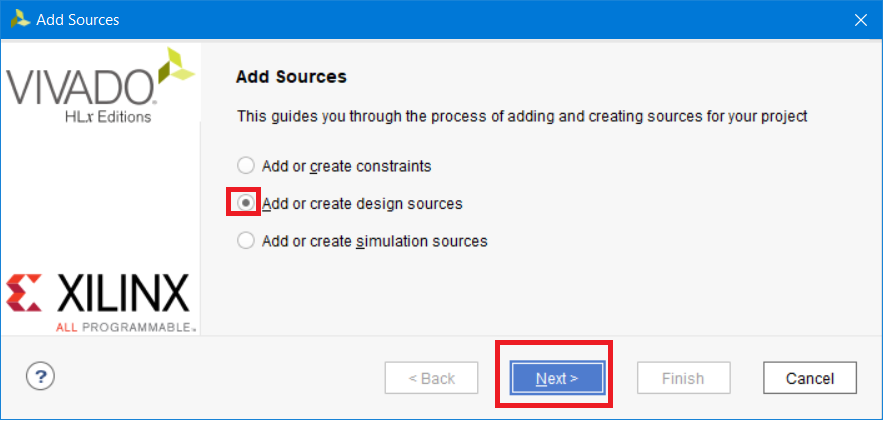
Рисунок 9 – Выбор типа, создаваемого или добавляемого файла
Выбираем Create file, после чего в появившемся окне в поле File name вводим имя создаваемого файла flash_led, нажимаем ОК (рис. 10).
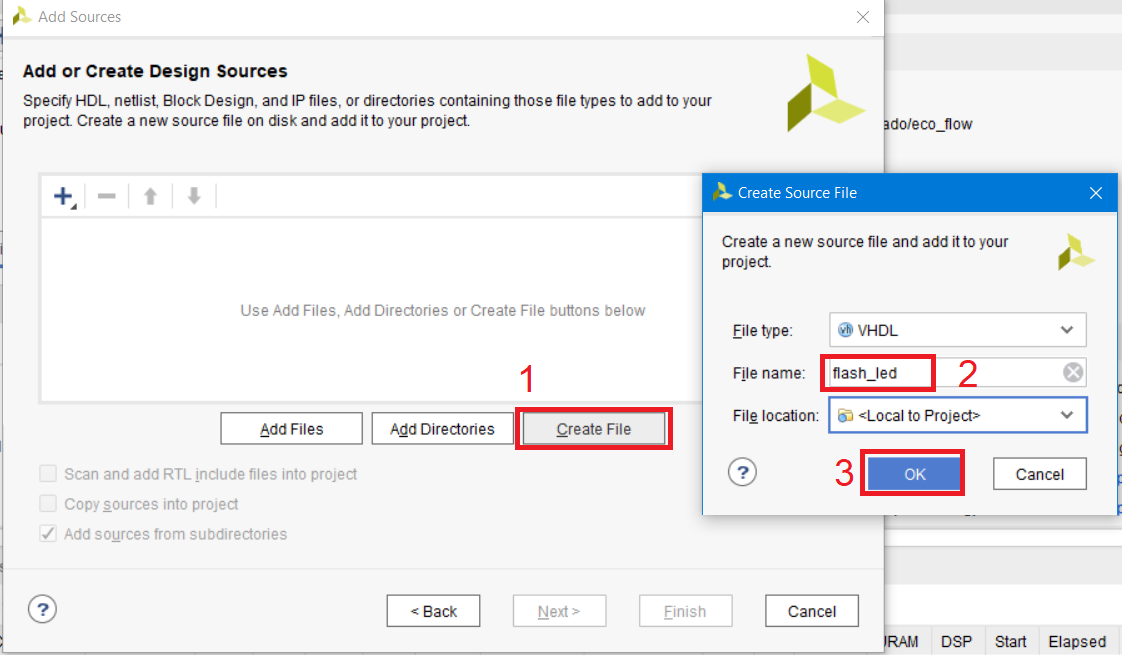
Рисунок 10 – Создание нового файла и ввод его имени
После этого фал появится в списке добавляемых. Нажимаем Finish (рис. 11)
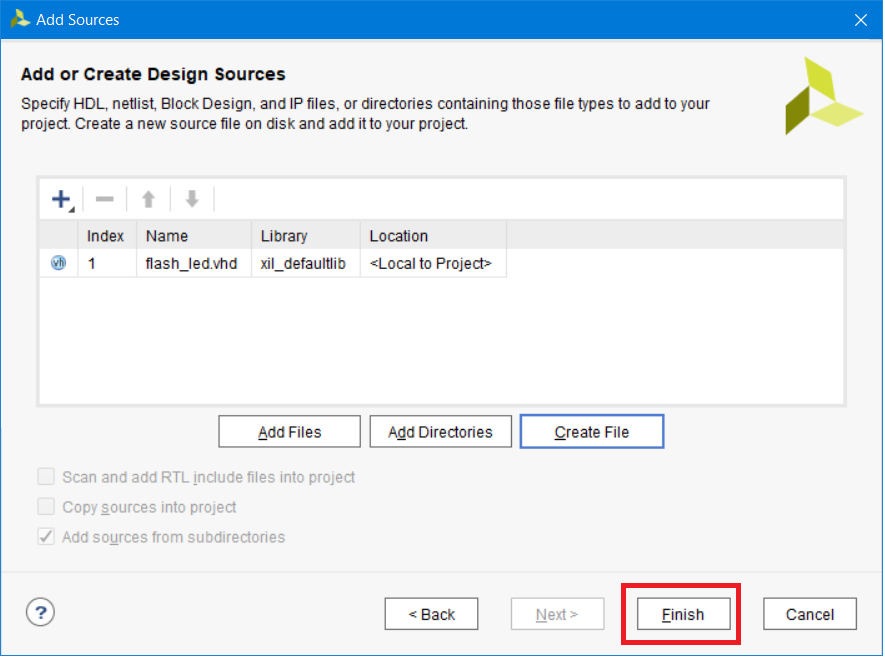
Рисунок 11 – Список добавляемых или создаваемых файлов
Теперь появился мастер создания шаблона для файла. Поскольку я использую VHDL, то я могу изменить имя архитектуры на rtl. Создаем два пина нашего модуля: iclk с направлением «in» (тактовый сигнал нашего модуля) и oled с направлением «out» (выход, подключаемый к светодиоду). Нажимаем ОК (рис. 12).
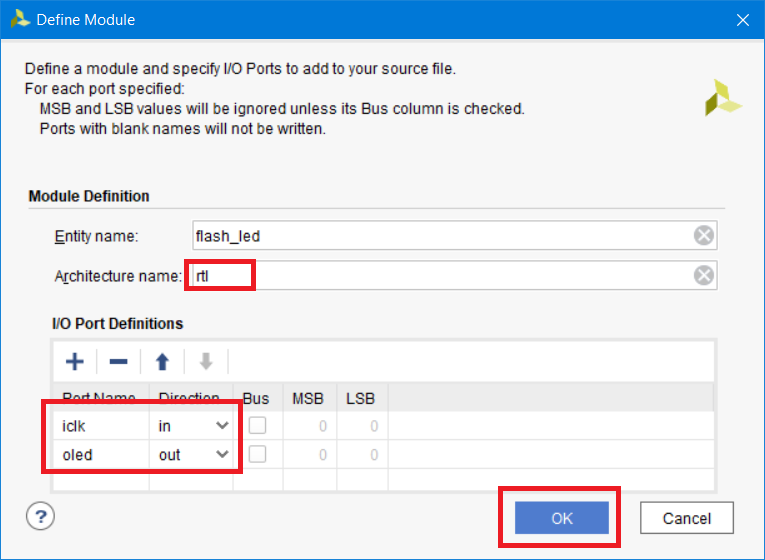
Рисунок 12 – Мастер создания шаблона модуля (для VHDL)
Теперь наш модуль находится в дереве проекта (рис. 13).
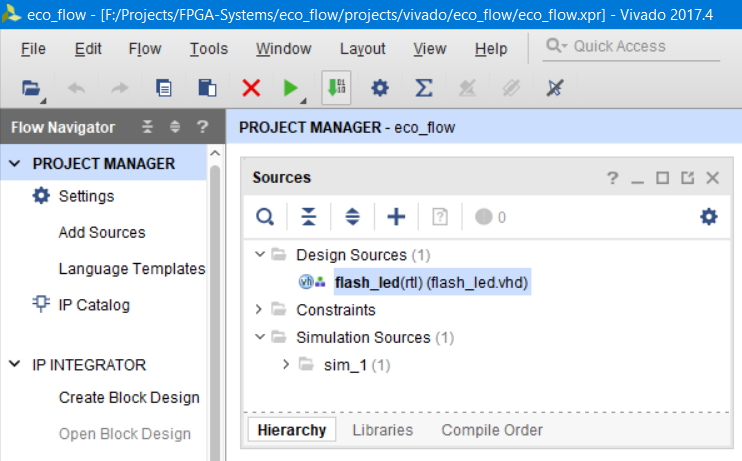
Рисунок 13 – Созданный модуль flash_led
Модуль должен выполнять простую функцию: просто моргать светодиодом с периодом в 1 секунду. Забегая вперед, скажу, что тактовая частота нашего проекта будет равна 100 МГц, а сам модуль Вам ещё пригодится при выполнении домашнего задания.
Замените содержимое файла на следующее (листинг 1 (текстовый варинт листинга 1 см. в приложении А)). Код достаточно прост, и не требует дополнительных комментариев для пояснения его работы.
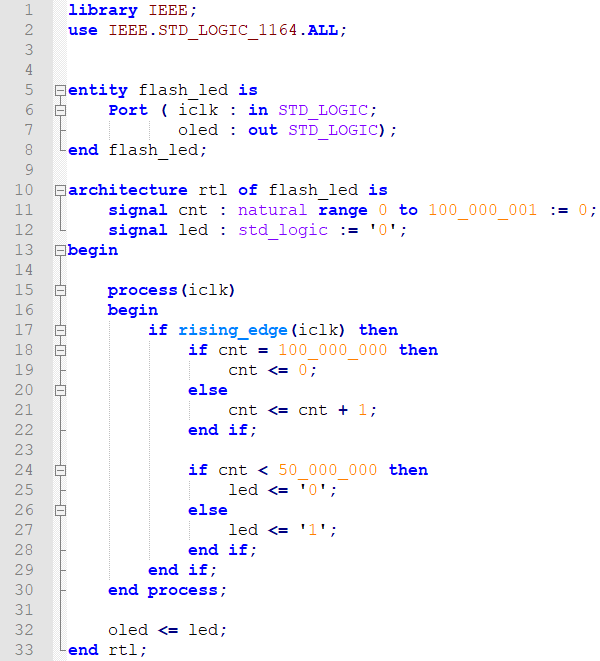
Листинг 1 – Код модуля flash_led
Теперь создайте новый модуль, который должен называться brom_reader, его порты iclk с направлением «in», и odout[7:0] с направлением «out» (повторите действия с рис. 8 по рис. 12).
Если все сделано правильно, то в дереве проекта должен появиться модуль brom_reader (рис. 14).
Рисунок 14 – Модуль brom_reader в дереве проекта
Замените содержимое модуля следующим текстом (листинг 2 (текстовый вариант листинга 2 см. в приложении Б)). Здесь потребуется несколько комментариев:
- Строка 13: типу std_logic_vector создается псевдоним. Те, кто работает с VHDL часто используют тип данных «std_logic_vector()». Чтобы каждый раз не писать эти длинные названия, можно объявить псевдоним (alias) и потом использовать его на протяжении всего кода модуля.
- Строки 14-20: стандартное объявление двухмерного массива натуральных чисел и инициализация массива (создается память с числами).
- Строка 22: использование псевдонима (alias) slv для объявления сигнала
- Строки 23-24: использование атрибута синтеза [11]. Для чего он здесь прописан? Мы создали достаточно маленький двумерный массив (строки 15-20) – и, вероятнее всего, во время синтеза он будет оптимизирован и реализован в виде распределённой памяти на LUT. А так как мы хотим разместить массив именно в блочной памяти (BRAM- Block RAM), нам необходимо об этом в явном виде сказать синтезатору, что и делается с помощью атрибутов синтеза. Подробнее о них читайте в руководстве по синтезу Vivado в [11].
В остальном все должно быть понятно: мы создали ROM-память, из которой непрерывно, последовательно и циклически считывается ее содержимое.
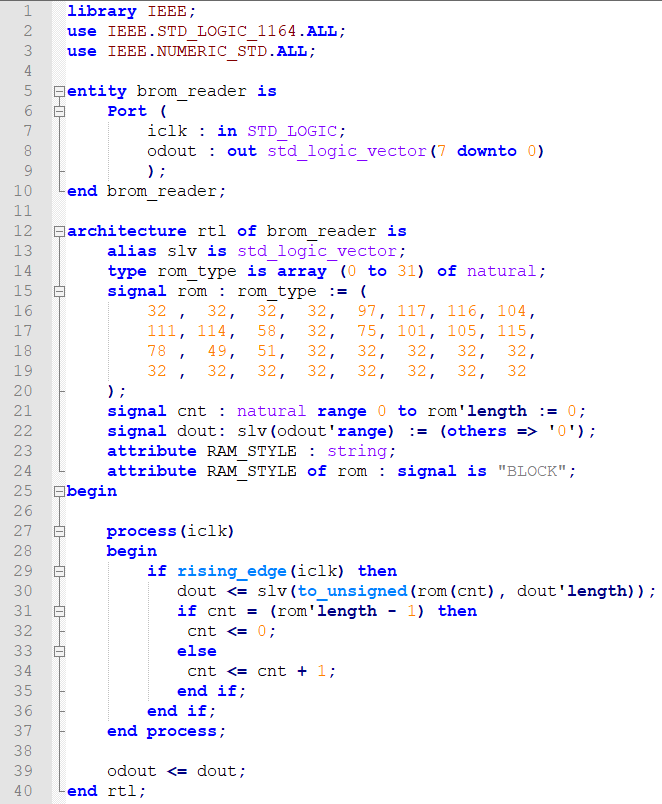
Листинг 2 – код модуля brom_reader
3.3. Создание проекта MicroBlaze и работа в IP Integrator
Теперь мы создадим проект с MicroBlaze. Еще раз обращу Ваше внимание на то, что есть пошаговое руководство на русском по созданию проектов на софт‑процессоре MicroBlaze для новичков [16].
Для создания блочного проекта необходимо создать Block Design. Выбираем Create Block Design, вводим имя system и нажимаем ОК (рис. 15).
Рисунок 15 – Создание нового Block Design и задание его имени
На поле Diagram добавляются ядра из IP каталога Vivado, либо RTL модули, написанные на VHDL/Verilog/SystemVerilog. Найдем в IP каталоге модуль MicroBlaze, для этого нажмите синий крестик и в поле поиска введите “MicroBlaze” и выберите его (рис. 16).
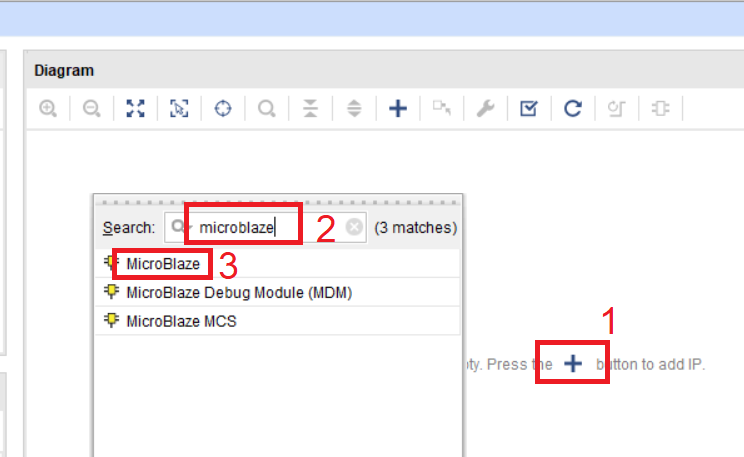
Рисунок 16 – Добавление IP ядра MicroBlaze на рабочее поле Diagram
После добавления MicroBlaze на рабочее поле, воспользуемся экспресс настройками софт-процессора. Выберите Run Block Automation и выставите настройки в соответствии с рис. 17. Нажмите ОК.
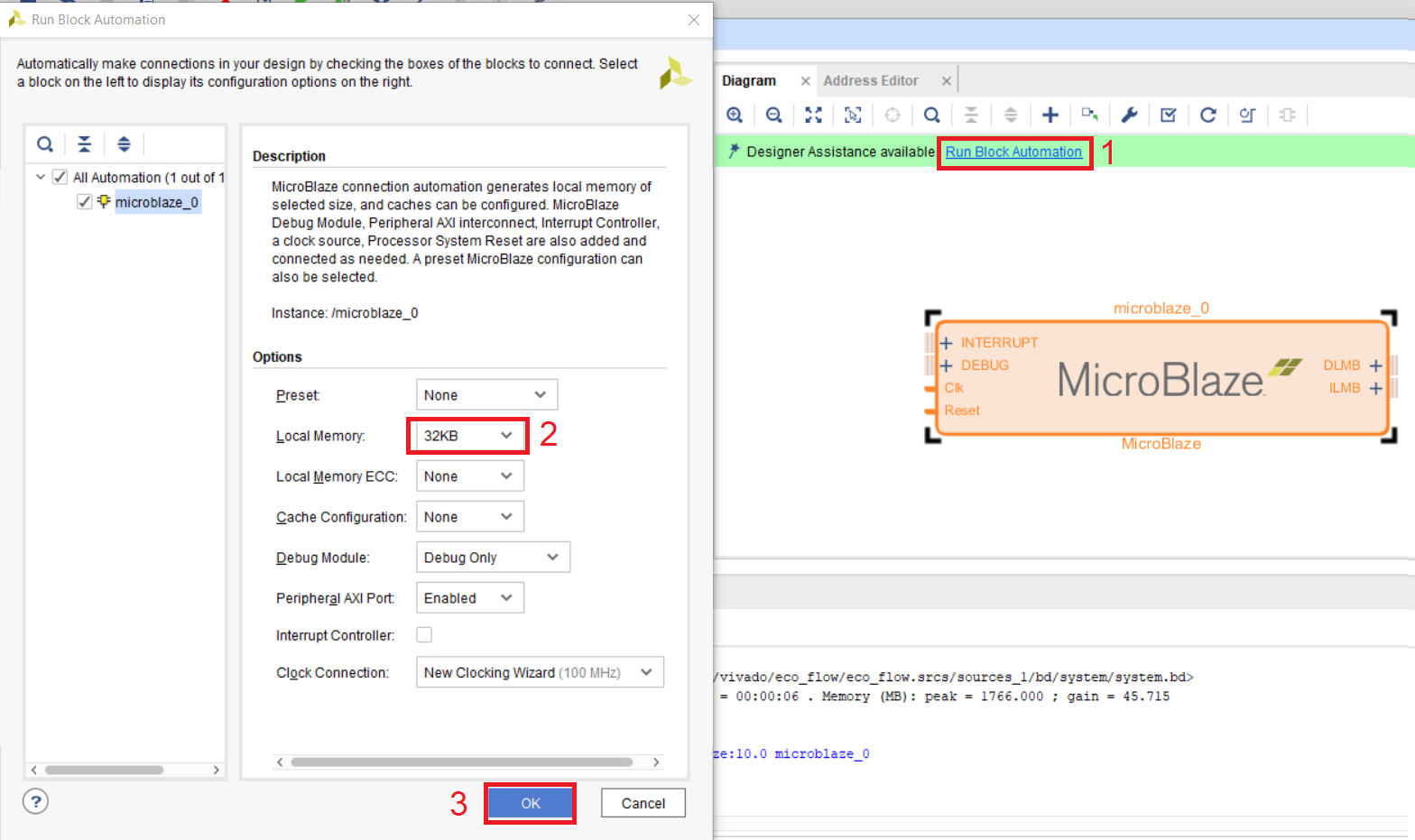
Рисунок 17 – Экспресс настройки MicroBlaze
После этого на рабочем поле Diagram появятся несколько новых IP ядер, включая генератор тактовых частот и локальную память процессора [11, 12]. Нажмите кнопку Regenerate для оптимизации рабочего поля (рис. 18).
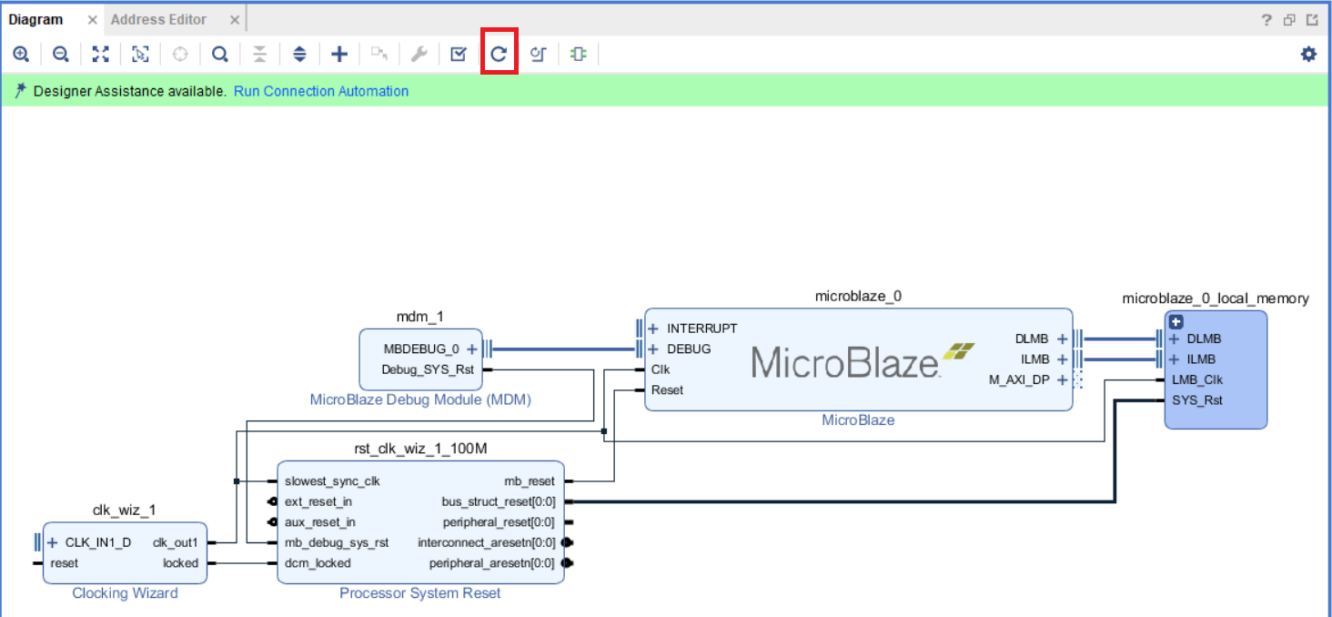
Рисунок 18 – Базовое включение MicroBlaze
Выполним настройку некоторых модулей в соответствии с нашей платой Arty. Настроим модуль генерирования сетки тактовых частот clk_wiz_1. Для вызова настроек модуля кликаем по нему два раза левой кнопкой мышки. В окне настроек устанавливаем значение входной тактовой частоты 100МГц, поскольку именно генератор на 100МГц установлен на плате [12]. Также устанавливаем тип источника как однополярный (рис. 19). Перейдём во вкладку Output Clocks, где настроим выходные частоты модуля.

Рисунок 19 – Настройка параметров входной частоты
Во вкладке Output Clocks мы зададим только одну частоту, основную частоту нашей процессорной системы и остальных модулей. Установим её равной 100МГц (рис. 20).
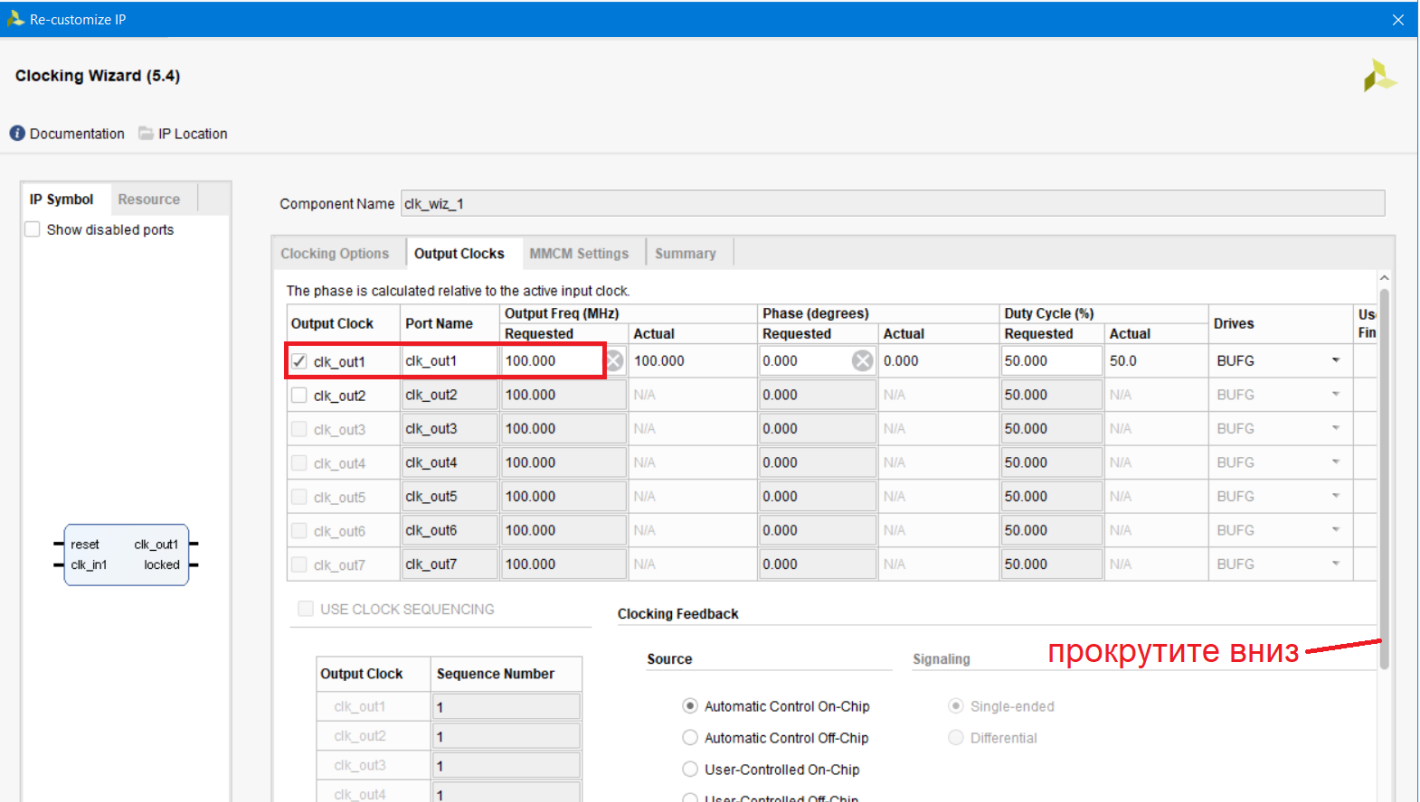
Рисунок 20 – настройка параметров выходной частоты
Прокрутите вниз для настройки дополнительных служебных сигналов. Мы уберем сигнал сброса Reset, который не будем использовать. Снимите с него галочку (рис. 21). Остальные настройки нам не нужны, нажимаем ОК.
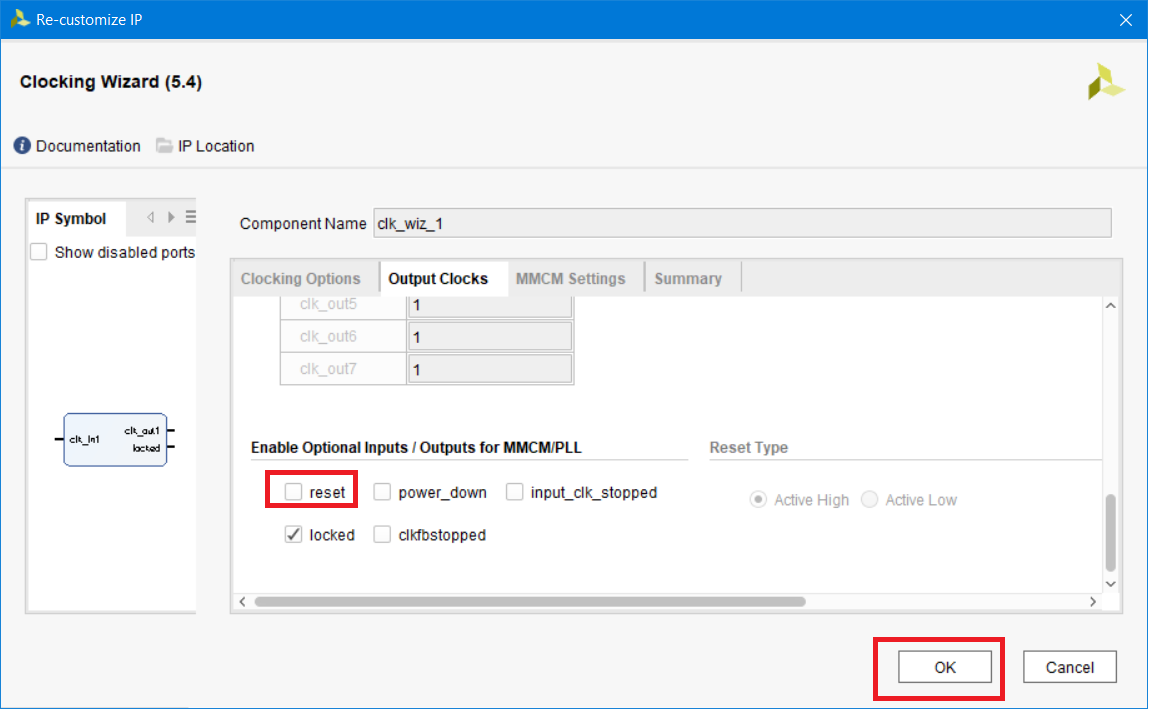
Рисунок 21 – Настройка служебных сигналов
Теперь объявляем вход clk_in1 модуля clk_wiz_1 внешним, фактически делаем из него input нашего Block Design. Для этого нажимаем на clk_in1 правой кнопкой мыши и выбираем Make External (рис. 22).
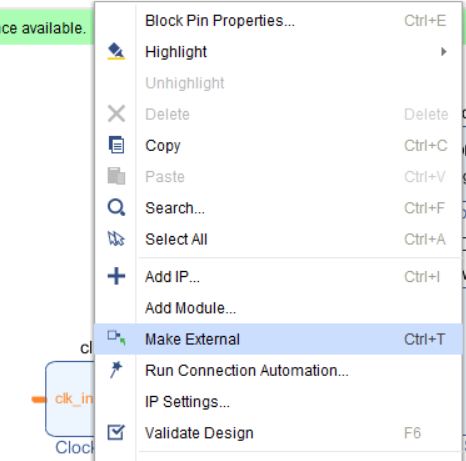
Рисунок 22 – Делаем порт clk_in1 внешним
Как видим появился порт clk_in1_0 (рис. 23).
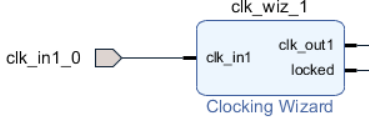
Рисунок 23 – Входной порт clk_in1_0
В модуле управления сбросом нашей процессорной системы подключим два неиспользуемых входа (внешний сброс и дополнительный сброс) к неактивному логическому уровню «1». Сделаем это с помощью IP блока, который называется constant. Для этого щелкнем синем крестике вверху, затем в строке поиска вводим «const»» и выберем модуль constant.

Рисунок 24 – Поиск IP блока constant в списке доступных IP
Выполним настройку модуля xlconstant_0, щелкнув по нему дважды левой кнопкой мыши. В строке значение (Const val ) вводим 1, в строке ширина (Const Width) вводим 1, нажимаем ОК (рис. 25)
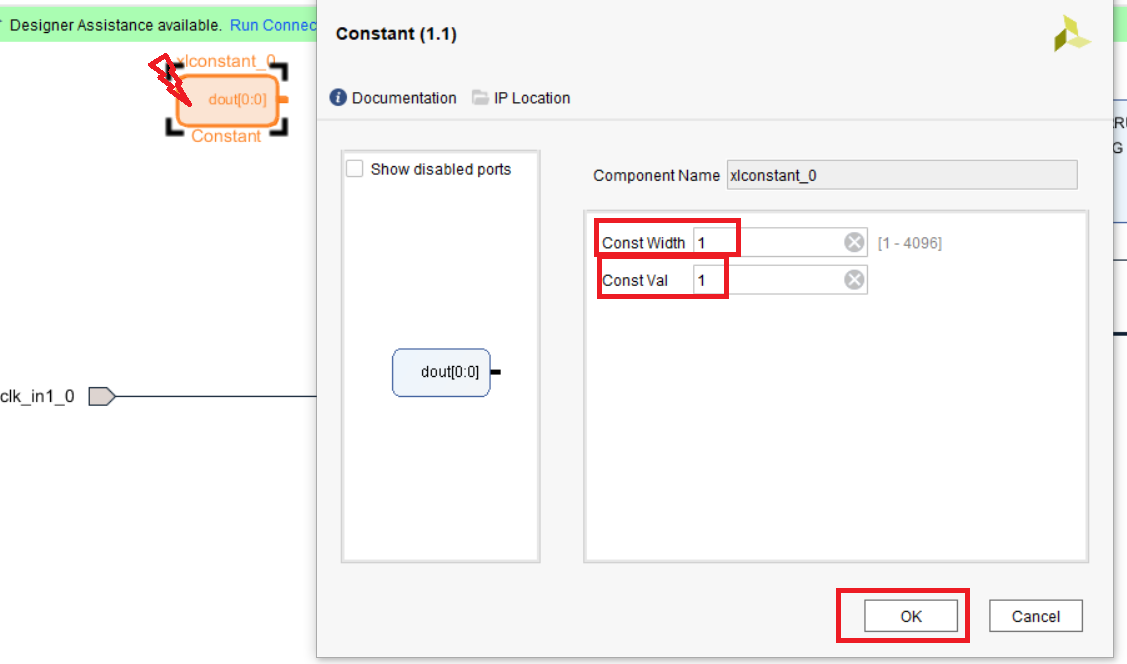
Рисунок 25 – Настройка модуля xlconstant_0
Выполним подключение выхода dout модуля xlconstant_0 ко входам ext_reset_in и aux_reset_in модуля rst_clk_wiz_1_100M. Просто соедините эти порты мышкой (рис. 26).

Рисунок 26 – Подключение неиспользуемых портов к константе
Добавим модуль UART, найдя его в каталоге доступных IP ядер (рис.27).
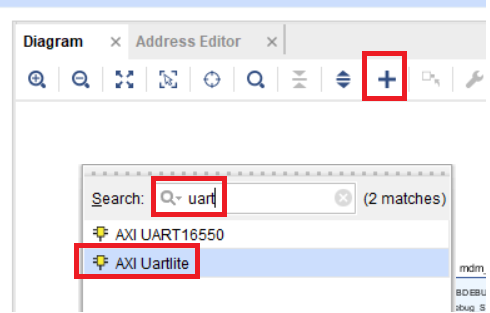
Рисунок 27 – Поиск модуля UART в списке доступных IP блоков
Выполним настройку модуля axi_uartlite_0, установив настройки передачи в соответствии с рис. 28. Затем нажимаем ОК.
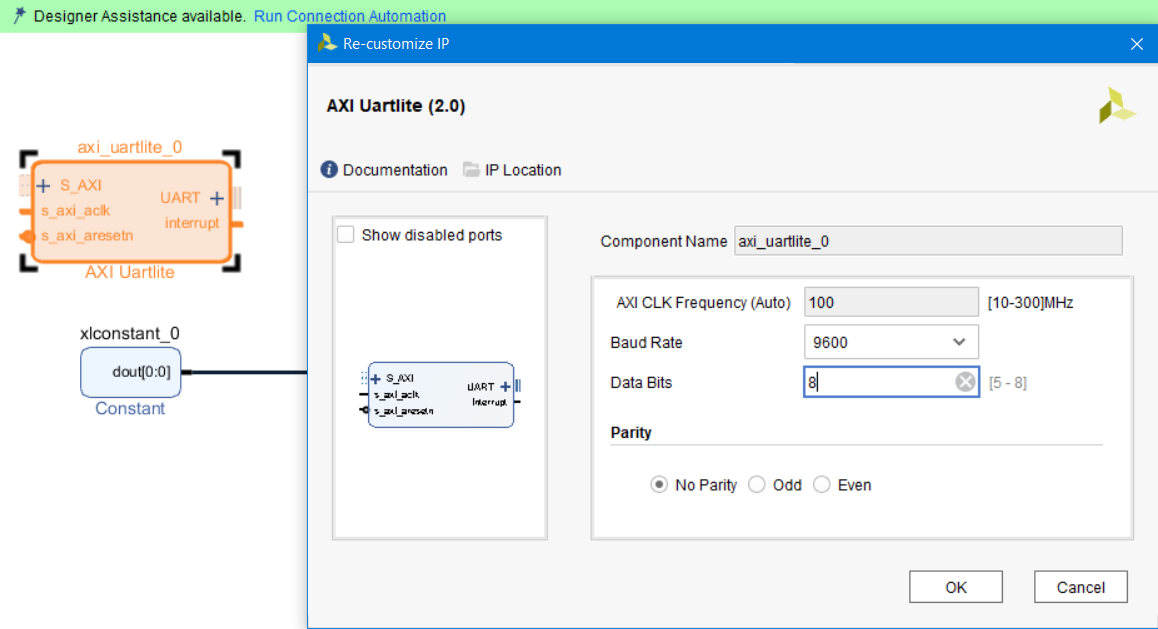
Рисунок 28 – Настройки модуля axi_uartlite_0
Теперь подключим модуль axi_uartlite_0 к процессору. Воспользуемся для этого автоматизированным методом. Нажимаем в верху Run Connection Automation и выбираем что к чему подключить (AXI вход UART к AXI MicroBlaze) рис. 29.

Рисунок 29 – Подключение axi_uartlite_0 к процессору
Интерфейс UART является стандартным и выделен в отдельный тип интерфейсов в Vivado IP Integrator. В пункте 2 на рис. 29 мы сказали, что хотим сделать rx и tx модуля axi_uartlite_0 внешними. Если вы раскроете интерфейс, то увидите это. Не смущайтесь, что в интерфейсе всего один синий провод, позже, когда создадим HDL обертку проекта, вы увидите, что там два порта (rx и tx).
Нажмите кнопку Regenerate Layout. После этого рабочее поле Block Design будет оптимизировано и схема примет ид, как на рис. 30. Убедитесь, что вы корректно выполнили подключение. Если на этом этапе все нормально, продолжим, если есть ошибки, выполните построение процессорной системы заново.
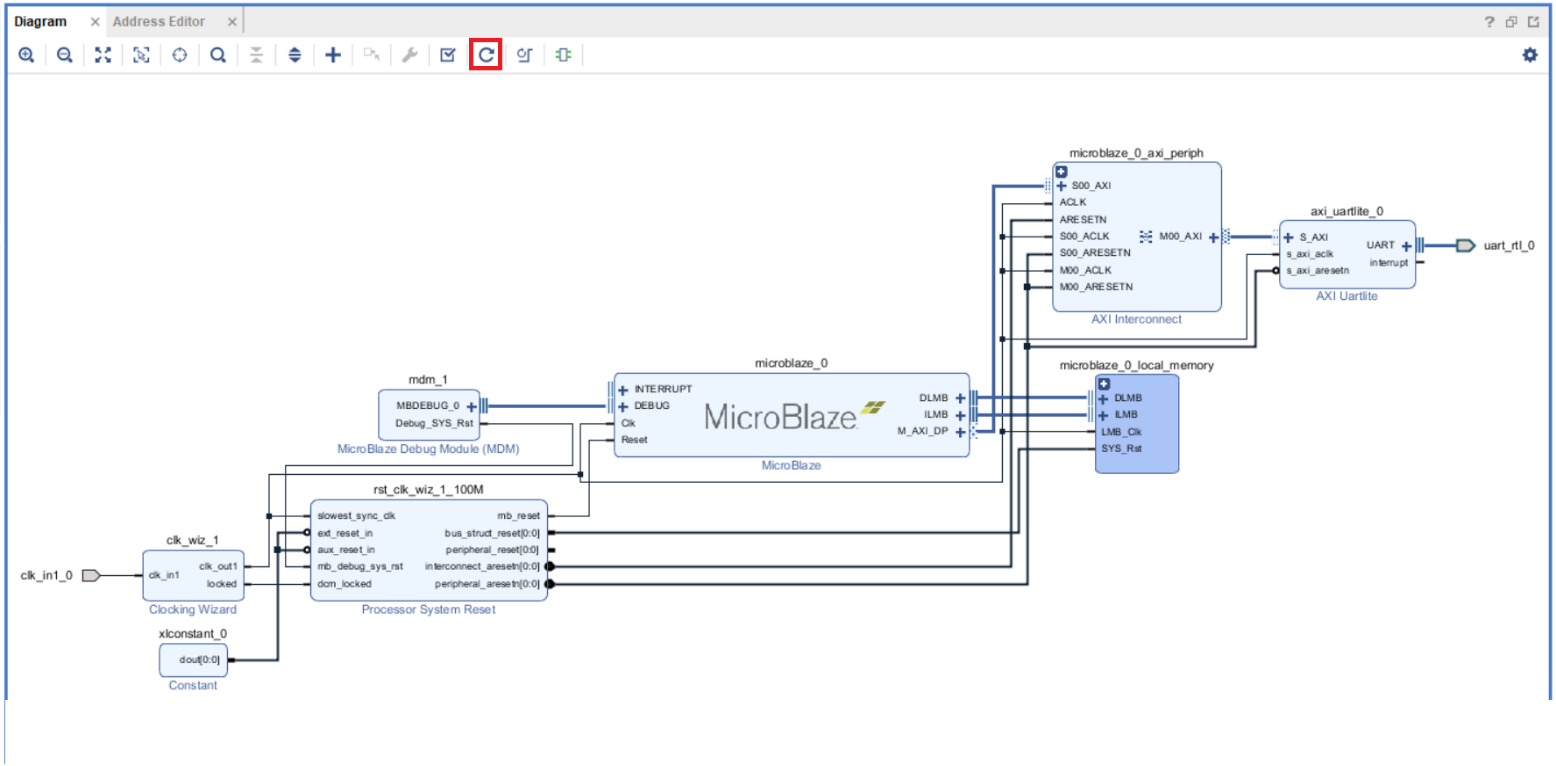
Рисунок 30 – Промежуточный этап сборки процессорной системы.
Давайте добавим еще один модуль на шину AXI. Это будет модуль GPIO, выход которого мы подключим на светодиод. Найдите в списке доступных IP блоков модуль AXI GPIO и добавьте его на рабочее поле (рис. 31).

Рисунок 31 – Модуль AXI GPIO в списке доступных IP
Выполните настройку модуля, в соответствии с рис. 32 (использовать будем только один канал и один выход).
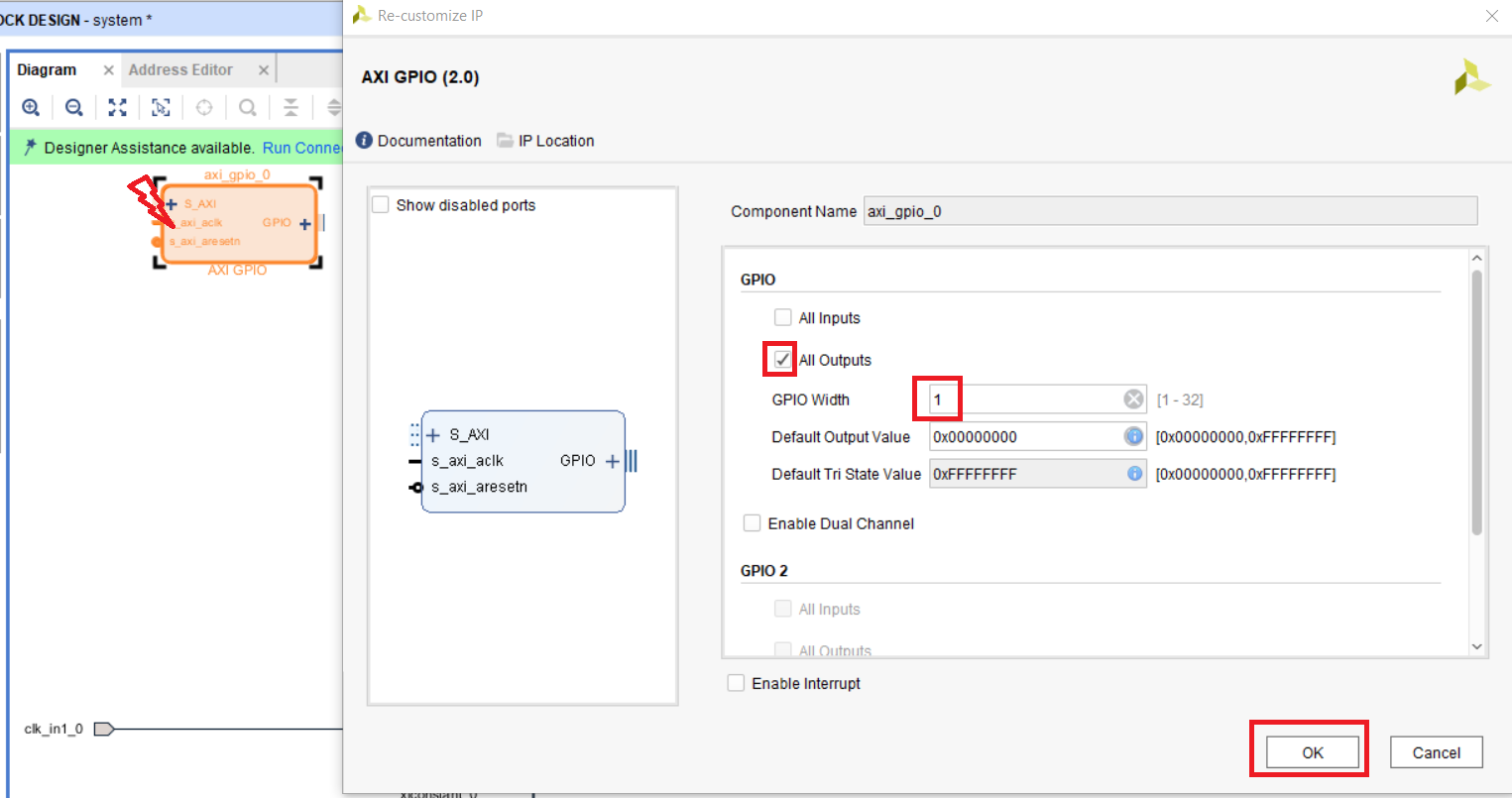
Рисунок 32 – Настройки модуля axi_gpio_0
Выполним подключение модуля axi_gpio_0 к процессору и сделаем выход внешним. Нажмите Run Connection Automation и поставьте все галочки (рис.33).

Рисунок 33 – Подключение axi_gpio_0 к процессору
Нажмите кнопку Regenerate Layout и убедитесь, что все подключения соответствуют рис. 34.
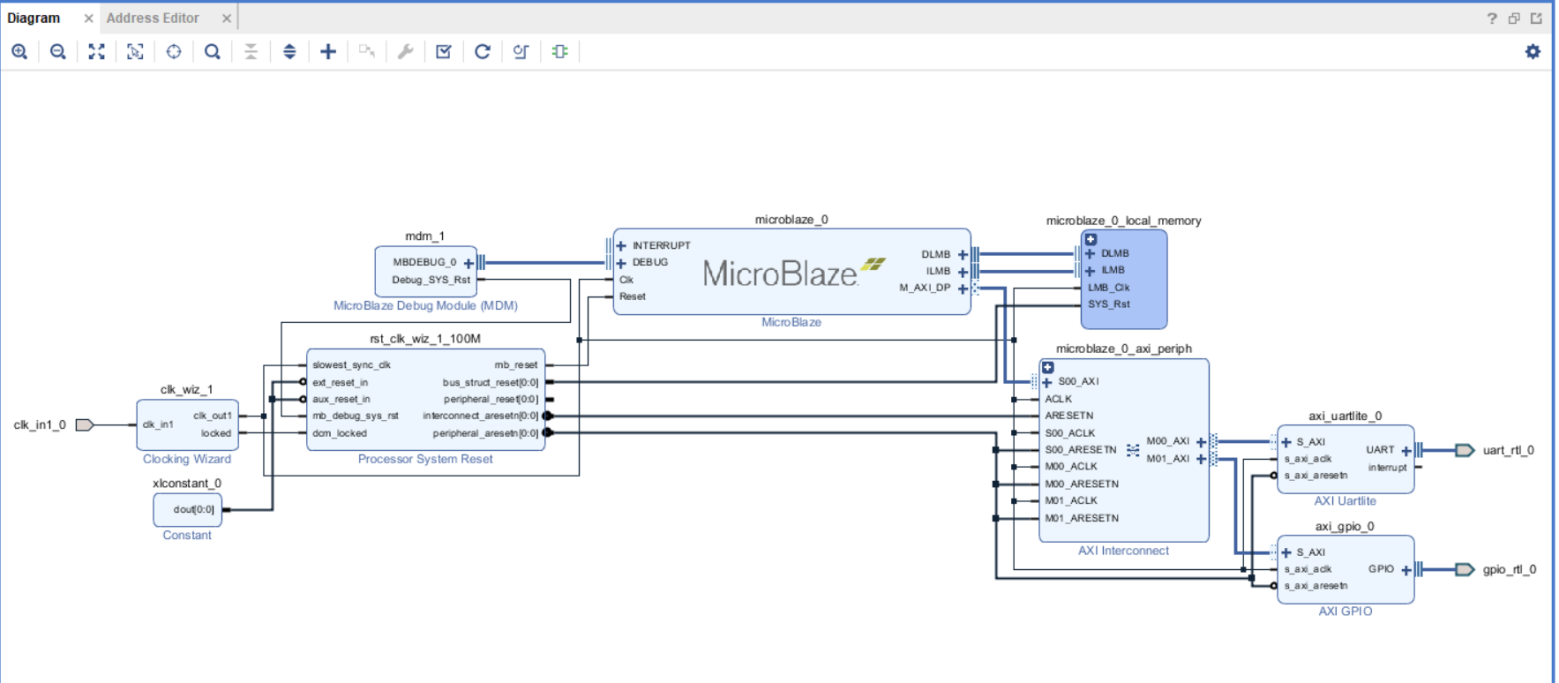
Рисунок 34 – Сборка процессорной cистемы.
Теперь добавим модуль отладки ILA. Предположим, что мы хотим просмотреть транзакции на шине AXI Lite для модуля UART. Находим в списке доступных IP модуль ILA (Integrated Logic Analyzer) рис. 35.
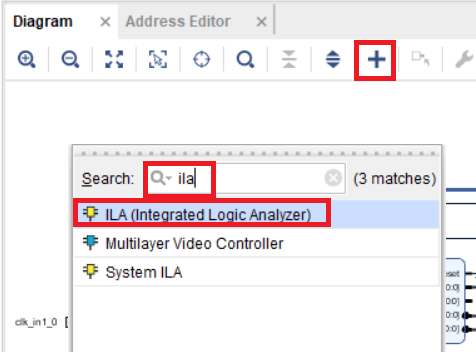
Рисунок 35 – IP блок ILA в списке доступных
Здесь мы используем некоторое подобие так называемого HDL Insertion Flow, когда модули отладки мы добавляем непосредственно в HDL код. Напомню, что выполнять поиск цепей для отладки вы можете и в нетлисте после синтеза. Такой подход называется Netlist Insertion Flow.
Так как мы хотим отлаживать AXI транзакции, то должны настроить тип пробника ILA как AXI (параметр Monitor Type в блоке ILA). Этот режим установлен по умолчанию, поэтому просто подключаем вход SLOT_0_AXI блока ila_0 к шине AXI, транзакции на которой мы хотим просмотреть. В нашем случае это шина, идущая от интерконнекта до модуля axi_uart_0 (рис. 36). Также подключаем тактовый сигнал для модуля к clk нашей системы и нажимаем кнопку Regenerate Layout.

Рисунок 36 – Подключение ila_0 к AXI шине axi_uart_0
По умолчанию длина записываемых данных установлена 1024, что вполне достаточно для просмотра транзакции.
Теперь добавим наши RTL модули в Block Design, для этого выберите модуль flash_led, нажмите правой кнопкой мыши и затем выберите Add Module to Block Design (это работает только в Vivado не ниже версии 2017.1).
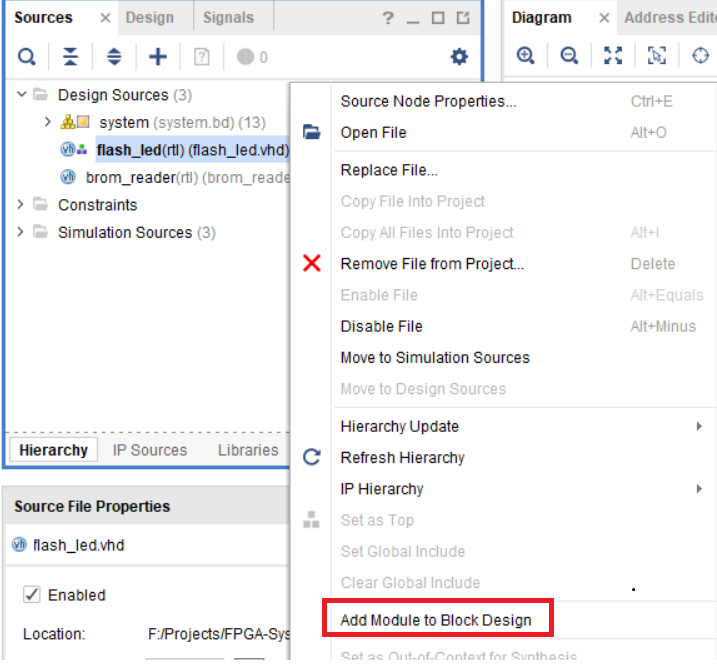
Рисунок 37 – добавление модуля flash_led на поле Diagram
Подключите вход iclk модуля flash_led_0 к тактовому сигналу нашей системы, а порт oled сделайте внешним (правой кнопкой мыши по порту, затем выберите Make Exernal). Нажимаем кнопку Regenerate Layout.
Если всё сделано корректно, то должно получиться как на рис. 38.
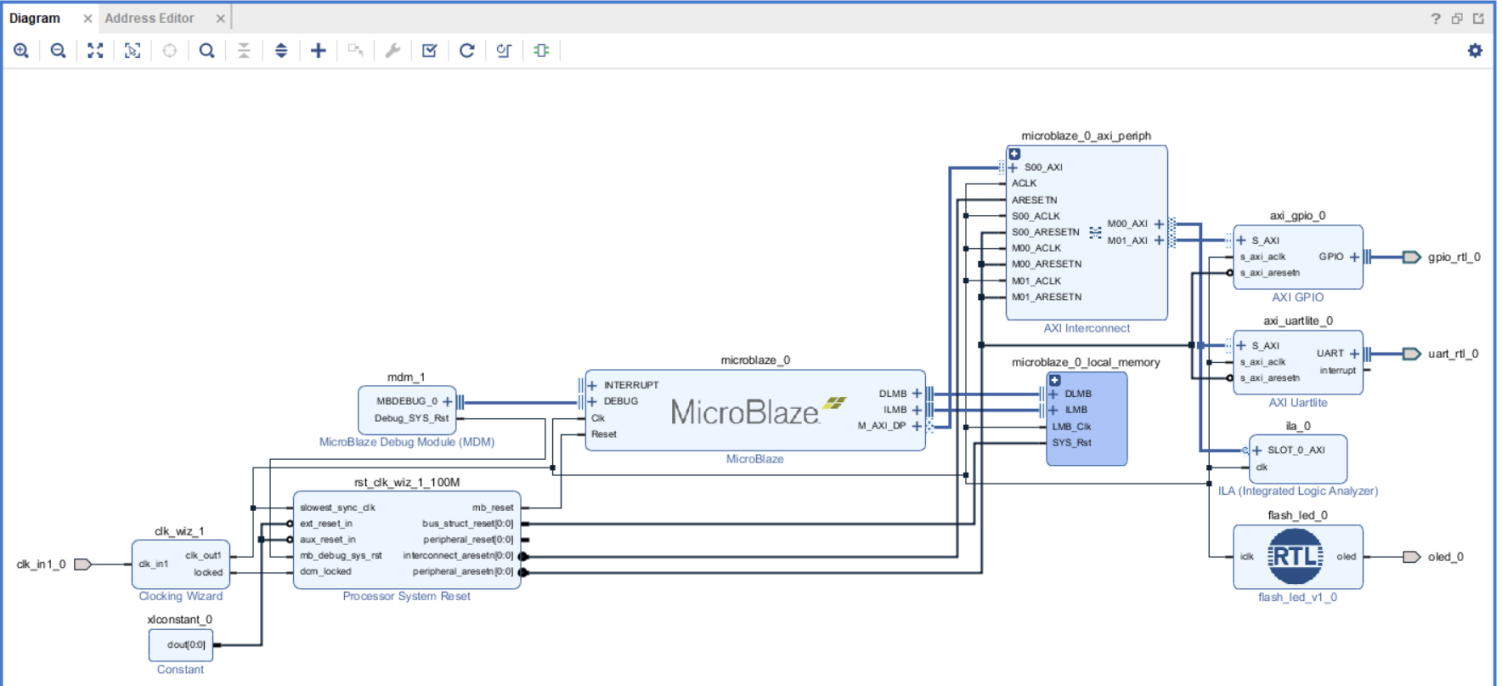
Рисунок 38 – Промежуточный этап построения проекта в IP Integrator
Повторите аналогичные действия, для добавления модуля brom_reader. Подключите его тактовый вход iclk к тактовой цепи, НО не объявляете выход odout[7:0] внешним. Нажмите Regenerate Layout. Если все сделано корректно, то должно получиться как на рис. 39.
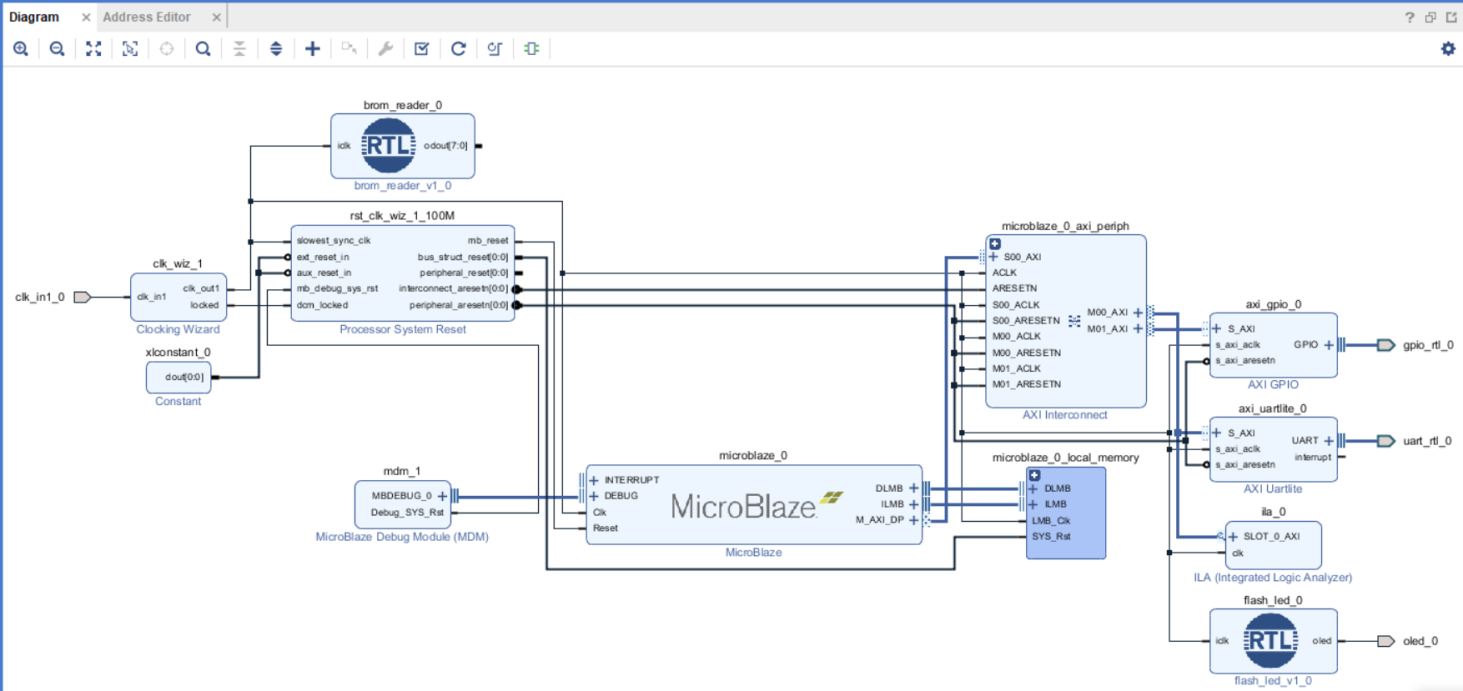
Рисунок 39 – Промежуточный этап построения проекта в IP Integrator
Теперь, добавим еще один ILA и подключим его к выходу odout[7:0] модуля brom_reader_0.
Находим IP блок ILA в списке доступных (рис. 35) и добавляем на поле Diagram. Выполним его настройку, дважды щелкнув по нему мышкой. Устанавливаем Monitor Type в значение Native (отлаживаем мы не шину AXI, а простые цепи). Остальное оставим по умолчанию. Перейдите во вкладку Probe_Ports(0..7) рис. 40.
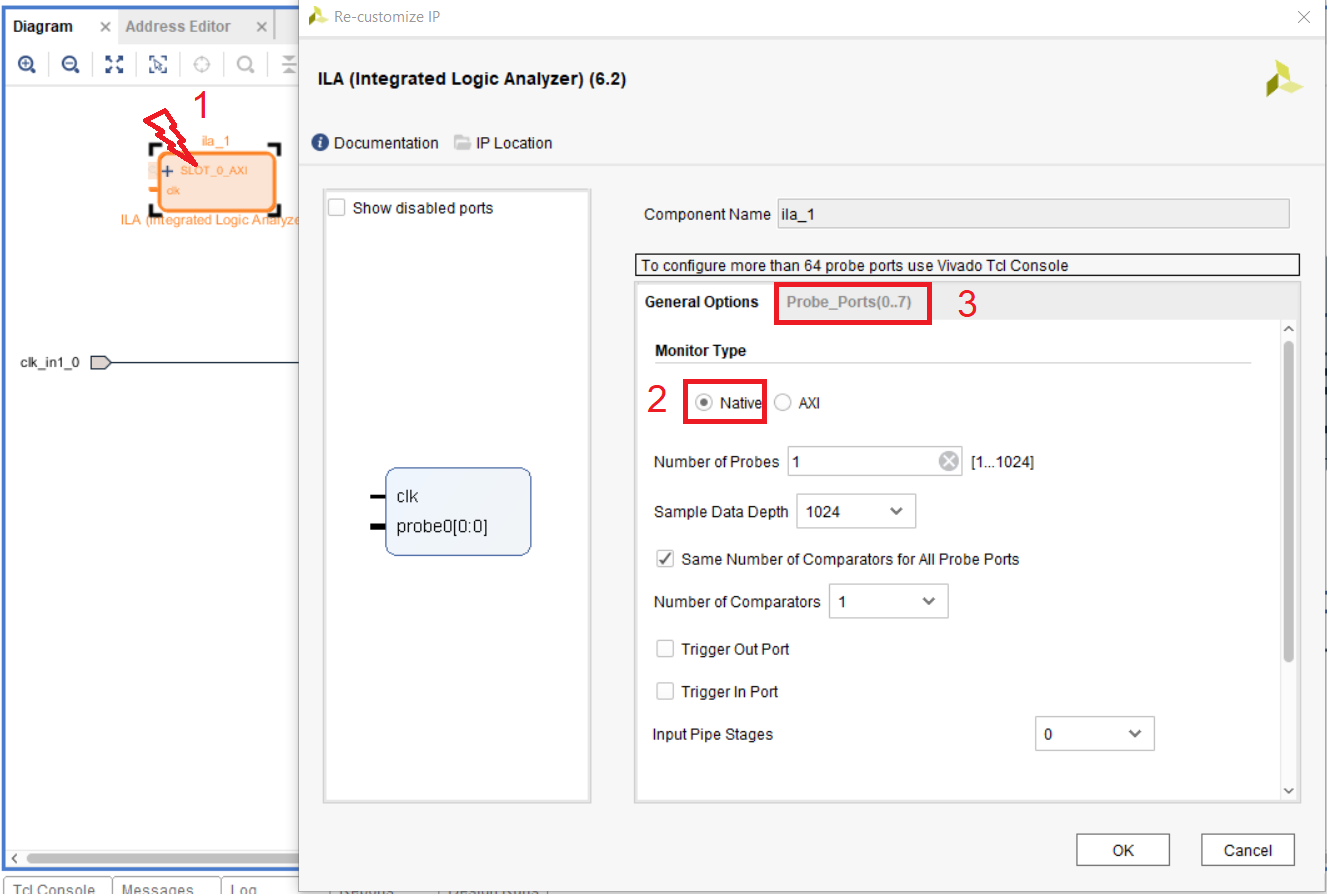
Рисунок 40 – Настройка ILA
Настроим ширину пробника. Установим значение ширины равное 8 (рис. 41), поскольку именно 8 бит – ширина шины выхода odout[7:0] модуля brom_reader_0. Нажимаем ОК.
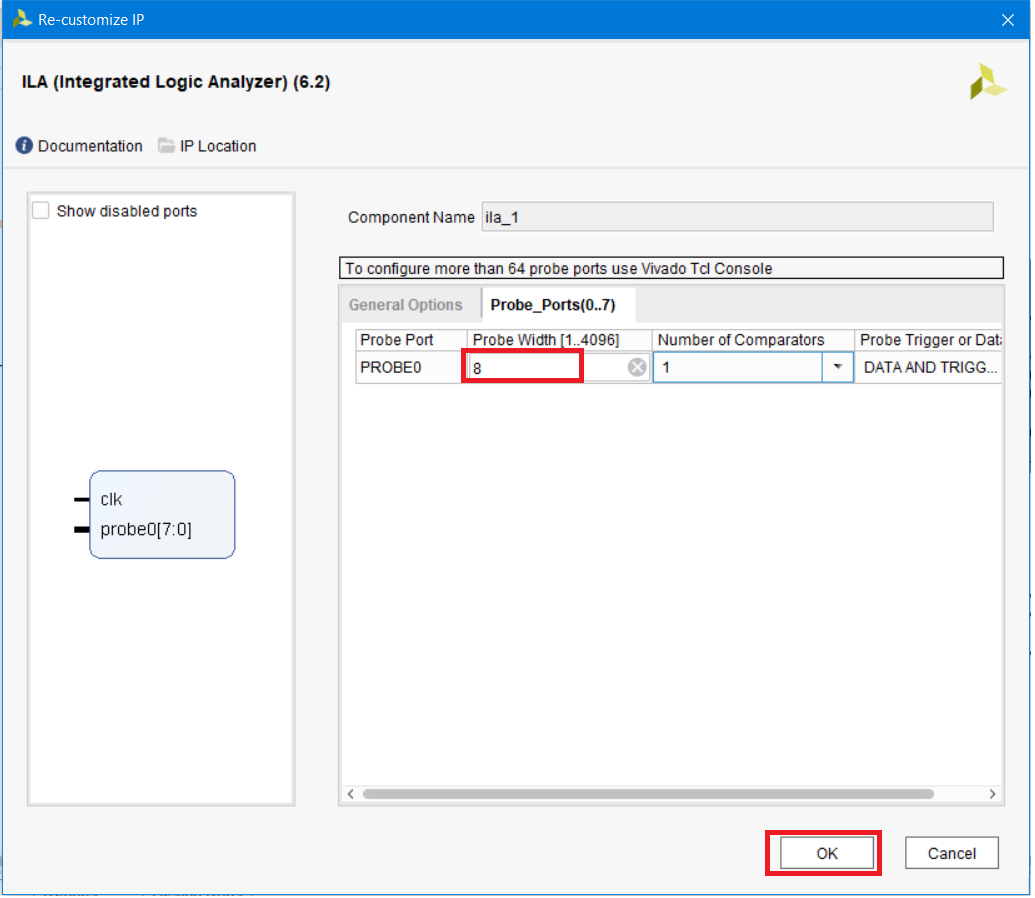
Рисунок 41 – Настройка ширины пробников ILA
Подключите выход odout[7:0] модуля brom_reader_0 ко входу probe_0[7:0] модуля ila_1, а вход clk модуля ila_1 подключите к тактовой цепи нашего проекта. Нажмите кнопку Regenerate Layout, и, если все корректно, должно получиться как на рис. 42.

Рисунок 42 –Промежуточный этап построения проекта в IP Integarator
Осталось только добавить кнопку и напрямую с ней включенный светодиод.
Создадим порт ввода, нажав на пустом месте нашей блок схемы правой кнопкой мыши и выбрав Create Port (рис. 43).

Рисунок 43 – Создание порта в IP Integrator
После появления мастера настроек порта, введите его имя ibtn, укажите направление input и, если нужно разрядность. Нажмите OK (рис. 44).
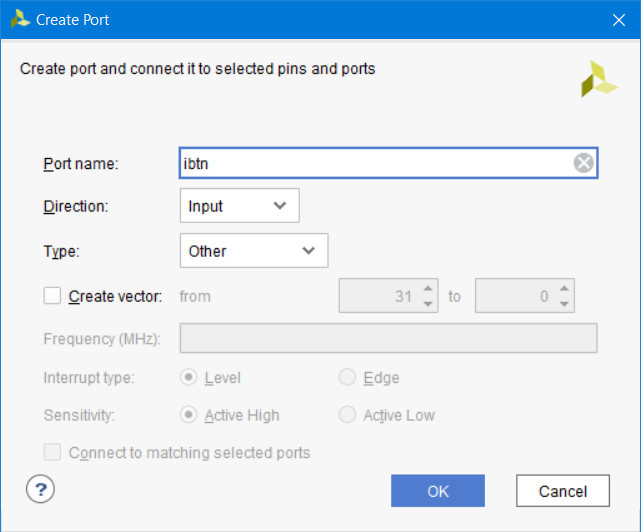
Рисунок 44 – Мастер настройки нового порта (кнопка ibtn)
После этого порт появится на поле Diagram (рис. 45).
Рисунок 45 – созданный порт ibtn
Создайте еще один порт с названием obtn_led, направлением output (повторите действия на рис. 43-44).
Теперь просто соединяем порт ibtn c obtn_led, нажимаем Regenerate Layout. Должно получиться как на рис. 47.
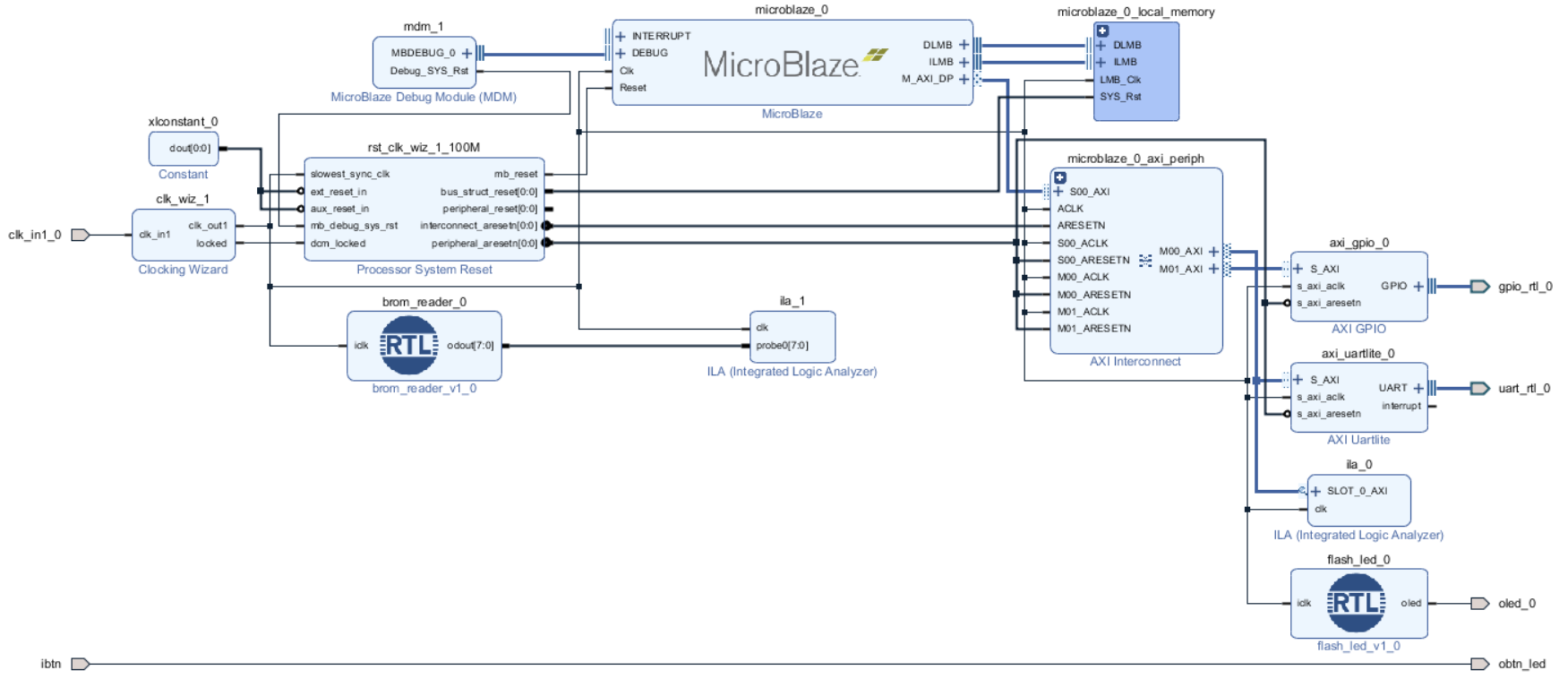
Рисунок 46 – Собранный проект в IP Integrator
Проверим, что нет ошибок в текущем Block Design, нажав на кнопку Validate Design. Если все корректно, но Vivado выдаст соответствующее сообщение. Нажимаем OK и сохраняем текущий Block Design (рис. 48).
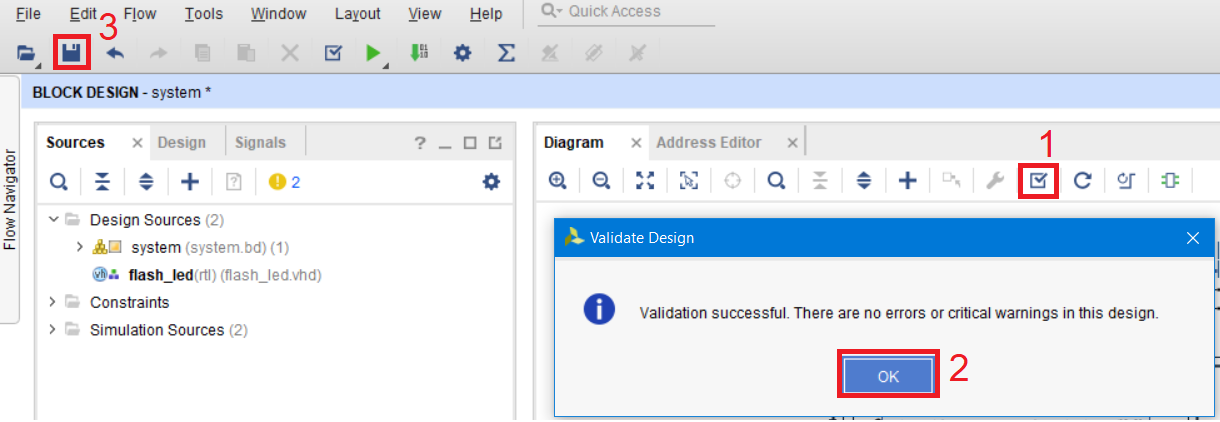
Рисунок 47 – Проверка корректности собранного проекта в IP Integrator
3.4. Синтез и имплементация
Перейдите во вкладку Sources, нажмите на system правой кнопкой мыши и выберите пункт Create HDL Wrapper (создать HDL обертку нашего Block Design) рис. 48.
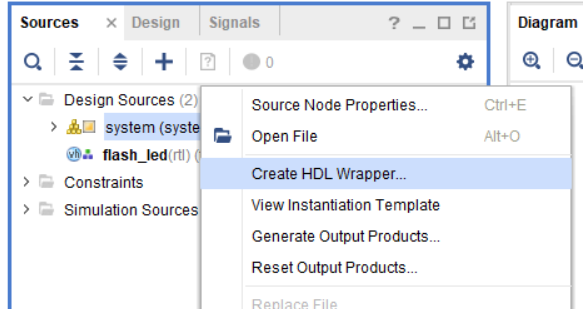
Рисунок 48 – Создание обертки проекта
После этого Vivado предложит либо обновлять вручную HDL обертку при внесении изменений в Block Design, либо делать это автоматически. Оставляем автоматическое обновление и нажимаем OK (рис. 49).
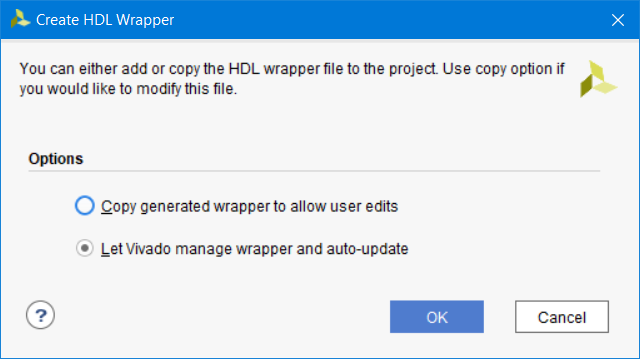
Рисунок 49 – Варианты обновления HDL обертки
Теперь укажем, что модуль system_wrapper является Top-модулем. Нажимаем правой кнопкой мыши на system_wrapper и выбираем Set as Top (рис. 50).
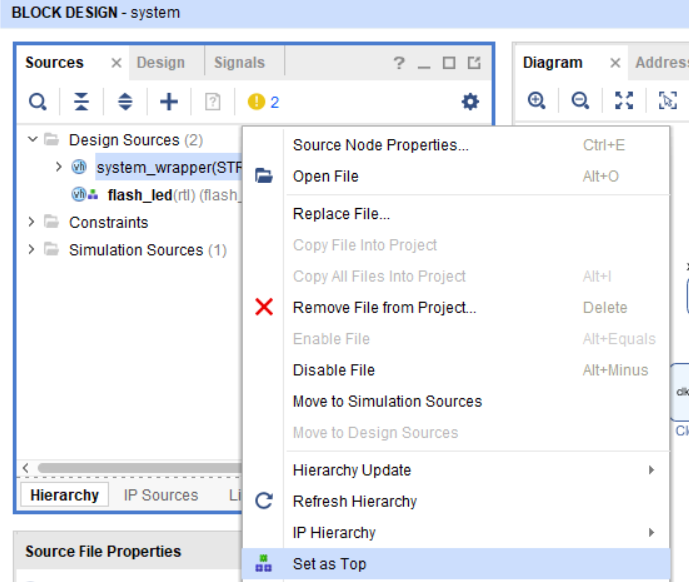
Рисунок 50 – Делаем модуль system_wrapper топ модулем
Теперь выполним синтез модуля system_wrapper, нажав на кнопку Run Synthesis (рис. 51).
Примечание: для подключения блоков отладки мы использовали фактически HDL Insertion Flow [4], то есть фактически вставляли в код наши ILA блоки и подключали к ним цепи. Нет никакой разницы как вы создаете и подключаете цепи для отладки: через HDL или Netlist. В конечном итоге ECO работает именно с синтезированным или имплементированным нетлистом, который хранится в Design Checkpoint.
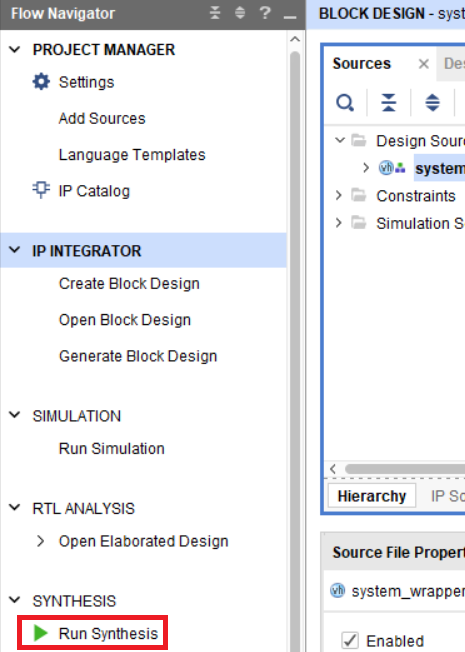
Рисунок 51 – Запуск синтеза проекта
После нажатия на кнопку Run Synthesis нажмите ОК и дождитесь окончания синтеза.
После окончания синтеза будет выведено окно, в котором будет предложено запустить имплементация, открыть результаты синтеза или посмотреть отчеты. Откройте результаты синтеза (рис. 52).

Рисунок 52 – Открытие результатов синтеза
Теперь подключим ножки в нашем проекте. Делается это с помощью Pin Planer. Чтобы его открыть нажмите Window→I/O Ports (рис. 54).
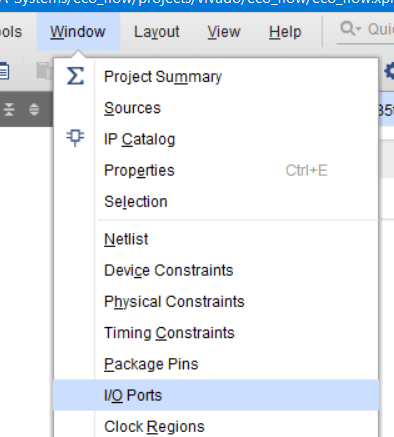
Рисунок 53 – Открытия окна для назначения пинов
Используя Reference Manual [12] для Arty назначим ножки (рис. 54).
БУДЬТЕ ВНИМАТЕЛЬНЫ!!! Я специально перепутал ножки для rx и tx модуля UART!
Назначьте ножки в соответствии с рис. 54.
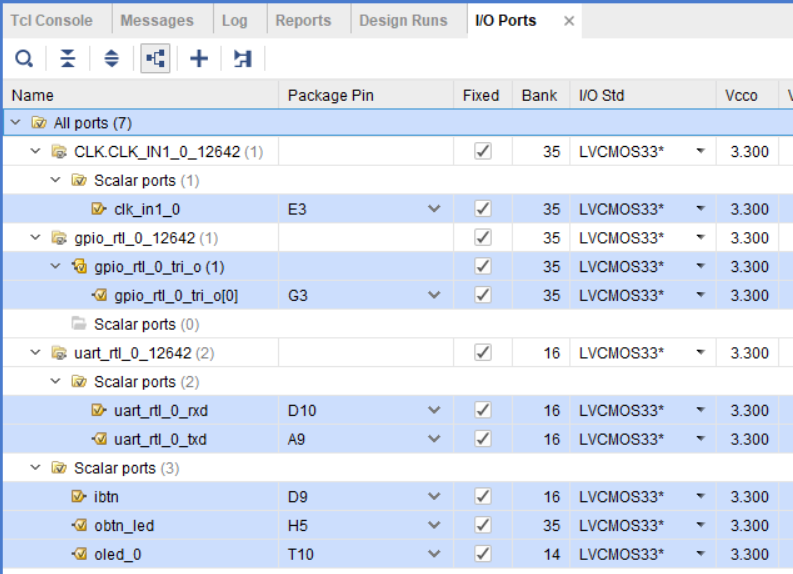
Рисунок 54 – Назначение ножек проекта (rx и tx UART перепутаны специально)
Нажмите кнопку сохранить, после чего Vivado укажет, что вы не создавали файл проектных ограничений, и предложит его создать Введите имя файла constr и нажмите ОК (рис. 55).
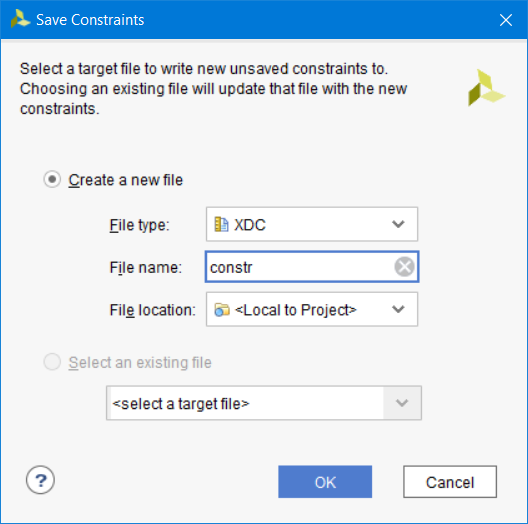
Рисунок 55 – Создание файла проектных ограничений
Теперь мы можем выполнить имплементацию нашего проекта и сгенерировать файл прошивки. Нажмите на кнопку Generate Bistream, затем OK и дождитесь окончания процедуры (рис. 56).

Рисунок 56 – Расположение кнопки Generate Bitstream
После окончания генерации Bitstream появится окно дальнейших действий. Нажмите Cancel (рис. 57)
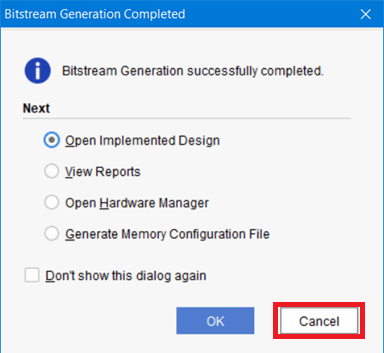
Рисунок 57 – Окно дальнейших действий после создания битсрима
3.5. Написание программы для MicroBlaze
Теперь выполним разработку ПО для MicroBlaze. Это выполняется в среде Xilinx Software Development Kit (SDK). Для того чтобы сообщить SDK информацию о собранной процессорной системе (IP ядрах, их адресации на шине AXI) необходимо выполнить экспорт в SDK. Это делается с помощь File → Export → Export Hardware (рис. 58).
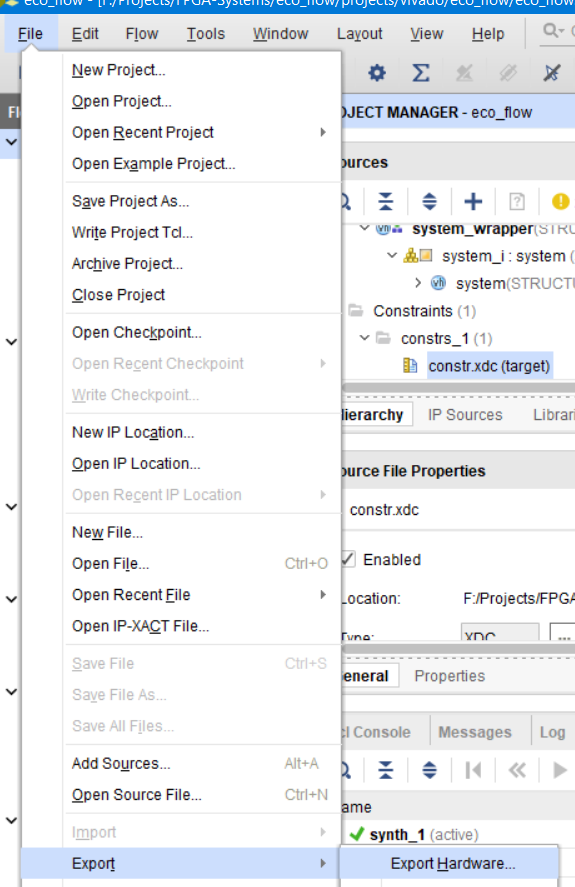
Рисунок 58 – Экспорт информации о процессорной системе в SDK
В появившемся окне не устанавливайте галочку Include Bitstream. Отставьте параметры по умолчанию и нажмите OK (рис. 59).
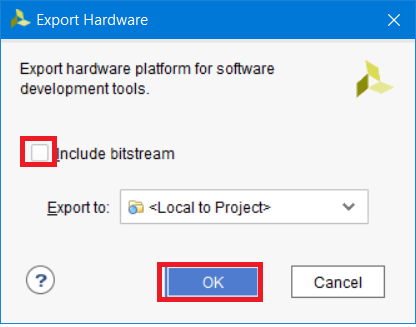
Рисунок 59 – Окно параметров экспорта
Теперь запустим SDK. Для этого выберите File → Launch SDK
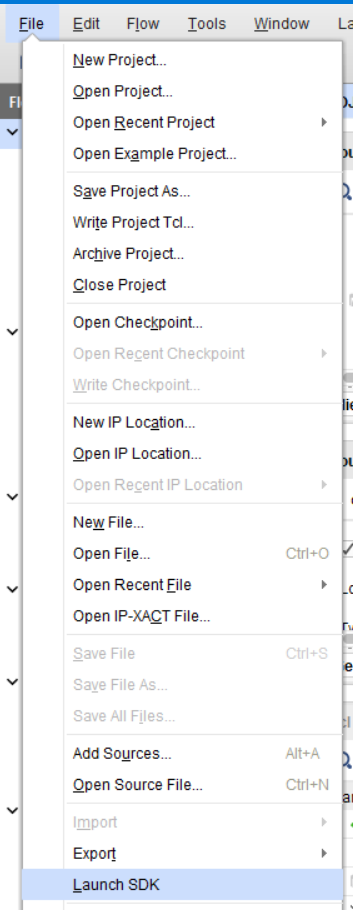
Рисунок 60 – запуск SDK
Дождитесь окончания выполнения служебных операций SDK. После их окончания можем приступить к созданию нового проекта. Выбираем File → New → Application Project.
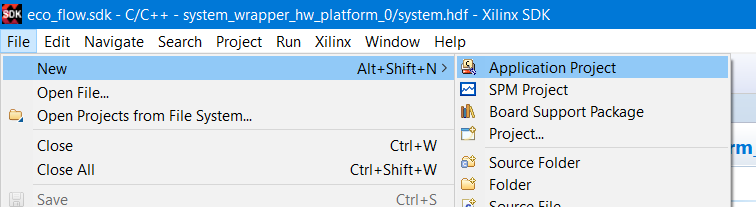
Рисунок 61 – Создание нового проекта в SDK
Введите название нового проекта MB_run, нажмите Next (рис. 62)
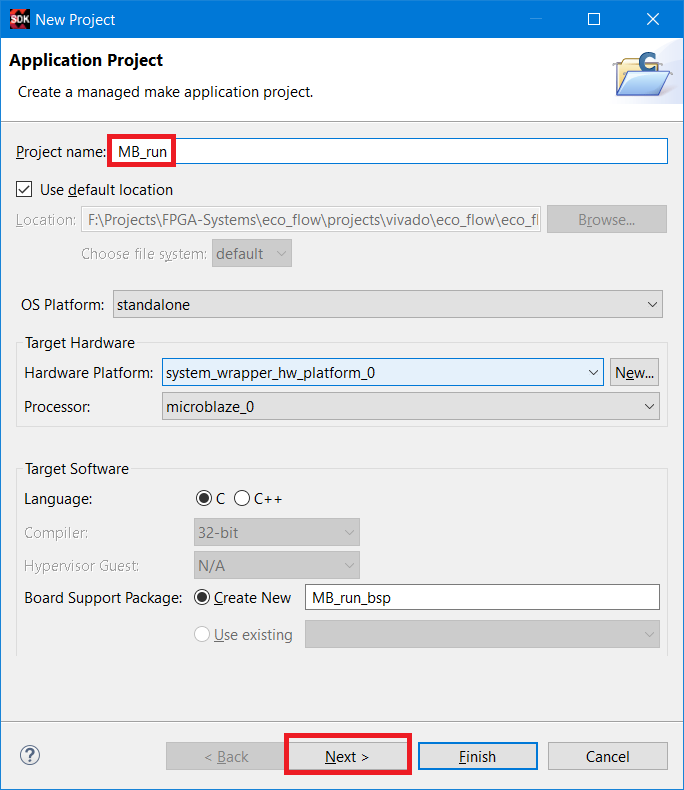
Рисунок 62 – Настройка нового проекта
В окне готовых шаблонов выберите создание приложения Hello World и нажмите Finish (рис. 63)
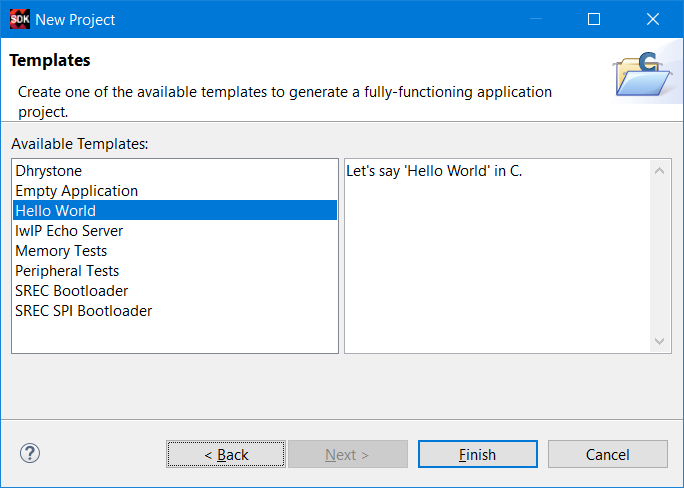
Рисунок 63 – Выбор шаблона создаваемого проекта
Откройте файл helloworld.c (расположение которого показано на рис. 64) и замените его содержимое кодом программы, показанным в листинге 3, и сохраните результат.
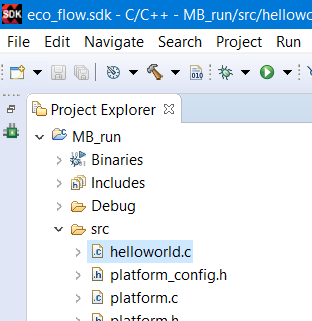
Рисунок 64 – Расположение файла helloworld.c
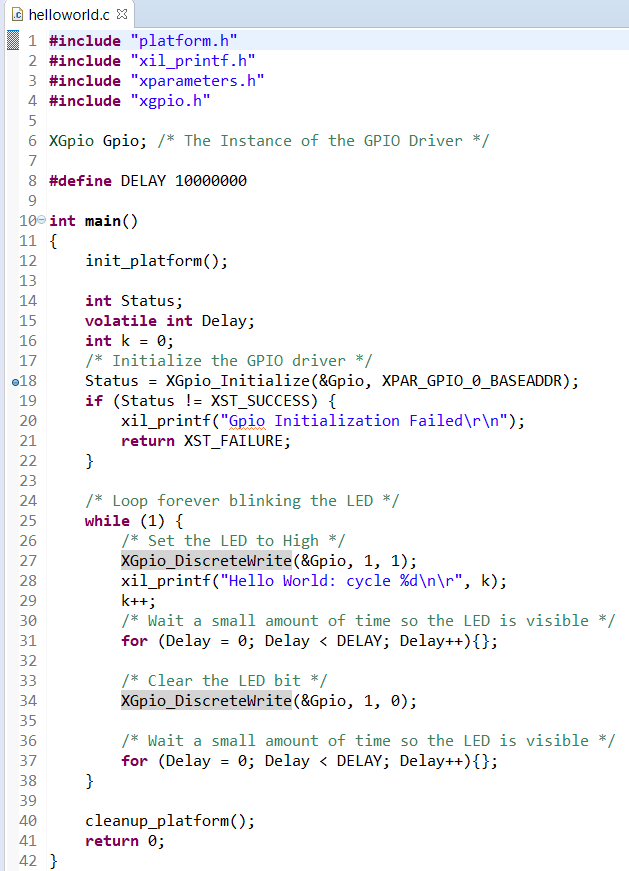
Листинг 3 – Заменённое содержимое файла helloworld.c
Программа отсылает «Hello World: cycle» примерно 1 раз в 2 секунды и моргает светодиодом LD1 (красной компонентой) также приблизительно 1 раз в 2 секунды.
3.6. Запуск программы и отладка
После завершения написания кода и сборки процессорной системы необходимо убедиться, что:
- Светодиод LD4 загорается по нажатию кнопки BTN0
- Процессор работает и шлет «Hello World: cycle» в консоль, однако мы не видим слов в консоли, поскольку выполнили неверное подключение rx и tx. Дополнительным сигнализатором работы процессора, является мигающий светодиод LD1.
- Выполняются транзакции по интерфейсу AXI-Lite от процессора до UART
- Блочная память считывается и выдает корректные значения.
Для начала подключаем Arty к компьютеру. Выполним настройку терминала, в котором должны будут показываться сообщения UART. Это можно сделать стандартными средствами SDK. В SDK имеется терминал, расположенный внизу (рис. 65).
Если терминала нет, то его можно найти в Window → Show View → Others → Xilinx → SDK Terminal (рис. 65).
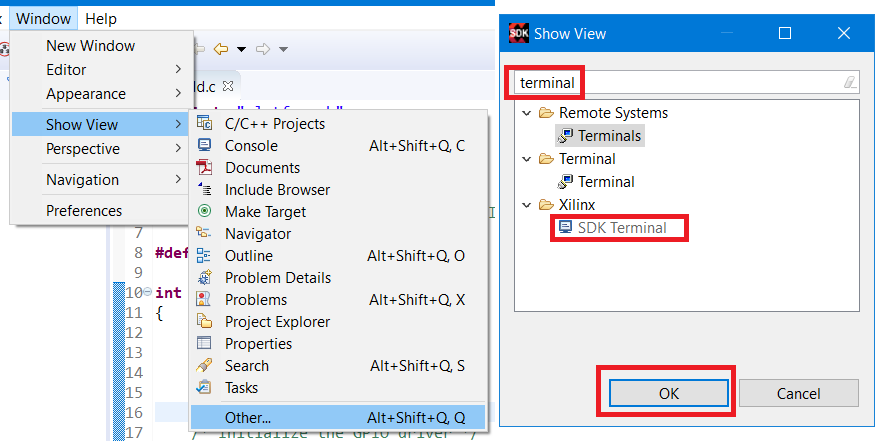
Рисунок 65 – Открытие встроенного терминала в SDK
Установите настройки терминала, в соответствии с рис. 66. Номер COM-порта может отличаться.

Рисунок 66 – Настройка SDK терминала
Теперь перейдём в Vivado и выполним программирование FPGA.
Нажимаем Open Hardware Manager и переходим в режим программирования и отладки. Выбираем Open Target и нажимаем автоматическое подсоединение Auto Connect (рис. 67)

Рисунок 67 – Открытие Hardware Manager и подключение в ПЛИС
Выбираем из списка наш кристалл и заливаем в него прошивку (рис. 68)
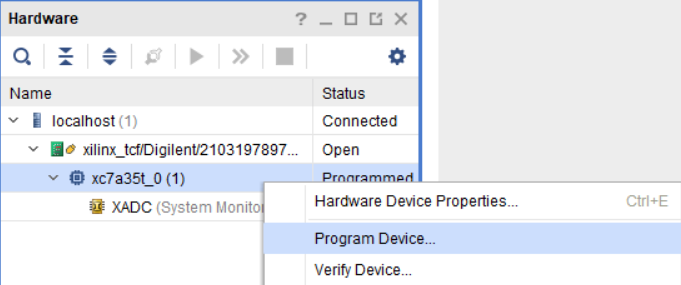
Рисунок 68 – Программирование ПЛИС
В появившемся диалоговом окне следует проверить, что выбраны нужные файлы прошивки .bit и список подключаемых цепей .ltx (рис.69) и затем нажать кнопку Program.

Рисунок 69 – Выбор файла прошивки и списка цепей
Если все сделано корректно, светодиод LD4 должен мигать, а по нажатию на кнопку BTN0 должен загораться светодиод LD4.
Теперь заставим процессор выполнять нашу программу по отправке данных в UART и мигать красной компонентой светодиода LD1.
Переключаемся обратно в SDK, кликаем правой кнопкой по нашему проекту MB_run, после чего выбираем Run As → Launch on Hardware (System Debugger), как показано на рис. 70. Мы заливаем сразу релиз программы, и не будем выполнять пошаговую отладку.
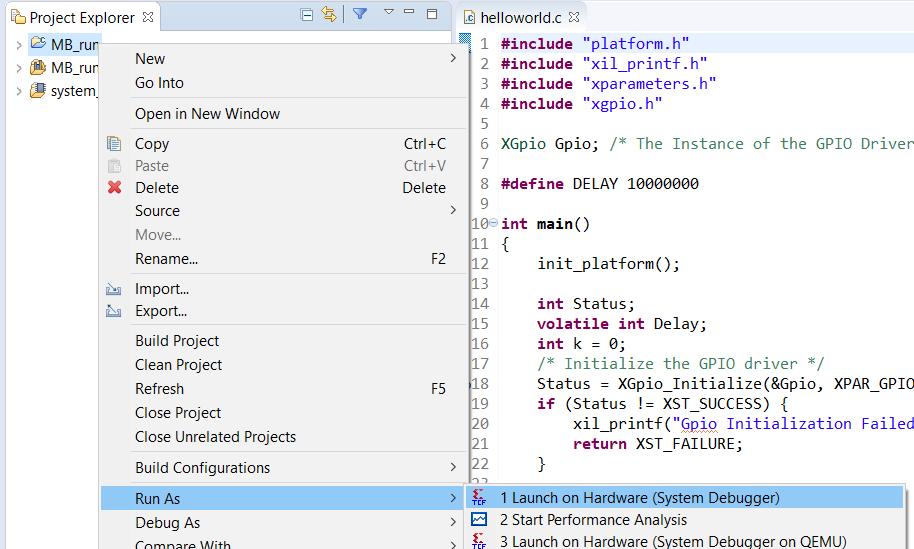
Рисунок 70 – Запуск исполняемой программы процессора
Подождав несколько секунд, видим, что светодиод LD1 мигает, но сообщения в SDK Terminal не появляются, поскольку rx и tx перепутаны.
Теперь давайте убедимся в том, что, транзакции до модуля UART всё-таки доходят.
Переключаемся в Vivado. Надеюсь, что вы помните, что мы подключали два ILA: один на транзакцию по шине AXI для UART, а второй к выходу блочной памяти. Но у нас в списке оказалось три ILA (рис. 71).

Рисунок 71 – Окно подключенных ILA
К сожалению, в результате оптимизации и синтеза, такое может случаться и это следует учитывать, как и то, что в результате оптимизации и различных настроек синтеза могут меняться названия цепей. Тем не менее, мы сможем провести отладку и убедиться, что транзакции до модуля UART все-таки доходят. Но нам нужно их «поймать», то есть настроить триггер, условие, по которому начнется запись состояния линий, к которым подключен ILA.
Дважды кликните мышкой по hw_ila_1 чтобы открыть окно временных диаграмм и окна настроек.
В окне Trigger Setup установите, триггер. Нажмите на синий крестик и в списке доступных цепей выберите цепь, показанную на рис. 72. И нажмите OK.
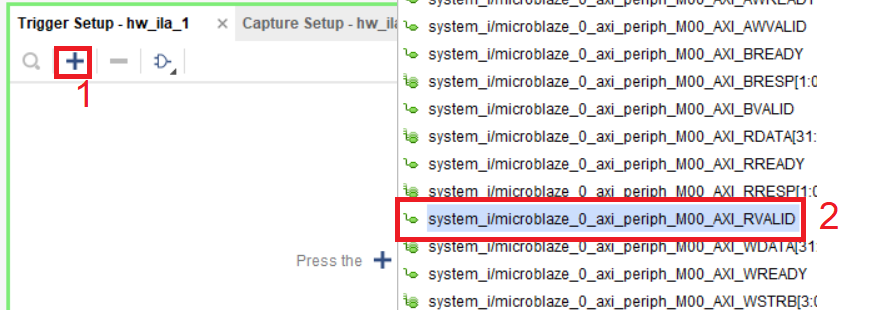
Рисунок 72 – Выбор триггера для запуска ILA
Примечание: мы работаем с интерфейсом AXI-Lite, в котором достаточно много сигналов. Не буду расписывать здесь функции, которые возложены на те или иные сигналы интерфейса. Если Вам интересно подробнее узнать об этом, пожалуйста, обратитесь к руководству [14].
Теперь установим параметры срабатывания триггера. Поскольку активный уровень сигала RVALID это «1», то скажем, что необходимо начать запись, когда этот сигнал будет равен «1». Установите значение срабатывания, как показано на рис. 73. И затем нажмите кнопку запуска триггера.

Рисунок 73 – Запись данных с ILA по срабатыванию триггера
Теперь, из этого гигантского списка цепей, которые имеются в интерфейсе найдем шину, которая отвечает за данные. Эта шина показана на рис. 74
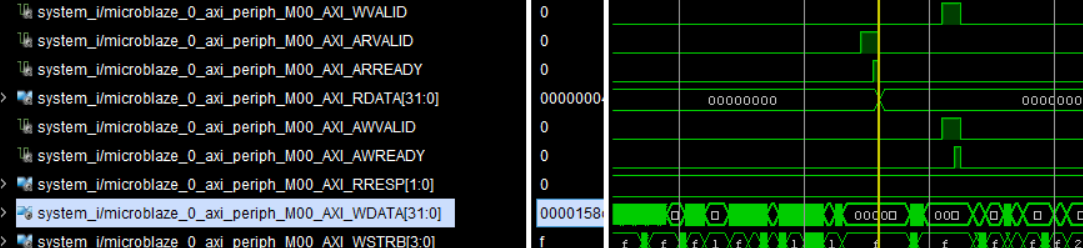
Рисунок 74 – Цепь с данными на шине AXI-Lite
Измените отображаемое состояние шины на ASCII. Для этого кликните правой кнопкой мыши по шине, затем выберите Radix, затем ASCII (рис. 76).

Рисунок 75 – Выбор представления данных на шине *WDATA[31:0]
После этого мы увидим на шине часть нашего сообщения, которое отсылает процессор. Это частично подтверждает, что транзакция проходит корректно (рис. 76).

Рисунок 76 – ASCII представление данных на шине *WDATA[31:0]
Попробуйте повторить самостоятельно действия с рис.71 по рис. 76 для hw_ila_2, который подключён к выходу модуля чтения блочной памяти. Устанавливать триггер не требуется. Если всё будет сделано корректно, то картинка должна быть аналогичной рис. 77.
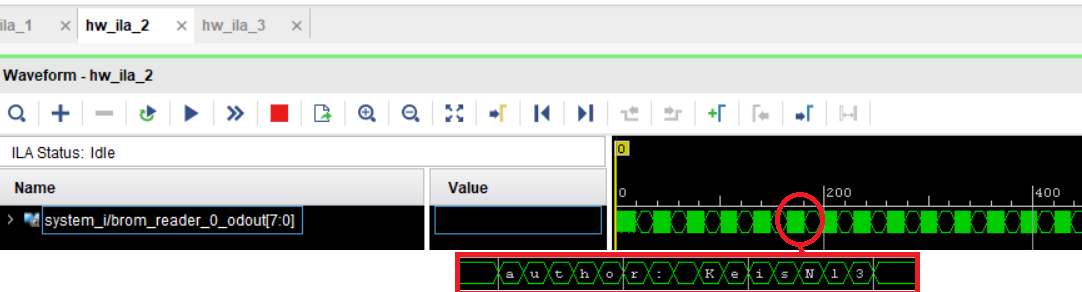
Рисунок 77 – данные, считываемые из блочной памяти
На этом сборка тестового проекта завершена, и мы можем приступить к редактированию нашего нетлиста и работе в режиме ECO.
4. Переход в режим ECO
Как мы убедились выше:
- По нажатию кнопки BTN0 загорается светодиод
- Посылки по UART отправляются, но мы не видим их в консоли (специально перепутаны rx и tx)
- Содержимое блочной памяти считывается циклически и непрерывно (содержимое блочной памяти в ASCII:”author: KeisN13”).
Для исправления ошибок, редактирования нетлиста и изменения содержимого и функционала некоторых компонентов мы воспользуемся режимом ECO, который доступен при работе с Design Checkpoint (DCP). Мы будем использовать DCP, который получается после этапа трассировки кристалла (post route).
При каждом новом запуске синтеза или имплементации Vivado удаляет DCP, поэтому общей практикой работы с DCP является «копипаста» необходимой DCP в новую директорию.
Давайте создадим папку edited_dcp. Я создам ее рядом с папкой проекта (рис. 78)

Рисунок 78 – Создание папки для сохранения DCP
Скопируем необходимый для дальнейшей работы DCP файл, который расположен «папка_проекта/название_проекта.runs/название_имплементации/имя_топ_модуля_routed.dcp» (рис. 79) в папку edited_dcp.
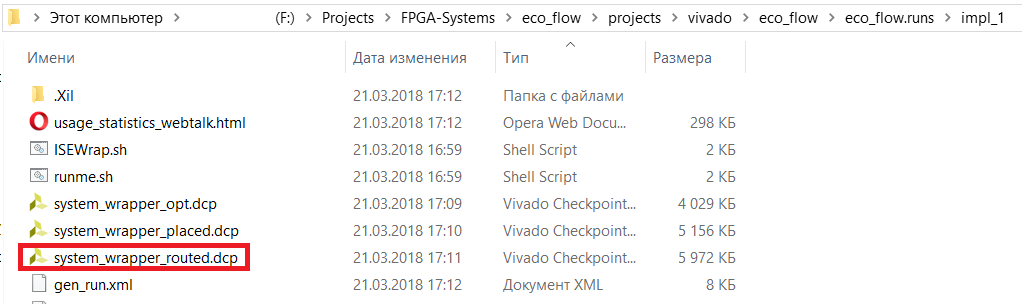
Рисунок 79 – Расположение DCP
Переходим в Vivado и выполняем открытие DCP. Для этого нажмите File → Open Checkpoint (рис. 80)
Рисунок 80 – Открытие DCP
Выберите расположение скопированного DCP файла в папке edited_dcp и нажмите OK.
После открытия DCP, по умолчанию, будет открыто представление (перспектива) Default или, та которую Вы использовали в последний раз, если открывали DCP (рис. 81).
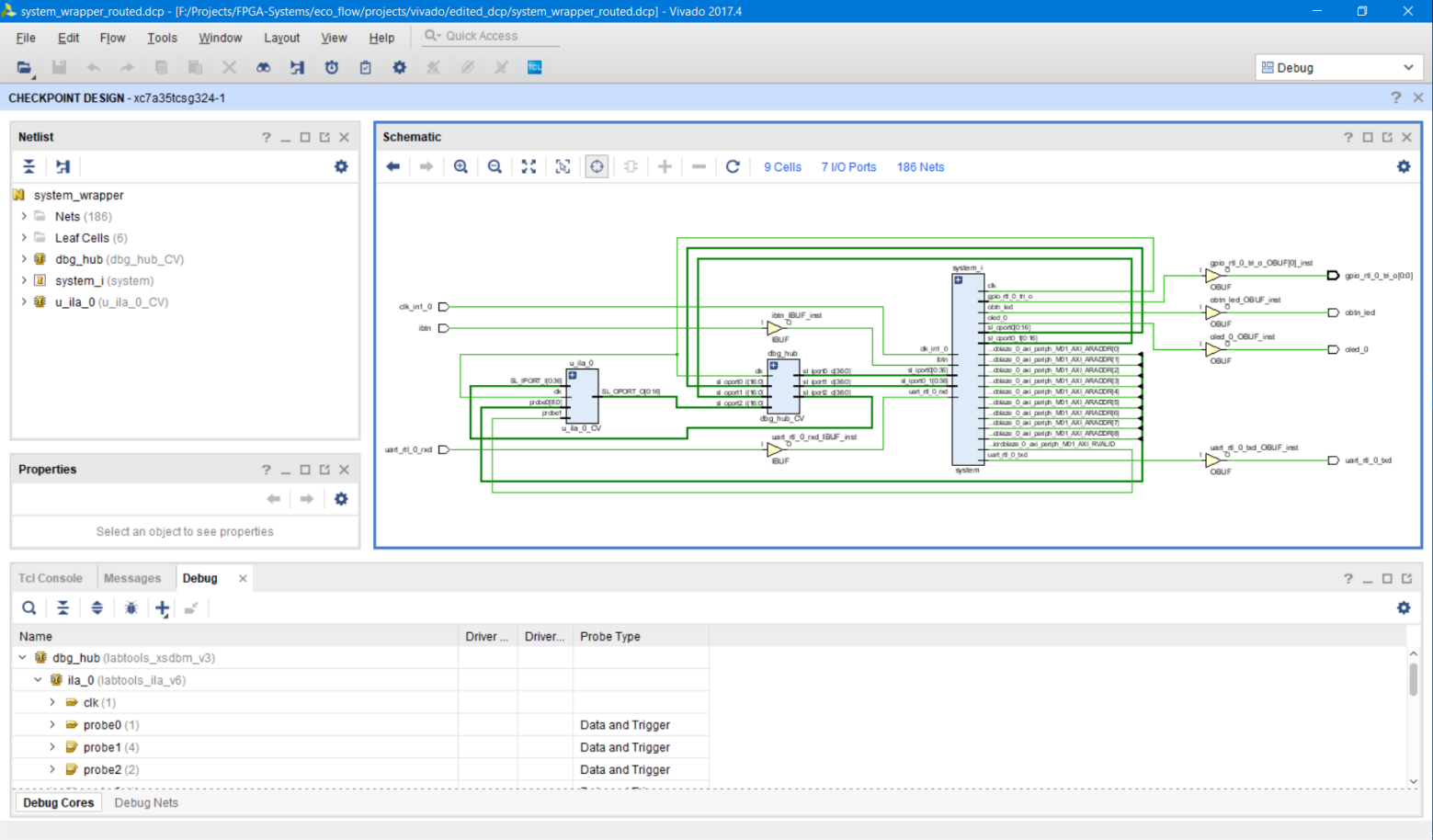
Рисунок 81 – Перспектива Debug открытого DCP
Существует несколько режимов работы с DCP, однако сегодня нас интересует именно ECO Flow. Для перехода в режим ECO необходимо сменить представление. Для этого в верхнем правом углу из выпадающего списка выберите ECO (рис. 82).
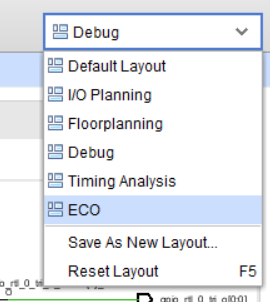
Рисунок 82 – Переход в режим ECO
Как видим, графическое представление при переходе в режим ECO изменилось (рис. 83). Появились новые элементы управления и графического интерфейса, которые рассмотрим далее.

Рисунок 83 – Представление в режиме ECO
5. ECO: описание интерфейса
Работа в режиме ECO имеет свой маршрут, который изображен на рис. 84. Вся работа выполняется в соответствующей DCP. После открытия DCP выполняются необходимые изменения в нетлисте, с помощью инструментов графического интерфейса и/или Tcl-команд. Изменения сохраняются, и, в зависимости от того уже размещен полностью проект в кристалле или нет, выполняются размещение и трассировка либо только трассировка. Затем выполняется разводка кристалла, после чего генерируются новые файлы прошивки (битстрима, .bit) и цепей логического анализатора (.ltx). Следующим шагом выполняется проверка внесенных изменений «в железе», и если всё нормально, то сделанные изменения вносятся в исходный проект. Если же нет – то внесение изменений в DCP может быть повторено.
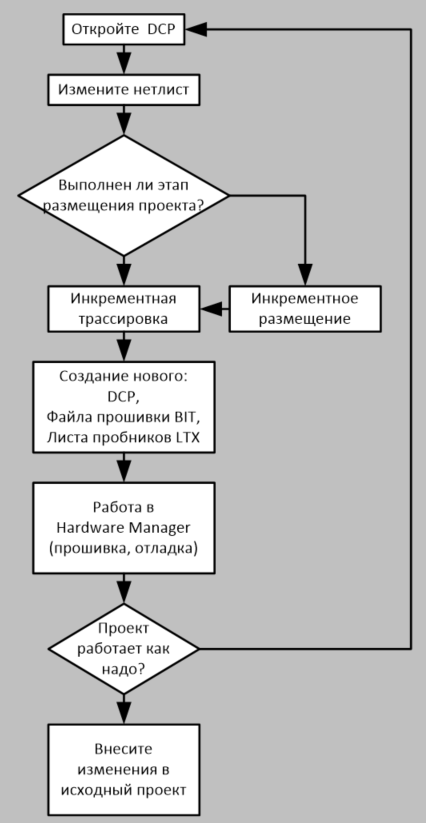
Рисунок 84 – Маршрут проектирования в режиме ECO
Внесение изменений возможно с помощью инструментов графического интерфейса. Оригинал описания интерфейса вы можете найти в [3] в разделе Vivado ECO Flow.
Графическое представление в режиме ECO разбито на несколько секций, расположение и назначение которых идентично стандартному представлению, в котором выполняется основное проектирование.
С левой стороны экрана расположен ECO Navigator, который представляет инструменты для маршрута проектирования. ECO Navigator состоит из нескольких секций.
Секция Edit (рис. 85): предоставляет доступ к инструментам, необходимым для редактирования нетлиста

Рисунок 85 – Команды секции Edit
Create Net: открывает диалоговое окно, предоставляющее доступ к созданию новых цепей. Цепи могут быть созданы для любого уровня иерархии, путём задания имени иерархии в названии цепи. Могут быть созданы шины. Если выбран pin или port, то цепь может быть автоматически подключена к ним, если установлена галка Connect selected pins and ports (рис. 86).
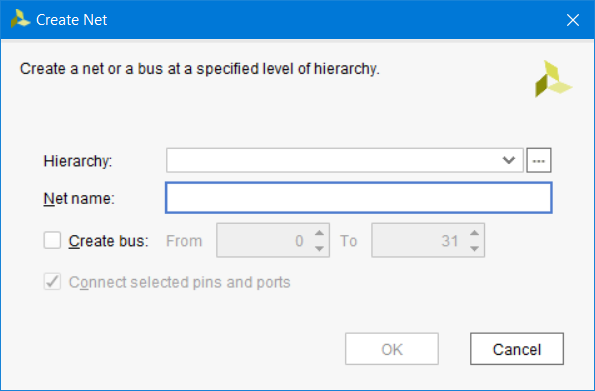
Рисунок 86 – Диалоговое окно Create Net
Create Cell: открывает диалоговое окно, позволяющее добавлять дополнительные компоненты в текущий нетлист. Также имеется возможность создавать ячейки в необходимом уровне иерархии. Можно создавать как библиотечные компоненты, которые доступны из списка, либо black box. Если вы создаёте LUT, то сразу можете редактировать функцию, которую она должна реализовывать (рис. 87).
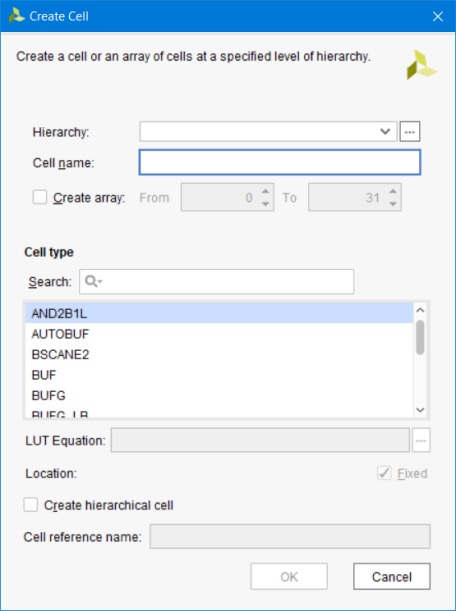
Рисунок 87 – Диалоговое окно Create Cell
Create Port: вызывает мастер для добавления и настройки дополнительных портов в текущий нетлист. Возможно настроить несколько параметров: направление, ширину шины, стандарт напряжений и т.д. (рис. 88).
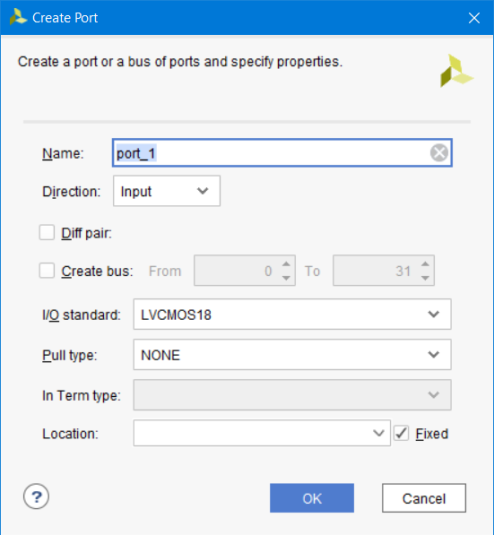
Рисунок 88 – Диалоговое окно Create Port
Create pin: выполняет добавление и настройку пинов в текущем нетлисте. Пин может быть создан для текущей ячейки (объектов типа cell) на любом уровне иерархии. Пин для иерархии верхнего уровня также может быть создан с помощью команды create_port. Пин не может быть создан, если не указана ячейка и название создаваемого пина (рис. 89).
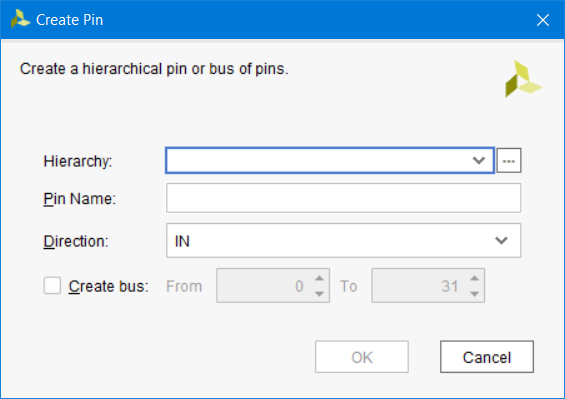
Рисунок 89 – Диалоговое окно Create Pin
Connect Net: подключеняет цепь к выбранному пину или порту. Вызываемое диалоговое окно позволяет просмотреть список цепей или выполнить их поиск. Выбранная цепь будет подключена через все уровни иерархии, автоматически создавая необходимые пины.
Disconnect Net: отключает выбранную цепь, пин или порт от цепи. В случае, если выбран объект типа cell, то буду отключены все цепи, подключенные к нему.
Replace Debug Probes: позволяет вызвать диалоговое окно, в котором возможно выполнить редактирование портов ILA и/или VIO (Virtual Input Output), которые были созданы ранее, то есть отключить текущие цепи от и подключить новые.
Place Cell: позволяет разместить объект типа cell в выбранных ресурсах кристалла.
Unplace Cell: убирает выбранный объект типа cell из текущего размещения.
Секция Run
Команды секции Run предоставляет доступ ко всем командам, необходимым для выполнения имплементации.
Check ECO: Выполняет запуск проверки ошибок (DRC – Design Rule Check)
Примечание: Vivado позволяет вносить в нетлист множество изменений, используя команды режима ECO. Однако, внесённые логические изменения, внесённые в проект, могут привести к неосуществимой физической имплементации. Запуск Check ECO следует делать перед тем как вы соберетесь выполнять имплементацию проекта, чтобы устранить ошибки на ранних этапах маршрута ECO Flow.
Optimize Logical Design: в некоторых случаях рекомендуется выполнять оптимизацию нетлиста с помощью команды opt_design и её соответствующих опций [9]. Optimize Logical Design позволяет вызвать диалоговое окно, позволяющее внести соответствующие аргументы Tcl команды opt_design, которые задаются в строке options.
Place Design: Выполняет инкрементное (т.е. основываясь на предыдущем нетлисте) размещение компонентов текущего нетлиста. Отчёт Incremental Placement Summary, который выводится в консоли в конце выполнения команды place_design позволяет просмотреть статистику переиспользования результаттов предыдущего размещения, которое было в оригинальном DCP до внесения изменений. Нажатие на Place Design вызывает окно, в котором могут быть заданы соответствующие опции команды place_design [9]. Подробнее об инкрементной имплементации см. в [3] в разделе Incremental Compile.
Optimize Physical Design: в некоторых случаях может потребоваться выполнить физическую оптимизацию (команда phys_opt_design [9]). Диалоговое окно, вызываемое по нажатию на Optimize Physical Design позволяет ввести соответствующие опции команды phys_opt_design.
Route Design: вызывает диалоговое окно, которое позволяет в зависимости от выбора выполнить инкрементную трассировку внесенных изменений в нетлист, трассировку выбранных пинов или цепей. В случае, если процент переизпользованных разъеденных цепей менее 75%, то будет выпалена обыкновенная трассировка нетлиста.
Подробнее об инкрементной имплементации см. в [3] в разделе Incremental Compile.
Секция Report
В этой секции возможна генерация необходимых отчётов для измененного нетлиста, включая отчет используемых ресурсов, временных характеристик, пересечения тактовых доменов и т.д.
Секция Program
Инструменты этой секции позволяют сохранить внесённые изменения в новы DCP, создать файл прошивки ПЛИС, создать новый лист отлаживаемых через ILA цепей, в случае, если ILA подвергался изменениям, запрограммировать ПЛИС и выполнить отладку стандартными средствами Hardware Manager Vivado.
Вкладка Scratch
Позволяет отслеживать внесенные изменения в нетлист, включая просмотр и подключение незадействованных пинов, портов, цепей. Столбец подключений Con отслеживает статус подключения объектов, PnR отслеживает статус размещения и трассировки объектов.
Нажатием правок кнопкой мыши по вкладке Scratch будет вызвано меню дополнительных действий (рис. 90). Функционал, которые они выполняют, предполагаю интуитивно понятен исходя из их названий. Полный список и действия, которые выполняют команды приведен в [3] в разделе Vivado ECO Flow → Scratch Pad → Scratch Pad Pop-up Menu.

Рисунок 90 – Меню дополнительных действий вкладки Scratch
6. Внесение изменений в проект
Теперь мы можем приступить к внесению изменений в наш проект. Первое, что мы сделаем, это установка нового компонента в нетлист. Сделаем так, чтобы светодиод LD0 светился, а при нажатии кнопки BTN0 гас. Иными словами, мы должны вставить в нетлист инвертор, которого нет.
6.1. Создание новых элементов в нетлисте
Для начала, найдите на схеме порт ibtn, нажмите на него левой кнопкой мыши один раз, а затем нажмите F4. Таким образом, мы попробуем отфильтровать все лишнее в схематике, для повышения читаемости нетлиста.

Рисунок 91 – Открытие схематики для выбранного порта
В появившемся окне, мы увидим только один порт ibtn. Теперь отобразим всю цепь от порта ibtn до светодиода LD1 (порта obtn_led). Нажимаем правой кнопкой мыши по порту ibtn, затем Expand Cone и выбираем To Flops or I/Os. И нажимаем кнопку Regenerate Layout (рис. 92)

Рисунок 92 – Отображение конечных точек, к котором подключён порт
Теперь мы видим полный «тракт» от кнопки до светодиода (рис. 93).

Рисунок 93 – «Тракт» от порта ibtn до obtn_led
Следующий шаг, который необходимо сделать, это определиться, в каком месте разорвать цепь. Предлагаю разорвать её от модуля system_i до выходного буфера. Для этого выбираем цепь от пина obtn_led модуля system_i до пина I буфера obtn_led_OBUF_inst, затем в секции Edit выбираем Disconnect Net.

Рисунок 94 – Выбор разрываемой цепи
После нажатия на кнопку Regenerate Layout видим, что цепь была удалена (рис. 95)
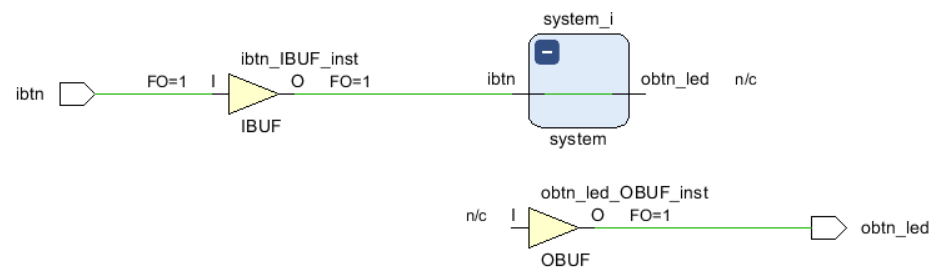
Рисунок 95 – Схематика после разрыва цепи
Также обратите внимание на вкладку Scratch Pad, содержимое которой изменилось.
Теперь добавим на схему инвертор. Нажимаем в секции Edit строку Create Cell, вводим название компонента invertor, находим шаблон INV и нажимаем OK (рис. 96)
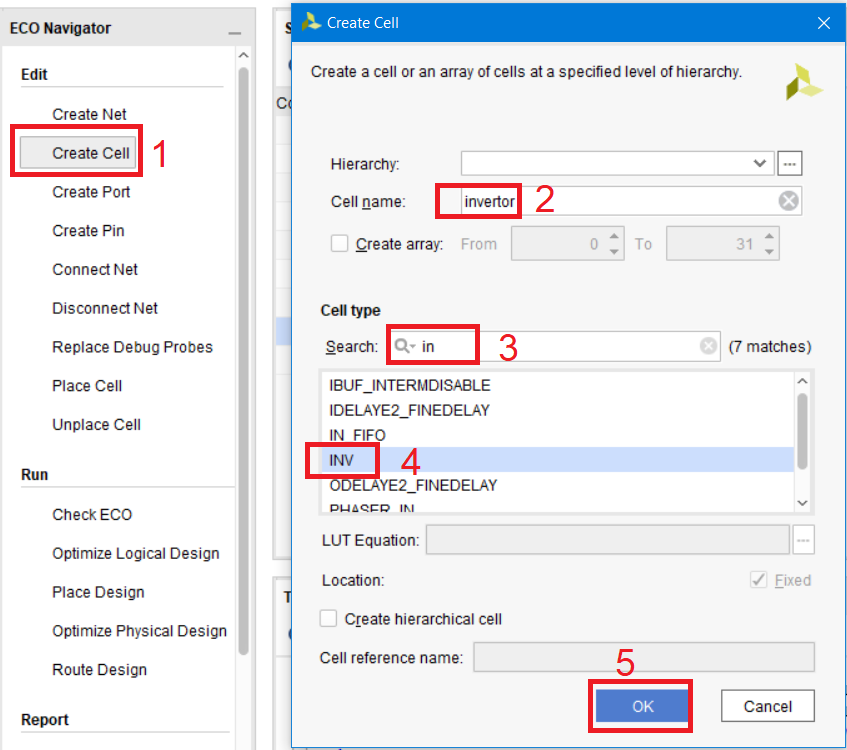
Рисунок 96 – Создание инвертора
Компонент INV будет добавлен на поле (рис. 97)
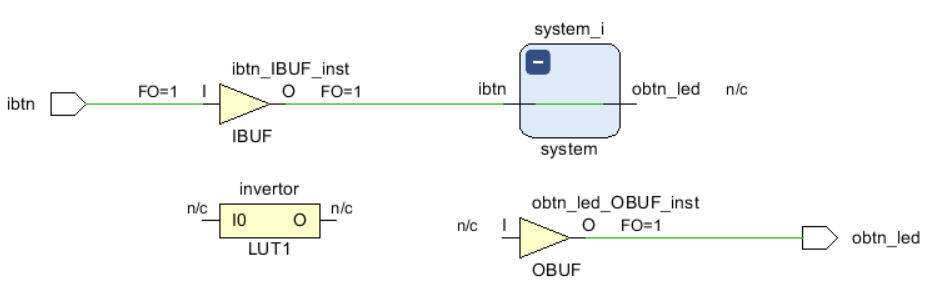
Рисунок 97 – Созданный инвертор на поле схематики
Как видите, инвертор реализован на LUT. Чтобы посмотреть логическую функцию, которую реализует LUT и при необходимости её изменить, Вы можете, нажав правой кнопкой мыши по компоненту, выбрать свойства Cell Properties, во вкладке Truth Table нажать Edit LUT Equation… (рис. 98).
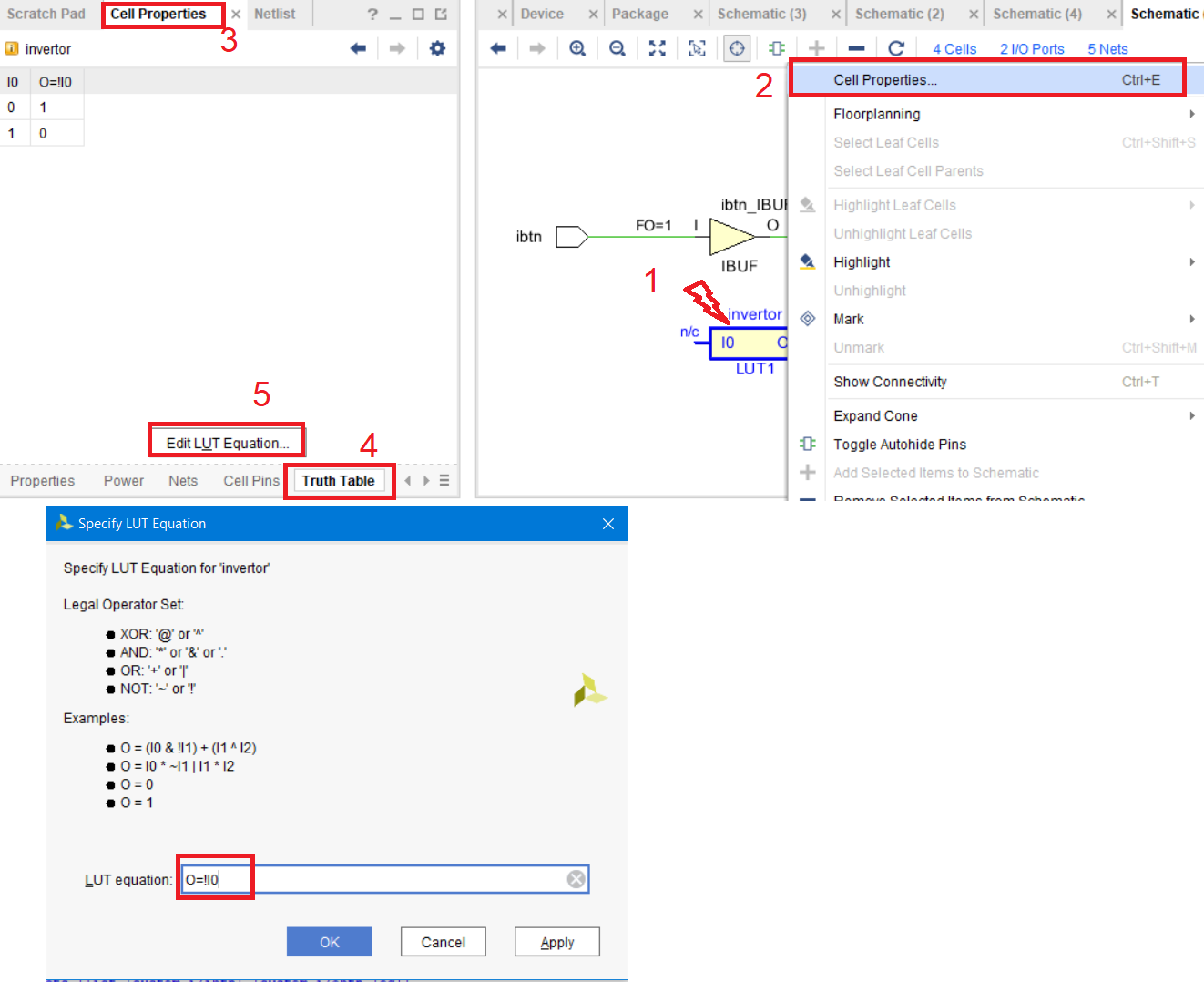
Рисунок 98 – Свойство и таблица логической функции LUT
Выполним соединение пинов. Выберите или на схематике, или во вкладке Scratch Pad пины I0 компонента invertor и obtn_led компонента system_i.
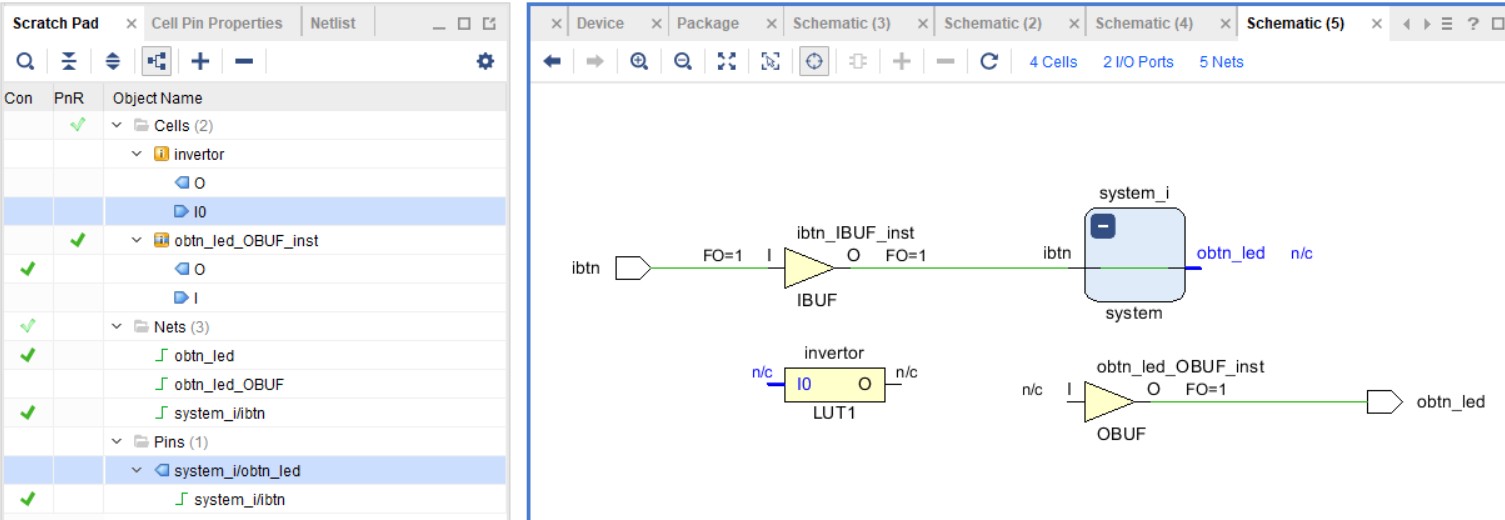
Рисунок 99 – Выбор соединяемых пинов
Теперь создадим между ними цепь. Для этого в секции Edit нажимаем кнопку Create Net. В диалоговом окне вводим имя создаваемой цепи btn_led, устанавливаем галочку автоматического соединения двух портов и нажимаем ОК (рис. 100)
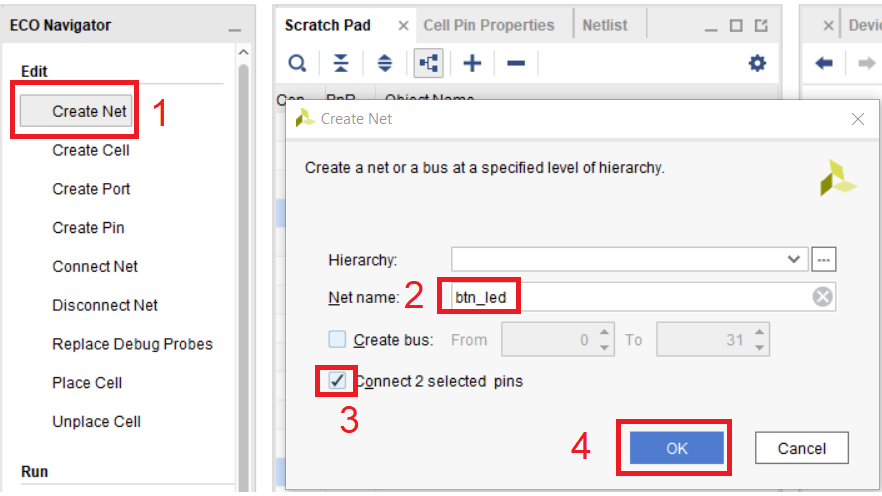
Рисунок 100 – Параметры создаваемой цепи
После этого два пина буду автоматически соединены. Нажмите Regenerate Layout (рис. 101)

Рисунок 101 – Созданная цепь
Повторим действия для двух оставшихся пинов и соединим пин O компонента invertor с пином I компонента obtn_led_OBUF_inst. Цепь назовём по-другому, поскольку не может быть в проекте двух цепей с одинаковыми названиями на одном уровне иерархии. Назовём цепь btn_led_o. Результат подсоединения показан на рис. 102

Рисунок 102 – Схематика с созданным инвертором
Теперь сохраняем наш DCP и проверяем наличие ошибок, перед тем как запустить размещение и трассировку новых компонентов (рис. 103).
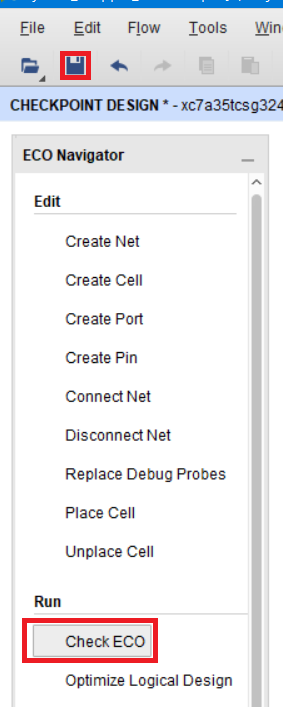
Рисунок 103 – Проверка ECO на ошибки
Из-за того, что мы не выполняли размещение и трассировку, появится ряд ошибок, говорящих об этом.
Теперь попробуем сгенерировать bit файл прошивки, и посмотреть, получилось ли внести изменения корректно. Для этого необходимо последовательно выполнить шаги из секции Run, не все разумеется и без каких-либо опций. Всё остаётся по умолчанию (рис. 104).
Нажимаем Place Design и не вводя никаких опций нажимаем OK. Дождавшись окончания выполнения операций нажимаем Route Design и выбрав Incremental Route в появившемся окне, нажимаем ОК.
После этого генерируем bit файл, нажав на Generate Bitstream. Убедитесь, что в поле пути к файлу указана папка edited_dcp. После этого открываем Hardware Manager для прошивки нашей ПЛИС.
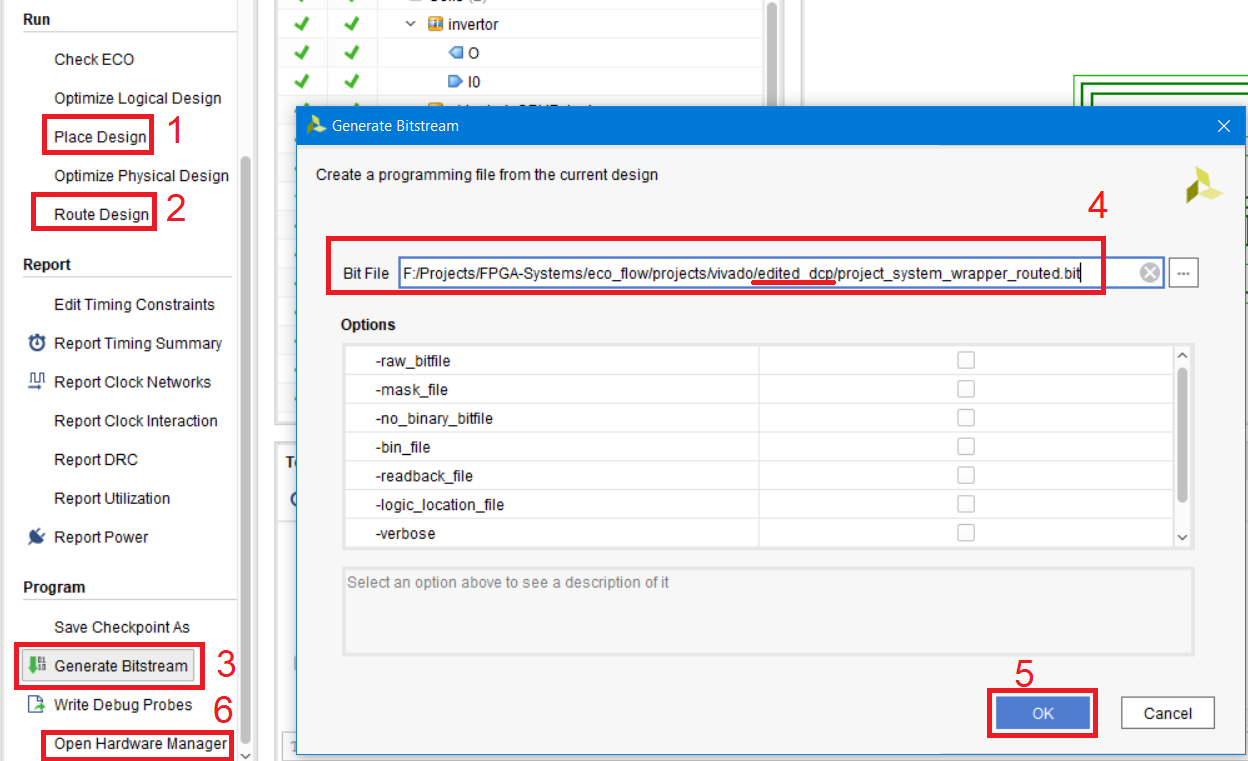
Рисунок 104 – Последовательность действий для получения файла прошивки .bit
При открытии следует учесть, что должен будет открыться новый экземпляр Vivado. Но у меня он не открылся, поэтому я просто открываю новый экземпляр Vivado и запускаю Hardware Manager (рис. 105). При этом будьте внимательны, при выборе файла прошивки .bit и файла цепей для ILA .ltx
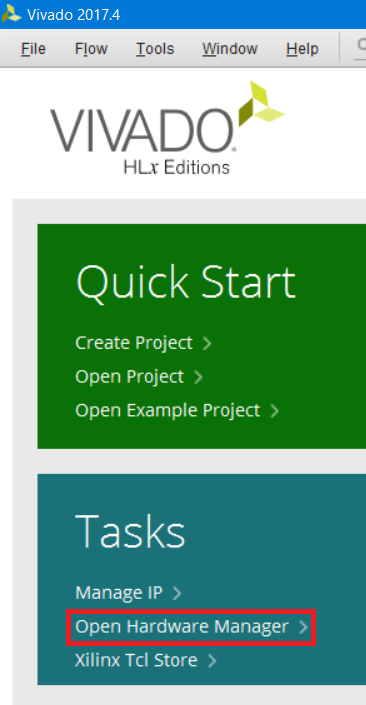
Рисунок 105 – Открытие Hardware Manager из начального окна Vivado
Выполните последовательность действий, согласно рис.67-69 и запрограммируйте ПЛИС. Обратите внимание, что прошивать мы будем файлом, расположенным в папке edited_dcp (рис. 106).
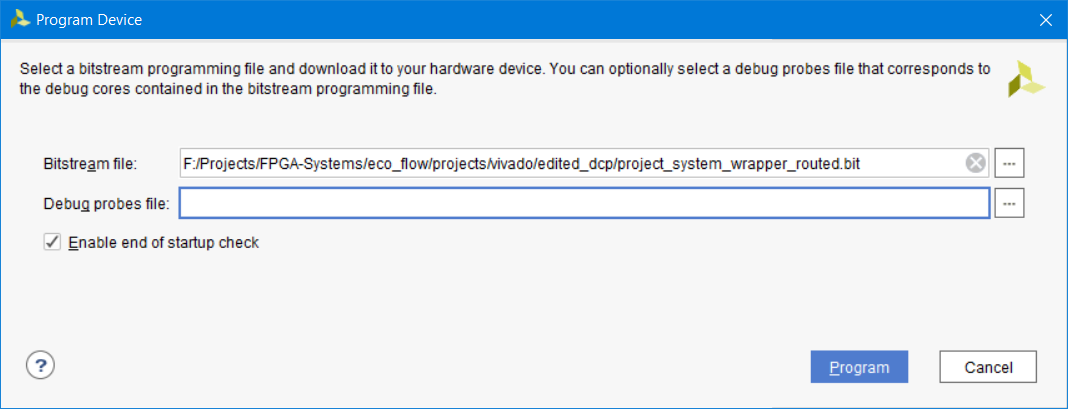
Рисунок 106 – Файл прошивки ПЛИС с изменённым нетлистом
Если всё было выполнено корректно, то светодиод LD0 должен будет светиться, а по нажатию кнопки BTN0 гаснуть.
6.2. Изменение свойств/параметров компонентов
В режиме ECO также возможно изменять содержимое компонентов и менять их параметры. Сейчас мы попробуем изменить содержимое блочной памяти модуля brom_reader, которая имитирует у нас, например, коэффициенты фильтра. Давайте найдём нашу BROM и просмотрим её свойство INIT, отвечающее за начальную инициализацию.
Перейдите во вкладку Netlist и найдите блочную память в модуле brom_reader (рис.107).
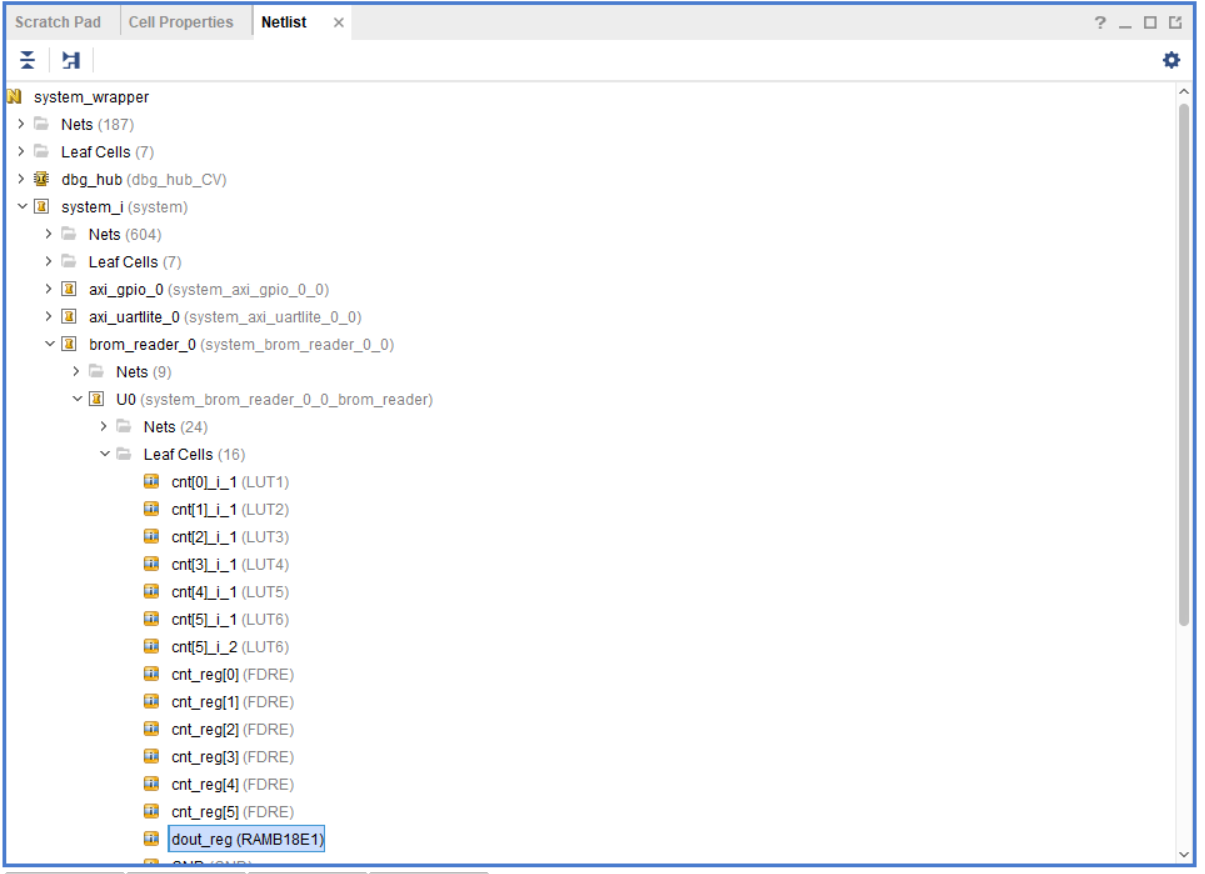
Рисунок 107 – Расположение блочной памяти модуля brom_reader в нетлисте
Нажав правой кнопкой по этому компоненту, мы можем просмотреть его свойства, выбрав Cell Properties (рис. 108). Затем перейдите во вкладку Properties и пролистайте до свойств INIT.

Рисунок 108 – Свойства INIT выбранной блочной памяти
Как видите, в свойствах INIT хранятся значения инициализации блочной памяти. Среди множества этих свойств нас интересуют только INIT_00 и INIT_01. Если скопировать содержимое этих двух свойств конвертор HEX to ASCII [15], то получим надпись, которую мы видели на рис. 77, но записанную в обратном порядке (рис. 109)
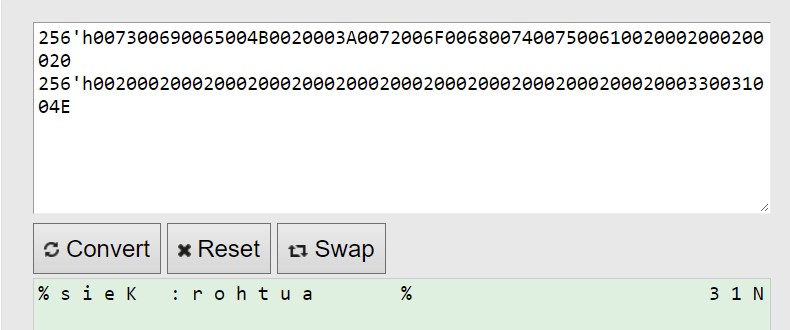
Рисунок 109 – Содержимое свойств INIT в формате ASCII
Изменить свойство компонента можно, если щелкнуть на значок карандашика и вписать новые значения или же воспользовавшись Tcl консолью и командой set_ptoperty.
Замените значения свойств согласно рис.110 и сохраните результат:
INIT_00: 256’h0061006700700066002E00770077007700200020002000200020002000200020
INIT_01: 256’h0020002000200020002000750072002E0073006D00650074007300790073002D
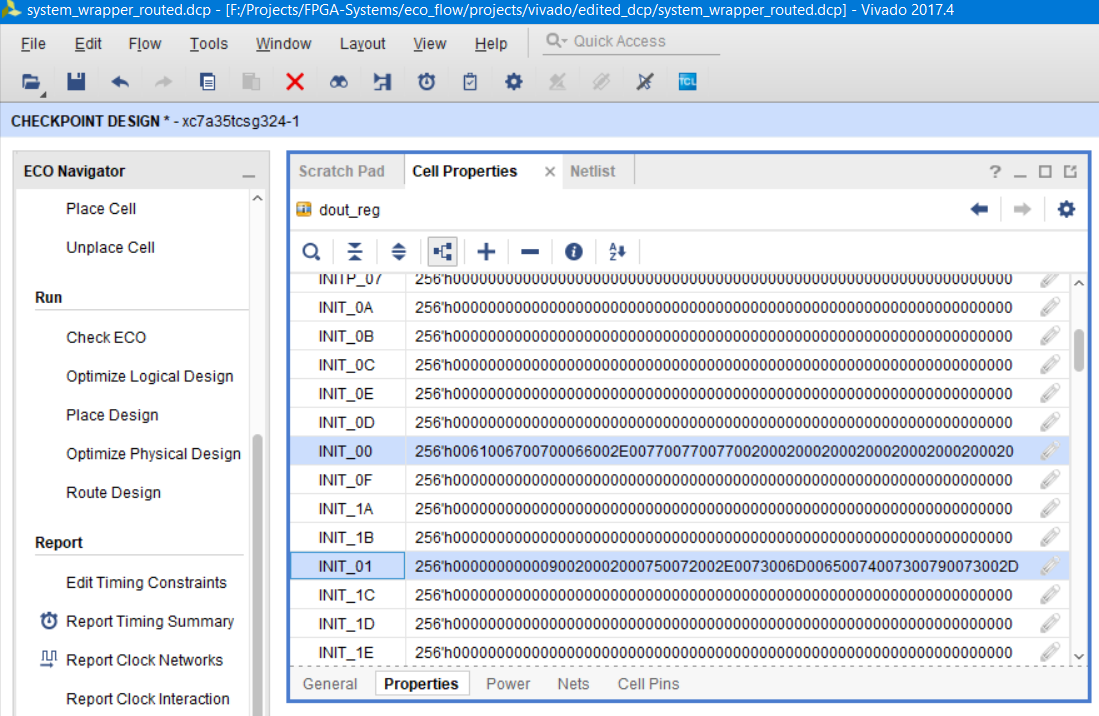
Рисунок 110 – Изменённое содержимое свойств INIT в формате ASCII
Поскольку мы не добавляли новых компонентов в нетлист и не переподключали цепи, то нет необходимости выполнять размещение и трассировку. Просто нажимаем Generate Bitstream и ожидаем окончания выполнения операции. На всякий случай сгенерируйте файл .ltx, который мы подцепим во время отладки (рис. 111).
Рисунок 111 – Генерация битсрима и файла цепей для отладки
Перейдите в Hardware manager и запрограммируйте FPGA только что сгенерированным файлом .bit и созданным списком пробников .ltx (рис.112). Обратите внимание, что файлы взяты из папки edit_dcp.

Рисунок 112 – Файлы прошивки измененного нетлиста и списка цепей
Выполните последовательность действий, описанных на рис. 73-75 (откройте hw_ila_2, переведите тип отображаемых значений в ASCII и просмотрите выводимую надпись). Если всё получилось корректно, то должна появиться надпись рис. 113.

Рисунок 113 – Измененное содержимое блочной памяти
Как видите, если Вам необходимо изменить содержимое или параметры компонентов не только блочной памяти, а в принципе любых, не требующих вмешательств в размещение и трассировку, то делается это очень быстро и достаточно просто. Однако следует быть осторожным, когда Вы изменяете параметры, отвечающие за рабочую частоту, например, когда вносите изменения в настройки MMCM или PLL Вашего проекта. В этом случае, прежде чем создавать файл прошивки, убедитесь, что тайминги проекта сходятся, а соответствующие отчёты не выдают ошибок (Report Timing Summary и т.д.).
6.3. Подключение других цепей к пробникам и ILA
Пожалуй, самым полезным вариантом использования ECO является замена в уже имплементированном проекте цепей, подключенных к пробникам. Единственным ограничением тут является то, что виртуальные пробники должны быть подключены все, ни один не должен «висеть в воздухе». Это ограничение обычно несущественно, так как неиспользуемые пробники всегда можно просто подключить к gnd или vcc.
Попробуем переключить пробник, наблюдавший за выходом блочной памяти, на значение счетчика, генерирующего для неё адрес.
Как мы знаем из описания интерфейса ECO, в нём есть инструмент, позволяющий выполнить переподключение пробников; им и воспользуемся.
Примечание: несмотря на наличие специального инструмента редактирования пробников и подключённых цепей, выполнять эти действия можно и «совсем вручную», подобно тому как мы делали при добавлении компонента: отсоединить одни цепи и подсоединить другие. Однако тут есть некоторые нюансы: по не совсем понятным причинам, иногда цепь от пина отсоединить не удается, нажатие на Disconnect Net не выполняется. В этом случае можно руками или через скрипты снять с цепи свойство «DONT_TOUCH» или отменить её трассировку (выполнить «unrote») – тогда Disconnect Net будет выполнятся. При работе мастером таких проблем не наблюдается.
Работа с мастером требует, чтобы мы знали название цепей, которые мы собираемся подключать. Давайте попробуем найти цепи, отвечающие за выставление адреса для блочной памяти в модуле brom_reader. Это можно сделать через схематическое представление или через сам нетлист. Поскольку модуль маленький, то просто просмотрим название через нетлист (рис. 114). Необходимая цепь называется cnt, это шина, шириной 5.
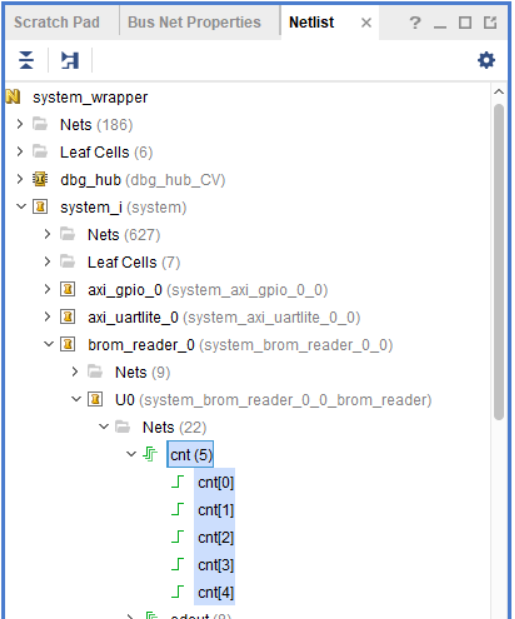
Рисунок 114 – Цепь адреса блочной памяти в нетлисте
Выбираем режим Replace Debug Probes. Поскольку наш счётчик считает только до 31, то требуется всего 5 линий, поэтому выбираем первые пять линий в ila_1, затем нажимаем правой кнопкой мыши и выбираем Edit Probes (рис. 115). Выбрать можно любой ila, но они достаточно громоздкие. Для руководства, выбраны попроще.
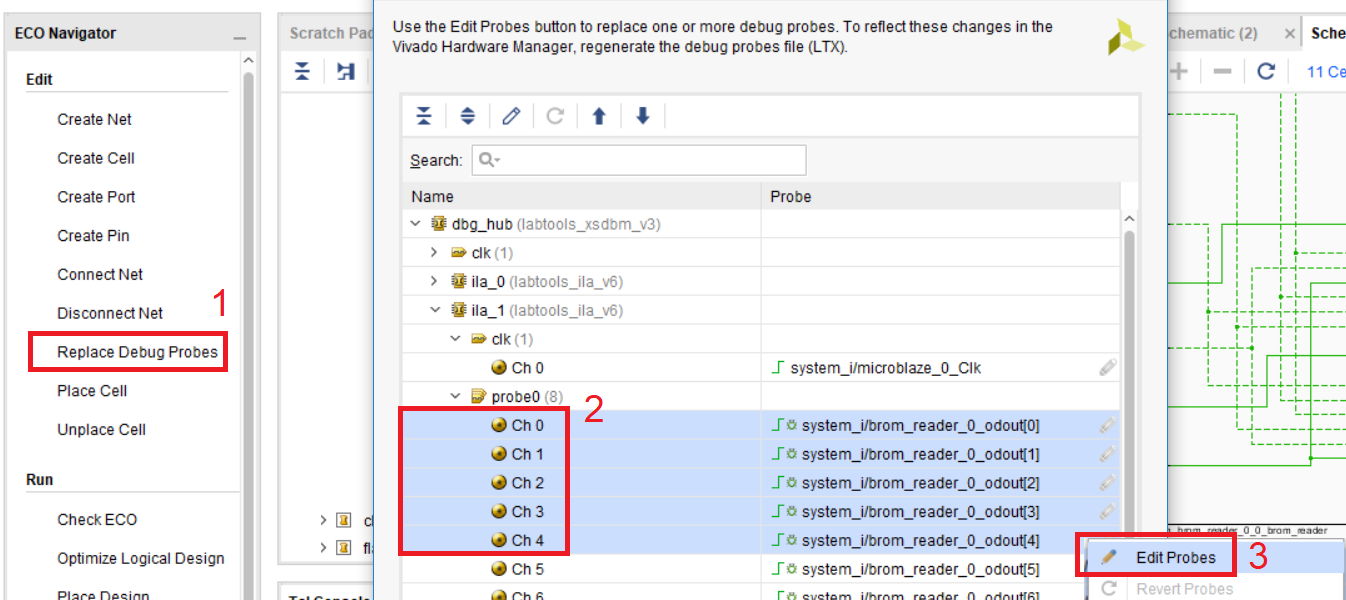
Рисунок 115 – Выбор заменяемых пробников
Выполняем поиск по списку цепей, введя название искомой цепи *cnt[*]. Пролистав вниз находим их, и нажимаем кнопку добавления в пробники. Обратите внимание, что мы одновременно заменяем 5 пробников, поэтому должно быть выбрано 5 цепей. Замена типа поиска с contains на match обусловлена правилами поиска в tcl и для текущего примера позволяет выводить более точный результат. При использовании поиска цепей рекомендуется хотя бы немного понимать и знать символы подстановки в языке Tcl и правила, по которым выполняется поиск.
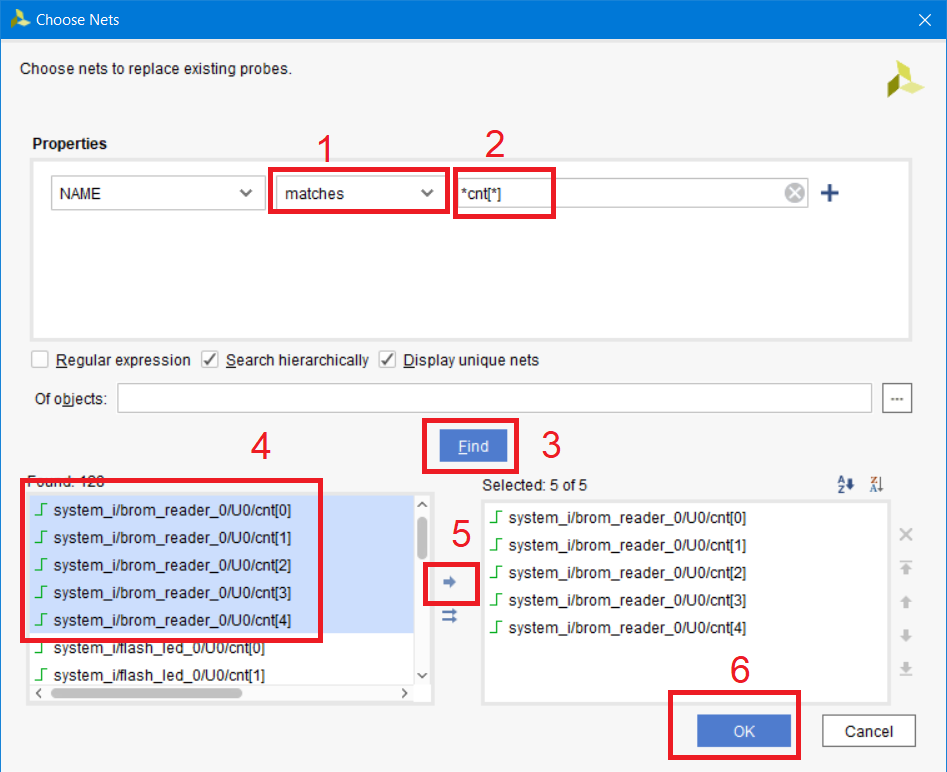
Рисунок 116 – Поиск подключаемых к пробникам цепей
Оставшиеся три цепи мы подключим к «0», в Vivado цепи, подключенные к gnd называются const0. Выберем три оставшиеся цепи, правой кнопкой Edit Probes (рис.117).

Рисунок 117 – Доукомплектовывание ila_1
Вводим название в строку поиска *const0 и добавляем первую цепь из списка, три раза кликнув по стрелке, поскольку мы должны подключить три линии (рис. 118). БУДЬТЕ ВНИМАТЕЛЬНЫ!!! Не добавляете линии из иерархии Debug Hub (dbg_hub), в этом случае Vivado выдаст ошибку только в самом конце настройки пробников, и вся работа пойдет на смарку. Выберите цепь из любого IP, например, uartlite.
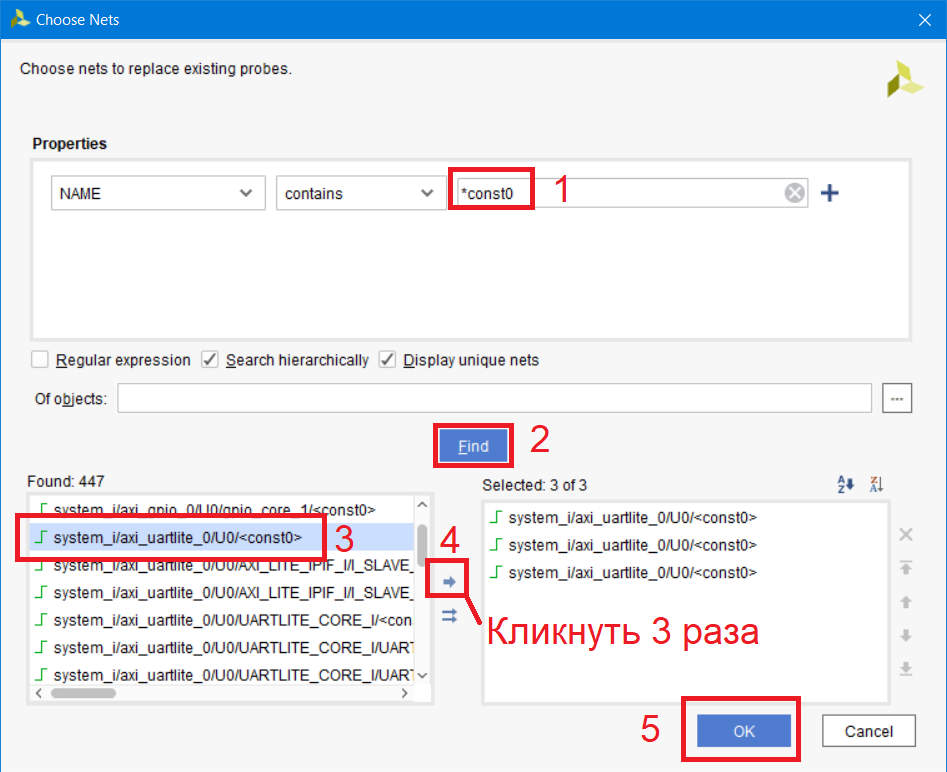
Рисунок 118 – Добавление константных цепей в пробники
Сформированный ila_1 должен выглядеть как на рис. 119. Еще раз отмечу, что не должно быть пустых пробников. В этом случае, будут ошибки на этапе DRC.

Рисунок 119 – Новые цепи в ila_1
После нажатия на кнопку OK появится окно, которое информирует, что атрибут DONT_TOUCH будет снят с цепей, ранее подключенных к пробникам ila_1. Это один из нюансов, которые я описал в примечании в начале этого раздела. Учитывайте это, в случае если вы не используете мастер подключений, а делаете всё вручную. Соглашаемся с изменениями, нажав Unset Property и сохраняем текущее состояние DCP.
Теперь последовательно выполняем размещение, трассировку, генерацию битсрима и создание списка цепей (рис.120). Все вместе занимает примерно 1 минуту на моем компьютере. Быстро, не правда ли!
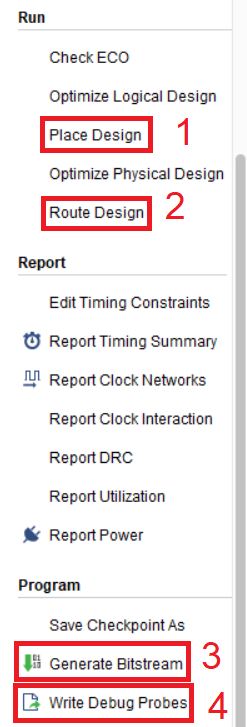
Рисунок 120 – последовательность действий для создания файла прошивки списка цепей для отладки
Теперь открываем Hardware Manger и программируем наш кристалл, на забывая подключить правильные .bit и .ltx файлы.
Открыв hw_ila_2 мы увидим 4 сигнала: шину cnt и три const0. Измените вывод значений шины cnt с hex на unsigned decimal (по аналогии с рис. 75) и запустите запись, нажав синий треугольник. Если все корректно, то Вы увидите изменение на шине cnt с 0 по 31 с инкрементом 1 (рис.121).
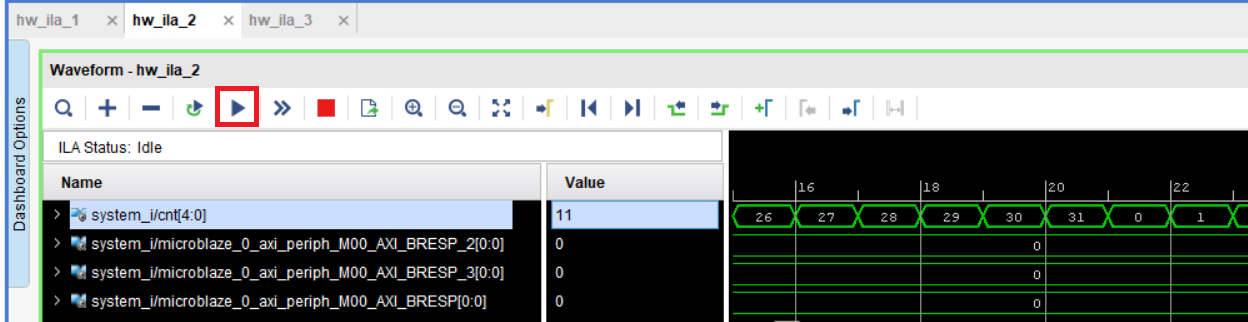
Рисунок 121 – Значение шины cnt в пробнике ila_1
Как видим, мы смогли отключить цепи выхода блочной памяти от пробников и подключить новые.
6.4. Замена портов ввода/вывода
Последнее, что остаётся сделать это изменить rx и tx для модуля uart и наконец-то увидеть Hello World в консоли. Следует отметить, что при работе с ECO есть несколько путей, чтобы достичь результата. Я покажу один из них.
Отрываем нетлист. Прежде чем приступить к переназначению ножек, стоит написать, что необходимо будет удалить всю входную цепь до первого объекта типа cell, после чего ее просто восставим заново. Удалять будем порт, цепь и буфер.
Сначала разберемся с входной цепью.
Выберите порт uart_rtl_0_rxd, подключенную у нем цепь и входной буфер. Нажмите unplace cell и затем удалить (рис. 122). После нажатия кнопки удалить, порт останется, просто выберите его и нажмите удалить еще один раз.
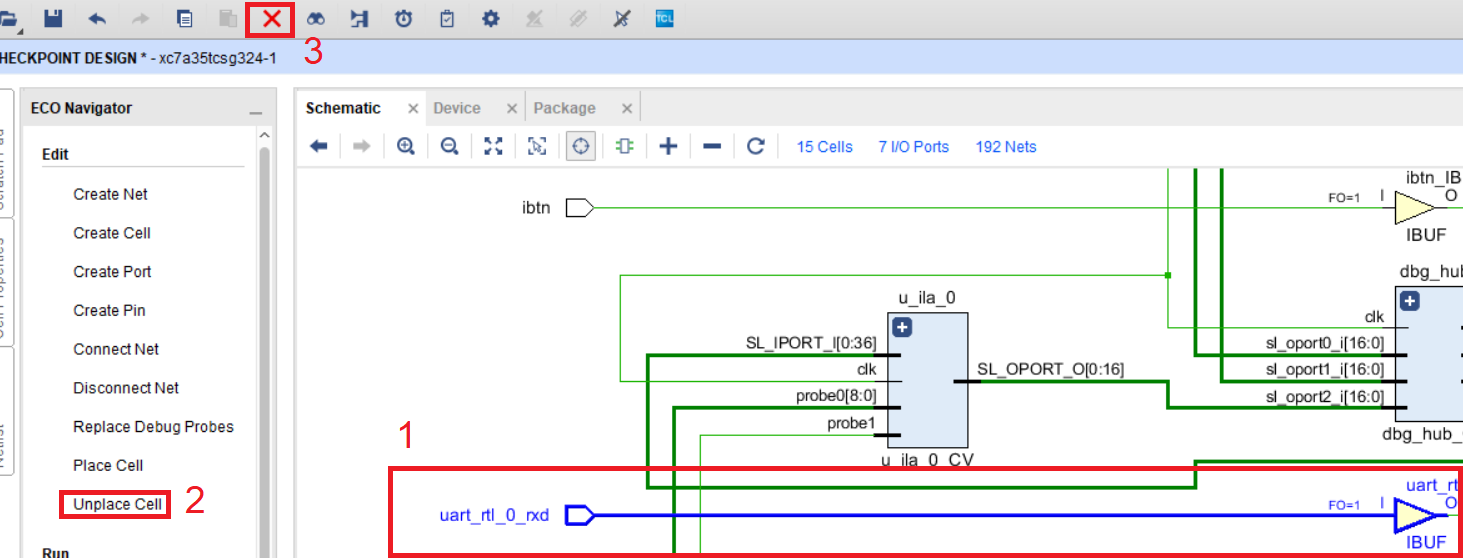
Рисунок 122 – Выбор входной цепи и детрассировка компонентов
Теперь восстановим удаленные компоненты. Первым делом добавим порт uart_rx, нажав на кнопку Create Port затем выставив настройки в соответствии с рис. 123

Рисунок 123 – Параметры создаваемого входного порта
Поскольку ножка A9 уже занята нашим выходным портом, Vivado выдаст сообщение, в которым предложит отменить привязку другого порта к ножке A9. Соглашаемся с этим (рис. 124)
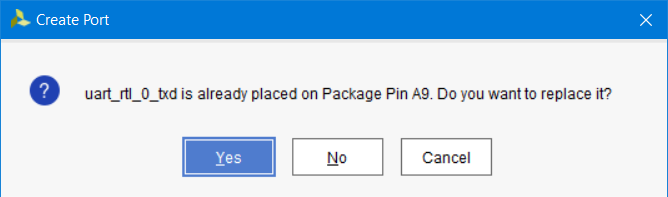
Рисунок 124 – Окно информации об уже имеющемся подключении к выбранной ножке
Теперь создадим входной буфер. Нажмем кнопку Create Cell, название создаваемой ячейки ibuf_rx (рис. 125)
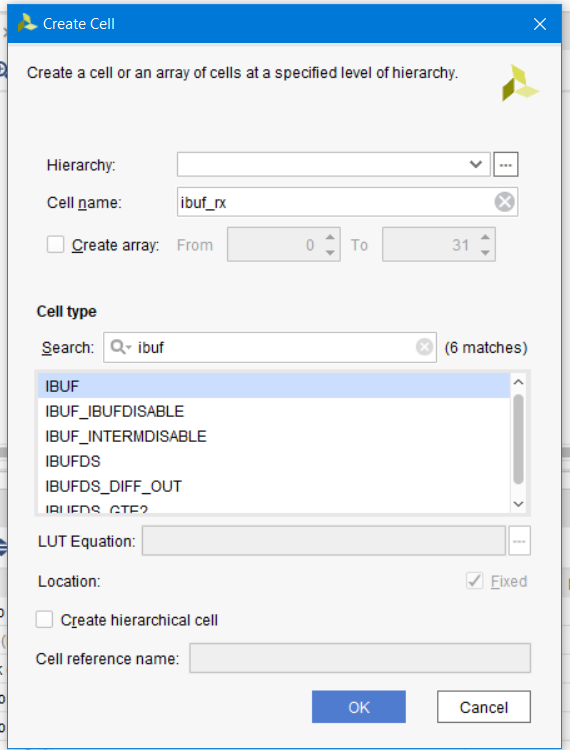
Рисунок 125 – Создание входного буфера
Теперь создаем цепь. Это делается в несколько этапов. Сначала цепь подключается к порту, а затем выполняется подключение к буферу. Выберите порт uart_rx и нажмите Create Net. Название цепи rx_net.

Рисунок 126 – Создание цепи
Теперь выберите цепь и порт I входного буфера и нажмите Connect Net. После этого появится цепь (рис. 127)
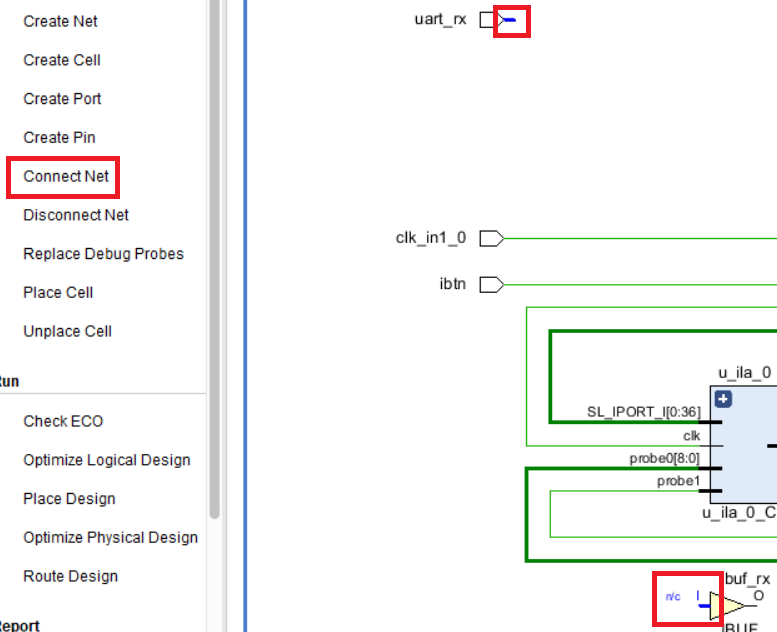
Рисунок 127 – Подключение порта и входного буфера
Теперь создадим цепь, межу буфером и модулем system_i. Выберите выходной пин O буфера и цепь uart_rtl_0_rxd, подключённую к system_i и нажмите Create Net
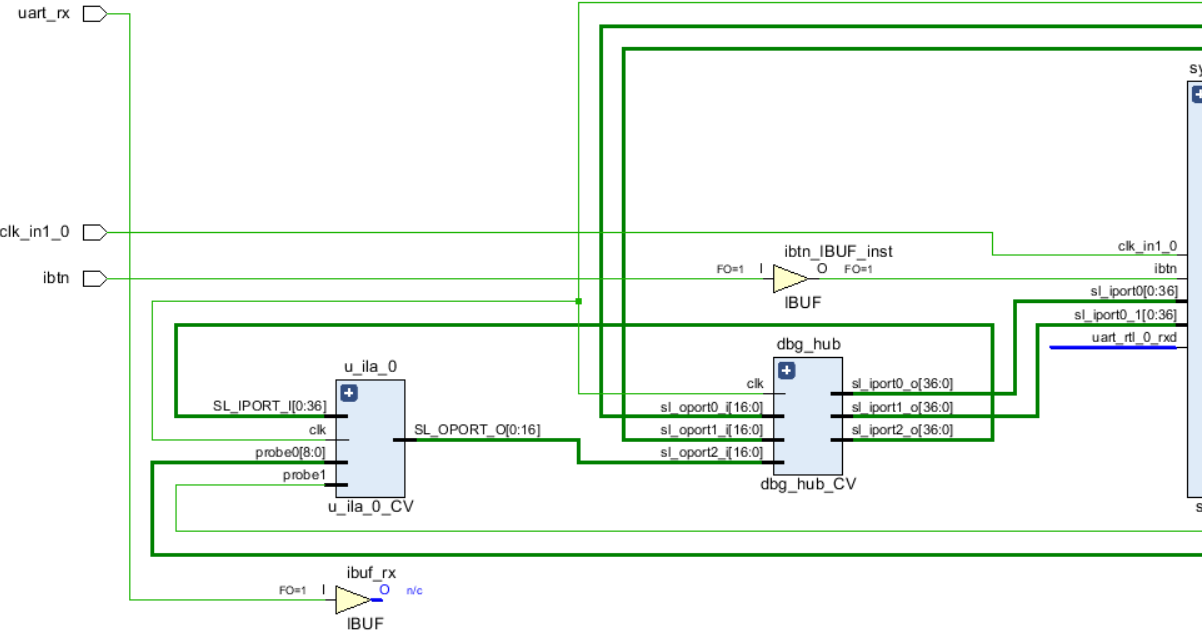
Рисунок 128 – Подключение буфера и цепи
Теперь повторим туже последовательность действий для выходного порта.
Выбираем выходной порт uart_rtl_0_txd, подключенную к нему цепь и выходной буфер. Нажимаем Unplace cell, а затем красный крестик, для удаления компонентов (рис. 122). После нажатия кнопки удалить, порт останется, просто выберите его и нажмите удалить еще один раз.

Рисунок 129 – Выбор выходной цепи
Создаём порт uart_tx, нажав кнопку Create Port, задаём направление Output и устанавливаем стандарт LVCMOS33 (рис. 130)
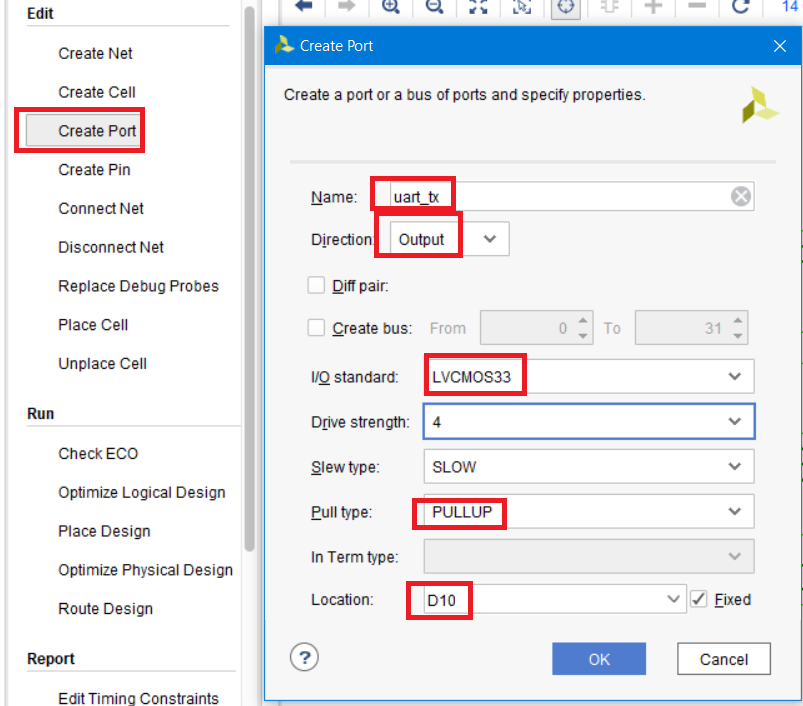
Рисунок 130 – Настройка параметров выходного порта
Создадим цепь tx_net, которая будет подключена к порту uart_tx. Выбираем uart_tx и нажимаем Create Net

Рисунок 131 – Создание цепи tx_net
Создаём выходной буфер tx_obuf, нажав Create Cell и выбрав тип OBUF (рис. 132)
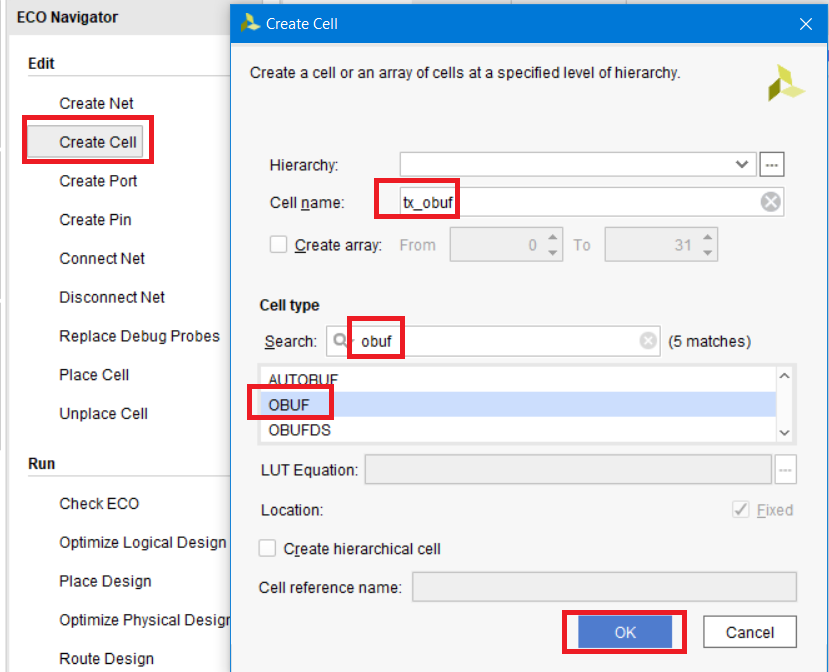
Рисунок 132 – Создание выходного буфера
Выбираем пин O выходного буфера и цепь, подключённую к порту uart_tx и нажимаем Connect Net.

Рисунок 133 – Подключение буфера и порта
Теперь подключим буфер к system_i. Выбираем пин I буфера и цепь uart_rtl_0_txd (рис. 134).

Рисунок 134 – Подключение буфера и цепи
Сохраняем проект и выполняем последовательно размещение и трассировку. После этого запускам генерацию бистрима (рис. 135).

Рисунок 135 – Последовательно действий для получения файла прошивки
Откройте Hardware Manager и запрограммируйте ПЛИС. Перейдите в SDK и выполните запуск приложения (см. рис. 70). Если всё нормально, но в консоли вы увидите сообщение Hello World: cycle (рис. 136).

Рисунок 136 – Сообщения Hello World в SDK Terminal
7. Сравнительный анализ
Проведем небольшой сравнительный анализ разных подходов к внесению изменений в проект по части времени, затрачиваемого на различные операции. Это сравнение будет, конечно, довольно условным, т.к. требуемое время сильно зависит от кристалла, от его загруженности, от количества свободных трассировочных ресурсов и т.д. Проделаны будут операции по изменению HDL файлов, после которого будет заново выполнен синтез, а также в «постсинтез-» нетлисте будут изменены пробники. Результаты приведены в таблице 1. Сразу следует отметить, что инкрементная имплементация даёт выигрыш только при работе с большими кристаллами, для которых получение конечного результата может занимать десяток часов. В учет тут не было включено время, затрачиваемое на внесение разработчиком изменений. Однако учтено то, что мы работали с IP Integrator – а он требует дополнительного времени на синтез IP и RTL.
Таблица 1. Сравнительный анализ времени, затрачиваемого на получение конечного файла прошивки в различных режимах.
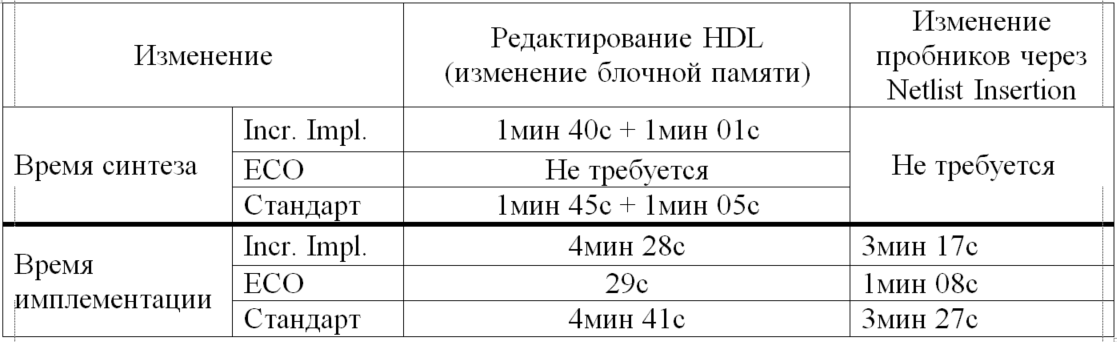
Резюмируя сравнительны анализ, ещё раз скажу, что он очень поверхностный. Вы прекрасно понимаете, что FPGA – это сложная система и время того или иного этапа маршрута проектирования может изменяться очень сильно. Тем не менее, ECO не требует синтеза, и внесение небольших изменений в проект выполняется гораздо быстрее, особенно когда требуется сохранить трассировку кристалла и внести изменения только в содержимое компонентов.
8. Заключение
Применял ли я когда-нибудь на практике режим ECO? Да. Стояла задача, не изменяя трассировку кристалла поменять содержимое блочной памяти, в которой были зашиты некоторые значения, позволяющие защитить продукцию от копирования. Там как раз и пригодился ECO; правда, по большей части работа была выполнена при помощи Tcl-скриптов, а не графического интерфейса. Тем не менее, режим ECO оказывается действительно полезен при работе с большими проектами – особенно в случае, если вы являетесь горячим фанатом внутрисхемной отладки с LogicAnalyser (ChipScope) и любите делать ILA на пару сотен (или даже тысяч) пробников. Возможно, Вы найдете работу в этом режиме полезной для Вас, если просто попробуете сделать что-то большее, чем описано в данном руководстве.
Если Вы нашли для ECO Flow интересное применение, или просто решили попробовать использовать его в своём проекте, оставьте небольшой комментарий: будет любопытно узнать для чего Вам в Vivado пригодился ECO Flow.
Не забудьте сделать и домашнее задание. Удачи!
9. Домашнее задание
- Используя исправленный нетлист, измените логическую функцию LUT, которая реализует инвертор, чтобы она не инвертировала входной сигнал.
- Попробуйте запустить различные оптимизации с различными опциями в режиме ECO. Используйте для помощи гайд с Tcl командами Vivado [9].
- Просмотрите транзакции на шине AXI-lIte, которые идут к модулю GPIO. В режиме ECO замените цепи, которые подключены к ila_1 от модуля uartlite, на цепи от модуля gpio.
- *Попробуйте изменить частоты, которую вырабатывает MMCM, текущее значение 100МГц. Сделайте его 50 МГц. Если все сделано корректно, то светодиод должен мигать в два раза медленней. Не забудьте просмотреть отчет по таймингам, поскольку вы изменили модуль, отвечающий за частоту всего проекта.
- *Попробуйте создать Tcl команду или скрипт, который бы автоматически выполнял необходимую последовательность действий при изменении нетлиста в режиме ECO. Скрипт должен сохранять изменения, запускать размещение, трассировку, генерировать фал прошивки и т.д.
- **Напишите скрипт, который бы позволял изменять содержимое блочной памяти в блоке brom_reader, записывая любые 32 символа ASCII, вводимые в качестве аргументов разрабатываемой процедуры/скрипта
Библиографический список
1. Vivado на сайте Xilinx
2. Описание Arty Board на сайте Digilent
3. UG904 Vivado Design Suite User Guide: Implementation
4. UG908 Vivado Design Suite User Guide Programming and Debugging
5. UG986 Vivado Design Suite Tutorial: Implementation
6. Wiki: ECO
7. UG949 UltraFast Design Methodology Guide
8. UG892 Vivado Design Suite User Guide Design Flows Overview
9. UG835 Vivado Design Suite Tcl Command Reference Guide
10. UG894 Using Tcl Scripting
11. UG901 Vivado Design Suite User Guide Synthesis
12. Arty Reference Manual
13. UG908 Programming and Debugging
14. UG1037 Vivado Design Suite AXI Reference Guide
15. Hex-to-ASCII
16. Руководство: Разработка процессорной системы на базе софт-процессора MicroBlaze в среде Xilinx Vivado IDE/HLx
Приложение А. Листинг модуля flash_led
Скрытый текст
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
entity flash_led is
Port ( iclk : in STD_LOGIC;
oled : out STD_LOGIC);
end flash_led;
architecture rtl of flash_led is
signal cnt : natural range 0 to 100_000_001 := 0;
signal led : std_logic := '0';
begin
process(iclk)
begin
if rising_edge(iclk) then
if cnt = 100_000_000 then
cnt <= 0;
else
cnt <= cnt + 1;
end if;
if cnt < 50_000_000 then
led <= '0';
else
led <= '1';
end if;
end if;
end process;
oled <= led;
end rtl;
Приложение Б. Листинг модуля brom_reader
Скрытый текст
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.NUMERIC_STD.ALL;
entity brom_reader is
Port (
iclk : in STD_LOGIC;
odout : out std_logic_vector(7 downto 0)
);
end brom_reader;
architecture rtl of brom_reader is
alias slv is std_logic_vector;
type rom_type is array (0 to 31) of natural;
signal rom : rom_type := (
32 , 32, 32, 32, 97, 117, 116, 104,
111, 114, 58, 32, 75, 101, 105, 115,
78 , 49, 51, 32, 32, 32, 32, 32,
32 , 32, 32, 32, 32, 32, 32, 32
);
signal cnt : natural range 0 to rom'length-1 := 0;
signal dout: slv(odout'range) := (others => '0');
attribute RAM_STYLE : string;
attribute RAM_STYLE of rom : signal is "BLOCK";
begin
process(iclk)
begin
if rising_edge(iclk) then
dout <= slv(to_unsigned(rom(cnt), dout'length));
if cnt = (rom'length - 1) then
cnt <= 0;
else
cnt <= cnt + 1;
end if;
end if;
end process;
odout <= dout;
end rtl;
Приложение В. Листинг программы helloworld
Скрытый текст
#include "platform.h"
#include "xil_printf.h"
#include "xparameters.h"
#include "xgpio.h"
XGpio Gpio; /* The Instance of the GPIO Driver */
#define DELAY 10000000
int main()
{
init_platform();
int Status;
volatile int Delay;
int k = 0;
/* Initialize the GPIO driver */
Status = XGpio_Initialize(&Gpio, XPAR_GPIO_0_BASEADDR);
if (Status != XST_SUCCESS) {
xil_printf("Gpio Initialization Failedrn");
return XST_FAILURE;
}
/* Loop forever blinking the LED */
while (1) {
/* Set the LED to High */
XGpio_DiscreteWrite(&Gpio, 1, 1);
xil_printf("Hello World: cycle %dnr", k);
k++;
/* Wait a small amount of time so the LED is visible */
for (Delay = 0; Delay < DELAY; Delay++){};
/* Clear the LED bit */
XGpio_DiscreteWrite(&Gpio, 1, 0);
/* Wait a small amount of time so the LED is visible */
for (Delay = 0; Delay < DELAY; Delay++){};
}
cleanup_platform();
return 0;
}
PS: Огромное спасибо пользователям intekus Des333, ishevchuk, roman-yanalov которые не только прочитали это 91 страничное руководство (именно столько оно занимает в Word), но и выполнили его и внесли необходимые редакторские правки.
Новое строительство
Откройте программное обеспечение Vivado, нажмите Создать новый проект непосредственно в интерфейсе приветствия или выберите «Файл» в меню «Пуск» — новый проект для создания нового проекта.

Нажмите «Далее;

Введите имя проекта и путь.

Выберите RTL Project, чтобы проверить не указывать источники в это время (что может пропустить шаги для добавления исходного файла, исходный файл может быть добавлен позже).

Выберите доски напрямую, затем выберите комплект для разработки Zedboard Zynq Recalucy и Development.

Нажмите Далее, затем нажмите Готово, проект новый

Добавить кVerilogПроектирование документов (Design Source)
В окне «Диспетчер проектов» щелкните правой кнопкой мыши, чтобы выбрать источники дизайна, щелкните правой кнопкой мыши на пустой или любой папке, выберите «Добавить источники».

Выберите «Добавить» или создайте источники дизайна, нажмите «Далее».

Нажмите кнопку Создать файл, введите имя файла во всплывающем окне, нажмите OK.

Вы можете создавать или добавлять несколько файлов за один раз и, наконец, нажмите «Готово».

Окно, которое определяет модуль, будет всплыть позже, то есть тестовый файл только что добавлен. Вы можете установить порт вход / вывод тестового модуля здесь; или нажмите OK напрямую, и запишите его позже.

После нажатия OK, если вы всплываете следующее окно, нажмите Да.

Тестовый файл и соответствующий модуль создаются, как показано ниже.

Добавить кVerilogФайл моделирования (Simulation Source)
Операция и последний шаг добавляет файлы дизайна Verilog в основном, уникальная разница состоит в том, чтобы выбрать Add или создание источников симуляции. Недавно построенный файл симуляции называется SIMU.

После того, как файл дизайна новый, существует источники дизайна и источники моделирования, а файл эмуляции появится только в папке источников симуляции. Файл дизайна может использоваться для симуляции, или его можно использовать для окончательно записи в доску разработки, а файл моделирования используется только для моделирования.

Написать код
Откройте тестовый модуль дизайна и напишите код для реализации одного.
1 тест модуля (A, B, C, D, E); // интерфейс модуля 2 вход [5: 0] A; // входной сигнал A 3 вход [5: 0] b; // входной сигнал b 4 вход [5: 0] C; // входной сигнал C 5 вход [5: 0] d; // входной сигнал d 6 выход [7: 0] E; // Qi и выходной сигнал 7 провод [6: 0] OUTA1, AUTA2; // Определить выходную сеть 8 Назначить E = Outa2 + Outa1; // объединить два результата вывода деталей 9 /* 10 Обычно наш модуль вызов написан следующим образом: 11 Название вызова модуля - пользовательское имя - внутренний сигнал 12 Здесь, такие как сигналы в скобках, .ina (INA1) 13 Этот метод написания наиболее распространен, порядок сигнала можно обменять 14 */ 15 adder myadder1 (.ina(a),.inb(b),.outa(outa1)); 16 // Позвоните в сумматорный модуль, пользовательские имена myAdder1 17 adder myadder2 (.ina(c),.inb(d),.outa(outa2)); 18 // Позвоните в сумматорный модуль, пользовательское имя в MyAdder2 19 endmodule 20 // субмодукция сумматора 21 модуль сумматор (ina, inb, outa); // интерфейс модуля 22 вход [5: 0] INA; // INA-входной сигнал 23 Вход [5: 0] INB; // INB-входной сигнал 24 Выход [6: 0] Auta; // enta-входной сигнал 25 Назначьте OUTA = INA + InB; // Поиск 26 // конец модулей 27 endmodule
Поведенческое моделирование и тестирование
Чтобы убедиться, что код правильный, вы можете сделать поведенческое моделирование на коде. При моделировании поведения входной сигнал можно записать с помощью TestBench.
Если вы напрямую изменяете тестовый модуль, добавьте код TestBench, а затем имитируйте его, это менее правая практика. Поскольку тестовый модуль представляет собой файл дизайна, он может записать на плату напрямую. Код Testbench добавляется, когда моделирование сделано, а затем снова сжигайте его в плате, чтобы удалить код TestBench, который подвержен ошибкам, и это более неприятно. В частности, количество интерфейсов велико, а внутренние сложные модули более сложны.
Таким образом, мы пишем весь код Testbench в файл симуляции SIMU и вызовите тестовый модуль в файле SIMU для симуляции.
Запишите код моделирования
Код кода в модуле SIMU выглядит следующим образом:
1 module simu();
2 reg [5:0] a;
3 reg [5:0] b;
4 reg [5:0] c;
5 reg [5:0] d;
6 wire[7:0] e;
7 Рег [5: 0] I; // промежуточная переменная
8 // Позвоните в модуль эмулируемого модуля
9 Test myTest (.a(a), .b(b),.c(c),.d(d),.e(e));
10 начальных начинающих // Первоначальный это ключевое слово инициализации
11 a = 0; b = 0; c = 0; d = 0; // должны инициализировать входной сигнал
12 for(i=1;i<31;i=i+1) begin
13 #10 ;
14 a = i;
15 b = i;
16 c = i;
17 d = i;
18 Конец / / Учитывая входной сигнал Назначение
19 end
20 initial begin
21 $ MONITOR (ВРЕМЯ В РАССМОТРЕТЕ, «% D +% D +% D +% d = {% d}», a, b, c, d, e); // выходной сигнал
22 #500 $finish;
23 end
24 endmodule
Код Описание:
Test mytest (.a (a), .b (b) ,. c (c), d (d) ,. e (e)) вызывает ранее письменный тестовый модуль, где mytest — это имя модуля, тест — это класс Имя, и mytest — это имя объекта. Точно так же, когда модуль вызывается в Verilog, могут быть созданы несколько тестовых объектов.
Моделирование поведения
Щелкните правой кнопкой мыши модуль SIMU, выберите набор в качестве верхней части, установите модуль SIMU в верхний модуль при моделировании. Верхний модуль аналогичен функции записи, когда C Программирование C, то есть основная функция. Главная функция может вызывать другие субъединицы; аналогичные, топ-модуль может вызывать другие модули. (Или сохраните настройки по умолчанию, если вы не установите модуль эмуляции в верхний файл, сделайте это.
Щелкните симуляцию прохождения моделирования.

Позже открывается окно моделирования поведений поведением, вы можете увидеть форму волны эмуляции выхода.

Рабочие навыки
Дважды щелкните вкладку «Без названия» на правой стороне фигуры, чтобы максимизировать окно формы симуляции. Нажмите и удерживайте кнопку CTRL и прокрутите колесо мыши в окне формы волны, чтобы увеличить форму волны сбоку; удерживайте сдвиг и прокрутите колесо мыши, чтобы перевести форму волны сбоку.

В подсчете SCOPES в окне моделирования поведений поведении выберите Mytest в соответствии с отношениями модуля, см. Все сигналы в модуле тестирования на окне объектов справа. Щелкните правой кнопкой мыши по сигналу, выберите Добавить в Wave Wave Wave, добавьте форму волны в правое окно сигнала для симуляции, сохраните файл эмуляции, и вы можете увидеть форму сигнала сигнала при моделировании.

Для некоторых случаев выходных сигналов цифровых сигналов, например, пусть Reg [7: 0] выходной сигнал Sine_out Sine_out Sine_Out, Simulation, Simulate, сигнал щелкните правой кнопкой мыши, выберите стиль формы волны — аналоговый, то есть сигнал можно просматривать в форме сигнала Отказ Как показано на рисунке, является синусоидальным волновым сигналом (обратите внимание, что сам сигнал все еще является цифровым сигналом, не является аналоговым сигналом, просто используйте программное обеспечение для отображения формы волны амплитуды со временем).

Для многобитовых сигналов, таких как провод [7: 0] P, по умолчанию отображается двоичная форма, вы можете изменить по мере необходимости. Например, Щелкните правой кнопкой мыши Выберите Radix — без знака, чтобы установить в беззнаковую десятичную дисплею, как показано на рисунке.

Аннотация
В статье рассмотрен режим работы Vivado, позволяющий вносить изменения в проект на уровне редактирования списка соединений (в дальнейшем – нетлиста). Описаны как сам режим ECO, так и некоторые нюансы, которые появляются во время работы в нём. Приведён демонстрационный пример и описана полная последовательность действий для получения результата, в работоспособности которой может убедиться каждый желающий. Статья будет полезна для «общего развития» FPGA-разработчикам, а особенно — тем, кто часто отлаживает проекты в Logic Analyzer. Надеюсь, работа в этом режиме вызовет интерес у разработчиков, работающих с большими кристаллами, время компиляции в которых может достигать часов (а то и десятков часов), поскольку в этом режиме время, затрачиваемое на имплементацию, при внесении изменений в нетлист может сократиться до буквально пары минут.
Оглавление
Скрытый текст
- Аннотация
- Введение
- 1. ECO: краткий обзор
- 2. Design Сheckpoint
- 3. Разработка тестового проекта
- 3.1. Создание проекта
- 3.2. Создание и добавление HDL файлов в проект
- 3.3.Создание проекта MicroBlaze и работа в IP Integrator
- 3.4.Синтез и имплементация
- 3.5.Написание программы для MicroBlaze
- 3.6.Запуск программы и отладка
- 4. Переход в режим ECO
- 5. ECO: описание интерфейса
- 6. Внесение изменений в проект
- 6.1. Создание новых элементов в нетлисте
- 6.2. Изменение свойств/параметров компонентов
- 6.3. Подключение других цепей к пробникам и ILA
- 6.4. Замена портов ввода/вывода
- 7. Сравнительный анализ
- 8. Заключение
- 9. Домашнее задание
- Библиографический список
Введение
Зачастую, когда мне приходится читать лекцию или вести семинар, я всегда стараюсь рассказать несколько больше, нежели предполагает программа. Так было на последних трёх семинарах, посвящённых работе с одноядерными Zynq-7000S. В этот раз было интересно посмотреть, насколько аудитория знает о некоторых «скрытых» режимах работы с Vivado. Вопрос был достаточно прост: «Кто-нибудь из присутствующих знает про режим ECO Flow?» Сразу за вопросом последовал, что называется, «лес рук, чему я особенно не удивился.
Желание несколько просветить разработчиков хотя бы о наличии этого режима в Vivado, не говоря уже о демонстрации работы в нём, появилась у меня очень давно. Но по какой-то загадочной причине, я «впрягся» в написание руководств по сборке проектов с использованием MicroBlaze и работе с ним. Однако, после недавних семинаров стало очевидно, что писать про ECO Flow всё таки нужно.
Цель статьи – дать общее представление о режиме ECO в среде Vivado [1], предоставляемой компанией Xilinx для своих кристаллов и показать на реальном примере работу в этом режиме, стараясь указать «тонкие» моменты и проанализировать его достоинства и недостатки.
Задачи, которые поставлены в этой статье:
- разработать тестовый пример, по возможности содержащий и демонстрирующий все (или хотя бы большинство) возможностей работы в режиме ECO;
- выполнить имплементацию проекта;
- пояснить понятие Design Checkpoint;
- описать переход в режим работы ECO;
- внести правки в нетлист и получить файл прошивки FPGA;
- убедиться в корректности внесенных изменений;
- составить сводную таблицу времени, затрачиваемого на стандартное внесение изменений в проект и сравнить его со временем, затрачиваемым в режиме ECO, а также инкрементной имплементации.
К сожалению, физически проверить методологию на достаточно «тяжёлом» кристалле (например, Virtex UltraScale) у меня возможности нет. Но, думаю, даже тот пример, который будет приведен – с проверкой на скромном Artix-7, установленном на плате Arty [2], окажется достаточно показательным. В процессе написания я буду опираться на несколько основных документов, в которых описан режим ECO [3], [4], [5]. Используемая версия Vivado (и, соответственно, документации) – 2017.4.
Небольшое отступление: да в руководстве много картинок и «банальщины» о том, как создать проект, собрать процессорную систему на MicroBlaze, работе в IP Integrator, отладке и т.д. Если Вы опытны и просто хотите прочитать об ECO – пожалуйста, перейдите сразу к главе 4: «Переход в режим ECO». Если же Вы не знаете, как собирать проект на MicroBlaze, ни разу не работали в IP Integrator, или любите руководства в стиле пошаговых иллюстраций – буду только рад, если Вы уделите дополнительные 75-90 минут представленному материалу. И, всё же, я надеюсь, что кто-нибудь выполнит руководство полностью, с проверкой в железе.
1. ECO: краткий обзор
ECO – Engineering change orders [6] («порядок внесения внесения инженерных изменений») – это режим, в котором возможно внести изменения в нетлист, синтезированного или имплементированного проекта с минимальным влиянием на исходный нетлист. В Vivado имеется режим ECO, в котором возможно изменять так называемые Design Checkpoint проекта(см. далее), имплементировать внесённые изменения, выполнять генерацию необходимых отчётов для изменённого нетлиста и генерировать по нему файл прошивки FPGA.
Наиболее типичное применение данного режима:
- Изменение пробников и подключаемых линий логических анализаторов (ILA – IntegratedLogicAnalyzer) при отладке проекта. Пользователь может изменить набор подключаемых к ILA линий, избежав при этом полной повторной имплементации проекта.
- Переназначение цепей, подключенных к ножкам ПЛИС. В случае, если разработчиком проекта, схемотехником или разработчиком печатной платы была допущена ошибка в назначении ножек (например, rx перепутан с tx), а проект на FPGA уже был имплементирован, таким способом можно выполнить переназначение портов в нетлисте, избежав повторной полной имплементации (т. е. синтеза, мапинга, оптимизации, размещения, трассировки – со всеми сопутствующими затратами машинного времени и ресурсов) проекта.
- Выполнение анализа «Что_если?» (редактирование содержимого памяти, изменение функционала LUT, улучшение таймингов и т.д.)
Основная задача работы в режиме ECO – экономия времени и избегание повторной имплементации проекта, при внесении изменений на этапе настройки или отладки проекта. Многие знакомы с режимом инкрементной имплементации, который в ECO также используется, однако в ECO, по сравнению с инкрементной имплементацией, быстрее удаётся получить файл прошивки и быстрее выполнить текущую итерацию отладки.
Примечание: работа в режиме ECO возможна только с Design Сheckpoint.
2. Design Сheckpoint
Маршрут проектирования делится на несколько составных частей:, включая синтез и имплементацию. Имплементация в свою очередь делится на подэтапы: различные оптимизации, размещение и трассировку. Промежуточные этапы маршрута проектирования при этом сохраняются в некий «контейнер», который называется Design Checkpoint (DCP) [7]. Это файл, имеющий расширение «.dcp». Design Checkpoint содержит:
- Текущий нетлист (в зависимости от этапа маршрута проектирования), включая все оптимизации, выполненные до записи dcp-файла.
- Ограничения, наложенные на проект (design constraints).
По умолчанию, Vivado создаёт четыре фала dcp: один – на этапе синтеза модуля верхнего уровня проекта (если выполняется синтез в режиме out-of-context, то для всех модулей, которые синтезируются в out-of-context, создается свой файл dcp) и три – на этапе имплементации. Эти файлы можно найти в папках:
«Название_проекта.runs/название_синтеза/название_топ_модуля.dcp»
«Название_проекта.runs/название_импелементации/».
На рис. 1 показан пример расположения и файлы .dcp, которые создаются по умолчанию для некоторого абстрактного проекта.


Рисунок 1 – создаваемые по умолчанию dcp-файлы (1 – «постсинтез-» и 3 – «постимплемент-»: после оптимизации (_opt), после размещения (_placed) и после трассировки (_routed))
В проектном режиме работы с Vivado (Project Mode [8]) файлы .dcp создаются автоматически. Но при работе в непроектном режиме (Non-ProjectMode [8]) пользователь сам должен следить за тем, чтобы «снимки» текущего состояния проекта записывались. Для этого следует использовать соответствующие Tcl команды [9, 10].:
write_checkpoint <file_name>.dcp
read_checkpoint<file_name>.dcp
О том, зачем, как и какие файлы dcp следует открывать, будет рассказано далее.
3. Разработка тестового проекта
Чтобы продемонстрировать на тестовом проекте возможности ECO, он должен содержать следующее:
- Элементы, которых нет в исходном нетлисте или элементы, у которых можно изменять функционал. Например, завести светодиод на кнопку – и в исходном проекте он будет загораться по нажатию, а в измененном – по нажатию он будет гаснуть. То есть нужно будет добавить в нетлист инвертор, которого нет в исходном проекте.
- Элементы, у которых можно менять содержимое. Например, таблица истинности в LUT или содержимое блочной памяти. Причём изменение содержимого блочной памяти тут будет более предпочтительным, поскольку изменение LUT мы уже выполним в п.1, когда будем создавать дополнительный инвертор.
- ILA – для возможности замены подключённых цепей на другие цепи. То есть, не трогая сам ILA, мы попробуемчерез нетлист заменить подключенные к нему выбранные в исходном проекте цепи на другие.
- Перепутанные выводы. Предположим, что при проектировании печатной платы ее разработчик выполнил pin-swap двух выводов для удобства разводки, не согласовав это с разработчиком FPGA, т.е. внёс ошибку путаницы rx с tx UART. В режиме ECO мы должны будем восстановить правильность подключения.
3.1. Создание проекта
Находим иконку Vivado и кликаем по ней два раза, откроется окно приветствия (рис. 2)

Рисунок 2 – Окно приветствия Vivado
Для создания нового проекта нажимаем кнопку Create Project. Нажатие кнопки вызывает мастер создания нового проекта. После его появления нажимаем кнопку Next (рис. 3).

Рисунок 3 – Окно мастера создания нового проекта
Вводим название проекта, в поле Project Name пишем «eco_flow». Указываем, где будет располагаться проект: в поле Project location укажите директорию с проектом. У меня она будет «F:/Projects/FPGA-Systems/eco_flow/projects/vivado». Если установить галочку «create project subdirectory» – будет создана дополнительная папка с именем проекта. Нажимаем Next (рис. 4).

Рисунок 4 – Ввод имени проекта и его расположения
Создаем мы обыкновенный проект, поэтому просто выбираем тип проекта RTL. На текущем этапе не будем добавлять какие-либо файлы в проект, поэтому поставим галку “Do not specify sources at this time” и нажимаем Next (рис. 5).

Рисунок 5 – Выбор типа создаваемого проекта
Работать мы будем с платой Arty [2], поэтому выберем кристалл, который на ней установлен: xc7a35tcsg324-1. Нажимаем Next (рис. 6).
Примечание: я специально не выбираю готовую плату из шаблона доступных плат. Это сделано для того, чтобы можно было вручную делать ошибки, которые потом мы будем исправлять.

Рисунок 6 – Выбор кристалла xc7a35tcsg324-1
Заключительным в мастере настройки нового проекта будет окно Summary создаваемого проекта. Нажимаем Finish (рис. 7).

Рисунок 7 – Окно кратких сведений создаваемого проекта
3.2. Создание и добавление HDL файлов в проект
Здесь мы создадим два модуля: просто мигающий светодиод и блочную память, которая постоянно считывается (фактически, это имитация памяти коэффициентов фильтра, значения которых мы потом попробуем изменить).
Для создания и добавления нового файла в проект воспользуемся мастером, который вызывается по нажатию на синий плюс (рис. 8).

Рисунок 8 – Вызов мастера создания добавления файлов в проект
В появившемся окне выбираем «Add or create design sources» и кликаем Next (рис. 9).

Рисунок 9 – Выбор типа, создаваемого или добавляемого файла
Выбираем Create file, после чего в появившемся окне в поле File name вводим имя создаваемого файла flash_led, нажимаем ОК (рис. 10).

Рисунок 10 – Создание нового файла и ввод его имени
После этого фал появится в списке добавляемых. Нажимаем Finish (рис. 11)

Рисунок 11 – Список добавляемых или создаваемых файлов
Теперь появился мастер создания шаблона для файла. Поскольку я использую VHDL, то я могу изменить имя архитектуры на rtl. Создаем два пина нашего модуля: iclk с направлением «in» (тактовый сигнал нашего модуля) и oled с направлением «out» (выход, подключаемый к светодиоду). Нажимаем ОК (рис. 12).

Рисунок 12 – Мастер создания шаблона модуля (для VHDL)
Теперь наш модуль находится в дереве проекта (рис. 13).

Рисунок 13 – Созданный модуль flash_led
Модуль должен выполнять простую функцию: просто моргать светодиодом с периодом в 1 секунду. Забегая вперед, скажу, что тактовая частота нашего проекта будет равна 100 МГц, а сам модуль Вам ещё пригодится при выполнении домашнего задания.
Замените содержимое файла на следующее (листинг 1 (текстовый варинт листинга 1 см. в приложении А)). Код достаточно прост, и не требует дополнительных комментариев для пояснения его работы.

Листинг 1 – Код модуля flash_led
Теперь создайте новый модуль, который должен называться brom_reader, его порты iclk с направлением «in», и odout[7:0] с направлением «out» (повторите действия с рис. 8 по рис. 12).
Если все сделано правильно, то в дереве проекта должен появиться модуль brom_reader (рис. 14).

Рисунок 14 – Модуль brom_reader в дереве проекта
Замените содержимое модуля следующим текстом (листинг 2 (текстовый вариант листинга 2 см. в приложении Б)). Здесь потребуется несколько комментариев:
- Строка 13: типу std_logic_vector создается псевдоним. Те, кто работает с VHDL часто используют тип данных «std_logic_vector()». Чтобы каждый раз не писать эти длинные названия, можно объявить псевдоним (alias) и потом использовать его на протяжении всего кода модуля.
- Строки 14-20: стандартное объявление двухмерного массива натуральных чисел и инициализация массива (создается память с числами).
- Строка 22: использование псевдонима (alias) slv для объявления сигнала
- Строки 23-24: использование атрибута синтеза [11]. Для чего он здесь прописан? Мы создали достаточно маленький двумерный массив (строки 15-20) – и, вероятнее всего, во время синтеза он будет оптимизирован и реализован в виде распределённой памяти на LUT. А так как мы хотим разместить массив именно в блочной памяти (BRAM- Block RAM), нам необходимо об этом в явном виде сказать синтезатору, что и делается с помощью атрибутов синтеза. Подробнее о них читайте в руководстве по синтезу Vivado в [11].
В остальном все должно быть понятно: мы создали ROM-память, из которой непрерывно, последовательно и циклически считывается ее содержимое.

Листинг 2 – код модуля brom_reader
3.3. Создание проекта MicroBlaze и работа в IP Integrator
Теперь мы создадим проект с MicroBlaze. Еще раз обращу Ваше внимание на то, что есть пошаговое руководство на русском по созданию проектов на софт‑процессоре MicroBlaze для новичков [11, 12].
Для создания блочного проекта необходимо создать Block Design. Выбираем Create Block Design, вводим имя system и нажимаем ОК (рис. 15).

Рисунок 15 – Создание нового Block Design и задание его имени
На поле Diagram добавляются ядра из IP каталога Vivado, либо RTL модули, написанные на VHDL/Verilog/SystemVerilog. Найдем в IP каталоге модуль MicroBlaze, для этого нажмите синий крестик и в поле поиска введите “MicroBlaze” и выберите его (рис. 16).

Рисунок 16 – Добавление IP ядра MicroBlaze на рабочее поле Diagram
После добавления MicroBlaze на рабочее поле, воспользуемся экспресс настройками софт-процессора. Выберите Run Block Automation и выставите настройки в соответствии с рис. 17. Нажмите ОК.

Рисунок 17 – Экспресс настройки MicroBlaze
После этого на рабочем поле Diagram появятся несколько новых IP ядер, включая генератор тактовых частот и локальную память процессора [11, 12]. Нажмите кнопку Regenerate для оптимизации рабочего поля (рис. 18).

Рисунок 18 – Базовое включение MicroBlaze
Выполним настройку некоторых модулей в соответствии с нашей платой Arty. Настроим модуль генерирования сетки тактовых частот clk_wiz_1. Для вызова настроек модуля кликаем по нему два раза левой кнопкой мышки. В окне настроек устанавливаем значение входной тактовой частоты 100МГц, поскольку именно генератор на 100МГц установлен на плате [12]. Также устанавливаем тип источника как однополярный (рис. 19). Перейдём во вкладку Output Clocks, где настроим выходные частоты модуля.

Рисунок 19 – Настройка параметров входной частоты
Во вкладке Output Clocks мы зададим только одну частоту, основную частоту нашей процессорной системы и остальных модулей. Установим её равной 100МГц (рис. 20).

Рисунок 20 – настройка параметров выходной частоты
Прокрутите вниз для настройки дополнительных служебных сигналов. Мы уберем сигнал сброса Reset, который не будем использовать. Снимите с него галочку (рис. 21). Остальные настройки нам не нужны, нажимаем ОК.

Рисунок 21 – Настройка служебных сигналов
Теперь объявляем вход clk_in1 модуля clk_wiz_1 внешним, фактически делаем из него input нашего Block Design. Для этого нажимаем на clk_in1 правой кнопкой мыши и выбираем Make External (рис. 22).

Рисунок 22 – Делаем порт clk_in1 внешним
Как видим появился порт clk_in1_0 (рис. 23).

Рисунок 23 – Входной порт clk_in1_0
В модуле управления сбросом нашей процессорной системы подключим два неиспользуемых входа (внешний сброс и дополнительный сброс) к неактивному логическому уровню «1». Сделаем это с помощью IP блока, который называется constant. Для этого щелкнем синем крестике вверху, затем в строке поиска вводим «const»» и выберем модуль constant.

Рисунок 24 – Поиск IP блока constant в списке доступных IP
Выполним настройку модуля xlconstant_0, щелкнув по нему дважды левой кнопкой мыши. В строке значение (Const val ) вводим 1, в строке ширина (Const Width) вводим 1, нажимаем ОК (рис. 25)

Рисунок 25 – Настройка модуля xlconstant_0
Выполним подключение выхода dout модуля xlconstant_0 ко входам ext_reset_in и aux_reset_in модуля rst_clk_wiz_1_100M. Просто соедините эти порты мышкой (рис. 26).

Рисунок 26 – Подключение неиспользуемых портов к константе
Добавим модуль UART, найдя его в каталоге доступных IP ядер (рис.27).

Рисунок 27 – Поиск модуля UART в списке доступных IP блоков
Выполним настройку модуля axi_uartlite_0, установив настройки передачи в соответствии с рис. 28. Затем нажимаем ОК.

Рисунок 28 – Настройки модуля axi_uartlite_0
Теперь подключим модуль axi_uartlite_0 к процессору. Воспользуемся для этого автоматизированным методом. Нажимаем в верху Run Connection Automation и выбираем что к чему подключить (AXI вход UART к AXI MicroBlaze) рис. 29.

Рисунок 29 – Подключение axi_uartlite_0 к процессору
Интерфейс UART является стандартным и выделен в отдельный тип интерфейсов в Vivado IP Integrator. В пункте 2 на рис. 29 мы сказали, что хотим сделать rx и tx модуля axi_uartlite_0 внешними. Если вы раскроете интерфейс, то увидите это. Не смущайтесь, что в интерфейсе всего один синий провод, позже, когда создадим HDL обертку проекта, вы увидите, что там два порта (rx и tx).
Нажмите кнопку Regenerate Layout. После этого рабочее поле Block Design будет оптимизировано и схема примет ид, как на рис. 30. Убедитесь, что вы корректно выполнили подключение. Если на этом этапе все нормально, продолжим, если есть ошибки, выполните построение процессорной системы заново.

Рисунок 30 – Промежуточный этап сборки процессорной системы.
Давайте добавим еще один модуль на шину AXI. Это будет модуль GPIO, выход которого мы подключим на светодиод. Найдите в списке доступных IP блоков модуль AXI GPIO и добавьте его на рабочее поле (рис. 31).

Рисунок 31 – Модуль AXI GPIO в списке доступных IP
Выполните настройку модуля, в соответствии с рис. 32 (использовать будем только один канал и один выход).

Рисунок 32 – Настройки модуля axi_gpio_0
Выполним подключение модуля axi_gpio_0 к процессору и сделаем выход внешним. Нажмите Run Connection Automation и поставьте все галочки (рис.33).

Рисунок 33 – Подключение axi_gpio_0 к процессору
Нажмите кнопку Regenerate Layout и убедитесь, что все подключения соответствуют рис. 34.

Рисунок 34 – Сборка процессорной cистемы.
Теперь добавим модуль отладки ILA. Предположим, что мы хотим просмотреть транзакции на шине AXI Lite для модуля UART. Находим в списке доступных IP модуль ILA (Integrated Logic Analyzer) рис. 35.

Рисунок 35 – IP блок ILA в списке доступных
Здесь мы используем некоторое подобие так называемого HDL Insertion Flow, когда модули отладки мы добавляем непосредственно в HDL код. Напомню, что выполнять поиск цепей для отладки вы можете и в нетлисте после синтеза. Такой подход называется Netlist Insertion Flow.
Так как мы хотим отлаживать AXI транзакции, то должны настроить тип пробника ILA как AXI (параметр Monitor Type в блоке ILA). Этот режим установлен по умолчанию, поэтому просто подключаем вход SLOT_0_AXI блока ila_0 к шине AXI, транзакции на которой мы хотим просмотреть. В нашем случае это шина, идущая от интерконнекта до модуля axi_uart_0 (рис. 36). Также подключаем тактовый сигнал для модуля к clk нашей системы и нажимаем кнопку Regenerate Layout.

Рисунок 36 – Подключение ila_0 к AXI шине axi_uart_0
По умолчанию длина записываемых данных установлена 1024, что вполне достаточно для просмотра транзакции.
Теперь добавим наши RTL модули в Block Design, для этого выберите модуль flash_led, нажмите правой кнопкой мыши и затем выберите Add Module to Block Design (это работает только в Vivado не ниже версии 2017.1).

Рисунок 37 – добавление модуля flash_led на поле Diagram
Подключите вход iclk модуля flash_led_0 к тактовому сигналу нашей системы, а порт oled сделайте внешним (правой кнопкой мыши по порту, затем выберите Make Exernal). Нажимаем кнопку Regenerate Layout.
Если всё сделано корректно, то должно получиться как на рис. 38.

Рисунок 38 – Промежуточный этап построения проекта в IP Integrator
Повторите аналогичные действия, для добавления модуля brom_reader. Подключите его тактовый вход iclk к тактовой цепи, НО не объявляете выход odout[7:0] внешним. Нажмите Regenerate Layout. Если все сделано корректно, то должно получиться как на рис. 39.

Рисунок 39 – Промежуточный этап построения проекта в IP Integrator
Теперь, добавим еще один ILA и подключим его к выходу odout[7:0] модуля brom_reader_0.
Находим IP блок ILA в списке доступных (рис. 35) и добавляем на поле Diagram. Выполним его настройку, дважды щелкнув по нему мышкой. Устанавливаем Monitor Type в значение Native (отлаживаем мы не шину AXI, а простые цепи). Остальное оставим по умолчанию. Перейдите во вкладку Probe_Ports(0..7) рис. 40.

Рисунок 40 – Настройка ILA
Настроим ширину пробника. Установим значение ширины равное 8 (рис. 41), поскольку именно 8 бит – ширина шины выхода odout[7:0] модуля brom_reader_0. Нажимаем ОК.

Рисунок 41 – Настройка ширины пробников ILA
Подключите выход odout[7:0] модуля brom_reader_0 ко входу probe_0[7:0] модуля ila_1, а вход clk модуля ila_1 подключите к тактовой цепи нашего проекта. Нажмите кнопку Regenerate Layout, и, если все корректно, должно получиться как на рис. 42.

Рисунок 42 –Промежуточный этап построения проекта в IP Integarator
Осталось только добавить кнопку и напрямую с ней включенный светодиод.
Создадим порт ввода, нажав на пустом месте нашей блок схемы правой кнопкой мыши и выбрав Create Port (рис. 43).

Рисунок 43 – Создание порта в IP Integrator
После появления мастера настроек порта, введите его имя ibtn, укажите направление input и, если нужно разрядность. Нажмите OK (рис. 44).

Рисунок 44 – Мастер настройки нового порта (кнопка ibtn)
После этого порт появится на поле Diagram (рис. 45).

Рисунок 45 – созданный порт ibtn
Создайте еще один порт с названием obtn_led, направлением output (повторите действия на рис. 43-44).
Теперь просто соединяем порт ibtn c obtn_led, нажимаем Regenerate Layout. Должно получиться как на рис. 47.

Рисунок 46 – Собранный проект в IP Integrator
Проверим, что нет ошибок в текущем Block Design, нажав на кнопку Validate Design. Если все корректно, но Vivado выдаст соответствующее сообщение. Нажимаем OK и сохраняем текущий Block Design (рис. 48).

Рисунок 47 – Проверка корректности собранного проекта в IP Integrator
3.4. Синтез и имплементация
Перейдите во вкладку Sources, нажмите на system правой кнопкой мыши и выберите пункт Create HDL Wrapper (создать HDL обертку нашего Block Design) рис. 48.

Рисунок 48 – Создание обертки проекта
После этого Vivado предложит либо обновлять вручную HDL обертку при внесении изменений в Block Design, либо делать это автоматически. Оставляем автоматическое обновление и нажимаем OK (рис. 49).

Рисунок 49 – Варианты обновления HDL обертки
Теперь укажем, что модуль system_wrapper является Top-модулем. Нажимаем правой кнопкой мыши на system_wrapper и выбираем Set as Top (рис. 50).

Рисунок 50 – Делаем модуль system_wrapper топ модулем
Теперь выполним синтез модуля system_wrapper, нажав на кнопку Run Synthesis (рис. 51).
Примечание: для подключения блоков отладки мы использовали фактически HDL Insertion Flow [4], то есть фактически вставляли в код наши ILA блоки и подключали к ним цепи. Нет никакой разницы как вы создаете и подключаете цепи для отладки: через HDL или Netlist. В конечном итоге ECO работает именно с синтезированным или имплементированным нетлистом, который хранится в Design Checkpoint.

Рисунок 51 – Запуск синтеза проекта
После нажатия на кнопку Run Synthesis нажмите ОК и дождитесь окончания синтеза.
После окончания синтеза будет выведено окно, в котором будет предложено запустить имплементация, открыть результаты синтеза или посмотреть отчеты. Откройте результаты синтеза (рис. 52).

Рисунок 52 – Открытие результатов синтеза
Теперь подключим ножки в нашем проекте. Делается это с помощью Pin Planer. Чтобы его открыть нажмите Window→I/O Ports (рис. 54).

Рисунок 53 – Открытия окна для назначения пинов
Используя Reference Manual [12] для Arty назначим ножки (рис. 54).
БУДЬТЕ ВНИМАТЕЛЬНЫ!!! Я специально перепутал ножки для rx и tx модуля UART!
Назначьте ножки в соответствии с рис. 54.

Рисунок 54 – Назначение ножек проекта (rx и tx UART перепутаны специально)
Нажмите кнопку сохранить, после чего Vivado укажет, что вы не создавали файл проектных ограничений, и предложит его создать Введите имя файла constr и нажмите ОК (рис. 55).

Рисунок 55 – Создание файла проектных ограничений
Теперь мы можем выполнить имплементацию нашего проекта и сгенерировать файл прошивки. Нажмите на кнопку Generate Bistream, затем OK и дождитесь окончания процедуры (рис. 56).

Рисунок 56 – Расположение кнопки Generate Bitstream
После окончания генерации Bitstream появится окно дальнейших действий. Нажмите Cancel (рис. 57)

Рисунок 57 – Окно дальнейших действий после создания битсрима
3.5. Написание программы для MicroBlaze
Теперь выполним разработку ПО для MicroBlaze. Это выполняется в среде Xilinx Software Development Kit (SDK). Для того чтобы сообщить SDK информацию о собранной процессорной системе (IP ядрах, их адресации на шине AXI) необходимо выполнить экспорт в SDK. Это делается с помощь File → Export → Export Hardware (рис. 58).

Рисунок 58 – Экспорт информации о процессорной системе в SDK
В появившемся окне не устанавливайте галочку Include Bitstream. Отставьте параметры по умолчанию и нажмите OK (рис. 59).

Рисунок 59 – Окно параметров экспорта
Теперь запустим SDK. Для этого выберите File → Launch SDK

Рисунок 60 – запуск SDK
Дождитесь окончания выполнения служебных операций SDK. После их окончания можем приступить к созданию нового проекта. Выбираем File → New → Application Project.

Рисунок 61 – Создание нового проекта в SDK
Введите название нового проекта MB_run, нажмите Next (рис. 62)

Рисунок 62 – Настройка нового проекта
В окне готовых шаблонов выберите создание приложения Hello World и нажмите Finish (рис. 63)

Рисунок 63 – Выбор шаблона создаваемого проекта
Откройте файл helloworld.c (расположение которого показано на рис. 64) и замените его содержимое кодом программы, показанным в листинге 3, и сохраните результат.

Рисунок 64 – Расположение файла helloworld.c

Листинг 3 – Заменённое содержимое файла helloworld.c
Программа отсылает «Hello World: cycle» примерно 1 раз в 2 секунды и моргает светодиодом LD1 (красной компонентой) также приблизительно 1 раз в 2 секунды.
3.6. Запуск программы и отладка
После завершения написания кода и сборки процессорной системы необходимо убедиться, что:
- Светодиод LD4 загорается по нажатию кнопки BTN0
- Процессор работает и шлет «Hello World: cycle» в консоль, однако мы не видим слов в консоли, поскольку выполнили неверное подключение rx и tx. Дополнительным сигнализатором работы процессора, является мигающий светодиод LD1.
- Выполняются транзакции по интерфейсу AXI-Lite от процессора до UART
- Блочная память считывается и выдает корректные значения.
Для начала подключаем Arty к компьютеру. Выполним настройку терминала, в котором должны будут показываться сообщения UART. Это можно сделать стандартными средствами SDK. В SDK имеется терминал, расположенный внизу (рис. 65).
Если терминала нет, то его можно найти в Window → Show View → Others → Xilinx → SDK Terminal (рис. 65).

Рисунок 65 – Открытие встроенного терминала в SDK
Установите настройки терминала, в соответствии с рис. 66. Номер COM-порта может отличаться.

Рисунок 66 – Настройка SDK терминала
Теперь перейдём в Vivado и выполним программирование FPGA.
Нажимаем Open Hardware Manager и переходим в режим программирования и отладки. Выбираем Open Target и нажимаем автоматическое подсоединение Auto Connect (рис. 67)

Рисунок 67 – Открытие Hardware Manager и подключение в ПЛИС
Выбираем из списка наш кристалл и заливаем в него прошивку (рис. 68)

Рисунок 68 – Программирование ПЛИС
В появившемся диалоговом окне следует проверить, что выбраны нужные файлы прошивки .bit и список подключаемых цепей .ltx (рис.69) и затем нажать кнопку Program.

Рисунок 69 – Выбор файла прошивки и списка цепей
Если все сделано корректно, светодиод LD4 должен мигать, а по нажатию на кнопку BTN0 должен загораться светодиод LD4.
Теперь заставим процессор выполнять нашу программу по отправке данных в UART и мигать красной компонентой светодиода LD1.
Переключаемся обратно в SDK, кликаем правой кнопкой по нашему проекту MB_run, после чего выбираем Run As → Launch on Hardware (System Debugger), как показано на рис. 70. Мы заливаем сразу релиз программы, и не будем выполнять пошаговую отладку.

Рисунок 70 – Запуск исполняемой программы процессора
Подождав несколько секунд, видим, что светодиод LD1 мигает, но сообщения в SDK Terminal не появляются, поскольку rx и tx перепутаны.
Теперь давайте убедимся в том, что, транзакции до модуля UART всё-таки доходят.
Переключаемся в Vivado. Надеюсь, что вы помните, что мы подключали два ILA: один на транзакцию по шине AXI для UART, а второй к выходу блочной памяти. Но у нас в списке оказалось три ILA (рис. 71).

Рисунок 71 – Окно подключенных ILA
К сожалению, в результате оптимизации и синтеза, такое может случаться и это следует учитывать, как и то, что в результате оптимизации и различных настроек синтеза могут меняться названия цепей. Тем не менее, мы сможем провести отладку и убедиться, что транзакции до модуля UART все-таки доходят. Но нам нужно их «поймать», то есть настроить триггер, условие, по которому начнется запись состояния линий, к которым подключен ILA.
Дважды кликните мышкой по hw_ila_1 чтобы открыть окно временных диаграмм и окна настроек.
В окне Trigger Setup установите, триггер. Нажмите на синий крестик и в списке доступных цепей выберите цепь, показанную на рис. 72. И нажмите OK.

Рисунок 72 – Выбор триггера для запуска ILA
Примечание: мы работаем с интерфейсом AXI-Lite, в котором достаточно много сигналов. Не буду расписывать здесь функции, которые возложены на те или иные сигналы интерфейса. Если Вам интересно подробнее узнать об этом, пожалуйста, обратитесь к руководству [14].
Теперь установим параметры срабатывания триггера. Поскольку активный уровень сигала RVALID это «1», то скажем, что необходимо начать запись, когда этот сигнал будет равен «1». Установите значение срабатывания, как показано на рис. 73. И затем нажмите кнопку запуска триггера.

Рисунок 73 – Запись данных с ILA по срабатыванию триггера
Теперь, из этого гигантского списка цепей, которые имеются в интерфейсе найдем шину, которая отвечает за данные. Эта шина показана на рис. 74

Рисунок 74 – Цепь с данными на шине AXI-Lite
Измените отображаемое состояние шины на ASCII. Для этого кликните правой кнопкой мыши по шине, затем выберите Radix, затем ASCII (рис. 76).

Рисунок 75 – Выбор представления данных на шине *WDATA[31:0]
После этого мы увидим на шине часть нашего сообщения, которое отсылает процессор. Это частично подтверждает, что транзакция проходит корректно (рис. 76).
![]()
Рисунок 76 – ASCII представление данных на шине *WDATA[31:0]
Попробуйте повторить самостоятельно действия с рис.71 по рис. 76 для hw_ila_2, который подключён к выходу модуля чтения блочной памяти. Устанавливать триггер не требуется. Если всё будет сделано корректно, то картинка должна быть аналогичной рис. 77.

Рисунок 77 – данные, считываемые из блочной памяти
На этом сборка тестового проекта завершена, и мы можем приступить к редактированию нашего нетлиста и работе в режиме ECO.
4. Переход в режим ECO
Как мы убедились выше:
- По нажатию кнопки BTN0 загорается светодиод
- Посылки по UART отправляются, но мы не видим их в консоли (специально перепутаны rx и tx)
- Содержимое блочной памяти считывается циклически и непрерывно (содержимое блочной памяти в ASCII:”author: KeisN13”).
Для исправления ошибок, редактирования нетлиста и изменения содержимого и функционала некоторых компонентов мы воспользуемся режимом ECO, который доступен при работе с Design Checkpoint (DCP). Мы будем использовать DCP, который получается после этапа трассировки кристалла (post route).
При каждом новом запуске синтеза или имплементации Vivado удаляет DCP, поэтому общей практикой работы с DCP является «копипаста» необходимой DCP в новую директорию.
Давайте создадим папку edited_dcp. Я создам ее рядом с папкой проекта (рис. 78)

Рисунок 78 – Создание папки для сохранения DCP
Скопируем необходимый для дальнейшей работы DCP файл, который расположен «папка_проекта/название_проекта.runs/название_имплементации/имя_топ_модуля_routed.dcp» (рис. 79) в папку edited_dcp.

Рисунок 79 – Расположение DCP
Переходим в Vivado и выполняем открытие DCP. Для этого нажмите File → Open Checkpoint (рис. 80)

Рисунок 80 – Открытие DCP
Выберите расположение скопированного DCP файла в папке edited_dcp и нажмите OK.
После открытия DCP, по умолчанию, будет открыто представление (перспектива) Default или, та которую Вы использовали в последний раз, если открывали DCP (рис. 81).

Рисунок 81 – Перспектива Debug открытого DCP
Существует несколько режимов работы с DCP, однако сегодня нас интересует именно ECO Flow. Для перехода в режим ECO необходимо сменить представление. Для этого в верхнем правом углу из выпадающего списка выберите ECO (рис. 82).

Рисунок 82 – Переход в режим ECO
Как видим, графическое представление при переходе в режим ECO изменилось (рис. 83). Появились новые элементы управления и графического интерфейса, которые рассмотрим далее.

Рисунок 83 – Представление в режиме ECO
5. ECO: описание интерфейса
Работа в режиме ECO имеет свой маршрут, который изображен на рис. 84. Вся работа выполняется в соответствующей DCP. После открытия DCP выполняются необходимые изменения в нетлисте, с помощью инструментов графического интерфейса и/или Tcl-команд. Изменения сохраняются, и, в зависимости от того уже размещен полностью проект в кристалле или нет, выполняются размещение и трассировка либо только трассировка. Затем выполняется разводка кристалла, после чего генерируются новые файлы прошивки (битстрима, .bit) и цепей логического анализатора (.ltx). Следующим шагом выполняется проверка внесенных изменений «в железе», и если всё нормально, то сделанные изменения вносятся в исходный проект. Если же нет – то внесение изменений в DCP может быть повторено.

Рисунок 84 – Маршрут проектирования в режиме ECO
Внесение изменений возможно с помощью инструментов графического интерфейса. Оригинал описания интерфейса вы можете найти в [3] в разделе Vivado ECO Flow.
Графическое представление в режиме ECO разбито на несколько секций, расположение и назначение которых идентично стандартному представлению, в котором выполняется основное проектирование.
С левой стороны экрана расположен ECO Navigator, который представляет инструменты для маршрута проектирования. ECO Navigator состоит из нескольких секций.
Секция Edit (рис. 85): предоставляет доступ к инструментам, необходимым для редактирования нетлиста

Рисунок 85 – Команды секции Edit
Create Net: открывает диалоговое окно, предоставляющее доступ к созданию новых цепей. Цепи могут быть созданы для любого уровня иерархии, путём задания имени иерархии в названии цепи. Могут быть созданы шины. Если выбран pin или port, то цепь может быть автоматически подключена к ним, если установлена галка Connect selected pins and ports (рис. 86).

Рисунок 86 – Диалоговое окно Create Net
Create Cell: открывает диалоговое окно, позволяющее добавлять дополнительные компоненты в текущий нетлист. Также имеется возможность создавать ячейки в необходимом уровне иерархии. Можно создавать как библиотечные компоненты, которые доступны из списка, либо black box. Если вы создаёте LUT, то сразу можете редактировать функцию, которую она должна реализовывать (рис. 87).

Рисунок 87 – Диалоговое окно Create Cell
Create Port: вызывает мастер для добавления и настройки дополнительных портов в текущий нетлист. Возможно настроить несколько параметров: направление, ширину шины, стандарт напряжений и т.д. (рис. 88).

Рисунок 88 – Диалоговое окно Create Port
Create pin: выполняет добавление и настройку пинов в текущем нетлисте. Пин может быть создан для текущей ячейки (объектов типа cell) на любом уровне иерархии. Пин для иерархии верхнего уровня также может быть создан с помощью команды create_port. Пин не может быть создан, если не указана ячейка и название создаваемого пина (рис. 89).

Рисунок 89 – Диалоговое окно Create Pin
Connect Net: подключеняет цепь к выбранному пину или порту. Вызываемое диалоговое окно позволяет просмотреть список цепей или выполнить их поиск. Выбранная цепь будет подключена через все уровни иерархии, автоматически создавая необходимые пины.
Disconnect Net: отключает выбранную цепь, пин или порт от цепи. В случае, если выбран объект типа cell, то буду отключены все цепи, подключенные к нему.
Replace Debug Probes: позволяет вызвать диалоговое окно, в котором возможно выполнить редактирование портов ILA и/или VIO (Virtual Input Output), которые были созданы ранее, то есть отключить текущие цепи от и подключить новые.
Place Cell: позволяет разместить объект типа cell в выбранных ресурсах кристалла.
Unplace Cell: убирает выбранный объект типа cell из текущего размещения.
Секция Run
Команды секции Run предоставляет доступ ко всем командам, необходимым для выполнения имплементации.
Check ECO: Выполняет запуск проверки ошибок (DRC – Design Rule Check)
Примечание: Vivado позволяет вносить в нетлист множество изменений, используя команды режима ECO. Однако, внесённые логические изменения, внесённые в проект, могут привести к неосуществимой физической имплементации. Запуск Check ECO следует делать перед тем как вы соберетесь выполнять имплементацию проекта, чтобы устранить ошибки на ранних этапах маршрута ECO Flow.
Optimize Logical Design: в некоторых случаях рекомендуется выполнять оптимизацию нетлиста с помощью команды opt_design и её соответствующих опций [9]. Optimize Logical Design позволяет вызвать диалоговое окно, позволяющее внести соответствующие аргументы Tcl команды opt_design, которые задаются в строке options.
Place Design: Выполняет инкрементное (т.е. основываясь на предыдущем нетлисте) размещение компонентов текущего нетлиста. Отчёт Incremental Placement Summary, который выводится в консоли в конце выполнения команды place_design позволяет просмотреть статистику переиспользования результаттов предыдущего размещения, которое было в оригинальном DCP до внесения изменений. Нажатие на Place Design вызывает окно, в котором могут быть заданы соответствующие опции команды place_design [9]. Подробнее об инкрементной имплементации см. в [3] в разделе Incremental Compile.
Optimize Physical Design: в некоторых случаях может потребоваться выполнить физическую оптимизацию (команда phys_opt_design [9]). Диалоговое окно, вызываемое по нажатию на Optimize Physical Design позволяет ввести соответствующие опции команды phys_opt_design.
Route Design: вызывает диалоговое окно, которое позволяет в зависимости от выбора выполнить инкрементную трассировку внесенных изменений в нетлист, трассировку выбранных пинов или цепей. В случае, если процент переизпользованных разъеденных цепей менее 75%, то будет выпалена обыкновенная трассировка нетлиста.
Подробнее об инкрементной имплементации см. в [3] в разделе Incremental Compile.
Секция Report
В этой секции возможна генерация необходимых отчётов для измененного нетлиста, включая отчет используемых ресурсов, временных характеристик, пересечения тактовых доменов и т.д.
Секция Program
Инструменты этой секции позволяют сохранить внесённые изменения в новы DCP, создать файл прошивки ПЛИС, создать новый лист отлаживаемых через ILA цепей, в случае, если ILA подвергался изменениям, запрограммировать ПЛИС и выполнить отладку стандартными средствами Hardware Manager Vivado.
Вкладка Scratch
Позволяет отслеживать внесенные изменения в нетлист, включая просмотр и подключение незадействованных пинов, портов, цепей. Столбец подключений Con отслеживает статус подключения объектов, PnR отслеживает статус размещения и трассировки объектов.
Нажатием правок кнопкой мыши по вкладке Scratch будет вызвано меню дополнительных действий (рис. 90). Функционал, которые они выполняют, предполагаю интуитивно понятен исходя из их названий. Полный список и действия, которые выполняют команды приведен в [3] в разделе Vivado ECO Flow → Scratch Pad → Scratch Pad Pop-up Menu.

Рисунок 90 – Меню дополнительных действий вкладки Scratch
6. Внесение изменений в проект
Теперь мы можем приступить к внесению изменений в наш проект. Первое, что мы сделаем, это установка нового компонента в нетлист. Сделаем так, чтобы светодиод LD0 светился, а при нажатии кнопки BTN0 гас. Иными словами, мы должны вставить в нетлист инвертор, которого нет.
6.1. Создание новых элементов в нетлисте
Для начала, найдите на схеме порт ibtn, нажмите на него левой кнопкой мыши один раз, а затем нажмите F4. Таким образом, мы попробуем отфильтровать все лишнее в схематике, для повышения читаемости нетлиста.

Рисунок 91 – Открытие схематики для выбранного порта
В появившемся окне, мы увидим только один порт ibtn. Теперь отобразим всю цепь от порта ibtn до светодиода LD1 (порта obtn_led). Нажимаем правой кнопкой мыши по порту ibtn, затем Expand Cone и выбираем To Flops or I/Os. И нажимаем кнопку Regenerate Layout (рис. 92)

Рисунок 92 – Отображение конечных точек, к котором подключён порт
Теперь мы видим полный «тракт» от кнопки до светодиода (рис. 93).

Рисунок 93 – «Тракт» от порта ibtn до obtn_led
Следующий шаг, который необходимо сделать, это определиться, в каком месте разорвать цепь. Предлагаю разорвать её от модуля system_i до выходного буфера. Для этого выбираем цепь от пина obtn_led модуля system_i до пина I буфера obtn_led_OBUF_inst, затем в секции Edit выбираем Disconnect Net.
![]()
Рисунок 94 – Выбор разрываемой цепи
После нажатия на кнопку Regenerate Layout видим, что цепь была удалена (рис. 95)

Рисунок 95 – Схематика после разрыва цепи
Также обратите внимание на вкладку Scratch Pad, содержимое которой изменилось.
Теперь добавим на схему инвертор. Нажимаем в секции Edit строку Create Cell, вводим название компонента invertor, находим шаблон INV и нажимаем OK (рис. 96)

Рисунок 96 – Создание инвертора
Компонент INV будет добавлен на поле (рис. 97)

Рисунок 97 – Созданный инвертор на поле схематики
Как видите, инвертор реализован на LUT. Чтобы посмотреть логическую функцию, которую реализует LUT и при необходимости её изменить, Вы можете, нажав правой кнопкой мыши по компоненту, выбрать свойства Cell Properties, во вкладке Truth Table нажать Edit LUT Equation… (рис. 98).

Рисунок 98 – Свойство и таблица логической функции LUT
Выполним соединение пинов. Выберите или на схематике, или во вкладке Scratch Pad пины I0 компонента invertor и obtn_led компонента system_i.

Рисунок 99 – Выбор соединяемых пинов
Теперь создадим между ними цепь. Для этого в секции Edit нажимаем кнопку Create Net. В диалоговом окне вводим имя создаваемой цепи btn_led, устанавливаем галочку автоматического соединения двух портов и нажимаем ОК (рис. 100)

Рисунок 100 – Параметры создаваемой цепи
После этого два пина буду автоматически соединены. Нажмите Regenerate Layout (рис. 101)

Рисунок 101 – Созданная цепь
Повторим действия для двух оставшихся пинов и соединим пин O компонента invertor с пином I компонента obtn_led_OBUF_inst. Цепь назовём по-другому, поскольку не может быть в проекте двух цепей с одинаковыми названиями на одном уровне иерархии. Назовём цепь btn_led_o. Результат подсоединения показан на рис. 102

Рисунок 102 – Схематика с созданным инвертором
Теперь сохраняем наш DCP и проверяем наличие ошибок, перед тем как запустить размещение и трассировку новых компонентов (рис. 103).

Рисунок 103 – Проверка ECO на ошибки
Из-за того, что мы не выполняли размещение и трассировку, появится ряд ошибок, говорящих об этом.
Теперь попробуем сгенерировать bit файл прошивки, и посмотреть, получилось ли внести изменения корректно. Для этого необходимо последовательно выполнить шаги из секции Run, не все разумеется и без каких-либо опций. Всё остаётся по умолчанию (рис. 104).
Нажимаем Place Design и не вводя никаких опций нажимаем OK. Дождавшись окончания выполнения операций нажимаем Route Design и выбрав Incremental Route в появившемся окне, нажимаем ОК.
После этого генерируем bit файл, нажав на Generate Bitstream. Убедитесь, что в поле пути к файлу указана папка edited_dcp. После этого открываем Hardware Manager для прошивки нашей ПЛИС.

Рисунок 104 – Последовательность действий для получения файла прошивки .bit
При открытии следует учесть, что должен будет открыться новый экземпляр Vivado. Но у меня он не открылся, поэтому я просто открываю новый экземпляр Vivado и запускаю Hardware Manager (рис. 105). При этом будьте внимательны, при выборе файла прошивки .bit и файла цепей для ILA .ltx

Рисунок 105 – Открытие Hardware Manager из начального окна Vivado
Выполните последовательность действий, согласно рис.67-69 и запрограммируйте ПЛИС. Обратите внимание, что прошивать мы будем файлом, расположенным в папке edited_dcp (рис. 106).

Рисунок 106 – Файл прошивки ПЛИС с изменённым нетлистом
Если всё было выполнено корректно, то светодиод LD0 должен будет светиться, а по нажатию кнопки BTN0 гаснуть.
6.2. Изменение свойств/параметров компонентов
В режиме ECO также возможно изменять содержимое компонентов и менять их параметры. Сейчас мы попробуем изменить содержимое блочной памяти модуля brom_reader, которая имитирует у нас, например, коэффициенты фильтра. Давайте найдём нашу BROM и просмотрим её свойство INIT, отвечающее за начальную инициализацию.
Перейдите во вкладку Netlist и найдите блочную память в модуле brom_reader (рис.107).

Рисунок 107 – Расположение блочной памяти модуля brom_reader в нетлисте
Нажав правой кнопкой по этому компоненту, мы можем просмотреть его свойства, выбрав Cell Properties (рис. 108). Затем перейдите во вкладку Properties и пролистайте до свойств INIT.

Рисунок 108 – Свойства INIT выбранной блочной памяти
Как видите, в свойствах INIT хранятся значения инициализации блочной памяти. Среди множества этих свойств нас интересуют только INIT_00 и INIT_01. Если скопировать содержимое этих двух свойств конвертор HEX to ASCII [15], то получим надпись, которую мы видели на рис. 77, но записанную в обратном порядке (рис. 109)

Рисунок 109 – Содержимое свойств INIT в формате ASCII
Изменить свойство компонента можно, если щелкнуть на значок карандашика и вписать новые значения или же воспользовавшись Tcl консолью и командой set_ptoperty.
Замените значения свойств согласно рис.110 и сохраните результат:
INIT_00: 256’h0061006700700066002E00770077007700200020002000200020002000200020
INIT_01: 256’h0020002000200020002000750072002E0073006D00650074007300790073002D

Рисунок 110 – Изменённое содержимое свойств INIT в формате ASCII
Поскольку мы не добавляли новых компонентов в нетлист и не переподключали цепи, то нет необходимости выполнять размещение и трассировку. Просто нажимаем Generate Bitstream и ожидаем окончания выполнения операции. На всякий случай сгенерируйте файл .ltx, который мы подцепим во время отладки (рис. 111).

Рисунок 111 – Генерация битсрима и файла цепей для отладки
Перейдите в Hardware manager и запрограммируйте FPGA только что сгенерированным файлом .bit и созданным списком пробников .ltx (рис.112). Обратите внимание, что файлы взяты из папки edit_dcp.

Рисунок 112 – Файлы прошивки измененного нетлиста и списка цепей
Выполните последовательность действий, описанных на рис. 73-75 (откройте hw_ila_2, переведите тип отображаемых значений в ASCII и просмотрите выводимую надпись). Если всё получилось корректно, то должна появиться надпись рис. 113.
![]()
Рисунок 113 – Измененное содержимое блочной памяти
Как видите, если Вам необходимо изменить содержимое или параметры компонентов не только блочной памяти, а в принципе любых, не требующих вмешательств в размещение и трассировку, то делается это очень быстро и достаточно просто. Однако следует быть осторожным, когда Вы изменяете параметры, отвечающие за рабочую частоту, например, когда вносите изменения в настройки MMCM или PLL Вашего проекта. В этом случае, прежде чем создавать файл прошивки, убедитесь, что тайминги проекта сходятся, а соответствующие отчёты не выдают ошибок (Report Timing Summary и т.д.).
6.3. Подключение других цепей к пробникам и ILA
Пожалуй, самым полезным вариантом использования ECO является замена в уже имплементированном проекте цепей, подключенных к пробникам. Единственным ограничением тут является то, что виртуальные пробники должны быть подключены все, ни один не должен «висеть в воздухе». Это ограничение обычно несущественно, так как неиспользуемые пробники всегда можно просто подключить к gnd или vcc.
Попробуем переключить пробник, наблюдавший за выходом блочной памяти, на значение счетчика, генерирующего для неё адрес.
Как мы знаем из описания интерфейса ECO, в нём есть инструмент, позволяющий выполнить переподключение пробников; им и воспользуемся.
Примечание: несмотря на наличие специального инструмента редактирования пробников и подключённых цепей, выполнять эти действия можно и «совсем вручную», подобно тому как мы делали при добавлении компонента: отсоединить одни цепи и подсоединить другие. Однако тут есть некоторые нюансы: по не совсем понятным причинам, иногда цепь от пина отсоединить не удается, нажатие на Disconnect Net не выполняется. В этом случае можно руками или через скрипты снять с цепи свойство «DONT_TOUCH» или отменить её трассировку (выполнить «unrote») – тогда Disconnect Net будет выполнятся. При работе мастером таких проблем не наблюдается.
Работа с мастером требует, чтобы мы знали название цепей, которые мы собираемся подключать. Давайте попробуем найти цепи, отвечающие за выставление адреса для блочной памяти в модуле brom_reader. Это можно сделать через схематическое представление или через сам нетлист. Поскольку модуль маленький, то просто просмотрим название через нетлист (рис. 114). Необходимая цепь называется cnt, это шина, шириной 5.

Рисунок 114 – Цепь адреса блочной памяти в нетлисте
Выбираем режим Replace Debug Probes. Поскольку наш счётчик считает только до 31, то требуется всего 5 линий, поэтому выбираем первые пять линий в ila_1, затем нажимаем правой кнопкой мыши и выбираем Edit Probes (рис. 115). Выбрать можно любой ila, но они достаточно громоздкие. Для руководства, выбраны попроще.

Рисунок 115 – Выбор заменяемых пробников
Выполняем поиск по списку цепей, введя название искомой цепи *cnt[*]. Пролистав вниз находим их, и нажимаем кнопку добавления в пробники. Обратите внимание, что мы одновременно заменяем 5 пробников, поэтому должно быть выбрано 5 цепей. Замена типа поиска с contains на match обусловлена правилами поиска в tcl и для текущего примера позволяет выводить более точный результат. При использовании поиска цепей рекомендуется хотя бы немного понимать и знать символы подстановки в языке Tcl и правила, по которым выполняется поиск.

Рисунок 116 – Поиск подключаемых к пробникам цепей
Оставшиеся три цепи мы подключим к «0», в Vivado цепи, подключенные к gnd называются const0. Выберем три оставшиеся цепи, правой кнопкой Edit Probes (рис.117).

Рисунок 117 – Доукомплектовывание ila_1
Вводим название в строку поиска *const0 и добавляем первую цепь из списка, три раза кликнув по стрелке, поскольку мы должны подключить три линии (рис. 118). БУДЬТЕ ВНИМАТЕЛЬНЫ!!! Не добавляете линии из иерархии Debug Hub (dbg_hub), в этом случае Vivado выдаст ошибку только в самом конце настройки пробников, и вся работа пойдет на смарку. Выберите цепь из любого IP, например, uartlite.

Рисунок 118 – Добавление константных цепей в пробники
Сформированный ila_1 должен выглядеть как на рис. 119. Еще раз отмечу, что не должно быть пустых пробников. В этом случае, будут ошибки на этапе DRC.

Рисунок 119 – Новые цепи в ila_1
После нажатия на кнопку OK появится окно, которое информирует, что атрибут DONT_TOUCH будет снят с цепей, ранее подключенных к пробникам ila_1. Это один из нюансов, которые я описал в примечании в начале этого раздела. Учитывайте это, в случае если вы не используете мастер подключений, а делаете всё вручную. Соглашаемся с изменениями, нажав Unset Property и сохраняем текущее состояние DCP.
Теперь последовательно выполняем размещение, трассировку, генерацию битсрима и создание списка цепей (рис.120). Все вместе занимает примерно 1 минуту на моем компьютере. Быстро, не правда ли!

Рисунок 120 – последовательность действий для создания файла прошивки списка цепей для отладки
Теперь открываем Hardware Manger и программируем наш кристалл, на забывая подключить правильные .bit и .ltx файлы.
Открыв hw_ila_2 мы увидим 4 сигнала: шину cnt и три const0. Измените вывод значений шины cnt с hex на unsigned decimal (по аналогии с рис. 75) и запустите запись, нажав синий треугольник. Если все корректно, то Вы увидите изменение на шине cnt с 0 по 31 с инкрементом 1 (рис.121).

Рисунок 121 – Значение шины cnt в пробнике ila_1
Как видим, мы смогли отключить цепи выхода блочной памяти от пробников и подключить новые.
6.4. Замена портов ввода/вывода
Последнее, что остаётся сделать это изменить rx и tx для модуля uart и наконец-то увидеть Hello World в консоли. Следует отметить, что при работе с ECO есть несколько путей, чтобы достичь результата. Я покажу один из них.
Отрываем нетлист. Прежде чем приступить к переназначению ножек, стоит написать, что необходимо будет удалить всю входную цепь до первого объекта типа cell, после чего ее просто восставим заново. Удалять будем порт, цепь и буфер.
Сначала разберемся с входной цепью.
Выберите порт uart_rtl_0_rxd, подключенную у нем цепь и входной буфер. Нажмите unplace cell и затем удалить (рис. 122). После нажатия кнопки удалить, порт останется, просто выберите его и нажмите удалить еще один раз.

Рисунок 122 – Выбор входной цепи и детрассировка компонентов
Теперь восстановим удаленные компоненты. Первым делом добавим порт uart_rx, нажав на кнопку Create Port затем выставив настройки в соответствии с рис. 123

Рисунок 123 – Параметры создаваемого входного порта
Поскольку ножка A9 уже занята нашим выходным портом, Vivado выдаст сообщение, в которым предложит отменить привязку другого порта к ножке A9. Соглашаемся с этим (рис. 124)

Рисунок 124 – Окно информации об уже имеющемся подключении к выбранной ножке
Теперь создадим входной буфер. Нажмем кнопку Create Cell, название создаваемой ячейки ibuf_rx (рис. 125)

Рисунок 125 – Создание входного буфера
Теперь создаем цепь. Это делается в несколько этапов. Сначала цепь подключается к порту, а затем выполняется подключение к буферу. Выберите порт uart_rx и нажмите Create Net. Название цепи rx_net.

Рисунок 126 – Создание цепи
Теперь выберите цепь и порт I входного буфера и нажмите Connect Net. После этого появится цепь (рис. 127)

Рисунок 127 – Подключение порта и входного буфера
Теперь создадим цепь, межу буфером и модулем system_i. Выберите выходной пин O буфера и цепь uart_rtl_0_rxd, подключённую к system_i и нажмите Create Net

Рисунок 128 – Подключение буфера и цепи
Теперь повторим туже последовательность действий для выходного порта.
Выбираем выходной порт uart_rtl_0_txd, подключенную к нему цепь и выходной буфер. Нажимаем Unplace cell, а затем красный крестик, для удаления компонентов (рис. 122). После нажатия кнопки удалить, порт останется, просто выберите его и нажмите удалить еще один раз.

Рисунок 129 – Выбор выходной цепи
Создаём порт uart_tx, нажав кнопку Create Port, задаём направление Output и устанавливаем стандарт LVCMOS33 (рис. 130)

Рисунок 130 – Настройка параметров выходного порта
Создадим цепь tx_net, которая будет подключена к порту uart_tx. Выбираем uart_tx и нажимаем Create Net

Рисунок 131 – Создание цепи tx_net
Создаём выходной буфер tx_obuf, нажав Create Cell и выбрав тип OBUF (рис. 132)

Рисунок 132 – Создание выходного буфера
Выбираем пин O выходного буфера и цепь, подключённую к порту uart_tx и нажимаем Connect Net.

Рисунок 133 – Подключение буфера и порта
Теперь подключим буфер к system_i. Выбираем пин I буфера и цепь uart_rtl_0_txd (рис. 134).

Рисунок 134 – Подключение буфера и цепи
Сохраняем проект и выполняем последовательно размещение и трассировку. После этого запускам генерацию бистрима (рис. 135).

Рисунок 135 – Последовательно действий для получения файла прошивки
Откройте Hardware Manager и запрограммируйте ПЛИС. Перейдите в SDK и выполните запуск приложения (см. рис. 70). Если всё нормально, но в консоли вы увидите сообщение Hello World: cycle (рис. 136).

Рисунок 136 – Сообщения Hello World в SDK Terminal
7. Сравнительный анализ
Проведем небольшой сравнительный анализ разных подходов к внесению изменений в проект по части времени, затрачиваемого на различные операции. Это сравнение будет, конечно, довольно условным, т.к. требуемое время сильно зависит от кристалла, от его загруженности, от количества свободных трассировочных ресурсов и т.д. Проделаны будут операции по изменению HDL файлов, после которого будет заново выполнен синтез, а также в «постсинтез-» нетлисте будут изменены пробники. Результаты приведены в таблице 1. Сразу следует отметить, что инкрементная имплементация даёт выигрыш только при работе с большими кристаллами, для которых получение конечного результата может занимать десяток часов. В учет тут не было включено время, затрачиваемое на внесение разработчиком изменений. Однако учтено то, что мы работали с IP Integrator – а он требует дополнительного времени на синтез IP и RTL.
Таблица 1. Сравнительный анализ времени, затрачиваемого на получение конечного файла прошивки в различных режимах.

Резюмируя сравнительны анализ, ещё раз скажу, что он очень поверхностный. Вы прекрасно понимаете, что FPGA – это сложная система и время того или иного этапа маршрута проектирования может изменяться очень сильно. Тем не менее, ECO не требует синтеза, и внесение небольших изменений в проект выполняется гораздо быстрее, особенно когда требуется сохранить трассировку кристалла и внести изменения только в содержимое компонентов.
8. Заключение
Применял ли я когда-нибудь на практике режим ECO? Да. Стояла задача, не изменяя трассировку кристалла поменять содержимое блочной памяти, в которой были зашиты некоторые значения, позволяющие защитить продукцию от копирования. Там как раз и пригодился ECO; правда, по большей части работа была выполнена при помощи Tcl-скриптов, а не графического интерфейса. Тем не менее, режим ECO оказывается действительно полезен при работе с большими проектами – особенно в случае, если вы являетесь горячим фанатом внутрисхемной отладки с LogicAnalyser (ChipScope) и любите делать ILA на пару сотен (или даже тысяч) пробников. Возможно, Вы найдете работу в этом режиме полезной для Вас, если просто попробуете сделать что-то большее, чем описано в данном руководстве.
Если Вы нашли для ECO Flow интересное применение, или просто решили попробовать использовать его в своём проекте, оставьте небольшой комментарий: будет любопытно узнать для чего Вам в Vivado пригодился ECO Flow.
Не забудьте сделать и домашнее задание. Удачи!
9. Домашнее задание
- Используя исправленный нетлист, измените логическую функцию LUT, которая реализует инвертор, чтобы она не инвертировала входной сигнал.
- Попробуйте запустить различные оптимизации с различными опциями в режиме ECO. Используйте для помощи гайд с Tcl командами Vivado [9].
- Просмотрите транзакции на шине AXI-lIte, которые идут к модулю GPIO. В режиме ECO замените цепи, которые подключены к ila_1 от модуля uartlite, на цепи от модуля gpio.
- *Попробуйте изменить частоты, которую вырабатывает MMCM, текущее значение 100МГц. Сделайте его 50 МГц. Если все сделано корректно, то светодиод должен мигать в два раза медленней. Не забудьте просмотреть отчет по таймингам, поскольку вы изменили модуль, отвечающий за частоту всего проекта.
- *Попробуйте создать Tcl команду или скрипт, который бы автоматически выполнял необходимую последовательность действий при изменении нетлиста в режиме ECO. Скрипт должен сохранять изменения, запускать размещение, трассировку, генерировать фал прошивки и т.д.
- **Напишите скрипт, который бы позволял изменять содержимое блочной памяти в блоке brom_reader, записывая любые 32 символа ASCII, вводимые в качестве аргументов разрабатываемой процедуры/скрипта
Библиографический список
1. Vivado на сайте Xilinx
2. Описание Arty Board на сайте Digilent
3. UG904 Vivado Design Suite User Guide: Implementation
4. UG908 Vivado Design Suite User Guide Programming and Debugging
5. UG986 Vivado Design Suite Tutorial: Implementation
6. Wiki: ECO
7. UG949 UltraFast Design Methodology Guide
8. UG892 Vivado Design Suite User Guide Design Flows Overview
9. UG835 Vivado Design Suite Tcl Command Reference Guide
10. UG894 Using Tcl Scripting
11. UG901 Vivado Design Suite User Guide Synthesis
12. Arty Reference Manual
13. UG908 Programming and Debugging
14. UG1037 Vivado Design Suite AXI Reference Guide
15. Hex-to-ASCII
Приложение А. Листинг модуля flash_led
Скрытый текст
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
entity flash_led is
Port ( iclk : in STD_LOGIC;
oled : out STD_LOGIC);
end flash_led;
architecture rtl of flash_led is
signal cnt : natural range 0 to 100_000_001 := 0;
signal led : std_logic := '0';
begin
process(iclk)
begin
if rising_edge(iclk) then
if cnt = 100_000_000 then
cnt <= 0;
else
cnt <= cnt + 1;
end if;
if cnt < 50_000_000 then
led <= '0';
else
led <= '1';
end if;
end if;
end process;
oled <= led;
end rtl;
Приложение Б. Листинг модуля brom_reader
Скрытый текст
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.NUMERIC_STD.ALL;
entity brom_reader is
Port (
iclk : in STD_LOGIC;
odout : out std_logic_vector(7 downto 0)
);
end brom_reader;
architecture rtl of brom_reader is
alias slv is std_logic_vector;
type rom_type is array (0 to 31) of natural;
signal rom : rom_type := (
32 , 32, 32, 32, 97, 117, 116, 104,
111, 114, 58, 32, 75, 101, 105, 115,
78 , 49, 51, 32, 32, 32, 32, 32,
32 , 32, 32, 32, 32, 32, 32, 32
);
signal cnt : natural range 0 to rom'length-1 := 0;
signal dout: slv(odout'range) := (others => '0');
attribute RAM_STYLE : string;
attribute RAM_STYLE of rom : signal is "BLOCK";
begin
process(iclk)
begin
if rising_edge(iclk) then
dout <= slv(to_unsigned(rom(cnt), dout'length));
if cnt = (rom'length - 1) then
cnt <= 0;
else
cnt <= cnt + 1;
end if;
end if;
end process;
odout <= dout;
end rtl;
Приложение В. Листинг программы helloworld
Скрытый текст
#include "platform.h"
#include "xil_printf.h"
#include "xparameters.h"
#include "xgpio.h"
XGpio Gpio; /* The Instance of the GPIO Driver */
#define DELAY 10000000
int main()
{
init_platform();
int Status;
volatile int Delay;
int k = 0;
/* Initialize the GPIO driver */
Status = XGpio_Initialize(&Gpio, XPAR_GPIO_0_BASEADDR);
if (Status != XST_SUCCESS) {
xil_printf("Gpio Initialization Failedrn");
return XST_FAILURE;
}
/* Loop forever blinking the LED */
while (1) {
/* Set the LED to High */
XGpio_DiscreteWrite(&Gpio, 1, 1);
xil_printf("Hello World: cycle %dnr", k);
k++;
/* Wait a small amount of time so the LED is visible */
for (Delay = 0; Delay < DELAY; Delay++){};
/* Clear the LED bit */
XGpio_DiscreteWrite(&Gpio, 1, 0);
/* Wait a small amount of time so the LED is visible */
for (Delay = 0; Delay < DELAY; Delay++){};
}
cleanup_platform();
return 0;
}
Автор: Барак Адама
Источник
Введение
Vivado HLS (High Level Synthesis) — новая САПР Xilinx, предназначенная для создания цифровых устройств с применением языков высокого уровня. Попытки использования таких языков (понимая под ними языки с Си-подобным синтаксисом) неоднократно предпринимались различными компаниями на протяжении последнего десятилетия. Основной целью таких продуктов было упрощение процесса проектирования для разработчика, знакомого с программированием.
Практическое использование ПЛИС часто вызывает трудности для «чистых» программистов, которые сталкиваются с целым рядом непривычных задач: необходимостью помнить о правильном формировании тактовых сигналов, учитывать латентность, а также вообще понимать, что операторы языков описания аппаратуры не вполне эквивалентны операторам языков программирования. Например, оператор сложения, естественный для программиста, в распространенных языках описания аппаратуры (HDL) требует соответствующего обрамления. Разные схемотехнические решения будут получены для случая, когда сложение выполняется в виде оператора непрерывного присваивания (continuousassignment) и внутри синхронного процесса. В то же время, цифровая схемотехника по мере уменьшения норм технологического процесса все больше тяготеет к синхронным схемам. В итоге оказывается, что много усилий при проектировании на базе ПЛИС тратится на разработку управляющего автомата, активирующего устройства в нужные моменты времени.
Зная необходимую последовательность операций, можно, применяя регулярные правила, построить соответствующий конечный автомат. В свою очередь, его построение можно автоматизировать, разработав соответствующую программу анализа исходного текста на языке высокого уровня. В начале 2000-х годов появилась серия программных продуктов, представлявших собой компиляторы, генерирующие VHDL или Verilog на уровне регистровых передач (RTL-уровень) из Си-подобного языка программирования. Получавшиеся файлы обычно можно было интегрировать в проект наравне с файлами, полученными другим способом.
Характеристики проектов, созданных с помощью инструментов C—to—RTL, по проводившимся обзорам, обычно отличали чуть больший объем ресурсов и чуть большая тактовая частота. Это стало следствием того, что компиляторы разбивали сложные вычисления на элементарные операции, каждая из которых имела небольшую задержку. Соединение таких элементарных схем, управляемых конечным автоматом, давало в результате регулярную структуру из регистров, передававших друг другу данные через вычислительные узлы. Подобные структуры эффективно реализуются в FPGA.
Схожесть языков C—to—RTL с языком программирования Си не означает при этом, что такой инструмент способен создать проект в FPGA, реализующий вычисления, эквивалентные программе на Си для компьютера или микроконтроллера. Выбор Си в качестве основы объяснялся широкой распространенностью этого языка и снижением входного порога освоения для разработчиков, знакомых с программированием. Однако, за исключением простейших примеров, программы на Си должны подвергаться глубочайшей переработке для получения аппаратного решения, способного выступать в качестве ускорителя интересующих нас вычислений.
В 2011 году компания Xilinx объявила о выпуске продукта, относящегося к упомянутому классу инструментов, — преобразование Си-подобного исходного текста в эквивалентный код на одном из языков описания аппаратуры. Создаваемое RTL-представление представляет собой конечный автомат (то есть схему, выполненную в синхронном стиле, что предпочтительно для современных FPGA), управляющий потоками вычислений. Результаты зависят от проектных ограничений (constraints), а также, причем в большой степени, от директив компилятора. Директивы также могут облегчить формирование интерфейсов создаваемого модуля: он может быть экспортирован в виде IP-ядра с интерфейсом, определенным пользователем, но также можно указать на необходимость его экспорта в виде периферийного модуля для шины AXI4 (для установки в процессорную систему) или модуля для инструмента System Generator for DSP. Упрощенный маршрут проектирования в VivadoHLS показан на рис. 1.

Рис. 1. Упрощенный маршрут проектирования в Vivado HLS
Основные сведения об HLS
Директивы HLS существенно сильнее влияют на RTL-представление по сравнению с тем, как директивы компилятора языка программирования влияют на скомпилированный код для процессора. Из одного исходного текста с помощью HLS можно получить несколько значительно различающихся схем.
Для анализа этой схемы необходимо определить два важных понятия:
• Пропускная способность (throughput) — задержка в тактах между поступлением новых входных данных.
• Латентность (latency) — задержка между поступлением входных данных и появлением соответствующих им выходных.
На рис. 2 эти понятия проиллюстрированы на примере простейшей конвейерной схемы. На показанной временной диаграмме видно, что каждым тактом входные данные сдвигаются на один регистр, освобождая при этом вход для приема новых данных. Таким образом, пропускная способность такой схемы составляет один такт, поскольку новые данные можно подавать каждым новым тактом. Латентность равна количеству триггеров в цепочке (в показанном случае это два такта).

Рис. 2. Понятия «латентность» и «пропускная способность»
Эти понятия играют важную роль при разработке высокопроизводительных цифровых схем. При построении сложных комбинаторных схем период тактового сигнала определяется самой длинной цепью, соединяющей синхронные компоненты. Поэтому очевидным способом повышения тактовой частоты (то есть уменьшения периода тактового сигнала) является разделение длинных цепей триггерами. При этом, очевидно, увеличивается латентность схемы, однако это является побочным эффектом на пути к достижению более приоритетной цели — увеличению тактовой частоты при сохранении пропускной способности, равной одному такту между новыми входными отсчетами.
На рис. 3 показан исходный текст, который содержит цикл с четырьмя итерациями. По умолчанию создается схема, воспроизводящая поведение процессора общего назначения: все итерации цикла выполняются последовательно. Такая реализация занимает наименьшую площадь на кристалле FPGA (то есть использует наименьшее количество ресурсов), однако требует большого числа тактов от начала работы до получения результатов (то есть имеет большую латентность). Кроме того, поскольку все итерации выполняются одним и тем же вычислительном блоком, невозможно начать новый цикл расчета до полного завершения текущего цикла. Таким образом, этот вариант имеет малую пропускную способность.

Рис. 3. Основы Vivado HLS — управление синтезом с помощью директив
По аналогии с разворачиванием цикла в компиляторах языков программирования такой цикл также можно развернуть (этот прием называется loop unrolling). При этом каждая итерация цикла рассчитывается индивидуальным элементом. За счет одновременного выполнения всех итераций латентность становится существенно меньше, однако количестворесурсов, требуемое для реализации такой схемы, возрастает практически пропорционально.
Дальнейшим улучшением такой схемы является конвейеризация вычислений. Если промежуточные результаты будут записываться в регистры, то это освободит соответствующую часть ресурсов для выполнения вычислений над следующей порцией данных. Латентность при этом не изменяется, но повышается пропускная способность.Логические ячейки FPGA, так же как и блочные ресурсы (память и блоки XtremeDSP), имеют регистры на выходе, поэтому глубокая конвейеризация вполне допустима для FPGA.
Исходя из представленного примера, можно определить приоритеты при разработке высокопроизводительных схем. В первую очередь, следует улучшать пропускную способность, вплоть до одного такта на входной отсчет. При этом номинальное значение тактовой частоты повышается путем более глубокой конвейеризации, что автоматически дает побочный эффект в виде увеличения латентности. Второстепенная цель — сохранение латентности на разумно малом уровне, при этом нельзя допустить появления избыточных стадий конвейера, которые в действительности не способствуют повышению тактовой частоты. В качестве примера такой избыточной конвейеризации легко представить вычислительное устройство, на выходе которого установлено несколько последовательно включенных регистров. Верхняя граница тактовой частоты такого устройства определится теми компонентами, которые осуществляют преобразование данных, и добавление регистров на выходе не уменьшает задержку распространения сигналов внутри вычислителя.
Для выполнения вычислений требуется обеспечить передачу сигналов данных от одного вычислительного узла к другому в определенные моменты времени. Vivado HLSавтоматически выделяет из исходного текста и пути данных, и последовательность управления работой (рис. 4). В примере показано, что автомат управления включает в себя начальное состояние 0, состояние циклического выполнения операций 1 и состояние завершения работы 2. По мере необходимости операции с данными могут быть распараллелены.
Рис. 4. Принципы автоматического создания управляющих автоматов в Vivado HLS
Вопрос параллельного выполнения операций важен для FPGA как таковых. Именно возможность организации большого количества параллельно работающих модулей является принципиальным конкурентным преимуществом FPGA как аппаратной платформы. Известен факт, что именно FPGA способны обеспечить реализацию устройства с уникальной аппаратной архитектурой. Однако это преимущество иногда полагается единственным. В действительности при корректном использовании FPGA способны обеспечить за счет параллельной работы не только высокую абсолютную производительность, но и соотношение производительность/цена, превышающее это соотношение для сигнальных процессоров и процессоров общего назначения. Например, FPGA семейства Kintex-7 начального уровня имеет 240 независимых блоков, выполняющих операцию «умножение с накоплением».Учитывая, что системная тактовая частота для Kintex-7 достигает 700 МГц, можно получить 168 GMAC/с. Это значение можно существенно скорректировать с учетом снижения частоты из-за особенностей трассировки и неполного использования ресурсов, однако вполне можно ожидать значения в 100 GMAC/с для устройства, выполняющего многоканальную цифровую фильтрацию или спектральный анализ. Можно представить, что суммарная стоимость процессоров, способных обеспечить подобную производительность (100 ГГц при условии, что на каждом такте будут выполняться только операции цифровой обработки сигналов), окажется существенно выше, чем стоимость одной ПЛИС 7K70.
Исходя из этого, становится очень важным не только выбрать алгоритм, который мог бы эффективно использовать особенности FPGA, но и реализовать его так, чтобы в проекте не появлялись линии с чрезмерно большой задержкой, по которым и будет выравнена тактовая частота. Важно, что эту работу Vivado HLS выполняет автоматически. На рис. 5 показаны варианты схемы, реализуемой для различных аппаратных платформ. Поскольку одним из параметров проекта в HLS является требуемая тактовая частота, САПР может оценить, укладывается ли синтезированная схема в эти параметры. Для первого варианта схемы для достижения высокой тактовой частоты требуется глубокая конвейеризация, поэтому четырестроки исходного текста преобразуются в четыре операции. Соответственно, латентность такой схемы равна четырем. Однако при переходе к аппаратной платформе с более высокой производительностью (например, с Artix на Kintex) задержки при выполнении отдельных операций оказываются меньше, поэтому за один такт удается выполнить две операции. Тактовая частота схемы сохраняется на требуемом уровне, однако латентность уменьшается до двух.

Рис. 5. Влияние характеристик аппаратной платформы на формирование управляющего автомата
Таким образом, при генерации схемы Vivado HLS действует следующим образом:
• Основным приоритетом является повышение пропускной способности схемы при соблюдении проектных ограничений по тактовой частоте, задаваемой пользователем.
• Следующим по важности приоритетом является снижение латентности.
• По возможности минимизируются занимаемые проектом ресурсы.
Другой задачей, которую автоматизирует Vivado HLS, является генерация интерфейсов с учетом управляющих сигналов. На рис. 6 показан исходный текст функции и схема сгенерированного модуля для реализации этой функции. Кроме сигналов, объявленных в качестве параметров функции, в модуле имеются также сигналы с суффиксами vld, от слова valid («готовность»). Отдельные блоки создаются из функций, описанных в C-коде. Функции могут быть «развернуты» для упрощения иерархии (inlining). Для небольших функций это преобразование выполняется автоматически.

Рис. 6. Формирование аппаратных интерфейсов для блоков
Циклы в Vivado HLS
Циклы по умолчанию реализуются итеративно: каждая итерация выполняется последовательно на базе одних и тех же ресурсов. Это обеспечивает поведение ПЛИС, схожее с поведением программ для ЭВМ: увеличение количества итераций означает увеличение времени работы, а объем ресурсов, необходимых для этой операции, остается постоянным.Реализацией циклов можно управлять с помощью директив. Для идентификации цикла в директиве каждый цикл должен начинаться с метки, как показано на рис. 7. На том же рисунке приведена схема преобразования текста на Си в эквивалентную схему. Видно, что все итерации суммирования выполняются одним и тем же сумматором. При необходимости цикл можно развернуть (unroll), однако для этого требуется, чтобы число итераций цикла было известно на этапе синтеза. (Переменное число итераций не может быть развернуто.)
Рис. 7. Реализация циклов в HLS
Пример «идеального цикла», приведенный в САПР Vivado HLS, показан в листинге 1. В нем видно, что оба уровня вложенного цикла имеют метки (что позволяет устанавливать индивидуальные директивы для каждого уровня), а число итераций является константой.
void loop_perfect(din_t A[N], dout_t B[N]) {
int i,j;
dint_t acc;
LOOP_I: for(i=0; i < 20; i++){
LOOP_J: for(j=0; j < 20; j++){
if(j==0) acc = 0;
acc += A[i] * j;
if(j==19) B[i] = acc / 20;
}
}
}
Листинг 1. Пример «идеального цикла» (perfect loop) в Vivado HLS
Этот пример хорошо подходит для иллюстрирования влияния директив компилятора на результаты синтеза RTL-представления. Уже было упомянуто, что директива UNROLLприводит к разворачиванию цикла: его итерации начинают выполняться параллельно на собственном наборе оборудования. Количество тактов на выполнение всего цикла уменьшается за счет роста размера схемы. В принципе такой эффект и лежит в основе одногоиз главных преимуществ FPGA, имеющих большое количество ресурсов. В таблицеприведены основные результаты синтеза примера из листинга 1 при разном наборе директив компиляции.
|
Набор директив |
Период, нс (требуемый период — 25 нс) |
Латентность, тактов |
Логических генераторов (LUT) |
Блоков DSP48 |
|
Без дополнительных директив |
19,94 |
403 |
129 |
2 |
|
HLS_UNROLLдля внутреннего цикла |
19,98 |
61 |
326 |
4 |
|
HLS_UNROLLдля внешнего цикла |
19,94 |
460 (?) |
1920 |
40 |
|
HLS_UNROLLдля внутреннего и внешнего циклов |
19,98 |
11 (!) |
6360 |
80 |
Результаты синтеза без дополнительных директив предсказуемы. Цикл имеет в общей сложности 400 итераций (200 на внешнем и 200 на вложенном уровне). Добавляя латентность на вспомогательные пересылки, можно объяснить появление значения 403 в таблице. Это решение имеет минимальный размер.
Установив директиву HLS_UNROLL для внутреннего цикла (LOOP_J), можно наблюдать ожидаемое уменьшение латентности. В цикле используется умножение на значение счетчика:
acc += A[i] * j
Это не потребовало привлечения дополнительных блоков DSP.
Следующий шаг эксперимента — установка директивы UNROLL только для внешнего цикла. Однако результаты оказываются, на первый взгляд, неожиданными: при резком увеличении ресурсов латентность не только не уменьшилась, но и несколько увеличилась. Внешний цикл действительно оказался развернут, и каждая итерация получила собственный экземпляр устройства умножения. Однако в этом случае каждая итерация внешнего цикла ожидает завершения работы вложенного цикла, поэтому для работы требуется целых 460 тактов.
Ожидаемого эффекта удается добиться при установке директивы UNROLL для обоих уровней цикла. Объем ресурсов существенно возрастает: вместо двух блоков DSP для проекта требуется 80, а также резко увеличилось количество LUT. Однако латентность составила всего 11 тактов! Если поставленная цель состояла в том, чтобы максимально задействовать ресурсы FPGA для сокращения времени работы, то она оказалась практически достигнута. Использованная в примере FPGA Kintex-7 XC7K160 имеет 600 блоков DSP и 101 тыс. LUT.При полном разворачивании циклов в проекте оказалось задействовано 13 и 6% этих ресурсов соответственно.
Таким образом, с помощью директив компилятора можно весьма широко изменять параметры проекта, регулируя количество выделенных на него ресурсов и латентность. Большая гибкость в установлении директив делает процесс их внедрения в проект не таким однозначным, поскольку далеко не все сочетания директив приводят к приемлемым результатам. Поэтому разработчики должны обращать дополнительное внимание на характеристики, достигаемые при текущем сочетании настроек, и рассматривать различные варианты построения проекта, стиля кодирования и установки директив компиляции.
Массивы и работа с памятью
Массивы в HLS реализуются на базе памяти. Если массив выступает в качестве аргумента функции верхнего уровня, память считается размещенной вне ПЛИС. При необходимости память может быть разбита на более мелкие блоки для реализации на базе триггеров и распределенной памяти (distributed RAM). HLS может использовать двухпортовый режим блочной памяти.
Использованию памяти в HLS следует уделять особое внимание. Обычно программист для PC не рассматривает память в качестве отдельного ресурса, поскольку все используемые данные автоматически помещаются в основную память компьютера. При оптимизации программ речь может идти о временном размещении каких-то значений в регистрах, учете особенностей кэширования и т. п. Однако для ПЛИС возможности размещения данных существенно шире.
Во-первых, память может быть физически реализована в виде следующих аппаратных ресурсов:
- триггеры логических ячеек;
- LUT секций типа SliceM (например, распределенная память);
- в блоках памяти BRAM.
Отдельно можно рассматривать внешнюю память. Она не является частью кристалла FPGA, однако участвует в работе проекта, в то время как на FPGA размещен контроллер для доступа к ней.
Во-вторых, важным преимуществом FPGA является крайне высокая теоретическая пропускная способность подсистемы памяти в целом. BRAM представляет собой обычную статическую память (то есть это не программируемый блок, а фрагмент кремниевой пластины с жесткими металлизированными соединениями). Блоки имеют полностью независимые интерфейсы и могут работать на системной тактовой частоте. Таким образом, теоретически FPGA большого объема способны обеспечить пропускную способность порядка сотен гигабайт в секунду, что оставляет далеко позади интерфейсы внешней памяти, в том числеDDR3. Однако важнейшим вопросом при этом является то, способен ли проект получить преимущество от множества параллельно работающих BRAM, и может ли вообще быть обеспечен такой поток данных внутри кристалла.
Из-за этих факторов необходимо тщательно продумывать распределение данных, чтобы обеспечить их размещение в ресурсе такого типа, который позволит максимально эффективно использовать особенности ПЛИС. При программировании также необходимо следить, чтобы выбранные синтаксические конструкции не сделали невозможным размещение данных в памяти, которую имеет в виду разработчик. Можно констатировать, что в настоящее время результаты работы компилятора HLS сильно зависят как от особенностей исходного текста, так и от использованных директив. У программиста, знакомого с С, может сложиться впечатление, что результаты работы HLS в ряде случаев весьма далеки от совершенства.
Разработчик, работающий с памятью в языках программирования высокого уровня, не нуждается в решении такой задачи, поскольку независимо от вида массивов и порядка обращения к ним пропускная способность памяти компьютера или микроконтроллера ограничена, причем чаще всего единственным интерфейсом. Вопросы распределения данных по областям памяти могут оказаться актуальными для редких случаев многоядерных систем, имеющих сложную структуру доступа к памяти по физически раздельным шинам.
В отличие от таких систем для эффективной работы с памятью в FPGA необходимо выбрать оптимальный способ использования большой суммарной пропускной способности интерфейсов независимых блоков памяти. Например, если все данные будут в целях экономии ресурсов размещены в одном блоке памяти, производительность такого блока будет ограничена двумя операциями за такт (в силу того, что блочная память в FPGA является двухпортовой). Если же распределить программные объекты по разным блокам памяти, то за один такт каждый из этих блоков будет способен выполнить две операции. Как и для блоков DSP, вопрос заключается в увеличении количества операций за такт путем вовлечения в проект все большего объема ресурсов FPGA. Конкретный тип ресурса для программного объекта HLS можно установить директивой RESOURCE, как показано на рис. 8.
Рис. 8. Установка типа ресурса для массива
Для гибкого управления памятью используется ряд директив. Директива ARRAY_PARTITION служит для разделения одного массива на несколько меньшего размера.Пример настройки этой директивы показан на рис. 9. Параметр dimension («размерность») позволяет указать, какая размерность должна быть подвергнута разделению. Например, для массива
my_array[10][6][4]
установка этого параметра в 1 заставит компилятор разделить массив на 10 независимых массивов (по максимальному значению первого индекса), каждый из которых будет иметь размерность [6][4]. Установка параметра в 0 приведет к синтезу 10×6×4 = 240 независимых регистров.

Рис. 9. Настройка параметров директивы ARRAY_PARTITION
Директива RESHAPE выполняет обратное действие — объединяет несколько независимых областей данных в один массив. В сочетании с предыдущей директивой она позволяет управлять размещением данных в физических блоках, увеличивая или уменьшая количество независимых шин, с помощью которых выполняется доступ к данным.
Директива PACK группирует данные, например, составляющие элемент структуры, формируя таким образом более широкую шину для одновременного доступа ко всем ее элементам.
Использование этих директив для различных объектов не однозначно. Крайними ситуациями являются чрезмерно низкая производительность шин для пересылки данных, с одной стороны, и перегруженность FPGA независимыми блоками, приводящая к чрезмерному расходованию ресурсов, с другой. Выбор оптимальной организации размещения данных индивидуален для каждого проекта. Гибкость архитектуры FPGA и огромное количество возможных вариантов (далеко не все из которых сопоставимы в смысле эффективности) не позволяет слишком надеяться на то, что компилятор самостоятельно выберет оптимальный способ размещения данных при любых операциях над ними, которые захочет выполнить разработчик.
Поддержка языков высокого уровня
В Vivado HLS можно использовать следующие языки высокого уровня: С, С++, SystemC. Они имеют схожий синтаксис, поэтому освоение группы «Си-подобных языков» обычно не составляет большого труда. Однако с формальной точки зрения С и С++ представляют собой разные языки, на что обращают внимание многие авторы литературы по программированию. То же относится и к SystemC.
Важным отличием от языков программирования является поддержка так называемых arbitrary—precision типов, то есть типов данных с явно указываемой разрядностью. Это отличие считается таким важным потому, что при программировании разработчик имеет дело с процессором, обрабатывающим данные фиксированной разрядности, определяемой конструкцией этого процессора. Изменение разрядности с точки зрения программы возможно, однако редко целесообразно. В противоположность этому при проектировании цифровых систем разработчик имеет возможность явно указать разрядность обрабатываемых данных, которая наилучшим образом соответствует решаемой задаче. Для разных языков типы отличаются:
- С: (u)int (с разрядностью 1–1024);
- C++: ap_(u)int (с разрядностью 1–1024), ap_fixed;
- SystemC: sc_(u)int, sc_fixed.
Типы с точным указанием разрядности позволяют устранять избыточность ресурсов, например, по сравнению с типом int, разрядность которого равна 32. Эта избыточность может оказаться существенной. Если рассмотреть архитектуру блока DSP, то видно, что такой блок способен умножить 18-разрядное число на 25-разрядное. Если же разрядность множителей будет не зафиксирована явно на достаточном для задачи уровне, а выбрана равной 32(автоматически, в результате использования типа int), для построения схемы будут привлечены дополнительные аппаратные ресурсы.
Vivado HLS позволяет синтезировать многие конструкции С/С++/SystemC, при условии, что их параметры известны во время компиляции (compile time). По понятным причинам не поддерживается синтез для описаний, элементы которых становятся известны только во время исполнения (run time). Кроме того, не синтезируются:
- функции динамического управления памятью (malloc/free);
- операции ввода/вывода (printf/scanf);
- истемные вызовы (опрос таймера).
В синтезируемом коде поддерживаются указатели (pointers). Как правило, они приводят к синтезу схемы, в которой указатель выступает как адрес устройства памяти. (Само устройство физически может представлять собой компонент любого доступного типа — регистр, распределенная или блочная память.) Указатели полезны, когда необходимо передать ссылку на объект большого размера (например, pass—by—reference). В этом случае передается адрес объекта, а не весь объект целиком. Гибкость архитектуры FPGA в принципе позволяет передать 1024 бита в качестве 128 8-разрядных элементов (что произойдет в случае передачи объекта «по значению» — pass—by—value), но такая схема скорее всего будет избыточной для многих практических применений (хотя и позволит обрабатывать все 128 значений параллельно).
При использовании указателей необходимо обращать дополнительное внимание на получаемые результаты. Вообще при работе с HLS необходимо помнить, что FPGA имеют гибкую архитектуру, позволяющую реализовать требуемое поведение множеством способов, в отличие от выполнения программы на процессоре или микроконтроллере. Стиль программного кода, используемые синтаксические конструкции и директивы компилятора способны оказать существенное влияние на получаемые результаты.
Работа с HLS
Vivado HLS представляет собой отдельный программный продукт, который может быть установлен в рамках инсталляции общего пакета САПР Xilinx, но имеет собственную среду разработки. При запуске Vivado HLS появляется стартовый экран, как показано на рис. 10. На этом экране можно как создать новый проект или открыть существующий, так и ознакомиться с готовыми примерами проектов и документацией по САПР.

Рис. 10. Стартовый экран Vivado HLS
Основные шаги по созданию проекта удобно рассмотреть на практическом примере, содержащем простейшую схему. На рис. 11 показано стартовое диалоговое окно «мастера»создания нового проекта.

Рис. 11. Стартовое диалоговое окно «мастера» создания нового проекта
На рис. 12 приведена настройка синтезируемой части проекта. Для синтеза функция верхнего уровня не может называться main(), как это принято в С; такое имя предназначено для верхнего уровня модели.

Рис. 12. Диалоговое окно настройки синтезируемой части проекта
Далее можно пропустить шаг добавления тестовых модулей, работа с которыми будет рассмотрена позднее. В следующем окне настройки решения (solution), показанном на рис. 13, следует указать желаемый период тактового сигнала для проекта и выбрать конкретное наименование FPGA. Как уже было упомянуто, эта информация не является абстрактной, а служит для выбора конкретных схемотехнических решений.

Рис. 13. Настройка решения (solution)
Если выбранная FPGA имеет недостаточное быстродействие, для схемы будет синтезирован конвейер с большим числом стадий. Соответственно, каждая стадия будет выполнять более простую операцию, и общая задержка окажется меньше. В приведенном примере для определенности можно выбрать плату KC-705 на базе FPGA KIntex-7. После завершения работы «мастера» окно САПР будет выглядеть, как показано на рис. 14.

Рис. 14. Окно САПР Vivado HLS после завершения работы «мастера» создания проекта
Для текущего проекта необходимо добавить синтезируемый файл верхнего уровня. Это можно сделать с помощью главного меню или же из контекстного меню, вызываемого правой кнопкой мышки в области структуры проекта (панель Explorer).
Файл верхнего уровня demo.c может содержать текст, показанный в листинге 2.
int top_synth(int a, int b)
{
return a + b;
}
Листинг 2. Основной синтезируемый файл проекта demo.c
На инструментальной панели имеются кнопки, запускающие моделирование и синтез соответственно. После завершения синтеза будет показан отчет с возможностью детализации по отдельным показателям (например, распределения ресурсов ПЛИС по отдельным элементам программы на HLS), что можно видеть на рис. 15.

Рис. 15. Окно САПР после завершения синтеза схемы и формирования отчета
После завершения синтеза в панели Explorer можно изучить синтезированный код. В группе solution → syn → vhdl находится сгенерированный модуль на языке VHDL, который может быть передан в другие инструменты проектирования Xilinx. Содержимое этого модуля показано в листинге 3.
-- ============================================================
-- RTL generated by Vivado(TM) HLS
-– High-Level Synthesis from C, C++ and SystemC
-- Version: 2013.3
-- Copyright (C) 2013 Xilinx Inc. All rights reserved.
--
-- ===========================================================
library IEEE;
use IEEE.std_logic_1164.all;
use IEEE.numeric_std.all;
entity top_synth is
port (
ap_start : IN STD_LOGIC;
ap_done : OUT STD_LOGIC;
ap_idle : OUT STD_LOGIC;
ap_ready : OUT STD_LOGIC;
a : IN STD_LOGIC_VECTOR (31 downto 0);
b : IN STD_LOGIC_VECTOR (31 downto 0);
ap_return : OUT STD_LOGIC_VECTOR (31 downto 0) );
end;
architecture behav of top_synth is
attribute CORE_GENERATION_INFO : STRING;
attribute CORE_GENERATION_INFO of behav : architecture is
"top_synth,hls_ip_2013_3,{HLS_INPUT_TYPE=c,HLS_INPUT_FLOAT=0,HLS_INPUT_FIXED=0,HLS_INPUT_PART=xc7k325tffg900-2,HLS_INPUT_CLOCK=10.000000,HLS_INPUT_ARCH=others,HLS_SYN_CLOCK=1.600000,HLS_SYN_LAT=0,HLS_SYN_TPT=none,HLS_SYN_MEM=0,HLS_SYN_DSP=0,HLS_SYN_FF=0,HLS_SYN_LUT=0}";
constant ap_const_logic_1 : STD_LOGIC := '1';
constant ap_const_logic_0 : STD_LOGIC := '0';
begin
ap_done <= ap_start;
ap_idle <= ap_const_logic_1;
ap_ready <= ap_start;
ap_return <= std_logic_vector(unsigned(b) + unsigned(a));
end behav;
Листинг 3. Результаты генерации RTL-представления проекта на языке VHDL
Несмотря на простоту, этот пример позволяет продемонстрировать некоторые особенности Vivado HLS. Собственно вычисление выполняется в строке:
ap_return <= std_logic_vector(unsigned(b) + unsigned(a));
Однако результаты сопровождаются сигналами готовности (ap_ready) и завершения работы (ap_done). Разрядность обрабатываемых сигналов автоматически установлена равной 32, поскольку для них указан тип int.
Далее в проект можно добавить тестовый модуль, с помощью которого можно будет проверить работу синтезированного проекта. Тестовый модуль является элементом болеевысокого уровня по отношению к синтезируемому, но он также может обращаться и к другим файлам, содержащим несинтезируемый код. Пример простейшего теста показан в листинге 4.
#include "stdio.h"
int main()
{
int result;
result = top_synth(2, 2);
printf("Testing 2 + 2 = %dnr", result);
return 0;
}
Листинг 4. Тестовый файл для моделирования поведения синтезированного модуля
Запуск модели (кнопка Run C Simulation на инструментальной панели) приведет к появлению в консоли сообщений от компилятора, а также сообщений, выводимых тестовой программой (рис. 16). Показанный в листинге 4 пример очевиден, хотя и не может рассматриваться как серьезный тест. Моделирование, претендующее на адекватный анализ характеристик синтезируемого описания, должно включать в себя анализ результатов. Рекомендуется разрабатывать, например, самопроверяющиеся (self—checking) модели, которые проверяют синтезируемые функции не с помощью вручную написанных последовательностей вызовов, а подавая на вход заранее сгенерированные последовательности данных и сравнивая их с так же заранее определенными эталонными откликами. С помощью такого подхода можно проверять большое количество вариантов (ограниченное в основном допустимым временем тестирования), а изменения тестов сводятся к изменению файлов с данными, а не кода на С. Создание файлов с входными данными и эталонными откликами можно автоматизировать, что еще больше повысит эффективность работы и обеспечит лучшее покрытие проекта тестовыми примерами.

Рис. 16. Консоль Vivado HLS после завершения работы теста
Простейший пример, призванный продемонстрировать порядок действий с САПР, не дает сколько-нибудь полного представления о практических возможностях этого инструмента и его назначении. Применимость языков высокого уровня и качество автоматически генерируемых схем необходимо анализировать на более сложных проектах. В листинге 5приведен исходный текст модуля верхнего уровня для модуля быстрого преобразования Фурье (БПФ, в англоязычном варианте — FFT). Этот проект входит в состав примеров, включенных в Vivado HLS.
#include "fft_top.h"
void dummy_proc_fe(
bool direction,
config_t* config,
cmpxDataIn in[FFT_LENGTH],
cmpxDataIn out[FFT_LENGTH])
{
int i;
config->setDir(direction);
config->setSch(0x2AB);
for (i=0; i< FFT_LENGTH; i++)
out[i] = in[i];
}
void dummy_proc_be(
status_t* status_in,
bool* ovflo,
cmpxDataOut in[FFT_LENGTH],
cmpxDataOut out[FFT_LENGTH])
{
int i;
for (i=0; i< FFT_LENGTH; i++)
out[i] = in[i];
*ovflo = status_in->getOvflo() & 0x1;
}
void fft_top(
bool direction,
complex<data_in_t> in[FFT_LENGTH],
complex<data_out_t> out[FFT_LENGTH],
bool* ovflo)
{
#pragma HLS interface ap_hs port=direction
#pragma HLS interface ap_fifo depth=1 port=ovflo
#pragma HLS interface ap_fifo depth=FFT_LENGTH port=in,out
#pragma HLS data_pack variable=in
#pragma HLS data_pack variable=out
#pragma HLS dataflow
complex<data_in_t> xn[FFT_LENGTH];
complex<data_out_t> xk[FFT_LENGTH];
config_t fft_config;
status_t fft_status;
dummy_proc_fe(direction, &fft_config, in, xn);
// FFT IP
hls::fft<config1>(xn, xk, &fft_status, &fft_config);
dummy_proc_be(&fft_status, ovflo, xk, out);
}
Листинг 5. Исходный текст модуля верхнего уровня быстрого преобразования Фурье
Сгенерированный проект обладает следующими характеристиками:
- FPGA — XC7K160TFBG484-1;
- заданный период тактового сигнала — 3,30 нс;
- оценка периода тактового сигнала средствами Vivado HLS — 2,89 нс (346 МГц);
- латентность — 3196–5247 тактов;
- число триггеров — 9934;
- число LUT — 8051.
Сгенерированный проект имеет высокую оценку тактовой частоты. В частности, это является следствием того, что в исходном тексте фактически вызвана функция, ссылающаяся на готовое IP-ядро, выполняющее быстрое преобразование Фурье:
hls::fft<config1>(xn, xk, &fft_status, &fft_config);)
Также можно обратить внимание на то, что латентность указана в виде интервала значений. Такое поведение HLS весьма важно для последующего анализа его применения.
Интервальный характер латентности связан с тем, что для компонентов проекта, генерируемых HLS, используется механизм «рукопожатия» (handshaking). Выше можно было видеть, что каждое ядро имеет сигналы готовности к приему новых данных, а выходные данные сопровождает сигналом их достоверности. Таким образом, каждый последующий компонент в цепочке обработки начинает работать, когда все входные данные сопровождены соответствующими сигналами готовности, а сам компонент свободен для обработки следующей порции входных данных. Существует много алгоритмов, подразумевающих переменное число тактов для завершения работы, поэтому итоговая латентность и оказывается переменной.
Vivado HLS в сравнении с другими средствами проектирования Xilinx
С учетом изложенного выше материала для практикующих разработчиков остро встает целый ряд вопросов. Какое же место занимает новая САПР в ряду инструментов проектирования для FPGA? Представляет ли она собой, безусловно, прорывное решение, которое призвано вытеснить ставший привычным маршрут проектирования на основе RTL-описаний? Является ли такое вытеснение, если оно состоится, вопросом ближайшего времени или же отдаленной перспективой? Существуют ли задачи, которые уже сейчас эффективно могут быть решены с использованием HLS, и на какие особенности проекта должен обратить внимание разработчик, чтобы усилия по освоению HLS оказались оправданными?
При сравнении необходимо сразу обратить внимание, что Xilinx позиционирует VivadoHLS в качестве инструмента разработки устройств цифровой обработки сигналов. Действительно, в HLS появилась возможность использования математических выражений и управляющих конструкций C-подобных языков программирования. При разработке в RTL-стиле первым же психологическим барьером была необходимость понять, что операторы HDLвыполняются не последовательно, по мере их появления в исходном тексте, а одновременно. В HLS же именно эта особенность разработки на ПЛИС была устранена, и появилась возможность привлечения к проектам программистов.
Почему при этом делается упор на разработку систем цифровой обработки сигналов?Прежде всего потому, что применение HLS само по себе не гарантирует качественного роста производительности. Далеко не каждая программа, написанная на С, может быть эффективно реализована в ПЛИС. Функциональности компилятора HLS недостаточно, чтобы для произвольного программного продукта определить именно те участки кода, аппаратное ускорение которых даст существенное увеличение эффективности программно-аппаратного комплекса в целом. Из известных сфер применений именно цифровая обработка сигналов с ее потенциальной возможностью задействовать параллельные вычислительные структуры может получить существенный выигрыш при реализации в FPGA по сравнению с другими аппаратными платформами. Это не исключает применения HLS и в других задачах, но для алгоритмов ЦОС, по крайней мере, хорошо известны типичные решения на основе параллельных вычислительных структур.
Таким образом, для систем цифровой обработки сигналов в настоящее время существует три подхода:
- разработка «вручную» в RTL-стиле, возможно, с использованием стандартных IP-ядер;
- разработка с использованием System Generation for DSP;
- разработка в HLS.
Эти пункты не являются взаимоисключающими, поскольку САПР Vivado, предназначенная для сквозного проектирования, технически позволяет иметь в проекте несколько модулей, разработанных с использованием перечисленных подходов, комбинируя их сильные стороны.
Как следует из материала этой статьи, HLS позволяет описывать проект на языках высокого уровня. Разработчик освобождается от необходимости управлять последовательностью операций; автоматически поддерживаются многие типы данных (в том числе с плавающей точкой). Алгоритмы, разработанные на С/С++, в принципе могут быть перенесены в FPGA, при этом они получают существенное ускорение при наличии в исходной задаче операций, выполняющихся параллельно. Разработанный на HLS модуль можно легко подключить к проекту в System Generator или к процессорной системе в качестве периферийного модуля с интерфейсом AXI4.
В то же время результаты работы HLS имеют две особенности, которые могут затруднить применение разработанных модулей:
- сильная зависимость результатов от директив компилятора и стиля кодирования;
- интервальный характер латентности, плохо предсказуемое потактовое поведение синтезированной схемы.
В целом HLS не очень хорошо подходит для компактных проектов с малой латентностью, основанных на хорошо известных разработчику схемотехнических решениях. Например, простой КИХ-фильтр имеет несложное RTL-представление и может быть реализован на VHDLили Verilog, либо в виде IP-ядра, а HLS представляется несколько избыточным. Кроме того, при реализации КИХ-фильтра необходимо строго следить за постоянством временного интервала между обработкой отдельных отсчетов, и переменный характер латентности здесь недопустим. Напротив, если речь идет о проекте, ориентированном на длительное моделирование, проведение различных экспериментов, то высокая скорость разработки на HLS является значимым преимуществом.
Ряд публикаций по применению HLS ориентирован на использование этого инструмента для проектирования систем обработки изображений или программно-зависимого радио [2, 3].Для таких проектов обычно характерна большая (и переменная) латентность, а также применение разработанного на HLS модуля в качестве периферийного устройства для процессорной системы. При этом процессор выполняет в основном функции управляющего устройства, обеспечивающего поддержку интерфейса, и получает результаты от аппаратного ускорителя с относительно низкой скоростью.
Заключение
Можно сделать вывод, что новая САПР, при всей ее неоднозначности, позволила иначевзглянуть на процесс проектирования цифровых устройств для FPGA. Для ускорения ее освоения компания Xilinx разработала учебные курсы, которые можно пройти в авторизованном учебном центре КТЦ «Инлайн Груп» (www.plis.ru). Для практикующих разработчиков новый инструмент может оказаться полезным при построении систем, предусматривающих сложные вычисления, особенно для устройств обработки изображений и видео, программно-зависимого радио и специализированных аппаратных ускорителей.
ПЛИС (Программируемая Логическая Интегральная Схема) — это интегральная схема, предназначенная для построения цифровых цепей из описания на специальном языке программирования. Другими словами, ПЛИС представляет собой чип, как бы содержащий в себе кучу элементов наподобие 74HCxx. Какие именно это будут логические элементы, какие между ними будут связи, и какие связи будет иметь получившаяся схема с внешним миром, определяется на этапе программирования ПЛИС.
Примечание: Насколько я смог выяснить, в русском языке на сегодняшний день термины ПЛИС и FPGA (Field-Programmable Gate Array, Программируемая Пользователем Вентильная Матрица), принято считать взаимозаменяемыми, что будет использовано далее по тексту. Однако стоит знать о существовании и альтернативной точки зрения, согласно которой FPGA (ППВМ) является одной из разновидностей ПЛИС (PLD, Programmable Logic Device).
Основные сведения об FPGA
Для программирования FPGA используются языки описания аппаратуры (HDL, Hardware Description Language). Среди них наибольшей популярностью пользуются Verilog (и его диалекты, в частности SystemVerilog), а также VHDL. Языки во многом похожи, но имеют разный синтаксис и различаются в некоторых деталях. Если Verilog — это такой C мира описания аппаратуры, то VHDL — соответственно, Pascal. Насколько мне известно, VHDL несколько менее популярен, в частности, из-за его многословности по сравнению с Verilog. Из преимуществ VHDL (или недостатков, кому как) можно назвать строгую статическую типизацию. Verilog же иногда допускает неявное приведение типов. Если продолжать аналогию с C и Pascal, языки различаются не настолько сильно, чтобы не выучить их оба.
На данный момент лидирующими производителями FPGA являются компании Altera (сейчас принадлежит Intel) и Xilinx. По информации из разных источников, вместе они контролируют не менее 80% рынка. Из других игроков стоит отметить Actel (куплена Microsemi), Lattice Semiconductor, Quicklogic и SiliconBlue. С железом от Xilinx можно работать только из среды разработки от Xilinx (называется Vivado), а среда разработки от Altra (называетя Quartus) понимает только железо от Altera. То есть, полный вендор лок, и выбирая конкретную FPGA для своего проекта, вы автоматически выбираете и инструменты разработки соответствующего производителя, их техническую поддержку, документацию, условия лицензирования софта, политику касаемо прекращения поддержки железа, и так далее.
FPGA часто используются в задачах, где некие вычисления хочется существенно ускорить, реализовав их прямо в железе. Например, FPGA нашли широкое применение в области обработки сигналов, скажем, в осциллографах, анализаторах спектра, логических анализаторах, генераторах сигналов, Software Defined Radio и даже некоторых мониторах. В частности, в LimeSDR используется Altera Cyclone IV, а в осциллографе Rigol DS1054Z стоит Xilinx Spartan-6, а также ProASIC 3 от компании Actel. Еще из применений, о которых я слышал, могу назвать компьютерное зрение, распознавание речи и биоинформатику. Есть и другие проекты, в частности по разработке веб-серверов и СУБД, работающих на FPGA [PDF]. Но, насколько мне известно, это направление все еще остается сильно экспериментальным.
Xilinx или Altera?
Как говорится, лучший Linux тот, который использует ваш знакомый гуру по Linux.
Мой знакомый гуру по FPGA в лице Дмитрия Олексюка посоветовал начать с девборды Arty Artix-7 от компании Digilent. Используемой в ней FPGA является Artix-7 от Xilinx. Сам Digilent не производит доставку в Россию, но устройство доступно и на AliExpress, хотя и с заметной наценкой (официальная цена составляет 99$). Также его продают на eBay. Это довольно мощная плата, которая, тем не менее, стоит вполне адекватных денег.
Fun fact! Если вам просто хочется попрограммировать на Verilog или VHDL, строго говоря, покупать какую-либо плату с FPGA не требуется. Первое время можно ограничиться симулятором, работа с которым будет рассмотрена далее.

Из интересных особенностей платы можно назвать расположение гнезд совместимым с Arduino-шилдами способом. Также в комплекте с платой идет вкладыш, по которому можно получить лицензию на Vivado, открывающую все его возможности. Лицензия действует один год с момента активации, а также привязана к одному компьютеру по типу ОС и MAC-адресу.
По доставке. Я слышал, что устройства с FPGA на борту имеют большие шансы не пройти таможню. Магазин на AliExpress, ссылку на который я привел выше, доставляет платы в Россию через курьерскую службу СПСР. Для прохождения таможни потребовалось заполнить онлайн-форму с паспортными данными (только данные, без фото) и контактным телефоном, как этого требует текущее российское законодательство. После этого плата была доставлена курьером прямо до двери без каких-либо вопросов.
Установка Vivado
Среда разработки Vivado доступна для скачивания на сайте Xilinx. Будьте морально готовы к тому, что перед скачиванием вам придется пройти регистрацию и заполнить довольно подробную форму о себе. Скачиваем архив под названием «Vivado HLx 2017.2: All OS installer Single-File Download». Не перепутайте случайно с каким-нибудь «Vivado Lab Solutions», это совершенно не то, что нужно. Архив весит более 20 Гб, поэтому запасаемся терпением.
Распаковываем архив, запускаем инсталлятор. Ставим Vivado HL System Edition. Полная его версия займет на диске 47 Гб. Лично я снял галочку напротив Software Development Kit и оставил поддержку только 7 Series устройств, что уменьшило размер до 12 Гб. Забегая немного вперед отмечу, что такой конфигурации оказалось вполне достаточно.
Перед запуском Vivado нужно добавить в него поддержку Arty Artix-7, так как из коробки он ничего об этой плате не знает. Делается это как-то так:
cd ~/opt/xilinx/Vivado/2017.2/data/boards/board_files
wget https://github.com/Digilent/vivado-boards/archive/master.zip
unzip master.zip
mv vivado-boards-master/new/board_files/* ./
rm -r vivado-boards-master
rm master.zip
Также скачиваем отсюда и сохраняем куда-нибудь файл Arty_Master.xdc. Он понадобится нам далее. Файл содержит описание находящихся на плате светодиодов, переключателей и так далее. Без него поморгать светодиодами на Verilog будет непросто.
Первый проект на SystemVerilog
В Vivado говорим File → New Project… В качестве типа проекта выбираем RTL Project, ставим галочку Do not specify sources at this time. В диалоге выбора типа платы находим в списке Arty.
Первым делом добавляем к проекту скачанный ранее XDC файл. Копируем его в каталог с проектом. Затем говорим File → Add Sources… → Add or create constraints → Add Files, находим копию файла, жмем Finish. В дереве файлов проекта (Sources) в группе Constraints появится файл Arty_Master.xdc, или как вы там назвали копию. Открываем его и раскомментируем все строчки в группах Clock signal, Switches и LEDs.
Далее говорим File → Add Sources… → Add or create design sources → Create File. В типе файла выбираем SystemVerilog, в имени файла вводим что-нибудь вроде hello. Говорим Finish. Далее появится диалог Define Module, который предложит накликать интерфейс модуля. Диалог довольно бесполезный, потому что то же самое удобнее сделать прямо в коде, так что жмем Cancel.
В дереве исходников находим новый файл hello.sv, он будет в группе Design Sources. Открываем и пишем следующий код:
`timescale 1ns / 1ps
module hello(
input logic CLK100MHZ,
input logic [3:0] sw,
output logic [3:0] led
);
always @(posedge CLK100MHZ)
begin
if(sw[0] == 0)
begin
led <= 4’b0001;
end
else
begin
led <= 4’b0000;
end
end
endmodule
Если все было сделано правильно, на этом этапе Vivado у вас будет выглядеть как-то так (кликабельно, PNG, 71 Кб):
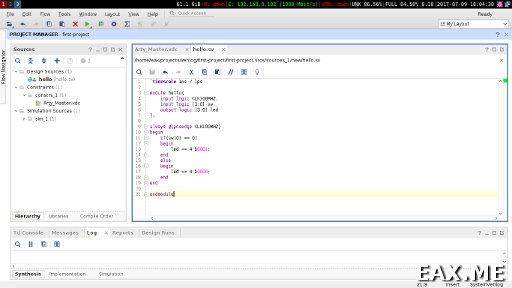
Компиляция программы осуществляется в два этапа — синтез (synthesis) и имплементация (implementation). На этапе синтеза программа транслируется в абстрактную цепь из логических вентилей и прочих элементов. На этапе имплементации принимается решение о том, как прошить эту цепь в конкретную железку.
Запустим синтез, сказав Flow → Run Synthesis, или просто нажав F11. В правом верхнем углу вы увидите индикацию того, что процесс идет. Он может занимать довольно много времени, в зависимости от вашего компьютера и сложности программы. На моем ноутбуке синтез приведенной выше программы выполнился где-то секунд за 10. Если теперь сказать Flow → Open Synthesized Design, то можно увидеть красивую картинку вроде такой:
Настало время прошить нашу плату. Говорим Flow → Run Imlementation, затем Flow → Generate Bitstream. Подключаем плату к компьютеру по USB, в Vivado говорим Flow → Open Hardware Manager → Open target → Auto Connect → Program device. Потребуется указать путь к bit-файлу. У меня он был следующим:
./first-project.runs/impl_1/hello.bit
Говорим Program. Теперь на плате горит светодиод LD4, если переключатель SW0 опущен (см приведенную выше фотографию платы). Если же переключатель поднят, светодиод не горит. Простенько, конечно, но это же «hello, world», чего вы ожидали? 
Симуляция
Симуляция — это виртуальное выполнение кода на Verilog или VHDL прямо на вашем компьютере, безо всяких там ПЛИС’ов. Это одновременно и отладочный инструмент, и своего рода фреймворк для покрытия кода тестами.
При знакомстве с симуляцией первое, что я обнаружил, было то, что она у меня не работает. В логах было просто:
ERROR: [XSIM 43-3409] Failed to compile generated C file […]xsim_1.c.
Google по этой ошибке находил только всякую ерунду в стиле «попробуйте отключить антивирус». В итоге решить проблему помогло добавление флага -v 2 в скрипт ~/opt/xilinx/Vivado/2017.2/bin/xelab. С его помощью я выяснил, что Clang, бинарник которого Vivado таскает за собой, падает со следующей ошибкой:
/a/long/path/to/clang: error while loading shared libraries:
libncurses.so.5: cannot open shared object file: No such file or
directory
А эта ошибка и ее решение уже описаны на Arch Wiki. Лично я просто скопировал уже существующий файл из каталога Vivado_HLS:
cp ~/opt/xilinx/Vivado_HLS/2017.2/lnx64/tools/gdb_v7_2/libncurses.so.5
~/opt/xilinx/Vivado/2017.2/lib/lnx64.o/libncurses.so.5
… после чего все заработало. Итак, а теперь, собственно, пример симуляции.
По аналогии с тем, как ранее мы создавали hello.sv, создаем новый файл hello_sim.sv в группе Simulation Sources. В файле пишем следующий код:
`timescale 1ns / 1ps
module hello_sim();
logic clck_t;
logic [3:0] sw_t;
logic [3:0] led_t;
hello hello_t(clck_t, sw_t, led_t);
initial begin
clck_t <= 0;
sw_t <= 4’b0000; #1; clck_t <= 1; #1; clck_t <= 0; #1;
assert(led_t === 4’b0001);
sw_t <= 4’b0001; #1; clck_t <= 1; #1; clck_t <= 0; #1;
assert(led_t === 4’b0000);
end
endmodule
В дереве исходников делаем правый клик по файлу, выбираем Source Node Properties. В секции Used In снимаем галочки Synthesis и Implementation. Мы же не хотим, чтобы какие-то там тесты засоряли нашу далеко не резиновую FPGA?
Теперь говорим Flow → Run Simulation → Run Behavioral Simulation. В итоге вы увидите что-то примерно такого плана:
Можно видеть, что когда sw[0] равен нулю, led[0] равен единице, и наоборот. При этом все изменения происходят по фронту тактового сигнала. Похоже, что программа работает корректно. Ну и на ассертах ничего не свалилось, что как бы намекает.
Заключение
Архив с описанным выше проектом можно скачать здесь. В качестве дополнительных источников информации я бы рекомендовал следующие:
- Если вас интересуют подробности по железу, обратите внимание на даташит Artix-7 [PDF], reference manual к Arty Artix-7 [PDF], а также схему платы [PDF];
- Книга Цифровая схемотехника и архитектура компьютера (Digital Design and Computer Architecture) — прекрасная книга, в которой, помимо прочего, подробно объясняются языки SystemVerilog и VHDL, а также внутреннее устройство FPGA;
- OpenCores.org — каталог всевозможных открытых проектов под FPGA. Для скачивания исходного кода требуется регистрация. Активация аккаунта производится модераторами вручную, поэтому может занимать несколько дней;
А пишите ли вы под FPGA? Если да, то на каком языке и какого производителя предпочитаете?
Дополнение: Также вас могут заинтересовать статьи Головоломка с логическими вентилями и решение на HDL и Знакомимся с iCEstick и полностью открытым ПО для разработки под FPGA.
Метки: FPGA, Электроника.